在Informix+Dynamic+Server+中创建并使用函数索引
- 格式:doc
- 大小:52.50 KB
- 文档页数:19

PDO配置及使⽤⽅法■PDO为何物?POD(PHP Data Object)扩展在PHP5中加⼊,PHP6中将默认识⽤PDO连接数据库,所有⾮PDO扩展将会在PHP6被从扩展中移除。
该扩展提供PHP内置类 PDO来对数据库进⾏访问,不同数据库使⽤相同的⽅法名,解决数据库连接不统⼀的问题。
我是配置在windows下做开发⽤的。
■PDO的⽬标提供⼀种轻型、清晰、⽅便的 API统⼀各种不同 RDBMS 库的共有特性,但不排除更⾼级的特性。
通过 PHP 脚本提供可选的较⼤程度的抽象/兼容性。
■PDO的特点:性能。
PDO 从⼀开始就吸取了现有数据库扩展成功和失败的经验教训。
因为 PDO 的代码是全新的,所以我们有机会重新开始设计性能,以利⽤ PHP 5 的最新特性。
能⼒。
PDO 旨在将常见的数据库功能作为基础提供,同时提供对于 RDBMS 独特功能的⽅便访问。
简单。
PDO 旨在使您能够轻松使⽤数据库。
API 不会强⾏介⼊您的代码,同时会清楚地表明每个函数调⽤的过程。
运⾏时可扩展。
PDO 扩展是模块化的,使您能够在运⾏时为您的数据库后端加载驱动程序,⽽不必重新编译或重新安装整个 PHP 程序。
例如,PDO_OCI 扩展会替代 PDO 扩展实现 Oracle 数据库 API。
还有⼀些⽤于 MySQL、PostgreSQL、ODBC 和 Firebird 的驱动程序,更多的驱动程序尚在开发。
■安装PDO版本要求:php5.1以及以后版本的程序包⾥已经带了;php5.0.x则要到下载,放到你的扩展库,就是PHP所在的⽂件夹的ext⽂件夹下;⼿册上说5.0之前的版本不能运⾏PDO扩展。
配置(Windows):修改你的php.ini配置⽂件,使它⽀持pdo.(php.ini这个东西没有弄懂的话,先弄清楚,要修改调⽤你的phpinfo()函数所显⽰的那个php.ini)把extension=php_pdo.dll前⾯的分号去掉,分毫是php配置⽂件注释符号,这个扩展是必须的。

sqlserver创建索引方法在SQL Server数据库中,索引是提高查询性能和加快数据检索速度的重要工具。
创建索引可以帮助数据库引擎在执行查询时更快地定位到所需的数据。
下面是一些创建索引的方法:1. CREATE INDEX 语句: 使用CREATE INDEX语句可以直接创建索引。
语法如下:```CREATE INDEX index_nameON table_name (column1, column2, ...)```这里,`index_name` 是要创建的索引的名称,`table_name` 是要在其上创建索引的表的名称,`column1, column2, ...` 是要为其创建索引的列的名称。
2. ALTER TABLE 语句: 使用ALTER TABLE语句也可以创建索引。
语法如下:```ALTER TABLE table_nameADD INDEX index_name (column1, column2, ...)```这里,`table_name` 是要在其上创建索引的表的名称,`index_name` 是要创建的索引的名称,`column1, column2, ...` 是要为其创建索引的列的名称。
3. SSMS (SQL Server Management Studio):对于使用SQL Server Management Studio的用户,可以通过图形化界面创建索引。
在“对象资源管理器”中找到表,右键点击并选择“设计”。
然后,在“列选择”选项卡中,选择要创建索引的列,并在“索引”选项卡中添加索引。
4. 聚集索引和非聚集索引:SQL Server支持两种类型的索引,即聚集索引和非聚集索引。
聚集索引决定了表中数据的物理存储顺序,而非聚集索引是基于聚集索引或堆表存储的。
- 聚集索引:使用CREATE INDEX或ALTER TABLE语句创建索引时,未指定索引类型时,默认创建的是聚集索引。

informix入门基础学习教程Informix是一个关系型数据库管理系统(RDBMS),是IBM公司开发的一种数据库管理系统。
它具有高效、可靠、安全的特点,被广泛应用于企业级应用程序中。
本文将介绍Informix的基础知识和学习教程。
一、Informix的概述Informix是一种面向企业级应用的数据库管理系统,它提供了高性能、可扩展、可靠的数据存储和处理能力。
Informix支持多种操作系统平台,包括Windows、Linux、Unix等。
它的特点包括事务处理、并发控制、数据安全等。
二、安装和配置Informix2. 配置Informix服务器,设置数据库存储路径、内存大小等参数。
3.创建数据库实例,设置数据库名称、用户名和密码等信息。
三、Informix的基本概念1. 数据库:Informix中的数据库是一组相关表的集合,用于存储和管理数据。
2.表:表是数据库中的基本组成单元,用于存储数据。
每个表包含多个列,每个列定义了一种数据类型。
3.列:列是表中的一个字段,用于存储特定类型的数据。
4.行:行是表中的一条记录,包含了一组相关的数据。
5.索引:索引是对表中一列或多列的值进行排序的数据结构,用于提高查询性能。
6.视图:视图是一个虚拟的表,它是基于一个或多个表的查询结果。
视图可以简化复杂的查询操作。
四、基本操作1.创建数据库:使用CREATEDATABASE语句创建一个新的数据库。
2.创建表:使用CREATETABLE语句创建一个新的表,并定义表中的列和其数据类型。
3.插入数据:使用INSERTINTO语句将数据插入到表中。
4.查询数据:使用SELECT语句从表中检索数据。
5.更新数据:使用UPDATE语句修改表中的数据。
6.删除数据:使用DELETEFROM语句从表中删除数据。
7.创建索引:使用CREATEINDEX语句在表上创建索引,以提高查询性能。
8.创建视图:使用CREATEVIEW语句创建一个新的视图。


⼀.建⽴索引⽂件:对打开的索引⽂件,可⽤下列命令建⽴索引:格式:index on 索引关键字|tag 索引名|to 索引⽂件名说明:(1).tag 索引名:指定索引名,此索引存放在与表名相同的.cdx⽂件中。
(2).to 索引⽂件名:选择此项⽣成独⽴索引,即⼀个索引存放在⼀个索引⽂件中;否则⽣成的是结构化复合索引。
例1:建⽴“⼯资情况”表的结构化复合索引⽂件,其索引关键字分别为姓名和⼯资,⽽索引名分别为xm和gz.use ⼯资情况browseindex on 姓名 tag xmindex on ⼯资 tag gzbrowse&&分别执⾏以上命令后,⽣成了“⼯资情况.cdx”⽂件,其中存放了xm和gz两个索引。
例2:⽤“姓名”作索引关键字,建⽴“职⼯档案.dbf”的独⽴索引⽂件,⽂件名为a.idx。
use 职⼯档案index on 姓名 to hello &&执⾏此命令,检查默认⽬录e:\myvfp,会发现多了⼀个⽂件:hello.idxuse⼆.打开索引:打开表时,系统会⾃动打开结构化复合索引,但此时显⽰的仍是物理顺序。
要使索引起作⽤,必须指定主控索引。
主控索引就是控制当前显⽰顺序的索引。
也可以在打开表的同时指定主控索引。
1.打开表的同时打开索引并指定主控索引:格式:use 表名 [index 索引⽂件名] [order tag 顺序号|索引名]说明:(1).index 索引⽂件名:⽤于打开独⽴索引⽂件。
(2).order tag 顺序号|索引名:⽤于打开结构化复合索引。
其中,顺序号为该索引在复合索引⽂件中的先后顺序,即在“表设计器”的“索引”选项卡中看到的该索引的位置。
例:在命令窗⼝输⼊以下命令依次执⾏:use 职⼯档案 index hello &&打开表的同时打开独⽴索引hellobrowse &&显⽰的是按姓名索引的顺序,useuse ⼯资情况 order tag 2 &&显⽰的是gz索引的顺序,因为gz在“表设计器”中位置为2,use2.打开表后再打开索引:格式1:set index to 索引⽂件名功能:打开独⽴索引⽂件格式2:set orer to 顺序号|tag 索引名功能:打开结构化复合索引例:在命令窗⼝依次执⾏以下命令:use 职⼯档案brow &&显⽰物理顺序,set index to hello &&打开独⽴索引⽂件hello.idxbrowse &&显⽰的是按姓名索引的顺序,useuse ⼯资情况browse &&显⽰物理顺序set order to 1 &&即将xm指定为主控索引,因为xm在“表设计器”中位置为1,browse &&显⽰按姓名索引的顺序,set orer to gz &&将gz指定为主控索引browse &&显⽰的是gz索引的顺序,use三.关闭索引:格式1:set index to格式2:set order to说明:上两条命令后不加选项,可关闭当前索引。

informix常用命令详解一(包括查询表结构信息,索引信息等)2011-08-03 18:27数据库文章很全的一个博客1 CREATE DATABASE database_name [WITH LOG IN “pat hname”]创建数据库。
database_name:数据库名称。
“pathname”:事务处理日志文件。
创建一database_name.dbs目录,存取权限由GRANT设定,无日志文件就不能使用BEGIN WORK等事务语句(可用START DATABASE语句来改变)。
可选定当前数据库的日志文件。
如:select dirpath form systables where tabtype = “L”;例:create databse customerdb with log in “/usr/john/log/custome r.log”;DATABASE databse-name [EXCLUSIVE]选择数据库。
database_name:数据库名称。
EXCLUSIVE:独占状态。
存取当前目录和DBPATH中指定的目录下的数据库,事务中处理过程中不要使用此语句。
例:dtabase customerdb;3. CLOSE DATABASE关闭当前数据库。
database_name:数据库名称。
此语句之后,只有下列语句合法:CREATE DATABASE; DATABASE; DROP DATABSE; ROLLF ORWARD DATABASE;删除数据库前必须使用此语句。
例:close database;4. DROP DATABASE database_name删除指定数据库。
database_name:数据库名称。
用户是DBA或所有表的拥有者;删除所有文件,但不包括数据库目录;不允许删除当前数据库(须先关闭当前数据库);事务中处理过程中不能使用此语句,通过ROLLBACK WORK 也不可将数据库恢复。



数据库索引的使用教程数据库索引是提高查询效率的重要工具,它能够加快对数据库中数据的检索速度。
本篇文章将详细介绍数据库索引的使用教程,包括索引的作用、创建索引的注意事项、索引的类型以及优化索引的方法等内容。
一、索引的作用索引是数据库中对某一列或者多个列进行排序的数据结构,能够快速地定位数据并加快数据的检索速度。
它类似于一本书的目录,可以根据索引找到相应的内容,而无需从头开始阅读整本书。
索引可以大大减少数据库的查询时间,提高系统的响应速度和性能。
二、创建索引的注意事项1.选择合适的列进行索引,通常是那些经常用于查询的列或者经常作为查询条件的列。
避免对更新频繁的列进行索引,因为索引的更新可能会导致性能下降。
2.对大型表进行索引时,建议使用分区索引,将数据分成较小的块进行存储,以减少查询时的扫描范围,从而提高查询效率。
3.避免创建过多的索引,索引的数量过多会增加数据库的存储空间和维护成本,并且在写操作时会减慢数据库的速度。
三、索引的类型常见的数据库索引类型包括主键索引、唯一索引、聚簇索引、非聚簇索引和全文索引等。
以下分别介绍各种索引的特点和适用场景:1.主键索引主键索引是用来保证表中每一行的唯一性,并且可以提升对主键列的查询性能。
主键索引在创建表时通过指定主键列来创建,主要用于快速查找和对表进行连接操作。
2.唯一索引唯一索引用于保证指定列的唯一性,可以对表中的多个列建立唯一索引。
当对唯一索引列进行查找时,数据库引擎会自动使用索引进行匹配加速。
3.聚簇索引聚簇索引是按照索引的顺序来组织表记录的物理存储方式,即按照索引的列值进行排序。
聚簇索引在表中只能存在一个,并且通常是主键索引。
它可以提高特定列的查询性能,但会增加对数据的插入、删除和更新操作的成本。
4.非聚簇索引非聚簇索引将索引和表的数据分开存储,即索引和表是分离的。
非聚簇索引可以提高对非索引列的查询性能,但对于索引列的查询速度可能较慢。
5.全文索引全文索引是对文本内容进行索引,常用于搜索引擎等需要进行文本检索的场景。

1. 索引(Index)索引是根据索引关键字(即索引表达式)的值进行逻辑排序的一组指针。
索引提供对数据的快速访问,可以对表的各行强制实现唯一性。
索引文件由索引序号和对应于索引序号的表的记录号(亦称为指针)组成。
2. 索引关键字(Index Key)索引关键字是用来作为建立索引的依据。
它通常是一个字段或字段表达式。
例如,学生表(XS.DBF)中有8个记录,输入时的物理顺序如下:记录号XH XM XB ZYDH XIMING1 950101 李林男102001 信息管理系2 950106 高山男102001 信息管理系3 950105 陆海涛男102001 信息管理系4 950104 柳宝女102001 信息管理系5 950102 李枫女102001 信息管理系6 950103 蓝军男102001 信息管理系7 960201 林一风男109003 计算机科学系8 960203 高平男109003 计算机科学系现以XH字段作为索引关键字,按升序建立索引,索引文件的情况如下:P83Index # Table Record # XH1 1 9501012 5 9501023 6 9501034 4 9501045 3 9501056 2 9501067 7 9602018 8 960203第一列是索引号,第二列是对应于表中的记录号。
当该索引起作用时,浏览学生表时,记录按学号的顺序排列。
索引表达式的构成2-1索引表达式的构成与一般表达式的构成一样,只是索引表达式一般与表的字段有关。
索引表达式可以由单个字段构成,也可以是多个字段的组合。
需要注意的是,不能基于备注型字段和通用型字段建立索引。
索引表达式的构成2-2对于基于多个字段的索引表达式,可以按多个字段的值进行排序。
用多个字段建立索引表达式时,要注意以下几点。
⒈字符型表达式⒉算术表达式⒊不同类型字段构成一个表达式⒈字符型表达式⒈表达式中字段的前后顺序将影响索引的结果。
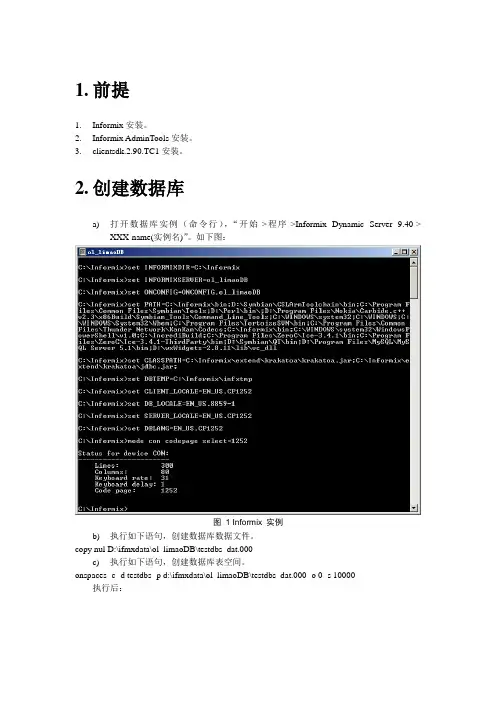
1.前提rmix安装。
rmix AdminTools安装。
3.clientsdk.2.90.TC1安装。
2.创建数据库a)打开数据库实例(命令行),“开始->程序->Informix Dynamic Server 9.40->XXX-name(实例名)”。
如下图:图 1 Informix 实例b)执行如下语句,创建数据库数据文件。
copy nul D:\ifmxdata\ol_limaoDB\testdbs_dat.000c)执行如下语句,创建数据库表空间。
onspaces -c -d testdbs -p d:\ifmxdata\ol_limaoDB\testdbs_dat.000 -o 0 -s 10000 执行后:图 2 创建数据库空间d)创建数据库。
启动dbaccess工具:图3启动dbaccess工具回车后,用键盘“上下左右键”,选择Database:图4选择Database 回车后,选择Create:图5选择Create回车后,输入数据库名:图6输入数据库名test回车后,选择创建数据库的类型Dbspace:图7选择Dbspace回车后,选择数据库所在的Dbspace,即我们刚创建的testdbs:图8选择test数据库所在的Dbspace 回车后,选择Exit。
再回车,选择Create-new-database:图9选择Create-new-database回车后,创建完成。
查看是否成功,选择Info:图10选择Database Info 回车后,选择Databases:图11选择Databases 查看我们刚创建的test数据库是否存在:图12查看test数据库3.创建用户。
a)由于Informix的用户管理机制是与操作系统用户管理绑定的,故新建Informix用户需要创建操作系统用户,然后将创建的用户增加到Informix-Admin用户组中。
b)创建计算机用户。
sqlite数据库索引使用方法SQLite是一种轻量级的嵌入式数据库管理系统,被广泛应用于移动设备和嵌入式系统中。
在处理大量数据时,为了提高查询效率,我们可以使用索引来加速数据库的查询操作。
本文将介绍SQLite数据库索引的使用方法。
一、索引的概念和作用索引是一种数据结构,用于加速数据库中的数据查找。
它类似于书籍的目录,可以根据关键字快速定位到书籍的具体内容。
在SQLite 中,索引可以大大提高查询的效率,减少查询所需的时间。
二、索引的创建在SQLite中,我们可以使用CREATE INDEX语句来创建索引。
创建索引时,需要指定要创建索引的表名、索引名以及要创建索引的列名。
例如,以下语句将在表中创建一个名为"index_name"的索引,该索引基于"column_name"列:CREATE INDEX index_name ON table_name (column_name);三、索引的类型SQLite支持多种类型的索引,包括B树索引、Hash索引和全文索引等。
其中,B树索引是SQLite默认的索引类型,也是最常用的索引类型。
它可以实现快速的范围查询和排序操作。
Hash索引适用于等值查询,但不支持范围查询。
全文索引可以用于文本搜索,但在SQLite中需要额外的配置和扩展。
四、索引的选择在选择创建索引时,需要考虑查询的频率和效率。
一般来说,对于经常被查询的列,应该创建索引以提高查询效率。
但是,过多的索引也会增加数据库的存储空间和维护成本,因此需要权衡利弊。
五、索引的优化为了使索引的使用更加高效,我们可以采取一些优化策略。
首先,可以使用复合索引来覆盖多个列,以减少索引的数量。
其次,可以使用合适的数据类型和字段长度,以减小索引的大小。
此外,还可以定期重新构建和优化索引,以保持索引的性能。
六、索引的注意事项在使用索引时,需要注意以下几点。
首先,索引只能加快查询操作,而对于插入、更新和删除操作,索引可能会导致性能下降。
编号:TN-070101001TIENON数据库培训教程INFORMIX基本操作及SQL语法2007年1月,V 1.00目录1、引言 (4)1.1、读者对象 (4)1.2、内容简介 (4)1.3、课程时间 (4)1.4、课程目标 (4)2、数据库基本概念...................................................... 错误!未定义书签。
2.1、从身边的例子了解数据库......................................................... 错误!未定义书签。
2.2、数据库系统概述......................................................................... 错误!未定义书签。
2.2.1、数据库的产生.................................................. 错误!未定义书签。
2.2.2、数据库系统组成................................................ 错误!未定义书签。
2.2.3、与数据库相关的软件系统........................................ 错误!未定义书签。
2.2.4、数据库系统特点................................................ 错误!未定义书签。
2.2.5、数据库系统的历史.............................................. 错误!未定义书签。
2.2.6、数据库系统的发展趋势.......................................... 错误!未定义书签。
2.2.7、数据库的分类.................................................. 错误!未定义书签。
RDBMS Fundamentals: 索引Relational data structures: Indexes (examples on Informix Dynamic Server –IDS)降序) 的Index 扫描时可以的. Examples Select fname, lname from customer order by customer_num;Select customer_num from customer order by customer_num desc;区间索引页能够从这种结构中获得性能提升. 例如:Select customer_num, fname, lname from customer where分配给的DBs, tables,我们可以把不同的数据库对象存储在不同的磁盘上–目的在于可以在磁盘驱动器和控制器之间均衡分散例如:–database stores_demo存储在dbspace•如果不指明dbspace, 默认为Root dbspace –table customer存储在dbspace dbs2•如果不指明dbspace, 表将创建在root dbspace –index ix_cust存储在dbspace dbs3•如果不指明dbspace,index将创建在表所在的•当对一个空表创建索引时,仅仅创建B-tree复合索引的好处在informix中,优化器在以下情况下可以使用复合索引:我们以如下方式使用基于列a, b, c 创建的索引:–CREATE INDEX ix_sample ON sample_table (a, b, c);–使用部分关键词定位特定的行:WHERE a=1WHERE a>=12 AND a<15WHERE a=1 AND b < 5WHERE a=1 AND b = 17 AND c >= 40–以下的过滤条件不能借助复合索引:WHERE b=10WHERE c=221WHERE a>=12 AND b=15–使用key-only搜索替换全表搜索•当查询的所有列都在索引中时–当使用列a, ab或者abc与其它表做连接时–需要基于列a, ab或者abc做ORDER BY或者GROUP BY操作时•如果是b, c, ac, or bc则不能获益Expression-based: tables 和indexes都支持col1 > 100 AND col1 < 500 IN dbspace2。
创建索引的方法索引是数据库中的一种数据结构,用于提高数据查询的效率。
在数据库中创建索引可以加快查询速度,降低系统负载,提高数据库的性能。
本文将介绍几种创建索引的方法,帮助读者更好地理解和应用索引。
1. 单列索引单列索引是最常见的索引类型,它仅对表中的单个列进行索引。
创建单列索引的方法是使用CREATE INDEX语句,指定要创建索引的表和列名即可。
例如,在一个员工表中,如果经常需要根据员工的工号进行查询,可以创建一个单列索引来加速查询。
2. 多列索引多列索引是对表中多个列进行索引,也被称为复合索引。
创建多列索引的方法与单列索引类似,只需要在CREATE INDEX语句中指定多个列名即可。
多列索引适用于需要根据多个列进行查询的场景,可以提高查询效率。
3. 唯一索引唯一索引是一种约束索引,用于确保表中的某个列的值唯一。
创建唯一索引的方法是在CREATE INDEX语句中添加UNIQUE关键字,表示该索引中的值不能重复。
例如,在一个学生表中,学生的学号是唯一的,可以创建一个唯一索引来保证学号的唯一性。
4. 全文索引全文索引是一种特殊的索引类型,用于对文本数据进行搜索。
创建全文索引的方法是使用CREATE FULLTEXT INDEX语句,指定要创建索引的表和列名。
全文索引可以提供更精确的搜索结果,适用于对文本进行模糊查询的场景。
5. 聚集索引聚集索引是一种特殊的索引类型,它决定了表中数据的物理排序方式。
创建聚集索引的方法是在CREATE TABLE语句中使用PRIMARY KEY关键字,指定要创建索引的列名。
聚集索引可以提高查询的效率,但每个表只能有一个聚集索引。
6. 非聚集索引非聚集索引是一种与聚集索引相对应的索引类型,它并不决定表中数据的物理排序方式。
创建非聚集索引的方法是使用CREATE INDEX 语句,指定要创建索引的列名。
非聚集索引适用于需要频繁进行查询和更新的表。
7. 稠密索引稠密索引是一种对所有记录进行索引的索引类型,即使某些记录的索引列为空值。
安装数据库管理实用程序IDS联网内核配置参数备份策略从sysmaster或者sysutils实例中监控备份小技巧影响CPU使用率的配置参数常用指令用法说明数据复制技术如何监控IDSIDS数据库维护技巧informix的用户权限管理基本概念安装数据库:1.配置informix安装空间:1G左右,用来存放数据库的安装文件,一般是/Informix2.创建informix用户和用户组3.对informix软件进行解包,有以下几种方法:cpio –icvdumB < /mnt/cdrom/*.cpirpm –iv –prefix $INFORMIXDIR /mnt/cdrom/*.rpmtar –xvfb 20 /mnt/cdrom/*.tar4.配置informix安装环境变量:INFORMIXDIR=/informixPATH=$INFORMIXDIR/bin:$PATHINFORMIXSERVER=szxaONCONFIG=onconfig.SZXATERMCAP=$INFORMIXDIR/etc/termcapTERM=vt1005.安装informix软件(用informix用户)/Informix/installserver安装完成后,会提示用root用户运行/Informix/RUN_AS_ROOT.server至今,informix软件安装完毕6.阅读版本说明:/$INFORMIXDIR/release/en_us/03337.配置/etc/services文件:Service_name port/protocol alias例如:sqlexecA 1526/tcp # SZXA informix database usesqlexecB 1527/tcp # SZXB informix database use8.配置sqlhosts文件:dbservername nettype hostname service_name例如:szxa onsoctcp S1_C_SZX_SHUJUKU 1526dbserver_name 网络接口协议主机服务别名注意,系统使用的网络接口类型,可以从版本说明文件获得9.生成磁盘存储:一般使用裸设备,并生成磁盘设备的链接,这样,如果磁盘设备失败,也可以把链接改变成指向可操作的磁盘ln -s /dev/rrootdbs /Informix/data/rootdbs10.配置onconfig文件:(第一次初始化只是针对于rootdbs,参数配置可以相对简单)ROOTOFFSET –指定KB数,确定在原始设备中移动多长距离之后再生成根dbspace PHYSFILE –第一次初始化,设置临时值2048,LOGFILES –第一次初始化,设置临时值3LOGSIZE –第一次初始化,设置临时值500TAPEDEV(存档),LTAPEDEV(日志存档)-- /dev/null,这样就可以运行档案程序ontape而不实际把数据写入磁带中SERVERNUM –运行多个服务器时确定服务器的共享内存地址,唯一值DBSERVERNAME –应该与sqlhosts文件中的项目相符DBSPACE TEMP –可以有多个dbspace组成,这样,每个排序操作就会平均分配在每个tempdbspace中进行DEADLOCK_TIMEOUT –等待多长时间确认某操作遭遇死锁NETTYPE –可选参数,配置如下协议类型轮询线程数每个轮询希望的并发连结数处理器类例如:soctcp,2,150,NETRESIDENT –驻留系统物理内存与否NUMCPUVPS –指定对实例启动的CPU类虚拟处理器个数,按照处理器的个数而定可以用onstat –g glo进行调整SINGLE_CPU_VP –指定服务器不运行多个CPU虚拟处理器,设置为true(1)使服务器跳过管理锁存资源的大部分代码,从而提高性能LOCKS –服务器对服务器线程分配的最大锁数,用onstat –p监控状态,如果ovlocks一直大于0,需要增加实例所用的锁数BUFFERS –定义实例分配的缓冲区数,检查onstat –p输出的缓冲读和缓冲写,调整该参数使这些值最大化CLEANERS –指定所需的页面清理线程数,用于把数据从共享内存写入磁盘。
在Informix Dynamic Server 中创建并使用函数索引随着数据量以惊人速度不断增长,数据库管理系统将继续关注性能问题。
本文主要介绍一种名为函数索引(functional index)的性能调优技术。
根据数据库使用情况的统计信息创建并使用函数索引,可以显著提升SELECT 查询的性能。
通过本文了解如何在IBM ® Informix ® Dynamic Server 中创建和使用函数索引并最大限度提升查询性能。
简介在选择数据库管理系统(DBMS)时,性能是一个关键的考虑因素。
在执行SELECT、INSERT、UPDA TE 和DELETE 操作时,很多因素都会对性能产生影响。
这些因素包括:持久性数据存储的速度和大小数据存储结构数据访问方法随着数据集不断变大,查询性能愈发变得重要。
通常,使用索引可以改善查询性能。
索引将数据库中的行位置与一组有序数据子集和/或数据派生物关联在一起。
索引可以减少DBMS 在执行查询时检查的行(或元组)数量,从而获得性能增益。
有时,仅通过搜索索引即可完成查询,而不需要从表中取回任何元组(tuple)。
例如,如果您在列c1 中建有索引,并且发出查询select c1 from t1 where c1 < 10 ,那么索引中包含了可以满足查询的所有信息。
有趣的是,ANSI SQL 标准并没有说明如何创建、实现或维护索引。
因此,数据库供应商可以按照自己的方式自由地实现索引。
本文讨论了Informix Dynamic Server 的函数索引特性。
要理解本文涉及的概念,您需要熟悉基本的数据库术语和概念,例如模式、表、行、列、索引和可扩展性。
还需了解Informix Dynamic Server (IDS) 的基本配置以及如何启动和停止服务器、如何使用ONCONFIG 文件进行配置。
此外,还需熟悉基本的SQL 命令以及如何使用dbaccess 对服务器执行SQL 命令。
本文的目的是帮助您理解函数索引的定义以及使用。
此外,您还将了解如何创建和使用函数索引,以及在创建函数索引之前需要考虑的一些问题。
函数索引的优势索引按照某种顺序保存列值。
函数索引对列中的数据进行转换并按照顺序保存转换后的值。
假设某个表中保存了一个企业的员工名称,并且需要保留名称的大小写形式。
那么,如果查询需要执行大小写不敏感的搜索(如下所示),则必须转换数据:SELECT * FROM t1 WHERE toUpper(name) LIKE 'ANTHONY % HOPKINS';如果没有为名称建立索引,那么DBMS 将执行全表扫描并对每个元组(tuple)的name 列应用toUpper 函数。
要确定元组(tuple)是否满足查询,必须调用toUpper 函数。
当表非常大或者大量会话发出这种类型的查询时,性能将会有所下降。
避免调用toUpper 函数的一种方法是在表中同时保存大小写混合的名称和大写名称。
应用程序查询大小写不敏感的列:SELECT * FROM t1 WHERE ucname like 'ANTHONY % HOPKINS';如果没有为ucname 创建索引,DBMS 仍然执行全表扫描,但是不会对数据进行进一步处理来判断其是否满足查询。
尽管这样做改善了性能,但并不是理想的解决方案,因为表非常大,而且所有需要操纵或访问数据的应用程序必须包括处理ucname 的逻辑。
改善查询性能的一种更好的方法是对name 创建函数索引:CREATE FUNCTION toUpper( name V ARCHER(100) ) RETURNS V ARCHAR(100)WITH (NOT V ARIANT);RETURN upper( name );END FUNCTION;CREATE INDEX ucnameIndex ON t1 ( toUpper(name) );当执行这种查询时,DBMS 可以使用函数索引判断哪些元组元组(tuple)满足查询。
DBMS 只获取并返回这些满足查询的元组(tuple),如下面的清单所示:SELECT * FROM t1 WHERE toUpper(name) LIKE 'ANTHONY % HOPKINS';DBMS 将自动管理函数索引以及不需要包含逻辑来管理大写形式数据的应用程序。
通过使用INSERT、UPDA TE 和DELETE 操作对索引进行更新,DBMS 能够确保索引始终与表数据一致。
接下来将深入讨论如何创建和使用函数索引,以及如何生成和检验查询计划,并提供具体的示例。
各种类型的函数索引函数索引是根据用户定义例程(User Defined Routine,UDR)返回的值创建的。
这里的UDR 一词通常用来指代返回值的函数。
UDR 必须是不可变的。
也就是说,对于给定的参数,UDR 始终返回相同的值,而且UDR 不能修改数据库或变量状态。
和随机数生成程序、当前日期/时间函数一样,UDR 通常是变化的,因此不能用于函数索引。
当定义UDR 并将之用于函数索引时,您必须显式将其指定为NOT V ARIANT。
可以将UDR 编写为一个存储过程语言(Stored Procedure Language,SPL)函数,或者使用外部语言(SQL、C/C++ 或Java)编写为一个外部函数。
函数索引可以根据用户定义的类型创建。
函数索引可以使用以下任意一种访问方法:B-树(默认)R-树用户定义的二级方法可针对单个列、单个列的派生值、多个列和多个列的派生值创建索引。
针对多个列创建的索引称为复合索引(composite index)。
例如,下面的查询针对一个列的列值和第二个列的派生值创建了一个复合索引:CREATE INDEX idx1 ON myTable( c1, f(c3) );函数索引的局限性函数索引不能是内置的代数、指数、对数或十六进制函数。
如果需要使用内置函数定义函数索引,那么必须从SQL 或外部语言函数中调用该函数。
不能针对返回大对象的UDR 创建函数索引。
不允许使用大对象作为索引键,因为一般情况下不能够对大对象进行比较和排序。
然而,需要注意,可以将大对象作为参数传递给UDR。
如果将某个UDR 用于函数索引,则该UDR 不能使用集合数据类型作为参数类型。
集合数据类型包括SET、MULTISET 和LIST。
对于用于函数索引的UDR,传递给它的参数在数量上有所限制。
根据所使用的Informix Data Server (IDS) 版本以及实现UDR 的具体语言的不同,这些限制也不尽相同。
例如,对于IDS 9.4,最多可以将102 列作为参数传递给 C UDR,并且最多可以将341 列作为参数传递给Java 或SPL UDR。
有关此方面的详细内容,请参考您的文档。
比较函数索引和非函数索引在创建和使用方面,函数索引和非函数索引之间存在着大量差异。
诸如UNIQUE 和CLUSTER 等索引选项,以及B-Tree、R-Tree 等访问方法和用户定义的访问方法,可以同时应用于函数索引和非函数索引。
同样,这两种类型的索引都可以指定一个FILLFACTOR,并可以指定存储选项来控制创建索引的位置以及是否对索引进行分段。
这两种索引都可以指定索引操作符类并按照降序或升序排列。
oncheck 实用工具可以对两种类型的索引进行验证和修复。
例如,下面的oncheck 命令将对db 数据库的tbl 表中名为i1 的索引进行验证:oncheck -ci db:tbl#i1。
如果oncheck 报告索引中存在一个问题,那么可以使用oncheck 的-y 选项进行修复。
该选项可以同时对函数索引和非功能性索进行修复。
从用户的角度来看,函数索引和非功能性索之间的一个差异就是它们执行CREA TE 和DROP 操作的方式不同。
在创建或删除一个函数索引时,不能指定ONLINE 关键字,如下所示:CREATE INDEX ... ONLINE; <== Not validDROP INDEX ... ONLINE; <== Not valid这说明,在创建或删除函数索引时,执行索引的表中始终持有一个排他锁。
在这段时间内,其他所有用户都无法访问这个表。
创建函数索引的注意事项任何索引都存在开销。
包括资源的使用和执行时间。
所有索引都需要进行保存,并且,所有索引都需要制定执行时间并保存其键值。
函数索引还会产生额外的函数执行开销。
在创建函数索引时,必须针对表中的每一行执行相关的函数。
并且,必须在INSERT 和UPDA TE 操作期间执行函数。
在创建函数索引之前,总是需要对数据库进行详细的成本收益分析。
分析的内容应该包括表中存储的数据量、执行数据查询的类型和频率。
如果表非常小,或者不经常执行使用函数索引的查询,那么创建函数索引可能收效甚微。
SQL EXPLAIN 文件查询计划被写入到SQL EXPLAIN 文件中。
下表展示了该文件的位置和名称。
平台IDS Server 位置SQL EXPLAIN 位置SQL EXPLAIN 名称UNIX 本地当前目录sqexplain.outUNIX 远程远程计算机的主目录sqexplain.outWindows 本地和远程<INFORMIXDIR>/sqexpln <username>.out现在,您已了解了函数索引的定义以及其使用方式和使用时机,接下来,将提供一些使用函数索引的例子。
我们将为您提供分步指导,使您能够亲自实现函数索引。
示例您已经了解了函数索引的定义以及其使用方式和使用时机。
下面的例子将展示一些具体应用。
每个例子都附带了分步指导,根据这些指导,您将能够亲自实现函数索引。
示例:对圆的面积执行函数索引本示例展示如何对圆的面积创建函数索引。
如果数据集较大,或者经常发出请求圆面积的查询,那么创建函数索引将有助于提高性能。
首先,创建一个表。
CREATE TABLE circles ( radius FLOAT );接着,创建一个SPL 函数,它将返回给定半径的圆的面积。
CREATE FUNCTION circleArea( radius FLOAT ) RETURNS floatWITH (NOT V ARIANT);RETURN 3.14159 * radius * radius;END FUNCTION;对这个圆形区域创建一个函数索引。
CREATE INDEX areaOfCircleIndex on circles( circleArea( radius ) );最后,执行查询,该查询将使用函数索引。
DBMS 使用索引判断哪些元组(tuple)满足查询,并且仅将这些元组(tuple)作为查询结果返回。