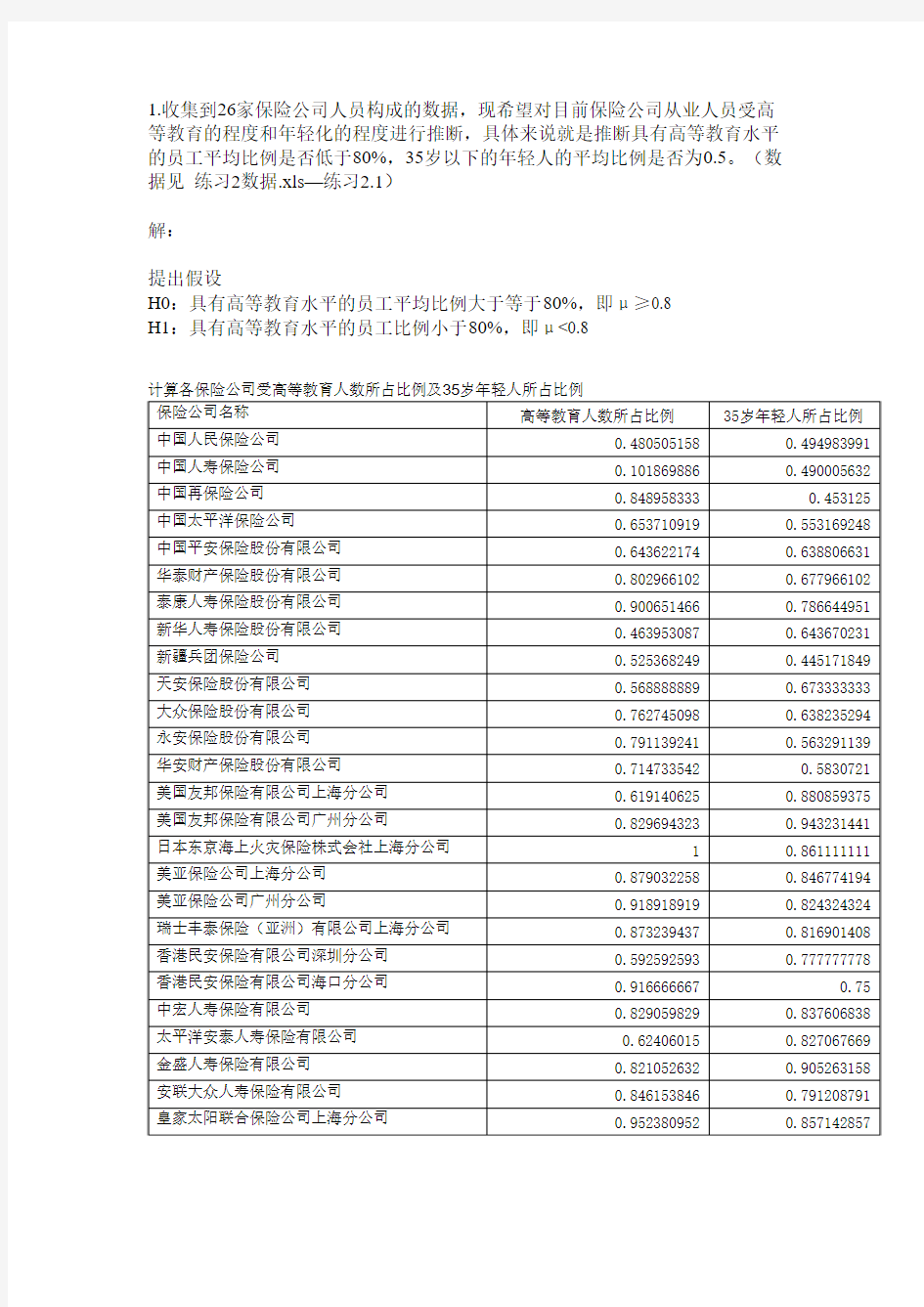
1.收集到26家保险公司人员构成的数据,现希望对目前保险公司从业人员受高等教育的程度和年轻化的程度进行推断,具体来说就是推断具有高等教育水平的员工平均比例是否低于80%,35岁以下的年轻人的平均比例是否为0.5。(数据见练习2数据.xls—练习
2.1)
解:
提出假设
H0:具有高等教育水平的员工平均比例大于等于80%,即μ≥0.8
H1:具有高等教育水平的员工比例小于80%,即μ<0.8
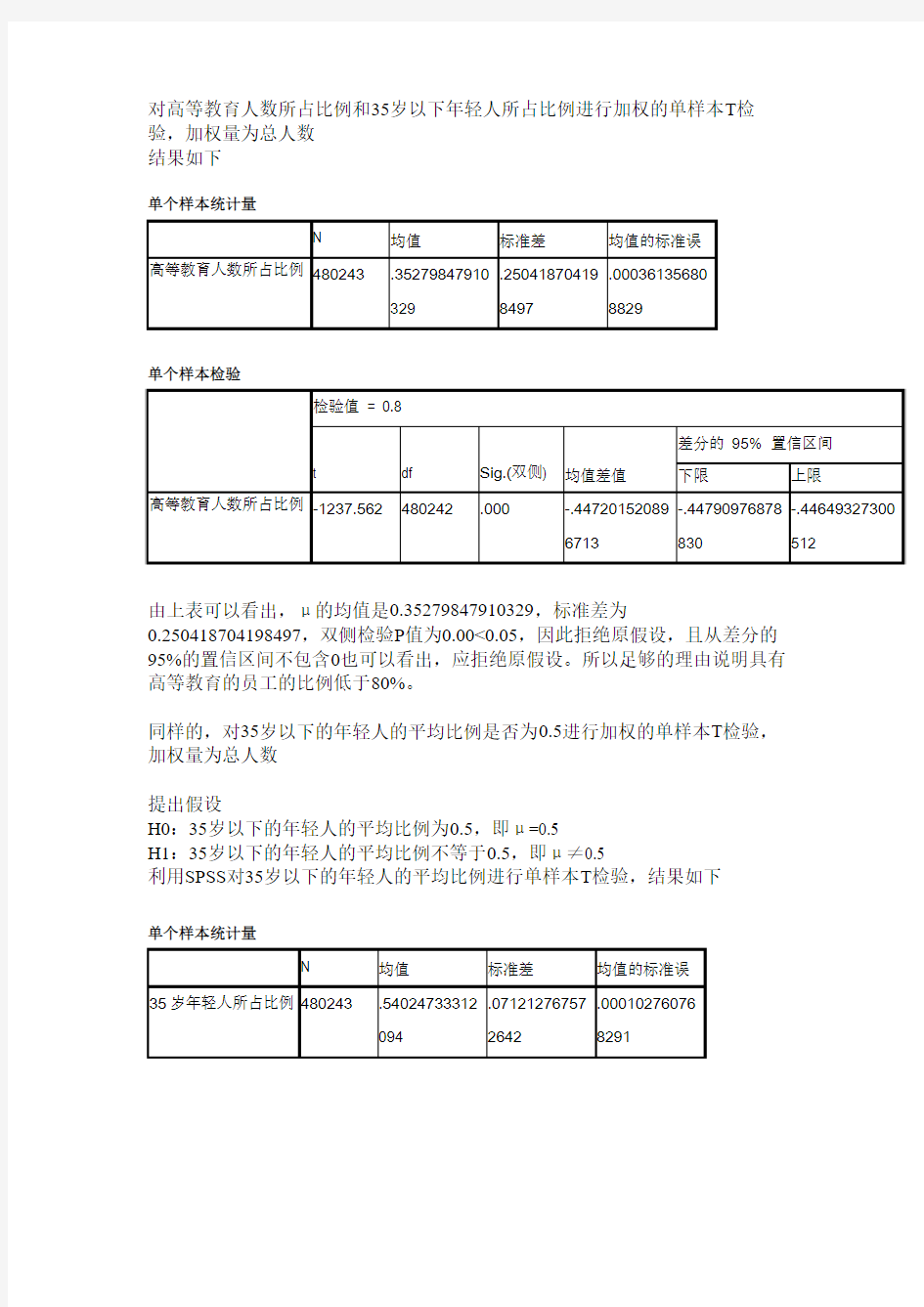
对高等教育人数所占比例和35岁以下年轻人所占比例进行加权的单样本T 检验,加权量为总人数 结果如下
单个样本统计量
N
均值
标准差
均值的标准误
高等教育人数所占比例 480243
.35279847910329
.250418704198497
.000361356808829
由上表可以看出,μ的均值是0.35279847910329,标准差为
0.250418704198497,双侧检验P 值为0.00<0.05,因此拒绝原假设,且从差分的95%的置信区间不包含0也可以看出,应拒绝原假设。所以足够的理由说明具有高等教育的员工的比例低于80%。
同样的,对35岁以下的年轻人的平均比例是否为0.5进行加权的单样本T 检验,加权量为总人数
提出假设
H0:35岁以下的年轻人的平均比例为0.5,即μ=0.5
H1:35岁以下的年轻人的平均比例不等于0.5,即μ≠0.5
利用SPSS 对35岁以下的年轻人的平均比例进行单样本T 检验,结果如下
由上表可以看出,μ的均值为0.54024733312094,样本标准差为
0.071212767572642,双侧检验的P值为0.00<0.05,且从差分的95%的置信区间不包含0也可看出,拒绝原假设H0。所以,有足够的证据表明35岁以下的年轻人的平均比例不等于0.5.
2. 练习1中保险公司的类别分为:1. 全国性公司;2. 区域性公司;
3. 外资和中外合资公司。试分析公司类别1与3的人员构成中,具有高等教育水平的员工比例的均值是否存在显著性的差异。(数据见练习2数据.xls—练习2.1)
解
提出假设
H0:公司类别1与3的人员构成中,具有高等教育水平的员工比例的均值相等,即μ1=μ2
H1:公司类别1与3的人员构成中,具有高等教育水平的员工比例的均值不相等,即μ1≠μ2
利用SPSS对公司类别1与3的人员构成中,具有高等教育水平的员工比例的均值进行加权的独立样本T检验,加权量为总人数,结果如下
组统计量
公司类别N 均值标准差均值的标准误
高等教育人数所占比例 1 476143 .349804575516
18 .249145201038
893
.000361063696
750
3 3039 .755182625863
77 .0898********
792
.001628968358
469
从组统计量表中可以看出,在全国性公司(公司类别1)中,高等教育人数所占比例的均值为0.34980457551618,样本标准差为0.249145201038893.在外资和中外合资公司(公司类别3)中,高等教育人数所占比例的均值为
0.75518262586377,样本标准差为0.001628968358469.可以看出两类不同的公司员工受高等教育人数所占比例的均值存在较大差异。
从独立样本检验表中可以看出F检验的P值为26710.867>0.05,认为总体的方差相等,接下来的t检验使用方差相等的检验结果。由于均值的t检验的P值为
0.000<0.05,且差分的95% 置信区间不包含0,因此拒绝H0,即有做够的证据表明全国性保险公司和外资与中外合资保险公司中,员工受高等教育比例的均值存在显著性差异。
3. 欲研究不同收入群体对某种特定商品是否有相同的购买习惯,市场研究人员调查了4个不同收入组的消费者共527人,购买习惯分别为:经常购买,不购买,有时购买。
要求:(1)提出假设;(2)计算x2值;(3)以99%的显著性水平进行检验。(数据见练习2数据.xls—练习2.3)
解
(1)提出假设
H0:不同收入人群对某种商品具有相同的购买习惯
H1:不同收入人群对某种商品具有不同的购买习惯
(2)
求得χ2=17.62584
(3)
α=0.01,自由度df=(3-1)*(4-1)=6
2=16.8
χ2=17.62584>χ0.01
因此拒绝H0,即有足够的证据表明,不同收入人群对某种商品具有不同的购买习惯。
4. 由我国某年沿海和非沿海省市自治区的人均国内生产总值(GDP)的抽样数据,采用各种非参数检验方法进行检验,判断它们的分布是否存在显著性差异,并进行评价。(数据见练习2数据.xls—练习2.4)
解:采用最小显著差数法对数据进行检验
2代表非沿海地区。
ANOVA
GDP
平方和df 均方 F 显著性
组间 2.213E8 1 2.213E8 21.012 .000
组内 2.949E8 28 10532396.122
总数 5.162E8 29
从描述表中可以看出,组1(沿海地区)的人均GDP的均值是9552.58,而组2(非沿海地区)的人均GDP的均值是4008.50,存在较大差距。
由ANOVA表可以看出,组间P值小于0.05,说明在5%的显著性水平下,沿海地区和非沿海地区的GDP有显著性的差异。这反映了我国区域发展不平衡的现状,东部和中西部差异巨大。
5.某企业在制定某商品的广告策略时,收集了该商品在不同地区采用不同广告形式促销后的销售额数据,希望对广告形式和地区是否对商品销售额产生影响进行分析,
以商品销售额为因变量,广告形式和地区为自变量,通过单因素方差分析方法分别对广告形式、地区对销售额的影响进行分析;
试进一步分析,究竟哪种广告形式的作用较明显,哪种不明显,以及销售额和地区之间的关系等。
试分析广告形式、地区以及两者的交互作用是否对商品销售额产生影响。(数据见练习2数据.xls—练习2.5,其中广告形式为:1. 报纸; 2. 广播; 3. 宣传品;4. 体验)
解(1)先分析广告形式对销售额的影响
ANOVA 销售额
平方和df 均方 F 显著性
组间5866.083 3 1955.3
61 13.
483
.000
组内20303.222 140 145.02
3
总数26169.306 143
从上表可以看出,组间显著性P值<0.05,说明不同广告形式对销售额有显著性差异
从上图可以看出,总体来说,广告形式1(报纸)对销售额增加最多,广告形式3(宣传品)对销售额的增加最少。
再分析地区差异对销售额的影响
在SPSS中分析,结果如下:
描述销售额
N
均值标准差标准误均值的95% 置信区间
极小值极大值下限上限
1 8 60.00 10.981 3.88
2 50.82 69.18 41 75
2 8 64.38 13.501 4.77
3 53.09 75.66 4
4 82
3 8 81.00 10.981 3.882 71.82 90.18 61 100
4 8 79.2
5 7.555 2.671 72.93 85.57 6
6 90
5 8 72.63 8.733 3.088 65.32 79.93 57 87
6 8 66.38 8.634 3.053 59.16 73.59 52 77
7 8 58.75 17.294 6.114 44.29 73.21 33 76
8 8 73.38 9.102 3.218 65.77 80.98 61 86
9 8 57.63 11.186 3.955 48.27 66.98 40 73
10 8 77.75 14.509 5.130 65.62 89.88 61 100
11 8 52.25 10.498 3.712 43.47 61.03 40 70
12 8 69.75 10.025 3.544 61.37 78.13 51 86
13 8 67.00 15.892 5.619 53.71 80.29 42 87
14 8 64.13 7.680 2.715 57.70 70.55 52 77
15 8 67.00 11.250 3.978 57.59 76.41 50 83
16 8 69.25 14.310 5.059 57.29 81.21 44 81
17 8 53.88 11.740 4.151 44.06 63.69 37 73
18 8 68.38 8.634 3.053 61.16 75.59 58 83 总数
144 66.82 13.528 1.127 64.59 69.05 33 100
从上表可以看出,组间显著性P值<0.05,说明地区差异对销售额具有显著性差异
从上图可以看出,地区差异对销售额的影响显著,地区3的销售额均值最大,地区11的销售额均值最小。
(b)对广告形式进行多重比较,结果如下
第1种广告形式和第2种广告形式的销量没有显著差异
第1种广告形式和第3种广告形式的销量有显著差异
第1种广告形式和第4种广告形式的销量有显著差异
第2种广告形式和第3种广告形式的销量有显著差异
第2种广告形式和第4种广告形式的销量没有显著差异
第3种广告形式和第4种广告形式的销量有显著差异
可以得到,广告形式3对销售量的影响较显著,广告形式2对销售量的影响较不显著。
10 -23.875* 5.791 .000 -35.34 -12.41
11 1.625 5.791 .779 -9.84 13.09
12 -15.875* 5.791 .007 -27.34 -4.41
13 -13.125* 5.791 .025 -24.59 -1.66
14 -10.250 5.791 .079 -21.71 1.21
15 -13.125* 5.791 .025 -24.59 -1.66
16 -15.375* 5.791 .009 -26.84 -3.91
18 -14.500* 5.791 .014 -25.96 -3.04 18 1 8.375 5.791 .151 -3.09 19.84
2 4.000 5.791 .491 -7.46 15.46
3 -12.625* 5.791 .031 -24.09 -1.16
4 -10.87
5 5.791 .063 -22.34 .59
5 -4.250 5.791 .464 -15.71 7.21
6 2.000 5.791 .730 -9.46 13.46
7 9.625 5.791 .099 -1.84 21.09
8 -5.000 5.791 .390 -16.46 6.46
9 10.750 5.791 .066 -.71 22.21
10 -9.375 5.791 .108 -20.84 2.09
11 16.125* 5.791 .006 4.66 27.59
12 -1.375 5.791 .813 -12.84 10.09
13 1.375 5.791 .813 -10.09 12.84
14 4.250 5.791 .464 -7.21 15.71
15 1.375 5.791 .813 -10.09 12.84
16 -.875 5.791 .880 -12.34 10.59
17 14.500* 5.791 .014 3.04 25.96 *. 均值差的显著性水平为 0.05。
数理统计 一、填空题 1、设n X X X ,,21为母体X 的一个子样,如果),,(21n X X X g , 则称),,(21n X X X g 为统计量。不含任何未知参数 2、设母体 ),,(~2 N X 已知,则在求均值 的区间估计时,使用的随机变量为 n X 3、设母体X 服从修正方差为1的正态分布,根据来自母体的容量为100的子样,测得子样均值为5,则X 的数学期望的置信水平为95%的置信区间为 。 025.010 1 5u 4、假设检验的统计思想是 。 小概率事件在一次试验中不会发生 5、某产品以往废品率不高于5%,今抽取一个子样检验这批产品废品率是否高于5%, 此问题的原假设为 。 0H :05.0 p 6、某地区的年降雨量),(~2 N X ,现对其年降雨量连续进行5次观察,得数据为: (单位:mm) 587 672 701 640 650 ,则2 的矩估计值为 。 1430.8 7、设两个相互独立的子样2121,,,X X X 与51,,Y Y 分别取自正态母体)2,1(2 N 与 )1,2(N , 2 *2 2*1,S S 分别是两个子样的方差,令2*2222*121)(,S b a aS ,已知)4(~),20(~22 2221 ,则__________, b a 。 用 )1(~)1(22 2 * n S n ,1,5 b a 8、假设随机变量)(~n t X ,则 2 1 X 服从分布 。)1,(n F 9、假设随机变量),10(~t X 已知05.0)(2 X P ,则____ 。 用),1(~2 n F X 得),1(95.0n F
应用数理统计大作业1——逐步回归法分析 终
应用数理统计多元线性回归分析 (第一次作业) 学院:机械工程及自动化学院 姓名: 学号: 2014年12月
逐步回归法在AMHS物流仿真结果中的应 用 摘要:本文针对自动化物料搬运系统 (Automatic Material Handling System,AMHS)的仿真结果,根据逐步回归法,使用软件IBM SPSS Statistics 20,对仿真数据进行分析处理,得到多元线性回归方程,建立了工件年产量箱数与EMS 数量、周转箱交换周期以及AGC物料交换服务水平之间的数学模型,并对影响 年产量箱数的显著性因素进行了分析,介绍了基本假设检验的情况。 关键词:逐步回归;残差;SPSS;AMHS;物流仿真
目录 1、引言 (1) 2、逐步回归法原理 (4) 3、模型建立 (6) 3.1确定自变量和因变量 (6) 3.2分析数据准备 (6) 3.3逐步回归分析 (7) 4、结果输出及分析 (9) 4.1输入/移去的变量 (9) 4.2模型汇总 (10) 4.3方差分析 (10) 4.4回归系数 (11) 4.5已排除的变量 (12) 4.6残差统计量 (13) 4.7残差分布直方图和观测量累计概率P-P图 (14) 5、异常情况说明 (15) 5.1异方差检验 (15) 5.2残差的独立性检验 (17) 5.3多重共线性检验 (17) 6、结论 (18) 参考文献 (20)
1、引言 回归被用于研究可以测量的变量之间的关系,线性回归则被用于研究一类特殊的关系,即可用直线或多维的直线描述的关系。这一技术被用于几乎所有的研究领域,包括社会科学、物理、生物、科技、经济和人文科学。逐步回归是在剔除自变量间相互作用、相互影响的前提下,计算各个自变量x与因变量y之间的相关性,并在此基础上建立对因变量y有最大影响的变量子集的回归方程。 SPSS(Statistical Package for the Social Science社会科学统计软件包)是世界著名的统计软件之一,目前SPSS公司已将它的英文名称更改为Statistical Product and Service Solution,意为“统计产品与服务解决方案”。SPSS软件不仅具有包括数据管理、统计分析、图表分析、输出管理等在内的基本统计功能,而且用它处理正交试验设计中的数据程序简单,分析结果明了。基于以上优点,SPSS已经广泛应用于自然科学、社会科学中,其中涉及的领域包括工程技术、应用数学、经济学、商业、金融等等。 本文研究内容主要来源于“庆安集团基于物联网技术的航空柔性精益制造系统”,在庆安集团新建的320厂房建立自动化物料搬运系统(AMHS),使用生产仿真软件EM-Plant对该系统建模并仿真,设计实验因子及各水平如表1-1,则共有3*4*6=72组实验结果,如表所示。为方便描述,将各因子定义为:X1表示AGC物料交换服务水平,X2表示周转箱交换周期,X3表示EMS数量,Y表示因变量年产量箱数。本文目的就是建立年产量箱数与AGC物料交换服务水平、周转箱交换周期和EMS数量之间的关系。
《应用数理统计》期末考试试题 (2011-11-26上午8:30—10:30) 学院: 学号: 姓名: 注意:所有题目答案均做在答题纸上,该试卷最后随答题纸一同上交,否则成绩无效。 1、(20分)设总体X 服从正态分布(0,1)N ,12,X X 为来自总体X 的简单样本,设112212; Y X X Y X X =+=-。 (1)求二维随机变量12(,)Y Y 的联合密度()21,y y f ; (2)分别求12,Y Y 的边缘密度函数()()2121,y f y f Y Y ; (3)12,Y Y 是否独立?说明根据。 (4)叙述2χ分布的构造性定义。能否通过取适当的常数c ,使得2212()c Y Y +服从2χ分布?若可以,求出c ,并写出所服从的2χ分布的自由度。 2、(20分)设12,,,n X X X 是来自正态总体() 2~0,X N σ的简单样本,记 22221 21111??();1n n i i i i X X X n n σσ===-=-∑∑,其中11n i i X X n ==∑, (1)证明:21?σ是2 σ的渐近有效估计量; (2)证明:22?σ是2 σ的有效估计量; (3)试分别以21?σ,22?σ为基础构造2 σ的两种1α-置信区间。你认为你得到的哪个估计区间会更好一些?为什么? 3、(20分)(1)简述假设检验的一般步骤; (2)某厂生产一批产品,质量检查规定:若次品率0.05p ≤,则这批产品可以出厂,否则不能出厂。现从这批产品中抽查400件产品,发现有30件是次品,问:在显著性水平0.05α=下,这批产品能否出厂?若取显著性水平0.02α=,会得出什么结论?α是越小越好吗?对你的答案说明理由。 要求:将此问题转化成统计问题,利用所学知识给出合理的、令人信服的推断,推断过程的每一步要给出理由或公式。分位点定义如下: 若随机变量W ,对任意的()1,0∈α,有()α=≤x W P ,称x 为W 的α分位点,记作αx 。
第一部分统计基础与概率计算(共10题,10分/题) 1.某人在每天上班途中要经过3个设有红绿灯的十字路口。设每个路口遇到红 灯的事件就是相互独立的,且红灯持续24秒而绿灯持续36秒。试求她途中遇到红灯的次数的概率分布及其期望值与方差、标准差。 解:读题可知每个路口遇到红灯的概率就是P=24/(24+36)=0、4 假设遇到红灯的次数为X,则,X~B(3,0、4),概率分布如下 0次遇到红灯的概率P0=(1-0、4)3=0、216 1次遇到红灯的概念P1=(1-0、4)2*0、4=0、432 2次遇到红灯的概念P2=(1-0、4)*0、42=0、288 3次遇到红灯的概念P3=0、43=0、064 期望:E(x)=nP=0、4*3=1、2 方差:D(X)=δ2=nPq=0、4*3*(1-0、4)=0、72 标准差: 2、一家人寿保险公司某险种的投保人数有20000人,据测算被保险人一年中的死亡率为万分之5。保险费每人50元。若一年中死亡,则保险公司赔付保险金额50000元。试求未来一年该保险公司将在该项保险中(这里不考虑保险公司的其它费用): (1)至少获利50万元的概率; (2)亏本的概率; (3)支付保险金额的均值与标准差。 解:设被保险人死亡数为X,X~B(20000,0、0005) 2.总收入为2万×50=100万,要获利至少50万,则赔付的保险金额应该不超过50万,也就就 是被保险的人当中死亡人数不能超过10人,精确点就就是用二项分布来做,但就是由于20000这个数比较大,就可以用正态近似来做,就就是认为死亡人数服从与原二项分布的均值方差相同的正态分布,结用正态函数表示。概率为P(X≤10)=0、58304
应用数理统计多元线性回归分析 (第一次作业) 学院:机械工程及自动化学院 姓名: 学号: 2014年12月
逐步回归法在AMHS物流仿真结果中的应 用 摘要:本文针对自动化物料搬运系统(Automatic Material Handling System,AMHS)的仿真结果,根据逐步回归法,使用软件IBM SPSS Statistics 20,对仿真数据进行分析处理,得到多元线性回归方程,建立了工件年产量箱数与EMS数量、周转箱交换周期以及AGC物料交换服务水平之间的数学模型,并对影响年产量箱数的显著性因素进行了分析,介绍了基本假设检验的情况。 关键词:逐步回归;残差;SPSS;AMHS;物流仿真
目录 1、引言 (1) 2、逐步回归法原理 (4) 3、模型建立 (5) 3.1确定自变量和因变量 (5) 3.2分析数据准备 (6) 3.3逐步回归分析 (7) 4、结果输出及分析 (8) 4.1输入/移去的变量 (8) 4.2模型汇总 (9) 4.3方差分析 (9) 4.4回归系数 (10) 4.5已排除的变量 (11) 4.6残差统计量 (11) 4.7残差分布直方图和观测量累计概率P-P图 (12) 5、异常情况说明 (13) 5.1异方差检验 (13) 5.2残差的独立性检验 (14) 5.3多重共线性检验 (15) 6、结论 (15) 参考文献 (17)
1、引言 回归被用于研究可以测量的变量之间的关系,线性回归则被用于研究一类特殊的关系,即可用直线或多维的直线描述的关系。这一技术被用于几乎所有的研究领域,包括社会科学、物理、生物、科技、经济和人文科学。逐步回归是在剔除自变量间相互作用、相互影响的前提下,计算各个自变量x与因变量y之间的相关性,并在此基础上建立对因变量y有最大影响的变量子集的回归方程。 SPSS(Statistical Package for the Social Science社会科学统计软件包)是世界著名的统计软件之一,目前SPSS公司已将它的英文名称更改为Statistical Product and Service Solution,意为“统计产品与服务解决方案”。SPSS软件不仅具有包括数据管理、统计分析、图表分析、输出管理等在内的基本统计功能,而且用它处理正交试验设计中的数据程序简单,分析结果明了。基于以上优点,SPSS已经广泛应用于自然科学、社会科学中,其中涉及的领域包括工程技术、应用数学、经济学、商业、金融等等。 本文研究内容主要来源于“庆安集团基于物联网技术的航空柔性精益制造系统”,在庆安集团新建的320厂房建立自动化物料搬运系统(AMHS),使用生产仿真软件EM-Plant对该系统建模并仿真,设计实验因子及各水平如表1-1,则共有3*4*6=72组实验结果,如表所示。为方便描述,将各因子定义为:X1表示AGC物料交换服务水平,X2表示周转箱交换周期,X3表示EMS数量,Y表示因变量年产量箱数。本文目的就是建立年产量箱数与AGC物料交换服务水平、周转箱交换周期和EMS数量之间的关系。 表1-1三因子多水平实验方案
一 填空题 1 设 6 21,,,X X X 是总体 ) 1,0(~N X 的一个样本, 26542321)()(X X X X X X Y +++++=。当常数C = 1/3 时,CY 服从2χ分布。 2 设统计量)(~n t X ,则~2X F(1,n) , ~1 2 X F(n,1) 。 3 设n X X X ,,,21 是总体),(~2 σu N X 的一个样本,当常数C = 1/2(n-1) 时, ∑-=+-=1 1 212 )(n i i i X X C S 为2σ的无偏估计。 4 设)),0(~(2σεε βαN x y ++=,),,2,1)(,(n i y x i i =为观测数据。对于固定的0x , 则0x βα+~ () 2 0201,x x N x n Lxx αβσ?? ? ?- ???++ ??? ?????? ? 。 5.设总体X 服从参数为λ的泊松分布,,2,2,, 为样本,则λ的矩估计值为?λ = 。 6.设总体2 12~(,),,,...,n X N X X X μσ为样本,μ、σ2 未知,则σ2的置信度为1-α的 置信区间为 ()()()()22 2212211,11n S n S n n ααχχ-??--????--???? 。 7.设X 服从二维正态),(2∑μN 分布,其中??? ? ??=∑??? ? ??=8221, 10μ 令Y =X Y Y ???? ??=???? ??202121,则Y 的分布为 ()12,02T N A A A A μ??= ??? ∑ 。 8.某试验的极差分析结果如下表(设指标越大越好): 表2 极差分析数据表
NBA球员科比单场总得分与上场时间的线性回归分析 摘要 篮球运动中,球员的上场时间与球员的场上得分的数学关系将影响到教练对每位球员上场时间的把握,若能得到某位球员的上场时间与场上得分的数据关系,将能更好的把握该名球员的场上时间分配。本次作业将针对现役NBA球员中影响力最大的球员科比布莱恩特进行研究,对其2012-2013年赛季常规赛的每场得分与出场时间进行线性回归,得到得分与出场时间的一元线性回归直线,并对显著性进行评估和进行区间预测。 正文 一、问题描述 随着2002年姚明加入NBA,越来越多的中国人开始关注篮球这一项体育运动,并使得篮球运动大范围的普及开来,尤其是青年学生。本着学以致用的原则,希望将所学理论知识与现实生活与个人兴趣相结合,若能通过建立相应的数理统计模型来做相应的分析,并且从另外一个角度解析篮球,并用以指导篮球这一项运动的更好发展,这也将是一项不同寻常的探索。篮球运动中,得分是取胜的决定因素,若要赢得比赛,必须将得分超出对手,而影响一位球员的得分的因素是多样的,例如:情绪,状态,体力,伤病,上场时间,防守队员等诸多因素,而上场时间作为最直接最关键的因素,其对球员总得分的影响方式有着重要的研究意义。 倘若知道了其分布规律,则可从数量上掌握得分与上场时间复杂关系的大趋势,就可以利用这种趋势研究球员效率最优化与上场时间的控制问题。 因此,本文针对湖人当家球星科比布莱恩特在2012-2013年赛季常规赛的每场得分与上场时间进行线性回归分析,并对显著性进行评估,以巩固所学知识,并发现自己的不足。 二、数据描述 抽出科比布莱恩特2012-2013年常规赛所有82场的数据记录(原始数据见附录),剔除掉其中没有上场的部分数据,得到有参考实用价值的数据如表2.1所示:
数理统计学作业 专业:飞行器设计 姓名:刘炜华 学号: 20130302002 2013年9月
1.数据的采集及说明 1.1数据的搜集方法及说明 当复合材料结构开始大量应用之后,在实际使用中可以积累大量的故障统计数据,航空公司在对故障数据进行收集和统计之后,可以对故障数据作故障率直方图和故障频率分布图来进行故障频率信息的统计和分析。 表 1是一架飞机在某段时间内故障间隔飞行小时,下面以该数据集为基础简单估计该架飞机在该时间段内的故障率曲线分布。 表1某飞机一段时间内故障间隔飞行小时 1.2.数据整理 1.表中共有 100 个维修数据,找出其中的最大值为max 652L =小时,最小值为 min 1L =小时; 2.计算组数: 根据经验公式:1 3.32lg k n =+, 计算得1 3.32lg 1 3.32lg1008k n =+=+≈, 所以将数据分为8组; 3.计算组距: max min 6521 828 L L t k --?= =≈; 4.根据公式计算并将所得的结果列成表2: 频率:/j j W f n =
表2故障频率分析过程计算结果 5.计算得:202.98X =,167.0697S =; 根据公式3 1 13 () 1.1035(1)n i i X X V n S =-= =-∑ 6.计算峰度: 根据公式4 1 24 () 3.4853(1)n i i X X V n S =-= =-∑ 1.3.直方图与折线图 图1-1故障频数直方图
图1-2故障频率折线图 图1-3故障频率直方图 图1-4累计频率折线图
从频率直方图即图3中可以看出,靠近左侧的数据出现较多。通过比较频率曲线和指数分布曲线可以看出,该图显示故障呈现典型的指数分布,所以说明趋势方程是指数函数。趋势线方程代表故障频数随时间的发展趋势,据此可以预测未来某一时间段内的故障数,来实现故障相关维修成本的估算。 1.4.经验分布函数 根据定义得出,总体X 的经验分布函数为: 0,1 (),1652,1,2,...,991001,652 n x k F x x k x
应用数理统计大作业1——逐步回归法分析终 -标准化文件发布号:(9456-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII
应用数理统计多元线性回归分析 (第一次作业) 学院:机械工程及自动化学院 姓名: 学号: 2014年12月
逐步回归法在AMHS物流仿真结果中的应 用 摘要:本文针对自动化物料搬运系统 (Automatic Material Handling System,AMHS)的仿真结果,根据逐步回归法,使用软件IBM SPSS Statistics 20,对仿真数据进行分析处理,得到多元线性回归方程,建立了工件年产量箱数与EMS数量、周转箱交换周期以及AGC物料交换服务水平之间的数学模型,并对影响年产量箱数的显著性因素进行了分析,介绍了基本假设检验的情况。 关键词:逐步回归;残差;SPSS;AMHS;物流仿真
目录 1、引言 (1) 2、逐步回归法原理 (4) 3、模型建立 (6) 3.1确定自变量和因变量 (6) 3.2分析数据准备 (6) 3.3逐步回归分析 (7) 4、结果输出及分析 (9) 4.1输入/移去的变量 (9) 4.2模型汇总 (10) 4.3方差分析 (10) 4.4回归系数 (11) 4.5已排除的变量 (12) 4.6残差统计量 (13) 4.7残差分布直方图和观测量累计概率P-P图 (14) 5、异常情况说明 (15) 5.1异方差检验 (15) 5.2残差的独立性检验 (17) 5.3多重共线性检验 (17) 6、结论 (18) 参考文献 (20)
1、引言 回归被用于研究可以测量的变量之间的关系,线性回归则被用于研究一类特殊的关系,即可用直线或多维的直线描述的关系。这一技术被用于几乎所有的研究领域,包括社会科学、物理、生物、科技、经济和人文科学。逐步回归是在剔除自变量间相互作用、相互影响的前提下,计算各个自变量x与因变量y之间的相关性,并在此基础上建立对因变量y有最大影响的变量子集的回归方程。 SPSS(Statistical Package for the Social Science社会科学统计软件包)是世界著名的统计软件之一,目前SPSS公司已将它的英文名称更改为Statistical Product and Service Solution,意为“统计产品与服务解决方案”。SPSS软件不仅具有包括数据管理、统计分析、图表分析、输出管理等在内的基本统计功能,而且用它处理正交试验设计中的数据程序简单,分析结果明了。基于以上优点,SPSS已经广泛应用于自然科学、社会科学中,其中涉及的领域包括工程技术、应用数学、经济学、商业、金融等等。 本文研究内容主要来源于“庆安集团基于物联网技术的航空柔性精益制造系统”,在庆安集团新建的320厂房建立自动化物料搬运系统(AMHS),使用生产仿真软件EM-Plant对该系统建模并仿真,设计实验因子及各水平如表1-1,则共有3*4*6=72组实验结果,如表所示。为方便描述,将各因子定义为:X1表示AGC物料交换服务水平,X2表示周转箱交换周期,X3表示EMS数量,Y表示因变量年产量箱数。本文目的就是建立年产量箱数与AGC物料交换服务水平、周转箱交换周期和EMS数量之间的关系。
2018年数理统计大作业题目和答案--0348
1、设总体X 服从正态分布),(2 σμN ,其中μ已知,2 σ 未知,n X X X ,,,2 1 为其样本,2≥n ,则下列说法中正 确的是( )。 (A )∑=-n i i X n 1 2 2 ) (μσ是统计量 (B )∑=n i i X n 1 22 σ是统计量 (C )∑=--n i i X n 1 2 2 ) (1μσ是统计量 (D )∑=n i i X n 1 2μ 是统计量 2、设两独立随机变量)1,0(~N X ,) 9(~2 χY ,则Y X 3服从 ( )。 )(A ) 1,0(N )(B ) 3(t )(C ) 9(t )(D ) 9,1(F 3、设两独立随机变量)1,0(~N X ,2 ~(16) Y χ,则Y 服 从( )。 )(A )1,0(N )(B (4) t )(C (16) t )(D (1,4) F 4、设n X X ,,1 是来自总体X 的样本,且μ=EX ,则下 列是μ的无偏估计的是( ). ) (A ∑-=-1 1 1 1 n i i X n )(B ∑=-n i i X n 1 11 )(C ∑=n i i X n 2 1 )(D ∑-=1 1 1n i i X n 5、设4 3 2 1 ,,,X X X X 是总体2 (0,)N σ的样本,2 σ未知,则下列随机变量是统计量的是( ).
() (1) D t n- 10、设 1,, n X X ???为来自正态总体2 (,) Nμσ的一个样本,μ,2σ未知。则2σ的置信度为1α-的区间估计的枢轴量为()。 (A) ()2 1 2 n i i Xμ σ = - ∑ (B) ()2 1 2 n i i Xμ σ = - ∑ (C) () ∑ = - n i i X X 1 2 2 1 σ (D) ()2 1 2 n i i X X σ = -∑ 11、在假设检验中,下列说法正确的是()。 (A) 如果原假设是正确的,但作出的决策是接受备择假设,则犯了第一类错误; (B) 如果备择假设是正确的,但作出的决策是拒绝备择假设,则犯了第一类错误; (C) 第一类错误和第二类错误同时都要犯; (D) 如果原假设是错误的,但作出的决策是接受备择假设,则犯了第二类错误。 12、对总体2 ~(,) X Nμσ的均值μ和作区间估计,得到置信度为95%的置信区 间,意义是指这个区间()。 (A)平均含总体95%的值(B)平 均含样本95%的值
数理统计第二次作业 ? 1. 某百货公司连续40 天的商品销售额如下(单位:万元): 41 46 35 42 25 36 28 36 29 45 46 37 47 37 34 37 38 37 30 49 34 36 37 39 30 45 44 42 38 43 26 32 43 33 38 36 40 44 44 35 根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。(数据见练 习1 数据.xls —练习 1.1 )解:频数分布表及直方图如下:由直方图可以看出,该百货公司连续 40 天的销售额近似服从单峰对称的正态分布。 2. 为了确定灯泡的使用寿命(小时),在一批灯泡中随机抽取100 只进行测试,所 得结果如下: 700 706 716 715 728 712 719 722 685 691 709 708 691 690 684 692
705 707 718 701 708 729 694 681 695 685 706 661 735 665 668 710 693 697 674 658 698 666 696 698 706 692 691 747 699 682 698 700 710 722 694 690 736 689 696 651 673 749 708 727 688 689 683 685 702 741 698 713 676 702 701 671 718 707 683 717 733 712 683 692 693 697 664 681 721 720 677 679 695 691 713 699 725 726 704 729 703 696 717 688 (1) 利用计算机对上面的数据进行排序; (2) 以组距为10 进行等距分组,整理成频数分布表,并绘制直方图;(3) 绘制茎叶图,并与直方图作比较. 解( 1)排序如下 (2)频数分布表及频数分布直方图如下:从直方图可以看出,灯泡的使用寿命近似服从单 峰对称的正态分布。 (3)茎叶图如下 与频数分布表比较可知:当频数分布表频数分布间隔为10,且从整10 开始,则茎叶 图各茎所含叶片数与对应频数区间所含项数相等。 3. 某企业决策人考虑是否采用一种新的生产管理流程。据对同行的调查得知,采用新生产管理流程后产品优质率达95%的占四成,优质率维持在原来水平(即80%)的占六成。该企业利用新的生产管理流程进行一次试验,所生产 5 件产品全部达到优质。问该企业决策者会倾向于如何决策? 解:设A =优质率达95%, C =优质率为80%, B =试验所生产的5件全部优质。 P(A) = 0.4 , P(A ) = 0.6 , P(B|A)=0.955 , P(B|A )=0.85 ,所求概率为:P (A I B ) P(A) ?P(B I A) P(A) ?P(B II A)+P(A ) ?P(B I A ) 0.50612 0.30951 0.6115 决策者会倾向于采用新的生产管理流程。
武汉大学2009-2010年度上学期研究生公共课 《应用数理统计》期末考试试题 (每题25分,共计100分) (请将答案写在答题纸上) 1设X 服从),0(θ上的均匀分布,其密度函数为 ?????<<=其它0 01)(θθx x f n X X X ,,,21" 为样本, (1)求θ的矩估计量1?θ和最大似然估计量2 ?θ; (2)讨论1?θ、2?θ的无偏性,1?θ、2?θ是否为θ的无偏估计量?若不是,求使得i c ?i i c θ为θ的无偏估计量,; 1,2i =(3)讨论1?θ、2 ?θ的相合性; (4)比较11?c θ和22?c θ的有效性. 2. 假设某种产品来自甲、乙两个厂家,为考查产品性能的差异,现从甲乙两厂产品中分别抽取了8件和9件产品,测其性能指标X 得到两组数据,经对其作相应运算得 2110.190,0.006,x s == 2220.238,0.008x s == 假设测定结果服从正态分布()()2~,1,2i i X i μσ=, (1).在显著性水平0.10α=下,能否认为2212σσ=? (2).求12μμ?的置信度为90%的置信区间,并从置信区间和假设检验的关系角度分析甲乙两厂生产产品的性能指标有无显著差异。 3.设是来自正态总体的样本, 总体均值n X X X ,,,21"),(2 σμN μ和方差未知,样本均值和方差分别记为2σ2211 11,(1n n i i i i )X X S X X n n ====?∑∑?
(1) 求2211 (n i i X )μσ=?∑的分布; (2)若0μ=,求212212()() X X X X +?的分布; (3)方差的置信度为12σα?的置信区间的长度记为L ,求()E L ; (4)1n X + 的分布。 4.为进行病虫害预报, 考察一只红铃虫一代产卵量Y (单位:粒)与温度x (单位:)的关系, 得到资料如下: C 0x 18 20 24 26 30 32 35 Y 7 11 21 24 66 115 325 假设Y 与x 之间有关系 bx Y ae ε+=, . ),0(~2σεN 经计算:26.43x =,ln 3.612y =,,, 7215125i i x ==∑721(ln )102.43i i y ==∑7 1ln 718.64i i i x y ==∑(1)求Y 对x 的曲线回归方程; x b e a y ???=(2)求的无偏估计; 2σ2?σ (3)对回归方程的显著性进行检验(05.0=α); (4)求当温度0x =33时,产卵量的点估计。 0Y 可能用到的数据: 0.02282z =,()()0.050.057,8 3.50,8,7 3.73F F ==,()0.0515 1.7531t =,,,,0.025(5) 2.5706t =0.05(5) 2.015t =0.025(7) 2.3646t =0.05(7) 1.8946t =,0.05(1,5) 6.61F =, 0.05(1,7) 5.59F =
吉林大学网络教育 大作业 1.仪器中有三个元件,它们损坏的概率都是0.2,并且损坏与否相互独立.当一个元件损坏时, 仪器发生故障的概率为0.25,当两个元件损坏时,仪器发生故障的概率为0.6,当三个元件损坏时,仪器发生故障的概率为0.95, 当三个元件都不损坏时,仪器不发生故障.求:(1)仪器发生故障的概率;(2)仪器发生故障时恰有二个元件损坏的概率. (1)解:设A 表示事件“仪器发生故障”,i=1,2,3 P(A)= )/()(3 1 B B i i i A P P ∑=, P(B1)=3*0.2*0.80.2=0.384,P(B2)=3*0.22*0.8=0.096,P(B3)=0.23=0.008 所以P(A)=0.384*0.25+0.096*0.6+0.008*0.95+0.1612 (2) P(B 2/A)= ) ()(2A P A p B =0.96*0.6/0.1612=0.3573 2.设连续型随机变量X 的分布函数为 0, ,()arcsin ,,(0)1, ,x a x F x A B a x a a a x a ≤-??? =+-<<>?? ≥?? 求:(1)常数A 、B .(2)随机变量X 落在,22a a ?? - ??? 内的概率.(3)X 的概率密度函数. 解:(1)F (a+0)=A-2πB=0,F (a-0) =A+2πB=1 所以A=0.5 B=π 1 (2)P{-2a 第一章 1.1 X~N(μ,2 σ) 则X~N(μ, 2 n σ ),所以X-μ~N(0, 2 n σ ) P{X-μ <1}= P{ = 0.95 N(0,1),而(0.975) 1.96 Φ= 所以n最小要取[2 1.96x2σ]+1 1.2 (1)至800小时,没有一个元件失效 这个事件等价于P{ 123456 X X X X X X>800}的概率 由已知X服从指数分布,可求得P{ 123456 X X X X X X>800}=7.2 e-(2)至3000小时,所有六个元件都失效的概率 等价与P{ 123456 X X X X X X<3000}的概率 可求得P{ 123456 X X X X X X<3000}= 4.56 (1) e- - 1.5 2 1 () n i i X a = - ∑=2 1 [()()] n i i X X X a = -+- ∑ =22 111 ()2()()() n n n i i i i i X X X a X X X a === -+--+- ∑∑∑ 因为 1 () n i i X X = - ∑=0 所以2 1 () n i i X a = - ∑=22 11 ()() n n i i i X X X a == -+- ∑∑ =22 1 () n i nS X a = +- ∑ 所以当a=X时,2 1 () n i i X a = - ∑有最小值且等于2nS 1.6 (1)由 1 1n i i X X n= =∑ 有等式的左边= 221 12n n i i i i X X n μμ==-+∑∑ 等式的右边= 22221122n n i i i i X X X nX nX nX n μμ==-++-+∑∑ = 22 2 2 211 22n n i i i i X nX nX nX X n μμ==-++-+∑∑ = 221 1 2n n i i i i X X n μμ==-+∑∑ 左边等于右边,结论得证。 (2) 等式的左边= 22 11 2n n i i i i X X X nX ==-+∑∑=221 n i i X nX =-∑ 等式的右边= 221 n i i X nX =-∑ 左边等于右边,结论得证。 1.7 (1)由11n n i i X X n ==∑ 及 22 1 1()n n i n i S X X n ==-∑ 有左边=1111111111()1111 n n n n n i i n i i i i X X X X X X n n n n ++++=====+=+++++∑∑∑ 111 ()111 n n n n n nX X X X X n n n ++= +=+-+++=右边 左边等于右边,结论得证。 (2)由 左边=12 21 11 1()1n n i n i S X X n +++==-+∑ 121111[()]11 n i n n n i X X X X n n ++==---++∑ 121111[()()]11 n i n n n i X X X X n n ++==---++∑ 12 2112 1121[()()()()]11(1) n i n i n n n n n i X X X X X X X X n n n +++==----+-+++∑ 北航数理统计大作业-多元线性回归 应用数理统计多元线性回归分析 (第一次作业) 学院: 姓名: 学号: 2013年12月 交通运输业产值的多元线性回归分析 摘要:本文基于《中国统计年鉴》(2012年版)统计数据,寻找影响交通运输业发展的因素,包括工农业发展水平、能源生产水平、进出口贸易交流以及居民消费水平等,利用统计软件SPSS对各因素进行了筛选分析,采用逐步回归法得到最优多元线性回归模型,并对模型的回归显著性、拟合度以及随机误差的正态性进行了检验,最后可以利用有效的最优回归模型对将来进行预测。 关键字:多元线性回归,逐步回归,交通运输产值,工业产值,进出口总额1,引言 交通运输业指国民经济中专门从事运送货物和旅客的社会生产部门,包括铁路、公路、水运、航空等运输部门。它是国民经济的重要组成部分,是保证人们在政治、经济、文化、军事等方面联系交往的手段,也是衔接生产和消费的一个重要环节。交通运输业在现代社会的各个方面起着十分重要的作用,因此研究交通运输业发展水平与各个影响因素间的关系显得十分重要,建立有效的数学相关模型对于预测交通运输业的发展,制定相关政策方案提供依据。根据经验交通运输业的发展受到工农业发展、能源生产、进出口贸易以及居民消费水平等众因素的影响,故建立一个完整精确的数学模型在理论上基本无法实现,并且在实际运用中也没有必要,一种简单有效的方式就是寻找主要影响因素,分析其与指标变量的相关性,建立多元线性回归模型就是一种有效的方式。 变量与变量之间的关系分为确定性关系和非确定性关系,函数表达确定性关系。研究变量间的非确定性关系,构造变量间经验公式的数理统计方法称为 北航2010《应用数理统计》考试题及参考解答 09B 一、填空题(每小题3分,共15分) 1,设总体X 服从正态分布(0,4)N ,而12 15(,,)X X X 是来自X 的样本,则22 110 22 11152() X X U X X ++=++服从的分布是_______ . 解:(10,5)F . 2,?n θ是总体未知参数θ的相合估计量的一个充分条件是_______ . 解:??lim (), lim Var()0n n n n E θθθ→∞ →∞ ==. 3,分布拟合检验方法有_______ 与____ ___. 解:2 χ检验、柯尔莫哥洛夫检验. 4,方差分析的目的是_______ . 解:推断各因素对试验结果影响是否显著. 5,多元线性回归模型=+Y βX ε中,β的最小二乘估计?β 的协方差矩阵?βCov()=_______ . 解:1?σ-'2Cov(β) =()X X . 二、单项选择题(每小题3分,共15分) 1,设总体~(1,9)X N ,129(,, ,)X X X 是X 的样本,则___B___ . (A ) 1~(0,1)3X N -; (B )1 ~(0,1)1X N -; (C ) 1 ~(0,1) 9X N -; (D ~(0,1)N . 2,若总体2(,)X N μσ,其中2σ已知,当样本容量n 保持不变时,如果置信度1α-减小,则μ的 置信区间____B___ . (A )长度变大; (B )长度变小; (C )长度不变; (D )前述都有可能. 3,在假设检验中,就检验结果而言,以下说法正确的是____B___ . (A )拒绝和接受原假设的理由都是充分的; (B )拒绝原假设的理由是充分的,接受原假设的理由是不充分的; (C )拒绝原假设的理由是不充分的,接受原假设的理由是充分的; (D )拒绝和接受原假设的理由都是不充分的. 4,对于单因素试验方差分析的数学模型,设T S 为总离差平方和,e S 为误差平方和,A S 为效应平方和,则总有___A___ . 对中国各地财政收入情况的聚类分析和判 别分析 应用数理统计第二次大作业 学院名称 学号 学生姓名 摘要 我国幅员辽阔,由于人才、地理位置、自然资源等条件的不同,各地区的财政收入类型各自呈现出不一样的发展趋势,通过准确定位中国各地区财政收入情况对于正确认识我国财政收入具有重要的意义。本文以中国各地财政收入情况为研究对象,从《中国统计年鉴》中选取2011年期间中国各地财政收入情况为因 变量,选取国内增值税、营业税、企业所得税、个人所得税、城市维护建设税、土地增值税、契税、专项收入、行政事业性收费收入、国有资本经营收入和国有资源(资产)有偿使用收入11个可能影响中国各地财政收入的因素为自变量,利用统计软件SPSS,对27个地区的财政收入进行了聚类分析,并对另外4个地区的财政收入进行了判别分析,并最终确定了中国各地区根据财政收入类型的分类情况。 关键词:聚类分析,判别分析,SPSS,中国各地财政收入类型 1、引言 财政收入,是指政府为履行其职能、实施公共政策和提供公共物品与服务需要而筹集的一切资金的总和。财政收入表现为政府部门在一定时期内(一般为一个财政年度)所取得的货币收入。财政收入是衡量一国政府财力的重要指标,政府在社会经济活动中提供公共物品和服务的范围和数量,在很大程度上决定于财政收入的充裕状况。通过准确定位中国各地区财政收入情况对于正确认识我国财政收入具有重要的意义。 本文利用统计软件SPSS,根据各地区的财政收入情况,对北京、天津、河北等27个地区进行聚类分析,并对青海、重庆、四川、贵州4个省市进行判别分析,判断属于聚类分析结果中的哪种财政收入类型。 1.1 聚类分析 聚类分析是根据研究对象的特征对研究对象进行分类的多元统计分析技术的总称,它直接比较各事物之间的性质,将性质相近的归为一类,将性质差别较大的归入不同的类。本文采用的是系统聚类分析,它又称集群分析,是聚类分析中应用最广的一种方法,其基本思想是:首先将每个聚类对象看作一类,然后根据对象间的相似程度,将相似程度最高的两类进行合并,并计算合并后的类与其他类之间的距离,再选择相近者进行合并,每合并一次减少一类,直至所有的对象都并为一类为止。 系统聚类分为Q型聚类和R型聚类两种:Q型聚类是对样本进行聚类,它使具有相似特征的样本聚集在一起,使差异性大的样本分离开来;R型聚类是对变量进行聚类,它使差异性大的变量分离开来,相似的变量聚集在一起,这样就 1、设总体X 服从正态分布),(2 σμN ,其中μ已知,2 σ未知,n X X X ,,,21 为其样本, 2≥n ,则下列说法中正确的是( ) 。 (A ) ∑=-n i i X n 1 2 2 )(μσ是统计量 (B ) ∑=n i i X n 1 22 σ是统计量 (C ) ∑=--n i i X n 1 2 2 )(1μσ是统计量 (D ) ∑=n i i X n 1 2 μ 是统计量 2、设两独立随机变量)1,0(~N X ,)9(~2 χY ,则 Y X 3服从( )。 )(A )1,0(N )(B )3(t )(C )9(t )(D )9,1(F 3、设两独立随机变量)1,0(~N X ,2 ~(16)Y χ )。 )(A )1,0(N )(B (4)t )(C (16)t )(D (1,4)F 4、设n X X ,,1 是来自总体X 的样本,且μ=EX ,则下列是μ的无偏估计的是( ). ) (A ∑ -=-1 1 1 1n i i X n )(B ∑=-n i i X n 1 11 )(C ∑=n i i X n 21 )(D ∑-=111n i i X n 5、设4321,,,X X X X 是总体2 (0,)N σ的样本,2 σ未知,则下列随机变量是统计量的是 ( ). (A )3/X σ; (B ) 4 1 4 i i X =∑; (C )σ-1X ; (D ) 4 221 /i i X σ=∑ 6、设总体),(~2 σμN X ,1,,n X X L 为样本,S X ,分别为样本均值和标准差,则 下列正确的是( ). 2() ~(,)A X N μσ 2() ~(,) B n X N μσ 222 1 1 () ()~()n i i C X n μχσ=-∑ () ~()D t n 7、设总体X 服从两点分布B (1,p ),其中p 是未知参数,15,,X X ???是来自总体的简单随机样本,则下列随机变量不是统计量为( ) ( A ) . 12X X + ( B ) {}max ,15i X i ≤≤西安交大数理统计作业(完整版)
最新北航数理统计大作业-多元线性回归
北航应用数理统计考试题及参考解答
北航-数理统计大作业
最新数理统计大作业题目和答案--0348资料
相关主题
文本预览