需求分析试题
一.选择题
◆在项目立项阶段应该进行需求定义,此时定义的需求属于需求三个层次中的(1):它不
应该包括的内容是(2)。
(1) A.业务需求 B.用户需求 C.软件需求 D.设计约束
(2) A.用上下文关系图表示的项目范围 B.包含的主题域及主题域之间的关系
C.业务活动的详细事件流
D.系统涉及的业务事件
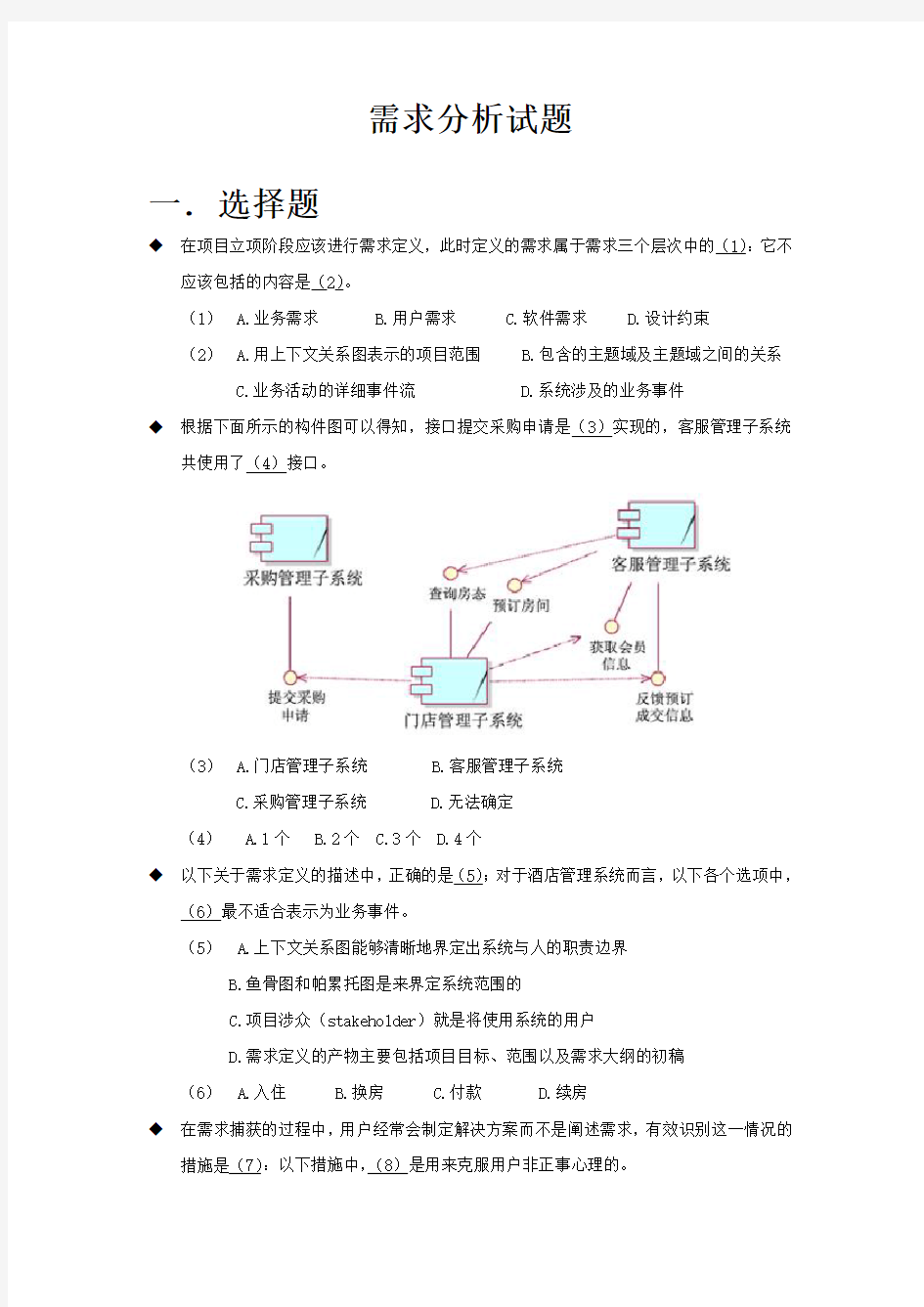
◆根据下面所示的构件图可以得知,接口提交采购申请是(3)实现的,客服管理子系统
共使用了(4)接口。
(3) A.门店管理子系统 B.客服管理子系统
C.采购管理子系统
D.无法确定
(4) A.1个 B.2个 C.3个 D.4个
◆以下关于需求定义的描述中,正确的是(5);对于酒店管理系统而言,以下各个选项中,
(6)最不适合表示为业务事件。
(5) A.上下文关系图能够清晰地界定出系统与人的职责边界
B.鱼骨图和帕累托图是来界定系统范围的
C.项目涉众(stakeholder)就是将使用系统的用户
D.需求定义的产物主要包括项目目标、范围以及需求大纲的初稿
(6) A.入住 B.换房 C.付款 D.续房
◆在需求捕获的过程中,用户经常会制定解决方案而不是阐述需求,有效识别这一情况的
措施是(7):以下措施中,(8)是用来克服用户非正事心理的。
(7) A.询问用户提出需求的理由 B.提前向用户提供访谈计划
C.利用原型来及时验证用户的需求
D.让用户介绍工作场景
(8) A.选择打扰较少的访谈场所 B避免向用户提出过细的问题
C.让用户以介绍工作场景为主
D.通过业务流程图确认访谈正确的对象
◆在下面关于需求验证任务的描述中,不正确的是(9):需求验证属于需求工程中的(10)
范畴。
(9) A.需要核查功能描述的正确性 B.需要核查功能描述的清晰性
C.需要明确需求的完整性
D.除管理者外的用户不能参与评审
(10) A.需求开发 B.需求管理 C需求文档化 D.需求跟踪
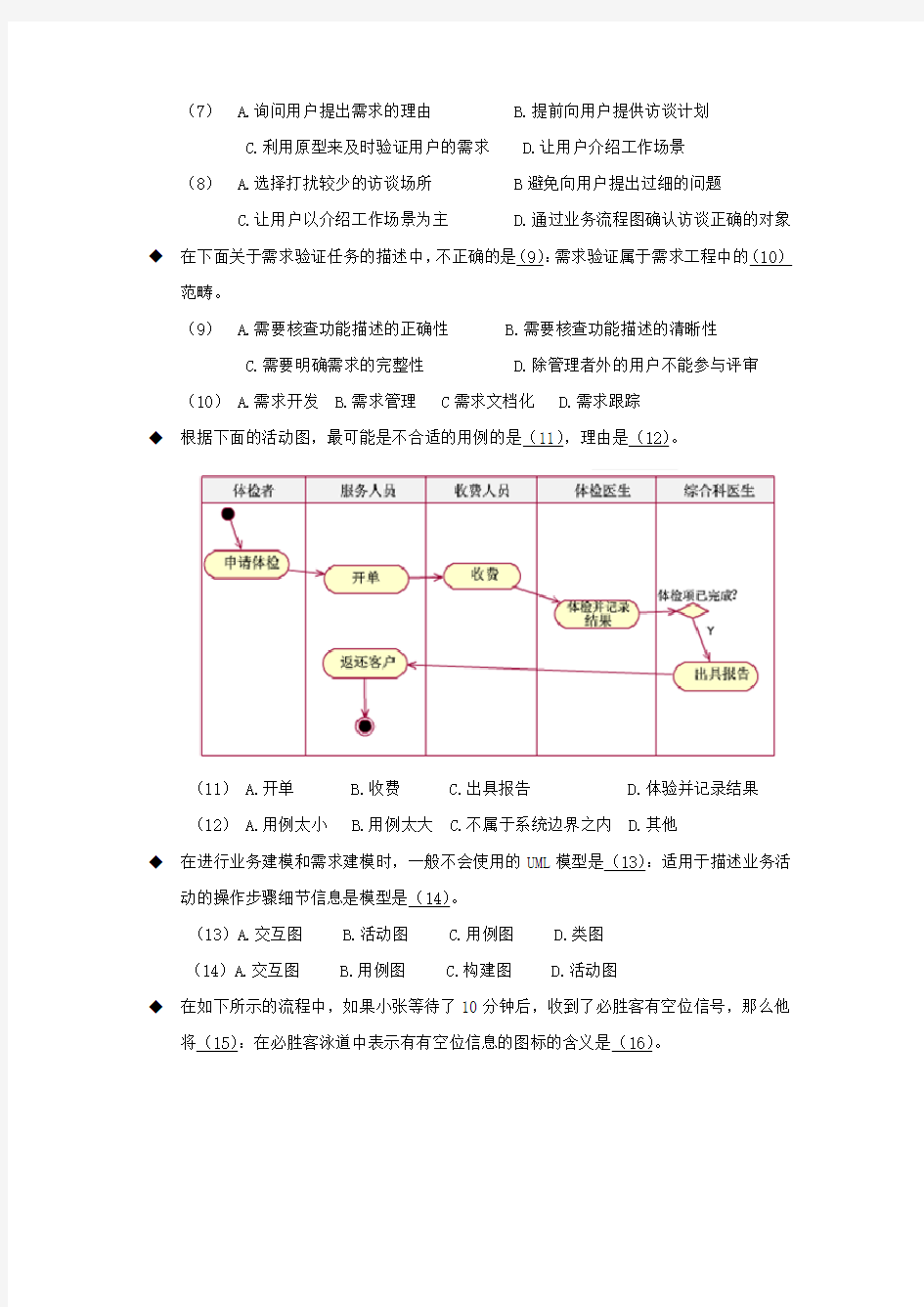
◆根据下面的活动图,最可能是不合适的用例的是(11),理由是(12)。
(11) A.开单 B.收费 C.出具报告 D.体验并记录结果
(12) A.用例太小 B.用例太大 C.不属于系统边界之内 D.其他
◆在进行业务建模和需求建模时,一般不会使用的UML模型是(13):适用于描述业务活
动的操作步骤细节信息是模型是(14)。
(13)A.交互图 B.活动图 C.用例图 D.类图
(14)A.交互图 B.用例图 C.构建图 D.活动图
◆在如下所示的流程中,如果小张等待了10分钟后,收到了必胜客有空位信号,那么他
将(15):在必胜客泳道中表示有有空位信息的图标的含义是(16)。
(15)A.进入必胜客 B.进入肯德基 C.不确定 D.都不进入
(16)A.发信号,用来描述同步事件 B.接受信号,用来描述同步事件
C. 发信号,用来描述异步事件
D.接受信号,用来描述异步事件
◆在如下所示的领域类图中,不属于遥测遥控设备的是(17):对于业务术语浮标与航标
之间的关系,正确的描述是(18)。
(17) A.航标灯 B.航标灯监控器 C.GPS设备 D.雷达应答器感应器
(18) A.浮标和航标之间存在关联关系 B.浮标是组成航标的一部分
C.浮标是航标的一种
D.它们之间没有什么联系
◆当用户与需求分析人员都对系统的需求没有清晰的认识时,适合采用的需求捕获方式是
(19):用户调查主要是用来弥补用户访谈(20)方面的不足。
(19) A.联合开发 B.用户调查 C.现场观摩 D.情节串联板
(20) A.捕获的信息不够完整 B.捕获的信息存在片面性
C.缺少非功能方面的需求信息
D.易于形而上学
二.简答题
1、高质量的需求过程给软件带来哪些好处?
2、优秀需求具有哪些特性?
3、常规的需求获取的方法有哪些?(列举三个就可以)
4、需求获取一般面临哪些挑战或困难?
5、静态建模法中的典型范例是用例图,用例图的基本组成元素是什么?
6、画系统用例图的四个步骤是什么?
7、简述快速原型法的特点?
8、简述快速原型法在系统分析和构造中的优势(优势列举三点就可以)?
数据分析笔试题 一、编程题(每小题20分)(四道题任意选择其中三道) 有一个计费表表名jifei 字段如下:phone(8位的电话号码),month(月份),expenses (月消费,费用为0表明该月没有产生费用) 下面是该表的一条记录:64262631,201011,30.6 这条记录的含义就是64262631的号码在2010年11月份产生了30.6元的话费。 按照要求写出满足下列条件的sql语句: 1、查找2010年6、7、8月有话费产生但9、10月没有使用并(6、7、8月话费均在51-100 元之间的用户。 2、查找2010年以来(截止到10月31日)所有后四位尾数符合AABB或者ABAB或者AAAA 的电话号码。(A、B 分别代表1—9中任意的一个数字) 3、删除jifei表中所有10月份出现的两条相同记录中的其中一条记录。
4、查询所有9月份、10月份月均使用金额在30元以上的用户号码(结果不能出现重复) 二、逻辑思维题(每小题10分)须写出简要计算过程和结果。 1、某人卖掉了两张面值为60元的电话卡,均是60元的价格成交的。其中一张赚了20%, 另一张赔了20%,问他总体是盈利还是亏损,盈/亏多少? 2、有个农场主雇了两个小工为他种小麦,其中A是一个耕地能手,但不擅长播种;而B 耕地很不熟练,但却是播种的能手。农场主决定种10亩地的小麦,让他俩各包一半,于是A从东头开始耕地,B从西头开始耕。A耕地一亩用20分钟,B却用40分钟,可是B播种的速度却比A快3倍。耕播结束后,庄园主根据他们的工作量给了他俩600元工钱。他俩怎样分才合理呢? 3、1 11 21 1211 111221 下一行是什么? 4、烧一根不均匀的绳,从头烧到尾总共需要1个小时。现在有若干条材质相同的绳子,问如何用烧绳的方法来计时一个小时十五分钟呢?(绳子分别为A 、B、C、D、E、F 。。。。。来代替)
从互联网巨头数据挖掘类招聘笔试题目看我们还差多少知识 1 从阿里数据分析师笔试看职业要求 以下试题是来自阿里巴巴招募实习生的一次笔试题,从笔试题的几个要求我们一起来看看数据分析的职业要求。 一、异常值是指什么?请列举1种识别连续型变量异常值的方法? 异常值(Outlier)是指样本中的个别值,其数值明显偏离所属样本的其余观测值。在数理统计里一般是指一组观测值中与平均值的偏差超过两倍标准差的测定值。 Grubbs’ test(是以Frank E. Grubbs命名的),又叫maximum normed residual test,是一种用于单变量数据集异常值识别的统计检测,它假定数据集来自正态分布的总体。 未知总体标准差σ,在五种检验法中,优劣次序为:t检验法、格拉布斯检验法、峰度检验法、狄克逊检验法、偏度检验法。 点评:考察的内容是统计学基础功底。 二、什么是聚类分析?聚类算法有哪几种?请选择一种详细描述其计算原理和步骤。 聚类分析(cluster analysis)是一组将研究对象分为相对同质的群组(clusters)的统计分析技术。聚类分析也叫分类分析(classification analysis)或数值分类(numerical taxonomy)。聚类与分类的不同在于,聚类所要求划分的类是未知的。 聚类分析计算方法主要有:层次的方法(hierarchical method)、划分方法(partitioning method)、基于密度的方法(density-based method)、基于网格的方法(grid-based method)、基于模型的方法(model-based method)等。其中,前两种算法是利用统计学定义的距离进行度量。 k-means 算法的工作过程说明如下:首先从n个数据对象任意选择 k 个对象作为初始聚类中心;而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止。一般都采用均方差(标准差)作为标准测度
1、海量日志数据,提取出某日访问百度次数最多的那个IP。 首先是这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中。注意到IP是32位的,最多有个2^32个IP。同样可以采用映射的方法,比如模1000,把整个大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP(可以采用hash_map进行频率统计,然后再找出频率最大的几个)及相应的频率。然后再在这1000个最大的IP中,找出那个频率最大的IP,即为所求。 或者如下阐述: 算法思想:分而治之+Hash 1.IP地址最多有2^32=4G种取值情况,所以不能完全加载到内存中处理; 2.可以考虑采用“分而治之”的思想,按照IP地址的Hash(IP)24值,把海量IP日志分别存储到1024个小文件中。这样,每个小文件最多包含4MB个IP地址; 3.对于每一个小文件,可以构建一个IP为key,出现次数为value的Hash map,同时记录当前出现次数最多的那个IP地址; 4.可以得到1024个小文件中的出现次数最多的IP,再依据常规的排序算法得到总体上出现次数最多的IP; 2、搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。 假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。 典型的Top K算法,还是在这篇文章里头有所阐述, 文中,给出的最终算法是:
第一步、先对这批海量数据预处理,在O(N)的时间内用Hash表完成统计(之前写成了排序,特此订正。July、2011.04.27); 第二步、借助堆这个数据结构,找出Top K,时间复杂度为N‘logK。 即,借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比所以,我们最终的时间复杂度是:O(N)+ N’*O(logK),(N为1000万,N’为300万)。ok,更多,详情,请参考原文。 或者:采用trie树,关键字域存该查询串出现的次数,没有出现为0。最后用10个元素的最小推来对出现频率进行排序。 3、有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。 方案:顺序读文件中,对于每个词x,取hash(x)P00,然后按照该值存到5000个小文件(记为x0,x1,…x4999)中。这样每个文件大概是200k左右。 如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M。 对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树/hash_map 等),并取出出现频率最大的100个词(可以用含100个结点的最小堆),并把100个词及相应的频率存入文件,这样又得到了5000个文件。下一步就是把这5000个文件进行归并(类似与归并排序)的过程了。 4、有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个
数据分析师常见的7道笔试题目及答案 导读:探索性数据分析侧重于在数据之中发现新的特征,而验证性数据分析则侧重于已有假设的证实或证伪。以下是由小编J.L为您整理推荐的实用的应聘笔试题目和经验,欢迎参考阅读。 1、海量日志数据,提取出某日访问百度次数最多的那个IP。 首先是这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中。注意到IP是32位的,最多有个2^32个IP。同样可以采用映射的方法,比如模1000,把整个大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP(可以采用 hash_map进行频率统计,然后再找出频率最大的几个)及相应的频率。然后再在这1000 个最大的IP中,找出那个频率最大的IP,即为所求。 或者如下阐述: 算法思想:分而治之+Hash 1.IP地址最多有2^32=4G种取值情况,所以不能完全加载到内存中处理; 2.可以考虑采用“分而治之”的思想,按照IP地址的Hash(IP)24值,把海量IP日志分别存储到1024个小文件中。这样,每个小文件最多包含4MB个IP地址; 3.对于每一个小文件,可以构建一个IP为key,出现次数为value的Hash map,同时记录当前出现次数最多的那个IP地址; 4.可以得到1024个小文件中的出现次数最多的IP,再依据常规的排序算法得到总体上出现次数最多的IP; 2、搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。 假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。 典型的Top K算法,还是在这篇文章里头有所阐述, 文中,给出的最终算法是: 第一步、先对这批海量数据预处理,在O(N)的时间内用Hash表完成统计(之前写成了排序,特此订正。July、2011.04.27); 第二步、借助堆这个数据结构,找出Top K,时间复杂度为N‘logK。 即,借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比所以,我们最终的时间复杂度是:O(N) + N’*O(logK),(N为1000万,N’为300万)。ok,更多,详情,请参考原文。 或者:采用trie树,关键字域存该查询串出现的次数,没有出现为0。最后用10个元素的最小推来对出现频率进行排序。 3、有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。 方案:顺序读文件中,对于每个词x,取hash(x)P00,然后按照该值存到5000 个小文件(记为x0,x1,…x4999)中。这样每个文件大概是200k左右。 如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M。 对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树 /hash_map等),并取出出现频率最大的100个词(可以用含100 个结点的最小堆),并把
数据分析师面试常见的77个问题 2013-09-28数据挖掘与数据分析 随着大数据概念的火热,数据科学家这一职位应时而出,那么成为数据科学家要满足什么条件?或许我们可以从国外的数据科学家面试问题中得到一些参考,下面是77个关于数据分析或者数据科学家招聘的时候会常会的几个问题,供各位同行参考。 1、你处理过的最大的数据量?你是如何处理他们的?处理的结果。 2、告诉我二个分析或者计算机科学相关项目?你是如何对其结果进行衡量的? 3、什么是:提升值、关键绩效指标、强壮性、模型按合度、实验设计、2/8原则? 4、什么是:协同过滤、n-grams, map reduce、余弦距离? 5、如何让一个网络爬虫速度更快、抽取更好的信息以及更好总结数据从而得到一干净的数据库? 6、如何设计一个解决抄袭的方案? 7、如何检验一个个人支付账户都多个人使用? 8、点击流数据应该是实时处理?为什么?哪部分应该实时处理? 9、你认为哪个更好:是好的数据还是好模型?同时你是如何定义“好”?存在
所有情况下通用的模型吗?有你没有知道一些模型的定义并不是那么好? 10、什么是概率合并(AKA模糊融合)?使用SQL处理还是其它语言方便?对于处理半结构化的数据你会选择使用哪种语言? 11、你是如何处理缺少数据的?你推荐使用什么样的处理技术? 12、你最喜欢的编程语言是什么?为什么? 13、对于你喜欢的统计软件告诉你喜欢的与不喜欢的3个理由。 14、SAS, R, Python, Perl语言的区别是? 15、什么是大数据的诅咒? 16、你参与过数据库与数据模型的设计吗? 17、你是否参与过仪表盘的设计及指标选择?你对于商业智能和报表工具有什么想法? 18、你喜欢TD数据库的什么特征? 19、如何你打算发100万的营销活动邮件。你怎么去优化发送?你怎么优化反应率?能把这二个优化份开吗? 20、如果有几个客户查询ORACLE数据库的效率很低。为什么?你做什么可以提高速度10倍以上,同时可以更好处理大数量输出? 21、如何把非结构化的数据转换成结构化的数据?这是否真的有必要做这样的转换?把数据存成平面文本文件是否比存成关系数据库更好? 22、什么是哈希表碰撞攻击?怎么避免?发生的频率是多少? 23、如何判别mapreduce过程有好的负载均衡?什么是负载均衡? 24、请举例说明mapreduce是如何工作的?在什么应用场景下工作的很好?云的安全问题有哪些? 25、(在内存满足的情况下)你认为是100个小的哈希表好还是一个大的哈希表,对于内在或者运行速度来说?对于数据库分析的评价? 26、为什么朴素贝叶斯差?你如何使用朴素贝叶斯来改进爬虫检验算法? 27、你处理过白名单吗?主要的规则?(在欺诈或者爬行检验的情况下) 28、什么是星型模型?什么是查询表?
数据分析岗面试题 It was last revised on January 2, 2021
数据分析岗面试题1、表:table1(Id,class,score),用最高效最简单的SQL列出各班成绩最高的列表,显 示班级,成绩两个字段。 2、有一个表table1有两个字段FID,Fno,字都非空,写一个SQL语句列出该表 中一个FID对应多个不同的Fno的纪录。 Fid Fno 101 a1001 101 a1001 102 a1002 102 a1003 103 a1004 104 a1005 104 a1006 105 a1007 105 a1007 105 a1007 3、有员工表empinfo ( Fempno varchar2(10) not null pk, Fempname varchar2(20) not null, Fage number not null, Fsalary number not null ); 假如数据量很大约1000万条; 写一个你认为最高效的SQL,用一个SQL计算以下四种人: fsalary>9999 and fage > 35 fsalary>9999 and fage < 35 fsalary <9999 and fage > 35 fsalary <9999 and fage < 35 每种员工的数量; 4、 Sheet1: sheet2: Sheet1、sheet2是Excel中两个表,sheet2中 记录了各产品类别下面对应的产品编码,现 要在sheet1 C列中对应A列产品编码所对应 的产品类别,请写出公式。
数据分析岗面试题-标准化文件发布号:(9556-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII
数据分析岗面试题 1、表:table1(Id,class,score),用最高效最简单的SQL列出各班成绩最高的列 表,显示班级,成绩两个字段。 2、有一个表table1有两个字段FID,Fno,字都非空,写一个SQL语句列出 Fno的纪录。 3、有员工表empinfo 4、( 5、Fempno varchar2(10) not null pk, 6、Fempname varchar2(20) not null, 7、Fage number not null, 8、Fsalary number not null 9、); 10、假如数据量很大约1000万条;写一个你认为最高效的SQL,用一个SQL 计算以下四种人: 11、fsalary>9999 and fage > 35 12、fsalary>9999 and fage < 35 13、fsalary <9999 and fage > 35 14、fsalary <9999 and fage < 35 15、每种员工的数量; 4、
Sheet1: sheet2: Sheet1、sheet2是Excel中两个表,sheet2中 记录了各产品类别下面对应的产品编码,现 要在sheet1 C列中对应A列产品编码所对应 的产品类别,请写出公式。 5、某商品零售公司有100万客户资料数据(客户数据信息包括客户姓名、电话、地址、购买次数、购买时间、购买金额、购买产品种类等等),现要从中抽取10万客户,对这些客户发送目录手册,为了能使这批手册产生的利润最大,从已有的客户数据信息,我们应该如何挑选这10万个客户?
阿里巴巴 1、异常值是指什么?请列举1种识别连续型变量异常值的方法? 异常值(Outlier) 是指样本中的个别值,其数值明显偏离所属样本的其余观测值。在数理统计里一般是指一组观测值中与平均值的偏差超过两倍标准差的测定值. 常见的异常值检验方法如下: ●基于统计的方法 ●基于距离的方法 ●基于密度的方法 ●基于聚类的方法 ●基于偏差的方法 ●基于深度的方法 t检验:按照t分布的实际误差分布范围来判别异常值,首先剔除一个可疑值,然后按t分布来检验剔除的值是否为异常值。 狄克逊检验法:假设一组数据有序x1 指数分布检验: SPSS和R语言中通过绘制箱图可以找到异常值,分布在箱边框外部; 2、什么是聚类分析?聚类算法有哪几种?请选择一种详细描述其计算原理和步骤。 聚类分析(cluster analysis)是一组将研究对象分为相对同质的群组(clusters)的统计分析技术。聚类分析也叫分类分析(classification analysis)或数值分类(numerical taxonomy)。聚类与分类的不同在于,聚类所要求划分的类是未知的。 聚类分析计算方法主要有:层次的方法(hierarchical method)、划分方法(partitioning method)、基于密度的方法(density-based method)、基于网格的方法(grid-based method)、基于模型的方法(model-based method)等。其中,前两种算法是利用统计学定义的距离进行度量。常见的聚类方法有:K-pototypes算法,K-Means算法,CLARANS算法(划分方法),BIRCH算法(层次方法),CURE算法(层次方法),DBSCAN算法(基于密度的方法),CLIQUE算法(综合了基于密度和基于网格的算法); k-means 算法的工作过程说明如下:首先从n个数据对象任意选择 k 个对象作为初始聚类中心;而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止。一般都采用均方差作为标准测度函数. k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。 其流程如下: (1)从 n个数据对象任意选择 k 个对象作为初始聚类中心; (2)根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分; 2016阿里巴巴数据分析师职位笔试题目 阿里巴巴作为全球领先的小企业电子商务公司,招聘阿里巴巴数据分析师职位都会出些什么笔试题目呢?咱们一起看看。 一、异常值是指什么?请列举1种识别连续型变量异常值的方法? 异常值(Outlier) 是指样本中的个别值,其数值明显偏离所属样本的其余观测值。在数理统计里一般是指一组观测值中与平均值的偏差超过两倍标准差的测定值。 Grubbs’test(是以Frank E. Grubbs命名的),又叫maximum normed residual test,是一种用于单变量数据集异常值识别的统计检测,它假定数据集来自正态分布的总体。 未知总体标准差σ,在五种检验法中,优劣次序为:t检验法、格拉布斯检验法、峰度检验法、狄克逊检验法、偏度检验法。 点评:考察的内容是统计学基础功底。 二、什么是聚类分析?聚类算法有哪几种?请选择一种详细描述其计算原理 和步骤。 聚类分析(cluster analysis)是一组将研究对象分为相对同质的群组(clusters)的统计分析技术。聚类分析也叫分类分析(classification analysis)或数值分类(numerical taxonomy)。聚类与分类的不同在于,聚类所要求划分的类是未知的。 聚类分析计算方法主要有:层次的方法(hierarchical method)、划分方法(partitioning method)、基于密度的方法(density-based method)、基于网格的 方法(grid-based method)、基于模型的方法(model-based method)等。其中,前两种算法是利用统计学定义的距离进行度量。 k-means 算法的工作过程说明如下:首先从n个数据对象任意选择k 个对象作为初始聚类中心;而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止。一般都采用均方差作为标准测度函数. k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。 其流程如下: (1)从n个数据对象任意选择k 个对象作为初始聚类中心; (2)根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分; (3)重新计算每个(有变化)聚类的均值(中心对象); (4)循环(2)、(3)直到每个聚类不再发生变化为止(标准测量函数收敛)。 优点:本算法确定的K 个划分到达平方误差最小。当聚类是密集的,且类与类之间区别明显时,效果较好。对于处理大数据集,这个算法是相对可伸缩和高效的,计算的复杂度为O(NKt),其中N是数据对象的数目,t是迭代的次数。一般来 说,K< 数据分析师面试题目 2011-03-13 12:30 363人阅读评论(0) 收藏举报 计算平均有哪些指标,各有哪些优缺点 数值平均数有算术平均数、调和平均数、几何平均数等形式位置平均数有众数、中位数、四分位数等形式前三种是根据各单位标志值计算的,故称为数值平均值,后三种是根据标志值所处的位置. 相关分析和回归分析有什么关系 回归分析与相关分析的联系:研究在专业上有一定联系的两个变量之间是否存在直线关系以及如何求得直线回归方程等问题,需进行直线相关和回归分析。从研究的目的来说,若仅仅为了了解两变量之间呈直线关系的密切程度和方向,宜选用线性相关分析;若仅仅为了建立由自变量推算因变量的直线回归方程,宜选用直线回归分析。 回归分析和相关分析都是研究变量间关系的统计学课题,它们的差别主要是: 1、在回归分析中,y被称为因变量,处在被解释的特殊地位,而在相关分析中,x与y 处于平等的地位,即研究x与y的密切程度和研究y与x的密切程度是一致的; 2、相关分析中,x与y都是随机变量,而在回归分析中,y是随机变量,x可以是随机变量,也可以是非随机的,通常在回归模型中,总是假定x是非随机的; 3、相关分析的研究主要是两个变量之间的密切程度,而回归分析不仅可以揭示x对y的影响大小,还可以由回归方程进行数量上的预测和控制。 3.给出一组数据说是服从正态分布,求方差和均值 4.给出一个概率分布函数,求极大似然估计 求极大似然函数估计值的一般步骤: (1)写出似然函数;(2)对似然函数取对数,并整理;(3)求导数;(4)解似然方程 极大似然估计,只是一种概率论在统计学的应用,它是参数估计的方法之一。说的是已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若 数据分析师常见的面试问题集锦 随着大数据概念的火热,数据科学家这一职位应时而出,那么成为数据科学家要满足什么条件?或许我们可以从国外的数据科学家面试问题中得到一些参考,下面是77个关于数据分析或者数据科学家招聘的时候会常会的几个问题,供各位同行参考。 1、你处理过的最大的数据量?你是如何处理他们的?处理的结果。 2、告诉我二个分析或者计算机科学相关项目?你是如何对其结果进行衡量的? 3、什么是:提升值、关键绩效指标、强壮性、模型按合度、实验设计、2/8原则? 4、什么是:协同过滤、n-grams, map reduce、余弦距离? 5、如何让一个网络爬虫速度更快、抽取更好的信息以及更好总结数据从而得到一干净的数据库? 6、如何设计一个解决抄袭的方案? 7、如何检验一个个人支付账户都多个人使用? 8、点击流数据应该是实时处理?为什么?哪部分应该实时处理? 9、你认为哪个更好:是好的数据还是好模型?同时你是如何定义好?存在所有情况下通用的模型吗?有你没有知道一些模型的定义并不是那么好? 10、什么是概率合并(AKA模糊融合)?使用SQL处理还是其它语言方便?对于处理半结构化的数据你会选择使用哪种语言? 11、你是如何处理缺少数据的?你推荐使用什么样的处理技术? 12、你最喜欢的编程语言是什么?为什么? 13、对于你喜欢的统计软件告诉你喜欢的与不喜欢的3个理由。 14、SAS, R, Python, Perl语言的区别是? 15、什么是大数据的诅咒? 16、你参与过数据库与数据模型的设计吗? 17、你是否参与过仪表盘的设计及指标选择?你对于商业智能和报表工具有什么想法? 18、你喜欢TD数据库的什么特征? 数据分析面试题及答案 linux的启动顺序 通电后读取ROM的BIOS程序进行硬件自检,自检成功后把计算机控制权交给BIOS中BOOTsequence中的下一个有效设备,读取该设备MBR找到操作系统,载入linux的bootloader,一般是grub。之后载入kernel,执行/etc/rc.d/sysinit ,开启其他组件(/etc/modules.conf),执行运行级别,执行/etc/rc.d/rc.local ,执行/bin/login,最后shell启动。 使用过的开源框架介绍 Struts2 Spring hibernate mybatis hadoop hive hbase flume sqoop Zookeeper Mahout Kafka Storm Spark 擅长哪种技术 Hadoop。介绍 HIVE的优化 底层是MapReduce,所以又可以说是MapReduce优化。 小文件都合并成大文件 Reducer数量在代码中介于节点数*reduceT ask的最大数量的0.95倍到1.75倍 写一个UDF函数,在建表的时候制定好分区 配置文件中,打开在map端的合并 开发中遇到的问题 Hbase节点运行很慢,发现是Hfile过小,hbase频繁split。 修改了hfile大小。或者设置major compack设置为手动 Major compack设置为手动会出现什么问题 ? Zookeeper的二次开发 Flume 的实时和定时数据采集,项目和flume的解耦 Mogodb和hbase的区别 Mogodb是单机 Hbase是分布式?? 项目组多少人?人员分配?数据量?集群的配置? 数据挖掘一些面试题总结(Data Mining) 摘录一段 企业面对海量数据应如何具体实施数据挖掘,使之转换成可行的结果/模型? 首先进行数据的预处理,主要进行数据的清洗,数据清洗,处理空缺值,数据的集成,数据的变换和数据规约。 请列举您使用过的各种数据仓库工具软件(包括建模工具,ETL工具,前端展现工具,OLAP Server、数据库、数据挖掘工具)和熟悉程度。 ETL工具:Ascential DataStage ,IBM warehouse MANAGER、Informatica公司的PowerCenter、Cognos 公司的DecisionStream 市场上的主流数据仓库存储层软件有:SQL SERVER、SYBASE、ORACLE、DB2、TERADATA 请谈一下你对元数据管理在数据仓库中的运用的理解。 元数据能支持系统对数据的管理和维护,如关于数据项存储方法的元数据能支持系统以最有效的方式访问数据。具体来说,在数据仓库系统中,元数据机制主要支持以下五类系统管理功能: (1)描述哪些数据在数据仓库中; (2)定义要进入数据仓库中的数据和从数据仓库中产生的数据; (3)记录根据业务事件发生而随之进行的数据抽取工作时间安排; (4)记录并检测系统数据一致性的要求和执行情况; (5)衡量数据质量。 数据挖掘对聚类的数据要求是什么? (1)可伸缩性 (2)处理不同类型属性的能力 (3)发现任意形状的聚类 (4)使输入参数的领域知识最小化 (5)处理噪声数据的能力 (6)对于输入顺序不敏感 (7)高维性 (8)基于约束的聚类 (9)可解释性和可利用性 简述Apriori算法的思想,谈谈该算法的应用领域并举例。 思想:其发现关联规则分两步,第一是通过迭代,检索出数据源中所有烦琐项集,即支持度不低于用户设定的阀值的项即集,第二是利用第一步中检索出的烦琐项集构造出满足用户最小信任度的规则,其中,第一步即挖掘出所有频繁项集是该算法的核心,也占整个算法工作量的大部分。 在商务、金融、保险等领域皆有应用。在建筑陶瓷行业中的交叉销售应用,主要采用了Apriori 算法 通过阅读该文挡,请同学们分析一下数据挖掘在电子商务领域的应用情况(请深入分析并给出实例,切忌泛泛而谈)? 单选题 1. 某超市研究销售纪录数据后发现,买啤酒的人很大概率也会购买尿布,这种属于数据挖掘的哪类问题?(A) A. 关联规则发现 B. 聚类 C. 分类 D. 自然语言处理 偏统计理论知识 1. 扑克牌54张,平均分成2份,求这2份都有2张A的概率。 C(4,2)*C(50,25)*C(2,2)*C(25,25) / C(54,27)*(C27,27)=(27*13)/(53*17) 2.男生点击率增加,女生点击率增加,总体为何减少? ?因为男女的点击率可能有较大差异,同时低点击率群体的占比增大。 如原来男性20人,点击1人;女性100人,点击99人,总点击率100/120。 现在男性100人,点击6人;女性20人,点击20人,总点击率26/120。 即那个段子“A系中智商最低的人去读B,同时提高了A系和B系的平均智商。” 3. 参数估计 用样本统计量去估计总体的参数 4.矩估计和极大似然估计 矩估计法: 矩估计法的理论依据是大数定律。矩估计是基于一种简单的“替换”思想,即用样本矩估计总体矩。 矩的理解: 在数理统计学中有一类数字特征称为矩。 首先要明确的是我们求得是函数的最大值,因为log是单调递增的,加上log后并不影响的最大值求解。为何导数为0就是最大值:就是我们目前所知的概率分布函数一般属于指数分布族(exponential family),例如正态分布,泊松分布,伯努利分布等。所以大部分情况下这些条件是满足的。但肯定存在那种不符合的情况,只是我们一般比较少遇到。 极大似然估计总结 似然函数直接求导一般不太好求,一般得到似然函数L(θ)之后,都是先求它的对数,即ln L(θ),因为ln函数不会改变L的单调性.然后对ln L(θ)求θ的导数,令这个导数等于0,得到驻点.在这一点,似然函数取到最大值,所以叫最大似然估计法.本质原理嘛,因为似然估计是已知结果去求未知参数,对于已经发生的结果(一般是一系列的样本值),既然他会发生,说明在未知参数θ的条件下,这个结果发生的可能性很大,所以最大似然估计求的就是使这个结果发生的可能性最大的那个θ.这个有点后验的意思 5. 假设检验 参数估计和假设检验是统计推断的两个组成部分,它们都是利用样本对总体进行某种推断,但推断的角度不同。 参数估计讨论的是用样本估计总体参数的方法,总体参数μ在估计前是未知的。 而在假设检验中,则是先对μ的值提出一个假设,然后利用样本信息去检验这个假设是否成立。 数据分析师面试常见的问题 随着大数据概念的火热,数据科学家这一职位应时而出,那么成为数据科学家要满足什么条件?或许我们可以从国外的数据科学家面试问题中得到一些参考,下面是77个关于数据分析或者数据科学家招聘的时候会常会的几个问题,供各位同行参考。 1、你处理过的最大的数据量?你是如何处理他们的?处理的结果。 2、告诉我二个分析或者计算机科学相关项目?你是如何对其结果进行衡量的? 3、什么是:提升值、关键绩效指标、强壮性、模型按合度、实验设计、2/8原则? 4、什么是:协同过滤、n-grams, map reduce、余弦距离? 5、如何让一个网络爬虫速度更快、抽取更好的信息以及更好总结数据从而得到一干净的数据库? 6、如何设计一个解决抄袭的方案? 7、如何检验一个个人支付账户都多个人使用? 8、点击流数据应该是实时处理?为什么?哪部分应该实时处理? 9、你认为哪个更好:是好的数据还是好模型?同时你是如何定义“好”?存在所有情况下通用的模型吗?有你没有知道一些模型的定义并不是那么好? 10、什么是概率合并(AKA模糊融合)?使用SQL处理还是其它语言方便?对于处理半结构化的数据你会选择使用哪种语言? 11、你是如何处理缺少数据的?你推荐使用什么样的处理技术? 12、你最喜欢的编程语言是什么?为什么? 13、对于你喜欢的统计软件告诉你喜欢的与不喜欢的3个理由。 14、SAS, R, Python, Perl语言的区别是? 15、什么是大数据的诅咒? 16、你参与过数据库与数据模型的设计吗? 17、你是否参与过仪表盘的设计及指标选择?你对于商业智能和报表工具有什么想法? 18、你喜欢TD数据库的什么特征? 网易数据分析专员笔试题目 一、基础题 1、中国现在有多少亿网民? 2、百度花多少亿美元收购了91无线? 3、app store排名的规则和影响因素 4、豆瓣fm推荐算法 5、列举5个数据分析的博客或网站 二、计算题 1、关于简单移动平均和加权移动平均计算 2、两行数计算相关系数。(2位小数,还不让用计算器,反正我没算) 3、计算三个距离,欧几里德,曼哈顿,闵可夫斯基距离 三、简答题 1、离散的指标,优缺点 2、插补缺失值方法,优缺点及适用环境 3、数据仓库解决方案,优缺点 4、分类算法,优缺点 5、协同推荐系统和基于聚类系统的区别 四、分析题 关于网易邮箱用户流失的定义,挑选指标。然后要构建一个预警模型。 五、算法题 记不得了,没做。。。反正是决策树和神经网络相关。 1、你处理过的最大的数据量?你是如何处理他们的?处理的结果。 2、告诉我二个分析或者计算机科学相关项目?你是如何对其结果进行衡量的? 3、什么是:提升值、关键绩效指标、强壮性、模型按合度、实验设计、2/8原则? 4、什么是:协同过滤、n-grams, map reduce、余弦距离? 5、如何让一个网络爬虫速度更快、抽取更好的信息以及更好总结数据从而得到一干净的数据库? 6、如何设计一个解决抄袭的方案? 7、如何检验一个个人支付账户都多个人使用? 8、点击流数据应该是实时处理?为什么?哪部分应该实时处理? 9、你认为哪个更好:是好的数据还是好模型?同时你是如何定义“好”?存在所有情况下通用的模型吗?有你没有知道一些模型的定义并不是那么好? 10、什么是概率合并(AKA模糊融合)?使用SQL处理还是其它语言方便?对于处理半结构化的数据你会选择使用哪种语言? 11、你是如何处理缺少数据的?你推荐使用什么样的处理技术? 12、你最喜欢的编程语言是什么?为什么? 13、对于你喜欢的统计软件告诉你喜欢的与不喜欢的3个理由。 14、SAS, R, Python, Perl语言的区别是? 15、什么是大数据的诅咒? 16、你参与过数据库与数据模型的设计吗? 17、你是否参与过仪表盘的设计及指标选择?你对于商业智能和报表工具有什么想法? 18、你喜欢TD数据库的什么特征? 19、如何你打算发100万的营销活动邮件。你怎么去优化发送?你怎么优化反应率?能把这二个优化份开吗? 20、如果有几个客户查询ORACLE数据库的效率很低。为什么?你做什么可以提高速度10倍以上,同时可以更好处理大数量输出? 21、如何把非结构化的数据转换成结构化的数据?这是否真的有必要做这样的转换?把数据存成平面文本文件是否比存成关系数据库更好? 22、什么是哈希表碰撞攻击?怎么避免?发生的频率是多少? 23、如何判别mapreduce过程有好的负载均衡?什么是负载均衡? 24、请举例说明mapreduce是如何工作的?在什么应用场景下工作的很好?云的安全问题有哪些? 25、(在内存满足的情况下)你认为是100个小的哈希表好还是一个大的哈希表,对于内在或者运行速度来说?对于数据库分析的评价? 26、为什么朴素贝叶斯差?你如何使用朴素贝叶斯来改进爬虫检验算法? 27、你处理过白名单吗?主要的规则?(在欺诈或者爬行检验的情况下) 数据分析师常见的道笔试 题目及答案 LELE was finally revised on the morning of December 16, 2020 数据分析师常见的7道笔试题目及答案 导读:探索性数据分析侧重于在数据之中发现新的特征,而验证性数据分析则侧重于已有假设的证实或证伪。以下是由小编为您整理推荐的实用的应聘笔试题目和经验,欢迎参考阅读。 1、海量日志数据,提取出某日访问百度次数最多的那个IP。 首先是这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中。注意到IP是32位的,最多有个2^32个IP。同样可以采用映射的方法,比如模1000,把整个大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP(可以采用hash_map进行频率统计,然后再找出频率最大的几个)及相应的频率。然后再在这1000个最大的IP中,找出那个频率最大的IP,即为所求。 或者如下阐述: 算法思想:分而治之+Hash 地址最多有2^32=4G种取值情况,所以不能完全加载到内存中处理; 2.可以考虑采用“分而治之”的思想,按照IP地址的Hash(IP)24值,把海量IP日志分别存储到1024个小文件中。这样,每个小文件最多包含4MB 个IP地址; 3.对于每一个小文件,可以构建一个IP为key,出现次数为value的Hash map,同时记录当前出现次数最多的那个IP地址; 4.可以得到1024个小文件中的出现次数最多的IP,再依据常规的排序算法得到总体上出现次数最多的IP; 2、搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。 假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。 典型的Top K算法,还是在这篇文章里头有所阐述, 文中,给出的最终算法是: 第一步、先对这批海量数据预处理,在O(N)的时间内用Hash表完成统计(之前写成了排序,特此订正。July、第二步、借助堆这个数据结构,找出Top K,时间复杂度为N‘logK。 即,借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比所以,我们最终的时间复杂度是:O(N) + N’*O(logK),(N 为1000万,N’为300万)。ok,更多,详情,请参考原文。 或者:采用trie树,关键字域存该查询串出现的次数,没有出现为0。最后用10个元素的最小推来对出现频率进行排序。 3、有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。 方案:顺序读文件中,对于每个词x,取hash(x)P00,然后按照该值存到5000个小文件(记为x0,x1,…x4999)中。这样每个文件大概是200k左右。 数据分析师笔试试题 【编者注】以下试题是来自阿里巴巴2011年招募实习生的一次笔试题,从笔试题的几个要求可见数据分析职业要求。 一、异常值是指什么?请列举1种识别连续型变量异常值的方法? 异常值(Outlier)是指样本中的个别值,其数值明显偏离所属样本的其余观测值。在数理统计里一般是指一组观测值中与平均值的偏差超过两倍标准差的测定值。 Grubbs’test(是以Frank E. Grubbs命名的),又叫maximum normed residual test,是一种用于单变量数据集异常值识别的统计检测,它假定数据集来自正态分布的总体。 未知总体标准差σ,在五种检验法中,优劣次序为:t检验法、格拉布斯检验法、峰度检验法、狄克逊检验法、偏度检验法。 点评:考察的内容是统计学基础功底。 二、什么是聚类分析?聚类算法有哪几种?请选择一种详细描述其计算原理和步骤。 聚类分析(cluster analysis)是一组将研究对象分为相对同质的群组(clusters)的统计分析技术。聚类分析也叫分类分析(classification analysis)或数值分类(numerical taxonomy)。聚类与分类的不同在于,聚类所要求划分的类是未知的。 聚类分析计算方法主要有:层次的方法(hierarchical method)、划分方法(partitioning method)、基于密度的方法(density-based method)、基于网格的方法(grid-based method)、基于模型的方法(model-based method)等。其中,前两种算法是利用统计学定义的距离进行度量。 k-means 算法的工作过程说明如下:首先从n个数据对象任意选择k 个对象作为初始聚类中心;而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然后再计算每个所获新聚类的聚类中阿里数据分析笔试题
数据分析师面试题目
数据分析师常见的面试问题集锦
数据分析面试题及答案
数据挖掘一些面试题总结
数据分析、大数据岗位常见面试问题
数据分析师面试常见问题
数据分析师笔试题目
数据分析师常见的道笔试题目及答案
数据分析师笔试题
相关主题
文本预览