遗传算法结合偏最小二乘法无损评价西洋梨糖度
- 格式:pdf
- 大小:1.34 MB
- 文档页数:4

基于GA-LSSVM的苹果糖度近红外光谱检测刘燕德;周延睿【摘要】[目的]结合遗传算法和最小二乘支持向量机(GA-LSSVM),优化苹果糖度近红外光谱检测的数学模型,提高模型的检测精度和稳定性.[方法]在GA-LSSVM模型建立过程中,采用遗传算法自动获取最小二乘支持向量机的最优参数.[结果]相比于偏最小二乘法(PLS)、传统最小二乘支持向量机(LSSVM)和遗传偏最小二乘法(GA-PLS)数学模型,GA-LSSVM法建立的模型预测效果最优,模型的相关系数为0.94,预测均方根误差为0.32°Brix.[结论]GA和LSSVM相结合的优化方法在提高苹果糖度近红外光谱检测精度和稳定性方面是可行的.【期刊名称】《西北农林科技大学学报(自然科学版)》【年(卷),期】2013(041)007【总页数】6页(P229-234)【关键词】苹果;糖度检测;近红外光谱;遗传算法;最小二乘支持向量机【作者】刘燕德;周延睿【作者单位】华东交通大学机电工程学院,江西南昌 330013;华东交通大学机电工程学院,江西南昌 330013【正文语种】中文【中图分类】S661.1;O657.33近红外光谱技术具有非破坏性、检测速度快、样品无需前处理等优点,所以被广泛用于农产品的品质检测[1-3]。
但是在近红外光谱检测技术的应用过程中,外界条件如温度、基线漂移、光源稳定性、样品状态等变化,都会对检测精度产生一定程度的影响,因此光谱信息变量的筛选和模型的优化,对于建立稳健的近红外光谱检测技术数学模型十分重要。
目前,在近红外光谱检测技术中使用的变量筛选方法,主要有连续投影算法(Successive projections algorithm,SPA)[4-5]、无信息变量的消除法(Uninformative variable elimination,UVE)[6]、蒙特卡罗方法(Monte carlo methods,M-C)[7-8]、间隔偏最小二乘法(Interval PLS,iPLS)[9]、遗传算法(Genetic algorithms,GA)[10]等,其中 GA 是近年来国内外应用较为广泛的一种特征变量筛选方法[11-12]。


近红外光谱结合偏最小二乘法快速测定糖果中水分含量沈乐丞;刘书航;邓海玲;何美霞;吴燕蕙;彭建飞;黄勇旗【期刊名称】《食品工业科技》【年(卷),期】2018(039)007【摘要】采用近红外光谱(NIR)结合偏最小二乘法(PLS)建立了一种糖果中水分含量快速准确的测定方法.在12500~3600 cm-1光谱范围内采集116批糖果的近红外漫反射光谱,并用减压干燥失重法测定其水分含量.通过比较不同参数对建模的影响,发现用多元散射校正法进行预处理,在11682.2~9826.1、8939.0~6267.9、5378.8~4487.8 cm-1光谱范围内,主成分数为15时,应用PLS方法建立的糖果水分的定量分析模型效果最佳.所建立模型的相关系数为0.9716,校正均方根误差和验证均方根误差分别为0.97%和1.03%.该方法结果准确可靠、操作简便,可用于糖果中水分含量的快速检测.【总页数】5页(P255-258,322)【作者】沈乐丞;刘书航;邓海玲;何美霞;吴燕蕙;彭建飞;黄勇旗【作者单位】深圳市计量质量检测研究院,广东深圳518131;河南工业大学粮油食品学院,河南郑州450001;深圳市计量质量检测研究院,广东深圳518131;深圳市计量质量检测研究院,广东深圳518131;深圳市计量质量检测研究院,广东深圳518131;深圳市计量质量检测研究院,广东深圳518131;深圳市计量质量检测研究院,广东深圳518131【正文语种】中文【中图分类】TS207.3【相关文献】1.基于近红外光谱及组合间隔偏最小二乘法的天南星中水分及总黄酮含量测定研究[J], 王维皓;张永欣;冯伟红;杨立新2.近红外光谱结合偏最小二乘法快速测定奥硝唑片的含量 [J], 王小亮;张秉华;衷红梅;席志芳;杜亚俊3.近红外光谱技术结合偏最小二乘法快速测定砂仁中乙酸龙脑酯的含量 [J], 樊明月;白雁;雷敬卫;谢彩侠;郝敏4.近红外光谱-偏最小二乘法快速测定八角茴香中莽草酸含量 [J], 范铭然;孟庆繁;王迪;王天然;杨光;滕利荣;林凤5.近红外光谱结合偏最小二乘法快速检测山苍子精油中柠檬醛的含量 [J], 陈梓云;黄晓霞;姚婉清;彭梦侠因版权原因,仅展示原文概要,查看原文内容请购买。
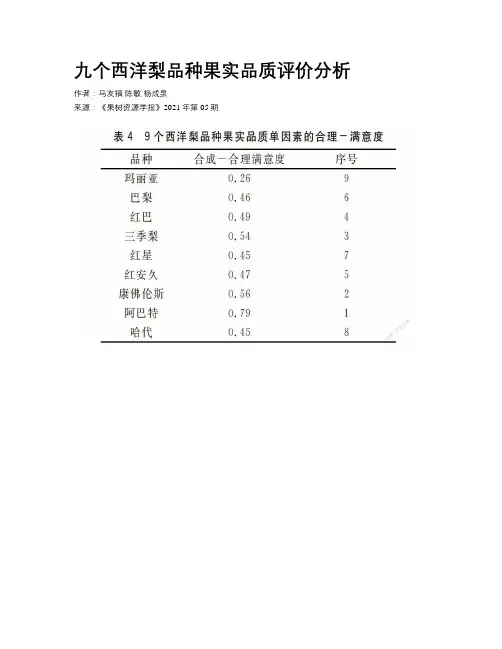
九个西洋梨品种果实品质评价分析作者:马友福陈敏杨成泉来源:《果树资源学报》2021年第05期摘要:为改善陕西省梨品种结构,以陕西引种栽培的9个西洋梨品种为材料,采用“合理-满意度”和多维价值理论的合并规则,通过对不同品种的单果重、可溶性固形物含量、可滴定酸含量、果肉硬度和石细胞含量等指标综合评价,以确定适宜陕西栽培的西洋梨良种。
结果表明:‘巴梨’ ‘红巴’ ‘三季梨’ ‘红星’ ‘红安久’ ‘康佛伦斯’果实品质合成-合理满意度较高,‘阿巴特’满意度最高,为0.79。
综上所述‘阿巴特’ ‘巴梨’ ‘红巴’ ‘三季梨’ ‘红星’ ‘红安久’ ‘康佛伦斯’7个品种果实综合品质俱佳,适合在陕西推广发展。
关键词:西洋梨;多维价值理论;合理-满意度;果实品质Abstract:In order to improve the pear cultivar structure in Shaanxi Province, the cultivation adaptability of nine European pear cultivars was evaluated using the combinated analysis of‘reasonableness and satisfaction index’ and ‘multi-dimensional value theory’ from quality traits, the single fruit weight, soluble solid content, titratable acid content, flesh firmness, and stone cell content.The results showed that ‘Bartlett’ ,‘Red Bartlett’,‘Docteur Jules Guyot’,‘Starkrimson’,‘Red Anjou’,and ‘Conference’ had higher satisfaction with fruit quality synthesis,and ‘Abart Fetel’ pear had the highest satisfactio n (0.79).In conclusion, the comprehensive quality of seven cultivars,‘Abate Fetel’,‘Bartlett’,‘Red Bartlett’,‘Docteur Jules Guyot’,‘Starkrimson’,‘Red Anjou’,and ‘Conference’ were suitable for pear fruit production in Shaanxi Province.Keywords:European pear; multidimensional value theory; reasonableness and satisfaction index; fruit quality梨是蔷薇科(Rosaceae)梨属(Pyrus)落叶果树,是我国仅次于苹果、柑橘的第三大水果,栽培历史悠久,种质资源丰富[1-2]。

分析化学中非线性拟合的最小二乘法及其与遗传算法的比较张小吐
【期刊名称】《分析化学》
【年(卷),期】1996(24)8
【摘要】本文从化学量测数据的分布特性出发,对数据进行了正态性检验。
对于分析化学中可化为线性函数的非线性拟合问题,利用文献数据对最小二乘法与遗传算法所得结果进行了比较,结果充分表明在数据满足Gauss-Markov假定时,对参数的最小二乘法估计所得结果要优于任何其它线性无偏估计以及遗传算法所得结果。
【总页数】4页(P947-950)
【作者】张小吐
【作者单位】无
【正文语种】中文
【中图分类】O651
【相关文献】
1.基于遗传算法的圆度公差评定法与采用最小二乘法评定的比较 [J], 李子芳;崔长彩;车仁生;黄庆成;叶东
2.线性拟合中的逐差法和最小二乘法的比较 [J], 单明;聂燕萍
3.分析化学中非线性多元函数拟合的遗传算法 [J], 蔡煜东
4.基于最小二乘法解决函数中的一元线性拟合问题的应用研究 [J], 阿依努尔·克热木
5.基于最小二乘法解决函数中的一元线性拟合问题的应用研究 [J], 阿依努尔·克热木
因版权原因,仅展示原文概要,查看原文内容请购买。

偏最小二乘法1.1基本原理偏最小二乘法(PLS)是基于因子分析的多变量校正方法,其数学基础为主成分分析。
但它相对于主成分回归(PCR)更进了一步,两者的区别在于PLS法将浓度矩阵Y和相应的量测响应矩阵X同时进行主成分分解:X二 TP+EY=UQ+F式中T和U分别为X和Y的得分矩阵,而P和Q分别为X和Y的载荷矩阵,E和F分别为运用偏最小二乘法去拟合矩阵X和Y时所引进的误差。
偏最小二乘法和主成分回归很相似,其差别在于用于描述变量Y中因子的同时也用于描述变量X。
为了实现这一点,数学中是以矩阵Y的列去计算矩阵X的因子。
同时,矩阵Y的因子则由矩阵X 的列去预测。
分解得到的T和U矩阵分别是除去了人部分测量误差的响应和浓度的信息。
偏最小二乘法就是利用各列向量相互正交的特征响应矩阵T和特征浓度矩阵U进行回归:U=TB得到回归系数矩阵,又称矢联矩阵E:B=(TT )F U因此,偏最小二乘法的校正步骤包括对矩阵Y和矩阵X的主成分分解以及对矢联矩阵B的计算。
12主成分分析主成分分析的中心目的是将数据降维,以排除众多化学信息共存中相互重叠的信息。
他是将原变量进行转换,即把原变量的线性组合成几个新变量。
同时这些新变量要尽可能多的表征原变量的数据结构特征而不丢失信息。
新变量是一组正交的,即互不相矢的变量。
这种新变量又称为主成分。
如何寻找主成分,在数学上讲,求数据矩阵的主成分就是求解该矩阵的特征值和特征矢量问题。
卞面以多组分混合物的量测光谱来加以说明。
假设有n个样本包含p个组分,在m个波长下测定其光谱数据,根据比尔定律和加和定理有:如果混合物只有一种组分,则该光谱矢量与纯光谱矢量应该是方向一致,而人小不同。
换句话说,光谱A表示在由p个波长构成的p维变量空间的一组点(n个),而这一组点一定在一条通过坐标原点的直线上。
这条直线其实就是纯光谱b。
因此由ni个波长描述的原始数据可以用一条直线,即一个新坐标或新变量来表示。
如果一个混合物由2个组分组成,各组分的纯光谱用bl,b2 表示,则有:<=c i{b: + Ci2bl有上式看出,不管混合物如何变化,其光谱总可以用两个新坐标轴bl,b2来表示。

基于遗传算法参数优化的最小二乘支持向量机财务困境预测赵冠华;李玥;赵娟【摘要】When using traditional support vector machine to make financial distress prediction, we need to solve the complex quadratic programming problems, which are quite difficult. At the same time, the least squares support vector machine (LS-SVM) can solve the quadratic programming problems by transferring them into linear equations, effectively reducing the difficulty. Especially when applying genetic algorithm to optimize parameters and kernel parameters of LSSVM, the prediction accuracy is significantly improved. We randomly selected 252 A-share listed companies during 2002-2007 from Shanghai and Shenzhen Stock Exchanges as the research samples and divided them into two Sample I and Sample II. Then we carried out short-term and long-term predictions of these two sets of samples res The empirical results showed that the prediction effects of LS-SVM model based on genetic algorithm was better of traditional statistical Logit Model as well as the traditional support vector machine. higher accuracy rate compared with long-term prediction. groups - pectively. than that Besides, short-term prediction had a In addition, the number of training samples directly affected the prediction accuracy and they were positively correlated.%传统支持向量机应用于财务困境预测时,需要求解复杂的二次规划问题,求解难度大。

增强偏最小二乘回归算法在近红外光谱法啤酒度数软测量建模中的应用谭超;吴同【摘要】软测量技术广泛应用于工业过程,其核心是建立一个可靠的软测量模型.常规的软测量都是基于建立单个的数学模型,常难达到需要的精确和稳健性.基于机器学习的集成思想,给出了增强偏最小二乘回归(boosting-PLS)算法,并将其用于一个基于近红外光谱法啤酒度数软测量中,试验结果表明:应用boosting-PLS算法所建模型是一种精确、稳健、有应用潜力的软测量方法,特别适合于类似涉及高维光谱数据的软测量.【期刊名称】《理化检验-化学分册》【年(卷),期】2010(046)008【总页数】4页(P891-894)【关键词】增强偏最小二乘回归算法;软测量;近红外光谱【作者】谭超;吴同【作者单位】宜宾学院,化学与化工系,宜宾,644007;宜宾学院,计算物理四川省高校重点实验室,宜宾,644007;宜宾学院,化学与化工系,宜宾,644007【正文语种】中文【中图分类】TP274随着现代工业过程日益复杂以及对产品质量要求的提高,产生了软测量技术,并在诸多领域得到了应用[1]。
概括地说,软测量是指根据某种最优准则,选择一组既与主变量密切联系,又容易测量的辅助变量,通过构造某种数学模型(即软测量模型),实现对主变量的估计和推断,建立一个好的软测量模型就成为应用软测量技术的关键[23]。
理论上讲,能用于建立变量之间关系模型的数学方法均可用于软测量,如多元线性回归(MLR)、人工神经网络(ANN)、支持向量机(SVM)等[4]。
不过,由于软测量模型不同于一般意义下的数学模型,它强调的是基于模型实现辅助变量对主变量的估计和推断,而模型的预测精度和稳健性往往直接决定该技术的可用性。
传统的软测量技术应用都是基于建立单个的数学模型,常常难以达到需要的精度和稳健性,这也是当前推广软测量应用的技术瓶颈。
近年来,起源于机器学习领域的“集成”技术为解决类似的技术瓶颈提供了新的思路,它是一种可用来提高任何学习算法精度和性能的通用策略,其核心思想是利用多个模型的协同互助来提升模型的综合性能[526]。

基于随机森林算法以及可见–近红外光谱的苹果糖度无损检测蒋雨鹏;任玉;蔡红星;周建伟;王康华;孙哲
【期刊名称】《传感器技术与应用》
【年(卷),期】2022(10)2
【摘要】本文基于可见–近红外光谱分析技术结合随机森林算法实现不同产地的苹果糖度无损检测。
研究通过漫反射采集系统收集三种不同产地苹果的光谱数据后经多种预处理办法比较,采用标准正态变换分别结合偏最小二乘、随机森林算法建立苹果糖度检测通用模型。
结果显示该模型预测集相关系数(Rp2)和预测均方根误差(RMSEP)分别为0.89和0.44,相比偏最小二乘法检测模型相关系数(Rp2)和预测均方根误差(RMSEP)的0.85和0.47,均有提高。
研究扩大了单一品种模型的预测范围,结合随机森林算法有效地提升模型的预测稳健性,对进一步实现水果品质无损检测具有良好的潜在意义。
【总页数】10页(P128-137)
【作者】蒋雨鹏;任玉;蔡红星;周建伟;王康华;孙哲
【作者单位】长春理工大学吉林省光谱探测科学与技术高校重点实验室长春
【正文语种】中文
【中图分类】TP3
【相关文献】
1.近红外光谱相似性评估结合局部回归方法无损检测苹果糖度
2.基于红外光谱的苹果糖度无损检测系统
3.利用近红外漫反射光谱技术进行苹果糖度无损检测的研究
4.
基于近红外光谱的红提维生素C含量、糖度及总酸含量无损检测方法5.基于可见/近红外透射光谱技术的红提糖度和含水率无损检测
因版权原因,仅展示原文概要,查看原文内容请购买。


基于改进遗传算法的最小二乘法的应用
菅倩;乔冠峰
【期刊名称】《机械管理开发》
【年(卷),期】2011(000)005
【摘要】为了克服基本遗传算法参数较多时编码表示冗长、烦杂以及实数编码等寻优效果的不足,提出了一种改进编码的遗传算法——矩阵编码遗传算法.它是在遗传算法大的框架不变的情况下仅改变其编码,即遗传编码改变的同时,相应的遗传操作,包括交叉、变异等都要随之变化.除此之外,适应度函数和计算也要变化.最小二乘法是系统辨识常用方法之一,将改进的遗传算法与最小二乘方法相结合来解决系统辨识的问题,给辨识问题的解决提供了新方法和新思路,同时也丰富了遗传算法的实际应用意义.MATLAB仿真实验结果表明,该算法可以解决系统辨识问题.
【总页数】3页(P207-208,212)
【作者】菅倩;乔冠峰
【作者单位】太原科技大学后勤管理处,山西太原030024;太原名仕达煤炭设计有限公司,山西太原030000;西建筑职业技术学院;山西太原030000
【正文语种】中文
【中图分类】TP29
【相关文献】
1.基于最小二乘法的灰色 GM(1,1)改进模型在非煤矿山事故预测中的应用 [J], 李明洋;姜福川
2.改进遗传算法及最小二乘法在计算机数学建模中的应用 [J], 孙庆锋;方来祥;戴柯寒;
3.基于规划理论的最小二乘法改进及其在Markov跳变系统参数估计中的应用 [J], 李颖;林洪生;刘严
4.改进Diebold & Li两步法的Nelson-Siegel模型——基于遗传算法与最小二乘法交叉运用 [J], 李国徽;谢贵知
5.计算机数学建模中改进遗传算法与最小二乘法应用 [J], 余航
因版权原因,仅展示原文概要,查看原文内容请购买。
收稿日期:2018-11-16 修回日期:2019-03-26基金项目:山东省高等学校科技计划(N o .J 17K B 131) *通讯作者:原帅,男,硕士,副教授,研究方向:光信号获取与处理㊂E -m a i l :yu a n s h u a i 1981@126.c o m 第36卷第1期V o l .36 N o .1分析科学学报J O U R N A LO FA N A L Y T I C A LS C I E N C E 2020年2月F e b .2020D O I :10.13526/j .i s s n .1006-6144.2020.01.020基于小波变换-遗传算法-偏最小二乘的草莓糖度检测研究张 娟1,原 帅*2,张 骏3(1.烟台汽车工程职业学院电子工程系,山东烟台265500;2.烟台大学文经学院,山东烟台264005;3.烟台大学光电信息科学技术学院,山东烟台264005)摘 要:采用近红外漫反射光谱分析技术,对草莓糖度进行了无损检测研究㊂利用便携式近红外光谱仪采集草莓样品在600~1100n m 波段内的漫反射光谱数据㊂首先利用小波变换(WT )多分辨率方法对光谱数据进行去噪预处理,然后利用遗传算法(G A )优选特征波长,最后运用偏最小二乘法(P L S )建立草莓糖度的WT -G A -P L S 校正模型㊂该模型校正集的相关系数R C 为0.9395,校正集的均方根误差R M S E C 为0.1615,预测集的相关系数R P 为0.9652,预测集的均方根误差E M S E P 为0.5042㊂与全光谱模型(F S -P L S )和小波变换模型(WT -P L S )相比,该模型预测能力更强,稳健性更优㊂关键词:近红外光谱;小波变换;遗传算法;偏最小二乘回归;草莓;糖度中图分类号:O 657.3 文献标识码:A 文章编号:1006-6144(2020)01-111-05草莓口感酸甜,营养丰富,是一种人们普遍喜爱的水果㊂草莓糖度是决定口感和营养的重要因素㊂传统的水果糖度检测的方法多采用理化分析法,检测时间长㊁步骤繁琐㊁成本高㊂随着近红外光谱测量技术和近红外光谱仪器的快速发展,近红外光谱技术现已广泛应用于无损检测领域[1]㊂新型便携式近红外光谱仪具有体积小㊁低功耗㊁高性能㊁高稳定性等优点,适合现场检测和在线分析,越来越广泛应用于水果生产中的管理监测㊁产后加工和质量评判中[2,3]㊂基于便携式-近红外光谱测量分析技术可实现水果内部品质的简单㊁快速㊁无损检测,具有成本低㊁重现性好㊁分析效率高等优势[4]㊂近年来,国内外利用近红外光谱技术对草莓糖度的检测和分析进行了大量的研究工作,其中光谱数据预处理和预测模型的建立方法是研究热点㊂金同铭等[5]采用一阶导数逐步回归的方法获取定量分析定标方程,对草莓的糖度㊁酸度等多指标进行分析;牛晓颖等[6]采用偏最小二乘法提取的潜在变量作为最小二乘-支持向量机和反向传播人工神经网络的输入变量,建立了草莓糖度的近红外定量模型;I T O [7]将草莓原始近红外光谱数据进行二阶导数处理,利用多元线性回归法建立预测模型㊂为了获得精确度更好㊁预测能力更高的红外光谱模型,本研究采用小波变换(WT )去噪预处理,以遗传算法(G A )并结合偏最小二乘法(P L S)实现波长优化选择,建立草莓糖度的近红外光谱模型,并进行分析和验证㊂1 实验部分实验所用的样品为市场购买的草莓,共选择了果形均匀的55个样本㊂将40个样本分为校正集,15个样本为预测集㊂为减小环境温度和湿度对草莓样品光谱测量的影响,将样品放置在环境温度为25ħ,相对湿度为65%的实验室中5h 后测量㊂1.1 实验仪器及测量条件草莓近红外光谱数据的采集使用A v a n t e s 公司的A v a S pe c -2048T E C 便携式光纤光谱仪,使用与仪器111第1期张娟等:基于小波变换-遗传算法-偏最小二乘的草莓糖度检测研究第36卷配套的A v a S o f t7.0软件㊂数据采集时光谱仪探头距离草莓样品正上方高度为5m m㊂光谱检测系统的参数设置为:测量波段范围为600~1100n m,积分时间5m s,光谱采样间隔0.28n m,光谱平滑阶数为3阶㊂为减小实验测量误差,每一样品的不同位置进行3次光谱测量,取其平均值,得到的光谱数据以e x c e l 形式导出㊂1.2糖度测定将采集完红外光谱的草莓样品榨汁,使用手持W Z113折射仪测量其糖度值㊂表1为校正集和预测集样本的糖度测量值㊂表1校正集和预测集样本糖度测量值T a b l e1T h em e a s u r e r e s u l t s o f c a l i b r a t i o na n d p r e d i c t i o n s a m p l e sM e a s u r e i t e m S a m p l en u m b e r M a xv a l u e M i nv a l u e M e a nv a l u e S t a n d a r dd e v i a t i o nC a l i b r a t i o n s e t4011.16.98.21.02P r e d i c t i o n s e t1510.97.08.41.011.3校正模型采用具有较强抗干扰能力的偏最小二乘法(P L S)[8]建立校正模型,对草莓糖度进行定量分析和预测㊂选择校正集相关系数R C㊁预测集相关系数R P㊁校正集均方根误差R M S E C和预测集均方根误差E M S E P 作为模型的评价指标[9]㊂2光谱数据预处理2.1数据规范化[10]对每一条光谱数据运用极差标准归一化公式进行计算变换㊂̇x i j=x i j-m i n x i jm a x x i j-m i n x i j(1)其中,i=1,2 n,n为校正集样品数;j=1,2 m,m为波长点数㊂采用极差标准归一化处理后的光谱数据在(0,1)之间,分布更均衡[11]㊂目的是一方面降低同一草莓样品多次测量之间的差别,减小因草莓大小差异引起的光散射和微小光程差变化带来的影响,为后续分析提供可靠的数据源;另一方面,消除冗余信息,加快模型收敛速度,提高模型的稳健性和预测能力㊂2.2小波去噪由于受到各种因素的影响,检测获得的近红外光谱信号夹杂噪声干扰㊂利用小波变换多分辨率方法[12],对近红外光谱信号进行不同分辨尺度的变换分解㊂通过调节尺度因子,将原始信号c0(n)(n=1,2, ,N)分解成某尺度的锐化信号(d1(n),d2(n), ,d1(n))和平滑信号(c1(n),c2(n), ,c1(n))[11]㊂最大限度的去除掉高频噪声元素,提取各尺度下的有效细节信息特征,然后再进行小波系数反变换,重构得到需要的光谱㊂本实验采用D a u b e c h i e s5滤波器5尺度分解,对草莓近红外光谱信号进行分解㊁重构[13],实现滤波预处理㊂2.3波长选择利用具有自适应的全局㊁快速搜索的遗传算法(G A)[12]与最小二乘法(P L S)有机结合[14],对草莓光谱进行波长优化选择㊂遗传算法是模拟生物进化机制随机优化的算法,应用于波长选择的实现主要包括染色体参数编码㊁群体初始化㊁适应度函数设计㊁遗传操作设计和评价六个基本步骤[15]㊂G A-P L S波长优选的思路是通过交互验证法评价模型的预测能力来选择适应度函数[16]㊂实现方法是以所选特征波长变量建立偏最小二乘回归校正模型,得到交互验证均方根误差R M S E C V最小作为遗传算法的适应度函数,通过遗传算法的选择㊁交换和突变等算子的操作,不断的遗传迭代,剔除不相关或非线性变量,选取最优的有效特征波长[17]㊂在保证精度的前提下,简化校正模型,提高校正模型的预测能力和稳健性[18]㊂R M S E C V=(y i-y'i)n(2)其中,y i表示校正集中样品含量的真实值,y'i表示模型的预测值,n表示对应校正集的样本数目㊂211第1期分析科学学报第36卷3 结果与分析3.1 数据预处理与分析图1为随机抽取的一个草莓样品的原始近红外光谱图㊂在600~1100n m 整个光谱区都有较高的信噪比,影响校正模型的精确性和稳定性㊂故首先对光谱数据进行极差归一化处理,为后期光谱预处理提供可靠数据源㊂然后利用D a u b e c h i e s 5滤波器多尺度小波分析,对原始光谱进行各个尺度下的分解重构㊂图2是草莓光谱小波分解第5阶信号㊂可以看出,变换后的光谱很好的消除了高频噪声,光谱轮廓清晰平滑,在700㊁760n m 附近特征峰明显㊂图1 草莓的原始近红外光谱F i g .1 O r i g i n a l n e a r i n f r a r e d s p e c t r u mo f s t r a w b e r r y 图2 小波分解第5阶信号F i g .2 T h e f i f t ho r d e r s i gn a l o fw a v e l e t t r a n s f o r m 3.2 遗传算法波长优选采用V i s u a l C ++编写遗传算法程序㊂便携式光谱仪测量波长范围600~1100n m ,共有2001个波长数据㊂以草莓近红外光谱全部2001个波点数作为选择对象,考虑其有效特征波长的个数,经过多次实验验证,确定遗传算法的控制参数:群体初始化为80,选择算子为转轮法,交叉概率p c 为0.5,变异概率p m 为0.01,选取遗传迭代次数为100㊂迭代终止,选取累计贡献率高于50%的201个波点数建立草莓糖度校正模型㊂3.3 草莓糖度校正模型建立及预测分别利用偏最小二乘法建立草莓糖度原始光谱全光谱模型(F S -P L S )㊁小波变换全光谱模型(WT -P L S )和小波变换与遗传算法波长选择模型(WT -G A -P L S ),通过M a t l a b 编程实现㊂表2列出了三种校正模型的预测结果㊂由表2可见,F S -P L S 模型预测精度最低,WT -G A -P L S 模型精度明显优于F S -P L S 和WT -P L S ㊂由于全光谱数据比较复杂,含有冗余信息和噪声,因此F S -P L S 模型误差较大,预测能力较低㊂利用小波滤波去除了其他干扰信息,采用遗传算法选用包含重要信息的特征波长建立WT -G A -P L S 模型,明显提高了模型的精确度和预测能力㊂表2 草莓糖度的不同偏最小二乘校正模型结果T a b l e 2 P L S c a l i b r a t i o nm o d e l s f o r p r e d i c t i o no f d i f f e r e n tm e t h o d s M o d e l i n g mo d e l V a r i a b l e R C (C o r r e l a t i o n c o e f f i c i e n t o f c a l i b r a t i o n s e t )R M S E C (C o r r e l a t i o n r o o tm e a n s q u a r e e r r o r )R P (C o r r e l a t i o n c o e f f i c i e n t o f p r e d i c t i o n s e t )R M S E P (P r e d i c t i o n r o o tm e a n s q u a r e e r r o r )F S -P L S 20010.90620.72360.88650.7854WT -P L S 200120.92990.54150.95320.6088WT -G A -P L S2010.93950.16150.96520.5042图3是WT -G A -P L S 模型40个校正集样本的预测值与实测值的散点图㊂从图中可以看出各点均匀的散布在回归线两侧,预测值与实测值有很好的相关性㊂该模型校正集的相关系数R C 为0.9395,校正集均方根误差R M S E C 为0.1615,具有较高的精度㊂图4是15个预测集样本的预测值与实测值的散点图㊂预测值与实测值同样有很好的相关性㊂模型预测集相关系数R P 为0.9652,预测集均方根误差E M S E P 为0.5042㊂表明校正模型具有较好的稳定性和可靠性㊂WT -G A -P L S 模型采用的波点数由2001减少到201个,在保证精度㊁稳定度的前提下简化了建模变量,可见遗传算法是一种有效的近红外光谱特征波长选择方法㊂311第1期张娟等:基于小波变换-遗传算法-偏最小二乘的草莓糖度检测研究第36卷图3校正集糖度预测值与实测值的散点图F i g.3P r e d i c t i v ea n da c t u a lv a l u eo fc a l i b r a t i o ns e t s u g a r d e g r ee 图4预测集糖度的预测值与实测值散点图F i g.4P r e d i c t i v ea n da c t u a lv a l u eo f p r e d i c t i o ns e t s u g a r d e g r e e4结论采用小波滤波㊁遗传算法和偏最小二乘回归法三者有机结合,建立了草莓糖度的近红外光谱的小波变换-遗传算法-偏最小二乘(WT-G A-P L S)校正模型㊂该模型校正集的相关系数R C为0.9395,校正集均方根误差R M S E C为0.1615,预测集的相关系数R P为0.9652,预测集均方根误差E M S E P为0.5042,模型具有良好的稳定性㊁可靠性和预测性能㊂研究表明,利用便携式光谱仪检测草莓糖度,不仅满足品质的检测需求,还为长期监控果实动态变化,实现果园生产中的管理提供了可能性㊂参考文献:[1] Y USH,L I UJ.J o u r n a l o fA n h u i I n s t i t u t e o fE d u c a t i o n(于绍慧,刘晶.合肥师范学院学报),2018,35(3):1.[2] L I U Y D,Z H O U Y R.J o u r n a l o fC h i n e s eA g r i c u l t u r a lM e c h a n i z a t i o n(刘燕德,周延睿.中国农机化学学报),2013,34(4):204.[3] Y U A NS,Z HA N GJ,L I U M J,e t a l.J o u r n a l o fA n a l y t i c a lS c i e n c e(原帅,张娟,刘美娟等.分析科学学报),2016,32(4):553.[4] Z HA O Y R,Y U K Q,L I UZP,e t a l.J o u r n a l o f S h a n x iA g r i c u l t u r a l S c i e n c e s(赵艳茹,余克强,刘志鹏等.山西农业科学),2012,40(6):698.[5]J I N T M,C U IH C.A c t aA g r i c u l t u r a eB o r e a l i-S i n i c a(金同铭,崔洪昌.华北农学报),1994,9(2):120.[6] N I U X Y,Z HA OZL,Z HA N GX Y.J o u r n a l o fA g r i c u l t u r a lM e c h a n i z a t i o nR e s e a r c h(牛晓颖,赵志磊,张晓瑜.农机化研究),2013,35(5):204.[7]I T O H.A c t aH o r t i c u l t u r a e,2002,567(2),751.[8] A n n aP e i r s,J e r o e nT i r r y,B e r tV e r l i n d e n.P o s t h a r v e s tB i o l o g y a n dT e c h n o l o g y,2000,28(2),269.[9] Y A N Y L,C H E N B,Z HU DZ.P r i n c i p l e,T e c h n o l o g y a n d A p p l i c a t i o no fN e a r I n f r a r e dS p e c t r o s c o p y.B e i j i n g:C h i n aL i g h t I n d u s t r y P r e s s(严衍禄,陈斌,朱大洲.近红外光谱分析的原理技术与应用.北京:中国轻工业出版社),2013: 165.[10]C H E N R,Z HA N GJ,L IXL.S p e c t r o s c o p y a n dS p e c t r a lA n a l y s i s(陈蕊,张骏,李晓龙.光谱学与光谱分析),2012,32(5):1230.[11]Z H E N G T T.E x t r a c t i o na n dC l a s s i f i c a t i o no fP e a n u tS e e d sb y V i s i b l e-N e a r I n f r a r e dS p e c t r o s c o p y,Y a nT a i:Y a n t a iU n i v e r s i t y(郑田田.花生种子可见-近红外光谱的特征提取与分类识别.烟台:烟台大学),2013:12.[12]F A NSX,HU A N G W Q,L I JB,e t a l.S p e c t r o s c o p y a n dS p e c t r a lA n a l y s i s(樊书祥,黄文倩,李江波等.光谱学与光谱分析),2014,34(8):2089.[13]X U CF,L IG K.P r a c t i c a lW a v e l e tM e t h o d.W u h a n:H u a z h o n g U n i v e r s i t y o f S c i e n c e&T e c h n o l o g y P r e s s(徐长发,李国宽.实用小波方法.武汉:华中科技大学出版社),2001:290.[14]S p i e g e l m a nC H,M e x h a n eMJ,G o e t zMJ.A n a l y t i c a l c h e m i s t r y,1998,70(1),35.[15]C HU Y XL,Y U A N H F,L U W Z.P r o g r e s s i nC h e m i s t r y(褚小立,袁洪福,陆婉珍.化学进展),2004,16(4):528.[16]WA N GJH,HA N D H.S p e c t r o s c o p y a n dS p e c t r a lA n a l y s i s(王加华,韩东海.光谱学与光谱分析),2008,28(10):2308.411第1期分析科学学报第36卷[17]J I ALJ,Z HA N G HJ,WA N GJ,e t a l.F o o da n dF e r m e n t a t i o n I n d u s t r i e s(贾柳君,张海红,王健等.食品与发酵工业),2017,43(2):191.[18]B I EJX,Z HA O YF.C o m p u t e r&D i g i t a l E n g i n e e r i n g(别军象,赵宇峰.计算机与数字工程),2014,42(16):6.D e t e c t i o no f S u g a rD e g r e e i nS t r a w b e r r yB a s e d o n W a v e l e t T r a n s f o r m-G e n e t i cA l g o r i t h m-P a r t i a l L e a s t S q u a r e sZ H A N GJ u a n1,Y U A NS h u a i*2,Z H A N GJ u n3(1.E l e c t r o n i cD e p a r t m e n t,A u t o m o t i v e E n g i n e e r i n g V o c a t i o n a lC o l l e g e,Y a n t a i265500;2.I n f o r m a t i o nE n g i n e e r i n g D e p a r t m e n t,W e n j i n g C o l l e g e o f Y a n t a iU n i v e r s i t y,Y a n t a i264005;3.I n s t i t u t e o f O p t o-E l e c t r o n i c I n f o r m a t i o n,Y a n t a iU n i v e r s i t y,Y a n t a i264005)A b s t r a c t:N e a r i n f r a r e d(N I R)d i f f u s er e f l e c t a n c es p e c t r o s c o p y w a su s e dt os t u d y t h en o n-d e s t r u c t i v e d e t e c t i o no f s t r a w b e r r y s u g a r c o n t e n t.F i r s t l y,t h ed i f f u s e r e f l e c t a n c e s p e c t r ao f s t r a w b e r r y s a m p l e s i n 600-1100n mb a n dw e r e c o l l e c t e db yp o r t a b l en e a r i n f r a r e d s p e c t r o m e t e r.T h ew a v e l e t t r a n s f o r m(WT) m u l t i-r e s o l u t i o na n a l y s i sm e t h o d w a su s e dt od e n o i s et h eo r i g i n a l s p e c t r a ld a t a,a n dt h es p e c t r a ld a t a w i t h o b v i o u s c h a r a c t e r i s t i c p e a k s a n d c l e a r c o n t o u r w e r e o b t a i n e d.T h e g e n e t i c a l g o r i t h m(G A) a l g o r i t h m w a s u s e d t oo p t i m i z e t h e s e l e c t i o no f2001w a v e l e n g t h p o i n t s i n600-1100n mb a n d,a n d201 w a v e l e n g t h p o i n t sw i t h a c u m u l a t i v e c o n t r i b u t i o n o fm o r e t h a n50%w e r e o b t a i n e d.P a r t i a l l e a s t s q u a r e s r e g r e s s i o n(P L S)w a s u s e d t o e s t a b l i s h t h e WT-G A-P L S c a l i b r a t i o n m o d e l o f s t r a w b e r r y.T h e c o r r e l a t i o nc o e f f i c i e n tR Co f t h e c a l i b r a t i o n s e t i s0.9395,t h eR M S E Co f t h e c a l i b r a t i o n s e t i s0.1615, t h e c o r r e l a t i o n c o e f f i c i e n tR Po f t h e p r e d i c t i o ns e t i s0.9652,a n dt h eE M S E Po f t h e p r e d i c t i o ns e t i s 0.5042.C o m p a r e dw i t h t h e f u l l s p e c t r u m m o d e l(F S-P L S)a n d t h ew a v e l e t t r a n s f o r m m o d e l(WT-P L S), t h em o d e lh a sb e t t e r p r e d i c t i o na b i l i t y a n dr o b u s t n e s s.T h ea p p l i c a t i o no f p o r t a b l es p e c t r a la n a l y s i s t e c h n o l o g yp r o v i d e sat h e o r e t i c a lb a s i s f o r t h en o n-d e s t r u c t i v ed e t e c t i o no fs t r a w b e r r y s u g a rc o n t e n t, a l s o p r o v i d e s a f e a s i b i l i t y f o r l o n g-t e r m m o n i t o r i n g o f f r u i td y n a m i c c h a n g e s,t h e r e a l i z a t i o no f o r c h a r d m a n a g e m e n t a n d p o s t-h a r v e s t d e t e c t i o n.K e y w o r d s:N e a r i n f r a r e d s p e c t r o s c o p y;W a v e l e t t r a n s f o r m;G e n e t i c a l g o r i t h m s;P a r t i a l l e a s t-s q u a r e s r e g r e s s i o n; S t r a w b e r r y;S u g a r d e g r e e511。
基于遗传算法和偏最小二乘法的电容式油气两相流空隙率测量新方法王微微;王保良;黄志尧;李海青【期刊名称】《传感技术学报》【年(卷),期】2006(19)1【摘要】电容传感器提供的电容测量信息反映了两相流空隙率的分布,采用12电极阵列式电容传感器提供的电容值的线性组合(即空隙率测量模型)来实现空隙率的测量.遗传算法和偏最小二乘方法用来确定空隙率测量模型.首先应用遗传算法获得对空隙率测量有贡献的最佳电容组合,再用偏最小二乘方法确定各有贡献电容对空隙率测量贡献的大小.实验结果表明,提出的空隙率测量新方法是有效的,测量精度和测量速度满足工业应用要求.【总页数】5页(P191-195)【作者】王微微;王保良;黄志尧;李海青【作者单位】浙江大学控制科学与工程学系工业控制技术国家重点实验室,杭州,310027;浙江大学控制科学与工程学系工业控制技术国家重点实验室,杭州,310027;浙江大学控制科学与工程学系工业控制技术国家重点实验室,杭州,310027;浙江大学控制科学与工程学系工业控制技术国家重点实验室,杭州,310027【正文语种】中文【中图分类】O241.5;O357.4【相关文献】1.基于LS-SVM的油气两相流空隙率测量方法的研究 [J], 蔡慧林;彭珍瑞;祁文哲;孟建军2.基于改进的LS-SVM测量油气两相流空隙率 [J], 彭珍瑞;王保良;黄志尧;李海青3.基于ECT和蚂蚁算法的油气两相流空隙率在线测量 [J], 李强伟;黄志尧;王保良;李海青4.基于PCR和PLSR的油气两相流空隙率测量 [J], 李霞;王保良;黄志尧;李海青5.基于ECT传感器和模式识别的气液两相流空隙率测量新方法研究 [J], 王雷;冀海峰;黄志尧;李海青因版权原因,仅展示原文概要,查看原文内容请购买。
随机森林算法的水果糖分近红外光谱测量李盛芳;贾敏智;董大明【摘要】近年来,有关水果糖分等内部品质的近红外光谱测量方法研究很多,并有部分商业化仪器问世.但由于近红外光谱复杂多变,模型的传递性较差,往往所建模型只能针对特定品种甚至特定产地的水果.随机森林(RF)是一种基于决策树的集成算法,通过对分类回归树(CART)模型的集成来提高预测精度.相对于偏最小二乘法(PLS),多元线型回归法(MLR)等方法,随机森林回归方法对非线性数据的解析能力较强.考虑到RF模型的随机性,通过调试决策树数量(ntree)和分裂变量数目(mtry)等变量来进行模型优选.尝试使用随机森林对不同种类的水果(苹果、梨)糖分进行预测.实验表明,对于同一种类的水果,随机森林和PLS的建模和预测结果均较好.但对于不同种类的水果,随机森林明显增加了模型的预测能力,将建模R2由PLS的0.878提高到了0.999,将建模的RMSEC由0.453降低到了0.015.经过独立的预测集样品对最优RF模型进行检验,预测R2由PLS的0.731提高到为0.888,预测RMSEP由1.148降低到0.334.随机森林在对多种水果糖分预测时,具有明显的优势.这一研究证明了随机森林有望应用于多种水果糖分的近红外光谱测定,进而解决模型的普适性和传递性问题.%In recent years ,many researchers have studied the measurement methods of fruit sugar and other internal quality by near-infrared (NIR) spectroscopy and some commercial instruments have been produced.However ,due to the complexity of the NIR spectra ,the transitivity of the models established with NIR is often poorly performed.The model is only built for a particu-lar species or even a certain variety.Random forest (RF) is an integrated algorithm based on decision tree ,which improves the prediction accuracy by integrating theclassification regression tree (CART) pared with partial least squares (PLS) , multiple linear regression (MLR) and other methods ,RF algorithm has the strong analytical ability of nonlinear data.Taking in-to account the randomness of the RF model ,the model is optimized by debugging the number of decision tree (ntree) and the number of split variables (mtry).In this study ,we used RF to predict the sugar content in different types of fruits (apple and pear).Experimental results showed that for the same kind of fruit ,the modeling and predicting results of RF and PLS were bet-ter.However ,for different types of fruits ,RF significantly increased the prediction ability of the model.The R2 of PLS model was 0.878 and the R2 of RF model was increased to 0.999.The RMSEC of PLS model and RF model were respectively 0.453 and 0.015.In addition ,the optimal RF model was tested by independent test set samples ,the R2 of PLS model was 0.731 and the R2 of RF model was increased to 0.888.The RMSEC of PLS model and RF model were respectively 1.148 and 0.334.RF showed a significant advantage in predicting a variety of fruit sugar.This research proved that the RF method could be applied to detect the sugar content in fruits by NIR spectroscopy ,thus solving the model problem of universality and transitivity.【期刊名称】《光谱学与光谱分析》【年(卷),期】2018(038)006【总页数】6页(P1766-1771)【关键词】近红外;随机森林;苹果糖分;快速检测【作者】李盛芳;贾敏智;董大明【作者单位】太原理工大学 ,山西太原 030024;北京农业智能装备技术研究中心 ,北京 100097;太原理工大学 ,山西太原 030024;北京农业智能装备技术研究中心 ,北京 100097;国家农业智能装备工程技术研究中心 ,北京 100097【正文语种】中文【中图分类】TP181引言苹果和梨是人们非常喜爱的水果,其糖分含量直接影响其口感。
用遗传区间偏最小二乘法建立苹果糖度近红外光谱模型李艳肖;邹小波;董英【期刊名称】《光谱学与光谱分析》【年(卷),期】2007(27)10【摘要】为了简化苹果糖度预测模型和提高模型的精度,用遗传区间偏最小二乘法(GA-iPLS)建立苹果近红外光谱预测模型.应用结果表明,整个光谱划分为40个子区间,GA-iPLS选择其中的第4,6,8,11,18号共5个子区间联合建立苹果糖度模型.遗传区间偏最小二乘法所建的模型,其校正时的相关系数rc和交互验证均方根误差RMSECV分别为0.962和0.334 6,预测时的相关系数rp和预测均方根误差RMSEP分别为0.932和0.384 2.与全光谱模型相比,该方法建立的模型不论对校正集还是预测集,模型的预测能力都提高了许多,且模型得到了很大的简化:其实际采用的波数点个数比全光谱模型采用的波数点个数大大减少,主因子数也比全光谱少,由此建立的模型更加简洁、数据运算量也更少.【总页数】4页(P2001-2004)【作者】李艳肖;邹小波;董英【作者单位】江苏大学农产品加工研究所,江苏,镇江,212013;江苏大学农产品加工研究所,江苏,镇江,212013;江苏大学农产品加工研究所,江苏,镇江,212013【正文语种】中文【中图分类】TP242162;S123【相关文献】1.遗传算法结合区间偏最小二乘法在草莓酸度近红外光谱检测的研究 [J], 艾施荣;刘木华2.用混合线性分析法建立苹果糖度近红外光谱预测模型 [J], 张纯;张海东;江水泉3.苹果酒发酵过程中糖度近红外光谱检测模型的建立 [J], 彭帮柱;岳田利;袁亚宏;高振鹏4.基于遗传算法的苹果糖度近红外光谱分析 [J], 王加华;韩东海5.不同品种苹果糖度近红外光谱在线检测通用模型研究 [J], 刘燕德; 徐海; 孙旭东; 姜小刚; 饶宇; 张雨因版权原因,仅展示原文概要,查看原文内容请购买。
LS-SVM和BP-ANN在草莓糖度NIR检测中的应用牛晓颖;赵志磊;张晓瑜【期刊名称】《农机化研究》【年(卷),期】2013(035)005【摘要】为了提高草莓糖度近红外光谱定量模型的性能,采用偏最小二乘法提取的潜在变量作为最小二乘-支持向量机和反向传播人工神经网络的输入变量,建立了草莓糖度的近红外定量模型,并与偏最小二乘模型结果进行了比较,建模所使用的光谱范围为6 000~9 000 cm-1.结果表明,所建立的最小二乘-支持向量机和反向传播人工神经网络定量模型的校正性能、预测性能和稳定性均优于偏最小二乘定量模型,最优模型为前10个潜在变量得分作为输入变量的最小二乘-支持向量机模型,其校正和预测相关系数分别为0.957和0.951,校正和预测均方根误差分别为0.279%和0.272%,剩余预测偏差为3.23,与以往研究文献相比,获得了较为理想的预测精度和稳定性能.【总页数】4页(P204-207)【作者】牛晓颖;赵志磊;张晓瑜【作者单位】河北大学质量技术监督学院,河北保定071002;河北大学质量技术监督学院,河北保定071002;河北大学质量技术监督学院,河北保定071002【正文语种】中文【中图分类】O657.33;TS207.3【相关文献】1.便携式糖度无损检测仪在甜瓜糖度检测中的应用 [J], 张立虎;李冠;张自强;王贤磊;宁雪飞;闫伟丽2.近红外光谱技术(NIRS)在检测牧草霉菌毒素中的应用 [J], 许庆方;韩建国;玉柱;岳文斌3.近红外光谱技术(NIRS)在干草品质检测中的研究与应用 [J], 丁武蓉;干友民;郭旭生;杨富裕4.NIRS技术无损检测组织氧含量在运动实践中的应用 [J], 马国东5.近红外光谱技术(NIRS)及其在牧草品质检测中的应用 [J], 胡超;白史且;张玉;陈智华因版权原因,仅展示原文概要,查看原文内容请购买。
基于近红外光谱无损检测的水果品质定量分析与预测马毅;汪西原【摘要】针对近红外光谱原理、检测技术及特点,利用近红外光谱检测漫反射技术在水果品质检测方法上的定量分析进行了深入系统研究.在光谱数据预处理上平滑和导数法最常见.建立模型以偏最小二乘法较常见.以遗传算法结合偏最小二乘法、小波分析结合偏最小二乘法等为代表的建模方法,其测量精度有所提高.模型优劣评价指标主要以相关系数(R)、校正集标准偏差(RMSEC)和预测集标准偏差(RMSEP)等参数决定.最后对相关研究进行展望.【期刊名称】《农业科学研究》【年(卷),期】2010(031)003【总页数】5页(P16-20)【关键词】近红外光谱;无损检测;水果;定量分析;漫反射;偏最小二乘法【作者】马毅;汪西原【作者单位】宁夏大学,物理电气信息学院,宁夏,银川,750021;宁夏大学,物理电气信息学院,宁夏,银川,750021【正文语种】中文【中图分类】O657水果品质检测技术多年来一直是农业工程领域的重要研究课题.随着计算机技术的迅速发展以及化学计量学方法研究的日益深入,近红外光谱技术在农产品品质检测领域得到较快发展.可溶性固形物含量、糖度、酸度和硬度等是评价果蔬品质的常规性状指标,对果蔬的定级和定价有着重要的影响[1].将近红外光谱技术应用于水果内部品质的检测,检测时间仅需数秒钟,而且可以同时检测多种成分,实现水果品质的快速分析,对水果分级、生产、加工质量控制具有十分重要的作用.本文就近红外光谱分析技术原理、特点及在水果定量检测方法上的应用做一些讨论.1 近红外光谱无损检测流程1.1 近红外光谱原理1800年近红外光谱区由 Herschel发现,是人类认识最早的非可见光光谱区[2].近红外光(Near Infrared,NIR)是介于可见光(VIS)和中红外光(MIR)之间的电磁波,按ASTM(美国试验和材料检测协会)定义是指波长为780~2526 nm(波数为12820~3959 cm-1)电磁波,近红外区划分为近红外短波(780~1100 nm)和近红外长波(1100~2526 nm)两个区域[3].由于NIR区的倍频和合频吸收弱,谱带复杂和重叠多,信息无法有效的分离和解析,限制了其应用.随着光学、电子技术、计算机技术和化学计量学的发展,多元信息处理的理论与技术得到发展,可以解决NIR谱区吸收弱和重叠的困难.有机物以及部分无机物分子中化学键结合的各种基团(如C=C,N=C,O=C,O=H,N=H)的运动(伸缩、振动、弯曲等)都有它固定的振动频率.当分子受到红外线照射时,被激发产生共振,同时光的能量一部分被吸收,测量其吸收光,可以得到极为复杂的图谱,这种图谱就表现为被测物质的特征.不同物质在近红外区域有丰富的吸收光谱,每种成分都有特定的吸收特征,这为近红外光谱定量分析提供了基础.1.2 近红外光谱无损检测技术、流程及特点目前常用的水果无损检测技术有:分光法检测技术(紫外光、可见光、近红外光)[4]、机器视觉检测技术、电磁特性检测技术、X线与激光分析法、力学特性检测技术、电子鼻与电子舌检测技术、超声波检测技术[5]、免疫学分析方法[6]等,其中应用最广泛、最成功的检测方法是光学方法.近红外光谱法是利用物质对光的吸收、散射、反射和透射等特性来确定其成分含量的一种非破坏性检测技术.近红外光谱检测水果样品中某种内部成分的具体过程为:①选择一定数量且具有代表性的水果样品(又称标准样品集).②用近红外光谱仪采集水果的近红外光谱.③用常规理化分析方法准确测定各个水果要预测的成分含量,并作为实测值.④应用化学计量学分析软件建立水果近红外光谱和成分分析值之间的数学模型.⑤利用已建立的定量数学模型对未知样品进行预测和精度分析.其流程见图1.图1 近红外光谱检测流程图近红外光谱技术用在水果品质检测上的优势是:①它属于非破坏性检测,可保留农产品完整外表而得其内在品质.②测试简单,无繁琐的前处理和化学反应过程.③测试速度快,大大缩短测试周期.④测试过程无污染,检测成本低.⑤近红外光谱包含了待测农产品的所有成分吸收信息,可同时检测多种内部成分.⑥对测试人员无专业化要求,且单人可完成多个化学指标的测试.⑦随模型中优秀数据的积累,模型不断优化,测试精度不断提高.⑧便于实现在线分析、远程控制.⑨测试范围可不断拓展.近红外光谱技术用在水果品质检测上的缺点和不足是:①近红外光谱容易受到样品温度、样品检测部位、样品状态以及检测参数等因素的影响,导致以系统误差为主的光谱信息存在差异性和光谱数据的不稳定性.因此,减少外界干扰,获得稳定光谱有待于研究.②目前研究中很少考虑水果的个体差异.同一品种水果由于产地、气候、采摘时间和储藏时间等条件不同,内部品质会有差异,这会导致水果对模型的适应性不同,模型对水果的预测度也有所不同.③近红外光谱技术依赖于采用化学计量学方法建立的数学模型,不同的建模方法存在差异.由于受使用条件、仪器稳定性等因素的影响,建立的数学模型的适应性也有所变化,而且每一种模型只能适应一定的时间和空间范围,因此需要不断对模型进行维护.2 近红外光谱水果品质无损检测方法与评价指标2.1 近红外光谱分析检测方法近红外光谱对水果分析可分为定量分析和定性分析,定性分析常用于水果的内部品质判别、浅层损伤、内部缺陷以及水果产地、品种鉴别等.定量分析一般用于评价水果内部成分含量,如糖度、酸度、硬度及维生素含量等.定量分析涉及光谱采集模式、光谱预处理、波段选择方法、建模方法和模型评价等[7].近红外光谱采集模式主要有反射、透射、漫反射等.(刘燕德等,2003)[8]研究了水果光特性检测原理及方法,并对三种不同检测方式进行了对比分析,结果表明,对于水果内部品质检测,最适宜用的方法是近红外漫反射光谱检测法.目前国内外水果光谱采集大多数使用漫反射光谱检测方式.光谱预处理方法有很多种,常见的有平滑、导数、标准归一化、傅立叶变换和小波变换[9]等.在波段选择方法上有相关系数法、遗传算法[10]、偏最小二乘法和独立分量分析法[11]等.建模方法常见的有多元线性回归(MLR)、偏最小二乘法(PLS)、主成分回归(PCR)、人工神经网络(ANN)[12]、支持向量机(SVM)[13]等.2.2 常见模型算法模型建立过程就是将通过预处理后的近红外光谱特征与水果有效含量数据进行关联,建立相关关系,建立模型以偏最小二乘(PLS)法最为常见,偏最小二乘法现已成为化学计量学中最有效的多变量校正方法,在化学测量及有关研究中得到广泛应用,它可以集多元线性回归分析、典型相关分析和主成分分析的基本功能为一体,将建模预测类型的数据分析方法与非模型式的数据认识性分析方法有机地结合起来,即:偏最小二乘回归≈多元线性回归分析十典型相关分析十主成分分析.其模型建立步骤可分为两步[14],具体如下:第一步,做矩阵分解,其模型为其中:T和U分别为X矩阵和Y矩阵的得分矩阵;P和Q分别为X矩阵和Y矩阵的载荷(主成分)矩阵;E和F分别为PLS模型拟合X和Y时所引进的误差.第二步,系数关联,将T和U作线性回归.令B为关联系数矩阵:U=TB,这里B=T′U(T′T)-1在预测时,由未知样品的矩阵X未知和校正得到的P校正求出未知样品X矩阵的T未知.然后得到利用PLS建模的优点是:①可以使用全光谱数据或部分光谱数据.②数据矩阵分解和回归交互结合为一步,得到的特征值向量与被测组分或性质相关,而不是与数据矩阵中变化最大的变量相关.③比较适用于小样本,多元数据分析.④可用于复杂的分析体系.其缺点是:①计算速度相对较慢,计算过程较繁,需要多次迭代.②模型建立过程复杂,较抽象,较难理解.2.3 模型评价指标评价建立后模型优劣指标一般常采用相关系数(R)、校正集标准偏差(RMSEC)和预测集标准偏差(RMSEP)[15].R越大,RMSEC和RMSEP越小,模型性能就越好.计算公式为式中:n为校正集样本数;N为预测集样本数;^yi为第i个样品的预测值;yi为第i个样品的参考值(真值);ym为校正集样本真值的平均值.RMSEC是衡量模型好坏的一个重要指标,RMSEP是衡量校正模型预测效果的重要指标.3 近红外光谱分析技术用于水果品质无损检测的研究3.1 苹果品质检测在对苹果的品质检测分析中,(Lammertyn et al,2001)[16] 、(Tsuyoshi etal,2002)[17] 、(Ying Yibin et al,2004)[18]、(刘燕德等,2005)[19]、(赵杰文等,2005)[20]、(王加华等,2008)[21]等人对苹果的糖酸度进行了近红外光谱检测分析.采用近红外漫反射采集方式采集数据,建立预测模型之前先进行光谱数据预处理,主要有平滑、导数、标准归一化和多元散射校正.平滑是去噪最常用的方法,以Savitzky-Golay卷积平滑法最为常见,但需要注意移动窗口及多项式次数的优化选择.导数可以有效地消除基线和其他背景所造成的干扰,但会引入噪声.建立模型的过程中以PLS算法最为常见,文献[21]中就PCR和PLS分别进行建立的模型进行了比较,结果以PLS所建立的模型最优.3.2 梨品质检测在对梨的品质检测分析中,(Liu Yande et al,2006)[22]、(刘燕德等,2006)[23]、(王加华等,2009)[24]、(潘璐等,2009)[25]等人对梨的糖酸度进行了近红外光谱检测分析.数据处理上大多采用平滑、导数、标准归一化和多元散射校正处理.文献[26]中对光谱进行了遗传算法波段优化,然后建立了遗传算法偏最小二乘法(GA-PLS)模型,建模结果为:R=0.966,RMSEC=0.469,RMSEP=0.797.将遗传算法用于波段选择,能更快达到最优解,有效提高测量精度,减少建模所用变量.3.3 其他水果品质检测除了对苹果和梨的研究之外,还有对橘子[26]、水蜜桃[27]、柑橘[28]、大白桃[29]和鲜枣[30]等水果进行近红外光谱分析检测.数据采集方式以漫反射为常见,对数据的预处理上采用平滑、导数、多元散射校正和小波变换等.多数以PLS建立模型,文献[12]还分别以偏最小二乘法结合遗传算法和人工神经网络(PLS-GA-BP)和偏最小二乘法结合BP神经网络(PLS-BP)建立模型进行相互比较,其结果PLS-GA-BP模型优于PLS-BP模型,其酸度和糖度的预测结果与测量值之间的相关系数和预测标准差分别为R=0.83699,RMSEP=0.109447;R=0.85409,RMSEP=0.60934.4 近红外光谱定量分析与传统测量部分水果品质比较近红外光谱分析技术应用在水果的定性与定量检测上有很明显的比较优势,见表1. 表1 苹果等水果糖度分析比较5 近红外光谱无损检测展望现代近红外光谱分析技术包括了近红外光谱仪、化学计量学软件和应用模型三部分.三者的有机结合才能满足快速分析的技术要求,缺一不可.近红外光谱分析的核心技术之一是光谱信息和组分之间建立函数关系及数学模型.在建立模型之前先要对光谱数据进行预处理,这样是为了去掉噪声等外界因素的干扰,从本文中可见平滑和导数是常见的去噪方法.小波变换由于降噪、消除基线漂移和满足局部性等优点,在数据预处理上有明显的优势,再结合遗传算法优化波段,剔除无用信息,这样建立的模型更优一些.建立模型时,PLS算法比较常见,这是因为PLS可以集多元线性回归、典型相关分析和主成分分析的基本功能为一体,其优点在本文中也提到.但是计算速度相对较慢,过程较繁,模型建立过程复杂、抽象和难理解等.最近也提到利用ANN和SVM算法来进行建模,在一些文章中也出现过,ANN能够很好解决抗干扰、抗噪声能力,ANN和SVM都能很好的解决非线性转换能力,但是学习时间都较长.6 结论本文就近红外光谱原理、检测流程、特点及水果定量检测上的应用进行了分析与探究,并就未来可能发展趋势进行了展望.近红外光谱分析技术具有快速、周期短、非破坏性,检测过程无污染、低成本及同时测定多种成分等特点,在很多领域得到广泛应用,随着算法的完善以及新的算法的提出,建立近红外光谱数据模型将会越来越优,精度也越来越高.从目前国内外研究进展情况来看,由于近红外光谱检测技术自身的许多优点,必将成为水果等无损检测中经济、有效且最具发展前景的分析技术之一. 参考文献:【相关文献】[1] 崔艳莉,冀晓磊,古丽菲娅,等.近红外光谱在果蔬品质无损检测中的研究进展[J].农产品加工:学刊,2007,(7):84-86.[2] 梁高峰,贾宏汝,谷运红,等.近红外光谱分析技术及其在农业研究中的应用[J].安徽农业科学,2007,35(29):9113-9115.[3] 李静,刘斌,岳田利,等.近红外光谱分析技术及其在食品中的应用[J].农产品加工:学刊,2007(3):44-47.[4] 应义斌,韩东海.农产品无损检测技术[M].北京:化学工业出版社,2005.[5] 刘燕德.无损智能检测技术及应用[M].武汉:华中科技大学出版社,2007.[6] 孙通,徐惠荣,应义斌.近红外光谱分析技术在农产品/食品品质在线无损检测中的应用研究进展[J].光谱学与光谱分析,2009,29(1):122-126.[7] 韩东海,王加华.水果内部品质近红外光谱无损检测研究进展[J].中国激光,2008,35(8):1123-1131.[8] 应义斌,刘燕德.水果内部品质光特性无损检测研究及应用[J].浙江大学学报:农业与生命科学版,2003,29(2):125-129.[9] 褚小立,袁洪福,陆婉珍.近红外分析中光谱预处理及波长选择方法进展与应用[J].化学进展,2004,29(4):528-541.[10] 陈斌,王豪,林松,等.基于相关系数法与遗传算法的啤酒酒精度近红外光谱分析[J].农业工程学报,2005,21(7):99-102.[11] 方利民,林敏.近红外光谱数据处理的独立分量分析方法研究[J].中国计量学院学报,2008,19(2):137-145.[12] 虞佳佳,何勇,鲍一丹.基于光谱技术的芒果糖度酸度无损检测方法研究[J].光谱学与光谱分析,2008,28(12):2839-2842.[13] 赵杰文,呼怀平,邹小波.支持向量机在苹果分类的近红外光谱模型中的应用[J].农业工程学报,2007,23(4):149-152.[14] 陆婉珍,袁洪福,徐广通,等.现代近红外光谱分析技术[M].北京:中国石化出版社,2000.[15] 夏俊芳,张战锋,王志山.番茄总糖含量的近红外光谱无损检测方法研究[J].食品科学,2009,6(30):171-174.[16] LAM MERTYN J,NICOLAI B,SM EDT D V,et al.Nonestructive measurement ofpH,soluble solids and firmness of Jonagold apples using NIRpectroscopy[J].Acta Horticulturae,2001(562):167-173.[17] TSUYOSHI T,KENKOH H,FUJITOSHI S.Measuring the Sugar Content of Apples and Apple Juice by Near Infrared Spectroscopy[J].OPTICAL REVIEW,2002,9(2):40-44.[18] YING YIBIN,LIU YANDE,FU XIAPING,et al.Effect of wavelet transform techniques upon the estimation of sugar content in apple with near-infraredspectroscopy[C].Nondestructive sensing for food safety,quality,and natural resources,2004,29-41.[19] 刘燕德,应义斌,傅霞萍.近红外漫反射用于检测苹果糖度及有效酸度的研究[J].光谱学与光谱分析,2005,25(11):51-54.[20] 赵杰文,张海东,刘木华.利用近红外漫反射光谱技术进行苹果糖度无损检测的研究[J].农业工程学报,2005,21(3):162-165.[21] 王加华,韩东海.基于遗传算法的苹果糖度近红外光谱分析[J].光谱学与光谱分析,2008,28(10):2308-2311.[22] LIU YANDE,YING YIBIN.Optical system for measurement ofinternal pearquality using near-infrared spectroscopy[J].Optical engineering,2005,44(7):1-5.[23] 刘燕德,应义斌,傅霞萍,等.一种近红外光谱水果内部品质自动检测系统[J].浙江大学学报:工学版,2006,40(1):53-56.[24] 王加华,潘璐,孙谦,等.遗传算法结合偏最小二乘法无损评价西洋梨糖度[J].光谱学与光谱分析,2009,29(3):678-681.[25] 潘璐,王加华,李鹏飞,等.砂梨糖度近红外光谱波段遗传算法优化[J].光谱学与光谱分析,2009,29(5):1246-1250.[26] SHAO YONGNI,HE YONG,BAO YIDAN.Nearinfrared spectroscopy for classification of oranges and prediction of the sugar content[J].International Journal of Food Properties,2009,12(3):644-658.[27] 刘燕德,应义斌.水蜜桃糖度和有效酸度的近红外光谱测定法[J].营养学报,2004,26(5):400-402.[28] 夏俊芳,李小昱,李培武,等.基于小波消噪柑橘内部品质近红外光谱的无损检测[J].华中农业大学学报,2007,26(1):120-123.[29] 马广,傅霞萍,周莹,等.大白桃糖度的近红外漫反射光谱无损检测试验研究[J].光谱学与光谱分析,2007,27(5):907-910.[30] 张淑娟,王凤花,张海红,等.鲜枣品种和可溶性固形物含量近红外光谱检测[J].农业机械学报,2009,40(4):139-142.[31] 李艳肖,邹小波,董英.用遗传区间偏最小二乘法建立苹果糖度近红外光谱模型[J].光谱学与光谱分析,2007,27(10):2001-2004.[32] 徐惠荣,汪辉君,黄康,等.PLS和 SMLR建模方法在水蜜桃糖度无损检测中的比较研究[J].光谱学与光谱分析,2008,28(11):2523-2526.。