JDBC入门入门入门入门
- 格式:pdf
- 大小:444.32 KB
- 文档页数:39

DBUnit数据库单元测试前言(出生地和原因)DBUnit是Junit家族中的一员,是专门用来测试数据库的工具。
本文将对其应用进行一个简单的介绍,帮助学习使用该工具。
DBUnit是对Junit的一个扩展,提供测试子类TestCase(对接触过Junit的人比较熟悉,如果没接触过,只要记住这个类名称就可以了),其关键类继承了Junit 的TestCase,并对其函数进行了重写和接口扩展工作,为对数据库的测试提供了很大的便利。
概述(DBUnit的便利)在数据库测试中,主要是测试程序中写的Query语句是否正确执行的工作。
在以前的实际应用中,在自己进行测试时,需要自己写入数据,执行后需查看数据是否正确,清理不正确数据,然后继续修改数据,已完成Query的正确性。
如果使用数据库IDE可能还会方便一点,但是其简单却繁琐的工作会耽误很多时间。
DBUnit则会帮助你完成这一部分对数据库数据的操作,即提供单元测试框架,并帮助测试者完成对数据的自动写入、正确性验证、数据清理等工作。
当然,你也可以完全脱离测试的目的,使用其里面的方法完成一些其他工作(如数据库数据的自动载入、备份等)。
准备(用到的jar包)使用前除了必须的Junit库之外,还需要其他几个包。
如图1.0图1.0 jar包DBUnit使用了一些日志功能,所以需用到后三个包内的一些方法。
核心(大量的xml文件)既然要对数据库进行自动载入、验证等工作,则必须需要数据。
但是数据从哪里来,这是使用前必须了解的事情。
一些使用DBUnit很长时间的程序猿会评价到:DBunit很好用,就是对xml 文件的操作太多。
从这句话就可以看出,xml文件对该工具的重要性。
没错,我们的数据来源就是xml文件。
一般情况下,对于一个用例,会用到两个xml文件:Query执行前数据库数据和正确执行后的数据库数据。
当然,你也可以加一个数据库备份数据文件,随人而定。
不过在这里提出xml文件可能会对初学者有些干扰,不过不用急,图1.1会先介绍用到的xml的文件结构,还有你只要先知道这些结构并记住,数据都是来自这些文件即可。


详解jdbc实现对CLOB和BLOB数据类型的操作详解jdbc实现对CLOB和BLOB数据类型的操作1、读取操作CLOB//获得数据库连接Connection con = ConnectionFactory.getConnection();con.setAutoCommit(false);Statement st = con.createStatement();//不需要“for update”ResultSet rs = st.executeQuery("select CLOBATTR from TESTCLOB where ID=1");if (rs.next()){java.sql.Clob clob = rs.getClob("CLOBATTR");Reader inStream = clob.getCharacterStream();char[] c = new char[(int) clob.length()];inStream.read(c);//data是读出并需要返回的数据,类型是Stringdata = new String(c);inStream.close();}inStream.close();mit();con.close();BLOB//获得数据库连接Connection con = ConnectionFactory.getConnection();con.setAutoCommit(false);Statement st = con.createStatement();//不需要“for update”ResultSet rs = st.executeQuery("select BLOBATTR from TESTBLOB where ID=1");if (rs.next()){java.sql.Blob blob = rs.getBlob("BLOBATTR");InputStream inStream = blob.getBinaryStream();//data是读出并需要返回的数据,类型是byte[]data = new byte[input.available()];inStream.read(data);inStream.close();}inStream.close();mit();con.close();2、写⼊操作CLOB//获得数据库连接Connection con = ConnectionFactory.getConnection();con.setAutoCommit(false);Statement st = con.createStatement();//插⼊⼀个空对象empty_clob()st.executeUpdate("insert into TESTCLOB (ID, NAME, CLOBATTR) values (1, "thename", empty_clob())");//锁定数据⾏进⾏更新,注意“for update”语句ResultSet rs = st.executeQuery("select CLOBATTR from TESTCLOB where ID=1 for update");if (rs.next()){//得到java.sql.Clob对象后强制转换为oracle.sql.CLOBoracle.sql.CLOB clob = (oracle.sql.CLOB) rs.getClob("CLOBATTR");Writer outStream = clob.getCharacterOutputStream();//data是传⼊的字符串,定义:String datachar[] c = data.toCharArray();outStream.write(c, 0, c.length);}outStream.flush();outStream.close();mit();con.close();BLOB//获得数据库连接Connection con = ConnectionFactory.getConnection();con.setAutoCommit(false);Statement st = con.createStatement();//插⼊⼀个空对象empty_blob()st.executeUpdate("insert into TESTBLOB (ID, NAME, BLOBATTR) values (1, "thename", empty_blob())"); //锁定数据⾏进⾏更新,注意“for update”语句ResultSet rs = st.executeQuery("select BLOBATTR from TESTBLOB where ID=1 for update");if (rs.next()){//得到java.sql.Blob对象后强制转换为oracle.sql.BLOBoracle.sql.BLOB blob = (oracle.sql.BLOB) rs.getBlob("BLOBATTR");OutputStream outStream = blob.getBinaryOutputStream();//data是传⼊的byte数组,定义:byte[] dataoutStream.write(data, 0, data.length);}outStream.flush();outStream.close();mit();con.close();3、读写CLOB/BLOB数据到⽂件TNS:# tnsnames.ora Network Configuration File: d:\oracle\product\10.2.0\client_1\NETWORK\ADMIN\tnsnames.ora # Generated by Oracle configuration tools.ORADB =(DESCRIPTION =(ADDRESS_LIST =(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.1.100)(PORT = 1521)))(CONNECT_DATA =(SID = ORCL)))MYORCL =(DESCRIPTION =(ADDRESS_LIST =(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.1.100)(PORT = 1521)))(CONNECT_DATA =(SERVICE_NAME = myorcl)))Table:create table TEST_ORALOB(ID VARCHAR2(20),TSBLOB BLOB not null,TSCLOB CLOB not null)测试代码:package mon;import oracle.sql.BLOB;import java.io.*;import java.sql.*;/*** JDBC读写Oracle10g的CLOB、BLOB**/public class TestOraLob {public static void main(String[] args) {insertBlob();queryBlob();}public static void insertBlob() {Connection conn = DBToolkit.getConnection();PreparedStatement ps = null;try {String sql = "insert into test_oralob (ID, TSBLOB, TSCLOB) values (?, ?, ?)";ps = conn.prepareStatement(sql);ps.setString(1, "100");//设置⼆进制BLOB参数File file_blob = new File("C:\\a.jpg");InputStream in = new BufferedInputStream(new FileInputStream(file_blob));ps.setBinaryStream(2, in, (int) file_blob.length());//设置⼆进制CLOB参数File file_clob = new File("c:\\a.txt");InputStreamReader reader = new InputStreamReader(new FileInputStream(file_clob));ps.setCharacterStream(3, reader, (int) file_clob.length());ps.executeUpdate();in.close();} catch (IOException e) {e.printStackTrace();} catch (SQLException e) {e.printStackTrace();} finally {DBToolkit.closeConnection(conn);}}public static void queryBlob() {Connection conn = DBToolkit.getConnection();PreparedStatement ps = null;Statement stmt = null;ResultSet rs = null;try {String sql = "select TSBLOB from TEST_ORALOB where id ='100'";stmt = conn.createStatement();rs = stmt.executeQuery(sql);if (rs.next()) {//读取Oracle的BLOB字段InputStream in = rs.getBinaryStream(1);File file = new File("c:\\a1.jpg");OutputStream out = new BufferedOutputStream(new FileOutputStream(file));byte[] buff1 = new byte[1024];for (int i = 0; (i = in.read(buff1)) > 0;) {out.write(buff1, 0, i);}out.flush();out.close();in.close();//读取Oracle的CLOB字段char[] buff2 = new char[1024];File file_clob = new File("c:\\a1.txt");OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream(file_clob)); Reader reader = rs.getCharacterStream(1);for (int i = 0; (i = reader.read(buff2)) > 0;) {writer.write(buff2, 0, i);}writer.flush();writer.close();reader.close();}rs.close();stmt.close();} catch (IOException e) {e.printStackTrace();} catch (SQLException e) {e.printStackTrace();} finally {DBToolkit.closeConnection(conn);}}}注:如果是具体的字符串写⼊CLOB字段,简化写法://设置⼆进制CLOB参数String xxx = "abcdefg";ps.setCharacterStream(3, new StringReader(xxx), xxx.getBytes("GBK").length);ps.executeUpdate();in.close();感谢阅读,希望能帮助到⼤家,谢谢⼤家对本站的⽀持,如有疑问请留⾔或者到本站社区交流讨论,感谢阅读,希望能帮助到⼤家,谢谢⼤家对本站的⽀持!。


【ShardingSphere】shardingjdbc⼊门案例-springboot整合。
该教程仅仅适⽤于4.x版本,在ShardingSphere的迭代历史中很多的配置和兼容问题很⼤,这⾥⼊⼿⼀定要注意版本。
构建⼀个SpringBoot项⽬SpringBoot项⽬的构建这⾥不再赘述,这⾥要提及的⼀点就是我们构建的时候,基本不需要引⼊依赖,后⾯会⼀步⼀步加⼊数据库准备构建两个库,库名安装ds0,ds1来定义数据库内建⽴t_order1,t_order2两个表,表结构⼀致,只是名字⽤数字排序对应SQL如下:DROP TABLE IF EXISTS `t_order1`;CREATE TABLE `t_order1` (`id` int(11) NOT NULL AUTO_INCREMENT,`user_id` int(11) DEFAULT NULL,`order_id` int(11) DEFAULT NULL,`cloumn` varchar(45) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;DROP TABLE IF EXISTS `t_order2`;CREATE TABLE `t_order2` (`id` int(11) NOT NULL AUTO_INCREMENT,`user_id` int(11) DEFAULT NULL,`order_id` int(11) DEFAULT NULL,`cloumn` varchar(45) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;完成基本的数据库和⼯程搭建之后,我们就可以来完成我们的整合sharding jdbc啦引⼊shardingsphere和HikariCP连接池这⾥引⼊的sharding sphere是4.1.1,版本问题⼀定要注意,不然后⾯可能没有办法成功。
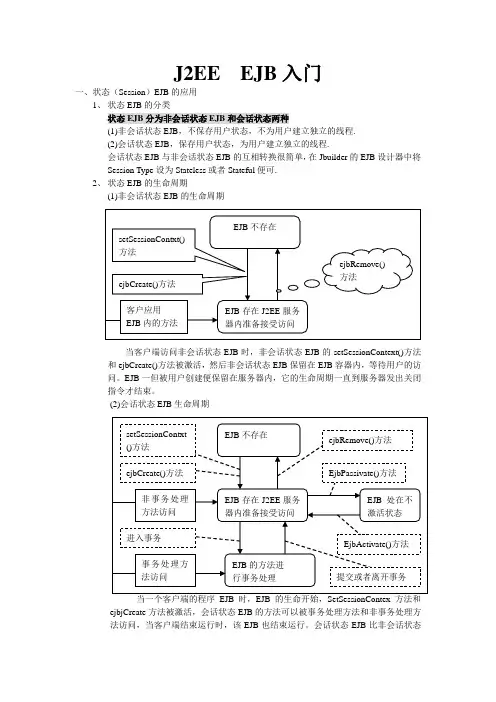
J2EE EJB入门一、状态(Session)EJB的应用1、状态EJB的分类状态EJB分为非会话状态EJB和会话状态两种(1)非会话状态EJB,不保存用户状态,不为用户建立独立的线程.(2)会话状态EJB,保存用户状态,为用户建立独立的线程.会话状态EJB与非会话状态EJB的互相转换很简单,在Jbuilder的EJB设计器中将Session Type设为Stateless或者Stateful便可.2、状态EJB的生命周期(1)非会话状态EJB的生命周期当客户端访问非会话状态EJB时,非会话状态EJB的setSessionContext()方法和ejbCreate()方法被激活,然后非会话状态EJB保留在EJB容器内,等待用户的访问。
EJB一但被用户创建便保留在服务器内,它的生命周期一直到服务器发出关闭指令才结束。
(2)会话状态EJB生命周期当一个客户端的程序EJB时,EJB的生命开始,SetSessionContex方法和ejbjCreate方法被激活,会话状态EJB的方法可以被事务处理方法和非事务处理方法访问,当客户端结束运行时,该EJB也结束运行。
会话状态EJB比非会话状态EJB多了一个状态,EJB可以处在不激活状态,并且会话状态EJB使用ejbPassivate方法和ejbActivate方法3、两种状态EJB的比较非会话状态EJB不会为客户创建独立的进程,它一旦创建便保留在服务器内,每个客户都是使用一个EJB对象;会话状态EJB为客户创建独立的进程,每个客户使用不同的EJB对象,需要使用remove方法删除服务器上的EJB对象.在实际项目中利用不同状态EJB实现不同的效果,如电子商城的公布板的信息对每个用户都是相同的,可以使用非会话状态EJB;如电子商城的购物车对每个用户是不同的,可以使用会话状态EJB。
我们也可以将一些耗时的处理过程放入非会话状态EJB共享。
二、全局(Entity)EJB的应用1、全居EJB的作用(1)可以和数据库的数据结合操作,全局EJB提供各种数据操作的方法。

从零开始的JavaWeb开发入门教程JavaWeb开发是当前IT行业最热门的领域之一,许多人以此作为自己的职业发展方向。
本篇文章将从零开始,为读者提供一份全面的JavaWeb开发入门教程。
文章将分为以下章节进行介绍:JavaWeb的概念与发展、JavaWeb的基础知识、JavaWeb开发的常见框架、JavaWeb开发的数据库连接、JavaWeb开发中的前端技术、JavaWeb开发的安全性。
第一章:JavaWeb的概念与发展JavaWeb是基于Java语言开发的一种Web应用程序开发模式。
它结合了Java编程语言的强大性能和Web应用程序的灵活性,使开发人员能够创建功能强大、交互性强的Web应用程序。
JavaWeb的发展经历了多个阶段,从最初的Servlet和JSP技术,到Struts、Spring、Spring MVC等框架的兴起,再到目前流行的Spring Boot和Spring Cloud等微服务框架,JavaWeb开发已经成为了软件开发的主流技术之一。
第二章:JavaWeb的基础知识想要从零开始学习JavaWeb开发,首先需要了解JavaWeb的基础知识。
这包括了HTTP协议、Servlet、JSP等。
HTTP协议是JavaWeb开发的基础,它是一种用来传输超文本的协议。
Servlet是在服务器端运行的Java程序,用于接收和响应HTTP请求。
JSP是一种通过嵌入Java代码在HTML页面中生成动态内容的技术。
了解了这些基础知识后,我们才能更好地进行JavaWeb开发。
第三章:JavaWeb开发的常见框架JavaWeb开发中有许多常见的框架,它们可以帮助开发人员更高效地进行开发。
这些框架包括Struts、Spring、Spring MVC等。
Struts是一个基于MVC模式的Web应用框架,它提供了一套完整的解决方案,用于处理请求、响应和页面渲染。
Spring是一个开源框架,它提供了一种松耦合的开发模式,使得开发人员能够更容易地进行模块化的开发。

Jeecg使用文档1.部署jeecg1.1.下载jeecg请在jeecg 发布地址下载jeecg工程1.2 导入myeclipse8.5按照如下视图选择jeecg项目存放路径然后导入项目工程1.3jeecg工程结构1.4 相关配置文件说明0)framemark 模版文件以及配置文件1) CKfinderConfig.xml 富文本框配置文件2)dbconfig.properties 数据库配置文件3) ehcache.xml 缓存配置文件4)log4j 配置文件5)minidao 配置文件6)aop 配置文件7)spring mvc的核心配置文件8)hibernate 配置文件9) 定时任务配置文件10)spring mvc配置文件1.5 修改数据库配置文件hibernate.dialect=org.hibernate.dialect.MySQLDialect validationQuery.sqlserver=SELECT1jdbc.url.jeecg=jdbc:mysql://localhost:3306/jeecg?useUnicode=true& characterEncoding=UTF-8ername.jeecg=rootjdbc.password.jeecg=rootjdbc.dbType=mysqlhibernate.hbm2ddl.auto=update1)hibernate引言2)数据库链接测试3)数据库链接url4)数据库用户名5)数据库登录密码6)数据库类型7)是否更新表结构1.6 部署工程将工程部署到tomcat 上,最终结果如下图所示1.7 初始系统1)在浏览器中输入:http://localhost:8080/jeecg-v3-simple 如下图所示2) 初始化数据数据点击下面的红框。
3)点击登录可以登录系统如下所示2. 使用onLine 模块生成代码1)点击表单配置如下图所示(点击红框)2)如下图所示。

Hibernate入门前言我们之所以要使用Hibernate,是因为传统的jdbc中的缺陷。
在java使用传统的jdbc编程的时候,我们需要在java代码中手动写sql语句。
那么,写sql语句有什么不好呢?1 ·不同的数据库使用的sql语法是不同的2 ·同样的功能在不同的数据库中有不同的实现方式,比如分页3 ·程序过分的依赖sql语句,对程序的移植和扩展是不好的所以我们要使用Hibernate。
它能够使我们的程序在在完成之后可以随意的更换数据库(只需要进行简单的配置就可以了)一、Hibernate的简介在jdbc的基础上进行了一定的封装,在使用不同的数据库的时候,在Hibernate中的语句是一样的。
图示如下:二、Hibernate的入门案例我们这个入门案例总共分为6步:步骤:1 ·导包2 ·编写配置文档hibernate.cfg.xml文件(核心配置文件)3 ·编写持久化类(JavaBean/PoJo)4 ·编写映射关系文件5 ·编写测试类6 ·通过Hibernate API编写访问数据库的代码2.1、详细步骤第一步:导包导包,与其他乱七八糟的框架一样,我们想要使用Hibernate框架,就必须要导入合适和jar包,我们这里需要导入的jar包分三类:1 · Hibernate需要的包(官网下载,这里使用的是hibernate4)2 ·链接数据库的包(链接什么数据库就使用什么包,本案例使用的是SQLserver2008数据库)3 · JUnit单元测试的包第二步:编写核心配置文件代码如下,配置的详解在附录的核心配置文件中详述,这里只需要拷贝就行了。
文件名:hibernate.cfg.xml(这个名称不能改)<?xml version='1.0'encoding='UTF-8'?><!DOCTYPE hibernate-configuration PUBLIC"-//Hibernate/Hibernate Configuration DTD 3.0//EN""/dtd/hibernate-configuration-3.0.dtd"><!-- Generated by MyEclipse Hibernate Tools. --><hibernate-configuration><session-factory><property name="ername">sa</property><property name="connection.password">123</property><propertyname="connection.driver_class">com.microsoft.sqlserver.jdbc.SQLServerDr iver</property><propertyname="connection.url">jdbc:sqlserver://localhost:1434;databaseName=stud ent</property><propertyname="hibernate.dialect">org.hibernate.dialect.SQLServerDialect</proper ty><propertyname="hibernate.connection.autocommit">false</property><property name="show_sql">true</property><property name="format_sql">true</property><property name="hbm2ddl.auto">create</property><!—这个地方是引入映射关系配置文件的,就是引入后面第四步的文件--><mapping resource="./student.hbm.xml"/></session-factory></hibernate-configuration>第三步:编写持久化类讲是持久化类,其实就是JavaBean注意:这个类里面的属性等会是要和数据库中的字段一一对应的,虽然可以自己起名字,但是建议还是将属性名和字段名保持一致,一般都是这样搞public class Student {private int sno;private String sname;private String ssex;public Student() {//}public Student(int sno, String sname, String ssex) {// super();this.sno = sno;this.sname = sname;this.ssex = ssex;}public int getSno() {return sno;}public void setSno(int sno) {this.sno = sno;}public String getSname() {return sname;}public void setSname(String sname) {this.sname = sname;}public String getSsex() {return ssex;}public void setSsex(String ssex) {this.ssex = ssex;}@Overridepublic String toString() {return"Student [sno=" + sno + ", sname=" + sname + ", ssex=" + ssex+ "]";}}第四步:编写映射关系文件代码如下。
演示和测试安装指南演示和测试安装指南简介本文档描述了一个初始安装过程和商业项目的基本配置选项打开了。
如需详细资料请参阅有关文件,如为框架OFBiz 的配置指南,在实体引擎(数据库)配置指南,在服务引擎配置指南,以及其他相关文件,您可以在发现OFBiz 的文档索引如果你遇到麻烦有帮助的各种资源。
第一个步骤将是寻找在新网站OFBiz 的文件和旧OFBiz 的维基(现存档),以及当时的OFBiz 的邮件列表。
如果你找不到你答案,然后订阅到Apache OFBiz 的用户邮件列表,发送的邮件有问题,你用尽可能多的细节尽可能有关。
快速和简易安装你可以通过下载并运行了完整的发行和OFBiz 的以下一些简单的指令迅速。
对于更多的选择和解释,请参见本文档的其余部分。
1. 下载并安装Sun 的Java(J2SE)的网站1.5 版的Java 2 系列JDK/J2SDK(不是JRE,您需要完整的SDK)如果你打算使用一个发布之前R10.04 否则使用或树干1.6,确保你的JAVA_HOME 环境变量设置为这个JDK 的安装后(注意,Mac OS X 的JVM的设置是没有必要的,只要确定了与Java 是在OS X 软件更新功能日期)。
还要注意的是OpenJDK 的仍然是不推荐,还有与它(今日:2010-05-27)一些汇编problmems 2. OFBiz 的新闻档案下载并解压缩它,在你选择的目录(见评论的下面,所以现在检查出库的svn是首选,见下文...). 这应该建立一个子目录:ofbiz 登录。
这将是OFBIZ_HOME 位置。
3. 启动OFBiz 的内嵌的Tomcat 可以走进OFBiz 的目录,然后运行"startofbiz.bat" (or "%JAVA_HOME%\bin\java -jar ofbiz.jar") 适用于Windows(or "./startofbiz.sh"(or "$JAVA_HOME/bin/java -jar ofbiz.jar")用于Linux / UNIX。
JDBC(Java Data Base Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。
JDBC提供了一种基准,据此可以构建更高级的工具和接口,使数据库开发人员能够编写数据库应用程序,同时,JDBC也是个商标名。
有了JDBC,向各种关系数据发送SQL语句就是一件很容易的事。
换言之,有了JDBC API,就不必为访问Sybase数据库专门写一个程序,为访问Oracle数据库又专门写一个程序,或为访问Informix数据库又编写另一个程序等等,程序员只需用JDBC API写一个程序就够了,它可向相应数据库发送SQL调用,将Java语言和JDBC结合起来使程序员只须写一遍程序就可以让它在任何平台上运行,这也是Java语言“编写一次Java数据库连接体系结构是用于Java应用程序连接数据库的标准方法。
JDBC对Java程序员而言是API,对实现与数据库连接的服务提供商而言是接口模型。
作为API,JDBC为程序开发提供标准的接口,并为数据库厂商及第三方中间件厂商实现与数据库的连接提供了标准方法。
JDBC使用已有的SQL标准并支持与其它数据库连接标准,如ODBC 之间的桥接。
JDBC实现了所有这些面向标准的目标并且具有简单、严格类型定义且高性能实现的接口。
JDBCTM 是一种用于执行SQL 语句的JavaTM API,它由一组用Java 编程语言编写的类和接口组成。
JDBC 为工具/数据库开发人员提供了一个标准的API,使他们能够用纯Java API 来编写数据库应用程序。
有了JDBC,向各种关系数据库发送SQL 语句就是一件很容易的事。
换言之,有了JDBC API,就不必为访问Sybase 数据库专门写一个程序,为访问Oracle 数据库又专门写一个程序,为访问Informix 数据库又写另一个程序,等等。
【java框架】JPA(1)--JPA⼊门1. JPA认识JPA是Java Persistence API的简称,它是Sun公司在充分吸收现有ORM框架(Hibernate)的基础上,开发⽽来的⼀个Java EE 5.0平台标准的开源的对象关系映射(ORM)规范。
Hibernate与JPA的关系:Hibernate是⼀个开放源代码的对象关系映射(ORM)框架,它对JDBC进⾏了⾮常轻量级的对象封装,将POJO与数据库表建⽴映射关系,是⼀个全⾃动的ORM框架,Hibernate可以⾃动⽣成SQL语句,⾃动执⾏,使Java程序员可以随⼼所欲地使⽤⾯向对象思维来操纵数据库。
⽽JPA是Sun官⽅提出的Java持久化规范,⽽JPA是在充分吸收Hibernate、TopLink等ORM框架的基础上发展⽽来的。
总结⼀句话就是:JPA是持久化的关系映射规范、接⼝API,⽽Hibernate是其实现。
1.1. JPA的优缺点优点:①操作代码很简单,插⼊—persist、修改—merge、查询—find、删除—remove;②直接⾯向持久化对象操作;③提供了世界级的数据缓存:包括⼀级缓存、⼆级缓存、查询缓存;④切换数据库移植性强,对应各种数据库抽取了⼀个⽅⾔配置接⼝,换数据库只需修改⽅⾔配置、驱动jar包、数据库连接4个信息即可。
缺点:①不能⼲预SQL语句的⽣成;②对于SQL优化效率要求较⾼的项⽬,不适合使⽤JPA;③对于数据量上亿级别的⼤型项⽬,也不适合使⽤JPA。
2. ⼿动创建⼀个Hello World的JPA项⽬2.1. 导⼊JPA项⽬所需jar包这⾥作为学习使⽤Hibernate 4.3.8的版本jar包,即JPA2.1版本为例进⾏项⽬jar包的构建:导⼊项⽬所需要的Hibernate的jar包分为三类:① Hibernate所必需的jar包:⽬录路径位置:\hibernate-release-4.3.8.Final\lib\required导⼊如下图所⽰jar包集合:②还需要导⼊JPA⽀持的jar包,⽬录路径:\hibernate-release-4.3.8.Final\lib\jpa与数据库Mysql连接驱动jar包;2.2. 配置核⼼配置⽂件persistence.xml配置⽂件必需放在项⽬的classpath⽬录的资源⽂件resources\META-INF⽬录下(JPA规范要求);persistence.xml⽂件具体配置如下:<persistence xmlns="/xml/ns/persistence" xmlns:xsi="/2001/XMLSchema-instance"xsi:schemaLocation="/xml/ns/persistence /xml/ns/persistence/persistence_2_0.xsd"version="2.0"><!--持久化单元 name:和项⽬名称对应--><persistence-unit name="cn.yif.jpa01" transaction-type="RESOURCE_LOCAL"><properties><!-- 必须配置4个连接数据库属性:配置信息可以在project/etc/hibernate.properties中找到 --><property name="hibernate.connection.driver_class" value="com.mysql.jdbc.Driver"/><property name="hibernate.connection.url" value="jdbc:mysql:///jpa01_0307"/><property name="ername" value="root"/><property name="hibernate.connection.password" value="admin"/><!-- 必须配置1个数据库⽅⾔属性 --><!-- 实现跨数据库关键类 :查询MySQLDialect的getLimitString⽅法 --><property name="hibernate.dialect" value="org.hibernate.dialect.MySQLDialect"/> <!-- 可选配置 --><!-- 是否⾃动⽣成表 --><property name="hibernate.hbm2ddl.auto" value="create"/><!-- 是否显⽰sql --><property name="hibernate.show_sql" value="true"/><!-- 格式化sql --><property name="hibernate.format_sql" value="true"/></properties></persistence-unit></persistence>2.3.创建持久化Domain类Employeepackage cn.yif.domain;import javax.persistence.*;//@Entity表⽰该类是由jpa管理的持久化对象,对应数据库中的⼀张表@Entity//@Table表⽰对应数据库的表名@Table(name = "t_employee")public class Employee {//@Id是必须的注解,表⽰对应数据库的主键@Id//@GeneratedValue表⽰主键的⽣成策略,多数都是使⽤AUTO//@GeneratedValue默认不配置也是AUTO@GeneratedValue(strategy = GenerationType.AUTO)private Integer id;//@Column表⽰如果数据库列名与属性名不⼀致,需要配置@Column(name = "e_name")private String name;@Column(name = "e_age")private Integer age;public Integer getId() {return id;}public void setId(Integer id) {this.id = id;}public String getName() {return name;}public void setName(String name) { = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}@Overridepublic String toString() {return "Employee{" +"id=" + id +", name='" + name + '\'' +", age=" + age +'}';}}2.4.创建Junit4测试类代码import cn.yif.domain.Employee;import org.junit.Test;import javax.persistence.EntityManager;import javax.persistence.EntityManagerFactory;import javax.persistence.EntityTransaction;import javax.persistence.Persistence;public class JPAHelloTest {@Testpublic void testInsertEmpByJPA(){Employee employee = new Employee();employee.setName("⾼伟翔");employee.setAge(34);// 对应配置⽂件⾥⾯的persistence-unit name="cn.yif.jpa01"// 通过持久化类创建⼀个实体类管理⼯⼚EntityManagerFactory entityManagerFactory = Persistence.createEntityManagerFactory("cn.yif.jpa01");//创建⼀个实体管理类,可以实现CRUDEntityManager entityManager = entityManagerFactory.createEntityManager();//由entityManager来开启事务EntityTransaction transaction = entityManager.getTransaction();transaction.begin();//持久操作CRUD 写⼊persistentityManager.persist(employee);// 提交事务mit();//关闭资源entityManager.close();entityManagerFactory.close();}}通过以上的步骤,就可以在创建的jpa01_0307数据库⾥⾯由JPA⾃动创建⼀张t_employee表并插⼊⼀条数据:3. 实现完整的JPA CRUD流程3.1.抽取JPAUtil类package cn.yif.utils;import javax.persistence.EntityManager;import javax.persistence.EntityManagerFactory;import javax.persistence.Persistence;/*** ⼯具类:单例模式/静态单例模式静态⽅法*/public class JPAUtil {// 私有化这个构造器,不让其它⼈创建这个类private JPAUtil(){}// 实体管理⼯⼚// 注意:EntityManagerFactory这个类是线程安全private static EntityManagerFactory entityManagerFactory;/*** 静态代码块,类加载的时候就会执⾏⾥⾯的代码,只会执⾏⼀次*/static{try {entityManagerFactory = Persistence.createEntityManagerFactory("cn.yif.jpa01");} catch (Exception e) {e.printStackTrace();throw new RuntimeException("拿到EntityManagerFactory运⾏时出错:"+e.getMessage());}}// 拿到⼀个EntityManager对象// 每次拿EntityManager都需要重新创建(EntityManager不是线程安全的对象,每次使⽤都重新创建⼀次)public static EntityManager getEntityManager(){return entityManagerFactory.createEntityManager();}public static void close(EntityManager entityManager){//关闭资源entityManager.close();entityManagerFactory.close();}}4. persitence.xml中hibernate.hbm2ddl.auto属性值配置如上,hibernate.hbm2ddl.auto属性的value值⼀共有4种配置:create-drop、create、update、validate。
五、构建自己的项目本平台目前只支持mysql 和mssql数据库。
下面以mysql版的部署为例子,mssql的部署操作也相同。
1、平台应用部署步骤(以mysql版数据库为例):把jabdp应用文件夹复制一份,改上自己喜欢的名字,注意:文件目录和名字要全英文的,而且不要有空格。
2、创建和连接数据库项目开发前首先需要定义数据来源,实际用户系统最常见的就是数据保存在数据库中,并且在不断更新中。
jabdc文件夹了已经自带了mysql数据库服务,而且mysql是绿色免安装的。
不过mysql数据库的客户端工具需要开发者自行下载,我们推荐使用Navicat工具。
2.1、打开自己下载好的Navicat客户端工具,新建连接,连接到jabdp自带的mysql服务。
默认的端口号是3366,用户名是root密码是jabdp。
Jabdp集成的mysql服务已经自带了一个叫jabdp的数据库,默认的工程项目就是使用这个的。
2.2、如果要新建一个工程项目,就在建好的连接下创建一个空的数据库。
3、修改数据库链接配置文件修改iPlatform工程目录WEB-INF\classes\application.properties文件:3.1、修改jdbc.url、ername、jdbc.password修改为新建数据库的相关属性;一般只要修改数据库名就可以了。
Mssql数据库的话是修改如下图所示的部分:3.2、删除 iPlatform\upload目录下的所有文件。
3.3、执行iPlatform工程目录WEB-INF\init-db.bat文件,即可进行数据库初始化(包括建表及数据初始化)。
4、启用JABDP应用服务4.1、点击启动服务.bat,右键以管理员身份运行,默认会自动注册mysql服务(第一次运行);4.2、如果命令窗口关闭,则需要再次点击启动服务.bat,右键以管理员身份运行,启动tomcat服务;4.3、启动成功后,打开chrome浏览器,输入http://127.0.0.1:9090/iDesigner(设计器)和http://127.0.0.1:9090/iPlatform(平台,用于项目运行)分别浏览即可。
第20章•JDBC入門–使用JDBC連接資料庫–使用JDBC進行資料操作簡介JDBC簡介JDBC•JDBC資料庫驅動程式依實作方式可以分為四個類型–Type 1:JDBC-ODBC Bridge–Type 2:Native-API Bridge–Type 3:JDBC-middleware–Type 4:Pure Java Driver連接資料庫•載入JDBC驅動程式try {Class.forName("com.mysql.jdbc.Driver");}catch(ClassNotFoundException e) {System.out.println("找不到驅動程式類別");}連接資料庫•提供JDBC URL–協定:子協定:資料來源識別jdbc:mysql://主機名稱:連接埠/資料庫名稱?參數=值&參數=值jdbc:mysql://localhost:3306/demo?user=root&password=123 jdbc:mysql://localhost:3306/demo?user=root&password=123& useUnicode=true&characterEncoding=Big5連接資料庫•取得Connectiontry {String url= "jdbc:mysql://localhost:3306/demo?" +"user=root&password=123";Connection conn= DriverManager.getConnection(url);....}catch(SQLException e) {....}String url= "jdbc:mysql://localhost:3306/demo";String user = "root";String password = "123";Connection conn= DriverManager.getConnection(url,user, password);簡單的Connection工具類別•取得Connection的方式,依所使用的環境及程式需求而有所不同•設計一個DBSource介面package onlyfun.caterpillar;import java.sql.Connection;import java.sql.SQLException;public interface DBSource{public Connection getConnection() throws SQLException;public void closeConnection(Connection conn) throws SQLException; }簡單的Connection工具類別public class SimpleDBSource implements DBSource{…public SimpleDBSource(String configFile) throws IOException,ClassNotFoundException{ props = new Properties();props.load(new FileInputStream(configFile));url= props.getProperty("onlyfun.caterpillar.url");user = props.getProperty("er");passwd= props.getProperty("onlyfun.caterpillar.password");Class.forName(props.getProperty("onlyfun.caterpillar.driver"));}public Connection getConnection() throws SQLException{return DriverManager.getConnection(url, user, passwd);}public void closeConnection(Connection conn) throws SQLException{ conn.close();}}簡單的Connection工具類別onlyfun.caterpillar.driver=com.mysql.jdbc.Driver onlyfun.caterpillar.url=jdbc:mysql://localhost:3306/demo er=rootonlyfun.caterpillar.password=123456DBSource dbsource= new SimpleDBSource();Connection conn= dbsource.getConnection();if(!conn.isClosed()) {System.out.println("資料庫連接已開啟…");}dbsource.closeConnection(conn);if(conn.isClosed()) {System.out.println("資料庫連接已關閉…");}簡單的連接池(Connection pool)•資料庫連接的取得是一個耗費時間與資源的動作–建立Socket connection–交換資料(使用者密碼驗證、相關參數)–資料庫初始會話(Session)–日誌(Logging)–分配行程(Process)–…簡單的連接池(Connection pool)public synchronized Connection getConnection()throws SQLException{ if(connections.size() == 0) {return DriverManager.getConnection(url, user, passwd);}else {int lastIndex= connections.size() -1;return connections.remove(lastIndex);}}public synchronized void closeConnection(Connection conn)throws SQLException{ if(connections.size() == max) {conn.close();}else {connections.add(conn);}}簡單的連接池(Connection pool)DBSource dbsource= new BasicDBSource("jdbc2.properties"); Connection conn1 = dbsource.getConnection();dbsource.closeConnection(conn1);Connection conn2 = dbsource.getConnection();System.out.println(conn1 == conn2);onlyfun.caterpillar.driver=com.mysql.jdbc.Driveronlyfun.caterpillar.url=jdbc:mysql://localhost:3306/demo er=rootonlyfun.caterpillar.password=123456onlyfun.caterpillar.poolmax=10簡單的連接池(Connection pool)•初始的Connection數量•Connection最大idle的數量•如果超過多久時間,要回收多少數量的Connection•Proxool–/index.html •Apache Jakarta的Common DBCP –/commons/dbcp/Statement、ResultSet•要執行SQL的話,必須取得java.sql.Statement物件,它是Java當中一個SQL敘述的具體代表物件Statement stmt = conn.createStatement();•插入一筆資料,可以如下使用Statement的executeUpdate()方法stmt.executeUpdate("INSERT INTO t_message VALUES(1, 'justin', " + "'justin@', 'mesage...')");Statement、ResultSet •executeUpdate()會傳回int結果,表示資料變動的筆數•executeQuery()方法則是用於SELECT等查詢資料庫的SQL•executeQuery()會傳回java.sql.ResultSet物件,代表查詢的結果•可以使用ResultSet的next()來移動至下一筆資料,它會傳回true 或false表示是否有下一筆資料•使用getXXX()來取得資料Statement、ResultSet•指定欄位名稱來取得資料ResultSet result =stmt.executeQuery("SELECT* FROM t_message"); while(result.next()) {System.out.print(result.getInt("id") + "\t");System.out.print(result.getString("name") + "\t");System.out.print(result.getString("email") + "\t");System.out.print(result.getString("msg") + "\t");}Statement、ResultSet•使用查詢結果的欄位順序來顯示結果ResultSet result =stmt.executeQuery("SELECT* FROM t_message"); while(result.next()) {System.out.print(result.getInt(1) + "\t");System.out.print(result.getString(2) + "\t");System.out.print(result.getString(3) + "\t");System.out.print(result.getString(4) + "\t");}Statement、ResultSet •Statement的execute()可以用來執行SQL,並可以測試所執行的SQL是執行查詢或是更新•傳回true的話表示SQL執行將傳回ResultSet表示查詢結果,此時可以使用getResultSet()取得ResultSet物件•如果execute()傳回false,表示SQL執行會傳回更新筆數或沒有結果,此時可以使用getUpdateCount()取得更新筆數•如果事先無法得知是進行查詢或是更新,就可以使用execute()Statement、ResultSet finally {if(stmt!= null) {try {stmt.close();}catch(SQLException e) {e.printStackTrace();}}if(conn!= null) {try {dbsource.closeConnection(conn);}catch(SQLException e) {e.printStackTrace();}}}Statement、ResultSet •Connection物件預設為「自動認可」(auto commit)•getAutoCommit()可以測試是否設定為自動認可•無論是否有無執行commit()方法,只要SQL 沒有錯,在關閉Statement或Connection 前,都會執行認可動作PreparedStatement •preparedStatement()方法建立好一個預先編譯(precompile)的SQL語句•當中參數會變動的部份,先指定"?"這個佔位字元PreparedStatement stmt = conn.prepareStatement("INSERT INTO t_message VALUES(?, ?, ?, ?)");PreparedStatement•需要真正指定參數執行時,再使用相對應的setInt()、setString()等方法,指定"?"處真正應該有的參數stmt.setInt(1, 2);stmt.setString(2, "momor");stmt.setString(3, "momor@");stmt.setString(4, "message2...");LOB讀寫•BLOB全名Binary Large Object,用於儲存大量的二進位資料•CLOB全名Character Large Object,用於儲存大量的文字資料•在JDBC中也提供了java.sql.Blob與java.sql.Clob兩個類別分別代表BLOB與CLOB資料LOB讀寫•取得一個檔案,並將之存入資料庫中File file= new File("./logo_phpbb.jpg");int length = (int) file.length();InputStream fin = new FileInputStream(file);// 填入資料庫PreparedStatement pstmt= conn.prepareStatement("INSERT INTO files VALUES(?, ?, ?)");pstmt.setInt(1, 1);pstmt.setString(2, "filename");pstmt.setBinaryStream(3, fin, length);pstmt.executeUpdate();pstmt.clearParameters();pstmt.close();fin.close();LOB讀寫•從資料庫中取得BLOB或CLOB資料Blob blob= result.getBlob(2); // 取得BLOBClob clob= result.getClob(2) // 取得CLOB交易(Transaction)•可以操作Connection的setAutoCommit()方法,給它false引數•在下達一連串的SQL語句後,自行呼叫Connection的commit()來送出變更交易(Transaction)try {…conn.setAutoCommit(false); // 設定auto commit為false stmt = conn.createStatement();stmt.execute("...."); // SQLstmt.execute("....");stmt.execute("....");mit(); // 正確無誤,確定送出}catch(SQLException e) { // 喔喔!在commit()前發生錯誤try {conn.rollback(); // 撤消操作} catch (SQLException e1) {e1.printStackTrace();}e.printStackTrace();}交易(Transaction)•設定儲存點(save point)conn.setAutoCommit(false);Statement stmt = conn.createStatement();stmt.executeUpdate("....");stmt.executeUpdate("....");Savepoint savepoint= conn.setSavepoint(); // 設定save pointstmt.executeUpdate("....");// 如果因故rollbackconn.rollback(savepoint);. . .mit();// 記得釋放save pointstmt.releaseSavepoint(savepoint);批次處理•使用addBatch()方法將要執行的SQL敘述加入,然後執行executeBatch()conn.setAutoCommit(false);Statement stmt = conn.createStatement();stmt.addBatch("..."); // SQLstmt.addBatch("...");stmt.addBatch("...");...stmt.executeBatch();mit();批次處理•使用PreparedStatement可以進行批次處理PreparedStatement stmt = conn.prepareStatement("INSERT INTO t_message VALUES(?, ?, ?, ?)");Message[] messages = ...;for(int i = 0; i < messages.length; i++) {stmt.setInt(1, messages[i].getID());stmt.setString(2, messages[i].getName());stmt.setString(3, messages[i].getEmail());stmt.setString(4, messages[i].getMsg());stmt.addBatch();}stmt.executeBatch();ResultSet游標控制•可以在建立Statement物件時指定resultSetType –ResultSet.TYPE_FORWARD_ONLY–ResultSet.TYPE_SCROLL_INSENSITIVE–ResultSet.TYPE_SCROLL_SENSITIVE•預設是第一個,也就是只能使用next()來逐筆取得資料•指定第二個或第三個時,則可以使用ResultSet的afterLast()、previous()、absolute()、relative()等方法ResultSet游標控制•還必須指定resultSetConcurrency –ResultSet.CONCUR_READ_ONLY–ResultSet.CONCUR_UPDATABLE •createStatement()不給定參數時,預設是TYPE_FORWARD_ONLY、CONCUR_READ_ONLYResultSet游標控制dbsource= new SimpleDBSource();conn= dbsource.getConnection();stmt = conn.createStatement(ResultSet.TYPE_SCROLL_INSENSITIVE,ResultSet.CONCUR_READ_ONLY);ResultSet result = stmt.executeQuery("SELECT * FROM t_message");result.afterLast();while(result.previous()) {System.out.print(result.getInt("id") + "\t");System.out.print(result.getString("name") + "\t");System.out.print(result.getString("email") + "\t");System.out.println(result.getString("msg"));}ResultSet新增、更新、刪除資料•建立Statement時必須在createStatement()上指定TYPE_SCROLL_SENSITIVE(或TYPE_SCROLL_INSENSITIVE,如果不想取得更新後的資料的話)與CONCUR_UPDATABLEStatement stmt = conn.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE,ResultSet.CONCUR_UPDATABLE);ResultSet新增、更新、刪除資料•針對查詢到的資料進行更新的動作ResultSet result = stmt.executeQuery("SELECT * FROM t_message WHERE name='justin'"); st();result.updateString("name", "caterpillar");result.updateString("email", "caterpillar@"); result.updateRow();ResultSet新增、更新、刪除資料•如果想要新增資料ResultSet result = stmt.executeQuery("SELECT * FROM t_message WHEREname='caterpillar'");result.moveToInsertRow();result.updateInt("id", 4);result.updateString("name", "jazz");result.updateString("email", "jazz@");result.updateString("msg", "message4...");result.insertRow();ResultSet新增、更新、刪除資料•要刪除查詢到的某筆資料ResultSet result = stmt.executeQuery("SELECT * FROM t_message WHEREname='caterpillar'");st();result.deleteRow();ResultSetMetaData •Meta Data即「資料的資料」(Data about data)•ResultSet用來表示查詢到的資料,而ResultSet資料的資料,即描述所查詢到的資料背後的資料描述,即用來表示表格名稱、欄位名稱、欄位型態•可以透過ResultSetMetaData來取得ResultSetMetaDatadbsource= new SimpleDBSource();conn= dbsource.getConnection();stmt = conn.createStatement();ResultSet result = stmt.executeQuery("SELECT * FROM t_message"); ResultSetMetaData metadata =result.getMetaData();for(int i = 1; i <= metadata.getColumnCount(); i++) { System.out.print(metadata.getTableName(i) + ".");System.out.print(metadata.getColumnName(i) + "\t|\t");System.out.println(metadata.getColumnTypeName(i));}。