Storm指南
- 格式:docx
- 大小:67.19 KB
- 文档页数:24


Webstorm常⽤快捷键备忘(Webstorm⼊门指南)WebStorm 是jetbrains公司旗下⼀款JavaScript 开发⼯具。
被⼴⼤中国JS开发者誉为“Web前端开发神器”、“最强⼤的HTML5编辑器”、“最智能的JavaSscript IDE”等。
与IntelliJ IDEA同源,继承了IntelliJ IDEA强⼤的JS部分的功能。
JetBrains WebStorm(java、html5开发⼯具) v8.0.5 官⽅英⽂版类型:编程⼯具⼤⼩:144.3MB语⾔:简体中⽂时间:2014-10-01查看详情现将最常⽤的快捷键挑出来备忘,既能⽅便记忆,⼜能提⾼⼯作效率。
WebStorm快捷键操作最近⼀段时间在写javascript时,找到⼀个灰常强悍的IDE。
名称叫:WebStorm⽬前是英⽂版的,功能很强⼤。
我也在慢慢摸索之中,现把它的⼀些常⽤的快捷键列出来,供使⽤者参考。
1. ctrl + shift + n: 打开⼯程中的⽂件,⽬的是打开当前⼯程下任意⽬录的⽂件。
2. ctrl + j: 输出模板3. ctrl + b: 跳到变量申明处4. ctrl + alt + T: 围绕包裹代码(包括zencoding的Wrap with Abbreviation)5. ctrl + []: 匹配 {}[]6. ctrl + F12: 可以显⽰当前⽂件的结构7. ctrl + x: 剪切(删除)⾏,不选中,直接剪切整个⾏,如果选中部分内容则剪切选中的内容8. alt + left/right:标签切换9. ctrl + r: 替换10. ctrl + shift + up: ⾏移动11. shift + alt + up: 块移动(if(){},while(){}语句块的移动)12. ctrl + d: ⾏复制13. ctrl + shift + ]/[: 选中块代码14. ctrl + / : 单⾏注释15. ctrl + shift + / : 块注释16. ctrl + shift + i : 显⽰当前CSS选择器或者JS函数的详细信息17. ctrl + '-/+': 可以折叠项⽬中的任何代码块,它不是选中折叠,⽽是⾃动识别折叠。

storm的用法总结大全- Storm是一个开源的实时大数据处理系统,用于处理实时数据流。
它可以与Hadoop 集成,提供高性能的实时数据处理能力。
- Storm可以用于实时分析和处理大规模数据流,如日志数据、传感器数据等。
它可以处理来自不同数据源的数据流,并将数据流分发到不同的处理单元进行处理。
- Storm使用一种称为拓扑(Topology)的方式来描述数据处理流程。
拓扑是由多个处理单元(称为Bolt)和连接它们的数据流(称为Spout)组成的。
- Spout可以从数据源中读取数据,并将数据流发射给Bolt进行处理。
Bolt可以对数据进行转换、过滤、聚合等操作,并将结果发射给下一个Bolt进行处理。
多个Bolt可以并行地执行不同的处理任务。
- Storm的拓扑可以灵活地配置,可以按照需要添加、删除、修改Bolt和Spout。
它支持高可靠性、高吞吐量的数据流处理,并且可以实现在不同的节点之间进行任务的负载均衡。
- Storm提供了可扩展性和容错性,可以通过水平扩展集群节点来处理更大规模的数据流,并且在节点故障时能够保证处理的连续性。
- Storm提供了丰富的API和工具,可以方便地开发和调试数据处理拓扑。
它支持多种编程语言,如Java、Python等,并提供了强大的拓扑调试和可视化工具,方便监控和管理拓扑的运行状态。
- Storm可以与其他大数据处理框架(如Hadoop、Hive、HBase等)集成,在数据处理过程中实现数据的交换和共享。
它还可以与消息中间件(如Kafka、RabbitMQ等)和实时数据库(如Redis、Cassandra等)集成,实现与其他系统的无缝连接。
- Storm有广泛的应用场景,如实时推荐系统、实时风控系统、实时数据分析、实时监控和报警等。
它在互联网、金融、电信、物联网等领域都有着广泛的应用。

英文作文关于暴风雨的安全指南Navigating the Storm: A Safety Guide for Weathering Fierce Winds and Heavy RainsWhen the skies darken and the winds begin to howl, it's crucial to be prepared and know how to stay safe during a powerful storm. Severe weather events, such as hurricanes, tornadoes, and intense thunderstorms, can pose significant threats to life and property if proper precautions are not taken. This comprehensive guide aims to provide you with the essential information and strategies to navigate through the challenges posed by violent storms and emerge unscathed.Understanding the ThreatSevere storms can manifest in various forms, each with its own unique characteristics and potential dangers. Hurricanes, for instance, are large, swirling systems that bring a combination of high winds, heavy rainfall, storm surges, and even tornadoes. Tornadoes, on the other hand, are rapidly rotating columns of air that can cause catastrophic damage in a localized area. Thunderstorms, while more common, can still pack a powerful punch with strong gusts, hail, and the risk of lightning strikes.Preparing for the StormPreparation is key to weathering the storm. Begin by staying informed about the latest weather updates and forecasts. Pay attention to warnings and advisories issued by local authorities and meteorological agencies. This will help you anticipate the storm's intensity and trajectory, allowing you to take the necessary precautions.Secure Your HomeYour home is your sanctuary, and it's crucial to ensure it is well-prepared to withstand the onslaught of a severe storm. Start by inspecting your roof, windows, and doors, and make any necessary repairs or reinforcements. Consider installing impact-resistant windows or shutters to protect your home from flying debris. Clear your yard of any loose objects that could become projectiles, and trim trees and shrubs to minimize the risk of falling branches.Assemble an Emergency KitIn the event of a power outage or the need to evacuate, having a well-stocked emergency kit can make all the difference. Include essential items such as non-perishable food, water, flashlights, batteries, a first-aid kit, and any necessary medications. Don't forget to have a battery-powered or hand-crank radio to stay informed about the storm's progress and any emergency instructions.Develop an Evacuation PlanDepending on the severity of the storm, you may need to evacuate your home. Identify safe evacuation routes and have a plan for where you will go, whether it's with family, friends, or at a designated emergency shelter. Make sure to have important documents, such as identification, insurance papers, and emergency contact information, readily available.During the StormWhen the storm hits, it's crucial to remain vigilant and follow safety protocols. Stay indoors and avoid venturing out unless absolutely necessary. If you must go out, wear appropriate protective gear, such as a helmet and sturdy shoes, to minimize the risk of injury from flying debris.Seek ShelterIf you are in a sturdy building, the safest place to be is in the interior of the lowest floor, away from windows and exterior doors. Avoid rooms with windows and seek refuge in a closet, bathroom, or basement if possible. If you are in a vehicle, pull over and seek shelter in a nearby building. Avoid seeking shelter in a vehicle or mobile home, as they offer little protection against the force of a severe storm.Avoid HazardsDuring a storm, be aware of potential hazards such as downed power lines, flooding, and falling trees or debris. Do not attempt to move or approach any downed power lines, as they may still be energized and pose a serious electrocution risk. If you encounter flooding, do not try to walk or drive through it, as the water depth may be deceptive and the current can be strong enough to sweep you away.Stay InformedThroughout the storm, continue to monitor local news and emergency broadcasts for updates and instructions. Follow the guidance of local authorities and be prepared to take immediate action if necessary. Heed any evacuation orders and leave the area as soon as possible if instructed to do so.Recovering from the StormOnce the storm has passed, it's important to assess the damage and take the necessary steps to recover and restore your home and community. Check for any structural damage to your property and report it to your insurance provider. If you encounter any downed power lines or flooding, contact the appropriate authorities immediately.Be Patient and ResilientThe aftermath of a severe storm can be overwhelming, but it's important to remain patient and resilient. Restoration efforts may take time, and it's crucial to follow the guidance of local authorities and emergency responders. Offer assistance to your neighbors and community, and be prepared to lend a helping hand in the recovery process.ConclusionNavigating the challenges posed by severe storms requires preparation, vigilance, and a willingness to take the necessary precautions to ensure your safety. By understanding the risks, developing a comprehensive plan, and staying informed during the event, you can increase your chances of weathering the storm and emerging unscathed. Remember, your safety and the safety of your loved ones should always be the top priority when faced with the power of nature's fury.。

w3cschool-Storm⼊门教程1.什么是stormStorm是Twitter开源的分布式实时⼤数据处理框架,被业界称为实时版Hadoop。
随着越来越多的场景对Hadoop的MapReduce⾼延迟⽆法容忍,⽐如⽹站统计、推荐系统、预警系统、⾦融系统(⾼频交易、股票)等等,⼤数据实时处理解决⽅案(流计算)的应⽤⽇趋⼴泛,⽬前已是分布式技术领域最新爆发点,⽽Storm更是流计算技术中的佼佼者和主流。
按照storm作者的说法,Storm对于实时计算的意义类似于Hadoop对于批处理的意义。
Hadoop提供了map、reduce原语,使我们的批处理程序变得简单和⾼效。
同样,Storm也为实时计算提供了⼀些简单⾼效的原语,⽽且Storm的Trident是基于Storm原语更⾼级的抽象框架,类似于基于Hadoop的Pig框架,让开发更加便利和⾼效。
2.storm应⽤场景推荐系统(实时推荐,根据下单或加⼊购物车推荐相关商品)、⾦融系统、预警系统、⽹站统计(实时销量、流量统计,如淘宝双11效果图)、交通路况实时系统等等。
3.storm的⼀些特性1.适⽤场景⼴泛: storm可以实时处理消息和更新DB,对⼀个数据量进⾏持续的查询并返回客户端(持续计算),对⼀个耗资源的查询作实时并⾏化的处理(分布式⽅法调⽤,即DRPC),storm的这些基础API可以满⾜⼤量的场景。
2. 可伸缩性⾼: Storm的可伸缩性可以让storm每秒可以处理的消息量达到很⾼。
扩展⼀个实时计算任务,你所需要做的就是加机器并且提⾼这个计算任务的并⾏度。
Storm使⽤ZooKeeper来协调集群内的各种配置使得Storm的集群可以很容易的扩展。
3. 保证⽆数据丢失:实时系统必须保证所有的数据被成功的处理。
那些会丢失数据的系统的适⽤场景⾮常窄,⽽storm保证每⼀条消息都会被处理,这⼀点和S4相⽐有巨⼤的反差。
4. 异常健壮: storm集群⾮常容易管理,轮流重启节点不影响应⽤。
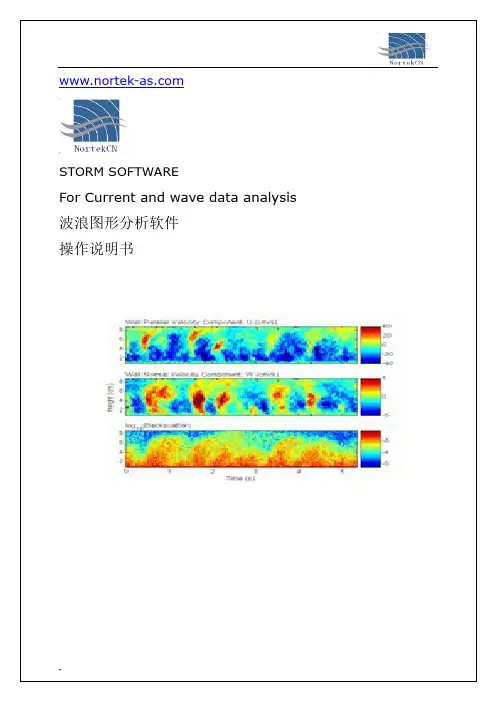
-STORM SOFTWAREFor Current and wave data analysis波浪图形分析软件操作说明书1.介绍:简介:Storm软件是专为Nortek多普勒系列测量仪器使用的,用于测量数据管理、后处理、和图形显示工具。
安装:与普通的软件安装一样,使用者从程序安装光盘中运行Setup.exe文件来开始安装步骤,按照操作说明直到安装完毕。
建议在安装软件之前关闭所有的操作。
PC系统要求:•英特尔奔腾Intel Pentium® III 500 MHz 处理器或接近。
•内存128 MB RAM以上•操作系统Windows 98, Windows NT 4.0 SP3, Windows Me, Windows 2000 or Windows XP•Super VGA Monitor running at 800x600 x 256 colors (1024x768 x High (16-bit) Color recommended)•网络浏览器4.0或以上Internet Explorer 4.0 or higher•光盘驱动器CD-ROM drive•鼠标或其他点击操作设施Mouse or other pointing device2.软件基本组成:工作区域:程序操作者只要在一个集成了数据处理、显示和输出文件功能的窗口、工具、菜单、工具框和其它操作界面就可以完成全部工作。
用户界面使用标准的Windows界面的功能,随着添加附加功能,使您的开发环境,易于使用。
这些基本特征,你最经常使用的是窗口和数据显示,工具栏,菜单和键盘快捷键。
您可以自定义用户界面,以适合您的偏好。
除了自定义设置,您可以创建一个与其他特殊项目需要相关的窗口布局。
您也可以创建自定义工具栏,菜单和快捷键。
这里是一些最常用的组件:•菜单栏(Menu bar)包含命令菜单,让您以不同的方式,视图设置选项来检查数据,自定义用户界面和访问一些通用操作,例如,控制数据处理。

webstorm使用指南WebStorm是一款非常强大的JavaScript集成开发环境(IDE),由JetBrains公司开发。
它提供了丰富的功能和工具,可以帮助开发者更高效地开发和调试Web应用程序。
在本篇文章中,我们将为您介绍如何使用WebStorm进行Web开发。
使用WebStorm进行Web开发的第一步是创建一个新的项目。
您可以通过点击菜单栏中的“File”选项,然后选择“New Project”来创建一个新的项目。
在创建项目的过程中,您需要选择项目的名称和存储位置。
同时,您还可以选择使用的模板和框架,以及其他相关的设置。
创建完项目后,您可以开始编写代码。
WebStorm提供了强大的代码编辑功能,包括语法高亮、代码自动完成、代码折叠等。
您可以使用这些功能来提高编码的效率和准确性。
在编写代码的过程中,您可以使用WebStorm提供的调试工具对代码进行调试。
WebStorm支持多种调试方式,包括单步调试、断点调试等。
您可以通过点击代码行号左侧的空白处来设置断点,然后点击菜单栏中的“Debug”选项,选择“Debug 'Your Application'”来启动调试。
除了代码编辑和调试功能外,WebStorm还提供了其他一些非常有用的功能。
例如,它可以自动检测代码中的错误和潜在问题,并提供相应的修复建议。
它还可以对代码进行格式化,使其符合统一的风格和规范。
WebStorm还支持版本控制系统,例如Git。
您可以通过点击菜单栏中的“VCS”选项,选择“Enable Version Control Integration”来启用版本控制功能。
一旦启用了版本控制功能,您就可以轻松地管理和提交代码。
另外一个非常实用的功能是WebStorm提供了内置的命令行工具。
您可以通过点击工具栏中的“Terminal”按钮来打开命令行工具。
在命令行工具中,您可以执行各种命令,例如运行测试、安装依赖等。

JetBrains PhpStorm注册流程指南JetBrains PhpStorm是一种广泛使用的集成开发环境(IDE),可以大幅提高PHP开发人员的工作效率和代码质量。
为了获得此强大的工具的完整功能,您需要注册并购买许可证。
在此文章中,我们将为您提供完整的JetBrains PhpStorm注册流程指南,以帮助您顺利获取许可证。
许可证种类JetBrains PhpStorm IDE有两种许可证类型:专业版和个人版。
专业版是一种面向大型企业和团队的许可证类型,具有最全面、最全面的功能集,可以支持高效协作和团队开发。
价格相对较高,如果您只是单独开发,可以考虑购买个人版。
个人版是一种价格适中的许可证类型,可以满足个人开发人员的需求,但可能无法实现全面的团队协作。
如果您只是独立开发人员或自由职业者,这可能是最好的选择。
获取注册码获取JetBrains PhpStorm注册码的方法很简单。
您只需前往官方网站,并购买所需许可证类型的许可证即可。
在购买完成后,您将收到一封包含注册码和其他信息的电子邮件。
请确保您妥善保管此邮件,以便将来使用。
激活许可证一旦您收到JetBrains PhpStorm许可证,您可以立即开始激活流程。
以下是激活步骤:1. 打开JetBrains PhpStorm的激活对话框。
2. 输入您的注册码,然后单击“完成”。
3. PhpStorm将自动连接到网络并验证您的许可证。
如果您的许可证有效且完整,JetBrains PhpStorm将自动激活。
4. 如果必要,按照屏幕上的指示进行授权并进行必要的登录。
完成以上步骤后,您就可以开始使用JetBrains PhpStorm的完整功能集。
结论总体而言,JetBrains PhpStorm是一种优秀的工具,可以为PHP开发人员带来极高的效率和代码质量。
通过购买并正确激活许可证,您可以获取IDE的最佳功能并使用它来快速、高效地进行开发。
希望本文可以为您提供帮助,并让您在JetBrains PhpStorm上取得成功。

关于暴风雨安全指南的句子英语版Storms are a common natural disaster that can cause significant damage to property and pose a threat to human life. In order to stay safe during a storm, it is important to be prepared and know what precautions to take. The following storm safety guide will provide you with tips and advice on how to best protect yourself and your loved ones during a storm:1. Stay Informed: Keep up to date with the latest weather forecasts and warnings by monitoring reliable sources such as the Weather Channel or the National Weather Service. Pay attention to severe weather alerts and be prepared to take action if necessary.2. Create a Safety Plan: Develop a storm safety plan with your family that includes designated safe areas within your home and a communication plan in case you become separated. Practice this plan regularly so that everyone knows what to do in the event of a storm.3. Secure Your Property: Before a storm hits, take time to secure your property by bringing in outdoor furniture, securing loose objects, and trimming trees and shrubs. Consider installingstorm shutters or impact-resistant windows to protect your home from strong winds.4. Stock Up on Supplies: Make sure you have a sufficient supply of food, water, and other essentials in case you lose power or become stranded during a storm. Don't forget to include flashlights, batteries, a first aid kit, and any necessary medications in your emergency kit.5. Stay Indoors: When a storm is approaching, stay indoors and avoid unnecessary travel. If you must be outside, seek shelter in a sturdy building and avoid standing near tall objects, such as trees or power lines, that could pose a risk during high winds.6. Avoid Flooded Areas: Never attempt to drive or walk through flooded streets or areas, as it only takes a few inches of water to sweep a person or vehicle away. If you encounter a flooded area, turn around and find an alternate route to safety.7. Seek Shelter: If you are caught outside during a storm, seek shelter in a sturdy building or vehicle immediately. Avoid open fields, isolated structures, and bodies of water, as they are more susceptible to lightning strikes and high winds.8. Stay Connected: Keep your phone charged and maintain communication with friends and family during a storm. Notify loved ones of your whereabouts and check in regularly to ensure everyone's safety.9. Listen to Authorities: Follow the instructions of local authorities and emergency responders during a storm, as they are equipped to provide guidance and assistance in a crisis situation. Do not ignore evacuation orders or warnings, as they are issued for your safety.10. Stay Calm: Remember to stay calm and focused during a storm, as panicking can hinder your ability to make rational decisions and respond effectively to emergencies. Keep a positive attitude and remain vigilant until the storm has passed.By following these storm safety tips and guidelines, you can better prepare yourself and your family for the impact of a storm and reduce the risk of injury or damage. Remember that safety is the top priority during a storm, so take precautions and stay informed to protect yourself and others from harm.。

webstorm 使用指南WebStorm 是一款由JetBrains 公司开发的集成开发环境(IDE),专门用于前端开发。
它提供了丰富的功能和工具,以提高开发人员的效率和工作质量。
本文将为大家介绍如何使用WebStorm,以及它的一些常用功能和快捷键。
一、安装和配置我们需要下载并安装WebStorm。
在安装过程中,可以根据个人喜好选择安装路径和相关插件。
安装完成后,打开WebStorm,按照提示进行注册或登录。
二、项目创建与导入在WebStorm中,可以通过创建新项目或导入已有项目来开始工作。
创建新项目时,可以选择项目类型、命名和存储路径。
导入已有项目时,可以选择项目所在的文件夹,并根据需求进行相关配置。
三、界面概览WebStorm的界面分为菜单栏、工具栏、编辑器区域、项目导航和工具窗口等部分。
菜单栏提供了各种功能和操作选项,工具栏提供了常用的快捷按钮。
编辑器区域是我们主要编写代码的地方,可以显示代码的语法高亮、代码提示和错误提示等。
项目导航可以查看项目的文件结构和层次。
工具窗口可以打开一些辅助工具,如版本控制、运行配置和终端等。
四、代码编辑WebStorm提供了丰富的代码编辑功能,包括语法高亮、代码折叠、自动缩进、智能代码提示等。
在编辑器中,可以使用快捷键快速完成一些常用操作,如复制、粘贴、撤销等。
还可以通过设置代码风格和格式化选项来统一代码风格。
五、代码导航在大型项目中,代码文件通常会很多,通过代码导航功能可以快速定位到所需的文件或代码块。
WebStorm提供了多种快捷键和功能,如文件搜索、代码跳转、书签、文件结构视图等,可以帮助开发人员更高效地浏览和编辑代码。
六、调试和测试WebStorm集成了调试和测试工具,可以方便地进行代码调试和单元测试。
通过设置断点和观察表达式,可以逐步执行代码并查看变量的值。
此外,还可以运行和调试JavaScript测试框架,如Mocha和Jasmine。
七、版本控制WebStorm支持常见的版本控制系统,如Git、SVN和Mercurial。

webstorm使用指南WebStorm是一款由JetBrains公司开发的集成开发环境(IDE),专门用于前端开发。
它提供了丰富的功能和工具,帮助开发人员编写、调试和测试JavaScript、HTML和CSS等前端技术。
下面我将从安装、界面、功能、调试和扩展等多个方面来介绍WebStorm的使用指南。
首先是安装。
要使用WebStorm,你需要先从JetBrains官网下载安装程序,并按照指示进行安装。
安装完成后,你可以启动WebStorm并开始使用。
接下来是界面。
WebStorm的界面分为菜单栏、工具栏、编辑器窗口、项目窗口和工具窗口等部分。
菜单栏包含了各种功能命令,工具栏则提供了快速访问常用功能的按钮。
编辑器窗口是你编写代码的地方,项目窗口显示了项目文件的结构,而工具窗口则包含了各种辅助工具和面板。
再来是功能。
WebStorm提供了丰富的功能,包括代码自动补全、语法检查、版本控制、重构、代码导航等。
它还集成了调试器,可以帮助你调试JavaScript代码。
另外,WebStorm还支持各种前端框架和库,如React、Angular、Vue等,提供了针对这些框架的特定功能和工具。
调试是前端开发中非常重要的一环。
WebStorm内置了强大的调试器,可以帮助你在浏览器中调试JavaScript代码。
你可以设置断点、观察变量、单步执行代码等,帮助你快速定位和解决问题。
最后是扩展。
WebStorm支持丰富的插件和扩展,可以帮助你定制和增强IDE的功能。
你可以从插件市场下载各种插件,如主题、工具集成、框架支持等,以满足个性化的需求。
综上所述,WebStorm是一款功能丰富的前端开发IDE,它提供了强大的功能和工具,帮助开发人员提高效率和质量。
通过本指南,你可以初步了解WebStorm的安装、界面、功能、调试和扩展等方面,希望对你有所帮助。
storm的用法总结大全1. 雷暴风暴(storm):指一种天气现象,通常包括强烈的风、降雨和电闪雷鸣。
2. 暴风雨(storm):指强烈的风暴和降水,通常伴随着雷电和狂风。
3. 暴风雪(snowstorm):指风速较高、降雪量较大的雪天气现象。
4. 暴风(gale):指一种非常强烈的风,通常指风速达到或超过8级以上。
5. 暴风骤雨(stormy rain):指强烈的降雨和风暴的组合。
6. 暴风雨洗礼(baptism by fire):指经历一次特别困难或挑战,并因此变得更强大或更有能力应对类似情况。
7. 风暴中心(eye of the storm):指风暴中心的相对安静区域,是飓风或台风的核心。
8. 风暴警告(storm warning):指官方发布的风暴即将到来或正在发生的警告。
9. 暴风警报(gale warning):指通常由海洋气象机构发布的强烈风暴即将到来或正在发生的警报。
10. 暴风雨设施(storm shelter):指一种供人们躲避风暴的地下或加固建筑物,通常用于保护人们免受风暴的威胁。
11. 暴风雨漫游(storm chasing):指追逐并观察风暴的行为,通常由专业气象学家、摄影师或冒险者进行。
12. 风暴潮(storm surge):指狂风吹袭海岸线时引起的海水暴涨现象,常常伴随着飓风或台风。
13. 欧洲风暴(European storm):指经常在欧洲各地出现的有风暴状况的天气。
14. 沙尘暴(sandstorm):指沙子或尘土等颗粒物被风吹起并形成的风暴。
15. 风暴袭击(storm assault):指突然而猛烈的攻击或袭击,比喻某种不愉快的事物突然降临。
总之,\。
JetBrains WebStorm注册流程指南JetBrains WebStorm是一款强大的集成开发环境(IDE),专注于Web开发。
它提供了丰富的功能和工具,使开发人员能够更高效地创建和维护Web应用程序。
为了充分利用WebStorm的功能,您需要进行注册。
本文将为您提供详细的JetBrains WebStorm注册流程指南,确保您能够顺利注册并开始使用这一出色的开发工具。
**步骤一:下载WebStorm**首先,您需要下载并安装WebStorm。
您可以在JetBrains官方网站上找到WebStorm的下载链接。
确保选择适合您操作系统的版本,然后按照安装向导完成安装过程。
安装完成后,可以打开WebStorm,但在注册之前,它将以试用版运行。
**步骤二:启动WebStorm**打开已安装的WebStorm应用程序。
您将看到试用版的提醒,以及一个用于输入注册信息的选项。
**步骤三:获取许可密钥**在此步骤中,您需要获取WebStorm的许可密钥。
许可密钥是一串字符,用于激活您的WebStorm副本。
您可以按照以下步骤获得许可密钥:1. 访问JetBrains官方网站。
2. 在网站上搜索"WebStorm",然后选择WebStorm产品页面。
3. 在产品页面上,您将找到一个选项,通常称为"购买"或"购买许可"。
单击这个选项。
4. 这将带您进入购买WebStorm许可的页面。
您可以选择不同类型的许可,如个人、专业或企业,选择适合您需求的类型。
5. 在购买页面,您需要提供您的联系信息和支付方式。
完成这些步骤后,您将获得许可密钥。
**步骤四:输入许可密钥**回到WebStorm中,您将看到一个要求输入许可密钥的选项。
在此处,您需要将从JetBrains官方网站获得的许可密钥粘贴到相应的字段中。
**步骤五:激活WebStorm**一旦输入许可密钥,您可以点击“激活”或类似的按钮,激活WebStorm。
storm的用法总结大全想了解storm的用法吗?今天就给大家带来了storm的用法,希望能够帮助到大家,下面就和大家分享,来欣赏一下吧。
\ storm的用法总结大全storm的意思n. 暴风雨,暴风雪,[军]猛攻,冲击,骚乱,动荡vi. 起风暴,下暴雨,猛冲,暴怒vt. 袭击,猛攻,暴怒,怒骂,大力迅速攻占变形:过去式: stormed; 现在分词:storming; 过去分词:stormed;storm用法storm可以用作名词storm的基本意思是“风暴,暴风雨”,指由于大气翻动,特别是伴有雨、雪、雹等现象的大气的旋转运动而形成的风暴或暴风雨,是可数名词,有复数形式。
storm引申可作“强烈如暴(风)雨般的东西,(生活中的)风波”,如情感、声音等的猛烈爆发,常与of连用。
storm的基本意思是“袭击”,指用武力攻取,包含一次攻击中所有的冲锋和激战,常常带有孤注一掷的感情色彩,竭尽全力避免失败和毁灭。
storm用作名词的用法例句In the storm I took shelter under the tree.暴风雨时,我正在树下躲避。
A storm arose during the night.夜间起风暴了。
The clouds threatened a big storm.乌云预示着暴风雨即将来临。
storm可以用作动词storm的基本意思是“袭击”,指用武力攻取,包含一次攻击中所有的冲锋和激战,常常带有孤注一掷的感情色彩,竭尽全力避免失败和毁灭。
storm既可用作及物动词,也可用作不及物动词。
用作及物动词时,可接名词或代词作宾语; 用作不及物动词时,表示“起风暴,刮大风下大雨”,这时常以it作主语。
storm还可表示“狂怒,咆哮”,其后可接about,表示“气愤地谈(某事)”; 接at表示“对…大发雷霆”; 接into表示“非常气愤地进入”; 接out表示“非常气愤地出去”。
storm用作动词的用法例句Help was lacking at sea during the storm.起风暴时海上无处可求援。
配置storm-contro l特性后,当从一个端口进入到交换机的单播、组播或广播数据帧超过设定值时,storm-control将采取相应的保护措施(例如关闭端口或者发送SNMP trap消息)交换机每1秒钟统计进入一个端口的各种类型的数据帧(单播、组播、广播)的数量,然后与该端口设置的抑制阈值对比。
【配置】int f0/1storm-control action shutdown或trap 设置检测到storm时端口采取的动作(shutdown参数表示端口将被置于error-disable,trap参数表示产生一个SNMP Trap消息)storm-control broadcast level [开始抑制的百分比] [重新使用的百分比]当广播数据流量达到该端口百分多少时认为是storm storm-control multicast level [开始抑制的百分比] [重新使用的百分比] 当组播数据流量达到该端口百分多少时认为是storm storm-control unicast level [开始抑制的百分比] [重新使用的百分比] 当单播数据流量达到该端口百分多少时认为是storm storm-control broadcast level bps [开始抑制的带宽值] [重新使用的带宽值] 当广播数据流量达到多少bps(即达到多少带宽)时认为是stormstorm-control multicast level bps [开始抑制的带宽值] [重新使用的带宽值] 当组播数据流量达到多少bps(即达到多少带宽)时认为是stormstorm-control unicast level bps [开始抑制的带宽值] [重新使用的带宽值] 当单播数据流量达到多少bps(即达到多少带宽)时认为是stormstorm-control broadcast level pps [开始抑制的每秒报文数] [重新使用的每秒报文数] 当广播数据流量达到多少pps(即每秒多少个数据包)时认为是stormstorm-control multicast levell pps [开始抑制的每秒报文数] [重新使用的每秒报文数] 当组播数据流量达到多少pps(即每秒多少个数据包)时认为是stormstorm-control unicast levell pps [开始抑制的每秒报文数] [重新使用的每秒报文数] 当单播数据流量达到多少pps(即每秒多少个数据包)时认为是storm-----------------示例:interface FastEthernet0/1switchport mode accessstorm-control broadcast level 30.00 20.00storm-control action shutdown!interface FastEthernet0/2switchport mode accessstorm-control unicast level pps 100kstorm-control action trap (需看ios版本支持否)!interface FastEthernet0/3switchport mode accessstorm-control multicast level 60.00 50.00【查看】1)使用命令show storm-control broadcast查看本交换机上针对广播帧的风暴控制信息SW#show storm-control broadcastInterface Filter State Upper Lower Current--------- ------------- ----------- ----------- ----------Fa0/1 Forwarding 30.00% 20.00% 0.00%2)使用命令show storm-control multicast查看本交换机上针对广播帧的风暴控制信息SW#show storm-control multicastInterface Filter State Upper Lower Current--------- ------------- ----------- ----------- ----------Fa0/3 Forwarding 60.00% 50.00% 0.00%3)使用命令show storm-control unicast查看本交换机上针对广播帧的风暴控制信息SW2#show storm-control unicastInterface Filter State Upper Lower Current--------- ------------- ----------- ----------- ----------Fa0/2 Forwarding 100k pps 100k pps 0 pps注:若使用show storm-control命令则效果与show storm-control broadcast相同,只查看本交换机上针对广播帧的风暴控制信4)使用命令show storm-control 接口名称broadcast或multicast或unicastLike it :SW1#show storm-controlStorm control: broadcast threshold 40 with default packet-size 64。
关于暴风雨安全指南的手抄报英语版A storm can be a dangerous and frightening experience, especially when it's a violent one like a hurricane or typhoon. 暴风雨可能是一种危险而令人恐惧的经历,尤其是当它是像飓风或台风这样的猛烈暴风雨时。
It's important to be prepared and to know how to stay safe during a storm. 在暴风雨期间要做好准备并知道如何保持安全至关重要。
First and foremost, it's essential to stay informed about the weather. 首先,要密切关注天气情况是非常重要的。
Listen to the radio, watch the news, or use a weather app to stay updated on the storm's progress. 听收音机,看新闻,或使用天气应用程序来了解暴风雨的进展情况。
This will help you know when the storm is coming, how severe it is, and what measures to take to stay safe. 这将帮助你知道暴风雨何时来临,有多严重,以及采取哪些措施来保持安全。
In addition to staying informed, it's important to have an emergency kit prepared. 除了保持了解情况外,准备好一个应急包也非常重要。
This kit should include essentials such as non-perishable food, water, a flashlight, batteries, a first aid kit, and any necessary medications. 这个包应该包括非易腐食品、水、手电筒、电池、急救包,以及任何必要的药物。
关于暴风雨安全指南的句子英语版English:During a storm, it is important to stay indoors and away from windows to avoid flying debris. Unplug all electronic devices to prevent damage from power surges. If you are driving, pull over to a safe location and wait for the storm to pass. Avoid flooded areas and never attempt to drive through standing water. Have an emergency kit prepared with essentials such as food, water, flashlights, and afirst aid kit. Stay tuned to weather updates and follow the advice of local authorities. Remember to check on neighbors, especially the elderly or disabled, to ensure their safety during the storm.Chinese:在暴风雨期间,重要的是要呆在室内远离窗户,以避免飞来的碎片。
拔掉所有电子设备的电源以防止电涌带来的损坏。
如果你在开车,就停车到一个安全的地点等待风暴经过。
避免涝区,绝对不要尝试开车穿过积水。
准备一个应急包,里面有食物、水、手电筒和急救包等必需品。
保持关注天气更新,并且遵循当地政府的建议。
记得去查看一下邻居,特别是老年人或残障人士,在暴风雨期间确保他们的安全。
Storm这是一个分布式的、容错的实时计算系统,它被托管在GitHub上,遵循Eclipse Public License 1.0。
Storm是由BackType开发的实时处理系统,BackType 现在已在Twitter麾下,基本是用Clojure写的。
Storm为分布式实时计算提供了一组通用原语,可被用于“流处理”之中,实时处理消息并更新数据库。
这是管理队列及工作者集群的另一种方式。
Storm也可被用于“连续计算”(continuous computation),对数据流做连续查询,在计算时就将结果以流的形式输出给用户。
它还可被用于“分布式RPC”,以并行的方式运行昂贵的运算。
Storm的主工程师Nathan Marz表示:Storm可以方便地在一个计算机集群中编写与扩展复杂的实时计算,Storm之于实时处理,就好比Hadoop之于批处理。
Storm保证每个消息都会得到处理,而且它很快——在一个小集群中,每秒可以处理数以百万计的消息。
更棒的是你可以使用任意编程语言来做开发。
Storm的主要特点如下:1.简单的编程模型。
类似于MapReduce降低了并行批处理复杂性,Storm降低了进行实时处理的复杂性。
2.可以使用各种编程语言。
你可以在Storm之上使用各种编程语言。
默认支持Clojure、Java、Ruby和Python。
要增加对其他语言的支持,只需实现一个简单的Storm通信协议即可。
3.容错性。
Storm会管理工作进程和节点的故障。
4.水平扩展。
计算是在多个线程、进程和服务器之间并行进行的。
5.可靠的消息处理。
Storm保证每个消息至少能得到一次完整处理。
任务失败时,它会负责从消息源重试消息。
6.快速。
系统的设计保证了消息能得到快速的处理,使用?MQ作为其底层消息队列。
7.本地模式。
Storm有一个“本地模式”,可以在处理过程中完全模拟Storm集群。
这让你可以快速进行开发和单元测试。
Storm集群由一个主节点和多个工作节点组成。
主节点运行了一个名为“Nimbus”的守护进程,用于分配代码、布置任务及故障检测。
每个工作节点都运行了一个名为“Supervisor”的守护进程,用于监听工作,开始并终止工作进程。
Nimbus和Supervisor 都能快速失败,而且是无状态的,这样一来它们就变得十分健壮,两者的协调工作是由Apache ZooKeeper来完成的。
Storm的术语包括Stream、Spout、Bolt、Task、Worker、Stream Grouping和Topology。
Stream是被处理的数据。
Sprout是数据源。
Bolt处理数据。
Task是运行于Spout或Bolt中的线程。
Worker是运行这些线程的进程。
Stream Grouping规定了Bolt 接收什么东西作为输入数据。
数据可以随机分配(术语为Shuffle),或者根据字段值分配(术语为Fields),或者广播(术语为All),或者总是发给一个Task(术语为Global),也可以不关心该数据(术语为None),或者由自定义逻辑来决定(术语为Direct)。
Topology 是由Stream Grouping连接起来的Spout和Bolt节点网络。
在Storm Concepts页面里对这些术语有更详细的描述。
可以和Storm相提并论的系统有Esper、Streambase、HStreaming和Yahoo S4。
其中和Storm最接近的就是S4。
两者最大的区别在于Storm会保证消息得到处理。
这些系统中有的拥有内建数据存储层,这是Storm所没有的,如果需要持久化,可以使用一个类似于Cassandra或Riak这样的外部数据库。
入门的最佳途径是阅读GitHub上的官方《Storm Tutorial》。
其中讨论了多种Storm 概念和抽象,提供了范例代码以便你可以运行一个Storm Topology。
开发过程中,可以用本地模式来运行Storm,这样就能在本地开发,在进程中测试Topology。
一切就绪后,以远程模式运行Storm,提交用于在集群中运行的Topology。
Maven用户可以使用提供的Storm依赖,地址是/repo。
要运行Storm集群,你需要Apache Zookeeper、?MQ、JZMQ、Java 6和Python 2.6.6。
ZooKeeper用于管理集群中的不同组件,?MQ是内部消息系统,JZMQ是?MQ的Java Binding。
有个名为storm-deploy的子项目,可以在AWS上一键部署Storm集群。
Storm指南在这个教程里面我们将学习如何创建Topologies, 并且把topologies部署到storm的集群里面去。
Java将是我们主要的示范语言,个别例子会使用python以演示storm的多语言特性。
准备工作这个教程使用storm-starter项目里面的例子。
我推荐你们下载这个项目的代码并且跟着教程一起做。
先读一下:配置storm开发环境和新建一个strom项目这两篇文章把你的机器设置好。
一个Storm集群的基本组件storm的集群表面上看和hadoop的集群非常像。
但是在Hadoop上面你运行的是MapReduce的Job, 而在Storm上面你运行的是Topology。
它们是非常不一样的—一个关键的区别是:一个MapReduce Job最终会结束,而一个Topology运永远运行(除非你显式的杀掉他)。
在Storm的集群里面有两种节点:控制节点(master node)和工作节点(worker node)。
控制节点上面运行一个后台程序:Nimbus,它的作用类似Hadoop里面的JobTracker。
Nimbus负责在集群里面分布代码,分配工作给机器,并且监控状态。
每一个工作节点上面运行一个叫做Supervisor的节点。
Supervisor会监听分配给它那台机器的工作,根据需要启动/关闭工作进程。
每一个工作进程执行一个Topology的一个子集;一个运行的Topology由运行在很多机器上的很多工作进程组成。
storm topology结构Nimbus和Supervisor之间的所有协调工作都是通过一个Zookeeper集群来完成。
并且,nimbus进程和supervisor 经常都是快速失败(fail-fast)和无状态的。
所有的状态要么在Zookeeper里面,要么在本地磁盘上。
这也就意味着你可以用kill -9来杀死nimbus和supervisor进程,然后再重启它们,它们可以继续工作,就好像什么都没有发生过似的。
这个设计使得storm不可思议的稳定。
Topologies为了在storm上面做实时计算,你要去建立一些topologies。
一个topology就是一个计算节点所组成的图。
Topology里面的每个处理节点都包含处理逻辑,而节点之间的连接则表示数据流动的方向。
运行一个Topology是很简单的。
首先,把你所有的代码已经所依赖的jar打进一个jar包。
然后运行类似下面的这个命令。
strom jar all-your-code.jar backtype.storm.MyTopology arg1 arg2这个命令会运行主类: backtype.strom.MyTopology, 参数是arg1, arg2。
这个类的main 函数定义这个topology并且把它提交给Nimbus。
storm jar负责连接到nimbus并且上传jar文件。
因为topology的定义其实就是一个Thrift结构并且nimbus就是一个Thrift服务,有可以用任何语言创建并且提交topology。
上面的方面是用JVM-based语言提交的最简单的方法, 看一下文章: Running topologies on a production cluster去看看怎么启动和停止topologies。
StreamStream是storm里面的关键抽象。
一个stream是一个没有边界的tuple序列。
storm提供一些语言来以分布式地,可靠地把一个stream传输进一个新的stream。
比如:你可以把一个tweets流传输到热门话题的流。
storm提供的最基本的处理stream的原语是spout和bolt。
Spout和bolt有接口可以实现以让你实现你的应用的逻辑。
spout的流的源头。
比如一个spout可能从Kestrel队列里面读取消息并且把这些消息发射成一个流。
又比如一个spout可以调用twitter的一个api并且把返回的tweets发射成一个流。
bolt可以接收任意多个输入stream,作一些处理,有些bolt可能还会发射一些新的stream。
一些复杂的流转换,比如从一些tweet里面计算出热门话题,需要多个步骤,从而也就需要多个bolt。
Bolt可以做任何事情: 运行函数,过滤tuple, 做一些聚合,做一些合并以及访问数据库等等。
spout和bolt所组成一个网络会被打包成topology,topology是storm里面最高一级的抽象,你可以把topology提交给storm的集群来运行。
topology的结构在Topology 那一段已经说过了,这里就不再赘述了。
topology结构topology里面的每一个节点都是并行运行的。
在你的topology里面,你可以指定每个节点的并行度,storm则会在集群里面分配那么多线程来同时计算。
一个topology会一直运行直到你杀死它。
storm自动重新分配一些运行失败的任务,并且storm保证你不会有数据丢失,即使在一些机器意外停机并且消息被丢掉的情况下。
数据模型(Data Model)storm使用tuple来作为它的数据模型。
每个tuple是一堆值,每个值有一个名字,并且每个值可以是任何类型,在我的理解里面一个tuple可以看作一个没有方法的java对象。
总体来看,storm支持所有的基本类型,字符串以及字节数组作为tuple的值类型。
你也可以使用你自己定义的类型来作为值类型,只要你实现对应的序列化器(serializer)。
topology里面的每个节点必须定义它要发射的tuple的每个字段。
比如下面这个bolt定义它锁发射的tuple包含两个字段,类型分别是: doble和triple。
publicclass DoubleAndTripleBolt implements IRichBolt {private OutputCollectorBase _collector;@Overridepublic void prepare(Map conf, TopologyContext context, OutputCollecto rBase collector){_collector = collector;}@Overridepublic void execute(Tuple input){int val = input.getInteger(0);_collector.emit(input, new Values(val*2, val*3));_collector.ack(input);}@Overridepublic void cleanup(){}@Overridepublic void declareOutputFields(OutputFieldsDeclarer declarer){declarer.declare(new Fields("double", "triple"));}}declareOutputFields方法定义要输出的字段:["double", "triple"]。