C#泛型类简介
- 格式:doc
- 大小:228.00 KB
- 文档页数:40

碘量法测定维生素C碘量法测定维生素C原理维生素C又称抗坏血酸Vc,分子式C6H8O6。
Vc具有还原性,可被I2定量氧化,因而可用I2标准溶液直接测定。
其滴定反应式:C6H8O6+I2= C6H6O6+2HI用直接碘量法可测定药片,注射液,饮料,蔬菜,水果等的V含量。
I2微溶于水而易溶于KI溶液,但在稀的KI溶液中溶解得很慢,所以配制I2溶液时不能过早加水稀释,应先将I2和KI混合,用少量水充分研磨,溶解完全后再加水稀释。
I与KI间存在如下平衡:I2+I-=I3-游离I2容易挥发损失,这是影响碘溶液稳定性的原因之一。
因此溶液中应维持适当过量的I-离子,以减少I2的挥发。
空气能氧化I-离子,引起I2浓度增加:4 I-+O2+4H+=2I2+2H2O此氧化作用缓慢,但能为光,热,及酸的作用而加速,因此I2溶液应处于棕色瓶中置冷暗处保存。
I2能缓慢腐蚀橡胶和其他有机物,所以I应避免与这类物质接触。
I2溶液的标定用Na2S2O3标定。
而Na2S2O3一般含有少量杂质,在PH=9-10间稳定,所以在Na2S2O3溶液中加入少量的Na2CO3,Na2S2O3见光易分解可用棕色瓶储于暗处。
碘量法的基本反应式:2S2O32-+I2=S4O62-+2I-由于Vc的还原性很强,较容易被溶液和空气中的氧氧化,在碱性介质中这种氧化作用更强,因此滴定宜在酸性介质中进行,以减少副反应的发生。
考虑到I2在强酸性中也易被氧化,故一般选在PH为3-4的弱酸性溶液中进行滴定。
三、试剂配制I2溶液:6.6g I2和18.5g KI,置于研钵中加少量水,在通风橱中研磨。
待I2全部溶解后,将溶液转入棕色试剂瓶,加水稀释至250ML,摇匀,放置暗处保存。
Na2S2O3溶液(0.1mol·dm-3)的配制:称取26g硫代硫酸钠(Na2S2O3·5H2O)(或无水硫代硫酸钠16g),加入1000ml新煮沸并冷却的蒸馏水,溶解后,加入约0.2g 的Na2CO3 ,(浓度为0.02%)贮存于棕色试剂瓶中,取上层清液标定。

排列组合c怎么算
A上3下3是3的全排名,C上2下4是4选2的排列。
排列组合c的公式:C(n,m)=A(n,m)/m!=n!/m!(n-m)!与
C(n,m)=C(n,n-m)。
(n为下标,m为上标)。
例如,
C(4,2)=4!/(2!2!)=43/(21)=6;C(5,2)=C(5,3)。
排列组合是组合学最基本的概念。
所谓排列,就是指从给定个数的元素中取出指定个数的元素进行排序。
组合则是指从给定个数的元素中仅仅取出指定个数的元素,不考虑排序。
排列组合的中心问题是研究给定要求的排列和组合可能出现的情况总数。
排列组合与古典概率论关系密切。
排列组合c的公式:C(n,m)=A(n,m)/m!=n!/m!(n-m)!与
C(n,m)=C(n,n-m)。
(n为下标,m为上标)。
例如,
C(4,2)=4!/(2!2!)=43/(21)=6;C(5,2)=C(5,3)。
计算概率组合C:从8个中任选3个:C上面写3下面写8,表示从8个元素中任取3个元素组成一组的方法个数,具体计算是:876/321;如果是8个当中取4个的组合就是:8765/4321。

词汇表(C-D ): cabbage n.洋白菜,卷心菜 cabin n.小屋;船舱,机舱 cabinet n.橱,柜;内阁 cable n.缆,索;电缆;电报 cafe n.咖啡馆;小餐厅 cafeteria n.自助食堂 cage n.笼;鸟笼,囚笼 cake n.饼,糕,蛋糕 calculate vt.计算;估计;计划 calculation n.计算,计算结果 calculator n.计算器,计算者 calendar n.日历,历书;历法 call vt.把…叫做;叫,喊 calm a.静的,平静的 camel n.骆驼camera n.照相机,摄影机camp n.野营,营地,兵营campaign n.战役;运动 campus n.校园,学校场地 can aux.v.能,会,可能 can n.罐头,听头;容器 Canada n.加拿大Canadian a.加拿大的 canal n.运河;沟渠;管 cancel vt.取消,撤消;删去cancer n.癌,癌症,肿瘤candidate n.候选人;投考者candle n.蜡烛;烛形物;烛光candy n.糖果;砂糖结晶cannon n.大炮,火炮;榴弹炮canoe n.独木舟,皮艇,划子canteen n.小卖部;临时餐室canvas n.粗帆布;一块油画布cap n.帽子,便帽;帽状物 capable a.有能力的,有才能的capacity n.容量;能力;能量 capital n.资本,资金;首都 captain n.陆军上尉;队长 captive n.俘虏,被监禁的人 capture vt.捕获,俘获;夺得 car n.汽车,小汽车,轿车carbon n.碳 card n.卡,卡片,名片 care vi.关心,介意 n.小心 career n.生涯,职业,经历 careful a.仔细的;细致的 careless a.粗心的,漫不经心的 cargo n.船货,货物 carpenter n.木工,木匠 carpet n.地毯,毡毯,毛毯 carriage n.客车厢;四轮马车carrier n.运输工具;运载工具 carrot n.胡罗卜carry vt.携带;运载;传送 cart n.二轮运货马车 carve vt.刻,雕刻;切开case n.情况;事实;病例case n.箱(子),盒(子),套 cash n.现金,现款cassette n.盒式录音带;盒子 cast vt.投,扔,抛;浇铸castle n.城堡;巨大建筑物casual a.偶然的;随便的cat n.猫,猫科,猫皮 catalog n.目录,目录册catch vt.捉住;赶上;领会 cathedral n.总教堂;大教堂 cattle n.牛;牲口,家畜cause n.原因,理由;事业cave n.山洞,洞穴,窑洞cease vi.&vi.&n.停止,停息 ceiling n.天花板,顶蓬 celebrate vt.庆祝;歌颂,赞美cell n.细胞;小房间 cellar n.地窑,地下室cement n.水泥;胶泥 vt.粘结cent n.分;分币;百 centigrade a.百分度的 centimetre n.公分,厘米 central a.中心的;主要的 centre n.中心;中枢 vt.集中 century n.世纪,百年 ceremony n.典礼,仪式;礼节 certain a.确实的;肯定的 certainly ad.一定,必定;当然 certainty n.必然;肯定 certificate n.证书,证件,执照 chain n.链,链条,项圈chair n.椅子;主席 chairman n.主席;议长,会长chalk n.白垩;粉笔 challenge n.挑战;要求,需要 chamber n.会议室;房间;腔 champion n.冠军,得胜者 chance n.机会,机遇;可能性change n.改变,变化;零钱channel n.海峡;渠道;频道chapter n.章,回,篇 character n.性格;特性;角色characteristic a.特有的 n.特性charge vt.索价;控告 n.费用 charity n.施舍;慈善事业 charming a.迷人的,可爱的chart n.图,图表;海图 chase n.追逐,追赶,追求cheap a.廉价的;劣质的cheat vt.骗取;哄 vi.行骗 check vt.检查;制止 n.检查 cheek n.面颊,脸蛋cheer vt.使振作;欢呼 cheerful a.快乐的,愉快的cheese n.乳酪,干酪 chemical a.化学的 n.化学制品 chemist n.化学家;药剂师chemistry n.化学cheque n.支票 cherry n.樱桃;樱桃树 chess n.棋;国际象棋 chest n.胸腔,胸膛;箱子 chew vt.咀嚼,嚼碎 chicken n.小鸡,小鸟;鸡肉 chief a.主要的;首席的 child n.小孩,儿童;儿子 childhood n.童年,幼年;早期 childish a.孩子的;幼稚的 chill vt.使变冷 n.寒冷 chimney n.烟囱,烟筒;玻璃罩chin n.颏,下巴China n.中国china n.瓷器,瓷料 Chinese a.中国的 n.中国人 chocolate n.巧克力;巧克力糖 choice n.选择,抉择 choke vt.使窒息;塞满 choose vt.选择,挑选;情愿chop vt.砍,劈;切细vi.砍Christian n.基督教徒;信徒 Christmas n.圣诞节 church n.教堂,礼拜堂;教会cigarette n.香烟,纸烟,卷烟cinema n.电影院;电影,影片 circle n.圆,圆周;圈子 circuit n.电路;环行;巡行 circular a.圆的;循环的 circulate vt.使循环 vi.循环circumference n.圆周,周长,圆周线 circumstance n.情况,条件;境遇citizen n.公民;市民,居民city n.城市,都市 civil a.公民的;文职的 civilization n.文明,文化;开化civilize vt.使文明;教育 claim vt.声称,主张;索取 clap vi.拍手 vt.拍,轻拍 clarify vt.澄清,阐明 clasp n.扣子,钩子;别针class n.班,班级;阶级classical a.古典的;经典的 classification n.分类;分级;分类法 classify vt.把…分类 classmate n.同班同学 classroom n.教室,课堂 claw n.爪,脚爪,螯 clay n.粘土,泥土;肉体 clean a.清洁的;纯洁的 clear a.清晰的 vt.清除 clearly ad.明白地,清晰地 clerk n.店员;办事员,职员 clever a.聪明的;机敏的cliff n.悬崖,峭壁 climate n.气候;风土,地带 climb vi.攀登,爬 vt.爬 cloak n.斗篷;覆盖(物) clock n.钟,仪表 close vt.关,闭;结束 closely ad.紧密地,接近地cloth n.布;衣料;桌布 clothe vt.给…穿衣服 clothes n.衣服,服装;被褥 clothing n.衣服,被褥 cloud n.云;云状物;阴影cloudy a.多云的;云一般的club n.俱乐部,夜总会 clue n.线索,暗示,提示 clumsy a.笨拙的;愚笨的coach n.长途公共汽车 coal n.煤,煤块 coarse a.粗的,粗糙的 coast n.海岸,海滨(地区)coat n.外套,上衣;表皮cock n.公鸡;雄禽;旋塞code n.准则;法典;代码coffee n.咖啡,咖啡茶 coil n.(一)卷;线圈 vt.卷coin n.硬币;铸造(硬币)cold a.冷的;冷淡的 n.冷collapse vi.倒坍;崩溃,瓦解 collar n.衣领,项圈colleague n.同事,同僚collect vt.收集 vi.收款 collection n.搜集,收集;收藏品 collective a.集体的;集合性的 college n.学院;大学 collision n.碰撞;冲突 colonel n.陆军上校;中校 colony n.殖民地;侨居地 color n.颜色,彩色;颜料 column n.柱,支柱,圆柱 comb n.梳子 vt.梳理 combination n.结合,联合;化合 combine vt.使结合;兼有 come vi.来,来到;出现comfort n.舒适;安慰 vt.安慰comfortable a.舒适的,安慰的command vt.命令,指挥;控制commander n.司令官,指挥员comment n.评论,意见;注释commerce n.商业,贸易;社交commercial a.商业的;商品化的commission n.委任状;委员会commit vt.犯(错误);干(坏事) committee n.委员会;全体委员 common a.普通的;共同的 commonly ad.普通地,一般地 communicate vi.通讯;传达;传播 communication n.通讯;传达;交通 communism munist 主义 communistmunistparty 员 community n.社区;社会;公社 companion n.同伴;共事者;伴侣 company n.公司,商号;同伴 comparative a.比较的,相对的compare vt.比较,对照;比作comparison n.比较,对照;比似 compass n.罗盘,指南针;圆规 compel vt.强迫,迫使屈服 compete vi.比赛;竞争;对抗 competent a.有能力的;应该做的 competition n.竞争,比赛 compile vt.编辑,编制,搜集 complain vi.抱怨,拆苦;控告 complaint n.抱怨;怨言;控告 complete a.完整的;完成的 completely ad.十分,完全地 complex a.结合的;复杂的 complicate vt.使复杂;使陷入 complicated a.复杂的,难懂的 component n.组成部分;分;组件 compose vt.组成,构成;创作 composition n.构成;作品;写作 compound n.化合物;复合词 comprehension n.理解,理解力;领悟 comprehensive a.广泛的;理解的 compress vt.压紧,压缩 comprise vt.包含,包括;构成 compromise n.妥协,和解compute vt.计算,估计,估算computer n.计算机,电脑comrade n.同志,亲密的同伴conceal vt.把…隐藏起来concentrate vt.集中;聚集;浓缩concentration n.集中;专注;浓缩concept n.概念,观念,设想concern n.关心,挂念;关系concerning prep.关于 concert n.音乐会,演奏会conclude vt.推断出;结束conclusion n.结论,推论;结尾 concrete n.混凝土;具体物 condemn vt.谴责,指责;判刑 condense vt.压缩,使缩短 condition n.状况,状态;环境 conduct n.举止,行为;指导 conductor n.售票员;(乐队)指挥 conference n.会议,讨论会 confess vt.供认,承认;坦白 confidence n.信任;信赖;信心 confident n.确信的,自信的 confine vt.限制;禁闭 confirm vt.证实,肯定;批准conflict n.争论;冲突;斗争confuse vt.使混乱,混淆confusion n.混乱;骚乱;混淆congratulate vt.祝贺,向…道喜congratulation n.祝贺;祝贺词congress n.大会;国会,议会conjunction n.接合,连接;连接词connect vt.连接,连结;联系connection n.连接,联系;连贯性conquer vt.征服,战胜;破除conquest n.攻取,征服;克服 conscience n.良心,道德心 conscious a.意识到的;有意的 consciousness n.意识,觉悟;知觉 consent n.同意,赞成vi.同意 consequence n.结果,后果 consequently ad.因此,因而,所以 conservation n.保存,保护;守恒 conservative a.保守的 n.保守的人 consider vt.认为;考虑;关心 considerable a.相当大的;重要的 considerate a.考虑周到的;体谅的 consideration n.考虑,思考;体贴 consist vi.由…组成;在于 consistent a.坚持的,一贯的 constant a.经常的;永恒的 constitution n.章程;体质;构造 construct vt.建造;建设;构筑 construction n.建造;建筑;建筑物 consult vt.请教,查阅 consume vt.消耗,消费;消灭 consumption n.消耗量;消耗 contact vt.使接触;与…联系contain vt.包含,容纳;等于container n.容器;集装箱contemporary a.当代的,同时代的contempt n.轻蔑;藐视;受辱content n.内容,目录;容量content a.满意的,满足的contest vt.争夺,争取;辩驳continent n.大陆;陆地;洲continual a.不断的;连续的 continue vt.继续,连续;延伸 continuous a.连续不断的,持续的 contract n.契约,合同;婚约 contradiction n.矛盾,不一致;否认 contrary a.相反的 n.相反 contrast n.对比,对照,悬殊 contribute vt.捐献,捐助;投稿 control vt.控制,克制n.控制 convenience n.便利,方便;厕所 convenient a.便利的;近便的 convention n.习俗,惯例;公约conventional a.普通的;习惯的conversation n.会话,非正式会谈 conversely ad.相反地 conversion n.转变,转化;改变 convert vt.使转变;使改变 convey vt.传送;运送;传播 convince vt.使确信,使信服 cook vt.烹调,煮 vt.烧菜 cool a.凉的,冷静的 cooperate vi.合作,协作;配合 coordinate vt.使协调,调节cope vi.对付,应付 copper n.铜;铜币,铜制器 copy n.抄件 vt.抄写,复制cord n.细绳,粗线,索 cordial a.真诚的,诚恳的core n.果实的心,核心 corn n.谷物;(英)小麦 corner n.角;犄角;边远地区corporation n.公司,企业;社团correct a.正确的 vt.纠正correction n.改正,纠正,修改correspond vi.相符合;相当 correspondent n.通信者;通讯员 corresponding a.相应的;符合的corridor n.走廊,回廊,通路 cost n.价格,代价;成本costly a.昂贵的;价值高的 cottage n.村舍,小屋 cotton n.棉;棉线;棉布cough vi.咳,咳嗽 n.咳嗽could aux.v.(can 的过去式)council n.理事会,委员会count vt.计算 vi.数,计数counter n.柜台;计数器country n.国家,国土;农村countryside n.乡下,农村county n.英国的郡,美国的县 couple n.夫妇;(一)对;几个 courage n.勇气,胆量,胆识 course n.课程;过程;一道菜 court n.法院,法庭;庭院 cousin n.堂(或表)兄弟(姐妹) cover vt.盖,包括 n.盖子 cow n.母牛,奶牛;母兽 coward n.懦夫;胆怯者 crack n.裂缝,裂纹 vi.爆裂 craft n.工艺;手艺,行业 crane n.起重机,摄影升降机 无效 vi.碰撞,坠落 n.碰撞 crawl vi.爬,爬行crazy a.疯狂的,荒唐的 cream n.奶油,乳脂;奶油色create vt.创造;引起,产生creative a.创造性的,创作的creature n.生物,动物,家畜credit n.信用贷款;信用creep vi.爬行;缓慢地行进 crew n.全体船员cricket n.板球;蟋蟀 crime n.罪,罪行;犯罪 criminal n.犯人,罪犯,刑事犯 cripple n.跛子;残废的人crisis n.危机;存亡之际 critic n.批评家,爱挑剔的人critical a.决定性的;批评的criticism n.批评;批判;评论criticize vt.批评;评论;非难crop n.农作物,庄稼;一熟cross vt.穿过;使交叉 crow n.鸦,乌鸦 vi.啼crowd n.群;大众;一伙人 crown n.王冠,冕;花冠crude a.简陋的;天然的cruel a.残忍的,残酷的crush vt.压碎,碾碎;镇压 crust n.面包皮;硬外皮 cry vi.哭,哭泣;叫喊 crystal n.水晶,结晶体;晶粒 cube n.立方形;立方 cubic a.立方形的;立方的cucumber n.黄瓜 cultivate vt.耕;种植;培养 culture n.文化,文明;教养 cunning a.狡猾的,狡诈的 cup n.杯子;(一)杯;奖杯 cupboard n.碗柜,碗碟橱;食橱 cure vt.医治;消除 n.治愈 curiosity n.好奇,好奇心;珍品curious a.好奇的;稀奇古怪的curl n.卷毛;螺旋 vi.卷曲current a.当前的;通用的curse n.诅咒,咒骂;天谴curtain n.帘,窗帘;幕(布)curve n.曲线;弯 vt.弄弯cushion n.垫子,坐垫,靠垫custom n.习惯,风俗;海关customer n.顾客,主顾 cut vt.切,割,剪;减少 cycle n 自行车,循环。

维生素c_百度百科我的百科我的贡献草稿箱百度首页| 登录新闻网页贴吧知道MP3 图片视频百科帮助设置首页自然文化地理历史生活社会艺术人物经济科学体育春节维他命C在百度百科中为本词条的同义词,已为您做自动跳转。
编辑词条维生素c百科名片维生素C图片维生素C(Vita min C,Asc orbicAci d)又叫L-抗坏血酸,是一种水溶性维生素。
食物中的维生素C被人体小肠上段吸收。
一旦吸收,就分布到体内所有的水溶性结构中,正常成人体内的维生素C代谢活性池中约有1500mg维生素C,最高储存峰值为3000mg维生素C。
正常情况下,维生素C绝大部分在体内经代谢分解成草酸或与硫酸结合生成抗坏血酸-2-硫酸由尿排出;另一部分可直接由尿排出体外。
目录[隐藏]基本性质物理性质化学性质发展历程功效适宜人群富含食物正常需求生理功能防病作用药物作用吸收代谢缺乏表现过量表现注意人工合成维生素C片说明书基本性质物理性质化学性质发展历程功效适宜人群富含食物正常需求生理功能防病作用药物作用吸收代谢缺乏表现过量表现注意人工合成维生素C片说明书[编辑本段]基本性质物理性质外观:无色晶体熔点:190 -192℃沸点:(无)紫外吸收最大值:245nm荧光光谱:激发波长-无nm,荧光波长-无nm;溶解性:水溶性维生素化学性质分子式:C6H8O6分子量:176.12uCAS号:50-81-7酸性,具有较强的还原性,加热或在溶液中易氧化分解,在碱性条件下更易被氧化。
构成:一个维生素分子由六个碳原子、八个氢原子和六个氧原子构成。

C开头的单词发音[K]carn.汽车,小汽车,轿车case n.情况;事实;病例cas e n.箱(子),盒(子),套casu ala.偶然的;随便的cancern.癌,癌症,肿瘤card n.卡,卡片,名片carevi.关心,介意n.小心cas h n.现金,现款can aux.v.能,会,可能can n.罐头,听头;容器c ab le n.缆,索;电缆;电报cal l vt.把…叫做;叫,喊caken.饼,糕,蛋糕ca fe n.咖啡馆;小餐厅cal cula tor n.计算器,计算者calend arn.日历,历书;历法calm a.静的,平静的Ca nada n.加拿大camera n.照相机,摄影机ca ncel vt.取消,撤消;删去can didat e n.候选人;投考者car gon.船货,货物c atalog n.目录,目录册ca tch vt.捉住;赶上;领会carr y vt.携带;运载;传送cap aci ty n.容量;能力;能量c apita l n.资本,资金;首都carpent er n.木工,木匠carpet n.地毯,毡毯,毛毯c arriage n.客车厢;四轮马车c arriern.运输工具;运载工具c arrot n.胡罗卜ca rt n.二轮运货马车carv evt.刻,雕刻;切开cassett e n.盒式录音带;盒子cast vt.投,扔,抛;浇铸castlen.城堡;巨大建筑物ca t n.猫,猫科,猫皮c abbagen.洋白菜,卷心菜c abin n.小屋;船舱,机舱cab inet n.橱,柜;内阁came ln.骆驼ca fet eria n.自助食堂cag e n.笼;鸟笼,囚笼cal cul ate vt.计算;估计;计划ca lculation n.计算,计算结果camp n.野营,营地,兵营ca mpaignn.战役;运动c ampu s n.校园,学校场地Ca nadian a.加拿大的ca na l n.运河;沟渠;管candle n.蜡烛;烛形物;烛光candyn.糖果;砂糖结晶c annon n.大炮,火炮;榴弹炮ca noe n.独木舟,皮艇,划子cant een n.小卖部;临时餐室canvas n.粗帆布;一块油画布cap n.帽子,便帽;帽状物capablea.有能力的,有才能的captai n n.陆军上尉;队长ca ptiv e n.俘虏,被监禁的人cap tu re vt.捕获,俘获;夺得car bon n.碳ca reer n.生涯,职业,经历ca re ful a.仔细的;细致的ca rele ss a.粗心的,漫不经心的cathe dra l n.总教堂;大教堂cattle n.牛;牲口,家畜cause n.原因,理由;事业c ave n.山洞,洞穴,窑洞[K]co ffeen.咖啡,咖啡茶c olo r n.颜色,彩色;颜料comevi.来,来到;出现computer n.计算机,电脑cook vt.烹调,煮vt.烧菜c ool a.凉的,冷静的co ld a.冷的;冷淡的n.冷co py n.抄件v t.抄写,复制c oncert n.音乐会,演奏会co at n.外套,上衣;表皮coden.准则;法典;代码coin n.硬币;铸造(硬币)col leag ue n.同事,同僚comfor ta ble a.舒适的,安慰的comm on a.普通的;共同的competevi.比赛;竞争;对抗compl ain t n.抱怨;怨言;控告co mplet e a.完整的;完成的co ncern n.关心,挂念;关系co nfidencen.信任;信赖;信心confirm vt.证实,肯定;批准c ongratu lat ion n.祝贺;祝贺词con nectvt.连接,连结;联系c ontactvt.使接触;与…联系containe r n.容器;集装箱contentn.内容,目录;容量contrac t n.契约,合同;婚约c ontro lvt.控制,克制n.控制co nvenien ta.便利的;近便的conventi on n.习俗,惯例;公约costn.价格,代价;成本costlya.昂贵的;价值高的co rrect a.正确的vt.纠正co rre ction n.改正,纠正,修改c otton n.棉;棉线;棉布cou gh vi.咳,咳嗽n.咳嗽co un t vt.计算vi.数,计数cou n ter n .柜台;计数器 c ountr y n .国家,国土;农村 court n .法院,法庭;庭院 c over vt.盖,包括 n.盖子 c o nsider v t .认为;考虑;关心c onsid e rab l e a.相当大的;重要的 c onsid e ra t e a.考虑周到的;体谅的 co n s ideratio n n.考虑,思考;体 coach n .长途公共汽车 c o a l n.煤,煤块 c o arse a .粗的,粗糙的 c oast n.海岸,海滨(地区) c ock n.公鸡;雄禽;旋塞 c o i l n.(一)卷;线圈 vt.卷 c o llapse v i .倒坍;崩溃,瓦解 c ollar n .衣领,项圈 c o lle c t vt .收集 v i .收款 colle c ti o n n.搜集,收集;收藏品 co l l ective a .集体的;集合性的 c ollege n .学院;大学 co l l i sion n .碰撞;冲突 co l one l n.陆军上校;中校 co l ony n .殖民地;侨居地 c o l u mn n.柱,支柱,圆柱 comb n.梳子 vt.梳理 combina t i on n.结合,联合;化合 co m bi n e vt.使结合;兼有 co m fort n.舒适;安慰 v t .安慰 comma n d vt.命令,指挥;控制 comma n der n.司令官,指挥员 comm e n t n.评论,意见;注释 com m er c e n.商业,贸易;社交 c o mmer c ial a.商业的;商品化的 comm i s s ion n.委任状;委员会 com m it vt.犯(错误);干(坏事) c o mmittee n .委员会;全体委员 c ommon l y a d .普通地,一般地c omm u nicat e v i .通讯;传达;传播 commun i c ation n.通讯;传达;交通c o mmunism n .Communi s t 主义 comm u ni s t n.C o mmu n istp a rty 员 com m unity n.社区;社会;公社 c ompanio n n.同伴;共事者;伴侣 compan y n.公司,商号;同伴 compa r a t ive a.比较的,相对的c o mpa r e vt .比较,对照;比作 compa r is o n n.比较,对照;比似 com p a ss n.罗盘,指南针;圆规 com p el vt.强迫,迫使屈服贴co m p e tent a .有能力的;应该做的 co m peti t ion n .竞争,比赛 co m pi l e vt.编辑,编制,搜集 co m p lain vi.抱怨,拆苦;控告 c o mpletely a d.十分,完全地 c omplex a.结合的;复杂的 co m plic a te v t .使复杂;使陷入 c om p licate d a .复杂的,难懂的 componen t n.组成部分;分;组件 compo s e vt.组成,构成;创作 com p os i tion n .构成;作品;写作 com p oun d n.化合物;复合词comp r e h ension n .理解,理解力;领悟comprehe n sive a.广泛的;理解的 co m p r ess vt .压紧,压缩 co m pri s e vt .包含,包括;构成 compr o mi s e n.妥协,和解 comput e vt.计算,估计,估算 comrad e n.同志,亲密的同伴 conce a l vt.把…隐藏起来conce n tra t e vt .集中;聚集;浓缩 conce n tr a tion n .集中;专注;浓缩 c o ncept n.概念,观念,设想 c o ncerning p rep.关于 c o n clude v t.推断出;结束 con c lusi o n n.结论,推论;结尾 c o nc r ete n.混凝土;具体物 co n d emn vt.谴责,指责;判刑co n dense vt .压缩,使缩短 c o n d ition n .状况,状态;环境 co n duct n.举止,行为;指导con d uc t or n.售票员;(乐队)指挥 c o nference n.会议,讨论会 c onfess v t .供认,承认;坦白 c onfide n t n .确信的,自信的c onfi n e vt .限制;禁闭 con f li c t n.争论;冲突;斗争 con f u se vt.使混乱,混淆 confu s ion n.混乱;骚乱;混淆 co n g r atulat e v t .祝贺,向…道喜 c ongr e ss n .大会;国会,议会c on j unctio n n .接合,连接;连接词 connec t ion n.连接,联系;连贯性co n q uer vt.征服,战胜;破除 c on q uest n .攻取,征服;克服 con s cie n ce n.良心,道德心con s c i ous a.意识到的;有意的 co n sciousnes s n.意识,觉悟;知觉 conse n t n.同意,赞成 v i .同意 c o nse q uenc e n.结果,后果 conse q ue n tly ad .因此,因而,所以 c o nservati o n n.保存,保护;守恒 conse r v ative a .保守的 n.保守的人 c onsis t vi .由…组成;在于 c o nsi s tent a .坚持的,一贯的 c o n stant a .经常的;永恒的 c o nstitutio n n.章程;体质;构造 const r u c t vt.建造;建设;构筑 c o nst r ucti o n n.建造;建筑;建筑物 c on s ult vt .请教,查阅 con s u me vt.消耗,消费;消灭 con s umption n .消耗量;消耗 c o n tain v t .包含,容纳;等于 co n temp o rary a.当代的,同时代的 c o ntempt n .轻蔑;藐视;受辱 convenie n ce n.便利,方便;厕所cont e n t a.满意的,满足的cont e st vt.争夺,争取;辩驳 co n tine n t n .大陆;陆地;洲 c ontinu a l a.不断的;连续的 continu e vt.继续,连续;延伸 conti n u ous a.连续不断的,持续的 c on t radic t ion n.矛盾,不一致;否认c o ntrar y a .相反的 n.相反 contras t n.对比,对照,悬殊 contrib u te vt.捐献,捐助;投稿 co n v e ntiona l a .普通的;习惯的c o nver s atio n n.会话,非正式会谈 c onvers e l y ad.相反地c onversio n n.转变,转化;改变 conver t vt.使转变;使改变 conve y v t .传送;运送;传播 conv i nce v t.使确信,使信服 co o perate v i .合作,协作;配合 coordin a te vt.使协调,调节cope v i .对付,应付c o p per n.铜;铜币,铜制器 c ord n.细绳,粗线,索 cor d ial a .真诚的,诚恳的 c o r e n.果实的心,核心 corn n .谷物;(英)小麦 c orner n.角;犄角;边远地区 c o rporat i on n.公司,企业;社团 cor r espo n d v i .相符合;相当c orresp o n d ent n.通信者;通讯员 cor r esponding a.相应的;符合的 corrido r n .走廊,回廊,通路 could aux .v.(c a n 的过去式) c o usin n .堂(或表)兄弟(姐妹)council n .理事会,委员会 cottage n .村舍,小屋 co u n tryside n .乡下,农村 c ou n ty n.英国的郡,美国的县 coup l e n .夫妇;(一)对;几个 cour a g e n.勇气,胆量,胆识 cours e n.课程;过程;一道菜 cow n .母牛,奶牛;母兽 c o ward n .懦夫;胆怯者 [K]cut v t.切,割,剪;减少 cup n.杯子;(一)杯;奖杯 cultur e n.文化,文明;教养 custom n .习惯,风俗;海关 custome r n .顾客,主顾 cu b e n.立方形;立方 cub i c a.立方形的;立方的 c u cu m ber n.黄瓜cultiva t e vt.耕;种植;培养 cunnin g a.狡猾的,狡诈的 cupboa r d n.碗柜,碗碟橱;食橱 cur e vt .医治;消除 n.治愈 cu r iosit y n .好奇,好奇心;珍品 curiou s a.好奇的;稀奇古怪的 curl n .卷毛;螺旋 vi .卷曲 curre n t a.当前的;通用的 curse n.诅咒,咒骂;天谴 cu r tai n n.帘,窗帘;幕(布) cu r v e n.曲线;弯 v t.弄弯 cus h ion n.垫子,坐垫,靠垫 [S ]cent n.分;分币;百cer t ainl y ad.一定,必定;当然 c e nt r e (cent e r ) n.中心;中枢 vt.集中ce n tury n.世纪,百年celeb r a te vt.庆祝;歌颂,赞美 c e ll n.细胞;小房间c erem o ny n .典礼,仪式;礼节 c er t ificat e n .证书,证件,执 cease vi .&vi.&n.停止,停息 ceili n g n.天花板,顶蓬 cellar n.地窑,地下室 cem e nt n .水泥;胶泥 vt .粘结 ce n ti g rade a .百分度的 cent i m etre n.公分,厘米 centr a l a.中心的;主要的照 cert a i n a.确实的;肯定的 cert a int y n.必然;肯定 [S]c ity n.城市,都市cigare t te n.香烟,纸烟,卷烟cin e m a n.电影院;电影,影片 ci r cle n.圆,圆周;圈子 cit i zen n .公民;市民,居民 c i r cuit n.电路;环行;巡行 c i rcular a.圆的;循环的 ci r c ulate v t .使循环 vi.循环 c ircum f ere n ce n .圆周,周长,圆周线circ u ms t ance n .情况,条件;境遇 c ivil a.公民的;文职的civ i lization n .文明,文化;开化 civili z e v t.使文明;教育 [S]c ycle n 自行车,循环 [ t ʃ ]China n .中国 china n .瓷器,瓷料 C h i nese a .中国的 n.中国人 ch e ck v t .检查;制止 n .检查 ch o co l ate n.巧克力;巧克力糖 c h i cken n.小鸡,小鸟;鸡肉 ch e ap a.廉价的;劣质的 chee r v t.使振作;欢呼 (cheer s :干杯)che a t vt .骗取;哄 vi.行骗 c h oice n .选择,抉择 cho o s e vt.选择,挑选;情愿 chai r man n.主席;议长,会长cha l l e nge n.挑战;要求,需要 c ham p ion n .冠军,得胜者 c hance n.机会,机遇;可能性 change n .改变,变化;零钱 charity n .施舍;慈善事业 c h art n.图,图表;海图 ch e qu e n.支票chi l d n.小孩,儿童;儿子 c hief a .主要的;首席的 c h a in n.链,链条,项圈 char m ing a.迷人的,可爱的chair n .椅子;主席c h a lk n.白垩;粉笔cham b er n .会议室;房间;腔 cha n nel n .海峡;渠道;频道 c h a pter n.章,回,篇 char g e vt.索价;控告 n.费用 ch a s e n.追逐,追赶,追求 che e k n .面颊,脸蛋 ch e erfu l a.快乐的,愉快的 che e se n.乳酪,干酪 c herry n .樱桃;樱桃树 ch e ss n.棋;国际象棋 chest n .胸腔,胸膛;箱子 c hew vt .咀嚼,嚼碎ch i ldh o od n .童年,幼年;早期 childi s h a.孩子的;幼稚的 chill v t .使变冷 n.寒冷chimney n .烟囱,烟筒;玻璃罩 chin n .颏,下巴 cho k e v t .使窒息;塞满 c h op v t.砍,劈;切细v i.砍 ch u r c h n.教堂,礼拜堂;教会[K] Christ m as n.圣诞节 C hristia n n .基督教徒;信徒 c harac t er n .性格;特性;角色 cha r acter i st i c a.特有的 n .特性 che m i cal a.化学的 n.化学制品 c h emist n.化学家;药剂师 c h e m istry n .化学[ʃ]c h ef n .厨师长;大师傅 C hicag o n .芝加哥 [K ]cl u b n.俱乐部,夜总会 c l ass n .班,班级;阶级 c l e a n a.清洁的;纯洁的 clock n.钟,仪表 cl o se vt.关,闭;结束 clot h e s n.衣服,服装;被褥 cle v er a .聪明的;机敏的 c lou d n.云;云状物;阴影 clo u d y a.多云的;云一般的 cloth i ng n.衣服,被褥claim v t .声称,主张;索取 c lassic a l a .古典的;经典的 c lear a.清晰的 vt .清除 cl e ar l y ad.明白地,清晰地 cle r k n.店员;办事员,职员clap v i .拍手 vt.拍,轻拍 clari f y vt.澄清,阐明 c lasp n .扣子,钩子;别针cl a ssi f icati o n n .分类;分级;分类法 class i f y vt.把…分类 classmat e n.同班同学c l assroom n .教室,课堂 c la w n.爪,脚爪,螯 clay n.粘土,泥土;肉体cl i ff n.悬崖,峭壁c limate n .气候;风土,地带 climb vi.攀登,爬 vt.爬 c loak n.斗篷;覆盖(物) c lo s ely a d .紧密地,接近地 clot h n.布;衣料;桌布 c l othe v t .给…穿衣服 cl u e n.线索,暗示,提示 clumsy a.笨拙的;愚笨的 [K]c r y v i.哭,哭泣;叫喊 crea m n.奶油,乳脂;奶油色 c r az y a.疯狂的,荒唐的 credi t n.信用贷款;信用 create v t .创造;引起,产生 crisis n .危机;存亡之际 cr i me n.罪,罪行;犯罪 c r oss v t.穿过;使交叉 c ry s tal n.水晶,结晶体;晶粒c r i tic n.批评家,爱挑剔的人 cr i tical a.决定性的;批评的 c r i ticism n.批评;批判;评论 c r ack n .裂缝,裂纹 v i .爆裂c r af t n.工艺;手艺,行业 cran e n.起重机,摄影升降机 无效 vi.碰撞,坠落 n.碰撞crawl v i .爬,爬行cre a ti v e a.创造性的,创作的c r eatu r e n .生物,动物,家畜 creep v i .爬行;缓慢地行进crew n.全体船员 cricke t n.板球;蟋蟀c riminal n .犯人,罪犯,刑事犯 cripp l e n .跛子;残废的人 c r iti c ize v t .批评;评论;非难 c r op n.农作物,庄稼;一熟 cr o w n.鸦,乌鸦 v i.啼 crow d n.群;大众;一伙人 crown n.王冠,冕;花冠cr u de a .简陋的;天然的c ruel a .残忍的,残酷的 c r u sh vt.压碎,碾碎;镇压 cr u st n.面包皮;硬外皮 字母y是一个非常特殊的字母。

c开头的与工程师相关的单词1. Civil Engineer(土木工程师)- 单词释义:从事与土木工程相关工作的专业人员,如设计、建造和维护道路、桥梁、建筑物等基础设施。
- 单词用法:可作主语,如“A civil engineer is responsible for the construction of this bridge.”;也可作宾语,“We need a civil engineer to help with the project.”- 近义词:Structural engineer(结构工程师,更侧重于结构设计方面)。
- 短语搭配:civil engineer in charge(主管土木工程师)。
- 双语例句:- “I want to be a civil engineer. Building those huge skyscrapers must be so cool! It's like creating something out of nothing, right?”- “My friend is a civil engineer. He says that whe n he sees a building he designed standing tall, he feels like a superhero. ‘Who else can make such a massive thing?’ he often brags.”- “A civil engineer once told me, ‘This road I'm building is like a lifeline for the village. Without it, they're cut off from the world.’”- “If you meet a civil engineer, ask him about his most challenging project. I bet he'll have an amazing story to tell. For example, one civil engineer I knew was so proud of the bridge he built over a deep gorge. ‘It was like taming a wi ld beast,’ he said.”- “Civil engineers don't just build things; they shape the world welive in. Think about it, without them, where would we be? Living in mudhuts maybe?”- “The civil engineer was so excited when his new design for the subway system got approved. ‘This is going to change the way people travel in the city!’ he shouted.”- “When the earthquake hit, the civil engineer rushed to check on the buildings he had designed. ‘I hope my babies are okay,’ he muttered nervously.”- “I asked a civil en gineer how he learned all that math and physics. He laughed and said, ‘It's like learning a secret language to talk to the buildings.’”- “Civil engineers have to deal with a lot of problems. One time, acivil engineer faced a situation where the ground was too soft for building. ‘It was like trying to build on quicksand,’ he groaned.”- “A civil engineer's job isn't easy. They have to consider so many factors. Just like a chef who has to balance flavors, a civil engineer hasto balance safety, cost, and fu nctionality.”2. Computer Engineer(计算机工程师)- 单词释义:主要负责计算机硬件、软件系统的研发、设计、测试等工作的专业人士。

词汇表(C-D ): cabbage n.洋白菜,卷心菜 cabin n.小屋;船舱,机舱 cabinet n.橱,柜;内阁 cable n.缆,索;电缆;电报 cafe n.咖啡馆;小餐厅 cafeteria n.自助食堂 cage n.笼;鸟笼,囚笼 cake n.饼,糕,蛋糕 calculate vt.计算;估计;计划 calculation n.计算,计算结果 calculator n.计算器,计算者 calendar n.日历,历书;历法 call vt.把…叫做;叫,喊 calm a.静的,平静的 camel n.骆驼camera n.照相机,摄影机camp n.野营,营地,兵营campaign n.战役;运动 campus n.校园,学校场地 can aux.v.能,会,可能 can n.罐头,听头;容器 Canada n.加拿大Canadian a.加拿大的 canal n.运河;沟渠;管 cancel vt.取消,撤消;删去cancer n.癌,癌症,肿瘤candidate n.候选人;投考者candle n.蜡烛;烛形物;烛光candy n.糖果;砂糖结晶cannon n.大炮,火炮;榴弹炮canoe n.独木舟,皮艇,划子canteen n.小卖部;临时餐室canvas n.粗帆布;一块油画布cap n.帽子,便帽;帽状物 capable a.有能力的,有才能的capacity n.容量;能力;能量 capital n.资本,资金;首都 captain n.陆军上尉;队长 captive n.俘虏,被监禁的人 capture vt.捕获,俘获;夺得 car n.汽车,小汽车,轿车carbon n.碳 card n.卡,卡片,名片 care vi.关心,介意 n.小心 career n.生涯,职业,经历 careful a.仔细的;细致的 careless a.粗心的,漫不经心的 cargo n.船货,货物 carpenter n.木工,木匠 carpet n.地毯,毡毯,毛毯 carriage n.客车厢;四轮马车carrier n.运输工具;运载工具 carrot n.胡罗卜carry vt.携带;运载;传送 cart n.二轮运货马车 carve vt.刻,雕刻;切开case n.情况;事实;病例case n.箱(子),盒(子),套 cash n.现金,现款cassette n.盒式录音带;盒子 cast vt.投,扔,抛;浇铸castle n.城堡;巨大建筑物casual a.偶然的;随便的cat n.猫,猫科,猫皮 catalog n.目录,目录册catch vt.捉住;赶上;领会 cathedral n.总教堂;大教堂 cattle n.牛;牲口,家畜cause n.原因,理由;事业cave n.山洞,洞穴,窑洞cease vi.&vi.&n.停止,停息 ceiling n.天花板,顶蓬 celebrate vt.庆祝;歌颂,赞美cell n.细胞;小房间 cellar n.地窑,地下室cement n.水泥;胶泥 vt.粘结cent n.分;分币;百 centigrade a.百分度的 centimetre n.公分,厘米 central a.中心的;主要的 centre n.中心;中枢 vt.集中 century n.世纪,百年 ceremony n.典礼,仪式;礼节 certain a.确实的;肯定的 certainly ad.一定,必定;当然 certainty n.必然;肯定 certificate n.证书,证件,执照 chain n.链,链条,项圈chair n.椅子;主席 chairman n.主席;议长,会长chalk n.白垩;粉笔 challenge n.挑战;要求,需要 chamber n.会议室;房间;腔 champion n.冠军,得胜者 chance n.机会,机遇;可能性change n.改变,变化;零钱channel n.海峡;渠道;频道chapter n.章,回,篇 character n.性格;特性;角色characteristic a.特有的 n.特性charge vt.索价;控告 n.费用 charity n.施舍;慈善事业 charming a.迷人的,可爱的chart n.图,图表;海图 chase n.追逐,追赶,追求cheap a.廉价的;劣质的cheat vt.骗取;哄 vi.行骗 check vt.检查;制止 n.检查 cheek n.面颊,脸蛋cheer vt.使振作;欢呼 cheerful a.快乐的,愉快的cheese n.乳酪,干酪 chemical a.化学的 n.化学制品 chemist n.化学家;药剂师chemistry n.化学cheque n.支票 cherry n.樱桃;樱桃树 chess n.棋;国际象棋 chest n.胸腔,胸膛;箱子 chew vt.咀嚼,嚼碎 chicken n.小鸡,小鸟;鸡肉 chief a.主要的;首席的 child n.小孩,儿童;儿子 childhood n.童年,幼年;早期 childish a.孩子的;幼稚的 chill vt.使变冷 n.寒冷 chimney n.烟囱,烟筒;玻璃罩chin n.颏,下巴China n.中国china n.瓷器,瓷料 Chinese a.中国的 n.中国人 chocolate n.巧克力;巧克力糖 choice n.选择,抉择 choke vt.使窒息;塞满 choose vt.选择,挑选;情愿chop vt.砍,劈;切细vi.砍Christian n.基督教徒;信徒 Christmas n.圣诞节 church n.教堂,礼拜堂;教会cigarette n.香烟,纸烟,卷烟cinema n.电影院;电影,影片 circle n.圆,圆周;圈子 circuit n.电路;环行;巡行 circular a.圆的;循环的 circulate vt.使循环 vi.循环circumference n.圆周,周长,圆周线 circumstance n.情况,条件;境遇citizen n.公民;市民,居民city n.城市,都市 civil a.公民的;文职的 civilization n.文明,文化;开化civilize vt.使文明;教育 claim vt.声称,主张;索取 clap vi.拍手 vt.拍,轻拍 clarify vt.澄清,阐明 clasp n.扣子,钩子;别针class n.班,班级;阶级classical a.古典的;经典的 classification n.分类;分级;分类法 classify vt.把…分类 classmate n.同班同学 classroom n.教室,课堂 claw n.爪,脚爪,螯 clay n.粘土,泥土;肉体 clean a.清洁的;纯洁的 clear a.清晰的 vt.清除 clearly ad.明白地,清晰地 clerk n.店员;办事员,职员 clever a.聪明的;机敏的cliff n.悬崖,峭壁 climate n.气候;风土,地带 climb vi.攀登,爬 vt.爬 cloak n.斗篷;覆盖(物) clock n.钟,仪表 close vt.关,闭;结束 closely ad.紧密地,接近地cloth n.布;衣料;桌布 clothe vt.给…穿衣服 clothes n.衣服,服装;被褥 clothing n.衣服,被褥 cloud n.云;云状物;阴影cloudy a.多云的;云一般的club n.俱乐部,夜总会 clue n.线索,暗示,提示 clumsy a.笨拙的;愚笨的coach n.长途公共汽车 coal n.煤,煤块 coarse a.粗的,粗糙的 coast n.海岸,海滨(地区)coat n.外套,上衣;表皮cock n.公鸡;雄禽;旋塞code n.准则;法典;代码coffee n.咖啡,咖啡茶 coil n.(一)卷;线圈 vt.卷coin n.硬币;铸造(硬币) cold a.冷的;冷淡的 n.冷 collapse vi.倒坍;崩溃,瓦解collar n.衣领,项圈 colleague n.同事,同僚 collect vt.收集 vi.收款 collection n.搜集,收集;收藏品 collective a.集体的;集合性的 college n.学院;大学 collision n.碰撞;冲突 colonel n.陆军上校;中校 colony n.殖民地;侨居地 color n.颜色,彩色;颜料 column n.柱,支柱,圆柱 comb n.梳子 vt.梳理 combination n.结合,联合;化合 combine vt.使结合;兼有 come vi.来,来到;出现 comfort n.舒适;安慰 vt.安慰comfortable a.舒适的,安慰的command vt.命令,指挥;控制commander n.司令官,指挥员comment n.评论,意见;注释commerce n.商业,贸易;社交commercial a.商业的;商品化的commission n.委任状;委员会commit vt.犯(错误);干(坏事) committee n.委员会;全体委员 common a.普通的;共同的commonly ad.普通地,一般地 communicate vi.通讯;传达;传播 communication n.通讯;传达;交通 communismmunist 主义 communistmunistparty 员 community n.社区;社会;公社 companion n.同伴;共事者;伴侣 company n.公司,商号;同伴 comparative a.比较的,相对的compare vt.比较,对照;比作comparison n.比较,对照;比似compass n.罗盘,指南针;圆规 compel vt.强迫,迫使屈服 compete vi.比赛;竞争;对抗 competent a.有能力的;应该做的 competition n.竞争,比赛 compile vt.编辑,编制,搜集 complain vi.抱怨,拆苦;控告 complaint n.抱怨;怨言;控告 complete a.完整的;完成的 completely ad.十分,完全地 complex a.结合的;复杂的 complicate vt.使复杂;使陷入 complicated a.复杂的,难懂的 component n.组成部分;分;组件 compose vt.组成,构成;创作 composition n.构成;作品;写作 compound n.化合物;复合词 comprehension n.理解,理解力;领悟 comprehensive a.广泛的;理解的 compress vt.压紧,压缩 comprise vt.包含,包括;构成 compromise n.妥协,和解compute vt.计算,估计,估算computer n.计算机,电脑comrade n.同志,亲密的同伴conceal vt.把…隐藏起来concentrate vt.集中;聚集;浓缩concentration n.集中;专注;浓缩concept n.概念,观念,设想concern n.关心,挂念;关系concerning prep.关于 concert n.音乐会,演奏会conclude vt.推断出;结束conclusion n.结论,推论;结尾 concrete n.混凝土;具体物 condemn vt.谴责,指责;判刑 condense vt.压缩,使缩短 condition n.状况,状态;环境 conduct n.举止,行为;指导 conductor n.售票员;(乐队)指挥 conference n.会议,讨论会 confess vt.供认,承认;坦白 confidence n.信任;信赖;信心 confident n.确信的,自信的 confine vt.限制;禁闭 confirm vt.证实,肯定;批准conflict n.争论;冲突;斗争confuse vt.使混乱,混淆confusion n.混乱;骚乱;混淆congratulate vt.祝贺,向…道喜congratulation n.祝贺;祝贺词congress n.大会;国会,议会conjunction n.接合,连接;连接词connect vt.连接,连结;联系connection n.连接,联系;连贯性conquer vt.征服,战胜;破除conquest n.攻取,征服;克服 conscience n.良心,道德心 conscious a.意识到的;有意的 consciousness n.意识,觉悟;知觉 consent n.同意,赞成vi.同意 consequence n.结果,后果 consequently ad.因此,因而,所以 conservation n.保存,保护;守恒 conservative a.保守的 n.保守的人 consider vt.认为;考虑;关心 considerable a.相当大的;重要的considerate a.考虑周到的;体谅的 consideration n.考虑,思考;体贴 consist vi.由…组成;在于 consistent a.坚持的,一贯的 constant a.经常的;永恒的 constitution n.章程;体质;构造 construct vt.建造;建设;构筑 construction n.建造;建筑;建筑物 consult vt.请教,查阅 consume vt.消耗,消费;消灭 consumption n.消耗量;消耗 contact vt.使接触;与…联系contain vt.包含,容纳;等于container n.容器;集装箱contemporary a.当代的,同时代的contempt n.轻蔑;藐视;受辱content n.内容,目录;容量content a.满意的,满足的contest vt.争夺,争取;辩驳continent n.大陆;陆地;洲continual a.不断的;连续的 continue vt.继续,连续;延伸 continuous a.连续不断的,持续的 contract n.契约,合同;婚约 contradiction n.矛盾,不一致;否认 contrary a.相反的 n.相反 contrast n.对比,对照,悬殊 contribute vt.捐献,捐助;投稿 control vt.控制,克制n.控制 convenience n.便利,方便;厕所 convenient a.便利的;近便的 convention n.习俗,惯例;公约conventional a.普通的;习惯的conversation n.会话,非正式会谈 conversely ad.相反地 conversion n.转变,转化;改变 convert vt.使转变;使改变 convey vt.传送;运送;传播 convince vt.使确信,使信服 cook vt.烹调,煮 vt.烧菜 cool a.凉的,冷静的 cooperate vi.合作,协作;配合 coordinate vt.使协调,调节cope vi.对付,应付 copper n.铜;铜币,铜制器 copy n.抄件 vt.抄写,复制 cord n.细绳,粗线,索 cordial a.真诚的,诚恳的core n.果实的心,核心 corn n.谷物;(英)小麦 corner n.角;犄角;边远地区corporation n.公司,企业;社团correct a.正确的 vt.纠正correction n.改正,纠正,修改correspond vi.相符合;相当 correspondent n.通信者;通讯员 corresponding a.相应的;符合的corridor n.走廊,回廊,通路cost n.价格,代价;成本costly a.昂贵的;价值高的 cottage n.村舍,小屋 cotton n.棉;棉线;棉布cough vi.咳,咳嗽 n.咳嗽could aux.v.(can 的过去式)council n.理事会,委员会count vt.计算 vi.数,计数counter n.柜台;计数器country n.国家,国土;农村countryside n.乡下,农村county n.英国的郡,美国的县couple n.夫妇;(一)对;几个 courage n.勇气,胆量,胆识 course n.课程;过程;一道菜 court n.法院,法庭;庭院 cousin n.堂(或表)兄弟(姐妹) cover vt.盖,包括 n.盖子 cow n.母牛,奶牛;母兽 coward n.懦夫;胆怯者 crack n.裂缝,裂纹 vi.爆裂 craft n.工艺;手艺,行业 crane n.起重机,摄影升降机 无效 vi.碰撞,坠落 n.碰撞crawl vi.爬,爬行 crazy a.疯狂的,荒唐的 cream n.奶油,乳脂;奶油色create vt.创造;引起,产生creative a.创造性的,创作的creature n.生物,动物,家畜credit n.信用贷款;信用creep vi.爬行;缓慢地行进 crew n.全体船员cricket n.板球;蟋蟀 crime n.罪,罪行;犯罪 criminal n.犯人,罪犯,刑事犯 cripple n.跛子;残废的人 crisis n.危机;存亡之际 critic n.批评家,爱挑剔的人critical a.决定性的;批评的criticism n.批评;批判;评论criticize vt.批评;评论;非难crop n.农作物,庄稼;一熟cross vt.穿过;使交叉 crow n.鸦,乌鸦 vi.啼crowd n.群;大众;一伙人 crown n.王冠,冕;花冠crude a.简陋的;天然的cruel a.残忍的,残酷的 crush vt.压碎,碾碎;镇压 crust n.面包皮;硬外皮 cry vi.哭,哭泣;叫喊 crystal n.水晶,结晶体;晶粒 cube n.立方形;立方 cubic a.立方形的;立方的cucumber n.黄瓜 cultivate vt.耕;种植;培养 culture n.文化,文明;教养 cunning a.狡猾的,狡诈的 cup n.杯子;(一)杯;奖杯 cupboard n.碗柜,碗碟橱;食橱 cure vt.医治;消除 n.治愈curiosity n.好奇,好奇心;珍品curious a.好奇的;稀奇古怪的curl n.卷毛;螺旋 vi.卷曲current a.当前的;通用的curse n.诅咒,咒骂;天谴curtain n.帘,窗帘;幕(布) curve n.曲线;弯 vt.弄弯cushion n.垫子,坐垫,靠垫custom n.习惯,风俗;海关customer n.顾客,主顾 cut vt.切,割,剪;减少 cycle n 自行车,循环。

C语⾔爱⼼代码⼤全(2022表⽩神器)⼀、C语⾔爱⼼代码1、love图案的C语⾔爱⼼代码C语⾔爱⼼源代码如下:#include <stdio.h>int main(){int i, j, k, n = 0, x = 0, y = 50;//爱⼼的头部没有规律,所以直接打印printf("\n\n\n\n\n");printf(" lovelove lovelove\n");printf(" lovelovelove lovelovelove\n");printf(" lovelovelovelove lovelovelovelove\n");printf(" lovelovelovelovelove lovelovelovelovelove\n");printf(" lovelovelovelovelovelo lovelovelovelovelovelo\n");printf(" lovelovelovelovelovelove lovelovelovelovelovelov\n");for (i = 0; i < 2; i++){printf("lovelovelovelovelovelovelovelovelovelovelovelovelove\n");}for(i=0;i<5;i++) //爱⼼的中间部分的上部分{y = 50;y = y - i*2;n++;for (k = 0; k < n; k++) //在每⼀⾏的起始位置先打印空格{printf(" ");}while(1) //空格后⾯打印love,但是要注意love即使没打印完,也要换⾏{if (x < y){printf("l");y--;}elsebreak;if (x < y){printf("o");y--;}elsebreak; if (x < y){printf("v");y--;}elsebreak; if (x < y){printf("e");y--;}elsebreak;}printf("\n");}//最下⾯的部分,具体内容同上,没和上⼀部分放⼀起是因为从这⾏开始多两个空格for (i = 0,n=3; i < 10; i++){y = 37;y = y - i * 4;n++;for (k = 0; k < n; k++){printf(" ");}while (1){if (x < y){printf("l");y--;}elsebreak;if (x < y){printf("o");y--;}elsebreak; if (x < y){printf("v");y--;}elsebreak; if (x < y){printf("e");y--;}elsebreak;}printf("\n");}printf("\n\n\n\n\n\n\n\n\n\n\n\n");return 0;}已把⼤量C语⾔源码整理为⼀个压缩包关注微信公众号:“C和C加加” 回复:“源码” 即可获取2、⼼形图案的C语⾔爱⼼代码C语⾔爱⼼代码如下:#include <stdio.h>int main(){int i, j, k, l, m;char c=3; //ASCII码⾥⾯ 3 就是⼀个字符⼩爱⼼for (i=1; i<=5; i++) printf("\n"); //开头空出5⾏for (i=1; i<=3; i++) { //前3⾏中间有空隙分开来写for (j=1; j<=32-2*i; j++) printf(" "); //左边的空格,每下⼀⾏左边的空格⽐上⼀⾏少2个 //8*n-2*ifor (k=1; k<=4*i+1; k++) printf("%c", c);//输出左半部分字符⼩爱⼼for (l=1; l<=13-4*i; l++) printf(" "); //中间的空格,每下⼀⾏的空格⽐上⼀⾏少4个for (m=1; m<=4*i+1; m++) printf("%c", c);//输出右半部分字符⼩爱⼼printf("\n"); //每⼀⾏输出完毕换⾏}for (i=1; i<=3; i++) { //下3⾏中间没有空格for (j=1; j<=24+1; j++) printf(" "); //左边的空格 //8*(n-1)+1for (k=1; k<=29; k++) printf("%c", c);//输出字符⼩爱⼼printf("\n"); //每⼀⾏输出完毕换⾏}for (i=7; i>=1; i--) { //下7⾏for (j=1; j<=40-2*i; j++) printf(" "); //左边的空格,每下⼀⾏左边的空格⽐上⼀⾏少2个//8*(n+1)-2*i for (k=1; k<=4*i-1; k++) printf("%c", c);//每下⼀⾏的字符⼩爱⼼⽐上⼀⾏少4个(这个循环是i--)printf("\n"); //每⼀⾏输出完毕换⾏}for (i=1; i<=39; i++) printf(" "); //最后⼀⾏左边的空格printf("%c\n", c); //最后⼀个字符⼩爱⼼for (i=1; i<=5; i++) printf("\n"); //最后空出5⾏return 0;}效果图展⽰:3、复杂动态C语⾔爱⼼代码C语⾔爱⼼代码:#include <stdio.h>#include <math.h>#include <windows.h>#include <tchar.h>float f(float x, float y, float z) {float a = x * x + 9.0f / 4.0f * y * y + z * z - 1;return a * a * a - x * x * z * z * z - 9.0f / 80.0f * y * y * z * z * z;}float h(float x, float z) {for (float y = 1.0f; y >= 0.0f; y -= 0.001f)if (f(x, y, z) <= 0.0f)return y;return 0.0f;}int main() {HANDLE o = GetStdHandle(STD_OUTPUT_HANDLE); _TCHAR buffer[25][80] = { _T(' ') };_TCHAR ramp[] = _T(".:-=+*#%@");for (float t = 0.0f;; t += 0.1f) {int sy = 0;float s = sinf(t);float a = s * s * s * s * 0.2f;for (float z = 1.3f; z > -1.2f; z -= 0.1f) {_TCHAR* p = &buffer[sy++][0];float tz = z * (1.2f - a);for (float x = -1.5f; x < 1.5f; x += 0.05f) {float tx = x * (1.2f + a);float v = f(tx, 0.0f, tz);if (v <= 0.0f) {float y0 = h(tx, tz);float ny = 0.01f;float nx = h(tx + ny, tz) - y0;float nz = h(tx, tz + ny) - y0;float nd = 1.0f / sqrtf(nx * nx + ny * ny + nz * nz); float d = (nx + ny - nz) * nd * 0.5f + 0.5f;*p++ = ramp[(int)(d * 5.0f)];}else*p++ = ' ';}}for (sy = 0; sy < 25; sy++) {COORD coord = { 0, sy };SetConsoleCursorPosition(o, coord);WriteConsole(o, buffer[sy], 79, NULL, 0);}Sleep(33);}}效果如下:。
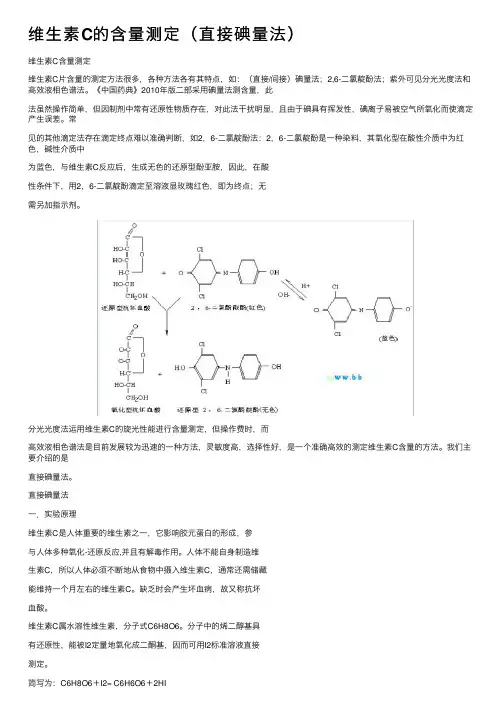
维⽣素C的含量测定(直接碘量法)维⽣素C含量测定维⽣素C⽚含量的测定⽅法很多,各种⽅法各有其特点,如:(直接/间接)碘量法;2,6-⼆氯靛酚法;紫外可见分光光度法和⾼效液相⾊谱法。
《中国药典》2010年版⼆部采⽤碘量法测含量,此法虽然操作简单,但因制剂中常有还原性物质存在,对此法⼲扰明显,且由于碘具有挥发性,碘离⼦易被空⽓所氧化⽽使滴定产⽣误差。
常见的其他滴定法存在滴定终点难以准确判断,如2,6-⼆氯靛酚法:2,6-⼆氯靛酚是⼀种染料,其氧化型在酸性介质中为红⾊,碱性介质中为蓝⾊,与维⽣素C反应后,⽣成⽆⾊的还原型酚亚胺,因此,在酸性条件下,⽤2,6-⼆氯靛酚滴定⾄溶液显玫瑰红⾊,即为终点;⽆需另加指⽰剂。
分光光度法运⽤维⽣素C的旋光性能进⾏含量测定,但操作费时,⽽⾼效液相⾊谱法是⽬前发展较为迅速的⼀种⽅法,灵敏度⾼,选择性好,是⼀个准确⾼效的测定维⽣素C含量的⽅法。
我们主要介绍的是直接碘量法。
直接碘量法⼀.实验原理维⽣素C是⼈体重要的维⽣素之⼀,它影响胶元蛋⽩的形成,参与⼈体多种氧化-还原反应,并且有解毒作⽤。
⼈体不能⾃⾝制造维⽣素C,所以⼈体必须不断地从⾷物中摄⼊维⽣素C,通常还需储藏能维持⼀个⽉左右的维⽣素C。
缺乏时会产⽣坏⾎病,故⼜称抗坏⾎酸。
维⽣素C属⽔溶性维⽣素,分⼦式C6H8O6。
分⼦中的烯⼆醇基具有还原性,能被I2定量地氧化成⼆酮基,因⽽可⽤I2标准溶液直接测定。
简写为:C6H8O6+I2= C6H6O6+2HI使⽤淀粉作为指⽰剂,⽤直接碘量法可测定药⽚、注射液、饮料、蔬菜、⽔果中维⽣素C的含量。
由于维⽣素C的还原性很强,较容易被溶液和空⽓中的氧氧化,在碱性介质中这种氧化作⽤更强,因此滴定宜在酸性介质中进⾏,以减少副反应的发⽣。
考虑到I - 在强酸性中也易被氧化,故⼀般选在pH为3~4的弱酸性溶液中进⾏滴定。
由于碘具有挥发性,碘离⼦易被空⽓所氧化⽽使滴定产⽣误差;⼜由于碘的挥发性和腐蚀性,使碘标准滴定溶液的配制及标定⽐较⿇烦。

化学c是什么意思
C在化学中有两种含义:1、表示浓度,单位为mol/L,计算式为:C=n/V.C=1000ρω/M。
2、表示碳元素。
碳是一种非金属元素,位于元素周期表的第二周期IVA族。
是一种很常见的元素,它以多种形式广泛存在于大气和地壳和生物之中。
1、表示浓度,单位为mol/L,计算式为:
C=n/V.C=1000ρω/M。
含义:用1升溶液中所含溶质的摩尔数表示的浓度。
用单位体积内溶质的量(摩尔数)表示的溶液组成的物理量称为溶质的摩尔浓度,也称为溶质的量浓度。
溶质含量越多,浓度越大。
浓度可以通过一定溶液中溶质的克数、分子数或当量数来计算。
一般用单位溶液中所含溶质的重量百分比来表示。
2、表示碳元素。
碳是一种非金属元素,位于元素周期表的第二周期IVA族。
拉丁语为Carbonium,意为“煤,木炭”。
碳是一种很常见的元素,它以多种形式广泛存在于大气和地壳和生物之中。
碳单质很早就被人认识和利用,碳的一系列化合物——有机物更是生命的根本。
碳是生铁、熟铁和钢的成分之一。
碳能在化学上自我结合而形成大量化合物,在生物上和商业上是重要的分子。
生物体内绝大多数分子都含有碳元素。

C开头的单词cab出租车cabbage卷心菜cabin客舱cabinet内阁cable电报cafe咖啡馆cafeteria自助食堂cage鸟笼cake糕calcium钙calculate计算calendar日历call叫calm平静calorie卡路里camel骆驼camera照相机camp野营campaign战役campus校园can能canal运河cancel取消cancer癌candidate候选人candle蜡烛candy糖cannon大炮canoe独木舟canteen餐厅canvas画布cap便帽capable有能力的capacity容量capitalism资本主义capsule胶囊captain首领captive俘虏capture捕获car车carbohydrate碳水化合物carbon碳card卡片cardinal红衣主教care小心career事业careful小心的caress爱抚cargo货carpenter木工carpet地毯carriage马车carrier搬运人carrot萝卜carry运送cart马车cartoon漫画carve刻case箱cash现金cashier收银员cassette盒子cast投castle城堡casual偶然的casualty伤员cat猫catalog目录catastrophe大灾难catch捕捉cathedral大教堂Catholic天主教的cattle牛cause原因caution警告cautious小心cave洞cease停止ceiling天花板celebrate庆祝celebrity名人cell细胞cellar地下室cement水泥cemetery坟census人口普查cent分centigrade摄氏温度计centimetre厘米central中心的centre中心century世纪cereal谷物ceremony典礼certain某certainly一定certainty必然certificate证书certify证明chain链chair椅chairman主席chalk粉笔challenge挑战chamber房间champagne香槟酒chancellor大臣change改变channel海峡chaos混乱chap发痛chapter章character性格characteristic特有的characterize描述…特性charcoal炭charge索charity慈善charm魅力chart图表charter租船chase追逐chat聊cheap便宜的cheat骗cheek脸cheer振奋cheese乳酪chef厨师chemical化学品chemist化学家chemistry化学cheque支票cherish爱护cherry樱桃chess棋chest胸腔chew咀嚼chicken鸡chief首领child孩childhood幼年chimney烟囱chin下巴china瓷chip切屑chocolate巧克力choice选择choke窒息choose选择chop砍chorus合唱Christ基督Christian基督教徒Christmas圣诞节chronic慢性的church教堂cigar雪茄烟cigaret香烟cinema影院circle圆circuit环行circular圆的circulate循环circumference圆周circus马戏团cite引用citizen公民city城civil公民的civilian平民civilization文明civilize使文明claim要求clap拍手clarify清楚clash碰撞clasp扣class班级classical经典的classification分级classify分类classmate同班同学classroom教室clause条款claw爪clay粘土clean清洁的clear清晰的clergy牧师clerk职员clever聪明的click滴答声client委托人cliff悬崖climate气候climax顶点climb攀cling粘clinic诊所clip剪cloak斗蓬clock钟clockwise顺时针clone克隆close关closet橱cloth布clothe穿衣clothes衣服clothing服装cloud云cloudy多云club俱乐部clue线索clumsy笨拙的clutch抓coach教练coal煤coalition同盟coarse粗糙的coast海滨coat上衣cocaine可卡因cock公鸡code代码coffee咖啡cognitive认知的coherent一致的cohesive粘性的coil卷coin硬币coincide巧合coincidence符合coke焦炭cold冷collaborate协作collapse倒collar衣领colleague同事collect收集collection收藏collective集体college学院collide互撞collision碰撞colonel上校colonial殖民地的colony殖民地color颜色column圆柱comb梳子combat战斗combine联合come来comedy喜剧comfort舒适comfortable舒适的comic喜剧的command命令commemorate纪念commence开始commend称赞comment注释commerce商业commercial商业的commission委员会commit提交committee全体委员commodity日用品common普通的commonplace平庸的东西commonwealth联邦communicate传达communication通讯communism共产主义community社区commute乘车compact压缩companion伴侣company公司comparable可比较的comparative比较的compare比较comparison比拟compartment隔层compass罗盘compassion同情compatible兼容的compel强迫compensation赔偿compete比赛competent有能力的competition竞争competitive竞争的compile编辑complain抱怨;申诉complaint诉苦complement补充complete完成complex复杂的complicate使..难懂complicated麻烦的complication复杂compliment问候comply遵照component成分compose组成composite复合材料composition作品compound混合comprehend理解comprehension理解力comprehensive综合的compress压紧comprise包含compromise妥协compulsory必修的compute计算computer计算机comrade同志conceal隐藏concede承认conceive设想concentrate集中concentration专心concept概念concerning关于concert音乐会concession让步concise简明的conclude结束conclusion结论concrete具体的condemn谴责condense浓缩condition条件conduct行为conductor管理者confer商讨conference会议confess供认confidence信任confident确信的confidential秘密的confine限制confirm确认conflict战斗conform遵守confront面对confuse混淆confusion困惑congratulate祝贺congratulation祝贺词congress大会conjunction接合connect连接connection联系conquer征服conquest征服地conscience良心conscientious认真的conscious自觉的consecutive连续的consequence结果consequently因此conservation保存conservative保守的consider考虑considerable可观的considerate考虑周到consideration考虑consist在于consistent一致console控制台consolidate使加固conspicuous显眼的conspiracy阴谋constant固定的constituent选民constitute组成constitution构成constrain限制construct建设construction建造consult请教consultant顾问consume消耗consumption消费contact接触contain包含container容器containment控制contaminate弄污contemplates盘算contemporary现代的contempt轻视contend竞争content容量contest竞争continual不断的continue继续continuous连续的contract合同contradict反驳contradiction反驳contrary相反的contrast对比contribute贡献contribution贡献contrive谋划control控制controversial争议controversy争论convenience方便convenient方便的convention惯例conventional惯例的conversation会话conversely相反地conversion转换convert变换convey运送convict囚犯conviction深信convince使信服cook烹调cool凉的cooperate合作cooperative合作的coordinate坐标cop警察cope处理copper铜copy抄本copyright版权cordial诚恳的core核corn谷corner角corona皇冠corporation法人correct正确的correlate相互关联的事物correspond一致correspondence通信correspondent记者corresponding符合的corridor走廊corrode腐蚀corrupt贿赂cosmic宇宙的cost成本costly昂贵的costume服饰cosy舒适的cottage村舍cotton棉花couch长沙发cough咳嗽could行council理事会counsel劝告count数counter柜台counterpart对应的人country国countryside村county县couple夫妇coupon票证courage勇气course课程courtesy有礼貌courtyard院cousin堂兄cover覆盖cow母牛coward懦夫crab螃蟹crack缝隙cradle摇篮craft手艺crane起重机crash撞车crawl爬crazy疯狂cream奶油create创creative创造性creature生物credential凭证credit信用creep蹑手蹑脚crew全体船员cricket板球crime罪行criminal罪犯cripple跛子crisis危机crisp脆的criterion标准critic批评家critical批评的criticism指责criticize批评crop庄稼cross十字架crow乌鸦crowd群集crucial决定性的crude天然的crude oil原油cruel残忍的cruise巡航crush压碎crust外皮cry哭crystal水晶cub兽仔cube立方cucumber黄瓜cue暗示cultivate耕作culture文化cunning狡猾cup杯cupboard碗柜curb路边cure治愈curiosity好奇curious好奇的curl卷发currency通货current当前的curriculum全部课程curriculum vitae个人履历curse诅咒curtain窗帘curve曲线cushion垫子custom习惯customary习惯的customer顾客cut切cyber赛博cyberspace虚拟空间cylinder圆锥。
组合c的计算方法组合C的计算方法组合C是组合数学中的一个重要概念,用于计算从n个元素中取出k个元素的组合数。
在实际应用中,组合C的计算方法有多种,下面将介绍几种常见的计算方法。
1. 公式法:组合C的计算可以使用数学公式来实现。
组合C的公式为C(n, k) = n! / (k! * (n-k)!),其中n!表示n的阶乘,即n! = n * (n-1) * (n-2) * ... * 2 * 1。
通过计算n的阶乘和k的阶乘以及(n-k)的阶乘,然后将它们相除,即可得到组合C的值。
这种方法适用于小规模的计算,但对于大规模的计算会出现溢出问题。
2. 递归法:递归法是一种常用的计算组合C的方法。
递归法的思想是将组合C的计算问题分解为更小规模的子问题。
具体而言,可以将问题分为两种情况:一种是选择第一个元素作为组合中的元素,然后从剩余的n-1个元素中选择k-1个元素;另一种情况是不选择第一个元素,然后从剩余的n-1个元素中选择k个元素。
通过递归调用这两种情况,最终可以得到组合C的值。
3. 动态规划法:动态规划法是一种更高效的计算组合C的方法。
动态规划法的基本思想是将问题分解为多个子问题,并缓存子问题的解,以避免重复计算。
具体而言,可以使用一个二维数组dp来存储组合C的值,其中dp[i][j]表示从i个元素中选择j个元素的组合C的值。
根据组合C的递推关系C(n, k) = C(n-1, k-1) + C(n-1, k),可以通过动态规划的方式计算出组合C的值。
4. Lucas定理:Lucas定理是一种利用数论思想来计算组合C的方法。
Lucas定理的基本思想是将组合C的计算转化为模素数的运算。
具体而言,可以将n和k分别表示为p进制数,并计算它们对p的模。
然后使用Lucas定理的公式C(n, k) = C(n mod p, k mod p) * C(n div p, k div p) mod p,其中div表示整除运算。
计算机二级c语言选择题知识点总结一、知识概述《计算机二级C语言选择题知识点》①基本定义:计算机二级C语言选择题就是从诸多关于C语言的知识领域出题,以选择题形式来考查对C语言知识的掌握程度,涵盖数据类型、运算符、程序结构等不同方面。
②重要程度:在计算机二级C语言考试中,选择题占了一定比例的分值,是能否通过考试的重要部分。
对理解C语言的整体规则和编写代码的能力考查很关键。
③前置知识:需要对计算机基本概念有个了解,像数据存储是怎么回事之类的。
也要知道基本的数学运算知识,因为C语言中的很多运算就跟数学类似。
④应用价值:在实际应用中,C语言编写软件、编写系统程序等都需要用到这些选择题涉及的知识。
比如说开发一个小型的文件管理系统,这些知识能帮助准确地管理数据类型、控制程序流程等。
二、知识体系①知识图谱:在计算机二级C语言知识体系里,选择题知识点分散在各个板块,像表达式计算这类可能就跟运算相关知识关联着,函数调用方面的知识点又跟程序模块化等知识紧密相连。
②关联知识:和编程逻辑相关知识联系紧密,例如变量定义如果不懂,程序流程控制那部分就很难理解,像循环控制中的变量使用就依赖变量定义。
③重难点分析:- 掌握难度:像指针这个知识点就很难,因为它很抽象。
比如指针可以指向不同的数据类型,还能进行复杂的运算,这需要对地址、内存存储机制有深刻理解。
- 关键点:掌握数据类型的范围、运算符的优先级还有程序控制结构的执行逻辑等。
④考点分析:- 在考试中的重要性:选择题会广泛涉及各类知识点,占分较多。
有可能几个考点混合成一道题考查。
- 考查方式:常把几个知识点糅合在一起,像问一个循环语句里面夹杂数据类型转换的结果是什么。
三、详细讲解【理论概念类】①概念辨析:- 数据类型:C语言有多种数据类型,例如整型就是整数类型,像1、2、3这种。
实型就是包含小数点的数,像。
- 变量:简单说就是能存储数据的一个盒子,比如我定义一个整型变量int num; 这里num就可以用来存一个整数。
c开头的单词大全集以内cacography(书写错误)、cacophony(嘈杂之声)、calamity (灾祸)、caliphate(哈里发)、calligraphy(书法)、callow(幼稚)、calumniate(诽谤)、calumny(诽谤)、calvary(十字军)、calvary(十字架)、camaraderie(友谊)、canard(谣言)、candescent(发白的)、candid(坦白的)、canker(溃疡)、cantata(管弦乐)、canticle(圣诗)、canto(诗篇)、capacious(宽敞的)、capitulate(投降)、caricature (漫画)、carnage(大屠杀)、carousal(狂欢)、cartographer(制图者)、castigation(惩罚)、castigate(惩罚)、casualty(受害者)、casuistry(诡辩)、cataclysm(灾变)、catalyze(催化)、catamaran(双体船)、catastrophe(灾难)、catechism(信条)、cautionary(警告性的)、cavil(苛求)、celestial(天体)、censor(审查人)、censure(谴责)、centurion(百夫长)、ceremony(仪式)、chimera(幻想)、choleric(怒火中烧的)、chronic(长期的)、circumlocution(回绕)、cipher(凯弗)、circumscribe(限定)、circumspect(谨慎的)、circumvent(谋避)、clairvoyance(透视)、clamor(叫嚣)、clarity(清晰)、classic(经典)、coercion(强制)、cogent(有力的)、commemorate(纪念)、commendable(值得称赞的)、commodious(宽敞的)、commute (改变)、compendium(汇编)、complacency(满足)、concession(让步)、concoct (捏造)、concord(调和)、condescension(屈尊)、condign(应有的)、confederacy(联盟)、conflagration(烈火)、conquest(征服)、consensus(共识)、contempt(蔑视)、contiguous(相邻的)、contingent(不确定的)、contiguity(接近)、contrite(悔悟的)、controversy(争论)、conundrum(谜语)、convenient(便利的)、convivial(快乐的)、convoluted(曲折的)、convolvulus(绑草)、copious(浩繁的)、corporeal(肉体的)、correlate(相关的)、correspondence(相似)、cosmopolitan(国际性的)、coterie(私密伙伴)、courtier(宰相)、covenant(公约)、covert(秘密的)、credence(信任)、credulous(易受骗的)、crescendo(增强)、criterion(标准)、crucible(考验)、crystallize(结晶)、culpable(有罪的)、cupidity(贪心)、curmudgeon(讨厌鬼)、curriculum(课程)、cynicism(愤世嫉俗态度)。
数学中c代表什么
数学中c代表复数集合,C还表示周长,组合会以C表示,在对称元素中,C表示旋转轴等一些数学符号。
数学是研究数量、结构、变化、空间以及信息等概念的一门学科,从某种角度看属于形式科学的一种。
数学透过抽象化和逻辑推理的使用,由计数、计算、量度和对物体形状及运动的观察而产生。
数学已成为许多国家及地区的教育范畴中的一部分。
它应用于不同领域中,包括科学、工程、医学、经济学和金融学等。
数学家也研究纯数学,就是数学本身的实质性内容,而不以任何实际应用为目标。
c开头的汉字C开头的汉字,是指拼音中以“c”为声母的汉字。
在汉语中,以“c”为声母的汉字并不多,但每一个字都有着独特的含义和用法。
在本文中,我们将会介绍一些常见的C开头的汉字,以及它们的用法和意义。
一、草草,是一种植物,也是汉字中常用的字。
草在汉语中有着丰富的含义和用法。
在汉字中,草的意义非常广泛,可以用来表示草地、植物、草稿等等。
同时,草也是汉字中的一个部首,常用于组成一些与植物有关的汉字,例如花、茶、苗等等。
二、城城,是指城市或城墙。
城在汉语中也有着丰富的含义和用法。
城可以用来表示一个城市或城镇的名称,也可以用来表示城市的建筑物或城墙。
在中国的历史中,城是一个非常重要的概念,它代表了一个国家或地区的文化和政治中心。
三、春春,是一年四季之一,也是汉字中常用的字。
春在汉语中有着丰富的含义和用法。
春可以用来表示一个季节,也可以用来表示新的开始和希望。
在中国文化中,春是一个非常重要的概念,它代表了新的开始和希望,同时也是一个重要的节日——春节的主题。
四、厕厕,是指厕所或公共厕所。
厕在汉语中也有着丰富的含义和用法。
厕可以用来表示一个厕所或公共厕所的名称,也可以用来表示厕所的建筑物或设施。
在现代社会中,厕所是一个非常重要的设施,它代表了卫生和公共卫生的重要性。
五、猫猫,是一种哺乳动物,也是汉字中常用的字。
猫在汉语中有着丰富的含义和用法。
猫可以用来表示一种动物,也可以用来表示一种态度或行为。
在中国文化中,猫是一个非常重要的动物,它代表了灵性和自由,同时也是一个非常受欢迎的宠物。
六、菜菜,是指食品中的蔬菜,也是汉字中常用的字。
菜在汉语中有着丰富的含义和用法。
菜可以用来表示一种食品,也可以用来表示一种文化或生活方式。
在中国文化中,菜是一个重要的元素,它代表了饮食文化和生活方式的重要性。
七、车车,是指交通工具中的车辆,也是汉字中常用的字。
车在汉语中有着丰富的含义和用法。
车可以用来表示一种交通工具,也可以用来表示一种文化或生活方式。
c中const的用法在C语言中,const是一个关键字,用于修饰变量、函数参数和函数返回值,表示该值不能被修改。
const关键字在C语言中被广泛用于提高程序的稳定性和安全性。
本文将介绍const在C语言中的用法。
一、const修饰变量1. 局部变量:在函数内部声明的局部变量,如果用const修饰,则该变量在函数内部是只读的,不能被修改。
2. 全局变量:在代码中声明的全局变量,如果用const修饰,则该全局变量在程序执行期间是只读的,不能被修改。
例如:```cconst int my_variable = 10; //全局常量变量void my_function() {const int local_variable = 5; //局部常量变量//...函数内部使用local_variable,但不能修改它}```二、const修饰指针1. 指向常量的指针:指向一个常量的指针,指向的变量不能被修改。
2. 指向普通变量的指针:如果一个指针指向一个普通变量,用const修饰该指针,表示该指针不能被用来修改它所指向的变量的值。
例如:```cint my_variable = 10;int* const p = &my_variable; // p指向my_variable,不能通过p来修改my_variable的值```三、const修饰函数参数和返回值1. 函数参数:如果一个函数接受一个常量指针或常量引用作为参数,则该参数的值不能被修改。
2. 返回值:如果一个函数返回一个常量指针或常量引用,则该函数的返回值不能被修改。
例如:```cconst int* get_constant_pointer() { //返回一个指向常量的指针return &my_variable; //my_variable不能被修改}```四、注意事项1. const关键字只保证变量的值不能被修改,但不能保证指针所指向的内存空间不会被释放或重新分配。
C# 泛型简介发布日期: 5/30/2005 | 更新日期: 5/30/2005Juval LowyIDesign摘要:本文讨论泛型处理的问题空间、它们的实现方式、该编程模型的好处,以及独特的创新(例如,约束、一般方法和委托以及一般继承)。
此外,本文还讨论 .NET Framework 如何利用泛型。
简介泛型是 C# 2.0 的最强大的功能。
通过泛型可以定义类型安全的数据结构,而无须使用实际的数据类型。
这能够显著提高性能并得到更高质量的代码,因为您可以重用数据处理算法,而无须复制类型特定的代码。
在概念上,泛型类似于 C++ 模板,但是在实现和功能方面存在明显差异。
本文讨论泛型处理的问题空间、它们的实现方式、该编程模型的好处,以及独特的创新(例如,约束、一般方法和委托以及一般继承)。
您还将了解在 .NET Framework 的其他领域(例如,反射、数组、集合、序列化和远程处理)中如何利用泛型,以及如何在所提供的基本功能的基础上进行改进。
泛型问题陈述考虑一种普通的、提供传统Push()和Pop()方法的数据结构(例如,堆栈)。
在开发通用堆栈时,您可能愿意使用它来存储各种类型的实例。
在 C# 1.1 下,您必须使用基于 Object 的堆栈,这意味着,在该堆栈中使用的内部数据类型是难以归类的 Object,并且堆栈方法与 Object 交互:public class Stack{object[] m_Items;public void Push(object item){...}public object Pop(){...}}代码块 1显示基于 Object 的堆栈的完整实现。
因为 Object 是规范的 .NET 基类型,所以您可以使用基于 Object 的堆栈来保持任何类型的项(例如,整数):Stack stack = new Stack();stack.Push(1);stack.Push(2);int number = (int)stack.Pop();代码块 1. 基于 Object 的堆栈public class Stack{readonly int m_Size;int m_StackPointer = 0;object[] m_Items;public Stack():this(100){}public Stack(int size){m_Size = size;m_Items = new object[m_Size];}public void Push(object item){if(m_StackPointer >= m_Size)throw new StackOverflowException();m_Items[m_StackPointer] = item;m_StackPointer++;}public object Pop(){m_StackPointer--;if(m_StackPointer >= 0){return m_Items[m_StackPointer];}else{m_StackPointer = 0;throw new InvalidOperationException("Cannot pop an empty stack");}}}但是,基于 Object 的解决方案存在两个问题。
第一个问题是性能。
在使用值类型时,必须将它们装箱以便推送和存储它们,并且在将值类型弹出堆栈时将其取消装箱。
装箱和取消装箱都会根据它们自己的权限造成重大的性能损失,但是它还会增加托管堆上的压力,导致更多的垃圾收集工作,而这对于性能而言也不太好。
即使是在使用引用类型而不是值类型时,仍然存在性能损失,这是因为必须从 Object 向您要与之交互的实际类型进行强制类型转换,从而造成强制类型转换开销:Stack stack = new Stack();stack.Push("1");string number = (string)stack.Pop();基于 Object 的解决方案的第二个问题(通常更为严重)是类型安全。
因为编译器允许在任何类型和 Object 之间进行强制类型转换,所以您将丢失编译时类型安全。
例如,以下代码可以正确编译,但是在运行时将引发无效强制类型转换异常:Stack stack = new Stack();stack.Push(1);//This compiles, but is not type safe, and will throw an exception: string number = (string)stack.Pop();您可以通过提供类型特定的(因而是类型安全的)高性能堆栈来克服上述两个问题。
对于整型,可以实现并使用IntStack:public class IntStack{int[] m_Items;public void Push(int item){...}public int Pop(){...}}IntStack stack = new IntStack();stack.Push(1);int number = stack.Pop();对于字符串,可以实现StringStack:public class StringStack{string[] m_Items;public void Push(string item){...}public string Pop(){...}}StringStack stack = new StringStack();stack.Push("1");string number = stack.Pop();等等。
遗憾的是,以这种方式解决性能和类型安全问题,会引起第三个同样严重的问题—影响工作效率。
编写类型特定的数据结构是一项乏味的、重复性的且易于出错的任务。
在修复该数据结构中的缺陷时,您不能只在一个位置修复该缺陷,而必须在实质上是同一数据结构的类型特定的副本所出现的每个位置进行修复。
此外,没有办法预知未知的或尚未定义的将来类型的使用情况,因此还必须保持基于 Object 的数据结构。
结果,大多数 C# 1.1 开发人员发现类型特定的数据结构不实用,并且选择使用基于 Object 的数据结构,尽管它们存在缺点。
什么是泛型通过泛型可以定义类型安全类,而不会损害类型安全、性能或工作效率。
您只须一次性地将服务器实现为一般服务器,同时可以用任何类型来声明和使用它。
为此,需要使用<和>括号,以便将一般类型参数括起来。
例如,可以按如下方式定义和使用一般堆栈:public class Stack{T[] m_Items;public void Push(T item){...}public T Pop(){...}}Stack stack = new Stack();stack.Push(1);stack.Push(2);int number = stack.Pop();代码块 2显示一般堆栈的完整实现。
将代码块 1与代码块 2进行比较,您会看到,好像代码块 1中每个使用 Object 的地方在代码块 2中都被替换成了T,除了使用一般类型参数 T 定义 Stack 以外:public class Stack{...}在使用一般堆栈时,必须通知编译器使用哪个类型来代替一般类型参数 T(无论是在声明变量时,还是在实例化变量时):Stack stack = new Stack();编译器和运行库负责完成其余工作。
所有接受或返回 T 的方法(或属性)都将改为使用指定的类型(在上述示例中为整型)。
代码块 2. 一般堆栈public class Stack{readonly int m_Size;int m_StackPointer = 0;T[] m_Items;public Stack():this(100){}public Stack(int size){m_Size = size;m_Items = new T[m_Size];}public void Push(T item){if(m_StackPointer >= m_Size)throw new StackOverflowException();m_Items[m_StackPointer] = item;m_StackPointer++;}public T Pop(){m_StackPointer--;if(m_StackPointer >= 0){return m_Items[m_StackPointer];}else{m_StackPointer = 0;throw new InvalidOperationException("Cannot pop an empty stack");}}}注T 是一般类型参数(或类型参数),而一般类型为 Stack。
Stack 中的 int 为类型实参。
该编程模型的优点在于,内部算法和数据操作保持不变,而实际数据类型可以基于客户端使用服务器代码的方式进行更改。
表面上,C# 泛型的语法看起来与 C++ 模板类似,但是编译器实现和支持它们的方式存在重要差异。
正如您将在后文中看到的那样,这对于泛型的使用方式具有重大意义。
注在本文中,当提到 C++ 时,指的是传统 C++,而不是带有托管扩展的Microsoft C++。
与 C++ 模板相比,C# 泛型可以提供增强的安全性,但是在功能方面也受到某种程度的限制。
在一些 C++ 编译器中,在您通过特定类型使用模板类之前,编译器甚至不会编译模板代码。
当您确实指定了类型时,编译器会以内联方式插入代码,并且将每个出现一般类型参数的地方替换为指定的类型。
此外,每当您使用特定类型时,编译器都会插入特定于该类型的代码,而不管您是否已经在应用程序中的其他某个位置为模板类指定了该类型。
C++ 链接器负责解决该问题,并且并不总是有效。
这可能会导致代码膨胀,从而增加加载时间和内存足迹。
在 .NET 2.0 中,泛型在 IL(中间语言)和 CLR 本身中具有本机支持。
在编译一般 C# 服务器端代码时,编译器会将其编译为 IL,就像其他任何类型一样。
但是,IL 只包含实际特定类型的参数或占位符。
此外,一般服务器的元数据包含一般信息。
客户端编译器使用该一般元数据来支持类型安全。
当客户端提供特定类型而不是一般类型参数时,客户端的编译器将用指定的类型实参来替换服务器元数据中的一般类型参数。
这会向客户端的编译器提供类型特定的服务器定义,就好像从未涉及到泛型一样。