
典型相关分析
典型相关分析(Canonical
correlation
)又称规则相关分析,用以分析两组变量间关系的一种方法;两个变量组均包含多个变量,所以简单相关和多元回归的解惑都是规则相关的特例。典型相关将各组变量作为整体对待,描述的是两个变量组之间整体的相关,
而不是
两个变量组个别变量之间的相关。
典型相关与主成分相关有类似,
不过主成分考虑的是一组变量,而典型相关考虑的是两
组变量间的关系,有学者将规则相关视为双管的主成分分析;因为它主要在寻找一组变量的
成分使之与另一组的成分具有最大的线性关系。
典型相关模型的基本假设:
两组变量间是线性关系,
每对典型变量之间是线性关系,每
个典型变量与本组变量之间也是线性关系;典型相关还要求各组内变量间不能有高度的复共
线性。典型相关两组变量地位相等,如有隐含的因果关系,可令一组为自变量,另一组为因
变量。
典型相关会找出一组变量的线性组合
*
*=
i i j j X a x Y b y 与,称为典型变量;以
使两个典型变量之间所能获得相关系数达到最大,这一相关系数称为典型相关系数。
i a 和j
b 称为典型系数。如果对变量进行标准化后再进行上述操作,得到的是标准化的典型系数。
典型变量的性质
每个典型变量智慧与对应的另一组典型变量相关,而不与其他典型变量相关;
原来所有
变量的总方差通过典型变量而成为几个相互独立的维度。一个典型相关系数只是两个典型变
量之间的相关,不能代表两个变量组的相关;各对典型变量构成的多维典型相关,
共同代表
两组变量间的整体相关。
典型负荷系数和交叉负荷系数典型负荷系数也称结构相关系数,
指的是一个典型变量与本组所有变量的简单相关系数,
交叉负荷系数指的是一个典型变量与另一组变量组各个变量的简单相关系数。典型系数隐含着偏相关的意思,而典型负荷系数代表的是典型变量与变量间的简单相关,两者有很大区别。
重叠指数
如果一组变量的部分方差可以又另一个变量的方差来解释和预测,就可以说这部分方差与另一个变量的方差之间相重叠,或可由另一变量所解释。将重叠应用到典型相关时,只要
CR),就得到这对典型变量方差的共同比例,代表一个典型
简单地将典型相关系数平方(2
变量的方差可有另一个典型变量解释的比例,如果将此比例再乘以典型变量所能解释的本组
变量总方差的比例,得到的就是一组变量的方差所能够被另一组变量的典型变量所能解释的
比例,即为重叠系数。
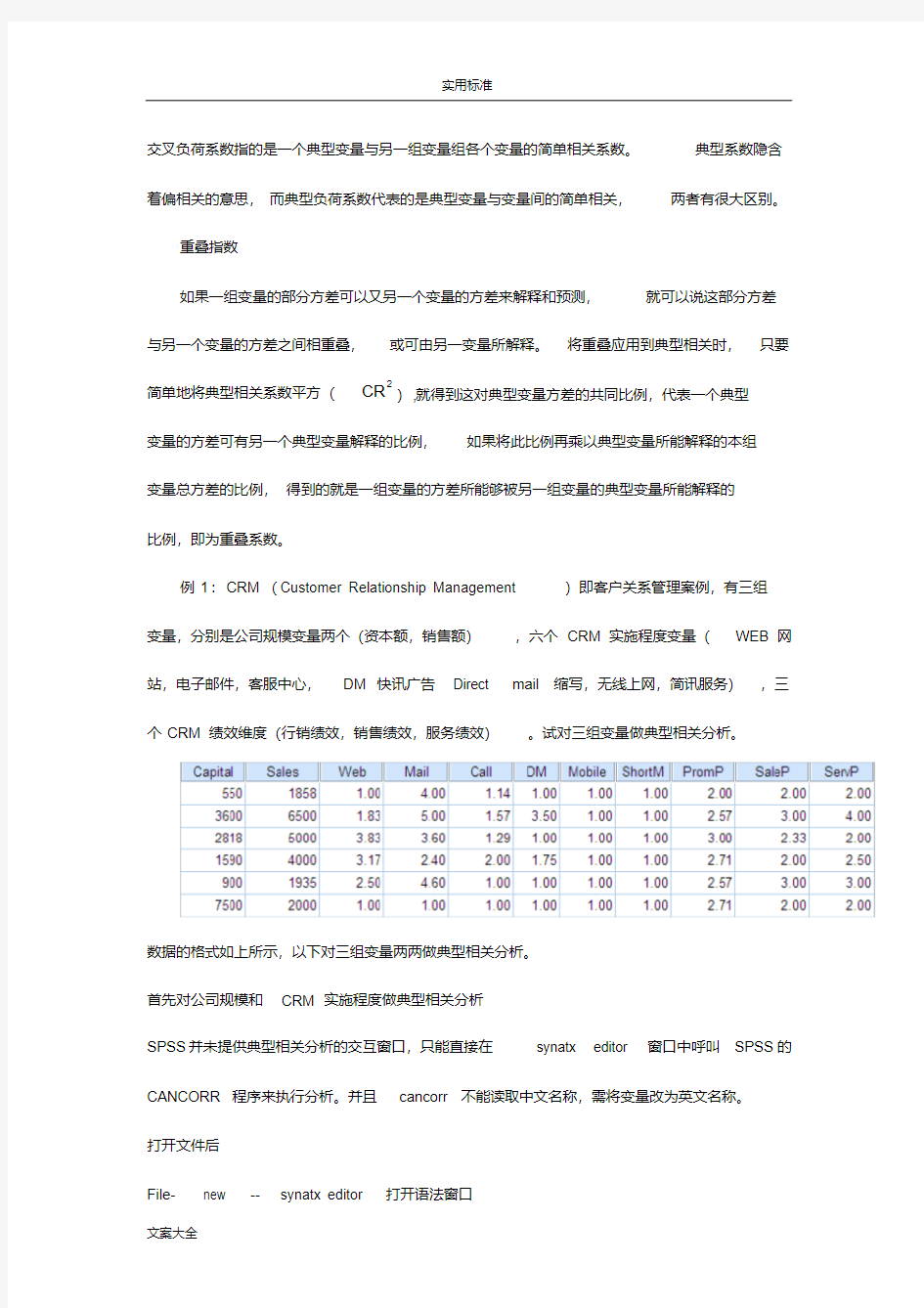
例1:CRM(Customer Relationship Management)即客户关系管理案例,有三组
变量,分别是公司规模变量两个(资本额,销售额),六个CRM实施程度变量(WEB网站,电子邮件,客服中心,DM快讯广告Direct mail缩写,无线上网,简讯服务),三个CRM绩效维度(行销绩效,销售绩效,服务绩效)。试对三组变量做典型相关分析。
数据的格式如上所示,以下对三组变量两两做典型相关分析。
首先对公司规模和CRM实施程度做典型相关分析
SPSS并未提供典型相关分析的交互窗口,只能直接在synatx editor 窗口中呼叫SPSS的CANCORR程序来执行分析。并且cancorr不能读取中文名称,需将变量改为英文名称。
打开文件后
File- new --synatx editor打开语法窗口
输入语句
INCLUDE 'D:\spss19\Samples\English\Canonical correlation.sps'. CANCORR Set1=Capital Sales
/Set2=Web Mail Call DM Mobile ShortM.
小写字母也行,但是变量名字必须严格一致
include 'D:\spss19\Samples\English\Canonical correlation.sps'. cancorr set1=Capital Sales
/set2=Web Mail Call DM Mobile ShortM.
注意第三行的“/”不能为“”
run all得到典型相关分析结果
第一组变量间的简单相关系数
第一对典型变量的典型相关系数为CR1=0.434,第二对典型变量的典型相关系数为
CR2=0.298.
此为检验相关系数是否显著的检验,原假设:相关系数为0.
每行的检验都是对此行及以后各行所对应的典型相关系数的多元检验。
第一行看出,第一对典型变量的典型相关系数是不为0的,相关性显著。第二行sig值P=0.263>0.05,在5%显著性水平下不显著。
第一个典型变量的标准化典型系数为-0.287和-0.774.
CV1-1=--0.287capital--0.774sales, CV1-2=--1.4capital+1.2sales
CV2-1=--0.341web+0.117mail+0.027call—0.091DM—0.767mobile—0.174shortm CV2-2=--0.433web—0.168mail—1.075call+0.490DM+0.139mobile+0.812shortm
典型负荷系数和交叉负荷系数表
重叠系数分析Redundancy index
CR*0.833=0.434^2*0.833 0.157=21
CR=0.434^2*0.425 0.08=21*0.425
此为计算的典型变量,保存到原文件后部。
公司规模与CRM绩效的典型相关分析
CRM绩效与CRM实施程度典型相关分析
自变量因变量规则相关系数检验的P值
公司规模CRM实施程度0.434 0.05
CRM实施程度CRM绩效0.368 0.00
公司规模CRM绩效0.358 0.112
由上表知,公司规模与CRM实施程度显著相关,且公司规模越大实施程度越高;此外CRM 实施程度越高越能实现CRM绩效,但公司规模与CRM绩效并不显著相关;就整体而言,
公司规模不直接影响CRM绩效,而是通过CRM实施程度间接影响CRM绩效。影响CRM 绩因素很多,光靠较大公司规模还不是CRM绩效的保证,还有其他因素影响CRM绩效。
例2:全国30省市自治区农村收入与支出的指标,x1—x4反映农村收入,y1---y8反映农村生活费支出,对收入与支出进行典型相关分析。
语法输入
INCLUDE 'D:/spss19/Samples/English/Canonical correlation.sps'. cancorr set1=x1 x2 x3 x4
/set2=y1 y2 y3 y4 y5 y6 y7 y8.
只有前两对典型相关系数是显著的;分别为CR1=0.982和CR2=0.910.
CV1-1=-0.511x1-0.039x2-0.448x3-0.142x4
CV1-2=-1.046x1-0.293x2+1.459x3-0.319x4
CV2-1=-0.199y1+0.017y2+0.442y3-0.615y4+0.096y5-0.415y6-0.07y7-0.22y8
CV2-2=-0.117y1-1.512y2-1.515y3+1.320y4-0.03y5+0.705y6+0.453y7+0.274y8
第一对典型变量说明靠劳动报酬和转移收入为主的家庭其对应的消费主要在家庭设备和服
务,交通和通讯支出上,在居住支出上比较少。
例三:已知294个被调查者的cesd(抑郁症),health与sex , age ,education,income两组指标建立数据文件。对两组进行典型相关分析。
语法输入
INCLUDE 'D:/spss19/Samples/English/Canonical correlation.sps'.
CANCORR Set1=cesd health
/Set2=sex age educ income.
结果选录
从第一对典型变量的表达式看出,年龄较大,教育程度较低,相对的无抑郁症趋势;显然健
康比较差。
第二对典型变量表明,年龄小,教育度低,收入低的女性相对的有抑郁症。
企业管理 对居民消费率影响因素的探究 ---以湖北省为例 改革开放以来,我国经济始终保持着高速增长的趋势,三十多年间综合国力得到显著增强,但我国居民消费率一直偏低,甚至一直有下降的趋势。居民消费率的偏低必然会导致我国内需的不足,进而会影响我国经济的长期健康发展。 本模型以湖北省1995年-2010年数据为例,探究各因素对居民消费率的影响及多元关系。(注:计算我国居民的消费率,用居民的人均消费除以人均GDP,得到居民的消费率)。通常来说,影响居民消费率的因素是多方面的,如:居民总 收入,人均GDP,人口结构状况1(儿童抚养系数,老年抚养系数),居民消费价格指数增长率等因素。 1.人口年龄结构一种比较精准的描述是:儿童抚养系数(0-14岁人口与 15-64岁人口的比值)、老年抚养系数(65岁及以上人口与15-64岁人口的比值〉或总抚养系数(儿童和老年抚养系数之和)。0-14岁人口比例与65岁及以上人口比例可由《湖北省统计年鉴》查得。
一、计量经济模型分析 (一)、数据搜集 根据以上分析,本模型在影响居民消费率因素中引入6个解释变量。X1:居民总收入(亿元),X2:人口增长率(‰),X3:居民消费价格指数增长率,X4:少儿抚养系数,X5:老年抚养系数,X6:居民消费占收入比重(%)。 Y:消费率(%)X1:总收入 (亿元) X2:人口增 长率(‰) X3:居民消 费价格指 数增长率 X4:少儿抚 养系数 X5:老年抚 养系数 X6:居民消 费比重(%) 1995 1997 200039 2001 2002 2003 2004 2005 2006 2007 2008 2009
2 2 SPSS 期末报告 关于员工受教育程度对其工资水 平的影响统计分析报告 SPSS 统计分析方法 姓汤重阳 号:学 三班所在班级: 目录 一、 数据样本描 述 ..................... 二、 要解决的问题描 述 ..................... 1数据管理与软件入门部分 1 1.1分类汇总 ............ 1.2个案排秩 ............ 1.3连续变量变分组变量 2统计描述与统计图表部分 2.1频数分析.…… 2.2描述统计分析 3假设检验方法部分 2 3.1分布类型检验 3.1.1 正态分布. 3.1.2 二项分布. 课程名称: 名: 人力资源管理 所在专业:
3.1.3 游程检验 (2) 3.2 单因素方差分析 (2) 3.3 卡方检验 (2) 3.4 相关与线性回归的分析方法 (2) 3.4.1 相关分析(双变量相关分析&偏相关分析) (2) 3.4.2 线性回归模型 (2) 4 高级阶段方法部分..................................... 2 三、具体步骤描述 (3) 1 数据管理与软件入门部分.................................. 3 1.1 分类汇总 (3) 1.2 个案排秩 (3) 1.3 连续变量变分组变量 (4) 5 ........................................................ 统计描述与统计图表部 分2 2.1 频数分析 (5) 2.2 描述统计分析 (6) 3 假设检验方法部分..................................... 7 3.1 分布类型检验 (7) 3.1.1 正态分布 (7) 3.1.2 二项分布 (8) 3.1.3 游程检验 (9) 3.2 单因素方差分析 (10) 3.3 卡方检验 (12) 3.4 相关与线性回归的分析方法 (13) 3.4.1 相关分析 (13) 3.4.2 线性回归模型 (15) 4 高级阶段方法部分..................................... 16 4.1 信度 (16) 71 ................................................................... 效度4.2 一、数据样本描述 分析数据来自于“微盘一一SPSS数据包data02-01 ”。 本次分析的数据为某公司474名职工状况统计表,其中共包含11 个变量,分别是: id (职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度), jobcat (职务等级),salbegin (起始工资),salary (现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用SPSS统计软件,对变量进行统计分析,以了解该公司职工总体状况,并分析职工受教育程度、起始工资、现工资的分布特点及相互间的关系。
SPSS皮尔逊相关分析实例操作步骤 选题: 对某地29名13岁男童的身高(cm)、体重(kg),运用相关分析法来分析其身高与体重是否相关。 实验目的: 任何事物的存在都不是孤立的,而是相互联系、相互制约的。相关分析可对变量进行相关关系的分析,计算29名13岁男童的身高(cm)、体重(kg),以判断两个变量之间相互关系的密切程度。 实验变量: 编号Number,身高height(cm),体重weight(kg) 原始数据: 实验方法: 皮 尔 逊 相 关 分 析 法 软件: 操作过程与结果分析:
第一步:导入Excel 数据文件 1.open data document ——open data ——open ; 2. Opening excel data source ——OK. 第二步:分析身高(cm )与体重(kg )是否具有相关性 1. 在最上面菜单里面选中Analyze ——correlate ——bivariate ,首先使用Pearson ,two-tailed ,勾选flag significant correlations 进入如下界面: 2. 点击右侧options ,勾选Statistics ,默认Missing Values ,点击Continue 输出结果: 图为基本的描述性统计量的输 出表格,其中身高的均值(mean ) 为、标准差(standard deviation ) 为、样本容量(number of cases ) 为29;体重的均值为、标准差为、 样本容量为29。两者的平均值和标准差值得差距不显着。 图为相关分析结果表,从表中可以看出体重和身高之间的皮尔逊相关系数为,即 |r|=,表示体重与身高呈正相关关系,且两变量是显着相关的。另外, 两者之间不相关的双侧检验值为,图中的双星号标 记的相关系数是在显着性水平为以下,认为标记的相关系数是显着的,验证了两者显着相关的关系。所以可以得出结论:学生的体重与身高存在显着的 Descriptive Statistics Mean Std. Deviation N 身高(cm ) 29 体重(kg) 29 Correlations 身高(cm ) 体重(kg) 身高(cm ) Pearson Correlation 1 .719** Sig. (2-tailed) .000 Sum of Squares and Cross-products Covariance N 29 29 体重(kg) Pearson Correlation .719** 1 Sig. (2-tailed) .000 Sum of Squares and Cross-products Covariance N 29 29 **. Correlation is significant at the level (2-tailed).
回归分析 实验内容:基于居民消费性支出与居民可支配收入的简单线性回归分析 【研究目的】 居民消费在社会经济的持续发展中有着重要的作用。影响各地区居民消费支出的因素很多,例如居民的收入水平、商品价格水平、收入分配状况、消费者偏好、家庭财产状况、消费信贷状况、消费者年龄构成、社会保障制度、风俗习惯等等。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的经济模型去研究。 【模型设定】 我们研究的对象是各地区居民消费的差异。由于各地区的城市与农村人口比例及经济结构有较大差异,现选用城镇居民消费进行比较。模型中被解释变量Y选定为“城市居民每人每年的平均消费支出”。从理论和经验分析,影响居民消费水平的最主要因素是居民的可支配收入,故可以选用“城市居民每人每年可支配收入”作为解释变量X,选取2010年截面数据。 1、实验数据 表1: (
2010年中国各地区城市居民人均年消费支出和可支配收入
} 数据来源:《中国统计年鉴》2010年 2、实验过程 作城市居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)的散点图,如图1:
表2 模型汇总b 模型… R R方调整R方标准估计的误差 1.965a.93 2.930 a.预测变量:(常量),可支配收入X(元)。 b.因变量:消费性支出Y(元) ~ 表3 相关性 消费性支出Y (元) 可支配收入X(元) Pearson相关 性消费性支出 Y(元) .965 从散点图可以看出居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)大体呈现为线性关系,所以建立如下线性模型:Y=a+bX
关于某地区361个人旅游情况统计分析报告 一、数据介绍: 本次分析的数据为某地区361个人旅游情况状况统计表,其中共包含七变量,分别是:年龄,为三类变量;性别,为二类变量(0代表女,1代表男);收入,为一类变量;旅游花费,为一类变量;通道,为二类变量(0代表没走通道,1代表走通道);旅游的积极性,为三类变量(0代表积极性差,1代表积极性一般,2代表积极性比较好,3代表积极性好 4代表积极性非常好);额外收入,一类变量。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、。。。以了解该地区上述方面的综合状况,并分析个变量的分布特点及相互间的关系。 二、数据分析 1、频数分析。基本的统计分析往往从频数分析开始。通过频数分地区359个人旅游基本状 况的统计数据表,在性别、旅游的积极性不同的状况下的频数分析,从而了解该地区的男女职工数量、不同积极性况的基本分布。 首先,对该地区的男女性别分布进行频数分析,结果如下 表说明,在该地区被调查的359个人中,有198名女性,161名男性,男女比例分别为44.8%和55.2%,该公司职工男女数量差距不大,女性略多于男性。 其次对原有数据中的旅游的积极性进行频数分析,结果如下表:
其次对原有数据中的是否进通道进行频数分析,结果如下表:
表说明,在该地区被调查的359个人中,有没走通道的占81.6%,占绝大多数。 上表及其直方图说明,被调查的359个人中,对与旅游积极性差的组频数最高的,为171 人数的47.6%,其次为积极性一般和比较好的,占比例都为22.0%,积性为好的和非常好的比例比较低,分别为24人和6人,占总体的比例为6.7%和1.7%。 2、探索性数据分析 (1)交叉分析。 通过频数分析能够掌握单个变量的数据分布情况,但是在实际分析中,不仅要了解单个变量的分布特征,还要分析多个变量不同取值下的分布,掌握多个变量的联合分布特征,进而分析变量之间的相互影响和关系。就本数据而言,需要了解现工资与性别、年龄、受教育水平、起始工资、本单位工作经历、以前工作经历、职务等级的交叉分析。现以现工资与职务等级的列联表分析为例,读取数据(下面数据分析表为截取的一部分): Count
典型相关分析 典型相关分析(Canonical correlation )又称规则相关分析,用以分析两组变量间关系的一种方法;两个变量组均包含多个变量,所以简单相关和多元回归的解惑都是规则相关的特例。典型相关将各组变量作为整体对待,描述的是两个变量组之间整体的相关, 而不是 两个变量组个别变量之间的相关。 典型相关与主成分相关有类似, 不过主成分考虑的是一组变量,而典型相关考虑的是两 组变量间的关系,有学者将规则相关视为双管的主成分分析;因为它主要在寻找一组变量的 成分使之与另一组的成分具有最大的线性关系。 典型相关模型的基本假设: 两组变量间是线性关系, 每对典型变量之间是线性关系,每 个典型变量与本组变量之间也是线性关系;典型相关还要求各组内变量间不能有高度的复共 线性。典型相关两组变量地位相等,如有隐含的因果关系,可令一组为自变量,另一组为因 变量。 典型相关会找出一组变量的线性组合 * *= i i j j X a x Y b y 与,称为典型变量;以 使两个典型变量之间所能获得相关系数达到最大,这一相关系数称为典型相关系数。 i a 和j b 称为典型系数。如果对变量进行标准化后再进行上述操作,得到的是标准化的典型系数。 典型变量的性质 每个典型变量智慧与对应的另一组典型变量相关,而不与其他典型变量相关; 原来所有 变量的总方差通过典型变量而成为几个相互独立的维度。一个典型相关系数只是两个典型变 量之间的相关,不能代表两个变量组的相关;各对典型变量构成的多维典型相关, 共同代表 两组变量间的整体相关。 典型负荷系数和交叉负荷系数典型负荷系数也称结构相关系数, 指的是一个典型变量与本组所有变量的简单相关系数,
相关分析 一、两个变量的相关分析:Bivariate 1.相关系数的含义 相关分析是研究变量间密切程度的一种常用统计方法。相关系数是描述相关关系强弱程度和方向的统计量,通常用r 表示。 ①相关系数的取值范围在-1和+1之间,即:–1≤r ≤ 1。 ②计算结果,若r 为正,则表明两变量为正相关;若r 为负,则表明两变量为负相关。 ③相关系数r 的数值越接近于1(–1或+1),表示相关系数越强;越接近于0,表示相关系数越弱。如果r=1或–1,则表示两个现象完全直线性相关。如果=0,则表示两个现象完全不相关(不是直线相关)。 ④3.0 Gender Educational Level (years)N Valid 474474Missing 00关于某公司474名职工综合状况的统计分析报告 1、 数据介绍: 本次分析的数据为某公司474名职工状况统计表,其中共包含十一变量,分别是:id (职工编号),gender(性别),bdate(出生日期),edcu (受教育水平程度),jobcat (职务等级),salbegin (起始工 资),salary (现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用spss 统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、。。。以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。2、 数据分析 1、 频数分析。基本的统计分析往往从频数分析开始。通过频数分析 能够了解变量的取值状况,对把握数据的分布特征非常有用。此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu (受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。 Statistics 首先,对该公司的男女 性别分布进行频数分析,结果如下: Gender FrequencyPercent Valid Percent Cumulative Percent Valid Female 21645.645.645.6 Male 258 54.4 54.4 100.0 Total 474100.0100.0 上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为45.6%和54.4%,该公司职工男女数量差距不大,男性略多于女性。 其次对原有数据中的受教育程度进行频数分析,结果如下表 : Educational Level (years) Valid Cumulative SPSS统计分析案例 一、我国城镇居民现状 近年来,我国宏观经济形势发生了重大变化,经济发展速度加快,居民收入稳定增加,在国家连续出台住房、教育、医疗等各项改革措施和实施“刺激消费、扩大内需、拉动经济增长”经济政策的影响下,全国居民的消费支出也强劲增长,消费结构发生了显著变化,消费结构不合理现象得到了一定程度的改善。本文通过相关数据分析总结出了我国城镇居民消费呈现富裕型、娱乐教育文化服务类消费攀升的趋势特点。 二、我国居民消费结构的横向分析 第一,食品消费支出比重随收入增加呈现出明显的下降趋势,这与恩格尔定律的表述一致。但最低收入户与最高收入恩格尔系数相差太过悬殊,城镇最低收入户刚刚解决了温饱问题,而最高收入户的生活水平按照恩格尔系数的评价标准早已达到了富裕型,甚至接近最富裕型。第二,衣着消费支出比重随收入增加缓慢上升,到高收入户又有所下降,但各收入组支出比重相差不大。衣着支出比重没有更多的递增且最高收入户的支出比重有所下降,这些都符合恩格尔定律关于衣着消费的引申。随着收入的增加,衣着支出比重呈现先上升后下降的走势。事实上,在当前的价格水平和服装业的发展水平下,城镇居民的穿着是有一定限度的,而且居民对衣着的需求也不是无限膨胀的,即使收入水平继续提高,也不需要将更大的比例用于购买服饰用品了。第三,家庭设备用品及服务、交通通讯、娱乐教育文化服务和杂项商品与服务的支出比重呈逐组上升趋势,说明居民的生活水平随收入的增加而不断提高和改善。第四,医疗保健支出比重随收入水平提高呈现一种两端高、中间低的走势。这是因为医疗保健支出作为生活必须支出,不论居民生活水平高低,都要将一定比例的收入用于维持自身健康,而且由于医疗制度改革,加重了个人负担的同时,也减小了旧制度可能造成的不同行业、不同体制下居民医疗保健支出的差别,因而不同收入等级的居民在医疗保健支出比重上差别不大。第五,居住支出比重基本上呈先上升后下降的趋势,这与我国居民消费能级不断提升,住宅商品正在越来越成为城镇居民关注的热点是相吻合的,同时与恩格尔定律的引申也是一致的。可以看出,城镇居民的消费状况虽然受价格水平、消费习惯、消费环境、消费心理预期等诸多因素的影响,但归根结底仍取决于居民的收入水平,要提高城镇居民的消费支出,必须增加居民收入。因此,采取切实有效的措施增加城镇居民的可支配收入,不仅可以提高全国城镇居民的总体消费水平,促进消费结构向着更加健康、合理的方向发展,而且在启动内需,促进我国的经济发展方面有着重大的现实意义。 三、我国居民消费结构的纵向分析 进入21世纪以来,随着经济体制改革的深入,国民经济的迅速发展,我国城乡居民的消费水平显著提高,居民的各项支出显著增加。随着消费水平的提高,我国城乡居民消费从注重量的满足到追求质的提高,从以衣食消费为主的生存型到追求生活质量的享受型、发展型,消费 本次实验采用2005年东部、中部和西部各地区省份城镇居民月平均消费类型划分的数据(课本139页),将东部、中部和西部看作三个不同总体,31个数据分别来自于这三个总体。本人对这三个不同地区的城镇居民月平均消费水平进行比较,并选取人均粮食支出、副食支出、烟酒及饮料支出、其他副食支出、衣着支出、日用杂品支出、水电燃料支出和其他非商品支出八个指标来衡量城镇居民月平均消费情况。 在进行比较分析之前,首先对个数据是否服从多元正态分布进行检验,输出结果为: 表一 如表一,因为该例中样本数n=31<2000,所以此处选用Shapiro-Wilk统计量。由正态性检验结果的sig.值可以看到,人均粮食支出、烟酒及饮料支出、其他副食支出、水电燃料支出和其他非商品支出均明显不遵从正态分布(Sig.值小于,拒绝服从正态分布的原假设),因此,在下面分析中,只对人均副食支出、衣着支出和日用杂品支出三项指标进行比较,并认为这三个变量组成的向量都遵从正态分布,并对城镇居民月平均消费状况做出近似的度量。另外,正态性的检验还可以通过Q-Q图来实现,此时应判别数据点是否与已知直线拟合得好。如果数据点均落在直线附近,说明拟合得好,服从正态分布,反之,不服从。具体情况这里 不再赘述。 下面进行多因素方差分析: 一、多变量检验 表二 由地区一栏的(即第二栏)所列几个统计量的Sig.值可以看到,无论从那个统计量来看,三个地区的城镇居民月平均消费水平都是有显著差别的(Sig.值小于,拒绝地区取值不同,对Y,即城镇居民月平均消费水平的取值没有显著影响的原假设)。 二、主体间效应检验 如表三,可以看到三个指标地区一栏的(即第三栏)Sig.值分别为、、,说明三个地区在人均衣着支出指标上没有明显的差别(Sig.值大于,不拒绝地区取值不同,对指标的取值没有显著影响的原假设),反之,而在人均副食支出和日用杂品支出指标上有显著差别。 三、多重比较 《统计分析软件(双语)》 实验报告 题目:关于“某地区买房数据”的分析报告 姓名: 学号:1204100215 专业:统计学 院系:统计学院 指导教师: 完成日期:2014年12月10日 摘要 利用SPSS统计分析软件对“某地区买房”数据进行了描述性统计分析,比较均值,相关分析,回归分析四大类型的数据分析。其中在描述性统计分析中作了频数分析,探索分析,交叉分析,得出了该地区中年龄段在25~45居多,就业大多在国企,文化程度高中和大学所占比重大;大学学历的现居住面积较大,其最大值,最小值以及均值均大于其他三种学历的居住面积。人均居住面积的单样本T检验的出了的结论是人均居住面积与均值之间存在显著性差异。现居住面积和人居住面积的双变量的相关分析得出了两者之间存在显著性差异。在回归分析中得出的结论是现居住面积是服从正态分布的且和满意度是显著相关的。 目录 一、数据简要 (3) 二、数据分析 (3) (一)描述分析性统计, (3) 1,就业状况的频数分析 (3) 2,文化程度的频数分析 (3) 3,现居住面积及人均居住面积的描述性分析 (3) 4,居住面积和文化程度的探索分析 (3) 5,文化程度与年收入的交叉列联表分析 (3) (二)均值比较 (3) 1,人均现住面积和年龄段的描述统计 (3) 2,人均居住面积的单样本T检验 (3) 3,现居住面积的独立样本T检验 (3) (三)相关分析 (3) 1,现居住面积和人居住面积的双变量的相关分析 (3) 2,人均居住面积,现居住面,居住类型的偏相关分析 (3) (四)回归分析 (3) 三、小结 (3) 一、数据简要 本次分析的数据为某年某地719个人买房情况统计表,一共有11个变量,其中现居住面积与人均居住面积为scale变量,其余9个变量为nonscale变量,依次为年龄段,文化程度,从业状况,家庭类型,家庭年收入,住房满意度,卖掉现房,购买户型,是否贷款。 关于某地区361个人旅游情况统计分析报告一、数据介绍: 本次分析的数据为某地区361个人旅游情况状况统计表,其中共包含七变量,分别是:年龄,为三类变量;性别,为二类变量(0代表女,1代表男);收入,为一类变量;旅游花费,为一类变量;通道,为二类变量(0代表没走通道,1代表走通道);旅游的积极性,为三类变量(0代表积极性差,1代表积极性一般,2代表积极性比较好,3代表积极性好 4代表积极性非常好);额外收入,一类变量。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析,以了解该地区上述方面的综合状况,并分析个变量的分布特点及相互间的关系。 二、数据分析 1、频数分析。基本的统计分析往往从频数分析开始。通过频数分地 区359个人旅游基本状况的统计数据表,在性别、旅游的积极性不同的状况下的频数分析,从而了解该地区的男女职工数量、不同积极性情况的基本分布。 统计量 积极性性别 N有效359359 缺失00 首先,对该地区的男女性别分布进行频数分析,结果如下 性别 频率百分比有效百分 比 累积百分 比 有效女19855.255.255.2 男16144.844.8100.0 合计359100.0100.0 表说明,在该地区被调查的359个人中,有198名女性,161名男性,男女比例分别为44.8%和55.2%,该公司职工男女数量差距不大,女性略多于男性。 其次对原有数据中的旅游的积极性进行频数分析,结果如下表: 积极性 频率百分比有效百分 比 累积百分 比 有效差17147.647.647.6一般7922.022.069.6 比较 好 7922.022.091.6好24 6.7 6.798.3 本科教学实验报告 (实验)课程名称:数据分析技术系列实验 实验报告 学生姓名: 一、实验室名称: 二、实验项目名称:相关分析 三、实验原理 相关关系是不完全确定的随机关系。在相关关系的情况下,当一个或几个相互联系的变量取一定值得时候,与之相应的另一变量的值虽然不确定,但它仍然按照某种规律在一定的范围内变化。 按照数据度量的尺度不同,相关分析的方法也不同,连续变量之间的相关性常用Pearson简单相关系数测定;定序变量的相关系数常用Spearman秩相关系数和Kendall 秩相关系数测定;定类变量的相关分析要使用列连表分析法。 四、实验目的 理解相关分析的基本原理,掌握在SPSS软件中相关分析的主要参数设置及其含义,掌握SPSS软件分析结果的含义及其分析。 五、实验内容及步骤 实验内容:以雇员表为例,共有474条数据,运用相关分析方法对变量间的相关关系进行分析。 1)分析性别与工资之间是否存在相关关系。 2)分析教育程度与工资之间是否存在相关关系。 实验要求:掌握相关分析方法的计算思路及其在SPSS环境下的操作方法,掌握输出结果的解释。 1.分析性别与工资之间是否存在相关关系。 分析:性别属于定类变量,是离散值,因使用卡方检验。 Step1.操作为Analyze\DescriptiveStatistics\Crosstabs Step2.将性别(Gender)和收入(CurrentSalary)分别移入Rows列表框和Columns 列表框。 Step3.单击Statistics按钮,在弹出的子对话框中选中默认的Chi-square,进行卡方检验。退回到主对话框,单击ok。 2.分析教育程度与工资之间是否存在相关关系。 分析:教育程度为定序变量,工资为连续变量,可使用Spearman和Kendall秩相关系数检验。 Step1.用散点图初步判断二变量的相关性,操作为Graphs/LegacyDialogs/Scatter,选择SimpleScatter,教育程度为自变量,工资为因变量,做散点图。 散点图结果如图示,二者存在线性相关关系。只有线性相关的关系确定后才能继续进行下一步分析。因此,在进行相关分析之前的预分析过程也是十分重要的。 Step2.两变量相关分析,操作为Analyze/Correlate/Bivariate,选择Kendall和Spearman 相关系数。 六、实验器材(设备、元器件): 计算机、打印机、硒鼓、碳粉、纸张 七、实验数据及结果分析 1.分析性别与工资之间是否存在相关关系。 卡方检验结果为 显着性水平为,即至少有%的把握认为性别和工资之间存在显着的相关系。 精选范文、公文、论文、和其他应用文档,希望能帮助到你们! SPSS简单数据分析报告 目录 一、数据样本描述 (4) 二、要解决的问题描述 (4) 1 数据管理与软件入门部分 (4) 1.1 分类汇总 (4) 1.2 个案排秩 (5) 1.3 连续变量变分组变量 (5) 2 统计描述与统计图表部分 (5) 2.1 频数分析 (5) 2.2 描述统计分析 (5) 3 假设检验方法部分 (5) 3.1 分布类型检验 (5) 3.1.1 正态分布 (5) 3.1.2 二项分布 (6) 3.1.3 游程检验 (6) 3.2 单因素方差分析 (6) 3.3 卡方检验 (6) 3.4 相关与线性回归的分析方法 (6) 3.4.1 相关分析(双变量相关分析&偏相关分析) (6) 3.4.2 线性回归模型 (6) 4 高级阶段方法部分 (6) 三、具体步骤描述 (7) 1 数据管理与软件入门部分 (7) 1.1 分类汇总 (7) 1.2 个案排秩 (8) 1.3 连续变量变分组变量 (10) 2 统计描述与统计图表部分 (11) 2.1 频数分析 (11) 2.2 描述统计分析 (14) 3 假设检验方法部分 (16) 3.1 分布类型检验 (16) 3.1.1 正态分布 (16) 3.1.2 二项分布 (17) 3.1.3 游程检验 (18) 3.2 单因素方差分析 (22) 3.3 卡方检验 (24) 3.4 相关与线性回归的分析方法 (26) 3.4.1 相关分析 (26) 3.4.2 线性回归模型 (28) 4 高级阶段方法部分 (32) 4.1 信度 (32) 一、数据样本描述 本次分析的数据为某公司474名职工状况统计表,其中共包含11个变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin(起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用SPSS统计软件,对变量进行统计分析,以了解该公司职工总体状况,并分析职工受教育程度、起始工资、现工资的分布特点及相互间的关系。 二、要解决的问题描述 1 数据管理与软件入门部分 1.1 分类汇总 以受教育水平程度为分组依据,对职工的起始工资和现工资进行数据 SPSS 数据分析报告 学生姓名:李婷 学号:0904100223 专业:统计学 班级:统计0902 指导教师:朱钰 完成日期:2011年12月17日 目录 一.数据简介 ........................................................................................... 错误!未定义书签。二.数据分析 .. (3) 三.描述性分析 (5) 四.探索性分析 (6) 1.交叉分析 (6) 2.茎叶图 (7) 3 p-p 图分析 (11) 五.证实性分析 (12) 1.相关分析 (12) 2.回归分析 (13) 3.参数检验 (15) (1)单样本T检验 (16) (2)独立样本T检验 ............................................................. 错误!未定义书签。 关于某地区361个人旅游情况统计分析报告 一、数据介绍: 此数据来源于https://www.doczj.com/doc/231494203.html,/publications/jse/jse_data_archive.htm 本次分析的数据为某地区361个人旅游情况状况统计表,其中共包含七变量,分别是:年龄,为三类变量;性别,为二类变量(0代表女,1代表男);收入,为一类变量;旅游花费,为一类变量;通道,为二类变量(0代表没走通道,1代表走通道);旅游的积极性,为三类变量(0代表积极性差,1代表积极性一般,2代表积极性比较好,3代表积极性好4代表积极性非常好);额外收入,一类变量。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、。。。以了解该地区上述方面的综合状况,并分析个变量的分布特点及相互间的关系。 二、频数分析: 基本的统计分析往往从频数分析开始。通过频数分地区359个人旅游基本状况的统计数据表,在性别、旅游的积极性不同的状况下的频数分析,从而了解该地区的男女职工数量、不同积极性况的基本分布。 首先,对该地区的男女性别分布进行频数分析,结果如下 表说明,在该地区被调查的359个人中,有198名女性,161名男性,男女比例分别为44.8%和55.2%,该公司职工男女数量差距不大,女性略多于男性。 SPSS与数据统计分析期末论文影响学生对学校服务满意程度的因素分析 一、数据来源 本次数据主要来源自本校同学,调查了同学们年级、性别、助学金申请情况、生源所在地、学院、毕业学校、游历情况、家庭情况、升高、体重、近视程度、学习时间、经济条件、兴趣、对学校各方面的评价、与对学校总评价以及建议等共41条信息,共收集数据样本724条。我们将运用SPSS,对变量进行频数分析、样本T检验、相关分析等手段,旨在了解同学们对学校提供的满意程度与什么因素有关。 二、频数分析 可靠性统计 克隆巴赫Alpha项数 .98562 对全体数值进行可信度分析 本次数据共计724条,首先从可靠性统计来看,alpha值为0.985,即全体数据绝大部分是可靠的,我们可以在原始数据的基础上进行分析与处理。 其中,按年级来看,绝大多数为大二学生填写(占了总人数的67.13%),之后分别依次为大二(23.76%)、大四(4.14%)、大一(4.97%)。而从专业来看,占据了数据绝大多数样本所在的学院为机械、材料、经管、计通。 三、数据预处理 拿到这份诸多同学填写的问卷之后,我们首先应对一些数据进行处理,对于数据的缺失值处理,由于我们对本份调查的分析重点方面是关于学生的经济情况的,因此对于确实的部分数据,升高、体重、近视度数、感兴趣的事等无关项我们均不需要进行缺失值的处理,而我们可能重点关注的每月家里给的钱、每月收入以及每月支出,由于其具有较强主观性,如果强行处理缺失值反而会破坏数据的完整性,因此我们筛去未填写的数据,将剩余数据当作新的样本进行分析。 而对于一些关键的数据,我们需要做一些必要的预处理,例如一些调查项,我们希望得到数值型变量,但是填写时是字符型变量,我们就应该新建一个数字型变量并将数据复制,以便后续分析。同时一些与我们分析相关的缺省值,一些明显可以看出的虚假信息,我们都需要先 关于某公司474名职工综合状况的统计分析报告 一、数据介绍: 本次分析的数据为某公司474名职工状况统计表,其中共包含十一变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin (起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、。。。以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。 二、数据分析 1、频数分析。基本的统计分析往往从频数分析开始。通过频数分析能够了解变量的取值状 况,对把握数据的分布特征非常有用。此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu(受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。 Statistics 首先,对该公司的男女性别分布进行频数分析,结果如下: Gender 上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为45.6%和54.4%,该公司职工男女数量差距不大,男性略多于女性。 其次对原有数据中的受教育程度进行频数分析,结果如下表: Educational Level (years) 上表及其直方图说明,被调查的474名职工中,受过12年教育的职工是该组频数最高的,为190人,占总人数的40.1%,其次为15年,共有116人,占中人数的24.5%。且接受过高于20年的教育的人数只有1人,比例很低。 2、描述统计分析。再通过简单的频数统计分析了解了职工在性别和受教育水平上的总体分 布状况后,我们还需要对数据中的其他变量特征有更为精确的认识,这就需要通过计算基本描述统计的方法来实现。下面就对各个变量进行描述统计分析,得到它们的均值、标准差、片度峰度等数据,以进一步把我数据的集中趋势和离散趋势。 SPSS期末报告 关于员工受教育程度对其工资水平的影 响统计分析报告 课程名称:SPSS统计分析方法 姓名:汤重阳 ________ 学号:______________ 所在专业:人力资源管理 所在班级:三班 目录 一、数据样本描述 (1) 二、要解决的问题描述 (1) 1数据管理与软件入门部分 (1) 1.1分类汇总 (1) 1.2个案排秩 (1) 1.3连续变量变分组变量 (1) 2统计描述与统计图表部分 (1) 2.1频数分析 (1) 2.2描述统计分析 (1) 3假设检验方法部分 (2) 3.1分布类型检验 (2) 3.1.1正态分布 . (2) 3.1.2二项分布 . (2) 3.1.3游程检验 . (2) 3.2单因素方差分析 (2) 3.3卡方检验 (2) 3.4相关与线性回归的分析方法 (2) 3.4.1相关分析(双变量相关分析 &偏相关分析) (2) 3.4.2线性回归模型. (2) 4高级阶段方法部分 (2) 三、具体步骤描述 (3) 1数据管理与软件入门部分 (3) 1.1分类汇总 (3) 1.2个案排秩 (3) 1.3连续变量变分组变量 (4) 2统计描述与统计图表部分 (5) 2.1频数分析 (5) 2.2描述统计分析 (6) 3假设检验方法部分 (7) 3.1分布类型检验 (7) 3.1.1正态分布 . (7) 3.1.2二项分布 . (8) 3.1.3游程检验 . (9) 3.2单因素方差分析 (10) 3.3卡方检验 (12) 3.4相关与线性回归的分析方法 (13) 3.4.1相关分析 . (13) 3.4.2线性回归模型 . (15) 4高级阶段方法部分 (16) 4.1信度 (16) 4.2效度 (17) 精心整理 相关分析 一、两个变量的相关分析:Bivariate 1.相关系数的含义 相关分析是研究变量间密切程度的一种常用统计方法。相关系数是描述相关关系强弱程度和方向的统计量,通常用r 表示。 2∑∑===--= n i n i i i i i i y y x x r 1 1 2 21 )()((1) (1)式是样本的相关系数。计算皮尔逊相关系数的数据要求:变量都是服从正态分布,相互独立的连续数据;两个变量在散点图上有线性相关趋势;样本容量30≥n 。 (2)斯皮尔曼(Spearman )等级相关系数 Spearman 相关系数又称秩相关系数,是用来测度两个定序数据之间的线性相关程度的指标。 当两组变量值以等级次序表示时,可以用斯皮尔曼等级相关系数反映变量间的关系密切程度。它是根据数据的秩而不是原始数据来计算相关系数的,其计算过程包括:对连续数据的排秩、对离散数据的排序,利用每对数据等级的差额及差额平方,通过公式计算得到相关系数。其计算公式为: () 1612 2 -- =∑n n d r R (2) (2)式中,R r 为等级相关系数;d 为每对数据等级之差;n 为样本容量。 斯皮尔曼等级相关对数据条件的要求没有积差相关系数严格,只要两个变量的观测值是成对的 样本简单相关系数的检验方法为: 当原假设0H :0=ρ,50≥n 时,检验统计量为: 2 11 r n r Z --= (4) 当原假设0H :0=ρ,50 2 12r n r t --=()2-=n df (5) 式中,r 为简单相关系数;n 为观测值个数(或样本容量)。 4.背景材料 设有10个厂家,序号为1,2,…,10,各厂的投入成本记为x ,所得产出记为y 。各厂家的投入和产出如表7-18-1所示,根据这些数据,可以认为投入和产出之间存在相关性吗? 表110个厂家的投入产出单位:万元 X-Axis 各点标以不同的颜色(或形状)。该项可以省略。 把标记变量指定到LabelCasesby 框中,表示将标记变量的各变量值标记在散点图的旁边。该项可以省略。 从左侧变量列表框中选择变量到Panelby 框中作为分类变量,可以使该变量作为行(Rows )或列(Columns )将数据分成不同的组,便于比较。该项可以省略。 选择UseChartSpecificationsFrom 选项,可以选择散点图的文件模板,单击“File ”可以选择指定的文件。 S P S S数据分析报告 WTD standardization office【WTD 5AB- WTDK 08- WTD 2C】 SPSS期末报告 关于员工受教育程度对其工资水平的影 响统计分析报告 课程名称:SPSS统计分析方法 姓名:汤重阳 学号: 所在专业:人力资源管理 所在班级:三班 目录 一、数据样本描述 分析数据来自于“微盘——SPSS数据包 data02-01”。 本次分析的数据为某公司474名职工状况统计表,其中共包含11个变量,分别是:id (职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin(起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用SPSS统计软件,对变量进行统计分析,以了解该公司职工总体状况,并分析职工受教育程度、起始工资、现工资的分布特点及相互间的关系。 二、要解决的问题描述 1 数据管理与软件入门部分 分类汇总 以受教育水平程度为分组依据,对职工的起始工资和现工资进行数据汇总。 个案排秩 对受教育水平程度不同的职工起始工资和现工资进行个案排秩。 连续变量变分组变量 将被调查者的年龄分为10组,要求等间距。 2 统计描述与统计图表部分 频数分析 利用了某公司474名职工基本状况的统计数据表,在性别、受教育水平程度不同的状况下进行频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。 描述统计分析 以职工受教育水平程度为依据,对职工起始工资进行描述统计分析,得到它们的均值、标准差、偏度峰度等数据,以进一步把握数据的集中趋势和离散趋势。 3 假设检验方法部分 分布类型检验 正态分布 分析职工的现工资是否服从正态分布。 二项分布 抽样数据中职工的性别分布是否平衡。 游程检验 该样本中的抽样数据是否随机。 单因素方差分析 把受教育水平和起始工资作为控制变量,现工资为观测变量,通过单因素方差分析方法研究受教育水平和起始工资对现工资的影响进行分析。 卡方检验spss的数据分析报告
SPSS统计分析分析案例
spss相关分析案例多因素方差分析
SPSS买房数据分析实施报告
spss的数据分析报告范例
SPSS相关分析实验报告精选
SPSS简单数据分析报告
spss的数据分析报告[1]要点
SPSS分析报告实例
spss的数据分析报告.doc
Spss数据分析报告
SPSS相关分析案例讲解
SPSS数据分析报告
相关主题
文本预览