
前面我们讲个搜索引擎如何搜集网页,今天说下第二个过程网页预处理,其中中文分词就显得尤其重要,下面就详细讲解一下搜索引擎是怎么进行网页预处理的:
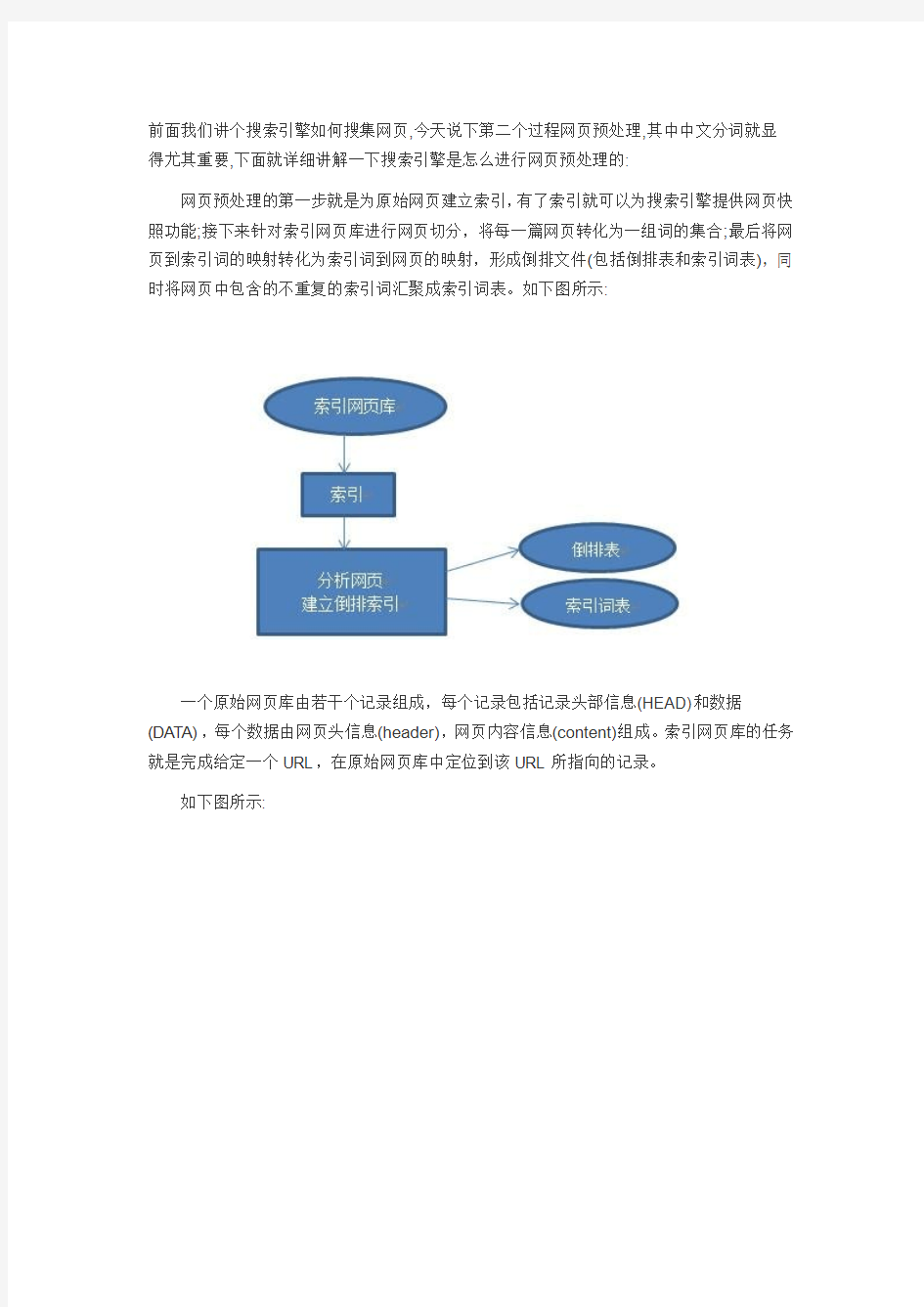
网页预处理的第一步就是为原始网页建立索引,有了索引就可以为搜索引擎提供网页快照功能;接下来针对索引网页库进行网页切分,将每一篇网页转化为一组词的集合;最后将网页到索引词的映射转化为索引词到网页的映射,形成倒排文件(包括倒排表和索引词表),同时将网页中包含的不重复的索引词汇聚成索引词表。如下图所示:
一个原始网页库由若干个记录组成,每个记录包括记录头部信息(HEAD)和数据(DATA),每个数据由网页头信息(header),网页内容信息(content)组成。索引网页库的任务就是完成给定一个URL,在原始网页库中定位到该URL所指向的记录。
如下图所示:
对索引网页库信息进行预处理包括网页分析和建立倒排文件索引两个部分。中文自动分词是网页分析的前提。文档由被称作特征项的索引词(词或者字)组成,网页分析是将一个文档表示为特征项的过程。在对中文文本进行自动分析前,先将整句切割成小的词汇单元,即中文分词(或中文切词)。切词软件中使用的基本词典包括词条及其对应词频。
自动分词的基本方法有两种:基于字符串匹配的分词方法和基于统计的分词方法。
1) 基于字符串匹配的分词方法
这种方法又称为机械分词方法,它是按照一定的策略将待分析的汉字串与一个充分大的词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功(识别出一个词)。
按照扫描方向的不同,串匹配分词方法可以分为正向匹配和逆向匹配;按照不同长度优先匹配的情况,可以分为最大或最长匹配,和最小或最短匹配;按照是否与词性标注过程相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。常用的几种机械分词方法如下:
? 正向最大匹配;
? 逆向最大匹配;
? 最少切分(使每一句中切出的词数最小)。
还可以将正向最大匹配方法和逆向最大匹配方法结合起来构成双向匹配法。由于汉语单字成词的特点,正向最小匹配和逆向最小匹配一般很少使用。一般说来,逆向匹配的切分精度略高于正向匹配,遇到的歧义现象也较少。
对于机械分词方法,可模型化表示为ASM(d,a,m),即Automatic Segmentation Model。其中,
d:匹配方向,+表示正向,-表示逆向;
a:每次匹配失败后增加或减少字串长度(字符数),+为增字,-为减字;
m:最大或最小匹配标志,+为最大匹配,-为最小匹配。
例如,ASM(+, -, +)就是正向减字最大匹配法(Maximum Match based approach,MM),ASM(-, -, +)就是逆向减字最大匹配法(简记为RMM方法)。
2)基于统计的分词方法
从形式上看,词是稳定的字的组合,因此上下文中,相邻的字同时出现的次数越多,就越有可能构成一个词。因此字与字相邻共现的频率或概率能够较好的反映成词的可信度。
可以对语料中相邻共现的各个字的组合的频度进行统计,计算它们的互现信息。
互现信息体现类汉字之间结合关系的紧密程度。当紧密程度高于某一个阈值时,便可认为此字组可能构成了一个词。这种方法只需对语料中的字组频度进行统计,不需要切分词典,因而又叫做无词典分词法或统计取词方法。
实际应用的统计分词系统都要使用一部基本的分词词典(常用词词典)进行串匹配分词,同时使用统计方法识别一些新的词,即将串频统计和串匹配结合起来,既发挥匹配分词切分速度快、效率高的特点,又利用了无词典分词结合上下文识别生词、自动消除歧义的优点。
正向减字最大匹配法
这是主要的中文切词方法,正向减字最大匹配法切分的过程是从自然语言的中文语句中提取出设定的长度字串,与词典比较,如果在词典中,就算一个有意义的词串,并用分隔符分隔输出,否则缩短字串,在词典中重新查找(词典是预先定义好的)。
算法要求为:
输入:中文词典,待切分的文本d,d中有若干被标点符号分割(我们可以利用标点符号协助搜索引擎准确分词)的句子s1,设定的最大词长MaxLen。
输出:每个句子s1被切为若干长度不超过MaxLen的字符串,并用分隔符分开,记为s2,所有s2的连接构成d切分之后的文本。
该中文分词的算法思想是:事先将网页预处理成每行是一个句子的纯文本格式。从d
中逐句提取,对于每个句子s1从左向右以MaxLen为界选出候选字串w,如果w在词典中,处理下一个长为MaxLen的候选字段;否则,将w最右边一个字去掉,继续与词典比较;s1切分完之后,构成词的字符串或者此时w已经为单字,用分隔符隔开输出给s2。从s1中减去w,继续处理后续的字串。s1处理结束,取T中的下一个句子赋给s1,重复前述步骤,直到整篇文本d都切分完毕。其中MaxLen是一个经验值,通常设为8个字节(即4个汉字),MaxLen过小,长词会被切断;过长,又会导致切分效率低。
除了上述从左到右切分一遍句子,还从右到左切分一遍,对于两遍切分结果不同的字符串,用回溯法重新处理。例如“学历史知识”顺向扫描的结果是:“学历/ 史/ 知识/”,通过查词典知道“史”不在词典中,于是进行回溯,将“学历”的尾字“历”取出与后面的“史”组成“历史”,再查词典,看“学”,“历史”是否在词典中,如果在,就将分词结果调整为:“学/ 历史/ 知识/”。
为网页建立全文索引是网页预处理的核心部分,包括分析网页和建立倒排文件。二者是顺序进行,先分析网页,后建立倒排文件(也称为反向索引)。如下图所示:
分析网页过程包括提取正文信息(指过滤网页标签,scripts,css,java,
embeddedobjects,comments等信息)和把正文信息切分为索引词两个阶段。形成的结果是文档号到索引词的对应关系表。每条记录中包括文档编号,索引词编号,索引词在文档中的位置信息,“索引词载体信息”(这些信息标识类文档中索引词的字体和大小等信息,或称载体信息)。
得到网页正文信息,调用切词模块,获得正向索引。每一个网页由两行信息组成,第一行是文档编号,第二行是使用切分模块将文档正文信息划分成索引词后的集合。
如上图所示,创建倒排索引包括建立正向索引和反向索引。分析完网页后,得到以网页编号为主键的正向索引表。然后将相同索引词对应的数据合并到一起,就得到了以索引词为主键的最终的倒排文件索引,即反向索引.
最后就可以为最后一个阶段信息查询服务提供服务了, 传递到信息查询服务阶段的数
据包括索引网页库和倒排文件,倒排文件中包括倒排表和索引词表。查询代理接受用户输入的查询短语,切分后,从索引词表和倒排文件中检索获得包含查询短语的文档并返回给用户。这样搜索引擎的三个阶段就算完成了.
一种基于词典的中文分词法的设计与实 现 摘要:中文分词就是把没有明显分隔标志的中文字串切分为词串,它是其他中文信息处理的基础,广泛应用于搜索引擎、自动翻译、语音合成、自动分类、自动摘要、自动校对等领域。就中文分词的基本方法作了简单阐述,并介绍了一种基于词典采用最大匹配法实现中文分词的方法。 关键词:中文分词;词库索引;正向最大匹配法 1 中文分词 中文分词技术属于自然语言处理技术范畴,对于一句话,人可以通过自己的知识来明白哪些是词,哪些不是词,但如何让计算机也能理解?其处理过程就是分词算法。 1.1中文分词方法的种类 中文自动分词方法有多种,一般来说大致可归结为以下三大类:基于词典的分词方法、基于统计的分词方法、基于规则和基于统计相结合的分词方法[2]。1.1.1基于词典的分词方法。基于词典的分词方法,又叫做基于字符串匹配的分词方法。其基本思想是:事先建立词库,其中包含所有可能出现的词。对于给定的待分词的汉子串Str,按照某种确定的原则切取Str 的子串,若该子串与词库中的某词条相匹配,则该子串是就是词,继续分割其余的部分,直到剩余部分为空;否则,该子串不是词,转到上面重新切取Str的子串进行匹配。1.1.2基于统计的分词方法。基于词典分词方法要借助词典来进行,而中文的构词非常灵活,词的数目几乎是无限的,因此要构造完备的词典几乎是不可能的。鉴于上述分词方法存在的这些缺点,一种基于统计的分词方法应运而生。这种方法撇开词典,根据字串出现的频率来判断这个字串是否是词。该方法对于大的语料,分全率还可以,但是对于小的语料分全率就比较低。该方法的另一个缺点就是不够准确,有些经常一起出现的单字构成的字串其实不是词。但是由于出现的频率很高,就被分出来当作词处理了,而且这样的“词”还非常多, 例如“这一”、“之一”、“有的”、“我的”、“许多的”等。实际应用的统计分词系统都要使用一部基本的分词词典进行串匹配分词,同时使用统计方法识别一些新的词,即将串频统计和串匹配结合起来,既发挥匹配分词切分速度快、效率高的特点,又利用了无词典分词结合上下文识别生词、自动消除歧义的优点。1.1.3基于规则和基于统计相结合的分词方法。该方法首先运用最大匹配作初步切分,然后对切分的边界处进行歧义探测,发现歧义,最后运用统计和规则相结合的方法来判断正确的切分[4]。运用不同的规则解决人名、地名、机构名识别,运用词法结构规则来生成复合词和衍生词。日前这种方法可以解决汉语中最常见的歧义类型:单字交集型歧义。并对人名、地名、机构名、后缀、动词/形容词重叠、衍生词等词法结构进行识别处理,基本解决了分词所面临的最关键的问题。若词典结构和算法设计优秀,分词速度将非常快。 1.2分词中的难题 有了成熟的分词算法,是否就能容易的解决中文分词的问题呢?事实远非如此。中文是一种十分复杂的语言,让计算机理解中文语言更是困难。在中文分词过程中,有两大难题一直没有完全突破。1.2.1歧义识别。歧义是指同样的一句话,可能有两种或者更多的切分方法。例如:“表面的”,因为“表面”和“面的”都是词,那么这个短语就可以分成“表面的”和“表面的”,这种称为交叉歧义,像这种交叉歧义十分常见。“化妆和服装”可以分成“化妆和服装”或者“化妆和服装”。由于没有人的知识去理解,计算机很难知道到底哪个方案正确。交叉歧义
信息检索课程结业报告 姓 学
信息检索与web搜索 应用背景及概念 信息检索(Information Retrieval)是指信息按一定的方式组织起来,并根据信息用户的需要找出有关的信息的过程和技术。狭义的信息检索就是信息检索过程的后半部分,即从信息集合中找出所需要的信息的过程,也就是我们常说的信息查寻(Information Search 或Information Seek)。 信息检索起源于图书馆的参考咨询和文摘索引工作,从19世纪下半叶首先开始发展,至20世纪40年代,索引和检索成已为图书馆独立的工具和用户服务项目。随着1946年世界上第一台电子计算机问世,计算机技术逐步走进信息检索领域,并与信息检索理论紧密结合起来;脱机批量情报检索系统、联机实时情报检索系统。 信息检索有广义和狭义的之分。广义的信息检索全称为“信息存储与检索”,是指将信息按一定的方式组织和存储起来,并根据用户的需要找出有关信息的过程。狭义的信息检索为“信息存储与检索”的后半部分,通常称为“信息查找”或“信息搜索”,是指从信息集合中找出用户所需要的有关信息的过程。狭义的信息检索包括3个方面的含义:了解用户的信息需求、信息检索的技术或方法、满足信息用户的需求。 搜索引擎(Search Engine,简称SE)是实现如下功能的一个系统:收集、整理和组织信息并为用户提供查询服务。面向WEB的SE是其中最典型的代表。三大特点:事先下载,事先组织,实时检索。 垂直搜索引擎:垂直搜索引擎为2006年后逐步兴起的一类搜索引擎。不同于通用的网页搜索引擎,垂直搜索专注于特定的搜索领域和搜索需求(例如:机票搜索、旅游搜索、生活搜索、小说搜索、视频搜索等等),在其特定的搜索领域有更好的用户体验。相比通用搜索动辄数千台检索服务器,垂直搜索需要的硬件成本低、用户需求特定、查询的方式多样。 Web检索的历史: 1989年,伯纳斯·李在日内瓦欧洲离子物理研究所(CERN)开发计算机远程控制时首次提出了Web概念,并在1990年圣诞节前推出了第一个浏览器。接下来的几年中,他设计出HTTP、URL和HTML的规范,使网络能够为普通大众所应用。 Ted Nelson 在1965年提出了超文本的概念.超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络传输协议,超文本标注语言(HTML)。 1993, 早期的 web robots (spiders) 用于收集 URL: Wanderer、ALIWEB (Archie-Like Index of the WEB)、WWW Worm (indexed URL’s and titles for regex search)。 1994, Stanford 博士生 David Filo and Jerry Yang 开发手工划分主题层次的雅虎网站。 1994年初,WebCrawler是互联网上第一个支持搜索文件全部文字的全文搜索引擎,在它之前,用户只能通过URL和摘要搜索,摘要一般来自人工评论或程
3 2009209218收到,2010201203改回 33 基金项目:国家级课题资助项目(30800446)。 333刘红芝,女,1980年生,硕士,研究方向:电子信息咨询与服务,计算机网络及数据库技术。 文章编号:100325850(2010)0320001203 中文分词技术的研究 Research on Ch i nese W ord Segm en ta tion Techn iques 刘红芝 (徐州医学院图书馆 江苏徐州 221004) 【摘 要】对中文分词的主要算法进行了研究,阐述了中文分词中存在的困难及其解决方法,最后指出了中文分词的未来研究工作。 【关键词】中文分词,算法,歧义,未登录词,停用词 中图分类号:T P 391 文献标识码:A ABSTRACT T h is paper analyzes the m ain am biguities of Ch inese w o rd segm entati on ,elabo rates difficulties in Ch inese w o rd segm entati on and their so luti ons ,and finally po ints out the existing p roblem s in Ch inese w o rd segm entati on and the future research w o rk 1 KEYWOR D S ch inese w o rd segm entati on ,algo ris m ,am biguity ,unknow n w o rd ,stop 2w o rd 随着因特网上信息给人们带来方便的同时,也存在信息查找不便、不良信息过多等弊端,信息过滤技术应运而生。信息过滤[1]就是根据用户的信息需求,利用一定的工具从大规模的动态信息流中自动筛选出满足用户需求的信息,同时屏蔽掉无用信息的过程。目前很多信息过滤系统的设计都是基于内容的过滤,即查找信息文本中是否含有特征词库中设置的关键词。这种设计思想符合人们正常的思维习惯,比较容易实现。但是在实际应用中,特别是在处理中文信息的时候由于缺乏中文策略,处理结果很难让人满意。 因此,进行中文信息过滤,首先就要对文本预处理,进行中文分词,将其表示成可计算和推理的模型。中文分词是中文文本过滤的首要基础性工作、难点问题,也是自然语言信息处理中最基本的一步。 1 中文分词技术 将连续的字序列按照一定的规范重新组合成词序列的过程被称为分词;中文分词就是把中文的汉字序列分成有意义的词[2]。分词只是中文信息处理的一部分,分词本身并不是目的,而是后续处理过程的必要阶段,是中文信息处理的基础技术。 2 中文分词的必要性 如何让计算机更好地读懂人类的语言,理解人类的思想,更好地让用户快速方便地搜索到自己所需要的资源,中文分词技术的产生是中文搜索质量提高的 至关重要的因素。众所周知,中文文本与英文文本的表示方法有所不同,英文文本中词与词中间都由空格或标点符号隔开,因而词与词之间的界限很明显,可以很容易地获取关键词,而中文文本中词与词则无明显的界限,这就影响了关键词的获取和匹配[3]。 3 分词的主要算法 中文分词技术属于自然语言处理技术的范畴,是语义理解过程中最初的一个环节,它将组成语句的核心词提炼出来供语义分析模块使用,在分词的过程中,如何能够恰当地提供足够的词来供分析程序处理,计算机如何完成这一过程?其处理过程就称为分词算法。 现有的分词算法按照是否使用分词词典来分,可分为基于词典的分词算法和基于无词典的分词算法[4]。基于词典的分词算法的分词精度在很大程度上依赖于分词词典的好坏,基于无词典的分词算法不需要利用词典信息,它通过对大规模的生语料库进行统计分析,自动地发现和学习词汇,从分词精度来看,基于词典的分词算法要大大优于无词典的分词算法。311 基于词典的分词算法 基于词典的分词算法主要基于一个词典和一个基本的切分评估规则。早期主要采取机械匹配的方法,但由于缺乏歧义切分的处理,故切分的精度较低,后来随着研究的发展,加入了规则的切分,但规则的制订不仅需要大量的人力而且对系统的开放性有很大的局限,因此后来又引入了从基于统计的分词方法,不仅统计 ? 1? 第23卷 第3期 电脑开发与应用(总173)
前面我们讲个搜索引擎如何搜集网页,今天说下第二个过程网页预处理,其中中文分词就显得尤其重要,下面就详细讲解一下搜索引擎是怎么进行网页预处理的: 网页预处理的第一步就是为原始网页建立索引,有了索引就可以为搜索引擎提供网页快照功能;接下来针对索引网页库进行网页切分,将每一篇网页转化为一组词的集合;最后将网页到索引词的映射转化为索引词到网页的映射,形成倒排文件(包括倒排表和索引词表),同时将网页中包含的不重复的索引词汇聚成索引词表。如下图所示: 一个原始网页库由若干个记录组成,每个记录包括记录头部信息(HEAD)和数据(DATA),每个数据由网页头信息(header),网页内容信息(content)组成。索引网页库的任务就是完成给定一个URL,在原始网页库中定位到该URL所指向的记录。 如下图所示:
对索引网页库信息进行预处理包括网页分析和建立倒排文件索引两个部分。中文自动分词是网页分析的前提。文档由被称作特征项的索引词(词或者字)组成,网页分析是将一个文档表示为特征项的过程。在对中文文本进行自动分析前,先将整句切割成小的词汇单元,即中文分词(或中文切词)。切词软件中使用的基本词典包括词条及其对应词频。 自动分词的基本方法有两种:基于字符串匹配的分词方法和基于统计的分词方法。 1) 基于字符串匹配的分词方法 这种方法又称为机械分词方法,它是按照一定的策略将待分析的汉字串与一个充分大的词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功(识别出一个词)。 按照扫描方向的不同,串匹配分词方法可以分为正向匹配和逆向匹配;按照不同长度优先匹配的情况,可以分为最大或最长匹配,和最小或最短匹配;按照是否与词性标注过程相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。常用的几种机械分词方法如下:
中文分词实验 一、实验目的: 目的:了解并掌握基于匹配的分词方法,以及分词效果的评价方法。 实验要求: 1、从互联网上查找并构建不低于10万词的词典,构建词典的存储结构; 2、选择实现一种机械分词方法(双向最大匹配、双向最小匹配、正向减字最大匹配法等)。 3、在不低于1000个文本文件,每个文件大于1000字的文档中进行中文分词测试,记录并分析所选分词算法的准确率、分词速度。 预期效果: 1、平均准确率达到85%以上 二、实验方案: 1.实验平台 系统:win10 软件平台:spyder 语言:python 2.算法选择 选择正向减字最大匹配法,参照《搜索引擎-原理、技术与系统》教材第62页的描述,使用python语言在spyder软件环境下完成代码的编辑。 算法流程图:
Figure Error! No sequence specified.. 正向减字最大匹配算法流程
Figure Error! No sequence specified.. 切词算法流程算法伪代码描述:
3.实验步骤 1)在网上查找语料和词典文本文件; 2)思考并编写代码构建词典存储结构; 3)编写代码将语料分割为1500个文本文件,每个文件的字数大于1000字; 4)编写分词代码; 5)思考并编写代码将语料标注为可计算准确率的文本; 6)对测试集和分词结果集进行合并; 7)对分词结果进行统计,计算准确率,召回率及F值(正确率和召回率的 调和平均值); 8)思考总结,分析结论。 4.实验实施 我进行了两轮实验,第一轮实验效果比较差,于是仔细思考了原因,进行了第二轮实验,修改参数,代码,重新分词以及计算准确率,效果一下子提升了很多。 实验过程:
国内中文分词技术研究新进展 冯书晓 徐 新 杨春梅 (石河子大学药学院 乌鲁木齐 832002) 摘 要 就开发中文搜索引擎在汉语语言方面的关键技术之一,即中文分词技术进行综述。 关键词 中文搜索引擎 中文分词 文献检索 搜索引擎通常由信息收集和信息检索两部分组成。对于英文,由于英文中词与词之间是用空格隔开,检索起来很方便,故计算机采用了词处理的方式,大大减轻了用户与计算机的工作量;相对来讲,中文的情形就复杂得多。中文的词与词之间是没有分隔符的,因此若想建立基于词的索引,就需要专门的技术,这种技术被称之为 汉语词语切分技术 。根据是否采用词语切分技术,中文搜索引擎又可分为基于字的搜索引擎和基于词的搜索引擎。由于中文信息处理的特殊性和复杂性,中文搜索引擎技术还很不成熟,开发中文搜索引擎决不像西文软件的汉化那样简单。在实现中文搜索引擎时,不能照搬国外现成的技术,需要对中文的信息处理技术作专门地研究。自然语言理解领域的应用已经越来越广,但是几乎任何一个基于汉语的系统,都必须经过分词这一步。自动分词系统是中文信息处理中的一个主要组成部分,是中文自然语言理解、文献检索、机器翻译即语音合成系统中最基本的一部分。在搜索引擎中,为了进行中文信息小型化,需要提取关键知识,也就是说首先要分隔出单个的中文词语,然后进行词频统计得到关键词。要开发中文搜索引擎,快速的汉语分词算法和可靠的汉化技术是至关重要的。本文将针对中文分词技术及近年来中文分词技术的发展作一综述。 1 中文分词技术 1.1 中文词的特点 与英文不同,字是汉语的基本独立单位,但是具有一定语义的最小单位却是词。词由单个或多个字构成,一般用得最多的是二字词,其次是单字词,另外还有一些多字词(如成语、专有名词等)。 1.1.1 数量多。汉语中常用的词有 几万条, 现代汉语词典 中收录的词就达 6万个之多。而且,随着社会的发展,不断 地有新词产生。 1.1.2 使用灵活、变化多样,容易产 生歧义。例如同样的两个连续汉字,在有 的句子中构成一个词,而在另外的句子环 境中,却可能不构成词。这给计算机的词 法分析工作带来了极大的困难。 1.1.3 书写习惯。在英文系统中, 词与词之间在书写上用空格隔开,计算机 处理时可以非常容易地从文档中识别出 一个一个的词。而在汉语系统中,书写以 句子为单位,句间有标点隔开,在句内,字 和词则是连续排列的,它们之间没有任何 分隔。这样,如果要对中文文档进行基于 词的处理,必须先要进行词的切分处理, 以正确地识别出每一个词。 1.1.4 其它特点。诸如汉字同音 字、同音异形字等等。 1.2 一般分词方法 目前采用的分词 方法主要有以下几种:最大匹配法、反向 最大匹配方法、逐词遍历法、设立切分标 志法、最佳匹配法、有穷多层次列举法、二 次扫描法、邻接约束方法、邻接知识约束 方法、专家系统方法、最少分词词频选择 方法、神经网络方法等等。除了这些,许 多基于统计的方法也引入到分词过程中。 例如分词与词性标注一体化方法,随机有 限状态算法用于分词,模拟物理研究中结 晶过程的统计方法也被尝试于分词过程。 此外,还有大量的基于统计或规则的汉语 未登录词识别的研究,这里不能一一列 举。但归纳起来不外乎两类:一类是理解 式切词法,即利用汉语的语法知识和语义 知识以及心理学知识进行分词,需要建立 分词数据库、知识库和推理机;另一类是 机械式分词法,一般以分词词典为依据, 通过文档中的汉字串和词表中的词逐一 匹配来完成词的切分。下面笔者就以此 对近年来中文分词技术的进展分类作一 综述。 2 中文分词技术的进展 目前的分词算法多种多样,基本上可 分为两大类:机械性分词和理解性分词 法。后者可谓理想的方法,但在语法分 析、语义分析乃至篇章理解还没有得到解 决之前,其分词实用系统主要采用机械分 词法,但实际上纯机械性分词也无人在 用,一般都使用介于二者之间的某种分词 法。在此,本人称之为综合式分词法,收 录了由作者本人明确指出同时采用了机 械式分词法和理解式分词法的文章。 2.1 机械式分词法 邹海山等在现有 分词技术的基础上,提出了一种基于词典 的正向最大匹配和逆向最大匹配相结合 的中文分词方案,可以高效、准确地实现 中文文档的主题词条的抽取和词频统计。 应志伟等基于一个实际的文语转换系统, 介绍了它的一些处理方法,采用了一种改 进的最大匹配法,可以切分出所有的交集 歧义,提出了一种基于统计模型的算法来 处理其中的多交集歧义字段,并用穷举法 和一些简单的规则相组合的方法从实用 角度解决多音字的异读问题以及中文姓 名的自动识别问题,达到实现文语转换的 目的。陈桂林等首先介绍了一种高效的 中文电子词表数据结构,它支持首字Hasb 和标准的二分查找,且不限词条长度,然 后提出了一种改进的快速分词算法。在 快速查找两字词的基础上,利用近邻匹配 方法来查找多字词,明显提高了分词效 情报杂志2002年第11期 情报检索
百度中文分词技巧 什么是中文分词?我们都知道,英文句子都是由一个一个单词按空格分开组成,所以在分词方面就方便多了,但我们中文是一个一个汉字连接而成,所以相对来说是比较复杂的。中文分词指的是将一个汉语句子切分成一个一个单独的词,按照一定的规则重新组合成词序列的过程。这个也称做“中文切词”。 分词对于搜索引擎有着很大的作用,是文本挖掘的基础,可以帮助程序自动识别语句的含义,以达到搜索结果的高度匹配,分词的质量直接影响了搜索结果的精确度。目前搜索引擎分词的方法主要通过字典匹配和统计学两种方法。 一、基于字典匹配的分词方法 这种方法首先得有一个超大的字典,也就是分词索引库,然后按照一定的规则将待分词的字符串与分词库中的词进行匹配,若找到某个词语,则匹配成功,这种匹配有分以下四种方式: 1、正向最大匹配法(由左到右的方向); 2、逆向最大匹配法(由右到左的方向); 3、最少切分(使每一句中切出的词数最小); 4、双向最大匹配法(进行由左到右、由右到左两次扫描) 通常,搜索引擎会采用多种方式组合使用。但这种方式也同样给搜索引擎带来了难道,比如对于歧义的处理(关键是我们汉语的博大精深啊),为了提高匹配的准确率,搜索引擎还会模拟人对句子的理解,达到识别词语的效果。基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。通常包括三个部分:分词子系统、句法语义子系统、总控部分。在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断,即它模拟了人对句子的理解过程。这种分词方法需要使用大量的语言知识和信息,当然我们的搜索引擎也在不断进步。 二、基于统计的分词方法 虽然分词字典解决了很多问题,但还是远远不够的,搜索引擎还要具备不断的发现新的词语的能力,通过计算词语相邻出现的概率来确定是否是一个单独的词语。所以,掌握的上下文越多,对句子的理解就越准确,分词也越精确。举个例子说,“搜索引擎优化”,在字典中匹配出来可能是:搜索/引擎/优化、搜/索引/擎/优化,但经过后期的概率计算,发现“搜索引擎优化”在上下文相邻出现的次数非常多,那么基于统计就会将这个词语也加入进分词索引库。关于这点我在《关于电商与圈的分词测试》就是同样的一个例子。 中文分词的应用分词准确性对搜索引擎来说十分重要,但如果分词速度太慢,即使准确性再高,对于搜索引擎来说也是不可用的,因为搜索引擎需要处理数以亿计的网页,如果分词耗用的时间过长,会严重影响搜索引擎内容更新的速度。因此对于搜索引擎来说,分词的准确性和速度,二者都需要达到很高的要求。 参考文档及网站: https://www.doczj.com/doc/1c12841261.html, https://www.doczj.com/doc/1c12841261.html, https://www.doczj.com/doc/1c12841261.html, https://www.doczj.com/doc/1c12841261.html,
**大学数学与信息工程学院《Python程序设计》实验报告
print(st) 2、提取附件中年龄大于20岁人员的姓名、年龄、性别;并进行二进制序列化存储和读取。 代码: f=open(r'C:\Users\17458\Desktop\实验13附件.txt','r') bbk=f.readlines() ppk='' f1=open(r'C:\Users\17458\Desktop\p.txt','a+') for i in range(1,len(bbk)): if int(bbk[i][9]+bbk[i][10])>20: ppk=bbk[i][5:17] f1.write(ppk+'\n') f1.close() 3、安装第三方库jieba,编写程序统计《三国演义》中前5位出场最多的人物。(在cmd命令行先安装jieba库,pip install jieba;如果utf-8编码不成功,采用“gb18030”编码格式) 代码: import jieba f1=open(r'C:\Users\17458\Desktop\三国演义.txt','r',encoding='gb18030') others={'将军','却说','荆州','二人','不可','不能','如此','正是',\ '次日','徐州','洛阳'} kkk=f1.read() f1.close() bbk=jieba.lcut(kkk) counts={} for word in bbk: if len(word)==1: continue elif word=='孟德' or word =='丞相': rword='曹操' elif word=='诸葛亮' or word =='孔明曰':
IKAnalyzer IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer3.0则发展为面向Java的公用分词组件,独立于Lucene 项目,同时提供了对Lucene的默认优化实现。 语言和平台:基于java 语言开发,最初,它是以开源项目Luence 为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer 3.0 则发展为面向 Java 的公用分词组件,独立于 Lucene 项目,同时提供了对Lucene 的默认优化实现。 算法:采用了特有的“正向迭代最细粒度切分算法”。采用了多子处理器分析模式,支持:英文字母( IP 地址、 Email 、 URL )、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理。优化的词典存储,更小的内存占用。支持用户词典扩展定义。针对 Lucene 全文检索优化的查询分析器 IKQueryParser ;采用歧义分析算法优化查询关键字的搜索排列组合,能极大的提高 Lucene 检索的命中率。 性能:60 万字 / 秒 IKAnalyzer基于lucene2.0版本API开发,实现了以词典分词为基础的正反向全切分算法,是LuceneAnalyzer接口的实现。该算法适合与互联网用户的搜索习惯和企业知识库检索,用户可以用句子中涵盖的中文词汇搜索,如用"人民"搜索含"人民币"的文章,这是大部分用户的搜索思维;不适合用于知识挖掘和网络爬虫技术,全切分法容易造成知识歧义,因为在语义学上"人民"和"人民币"是完全搭不上关系的。 je-anlysis的分词(基于java实现) 1. 分词效率:每秒30万字(测试环境迅驰1.6,第一次分词需要1-2秒加载词典) 2. 运行环境: Lucene 2.0 3. 免费安装使用传播,无限制商业应用,但暂不开源,也不提供任何保证 4. 优点:全面支持Lucene 2.0;增强了词典维护的API;增加了商品编码的匹配;增加了Mail地址的匹配;实现了词尾消歧算法第二层的过滤;整理优化了词库; 支持词典的动态扩展;支持中文数字的匹配(如:二零零六);数量词采用“n”;作为数字通配符优化词典结构以便修改调整;支持英文、数字、中文(简体)混合分词;常用的数量和人名的匹配;超过22万词的词库整理;实现正向最大匹配算法;支持分词粒度控制 ictclas4j ictclas4j中文分词系统是sinboy在中科院张华平和刘群老师的研制的FreeICTCLAS的基础上完成的一个java开源分词项目,简化了原分词程序的复
自然语言检索中的中文分词技术研究进展及应用 何 莘1 ,王琬芜 2 (1.西安石油大学机械工程学院,陕西西安710065;2.浙江大学信息科学与工程学院,浙江杭州310058)摘 要:中文分词技术是实现自然语言检索的重要基础,是信息检索领域研究的关键课题,无论是专业信息检索系统还是搜索引擎都依赖于分词技术的研究成果。本文通过在国内外著名数据库中进行相关检索,分析了研究中文分词技术及其在著名搜索引擎中的应用。 关键词:中文分词;自动分词;分词算法 中图分类号:TP391,G354 文献标识码:A 文章编号:1007-7634(2008)05-0787-05 Research and Application of Chinese Word Segmentation Technical Based on Natural Language Information Retrieval HE Xin 1 ,W ANG Wan -wu 2 (1.School o f Mechanical Engineering ,Xi p an Shiyou University ,Xi p an 710065,China ;2.School o f In f o rmation Science and Engineering ,Zhejiang University ,Hangzhou 310058,China )Abstract :Chinese word segmentation technique is the important foundation that realize the natural language re -trieval,also is the key topic of the research in information retrieval domain.Professional information retrieval sys -te m and search engine both depend on the research achievements of word segmentation technique.This paper in -dexes in the domestic and international famous database,then Chinese word segmentation technique has been ana -lyzed in fa mous search engines is sum marized. Key words :Chinese word segmentation;automatic word se gmentation;word segmentation algorithm 收稿日期:2007-10-23 作者简介:何 莘(1968-),女,河北保定人,工程师,从事信息存储与检索技术、数字资源管理、搜索引擎技术等研究. 1 分词及分词算法 从中文自然语言句子中划分出有独立意义词的过程被称为分词。众所周知,英文是以词为单位的,词和词之间是靠空格隔开,而中文是以字为单位。由于中文词与词之间没有明确的边界,因此,中文分词技术中文信息处理的基础是机器翻译、分类、搜索引擎以及信息检索。中文分词技术属于自然语言处理技术的范畴,是语义理解过程中最初的一个环节,它将组成语句的核心词提炼出来供语义分析模块使用,在分词的过程中,如何能够恰当地提供足够的词来供分析程序处理,计算机如何完成这一过程?其处理过程就称为分词算法。现有的分 词算法可分为三大类:基于字符串匹配的分词方 法、基于理解的分词方法和基于统计的分词方法。 111 基于字符串匹配的分词方法 这种方法又叫做机械分词方法,它是按照一定的策略将待分析的汉字串与一个/充分大的0机器词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功(识别出一个词)。按照扫描方向的不同,串匹配分词方法可以分为正向匹配和逆向匹配;按照不同长度优先匹配的情况,可以分为最大(最长)匹配和最小(最短)匹配;按照是否与词性标注过程相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。 (1)正向最大匹配法(MM 法)。其基本思想 第26卷第5期2008年5月 情 报 科 学 Vol.26,No.5May,2008
统计与词典相结合的领域自适应中文分词* 张梅山,邓知龙,车万翔,刘挺 哈尔滨工业大学信息检索研究中心哈尔滨150001 E-mail: {mszhang, zldeng, car, tliu}@https://www.doczj.com/doc/1c12841261.html, 摘要:基于统计的中文分词方法往往不具有良好的领域自适应性。本文通过将外部词典信息融入统计分词模型(本文使用CRF统计模型)来实现领域自适应性。实验表明,这种方法具有良好的领域自适应性。当测试领域和训练领域相同时,分词的F-measure值提升了2%;当测试领域和训练领域不同时,分词的F-measure值提升了6%。最终优化后的分词速度也得到了很大的改善。 关键词:中文分词;CRF;领域自适应 Combining Statistical Model and Dictionary for Domain Adaption of Chinese Word Segmentation Meishan Zhang, Zhilong Deng, Wanxiang Che, Ting Liu Center for Information Retrieval of Computer Science & Technology School, Harbin Institute of Technology, Harbin 150001 E-mail: : {mszhang, zldeng, car, tliu}@https://www.doczj.com/doc/1c12841261.html, Abstract: Generally, statistical methods for Chinese W ord Segmentation don’t have good domation adaption. We propose an approach which can integrate extern dictionary information into statistical models to realize domain adaption for Chinese W ord Segmentation.In the paper, we use the CRF statistical model.. Experimental results show that our approach have good domain adaption. When domain of test corpus is identical to the training corpus, the F-measure value has an increase of 2%; when domain of test corpus is different with the training corpus, the F-measure value has an increase of 6%. The final speed of segmentation has also been improved greatly after optimized. Key words: Chinese W ord Segmentation; CRF; Domain Adaption 1引言 中文分词是中文自然语言处理中最基本的一个步骤,非常多的研究者对它做了很深入的研究,也因此产生了很多不同的分词方法,这些方法大体上可以分为两类:基于词典匹配的方法和基于统计的方法。 基于词典的方法[1]利用词典作为主要的资源,这类方法不需要考虑领域自适应性的问题,它只需要有相关领域的高质量词典即可,但是这类方法不能很好的解决中文分词所面临的歧义性问题以及未登录词问题。 基于统计的方法[2][3][4][5]是近年来主流的分词方法,它采用已经切分好的分词语料作为主要的资源,最终形成一个统计模型来进行分词解码。基于统计的方法在分词性能方面有了很大的提高,但是在跨领域方面都存在着很大的不足,它们需要针对不同的领域训练不同的统计分词模型。这样导致在领域变换后,必须为它们提供相应领域的分词训练语料,但是分词训练语料的获得是 *本文承国家自然科学基金(60803093;60975055),哈尔滨工业大学科研创新基金(HIT.NSRIF.2009069)和中央高效基本科研业务费专项资金(HIT.KLOF.2010064)的资助。
关于百度中文分词系统研究
所谓分词就是把字与字连在一起的汉语句子分成若干个相互独立、完整、正确的单词。词是最小的、能独立活动的、有意义的语言成分。计算机的所有语言知识都来自机器词典(给出词的各项信息) 、句法规则(以词类的各种组合方式来描述词的聚合现象) 以及有关词和句子的语义、语境、语用知识库。中文信息处理系统只要涉及句法、语义(如检索、翻译、文摘、校对等应用) ,就需要以词为基本单位。当汉字由句转化为词之后,才能使得句法分析、语句理解、自动文摘、自动分类和机器翻译等文本处理具有可行性。可以说,分词是机器语言学的基础。 分词准确性对搜索引擎来说十分重要,但如果分词速度太慢,即使准确性再高,对于搜索引擎来说也是不可用的,因为搜索引擎需要处理数以亿计的网页, 如果分词耗用的时间过长,会严重影响搜索引擎内容更新的速度。因此对于搜索引擎来说,分词的准确性和速度,二者都需要达到很高的要求。 分词算法的三种主要类型 现有的分词算法可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。 》基于字符串匹配的分词方法。 这种方法又叫做机械分词方法,它是按照一定的策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功 (识别出一个词) 。按照扫描方向的不同,串匹配分词方法可以分为正向匹配和逆向匹配;按照不同长度优先匹配的情况,可以分为最大(最长) 匹配 和最小(最短) 匹配;按照是否与词性标注过程相结合,又可以分为单纯分词方 法和分词与标注相结合的一体化方法。常用的几种机械分词方法如下: 1) 正向最大匹配法(由左到右的方向) 。 通常简称为MM(Maximum Matching Method) 法。其基本思想为:设D 为词典,MAX 表示D 中的最大词长,STR 为待切分的字串。MM 法是每次从STR 中取长度为MAX 的子串与D 中的词进行匹配。若成功,则该子串为词,指针后移MAX 个汉字后继续匹配,否则子串逐次减一进行匹配。 2) 逆向最大匹配法(由右到左的方向) 。 通常简称为RMM ( Reverse Maximum MatchingMethod) 法。RMM 法的基本原理与MM 法相同,不同的是分词的扫描方向,它是从右至左取子串进行匹配。 3) 最少切分法(使每一句中切出的词数最小) 。 还可以将上述各种方法相互组合,例如,可以将正向最大匹配方法和逆向 最大匹配方法结合起来构成双向匹配法。由于汉语单字成词的特点,正向最小匹配和逆向最小匹配一般很少使用。一般说来,逆向匹配的切分精度略高于正向匹配,遇到的歧义现象也较少。统计结果表明,单纯使用正向最大匹配的错误率为1/169 ,单纯使用逆向最大匹配的错误率为1/ 245 。但这种精度还远远不能满足实际的需要。实际使用的分词系统,都是把机械分词作为一种初分手段,还需通过利用各种其它的语言信息来进一步提高切分的准确率。一种方法是改进
院系:计算机科学学院 专业、年级: 07计科2大班 课程名称:编译原理 学号姓名: 指导教师: 2010 年11月17 日 组员学号姓名
实验 名称 实验一:词法分析实验室9205 实验目的或要求 通过设计一个具体的词法分析程序,加深对词法分析原理的理解。并掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。 编制一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分隔符五大类。并依次输出各个单词的内部编码及单词符号自身值。 具体要求:输入为某语言源代码,达到以下功能: 程序输入/输出示例:如源程序为C语言。输入如下一段: main() { int a,b; a=10; b=a+20; } 要求输出如下(并以文件形式输出或以界面的形式输出以下结果)。 (2,”main”) (5,”(“) (5,”)“) (5,”{“} (1,”int”) (2,”a”) (5,”,”) (2,”b”) (5,”;”) (2,”a”) (4,”=”) (3,”10”) (5,”;”) (2,”b”) (4,”=”) (2,”a”) (4,”+”) (3,”20”) (5,”;”) (5,”}“) 要求: 识别保留字:if、int、for、while、do、return、break、continue等等,单词种别码为1。 其他的标识符,单词种别码为2。常数为无符号数,单词种别码为3。 运算符包括:+、-、*、/、=、>、<等;可以考虑更复杂情况>=、<=、!= ;单词种别码为4。分隔符包括:“,”“;”“(”“)”“{”“}”等等,单词种别码为5。
分词算法一般有三类:基于字符串匹配、基于语义分析、基于统计。复杂的分词程序会将各种算法结合起来以便提高准确率。Lucene被很多公司用来提供站内搜索,但是Lucene本身并没有支持中文分词的组件,只是在Sandbox里面有两个组件支持中文分词:ChineseAnalyzer和CJKAnalyzer。ChineseAnalyzer 采取一个字符一个字符切分的方法,例如"我想去北京天安门广场"用ChineseAnalyzer分词后结果为:我#想#去#北#京#天#安#门#广#场。CJKAnalyzer 则是二元分词法,即将相邻的两个字当成一个词,同样前面那句用CJKAnalyzer 分词之后结果为:我想#想去#去北#北京#京天#天安#安门#门广#广场。 这两种分词方法都不支持中文和英文及数字混合的文本分词,例如:IBM T60HKU现在只要11000元就可以买到。用上述两种分词方法建立索引,不管是搜索IBM还是11000都是没办法搜索到的。另外,假如我们使用"服务器"作为关键字进行搜索时,只要文档包含"服务"和"器"就会出现在搜索结果中,但这显然是错误的。因此,ChineseAnalyzer和CJKAnalyzer虽然能够简单实现中文的分词,但是在应用中仍然会感觉到诸多不便。基于字符串匹配的分词算法用得很多的是正向最大匹配和逆向最大匹配。其实这两种算法是大同小异的,只不过扫描的方向不同而已,但是逆向匹配的准确率会稍微高一些。"我想去北京天安门广场"这句使用最大正向分词匹配分词结果:我#想去#北京#天安门广场。这样分显然比ChineseAnalyzer和CJKAnalyzer来得准确,但是正向最大匹配是基于词典的,因此不同的词典对分词结果影响很大,比如有的词典里面会认为"北京天安门"是一个词,那么上面那句的分词结果则是:我#想去#北京天安门#广场。 如果用"广场"作为关键字进行检索,那么使用后一个词典分出来的便可检索到,而使用前一个的则不行,而事实上应该是不管搜索北京天安门、天安门广场、天安门、广场都能检索到这篇文档。使用全切分可以实现这个想法,同样是那句使用正向全切分分词结果为:我#想去#北京天安门#北京#天安门#天安门广场#广场,这样不管用"北京天安门"、"天安门广场"、"天安门"、"广场"中的哪一个作为关键字搜索都可以搜索到。采取这种分法会在一定程度上提高分词的准确率,但也会出现问题,例如"我要在上海南站上车"这句采用正向全切分结果为:我#要在#上海#海南#南站,分出海南这个词显然是错误的,这属于交叉歧义。 正如前面所说,基于字符串匹配的分词算法都是依赖于词典的,但是不管再
一、为什么要进行中文分词? 词是最小的能够独立活动的有意义的语言成分,英文单词之间是以空格作为自然分界符的,而汉语是以字为基本的书写单位,词语之间没有明显的区分标记,因此,中文词语分析是中文信息处理的基础与关键。 Lucene中对中文的处理是基于自动切分的单字切分,或者二元切分。除此之外,还有最大切分(包括向前、向后、以及前后相结合)、最少切分、全切分等等。 二、中文分词技术的分类 我们讨论的分词算法可分为三大类:基于字典、词库匹配的分词方法;基于词频度统计的分词方法和基于知识理解的分词方法。 第一类方法应用词典匹配、汉语词法或其它汉语语言知识进行分词,如:最大匹配法、最小分词方法等。这类方法简单、分词效率较高,但汉语语言现象复杂丰富,词典的完备性、规则的一致性等问题使其难以适应开放的大规模文本的分词处理。第二类基于统计的分词方法则基于字和词的统计信息,如把相邻字间的信息、词频及相应的共现信息等应用于分词,由于这些信息是通过调查真实语料而取得的,因而基于统计的分词方法具有较好的实用性。 下面简要介绍几种常用方法: 1).逐词遍历法。 逐词遍历法将词典中的所有词按由长到短的顺序在文章中逐字搜索,直至文章结束。也就是说,不管文章有多短,词典有多大,都要将词典遍历一遍。这种方法效率比较低,大一点的系统一般都不使用。 2).基于字典、词库匹配的分词方法(机械分词法) 这种方法按照一定策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功。识别出一个词,根据扫描方向的不同分为正向匹配和逆向匹配。根据不同长度优先匹配的情况,分为最大(最长)匹配和最小(最短)匹配。根据与词性标注过程是否相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。常用的方法如下: (一)最大正向匹配法 (MaximumMatchingMethod)通常简称为MM法。其基本思想为:假定分词词典中的最长词有i个汉字字符,则用被处理文档的当前字串中的前i个字作为匹配字段,查找字典。若字典中存在这样的一个i字词,则匹配成功,匹配字段被作为一个词切分出来。如果词典中找不到这样的一个i字词,则匹配失败,将匹配字段中的最后一个字去掉,对剩下的字串重新进行匹配处理……如此进行下去,直到匹配成功,即切分出一个词或剩余字串的长度为零为止。这样就完成了一轮匹配,然后取下一个i字字串进行匹配处理,直到文档被扫描完为止。