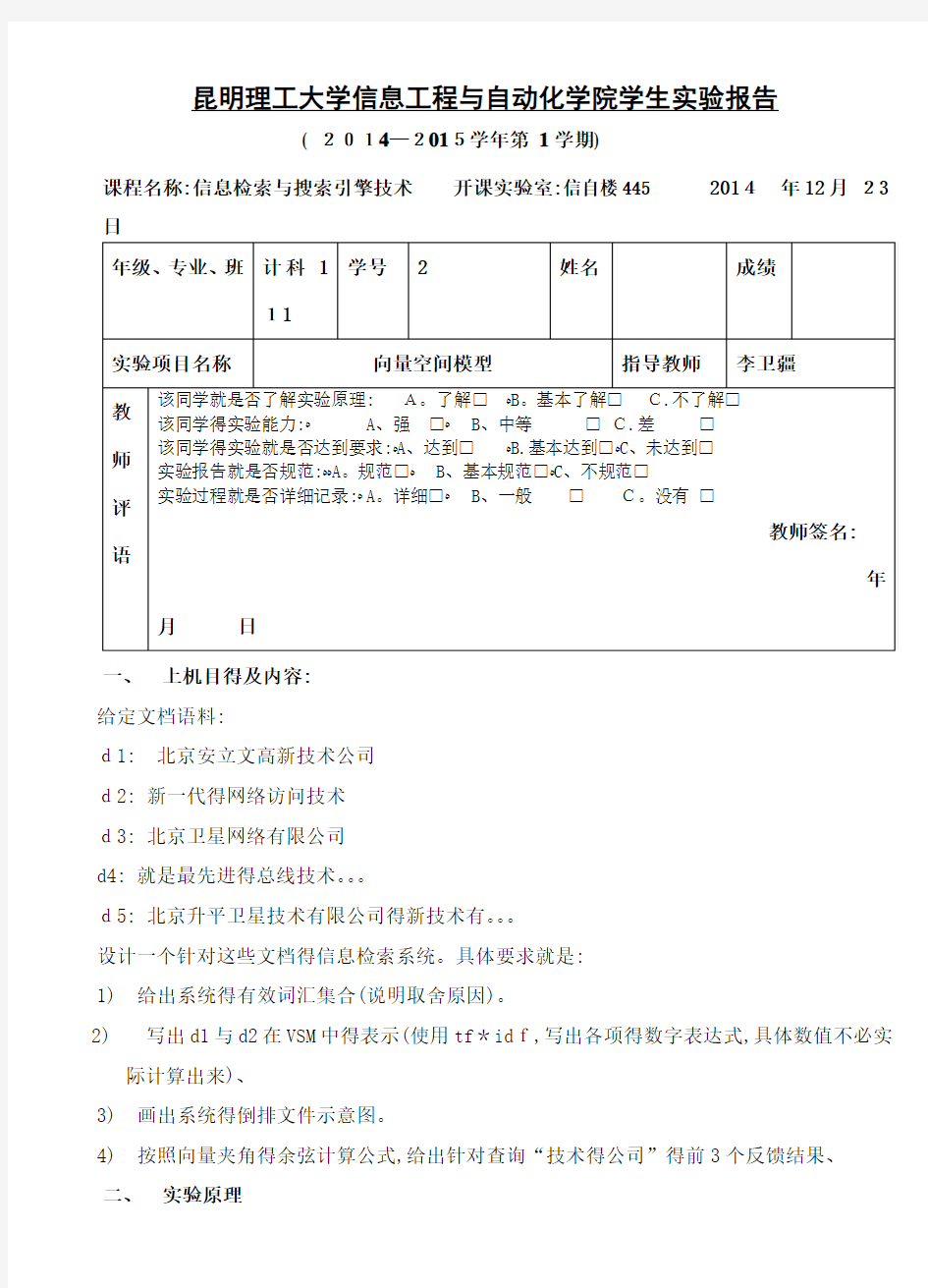

昆明理工大学信息工程与自动化学院学生实验报告
( 2014—2015学年第1学期)
课程名称:信息检索与搜索引擎技术开课实验室:信自楼445 2014年12月23日
一、上机目得及内容:
给定文档语料:
d1: 北京安立文高新技术公司
d2: 新一代得网络访问技术
d3: 北京卫星网络有限公司
d4: 就是最先进得总线技术。。。
d5: 北京升平卫星技术有限公司得新技术有。。。
设计一个针对这些文档得信息检索系统。具体要求就是:
1)给出系统得有效词汇集合(说明取舍原因)。
2)写出d1与d2在VSM中得表示(使用tf*idf,写出各项得数字表达式,具体数值不必实
际计算出来)、
3)画出系统得倒排文件示意图。
4)按照向量夹角得余弦计算公式,给出针对查询“技术得公司”得前3个反馈结果、
二、实验原理
1)给出系统得有效词汇集合(说明取舍原因)、
北京、安、立、文、高新、技术、公司、新、网络、访问、卫星、有限、先进、总线、升、平
得、就是、最、有,这些词作为停用词不能加入系统得有效集合
一、代,去除后并不影响原来句子语义得表达也不能算作系统得有效集合。
2)写出d1与d2在VSM中得表示(使用tf*idf,写出各项得数字表达式,具体数值不必实际计
算出来)、
得到得矩阵:
说明: TF:表示词项在
该文档或
者查询词
中出现得频度。即该词项出现次数除以该文档得长度(所有词得个数)
:表示词项k 在D i 中得出现次数。
:表示该文档得长度(所有词得个数)
IDF:表示词项在文档集合中得重要程度。一个词项出现得文档数越多,说明该词项得区分度越差,其在文档集合中得重要性就越低。
N:表示集合中得文档数; :表示出现词项k 得文档数。 d1中各词项得数字表达式
“北京"得
“安”得
“立”得
“文”得
北京 1
0 1 0 1 3 安 1 0 0 0 0 1 立 1 0 0 0 0 1 文 1 0 0 0 0 1 高新
1 0 0 0 0 1 技术
1 1 0 0 1 3 公司
1 0 1 0 1 3 新
0 1 0 0 1 2 网络 0 1 1 0 0 2 访问 0 1 0 0 0 1 卫星 0 0 1 0 1 2 有限 0 0 1 0 1 2 先进 0 0 0 1 0 1 总线 0 0 0 1 0 1 升
0 0 0 0 1 1 平 0
0 0 0 1 1
“高新”得
“技术”得
“公司”得
d2中各词项得数字表达式:
“新"得
“网络”得
“访问"得
“技术"得
3)画出系统得倒排文件示意图。
4)按照向量夹角得余弦计算公式,给出针对查询“技术得公司"得前3个反馈
结果。
该部分由代码实现。
三、实验方法、步骤
1.建立Java项目,
2.建立DocumentStruct.java类文件并编辑
3.建立TextVector.java类文件并编辑,如图4-1,图4-2所示
图4—1
图4-2
4.建立TF、java类文件并编辑,如图图4-7所示
图4—4
5.建立IDF。java类文件并编辑,如图图4—5所示
图4-5
6.建立CaculateSim。java类文件并编辑,如图4-6所示
图4-6
7.建立MainApp、java类文件并编辑,图4-7所示
图4-7
8.完成后得项目文件夹如图4-8所示
图4-8
9.运行结果如图4-9所示
1.DocumentStruct。java代码:
packageacm.model;
public class DocumentStruct{
?publicDocumentStruct(){?this。documentID =0;
??this。documentSimValue=0;
this、documentContent =”None”;
this.documentName ="None";
?}
publicDocumentStruct(int ID, double
sim, Stringname, String content){
this、documentID = ID;
this.documentSimValue=sim;
?this。documentName= name;
??this。documentContent = content;
}
?public String getDocumentContent() {
?returndocumentContent;
}
?public void setDocumentContent(String documentContent) {
?this.documentContent = documentC
ontent;
?}
publicString getDocumentName() {
??returndocumentName;
}
publicvoid setDocumentName(String documentName){
??this。documentName= documentName;
?}
?public double getDocumentSimValue() {??returndocumentSimValue;
?}
?public void setDocumentSimValue(double documentSimValue) {
?this、documentSimValue =docume ntSimValue;
?}
?publicintgetDocumentID() {
?returndocumentID;
}
?publicvoid setDocumentID(intdocumentID) {
?this。documentID=documentID;
?}
?publicDocumentStruct[] sortDocByS
im(DocumentStruct[]docList){
?DocumentStructtemp;
for(inti=0; i ?for(int j=i; j〈docList。length—1; j++){ ?if(docList[i]、getDocum entSimValue() <docList[j]。getD ocumentSimValue() ){ ??temp= docList[i]; ???docList[i] = docList[j]; ????docList[j]=temp; ?} ??} } ?returndocList; } ?private String documentName; private StringdocumentContent; ?private doubledocumentSimValue; ?privateintdocumentID; } 2.TextVector。java代码: packageacm、model; publicclass TextVector { publicTextVector(intdimension, int[]termCount,intdocument TermCount, intdocumentCount, int[] documentContainTermCount){ ??vectorWeight=new double[dimensi on]; for(inti=0; i (termCount[i], documentTermCount, documentCount,documentContainTe rmCount[i]); ?} ?} public double caculateWeight(intter mCount,intdocumentTermCount, int documentCount, intdocumentContainT ermCount){ ?TF termTF =new TF(termCount, documentTermCount); IDF termIDF= newIDF(documentCount, documentContainTermCou nt); ??termTF、caculateTF(); ?termIDF.caculateIDF(); ?return(termTF。getTf()*termIDF。get Idf()); ?} public double[] getVectorWeight() { returnvectorWeight; ?} public void setVectorWeight(double[] vectorWeight) { this.vectorWeight=vectorWeight; } private double[]vectorWeight; } } 3.TF、java代码 packageacm、model; public class TF { publicTF(){ ?tf =0.0; termCount = 0; ?termInDocumentCount = 0; ?} public TF(inttermCount, intdocu mentTermCount){ ?this、tf= 0、0; ?this、termCount = termCount; ?this.termInDocumentCount= doc umentTermCount; } public voidcaculateTF(){ if(termInDocumentCount ==0){ ??System.out。println(”请先设置文档总数!”); ?return; ?} ?this。tf=(double)termCount/ (double)termInDocumentCount; ?} ?public doublegetTf(){ returntf; ?} publicintgetTermCount() { returntermCount; } ?public void setTermCount(inttermCount) { ?this。termCount = termCount; ?} ?publicintgetTermInDocumentCount() { ??returntermInDocumentCount; ?} public voidsetTermInDocumen tCount(inttermInDocumentCount) { ??this、termInDocumentCount=termInD ocumentCount; ?} ?private double tf; ?privateinttermCount; privateinttermInDocumentCount; } 4.IDF.java代码 packageacm、model; publicclass IDF { ?public IDF(){ ?idf= 0.0; ?documentContainTermCount= 0; ?documentCount =0; ?} ?publicIDF(intdocumentCount, intd ocumentContainTermCount){ ?idf =0、0; ?this.documentCount =docume ntCount; ??this、documentContainTermCount = documentContainTermCount; ?} ?publicintgetDocumentCount() { ?returndocumentCount; } publicvoidsetDocumentCount(intdocumentCount) { this。documentCount= documentCount; ?} publicintgetDocumentContainTermCount() { ?returndocumentContainTermCount; } public void setDocumentContain TermCount(intdocumentContainTerm Count) { ??this.documentContainTermCount = documentContainTermCount; } public double getIdf() { returnidf; } ?public void caculateIDF(){ ??if(documentContainTermCount==0){ ?System、out、println("请设置文档得长度(所有词得个数)!"); ??return; ?} ?this、idf=Math、log10((double)thi s.documentCount/ (double)this。docume ntContainTermCount); ?} private double idf; privateintdocumentCount; privateintdocumentContainTe rmCount; } 5.CaculateSim.java代码 packageacm、model; public class CaculateSim{ ?publicCaculateSim(TextVector vector1, TextVector vector2){ ??doublesimDividend=0。0, simDivider=0、0; ?doubletempVector1=0。0, tempV ector2=0。0; ?for(inti=0; i<vector1。getVectorW eight()、length; i++){ ?simDividend+=vector1.getVec torWeight()[i]* vector2.getVectorWeigh t()[i]; ??} for(inti=0; i<vector1、getVe ctorWeight()。length; i++){ ?tempVector1 +=Math、pow(vec tor1、getVectorWeight()[i], 2.0); ?tempVector2+= Math。pow(vect or2。getVectorWeight()[i],2。0); ?simDivider= Math。sqrt((tempVector1*tempVector2)); ?} ?this.sim =simDividend/sim Divider; ?} publicdouble getSim() { returnsim; ?} ?privatedoublesim; } 6.MainApp。java代码 packageacm。model; public class MainApp{ public staticvoidmain(String[]ar gs) { ?intTermCount[][] = { {1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0}, ???{0,0,0,0,0,1,0,1, 1,1,0,0,0,0,0,0}, ????{1,0,0,0,0,0,1,0,1,0,1,1,0,0,0,0}, ???{0,0,0,0,0,0,0,0,0,0,0,0,1,1,0,0}, ???{1,0,0,0,0,1,1,1,0,0,1,1,0,0,1,1}, ?????{0,0,0,0,0,1,1,0,0,0,0,0,0, 0,0,0}}; intdocumentTermCount[] ={7, 7, 5,6, 11, 3}; ??intdocumentContainTermCount[] = {3,1,1,1,1,4,4,2,2,1,2,2,1,1,1,1}; ?DocumentStruct[]docList = new DocumentStruct[6]; ?StringdocumentContent[]={”北京安立文高新技术公司", ?????”新一代得网络访问技术", ??????"北京卫星网络有限公司”, ????”就是最先进得总线技术、。、", ?????"北京升平卫星技术有限公司得新技术有。。、", ??????”技术得公司"}; ??TextVectorqueryVector=new TextVector(16,TermCount[5], documentTermCount[5], 6, documentContainTermCount); for(inti=0; i<5;i++) { ??TextVectortempVector = new TextVe ctor(16,TermCount[i],documentTermCount[i], 6, documentContainTermCount); ??CaculateSimtempSim=new CaculateSim(tempVector, queryVector); ??DocumentStructtempDoc=new Do cumentStruct(i+1,tempSim.getSim(), "文档"+(i+1),documentContent[i]); ?docList[i] =tempDoc; } docList = docList[1]、sortDocBySim(docList); ??System、out。println("以\"技术得公司\"为查询关键字得到得前3个结果为:”); ?for(inti=0; i<3; i++){ ??System、out。println((i+1) + "。"+docList[i]、getDocumentName()+":"+docL ist[i]、getDocumentContent()); } ?}} 四、实验结果、分析与结论 本次实验我学会了针对文档进行信息检索系统,向量空间模型就是信息检索得一个重要方面,向量空间模型得建立能让您对信息有更好得把握,所以向量空间模型对我们以后信息检索至关重要,在编程方面我来遇到了很多得问题,这些都就是在老师得帮助下完成得,在这次实验中我学到了很多。 搜索引擎检索技巧 搜索引擎 搜索引擎(search engine),1995年开始搜索引擎以一定的策略从网络收集、发现信息,对信息进行理解、提取、组织和处理,并为用户提供检索服务,从而起到信息导航的目的。 搜索引擎站---“网络门户” 1、搜索引擎的工作原理 信息的收集处理 信息的检索输出 2、搜索引擎的分类 搜索引擎按其工作方式主要可分为三种: 目录索引类搜索引擎(Search Index/Directory) 机器人搜索引擎(全文搜索引擎)(Full Text Search Engine)元搜索引擎(Meta Search Engine) 2、搜索引擎的分类(续) 目录式搜索引擎 目录式搜索引擎:以人工方式或半自动方式搜集信息,由编辑员查看信息之后,人工形成信息摘要,并将信息置于事先确定的分类框架中。信息大多面向网站,提供目录浏览服务和直接检索服务。 该类搜索引擎因为加入了人的智能,所以信息准确、导航质量高,缺点是需要人工介入、维护量大、信息量少、信息更新不及时。 这类搜索引擎的代表是:yahoo!、Galaxy、Open Directory…… 2、搜索引擎的分类(续) 机器人搜索引擎 由一个称为蜘蛛(Spider)的机器人程序以某种策略自动地在互联网中搜集和发现信息,由索引器为搜集到的信息建立索引,由检索器根据用户的查询输入检索索引库,并将查询结果返回给用户。服务方式是面向网页的全文检索服务。 该类搜索引擎的优点是信息量大、更新及时、毋需人工干预,缺点是返回信息过多,有很多无关信息,用户必须从结果中进行筛选。 这类搜索引擎的代表是:AltaVista、Northern Light、Excite、Infoseek、Inktomi、FAST、Lycos、Google;国内代表为:百度等。 using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Text.RegularExpressions; namespace Felomeng.VSMSimilarity { class SVMModle { /// } /// 立体几何与空间向量(1) 知识点1 空间向量的坐标运算 设a=(1,5,-1),b=(-2,3,5). (1)若(k a+b)∥(a-3b),求k; (2)若(k a+b)⊥(a-3b),求k. 已知A(3,3,1),B(1,0,5),求: (1)线段AB的中点坐标和长度; (2)到A,B两点距离相等的点P(x,y,z)的坐标x,y,z满足的条件.知识点2 证明线面的平行、垂直 在正方体ABCD-A1B1C1D1中,E,F分别为BB1,CD的中点,求证:D1F⊥平面ADE. 已知A (-2,3,1),B (2,-5,3),C (8,1,8),D (4,9,6),求证:四边形ABCD 为平行四边形. 证明 知识点3 向量坐标的应用 棱长为1的正方体ABCD -A 1B 1C 1D 1中,P 为DD 1的中点,O 1、O 2、O 3分别是 平面A 1B 1C 1D 1、平面BB 1C 1C 、平面ABCD 的中心. (1)求证:B 1O 3⊥PA ; (2)求异面直线PO 3与O 1O 2所成角的余弦值; (3)求PO 2的长. 直三棱柱ABC —A 1B 1C 1的底面△ABC 中,CA =CB =1,∠BCA =90°,AA 1 =2,N 是AA 1的中点. (1)求BN 的长; (2)求BA 1,B 1C 所成角的余弦值. 解 以C 为原点建立空间直角坐标系,则 知识点4 棱柱、棱锥和棱台 圆柱、圆锥、圆台和球 例1:如图,用过BC 的一个平面(此平面不过D A '')截去长方体的一个角,剩下的几何 体是什么?截去的几何体是什么?请说出各部分的名称. A ' D ' B ' C ' 期末课程论文 论文标题:基于音频的信息检索 课程名称:信息检索技术 课程编号:1220500 学生姓名:潘国伟 学生学号:1100310220 所在学院:计算机科学与工程学院 学习专业:计算机科学与技术 课程教师:王冲 2013年7月3 日 引言: 进入知识经济时代,知识管理、知识服务的理念得到广泛认同,信息检索技术也由基于关键词的信息检索逐步转向针对内容的基于知识的信息检索。较之前者,其检索结果更准确,更贴近用户需求。信息检索是将信息按照一定的规律组织起来,找到所需信息的过程和技术,简单的说,就是信息的有序化识别和查找。信息检索效率就是实施识别和查找过程的效率。信息检索效率不仅是影响信息检索工具价值的重要因素,也是评价信息检索技术发展的重要指标。目前一些基于文本的Web引擎,如Google,Baidu,功能已非常强大,但还缺乏比较实用的音频搜索引擎。Internet上的多媒体流非常巨大,需要一些高效的搜索引擎从浩如烟海的数据中找出需要的信息。另外,音频检索在辅助视频检索和卡拉OK检索系统以及军事、刑侦领域方面都有巨大的应用价值和广阔的研究前景。 基于内容的音频检基索关键技术 问题: 传统的方法,其主要缺点有: 一是当数据量越来越多时,人工注释的工作量加大; 二是人对音频的感知有时难以用文字注释表达清楚,人工注释存在不完整性和主观性; 三是不能支持实时音频数据流的检索。 这里主要综述了音频检索方法,讨论了一些音频检索中的关键技术:音频特征提取、音频分类、语音识别技术等。 总体介绍: 语音识别技术概述 语音识别技术,也被称为自动语音识别(Automatic Speech Recognition, ASR),其目标是将人类的语音中的词汇内容转换为计算机可读的输入,例如按键、二进制编码或者字符序列。与说话人识别及说话人确认不同,后者尝试识别或确认发出语音的说话人而非其中所包含的词汇内容。 语音识别技术是以语音信号处理为研究对象,让机器接收并识别、理解语音信号,并将其转换为相应数字信号的技术。让机器听懂人类的语言,这是人们长期以来梦寐以求的事情,而语音识别是一门非常复杂的交叉性学科,它涉及语音语言学、计算机科学、信号处理学、生理学、心理学等一系列学科,是模式识别的重要分支。50年代,是语音识别研究工作的开始时期,它以贝尔实验室研制成功可识别十个数字的Audry系统为标志。20世纪80年代语言识别研究进一步走向深入,基于特定人孤立语音技术的系统研制成功。在过去的30年里,隐马尔可夫模型和人工神经元网络在语音识别中得到了成功的应用。 语音识别技术所涉及的领域包括:信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等。并通过算法和计算机技术相结合的方式来实现。目前,这样的系统能够做到识别理解数十万条词汇的连续语音信号。这种现代模式识别系统除了在语音领域的应用外,还可以广泛应用于信号处理和模式识别的其他领域。语音识别一般分为两个步骤: .html .asp/.aspx .php .jsp Html语言变量、函数、组建、流程、循环、结构 代码结构进行优化 URL 统一资源定位符号universal resources locator 网络地址 Filetype Intitle Inurl 美萍点播系统VOD down:43 Site: 在站内进行检索 Intext: Seo搜索引擎优化-》sem搜索引擎营销-》网络营销 【项目背景介绍】 信息社会,信息以爆炸式的方式增长,网络环境下,搜索引擎是我们通往目的地的必备武器,但是在浩如烟海的网络信息里面,很多网友都只会简单的搜索,往往不能够很好的达到搜索的目的,因此也无法完成对海量信息的综合处理。作为电子商务专业学生,如何高效的完成信息检索,无论是对个人依托网络进行的学习还是今后的网络商务工作,都十分重要。 【项目工具简介和环境要求】 互联网机房 能正常访问互联网、IE插件正常 【项目延伸思考题】 搜索引擎的商用价值 各类搜索引擎通用的高级搜索命令 提高网站被检索可能性的建议 【项目教学难点】 网站备案机制 网站支付流程的合理性 网站联系信息的真实性判断 【项目实施步骤】 项目简介—快速测试—软件包传送—学生自我摸索(安装、调试、搜索等)—手把手—应用场合分析—新模式联想 随着网络技术尤其是WWW站点的快速发展和普及,人们通过Internet获取全球信息的可能性越来越大。可以说,我们所需要的信息,绝大部分都可以通过因特网获取。但是网络信息内容庞杂、分散无序,各种有价值、所需的信息资源淹没在信息的“汪洋大海”中,给人们查询和利用网络信息资源带来了极大的不便。为了更有效地开发和利用网络信息资源,人们研制了许多网络信息检索工具,其中WWW是Internet上增长最快、使用最方便灵活的多媒体信息传输与检索系统,越来越多的用户将自己的信息以WWW的方式在网上发布。WWW服务器已称为互联网上数量最大和增长最快的信息系统,因而可以检索WWW网址网页以及新闻论坛、BBS文章的检索工具——搜索引擎称为查询网络信息的最主要的检索工具。 有人说,会搜索才叫会上网,搜索引擎在我们日常生活中的地位已是举足轻重。你也许是个刚买了“猫”兴冲冲地要上网冲浪,也许已经在互联网上蛰伏了好几年,无论怎样,要想在浩如烟海的互联网信息中找到自己所需的信息,都需要一点点技巧。对于企业而言,学习搜索,提高技巧,就能找到更多的潜在客户。 向量空间模型(VSM)的余弦定理公式(cos) 相信很多学习向量空间模型(Vector Space Model)的人都会被其中的余弦定理公式所迷惑.. 因为一看到余弦定理,肯定会先想起初中时的那条最简单的公式cosA=a/c(邻边比斜边),见下图: 但是,初中那条公式是只适用于直角三角形的,而在非直角三角形中,余弦定理的公式是: cosA=(c2 + b2 - a2)/2bc 不过这条公式也和向量空间模型中的余弦定理公式不沾边,迷惑.. 引用吴军老师的数学之美系列的余弦定理和新闻的分类里面的一段: -------------------引用开始分界线------------------------ 假定三角形的三条边为a, b 和c,对应的三个角为A, B 和C,那么角A 的余弦 如果我们将三角形的两边b 和 c 看成是两个向量,那么上述公式等价于 其中分母表示两个向量b 和 c 的长度,分子表示两个向量的内积。 举一个具体的例子,假如新闻X 和新闻Y 对应向量分别是x1,x2, (x64000) y1,y2,...,y64000, 那么它们夹角的余弦等于 -------------------引用完毕分界线------------------------ 高中那条公式又怎么会等价于向量那条公式呢? 原来它从高中的平面几何跳跃到大学的线性代数的向量计算.. 关于线性代数中的向量和向量空间,可以参考下面两个页面: Egwald Mathematics: Linear Algebra Linear Algebra: Direction Cosines 在线性代数的向量计算的余弦定理中, * 分子是两个向量的点积(wiki),点积的定理和计算公式: The dot product of two vectors a = [a1, a2, … ,a n] and b = [b1, b2, … , b n] is defined as: 点积(dot product),又叫内积,数量积..(Clotho注: product常见的是产品的意思,但在数学上是乘积的意思.) * 分母是两个向量的长度相乘.这里的向量长度的计算公式也比较难理解. 假设是二维向量或者三维向量,可以抽象地理解为在直角坐标轴中的有向线段,如图: d2 = x2 + y2-> d = sprt(x2 + y2) 信息检索与搜索引擎技术实 验向量空间模型 -标准化文件发布号:(9456-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII 昆明理工大学信息工程与自动化学院学生实验报告 ( 2014—2015学年第 1学期) 课程名称:信息检索与搜索引擎技术开课实验室:信自楼445 2014 年12月 23日 一、上机目的及内容: 给定文档语料: d1: 北京安立文高新技术公司 d2: 新一代的网络访问技术 d3: 北京卫星网络有限公司 d4: 是最先进的总线技术。。。 d5: 北京升平卫星技术有限公司的新技术有。。。 设计一个针对这些文档的信息检索系统。具体要求是: 1)给出系统的有效词汇集合(说明取舍原因)。 2)写出d1和d2在VSM中的表示(使用tf*idf,写出各项的数字表达式,具体数值不必 实际计算出来)。 3)画出系统的倒排文件示意图。 4)按照向量夹角的余弦计算公式,给出针对查询“技术的公司”的前3个反馈结果。 2 二、实验原理 1)给出系统的有效词汇集合(说明取舍原因)。 北京、安、立、文、高新、技术、公司、新、网络、访问、卫星、有限、先进、总线、升、平 的、是、最、有,这些词作为停用词不能加入系统的有效集合 一、代,去除后并不影响原来句子语义的表达也不能算作系统的有效集合。 2)写出d1和d2在VSM中的表示(使用tf*idf,写出各项的数字表达式,具体数值不必实际 计算出来)。 得到的矩阵: 3 4 说明: TF :表示词项在该文档或者查询词中出现 的频度。即该词项出现次数除以该文档的长度(所有词的个数) :表示词项k 在D i 中的出现次数。 :表示该文档的长度(所有词的个数) IDF :表示词项在文档集合中的重要程度。一个词项出现的文档数越多,说明该词项的区分度越差,其在文档集合中的重要性就越低。 N :表示集合中的文档数; :表示出现词项k 的文档数。 d1中各词项的数字表达式 “北京”的 “安”的 “立”的 北京 1 0 1 0 1 3 安 1 0 0 0 0 1 立 1 0 0 0 0 1 文 1 0 0 0 0 1 高新 1 0 0 0 0 1 技术 1 1 0 0 1 3 公司 1 0 1 0 1 3 新 0 1 0 0 1 2 网络 0 1 1 0 0 2 访问 0 1 0 0 0 1 卫星 0 0 1 0 1 2 有限 0 0 1 0 1 2 先进 0 0 0 1 0 1 总线 0 0 0 1 0 1 升 0 0 0 0 1 1 平 0 0 0 0 1 1 详细介绍常用的几类搜索引擎技术 因特网的迅猛发展、WEB信息的增加,用户要在信息海洋里查找信息,就像大海捞针一样,搜索引擎技术恰好解决了这一难题,它可以为用户提供信息检索服务。目前,搜索引擎技术正成为计算机工业界和学术界争相研究、开发的对象。 搜索引擎(Search Engine)是随着WEB信息的迅速增加,从1995年开始逐渐发展起来的技术。 据发表在《科学》杂志1999年7月的文章《WEB信息的可访问性》估计,全球目前的网页超过8亿,有效数据超过9TB,并且仍以每4个月翻一番的速度增长。例如,Google 目前拥有10亿个网址,30亿个网页,3.9 亿张图像,Google支持66种语言接口,16种文件格式,面对如此海量的数据和如此异构的信息,用户要在里面寻找信息,必然会“大海捞针”无功而返。 搜索引擎正是为了解决这个“迷航”问题而出现的技术。搜索引擎以一定的策略在互联网中搜集、发现信息,对信息进行理解、提取、组织和处理,并为用户提供检索服务,从而起到信息导航的目的。 目前,搜索引擎技术按信息标引的方式可以分为目录式搜索引擎、机器人搜索引擎和混合式搜索引擎;按查询方式可分为浏览式搜索引擎、关键词搜索引擎、全文搜索引擎、智能搜索引擎;按语种又分为单语种搜索引擎、多语种搜索引擎和跨语言搜索引擎等。 目录式搜索引擎 目录式搜索引擎(Directory Search Engine)是最早出现的基于WWW的搜索引擎,以雅虎为代表,我国的搜狐也属于目录式搜索引擎。 目录式搜索引擎由分类专家将网络信息按照主题分成若干个大类,每个大类再分为若干个小类,依次细分,形成了一个可浏览式等级主题索引式搜索引擎,一般的搜索引擎分类体系有五六层,有的甚至十几层。 目录式搜索引擎主要通过人工发现信息,依靠编目员的知识进行甄别和分类。由于目录式搜索引擎的信息分类和信息搜集有人的参与,因此其搜索的准确度是相当高的,但由于人工信息搜集速度较慢,不能及时地对网上信息进行实际监控,其查全率并不是很好,是一种网站级搜索引擎。 机器人搜索引擎 机器人搜索引擎通常有三大模块:信息采集、信息处理、信息查询。信息采集一般指爬行器或网络蜘蛛,是通过一个URL列表进行网页的自动分析与采集。起初的URL并不多,随着信息采集量的增加,也就是分析到网页有新的链接,就会把新的URL添加到URL列表,以便采集。 信息检索技术方法及搜索引擎.txt 1 截词检索技术 2 邻近检索技术 3 字段检索技术 4 布尔逻辑检索是指通过标准的布尔逻辑关系算符来表达检索词与检索词间的逻辑关系的检索 方法. 主要的布尔逻辑关系词有:逻辑与(AND),逻辑或(OR),逻辑非(NOT) 1 布尔逻辑检索技术 逻辑与 逻辑乘: "and"或"*"表示 组配方式:A*B或者A and B 表示两个概念的交叉和限定关系,只有同时含有这两个概念的记 录才算命中信息 作用:增加限制条件,即增加检索的专指性,以缩小提问范围,减少文献输出量,提高查准率. 逻辑或 又称逻辑和:"or","+" 组配方式:A OR B或者A+B,表示检索含有A词,或含有B词,或同时包含A,B两词的文章. 作用:放宽提问范围,增加检索结果,起扩检作用,提高查全率. 逻辑非 又称逻辑差: "not" "-" 组配方式:A-B,表示检索出含有A词而不含有B 词的文章. 作用:逻辑非用于排除不希望出现的检索词,它和"*"的作用相似,能够缩小命中文献范围,增 强检索的准确性. 例如检索:"打印机驱动程序" 查询关键词:打印机,驱动程序 检索表达式:打印机 AND 驱动程序 例如检索:"微型计算机"方面的有关信息 查询关键词:微型计算机,微机 检索表达式:微型计算机OR 微机 布尔逻辑检索举例 布尔运算符优先级比较 有括号时:括号内的先执行; 无括号时:NOT > AND > OR 例:检索"唐宋诗歌"的有关信息. 关键词:唐,宋,诗歌; 检索表达式: (唐 OR 宋)AND 诗歌; 唐 AND 诗歌 OR 宋 AND 诗歌; 错误表达式: 唐 OR 宋AND诗歌; 唐 AND 宋AND诗歌; 创建基于DLL的Proteus VSM仿真模型 一、Proteus VSM仿真模型简介 在使用Proteus仿真单片机系统的过程中,经常找不到所需的元件,这就需要自己编写。Proteus VSM的一个主要特色是使用基于DLL组件模型的可扩展性。这些模型分为两类:电气模型(Electrical Model)和绘图模型(Graphical Model)。电气模型实现元件的电气特性,按规定的时序接收数据和输出数据;绘图模型实现仿真时与用户的交互,例如LCD的显示。一个元件可以只实现电气模型,也可以都实现电气和绘图模型。 Proteus为VSM模型提供了一些C++抽象类接口,用户创建元件时需要在DLL中实现相应的抽象类。VSM模型和Proteus系统通信的原理如下图: 绘图模型接口抽象类: ICOMPONENT――ISIS内部一个活动组件对象,为VSM模型提供在原理图上绘图和用户交互的服务。 IACTIVEMODEL――用户实现的VSM绘图模型要继承此类,并实现相应的绘图和键盘鼠标事件处理。 电气模型接口抽象类: IINSTANCE――一个PROSPICE仿真原始模型,为VSM模型提供访问属性、模拟节点和数据引脚的服务,还允许模型通过仿真日志发出警告和错误信息。 ISPICECKT(模拟)――SPICE拥有的模拟元件,提供的服务:访问、创建和删除节点,在稀疏矩阵上分配空间,同时还允许模型在给定时刻强制仿真时刻点的发生和挂起仿真。 ISPICEMODEL(模拟)――用户实现的VSM模拟元件要继承此类,并实现相应的载入数据,在完成的时间点处理数据等。 IDSIMCKT(数字)――DSIM拥有的数字元件,提供的服务:访问数字系统的变量,创建回调函数和挂起仿真。 IDSIMMODEL(数字)――用户实现的VSM数字元件要继承此类,并实现相应的引脚状态变化的判断和回调事件的处理。 IDSIMPIN(数字)――数字组件的引脚,提供检测引脚状态和创建输出事务事件的服务。 IDBUSPIN(数字)――数字组件的数据或地址总线,提供检测总线状态和创建总线输出事务事件的服务。 IMIXEDMODEL(混合)――同时继承了ISPICEMODEL和 IDSIMMODEL,元件既有模拟特性,又有数字特性。 《信息检索搜索引擎技术》期末考试报告 学期:2016-2017学年第一学期 任课教师:毛存礼 专业年级:计科133 学号:201310405339、 201310405326、 201310405330、201310405325 学生姓名:李然、毛子铭、张倩、黄枫 目录 一、系统概述 (3) 二、系统需求分析 (3) 2.1功能需求分析 (3) 三、程序实现 (4) 3.1 爬虫的实现 (4) 3.1.1 对网页进行分析 (4) 3.1.2编写爬虫 (5) 3.2索引的实现 (7) 3.2.1分词的实现 (7) 3.2.2索引的建立 (8) 3.2.3检索索引 (9) 3.3向量空间模型的实现 (10) 3.3.1向量空间模型概述 (10) 3.3.2建立向量空间模型 (11) 3.4利用Lucene打分机制对文档打分 (13) 四、测试 (14) 五、心得体会 (17) 一、系统概述 随着互联网的迅猛发展、WEB信息的增加,用户要在信息海洋里查找自己所需的信息,就像大海捞针一样,搜索引擎技术恰好解决了这一难题。搜索引擎是指互联网上专门提供检索服务的一类网站,这些站点的服务器通过网络搜索软件或网络登录等方式,将Intenet上大量网站的页面信息收集到本地,经过加工处理建立信息数据库和索引数据库,从而对用户提出的各种检索做出响应,提供用户所需的信息或相关指针。 用户的检索途径主要包括自由词全文检索、关键词检索、分类检索及其他特殊信息的检索。本系统基于HTMLUNIT框架,构建爬虫,基于LUCENE框架,构建索引,利用向量空间模型向量化表示文档间的相关性,利用LUCENE 给相关文档打分。 二、系统需求分析 2.1功能需求分析 该系统分为四个功能模块: (1)爬虫模块 (2)索引模块 (3)向量化表示模块 (4)打分模块 具体实现分工如下: ①爬虫模块:该模块采用Htmlunit框架,主要负责爬取网页内容,在 本地建立文档库,以便于索引功能模块,将文档库里的文档内容建立成索引。 (毛子铭所做) ②索引模块:该模块采用Lucene框架,功能分为两块:一是建立索引, 将爬取的内容建立成索引。二是检索索引,即提供给用户检索索引。(张倩所做) ③向量化表示模块:该模块采用向量空间模型,其功能是将查询文本和 《信息检索技术》(第三版)书后习题及参考答案(部分) 第1章绪论 【综合练习】 一、填空题 1.文献是信息的主要载体,根据对信息的加工层次可将文献分为_________文献、__________文献、___________文献和___________文献。 2.追溯法是指利用已经掌握的文献末尾所列的__________,进行逐一地追溯查找_________的一种最简便的扩大情报来源的方法。 3.用规范化词语来表达文献信息__________的词汇叫主题词。主题途径是按照文献信息的主题内容进行检索的途径,利用能代表文献内容的主题词、关键词、叙词、并按字顺序列实现检索。 4.计算机信息检索过程实际上是将___________与____________进行对比匹配的过程。 5.无论是手工检索还是计算机检索,都是一个经过仔细地思考并通过实践逐步完善查找方法的过程。检索过程通常包含以下几个步骤_________、__________、__________、__________、_________。 6.检索工具按信息加工的手段可以分文__________、____________、___________。 7.《中国图书馆图书分类法》共分___________个基本部类,下分________个大类。 8.索引包括4个基本要素:索引源、___________、___________、和出处指引系统。 答案1.零次,一次,二次,三次 2.参考文献,引文 3.内容特征 4.检索提问词,文献记录标引词 5.分析课题,选择检索工具,确定检索途径及检索式,进行检索,获取原文 6.手工检索工具,机械检索工具,计算机检索工具 7.五,22 8.索引款目,编排方法 二、判断题 1.在检索信息时,使用逻辑符“AND”可以缩小收缩范围。() 2.逆查法是由近及远地查找,顺着时间的顺序利用检索工具进行文献信息检索的方法。() 3.按编制方法划分,信息检索工具可以分为:手工检索工具、机械检索工具、计算机检索工具。() 4.请判断下面图书的国际标准书号的格式是否正确。ISBN:978-030-26151-X。() 5.文献的专利号、报告号、合同号、标准号、索取号、国际标准书号、刊号属于文献的内部特征。 6.二次检索是指在第一次检索结果不符合要求时,重新选择检索条件再次进行检索。 答案1.√2.×3.×4.√5.√6.× 搜索引擎分析 在当今的社会,上网成为了我们大部分人每天必不可少的一部分,网络具有太多的诱惑和开发的潜力,查询资料,消遣娱乐等等,但是这些大部分都离不开搜索引擎技术的应用。今天在我的这篇论文里将会对搜索引擎进行一个分析和相关知识的概括。就如大家所知道的互联网发展早期,以雅虎为代表的网站分类目录查询非常流行。网站分类目录由人工整理维护,精选互联网上的优秀网站,并简要描述,分类放置到不同目录下。用户查询时,通过一层层的点击来查找自己想找的网站。也有人把这种基于目录的检索服务网站称为搜索引擎,但从严格意义上讲,它并不是搜索引擎。1990年,加拿大麦吉尔大学计算机学院的师生开发出Archie。当时,万维网还没有出现,人们通过FTP来共享交流资源。Archie能定期搜集并分析FTP服务器上的文件名信息,提供查找分别在各个FTP主机中的文件。用户必须输入精确的文件名进行搜索,Archie告诉用户哪个FTP服务器能下载该文件。虽然Archie搜集的信息资源不是网页,但和搜索引擎的基本工作方式是一样的:自动搜集信息资源、建立索引、提供检索服务。所以,Archie被公认为现代搜索引擎的鼻祖。 搜索引擎是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。搜索引擎包括全文索 引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。百度和谷歌等是搜索引擎的代表。那么搜索引擎将来的发展方向和发展的前景又是如何?我们就先从以下的各类主流搜索引擎先进行一个大致的分析。 1.全文索引 全文搜索引擎是当今主要网络搜素时所应用的搜索引擎,在网络上也是大家所熟知的,比如google和百度都是我们平时经常使用的。它们从互联网提取各个网站的信息,建立起数据库,并能检索与用户查询条件相匹配的记录,按一定的排列顺序返回结果。根据搜索结果来源的不同,全文搜索引擎可分为两类,一类拥有自己的检索程序,俗称“蜘蛛”程序或“机器人”程序,能自建网页数据库,搜索结果直接从自身的数据库中调用,上面提到的Google 和百度就属于这种类型;另一类则是租用其他搜索引擎的数据库,并按自定的格式排列搜索结果,如Lycos搜索引擎。在搜索引擎分类部分提到过全文搜索引擎从网站提取信息建立网页数据库的概念。搜索引擎的自动信息搜集功能分两种。一种是定期搜索,就是每隔一段时间,搜索引擎就会发启“蜘蛛”程序,对一定IP 地址范围内的互联网站进行检索,一旦发现新的网站,它会自动提取网站的信息和网址加入自己的数据库。而另一种是提交网站搜索,即网站拥有者主动向搜索引擎提交网址,它在一定时间内定向向你的网站派出“蜘蛛”程序,扫描你的网站并将有关信息存入数据库,以备用户查询。由于近年来搜索引擎索引规则发生很 基于向量空间模型的信息检索技术 作者:张朝阳摘要:向量空间模型是信息检索技术中使用的最原始、最简单、最成熟、最有效的模型,它以文本的向量表示为基础展开后续的计算工作。本文讲解了文本的向量表示法和文本相似度的计算方法。在文本检索之前往往需要对原始文本集进行分类和聚类,以减小查找的范围,提供个性化的信息推荐。本文介绍了最常用的文本分类和聚类的方法。 关键字:向量空间模型,文本相似度,特征选择和特征抽取,文本分类与聚类 1.引言 信息检索的一般情形是由用户给出检索项,应用程序从系统文档集中查找与检索项最匹配(亦即最相似)的文档返回给用户。说起来简单,实际上这之间经历了复杂的过程,如图1.1所示。 图 1.1信息检索基本步骤 文本预处理包括去除标记,去除停用词,词根还原。比如我们收集的原始文档是一些HTML文件,则首先要把HTML标签和脚本代码去除掉。停用词指像“的”、“吧”这样几乎不包含任何信息含量的词。词根还原指把同一个词的动词、形容词、副词形式都还原为名词形式。经过词频统计后我们得到每个文档里包含哪些词以及每个词出现的次数。如图 1.2所示。 图 1.2文档词频统计 D表示文档,Wi,j表示单词i在相应文档中出现了j次。 在实际的根据关键词进行信息检索过程中,为避免在每篇文档中使用冗长的顺序查找关键词,我们往往使用倒排序索引,如图 1.3所示。 图 1.3文档倒排序索引 W 表示单词,Di,j 表示相应的单词在文档i 中出现了j 次。 建立倒排序索引后,就可以直接根据关键词来查找相关的文档。找到相关文档还需要对文档进行排序再返回给用户,即要把用户最希望找到的文档排在最前面。这里引入文档和查询词之间的相似度(Similarity Coefficient,SC )的概念,相似度越大,表明文档与查询词的相关度越大,与用户的需求越接近。 在信息检索的研究与应用中人们用到了很多常用的模型,包括向量空间模型、概率模型、语言模型、推理网络、布尔检索、隐性语义检索、神经网络、遗传算法和模糊集检索。向量空间模型是最原始最简单的模型,在实际应用中也十分的成熟,它通过把文档和查询词展示为词项空间的向量,进而计算两个向量之间的相似度。 2.向量空间模型 2.1.文档向量表示 向量空间空间模型由哈佛大学G Salton 提出,他把文档表示为一个向量: 11()((),(),...,()) i i i n i v d w d w d w d =n 表示文本特征抽取时所选取的特征项的数目。 w i (d j )表示第i 个特征项在文档d j 中的权重。 特征词频率用tf 表示,指特征词在一个文档中出现的频率。文档频率用df 表示,指出现某一个特征词的文档数量。显然tf 越大,特征词在文档中的权重就应该越大,而df 越大,表明特征词越不能表示文档之间的差异性,特征词对于文档的权重就应该越小。经过综合考虑调整之后特征词权重的计算公式为:()i j w d =tf ij 是第i 个文本特征项在文档d j 中出现的频率。 N 为全部文档的数目。 N i 为出现第i 个文本特征项的文档数目。 上述特征词权重计算公式实际上忽略了几外因素的影响:文档长度的差异,文档越长,其中包含的特征词权重就应该越小,因为单个的特征词越无法表示文档全部的特征;特征项长度的差异,一般来说较长的特征项能够表达更为专业的概念,应该赋予更高的权重,而有些短小的特征词虽然出现的频率较高,但往往包含的信息量较少;特征项在文档中出现的位置,显然出现在标题、摘要中的特征词应该赋予很高的权重。 实验五搜索引擎使用实验一、实验目的 1.了解搜索引擎的发展情况和现状;理解搜索引擎的工作原理;2.了解中英文搜索引擎的基本知识和种类; 3. 掌握中英文搜索引擎的初级检索与高级检索两种方式; 4. 分析和对比各种中英文搜索引擎的共性与区别; 5. 了解网络促销的主要方式二、实验内容: 1. 找网上的中英文搜索引擎,并列出5个中文搜索引擎和5个英文搜索引擎的名称; 2.掌握google、百度中高级搜索语法应用方法。 3. 用3个中文、2个英文搜索引擎对同一主题\同一检索词(关键词)进行检索,从检索效果分析得到的检索结果,并比较分析你所选择的搜索引擎的共性与区别。 4.了解网络促销的应用方式和网络广告促销的特点三、实验步骤 1. 搜索引擎的关键词检索(1)进入Google,熟悉并掌握以下功能:掌握Google 的网站检索功能,选取一些关键词在主页上使用“所有网页”检索网页,并通过使用运算符提高查准率;同时使用“高级检索”功能;掌握Google的图像检索功能;掌握Google的网上论坛功能;掌握Google的主题分类检索功能。(2)进入百度,熟悉并掌握Baidu各功能。搜索到至少两个专利介绍网站,并搜索一条关于手机防盗产品的专利技术,写出检索步骤并截图。 2. 搜索引擎的高级搜索语法应用(百度或谷歌) 3.浏览不同类型的网络广告。四、实验报告 1.进入Google, 搜索关键词“搜索引擎优化”,要求结果格式为Word格式;搜索关键词“电子商务”,但结果中不要出现“网络营销”字样;分别写出检索步骤并截图。 2. 精确匹配——双引号和书名号,分别加和不加双引号搜索“山东财经大学”,查看搜索结果。分别加和不加书名号搜索“围城”,查看搜索结果。 3. 搜索同时包含“山东财经大学”和“会计学院”的网页,并查看数量。 4.利用百度搜索两个专利介绍网站,并搜索一条关于手机防盗产品的专利技术,写出检索步骤并截图。 5.选择使用Google和百度,查询某商务信息(自定,如“海尔2012年销售额” )。要求写出:搜索引擎的名称、检索信息的主题、检索结果(列出前5个)。6.分析实验中所使用搜索引擎的优缺点。 7.比较说明中国和美国的网络广告发展情况。五.实验操作答案 1.(1)可以直接搜索word版的搜索引擎优化即可。如下图 (2)操作和上面差不多,看下图 2.不加引号搜索“山东财经大学”时,没有结果;而加引号时则有许多搜索结果。但是加不加引号搜索“围城”时,结果却是相同的。 3.大多为关于山东财经大学的信息,而会计学院则是属于山财的分支。 4. 1.进入 基于向量空间模型的文本分类 在向量空间模型中,文档以由n 个词组成的向量表示(这些词从文档集中选取得到),词也可以由m 篇文档组成的向量表示。在实际使用中,用“文档向量矩阵”X 能最好的代表这种对偶的信息表示,其中一列j X ?代表一个词、一行?i X 代表一篇文档: ??????? ??==??????? ??=??????m n mn m m n n X X X X X X x x x x x x x x x X 2121212222111211),,,( 矩阵中的元素ij x ,一般表示词j 在文档i 中出现的频数;也可以根据其他因素调整它的权重 [4]。比如,以反向文档频率(IDF: Inverse Document Frequency )调整: )/log(*j ij ij df m tf x = 其中,文档频数j df 是出现词j 的文档数量。说明一下,由于一个词只会在很少的文档中出现,因此矩阵X 中的大多数元素都会是零。 信息检索的典型处理方式就是关键字匹配。用户提出一个查询q ,然后用和文档一样的方式,把它看成一个由关键字组成的向量。通过计算查询向量和文档向量之间的点积(对向量的规一化消除文档长度的影响),可以得出两者之间的相似度。所有m 篇文档的相似度可以构成一个向量s(T Xq s =),查询q 的相关文档就可以根据这个指标排序并返回给用户。 文本分类,就是把新的文档归到已有的类别体系中去。有很多方法可以实现这个目的,一种简单的分类方法是为每个类别计算一个中心向量i C (类中所有文档向量的平均值)[5]。这些中心向量被认为是每个类别的代表。所有k 个类别的k 个中心向量,组成一个n k ? 的矩阵T k 21)c ,,c ,(c C ???=。判别文档属于某个类的标准是,该文档距离哪个类别的中心向量更近。其他的方法[6]则是通过最小化误差平方和C ,来解决文本分类问题,C 的定义如下: ||||min arg B CX C T C -= 其中,B 是保存训练集文档的正确类别信息的m k ?矩阵。一篇新进文档,要通过投影到变换向量上得到与每个类的相似度,并由具体的阈值,决定其到底属于哪个类或哪几个类。 应用LSI 模型的文本分类 在原始的“文档向量矩阵”中,存在着冗余、词语多义和噪音问题。我们希望建立一个比原始矩阵小得多,并只包含有效语义的子空间。要达到这个目的,一般可以通过有效的维数约减。维数约减后,冗余的信息可以合并在一起,词语多义可以通过考虑上下文相关信息解决,把相对不重要的一些特征约去则可以部分解决噪音问题。 LSI 就是这样一种维数约减方法。它可以通过对“文档向量矩阵”进行解奇异值分解(SVD: Singular Value Decomposition )运算,自动计算得到一个比原始空间小得多的有效语义空间: 各类搜索引擎的分类、特点、工作原理及代表 1,图片搜索引擎 图片搜索是通过搜索程序,向用户提供互联网上相关的图片资料的服务。 从所使用的技术上来分类,可分为: (1) 基于上下文本(context)的图片搜索,传统意义上图片搜索通常是通过Alt等锚来索引,搜索的,《浅谈图片搜索引擎的实现》中提出了跨越性的图片搜索的实现,具有很高的参考价值。如果这一设想可以实现,那将极大的改变人们的生活具有很高的参考价值。(2) 基于图片内容的搜索基于文本的图片搜索涉及了数据库管理、计算机视觉、图像处理、模式识别、信息检索和认知心理学等诸多学科,其相关技术主要包括:图像数据模型、特征提取方法、索引结构、相似性度量、查询表达模式、检索方法等。相似图片的检测主要涉及特征表示和相似性度量这两类关键技术。图像特征的提取与表达是基于内容的图像处理技术的基础。从广义上讲,图像的特征包括基于文本的特征(如关键字、注释等)和视觉特征(如颜色、纹理、形状等)两类。 2.全文索引 全文搜索引擎的代表是网络爬虫,网络爬虫是一个自动提取网页的程序,它为搜索引擎从Internet网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL 开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页,并重复上述过程,直到达到系统的某一条件时停止。所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。 爬虫设计是否合理将直接影响它访问Web的效率,影响搜索数据库的质量,另外在设计爬虫时还必须考虑它对网络和被访问站点的影响,因为爬虫一般都运行在速度快,带宽高的主机上,如果它快速访问一个速度较慢的目标站点,可能导致该站点出现阻塞。Robot应遵守一些协议,以便被访问站点的管理员能够确定访问内容,Index是一个庞大的数据库,爬虫提取的网页将被放入到Index中建立索引,不同的搜索引擎会采取不同方式来建立索引,有的对整个HTML文件的所有单词都建立索引,有的只分析HTML文件的标题或前几段内容,还有的能处理HTML文件中的META标记或特殊标记。 3.目录索引 目录搜索引擎的数据库是依靠专职人员建立的,这些人员在访问了某个Web站点后撰写一段对该站点的描述,并根据站点的内容和性质将其归为一个预先分好的类别,把站点URL 和描述放在这个类别中,当用户查询某个关键词时,搜索软件只在这些描述中进行搜索。很多目录也接受用户提交的网站和描述,当目录的编辑人员认可该网站及描述后,就会将之添加到合适的类别中。 目录的结构为树形结构,首页提供了最基本的入口,用户可以逐级地向下访问,直至找到自己的类别,另外,用户也可以利用目录提供的搜索功能直接查找一个关键词。由于目录式搜索引擎只在保存了对站点的描述中搜索,因此站点本身的变化不会反映到搜索结果中,这也是目录式搜索引擎与基于Robot的搜索引擎之间的区别。分类目录在网络营销中的应用主要有下列特点: 通常只能收录网站首页(或者若干频道),而不能将大量网页都提交给分类目录;网站一旦被收录将在一定时期内保持稳定;无法通过"搜索引擎优化"等手段提高网站在分类目录中 《信息检索技术》书后习题及参考答案(部分) 第1章绪论 【综合练习】 一、填空题 1.文献是信息的主要载体,根据对信息的加工层次可将文献分为_________文献、__________文献、___________文献和___________文献。 2.追溯法是指利用已经掌握的文献末尾所列的__________,进行逐一地追溯查找_________的一种最简便的扩大情报来源的方法。 3.用规化词语来表达文献信息__________的词汇叫主题词。主题途径是按照文献信息的主题容进行检索的途径,利用能代表文献容的主题词、关键词、叙词、并按字顺序列实现检索。 4.计算机信息检索过程实际上是将___________与____________进行对比匹配的过程。 5.无论是手工检索还是计算机检索,都是一个经过仔细地思考并通过实践逐步完善查找方法的过程。检索过程通常包含以下几个步骤_________、__________、__________、__________、_________。 6.检索工具按信息加工的手段可以分文__________、____________、___________。 7.《中国图书馆图书分类法》共分___________个基本部类,下分________个大类。 8.索引包括4个基本要素:索引源、___________、___________、和出处指引系统。 答案1.零次,一次,二次,三次 2.参考文献,引文 3.容特征 4.检索提问词,文献记录标引词 5.分析课题,选择检索工具,确定检索途径及检索式,进行检索,获取原文 6.手工检索工具,机械检索工具,计算机检索工具 7.五,22 8.索引款目,编排方法 二、判断题 1.在检索信息时,使用逻辑符“AND”可以缩小收缩围。() 2.逆查法是由近及远地查找,顺着时间的顺序利用检索工具进行文献信息检索的方法。() 3.按编制方法划分,信息检索工具可以分为:手工检索工具、机械检索工具、计算机检索工具。() 4.请判断下面图书的国际标准书号的格式是否正确。ISBN:978-030-26151-X。() 5.文献的专利号、报告号、合同号、标准号、索取号、国际标准书号、刊号属于文献的部特征。 6.二次检索是指在第一次检索结果不符合要求时,重新选择检索条件再次进行检索。 答案1.√2.×3.×4.√5.√6.× 三、选择题(单选或多选)搜索引擎检索技巧
向量空间模型文档相似度计算实现(c#)
空间向量与立体几何(1)s
信息检索技术论文
各种搜索引擎技巧
向量空间模型(VSM)的余弦定理公式(cos)
信息检索与搜索引擎技术实验向量空间模型
常用的几类搜索引擎技术
信息检索技术方法及搜索引擎
创建基于DLL的Proteus VSM仿真模型
信息检索与搜索引擎课程报告
信息检索技术 习题答案(试题题目)
搜索引擎
基于向量空间模型的信息检索技术
实验五搜索引擎使用实验
基于向量空间模型的文本分类
各类搜索引擎的分类
《信息检索技术》书中答案
相关主题
文本预览