Chapter 1 误差
误差限计算、有效数字分析
Chapter 2 插值法
差值条件(唯一性)
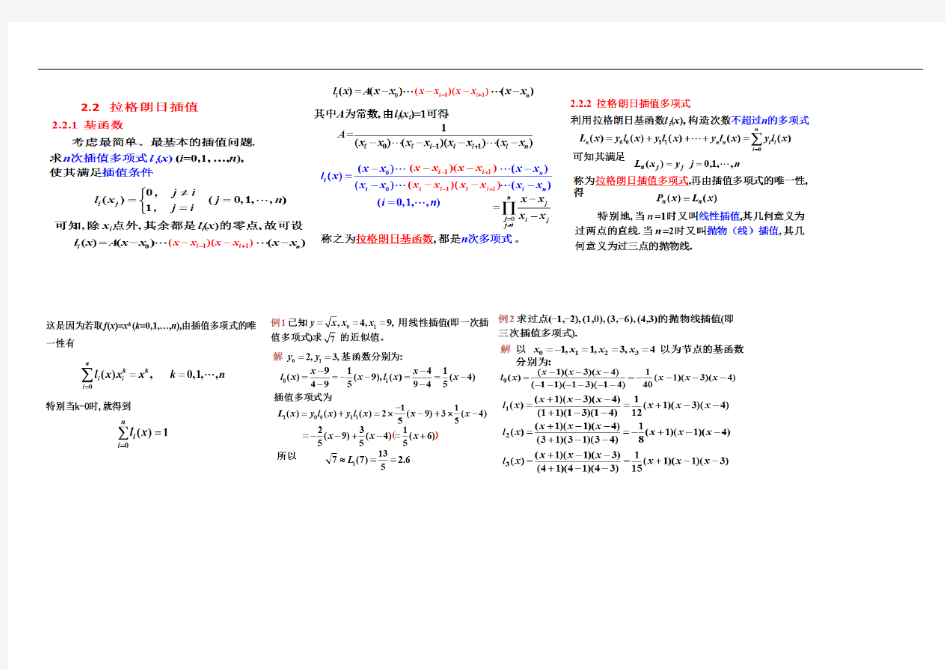
1、拉格朗日差值
a)插值基函数
b)差值余项
2、牛顿插值
构造差商表
3、埃尔米特插值
构造三次埃尔米特插值多项式如下
4、分段低次插值
5、三次样条插值(概念)
2、式计算(向量、矩阵)
Chapter 4 数值积分与数值微分1、梯形公式、辛普森公式
2、
代数精度判断
3、龙贝格求积公式
4、高斯求积公式
5、高斯-勒让德求积公式
6、数值微分了解即可
Chapter 5解线性方程组的直接方法
1、消元法
2、LU分解法
Chapter 6解线性方程组的迭代法
1、雅克比迭代法、高斯-
塞德尔迭代法公式(会写)
2、给迭代公式,判断收敛性,谱半径。
Chapter 7非线性方程求根
1、二分法
(先判断有根区间)
2、
迭代的收敛性
3、牛顿迭代法
(代公式)
Chapter 9常微分方程初值问题数值解法
1、公式计算:四种,欧拉公式、改进的欧拉公式、隐式、梯形公式
2、判断局部截断误差(泰勒公式)
3、单步法的收敛性和稳定性分析
4、
第一章 绪论 1.设0x >,x 的相对误差为δ,求ln x 的误差。 解:近似值* x 的相对误差为* **** r e x x e x x δ-= = = 而ln x 的误差为()1 ln *ln *ln ** e x x x e x =-≈ 进而有(ln *)x εδ≈ 2.设x 的相对误差为2%,求n x 的相对误差。 解:设()n f x x =,则函数的条件数为'() | |() p xf x C f x = 又1 '()n f x nx -=Q , 1 ||n p x nx C n n -?∴== 又((*))(*)r p r x n C x εε≈?Q 且(*)r e x 为2 ((*))0.02n r x n ε∴≈ 3.下列各数都是经过四舍五入得到的近似数,即误差限不超过最后一位的半个单位,试指 出它们是几位有效数字:*1 1.1021x =,*20.031x =, *3385.6x =, *456.430x =,* 57 1.0.x =? 解:* 1 1.1021x =是五位有效数字; *20.031x =是二位有效数字; *3385.6x =是四位有效数字; *456.430x =是五位有效数字; *57 1.0.x =?是二位有效数字。 4.利用公式(2.3)求下列各近似值的误差限:(1) ***124x x x ++,(2) ***123x x x ,(3) **24/x x . 其中**** 1234,,,x x x x 均为第3题所给的数。 解:
*4 1* 3 2* 13* 3 4* 1 51()1021()1021()1021()1021()102 x x x x x εεεεε-----=?=?=?=?=? *** 124***1244333 (1)()()()() 1111010102221.0510x x x x x x εεεε----++=++=?+?+?=? *** 123*********123231132143 (2)() ()()() 111 1.10210.031100.031385.610 1.1021385.610222 0.215 x x x x x x x x x x x x εεεε---=++=???+???+???≈ ** 24**** 24422 *4 33 5 (3)(/) ()() 11 0.0311056.430102256.43056.430 10x x x x x x x εεε---+≈ ??+??= ?= 5计算球体积要使相对误差限为1,问度量半径R 时允许的相对误差限是多少? 解:球体体积为343 V R π= 则何种函数的条件数为 2 3'4343 p R V R R C V R ππ===g g (*)(*)3(*)r p r r V C R R εεε∴≈=g 又(*)1r V ε=Q
高密市城南中学七年级信息技术教学设计 课题:《数据分析》 执教:常小燕 一、教材分析: 《数据分析》青岛出版社是七年级信息技术下册第一单元第二节内容。本节课是在学生掌握了数据计算基本知识的基础上,进一步对数据进行分析的一节新授课。“对数据进行排序和筛选”是用Excel管理数据中的基础方法,也是学生必须掌握的基本技能。它是本册书中学生必须掌握的几个重点之一,是对所学知识的一个综合运用,也是学习用图表表示数据的重要基础。教材中以学生身边经常见到的“图书统计表”为载体,引导学生学习数据排序及筛选的操作。以“加油站、一点通”作为排序、筛选知识点的补充,以“练一练”作为操作技能的巩固。以“实践与创新”作为知识的延伸,帮助学生掌握数据分析和管理的一般方法,提高学生处理信息的能力。 二、学情分析: 七年级学生已经掌握了Word的基本操作,并经过第一课数据计算的学习,对Excel的基本知识,基本技能也有了一定的了解,初步掌握了Excel 的学习方法,并能处理一些生活中的实际问题,包括数据的输入,对数据的统计分析等知识学习兴致非常高,但基于他们年龄的特征,他们对理论性强的知识点不易理解,认知较直观,而对具体操作易于接受。另外因诸多因素的不同,造成他们对信息技术的认知能力实际操作能力、知识水平各不相同,形成了不同的层次,因此教学设计中要体现分层教学。
三、教学目标: 1、知识目标:理解数据清单、数据的排序、筛选的概念和作用。 2、技能目标:熟练掌握数据排序和筛选的操作方法。 3、情感态度价值观目标:感受通过数据分析解决、实际问题的过程, 培养学生遇事要善于分析、判断的意识,引导学生热爱读书,并学 会与他人分享信息资源。 四、教学重点与难点: 熟练掌握数据的排序和筛选的操作方法。 五、教学策略: 本课是让学生学会用Excel对数据进行排序和筛选操作。采用“任务驱动”的教学模式和学生“自主、合用、探究”的学习模式,老师仅起以引导启示的作用,使学生熟练掌握所学内容并能将信息技术应用于生活,以解决生活中的具体问题。这样的教学方法在教学实践中效果比较好。六、教学过程
7、设y0=28,按递推公式 y n=y n?1? 1 100 783,n=1,2,… 计算y100,若取≈27.982,试问计算y100将有多大误差? 答:y100=y99?1 100783=y98?2 100 783=?=y0?100 100 783=28?783 若取783≈27.982,则y100≈28?27.982=0.018,只有2位有效数字,y100的最大误差位0.001 10、设f x=ln?(x? x2?1),它等价于f x=?ln?(x+ x2?1)。分别计算f30,开方和对数取6位有效数字。试问哪一个公式计算结果可靠?为什么? 答: x2?1≈29.9833 则对于f x=ln x?2?1,f30≈?4.09235 对于f x=?ln x+2?1,f30≈?4.09407 而f30= ln?(30?2?1) ,约为?4.09407,则f x=?ln?(x+ x2?1)计算结果更可靠。这是因为在公式f x=ln?(x? x2?1)中,存在两相近数相减(x? x2?1)的情况,导致算法数值不稳定。 11、求方程x2+62x+1=0的两个根,使它们具有四位有效数字。 答:x12=?62±622?4 2 =?31±312?1 则 x1=?31?312?1≈?31?30.98=?61.98 x2=?31+312?1= 1 31+312?1 ≈? 1 ≈?0.01613
12.(1)、计算101.1?101,要求具有4位有效数字 答:101.1?101= 101.1+101≈0.1 10.05+10.05 ≈0.004975 14、试导出计算积分I n=x n 4x+1dx 1 的一个递推公式,并讨论所得公式是否计算稳定。 答:I n=x n 4x+1dx 1 0= 1 4 4x+1x n?1?1 4 x n?1 4x+1 dx= 1 1 4 x n?1 1 dx?1 4 x n?1 4x+1 dx 1 = 1 4n ? 1 4 I n?1,n=1,2… I0= 1 dx= ln5 1 记εn为I n的误差,则由递推公式可得 εn=?1 εn?1=?=(? 1 )nε0 当n增大时,εn是减小的,故递推公式是计算稳定的。
高等数值计算实践题目一 1. 实践目的 本次计算实践主要是在掌握共轭梯度法,Lanczos 算法与MINRES 算法的基础上,进一步探讨这3种算法的数值性质,主要研究特征值特征向量对算法收敛性的影响。 2. 实践过程 (一)生成矩阵 (1)作5个100阶对角阵i D 如下: 1D 对角元:1,1,...,20,1+0.1(-20),21,...,100j j d j d j j ==== 2D 对角元:1,1,...,20,1+(-20),21,...,100j j d j d j j ==== 3D 对角元:,1,...,80,81,81,...,100j j d j j d j ==== 4D 对角元:,1,...,40,41,41,...,60,41+(60),61,...,100j j j d j j d j d j j =====-= 5D 对角元:,1,...,100j d j j == 记i D 的最大模特征值和最小模特征值分别为1i λ和i n λ,则i D 特征值分布有如下特点: 1D 的特征值有较多接近于i n λ,并且1/i i n λλ较小, 2D 的特征值有较多接近于i n λ,并且1/i i n λλ较大, 3D 的特征值有较多接近于1i λ,并且1/i i n λλ较大, 4D 的特征值有较多接近于中间模特征值,并且1/i i n λλ较大, 5D 的特征值均匀分布,并且1/i i n λλ较大 (2)随机生成10个100阶矩阵j M : (100(100))j M fix rand = 并作它们的QR 分解,得j Q 和j R ,这样可得50个对称的矩阵T ij j i j A Q DQ =,其中i D 的对角元就是ij A 的特征值,若它们都大于0,则ij A 正定,j Q 的列就是相应的特征向量。结合(1)可知,ij A 都是对称正定阵。
广西大学实验报告纸 组长: 组员: 指导老师: 成绩: 学院:电气工程学院 专业:自动化 班级:163 实验容:实验五 二阶瞬态响应特性与稳定性分析 2018年5月11日 【实验时间】 2018年 5月 11日 【实验地点】 综合808 【实验目的】 1、以实际对象为基础,了解和掌握典型二阶系统的传递函数和模拟电路图。 2、观察和分析典型二阶系统在欠阻尼、临界阻尼、过阻尼的响应曲线。 3、学会用MATLAB 分析系统稳定性。 【实验设备与软件】 1、Multisim 10电路设计与仿真软件 2、labACT 试验台与虚拟示波器 3、MATLAB 数值分析软件 【实验原理】 1、被模拟对象模型描述 永磁他励电枢控制式直流电机如图1(a )所示。根据Kirchhoff 定律和机电转换原理,可得如下方程 u k Ri dt di L e =++ω (1) l t T i k b dt d J -=+ωω (2) ωθ =dt d (3) 式中,各参数如图1(a )所示:L 、R 为电机和负载折合到电机轴上的转动惯量,Tl 是折合到电机轴上的总的负载转矩,b 是电机与负载折合到电机轴上的粘性摩擦系数;kt 是转矩系数(Nm/A ),k e 是反电动势 系数(Vs/rad )。令R L /e =τ(电磁时间常数),b J /m =τ(机械时间常数) ,于是可由这三个方程 画出如图1(b )的线性模型框图。 将Tl 看成对控制系统的扰动,仅考虑先行模型框图中()()s s U Θ→的传递函数为 ()()()()()s Rb k k s s Rb k s U s s G t e m e t 1 /11/?+++=Θ= ττ (4) 考虑到电枢电感L 较小,在工程应用中常忽略不计,于是上式转化为
同济大学2009—2010学年《国家学生体质健康标准》测试数据汇总与分析报告 同济大学体育部 2010.6
目录 1、《标准》测试人数情况汇总 (3) 2、《标准》测试总分平均分情况汇总 (3) 2.1各年级男、女生《标准》测试总分平均分情况汇总 (3) 2.2各学院学生《标准》测试总分平均分情况汇总 (4) 2.3各体育专项课学生《标准》测试总分平均分情况汇总 (5) 3、《标准》测试达标率情况汇总 (6) 3.1各年级男、女生《标准》测试达标率情况汇总 (6) 3.2各学院学生《标准》测试达标率情况汇总 (7) 3.3各体育专项课学生《标准》测试达标率情况汇总 (9) 4、学生身体形态、机能、身体素质现状 (11) 4.1身体形态现状 (11) 4.2身体机能现状 (12) 4.3身体素质现状 (14) 5、结论 (15) 6、建议 (16)
2009—2010学年同济大学学生体质健康 《标准》测试数据汇总报告 1、2009—2010学年同济大学学生体质健康《标准》测试人数情况汇总 2009—2010学年同济大学学生体质健康《标准》测试工作共测试学生13461人,其中男生8414人,女生5047人。一年级测试人数为4224人,二年级测试人数为2258人,三年级测试人数为3852人,四、五年级测试人数为3127人。测试人数整体上呈正常情况,二年级人数偏少是由于有部分学院二年级时搬至嘉定校区《标准》测试在三年级时再测的原因,四、五年级测试的学生人数少于三年级。(祥见表1.1、图1.1) 图1.1 测试学生样本量情况 一年级 二年级 三年级 四、五年 2、2009—2010学年同济大学学生体质健康《标准》测试总分平均分情况汇总2.1各年级男、女生《标准》测试总分平均分情况汇总 各年级学生体质健康《标准》测试总分情况详见表2.1。全体男生《标准》测试总分平均值为65.54分,全体女生《标准》测试总分平均值为69.30分。一、二、三、四五年级男生《标准》测试总分平均值分别为:64.89、64.60、68.55、63.14分;各年级女生《标准》测试总分平均值分别为:68.43、69.47、71.38、67.90分。从整体分数上来看三年级男、女
数据分析报告范文 数据分析报告范文数据分析报告范文: 目录 第一章项目概述 此章包括项目介绍、项目背景介绍、主要技术经济指标、项目存在问题及推荐等。 第二章项目市场研究分析 此章包括项目外部环境分析、市场特征分析及市场竞争结构分析。 第三章项目数据的采集分析 此章包括数据采集的资料、程序等。第四章项目数据分析采用的方法 此章包括定性分析方法和定量分析方法。 第五章资产结构分析 此章包括固定资产和流动资产构成的基本状况、资产增减变化及原因分析、自西汉结构的合理性评价。 第六章负债及所有者权益结构分析 此章包括项目负债及所有者权益结构的分析:短期借款的构成状况、长期负债的构成状况、负债增减变化原因、权益增减变化分析和权益变化原因。 第七章利润结构预测分析
此章包括利润总额及营业利润的分析、经营业务的盈利潜力分析、利润的真实决定性分析。 第八章成本费用结构预测分析 此章包括总成本的构成和变化状况、经营业务成本控制状况、营业费用、管理费用和财务费用的构成和评价分析。 第九章偿债潜力分析此章包括支付潜力分析、流动及速动比率分析、短期偿还潜力变化和付息潜力分析。第十章公司运作潜力分析此章包括存货、流动资产、总资产、固定资产、应收账款及应付账款的周转天数及变化原因分析,现金周期、营业周期分析等。 第十一章盈利潜力分析 此章包括净资产收益率及变化状况分析,资产报酬率、成本费用利润率等变化状况及原因分析。 第十二章发展潜力分析 此章包括销售收入及净利润增长率分析、资本增长性分析及发展潜力状况分析。第十三章投资数据分析 此章包括经济效益和经济评价指标分析等。 第十四章财务与敏感性分析 此章包括生产成本和销售收入估算、财务评价、财务不确定性与风险分析、社会效益和社会影响分析等。 第十五章现金流量估算分析 此章包括全投资现金流量的分析和编制。
高等数值分析第二次实验作业
T1.构造例子特征值全部在右半平面时, 观察基本的Arnoldi 方法和GMRES 方法的数值性态, 和相应重新启动算法的收敛性. Answer: (1) 构造特征值均在右半平面的矩阵A : 根据实Schur 分解,构造对角矩阵D 由n 个块形成,每个对角块具有如下形式,对应一对特 征值i i i αβ± i i i i i S αββα-?? = ??? 这样D=diag(S 1,S 2,S 3……S n )矩阵的特征值均分布在右半平面。生成矩阵A=U T AU ,其中U 为 正交阵,则A 矩阵的特征值也均在右半平面。不妨构造A 如下所示: 2211112222 /2/2/2/2N N A n n n n ?-?? ? ? ?- ? = ? ? ? - ? ?? ? 由于选择初值与右端项:x0=zeros(2*N,1);b=ones(2*N,1); 则生成矩阵A 的过程代码如下所示: N=500 %生成A 为2N 阶 A=zeros(2*N); for a=1:N A(2*a-1,2*a-1)=a; A(2*a-1,2*a)=-a; A(2*a,2*a-1)=a; A(2*a,2*a)=a; end U = orth(rand(2*N,2*N)); A1 = U'*A*U; (2) 观察基本的Arnoldi 和GMRES 方法 编写基本的Arnoldi 函数与基本GMRES 函数,具体代码见附录。 function [x,rm,flag]=Arnoldi(A,b,x0,tol,m) function [x,rm,flag]=GMRES(A,b,x0,tol,m) 输入:A 为方程组系数矩阵,b 为右端项,x0为初值,tol 为停机准则,m 为人为限制的最大步数。 输出:x 为方程的解,rm 为残差向量,flag 为解是否收敛的标志。 外程序如下所示: e=1e-6; m=700;
L- 腈化物稳定性试验报告 一、概述 L-腈化物是L- 肉碱生产过程中的第一步中间体(第二步中间体: L-肉碱粗品;第三步中间体:L-肉碱潮品),由于L- 肉碱生产工艺为 间歇操作,即每生产一步中间体,生产完毕并出具合格检测报告后,存 入中间体仓库,以备下一步生产投料所需。根据本公司L- 肉碱产品的 整个生产周期,L- 腈化物入库后可能存放的最长时间为4 周(约28 天)。以此周期为时间依据制定了L- 腈化物稳定性试验方案,用于验 证L-腈化物在再试验期限内的各项质量指标数据的稳定性,并且能否符 合L- 腈化物的质量标准,此次稳定性试验的整个周期为28 天,具体 的稳定性试验方案以ICH 药物稳定性指导原则为基础制定,以确保L- 腈化化物稳定性试验的可操作性。 二、验证日期 2010 年1 月13 日- 2010 年2 月10 日 三、验证方案 1)样品储存和包装: 考虑到L- 腈化物今后的贮藏、使用过程,本次用于稳定性试验的样品 批次与最终规模生产所用的L- 腈化物的包装和放置条件相同。 2)样品批次选择:此次稳定性试验共抽取三批样品,且抽取样品的批次与 最终规模生产时的合成路线和生产工艺相同
3)抽样频率和日期:从2010.1.13 起,每隔7 天取样一次,共取五次,具体日期为:2010.1.13 、2010.1.20 、2010.1.27 、 2010.2.3 、2010.2.10 ,以确保试验次数足以满足L- 腈化物的稳 定性试验的需要。。 4)检测项目:根据L- 腈化物的质量标准的规定,此次稳定性试验的检测项目共五项,分别为外观、氯含量、熔点、比旋度、干燥失重。这 些指标在L- 腈化物的储存过程中可能会发生变化,且有可能影响 其质量和有效性。 5)试样来源和抽样:L- 腈化物由公司102 车间生产,经检测合格后储存于中间体仓库,本次稳定性试验的L- 腈化物均取自于该中间体仓 库,其抽样方法和抽样量均按照L- 腈化物抽样方案进行抽样。抽 样完毕后直接进行检测分析,并对检测结果进行登记,保存,作为稳 定性数据评估的依据。 四、稳定性试验数据变化趋势分析及评估 通过对三批L- 腈化物的稳定性试验,对其物理、化学方面稳定性资料进行评价,旨在建立未来相似情况下,大规模生产出的L- 腈化物是否适用 现有的再试验期(28天)。批号间的变化程度是否会影响未来生产的
数据分析 我们设样本一为抽样总体,样本二为男生的抽样总体,样本三为女生的抽样总体。 一、生活费水平的分析 1. 对样本一的分析 由整理后输入计算机的数据,我们绘制出样本一生活费水平的频数分布表和直方图,结果如下: 样本一生活费水平的频数分布表 频率百分比有效百分比累积百分 500以下26 500-70024 700-9009 900以上6 总数65 由上图可以看出:样本一(即本科生抽样全体)月生活费500元以下所占频数最高。 样本一(总体)平均月生活费置信区间的构造表 One-Sample Statistics N Mean Std. Deviation Std. Error Mean 频数65
从上述分析可知:我们有95%的把握认为重庆工商大学本科生的月生活费平均水平在元~元之间。 样本一男生月生活费水平的频数分布表 Statistics 频数 N Valid38 Missing0 Mean Std. Error of Mean Std. Deviation 频数 Frequency Percent Valid Percent Cumulative Percent Valid500以下14 500-70015 700-9004 900以上5 Total38 由上图可以看出:样本二月生活费500-700所占频数最高,是月生活费的众数。分析众数后,我们进一步分析月生活费的平均水平,得出结果如下: T-Test
One-Sample Statistics N Mean Std. Deviation Std. Error Mean 频数38 从上述分析可知:我们有95%的把握认为重庆工商大学科生男生的月生活费平均水平在 元~元之间。 3.对样本三的分析 由整理后输入计算机的数据,绘制出样本三女生月生活费水平的频数分布表和直方图,结果如下: 样本三女生月生活费水平的频数分布表 Statistics 频数 N Valid27 Missing0 Mean Std. Error of Mean Std. Deviation
学生实验报告实验课程名称 开课实验室 学院年级专业班 学生姓名学号 开课时间至学年学期
if(A(m,k)~=0) if(m~=k) A([k m],:)=A([m k],:); %换行 end A(k+1:n, k:c)=A(k+1:n, k:c)-(A(k+1:n,k)/ A(k,k))*A(k, k:c); %消去end end x=zeros(length(b),1); %回代求解 x(n)=A(n,c)/A(n,n); for k=n-1:-1:1 x(k)=(A(k,c)-A(k,k+1:n)*x(k+1:n))/A(k,k); end y=x; format short;%设置为默认格式显示,显示5位 (2)建立MATLAB界面 利用MA TLAB的GUI建立如下界面求解线性方程组: 详见程序。 五、计算实例、数据、结果、分析 下面我们对以上的结果进行测试,求解:
? ? ? ? ? ? ? ? ? ? ? ? - = ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? - - - - - - 7 2 5 10 13 9 14 4 4 3 2 1 13 12 4 3 3 10 2 4 3 2 1 x x x x 输入数据后点击和,得到如下结果: 更改以上数据进行测试,求解如下方程组: 1 2 3 4 43211 34321 23431 12341 x x x x ?? ???? ?? ???? ?? ???? = ?? ???? - ?? ???? - ???? ?? 得到如下结果:
性能稳定性分析 1功角的具体含义。 电源电势的相角差,发电机q轴电势与无穷大系统电源电势之间的相角差。 电磁功率的大小与δ密切相关,故称δ为“功角”或“功率角”。电磁功率与功角的关系式被称为“功角特性”或“功率特性”。 功角δ除了表征系统的电磁关系之外,还表明了各发电机转子之间的相对空间位置。 2功角稳定及其分类。 电力系统稳态运行时,系统中所有同步发电机均同步运行,即功角δ是稳定值。系统在受到干扰后,如果发电机转子经过一段时间的运动变化后仍能恢复同步运行,即功角δ能达到一个稳定值,则系统就是功角稳定的,否则就是功角不稳定。 根据功角失稳的原因和发展过程,功角稳定可分为如下三类: 静态稳定(小干扰) 暂态稳定(大干扰) 动态稳定(长过程) 3电力系统静态稳定及其特点。 定义:指电力系统在某一正常运行状态下受到小干扰后,不发生自发振荡或非周期性失步,自动恢复到原始运行状态的能力。如果能,则认为系统在该正常运行状态下是静态稳定的。不能,则系统是静态失稳的。 特点:静态稳定研究的是电力系统在某一运行状态下受到微小干扰时的稳定性问题。系统是否能够维持静态稳定主要与系统在扰动发生前的原始运行状态有关,而与小干扰的大小、类型和地点无关。 4电力系统暂态稳定及其特点。 定义:指电力系统在某一正常运行状态下受到大干扰后,各同步发电机保持同步运行并过渡到新的或恢复到原来的稳态运行状态的能力。通常指第一或第二振荡周期不失步。如果能,则认为系统在该正常运行状态下该扰动下是暂态稳定的。不能,则系统是暂态失稳的。 特点:研究的是电力系统在某一运行状态下受到较大干扰时的稳定性问题。系统的暂态稳定性不仅与系统在扰动前的运行状态有关,而且与扰动的类型、地点及持续时间均有关。 作业2 5发电机组惯性时间常数的物理意义及其与系统惯性时间常数的关系。 表示在发电机组转子上加额定转矩后,转子从停顿状态转到额定转速时所经过的时间。TJ=TJG*SGN/SB 6例题6-1 (P152) (补充知识:当发电机出口断路器断开后,转子做匀加速旋转。汽轮发电机极对数p=1。额定频率为50Hz。要求列写每个公式的来源和意义。)题目:已知一汽轮发电机的惯性时间常数Tj=10S,若运行在输出额定功率状态,在t=0时其出口处突然断开。试计算(不计调速器作用) (1)经过多少时间其相对电角度(功角)δ=δ0+PAI.(δ0为断开钱的值)(2)在该时刻转子的转速。 解:(1)Tj=10S,三角M*=1,角加速度d2δ/dt2=三角M*W0/Tj=W0/10=31.4RAD/S2 δ=δ0+0.5dd2δ/dt2 所以PI=0.5*2PI*f/10t方 t=更号10/50=0.447 (2)t=0.447时,
数据的收集、整理与描述——备课人:发 【问题】统计调查的一般过程是什么?统计调查对我们有什么帮助?统计调查一般包括收集数据、整理数据、描述数据和分析数据等过程;可以帮助我们更好地了解周围世界,对未知的事物作出合理的推断和预测. 一、数据处理的一般程序 二、回顾与思考 Ⅰ、数据的收集 1、收集数据的方法(在收集数据时,为了方便统计,可以用字母表示调查的各种类型。) ①问卷调查法:为了获得某个总体的信息,找出与该信息有关的因素,而编制的一些带有问题的问卷调查。 ②媒体调查法:如利用报纸、、电视、网络等媒体进行调查。 ③民意调查法:如投票选举。 ④实地调查法:如现场进行观察、收集和统计数据。 例1、调查下列问题,选择哪种方法比较恰当。 ①班里谁最适合当班长()②正在播出的某电视节目收视率() ③本班同学早上的起床时间()④黄河某段水域的水污染情况() 2、收集数据的一般步骤: ①明确调查的问题;——谁当班长最合适 ②确定调查对象;——全班同学 ③选择调查方法;——采用推荐的调查方法 ④展开调查;——每位同学将自己心目中认为最合适的写在纸上,投入推荐箱 ⑤统计整理调查结果;——由一位同学唱票,另一位同学记票(划正字),第三位同学在旁边监督。 ⑥分析数据的记录结果,作出合理的判断和决策; 3、收集数据的调查方式 (1)全面调查 定义:考察全体对象的调查叫做全面调查。
全面调查的常见方法:①问卷调查法;②访问调查法;③调查法; 特点:收集到的数据全面、准确,但花费多、耗时长、而且某些具有破坏性的调查不宜用全面调查;(2)抽样调查 定义:只抽取一部分对象进行调查,然后根据调查数据来推断全体对象的情况,这种方法是抽样调查。 总体:要考察的全体对象叫做总体; 个体:组成总体的每一个考察对象叫做个体; 样本:从总体中抽取的那一部分个体叫做样本。 样本容量:样本中个体的数目叫做样本容量(样本容量没有单位); 特点:省时省钱,调查对象涉及面广,容易受客观条件的限制,结果往往不如全面调查准确,且样本选取不当,会增大估计总体的误差。 性质:具有代表性与广泛性,即样本的选取要恰当,样本容量越大,越能较好地反映总体的情况。(代表性:总体是由有明显差异的几个部分组成时,每一个部分都应该按照一定的比例抽取到) (3)实际调查中常常采用抽样调查的方法获取数据,抽样调查的要什么? ①总体中每个个体都有相等的机会被抽到;②样本容量要适当. 例2、〔1〕判断下面的调查属于哪一种方式的调查。 ①为了了解七年级(22班)学生的视力情况(全面调查) ②我国第六次人口普查(全面调查) ③为了了解全国农民的收支情况(抽样调查) ④灯泡厂为了掌握一批灯泡的使用寿命情况(抽样调查) 〔2〕下面的调查适合用全面调查方式的是 . ①调查七年级十班学生的视力情况;②调查全国农民的年收入状况; ③调查一批刚出厂的灯泡的寿命;④调查各省市感染禽流感的病例。 〔3〕为了了解某七年级2000名学生的身高,从中抽取500名学生进行测量,对这个问题,下面的说确的是〔〕 A、2000名学生是总体 B、每个学生是个体 C、抽取的500名学生是样本 D、样本容量是500〔4〕请指出下列哪些抽查的样本缺少代表性: ①在大学生中调查我国青年的上网情况; ②从具有不同文化层次的市民中,调查市民的法治意识; ③抽查电信部门的家属,了解市民对电信服务的满意程度。 Ⅱ、数据的整理1、表格整理2、划记法
一、描述统计 描述性统计是指运用制表和分类,图形以及计筠概括性数据来描述数据的集中趋势、离散趋势、偏度、峰度。 1、缺失值填充:常用方法:剔除法、均值法、最小邻居法、比率回归法、决策树法。 2、正态性检验:很多统计方法都要求数值服从或近似服从正态分布,所以之前需要进行正态性检验。常用方法:非参数检验的K-量检验、P-P图、Q-Q图、W检验、动差法。 二、假设检验 1、参数检验 参数检验是在已知总体分布的条件下(一股要求总体服从正态分布)对一些主要的参数(如均值、百分数、方差、相关系数等)进行的检验。 1)U验使用条件:当样本含量n较大时,样本值符合正态分布 2)T检验使用条件:当样本含量n较小时,样本值符合正态分布 A 单样本t检验:推断该样本来自的总体均数μ与已知的某一总体均数μ0 (常为理论值或标准值)有无差别; B 配对样本t检验:当总体均数未知时,且两个样本可以配对,同对中的两者在可能会影响处理效果的各种条件方面扱为相似;
C 两独立样本t检验:无法找到在各方面极为相似的两样本作配对比较时使用。 2、非参数检验 非参数检验则不考虑总体分布是否已知,常常也不是针对总体参数,而是针对总体的某些一股性假设(如总体分布的位罝是否相同,总体分布是否正态)进行检验。适用情况:顺序类型的数据资料,这类数据的分布形态一般是未知的。 A 虽然是连续数据,但总体分布形态未知或者非正态; B 体分布虽然正态,数据也是连续类型,但样本容量极小,如10以下; 主要方法包括:卡方检验、秩和检验、二项检验、游程检验、K-量检验等。 三、信度分析 检査测量的可信度,例如调查问卷的真实性。 分类: 1、外在信度:不同时间测量时量表的一致性程度,常用方法重测信度 2、在信度;每个量表是否测量到单一的概念,同时组成两表的在体项一致性如何,常用方法分半信度。 四、列联表分析 用于分析离散变量或定型变量之间是否存在相关。
2.定义映射22:B R R →,()B x y =,满足y Ax =,其中 0.80.40.10.4A ??=????,2,x y R ∈ 则对任意的2 ,u v R ∈ 1111119 ||()()||||||||()||||||||||||||10B u B v Au Av A u v A u v u v -=-=-≤-=- 故映射B 对一范数是压缩的 由范数定义 ||||1 ||||max |||| 1.2 x A Ax ∞∞∞===,知必然存在0 x , 0||||1 x ∞= 使得0|||||||| 1.2 Ax A ∞∞== 设012(,)T x x x = 取 12(,0),(0,)T T u x v x ==-,则 u v x -=,有 00||()()||||||||()|||||||||| 1.21||||||||B u B v Au Av A u v Ax A x u v ∞∞∞∞∞∞∞ -=-=-===>==- 故有||()()||B u B v ∞->||||u v ∞ -,从而映射B 对无穷范数不是压缩的 4. 证明:对任意的,[,]x y a b ∈ 由拉格朗日中值定理,有 ()()'()()() 1e G x G y G x y x y e ξ ξξ-=-=-+ 其中0111b b e e e e ξξ<≤<++ 所以 |()()||()||| 11b b e e G x G y x y x y e e ξξ-=-≤-++ 故G 为[,]a b 上的压缩映射 而 ()ln(1)ln x x G x e e x =+>= 即()G x x =无根
高等数值分析实验一 工物研13 成彬彬2004310559 一.用CG,Lanczos和MINRES方法求解大型稀疏对称正定矩阵Ax=b 作实验中,A是利用A= sprandsym(S,[],rc,3)随机生成的一个对称正定阵,S是1043阶的一个稀疏阵 A= sprandsym(S,[],0.01,3); 检验所生成的矩阵A的特征如下: rank(A-A')=0 %即A=A’,A是对称的; rank(A)=1043 %A满秩 cond(A)= 28.5908 %A是一个“好”阵 1.CG方法 利用CG方法解上面的线性方程组 [x,flag,relres,iter,resvec] = pcg(A,b,1e-6,1043); 结果如下: Iter=35,表示在35步时已经收敛到接近真实x relres= norm(b-A*x)/norm(b)= 5.8907e-007为最终相对残差 绘出A的特征值分布图和收敛曲线: S=svd(A); %绘制特征值分布 subplot(211) plot(S); title('Distribution of A''s singular values');; xlabel('n') ylabel('singular values') subplot(212); %绘制收敛曲线 semilogy(0:iter,resvec/norm(b),'-o'); title('Convergence curve'); xlabel('iteration number'); ylabel('relative residual'); 得到如下图象:
为了观察CG方法的收敛速度和A的特征值分布的关系,需要改变A的特征值: (1).研究A的最大最小特征值的变化对收敛速度的影响 在A的构造过程中,通过改变A= sprandsym(S,[],rc,3)中的参数rc(1/rc为A的条件数),可以达到改变A的特征值分布的目的: 通过改变rc=0.1,0.0001得到如下两幅图 以上三种情况下,由收敛定理2.2.2计算得到的至多叠代次数分别为:48,14和486,由于上实验结果可以看出实际叠代次数都比上限值要小较多。 由以上三图比较可以看出,A的条件数越大,即A的最大最小特征值的差别越大,叠代所需要的步骤就越多,收敛越慢。 (2)研究A的中间特征值的分布对于收敛特性的影响: 为了研究A的中间特征值的分布对收敛速度的影响,进行了如下实验: 固定A的条件数,即给定A的最大最小特征值,改变中间特征值得分布,再来生成A,具体的实现方法是,先将原来的生成A进行特征值分解: [U,S]=svd(A);
第1部分 方法介绍 奇异值分解(SVD )定理: 设m n A R ?∈,则存在正交矩阵m m V R ?∈和n n U R ?∈,使得 T O A V U O O ∑??=?? ?? 其中12(,, ,)r diag σσσ∑=,而且120r σσσ≥≥≥>,(1,2, ,)i i r σ=称为A 的 奇异值,V 的第i 列称为A 的左奇异向量,U 的第i 列称为A 的右奇异向量。 注:不失一般性,可以假设m n ≥,(对于m n <的情况,可以先对A 转置,然后进行SVD 分解,最后对所得的SVD 分解式进行转置,就可以得到原来的SVD 分解式) 方法1:传统的SVD 算法 主要思想: 设()m n A R m n ?∈≥,先将A 二对角化,即构造正交矩阵1U 和1V 使得 110T B n U AV m n ?? =?? -?? 其中1200n n B δγγδ??? ???=?????? 然后,对三角矩阵T T B B =进行带Wilkinson 位移的对称QR 迭代得到:T B P BQ =。 当某个0i γ=时,B 具有形状12B O B O B ?? =? ??? ,此时可以将B 的奇异值问题分解为两个低阶二对角阵的奇异值分解问题;而当某个0i δ=时,可以适当选取'Given s 变换,使得第i 行元素全为零的二对角阵,因此,此时也可以将B 约化为两个低 阶二对角阵的奇异值分解问题。 在实际计算时,当i B δε∞≤或者() 1j j j γεδδ-≤+(这里ε是一个略大于机器精度的正数)时,就将i δ或者i γ视作零,就可以将B 分解为两个低阶二对角阵的奇异值分解问题。
L11整车操纵稳定性仿真分析报告 (HB11A/HB12A) 编制(日期) 校对(日期) 审核(日期) 批准(日期) 简式国际汽车设计(北京)有限公司 L11整车操纵稳定性仿真分析报告(HB11A/HB12A) 1.定半径稳态圆周试验 试验方法 HB11A处于满载状态,沿半径为40m的定半径圆周进行回转运动,开始以最低稳定速度进入圆周,找准方向盘的位置,使汽车可以沿圆周进行回转运动,开始记录,然后缓慢连续而均匀地加速(纵向加速度不超过m/s2),加速的同时调整方向盘转角以维持定半径圆周运动,这个过程中车辆不应超出车道m,直至不能维持稳态定半径圆周运动条件时或受发动机功率限制所能达到的最大侧向加速度为止。记录整个过程,建议使用满足试验条件的最高档位。试验按向左转和向右转两个方向进行,每次试验开始时车身应处于正中位置。 数据处理 “方向盘转角——侧向加速度”拟合曲线线性部分的斜率,取侧向加速度为时的曲线斜率。 图1 方向盘转角—侧向加速度(左转) 从图1 计算得到左转不足转向梯度为137o/g
图2 方向盘转角—侧向加速度(右转) 右转不足转向梯度为g,则HB11A平均不足转向梯度为g。 HB11A的角传动比约为,则不足转向梯度/转向系角传动比为g。 “质心侧偏角——侧向加速度”拟合曲线线性部分的斜率,取侧向加速度为时的曲线斜率。 图3 质心侧偏角——侧向加速度(左转) 左转侧偏角梯度为g。 图4 质心侧偏角——侧向加速度(右转) 右转侧偏角梯度为g,则HB11A平均侧偏角梯度为g。 “车身侧倾角——侧向加速度”拟合曲线线性部分的斜率,取侧向加速度为时的曲线斜率。 图5 车身侧倾角——侧向加速度(左转) 左转侧倾角梯度为g。 图6 车身侧倾角—侧向加速度(右转) 右转侧倾角梯度为g,则HB11A平均侧倾角梯度为g。 2.方向盘转角阶跃输入试验 试验方法 HB11A处于满载状态,以70km/h的车速稳定直线行驶,开始记录数据,以尽可能快的速度(阶跃时间为转动方向盘,达到预定的转角,保持方向盘转角不变直至汽车恢复稳定状态,试验过程中油门踏板开度应尽可能保持不变。方向盘转角初始值是10°,每次增加5°,直到车辆达到附着极限,试验分为向左、向右两个方向进行。 数据处理 —方向盘转角滞后时间 横摆角速度达到50%稳态值时相对于方向盘转角达到50%阶跃值时的滞后时间。 图7 时横摆角速度—方向盘转角滞后时间 左转时,横摆角速度——方向盘转角滞后时间为
数据分析处理需求分类 1 事务型处理 在我们实际生活中,事务型数据处理需求非常常见,例如:淘宝网站交易系统、12306网站火车票交易系统、超市POS系统等都属于事务型数据处理系统。这类系统数据处理特点包括以下几点: 一就是事务处理型操作都就是细粒度操作,每次事务处理涉及数据量都很小。 二就是计算相对简单,一般只有少数几步操作组成,比如修改某行得某列; 三就是事务型处理操作涉及数据得增、删、改、查,对事务完整性与数据一致性要求非常高。 四就是事务性操作都就是实时交互式操作,至少能在几秒内执行完成; 五就是基于以上特点,索引就是支撑事务型处理一个非常重要得技术. 在数据量与并发交易量不大情况下,一般依托单机版关系型数据库,例如ORACLE、MYSQL、SQLSERVER,再加数据复制(DataGurad、RMAN、MySQL数据复制等)等高可用措施即可满足业务需求。 在数据量与并发交易量增加情况下,一般可以采用ORALCERAC集群方式或者就是通过硬件升级(采用小型机、大型机等,如银行系统、运营商计费系统、证卷系统)来支撑. 事务型操作在淘宝、12306等互联网企业中,由于数据量大、访问并发量高,必然采用分布式技术来应对,这样就带来了分布式事务处理问题,而分布式事务处理很难做到高效,因此一般采用根据业务应用特点来开发专用得系统来解决本问题。
2数据统计分析 数据统计主要就是被各类企业通过分析自己得销售记录等企业日常得运营数据,以辅助企业管理层来进行运营决策。典型得使用场景有:周报表、月报表等固定时间提供给领导得各类统计报表;市场营销部门,通过各种维度组合进行统计分析,以制定相应得营销策略等. 数据统计分析特点包括以下几点: 一就是数据统计一般涉及大量数据得聚合运算,每次统计涉及数据量会比较大。二就是数据统计分析计算相对复杂,例如会涉及大量goupby、子查询、嵌套查询、窗口函数、聚合函数、排序等;有些复杂统计可能需要编写SQL脚本才能实现. 三就是数据统计分析实时性相对没有事务型操作要求高。但除固定报表外,目前越来越多得用户希望能做做到交互式实时统计; 传统得数据统计分析主要采用基于MPP并行数据库得数据仓库技术.主要采用维度模型,通过预计算等方法,把数据整理成适合统计分析得结构来实现高性能得数据统计分析,以支持可以通过下钻与上卷操作,实现各种维度组合以及各种粒度得统计分析。 另外目前在数据统计分析领域,为了满足交互式统计分析需求,基于内存计算得数据库仓库系统也成为一个发展趋势,例如SAP得HANA平台。 3 数据挖掘 数据挖掘主要就是根据商业目标,采用数据挖掘算法自动从海量数据中发现隐含在海量数据中得规律与知识。