udf中文帮助第3章 编写UDF
- 格式:pdf
- 大小:2.06 MB
- 文档页数:27

FLUENTUDF官方培训教程一、引言FLUENTUDF(UserDefinedFunctions)是一种强大的功能,允许用户在FLUENT软件中自定义自己的函数,以满足特定的模拟需求。
为了帮助用户更好地了解和使用UDF功能,FLUENT官方提供了一系列培训教程,本教程将对其中的重点内容进行详细介绍。
二、UDF基础知识1.UDF概述UDF是FLUENT软件中的一种编程接口,允许用户自定义自己的函数,包括自定义物理模型、边界条件、求解器控制等。
UDF功能使得FLUENT软件具有很高的灵活性和扩展性,能够满足各种复杂流动问题的模拟需求。
2.UDF编程语言UDF使用C语言进行编程,因此,用户需要具备一定的C语言基础。
UDF编程遵循C语言的语法规则,但为了与FLUENT软件的求解器进行交互,UDF还提供了一些特定的宏和函数。
3.UDF编译与加载编写完UDF代码后,需要将其编译成动态库(DLL)文件,然后加载到FLUENT软件中。
编译和加载UDF的过程如下:(1)编写UDF代码,保存为.c文件;(2)使用FLUENT软件提供的编译器(如gfortran)将.c文件编译成.dll文件;(3)在FLUENT软件中加载编译好的.dll文件。
三、UDF编程实例1.自定义物理模型cinclude"udf.h"DEFINE_TURBULENCE_MODEL(my_k_epsilon_model,d,q){realrho=C_R(d,Q_REYNOLDS_AVERAGE);realmu=C_MU(d,Q_REYNOLDS_AVERAGE);realk=C_K(d,Q_KINETIC_ENERGY);realepsilon=C_EPSILON(d,Q_DISSIPATION_RATE);//自定义湍流模型计算过程}2.自定义边界条件cinclude"udf.h"DEFINE_PROFILE(uniform_velocity_profile,thread,position ){face_tf;realx[ND_ND];begin_f_loop(f,thread){F_CENTROID(x,f,thread);realvelocity_magnitude=10.0;//自定义速度大小realvelocity[ND_ND];velocity[0]=velocity_magnitude;velocity[1]=0.0;velocity[2]=0.0;F_PROFILE(f,thread,position)=velocity_magnitude;}end_f_loop(f,thread)}3.自定义求解器控制cinclude"udf.h"DEFINE_CG_SUBITERATION_BEGIN(my_cg_subiteration_begin,d ,q){realdt=0.01;//自定义时间步长DT(d)=dt;}四、总结本教程对FLUENTUDF官方培训教程进行了简要介绍,包括UDF 基础知识、编程实例等内容。

UDF 第3章写UDF本章主要概述了如何在FLUENT写UDF。
3.1 概述3.2写解释式UDF的限制3.3 FLUENT中UDF求解过程的顺序3.4 FLUENT网格拓扑3.5 FLUENT数据类型3.6 使用DEFINE Macros定义你的UDF3.7在你的UDF源文件中包含udf.h文件3.8 定义你的函数中的变量3.9函数体3.10 UDF 任务3.11 为多相流应用写UDF3.12在并行中使用你的UDF3.1概述(Introduction)UDF是用来增强FLUENT代码的标准功能的,在写UDF之前,我们要明确以下几个基本的要求。
首先,必须用C语言编写UDF。
必须使用FLUENT提供的DEFINE宏来定义UDF。
UDF必须含有包含于源代码开始指示的udf.h文件;它允许为DEFINE macros和包含在编译过程的其它FLUENT提供的函数定义。
UDF只使用预先确定的宏和函数从FLUENT 求解器访问数据。
通过UDF传递到求解器的任何值或从求解器返回到UDF的值,都指定为国际(SI)单位。
总之,当写UDF时,你必须记住下面的FLUENT要求。
UDF:1.采用C语言编写。
2.必须为udf.h文件有一个包含声明。
3.使用Fluent.Inc提供的DEFINE macros来定义。
4.使用Fluent.Inc提供的预定义宏和函数来访问FLUENT求解器数据。
5.必须使返回到FLUENT求解器的所有值指定为国际单位。
3.2写解释式UDF的限制(Restriction on Writing Interpreted UDF)无论UDF在FLUENT中以解释还是编译方式执行,用户定义C函数(说明在Section 3.1中)的基本要求是相同的,但还是有一些影响解释式UDF的重大编程限制。
FLUENT解释程序不支持所有的C语言编程原理。
解释式UDF不能包含以下C语言编程原理的任何一个:1.goto 语句。
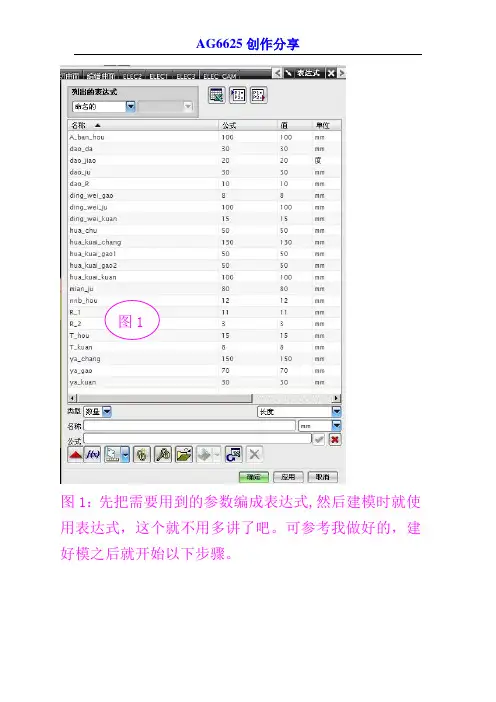
图1
图1:先把需要用到的参数编成表达式,然后建模时就使用表达式,这个就不用多讲了吧。
可参考我做好的,建好模之后就开始以下步骤。
图2
图2:执行用户定义特征功能里的向导。
图3
图5
图8
1.完成后。
(.cgm和.prt文件)会生成于UGII目录下,
2.把这两个文件剪切到
\UGS\NX 7.5\UGII\udf\resource\metric下。
3.再把udf_database.txt复制到\UGS\NX 7.5\UGII下
图9
4.如果你只做了一个自定义特征,那就要把第2组和第3组删掉。
如果你做了好几个,那就把红线画掉的部分改成你取的名字。
如此类推。
如还不够,就在第3
组后面增加一组,把第1组复制下来,再改XXX即可。
图9:把自定义特征库添加到资源板。
图10
图11
图12
到此结束了
最后跟各位说几点:
1. 做自定义特征时,父项越少越好,父子关系要关
联好。
修改表达式参数时才不会容易出错。
2. 拉伸的时候,矢量方向不要选基准轴和基准平面
(即XYZ 面、轴),要改选面或边。
执行其它命令时的矢量方向亦如此。
3. 下面图14、图15是插入时的选项了,
图14
图15
图16。

hive3 udf函数编写-回复UDF (User-Defined Function),即用户自定义函数,是Hive中的一种函数类型。
Hive是建立在Apache Hadoop之上的数据仓库基础架构,它提供了一种类似于SQL的查询语言,用于分析和处理大规模非结构化数据。
UDF函数的编写是Hive中的一项重要功能,通过编写自定义函数,可以扩展Hive的功能,满足具体业务需求。
本文将详细介绍Hive3 UDF函数的编写步骤和详细示例。
一、UDF函数介绍UDF函数是Hive中最简单的一种自定义函数。
它接受一个或多个输入参数,并返回一个或多个输出结果。
UDF函数可以处理任意类型的数据,包括字符串、数字、日期等。
UDF函数在处理每个输入数据时都会独立运行,并对该输入数据进行操作后返回结果。
二、UDF函数编写步骤1. 创建一个Java类UDF函数是基于Java编写的,因此第一步是创建一个Java类。
可以使用任何Java IDE,如Eclipse或IntelliJ IDEA来创建Java类。
假设我们创建了一个名为MyUDF的Java类。
2. 继承Hive的UDF类在创建的Java类中,需要继承Hive提供的UDF类。
UDF类提供了一些必要的方法和函数,用于处理和返回结果。
在MyUDF类中添加以下代码:javaimport org.apache.hadoop.hive.ql.exec.UDF;public class MyUDF extends UDF {添加自定义的函数逻辑}3. 实现evaluate方法在MyUDF类中,需要实现一个名为evaluate的方法,该方法是UDF函数的核心。
evaluate方法接受输入参数并返回结果。
例如,我们创建一个名为concat的函数,用于将两个字符串拼接起来。
在evaluate方法中添加以下代码:javapublic String evaluate(String arg1, String arg2) {if (arg1 == null arg2 == null) {return null;}return arg1 + arg2;}4. 打包Java类完成上述步骤后,需要将Java类打包为一个可执行的jar文件。

第 3 章 编写 UDF第 3 章 编写 UDF本章包含了 FLUENT 中如何写 UDFs 的概述。
3.1 概述 3.2 写解释式 UDFs 的限制 3.3 FLUENT 中 UDFs 求解过程的顺序 3.4 FLUENT 网格拓扑 3.5 FLUENT 数据类型 3.6 使用 DEFINE Macros 定义你的 UDF 3.7 在你的 UDF 源文件中包含 udf.h 文件 3.8 定义你的函数中的变量 3.9 函数体 3.10 UDF 任务 3.11 为多相流应用写 UDFs 3.12 在并行中使用你的 UDF 3.1 概述(Introduction) 在你开始编写将挂到 FLUENT 代码以增强其标准特征的 UDF 之前,你必须 知道几个基本的要求。
首先,UDFs 必须用 C 语言编写。
它们必须使用 FLUENT 提供的 DEFINE macros 来定义。
UDFs 必须含有包含于源代码开始指示的 udf.h 文件;它允许为 DEFINE macros 和包含在编译过程的其它 FLUENT 提供的函数 定义。
UDFs 只使用预先确定的宏和函数从 FLUENT 求解器访问数据。
通过 UDF 传递到求解器的任何值或从求解器返回到 UDF 的,都指定为国际(SI)单位。
总之,当写 UDF 时,你必须记住下面的 FLUENT 要求。
UDFs: 1. 采用 C 语言编写。
2. 必须为 udf.h 文件有一个包含声明。
3. 使用 Fluent.Inc 提供的 DEFINE macros 来定义。
4. 使用 Fluent.Inc 提供的预定义宏和函数来访问 FLUENT 求解器数据。
5. 必须使返回到 FLUENT 求解器的所有值指定为国际单位。
3.2 写解释式 UDFs 的限制(Restriction on Writing Interpreted UDFs)第 3 章 编写 UDF无论 UDFs 在 FLUENT 中以解释还是编译方式执行,用户定义 C 函数(说明在 Section 3.1 中)的基本要求是相同的,但还是有一些影响解释式 UDFs 的重大编 程限制。

Fluent中的UDF详细中文教程(7)第七章 UDF的编译与链接编写好UDF件(详见第三章)后,接下来则准备编译(或链接)它。
在7.2或7.3节中指导将用户编写好的UDF如何解释、编译成为共享目标库的UDF。
_ 第 7.1 节: 介绍_ 第 7.2 节: 解释 UDF_ 第 7.3 节: 编译 UDF7.1 介绍解释的UDF和编译的UDF其源码产生途径及编译过程产生的结果代码是不同的。
编译后的UDF由C语言系统的编译器编译成本地目标码。
这一过程须在FLUENT运行前完成。
在FLUENT运行时会执行存放于共享库里的目标码,这一过程称为“动态装载”。
另一方面,解释的UDF被编译成与体系结构无关的中间代码或伪码。
这一代码调用时是在内部模拟器或解释器上运行。
与体系结构无关的代码牺牲了程序性能,但其UDF可易于共享在不同的结构体系之间,即操作系统和FLUENT版本中。
如果执行速度是所关心的,UDF 文件可以不用修改直接在编译模式里运行。
为了区别这种不同,在FLUENT中解释UDF和编译UDF的控制面板其形式是不同的。
解释UDF的控制面板里有个“Compile按钮”,当点击“Compile按钮”时会实时编译源码。
编译UDF的控制面板里有个“Open 按钮”,当点击“Open按钮” 时会“打开”或连接目标代码库运行FLUENT(此时在运行FLUENT之前需要编译好目标码)。
当FLUENT程序运行中链接一个已编译好的UDF库时,和该共享库相关的东西都被存放到case文件中。
因此,只要读取case文件,这个库会自动地链接到FLUENT处理过程。
同样地,一个已经经过解释的UDF文件在运行时刻被编译,用户自定义的C函数的名称与内容将会被存放到用户的case文件中。
只要读取这个case文件,这些函数会被自动编译。
注:已编译的UDF所用到的目标代码库必须适用于当前所使用的计算机体系结构、操作系统以及FLUENT软件的可执行版本。

创建UDF(基本)在创建UDF 前,必须定义某些元素。
其它元素是可选的,可以在创建UDF 过程中或稍后的修改中定义它们。
1.单击“工具”(Tools)>“UDF 库”(UDF Library)。
UDF 菜单出现,含有以下命令:o创建(Create) - 将新UDF 添加到UDF 库。
o修改(Modify) - 修改现有的UDF。
如果有参照零件,系统将在单独的零件窗口显示UDF。
此命令在“组件”模式中不可用。
o列表(List) - 列出当前目录中的所有UDF 文件。
o数据库管理(Dbms) - 为当前UDF 执行数据库管理功能。
o集成(Integrate) - 解决源UDF 和目标UDF 之间的差异。
2.单击“创建”(Create)。
3.在图形窗口消息区域,键入新UDF 的名称并单击。
出现“UDF 选项”(UDF OPTIONS) 菜单。
4.在“UDF 选项”(UDF OPTIONS) 菜单中,单击下列命令之一:o独立(Stand Alone) - 将全部所需信息复制到UDF。
o从属(Subordinate) - 运行时,自原始零件中复制大部分信息。
注意:o独立的UDF 不能有作为参照模型的组件,但从属的UDF 可以有。
o冲孔和切口UDF(Pro/SHEETMETAL)不能是从属的。
5.单击“完成”(Done)。
“UDF <udf 名称> 独立”(UDF <udf name> Standalone)或“UDF <udf 名称> 附属”(UDF <udf name> Subordinate)对话框打开,列出下列元素:注意,缺省情况下选取的是“特征”(Features)。
o特征(Features) - 选取要包括在UDF 中的特征。
o参照提示(Ref Prompts) - 为指定放置参照,输入提示。
放置UDF 时,系统将打印这些提示作为指导。
o可变元素(Var Elements) - 在零件中放置UDF 时,指定要重定义的特征元素。


hive3 udf函数编写Hive是一个用于数据仓库和大数据分析的开源数据仓库工具,它是基于Hadoop的一个数据仓库基础架构,提供类似于SQL的查询语言HiveQL,使得开发人员可以使用常见的SQL语言来处理分布式存储中的大数据。
在Hive中,用户自定义函数(User-Defined Functions,UDFs)可以用于扩展HiveQL语言的功能,使得开发人员可以根据自己的需求编写自定义的函数。
本文将讨论在Hive3中编写UDF函数的方法和步骤。
首先,我们需要了解Hive的UDF函数的分类。
Hive的UDF函数可以分为以下几类:1. 标量函数(Scalar Functions):接受一些输入参数,并返回一个单一的输出结果。
例如,将一个字符串转换为大写或者将两个数字相加。
2. 聚合函数(Aggregate Functions):接受一组输入值,并返回一个聚合结果。
例如,计算平均值或求和。
3. 表生成函数(Table Generating Functions):接受一些输入参数,并生成一个输出表。
接下来,我们将以一个简单的示例来演示如何编写Hive3的UDF函数。
假设我们有一个包含员工姓名和薪水的表格,我们想要创建一个函数来计算员工薪水的增长百分比。
首先,我们需要创建一个新的Java类来实现我们的UDF函数。
这个类需要继承Hive的UDF类,并且重写evaluate()方法。
```import org.apache.hadoop.hive.ql.exec.Description;import org.apache.hadoop.hive.ql.exec.UDF;import org.apache.hadoop.hive.ql.udf.UDFType;@Description(name = "salary_growth_percentage",value = "Calculates the growth percentage of an employee's salary",extended = "SELECT salary_growth_percentage(salary) FROM employees")@UDFType(deterministic = true, stateful = false)public class SalaryGrowthPercentage extends UDF {public Double evaluate(Double currentSalary, Double previousSalary) {if (currentSalary == null || previousSalary == null) {return null;}double growthPercentage = (currentSalary - previousSalary) / previousSalary * 100;return growthPercentage;}}```在上述代码中,我们创建了一个名为SalaryGrowthPercentage的类,它继承自Hive的UDF类。

UDF的创建和使用用户自定义特征(User Defined Functions,UDF)是一种在关系型数据库或数据分析工具中创建和使用的函数,用于自定义数据处理逻辑。
UDF允许用户根据自己的需求创建函数,以便在数据库查询或数据处理过程中使用。
UDF的创建和使用分为三个主要步骤:定义、注册和使用。
首先是定义UDF的逻辑。
定义UDF时,需要指定函数的输入和输出类型,以及函数的处理逻辑。
根据具体需求,UDF可以是纯粹的数据转换逻辑,也可以是复杂的算法或模型。
例如,假设我们需要在数据库中创建一个计算两个数的平方和的UDF。
我们可以定义一个输入类型为两个整数,输出类型为整数的UDF函数,如下所示:```sqlCREATE FUNCTION square_sum(a INT, b INT) RETURNS INTBEGINDECLARE result INT;SET result = a*a + b*b;RETURN result;END;```接下来是UDF的注册。
将定义好的UDF注册到数据库中,以便其他用户可以在查询或数据处理过程中调用该函数。
注册UDF的方式与具体数据库或工具有关。
例如,在MySQL数据库中,可以使用以下命令来注册上述定义的UDF:```sqlCREATE FUNCTION square_sum(a INT, b INT) RETURNS INTBEGINDECLARE result INT;SET result = a*a + b*b;RETURN result;END;```Once the UDF is defined and registered, it can be used in database queries or data processing tasks. Users can call the UDF by its name and pass the required parameters.For example, assuming we have a table named "numbers" with two columns "num1" and "num2", we can use the UDF in a querylike this:```sqlSELECT square_sum(num1, num2) AS sum_of_squares FROM numbers;```This will calculate the square sum of each pair of numbers in the table and return the result as a new column"sum_of_squares".UDFs can also be used in data analysis tools like Apache Spark or Python libraries like Pandas. The process of creating and using UDFs in these tools may vary, but the generalprinciple is the same – define the function logic, register the function, and then use it in data processing tasks.In Spark, for example, UDFs can be defined using Python or Scala and registered using the `spark.udf.register` method. Once registered, the UDF can be used in Spark SQL queries or DataFrame operations.Overall, UDFs provide users with the flexibility to define and use custom functions in database queries or data processing tasks. This allows for more advanced data manipulation and analysis, as users can tailor the functions to their specific needs.。

在使用Fluent软件进行模拟计算时,经常会遇到需要自定义用户子程序(User Defined Function,简称UDF)的情况。
UDF是Fluent中用户自己编写的函数,用于描述流场中的边界条件、源项等物理过程。
为了正确地使用UDF并进行模拟计算,我们需要了解如何编写和编译UDF。
本教程将向大家介绍如何使用ANSYS Fluent进行UDF的编译,并提供一些常见问题的解决方法。
一、准备工作在进行UDF编译之前,我们需要进行一些准备工作。
1. 确保已安装ANSYS Fluent软件,并且能够正常运行;2. 确保已安装C/C++编译器,常见的编译器有Microsoft Visual Studio、GCC等;3. 编写好UDF的源代码文件,可以使用任何文本编辑器编写,但建议使用支持C/C++语法高亮的编辑器,以便于排查语法错误。
二、设置Fluent编译环境在进行UDF编译之前,我们需要设置Fluent的编译环境,以确保编译器可以正确地识别Fluent的API。
1. 打开命令行终端(Windows系统为cmd,Linux/Unix系统为Terminal);2. 运行以下命令设置Fluent的编译环境:对于Windows系统:```bashcd C:\Program Files\ANSYS Inc\v200\fluentfluent 3d -i```对于Linux/Unix系统:```bashcd /usr/ansys_inc/v200/fluent./fluent 3d -t xxx -g -i```其中,xxx是你的图形界面类型,可以根据你实际的图形界面类型进行替换,一般为Gl 或 X11。
运行上述命令后,Fluent将会启动,并且设置了编译环境。
在Fluent 的命令行界面中,我们可以进行UDF的编译和加载。
三、编译UDF在设置了Fluent的编译环境后,我们可以开始编译UDF了。
1. 将编写好的UDF源代码文件(后缀名通常为.c或.cpp)放置在Fluent的工作目录中;2. 在Fluent的命令行界面中,输入以下命令进行编译:```bash/define/user-definedpiled-functions load my_udf-name/define/user-definedpiled-functionspile my_udf-name/define/user-definedpiled-functions write my_udf-name/exit```其中,my_udf-name是你的UDF源代码文件的文件名(不包括后缀名),例如my_udf。
Fluent_UDF_中文教程Fluent_UDF是Fluent中的用户定义函数,能够定制化模拟中的物理过程和边界条件。
通过Fluent_UDF,用户可自由地编写自己的程序,以扩展Fluent的功能。
Fluent_UDF具有灵活性和可移植性,可以用C语言或Fortran语言编写。
下面我们将介绍Fluent_UDF的使用方法和编写过程。
1. Fluent_UDF的基本概念在Fluent中运行的模拟,都是由CFD模型和相应的物理模型组成。
CFD模型负责离散化解决流动方程,在CFD模型的基础上,物理模型定义了流体在不同条件下的行为,例如燃烧过程、湍流模型、多相流模型等。
而Fluent_UDF则是一套可以编写自定义的物理模型或者边界条件的库,可以与Fluent中的各类模型进行整合工作。
用户可以通过编写Fluent_UDF来与Fluent交互,其中可以定义用户自定义的边界条件,定义新的物性模型、初始或边界条件以及仿真的物理过程等。
2. Fluent_UDF编译器Fluent_UDF需要使用自带的编译器来编译用户自定义函数,这个编译器名为Fluent_Compiler。
Windows系统下,Fluent_Compiler可在Fluent程序安装目录内找到。
在运行Fluent程序之前,用户需要确保其系统环境变量中设置了编译器路径的系统变量。
Linux系统下,Fluent_Compiler亦随Fluent程序安装,其使用方法与Windows类似。
3. Fluent_UDF文件夹的创建在Fluent安装目录下,用户必须创建一个名为udf的文件夹,以存储用户自定义的函数。
用户可以在命令行中进入Fluent 安装目录下的udf文件夹中,输入以下命令创建文件:mkdir myudf其中myudf是用户自定义的函数文件夹名称。
4. Fluent_UDF函数编写Fluent_UDF支持两种编程语言:C语言和Fortran语言。
UDF的创建和使用用户自定义特征(User-Defined Functions,UDF)是一种在数据处理过程中自定义函数的方式。
在大数据处理和分析中,UDF提供了一种灵活且高效的方法来处理和转换数据。
下面将详细介绍UDF的创建和使用。
UDF的创建需要根据具体的处理需求,使用编程语言来定义函数的逻辑。
常用的编程语言包括Python、Java、Scala等。
以下是UDF的创建步骤:1.确定处理逻辑:首先,需要确定要实现的处理逻辑,例如字符串的转换、数值计算等。
这些逻辑将作为UDF的函数体。
2. 编写函数代码:根据处理逻辑,使用所选的编程语言编写相应的函数代码。
例如,使用Python时,可以使用`def`关键字定义函数。
同时,可以利用编程语言提供的丰富特性和库来实现函数的功能。
3.添加输入参数:根据需要,添加相应的输入参数。
输入参数可以是一到多个,可以是任意数据类型。
在函数体中,可以使用这些输入参数进行处理。
4. 指定返回值:确定函数的返回值类型,并在函数体中使用`return`语句返回结果。
返回值可以是标量,也可以是复合类型,如数组或结构体。
5. 注册UDF:将编写的函数注册为UDF。
不同的数据处理平台和工具可能有不同的注册方式。
例如,在Spark中,可以使用`sqlContext.udf.register`方法来注册UDF。
UDF的使用可以在各种数据处理环境中实现,如Spark、Hive等。
以下是UDF的使用步骤:1.导入UDF:首先,需要导入所需的UDF。
导入的方式取决于所使用的数据处理平台和工具。
2.调用UDF:使用导入的UDF,在数据处理流程中调用相应的函数。
可以将UDF应用于单个数据点或整个数据集。
3.传递参数:根据函数定义,将需要处理的数据传递给UDF。
参数的传递方式可以根据具体情况来确定,例如使用变量、列名称等。
4.获取结果:根据函数定义,获取UDF的输出结果。
可以将结果赋值给变量、存储到数据库或写入文件等。
编写自定义函数与UDF的指南与案例自定义函数(User Defined Function,简称UDF)是现代编程语言中常见的功能。
它允许开发人员定义自己的函数,以满足特定需求。
在数据分析和软件开发领域,自定义函数通常用于提供更高级的功能和灵活性。
本文将介绍如何编写自定义函数和UDF,并提供一些案例以帮助读者更好地理解和应用它们。
一、自定义函数的基本概念自定义函数是由开发人员编写的、满足特定需求的函数。
与编程语言中的内置函数相比,自定义函数提供了更大的灵活性和自定义能力。
开发人员可以根据自己的需求定义函数名、参数和返回值,并在程序中自由调用。
在大多数编程语言中,例如Python,Java,R等,都支持自定义函数的编写。
下面将以Python为例,介绍自定义函数的编写过程。
二、编写自定义函数的步骤1. 确定函数的目的和功能:在编写自定义函数之前,明确函数的目的和功能是非常重要的。
对于某些常见的功能,可以参考已有的内置函数,如数学运算、字符串处理等。
如果需求较为复杂,需要先分析问题,再设计函数的解决方案。
2. 定义函数名和参数:根据函数的目的和功能,给函数起个有意义的名字,并确定需要的参数。
函数名应该简洁明了,体现函数的功能。
参数可以分为必需参数和可选参数,根据实际需求进行定义。
3. 编写函数的实现代码:根据函数的目的和功能,编写相应的实现代码。
注意代码的可读性和可维护性,使用适当的注释和命名规范,提高代码质量。
在编写过程中,可以根据需要调用其他函数或者库来辅助实现。
4. 定义返回值:确定函数的返回值,即函数完成后需要返回的结果。
根据函数的功能,返回值可以是一个具体的数据类型,例如整数、浮点数、字符串等,也可以是一个数据结构,如列表、字典等。
5. 测试函数:编写好自定义函数后,需要进行测试以验证其正确性和稳定性。
可以设计一些测试用例,输入不同的参数,检查函数的输出是否符合预期结果。
如有错误或异常情况,可以根据需要进行调试和修复。
3-udf的解释和编译udf的解释和编译包含udf的源代码文件可以在ANSYS FLUENT中进行解释或编译,在这两种情况下,都会编译函数,但是对于这两种方法,编译源代码的方式和编译过程产生的代码是不同的。
编译udf编译后的udf的构建方式与ANSYS FLUENT可执行文件本身的构建方式相同:使用Makefile脚本调用system C编译器来构建目标代码库。
在“已编译UDFs”对话框中单击“build”来启动此操作。
目标代码库包含高级C源代码的本机机器语言翻译。
共享库必须在运行时通过一个称为“动态加载”的过程加载到ANSYS FLUENT中。
在已编译的UDFs对话框中,通过单击Load启动此操作。
对象库特定于所使用的计算机体系结构,以及正在运行的ANSYS FLUENT可执行程序的特定版本。
因此,当ANSYS FLUENT升级、计算机的操作系统级别发生变化或作业在不同类型的计算机上运行时,必须重新构建这些库。
总之,编译后的udf是使用图形用户界面从源文件编译而来的,这需要两个步骤。
该过程涉及到已编译UDFs对话框,在该对话框中,首先从源文件构建一个共享库对象文件,然后加载刚构建到ANSYS FLUENT中的共享库。
解释udf解释过的udf使用图形用户界面从源文件解释,但在单个步骤过程中。
该过程在运行时发生,涉及到使用解释的UDFs对话框,在该对话框中解释源文件。
在ANSYS FLUENT中,使用C预处理器将源代码编译成与体系结构无关的中间机器码。
然后,当调用UDF时,此机器码在内部仿真器或解释器上执行。
这一额外的代码层会带来性能损失,但是可以在不同的体系结构、操作系统和ANSYS FLUENT版本之间轻松地共享经过解释的UDF。
如果执行速度确实成为一个问题,则解释的UDF始终可以在编译模式下运行,而无需修改。
用于解释udf 的解释器不具备标准C编译器(用于编译udf)的所有功能。
具体来说,解释udf不能包含以下任何C编程语言元素:· goto statements·Non-ANSI-C prototypes for syntax· Directdata structure references·Declarations of local structures· Unions· Pointersto functions· Arrays of functions· Multi-dimensionalarrays.解释的udf和编译的udf之间的差异解释的udf和编译的udf之间的主要区别是,解释的udf不能使用直接的结构引用访问ANSYS FLUENT求解器数据; 他们只能通过ANSYS提供的宏间接访问数据。
主题:Fluent UDF编译与解释近年来,计算流体力学(CFD)领域得到了迅速的发展,并成为了工程学、地球科学、医学等领域中一个重要的研究工具。
在进行CFD仿真时,用户自定义函数(User Defined Function,UDF)作为一种重要的边界条件和源项模型,可以有效地增强FLUENT软件的功能。
但是,与普通的FLUENT软件中的命令不同,UDF需要用户自行编写程序,然后通过编译器将其转换成FLUENT软件可识别的格式。
对于大部分工程师和研究人员来说,编写、编译和解释UDF仍然是一个具有一定挑战性的任务。
本文将围绕Fluent UDF编译与解释展开,从编译器的选择、编译过程的原理、编译中可能遇到的问题以及UDF的解释与调试等方面,为读者详细介绍与分析Fluent UDF编译与解释相关的知识和技巧。
一、编译器的选择在进行Fluent UDF编译之前,用户需要选择适合的编译器。
FLUENT 软件支持多种编译器,包括Microsoft Visual Studio、gcc、Intel Compiler等。
用户可以根据自己的喜好和系统环境选择合适的编译器。
二、编译过程的原理Fluent UDF的编译过程是将用户编写的程序源文件经过编译器进行编译,生成动态信息库(.dll文件)或共享对象文件(.so文件),然后再将生成的库文件加载到FLUENT软件中。
编译器将源文件翻译成机器语言,使得FLUENT软件可以识别并运行用户自定义的函数。
三、编译中可能遇到的问题在编写UDF并进行编译的过程中,用户可能会遇到一些常见的问题,如编译器报错、信息错误、库文件加载失败等。
这些问题通常是由于用户编写的程序存在语法错误、逻辑错误或者编译器的设置问题所致。
在遇到这些问题时,用户需要逐一排查并修正,保证程序能够正确地编译通过。
四、 UDF的解释与调试编译通过的UDF需要在FLUENT软件中进行解释与调试,确保其能够正确地加载和运行。
第一章. 介绍本章简要地介绍了用户自定义函数(UDF)及其在Fluent 中的用法。
在1.1 到1.6 节中我们会介绍一下什么是UDF;如何使用UDF,以及为什么要使用UDF,在1.7 中将一步步的演示一个UDF 例子。
1.1 什么是UDF?1.2 为什么要使用UDF?1.3 UDF 的局限1.4 Fluent5 到Fluent6 UDF 的变化1.5 UDF 基础1.6 解释和编译UDF 的比较1.7 一个step-by-stepUDF 例子1.1 什么是UDF?用户自定义函数,或UDF,是用户自编的程序,它可以动态的连接到Fluent 求解器上来提高求解器性能。
用户自定义函数用C 语言编写。
使用DEFINE 宏来定义。
UDF 中可使用标准C 语言的库函数,也可使用Fluent Inc.提供的预定义宏,通过这些预定义宏,可以获得Fluent 求解器得到的数据。
UDF 使用时可以被当作解释函数或编译函数。
解释函数在运行时读入并解释。
而编译UDF 则在编译时被嵌入共享库中并与Fluent 连接。
解释UDF 用起来简单,但是有源代码和速度方面的限制不足。
编译UDF 执行起来较快,也没有源代码限制,但设置和使用较为麻烦。
1.2 为什么要使用UDF?一般说来,任何一种软件都不可能满足每一个人的要求,FLUENT 也一样,其标准界面及功能并不能满足每个用户的需要。
UDF 正是为解决这种问题而来,使用它我们可以编写FLUENT 代码来满足不同用户的特殊需要。
当然,FLUENT 的UDF 并不是什么问题都可以解决的,在下面的章节中我们就会具体介绍一下FLUENT UDF 的具体功能。
现在先简要介绍一下UDF 的一些功能:z定制边界条件,定义材料属性,定义表面和体积反应率,定义FLUENT 输运方程中的源项,用户自定义标量输运方程(UDS)中的源项扩散率函数等等。
z在每次迭代的基础上调节计算值z方案的初始化z(需要时)UDF 的异步执行z后处理功能的改善z FLUENT 模型的改进(例如离散项模型,多项混合物模型,离散发射辐射模型)由上可以看出FLUENT UDF 并不涉及到各种算法的改善,这不能不说是一个遗憾。
第 3 章 编写 UDF第 3 章 编写 UDF本章包含了 FLUENT 中如何写 UDFs 的概述。
3.1 概述 3.2 写解释式 UDFs 的限制 3.3 FLUENT 中 UDFs 求解过程的顺序 3.4 FLUENT 网格拓扑 3.5 FLUENT 数据类型 3.6 使用 DEFINE Macros 定义你的 UDF 3.7 在你的 UDF 源文件中包含 udf.h 文件 3.8 定义你的函数中的变量 3.9 函数体 3.10 UDF 任务 3.11 为多相流应用写 UDFs 3.12 在并行中使用你的 UDF 3.1 概述(Introduction) 在你开始编写将挂到 FLUENT 代码以增强其标准特征的 UDF 之前,你必须 知道几个基本的要求。
首先,UDFs 必须用 C 语言编写。
它们必须使用 FLUENT 提供的 DEFINE macros 来定义。
UDFs 必须含有包含于源代码开始指示的 udf.h 文件;它允许为 DEFINE macros 和包含在编译过程的其它 FLUENT 提供的函数 定义。
UDFs 只使用预先确定的宏和函数从 FLUENT 求解器访问数据。
通过 UDF 传递到求解器的任何值或从求解器返回到 UDF 的,都指定为国际(SI)单位。
总之,当写 UDF 时,你必须记住下面的 FLUENT 要求。
UDFs: 1. 采用 C 语言编写。
2. 必须为 udf.h 文件有一个包含声明。
3. 使用 Fluent.Inc 提供的 DEFINE macros 来定义。
4. 使用 Fluent.Inc 提供的预定义宏和函数来访问 FLUENT 求解器数据。
5. 必须使返回到 FLUENT 求解器的所有值指定为国际单位。
3.2 写解释式 UDFs 的限制(Restriction on Writing Interpreted UDFs)第 3 章 编写 UDF无论 UDFs 在 FLUENT 中以解释还是编译方式执行,用户定义 C 函数(说明在 Section 3.1 中)的基本要求是相同的,但还是有一些影响解释式 UDFs 的重大编 程限制。
FLUENT 解释程序不支持所有的 C 语言编程原理。
解释式 UDFs 不能 包含以下 C 语言编程原理的任何一个: 1. goto 语句。
2. 非 ANSI-C 原型语法 3. 直接的数据结构查询(direct data structure references) 4. 局部结构的声明 5. 联合(unions) 6. 指向函数的指针(pointers to functions) 7. 函数数组。
在访问 FLUENT 求解器数据的方式上解释式 UDFs 也有限制。
解释式 UDFs 不能 直接访问存储在 FLUENT 结构中的数据。
它们只能通过使用 Fluent 提供的宏间 接地访问这些数据。
另一方面, 编译式 UDFs 没有任何 C 编程语言或其它注意的 求解器数据结构的限制。
3.3 FLUENT 求解过程中 UDFs 的先后顺序 (Sequencing of UDFs in the FLUENT Solution Process) 当你开始写 UDF 代码的过程时(依赖于你写的 UDF 的类型) ,理解 FLUENT 求 解过程中 UDFs 调用的内容或许是重要的。
求解器中包含连接你写的用户定义函 数的 call-outs。
知道 FLUENT 求解过程中迭代之内函数调用的先后顺序能帮助你 在给定的任意时间内确定那些数据是当前的和有效的。
分离式求解器 在分离式求解器求解过程中(Figure 3.3.1) ,用户定义的初始化函数(使用 DEFINE_INIT 定义的)在迭代循环开始之前执行。
然后迭代循环开始执行用户 定义的调整函数(使用 DEFINE_ADJUST 定义的) 。
接着,求解守恒方程,顺序 是从动量方程和后来的压力修正方程到与特定计算相关的附加标量方程。
守恒方 程之后,属性被更新(包含用户定义属性) 。
这样,如果你的模型涉及到气体定 律,这时,密度将随更新的温度(和压力 and/or 物质质量分数)而被更新。
进 行收敛或者附加要求的迭代的检查,循环或者继续或停止。
第 3 章 编写 UDFFigure 3.3.1: Solution Procedure for the Segregated Solver耦合求解器 在耦合求解器求解过程中(Figure 3.3.2),用户定义的初始化函数(使用 DEFINE_INIT 定义的)在迭代循环开始之前执行。
然后,迭代循环开始执行用 户定义的调整函数 (使用 DEFINE_ADJUST 定义的) 接着, 。
FLUENT 求解连续、 动量和(适合的地方)能量的控制方程和同时地一套物质输运或矢量方程。
其余 的求解步骤与分离式求解器相同(Figure 3.3.1) 。
Figure 3.3.2: Solution Procedure for the Coupled Solver第 3 章 编写 UDF3.4 FLUENT 网格拓扑 在我们开始讨论 FLUENT 特殊的数据类型之前,你必须理解网格拓扑学的术语 因为 FLUENT 数据类型是为这些实体定义的。
下面是显示在 Figure 3.4.1 中的网 格实体的定义。
单元(cell) 单元中心(cell center) 面(face) 边(edge) 节点(node) 单元线索(cell thread) 区域被分割成的控制容积 FLUENT 中场数据存储的地方 单元(2D or 3D)的边界 面(3D)的边界 网格点 在其中分配了材料数据和源项的单元组第 3 章 编写 UDF面线索(face thread) 节点线索(node thread) 区域(domain)在其中分配了边界数据的面组 节点组 由网格定义的所有节点、面和单元线索的组合Figure 3.4.1: Grid Terminology3.5 FLUENT 数据类型(FLUENT Data Types) 除了标准的 C 语言数据类型如 real, int 等可用于在你的 UDF 中定义数据外,还 有几个 FLUENT 指定的与求解器数据相关的数据类型。
这些数据类型描述了 FLUENT 中定义的网格的计算单位(见 Figure 3.4.1) 。
使用这些数据类型定义的 变量既有代表性地补充了 DEFINE macros 的自变量,也补充了其它专门的访问 FLUENT 求解器数据的函数。
一些更为经常使用的 FLUENT 数据类型如下: cell_t face_t第 3 章 编写 UDFThread Domain Node cell_t 是线索(thread)内单元标识符的数据类型。
它是一个识别给定线索内单 元的整数索引。
face_t 是线索内面标识符的数据类型。
它是一个识别给定线索内 面的整数索引。
Thread 数据类型是 FLUENT 中的数据结构。
它充当了一个与它描述的单元或面 的组合相关的数据容器。
Node 数据类型也是 FLUENT 中的数据结构。
它充当了一个与单元或面的拐角相 关的数据容器。
Domain 数据类型代表了 FLUENT 中最高水平的数据结构。
它充当了一个与网格 中所有节点、面和单元线索组合相关的数据容器。
! !注意,FLUENT 中所有数据类型都是 情形敏感的(case-sensitive) 。
3.6 使用 DEFINE Macros 定义你的 UDF(Defining Your UDF Using DEFINE Macros) Fluent.Inc 为你提供了一套你必须使用它来定义你的 UDF 的预定义函数。
这些定 义 UDFs 的函数在代码中作为宏执行,可在作为 DEFINE(全部大写)宏的文献中 查阅。
对每个 DEFINE 宏的完整描述和它的应用例子,可参考第四章。
DEFINE 宏的通用格式为: DEFINE_MACRONAME(udf_name, passed-in variables) 这里括号内第一个自变量是你的 UDF 的名称。
名称自变量是情形敏感的必须用 小写字母指定。
一旦函数被编译 (和连接)你为你的 UDF 选择的名字在 FLUENT , 下拉列表中将变成可见的和可选的。
第二套输入到 DEFINE 宏的自变量是从 FLUENT 求解器传递到你的函数的变量。
在下面的例子中,宏 DEFINE_PROFILE(inlet_x_velocity, thread, index) 用 两 个 从 FLUENT 传 递 到 函 数 的 变 量 thread 和 index 定 义 了 名 字 为 inlet_x_velocity 的分布函数。
这些 passed-in 变量是边界条件区域的 ID(作为指 向 thread 的指针)而 index 确定了被存储的变量。
一旦 UDF 被编译,它的名字第 3 章 编写 UDF(例如, inlet_x_velocity) 将在 FLUENT 适当的边界条件面板 (例如, Velocity Inlet 面板)的下拉列表中变为可见的和可选的。
! !注意,所有用于 DEFINE 宏的自变量必须放在你的源代码的同一行上。
分割 DEFINE 的声明为几行可能导致编译错误。
3.7 在你的 UDF 源文件中包含 udf.h 文件(Including the udf.h File in Your UDF Source File) DEFINE 宏的定义位于称为 udf.h(见附录 A 的列表)的头文件中。
为了使 DEFINE 宏延伸到编译过程,你必须在你写的每个 UDF 源文件的开始包含 udf.h 文件。
#include "udf.h"/* Always include udf.h when writing a UDF. It translates the DEFINE */ /* and other macros into C, which is what the compiler understands. */通过在你的 UDF 源文件中包含 udf.h, 编译过程中所有的 DEFINE 宏的定义与源 代码一起被包含进来。
udf.h 文件也为所有的 C 库函数头文件包含#include 指示, 与大部分头文件是针对 Fluent 提供的宏和函数是一样的(例如,mem.h) 。
除非 有另外的指示,没必要在你的 UDF 中个别地包含这些头文件。
还有,当你编译你的 UDF 时,你不必放置 udf.h 的拷贝在你的当地目录下;一旦 你的 UDF 被编译,FLUENT 求解器会自动地从 Fluent.Inc/fluent6.x/src/目录来读 取 udf.h 文件。