
第一章
1、数据类型:按照所采用的计量尺度不同,我们将数据分为:分类数据(归于某一类别的非数字型数据,ex:血型),顺序数据(有序类别的非数据型数据,ex:喜好,产品等级),数值型数据(按照数字尺度测量的观测值)
2、统计量:用来描述样本特征的概括性数字度量,它是根据样本数据计算出来的一些量,是样本的函数,样本统计量通常用小写英文字母表示,若存在未知变量就不是统计量。
第二章
1、概率抽样(随机抽样):
(1)特点:按一定的概率以随机原则抽取样本(抽取样本时使每个单位都有一定的机会被抽中)。每个单位被抽中的概率是已知的,或是可以计算出来的。当用样本对总体目标量进行估计时,要考虑到每个样本单位被抽中的概率
(2)简单随机抽样:体现在每一个样本点的选取上(简单直观方便,但是效率低)(3)分层抽样:适用于总体差距大,体现在每一层样本点选取上(精度最高)
(4)系统抽样:第一个样本点的选取是随机的(简单,提高精度,但是方差估计难)(5)整群抽样:要求:群集间互斥且周延,群集与群集间差异小,群集内类似总体
每一群的选取是随机的(简单,相对集中,方便,但是精度较差)(6)多阶段抽样:先抽取群,但并不是调查群内的所有单位,而是再进行一步抽样,从选中的群中抽取出若干个单位进行调查。
2、非概率抽样
(1)抽取样本时不是依据随机原则,而是根据研究目的对数据的要求,采用某种方式从总体中抽出部分单位对其实施调查
(2)有方便抽样、判断抽样、自愿样本、滚雪球抽样、配额抽样等方式
3、比较:
4、抽样误差:所有样本可能的结果与总体真值之间的平均性差异
影响因素:样本量的大小、总体的变异性
第三章
1、数据审核:
(1)原始数据:完整性,准确性;(2)二手数据:适用性,时效性,确认是否有必要做进一步的加工整理
2、分类数据的图示:
(1)条形图:主要反映分类数据的频数分布
(2)帕累托图:各类别数据出现的频数多少排序的柱形图,用于展示分类数据分布。
(3)饼图:主要用于表示样本或总体中各组成部分所占的比例,用于研究结构性问题。
(4)环形图:同时绘制多个样本或总体的数据系列,每一个样本或总体的数据系列为一个环。用于结构比较研究、用于展示分类和顺序数据
3、数值型数据的整理:
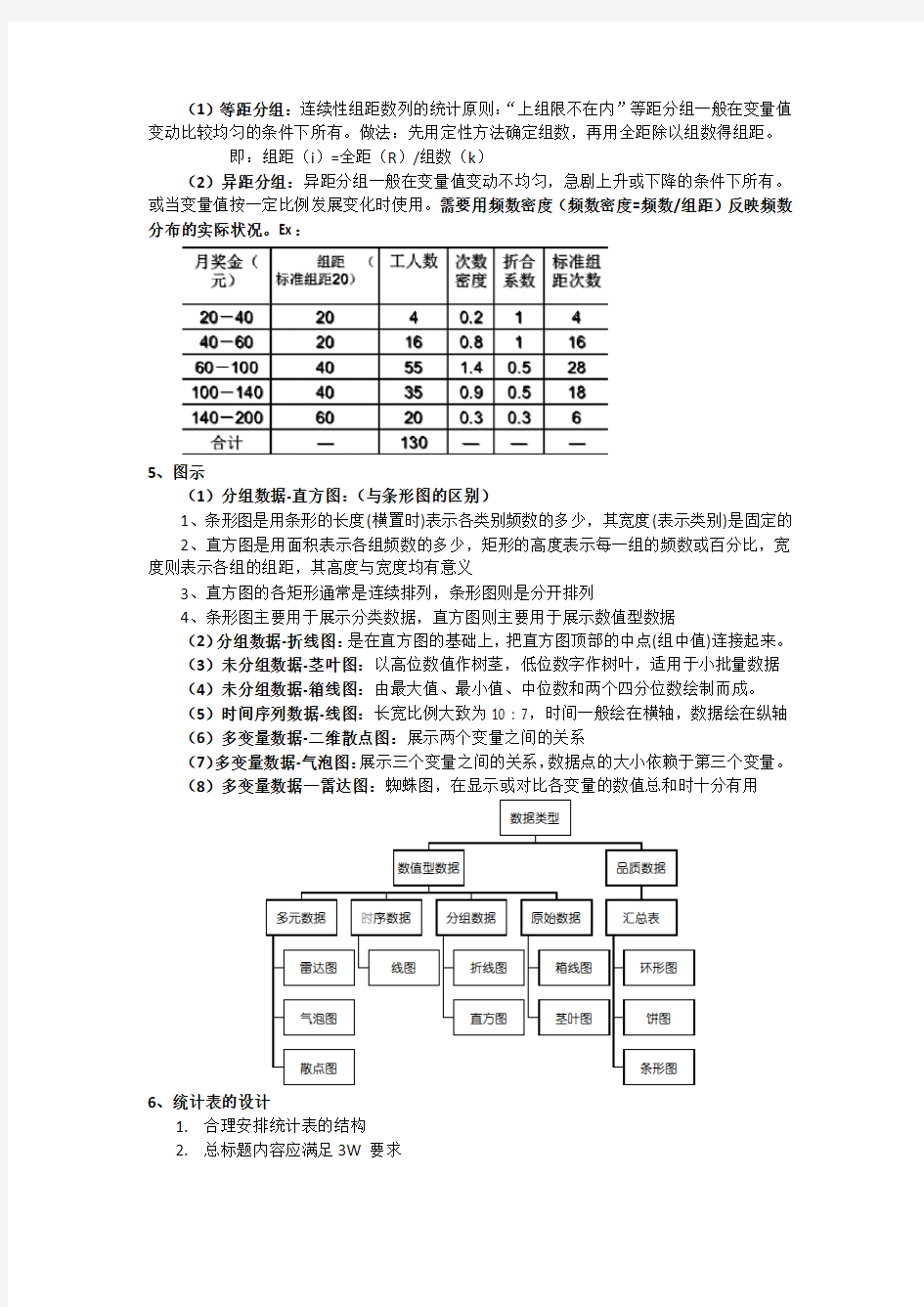
(1)分组方法:1、单变量值分组,2、组距分组(1、等距分组,2、异距分组)
4、组距分组:
(1)等距分组:连续性组距数列的统计原则:“上组限不在内”等距分组一般在变量值变动比较均匀的条件下所有。做法:先用定性方法确定组数,再用全距除以组数得组距。
即:组距(i)=全距(R)/组数(k)
(2)异距分组:异距分组一般在变量值变动不均匀,急剧上升或下降的条件下所有。或当变量值按一定比例发展变化时使用。需要用频数密度(频数密度=频数/组距)反映频数分布的实际状况。Ex:
5、图示
(1)分组数据-直方图:(与条形图的区别)
1、条形图是用条形的长度(横置时)表示各类别频数的多少,其宽度(表示类别)是固定的
2、直方图是用面积表示各组频数的多少,矩形的高度表示每一组的频数或百分比,宽度则表示各组的组距,其高度与宽度均有意义
3、直方图的各矩形通常是连续排列,条形图则是分开排列
4、条形图主要用于展示分类数据,直方图则主要用于展示数值型数据
(2)分组数据-折线图:是在直方图的基础上,把直方图顶部的中点(组中值)连接起来。
(3)未分组数据-茎叶图:以高位数值作树茎,低位数字作树叶,适用于小批量数据(4)未分组数据-箱线图:由最大值、最小值、中位数和两个四分位数绘制而成。
(5)时间序列数据-线图:长宽比例大致为10 : 7,时间一般绘在横轴,数据绘在纵轴(6)多变量数据-二维散点图:展示两个变量之间的关系
(7)多变量数据-气泡图:展示三个变量之间的关系,数据点的大小依赖于第三个变量。
(8)多变量数据—雷达图:蜘蛛图,在显示或对比各变量的数值总和时十分有用
6、统计表的设计
1.合理安排统计表的结构
2.总标题内容应满足3W要求
3. 数据计量单位相同时,可放在表的右上角标明,不同时应放在每个变量后或单列出
一列标明
4. 表中的上下两条横线一般用粗线,其他线用细线
5. 通常情况下,统计表的左右两边不封口
6. 表中的数据一般是右对齐,有小数点时应以小数点对齐,而且小数点的位数应统一
7. 对于没有数字的表格单元,一般用“—”表示
8. 必要时可在表的下方加上注释
第四章
1、众数:异距数列,用频数密度
2、中位数:
3、四分位数:
4、分类数据-异众比率:非众数组的频数占总频数的比例,对分类数据离散程度的测度
∑∑∑-
=-=
i
m i
m
i r f f f f f v 1
5、顺序数据-四分位差:
对顺序数据离散程度的测度,用于衡量中位数的代表性,上四分位数与下四分位数之差,即Q3-Q1。
6、方差和标准差:
分组数据方差(重复抽样):N
f M K
i
i
i ∑=-=
1
22)(μσ(fi 为组中值,u 为均值,若是样本,
除以N-1)
不重复抽样:
x
σ-
=
i f f f f f f L M ?-+--+
=+--)
()(111
&
方差加法定理:总方差=组内方差的平均数+组间方差
组间方差是:分组均值与总均值的差的平方乘以组内个数的和除以总数。
7、标准分数:
s x x z i i -=
服从N (0,1)分布。
8、相对离散程度-离散系数:标准差与其相应的均值之比,x
s
v s =
9、偏态:偏态系数=0为对称分布,偏态系数> 0为右偏分布,偏态系数< 0为左偏分布
10、峰态:峰态系数=0峰度适中,峰态系数<0为扁平分布,峰态系数>0为尖峰分布
第六章
1、中心极限定理:设从均值为μ,方差为σ 2的一个任意总体中抽取容量为n 的样本,当n 充分大时,样本均值的抽样分布近似服从均值为μ、方差为σ2/n 的正态分布
2、样本均值的抽样分布:
3、均值的抽样标准误:所有可能的样本均值的标准差,测度所有样本均值的离散程度,小于总体标准差,计算公式为:
n X σσ=
4、比例:
5、样本比例的抽样分布:
6、比率的抽样标准误:
7、两个样本均值之差的抽样分布:
(1)两个总体都为正态分布,即),(~2
111σμN X ,),(~2
222σμN X ,
(2)两个样本均值之差21X X -的抽样分布服从正态分布, (3)数学期望为两个总体均值之差:2121)(μμ-=-X X E ,
(4)方差为各自的方差之和
22
2
1
212
2
1n n X X σσσ
+
=
-。
8、两个样本比例之差的抽样分布:
(1)两个总体都服从二项分布
(2)分别从两个总体中抽取容量为n1和n2的独立样本,当两个样本都为大样本时,两个样本比例之差的抽样分布可用正态分布来近似
(3)分布的数学期望为2121)(ππ-=-P P E (4)方差为各自的方差之和
2
221
112)
1()1(2
1
n n P P ππππσ-+
-=
-
第七章
1、评价估计量的标准
无偏性:估计量抽样分布的数学期望等于被估计的总体参数
有效性:对同一总体参数的两个无偏点估计量,有更小标准差的估计量更有效 一致性:随着样本容量的增大,估计量的值越来越接近被估计的总体参数 2、总体均值的区间估计
3、总体比率的区间估计
假定条件:总体服从二项分布、可以由正态分布来近似。总体比率π在1-α置信水平下的置信区间为
。
正态分布统计量 z:
4、两个总体均值之差的区间估计
其中:
2
)1
(
)1
(
2
1
2
2
2
2
1
1
2
-
+
-
+
-
=
n
n
s
n
s
n
s
p
,1
)
/
(
1
)
/
(
)
(
2
2
2
2
2
1
2
1
2
1
2
2
2
2
1
2
1
-
+
-
+
=
n
n
s
n
n
s
n
s
n
s
v
5、两个总体比率之差的区间估计
假定条件:两个总体服从二项分布、可以用正态分布来近似、两个样本是独立的
两个总体比率之差π1-π2在1-α置信水平下的置信区间为
6、估计总体均值时样本容量的确定
估计总体均值时样本容量n为,样本容量n与总体方差σ2、允许误差E、可靠性系数Z或t之间的关系为:与总体方差成正比、与允许误差成反比、与可靠性系数成正比
7、估计总体比率时样本容量的确定
根据比率区间估计公式可得样本容量n为。
第八章
1、两类错误:显著性水平为a
影响 b 错误的因素:
1、随着假设的总体参数与真实参数值差异的减小而增大
2、当显著性水平a减少时增大
3、当总体标准差 增大时增大
4、当样本容量n减少时增大。
2、假设检验:
3、单边检验
单边检验解题步骤: 1、计算样本均值,2、用样本均值和要比较的K 比较,若样本均值大于K,则右边检验。若样本均值小于k则左边检验3、画图4、计算统计量值5、查找临界值并和统计量值比较
其中:右边检验:,拒绝域在右边
左边检验:,拒绝域在左边
4、假设检验步骤与注意点
步骤:1、陈述原假设和备择假设2、从所研究的总体中抽出一个随机样本3、确定一个适当的检验统计量,并利用样本数据算出其具体数值4、确定一个适当的显著性水平,并计算出其临界值,指定拒绝域5、将统计量的值与临界值进行比较,作出决策
a)统计量的值落在拒绝域,拒绝H0,否则不拒绝H0
b)也可以直接利用P值作出决策
注意点:(1)当检验统计量落在拒绝域内,不代表我们证明原假设为错误的。只能说我们对于原假设所陈述的内容真实性有很大的怀疑—零假设不是不正确,就是极不可能发生,(2)当检验统计量落在无法拒绝域中,并不是证明原假设为真,仅是表示证据不足以推翻我们的假设。
5、P值
(1)在原假设为真的条件下,P值是抽样分布中大于或小于样本统计量的概率即:双侧检验为分布中两侧面积的总和、左侧检验为小于等于检验统计量部分的面积、右侧检验为大于等于检验统计量部分的面积
(2)反映实际观测到的数据与原假设H0之间不一致的程度
(3)被称为观察到的(或实测的)显著性水平
(4)决策规则:若p值< ,拒绝H0
(5)P<0.10代表有“一些证据”不利于原假设、P<0.05代表有“适度证据”不利于原假设、P<0.01代表有“很强证据”不利于原假设
6、一个参数总体均值的检验
7、一个参数总体比率的检验
8、两个总体均值之差的检验
其中:2)1()1(212222112-+-+-=
n n s n s n s p ,
()()
112222
2121
212
22
2121-+-???? ??+=n n s n n s n s n s v 9、两个总体比率之差的检验
(1)
(2)
其中:
2
2
21121211n n n p n p n n x x p ++=++=
第九章
一、单因素方差分析 1、误差平方和-ss
组内平方和SSE :()
∑∑==-=k i n j i ij i
x x SSE 11
2
,每个组各样本数据与其组平均值的离差平方和
组间平方和SSA :
()()
∑∑∑===-=-=k
i i i k
i n j i x x n x x SSA i
1
2
11
2
,组平均值
)
,,2,1(k i x i Λ=与总平均值x 离差平方和
总平方和SST :
()
∑∑==-=k i n j ij i
x x SST 11
2
全部观察值
ij
x 与总平均值x 的离差平方和
总离差平方和(SST )、误差项离差平方和(SSE )、水平项离差平方和 (SSA ) 之间的关系
()()()
∑∑∑∑∑=====-+-=-k i n j ij k i i i k i n j ij
i
i
x x x x n x x
11
2
1
2
11
2
,即SST = SSA + SSE
三个平方和的作用:1、SST 反映全部数据总的误差程度;SSE 反映随机误差的大小;SSA 反映随机误差和系统误差的大小2、如果原假设成立,则表明没有系统误差,组间平方和SSA 除以自由度后的均方与组内平方和SSE 除以自由度后的均方差异就不会太大;如果组间均方显著地大于组内均方,说明各水平(总体)之间的差异不仅有随机误差,还有系统误差3、判断因素的水平是否对其观察值有影响,实际上就是比较组间方差与组内方差之间差异的大小 2、平方和除以相应的自由度----均方(方差)—MS
(1)各误差平方和的大小与观察值的多少有关,为消除观察值多少对误差平方和大小的影响,需要将其平均,这就是均方,也称为方差,计算方法是用误差平方和除以相应的自由度。
(2)三个平方和对应的自由度分别是:SST 的自由度为n-1,其中n 为全部观察值的个数;SSA 的自由度为k-1,其中k 为因素水平(总体)的个数;SSE 的自由度为n-k 。
组间方差:组间误差经过平均后的数值(MSA )
1-=
k SSA MSA
组内方差:组内误差经过平均后的数值(MSE )
k n SSE
MSE -=
3、计算检验统计量 F
(1)将MSA 和MSE 进行对比,即得到所需要的检验统计量F (2)当H0为真时,二者的比值服从分子自由度为k-1、分母自由度为 n-k 的 F 分布,即
),1(~k n k F MSE MSA
F --=
(3)根据给定的显著性水平α,在F 分布表中查找与第一自由度df 1=k -1、第二自由度df 2=n -k 相应的临界值 F α 。若F>F α ,则拒绝原假设H 0 ,表明均值之间的差异是显著的,所检验的因素对观察值有显著影响
4、关系强度的测定 (1)变量间关系的强度用自变量平方和(SSA)及残差平方和(SSE)占总平方和(SST)的比例
大小来反映;自变量平方和占总平方和的比例记为R2 ,即
)()
(2总平方和组间平方和SST SSA R =
5、方差分析中的多重比较
(1)提出假设
H 0: m i = m j (第i 个总体的均值等于第j 个总体的均值) H 1: m i ≠ m j (第i 个总体的均值不等于第j 个总体的均值)
(2)计算检验的统计量:
j
i x x -
(3)计算LSD :?
?
?? ??+=j i
n n MSE t LSD 11α
(4)决策:若
LSD x x j i >-,拒绝H 0,若
LSD
x x j i <-,不拒绝H 0
二、双因素方差分析 综述: 分析两个因素(行因素和列因素)对试验结果的影响,如果两个因素对试验结果的影响是相互独立的,分别判断行因素和列因素对试验数据的影响,这时的双因素方差分析称为无交互作用的双因素方差分析或无重复双因素方差分析,如果除了行因素和列因素对试验数据的单独影响外,两个因素的搭配还会对结果产生一种新的影响,这时的双因素方差分析称为有交互作用的双因素方差分析或可重复双因素方差分析。 基本假定:(1)每个总体服从正态分布(2)各个总体方差相同(3)观察值是独立的 6、无交互作用的双因素方差分析
(1)数据结构:
(2)计算平方和(ss)
(3)总离差平方和(SST)、水平项离差平方和(SSR和SSC)、误差项离差平方和(SSE)之间的关系:SST = SSR +SSC+SSE
即:
(4)均方的计算(ms)
(总离差平方和SST的自由度为kr-1)
(5)双因素方差分析
列平方和与行平方和加在一起则度量了两个自变量对因变量的联合效应,联合效应与
总平方和的比值定义为R2:
SST
SSC
SSR
R
+
=
=
总效应
联合效应
2
7、有交互作用的双因素方差分析(估计不考,根本不懂)
8、试验设计:
第十一章
1、相关分析与回归分析的联系区别: 联系:共同的研究对象:都是对变量间相关关系的分析。只有当变量间存在相关关系时,用回归分析去寻求相关的具体数学形式才有实际意义。相关分析只表明变量间相关关系的性质和程度,要确定变量间相关的具体数学形式依赖于回归分析。 区别:(1)从研究目的看:相关分析主要通过相应指标来研究变量间相互联系的方向和密切程度;而回归分析要在变量之间建立其联系的具体数学形式 ,并根据自变量的取值去估计因变量的取值.(2)从对变量的处理来看:相关分析中的变量不需区分自变量与因变量,它们是对等的关系;而回归分析中要区分自变量与因变量, 自变量与因变量之间要具有一定的因果关系,且作为自变量的必须是可控制变量,作为因变量的必须是随机变量。
2、相关关系的测度 (1)总体相关系数:
对于所研究的总体,表示两个相互联系变量相关程度的总体相关系数为:
。总体相关系数反映总体两个变量X 和Y 的线性相关程度。
特点:对于特定的总体来说,X 与Y 数值既定,总体相关系数是客观存在特定数值。 (2)样本相关系数:
通过X 和Y 样本观测值估计样本相关系数变量,X 和Y 的样本相关系数通常用XY r 表示.
(,)
()()Cov X Y Var X Var Y ρ=
()()
2
22
2∑∑∑∑∑∑∑-?--=
y y n x x
n y
x xy n r
特点:样本相关系数是根据从总体中抽取的随机样本的观测值计算出来的,是对总体相关系数的估计,它是个随机变量。 3、相关系数的显著性检验
(1)检验两个变量之间是否存在线性相关关系 (2)等价于对回归系数b 1的检验,采用t 检验 检验的步骤为:
1、提出假设:H 0:ρ = 0 ;H 1: ρ ≠ 0
2、计算检验的统计量:
)
2(~122
---=
n t r
n r t
3、确定显著性水平α,若|t |>t α/2,拒绝H 0 若|t | 4、一元线性回归模型: 概念:当只涉及一个自变量时称为一元回归,若因变量y 与自变量x 之间为线性关系时称为一元线性回归,对于具有线性关系的两个变量,可以用一条线性方程来表示它们之间的关系,描述因变量y 如何依赖于自变量x 和误差项μ的方程称为回归模型。 模型:(1)对于只涉及一个自变量的简单线性回归模型可表示为y = b 0 + b 1 x + μ(其中,误差项μ是随机变量,反映了除 x 和 y 之间的线性关系之外的随机因素对 y 的影响,是不能由 x 和 y 之间的线性关系所解释的变异性) (2) 描述 y 的平均值或期望值如何依赖于x 的方程称为回归方程,E( y ) = β0+ β1 x (β0是回归直线在 y 轴上的截距,β1是直线的斜率,称为回归系数) (3)估计回归方程:总体回归参数 β和1β是未知的,用样本数据去估计,用样本 统计量0?β和1?β代替回归方程中的未知参数0β和1β,就得到估计回归方程 x y 10???ββ+=。 5、参数 β0 和 β1 的最小二乘估计 最小二乘法:使因变量的观察值与估计值之间的离差平方和达到最小来求得 0?β和1?β的 方法。即最小==-=∑∑==n i i n i i e y y Q 1 21 21 0)?()?,?(ββ,用最小二乘法拟合的直线来代表x 与y 之间 的关系与实际数据的误差比其他任何直线都小。 根据最小二乘法的要求,可得求解 0?β和1?β的标准方程如下: ____ ()()XY X X Y Y r --= 6、离差平方和的分解:SST = SSR + SSE (1)总平方和(SST):反映因变量的 n 个观察值与其均值的总离差。 (2)回归平方和(SSR):反映自变量 x 的变化对因变量 y 取值变化的影响,或者说,是由于 x 与 y 之间的线性关系引起的 y 的取值变化,也称为可解释的平方和。 (3)残差平方和(SSE):反映除 x 以外的其他因素对 y 取值的影响,也称为不可解释的平方和或剩余平方和. 7、样本判决系数(判定系数 r 2) 回归平方和占总离差平方和的比例: ()()()()∑∑∑∑====--- =--== n i i n i i n i i n i i y y y y y y y y SST SSR r 1212 1 2 12 2??1? 判定系数等于相关系数的平方,即r2=(r)2 8、估计标准误差Se : 实际观察值与回归估计值离差平方和的均方根,反映实际观察值在回归直线周围的分散状况,从另一个角度说明了回归直线的拟合程度。Se 越小越好。 9、 回归系数的显著性检验: (1)提出假设 H 0: b 1 = 0 (没有线性关系) ;H 1: b 1 ≠ 0 (有线性关系) (2)计算检验的统计量: ) 2(~?1 ? 1-= n t S t ββ (3)确定显著性水平α,并进行决策? t ?>t α/2,拒绝H 0;? t ? 10、显著性检验图表公式: (1)各项标准误差 ; ∑=-+=n i i y x x x n S S 1 2 2 ?) ()(10 β; ∑=-= n i i y x x S S 1 2 ?) (1 β (2) ()t 检验:数值 ? 0??βββS t = ;1 1 ? 1??βββS t = 。 11、区间估计 (1)置信区间估计 利用估计的回归方程,对于自变量 x 的一个给定值 x 0 ,求出因变量 y 的平均值的估计区间 ,这一估计区间称为置信区间(confidence interval) 式中:s e 为估计标准误差 (2) 预测区间估计 利用估计的回归方程,对于自变量 x 的一个给定值 x 0 ,求出因变量 y 的一个个别值的估计区间,这一区间称为预测区间(prediction interval) ()() ∑=--++-±n i i e x x x x n S n t y 1 2 20201 1)2(?α式中:s e 为估计标准误差 第十三章 1、时间序列 定义:同一现象在不同时间上的相继观察值排列而成数列,形式上由现象所属时间和现象在不同时间上观察值两部分组成,排列时间可以是年份、季度、月份或其他任何时间形式。 成分:1)趋势:持续向上或持续下降的状态或规律2)季节性:也称季节变动,时间序列在一年内重复出现的周期性波动3)周期性:也称循环波动,围绕长期趋势的一种波浪形或振荡式变动4)随机性:也称不规则波动,除去趋势、周期性和季节性之后的偶然性波动。 2、增长量,增长速度 ??? ??? ? ----------11 22311200100003002001,.........,,,........,,n n n n a a a a a a a a a a a a a a a a a a a a a a a a 环比增长速度:定基增长速度: 100%1前期水平 绝对值增长= 3、线性趋势预测 t b b Y t 10?+=,?????+=+=∑∑∑∑∑2 1010t b t b tY t b nb Y 得:()?????-=--=∑∑∑∑∑t b Y b t t n Y t tY n b 10221 4、季节比率 1. 计算各年同期(月或季)的平均数 2.计算全部数据的总平均数 3.计算季节比率,Si=月度平均除总平均 季节比率特性:其总和等于季节周期 L (=12或=4)
相关主题
文本预览