
四级数据库第八章-事务调度与并发控制8.1 并发控制概述
在第七章中己经讲到,事务是并发控制的基本单位,保证事务ACID特性是事务处理的重要任务,而事务ACID特性可能遭到破坏的原因之一是多个事务对数据库的并发操作造成的。为了保证事务的隔离性更一般,为了保证数据库的一致性,DBMS需要对并发操作进行正确调度。这些就是数据库管理系统中并发控制机制的责任。
下面先来看一个例子,说明并发操作带来的数据的不一致性问题。
考虑飞机订票系统中的一个活动序列:
①甲售票点(甲事务)读出某航班的机票余额A,设A=16;
②乙售票点(乙事务)读出同一航班的机票余额A,也为16;
③甲售票点卖出一张机票,修改余额A A-l,所以A为15,把A写回数据库;
④乙售票点也卖出一张机票,修改余额A A-l,所以A为15,把A写回数据库。结果明明卖出两张机票,数据库中机票余额只减少1。
这种情况称为数据库的不一致性。这种不一致性是由并发操作引起的。在并发操作情况下,对甲、乙两个事务的操作序列的调度是随机的。若按上面的调度序列执行,甲事务的修改就被丢失。这是由于第④步中乙事务修改A并写回后覆盖了甲事务的修改。
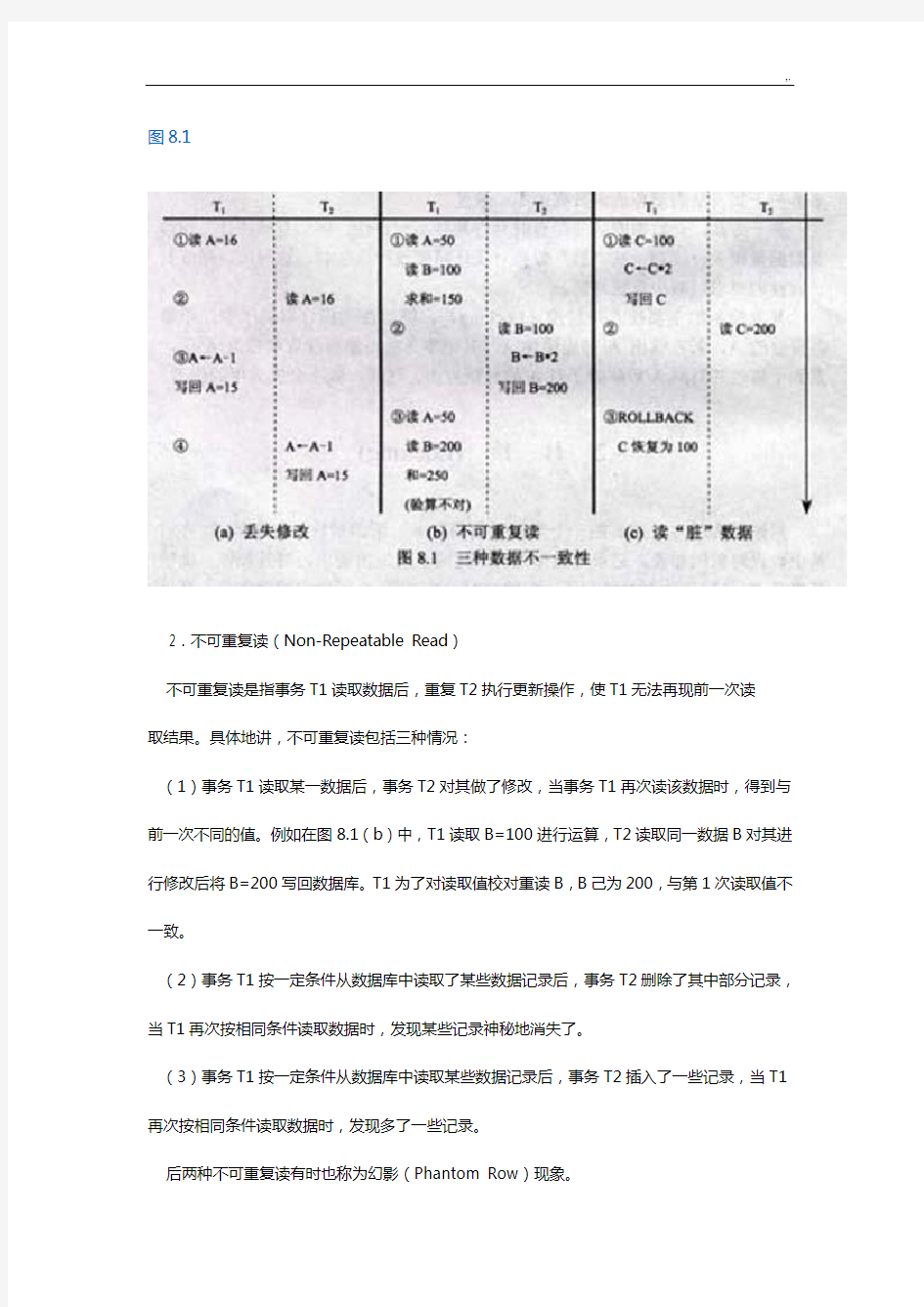
仔细分析并发操作带来的数据不一致性包括三类:丢失修改、不可重复读和读“脏”数据,如图8.1所示。
1.丢失修改(Lost Update)
两个事务T1和T2。读入同一数据并修改,T2提交的结果破坏了T1提交的结果,导致T1的修改被丢失,如图8.1(a)所示。上面飞机订票例子就属此类。
图8.1
2.不可重复读(Non-Repeatable Read)
不可重复读是指事务T1读取数据后,重复T2执行更新操作,使T1无法再现前一次读
取结果。具体地讲,不可重复读包括三种情况:
(1)事务T1读取某一数据后,事务T2对其做了修改,当事务T1再次读该数据时,得到与前一次不同的值。例如在图8.1(b)中,T1读取B=100进行运算,T2读取同一数据B对其进行修改后将B=200写回数据库。T1为了对读取值校对重读B,B己为200,与第1次读取值不一致。
(2)事务T1按一定条件从数据库中读取了某些数据记录后,事务T2删除了其中部分记录,当T1再次按相同条件读取数据时,发现某些记录神秘地消失了。
(3)事务T1按一定条件从数据库中读取某些数据记录后,事务T2插入了一些记录,当T1再次按相同条件读取数据时,发现多了一些记录。
后两种不可重复读有时也称为幻影(Phantom Row)现象。
3.读“脏”数据(Dirty Read)
读“脏”数据是指事务T1修改某一数据,并将其写回磁盘,事务T2读取同一数据后,T1由于某种原因被撤销,这时T1己修改过的数据恢复原值,T2读到的数据就与数据库中的数据不一致,则T2读到的数据就为“脏”数据,即不正确的数据。例如在图8.1(C)中T1将C值修改为200,T2读到C为200,而T1由于某种原因撤销,其修改作废,C恢复原值100,这时T2读到的C为200,与数据库内容不一致就是“脏”数据。
产生上述三类数据不一致性的主要原因是并发操作破坏了事务的隔离性。并发控制就是要用正确的方式调度并发操作,使一个用户事务的执行不受其他事务的干扰,从而避免造成数据的不一致性。
另一方面,对数据库的应用有时允许某些不一致性,例如有些统计工作涉及数据量很大,读到一些“脏”数据对统计精度没什么影响,这时可以降低对一致性的要求以减少系统开销。
并发控制的主要技术是封锁(Locking)。例如在飞机订票例子中,甲事务要修改A,若在读出A前先锁住A,其他事务就不能再读取和修改A了,直到甲修改并写回A后解除了对A的封锁为止。这样,就不会丢失甲的修改。
8.2 封锁(Locking)
封锁是实现并发控制的一个非常重要的技术。所谓封锁就是事务T在对某个数据对象例如表、记录等操作之前,先向系统发出请求,对其加锁。加锁后事T就对该数据对象有了一定的控制,在事务T释放它的锁之前,其他的事务不能更新此数据对象。
确切的控制由封锁的类型决定。基本的封锁类型有两种:排它锁(Exclusive Locks,简称X 锁)和共享锁(Share Locks,简称S锁)。
排它锁又称为写锁。若事务T对数据对象A加上X锁,则只允许T读取和修改A,其他任何事务都不能再对A加任何类型的锁,直到T释放A上的锁。这就保证了其他事务在T释放A上
的锁之前不能再读取和修改A。
共享锁又称为读锁。若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。这就保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
排它锁与共享锁的控制方式可以用图8.2的相容矩阵来表示。
图8.2
在图8.2的封锁类型相容矩阵中,最左边一列表示事务T1已经获得的数据对象上的锁的类型,其中横线表示没有加锁。最上面一行表示另一事务T2。对同一数据对象发出的封锁请求。T2的封锁请求能否被满足用矩阵中的Y和N表示,其中Y表示事务T2的封锁要求与T1已持有的锁相容,封锁请求可以满足。N 表示T2的封锁请求与T1己持有的锁冲突,T2的请求被拒绝。
8.3 封锁协议
在运用X锁和S锁这两种基本封锁,对数据对象加锁时,还需要约定一些规则,例如何时申请X锁或S锁、持锁时间、何时释放等。称这些规则为封锁协议(Locking Protocol)。对封锁方式规定不同的规则,就形成了各种不同的封锁协议。下面介绍三级封锁协议。对并发操作的不正确调度可能会带来丢失修改、不可重复读和读“脏”数据等不一致性问题,三级封锁协议分别在不同程度上解决了这一问题。为并发操作的正确调度提供一定的保证。不同级别的封锁协议
达到的系统一致性级别是不同的。
一、一级封锁协议
一级封锁协议是:事务T在修改数据R之前必须先对其加X锁,直到事务结束才释放。事务结束包括正常结束(COMMIT)和非正常结束(ROLLBACK)。
一级封锁协议可防止丢失修改,并保证事务T是可恢复的。例如图8.3(a)使用一级封锁协议解决了图8.1(a)中的丢失修改问题。
图8.3(a)事务T1在读A进行修改之前先对A加X锁,当T2再请求对A加X锁时被拒绝,T2只能等待T1释放A上的锁后T2获得对A的X锁,这时它读到的A己经是T1更新过的值15,再按此新的A值进行运算,并将结果值A=14送回到磁盘。这样就避免了丢失T1的更新。在一级封锁协议中,如果仅仅是读数据不对其进行修改,是不需要加锁的,所以它不能保证可重复读和不读“脏”数据。
二、二级封锁协议
二级封锁协议是:一级封锁协议加上事务T在读取数据R之前必须先对其加S锁,读完后即可释放S锁。
二级封锁协议除防止了丢失修改,还可进一步防止读“脏”数据。例如图8.3(C)使用二级封锁协议解决了图8.1(c)中的读“脏”数据问题。
图8.3(c)中,事务T1在对C进行修改之前,先对C加X锁,修改其值后写回磁盘。这时T2请求在C上加S锁,因T1己在C上加了X锁,T2只能等待。T1因某种原因被撤销,C恢复为原值100,T1释放C上的X锁后T2获得C上的S锁,读C=100。这就避免了T2读“脏”数据。
在二级封锁协议中,由于读完数据后即可释放S锁,所以它不能保证可重复读。
三、三级封锁协议
三级封锁协议是:一级封锁协议加上事务T在读取数据R之前必须先对其加S锁,直到事务结束才释放。
三级封锁协议除防止了丢失修改和不读“脏”数据外,还进一步防止了不可重复读。例如图8.3(b)使用三级封锁协议解决了图8.1(b)不可重复读问题。
图8.3(b)中,事务T1在读A,B之前,先对A,B加S锁,这样其它事务只能再对A,B 加S锁,而不能加X锁,即其他事务只能读A,B,而不能修改它们。所以当T2为修改B而申请对B的X锁时被拒绝只能等待T1释放B上的锁。T1为验算再读A,B,这时读出的B仍是100,求和结果仍为150,即可重复读。T1结束才释放A,B上的S锁。T2才获得对B的X 锁。
上述三级协议的主要区别在于什么操作需要申请封锁,以及何时释放锁(即持锁时间)。三个级别的封锁协议可以总结为表8.1。
图8.3
表8.1
8.4 活锁和死锁
和操作系统一样,封锁的方法可能引起活锁和死锁。
一、活锁
如果事务T1封锁了数据R,事务T2又请求封锁R,于是T2等待。T3也请求封锁R,当T1释放了R上的封锁之后系统首先批准了T3的请求,T2仍然等待。然后T4又请求封锁R,当T3释放了R上的封锁之后系统又批准了T4的请求……T2有可能永远等待,这就是活锁的情形,如图8.4(a)所示。
避免活锁的简单方法是采用先来先服务的策略。当多个事务请求封锁同一数据对象时,封锁子系统按请求封锁的先后次序对事务排队,数据对象上的锁一旦释放就批准申请队列中第1个事务获得锁。
二、死锁
如果事务T1封锁了数据R1,T2封锁了数据R2,然后T1又请求封锁R2,因T2已封锁了R2,于是T1等待T2释放R2上的锁。接着T2又申请封锁R1,因T1己封锁了R1,T2也只能等待T1释放R1上的锁。这样就出现了T1在等待T2,而T2又在等待T1的局面,T1和T2两个事务永远不能结束,形成死锁。如图8.4(b)所示。
死锁的问题在操作系统和一般并行处理中已做了深入研究,目前在数据库中解决死锁问题主要有两类方法,一类方法是采取一定措施来预防死锁的发生,另一类方法是允许发生死锁,采用一定手段定期诊断系统中有无死锁,若有则解除之。
1.死锁的预防
在数据库中,产生死锁的原因是两个或多个事务都已封锁了一些数据对象,然后又都请求对已为其他事务封锁的数据对象加锁,从而出现死等待。防止死锁的发生其实就是要破坏产生死锁的条件。预防死锁通常有两种方法;
(1)一次封锁法
一次封锁法要求每个事务必须一次将所有要使用的数据全部加锁,否则就不能继续执行。如图8.4(b)的例子中,如果事务T1将数据对象R1和R2一次加锁,T1就可以执行下去,而T2等待。T1执行完后释放R1,R2上的锁,T2继续执行。这样就不会发生死锁。
一次封锁法虽然可以有效地防止死锁的发生,但也存在问题。第一,一次就将以后要用到的全部数据加锁,势必扩大了封锁的范围,从而降低了系统的并发度。第二,数据库中数据是不断变化的,原来不要求封锁的数据,在执付过程中可能会变成封锁对象,所以很难事先精确地确定每个事务所要封锁的数据对象,为此只能扩大封锁范围,将事务在执行过程中可能要封锁的数据对象全部加锁,这就进一步降低了并发度。
(2)顺序封锁法
顺序劫锁法是预先对数据对象规定一个封锁顺序,所有事务都按这个顺序实行封锁。例如在B 树结构的索引中,可规定封锁的顺序必须是从根结点开始,然后是下一级的子女结点,逐级封锁。顺序封锁法可以有效地防止死锁,但也同样存在问题。第一,数据库系统中封锁的数据对象极多,并且随数据的插入、删除等操作而不断地变化,要维护这样的资源的封锁顺序非常困难;成本很高。第二,事务的封锁请求可以随着事务的执行而动态地诀定,很难事先确定每一个事务要封锁哪些对象,因此也就很难按规定的顺序去施加封锁。
可见,在操作系统中广为采用的预防死锁的策略并不很适合数据库的特点,因此DBMS在解决死锁的问题上普遍采用的是诊断并解除死锁的方法
2.死锁的诊断与解除
数据库系统中诊断死锁的方法与操作系统类似,一般使用超时法或事务等待图法。
(1)超时法
如果一个事务的等待时间超过了规定的时限,就认为发生了死锁。超时法实现简单,但其不足也很明显。一是有可能误判死锁,事务因为其他原因使等待时间超过时限,系统会误认为发生了死锁。二是时限若设置得太长,死锁发生后不能及时发现。
(2)等待图法
事务等待图是一个有向图G=(T,U)。T为结点的集合,每个结点表示正运行的事务;U 为边的集合,每条边表示事务等待的情况。若T1等待T2,则T1,T2之间划一条有向边,从T1指向T2。事务等待图动态地反映了所有事务的等待情况。并发控制子系统周期性地(比如每隔1 min)检测事务等待图,如果发现图中存在回路,则表示系统中出现了死锁。
DBMS的并发控制子系统一旦检测到系统中存在死锁,就要设法解除。通常采用的方法是选
择一个处理死锁代价最小的事务,将其撤销,释放此事务持有的所有的锁,使其他事务得以继续运行下去。当然,对撤销的事务所执行的数据修改操作必须加以恢复。
8.5 并发调度的可串行性
计算机系统对并发事务中并发操作的调度是随机的,而不同的调度可能会产生不同的结果,那么哪个结果是正确的,哪个是不正确的呢?
如果一个事务运行过程中没有其他事务同时运行,也就是说它没有受到其他事务的干扰,那么就可以认为该事务的运行结果是正常的或者预想的。因此将所有事务串行起来的调度策略一定是正确的调度策略。虽然以不同的顺序串行执行事务可能会产生不同的结果,但由子不会将数据库置于不一致状态,所以都是正确的。
定义多个事务的并发执行是正确的,当且仅当其结果与按某一次序串行地执行它们时的结果相同,我们称这种调度策略为可串行化(Serializable)的调度。
可串行性(Serializability)是并发事务正确性的准则。按这个准则规定,一个给定的并发调度,当且仅当它是可串行化的,才认为是正确调度。
例如,现在有两个事务,分别包含下列操作:
事务T1:读B;A=B+1;写回A;
事务T2:读A;B=A+1;写回B;
假设A,B的初值均为2。按T1→T2次序执行结果为A=3,B=4;按T2→T1次序执行结果为B=3,A=4。
图8.5给出了对这两个事务的三种不同的调度策略。
图8.5(a)和(b)为两种不同的串行调度策略,虽然执行结果不同,但它们都是正确的调度;图8.5(c)产两个事务是交错执行的;由于其执行结果与(a),(b)的结果都不同,所以是错误的调度;图8.5(d)中两个事务也是交错执行的,其执行结果与串行调度(a)执行结
果相同,所以是正确的调度。
图8.5
为了保证并发操作的正确性,DBMS的并发控制机制必须提供一定的手段来保证调度
是可串行化的。
从理论上讲,在某一事务执行时禁止其他事务执行的调度策略一定是可串行化的调度,这也是最简单的调度策略,但这种方法实际上是不可取的,这使用户不能充分共享数据库资源。目前DBMS普遍采用封锁方法实现并发操作调度的可串行性,从而保证调度的正确性。
两段锁(Two-Phase Locking,简称2PL)协议就是保证并发调度可串行性的封锁协议。除此之外还有其他一些方法,如时标方法、乐观方法等来保证调度的正确性。
8.6 两段锁协议
所谓两段锁协议是指所有事务必须分两个阶段对数据项加锁和解锁。
·在对任何数据进行读、写操作之前,首先要申请并获得对该数据的封锁;
·在释放一个封锁之后,事务不再申请和获得任何其他封锁。
所谓“两段”锁的含义是,事务分为两个阶段,第一阶段是获得封锁,也称为扩展阶段。在这阶段,事务可以申请获得任何数据项上的任何类型的锁,但是不能释放任何锁。第二阶段是释放封锁,也称为收缩阶段。在这阶段,事务可以释放任何数据项上的任何类型的锁,但是不能再申请任何锁。
例如事务T1遵守两段锁协议,其封锁序列是:
可以证明,若并发执行的所有事务均遵守两段锁协议,则对这些事务的任何并发调度策
略都是可串行化的。
需要说明的是,事务遵守两段锁协议是可串行化调度的充分条件,而不是必要条件。也就是说;若并发事务都遵守两段锁协议,则对这些事务的任何并发调度策略都是可串行化的:若对并发事务的一个调度是可串行化的,不一定所有事务都符合两段锁协议。
在图8.6中,(a)和(b)都是可串行化的调度,但(a)中T1和T2都遵守两段锁协议,(b)中T1和T2不遵守两段锁协议。又如图8.5中(d)是可串行化的调度,但T1和T2也不遵守两段锁协议。
另外要注意两段锁协议和防止死锁的一次封锁法的异同之处。一次封锁法要求每个事务必须
一次将所有要使用的数据全部加锁,否则就不能继续执行,因此一次封锁法遵守两段锁协议;但是两段锁协议并不要求事务必须一次将所有要使用的数据全部加锁,因此遵守两段锁协议的事务可能发生死锁,如图8.7所示。
图8.6、8.7
8.7.1 多粒度封锁
下面讨论多粒度封锁,首先定义多粒度树。多粒度树的根结点是整个数据库,表示最大的数据粒度。叶结点表示最小的数据粒度。图8.8给出了一个三级粒度树。根结点为数据库,数据库的子结点为关系,关系的子结点为元组。
图8.8
然后,来讨论多粒度封锁的封锁协议。多粒度封锁协议允许多粒度树中的每个结点被独立地加锁。对一个结点加锁意味着这个结点的所有后裔结点也被加以同样类型的锁。因此,在多粒度封锁中一个数据对象可能以两种方式封锁,显式封锁和隐式封锁。
显式封锁是应事务的要求直接加到数据对象上的封锁;隐式封锁是该数据对象没有独立加锁,是由于其上级结点加锁而使该数据对象加上了锁。
多粒度封锁方法中,显式封锁和隐式封锁的效果是一样的,因此系统检查封锁冲突时不仅要检查显式封锁还要检查隐式封锁。例如事务T要对关系R1加X锁。系统必须搜索其上级结点数据库、关系R1以及R1中的每一个元组,如果其中某一个数据对象己经加了不相容锁,则T必须等待。
一般地,对某个数据对象加锁,系统要检查该数据对象上有无显式封锁与之冲突;还要检查其所有上级结点,看本事务的显式封锁是否与该数据对象上的隐式封锁(即由于上级结点已加的封锁造成的)冲突;还要检查其所有下级结点,看上面的显式封锁是否与本事务的隐式封锁(将加到下级结点的封锁)冲突。显然,这样的检查方法效率很低。为此人们引进了一种新型锁,称为意向锁(Intention Lock)。
8.7.2 意向锁
意向锁的含义是如果对一个结点加意向锁,则说明该结点的下层结点正在被加锁;对任一结点加锁时,必须先对它的上层结点加意向锁。
例如,对任一元组加锁时,必须先对它所在的关系加意向锁。
于是,事务T要对关系R1加X锁时,系统只要检查根结点数据库和关系R1是否己加了不相容的锁,而不再需要搜索和检查尺中的每一个元组是否加了X锁。
下面介绍三种常用的意向锁:意向共享锁(Intent Share Lock,简称IS锁);意向排它锁(Intent Exclusive Lock,简称IX锁);共享意向排它锁(Share Intent Exclusive Lock,简称SIX锁)。
如果对一个数据对象加IS锁,表示它的后裔结点拟(意向)加S锁。例如,要对某个元组加S 锁,则要首先对关系和数据库加IS锁。
2.IX锁
如果对一个数据对象加IX锁,表示它的后裔结点拟(意向)加X锁。例如,要对某个元组加X 锁,则要首先对关系和数据库加IX锁。
3.SIX锁
如果对一个数据对象加SIX锁,表示对它加S锁,再加IX锁,即SIX=S+IX。例如对某个表加SIX锁,则表示该事务要读整个表(所以要对该表加S锁),同时会更新个别元组(所以要对该表加IX锁)。
图8.9(a)给出了这些锁的相容矩阵,从中可以发现这5种锁的强度如图8.9(b)所示的偏序关系。所谓锁的强度是指它对其他锁的排斥程度。一个事务在申请封锁时以强锁代替弱锁是安全的,反之则不然。
具有意向锁的多粒度封锁方法中任意事务T要对一个数据对象加锁,必须先对它的上层结点加意向锁。申请封锁时应该按自上而下的次序进行;释放封锁时则应该按自下而上的次序进行。具有意向锁的多粒度封锁方法提高了系统的并发度,减少了加锁和解锁的开销,它己经在实际的数据库管理系统产品中得到广泛应用,例如新版的Oracle数据库系统就采用了这种封锁方法。
8.8 Oracle的并发控制
前面讨论了并发控制的一般原则与方法,下面简单介绍Oracle数据库系统中的并发控制机制。 Oracle采用封锁技术保证并发操作的可串行性。Oracle的锁分为两大类:数据锁(亦称DML 锁)和字典锁。字典锁是Oracle DBMS内部用于对字典表的封锁。字典锁包括语法分析锁和DDL锁,由DBMS在必要的时候自动加锁和释放锁,用户无权控制。
Oracle主要提供了5种数据锁:共享锁(S锁)、排它锁(X锁)、行级共享锁(RS锁)、行级排它锁(RX锁)和共享行级排它锁(SRX锁)。其封锁粒度包括行级和表级。数据锁的相容矩阵如图8.10所示。
图8.10
可以看出Oracle的RS锁、RX锁、SRX锁实际上就是上面介绍的IS锁、IX锁、SIX锁。在通常情况下,数据封锁由系统控制,对用户是透明的。但Oracle也允许用户用LOCK TABLE 语句显式对封锁对象加锁。
Oracle数据锁的一个显著特点是,在缺省情况下,读数据不加锁。也就是说,当一个用户更新数据时,另一个用户可以同时读取相应数据,反之亦然。Oracle通过回滚段(Rollback Segnent)的内存结构来保证用户不读“脏”数据和可重复读。这样做的好处是提高了数据的并发度。
Oracle提供了有效的死锁检测机制,周期性诊断系统中有无死锁,若存在死锁,则撤销执行更新操作次数最少的事务。
实验十五事务与并发控制 【实验目的与要求】 1.掌握数据库事务的概念 2.熟悉数据库的四个特性 3.熟练掌握数据库事务的实现方法 【实验内容与步骤】 15.1.SQL Server数据库事务基础知识 1.事务的概念( Transaction ) 所谓事务是用户定义的一个数据库操作序列,这些操作要么都做,要么都不做,是一个不可分割的工作单位。 关系数据库中,事务可以是一条SQL语句、一组SQL语句。 在SQL语言中,定义事务的语句有三条: Begin Transaction 开始 Commit 结束 Rollback 回滚 2.事务开始:BEGIN TRANSACTION 标记一个显式本地事务的起始点。BEGIN TRANSACTION将@@TRANCOUNT 加1。 语法结构: BEGIN TRAN [ SACTION ] [ transaction_name | @tran_name_variable [ WITH MARK [ 'description' ] ] ] 参数说明: transaction_name:是给事务分配的名称。transaction_name 必须遵循标识符规则,但是不允许标识符多于32 个字符。仅在嵌套的https://www.doczj.com/doc/218394796.html,MIT 或BEGIN...ROLLBACK 语句的最外语句对上使用事务名。 @tran_name_variable:是用户定义的、含有有效事务名称的变量的名称。必须用char、varchar、nchar 或nvarchar 数据类型声明该变量。 WITH MARK ['description']:指定在日志中标记事务。Description 是描述该标记的字符串。 如果使用了WITH MARK,则必须指定事务名。WITH MARK 允许将事务日志还原到命名标记。 4.事务提交:COMMIT TRANSACTION 标志一个成功的隐性事务或用户定义事务的结束。如果@@TRANCOUNT 为1,COMMIT TRANSACTION 使得自从事务开始以来所执行的所有数据修改成为数据库的永
第八章并发控制 习题解答和解析 1. 1.在数据库中为什么要并发控制? 答:数据库是共享资源,通常有许多个事务同时在运行。当多个事务并发地存取数据库时就会产生同时读取和/或修改同一数据的情况。若对并发操作不加控制就可能会存取和存储不正确的数据,破坏数据库的一致性。所以数据库管理系统必须提供并发控制机制。 2. 2.并发操作可能会产生哪几类数据不一致?用什么方法能避免各种不一致的情况? 答:并发操作带来的数据不一致性包括三类:丢失修改、不可重复读和读"脏"数据。 (1)丢失修改(Lost Update)两个事务T1和T2读入同一数据并修改,T2提交的结果破坏了(覆盖了)T1提交的结果,导致T1的修改被丢失。 (2)不可重复读(Non -Repeatable Read)不可重复读是指事务T1读取数据后,事务T2 执行更新操作,使T1无法再现前一次读取结果。不可重复读包括三种情况:详见《概论》8.1(P266)。 (3)读"脏"数据(Dirty Read)读"脏"数据是指事务T1修改某一数据,并将其写回磁盘,事务T2读取同一数据后,T1由于某种原因被撤销,这时T1已修改过的数据恢复原值,T2读到的数据就与数据库中的数据不一致,则T2读到的数据就为"脏"数据,即不正确的数据。 避免不一致性的方法和技术就是并发控制。最常用的技术是封锁技术。也可以用其他技术,例如在分布式数据库系统中可以采用时间戳方法来进行并发控制。 3. 3.什么是封锁? 答:封锁就是事务T在对某个数据对象例如表、记录等操作之前,先向系统发出请求,对其加锁。加锁后事务T就对该数据对象有了一定的控制,在事务T释放它的锁之前,其他的事务不能更新此数据对象。封锁是实现并发控制的一个非常重要的技术。 4. 4.基本的封锁类型有几种?试述它们的含义。 答:基本的封锁类型有两种:排它锁(Exclusive Locks, 简称 X 锁 )和共享锁(Share Locks,简称 S 锁)。 排它锁又称为写锁。若事务T对数据对象A加上X锁,则只允许T读取和修改A,其他任何事务都不能再对A加任何类型的锁,直到T释放A上的锁。这就保证了其他事务在T释放A上的锁之前不能再读取和修改A。 共享锁又称为读锁。若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。这就保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。 5.如何用封锁机制保证数据的一致性 ? 答:DBMS在对数据进行读、写操作之前首先对该数据执行封锁操作,例如下图中事务T1在对A进行修改之前先对A执行XLock(A),即对A加X锁。这样,当T2请求对A加X锁时就被拒绝,T2只能等待T1释放A上的锁后才能获得对A的X锁,这时它读到的A是T1更新后 的值,再按此新的A值进行运算。这样就不会丢失 T1的更新。
1.实验七:事务与并发控制 1.1.实验目的 1.掌握事务机制,学会创建事务。 2.理解事务并发操作所可能导致的数据不一致性问题,用实验展现四种数据不一致性 问题:丢失修改、读脏数据、不可重复读以及幻读现象。 3.理解锁机制,学会采用锁与事务隔离级别解决数据不一致的问题。 4.了解数据库的事务日志。 1.2.实验内容 假设学校允许学生将银行卡和校园卡进行绑定,在student数据库中有如下的基本表,其中校园卡编号cardid即为学生的学号: icbc_card(studcardid,icbcid,balance) //校园卡ID,工行卡ID,银行卡余额campus_card(studcardid,balance) //校园卡ID,校园卡余额 数据创建的代码: use student createtable campus_card ( studcardid Char(8), balance Decimal(10,2)) createtable icbc_card ( studcardid Char(8), icbcid Char(10), balance Decimal(10,2) )
insertinto campus_card values('20150031', 30) insertinto campus_card values('20150032', 50) insertinto campus_card values('20150033', 70) insertinto icbc_card values('20150031','2015003101', 1000) insertinto icbc_card values('20150032','2015003201', 1000) insertinto icbc_card values('20150033','2015003301', 1000) 针对以上数据库按照要求完成下列实验: 1.编写一个事务处理(begin tran)实现如下的操作:某学号为20150032的学生要从银 行卡中转账200元到校园卡中,若中间出现故障则进行rollback。(15分)settransactionisolationlevel repeatableread
四级数据库第八章-事务调度与并发控制8.1 并发控制概述 在第七章中己经讲到,事务是并发控制的基本单位,保证事务ACID特性是事务处理的重要任务,而事务ACID特性可能遭到破坏的原因之一是多个事务对数据库的并发操作造成的。为了保证事务的隔离性更一般,为了保证数据库的一致性,DBMS需要对并发操作进行正确调度。这些就是数据库管理系统中并发控制机制的责任。 下面先来看一个例子,说明并发操作带来的数据的不一致性问题。 考虑飞机订票系统中的一个活动序列: ①甲售票点(甲事务)读出某航班的机票余额A,设A=16; ②乙售票点(乙事务)读出同一航班的机票余额A,也为16; ③甲售票点卖出一张机票,修改余额A A-l,所以A为15,把A写回数据库; ④乙售票点也卖出一张机票,修改余额A A-l,所以A为15,把A写回数据库。结果明明卖出两张机票,数据库中机票余额只减少1。 这种情况称为数据库的不一致性。这种不一致性是由并发操作引起的。在并发操作情况下,对甲、乙两个事务的操作序列的调度是随机的。若按上面的调度序列执行,甲事务的修改就被丢失。这是由于第④步中乙事务修改A并写回后覆盖了甲事务的修改。 仔细分析并发操作带来的数据不一致性包括三类:丢失修改、不可重复读和读“脏”数据,如图8.1所示。 1.丢失修改(Lost Update) 两个事务T1和T2。读入同一数据并修改,T2提交的结果破坏了T1提交的结果,导致T1的修改被丢失,如图8.1(a)所示。上面飞机订票例子就属此类。
图8.1 2.不可重复读(Non-Repeatable Read) 不可重复读是指事务T1读取数据后,重复T2执行更新操作,使T1无法再现前一次读 取结果。具体地讲,不可重复读包括三种情况: (1)事务T1读取某一数据后,事务T2对其做了修改,当事务T1再次读该数据时,得到与前一次不同的值。例如在图8.1(b)中,T1读取B=100进行运算,T2读取同一数据B对其进行修改后将B=200写回数据库。T1为了对读取值校对重读B,B己为200,与第1次读取值不一致。 (2)事务T1按一定条件从数据库中读取了某些数据记录后,事务T2删除了其中部分记录,当T1再次按相同条件读取数据时,发现某些记录神秘地消失了。 (3)事务T1按一定条件从数据库中读取某些数据记录后,事务T2插入了一些记录,当T1再次按相同条件读取数据时,发现多了一些记录。 后两种不可重复读有时也称为幻影(Phantom Row)现象。
文章编号:1000-2375(2005)01-0019-05 事务并发控制中的两段锁和 可串行化冲突图的对比 金 蓉,李跃新 (湖北大学数学与计算机科学学院,湖北武汉430062) 摘 要:数据库中并发操作一般分为数据级和事务级两种,由于资源的竞争可能引起数据级的冲突和事 务级的冲突,因此需要对并发执行的事务转化为某个可串行化调度,从而确保数据库的一致性.目前并发控制的方法有很多,从锁和非锁机制两个方面分析了两段锁和可串行化冲突图两种并发控制的规则和数据结构及分类,并从事务的冲突可串行化方面和结构上分析了各自的性能和优缺点. 关键词:锁;两段锁协议;可串行化冲突图 中图分类号:TP311 文献标志码:A 收稿日期:2004-03-25 作者简介:金 蓉(1979- ),女,硕士生1 引 言 数据库中的并发操作一般分为数据级和事务级两种,一方面在微观数据级上有数据对象的读(Read )操作和写(Write )操作,另一方面在宏观事务级上有事务的操作原语:终止(Abort ),开始(Begin ),提交(C ommit ),结束(End ),实质上事务中包含着对一系列数据对象的操作,因为一个事务系统主要由3个部分构成:数据项集、对数据项集的操作和控制事务存取数据的管理器(我们称为事务管理器T M ).并发控制的作用是正确协调同一时间里多个事务对数据库的并发操作,解决资源竞争问题以保证数据库的一致性和完整性. 并发控制是通过调度来确保事务的并发执行的效果等同于没有并发执行时的执行效果,也就是使事务的并发执行调度等价于事务的某个可串行化调度,从而确保数据库的一致性.可串行化简单的说就是一个并发操作等效于某个串行执行的效果,也即有相同的输出结果,与串行操作对数据库有同样的效果. 冲突有数据级的冲突和事务级的冲突,数据间的冲突体现在数据库中同时对相同的数据对象操作,事务间的冲突是由事务的数据相关性及在共享数据对象上的交互作用而引起的,通常用事务的“冲突关系”来表示. 定义1 数据对象d 上的两个操作p 、q 是“冲突”的,记为CT (d ,p ,q ),当且仅当S (S (s ,p ),q )≠S (S (s ,q ),p )∨R (s ,p )≠R (S (s ,q ),p )∨R (s ,q )≠R (S (s ,p ),q ).其中,S (s ,p )和R (s ,p )分别表示操作p 对d 的给定状态s 所产生的结果状态和结果输出(返回). 由定义可知,两个或多个数据操作产生冲突的条件是1)它们属于不同的事务;2)都访问数据库中相同的数据对象;3)并且至少有一个是写操作否则就不会产生冲突. 定义2 两个事务t 1、t 2是“冲突”的,记为t 1CR t 2,是指它们包含了(至少)一对冲突操作.即对于任何t 1≠t 2,t 1CR t 2,当且仅当?d 、?p ,q (p (d )∈t 1∧q (d )∈t 2∧CT (d ,p ,q ). 事务间的冲突归根结底集中在数据操作的冲突上,因此解决冲突最初的方法是对数据对象采用锁机制,而锁可以分为读锁和写锁,当数据对象加了读锁后可以再加读锁但不能加写锁,因此读锁是共享的,当数据对象加了写锁后就不能加其他任何锁,因此写锁是排它的,显然读锁较写锁的并发度高. 第27卷第1期2005年3月湖北大学学报(自然科学版)Journal of Hubei University (Natural Science ) V ol.27 N o.1 Mar.,2005
基于封锁的事务并发控制概述 发表时间:2010-05-14T10:46:24.013Z 来源:《计算机光盘软件与应用》2010年第4期供稿作者:卢成浪,徐湖鹏 [导读] 叙述了关系型数据库管理系统中的事务管理和基于锁的事务并发控制方法。 卢成浪,徐湖鹏 (温州大学瓯江学院,温州 325035) 摘要:叙述了关系型数据库管理系统中的事务管理和基于锁的事务并发控制方法。详细介绍了事务的串行化调度方法中的锁技术和锁 协议,并深入讨论了锁的管理、死锁处理、幻影问题和其它加锁过程中可能出现的一些问题。 关键词:数据库管理系统;事务;并发控制;封锁 中图分类号:TP311.131 文献标识码:A 文章编号:1007-9599 (2010) 04-0000-03 Lock-Based Transaction Concurrency Control Overview Lu Chenglang,Xu Hupeng (Wenzhou University,Oujiang College,Wenzhou 325035,China) Abstract:An overview on the management of lock- based concurrency control of transactions is presented in this paper.The locking protocols and locking techniques of the locking are discussed in depth. Keywords:Database management systems;Transaction;Concurrency control;Lock 一、引言 事务是用户定义的一组数据库操作序列。事务的执行结果将使数据库从一个一致性状态转变到另一个一致性状态。为了提高吞吐量, 系统中常常是多个事务并发执行。这会产生多个事务同时存取同一数据的情况,从而破坏数据库的一致性。所以数据库管理系统 (Database Management System,DBMS)必须提供并发控制机制,使得并发的事务在冲突的时候被串行化执行。这种调度称为可串行化 调度。其中基于封锁的并发控制机制是一种被广泛应用于商业DBMS中的并发控制机制。 二、事务的特性和并发的数据不一致性 事务具有ACID特性:原子性(Atomicity),一致性(Consistency),隔离性(Isolation)和持续性(Durability)。原子性指:事 务包含的所有操作要么全部被执行,要么都不被执行;一致性指:事务的执行结果必须使数据库从一个一致性状态变到另一个一致性状 态;隔离性指:在事务被提交以前,其操作结果对于其他事务不可见;持续性指:一旦事务成功提交,其对数据库中数据的改变是永久 的。事务是并发控制的基本单位,保证事务的ACID特性是事务处理的重要任务。然而,事务的并发执行可能会破坏事务的ACID特性,而导 致数据的不一致性: (一)Write-Write冲突,丢失更新。它是由于事务之间的写冲突造成的。两个事务T1和T2同时读入同一数据并修改,T2的提交破坏 了T1的提交结果,导致T1的修改丢失。 (二)Read-Write冲突,也称不一致读。不一致读是指事务T1读取数据后,事务T2执行更新操作,使T1无法再现前一次读取结果。它 包括三种情况:1.T1读取某一数据后, T2对其做了修改,当T1再次读取该数据时,得到与前一次不同的值;2.T1按一定的条件从数据库 中读取了某些记录后,T2删除其中部分记录,当T1再次按相同条件读取数据时,发现某些记录神秘的消失了;3.T1按一定的条件从数据库 中读取了某些记录后,T2插入了一些记录,当T1再次按相同条件读取数据时,发现多了一些记录。后两种情况也称幻影现象。 (三)Write-Read冲突,也称读脏数据。读脏数据指事务T1修改某数据,事务T2读取同一数据后,T1由于某种原因被撤销,这时T1已 修改过的数据恢复原值,T2读到的数据就与数据中的数据不一致,则称T2读到的数据就为脏数据。 三、基于封锁的事务并发控制机制 (一)锁的类型 封锁是实现并发控制的一个非常重要的技术。所谓封锁就是事务T在对某个数据对象例如表,记录等操作之前,先向系统发出请求,对 其加锁。加锁后事务T就对该数据对象有了一定的控制,在事务T释放它之前,其他事务不能更新该数据对象。下面介绍DBMS涉及的锁: 1.互斥锁(Exclusive Lock):用于写操作,又称写锁或者排他锁,记做X锁。若事务T对数据对象A加上X锁,则只允许T读写A,其他 事务都不能对A加任何锁,直到T释放A上的锁。 2.共享锁(Shared Lock):用于读操作,又称读锁,记做S锁。若事务T对数据对象A加上S锁,则T可读A但不能写A,其他事务只能对 A加S锁,而不能加X锁,直到T释放锁。 3.更新锁(Update Lock):用于更新操作。等价于先加共享锁,在真正执行更新操作时,将共享锁升级为互斥锁。大部分DMBS 都 不使用这种锁。 4.增量锁(Increment Lock):用于增量操作,如果一个对象被上了增量锁,除增量操作以外任何读写操作都是被禁止的。即增量锁 之间不排斥。因同时对某一对象的数值进行加一或者减一操作时,其结果与操作先后顺序是无关的,可以交换。这种锁使用并不广泛。 5.意向锁(Intention Lock):它是因为引入多粒度对象而产生的,又可 细分为:意向共享锁,意向排他锁和共享意向排他锁。 在DBMS 中被广泛使用的是共享锁,互斥锁和意向锁。为了保证写操作的互 斥性,不同事务对同一数据对象加锁时需要进行冲突检测。检测可以借助锁的相 容矩阵来判断,如图1(a)所示。从中可以发现5种锁的强度偏序关系,如图1 (b)所示。 (二)加锁管理和锁转换 DBMS中处理事务加锁事宜的部分被称为锁管理器。锁管理器维护着一个锁 表,这是一个以数据对象标志为码的哈希表。DBMS也在事务表中维护着每个事务的描述信息项,该记录中包含一个指向事务拥有的锁列表 的指针。在请求锁之前要检查这个列表,以确定不会对同一个锁请求两次。 加锁表中的每一项针对某个数据对象(可以是一页,一条记录等等),它包括下面的信息:拥有数据对象锁的事务数目,锁的属性 (共享锁、互斥锁等)和一个指向加锁请求队列的指针。
Informix的事务、并发控制、锁机制、隔离级别 1、事务 事务是指作为单个逻辑工作单元执行的一系列操作。事务处理可以确保除非事务性单元内的所有操作都成功完成,否则不会永久更新面向数据的资源。通过将一组相关操作组合为一个要么全部成功要么全部失败的单元,可以简化错误恢复并使应用程序更加可靠。数据库服务器保证在事务范围内执行的操作完整且正确地提交至磁盘,否则数据库会复原至事务启动之前的状态。 一个逻辑工作单元要成为事务,必须满足所谓的ACID属性。ACID的具体含义如下: 1)A(Atomicity):操作序列要么完整的执行,否则什么都不做; 2)C(Consistency):一致性,事务执行后,保证数据库从一个一致性状态到另外一个一致性状态; 3)I(Isolation):隔离,一个事务的中间状态对其他事务不可见,即每个用户都感觉他们在单独使用数据库。隔离级别用来定义多大程度的隔离多个不同的事务; 4)D(Durability):持久性,事务的有效性,不会应用硬件或软件的失败而丢失。 2、并发控制 1)相关概念 i)隔离(+一致性) => 并发控制; ii)多个事务可以访问或修改相同的资源; iii)只要多个进程共享资源,就需要对访问进程进行排队控制; iv)在进行并发控制时,数据库内部将生成多个并发事务访问资源的操作序列表,并且每一个事务内部的各个操作都需要序列化。 2)串行调度存在的问题 在串行调度中,采用操作序列,一个事务完成了再完成另外一个,即使两个事务T1、T2更新的是数据库中不同的对象。此种方式从并发和性能角度考虑,都不能很好的利用计算机资源。 为了改善性能,需要采用非串行调度,即允许事务并发执行,即一个事务内的操作可以在其他事务提交前开始执行。 3)并发调度的常见问题 i)脏读:事务T2读取到了事务T1没有提交的结果 例如如下的操作序列会导致脏读: 事务T1读取记录,然后更新记录; 事务T2读取了更新后的记录;
数据库是一个共享资源,可以提供多个用户使用。这些用户程序可以一个一个地串行执行,每个时刻只有一个用户程序运行,执行对数据库的存取,其他用户程序必须等到这个用户程序结束以后方能对数据库存取。但是如果一个用户程序涉及大量数据的输入/输出交换,则数据库系统的大部分时间处于闲置状态。因此,为了充分利用数据库资源,发挥数据库共享资源的特点,应该允许多个用户并行地存取数据库。但这样就会产生多个用户程序并发存取同一数据的情况,若对并发操作不加控制就可能会存取和存储不正确的数据,破坏数据库的一致性,所以数据库管理系统必须提供并发控制机制。并发控制机制的好坏是衡量一个数据库管理系统性能的重要标志之一。 DM用封锁机制来解决并发问题。它可以保证任何时候都可以有多个正在运行的用户程序,但是所有用户程序都在彼此完全隔离的环境中运行。 一、并发控制的预备知识 (一) 并发控制概述 并发控制是以事务(transaction)为单位进行的。 1. 并发控制的单位――事务 事务是数据库的逻辑工作单位,它是用户定义的一组操作序列。一个事务可以是一组SQL 语句、一条SQL语句或整个程序。 事务的开始和结束都可以由用户显示的控制,如果用户没有显式地定义事务,则由数据库系统按缺省规定自动划分事务。 事务应该具有4种属性:原子性、一致性、隔离性和持久性。 (1)原子性 事务的原子性保证事务包含的一组更新操作是原子不可分的,也就是说这些操作是一个整体,对数据库而言全做或者全不做,不能部分的完成。这一性质即使在系统崩溃之后仍能得到保证,在系统崩溃之后将进行数据库恢复,用来恢复和撤销系统崩溃处于活动状态的事务对数据库的影响,从而保证事务的原子性。系统对磁盘上的任何实际数据的修改之前都会将修改操作信息本身的信息记录到磁盘上。当发生崩溃时,系统能根据这些操作记录当时该事
6、事务管理与并发控制学习笔记——数据库的三种日志详解 6.1、概念:acid性质、共享锁、排它锁 6.1.1 事务的ACID特性 A:表示事务的原子性(Atomicity),即事务完全执行或完全不执行 –事务中包含的所有操作要么全做,要么全不做原子性由恢复机制实现 C:表示一致性(Consistency),所有数据库都有一致性约束,或关于数据之间联系的预期状态 –事务的隔离执行必须保证数据库的一致性。事务开始前,数据库处于一致性的状态;事务结束后,数据库必须仍处于一致性状态。 –数据库的一致性状态由用户来负责,由并发控制机制实现。如银行转帐,转帐前后两个帐户金额之和应保持不变 I:表示隔离(Isolation),即表面看起来,每个事务都是在没有其它事务同时执行的情况下执行的 –系统必须保证事务不受其它并发执行事务的影响。对任何一对事务T1,T2,在T1看来,T2要么在T1开始之前已经结束,要么在T1完成之后再开始执行 –隔离性通过并发控制机制实现 D:表示持久性(Durability),即一旦事务完成了,事务对数据库的影响就不会丢失 –一个事务一旦提交之后,它对数据库的影响必须是永久的 –系统发生故障不能改变事务的持久性。持久性通过恢复机制实现这里大家要知道,事务是我们对数据库操作的执行单位。我们要注意事务的整体性,即原子性,事务是绝对不能做一半的,否则很难保证数据库的一致性。而对于数据库来说,必须要保证一致性,因为一个数据库如果没有一致性,那么这个数据库是失败的!隔离性是数据库并发处理性能的体现,当然如果数据库没有很好的并发性那么你还是改用Excel吧,呵呵,开个玩笑而已。 6.2、三种日志例题 系统是很可能崩溃的,但是崩溃后我们不能坐以待毙,我们要保证事务的原子性,进而保证数据库的一致性和持久性。那么我们就应该考虑怎样建立一个合理的运行机制,让系统崩溃后能够通过一系列办法将那些不能确定是否真正写盘的事务回滚或者重做,哪怕数据库回到之前好久的状态。还好,高手们很有正事,他们研究出来一些针对故障的恢复机制!也就是我们下面要说到的日志系统!6.2.1 日志与故障恢复 数据库系统(例如Oracle)一般都有一个日志系统,它由日志管理服务和日志文件组成,这个如果大家有兴趣复习一下Oracle的体系架构,这里就不多说了。这个日志文件中存储的是一些文本行,当我们对一个数据库中的数据进行操作时,数据库系统首先按照一定的规则将你的操作命令和一些附加参数记录到这些日志文件中,(注意记录的只是命令语句、参数和一些标记等等)。然后再对数据库中的数据进行操作,最后完成所有操作后,再写一些标志到日志文件中。 根据对日志文件的管理规则的不同(对应的恢复机制也不同。),我们现在常用的是Undo、Redo还有Undo/Redo三种日志模式。 注意:在故障恢复里我们只对数据库的写操作感兴趣,因为读操作根本不会
基于封锁的事务并发控制概述 摘要:叙述了关系型数据库管理系统中的事务管理和基于锁的事务并发控制方法。详细介绍了事务的串行化调度方法中的锁技术和锁协议,并深入讨论了锁的 管理、死锁处理、幻影问题和其它加锁过程中可能出现的一些问题。 关键词:数据库管理系统;事务;并发控制;封锁 中图分类号:TP311.131 文献标识码:A 文章编号:1007-9599 (2010) 04-0000-03 Lock-Based Transaction Concurrency Control Overview Lu Chenglang,Xu Hupeng (Wenzhou University,Oujiang College,Wenzhou 325035,China) Abstract:An overview on the management of lock- based concurrency control of transactions is presented in this paper.The locking protocols and locki ng techniques of the transaction concurrency control are investigated in detail, and the approach t o avoiding phantom problem as well as the way for handling dead-locking are discussed in depth. Keywords:Database management systems;Transaction;Concurrency control;Lock 一、引言 事务是用户定义的一组数据库操作序列。事务的执行结果将使数据库从一个一致性状 态转变到另一个一致性状态。为了提高吞吐量,系统中常常是多个事务并发执行。这会产生 多个事务同时存取同一数据的情况,从而破坏数据库的一致性。所以数据库管理系统(Database Management System,DBMS)必须提供并发控制机制,使得并发的事务在冲突的 时候被串行化执行。这种调度称为可串行化调度。其中基于封锁的并发控制机制是一种被广 泛应用于商业DBMS中的并发控制机制。 二、事务的特性和并发的数据不一致性 事务具有ACID特性:原子性(Atomicity),一致性(Consistency),隔离性(Isolation)和持续性(Durability)。原子性指:事务包含的所有操作要么全部被执行,要么都不被执行;一致性指:事务的执行结果必须使数据库从一个一致性状态变到另一个一致性状态;隔离性指:在事务被提交以前,其操作结果对于其他事务不可见;持续性指:一旦事务成功提交, 其对数据库中数据的改变是永久的。事务是并发控制的基本单位,保证事务的ACID特性是事务处理的重要任务。然而,事务的并发执行可能会破坏事务的ACID特性,而导致数据的不一致性: (一)Write-Write冲突,丢失更新。它是由于事务之间的写冲突造成的。两个事务 T1和T2同时读入同一数据并修改,T2的提交破坏了T1的提交结果,导致T1的修改丢失。 (二)Read-Write冲突,也称不一致读。不一致读是指事务T1读取数据后,事务T2 执行更新操作,使T1无法再现前一次读取结果。它包括三种情况:1.T1读取某一数据 后, T2对其做了修改,当T1再次读取该数据时,得到与前一次不同的值;2.T1按一定的条 件从数据库中读取了某些记录后,T2删除其中部分记录,当T1再次按相同条件读取数据时,发现某些记录神秘的消失了;3.T1按一定的条件从数据库中读取了某些记录后,T2插入了一 些记录,当T1再次按相同条件读取数据时,发现多了一些记录。后两种情况也称幻影现象。 (三)Write-Read冲突,也称读脏数据。读脏数据指事务T1修改某数据,事务T2读 取同一数据后,T1由于某种原因被撤销,这时T1已修改过的数据恢复原值,T2读到的数据 就与数据中的数据不一致,则称T2读到的数据就为脏数据。 三、基于封锁的事务并发控制机制
数据库系统原理及MySQL应用教程(第2版) 课后习题参考答案 第14章事务与MySQL的多用户并发控制 1、事务是DB的逻辑工作单位,由用户定义的一组操作序列组成,序列中的操作要么全做要么全不做。 2、InnoDB和BDB存储引擎支持事务。 3、每个事务的处理必须满足ACID原则,即原子性(A):原子性意味着每个事务都必须被认为是一个不可分割的单元。一致性(C):不管事务是完全成功完成还是中途失败,当事务使系统处于一致的状态时存在一致性。隔离性(I):隔离性是指每个事务在它自己的空间发生,和其他发生在系统中的事务隔离,而且事务的结果只有在它完全被执行时才能看到。持久性(D):持久性是指即使系统崩溃,一个提交的事务仍然存在。 4、MySQL中可以使用begin开始事务,使用commint结束事务。 5、每一个事务都有一个所谓的隔离级,它定义了用户彼此之间隔离和交互的程度。 MySQL提供了下面4种隔离级:序列化(serializable)、可重复读(repeatable read)、提交读(read committed)、未提交读(read uncommitted) 。 6、若对并发操作不加控制可能会存取和存储不正确的数据,就会出现数据的不一致问题。 (1)丢失更新(lost update) 问题 (2)脏读(dirty read)问题 (3)不可重复读( unrepeatableread) 问题 (4)幻读(phantom read) 问题 7、MySQL中可以使用begin开始事务,使用commint结束事务,中间可以使用rollback回滚事务。MySQL通过set autocommint 、start transaction 、
事物处理与并发控制 授课教师:李斌 目标: ●Oracle中的事务处理是什么 ●怎样控制Oracle中的事务处理 ●Oracle怎样在数据库中实现并发控制,让多个用户同时访问和修改相同的数据表 1 什么是事务 事务就是在数据库上完成的一个操作。要么全部执行并且存储需要的操作,要么全部撤销已经进行的操作,使得数据库恢复到没有改变之前的状态。 2 事务处理控制语句 Oracle中的一个重要的概念就是没有“开始事务处理”的语句。用户不能显式开始一个事务,事务结束时需要向数据库提交(Commit),或者回滚(Rollback)操作。 ●COMMIT ●ROLLBACK ●SA VEPOINT ●ROLLBACK TO SA VEPOINT ●SET TRANSACTION ●SET CONSTRAINTS 2.1 COMMIT处理 当提交时,我们需要处理三个任务: 1、为我们的事务处理生成SCN(系统改变号)。 2、将所有剩余的已经缓冲的重做日志表项写入磁盘,并且将SCN记录到在线重做日志文 件中。由LGWR执行处理。 3、释放我们的会话所锁定的资源。 LGWR会在下列情况之一发生时执行清理工作: ●每隔3秒 ●当SGA中的Redo Log Buffer Cache容量超过1/3的空间,或者包含了1MB或者更 多的已经缓冲数据
●进行任何事务处理提交 2.2 ROLLBACK处理 回滚是一项比较耗费资源的操作。当我们不需要存储所作出的修改时,就回滚我们的操作。回滚可以归结为异常处理范畴。 2.3 SA VEPOINT 和ROLLBACK TO SAVEPOINT SA VEPOINT可以在应用中建立保存点。它可以让用户将单独的大规模事务处理分割成一系列较小的部分。 2.4 SET TRANSACTION SET TRANSACTION必须是你的事务处理的第一条语句,用来设置事务之间的隔离级别。 ●规定事务处理的隔离级别 ●规定为用户事务处理所使用的特定回滚段 ●命名用户事务处理 SET TRANSACTION READ ONLY SET TRANSACTION READ WRITE SET TRANSACTION ISOLA TION LEVEL SERIALIZABLE SET TRANSACTION ISOLA TION LEVEL READ COMMITED 1、READ ONLY 命令SET TRANSACTION READ ONLY将会做两件事情。 首先而且最明显的是:它会确保你无法执行修改数据的DML操作。如果你要执行这样的操作,就会报错。 另外,READ ONLY可以使得我们把数据库视图冻结在某个时间点。 例如:我们需要获得上午10:00使,数据库中某个数据表中的数据,而这张表又与其它很多数据表之间存在复杂的关联关系。数据库的其它用户有可能继续对其它的一些表随时都在进行DML操作。我们如何获得10:00时我们需要的数据? 一种方法是:停止其它用户的所有活动,锁定相关的数据表。 好的方法是:用户可以使用SET TRANSACTION READ ONLY语句,冻结10:00的用户数据库视图。这样你会看到你需要的数据,而且不会影响其它用户的操作。
5.3 并发控制——事务调度
【本节学习目标】 ?了解数据库并发事务控制目的 ?了解并发事务调度控制需要解决的问题?理解并发事务调度原理与策略
一、为什么需要并发控制 并发控制目的 ?支持并发事务处理,使更多用户并行操作,提高系统的并发访问能力。?保证一个事务工作不会对另一个事务工作产生不合理的影响。 当多个事务程序在DBMS系统中同时运行时,可能会出现对一些共享数据同时进行访问操作,如一些事务修改数据,另一些事务读取数据。这些并发的共享数据操作,如果在DBMS中没有一定的约束控制情况下,可能会带来数据不一致性或事务程序死锁问题。因此,在多个事务并发运行时,必须进行并发控制处理。
3 二、并发控制需解决的问题A=16读 读 A=A-1 A=A-1 A=15 A=16A=16 出售1出售1 事务T1事务T2 执行结果分析:剩余机票数A值为15,该数据有错,应为14。1.丢失更新数据 A=15售票点2 机票数量A 售票点1
错误分析: ?T1、T2两个事务并发执行,它们均对数据库共享数据A进行了非锁定资源的读写操作。 ?当事务T1和T2均读入该共享数据A并修改,T2提交的结果破坏了T1提交的结果,导致T1的修改被丢失。 4
5 2.不可重复读取 问题分析: 为什么出现不可重复读取? 事务T1读取某一数据后,事务T2对其做了修改,当事务T1再次读该数据时,得到与前一次不同的值。不可重复读取是指一个事务对一个共享数据重复多次读取,但前后读取的数据不一致。 假如A的初始数据为100 事务T1首次读取A的值为100 事务T1不知道其它事务修改A值 事务T1第2次读取A的值为200 因此,事务T1前后读取数据A的值不一致。
数据库实验报告记录:事务与并发控制
————————————————————————————————作者:————————————————————————————————日期:
《数据库原理》实验报告 题目:实验七 事务与并发控制 学号姓名班级日期2013302478 纪昌宇10011301 2015.11.14 1.实验七:事务与并发控制 1.1.实验目的 1.掌握事务机制,学会创建事务。 2.理解事务并发操作所可能导致的数据不一致性问题,用实验展现四种数据不一致性 问题:丢失修改、读脏数据、不可重复读以及幻读现象。 3.理解锁机制,学会采用锁与事务隔离级别解决数据不一致的问题。 4.了解数据库的事务日志。 1.2.实验内容 假设学校允许学生将银行卡和校园卡进行绑定,在student数据库中有如下的基本表,其中校园卡编号cardid即为学生的学号: icbc_card(studcardid,icbcid,balance) //校园卡ID,工行卡ID,银行卡余额 campus_card(studcardid,balance) //校园卡ID,校园卡余额 数据创建的代码: use student create table campus_card (studcardid Char(8) , balance Decimal(10,2)) create table icbc_card ( studcardid Char(8), icbcid Char(10), balance Decimal(10,2) )
insert into campus_card values('20150031', 30) insert into campus_card values('20150032', 50) insert into campus_card values('20150033', 70) insert into icbc_card values('20150031','2015003101', 1000) insert into icbc_card values('20150032','2015003201', 1000) insert into icbc_card values('20150033','2015003301', 1000) 针对以上数据库按照要求完成下列实验: 1.编写一个事务处理(begin tran)实现如下的操作:某学号为20150032的学生要从银 行卡中转账200元到校园卡中,若中间出现故障则进行rollback。(15分) set transaction isolation level repeatable read