dwr怎么返回对象
- 格式:doc
- 大小:97.50 KB
- 文档页数:17

DWR调用方式1. 什么是DWRDWR(Direct Web Remoting)是一个开源的Java框架,用于简化在Web应用程序中使用Ajax技术。
它提供了一种简单的方式来将Java代码暴露给JavaScript,并使得在客户端和服务器之间进行远程通信变得更加容易。
DWR允许开发人员通过直接调用服务端的Java方法来处理客户端的请求,而无需编写大量的JavaScript代码来处理网络通信。
这使得开发人员可以更专注于业务逻辑,而无需过多关注底层的网络细节。
2. DWR调用方式DWR提供了多种方式来进行远程调用,包括:2.1. 代理方式(Proxy)代理方式是最常见和推荐的一种DWR调用方式。
通过代理对象,我们可以直接调用服务端的Java方法,并将结果返回给客户端。
在客户端,我们需要首先创建一个代理对象,该对象负责与服务端进行通信。
我们可以使用dwr.engine命名空间下的Proxy对象来创建代理对象,并指定要调用的Java类和方法。
var proxy = new dwr.engine.Proxy();proxy.setRemoteClass(MyService);proxy.setRemoteMethod('myMethod');在上述代码中,MyService是服务端中定义的Java类,myMethod是该类中的一个方法。
然后,我们可以使用代理对象来调用服务端的方法,并处理返回的结果。
proxy.myMethod(param1, param2, {callback: function(result) {// 处理返回结果},errorHandler: function(message) {// 处理错误信息}});在上述代码中,param1和param2是传递给服务端方法的参数。
callback函数用于处理返回结果,而errorHandler函数则用于处理错误信息。
2.2. 反向Ajax方式(Reverse Ajax)反向Ajax方式是一种特殊的DWR调用方式,它允许服务端主动推送数据给客户端。

DWR的作用:DWR是一个可以允许你去创建AJAX WEB站点的JAVA开源库。
它可以让你在浏览器中的Javascript代码调用Web服务器上的Java代码,就像在Java 代码就在浏览器中一样。
在使用dwr前,先介绍下我们远程调用的方法,以方便下文解说其中的KnowDAO类是实现了CRUD方法的dao类,返回一个字符串,内容是当前时间和数据库中的数据数量。
注:别忘了写getter,setter方法。
DWR的配置:web.xml:首先要在你的web.xml中加入dwr的配置代码,代码如下:.其中<init-param>中配置了debug的值,表示可以进入调试模式,其他都是必须有的dwr.xml:要建立一个dwr.xml的配置文件,这个文件放在你的项目的根目录下。
和你的web.xml放在一起。
在demo中我的代码如下:其中<dwr>中的部分就是dwr的配置,<dwr>中<allow>标签中定义了DWR能够创建和转换的类.<create>中的create属性有很多类型,这里使用的是spring表示整合spring。
javascript属性的值是DwrTime是在js的页面中使用的,类似于beans.xml中,bean id的作用不同的是bean id的值作为一个对象的实例,可以直接使用在java中,而javascript属性是直接使用在js中。
<param>标签中的值表示的是与beans.xml注入的哪个实例相对应,name属性是固定的表示这个属性是与bean id相关,value属性和bean id的值是相同的.beans.xml中的注入文件如下:<include>标签表示的是类中那些方法可以在js中使用,如果不想让某些方法在js被调用,那么就不要include它,注意method属性的值可以是”*”,用来表示所有方法. PS:除了include标签以外,还可以用exclude 标签来声明, exclude表示的是不能使用的方法,凡是没声明的就可以使用, exclude不推荐使用。

Dwr 框架基础用法1. Web.xml 中的配置:<servlet> <description>Direct Web Remoter Servlet</description> <display-name>DWR Servlet</display-name> <servlet-name>dwr-invoker</servlet-name> <servlet-class>uk.ltd.getahead.dwr.DWRServlet</servlet-class> <init-param> <param-name>debug</param-name> <param-value>false</param-value> </init-param> <load-on-startup>10</load-on-startup> </servlet> <servlet-mapping> <servlet-name>dwr-invoker</servlet-name> <url-pattern>/dwr/*</url-pattern> </servlet-mapping>2. Dwr.xml 中的配置:<dwr> <allow> <createcreator="new"javascript="JDate"> <paramname="class"value="java.util.Date" /> </create> <createcreator="new"javascript="DwrInvokeData"> <paramname="class"value="com.xxx.xxx.DWRACTION" /></create> </allow> </dwr>3. JSP 中需要引入:<scripttype='text/javascript' src='/项目名 /dwr/interface/DwrInvokeData.js'></script> <scripttype='text/javascript' src='/项目名/dwr/engine.js'></script> <scripttype='text/javascript' src='/项目名/dwr/util.js'></script>4. Java 代码还需要一个 java 类 Action 中些处理方法publicObjectTest(argType1arg1,argType2arg2,………,argTypeNargN)throws Exception{ //处理逻辑 Return Object; }5. Javascript 调用function test(){ //其他代码 DwrInvokeData.方法名(参数 1,参数 2,..,参数,testCallBack); //如:DwrInvokeData.Test(参数 1,参数 2,..,参数,testCallBack); //其他代码} //回调函数中返回参数为后台处理 Action 中的返回值,可以是任意 JavaBean,基本类型,数//组,集 合等 functiontestCallBack(返回参数){ //处理界面展代码 }。

dwrinvokedataaction 方法详解摘要:1.DWR简介2.dwrinvokedataaction方法概述3.参数详解4.示例代码与应用5.总结与建议正文:一、DWR简介DWR(Direct Web Remoting)是一个基于Java的远程方法调用框架,它允许在不同的Java应用程序之间直接调用方法,而无需共享任何中间对象。
DWR的核心思想是让Java对象直接在客户端运行,从而实现客户端与服务器端的无缝通信。
在本篇文章中,我们将重点介绍dwrinvokedataaction方法,它是DWR中非常重要的一个方法。
二、dwrinvokedataaction方法概述dwrinvokedataaction方法是用于在客户端调用服务器端方法的。
它接收一个Method对象作为参数,该对象包含了服务器端方法的所有信息。
在调用此方法时,DWR会自动将服务器端方法的参数转换为JSON格式,并通过Ajax请求发送到服务器。
同时,DWR还支持返回值的处理,可以将服务器端方法的返回值转换为JSON格式并返回给客户端。
三、参数详解1.Method对象:包含了服务器端方法的所有信息,如方法名、参数类型及参数值等。
2.参数值:可以是任意类型的对象,如基本数据类型、Java对象等。
需要注意的是,如果参数值为Java对象,则需要实现Serializable接口,以便在客户端和服务器之间传输。
3.异常处理:可以通过Throwable对象或Exception对象指定异常处理方式。
如果不需要处理异常,可以设置为null。
4.回调函数:可以设置一个回调函数,当服务器端方法调用成功或失败时,该回调函数会被调用。
回调函数接收一个Object参数,可以返回任何类型的值。
四、示例代码与应用以下是一个简单的示例代码,演示了如何使用dwrinvokedataaction方法调用服务器端方法:```java// 服务器端方法public class Server {public String sayHello(String name) {return "Hello, " + name;}}// 客户端代码public class Client {public static void main(String[] args) {// 创建服务器端对象Server server = new Server();// 调用服务器端方法String result = (String) DWR.invokeDataAction(server, "sayHello", "World");System.out.println(result);}}```在这个示例中,我们创建了一个简单的服务器端方法sayHello,并在客户端使用dwrinvokedataaction方法调用它。

DWR技术总结目录1DWR入门 (3)1.1DWR(Direct Web Remoting)概述 (3)1.2DWR使用入门 (3)2web.xml的配置 (7)3dwr.xml的配置 (8)3.1创建dwr.xml文件 (8)3.2<init>标签 (8)3.3<allow>标签 (8)3.3.1Creators构造器 (9)3.3.2Converters转换器 (10)3.3.3Filters过滤器 (11)3.4<signatures>标签 (12)4engine.js功能 (12)5util.js功能 (13)6DWR中的javascript (13)6.1DWR的远程调用——使用回调函数处理Ajax的异步特性 (13)6.2创建一个与Java对象相匹配的JavaScript对象 (14)1DWR入门1.1DWR(Direct Web Remoting)概述DWR是一种AJAX(Asynchronous JavaScript and XML)的JAVA实现,是一个能够使运行在服务器上java和运行在浏览器中的JavaScript交互,并能简单的相互调用的Java库。
官方网站:最新版本:3.0.rc2稳定版本:2.0.7DWR包括两个主要部分:*运行在服务器上的Java Servlet,用以处理请求和向浏览器发回响应。
*运行在浏览器上的JavaScript,用以发送请求,并可以动态的更新网页。
DWR的工作原理是动态生成基于Java类的JavaScript。
生成的代码具有ajax 功能,使效果看起来就好像在浏览器上执行的一样,实际上是,代码调用发生在服务器端,DWR负责数据的传递和转换。
这种从java到javascript的运程调用功能的方式使DWR用起来有种非常像RMI或者SOAP的常规RPC机制,而且DWR 的优点在于不需要任何的网页浏览器插件就能够运行在网页上。

1.1跟我学DWR框架——如何应用DWR框架中的回调机制及应用示例1.1.1DWR框架中的回调机制及相关的应用示例1、DWR框架中的回调机制(1)在DWR框架中是如何实现AJAX技术中的“异步”功能由于DWR框架是根据dwr.xml生成和Java代码类似的JavaScript代码,因此在DWR 框架中通过引入回调函数来实现Ajax的异步调用特性——当执行的结果被返回时,DWR 框架会调用这个回调函数。
(2)回调函数定义的要求通常我们都需要传递外部信息给一个回调函数,因此所有的回调函数都应该只有一个参数——参数就是从远程方法返回的值,从而实现将服务器端的组件的方法的返回值给回调函数。
如下为代码示例:function callbackFunc(dataFromServer){// do something with dataFromServer and dataFromBrowser …}2、DWR框架中的回调机制的某个示例<%@ page contentType="text/html; charset=GBK" %><html><head><title> 体现DWR框架中的回调机制的Demo示例</title><script type='text/javascript'src='/DWRWebTest/dwr/interface/JDate.js'></script><script type='text/javascript' src='/DWRWebTest/dwr/engine.js'></script><script type='text/javascript' src='/DWRWebTest/dwr/util.js'></script><script language="javascript">function showTime(){JDate.toString(callBackFun);}callBackFun = function(toStringReturnTimeString){alert("当前的时间是:"+toStringReturnTimeString);}</script></head><body bgcolor="#ffffff"><a href="#" onclick="javascript:showTime()">点击我可以获得当前的时间</a></body></html>3、DWR框架中的回调机制与RMI 或者 SOAP等其它的实现机制的不同这种从远程的 Java 方法到 JavaScript 程序的方式给 DWR框架使用者一个感觉,好像传统的 RPC 方式,比如 RMI 或者 SOAP,事实上与之相比 DWR 的优势在于它不需要任何浏览器插件或者某种客户端的代理程序。

dwr使用教程DWR(Direct Web Remoting)是一个WEB远程调用框架.利用这个框架可以让AJAX 开发变得很简单.利用DWR可以在客户端利用JavaScript直接调用服务端的Java方法并返回值给JavaScript就好像直接本地客户端调用一样(DWR根据Java类来动态生成JavaScrip代码).它的最新版本 DWR0.6添加许多特性如:支持Dom Trees的自动配置,支持Spring(JavaScript远程调用spring bean),更好浏览器支持,还支持一个可选的commons-logging日记操作.以上摘自open-open,它通过反射,将java翻译成javascript,然后利用回调机制,轻松实现了javascript调用Java代码。
其大概开发过程如下:1.编写业务代码,该代码是和dwr无关的。
2.确认业务代码中哪些类、哪些方法是要由javascript直接访问的。
3.编写dwr组件,对步骤2的方法进行封装。
4.配置dwr组件到dwr.xml文件中,如果有必要,配置convert,进行java和javascript类型互转。
5.通过反射机制,dwr将步骤4的类转换成javascript代码,提供给前台页面调用。
5.编写网页,调用步骤5的javascript中的相关方法(间接调用服务器端的相关类的方法),执行业务逻辑,将执行结果利用回调函数返回。
6.在回调函数中,得到执行结果后,可以继续编写业务逻辑的相关javascript 代码。
下面以用户注册的例子,来说明其使用。
(注意,本次例子只是用于演示,说明DWR的使用,类设计并不是最优的)。
1.先介绍下相关的Java类User: 用户类,public class User {//登陆ID,主键唯一private String id;//姓名private String name;//口令private String password;//电子邮件private String email;//以下包含getXXX和setXXX方法.......}UserDAO:实现User的数据库访问,这里作为一个演示,编写测试代码public class UserDAO {//存放保存的数据private static Map dataMap = new HashMap();//持久用户public boolean save(User user) {if (dataMap.containsKey(user.getId()))return false;System.out.println("下面开始保存用户");System.out.println("id:"+user.getId());System.out.println("password:"+user.getPassword());System.out.println("name:"+user.getName());System.out.println("email:"+user.getEmail());dataMap.put(user.getId(), user);System.out.println("用户保存结束");return true;}//查找用户public User find(String id) {return (User)dataMap.get(id);}}DWRUserAccess:DWR组件,提供给javascript访问的。

一、dwr简介DWR(Direct Web Remoting)是一种AJAX解决方案。
DWR包括一个java库,以及一套javascript,使得我们可以用一种非常简单的方式,在页面上使用javascript直接调用后台的java对象。
DWR 是一个WEB远程调用框架.利用这个框架可以让AJAX开发变得很简单。
利用DWR可以在客户端利用JavaScript直接调用服务端的Java 方法并返回值给JavaScript就好像直接本地客户端调用一样(DWR 根据Java类来动态生成JavaScrip代码)。
Dwr在运行的时候,动态生成一个javascript库,这个库是对后台javabean调用的封装,我们可以直接使用这个库来实现直接调用JavaBean的目的。
二、dwr开发步骤开发步骤如下:1、为项目添加dwr框架(jar包)下载dwr.jar文件,并将其拷贝到项目的WebRoot/lib目录下;2、在web.xml中添加dwr控制器3、创建dwr.xml4、在dao层设置访问方法5、修改adminAddCate.jsp6、测试三、dwr实例1、创建一个Web项目2、导入dwr.jar包3、修改web.xml4、编辑业务代码5、创建并编辑dwr.xml代码如下:------------nameForm.java--------------public class nameForm{private String name;public String getName() {return name;}public void setName(String name) { = name;}}------------nameService.java--------------public class nameService{public int isExist(String name){int status;nameForm dealer = new nameForm();dealer.setName("泰山");if(name.equals(dealer.getName()))status = 1;elsestatus = 0;return status;}}----------------index.jsp------------------<%@page contentType="text/html; charset=gb2312"%><html><head><title></title><script type="text/javascript" src="/dwr/dwr/interface/test.js"></script><script type="text/javascript"src="/dwr/dwr/engine.js"></script> <script type="text/javascript"src="/dwr/dwr/util.js"></script><script type="text/javascript">function save(flag){var termName = document.all.input.value;test.isExist(termName,reply);function reply(data){if(data==1){alert("该名称已存在!");return false;}else{alert("该名称不存在!");}}}</script></head><body><center>请输入一座山名:<br><input type="text"name="input"id="input"/><br><input type="button"onClick="save('0')"value="检测"/></center></body></html>----------------web.xml------------------<?xml version="1.0"encoding="UTF-8"?><web-app version="2.5"xmlns="/xml/ns/javaee"xmlns:xsi="/2001/XMLSchema-instance"xsi:schemaLocation="/xml/ns/javaee/xml/ns/javaee/web-app_2_5.xsd"><welcome-file-list><welcome-file>index.jsp</welcome-file></welcome-file-list><!--配置dwr --><servlet><servlet-name>dwr-invoker</servlet-name><servlet-class>uk.ltd.getahead.dwr.DWRServlet</servlet-class> <init-param><param-name>debug</param-name><param-value>true</param-value></init-param><init-param><param-name>scriptCompressed</param-name><param-value>false</param-value></init-param><load-on-startup>1</load-on-startup></servlet><servlet-mapping><servlet-name>dwr-invoker</servlet-name><url-pattern>/dwr/*</url-pattern></servlet-mapping></web-app>----------------dwr.xml------------------<?xml version="1.0"encoding="UTF-8"?><!DOCTYPE dwr PUBLIC"-//GetAhead Limited//DTD Direct Web Remoting 1.0//EN""/dwr/dwr10.dtd"><dwr><allow><create creator="new"javascript="test"><param name="class"value="nameService"/><include method="isExist"/></create></allow></dwr>。
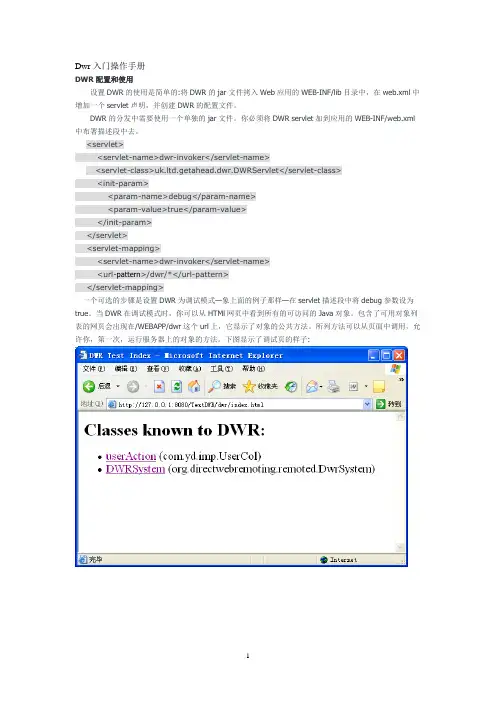
Dwr入门操作手册DWR配置和使用设置DWR的使用是简单的:将DWR的jar文件拷入Web应用的WEB-INF/lib目录中,在web.xml中增加一个servlet声明,并创建DWR的配置文件。
DWR的分发中需要使用一个单独的jar文件。
你必须将DWR servlet加到应用的WEB-INF/web.xml 中布署描述段中去。
<servlet><servlet-name>dwr-invoker</servlet-name><servlet-class>uk.ltd.getahead.dwr.DWRServlet</servlet-class><init-param><param-name>debug</param-name><param-value>true</param-value></init-param></servlet><servlet-mapping><servlet-name>dwr-invoker</servlet-name><url-pattern>/dwr/*</url-pattern></servlet-mapping>一个可选的步骤是设置DWR为调试模式—象上面的例子那样—在servlet描述段中将debug参数设为true。
当DWR在调试模式时,你可以从HTMl网页中看到所有的可访问的Java对象。
包含了可用对象列表的网页会出现在/WEBAPP/dwr这个url上,它显示了对象的公共方法。
所列方法可以从页面中调用,允许你,第一次,运行服务器上的对象的方法。
下图显示了调试页的样子:调试页现在你必须让DWR知道通过XMLHttpRequest对象,什么对象将会接收请求。

使用dwr的一点经验1.需要jdom.jar和bsf.jar,否则无法跟spring整合.2.dwr生成的javascript函数会自动加一个回调函数的参数,如原来的函数是checkExist(String name),那么生成的javascript函数是checkExist(callbackFunc,String name).3.注意回调函数只能有一个参数,就是服务器的返回值,如function(messFromServer),这里messFromServer是该操作在服务器上的返回值.4.util.js里面有很多有用的方法,最好熟悉一下.5.convert并不是必须的,只有你的函数需要传递非基本数据类型的数据时需要此项.DWR中的util.js先简单介绍一下什么是DWRDWR - Direct Web Remotingajax是一种提高web站点吸引力和实用性的书写web页面的方法。
它从服务器端更新web 页面的特殊区域,从而增强用户的交互性。
它允许信息在短时间的延迟或不用刷新页面的情况下更新。
DWR减少了开发时间,也减少了一些可能的错误,这些错误是在提供常用的方法函数并消除一些与高交互性web站点有关的重复性代码的时候产生的。
DWR是作为开源软件(ASL verssion 2.0)而可以免费得到的。
它凭借它的广阔的库、例子和指南非常易于实现。
把它结合到一个现有的站点是非常简单的,同样它也可以简单地与大多数java框架结合。
util.js util.js包含了一些使用的方法,从而帮助你利用j avascript(可能)从服务器端更新你的web数据。
你可以在DWR之外的地方使用它,因为它并不依赖与DWR而实现。
它包含四个页面处理函数:getValue[s]()、setValue[s]()作用于除tables、lists和images以外的大多数html元素。
getText()作用于select lists。

1 DWR 是什么DWR是一个可以允许你去创建AJAX WEB站点的JAVA开源库,它可以通过浏览器端的Javascript代码去调用服务器端的Java代码,看起来就像是Java代码运行在浏览器上一样。
DWR是一个完整的异步AJAX框架,它隐藏了XMLHttpRequest对象,程序员在开发过程中不需要接触XMLHttpRequest 对象就可以向服务器发送异步请求并通过回调方式处理服务器的返回值。
DWR包含两个主要部分:∙ 运行在服务器端的servlet控制器(DwrServlet),它负责接收请求,调用相应业务逻辑进行处理,向客户端返回响应。
∙ 运行在浏览器端的Javascript,它负责向服务器端发送请求,接收响应,动态更新页面。
DWR工作原理是通过动态把Java类生成为Javascript。
它的代码就像Ajax魔法一样,你感觉调用就像发生在浏览器端,但是实际上代码调用发生在服务器端,DWR负责数据的传递和转换。
这种从JavaScript到Java的远程调用功能的方式使DWR用起来有种非常像RMI或者SOAP的常规RPC机制,而且DWR的优点在于不需要任何的网页浏览器插件就能运行在网页上。
Java从根本上讲是同步机制,然而Ajax却是异步的。
所以你调用远程方法时,当数据已从网络上返回的时候,你要提供有回调(callback)来接收数据。
DWR动态在浏览器端生成一个AjaxService的JavaScript类,以匹配服务器端AjaxService的Java类。
由eventHandler去调用它,然后DWR处理所有的远程细节,包括转换所有的参数以及将返回的Java对象映射成Javascript 对象。
在示例中,先在eventHandler方法里调用AjaxService的getOptions() 方法,然后通过回调(callback)方法populateList(data) 得到返回的数据,其中data 就是String[]{"1", "2", "3"},最后再使用DWR utility 把data加入到下拉列表。
Js一些操作手动添加表格选项:1.添加表格:<table align="center" border="1"><thead></thead><tbody id="userTable"> </tbody></table>2. JS代码如下:var table=document.getElementById("userTable");var dtr=table.insertRow();var uid=dtr.insertCell();uid.innerHTML=user.uid;3.JS添加下拉列表document.getElementById("name").options.add(new Option(“”,“”));4删除下拉列表的值document.getElementById("shi").options.length=0;DWR一些操作:1.增加dwr.xml文件,和修改web.xml,内容为:<dwr><allow><create javascript="DwrTe" creator="new" scope="application"> <param name="class" value="com.newer.bean.DwrTest"></param> </create></allow></dwr>修改web.xml 代码为:<servlet><servlet-name>dwr</servlet-name><servlet-class>org.directwebremoting.servlet.DwrServlet</servlet-class><init-param><param-name>debug</param-name><param-value>true</param-value></init-param></servlet><servlet-mapping><servlet-name>dwr</servlet-name><url-pattern>/dwr/*</url-pattern></servlet-mapping>2.在页面引入两个虚拟的JS文件engine.js 和util.js 代码如下:<script type="text/javascript" src="dwr/engine.js"></script><script type="text/javascript" src="dwr/util.js"></script>3.创建DWR操作对象:<script type="text/javascript" src="dwr/interface/ DwrTe.js"></script>4.DWR操作对象:封装对象:var user={uname:name,upwd:pwd,uaddress:address};操作类返回的是bean 的话,可以直接通过对象.属性名就能拿到值;如果是集合可以通过遍历取出,代码:for(var i=0;i<userList.length;i++){var user=userList[i];user.uid;}5.下拉列表的添加:--注释:selClass为下拉列表名字claassList 为集合cid,cname 为classList集合中对象的属性。
DWR(direct web remote)是一个基于服务器端的ajax框架。
通过该框架,我们可以使用js来直接调用java方法。
是一个基于浏览器其端的ajax框架,只需要引入即可使用。
Jquery:1.引入jar包到WEB-INF/lib2.中写入:<servlet><servlet-name>dwr-invoker</servlet-name><servlet-class><init-param><param-name>debug</param-name><param-value>true</param-value></init-param></servlet><servlet-mapping><servlet-name>dwr-invoker</servlet-name><url-pattern>/dwr/*</url-pattern></servlet-mapping>3.建立java类(普通java类即可,不是servlet)TestClasspublic class TestClass {public void testMethod1(){"hello dwr!");}}4.在/WEB-INF/中配置java类:<xml version="" encoding="UTF-8">5.<!DOCTYPE dwr PUBLIC "-html中使用,需要首先引入:(需要保证dwr这个目录位于web应用的根目录)<script src='dwr/interface/'></script><script src='dwr/'></script><script src='dwr/'></script>6.在javascript方法中调用后台java类方法:function test(){();}用dwr调用有参数或有返回值的java方法:f unction test(){("bbb",parseInfo);nnerHTML=data;}DWR调用的简单顺序:1.js调用相应的方法发送请求。
什么是DWR?DWR是一种AJAX解决方案!DWR包括一个java库,以及一套javascript,使得我们可以用一种非常简单的方式,在页面上使用javascript直接调用后台的java对象!DWR架构DWR的javascript库包括几个部分:dwr的javascript引擎(即对AJAX调用的封装)、dwr 提供的一些非常有用的辅助javascript函数库、以及dwr自动帮我们生成的专门用于调用后台JavaBean方法的javascript库!Dwr在运行的时候,动态生成一个javascript库,这个库是对后台javabean调用的封装,我们可以直接使用这个库来实现直接调用JavaBean的目的!注意:是在运行的时候动态生成!下面我们来看看如何安装和使用(基于DWR2.x版本):如何下载、安装与使用?官方网址:/dwr1、下载dwr.jar,将其加入web-inf/lib目录3、配置dwr,即在WEB-INF目录下,添加dwr.xml文件,让dwr知道在运行的时候应该给哪些JavaBean生成相应的javascript库!这个配置的意思是,要创建的是Test1对象的javascript库,而且这个库的名字叫test1,同时,这也是我们在JSP页面上调用这个对象的时候所使用的名称,请看下面的JavaBean代码和JSP实例:5、在JSP中的使用!util.js,它们分别是dwr中的核心引擎库和辅助工具函数库!第三个引入的dwr/interface/test1.js,实际上这个文件并不存在,这是由dwr在运行的时候动态生成的!test1这个名称,跟dwr.xml文件中配置的对应对象的javascript属性一致!而且,我们在使用的时候,直接使用test1这个名称,作为这个对象的引用。
直接调用这个对象的方法:sayHello,这个方法的名称必须与JavaBean中的方法名称一致!sayHello方法有一个参数,同时返回一个值。
DWR1 DWRDWR(Direct Web Remoting)是getahead公司开发的一个实现Ajax应用的框架。
它允许客户端Javascript远程调用服务器端Java类的方法,执行相关的事务操作。
本节将从DWR简介、使用入门、适用范围等方面详细介绍DWR。
1.1 DWR简介DWR(Direct Web Remoting)是一个开源的类库,可以帮助开发人员开发包含Ajax技术的网站。
它可以允许在浏览器里的代码使用运行在Web服务器上的Java函数,就像它在浏览器里一样。
DWR包含两个主要的部分,其一是运行在浏览器客户端的Javascript,这部分被用来与服务器通信,并更新页面内容;其二是运行在服务器端的Java Servlet,这部分被用来处理请求并将响应结果发送给浏览器。
DWR采取了一种动态生成基于Java类的Javascript代码的新方法来实现和处理Ajax。
这样Web开发人员就可以在Javascript里像使用浏览器的本地代码一样使用Java代码,而实际上这些Java代码是运行在服务器端并且可以自由访问Web 服务器资源的。
出于安全的考虑,Web开发者必须适当地配置,决定哪些Java类可以安全地被外部使用。
图11-1来自DWR的官方文档,展示了DWR如何利用一些类似Javascript的onClick等事件的结果来改变一个下拉列表框的内容。
这个事件处理器调用一个DWR生成的Javascript函数,它和服务器端的Java函数是匹配的。
DWR接着处理了Java和Javascript之间的所有远程信息,包括转换所有的参数和返回需要的值。
接着DWR执行了相应的回调函数(populateList)。
这个例子演示了如何使用DWR功能函数来改变网页内容。
图11-1 DWR交互过程使用DWR可以有效地从应用程序代码中把Ajax的全部请求-响应循环消除掉。
这意味着,客户端代码再也不需要直接处理XMLHttpRequest对象或者服务器的响应,不再需要编写对象的序列化代码或者使用第三方工具才能把对象变成XML,甚至不再需要编写servlet代码把Ajax请求调整成对Java对象的调用。
DWR中Java方法的参数及返回值DWR是一个框架,简单的说就是能够在javascript直接调用java方法,而不必去写一大堆的javascript代码。
它的实现是基于ajax的,可以实现无刷新效果。
网上有不少DWR的例子,但大都只是某种方法的调用,本文只在使用层面上介绍DWR,并不涉更多的技术与设计,其目的是让初学者能够很快的学会各种java方法在javascript 中是如何调用的。
本文以DWR 1.1 为基础,对于DWR 2.0,因为还没有正式发布版,故不做介绍。
一、DWR配置篇之web.xml1 、最小配置Xml代码<servlet><servlet-name>dwr-invoker</servlet-name><servlet-class>uk.ltd.getahead.dwr.DWRServlet</servle t-class></servlet><servlet-mapping><servlet-name>dwr-invoker</servlet-name><url-pattern>/dwr/*</url-pattern></servlet-mapping><servlet><servlet-name>dwr-invoker</servlet-name><servlet-class>uk.ltd.getahead.dwr.DWRServlet</servle t-class></servlet><servlet-mapping><servlet-name>dwr-invoker</servlet-name><url-pattern>/dwr/*</url-pattern></servlet-mapping>2、当我们想看DWR自动生成的测试页(Using debug/test mode)时,可在servlet配置中加上Xml代码<init-param><param-name>debug</param-name><param-value>true</param-value></init-param><init-param><param-name>debug</param-name><param-value>true</param-value></init-param>这个参数DWR默认是false。
dwr结构DWR结构DWR(Direct Web Remoting)是一种用于将Java服务器端的方法暴露给JavaScript客户端调用的技术。
它允许开发者通过简单的配置和少量的代码,实现Java和JavaScript之间的双向通信。
本文将介绍DWR结构以及其在Web开发中的应用。
一、DWR结构概述DWR的结构主要包括以下几个核心组件:1. DWR框架:负责处理客户端请求并将其转发到相应的Java方法。
2. JavaScript引擎:用于解析和执行JavaScript代码。
3. Java对象:包含服务器端的业务逻辑代码,通过DWR框架对外暴露方法供JavaScript调用。
4. Servlet容器:负责接收和处理客户端的HTTP请求。
二、DWR的工作原理1. 客户端发起请求:当客户端需要调用服务器端的方法时,使用DWR提供的JavaScript库发起Ajax请求。
2. DWR框架接收请求:Servlet容器接收到客户端的请求后,将其转发给DWR框架进行处理。
3. DWR框架解析请求:DWR框架根据请求中的信息,找到对应的Java方法,并将请求参数传递给该方法。
4. 服务器端方法执行:Java方法在服务器端执行,并返回结果给DWR框架。
5. DWR框架返回结果:DWR框架将Java方法的执行结果封装成JSON格式,并返回给客户端。
6. 客户端处理结果:客户端接收到服务器端返回的结果后,可以根据需要进行相应的处理,如更新页面内容或显示提示信息。
三、DWR在Web开发中的应用1. 表单验证:通过DWR可以实现客户端表单验证,如验证用户名是否已存在、密码是否符合要求等。
通过在服务器端编写相应的验证方法,并在客户端调用这些方法,可以实现实时的表单验证功能。
2. 数据更新:DWR可以实现页面的实时数据更新,如在线聊天、股票行情等。
服务器端可以定时推送数据给客户端,或者客户端通过DWR发送请求获取最新数据,从而实现数据的实时展示。
查看文章DWR如何获得返回对象 list Map Set list.add(JavaBean) 2009-05-11 14:231、调用没有返回值和参数的JAVA方法1.1、dwr.xml的配置<dwr><allow><create creator="new" javascript="testClass" ><param name="class" value="/com.dwr.TestClass" /><include method="testMethod1"/></create></allow></dwr><allow>标签中包括可以暴露给javascript访问的东西。
<create>标签中指定javascript中可以访问的java类,并定义DWR应当如何获得要进行远程的类的实例。
creator="new"属性指定java类实例的生成方式,new 意味着DWR应当调用类的默认构造函数来获得实例,其他的还有spring方式,通过与IOC容器Spring进行集成来获得实例等等。
javascript=" testClass "属性指定javascript代码访问对象时使用的名称。
<param>标签指定要公开给javascript的java类名。
<include>标签指定要公开给javascript的方法。
不指定的话就公开所有方法。
<exclude>标签指定要防止被访问的方法。
1.2、javascript中调用首先,引入javascript脚本<script src='dwr/interface/ testClass.js'></script><script src="/dwr/engine.js"></script><script src="/dwr/util.js"></script>其中TestClass.js是dwr根据配置文件自动生成的,engine.js和util.js是dwr自带的脚本文件。
其次,编写调用java方法的javascript函数Function callTestMethod1(){testClass.testMethod1();}2、调用有简单返回值的java方法2.1、dwr.xml的配置配置同1.1<dwr><allow><create creator="new" javascript="testClass" ><param name="class" value="/com.dwr.TestClass" /><include method="testMethod2"/></create></allow></dwr>2.2、javascript中调用首先,引入javascript脚本其次,编写调用java方法的javascript函数和接收返回值的回调函数Function callTestMethod2(){testClass.testMethod2(callBackFortestMethod2);}Function callBackFortestMethod2(data){//其中date接收方法的返回值//可以在这里对返回值进行处理和显示等等alert("the return value is " + data);}其中callBackFortestMethod2是接收返回值的回调函数3、调用有简单参数的java方法3.1、dwr.xml的配置配置同1.1<dwr><allow><create creator="new" javascript="testClass" ><param name="class" value="/com.dwr.TestClass" /><include method="testMethod3"/></create></allow></dwr>3.2、javascript中调用首先,引入javascript脚本其次,编写调用java方法的javascript函数Function callTestMethod3(){//定义要传到java方法中的参数var data;//构造参数data = “test String”;testClass.testMethod3(data);}4、调用返回JavaBean的java方法4.1、dwr.xml的配置<dwr><allow><create creator="new" javascript="testClass" ><param name="class" value="/com.dwr.TestClass" /><include method="testMethod4"/></create><convert converter="bean" match=""com.dwr.TestBean"><param name="include" value="username,password" /></convert></allow></dwr><creator>标签负责公开用于Web远程的类和类的方法,<convertor>标签则负责这些方法的参数和返回类型。
convert元素的作用是告诉DWR在服务器端Java 对象表示和序列化的JavaScript之间如何转换数据类型。
DWR自动地在Java和JavaScript表示之间调整简单数据类型。
这些类型包括Java原生类型和它们各自的封装类表示,还有String、Date、数组和集合类型。
DWR也能把JavaBean 转换成JavaScript 表示,但是出于安全性的原因,要求显式的配置,<convertor>标签就是完成此功能的。
converter="bean"属性指定转换的方式采用JavaBean命名规范,match=""com.dwr.TestBean"属性指定要转换的javabean 名称,<param>标签指定要转换的JavaBean属性。
4.2、javascript中调用首先,引入javascript脚本其次,编写调用java方法的javascript函数和接收返回值的回调函数Function callTestMethod4(){testClass.testMethod4(callBackFortestMethod4);}Function callBackFortestMethod4(data){//其中date接收方法的返回值//对于JavaBean返回值,有两种方式处理//不知道属性名称时,使用如下方法for(var property in data){alert("property:"+property);alert(property+":"+data[property]);}//知道属性名称时,使用如下方法alert(ername);alert(data.password);}其中callBackFortestMethod4是接收返回值的回调函数5、调用有JavaBean参数的java方法5.1、dwr.xml的配置配置同4.1<dwr><allow><create creator="new" javascript="testClass" ><param name="class" value="/com.dwr.TestClass" /><include method="testMethod5"/></create><convert converter="bean" match="com.dwr.TestBean"><param name="include" value="username,password" /></convert></allow></dwr>5.2、javascript中调用首先,引入javascript脚本其次,编写调用java方法的javascript函数Function callTestMethod5(){//定义要传到java方法中的参数var data;//构造参数,date实际上是一个objectdata = { username:"user", password:"password" }testClass.testMethod5(data);}6、调用返回List、Set或者Map的java方法6.1、dwr.xml的配置配置同4.1<dwr><allow><create creator="new" javascript="testClass" ><param name="class" value="/com.dwr.TestClass" /><include method="testMethod6"/></create><convert converter="bean" match="com.dwr.TestBean"><param name="include" value="username,password" /></convert></allow></dwr>注意:如果List、Set或者Map中的元素均为简单类型(包括其封装类)或String、Date、数组和集合类型,则不需要<convert>标签。