ABSTRACT Cloud Control with Distributed Rate Limiting
- 格式:pdf
- 大小:1020.54 KB
- 文档页数:12

模糊云资源调度的CMAPSO算法作者:李成严,宋月,马金涛来源:《哈尔滨理工大学学报》2022年第01期摘要:针对多目标云资源调度问题,以优化任务的总完成时间和总执行成本为目标,采用模糊数学的方法,建立了模糊云资源调度模型。
利用协方差矩阵能够解决非凸性问题的优势,采取协方差进化策略对种群进行初始化,并提出了一种混合智能优化算法CMAPSO算法(covariance matrix adaptation evolution strategy particle swarm optimization,CMAPSO ),并使用该算法对模糊云资源调度模型进行求解。
使用Cloudsim仿真平台随机生成云计算资源调度的数据,对CMAPSO算法进行测试,实验结果证明了CMAPSO算法对比PSO算法(particle wwarm optimization),在寻优能力方面提升28%,迭代次数相比提升20%,并且具有良好的负载均衡性能。
关键词:云计算;任务调度;粒子群算法; 协方差矩阵进化策略DOI:10.15938/j.jhust.2022.01.005中图分类号: TP399 文献标志码: A 文章编号: 1007-2683(2022)01-0031-09CMAPSO Algorithm for Fuzzy Cloud Resource SchedulingLI Chengyan,SONG Yue,MA Jintao(School of Computer Science and Technology, Harbin University of Science and Technology, Harbin 150080,China)Abstract:Aiming at the multiobjective cloud resource scheduling problem, with the goal of optimizing the total completion time and total execution cost of the task, a fuzzy cloud resource scheduling model is established using the method of fuzzy mathematics. Utilizing the advantage of the covariance matrix that can solve the nonconvexity problem, adopting the covariance evolution strategy to initialize the population, a hybrid intelligent optimization algorithm CMAPSO algorithm (covariance matrix adaptation evolution strategy particle swarm optimization,CMAPSO) is proposed to solve the fuzzy cloud resource scheduling model. The Cloudsim simulation platform was used to randomly generate cloud computing resource scheduling data, and the CMAPSO algorithm was tested. The experimental results showed that compared with the PSO algorithm (particle swarm optimization), the optimization capability of CMAPSO algorithm is increased by 28%, the number of iterations of CMAPSO algorithm is increased by 20%, and it has good load balancing performance.Keywords:cloud computing; task scheduling; particle swarm algorithm; covariance matrix adaptation evolution strategy0引言云計算是一种商业计算的模型和服务模式[1],而云计算资源调度的主要目的是将网络上的资源进行统一的管理和调式,再给予用户服务调用。

OverviewRubrik, the Zero Trust Data Security Company™, delivers data security and operational resilience for enterprises. Rubrik provides data security and data protection on a single platform, going beyond just backup and recovery with Zero Trust Data Protection, Ransomware Investigation, Incident Containment, Sensitive Data Discovery, and Orchestrated Application Recovery. Data is ready at all times so users can recover the data they need, and avoid paying a ransom. Rubrik’s software solution scales linearly and can be quickly deployed anywhere across on-prem, hybrid cloud, and multi-cloud environments to protect physical, virtual, and cloudnative apps.Discovery QuestionsDue to a massive increase in cyber-attacks, security is top of mind to every customer and vertical. What are you doing to ensure your data is safe and recoverable?Rubrik cyber resilience capabilities empower IT and Security teams across the lifecycle of a cyber incident. Rubrik can identify indicators of compromise from backup data to alert teams and help contain the impact of ransomware. Rubrik can also perform analytics across snapshots to identify the last knowngood state to prevent reinfection and delayed recovery. Plus, Rubrik can preserve point-in-time snapshots for use in both internal post incident reviews and cyber investigations for external regulatory compliance.What tools are you using to drive efficiencies in delivering IT services via automation?Rubrik enables users to build custom workflows through integrations with automation tools such as Terraform, ServiceNow, Chef, Puppet, and Ansible.Every organization has a different stance on Cloud. What does cloud mean for your business? Rubrik simplifies multi-cloud data protection across AWS, Azure, Google Cloud, Microsoft 365 andhybrid-cloud workloads, facilitating compliance and governance with centralized reporting. Rubrik also optimizes storage costs with tiering, and automates backup across hundreds of cloud accounts.Microsoft has also made an equity investment in Rubrik, partnering with Rubrik to deliver regulatorycompliance tools alongside data security. One such benefit is Rubrik Cloud Vault, built to reduce the risk of backup data breach, loss, or theft. Rubrik Cloud Vault is a fully managed solution for isolated, offsite cloud archival, allowing users to set up archival policies, select the tier and available regions, and begin direct, authenticated Azure Blob integration for encrypted data upload.Target Customer•Decision-maker is VP of Infrastructure,IT Director/Manager•User is IT Ops, Systems or Network Manager/Admin, Virtualization or Backup Admin•Influencer is SecOps, DBA, Enterprise Architect •Looking to reduce risk of paying the ransom inthe case of ransomware attack•Using enterprise backup software/storage •Looking to reduce financial, operational, andbusiness costs of backup, archival, test/dev •Using or exploring private/public cloud archival(object store, Azure, AWS, GCP)What is your current disaster recovery solution?Rubrik customers can migrate VMs to public cloud; Rubrik automatically converts vSphere and Hyper-V VMs to cloud-native instances such as Amazon EC2 and Azure VM. Rubrik also provides “Brik-to-Brik” replication that is WAN-optimized, meaning that Rubrik minimizes the amount of data sent over long distance network connections. And, Rubrik offers Orchestrated Application Recovery, automating the configuration process for VMs, taking into account application dependencies with predefined blueprints for 2-click DR.Are you meeting your backup and recovery objectives/SLAs?Rubrik customers reduce RTOs and RPOs from hours to seconds With Continuous Data Protection, users can recover missioncritical VMs to just seconds before a disaster or corruption point.Rubrik’s SLA policy engine also simplifies compliance for a “set-it-and-forget-it” approachto backup, replication, and archival.Object HandlingOur air gap has to be physical.99.9% of Rubrik customers buy Rubrik for the security of a physical air gap without the need and the cost/expense of implementing one. But if you do want a physical air gap, Rubrik has options.Aren’t you just going to restore infected files? How do you know what point to recover to?Rubrik users can threat hunt within backups and restore everything except the executable that launched the attack. Rubrik can show what the executable did and if sensitive or regulated data was in scope. Everyone says they are immutable. How is Rubrik any different?Immutability is table stakes these days. Rubrik solutions offer not only that, but also help organizationsin terms of speeding up time to recovery, identifying the blast radius of an attack, and identifying what sensitive data has potentially been impacted in order to help customers get back up and running quickly.I don’t buy into the Zero Trust hype. What does it even mean?Assume a breach has already happened. Authenticate everything. Trust nothing. That is a cornerstone of a successful cyber resilience program and what many executives and boards ask for. It’s also a vital, last line of defense approach. One of the most trusted roles is the backup admin. If they go rogue, and expire all of an organization’s backups, Zero Trust is a critical platform defense strategy. With Rubrik,all data is encrypted and logically air gapped from the rest of the environment, with all access governed by comprehensive authentication and access controls.Unique Selling Points1. Built-in recovery: Recover quickly from ransomware and other DR events via immutable backups, ML-driven detection, detailed impact analysis, and single-click recovery.2. High performance (backup and recovery) at large scale: Near-zero RTOs for VMs and databases via Live Mount. Accelerate test/dev, perform application health checks, and deliver ad-hoc restores with self-service access.3. Policy-driven automation to simplify management operations and protect more apps.4. An API-first design that makes it easy to integrate data management into a larger IT environment for greater efficiency and control.5. Automated protection that applies SLA policies to new cloud applications.6. Consolidated multi-cloud protection eliminates the need to rely on multiple native tools.7. Easy configuration and control with SaaS-based management.8. Zero Trust Security protects cloud and SaaS data so that applications running on-prem, at the edge, and in the cloud can be recovered reliably. Rubrik indexes all app data stored in the cloud,enabling instant access to cloud data through predictive search.Customer Use CasesWED2B prevented disruption from a ransomware attack in November 2019,restoring critical SQL databases with Active Directory immediately. “With Rubrik,we experienced zero data loss, zero impact to our core business, we paidnothing in ransom fees and were up and running in 24 hours, which is fantastic”Rob Mole, Head of IT & Solutions.Langs Building Supplies was hacked in May of 2021. With Rubrik, they recovered100% of their data within 24 hours and paid $0 in ransom. CIO, Matthew Day,stated “Rubrik is not just about recovering from ransomware. Rubrik is thedifference between survival and non-survival in this new digital age.”Colchester Institute recovered from a crippling ransomware attack within daysleveraging Rubrik Zero Trust Data Security. Ben Williams, IT Services Managersaid, “Rubrik safeguarded our backups. Due to its native immutability, 100% ofour backups were protected against corruption and deletion. We were able tokeep the lights on and deliver a robust service to our students and staff.Estée Lauder — Leading house of prestige beauty, Estée Lauder is a collection ofover 25 globally renowned beauty brands, each with its own unique set of dataand unique challenges. To protect all data at scale while keeping costs low, thebeauty company partners with Rubrik to break free from legacy data protectionand mobilize to the cloud.For more customer stories, check out /customers。

外研版英语必修五单词表在本文中,我将按照外研版英语必修五单词表的内容来进行论述。
以下是按照字母顺序排列的单词表:A: abandon, abbreviation, abdomen, abide, ability, abnormal, aboard, abolish, about, above, abroad, abrupt, absence, absolute, absorb, abstract, absurd, abundance, abuse, academic, accelerate, accent, accept, access, acclaim, accommodate, accompany, accomplish, accord, account, accumulate, accurate, accuse, achieve, acknowledge, acquire, act, adapt, addict, addition, adequate, adjust, administration, admire, admit, adopt, adore, adult, advance, advice, advocate, aerial, aesthetic, affirm, affix, affordable, Afro-American, afterwards, agenda, aged, agency, aggress, agony, agree, aid, aim, air, aircraft, aisle, alert, alien, alive, allocate, allot, aloud, amateur, ambassador, ambiguous, ambition, ambulance, among, amount, amuse, analyze, anchor, ancient, anecdote, angel, anger, angle, anniversary, announce, annoy, anonymous, anticipate, antique, anxiety, apart, apartment, ape, apologise, apparent, appeal, applause, appoint, appreciate, approach, appropriate, approve, approximate, aquarium, arch, architect, architecture, archive, area, argue, arise, arm, armed, army, arouse, articulate, artificial, ascend, ash, ashamed, aside, ask, aspect, aspirin, assemble, assert, assess, assign, assist, associate, assume, assurance, astonish, attach, attack, attain, attempt, attend, attention, attitude, attract, attribute, auction, audition, authentic, author, authority, autobiography, automobile, autumn, available, avenue, average, avoid, await, aware, awful, awkward, axeB: baby, bachelor, background, backup, bacteria, badminton, bag, baggage, bait, balance, balcony, bald, ball, ballet, balloon, ballot, ban, band,bandage, bank, bankruptcy, banner, banquet, bar, barbarian, barber, bare, bargain, bark, barn, barrel, barrier, barter, base, baseball, basic, basket, bat, batch, batter, battle, bay, beam, bean, bear, beard, beast, beat, beatify, because, beckon, become, bed, bedroom, bee, beef, beer, beetle, beforehand, beg, begin, behalf, behavior, belief, bell, belle, bellow, belly, belong, belt, bench, bend, beneath, beneficial, benefit, bent, beside, best, betray, better, between, beverage, beware, beyond, bicycle, bid, big, bike, bill, biology, bird, birth, biscuit, bit, bite, bitter, bizarre, blackboard, blade, blame, blank, blanket, blast, blaze, bleach, blend, bless, blind, block, blossom, blouse, blow, blush, board, boast, boat, bob, boil, bold, bolt, bond, bone, bonus, bookcase, booth, border, bore, born, bother, bottle, bottom, bounce, bour, bow, bowling, box, boxer, boy, brac, bracelet, bracket, brave, breach, bread, breakfast, break, breeze, brick, bride, bridge, brief, bright, brilliant, bring, broom, brooch, brood, brother, brow, brown, browse, brush, brutal, bubble, bucket, buckle, bud, bug, build, bulb, bull, bullet, bulletin, bump, bun, bundle, burden, bureau, burglar, burst, business, bust, butcher, butterfly, button, buy, buzz, by, cab, cabin, cabinet, cafe, cafeteria, cage, calculate, calendar, calf, call, calm, calory, camera, campaign, camp, campsite, campus, canal, candidate, candle, canteen, canvas, cap, capability, capacity, capital, capitalism, capsize, capsule, captain, capture, car, carbon, card, care, career, careless, cargo, carpenter, carpet, carriage, carrot, carry, cart, cartoon, case, cassette, cast, castle, casually, cat, cattle, cause, caution, cave, ceiling, celebrate, celebrity, censor, certain, certificate, chain, chair, chairman, chalk, challenge, champion, chance, change, channel, chaos, chap, chapel, chapter, character, charge, charity, charm, chart, chase, cheap, check, cheese, chef, chemical, chemistry, cherry, chess, chest, chew, chicken, chief, child, chill, chin, chip, chorus, choose, chop, chuckle, church, cigarette, cinema, circle,circumstance, cite, citizen, city, civilization, claim, clasp, classical, classify, clean, clergy, clerk, clever, cliff, climate, climb, clinic, clip, cloak, clock, close, clothes, clothing, cloud, clown, club, clue, clumsy, coach, coal, coast, collapse, collar, colleague, collect, college, collocation, colony, column, comb, combat, combine, comedian, comedy, comma, command, comment, commercial, commission, commitment, committee, common, communicate, communism, community, commute, compact, companion, company, compare, comparison, compel, compensate, compete, competition, compile, complain, complaint, complete, complicated, comply, compose, composition, comprehend, comprehensive, compress, comprise, compute, computer, concentrate, concept, concern, concert, conclude, conclusion, concrete, condense, condition, conduct, cone, confess, confidence, confirm, conflict, confuse, confusion, congratulate, congress, connect, connection, conquer, conscience, conscious, consent, consequence, conservative, consider, consist, consistent, console, consolidate, conspiracy, constant, constitute, construct, construction, consult, consume, consumer, consumption, contact, contain, contemporary, contempt, content, contest, context, continent, continue, contradiction, contrary, contribution, control, convert, conviction, convince, cook, cool, cooperation, coordinate, cope, copper, copy, core, corn, corner, correct, correspondence, corridor, corrupt, corruption, cost, costume, cosy, cotton, couch, cough, council, counsel, count, country, countryside, county, couple, courage, course, court, cousin, cover, coward, cow, crack, craft, cram, crane, crash, crawl, crazy, cream, create, creature, credit, crew, cricket, crime, criminal, crisis, crisp, criterion, criticize, crop, cross, crowd, crown, crucial, cruel, cruise, crush, crust, cry, crystal, cube, cucumber, cuddle, cuisine, cultivate, culture, cup, cupboard, cure, curious, curl, currency,current, curriculum, curse, curtain, curve, cushion, custom, customer, customs, cute, cycle, cylinderD: dad, daily, dairy, dam, damage, dame, damp, dance, danger, dangerous, dare, dark, darling, dart, dash, date, daughter, dawn, day, daylight, dazzle, dead, deaf, deal, dear, death, debate, debris, debt, decay, deceit, deceive, decide, decision, declare, decline, decorate, decrease, dedicate, deem, deep, deer, defeat, defend, defendant, defense, define, defy, degree, delay, delete, deliberate, delightful, deliver, delivery, demand, democracy, demonstrate, deny, depart, department, departure, depend, dependant, deposit, depress, depression, deputy, depth, derive, describe, desert, deserve, design, designate, desirable, desire, desk, despair, desperate, despise, destination, destroy, destruction, detach, detail, determination, determine, devote, diamond, diary, dice, dictionary, die, difference, different, difficult, dig, dilemma, dimension, dine, dinner, dip, direct, director, dirt, dirty, disability, disaster, discard, discharge, disciple, discipline, disclose, discount, discourse, discover, discretion, discriminate, discuss, disease, disguise, disgust, dish, dismay, dismiss, disorder, display, disposal, dispose, dispute, dissent, dissolve, distance, distinguish, distract, distress, distribute, district, disturb, dive, divide, divine, division, divorce, dizzy, document, dog, doll, dollar, dolphin, domain, dome, domestic, dominant, dominate, donate, donation, donkey, doom, door, dope, dose, dot, double, doubt, dough, dove, down, downstairs, downward, dozen, draft, drag, drain, drama, drapery, draw, dread, dream, dreary, dress, dressmaker, dribble, drift, drill, drink, drip, drive, drop, drown, drug, drum, drunk, dry, dual, duck, dull, dumb, dump, dust, duty, dwell, dynamicE: each, eager, eagle, ear, earnest, ease, easily, east, easy, eat, echo, economic, economics, economize, economy, edge, edit, edition, editor, educate, education, effective, effectiveness, efficient, effort, either, elastic, elation, electric, electricity, electronic, elegant, elevator, eliminate, elite, else, elsewhere, embarrass, embassy, emerge, emergency, emotion, emotional, emphasis, emphasize, employ, employee, employer, employment, empty, enable, enclose, enclosure, encourage, end, endless, enemy, energy, engage, engine, engineer, engineering, enhance, enjoy, enlarge, enormous, enough, ensure, enter, entertain, enthusiasm, entire, entrance, entry, envelope, environment, envy, episode, equal, equality, equator, equip, equipment, equivalent, era, erode, error, escape, especially, essay, essence, essential, establish, estate, esteemed, estimate, eternal, ethics, ethnic, evaporate, even, event, eventual, ever, every, evidence, evil, evolution, evolve, exaggerate, examine, example, excavate, exceed, excel, excellent, except, exception, excess, exchange, excited, exciting, exclude, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation,exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse,execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise,exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhaust, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhausted, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhausted, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhausted, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhausted, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhausted, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhausted, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhausted, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhausted, exhibit, existence, exit,exclamation, exclude, excursion, excuse, execute, executive, exercise, exhausted, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhausted, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhausted, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhausted, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhausted, exhibit, existence, exit, exclamation, exclude, excursion, excuse, execute, executive, exercise, exhausted, exhibit, existence, exit, exclamation, exclude, excursion, excuse,。

云计算中分布式系统技术的使用教程推荐云计算已经成为当今科技领域的热门话题,如何利用分布式系统技术实现云计算的应用,是每个云计算从业者都需要掌握的关键技能。
在本文中,我将为您介绍几本经典的分布式系统技术使用教程,帮助您更好地理解和应用云计算中的分布式系统技术。
1. 《分布式系统:概念与设计》(Distributed Systems: Concepts and Design)这本经典教材由George Coulouris等人合著,已经成为分布式系统领域的标准参考书之一。
书中详细介绍了分布式系统的概念、架构和设计原则。
从分布式系统的基础概念开始介绍,涵盖了分布式系统的通信、一致性、容错、安全等方面的内容,适合初学者和高级从业者阅读。
此外,书中还涉及了很多经典的分布式系统技术和实际案例,对于深入理解分布式系统有很大帮助。
2. 《分布式系统原理与范型》(Distributed Systems: Principles and Paradigms)由Andrew S. Tanenbaum和Maarten van Steen合著,该书是分布式系统领域的另一本经典之作。
除了介绍分布式系统的基本原理外,还强调了分布式系统中常见的范型,如客户端-服务器模型、对等网络模型等。
该书提供了大量实例和案例研究,让读者更好地理解实际应用中的分布式系统设计和实现。
3. 《分布式系统:原理与范型(第二版)》(Distributed Systems: Principles and Paradigms)该书是前述《分布式系统原理与范型》的第二版,由Andrew S. Tanenbaum和Maarten van Steen继续合著。
相较于第一版,第二版增加了对最新分布式系统技术和云计算的介绍。
书中详细介绍了云计算的概念、架构和关键技术,包括虚拟化、容器化等。
此外,还讨论了云计算中的安全与隐私、大数据处理等前沿问题。
对于想要深入了解云计算中的分布式系统技术的读者来说,这本书是不可或缺的。


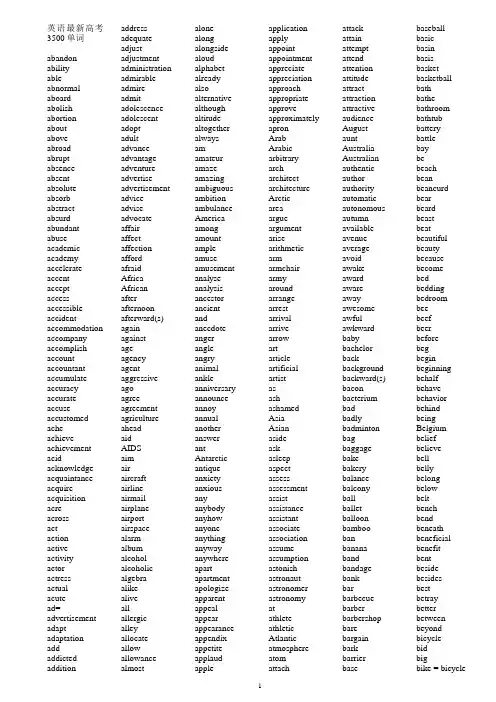
英语最新高考3500单词abandon abilityable abnormal aboard abolish abortion aboutaboveabroadabrupt absence absent absolute absorb abstract absurd abundant abuse academic academy accelerate accentaccept access accessible accident accommodation accompany accomplish account accountant accumulate accuracy accurate accuse accustomed acheachieve achievement acid acknowledge acquaintance acquire acquisition acreacrossactactionactiveactivityactoractressactualacutead= advertisement adapt adaptationaddaddicted addition addressadequateadjustadjustmentadministrationadmirableadmireadmitadolescenceadolescentadoptadultadvanceadvantageadventureadvertiseadvertisementadviceadviseadvocateaffairaffectaffectionaffordafraidAfricaAfricanafterafternoonafterward(s)againagainstageagencyagentaggressiveagoagreeagreementagricultureaheadaidAIDSaimairaircraftairlineairmailairplaneairportairspacealarmalbumalcoholalcoholicalgebraalikealiveallallergicalleyallocateallowallowancealmostalonealongalongsidealoudalphabetalreadyalsoalternativealthoughaltitudealtogetheralwaysamamateuramazeamazingambiguousambitionambulanceAmericaamongamountampleamuseamusementanalyseanalysisancestorancientandanecdoteangerangleangryanimalankleanniversaryannounceannoyannualanotheranswerantAntarcticantiqueanxietyanxiousanyanybodyanyhowanyoneanythinganywayanywhereapartapartmentapologizeapparentappealappearappearanceappendixappetiteapplaudappleapplicationapplyappointappointmentappreciateappreciationapproachappropriateapproveapproximatelyapronArabArabicarbitraryarcharchitectarchitectureArcticareaargueargumentarisearithmeticarmarmchairarmyaroundarrangearrestarrivalarrivearrowartarticleartificialartistasashashamedAsiaAsianasideaskasleepaspectassessassessmentassistassistanceassistantassociateassociationassumeassumptionastonishastronautastronomerastronomyatathleteathleticAtlanticatmosphereatomattachattackattainattemptattendattentionattitudeattractattractionattractiveaudienceAugustauntAustraliaAustralianauthenticauthorauthorityautomaticautonomousautumnavailableavenueaverageavoidawakeawardawareawayawesomeawfulawkwardbabybachelorbackbackgroundbackward(s)baconbacteriumbadbadlybadmintonbagbaggagebakebakerybalancebalconyballballetballoonbamboobanbananabandbandagebankbarbarbecuebarberbarbershopbarebargainbarkbarrierbasebaseballbasicbasinbasisbasketbasketballbathbathebathroombathtubbatterybattlebaybebeachbeanbeancurdbearbeardbeastbeatbeautifulbeautybecausebecomebedbeddingbedroombeebeefbeerbeforebegbeginbeginningbehalfbehavebehaviorbehindbeingBelgiumbeliefbelievebellbellybelongbelowbeltbenchbendbeneathbeneficialbenefitbentbesidebesidesbestbetraybetterbetweenbeyondbicyclebidbigbike = bicycle1billbingo biochemistry biography biologybirdbirth birthday birthplace biscuit bishopbitbitebitterblack blackboard blame blank blanket bleedblessblindblock blood blouseblowblueboardboatbodyboilbombbondbone bonusbookboombootbooth border bored boringborn borrow boss botanical botanyboth bother bottle bottom bounce bound boundary bowbowl bowling boxboxingboy boycott brainbrake branch brand bravebraverybreadbreakbreakfastbreakthroughbreastbreathbreathebreathlessbrewerybrickbridebridegroombridgebriefbrightbrilliantbringBritainBritishbroadbroadcastbrochurebrokenbroombrotherbrownbrushbucketBuddhismbudgetbuildbuildingbuildingbunchbungalowburdenbureaucraticburnburstburybusbushbusinessbusinessmanbusybutbutcherbutterbutterflybuttonbuybybyecabcabbagecafecafeteriacagecakecalculatecallcalmcamelcameracampcampaigncanCanadiancanalcancelcancercandidatecandlecandycanteencapcapitalcapsulecaptaincaptioncarcarboncardcarecarefulcarelesscarpentercarpetcarriagecarriercarrotcarrycartcartooncarvecasecashcassettecastcastlecasualcatcataloguecatastrophecatchcategorycaterCatholiccattlecausecautiouscautiouscavecelebratecelebrationcellcentcentigradecentimetercentralcentrecenturyceremonycertaincertificatechainchairchairmanchalkchallengechallengingchampionchancechangechangeablechannelchantchaoschaptercharactercharacteristicchargechartchatcheapcheatcheckcheekcheercheerfulcheesechefchemicalchemistchemistrychequechesschestchewchickenchiefchildchildhoodchimneyChinaChinesechocolatechoicechoirchokechoosechopstickschorusChristianChristmaschurchcigarcigarettecinemacirclecircuitcirculatecircumstancecircuscitizencitycivilcivilizationclaimclapclarifyclassclassicclassmateclassroomclawclaycleancleanerclearclerkcleverclickclimateclimbclinicclockclonecloseclothclothesclothingcloudcloudyclubclumsycoachcoalcoastcoatcockcocoacoffeecoincoincidencecokecoldcollarcolleaguecollectcollectioncollegecollisioncolourcombcombinecomecomedycomfortcomfortablecommandcommentcommercialcommitcommitteecommoncommunicatecommunicationcommunismcommunistcompanioncompanycomparecompasscompensatecompetecompetencecompetitioncomplaincompletecomplexcomponentcompositioncomprehensioncompromisecompulsorycomputercomradeconcentrateconceptconcernconcertconcludeconclusionconcretecondemnconditionconductconductorconferenceconfidentconfidentialconfirmconflictconfusecongratulatecongratulationconnectconnectionconscienceconsensusconsequenceconservativeconsiderconsiderateconsiderationconsistconsistentconstantconstitutionconstructconstructionconsultconsultantconsumecontaincontainercontemporarycontentcontentcontinentcontinuecontradictcontradictorycontrarycontributecontributioncontrolcontroversialconvenienceconvenientconventionalconversation2convey convince cook cooker cookie coolcopycorn corner corporation correct correction correspond corrupt costcosy cottage cotton cough could count counter country countryside couple courage course court courtyard cousin covercow crash crayon crazy cream create creature credit crew crime criminal criterion crop cross crossing crossroads crowd cruelcrycube cubic cuisine culture cup cupboard cure curious currency curriculum curtain cushion custom customer customs cutcyclecyclistdad = daddydailydamdamagedancedangerdangerousdaredarkdarknessdashdatadatabasedatedatedaughterdawndaydeaddeadlinedeafdealdeardeathdebatedebtdecadeDecemberdecidedecisiondeclaredeclinedecoratedecorationdecreasedeeddeepdeerdefeatdefencedefenddegreedelaydeletedeliberatelydelicatedeliciousdelightdelighteddeliverdemanddentistdepartmentdeparturedependdepositdepthdescribedescriptiondesertdeservedesigndesiredeskdesperatedessertdestinationdestroydetectivedeterminedevelopdevelopmentdevotedevotiondiagramdialdialoguediarydictationdictionarydiedietdifferdifferencedifferentdifficultdifficultydigdigestdigitaldignitydilemmadimensiondinedinnerdinosaurdioxidedipdiplomadirectdirectiondirectordirectorydirtydirtydisabilitydisableddisadvantagedisagreedisagreementdisappeardisappointeddisasterdiscountdiscouragediscoverdiscoverydiscriminationdiscussdiscussiondiseasedisgustingdiskdislikedismissdisobeydistancedistantdistinctiondistinguishdistributedistrictdisturbdisturbingdivediversedividedivisiondivorcedizzydodoctordocumentdogdolldollardonatedoordormitorydotdoubledoubtdowndownloaddownstairsdowntowndozendraftdragdrawdrawbackdrawerdrawingdreamdressdrilldrinkdrivedriverdropdrowndrugdrumdryduckduedullduringduskdustdustbindustydutydynamicdynastyeacheagereagleearearlyearnearthearthquakeeastEastereasterneasyeatedgeeditioneditoreducateeducationeducatoreffectefforteggEgyptEgyptianeighteeneightheightyeitherelderelectelectricelectricalelectricityelectronicelegantelephantelevenelsee-maile-mailembarrassembassyemergencyemperoremployemptyencourageencouragementendendingendlessenemyenergeticenergyengineengineerEnglandEnglishenjoyenjoyableenlargeenoughenquiryenterenterpriseentertainmententhusiasticentireentranceentryenvelopeenvironmentenvyequalequalityequipequipmenterasererroreruptescapeespeciallyessayEuropeEuropeanevaluateeveeveneveningeventeventuallyevereveryeverybodyeverydayeveryoneeverythingeverywhereevidenceevidentevolutionexactexamexamineexampleexcellentexceptexchangeexciteexcuseexerciseexhibitionexistexistenceexitexpandexpectexpectationexpenseexpensiveexperienceexperimentexpertexplainexplanationexplicitexplodeexploreexportexposeexpressexpressionextensionextraextraordinaryextremeextremely3eye eyesight face facial fact factory fadefail failure fair faithfall false familiar family famous fan fancy fantastic fantasy farfare farm farmer fashion fast fasten fat father fault favour favourite faxfear feast feather February federal fee feed feel feeling fellow female fence ferry festival fetch fever few fibre fiction fiction field fierce fifteen fifth fifty fight figure figure filefillfilm final financefindfinefingerfinishfirefireworkfirmfirstfishfishermanfistfitfivefixflagflameflashflashlightflatfleefleshflexibleflightfloatfloodfloorflourflowflowerflufluencyfluentfluentflyfocusfogfoggyfoldfolkfollowfondfoodfoolfoolishfootfootballforforbidforceforecastforeheadforeignforeignerforeseeforestforeverforgetforgetfulforgiveforkformformerfortnightfortunatefortunefortyforwardfosterfoundfoundfountainfourfourteenfourthfoxfragilefragrantframeworkfrancfreefreedomfreewayfreezefreezingfrequentfreshFridayfridgefriendfriendlyfriendshipfrightenfrogfromfrontfrontierfrostfruitfryfuelfullfunfunctionfundamentalfuneralfunnyfurfurnishedfurniturefuturegaingallerygallongamegaragegarbagegardengarlicgarmentgasgategathergaygeneralgenerallygenerationgenerousgentlegentlemangeographygeometrygesturegetgiftgiftedgiraffegirlgivegladglareglassglobegloryglovegluegogoalgoatgodgoldgolfgoodgoodsgoosegoverngovernmentgradegradualgraduategraduationgraingramgrammargrandgrandchildgranddaughtergrandmagrandpagrandparentsgrandsongrannygrapegraphgraspgrassgratefulgravitygreatGreecegreedyGreekgreengreengrocergreetgreetinggreygrocergrocerygroundgroupgrowgrowthguaranteeguardguessguestguidanceguideguiltyguitargungymgymnasticshabithairhaircuthalfhallhamhamburgerhammerhandhandbaghandfulhandkerchiefhandlehandsomehandwritinghandyhanghappenhappinesshappyharbourhardhardlyhardshiphardworkingharmharmfulharmonyharvesthathatchhatehaveheheadheadacheheadlineheadmasterheadmistresshealthhealthyheaphearhearingheartheatheavyheelheighthelicopterhellohelmethelphelpfulhenherhereherohersherselfhesitatehihidehighhighwayhillhimhimselfhirehishistoryhithobbyholdholeholidayholyhomehomelandhometownhomeworkhonesthonourhookhopehopefulhopelesshorriblehorsehospitalhosthostesshothotdoghotelhourhousehousewifehouseworkhowhoweverhowlhughugehumanhuman beinghumoroushumourhundredhungerhungryhunthunterhurricanehurryhurthusbandhydrogenIiceice-cream4Icelandidea identification identity idiomifignoreillillegal illness imagine immediately immigration import importance important impossible impress impression improveininch incident include income increase indeed independence independent IndiaIndian indicate industry infer influence inform information initialinjureinjuryinkinn innocent insect insideinsist inspect inspire instant instead institute institution instruction instrument insurance insure intelligence intend intention interest interesting international Internet interpreter interrupt interviewintointroduceintroductioninventinventioninvitationinviteinviteIrelandIrishironirrigationislanditItalianItalyitsitselfjacketjamJanuaryJapanJapanesejarjawjazzjeansjetjewelleryjobjogjoinjokejournalistjourneyjoyjudgejudgmentjuiceJulyjumpJunejunglejuniorjustjusticekangarookeepkettlekeykeyboardkickkidkillkilokilogramkilometrekindkindergartenkindnesskingkingdomkisskitchenkitekneeknifeknockknowknowledgelab = laboratorylabourlackladylakelamelamplandlanguagelanternlaplargelastlatelatterlaughlaughterlaundrylawlawyerlaylazyleadleaderleadingleafleagueleaklearnleastleatherleavelectureleftleglegallemonlemonadelendlengthlessonletletterlevellibertylibrarianlibrarylicencelidlielifelifetimeliftlightlightninglikelikelylimitlinelinklionlipliquidlistlistenliteraryliteraturelitrelitterlittlelivelivelylivingloadloaflocallocklonelylonglooklooselorryloselosslotloudloungelovelovelylowluckluckyluggagelunchlungmachinemadmadam/madamemagazinemagicmaidmailmailboxmainmainlandmajormajoritymakemalemanmanagemanagermankindmannermanymapmaplemarathonmarblemarchmarketmarketmarriagemarriedmarrymaskmassmastermatmatchmaterialmathematics =mathsmattermaturemaximummaymaybememealmeanmeaningmeansmeanwhilemeasuremeatmedalmediamedicalmedicinemediummeetmeetingmelonmembermemorialmemorymendmentalmentionmenumerchantmercifulmercymerelymerrymessmessagemessymetalmethodmeterMexicanMexicomicroscopemicrowavemiddlemidnightmightmildmilemilkmillionmillionairemindminemineralminibusminimumministerministryminorityminusminutemirrormissmissilemistmistakemistakenmisunderstandmixmixturemmmobilemodelmodemmodernmodestmom = mummomentmommyMondaymoneymonitormonkeymonthmoonmopmoralmoremorningMoslemmosquitomostmothermotherlandmotivationmotormotorcyclemottomountainmountainousmournmousemoustachemouthmovemovementmovieMr.Mrs.Ms.muchmudmuddymultiplymurdermuseummushroommusicmusicalmusician5must mustard muttonmymyselfnailnamenarrow nation national nationality nationwide native natural naturenavynearnearby nearlyneat necessary neck necklace needneedle negotiate neighbour neighbourhood neither nephew nervousnestnetnetwork nevernewNew Zealand news newspaper nextniceniecenightnine nineteen ninetyninthnoNo. = number noble nobodynodnoisenoisynonenoodlenoonnornormalnorth northeast northern northwest nosenot notenotebooknothingnoticenovelnovelistNovembernownowadaysnowherenuclearnuclearnumbnumbernursenurserynutnutritionnylonO.K.o’clockobeyobjectobserveobtainobviousoccupationoccupyoccuroceanOceaniaofoffofferofficeofficerofficialoffshoreoftenohoiloilfieldOKoldOlympic(s)ononceoneoneselfoniononlyontoopenopeningoperaoperateoperationoperatoropinionopposeoppositeoptimisticoptionalororalorangeorbitorderordinaryorganorganizeorganizationorganizeoriginotherotherwiseoughtouroursourselvesoutoutcomeoutdoorsouteroutgoingoutingoutlineoutputoutsideoutspokenoutstandingoutwardsovaloverovercoatovercomeoverheadoverlookoverweightoweownownerownershipoxoxygenP.E.p.m./pm,P.M./PMpacePacificpackpackagepacketpaddlepagepainpainfulpaintpainterpaintingpairpalacepalepanpancakepandapanicpaperpaperworkparagraphparallelparcelpardonparentparkparrotpartparticipateparticularpartlypartnerpart-timepartypasspassagepassengerpasser-bypassivepassportpastpatentpathpatiencepatientpatternpausepavementpayPCpeapeacepeacefulpeachpearpeasantpedestrianpenpencilpennypensionpeoplepepperperpercentpercentageperfectperformperformanceperformerperfumeperhapsperiodpermanentpermissionpermitpersonpersonalpersonnelpersuadepestpetpetrolphenomenonphonephoto =photographphotographerphrasephysicalphysicistphysicspianistpianopickpicnicpicturepiepiecepigpilepillpillowpilotpinpinepineapplepingpongpinkpintpioneerpipepityplaceplainplanplaneplanetplantplasticplateplatformplayplayerplaygroundpleasantpleasepleasedpleasureplentyplotploughplugpluspmpocketpoempoetpointpoisonpoisonouspolepolicepolicemanpolicypolishpolitepoliticalpoliticianpoliticspollutepollutionpondpoolpoorpop = popularpopcornpopularpopulationporkporridgeportportableporterpositionpositivepossesspossessionpossibilitypossiblepostpostagepostcardpostcodepostmanpostponepotpotatopotentialpoundpourpowderpowerpowerfulpracticalpracticepractisepraiseprayprayerpreciousprecisepredictpreferpreferencepregnantprejudicepremierpreparationprepareprescriptionpresentpresentationpreservepresidentpresspressurepretendprettypreventpreviewpreviouspriceprideprimaryprimitive6principle printprison prisoner private privilege prize probably problem procedure process produce product production profession professor profit programme progress prohibit project promise promote pronounce pronunciation proper properly protect protection proudprove provide province psychology pubpublic publishpullpulsepump punctual punctuation punish punishment pupil purchase purepurple purpose pursepushputpuzzle pyramid quake qualification quality quantity quarrel quarter queen question questionnaire queuequick quietquitquitequizrabbitraceracialradiationradioradioactiveradiumragrailrailwayrainrainbowraincoatrainfallrainyraiserandomrangerankrapidrareratrateratherrawrayrazorreachreactreadreadingreadyrealrealiserealityreallyreasonreasonablerebuildreceiptreceivereceiverrecentreceptionreceptionistrecipereciterecogniserecommendrecordrecorderrecoverrecreationrecycleredreducereferrefereereferencereflectreformrefreshrefrigeratorrefuseregardregardlessregisterregretregularregulationrejectrelaterelationrelationshiprelativerelaxrelayrelevantreliablereliefreligionreligiousrelyremainremarkrememberremindremoteremoverentrepairrepeatreplacereplyreportreporterrepresentrepresentativerepublicrequestrequirerequirementrescueresearchresemblereservationreserveresignresistrespectrespondresponsibilityrestrestaurantrestrictionresultretellretirereturnreviewrevisionrevolutionrewardrewindrhymericerichriddlerideridiculousrightrigidringriperipenriseriskriverroadroastrobrobotrockrocketrolerollroofroomroosterrootroperoserotroughroundroundaboutroutinerowroyalrubberrubbishruderugbyruinrulerulerrunrunnerrunningrushRussiaRussiansacredsacrificesadsadnesssafesafetysailsailorsaladsalarysalesalesgirlsalesmansaltsaltysalutesamesandsandwichsatellitesatisfactionsatisfySaturdaysaucersausagesavesaysayingscanscarescarfscenesceneryschedulescholarscholarshipschoolschoolbagschoolboyschoolmatesciencescientificscientistscissorsscoldscoreScotlandScottishscratchscreamscreensculptureseaseagullsealsearchseashellseasideseasonseatseaweedsecondsecretsecretarysectionsecuresecurityseeseedseekseemseizeseldomselectselfselfishsellsemicircleseminarsendseniorsensesensitivesentenceseparateseparationSeptemberseriousservantserveservicesessionsetsettlesettlementsettlersevenseventeenseventhseventyseveralseveresewsexshabbyshadeshadowshakeshallshallowshameshapesharesharksharpsharpensharpenershaveshavershesheepsheetshelfshelfsheltershineshipshirtshockshoeshootshopshopkeepershoppingshoreshortshortcomingshortlyshortsshotshouldshouldershoutshowshowershrinkshutshuttleshy7sick sickness side sideroad sideway sideways sighsight sightseeing sign signal signature significance silence silentsilksillysilver similar simple simplify simply since sincerely sing singlesinksirsistersit situation six sixteen sixteenth sixthsixtysizeskate skateboard skeptical skiskill skillful skinskipskirtsky skyscraper slave slavery sleep sleepy sleeve sliceslideslightslimslipslowsmall smart smell smile smog smoke smokersmoothsnakesneakersneezesniffsnowsnowysosoapsobsoccersocialsocialismsocialistsocietysocksocketsofasoftsoftwaresoilsolarsoldiersolidsomesomebodysomehowsomeonesomethingsometimessomewheresonsongsoonsorrowsorrysortsoulsoundsoupsoursouthsoutheastsouthernsouvenirsowspacespaceshipspadeSpainSpanishsparesparrowspeakspeakerspearspecialspecialistspecificspeechspeedspellspellingspendspinspiritspiritualspitsplendidsplitspoilspokenspokesmansponsorspoonspoonfulsportspotsprayspreadspringspysquaresqueezesquidsquirrelstablestadiumstaffstagestainstainlessstairstampstandstandardstarstarestartstarvationstarvestatestatementstatesmanstationstatisticstatuestatusstaysteadysteakstealsteamsteelsteepstepstewardstewardessstickstillstockingstomachstonestopstoragestorestormstorystoutstovestraightstraightforwardstraitstrangestrangerstrawstrawberrystreamstreetstrengthstrengthenstressstrictstrikestringstrongstrugglestubbornstudentstudiostudystupidstylesubjectsubjectivesubmitsubscribesubstitutesucceedsuccesssuchsucksuddensuffersufferingsugarsuggestsuggestionsuitsuitablesuitcasesuitesummarysummersunsunburntSundaysunlightsunnysunsetsunshinesupersuperiorsupermarketsuppersupplysupportsupposesupremesuresurfacesurgeonsurplussurprisesurroundsurroundingsurvivalsurvivesuspectsuspensionswallowswapswearsweatsweatersweepsweepsweetswellswiftswimswingSwissswitchSwitzerlandswordsymbolsympathysymphonysymptomsystemsystematictabletable tennistailtailortaketaletalenttalktalltanktaptapetargettasktastetastelesstastytaxtaxitaxpayerteateachteacherteamteamworkteapottearteasetechnicaltechniquetechnologyteenagertelephonetelescopetelevisiontelltemperaturetempletemporarytentendtendencytennistensetenttentativetermterminalterribleterrifyterrortesttexttextbookthanthankthankfulthatthetheatrethefttheirtheirsthemthemethemselvesthentheoreticaltheorytherethereforethermosthesetheythickthiefthinthingthinkthinkingthirdthirstthirstythirteenthirtythisthoroughthosethoughthoughtthousandthreadthreethrillthrillerthroatthroughthroughoutthrowthunderthunderstormThursday8。
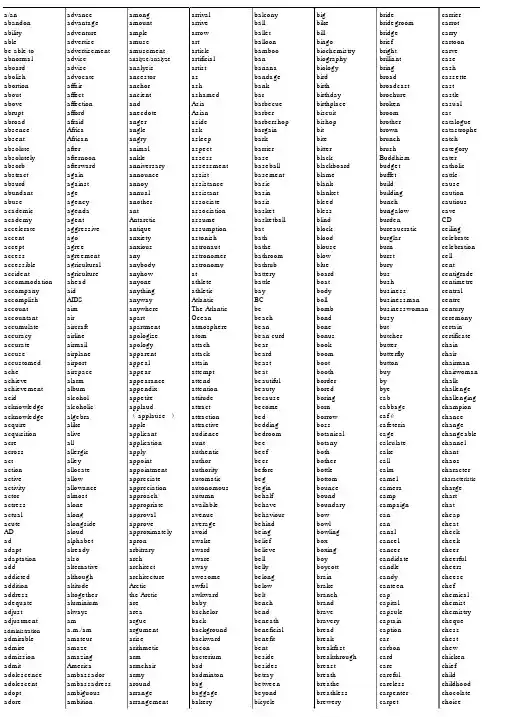
---------a/an advance among arrival balcony big bride carrier abandon advantage amount arrive ball bike bridegroom carrot ability adventure ample arrow ballet bill bridge carryable advertise amuse art balloon bingo brief cartoonbe able to advertisement amusement article bamboo biochemistry bright carve abnormal advice analyse/analyze artificial ban biography brilliant case aboard advise analysis artist banana biology bring cash abolish advocate ancestor as bandage bird broad cassette abortion affair anchor ash bank birth broadcast castabout affect ancient ashamed bar birthday brochure castle above affection and Asia barbecue birthplace broken casual abrupt afford anecdote Asian barber biscuit broom catabroad afraid anger aside barbershop bishop brother catalogue absence Africa angle ask bargain bit brown catastrophe absent African angry asleep bark bite brunch catch absolute after animal aspect barrier bitter brush category absolutely afternoon ankle assess base black Buddhism cater absorb afterward anniversary assessment baseball blackboard budget catholic abstract again announce assist basement blame buffet cattle absurd against annoy assistance basic blank build cause abundant age annual assistant basin blanket building caution abuse agency another associate basis bleed bunch cautious academic agenda ant association basket bless bungalow cave academy agent Antarctic assume basketball blind burden CD accelerate aggressive antique assumption bat block bureaucratic ceiling accent ago anxiety astonish bath blood burglar celebrate accept agree anxious astronaut bathe blouse burn celebration access agreement any astronomer bathroom blow burst cell accessible agricultural anybody astronomy bathtub blue bury cent accident agriculture anyhow at battery board bus centigrade accommodation ahead anyone athlete battle boat bush centimetre accompany aid anything athletic bay body business central accomplish AIDS anyway Atlantic BC boll businessman centre account aim anywhere The Atlantic be bomb businesswoman century accountant air apart Ocean beach bond busy ceremony accumulate aircraft apartment atmosphere bean bone but certain accuracy airline apologize atom bean curd bonus butcher certificate accurate airmail apology attach bear book butter chain accuse airplane apparent attack beard boom butterfly chair accustomed airport appeal attain beast boot button chairman ache airspace appear attempt beat booth buy chairwoman achieve alarm appearance attend beautiful border by chalk achievement album appendix attention beauty bored bye challenge acid alcohol appetite attitude because boring cab challenging acknowledge alcoholic applaud attract become born cabbage champion acknowledge algebra( applause)attraction bed borrow caf échance acquire alike apple attractive bedding boss cafeteria change acquisition alive applicant audience bedroom botanical cage changeable acre all application aunt bee botany calculate channel across allergic apply authentic beef both cake chantact alley appoint author beer bother call chaos action allocate appointment authority before bottle calm character active allow appreciate automatic beg bottom camel characteristic activity allowance appreciation autonomous begin bounce camera charge actor almost approach autumn behalf bound camp chart actress alone appropriate available behave boundary campaign chatactual along approval avenue behaviour bow can cheap acute alongside approve average behind bowl can cheatAD aloud approximately avoid being bowling canal checkad alphabet apron awake belief box cancel cheek adapt already arbitrary award believe boxing cancer cheer adaptation also arch aware bell boy candidate cheerful add alternative architect away belly boycott candle cheers addicted although architecture awesome belong brain candy cheese addition altitude Arctic awful below brake canteen chef address altogether the Arctic awkward belt branch cap chemical adequate aluminium are baby bench brand capital chemist adjust always area bachelor bend brave capsule chemistry adjustment am argue back beneath bravery captain cheque administration a.m./am argument background beneficial bread caption chess admirable amateur arise backward benefit break car chest admire amaze arithmetic bacon bent breakfast carbon chew admission amazing arm bacterium beside breakthrough card chicken admit America armchair bad besides breast care chief adolescence ambassador army badminton betray breath careful child adolescent ambassadress around bag between breathe careless childhood adopt ambiguous arrange baggage beyond breathless carpenter chocolate adore ambition arrangement bakery bicycle brewery carpet choiceadult ambulance arrest balance bid brick carriage choir---------choke communication cookie dawn dioxide due equality fantastic choose communism cool day dip dull equip fantasy chopsticks communist copy dead diploma dumpling equipment far chorus companion corn deadline direct during eraser fare Christian company corner deaf direction dusk error farm Christmas compare corporation deal director dust erupt farmer church compass correct dear directory dustbin escape fastcigar compensate correction death dirty dusty especially fasten cigarette compete correspond debate disability duty essay fat cinema competence corrupt debt disabled DVD Europe father circle competition cost decade disadvantage dynamic European fault circuit complete cosy/cozy decide disagree dynasty evaluate favour circulate complex cottage decision disagreement each even favourite circumatance component cotton declare disappear eager evening fax circus composition cough decline disappoint eagle event fear citizen comprehension count decorate disappointed ear eventually feastcity compromise counter decoration disaster early ever feather civil compulsory country decrease discount earn every federal civilian computer countryside deed discourage earth everybody fee civilization concentrate couple deep discover earthquake everyday feedclap concept courage deer discovery east everyone feel clarify concern course defeat discrimination Easter everything feeling class concert court defence discuss eastern everywhere fellow classic conclude courtyard defend discussion easy evidence female classify conclusion cousin degree disease eat evident fence classmate concrete cover delay disgusting ecology evolution ferry classroom condition cow delete dish edge exact festival claw condemn crash deliberately dislike edition exam fetch clay conduct crayon delicate dislike editor examine fever clean conductor crazy delicious dismiss educate example few cleaner conference cream delight distance educator excellent fibre clear confident create delighted distant education except fiction clerk confidential creature deliver distinction effect exchange field clever confirm credit demand distinguish effort excite fierce click conflict crew dentist distribute egg excuse fight climate confuse crime department district eggplant exercise figure climb congratulate criminal departure disturb either exhibition fileclinic congratulation criterion depend disturbing elder exist fillclock connect crop deposit dive elect existence film clone connection cross depth diverse electric exit final close conscience crossing describe divide electrical expand finance cloth consensus crossroads description division electricity expect find clothes consequence crowd desert divorce electronic expectation fine clothing conservation cruel deserve dizzy elegant expense fine cloud conservative cry design do elephant expensive finger cloudy consider cube desire doctor else experience fingernail club considerate cubic desk document e-mail experiment finish clumsy consideration cuisine desperate dog embarrass expert fire coach consist culture dessert doll embassy explain fireworks coal consistent cup destination dollar emergency explanation firm coast constant cupboard destroy donate emperor explicit firmcoat constitution cure detective door employ explode fish cocoa construct curious determine dormitory empty explore fisherman coffee construction currency develop dot encourage export fistcoin consult curriculum development double encouragement expose fit coincidence consultant curtain devote doubt end express fixcoke consume cushion devotion down ending expression flagcold contain custom diagram download endless extension flame collar container customer dial downstairs enemy extra flash colleague contemporary customs dialogue downtown energetic extraordinary flashlight collect content cut diamond dozen energy extreme flat collection content cycle diary Dr.engine eye flat college continent cyclist dictation draft engineer eyesight Flee collision continue dad dictionary drag enjoy face flexible colour contradict daily die draw enjoyable facial flesh comb contradictory dam diet drawback enlarge fact flight combine contrary damage differ drawer enough factory float come contribute damp difference dream enquiry fade flood comedy contribution dance different dress enter failure floor comfort control danger difficult drill enterprise fair flour comfortable controversial dangerous difficulty drink entertainment faith flow command convenience dare dig drive enthusiastic fall flower comment convenient dark digest driver entire fall flu commercial conventional darkness digital drop entrance FALSE fluency commit conversation dash dignity drug entry familiar fluent commitment convey data dilemma drum envelope family fly committee convince database dimension drunk environment famous fly common cook date dinner dry envy fan focuscommunicate cooker daughter dinosaur duck equal fancy fog---------foggy gas guide hobby information kilogram liquid mealfold gate guilty hold initial Kilometre list meanfolk gather guitar hole injure kind listen meaningfollow gay gun holiday injury kind literature meansfond general gym holy ink kindergarten literary meanwhile food generation gymnastics home inn kindness litre measurefool generous habit homeland innocent King litter meatfoolish gentle hair Hometown insect kingdom little medal gold foot gentleman haircut homework insert kiss live medalfootball geography half honest inside kitchen lively mediafor geometry hall honey insist kite load medicalforbid gesture ham honour inspect knee loaf medicineforce get hamburger hook inspire knife local medium forecast gift hammer hope instant knock lock meetforehead gifted hand hopeful instead know lonely meeting foreign giraffe handbag hopeless institute knowledge long melon foreigner girl handful horrible institution lab look member foresee give handkerchief horse instruct labour loose memorial forest glad handle hospital instruction lack lorry memory forever glance handsome host instrument lady loss mendforget glare handwriting hostess insurance lake lose mental forgetful glass handy hot insure lamb lot mention forgive globe hang hot dog intelligence lame Lost & Found menufork glory happen hotel intend lamp loud merchantform glove happiness hour intention land lounge mercifulformat glue happy house interest language love mercyformer go harbour housewife interesting lantern lovely merely fortnight goal hard housework international lap low merry fortunate goat hardly how internet large luck messfortune god hardship however interpreter last lucky messageforty gold hardworking howl interrupt late luggage messyforward golden harm hug interval latter lunch metalfound golf harmful huge interview laugh lung method fountain good harmony human into laughter machine metrefox goods harvest human being introduce laundry mad microscope fragile goose hat humorous introduction law madam/madame microwave fragrant govern hatch hunger invent lawyer magazine middle framework government hate hungry invention lay magic Middle East franc grade have hunt invitation lazy maid midnightfree gradual he hunter invite lead mail mightfreedom graduate head hurricane iron leader mailbox mildfreeway graduation headache hurry irrigation leaf main milefreeze grain headline hurt island league mainland milkfreezing gram headmaster husband it leak major millionaire frequent grammar headmistress hydrogen its learn majority mindfresh grand health ice itself least make minefriction grandchild healthy ice-cream jacket leather make minefridge granddaughter hear idea jam leave male mineralfriend grandma hearing identity jar lecture man minibus friendly grandpa heart identification jaw left manage minimum friendship grandparents heat idiom jazz leg manager minister frighten grandson heaven if jeans legal mankind ministryfrog granny heavy ignore jeep lemon manner table minorityfrom grape heel ill jet lemonade manners minusfront graph height illegal jewellery lend many minutefrontier grasp helicopter illness job length map mirrorfrost grass hello imagine jog lesson maple missfruit grateful helmet immediately join let maple missilefry gravity help immigration joke letter leaves mistfuel great helpful import journalist level marathon mistakefull greedy hen importance journey liberty marble mistakenfun green her important joy liberation march misunderstand function green herb impossible judge librarian mark mix fundamental grocer here impress judgement library market mixturefuneral greet hero impression juice license marriage mmfunny greeting hers improve jump lid marry mobilefur grey herself in jungle lie mask mobile phone furnished grill hesitate inch junior lie mass model furniture grocer hi incident just life master modemfuture grocery hide include justice lift mat moderngain ground high income kangaroo light match modestgallery group highway increase keep lightning material momgallon grow hill indeed kettle like mathematics momentgame growth him independence key likely matter mommy garage guarantee himself independent keyboard limit mature money garbage guard hire indicate Kick line maximum monitor garden guess his industry kid link may monkeygarlic guest history influence kill lion maybe monthgarment guidance hit inform kilo lip me monument---------moon No.or Party pineapple power punish recorder moon cake noble oral pass ping-pong powerful punishment recovermop nobody orange passage Pink practical Pupil recreationmoral nod orbit passenger pint practice purchase recycle more noise order passer-by pioneer practise pure rectangle morning noisy ordinary passive pipe praise Purple red Moslem none organ passport pity pray Purpose reduce mosquito noodle organise past place prayer purse refer mother noon organization patent plain precious push referee motherland nor origin path plan precise put reference motivation normal other patience plane predict puzzle reflect motor north otherwise patient Planet prefer pyramid reform motorcycle northeast ought patient plant preference quake refresh motto northern our pattern plastic pregnant qualification refrigerator mountain northwest ours pause plate prejudice quality refusemountainous nose ourselves Pavement platform premier quantity regard mourn not out pay play Preparation quarrel regardless mouse note outcome P.E.playground prepare quarter register moustache notebook outdoors P.C.pleasant prescription queen regret mouth nothing outer pea please present question regular from mouth to mouth notice outgoing peace pleased present questionnaire regulation move novel outing peaceful pleasure presentation queue rejectmovement novelist outline peach Plenty preserve quick relatemovie now output pear plot president quiet relation Mr.nowadays outside pedestrian plug press quilt relationship Mrs.nowhere outspoken pen Plus press quit relative Ms.nuclear outstanding pence p.m./pm,P.M./PM pressure quite relaxmud numb outward (s )pencil pocket pretend quiz relay muddy number oval penny poem pretty rabbit relevant multiply nurse over pension poet prevent race reliable murder nursery overcoat People point preview racial relief museum nut overcome pepper poison previous radiation religion mushroom nutrition overhead per poisonous price radio religious music obey overlook percent pole pride radioactive rely musical object overweight percentage<the North primary radium remain musician observe owe perfect(South ) Pole >primary school rag remark must obtain own perform police primitive rail remember mustard obvious owner performance policeman principle railway remind mutton occupation ownership performer Policewoman print rain remotemy occupy ox perfume policy prison rainbow remove myself occur oxygen perhaps polish prisoner raincoat rentnail ocean pace period Polite private rainfall repair name Oceania Pacific permanent Political privilege rainy repeat narrow o'clock the Pacific Ocean permission politician prize raise replace nation of pack permit politics Probably random reply national off package Person pollute problem range report nationality offence packet personal pollution procedure rank reporter nationwide offer paddle personnel pond process rapid represent native office page personally pool produce rare representative natural officer Pain persuade poor product rat republic nature official painful pest pop production rather reputation navy offshore paint pet popcorn profession raw request near often Painter petrol Popular professor raw material require nearby oh painting phenomenon population profit ray requirement nearly oil pair phone pork programme razor rescue neat oilfield palace photo porridge progress reach research necessary O.K.pale photograph port Prohibit react resemble neck old pan Photographer Portable project read reservation necklace Olympic ( s)pancake phrase porter promise reading reserve need Olympic Games panda physical position promote ready resign needle on panic physical positive pronounce real Resist negotiate once paper examination possess Pronunciation reality Respect neighbour one paperwork physician possession proper realise respond neighbourhood oneself paragraph physicist possibility properly really responsibility neither onion parallel physics possible protect reason rest nephew only parcel Pianist post protection reasonable restaurant nervous onto pardon piano post Proud rebuild restriction nest open parent pick postage prove receipt resultnet opening park Picnic Postcard provide receive retell network opera park picture postcode province receiver Retire never opera house Parking pie poster psychology recent returnnew operate parking lot piece postman pub reception review news operation parrot pig postpone public receptionist revision newspaper operator part pile pot publish recipe revolution next opinion participate pill Potato pull recite reward nice oppose particular pillow potential pulse recognise rewind niece opposite partly pilot pound pump recommend rhyme night optimistic Partner pin pour punctual record riceno optional part-time pine powder Punctuation record holder rich---------rid scholar she slip spoken stupid tap throatriddle scholarship sheep slow spokesman/woman style tape throughride schoolbag sheet small sponsor subject target throughout ridiculous schoolboy/girl shelf smart spoon subjective task throwright schoolmate shelter smell spoonful submit tasteless thunderrigid science shine smile sport subscribe tasty thunderstorm ring scientific ship smog spot substitute tax thusripe scientist shirt smoke spray succeed taxi tickripen scissors shock smoker spread success taxpayer ticketrise scold shoe smooth spring successful tea tidyrisk score shoot snake spy such teach tieriver scratch shop sneaker square suck teacher tigerroad scream shop assistant sneeze squeeze sudden team tightroast screen shopkeeper sniff squirrel suffer teamwork tillrob sculpture shopping snow stable suffering teapot timerobot sea shore snowy stadium sugar tear timetable rock seagull short so staff suggest tear tinrocket seal shortcoming soap stage suggestion tease tinyrole search shortly sob stain suit technical tiproll seashell shorts soccer stainless suitable technique tireroof seaside shot social stair suitcase technology tiredroom season should socialism stamp suite teenager tiresome rooster seat shoulder socialist stand summary telephone tissueroot seaweed shout society standard summer telescope titlerope second show sock star sun television torose secret shower socket stare sunburnt tell toastrot secretary shrink sofa start sunlight temperature tobacco rough section shut soft starvation sunny temple todayround secure shuttle soft drink starve sunshine temporary together roundabout security shy software state super tend toiletroutine see sick soil station superb tendency toleraterow seed melon sickness solar statement superior tennis tomatorow seed side soldier<statesman/st supermarket tense tombroyal seek sideroad solid ateswoman>supper tension tomorrow rubber seem sideway some statistics supply tent tonrubbish seize sideways somebody statue support tentative tonguerude seldom sigh somehow status suppose term tonightrugby select sight someone stay supreme terminal tooruin self sightseeing something steady surplus terrible toolrule selfish signal sometimes steal sure terrify toothruler sell signature somewhere steam surface terror toothacherun semicircle significance son steel surgeon test toothbrush rush seminar silence song steep surprise text toothpaste sacred send silent soon step surround textbook topsacrifice senior silk sorrow steward surrounding than topicsad sense silly sorry stewardess survival thank tortoise sadness sensitive silver sort stick survive thankful totalsafe sentence similar soul still suspect that touchsafety separate simple sound stocking suspension the toughsail separation simplify soup stomach swallow theatre toursailor serious since sour stone swap theft tourismsalad servant sincerely south stop swear their touristsalary serve sing southeast storage sweat theirs tournament sale service single southern store sweater them toward (s )salesgirl session sink southwest storm sweep theme towel salesman set sir souvenir story sweet themselves tower saleswoman settle sister sow stout swell then townsalt settlement sit space stove swift theoretical toysalty settler situation spaceship straight swim theory tracksalute several size spade straightforward swing there tractorsame severe skate spare strait switch therefore tradesand sew skateboard sparrow strange sword thermos tradition sandwich sex ski speak stranger symbol these traditional satellite shabby skill speaker straw sympathy they traffic satisfaction shade skillful spear strawberry symphony thick trainsatisfy shadow skin special stream symptom thief training saucer shake skip specialist street system thin tram sausage shall skirt specific strength systematic thing transform save shallow sky speech strengthen table think translatesay shame skyscraper speed stress table tennis thinking translation saying shape slave spell strict tablet thirst translator scan share slavery spelling strike tail this transparent scar shark sleep spend string tailor thorough transport scarf sharp sleepy spin strong take those trapscene sharpen sleeve spirit struggle tale though travel scenery sharpener pencil slice spiritual stubborn talent thought traveler sceptical sharpener slide spit student talk thread treasure schedule shave slight splendid studio tall thrill treatschool shaver slim split study tank thriller treatment--------- tree urgent waste withouttremble use watch witnesstrend used water wolftrial useful watermelon womantriangle useless wave wondertrick user wax wonderfultrip usual way woodtrolleybus vacation we wooltroop vacant weak woolentrouble vague weakness word troublesome vain wealth worktrousers valid wealthy workertruck valley wear worldTRUE valuable weather worldwidetruly value web wormtrunk variety website worriedtrust various wedding worrytruth vase weed worthtry vast week worthwhileT-shirt VCD weekday worthytube vegetable weekend woundtune vehicle weekly wrestleturkey version weep wrinkleturn vertical weigh wristturning very weight writetutor vest welcome wrongTV via welfare X-raytwice vice well yardtwin victim west yawntwist victory western yelltype video westwards yeartypewriter videophone wet yellowtypical view whale yestyphoon village what yesterdaytypist villager whatever wettyre vinegar wheat yoghurtugly violate wheel youumbrella violence when youngunable violent whenever yourunbearable violin where yours unbelievable violinist wherever yourself uncertain virtue whether yourselvesuncle virus which youth uncomfortable visa whichever yummy unconditional visit while zebra unconscious visitor whisper zebra crossing under visual whistle zero underground vital white zipunderline vivid who zip code understand vocabulary whole zipperundertake voice whom who zoneunderwear volcano whose zoo unemployment volleyball why zoomunfair voluntary wideunfit volunteer widespreadunfortunate vote widowuniform voyage wifeunion wag wildunique wage wildlifeunit waist willunite wait willuniversal waiter willinguniverse waiting-room winuniversity waitress windunless wake windunlike walk windowunrest wall windyuntil wallet wineunusual walnut wingunwilling wander winnerup want winterupdate war wipeupon ward wireupper warehouse wisdomupset warm wiseupstairs warmth wishupward ( s )Warn withurban wash withdrawurge washroom within---------。

【托福阅读】精选阅读真题长难句50句1、 Later experiments in which researchers played recordings of songs to youngbirds showed just how precise this influence was, many of them would learnthe exact pattern of the recording they had heard.2、 The crude song of a bird reared in isolation gives some clues as to what thisrough idea may be the length, the frequency range and the breaking up intonotes are all aspects of chaffinch song shared between normal birds andthose reared in isolation.3、 Whatever the nature of the learning rules in a particular species, there is nodoubt that they are effective, it is very unusual to hear a wild bird singing asong which is not typical of its own species despite the many different songswhich often occur in a small patch of woodland.4、 Chemical analysis of bones enables archaeologists to determine theproportion of meat to vegetable foods in the diet by measuring the proportionof calcium to strontium in ancient bone because strontium in place of calciumin bones comes primarily from ingested plants.5、 Each dwelling had a different arrangement of the giant bones, which camefrom the skeletons of long-dead animals retrieved from the surrounding areaby occupants of the site, not from animals they had recently hunted.6、 In a precedent-setting decision, the Federal Energy Regulatory Commissionordered the dam removed after concluding that the environmental andeconomic benefits of a free-flowing river outweighed the electricity generatedby the dam.7、 Built nearly a century ago to provide power to lumber and paper mills in thetown of Port Angeles, these dams blocked access to upstream spawning bedsfor six species of salmon on what once was one of the most productivesalmon rivers in the world.8、 The Hetch Hetchy Dam in Yosemite National Park might be taken down toreveal what John Muir, the founder of the prestigious environmentalorganization Sierra Club, called a valley “just as beautiful and worthy ofpreservation as the maj estic Yosemite.”9、 A chance collision between two comets, or the gravitational influence of oneof the Jovian planets—Jupiter, Saturn, Uranus, and Neptune—mayoccasionally alter the orbit of a comet in these regions enough to send it tothe inner solar system and into our view.10、 These comets appear to be distributed in all directions from the Sun, forminga spherical shell around the solar system, called the Oort cloud, after theDutch astronomer Jan Oort.11、 After the arrival of hunter-gatherers in the southwestern region of NorthAmerica, several alternative types of agriculture emerged, all involvingdifferent solutions to the Southwest’s fundamental problem: how to obtainenough water to grow crops in an environment in which rainfall is so low andunpredictable that little or no farming is practiced there today.12、 That fate actually befell the Mimbres, who started by farming the floodplainand then began to farm adjacent land above the floodplain as their population ca me to exceed the floodplain’s capacity to support it.13、 However, when drought conditions returned, that gamble left them with apopulation double what the floodplain could support, and Mimbres societycollapsed suddenly under the stress.14、 One more strategy was to plant crops at many sites even though rainfall waslocally unpredictable and then to harvest crops at whichever sites did getenough rain to produce a good harvest and to redistribute some of theharvest to the people still living at all the sites that did not happen to receiveenough rain that year.15、 Sanitation problems caused by larger, more sedentary populations wouldhave helped transmit diseases in human waste, as would the use of animaldung for fertilizer.16、 The increase in many of these came not only from the fact that fewer peoplewere dying from infectious disease and were living longer but also from theresults of modern lifestyles in developed countries and among the upperclasses of developing countries – a more sedentary life leading to lessphysical activity, more stress; environmental pollution, andhigh-fat diets.17、 This evolution may have been encouraged by what some authorities considerour overuse of antibiotics, giving microorganisms a greater chance to evolveresistance by exposing them to a constant barrage of selective challenges.18、 Therefore, on many reefs it is the fast-growing, branching corals thatultimately dominate at the upper, shallower portion of the reef, whereasmore massive forms dominate in deeper areas.19、 The fact that almost all small invertebrates on reefs are so well hidden orhighly camouflaged is another indicator of how prevalent predation is onreefs and its importance in determining reef structure.20、 Finally, they need reliable methods of storage because, where plant foodscannot provide a dietary safety net, planning has to be precise and detailedto ensure that there is enough to tide them over in periods of shortage.21、 Coins also provide a valuable source of written records: they can revealinformation about the location where they are found, which can provideevidence about trade practices there, and their inscriptions can beinformative about the issuing authority, whether they werecity-states (as inancient Greece) or sole rulers (as in Imperial Rome or in the kingdoms ofmedieval Europe).22、 The great risk with historical records is that they can impose their ownperspective so that they begin not only to supply the answers to ourquestions but subtly to determine the nature of those questions and even ourconcepts and terminology.23、 Not all botanists agree with an African-South American center for theevolution and dispersal of the angiosperms, pointing out that many of themost primitive forms of flowering plants are found in the South Pacific,including portions of Fiji, New Caledonia, New Guinea, eastern Australia, andthe Malay Archipelago.24、 To elaborate, before the eighth century, the elite marriage practice, whichwas an important instrument of political alliance making, had encouragedrulers to maintain multiple palaces: that of their own family and those of theirspouses, who commonly remained at or near their native family headquarters,at least for some years after marriage.25、 Nearly five billion years ago, some external influence, such asa shock wavetraveling from a catastrophic explosion (supernova), may have triggered thecollapse of this huge cloud of gases and minute grains of heavier elements,causing the cloud to begin to slowly contract due to the gravitationalinteractions among its particles.26、 Nearly five billion years ago, some external influence, such asa shock wavetraveling from a catastrophic explosion (supernova), may have triggered thecollapse of this huge cloud of gases and minute grains of heavier elements,causing the cloud to begin to slowly contract due to the gravitationalinteractions among its particles.27、 Steady overseas demand for colonial products created a prosperity thatenabled colonists to consume ever-larger amounts not only of clothing but ofdishware, home furnishings, tea, and a range of other items both produced inBritain and imported by British and colonial merchants from elsewhere.28、 Such materials as iron and nickel and the elements of which the rock-formingminerals are composed—silicon, calcium, sodium, and so forth—formedmetallic and rocky clumps that orbited the Sun.29、 This act was intended less to raise revenue than to serve as a protective tariff(tax) that would benefit British West Indian sugar producers at the expenseof their French rivals.30、 Parliament used British tax money to pay modest incentives to Americansproducing such items as silk, iron, dyes, hemp, and lumber, which Britainwould otherwise have had to import from other countries, and it raised theprice of commercial rivals’ imports by imposing protective tariffs on them.31、 The concept of chromatic adaptation was proposed in 1883; and thehypothesis was accepted for about 100 years, until it was realized that suchzonation did not necessarily occur and that the distribution of seaweedsdepended more on herbivory (the consumption of plant material),competition, varying concentration of the specialized pigments, and the abilityof seaweeds to alter their forms of growth.32、First, demand for news increased as Europe’s commercial and politicalinterests spread around the globe—merchants in London, Liverpool, orGlasgow, for example, came to depend on early news of Caribbean harvestsand gains and losses in colonial wars.33、 Industries with high concentrations of employment in urban areas, where aworker’s change of employer does not necessarily require investing in achange of residence, appear to have higher rates of job turnover thanindustries concentrated in nonmetropolitan areas do.34、 Some researchers, for example, have argued that a particular kind of pottery,called Ramey incised (which is incised with figures of eyes, fish, arrows, andabstract objects and was used by the people in the area of present-dayMissouri and Illinois at about A.D 900), was primarily used to distribute foodbut was also used to communicate the idea that the society’s elite, for whomthe pots were made, were mediators of cosmic forces.35、 There are several limiting factors, but results from a recent experimentsuggest that in areas of the ocean where other nutrients are plentiful, ironmay be one of the most important and, until recently, unrecognized variablescontrolling phytoplankton production.36、 In 1894, C. Lloyd Morgan, an early comparative behaviorist, insisted thatanimal behavior be explained as simply as possible without reference toemotions or motivations since these could not be observed or measured.37、 Assuming that in the early 1770s at least half of the demand for grain fromfarmers with surpluses was satisfied through long-distance channels, theproportion of grain produced for consumption beyond the local marketprobably accounted for about a quarter of total grain production consumedby humans.38、Sea turtles’ eggs are laid at night to minimize the likelihood of their discoveryby predators, and the offspring, when ready to emerge from their eggshellsand dig their way out of the sand, hatch at night for the same reason.39、 In short, therefore, the site Memphis offered the rulers of the Early DynasticPeriod an ideal location for controlling internal trade within their realm, anessential requirement for a state-directed economy that depended on themovement of goods.40、 In particular, research has focused on determining why such an apparentlyinhospitable place as Chaco, which today is extremely arid and has very shortgrowing seasons, should have favored the concentration of labor that musthave been required for such massive construction projects over brief periodsof time.41、 In one case, seeds of the arctic lupine, a member of the pea family recoveredfrom ancient lemming burrows in the Arctic, germinated in three days eventhough they were carbon-dated at more than 10,000years old!42、 In fact, unpredictability is probably a greater problem than is the severity ofthe unfavorable period.43、 Similar reasoning suggested that one could estimate total elapsed geologictime by dividing the average thickness of sediment transported annually tothe oceans into the total thickness of sedimentary rock that had ever beendeposited in the past.44、 The process that marine creatures use to create light is like that of thecommon firefly and similar to that which creates the luminous green colorseen in plastic glow sticks, often used as children’s toys or for illuminationduring nighttime events.45、 But its appearance under a microscope is even more spectacular, the livingcopepod appears as if constructed of delicately handcrafted, multicoloredpieces of stained glass.46、 Cleared lands would more likely have been worked by hand tilling, with littledirect help from animals, and the vast forests natural to Northern Europeremained either untouched, or perhaps cleared in small sections by fire, andthe land probably used only so long as the ash-enriched soil yielded goodcrops and then abandoned for some other similarly cleared field.47、 Because nests at the edges of breeding colonies are more vulnerable topredators than those in the centers, the preference for advantageous centralsites promotes dense centralized packing of nests.48、 In discussing the growth of cities in the United States in the nineteenthcentury, one cannot really use the term “urban planning,” as it suggestsmodern concerns for spatial and service organization which, in most instances,did not exist before the planning revolution called the City BeautifulMovement that began in the 1890s.49、 There the limits that topography imposed on production have been tightenedby climate, with the result that agricultural output has been more modest andless reliable, making the risk of crop failure and hardship commensuratelygreater.50、 Because liquid water was present, self-replicating molecules of carbon,hydrogen, and oxygen developed life early in Earth’s history and haveradically modified its surface, blanketing huge parts of the continents withgreenery.。

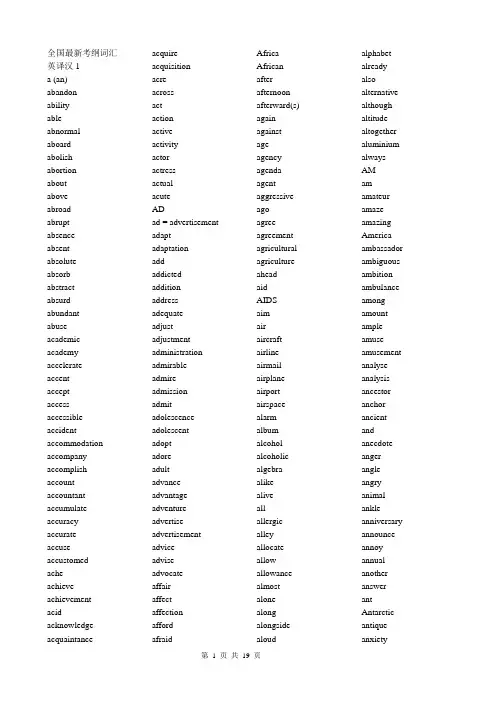
全国最新考纲词汇英译汉1a (an)abandonabilityableabnormalaboardabolishabortionaboutaboveabroadabruptabsenceabsentabsoluteabsorbabstractabsurdabundantabuseacademic academy accelerateaccentacceptaccess accessible accident accommodation accompany accomplish account accountant accumulate accuracy accurateaccuse accustomedacheachieve achievementacid acknowledge acquaintance acquireacquisitionacreacrossactactionactiveactivityactoractressactualacuteADad = advertisementadaptadaptationaddaddictedadditionaddressadequateadjustadjustmentadministrationadmirableadmireadmissionadmitadolescenceadolescentadoptadoreadultadvanceadvantageadventureadvertiseadvertisementadviceadviseadvocateaffairaffectaffectionaffordafraidAfricaAfricanafterafternoonafterward(s)againagainstageagencyagendaagentaggressiveagoagreeagreementagriculturalagricultureaheadaidAIDSaimairaircraftairlineairmailairplaneairportairspacealarmalbumalcoholalcoholicalgebraalikealiveallallergicalleyallocateallowallowancealmostalonealongalongsidealoudalphabetalreadyalsoalternativealthoughaltitudealtogetheraluminiumalwaysAMamamateuramazeamazingAmericaambassadorambiguousambitionambulanceamongamountampleamuseamusementanalyseanalysisancestoranchorancientandanecdoteangerangleangryanimalankleanniversaryannounceannoyannualanotheranswerantAntarcticantiqueanxiety第 1 页共19 页anxiousany anybody anyhow anyone anything anyway anywhere apart apartment apologize apology apparent appeal appear appearance appendix appetite applaud apple applicant application apply appoint appointment appreciate appreciation approach appropriate approval approve approximately apron arbitrary arch architect architecture Arcticareareaargue argument arise arithmetic arm armchair armyaroundarrangearrangementarrestarrivalarrivearrowartarticleartificialartistasashashamedAsiaAsianasideaskasleepaspectassessassessmentassistassistanceassistantassociateassociationassumeassumptionastonishastronautastronomerastronomyatathleteathleticAtlanticatmosphereatomattachattackattainattemptattendattentionattitudeattractattractionattractiveaudienceauntauthenticauthorauthorityautomaticautonomousautumnavailableavenueaverageavoidawakeawardawareawayawesomeawfulawkwardbabybachelorbackbackgroundbackward(s)baconbacteriumbadbadmintonbagbaggagebakerybalancebalconyballballetballoonbamboobanbananabandbandagebankbarbarbecuebarberbarbershopbarebargainbarkbarrierbasebaseballbasementbasicbasinbasisbasketbasketballbatbathbathebathroombathtubbatterybattlebayBCbebeachbeanbeancurdbear1bear2beardbeastbeatbeautifulbeautybecausebecomebedbeddingsbedroombeebeefbeerbeforebeg第 2 页共19 页beginbehalf behave behaviour behind beingbelief believebellbelly belong belowbeltbenchbend beneath beneficial benefitbentbeside besides betray between beyond bicyclebidbigbike = bicycle billbingo biochemistry biography biologybirdbirth birthday birthplace biscuit bishopbitbitebitterblack blackboard blameblank blanketbleedblessblindblockbloodblouseblowblueboardboatbodyboilbombbondbonebonusbookboombootboothborderboredboringbornborrowbossbotanicalbotanybothbotherbottlebottombounceboundboundarybowbowlbowlingboxboxingboyboycottbrainbrakebranchbrandbravebraverybreadbreakbreakfastbreakthroughbreastbreathbreathebreathlessbrewerybrickbridebridegroombridgebriefbrightbrilliantbringbroadbroadcastbrochurebrokenbroombrotherbrownbrunchbrushBuddhismbudgetbuffetbuildbuildingbunchbungalowburdenbureaucraticburglarburnburstburybusbushbusinessbusinessmanbusybutbutcherbutterbutterflybuttonbuybybyecabcabbagecafecafeteriacagecakecalculatecallcalmcamelcameracampcampaigncan1can2canalcancelcancercandidatecandlecandycanteencapcapitalcapsulecaptaincaptioncarcarboncardcarecarefulcarelesscarpentercarpetcarriagecarrier第 3 页共19 页carrot carry cartoon carve casecash cassette cast castle casualcat catalog(ue) catastrophe catch category cater Catholic cattle cause caution cautious caveCD ceiling celebrate celebration cellcent centigrade centimetre central centre century ceremony certain certificate chain chair chairman chalk challenge challenging champion chance change changeable channelchantchaoschaptercharactercharacteristicchargechartchatcheapcheatcheckcheekcheercheerfulcheerscheesechefchemicalchemistchemistrychequechesschestchewchickenchiefchildchildhoodchocolatechoicechoirchokechoosechopstickschorusChristianChristmaschurchcigarcigarettecinemacirclecircuitcirculatecircumstancecircuscitizencitycivilcivilizationclapclarifyclassclassicclassifyclassmateclassroomclawclaycleancleanerclearclerkcleverclickclimateclimbclinicclockclonecloseclothclothesclothingcloudcloudyclubclumsycoachcoalcoastcoatcocoacoffeecoincoincidencecokecoldcollarcolleaguecollectcollectioncollegecollisioncolourcombcombinecomecomedycomfortcomfortablecommandcommentcommercialcommitcommitmentcommitteecommoncommunicatecommunicationcommunismcommunistcompanioncompanycomparecompasscompensatecompetecompetencecompetitioncompletecomplexcomponentcompositioncomprehensioncompromisecompulsorycomputerconcentrateconceptconcernconcertconcludeconclusionconcretecondemncondition第 4 页共19 页conduct conductor conference confident confidential confirm conflict confuse congratulate congratulation connect connection conscience consensus consequence conservative conservation consider considerate consideration consist consistent constant constitution construct construction consult consultant consume contain container contemporary content1 content2 continent continue contradict contradictory contrary contribute contribution control controversial convenience convenient conventional conversationconveyconvincecookcookercookiecoolcopycorncornercorporationcorrectcorrectioncorrespondcorruptcostcosycottagecottoncoughcouldcountcountercountrycountrysidecouplecouragecoursecourtcourtyardcousincovercowcrashcrayoncrazycreamcreatecreaturecreditcrewcrimecriminalcriterioncropcrosscrossingcrossroadscrowdcruelcrycubecubiccuisineculturecupcupboardcurecuriouscurrencycurriculumcurtaincushioncustomcustomercustomscutcyclecyclistdad = daddydailydamdamagedampdancedangerdangerousdaredarkdarknessdashdatadatabasedatedatedaughterdawndaydeaddeadlinedeafdealdeardeathdebatedebtdecadedecidedecisiondeclaredeclinedecoratedecorationdecreasedeeddeepdeerdefeatdefencedefenddegreedelaydeletedeliberatelydelicatedeliciousdelightdelighteddeliverdemanddentistdepartmentdeparturedependdepositdepthdescribedescriptiondesertdeservedesigndesiredeskdesperatedessertdestinationdestroydetective第 5 页共19 页determine develop development devote devotion diagramdialdialog(ue) diomond diary dictation dictionary diedietdiffer difference different difficult difficultydigdigest digital dignity dilemma dimension dinner dinosaur dioxidedip diploma direct direction director directory dirty disability disabled disadvantage disagree disagreement disappear disappoint disappointed disaster discount discourage discoverdiscoverydiscriminationdiscussdiscussiondiseasedisgustingdishdisk=discdislikedismissdisobeydistancedistantdistinctiondistinguishdistributedistrictdisturbdisturbingdivediversedividedivisiondivorcedizzydodoctordocumentdogdolldollardonatedoordormitory (dorm)dotdoubledoubtdowndownloaddownstairsdowntowndozenDrdraftdragdrawdrawbackdrawerdreamdressdrilldrinkdrivedriverdropdrugdrumdryduckduedulldumplingduringduskdustbindustydutyDVDdynamicdynastyeacheagereagleearearlyearnearthearthquakeeastEastereasterneasyeatecologyedgeeditioneditoreducateeducationeducatoreffectefforteggeggplanteitherelderelectelectricelectricalelectricityelectronicelegantelephantelsee-mailembarrassembassyemergencyemperoremployemptyencourageencouragementendendingendlessenemyenergeticenergyengineengineerenjoyenjoyableenlargeenoughenquiryenterenterpriseentertainmententhusiasticentireentranceentryenvelopeenvironmentenvyequal第 6 页共19 页equality equip equipment eraser error erupt escape especially essay Europe European evaluate even evening event eventually ever every everybody everyday everyone everything everywhere evidence evident evolution exact exam examine example excellent except exchange excite excuse exercise exhibition exist existence exit expand expect expectation expense expensive experience experimentexpertexplainexplanationexplicitexplodeexploreexportexposeexpressexpressionextensionextraextraordinaryextremeeyeeyesightfacefacialfactfactoryfadefailfailurefair1fair2 n.faithfall1fall2 n.falsefamiliarfamilyfamousfanfancy n.,v.&a.fantasticfantasyfarfarefarmfarmerfastfastenfatfatherfaultfavourfavouritefaxfearfeastfeatherfederalfeefeedfeelfeelingfellowfemalefenceferryfestivalfetchfeverfewfibrefictionfieldfiercefightfigurefilefillfilmfinalfinancefindfine1fine2 v.fingerfingernailfinishfirefireworksfirm1 n.firm2 a.fishfishermanfistfitfixflagflameflashflashlightflat1 n.flat2 a.fleefleshflexibleflightfloatfloodfloorflourflowflowerflufluencyfluentfly1 v.fly2 n.focusfogfoggyfoldfolkfollowfondfoodfoolfoolishfootfootballforforbidforceforecastforeheadforeignforeignerforeseeforestforeverforgetforgetfulforgivefork第7 页共19 页formformer fortnight fortunate fortuneforty forward found v. fountainfoxfragile fragrant framework francfree freedom freeway freeze freezing frequent freshfridgefriend friendly friendship frightenfrogfromfront frontierfrostfruitfryfuelfullfun function fundamental funeral funnyfur furnished furniture futuregaingallery gallongamegaragegarbagegardengarlicgarmentgasgategathergaygeneralgenerationgenerousgentlegentlemangeographygeometrygesturegetgiftgiftedgiraffegirlgivegladglanceglareglassglobegloryglovegluegogoalgoatgodgoldgoldengolfgoodgoodsgoosegoverngovernmentgradegradualgraduategraduationgraingramgrammargrandgrandchildgranddaughtergrandmagrandpagrandparentsgrandsongrannygrapegraphgraspgrassgratefulgravitygreatgreedygreengreengrocergreetgreetinggreygrocergrocerygroundgroupgrowgrowthguaranteeguardguessguestguidanceguideguiltyguitargungymgymnasticshabithairhaircuthalfhallhamhamburgerhammerhandhandbaghandfulhandkerchiefhandlehandsomehandwritinghandyhanghappenhappinesshappyharbourhardhardlyhardshiphardworkingharmharmfulharmonyharvesthathatchhatehaveheheadheadacheheadlineheadmasterhealthhealthyhearhearingheartheatheavenheavyheelheight第8 页共19 页helicopter hello helmet help helpful henherherb hereherohers herself hesitatehihidehigh highway hillhim himself hirehis historyhit hobby holdhole holiday holy home homeland hometown homework honest honey honour hook hope hopeful hopeless horrible horse hospital host hostess hot hotdoghotelhourhousehousewifehouseworkhowhoweverhowlhughugehumanhuman beinghumoroushumourhungerhungryhunthunterhurricanehurryhurthusbandhydrogenIiceice-creamideaidentificationidentityidiomifignoreillillegalillnessimagineimmediatelyimmigrationimportimportanceimportantimpossibleimpressimpressionimproveininchincidentincludeincomeincreaseindeedindependenceindependentindicateindustryinfluenceinforminformationinitialinjureinjuryinkinninnocentinsertinsectinsideinsistinspectinspireinstantinsteadinstituteinstitutioninstructinstructioninstrumentinsuranceinsureintelligenceintendintentioninterestinterestinginternationalInternetinterpreterinterruptintervalinterviewintointroduceintroductioninventinventioninvitationinviteironirrigationisislandititsitselfjacketjamjarjawjazzjeansjeepjetjewelleryjobjogjoinjokejournalistjourneyjoyjudgejudgmentjuicejumpjunglejuniorjustjusticekangarookeepkettlekeykeyboardkickkidkill第9 页共19 页kilokilogram kilometrekind1 n. kind2 a. kindergarten kindnesskingkingdomkisskitchenkitekneeknifeknockknow knowledgelab = laboratory labourlackladylakelamelampland language lanternlaplargelastlatelatterlaugh laughter laundrylawlawyerlaylazylead v.&n. leaderleafleagueleaklearnleast leatherleavelectureleft a.,ad. &n.leglegallemonlemonadelendlengthlessonletletterlevellibertylibrarianlibrarylicencelidlielifeliftlightlightninglikelikelylimitlinelinklionlipliquidlistlistenliteraryliteraturelitrelitterlittlelivelivelyloadloaflocallocklonelylonglink v.&n.looklooselorryloselosslotloudloungelovelovelylowluckluckyluggagelunchlungmachinemadmadam/madamemagazinemagicmaidmailmailboxmainmainlandmajormajoritymake1make2 n.malemanmanagemanagermankindmannermanymapmaplemarathonmarblemarchmarkmarketmarriagemarrymaskmassmastermatmatchmaterialmathematics = mathsmattermaturemaximummaymaybememealmeanmeaningmeansmeanwhilemeasuremeatmedalmediamedicalmedicinemediummeetmeetingmelonmembermemorialmemorymendmentalmentionmenumerchantmercifulmercymerelymerrymessmessagemessymetal第10 页共19 页methodmetre microscope microwave middle midnightmightmildmilemilk millionairemindmine1 pron. mine2 v.&n. mineral minibus minimum minister ministry minorityminusminutemirrormiss1 v. miss2 n. missilemistmistake mistaken misunderstand mixmixturemmmobilemodelmodemmodernmodestmom = mum moment mommymoneymonitor monkeymonthmoon mopmoralmoremorningMoslemmosquitomostmothermotherlandmotivationmotormotorcyclemottomountainmountainousmournmousemoustachemouthmovemovementmovieMr.Mrs.Ms.mudmuddymultiplymurdermuseummushroommusicmusicalmusicianmustmustardmuttonmymyselfnailnamenarrownationnationalnationalitynationwidenativenaturalnaturenavynearnearbynearlyneatnecessarynecknecklaceneedneedlenegotiateneighbourneighbourhoodneithernephewnervousnestnetnetworknevernewnewsnewspapernextniceniecenightnoNo. = numbernoblenobodynodnoisenoisynonenoodlenoonnornormalnorthnortheastnorthernnorthwestnosenotnotenotebooknothingnoticenovelnovelistnownowadaysnowherenuclearnumbnumbernursenurserynutnutritionobeyobjectobserveobtainobviousoccupationoccupyoccuroceano'clockofoffoffenceofferofficeofficerofficialoffshoreoftenohoiloilfieldOKoldOlympic(s)ononceone第11 页共19 页oneself oniononlyontoopen opening opera operate operation operator opinion oppose opposite optimistic optionalororal orange orbitorder ordinary organ organise organization organize origin other otherwise oughtourours ourselves out outcome outdoors outer outgoing outing outline output outside outspoken outstanding outwards ovalover overcoatovercomeoverheadoverlookoverweightoweownownerownershipoxoxygenP.E.p.m./pm, P.M./PMpacePacificpackpackagepacketpaddlepagepainpainfulpaintpainterpaintingpairpalacepalepanpancakepandapanicpaperpaperworkparagraphparallelparcelpardonparentpark1park2parrotpartparkingparticipateparticularpartlypartnerpart-timepartypasspassagepassengerpasser-bypassivepassportpastpatentpathpatiencepatient1patient2patternpausepavementpayPCpeapeacepeacefulpeachpearpeasantpedestrianpenpencilpencepennypensionpeoplepepperperpercentpercentageperfectperformperformanceperformerperfumeperhapsperiodpermanentpermissionpermitpersonpersonalpersonnelpersonallypersuadepestpetpetrolphenomenonphonephoto = photograpphotograpphotographerphrasephysicalphysicianphysicistphysicspianistpianopickpicnicpicturepiepiecepigpilepillpillowpilotpinpinepineappleping-pongpinkpintpioneerpipepityplaceplainplanplaneplanet第12 页共19 页plantplasticplate platform play playground pleasant please pleased pleasure plentyplotplugpluspmpocket poempoetpointpoison poisonous polepolice policeman policy polishpolite political politician politics pollute pollution pondpoolpoorpop = popular popcorn popular population pork porridgeport portable porter position positive possesspossessionpossibilitypossiblepost1 n.post2 n.&v.postagepostcardpostcodeposterpostmanpostponepotpotatopotentialpoundpourpowderpowerpowerfulpracticalpracticepractisepraiseprayprayerpreciousprecisepredictpreferpreferencepregnantprejudicepremierpreparationprepareprescriptionpresent1 a.&v.present2 n.presentationpreservepresidentpress1 v.press2 n.pressurepretendprettypreventpreviewpreviouspriceprideprimaryprimitiveprincipleprintprisonprisonerprivateprivilegeprizeprobablyproblemprocedureprocessproduceproductproductionprofessionprofessorprofitprogram(me)progressprohibitprojectpromisepromotepronouncepronunciationproperproperlyprotectprotectionproudproveprovideprovincepsychologypubpublicpublishpullpulsepumppunctualpunctuationpunishpunishmentpupilpurchasepurepurplepurposepursepushputpuzzlepyramidquakequalificationqualityquantityquarrelquarterqueenquestionquestionnairequeuequickquietquitquitequizrabbitraceracialradiationradioradioactiveradiumragrailrailwayrainrainbowraincoatrainfallrainy第13 页共19 页raise random rangerankrapidrareratrate ratherrawrayrazor reach reactread reading readyreal realise reality really reason reasonable rebuild receipt receive receiver recent reception receptionist recipe recite recognise recommend record recorder recover recreation recycle rectangle red reduce refer referee reference reflect reformrefreshrefrigeratorrefuseregardregardlessregisterregretregularregulationrejectrelaterelationrelationshiprelativerelaxrelayrelevantreliablereliefreligionreligiousrelyremainremarkrememberremindremoteremoverentrepairrepeatreplacereplyreportreporterrepresentrepresentativerepublicreputationrequestrequirerequirementrescueresearchresemblereservationreserveresignresistrespectrespondresponsibilityrestrestaurantrestrictionresultretellretirereturnreviewrevisionrevolutionrewardrewindrhymericerichrid v.riddlerideridiculousrightrigidringriperipenriseriskriverroadroastrobrobotrockrocketrolerollroofroomroosterrootroperoserotroughroundroundaboutroutinerowroyalrubberrubbishruderugbyruinrulerulerrunrushsacredsacrificesadsadnesssafesafetysailsailorsaladsalarysalesalesgirlsalesmansaltsaltysalutesamesandsandwichsatellitesatisfactionsatisfysaucersausagesavesaysayingscan第14 页共19 页scare scarf scene scenery sceptical schedule scholar scholarship school schoolbag schoolboy schoolmate science scientific scientist scissors scold score scratch scream screen sculpture sea seagull seal search seashell seaside season seat seaweed second secret secretary section secure security seeseedseek seem seize seldom selectself selfish sellsemicircleseminarsendseniorsensesensitivesentenceseparateseparationseriousservantserveservicesessionsetsettlesettlementsettlersevenseveralseveresewsexshabbyshadeshadowshakeshallshallowshameshapesharesharksharpsharpensharpenershaveshavershesheepsheetshelfsheltershineshipshirtshockshoeshootshopshopkeepershoppingshoreshortshortcomingshortlyshortsshotshouldshouldershoutshowshowershrinkshutshuttleshysicksicknesssidesideroadsidewaysidewayssighsightsightseeingsignalsignaturesignificancesilencesilentsilksillysilversimilarsimplesimplifysincesincerelysingsinglesinksirsistersitsituationsizeskateskateboardskiskillskillfulskinskipskirtskyskyscraperslaveslaverysleep1sleep2sleepysleevesliceslideslightslimslipslowsmallsmartsmellsmilesmogsmokesmokersmoothsnakesneakersneezesniffsnowsnowysosoapsobsoccer第15 页共19 页social socialism socialist society sock socket sofasoft software soilsolar soldier solid some somebody somehow someone something sometimes somewhere sonsongsoon sorrow sorrysortsoul sound soupsour south southeast southern southwest souvenir sow space spaceship spade spare sparrow speak speaker spear special specialist specificspeechspeedspellspellingspendspinspiritspiritualspitsplendidsplitspokenspokesmansponsorspoonspoonfulsportspotsprayspreadspringspysquaresqueezesquirrelstablestadiumstaffstagestainstainlessstairstampstandstandardstarstarestartstarvationstarvestatestatementstatesmanstationstatisticsstatuestatusstaysteadysteakstealsteamsteelsteepstepstewardstewardessstickstillstockingstomachstonestopstoragestorestormstorystoutstovestraightstraightforwardstraitstrangestrangerstrawstrawberrystreamstreetstrengthstrengthenstressstrictstrikestringstrongstrugglestubbornstudentstudiostudystupidstylesubjectsubjectivesubmitsubscribesubstitutesucceedsuccesssuccessfulsuchsucksuddensuffersufferingsugarsuggestsuggestionsuitsuitablesuitcasesuitesummarysummersunsunburntsunlightsunnysunshinesupersuperbsuperiorsupermarketsuppersupplysupportsupposesupremesuresurfacesurgeonsurplussurprisesurroundsurroundingsurvivalsurvive第16 页共19 页。
AA (an honest man, a university, a piece of paper/message/furniture), abandon = give up, ABC,abide by, ability to do sth, be able to do sth, abnormal -normal, go aboard, study abroad, abolish = cancel/do away with, talk about, sit about, above all, to put money above everything, abrupt = sudden/tough, absence =lack, be absent from, absent-minded, absolute = complete, be absorbed in, abstract / concrete, absurd = foolish, be abundant in = be rich in, academic, accelerate =speed up, accept,acceptable, gain/have access to, accessible = easily obtained/approached, by accident = by mistake,accomplish = finish/ complete, in accordance with, according to, account for, on account of = because of/due to, on no account = in no way, take into account/consideration, accurate,accuse…of ……= charge … with …, be accustomed to, ache = pain/ toothache, headache, get/catch a headache/ cold, achieve/ meet one‘s goals, achievement(s), acknowledge = admit, be acquainted with = be familiar with, acquire (knowledge, habit), go across, come across = meet unexpectedly, act upon, physical activities, actor/ actress, actually = in fact = in reality, acute / chronic, ad = advertisement, adapt/adopt,adapt…… to…… add up to, be addicted to, in addition to, additional = added, address the envelop/ address the audience, adequate = enough/ample, adhere to, administer = control/ manage, gain admission to, adopt (attitude), adult, adulthood, in advance, advance = promote, take advantage of ,adventure = risk,adverse = harmful, a piece of advice, advisable = wise, advise sb. to do sth, advocate = support, current affairs, affect/ effect, affirm =assert, afford sth, be afraid of =fear, look after sb., in the afternoon,afterwards, again and again, now and again = from time to time, lean against, vote against, at the age of, age = get older, agree to sb. agree with sth. agreeable = pleasing, agriculture, ahead of,aid, aim at, aim = goal/target, by air, in the open air, aircraft =plane =airplane, at the airport,alarm = frighten, alcohol, aler t……to……,=warn …of/against …, alien = foreign, look alike, keep alive, above all, after all, all over, in all, allege = declare, state, alleviate = relieve, alliance = union, allied = united, allocate = distribute, allow = permit, almost = nearly, live alone, go along the street, talk aloud,not only…but also…, /(I like it, too./ I also like it.), alter = change,although/though, at an altitude of/ at the height of, altogether = in all, always = often, amazing = surprising, ambiguous = doubtful, uncertain, ambition, ambitious, amend = improve, America, American,amid = in the middle of, amongst = among, a great amount of money, amplify = talk in detail, amuse = entertain, amusement/entertainment, analyze, analysis, ancestor, ancient, and, anger, angry, angle (from the angle of ), animal, animate/inspire, annoy, announce/declare, annual, another, answer ( answer to the problem, answer for), anticipate/foresee, antique, anxious (be anxious about),any, anyone/anybody, anything, anywhere, apart (set apart, apart from), apartment, apologize,apparently, apparent, appeal( appeal to), appear/seem, appetite/stomach, apple, apply( apply for a job,apply… to……), appoint, appointment, appreciate, approach (+ to) = method, approval,approve, approximate, April, apt (be apt to do sth.), aptitude/ability, architecture, area, argue (argue for/against), arise, arm in arm/hand in hand, army, around (all around/all over), arouse,arrange(a meeting), arrest, arrival, arrive at/in, art, article, artist, as (consider…as, look upo n……as……,treat …as……,as/so…as……,as for/to…, as if/though), ascend/descend, ash,Asia, Asian, aside (aside from/apart from), ask (ask after, ask for, ask sb. to do sth,), asleep,aspect, assemble, assembly line, assert, assess, asset, assign(assign sb. to do sth.), assimilate,assist/aid, assistant, associate (associate sth. with sth., associate with),association/committee,assume/suppose, assure/insure/ensure/sure, astonish, astronaut, at( be good at, look at, at the age/speed/rate of, at home), atmosphere, attack, attach (be attached to), attempt, attend (a meeting/school/sb., attend to), attendance/presence, attention (pay attention to), attitude, attract,attractive, attribute (attribute…to …), audit, August, Australia, Australian,authentic/real/reliable, author, authority/power, automate, automatic, automobile, autumn/fall,available, avenue/street/road, average (on (an, the) average, to average three hours of work a day),avoid, await = wait for, awake =wake up (awake = sleepless), award, aware (be aw are of……), away (put…… away, right away. ), awful/terrible, awkward (注意该词的几种词义)。
学术英语理工教师手册Unit 1 Choosing a TopicI Teaching ObjectivesIn this unit , you will learn how to:a particular topic for your researcha research questiona working title for your research essayyour language skills related with reading and listening materials presented in this unit II. Teaching Procedureson a topicTask 1Answers may vary.Task 21 No, because they all seem like a subject rather than a topic, a subject which cannot be addressed even by a whole book, let alone by a1500-wordessay.2Each of them can be broken down into various and more specific aspects. For example, cancer can be classified into breast cancer, lung cancer, liver cancer and so on. Breast cancer can have such specific topics for research as causes for breast cancer, effects of breast cancer and prevention or diagnosis of breast cancer.3 Actually the topics of each field are endless. Take breast cancer for example, we can have the topics like:Why Women Suffer from Breast Cancer More Than MenA New Way to Find Breast TumorsSome Risks of Getting Breast Cancer in Daily LifeBreast Cancer and Its Direct Biological ImpactBreast Cancer—the Symptoms & DiagnosisBreastfeeding and Breast CancerTask 31 Text 1 illustrates how hackers or unauthorized users use one way or another to get inside a computer, while Text2 describes the various electronic threats a computer may face.2 Both focus on the vulnerability of a computer.3 Text 1 analyzes the ways of computer hackers, while Text 2 describes security problems of a computer.4 Text 1: The way hackers “get inside” a computerText 2: Electronic threats a computer facesYes, I think they are interesting, important, manageable and adequate.Task 41Lecture1:Ten Commandments of Computer EthicsLecture 2:How to Deal with Computer HackersLecture 3:How I Begin to Develop Computer Applications2Answersmay vary.Task 5Answers may vary.2 Formulating a research questionTask 1Text 3Research question 1: How many types of cloud services are there and what are they Research question 2: What is green computingResearch question 3: What are advantages of the cloud computingText 4Research question 1: What is the WebResearch question 2: What are advantages and disadvantages of the cloud computing Research question 3: What security benefits can the cloud computing provideTask 22 Topic2: Threats of Artificial IntelligenceResearch questions:1) What are the threats of artificial intelligence2) How can human beings control those threats3) What are the difficulties to control those threats3 Topic3: The Potentials of NanotechnologyResearch questions:1) What are its potentials in medicine2) What are its potentials in space exploration3) What are its potentials in communications4 Topic4: Global Warming and Its EffectsResearch questions:1) How does it affect the pattern of climates2) How does it affect economic activities3) How does it affect human behaviorTask 3Answers may vary.3 Writing a working titleTask 1Answers may vary.Task 21 Lecture 4 is about the security problems of cloud computing, while Lecture 5 is about the definition and nature of cloud computing, hence it is more elementary than Lecture 4.2 The four all focus on cloud computing. Although Lecture 4 and Text 4 address the same topic, the former is less optimistic while the latter has more confidence in the security of cloud computing. Text3 illustrates the various advantages of cloud computing.3 Lecture 4: Cloud Computing SecurityLecture 5: What Is Cloud ComputingTask 3Answers may vary.4 Enhancing your academic languageReading: Text 1the words with their definitions.1g 2a 3e 4b 5c 6d 7j 8f 9h 10i2. Complete the following expressions or sentences by using the target words listed below with the help of the Chinese in brackets. Change the form if necessary.1 symbolic 2distributed 3site 4complex 5identify6fairly 7straightforward 8capability 9target 10attempt11process 12parameter 13interpretation 14technical15range 16exploit 17networking 18involve19 instance 20specification 21accompany 22predictable 23profile3. Read the sentences in the box. Pay attention to the parts in bold.Now complete the paragraph by translating the Chinese in brackets. You may refer to the expressions and the sentence patterns listed above.ranging from(从……到)arise from some misunderstandings(来自于对……误解)leaves a lot of problems unsolved(留下很多问题没有得到解决)opens a path for(打开了通道)requires a different frame of mind(需要有新的思想)the following sentences from Text 1 into Chinese.1) 有些人声称黑客是那些超越知识疆界而不造成危害的好人(或即使造成危害,但并非故意而为),而“骇客”才是真正的坏人。
..a/anadministrationalphabet apply attainbattery blankbrochureabandon admirable already appoint attempt battle blanket broken ability admire also appointment attend bay bleed broomable admission alternative appreciate attention BC bless brotherbeableto admit although appreciation attitude be blind brownabnormal adolescence altitude approach attract beach block brunchaboard adolescent altogether appropriate attraction bean blood brushabolish adopt aluminium approval attractive beancurd blouse Buddhismabortion adore always approve audience bear blow budgetabout adult am approximately aunt beard blue buffetabove advance a.m./am apron authentic beast board build abrupt advantage amateur arbitrary author beat boat building abroad adventure amaze arch authority beautiful body bunch absence advertise amazing architect automatic beauty boll bungalowabsent advertisement Americaarchitecture autonomous because bomb burdenabsolute advice ambassador Arctic autumn become bondbureaucraticabsolutely advise ambassadress theArctic available bed bone burglarabsorb advocate ambiguous are avenue bedding bonus burnabstract affair ambition area average bedroom book burstabsurd affect ambulance argue avoid bee boom buryabundant affection among argument awake beef boot bus abuse afford amount arise award beer booth bush academic afraid ample arithmetic aware before border businessacademy Africa amuse arm away beg bored businessma naccelerate African amusement armchair awesome begin boringbusinesswomanaccent after analyse/analyze army awful behalf born busyaccept afternoon analysis around awkward behave borrow but access afterward ancestor arrange baby behaviour boss butcher accessible again anchor arrangement bachelor behind botanical butter accident against ancient arrest back being botany butterfly accommodation age and arrival background belief both buttonaccountagentangle artbacterium belly bottom bye accountant aggressive angry articlebadbelong bounce cabaccumulate ago animal artificial badminton below boundcabbage accuracy agreeankle artist bag belt boundary caféaccurate agreement annivers ary asbaggage benchbow cafeteria accuseagricultura lannounce ashbakery bendbowlcageaccustomed agriculture annoy ashamed balance beneathbowling calculate acheahead annual Asia balcony beneficial boxcake achieveaid another Asian ball benefit boxing call achievement AIDS ant asideballet bent boycalmacidaim Antarcti c askballoon beside boycott camel acknowledge airantique asleep bamboo besides brain camera acknowledge aircraft anxiety aspect banbetray brake campacquireairline anxious assessbanana between branch campaign acquisition airmail any assessment bandage beyond brand can acre airplane anybody assistbank bicycle brave can across airport anyhow assistance barbid bravery canal actairspace anyone assistant barbecue big bread cancel action alarm anything associate barberbike breakcanceractive album anyway association barbershop billbreakfast candidate activity alcohol anywhere assume bargain bingobreakthrou gh candle actor alcoholic apart assumption bark biochemist rybreast candy actress algebra apartmen t astonish barrier biography breath canteen actual alike apologiz e astronaut basebiology breathecapacute alive apology astronomer baseball bird breathless capital AD allapparent astronomy basement birthbrewery capsule adallergic appeal atbasic birthday brick captain adaptalley appear athlete basinbirthplace bridecaption adaptation allocate appearan ce athletic basis biscuit bridegroom caraddallowappendix Atlanticbasketbishop bridge carbon addicted allowance appetite TheAtlantic basketball bit brief card addition almost applaud Oceanbat bite bright care address alone 〔applau se 〕 atmosphere bath bitter brilliant careful adequate along apple atom bathe blackbring careless adjust alongside applican t attach bathroom blackboard broad carpenter adjustment aloudapplicat ionattackbathtubblamebroadcastcarpet;.carriage cheque collar consist crop delicate discourage dutycarrier chess colleague consistent cross delicious discover DVDcarrot chest collect constant crossing delight discovery dynamiccarry chew collection constitution crossroads delighted discrimination dynasty cartoon chicken college construct crowd deliver discuss eachcarve chief collision construction cruel demand discussion eagercase child colour consult cry dentist disease eaglecash childhood comb consultant cube department disgusting earcassette chocolate combine consume cubic departure dish earlycast choice come contain cuisine depend dislike earncastle choir comedy container culture deposit dislike earthcasual choke comfort contemporary cup depth dismiss earthquakecat choose comfortable content cupboard describe distance east catalogue chopsticks command content cure description distant Easter catastrophe chorus comment continent curious desert distinction easterncatch Christian commercial continue currency deserve distinguish easy category Christmas commit contradict curriculum design distribute eatcater church commitment contradictory curtain desire district ecology catholic cigar committee contrary cushion desk disturb edgecattle cigarette common contribute custom desperate disturbing editioncause cinema communicate contribution customer dessert dive editorcaution circle communication control customs destination diverse educate cautious circuit communism controversial cut destroy divide educatorcave circulate communist convenience cycle detective division educationCD circumatance companion convenient cyclist determine divorce effectceiling circus company conventional dad develop dizzy effort celebrate citizen compare conversation daily development do egg celebration city compass convey dam devote doctor eggplantcell civil compensate convince damage devotion document eithercent civilian compete cook damp diagram dog elder centigrade civilization competence cooker dance dial doll elect centimetre clap competition cookie danger dialogue dollar electric central clarify complete cool dangerous diamond donate electrical centre class complex copy dare diary door electricity century classic component corn dark dictation dormitory electronic ceremony classify composition corner darkness dictionary dot elegant certain classmate comprehension corporation dash die double elephant certificate classroom compromise correct data diet doubt elsechain claw compulsory correction database differ down e-mailchair clay computer correspond date difference download embarrass chairman clean concentrate corrupt daughter different downstairs embassy chairwoman cleaner concept cost dawn difficult downtown emergency chalk clear concern cosy/cozy day difficulty dozen emperor challenge clerk concert cottage dead dig Dr.employ challenging clever conclude cotton deadline digest draft empty champion click conclusion cough deaf digital drag encourage chance climate concrete count deal dignity draw encouragement change climb condition counter dear dilemma drawback end changeable clinic condemn country death dimension drawer ending channel clock conduct countryside debate dinner dream endlesschant clone conductor couple debt dinosaur dress enemychaos close conference courage decade dioxide drill energetic character cloth confident course decide dip drink energy characteristic clothes confidential court decision diploma drive engine charge clothing confirm courtyard declare direct driver engineerchart cloud conflict cousin decline direction drop enjoychat cloudy confuse cover decorate director drug enjoyable cheap club congratulate cow decoration directory drum enlargecheat clumsy congratulation crash decrease dirty drunk enoughcheck coach connect crayon deed disability dry enquirycheek coal connection crazy deep disabled duck entercheer coast conscience cream deer disadvantage due enterprise cheerful coat consensus create defeat disagree dull entertainment cheers cocoa consequence creature defence disagreement dumpling enthusiastic cheese coffee conservation credit defend disappear during entirechef coin conservative crew degree disappoint dusk entrance chemical coincidence consider crime delay disappointed dust entrychemist coke considerate criminal delete disaster dustbin envelope chemistry cold consideration criterion deliberately discount dusty environmentenvy fade flame fridge government hard horse insect equal failure flash friend grade hardly hospital insert equality fair flashlight friendly gradual hardship host inside equip faith flat friendship graduate hardworking hostess insist equipment fall flat frighten graduation harm hot inspect eraser fall Flee frog grain harmful hotdog inspire error FALSE flexible from gram harmony hotel instant erupt familiar flesh front grammar harvest hour instead escape family flight frontier grand hat house institute especially famous float frost grandchild hatch housewife institution essay fan flood fruit granddaughter hate housework instruct Europe fancy floor fry grandma have how instruction European fantastic flour fuel grandpa he however instrument evaluate fantasy flow full grandparents head howl insurance even far flower fun grandson headache hug insure evening fare flu function granny headline huge intelligence event farm fluency fundamental grape headmaster human intend eventually farmer fluent funeral graph headmistress humanbeing intention ever fast fly funny grasp health humorous interest every fasten fly fur grass healthy hunger interesting everybody fat focus furnished grateful hear hungry international everyday father fog furniture gravity hearing hunt internet everyone fault foggy future great heart hunter interpreter everything favour fold gain greedy heat hurricane interrupt everywhere favourite folk gallery green heaven hurry interval evidence fax follow gallon green heavy hurt interview evident fear fond game grocer heel husband into evolution feast food garage greet height hydrogen introduce exact feather fool garbage greeting helicopter ice introduction exam federal foolish garden grey hello ice-cream invent examine fee foot garlic grill helmet idea invention example feed football garment grocer help identity invitation excellent feel for gas grocery helpful identification invite except feeling forbid gate ground hen idiom iron exchange fellow force gather group her if irrigation excite female forecast gay grow herb ignore island excuse fence forehead general growth here ill itexercise ferry foreign generation guarantee hero illegal its exhibition festival foreigner generous guard hers illness itselfexist fetch foresee gentle guess herself imagine jacket existence fever forest gentleman guest hesitate immediately jamexit few forever geography guidance hi immigration jarexpand fibre forget geometry guide hide import jawexpect fiction forgetful gesture guilty high importance jazz expectation field forgive get guitar highway important jeans expense fierce fork gift gun hill impossible jeep expensive fight form gifted gym him impress jet experience figure format giraffe gymnastics himself impression jewellery experiment file former girl habit hire improve jobexpert fill fortnight give hair his in jog explain film fortunate glad haircut history inch join explanation final fortune glance half hit incident joke explicit finance forty glare hall hobby include journalist explode find forward glass ham hold income journey explore fine found globe hamburger hole increase joyexport fine fountain glory hammer holiday indeed judge expose finger fox glove hand holy independence judgement express fingernail fragile glue handbag home independent juice expression finish fragrant go handful homeland indicate jump extension fire framework goal handkerchief Hometown industry jungle extra fireworks franc goat handle homework influence junior extraordinary firm free god handsome honest inform just extreme firm freedom gold handwriting honey information justiceeye fish freeway golden handy honour initial kangaroo eyesight fisherman freeze golf hang hook injure keepface fist freezing good happen hope injury kettle facial fit frequent goods happiness hopeful ink keyfact fix fresh goose happy hopeless inn keyboard factory flag friction govern harbour horrible innocent Kickkid lie maple mine must nuclear out passportkill lie maple mineral mustard numb outcome pastkilo life leaves minibus mutton number outdoors patent kilogram lift marathon minimum my nurse outer path Kilometre light marble minister myself nursery outgoing patience kind lightning march ministry nail nut outing patientkind like mark minority name nutrition outline patient kindergarten likely market minus narrow obey output pattern kindness limit marriage minute nation object outside pauseKing line marry mirror national observe outspoken Pavement kingdom link mask miss nationality obtain outstanding paykiss lion mass missile nationwide obvious outward〔s〕P.E.kitchen lip master mist native occupation oval P.C.kite liquid mat mistake natural occupy over peaknee list match mistaken nature occur overcoat peaceknife listen material misunderstand navy ocean overcome peaceful knock literature mathematics mix near Oceania overhead peachknow literary matter mixture nearby o'clock overlook pear knowledge litre mature mm nearly of overweight pedestrian lab litter maximum mobile neat off owe penlabour little may mobilephone necessary offence own pencelack live maybe model neck offer owner pencillady lively me modem necklace office ownership pennylake load meal modern need officer ox pension lamb loaf mean modest needle official oxygen Peoplelame local meaning mom negotiate offshore pace pepperlamp lock means moment neighbour often Pacific perland lonely meanwhile mommy neighbourhood oh thePacificOcean percent language long measure money neither oil pack percentage lantern look meat monitor nephew oilfield package perfectlap loose medal gold monkey nervous O.K.packet perform large lorry medal month nest old paddle performance last loss media monument net Olympic〔s〕page performer late lose medical moon network OlympicGames Pain perfume latter lot medicine mooncake never on painful perhaps laugh Lost&Found medium mop new once paint period laughter loud meet moral news one Painter permanent laundry lounge meeting more newspaper oneself painting permission law love melon morning next onion pair permit lawyer lovely member Moslem nice only palace Personlay low memorial mosquito niece onto pale personal lazy luck memory mother night open pan personnel lead lucky mend motherland no opening pancake personally leader luggage mental motivation No.opera panda persuade leaf lunch mention motor noble operahouse panic pestleague lung menu motorcycle nobody operate paper petleak machine merchant motto nod operation paperwork petrollearn mad merciful mountain noise operator paragraph phenomenon least madam/madame mercy mountainous noisy opinion parallel phone leather magazine merely mourn none oppose parcel photoleave magic merry mouse noodle opposite pardon photograph lecture maid mess moustache noon optimistic parent Photographer left mail message mouth nor optional park phraseleg mailbox messy frommouthtomouth normal or park physical legal main metal move north oral Parking physical lemon mainland method movement northeast orange parkinglot examination lemonade major metre movie northern orbit parrot physician lend majority microscope Mr.northwest order part physicist length make microwave Mrs.nose ordinary participate physics lesson make middle Ms.not organ particular Pianistlet male MiddleEast mud note organise partly pianoletter man midnight muddy notebook organization Partner picklevel manage might multiply nothing origin part-time Picnic liberty manager mild murder notice other Party picture liberation mankind mile museum novel otherwise pass pielibrarian mannertable milk mushroom novelist ought passage piecelibrary manners millionaire music now our passenger piglicense many mind musical nowadays ours passer-by pilelid map mine musician nowhere ourselves passive pillpillow post progress range remark rose sea shinepilot post Prohibit rank remember rot seagull shippin postage project rapid remind rough seal shirtpine Postcard promise rare remote round search shock pineapple postcode promote rat remove roundabout seashell shoeping-pong poster pronounce rather rent routine seaside shootPink postman Pronunciation raw repair row season shoppint postpone proper rawmaterial repeat row seat shopassistant pioneer pot properly ray replace royal seaweed shopkeeper pipe Potato protect razor reply rubber second shopping pity potential protection reach report rubbish secret shoreplace pound Proud react reporter rude secretary shortplain pour prove read represent rugby section shortcoming plan powder provide reading representative ruin secure shortly plane power province ready republic rule security shorts Planet powerful psychology real reputation ruler see shotplant practical pub reality request run seedmelon should plastic practice public realise require rush seed shoulder plate practise publish really requirement sacred seek shout platform praise pull reason rescue sacrifice seem showplay pray pulse reasonable research sad seize shower playground prayer pump rebuild resemble sadness seldom shrink pleasant precious punctual receipt reservation safe select shutplease precise Punctuation receive reserve safety self shuttle pleased predict punish receiver resign sail selfish shy pleasure prefer punishment recent Resist sailor sell sickPlenty preference Pupil reception Respect salad semicircle sicknessplot pregnant purchase receptionist respond salary seminar sideplug prejudice pure recipe responsibility sale send sideroad Plus premier Purple recite rest salesgirl senior sidewayp.m./pm,P.M./PM Preparation Purpose recognise restaurant salesman sense sideways pocket prepare purse recommend restriction saleswoman sensitive sighpoem prescription push record result salt sentence sightpoet present put recordholder retell salty separate sightseeing point present puzzle recorder Retire salute separation signal poison presentation pyramid recover return same serious signature poisonous preserve quake recreation review sand servant significance pole president qualification recycle revision sandwich serve silence<theNorth press quality rectangle revolution satellite service silent 〔South〕Pole>press quantity red reward satisfaction session silkpolice pressure quarrel reduce rewind satisfy set silly policeman pretend quarter refer rhyme saucer settle silver Policewoman pretty queen referee rice sausage settlement similar policy prevent question reference rich save settler simple polish preview questionnaire reflect rid say several simplify Polite previous queue reform riddle saying severe since Political price quick refresh ride scan sew sincerely politician pride quiet refrigerator ridiculous scar sex singpolitics primary quilt refuse right scarf shabby single pollute primaryschool quit regard rigid scene shade sink pollution primitive quite regardless ring scenery shadow sirpond principle quiz register ripe sceptical shake sisterpool print rabbit regret ripen schedule shall sitpoor prison race regular rise school shallow situationpop prisoner racial regulation risk scholar shame size popcorn private radiation reject river scholarship shape skate Popular privilege radio relate road schoolbag share skateboard population prize radioactive relation roast schoolboy/girl shark skipork Probably radium relationship rob schoolmate sharp skill porridge problem rag relative robot science sharpen skillfulport procedure rail relax rock scientific sharpenerpencil skin Portable process railway relay rocket scientist sharpener skipporter produce rain relevant role scissors shave skirt position product rainbow reliable roll scold shaver skypositive production raincoat relief roof score she skyscraper possess profession rainfall religion room scratch sheep slave possession professor rainy religious rooster scream sheet slavery possibility profit raise rely root screen shelf sleep possible programme random remain rope sculpture shelter sleepysleeve spear storm surrounding tent to truly useless slice special story survival tentative toast trunk userslide specialist stout survive term tobacco trust usualslight specific stove suspect terminal today truth vacation slim speech straight suspension terrible together try vacantslip speed straightforward swallow terrify toilet T-shirt vagueslow spell strait swap terror tolerate tube vainsmall spelling strange swear test tomato tune validsmart spend stranger sweat text tomb turkey valleysmell spin straw sweater textbook tomorrow turn valuable smile spirit strawberry sweep than ton turning valuesmog spiritual stream sweet thank tongue tutor variety smoke spit street swell thankful tonight TV various smoker splendid strength swift that too twice vase smooth split strengthen swim the tool twin vastsnake spoken stress swing theatre tooth twist VCD sneaker spokesman/woman strict switch theft toothache type vegetable sneeze sponsor strike sword their toothbrush typewriter vehiclesniff spoon string symbol theirs toothpaste typical version snow spoonful strong sympathy them top typhoon vertical snowy sport struggle symphony theme topic typist veryso spot stubborn symptom themselves tortoise tyre vestsoap spray student system then total ugly viasob spread studio systematic theoretical touch umbrella vicesoccer spring study table theory tough unable victim social spy stupid tabletennis there tour unbearable victory socialism square style tablet therefore tourism unbelievable video socialist squeeze subject tail thermos tourist uncertain videophone society squirrel subjective tailor these tournament uncle viewsock stable submit take they toward〔s〕uncomfortable village socket stadium subscribe tale thick towel unconditional villager sofa staff substitute talent thief tower unconscious vinegarsoft stage succeed talk thin town under violate softdrink stain success tall thing toy underground violence software stainless successful tank think track underline violentsoil stair such tap thinking tractor understand violinsolar stamp suck tape thirst trade undertake violinist soldier stand sudden target this tradition underwear virtuesolid standard suffer task thorough traditional unemployment virussome star suffering tasteless those traffic unfair visa somebody stare sugar tasty though train unfit visit somehow start suggest tax thought training unfortunate visitor someone starvation suggestion taxi thread tram uniform visual something starve suit taxpayer thrill transform union vital sometimes state suitable tea thriller translate unique vivid somewhere station suitcase teach throat translation unit vocabulary son statement suite teacher through translator unite voicesong<statesman/st summary team throughout transparent universal volcano soon ateswoman>summer teamwork throw transport universe volleyball sorrow statistics sun teapot thunder trap university voluntary sorry statue sunburnt tear thunderstorm travel unless volunteer sort status sunlight tear thus traveler unlike votesoul stay sunny tease tick treasure unrest voyage sound steady sunshine technical ticket treat until wagsoup steal super technique tidy treatment unusual wagesour steam superb technology tie tree unwilling waistsouth steel superior teenager tiger tremble up wait southeast steep supermarket telephone tight trend update waiter southern step supper telescope till trial upon waiting-room southwest steward supply television time triangle upper waitress souvenir stewardess support tell timetable trick upset wakesow stick suppose temperature tin trip upstairs walkspace still supreme temple tiny trolleybus upward〔s〕wall spaceship stocking surplus temporary tip troop urban wallet spade stomach sure tend tire trouble urge walnut spare stone surface tendency tired troublesome urgent wander sparrow stop surgeon tennis tiresome trousers use wantspeak storage surprise tense tissue truck used war speaker store surround tension title TRUE useful ward.. warehousewarm warmth Warn wash washroom waste watch water watermelon wavewaxwayweweak weakness wealth wealthy wear weather web website wedding weed week weekday weekend weekly weep weigh weight welcome welfare wellwest western westwards wetwhale what whatever wheat wheel when whenever where wherever whether which whichever while whisper whistle whitewho whole whomwho whose whywide widespread widowwifewild wildlifewillwillwin;.windwind window windywinewingwinner winterwipewirewisdomwisewishwith withdraw within without witnesswolfwoman wonder wonderful woodwoolwoolenwordworkworkerworld worldwide worm worried worryworth worthwhile worthy wound wrestle wrinklewristwritewrongX-rayyardyawnyellyearyellowyes yesterday wetyoghurtyouyoungyouryours yourself yourselves youth yummy zebra zebracrossing zerozipzipcode zipperzonezoom.. ;.。
云存储中的数据完整性及其关键技术在船舶信息中心的应用定 会(武昌首义学院,湖北 武汉 430064)摘要: 基于分布式的云存储技术在船舶信息中心中得到广泛应用。
数据的每份副本按照一定概率进行保存,实现了数据的冗余备份。
同时,由于海上恶劣的气候环境,硬件故障率较高,为保障船舶信息中心数据完整性及可靠性,需要通过多层级的分布式云存储技术来实现。
本文分析了基于云存储的数据完整性及安全性的技术指标,设计了基于分层模型的二叉树型数据存储机制。
关键词:数据完整性;分层二叉树模型;云存储中图分类号:TP333 文献标识码:A文章编号: 1672 – 7649(2018)4A – 0115 – 03 doi:10.3404/j.issn.1672 – 7649.2018.4A.039The application of data integrity in cloud storage and its key technologies inthe ship information centerDING Hui(Wuchang Shouyi University, Wuhan 430064, china)Abstract: Distributed cloud storage technology is widely used in Ship Information Center. Each copy of the data is saved in accordance with a certain probability, and the redundant backup of the data is realized.At the same time, due to the harsh weather environment at sea, the failure rate of hardware storage is very high. In order to ensure data integrity and reli-ability of Ship Information Center, we need to realize it through multi-level cloud storage technology.This paper analyzes the technical indexes of cloud storage in the implementation of data integrity security, and designs a hierarchical model based two forked tree type data storage mechanism.Key words: data integrity;hierarchical two forked tree model;cloud storage0 引 言相比于稳态环境下的存储环境,海上分布式存储中单个节点数据的故障率较高;船舶信息中心数据传输、获取及存储首先要验证数据的完整性,节点数据被损坏时,若不能较快的进行数据恢复,平台可靠性降低。
云数据中心基于任务映射的虚拟机选择策略刘开南【期刊名称】《《计算机工程》》【年(卷),期】2019(045)010【总页数】7页(P33-39)【关键词】云数据中心; 虚拟机选择; 虚拟机放置; 虚拟机迁移; 任务映射【作者】刘开南【作者单位】三亚学院信息与智能工程学院海南三亚572022; 三亚学院院士工作站海南三亚572022; 三亚学院超算中心海南三亚572022【正文语种】中文【中图分类】TP393.0930 概述云数据中心的构造与使用已成为目前政府和云服务提供商日益重视的问题。
一个云数据中心通常配置有大量紧密堆积的物理节点,而虚拟化是云数据中心的关键技术。
虚拟化指通过虚拟机的形式封装应用程序的任务与数据,并利用虚拟机调度策略将其分配到具体的物理节点中执行。
为节省能量消耗,云服务提供商采用虚拟机迁移策略将虚拟机在各个物理服务器上进行选择与放置,最终达到降低云数据中心低能量消耗和物理空间、提高服务质量(Quality of Service,QoS)和可靠性的目标[1-3]。
文献[4-5]以Cloudsim项目为研究内容,把虚拟机迁移策略划分为物理主机负载状态检测、虚拟机选择与虚拟机放置3个过程,最终完成整个虚拟机的迁移。
虚拟机选择指通过映射的方式把计算任务分配给虚拟机;虚拟机放置指把虚拟机选择算法中选择出的虚拟机利用相应算法均匀放置到云数据中心最合适的物理节点上。
由上述过程可以看出,虚拟机选择和虚拟机放置应属于2个独立的过程,但都可以通过算法进行优化。
前者主要通过任务粒度、软件代价等来进行调整;后者属于一类经典装箱问题,即把大量的虚拟机放置到大量的物理节点之中。
常见方法有首次适应算法First Fit、最好适应算法Best Fit、最坏适应算法Worst Fit等。
但目前鲜有研究虚拟机选择与虚拟机放置过程之间关系的文献,事实上虚拟机选择可以影响到虚拟机放置,至少在私有云中虚拟机选择和虚拟机放置都可以由一个机构去控制。
Cloud Control with Distributed Rate LimitingBarath Raghavan,Kashi Vishwanath,Sriram Ramabhadran,Kenneth Y ocum,and Alex C.SnoerenDepartment of Computer Science and EngineeringUniversity of California,San DiegoABSTRACTToday’s cloud-based services integrate globally distributed re-sources into seamless computing platforms.Provisioning and ac-counting for the resource usage of these Internet-scale applications presents a challenging technical problem.This paper presents the design and implementation of distributed rate limiters,which work together to enforce a global rate limit across traffic aggregates at multiple sites,enabling the coordinated policing of a cloud-based service’s network traffic.Our abstraction not only enforces a global limit,but also ensures that congestion-responsive transport-layer flows behave as if they traversed a single,shared limiter.We present two designs—one general purpose,and one optimized for TCP—that allow service operators to explicitly trade off between communication costs and system accuracy,efficiency,and scalabil-ity.Both designs are capable of rate limiting thousands offlows with negligible overhead(less than3%in the tested configuration). We demonstrate that our TCP-centric design is scalable to hundreds of nodes while robust to both loss and communication delay,mak-ing it practical for deployment in nationwide service providers. Categories and Subject DescriptorsC.2.3[Computer Communication Networks]:Network manage-mentGeneral TermsAlgorithms,Management,PerformanceKeywordsRate Limiting,Token Bucket,CDN1.INTRODUCTIONYesterday’s version of distributed computing was a self-contained,co-located server farm.Today,applications are increas-ingly deployed on third-party resources hosted across the Inter-net.Indeed,the rapid spread of open protocols and standards like Web2.0has fueled an explosion of compound services that Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on thefirst page.To copy otherwise,to republish,to post on servers or to redistribute to lists,requires prior specific permission and/or a fee.SIGCOMM’07,August27–31,2007,Kyoto,Japan.Copyright2007ACM978-1-59593-713-1/07/0008...$5.00.script together third-party components to deliver a sophisticated service[27,29].These specialized services are just the beginning:flagship consumer and enterprise applications are increasingly be-ing delivered in the software-as-a-service model[9].For example, Google Documents,Groove Office,and Windows Live are early ex-amples of desktop applications provided in a hosted environment, and represent the beginning of a much larger trend.Aside from the functionality and management benefits Web-based services afford the end user,hosted platforms present sig-nificant benefits to the service provider as well.Rather than de-ploy each component of a multi-tiered application within a partic-ular data center,so-called“cloud-based services”can transparently leverage widely distributed computing infrastructures.Google’s service,for example,reportedly runs on nearly half-a-million servers distributed around the world[8].Potential world-wide scale need not be limited to a few large corporations,however.Recent offerings like Amazon’s Elastic Compute Cloud(EC2)promise to provide practically infinite resources to anyone willing to pay[3]. One of the key barriers to moving traditional applications to the cloud,however,is the loss of cost control[17].In the cloud-based services model,cost recovery is typically accomplished through metered pricing.Indeed,Amazon’s EC2charges incrementally per gigabyte of traffic consumed[3].Experience has shown,how-ever,that ISP customers preferflat fees to usage-based pricing[30]. Similarly,at a corporate level,IT expenditures are generally man-aged asfixed-cost overheads,not incremental expenses[17].A flat-fee model requires the ability for a provider to limit consump-tion to control costs.Limiting global resource consumption in a distributed environment,however,presents a significant technical challenge.Ideally,resource providers would not require services to specify the resource demands of each distributed component a priori;suchfine-grained measurement and modeling can be chal-lenging for rapidly evolving services.Instead,they should provide afixed price for an aggregate,global usage,and allow services to consume resources dynamically across various locations,subject to the specified aggregate limit.In this paper,we focus on a specific instance of this problem: controlling the aggregate network bandwidth used by a cloud-based service,or distributed rate limiting(DRL).Our goal is to allow a set of distributed traffic rate limiters to collaborate to subject a class of network traffic(for example,the traffic of a particular cloud-based service)to a single,aggregate global limit.While traffic policing is common in data centers and widespread in today’s networks,such limiters typically enforce policy independently at each location[1]. For example,a resource provider with10hosting centers may wish to limit the total amount of traffic it carries for a particular service to100Mbps.Its current options are to either limit the service to 100Mbps at each hosting center(running the risk that they may alluse this limit simultaneously,resulting in1Gbps of total traffic),or to limit each center to afixed portion(i.e.,10Mbps)which over-constrains the service traffic aggregate and is unlikely to allow the service to consume its allocated budget unless traffic is perfectly balanced across the cloud.The key challenge of distributed rate limiting is to allow indi-vidualflows to compete dynamically for bandwidth not only with flows traversing the same limiter,but withflows traversing other limiters as well.Thus,flows arriving at different limiters should achieve the same rates as they would if they all were traversing a single,shared rate limiter.Fairness betweenflows inside a traffic aggregate depends critically on accurate limiter assignments,which in turn depend upon the local packet arrival rates,numbers offlows, and up/down-stream bottleneck capacities.We address this issue by presenting the illusion of passing all of the traffic through a single token-bucket rate limiter,allowingflows to compete against each other for bandwidth in the manner prescribed by the transport pro-tocol(s)in use.For example,TCPflows in a traffic aggregate will share bandwidth in aflow-fair manner[6].The key technical chal-lenge to providing this abstraction is measuring the demand of the aggregate at each limiter,and apportioning capacity in proportion to that demand.This paper makes three primary contributions: Rate Limiting Cloud-based Services.We identify a key challenge facing the practical deployment of cloud-based services and iden-tify the chief engineering difficulties:how to effectively balance accuracy(how well the system bounds demand to the aggregate rate limit),responsiveness(how quickly limiters respond to varying traffic demands),and communication between the limiters.A dis-tributed limiter cannot be simultaneously perfectly accurate and re-sponsive;the communication latency between limiters bounds how quickly one limiter can adapt to changing demand at another. Distributed Rate Limiter Design.We present the design and im-plementation of two distributed rate limiting algorithms.First,we consider an approach,global random drop(GRD),that approxi-mates the number,but not the precise timing,of packet drops.Sec-ond,we observe that applications deployed using Web services will almost exclusively use TCP.By incorporating knowledge about TCP’s congestion control behavior,we design another mechanism,flow proportional share(FPS),that provides improved scalability. Evaluation and Methodology.We develop a methodology to eval-uate distributed rate limiters under a variety of traffic demands and deployment scenarios using both a local-area testbed and an Inter-net testbed,PlanetLab.We demonstrate that both GRD and FPS exhibit long-term behavior similar to a centralized limiter for both mixed and homogeneous TCP traffic in low-loss environments. Furthermore,we show that FPS scales well,maintaining near-ideal 50-Mbps rate enforcement and fairness up to490limiters with a modest communication budget of23Kbps per limiter.2.CLASSES OF CLOUDSCloud-based services come in varying degrees of complexity; as the constituent services become more numerous and dynamic, resource provisioning becomes more challenging.We observe that the distributed rate limiting problem arises in any service composed of geographically distributed sites.In this section we describe three increasingly mundane applications,each illustrating how DRL em-powers service providers to enforce heretofore unrealizable traffic policies,and how it offers a new service model to customers. 2.1Limiting cloud-based servicesCloud-based services promise a“utility”computing abstraction in which clients see a unified service and are unaware that the sys-tem stitches together independent physical sites to provide cycles, bandwidth,and storage for a uniform purpose.In this context,we are interested in rate-based resources that clients source from a sin-gle provider across many sites or hosting centers.For clouds,distributed rate limiting provides the critical ability for resource providers to control the use of network bandwith as if it were all sourced from a single site.A provider runs DRL across its sites,setting global limits on the total network usage of particular traffic classes or clients.Providers are no longer required to mi-grate requests to accomodate static bandwidth limits.Instead,the available bandwidth gravitates towards the sites with the most de-mand.Alternatively,clients may deploy DRL to control aggregate usage across providers as they seefit.DRL removes the artificial separation of access metering and geography that results in excess cost for the client and/or wasted resources for service providers. 2.2Content distribution networksWhile full-scale cloud-based computing is in its infancy,simple cloud-based services such as content-distribution networks(CDNs) are prevalent today and can benefit from distributed rate limiting. CDNs such as Akamai provide content replication services to third-party Web sites.By serving Web content from numerous geograph-ically diverse locations,CDNs improve the performance,scalabil-ity,and reliability of Web sites.In many scenarios,CDN operators may wish to limit resource usage either based on the content served or the requesting identity.Independent rate limiters are insufficient, however,as content can be served from any of numerous mirrors around the world according tofluctuating demand.Using DRL,a content distribution network can set per-customer limits based upon service-level agreements.The CDN provides ser-vice to all sites as before,but simply applies DRL to all out-bound traffic for each site.In this way,the bandwidth consumed by a cus-tomer is constrained,as is the budget required to fund it,avoiding the need for CDNs to remove content for customers who cannot pay for their popularity.1Alternatively,the CDN can use DRL as a protective mechanism.For instance,the CoDeeN content distribu-tion network was forced to deploy an ad-hoc approach to rate limit nefarious users across proxies[37].DRL makes it simple to limit the damage on the CDN due to such behavior by rate limiting traffic from an identified set of users.In summary,DRL provides CDNs with a powerful tool for managing access to their clients’content.2.3Internet testbedsPlanetlab supports the deployment of long-lived service proto-types.Each Planetlab service runs in a slice—essentially a fraction of the entire global testbed consisting of1/N of each machine. Currently Planetlab provides work-conserving bandwidth limits at each individual site,but the system cannot coordinate bandwidth demands across multiple machines[18].DRL dynamically apportions bandwidth based upon demand,al-lowing Planetlab administrators to set bandwidth limits on a per-slice granularity,independent of which nodes a slice uses.In the context of a single Planetlab service,the service administrator may limit service to a particular user.In Section5.7we show that DRL provides effective limits for a Planetlab service distributed across North America.In addition,while we focus upon network rate lim-iting in this paper,we have begun to apply our techniques to control other important rate-based resources such as CPU.2.4Assumptions and scopeLike centralized rate limiting mechanisms,distributed rate lim-iting does not provide QoS guarantees.Thus,when customers pay for a given level of service,providers must ensure the availability of adequate resources for the customer to attain its given limit.In the extreme,a provider may need to provision each limiter with enough capacity to support a service’s entire aggregate limit.Nevertheless, we expect many deployments to enjoy considerable benefits from statistical multiplexing.Determining the most effective provision-ing strategy,however,is outside the scope of this paper. Furthermore,we assume that mechanisms are already in place to quickly and easily identify traffic belonging to a particular ser-vice[25].In many cases such facilities,such as simple address or protocol-based classifiers,already exist and can be readily adopted for use in a distributed rate limiter.In others,we can leverage re-cent work on network capabilities[32,39]to provide unforgeable means of attribution.Finally,without loss of generality,we discuss our solutions in the context of a single service;multiple services can be limited in the same fashion.3.LIMITER DESIGNWe are concerned with coordinating a set of topologically dis-tributed limiters to enforce an aggregate traffic limit while retaining the behavior of a centralized limiter.That is,a receiver should not be able to tell whether the rate limit is enforced at one or many lo-cations simultaneously.Specifically,we aim to approximate a cen-tralized token-bucket traffic-policing mechanism.We choose a to-ken bucket as a reference mechanism for a number of reasons:it is simple,reasonably well understood,and commonly deployed in In-ternet routers.Most importantly,it makes instantaneous decisions about a packet’s fate—packets are either forwarded or dropped—and so does not introduce any additional queuing.We do not assume anything about the distribution of traffic across limiters.Thus,traffic may arrive at any or all of the limiters at any time.We use a peer-to-peer limiter architecture:each limiter is functionally identical and operates independently.The task of a limiter can be split into three separate subtasks:estimation,com-munication,and allocation.Every limiter collects periodic mea-surements of the local traffic arrival rate and disseminates them to the other limiters.Upon receipt of updates from other limiters,each limiter computes its own estimate of the global aggregate arrival rate that it uses to determine how to best service its local demand to enforce the global rate limit.3.1Estimation and communicationWe measure traffic demand in terms of bytes per unit time.Each limiter maintains an estimate of both local and global demand.Es-timating local arrival rates is well-studied[15,34];we employ a strategy that computes the average arrival rate overfixed time in-tervals and applies a standard exponentially-weighted moving av-erage(EWMA)filter to these rates to smooth out short-termfluc-tuations.The estimate interval length and EWMA smoothing pa-rameter directly affect the ability of a limiter to quickly track and communicate local rate changes;we determine appropriate settings in Section5.At the end of each estimate interval,local changes are merged with the current global estimate.In addition,each limiter must dis-seminate changes in local arrival rate to the other limiters.The sim-plest form of communication fabric is a broadcast mesh.While fast and robust,a full mesh is also extremely bandwidth-intensive(re-quiring O(N2)update messages per estimate interval).Instead,we implement a gossip protocol inspired by Kempe et al.[22].SuchGRD-H ANDLE-P ACKET(P:Packet)1demand←nPir i2bytecount←bytecount+L ENGTH(P)3if demand>limit then4dropprob←(demand−limit)/demand5if R AND()<dropprob then6D ROP(P)7return8F ORWARD(P)Figure1:Pseudocode for GRD.Each value r i corresponds to the current estimate of the rate at limiter i.“epidemic”protocols have been widely studied for distributed co-ordination;they require little to no communication structure,and are robust to link and node failures[10].At the end of each es-timate interval,limiters select afixed number of randomly chosen limiters to update;limiters use any received updates to update their global demand estimates.The number of limiters contacted—the gossip branching factor—is a parameter of the system.We com-municate updates via a UDP-based protocol that is resilient to loss and reordering;for now we ignore failures in the communication fabric and revisit the issue in Section5.6.Each update packet is 48bytes,including IP and UDP headers.More sophisticated com-munication fabrics may reduce coordination costs using structured approaches[16];we defer an investigation to future work.3.2AllocationHaving addressed estimation and communication mechanisms, we now consider how each limiter can combine local measure-ments with global estimates to determine an appropriate local limit to enforce.A natural approach is to build a global token bucket (GTB)limiter that emulates thefine-grained behavior of a central-ized token bucket.Recall that arriving bytes require tokens to be allowed passage;if there are insufficient tokens,the token bucket drops packets.The rate at which the bucket regenerates tokens dic-tates the traffic limit.In GTB,each limiter maintains its own global estimate and uses reported arrival demands at other limiters to esti-mate the rate of drain of tokens due to competing traffic.Specifically,each limiter’s token bucket refreshes tokens at the global rate limit,but removes tokens both when bytes arrive locally and to account for expected arrivals at other limiters.At the end of every estimate interval,each limiter computes its local arrival rate and sends this value to other limiters via the communication fabric.Each limiter sums the most recent values it has received for the other limiters and removes tokens from its own bucket at this “global”rate until a new update arrives.As shown in Section4, however,GTB is highly sensitive to stale observations that con-tinue to remove tokens at an outdated rate,making it impractical to implement at large scale or in lossy networks.3.2.1Global random dropInstead of emulating the precise behavior of a centralized token bucket,we observe that one may instead emulate the higher-order behavior of a central limiter.For example,we can ensure the rate of drops over some period of time is the same as in the centralized case,as opposed to capturing the burstiness of packet drops—in this way,we emulate the rate enforcement of a token bucket but not its burst limiting.Figure1presents the pseudocode for a global ran-dom drop(GRD)limiter that takes this approach.Like GTB,GRD monitors the aggregate global input demand,but uses it to calculate a packet drop probability.GRD drops packets with a probabilityproportional to the excess global traffic demand in the previous in-terval(line4).Thus,the number of drops is expected to be the same as in a single token bucket;the aggregate forwarding rate should be no greater than the global limit.GRD somewhat resembles RED queuing in that it increases its drop probability as the input demand exceeds some threshold[14]. Because there are no queues in our limiter,however,GRD requires no tuning parameters of its own(besides the estimator’s EWMA and estimate interval length).In contrast to GTB,which attempts to reproduce the packet-level behavior of a centralized limiter,GRDtries to achieve accuracy by reproducing the number of losses over longer periods of time.It does not,however,capture short-term effects.For inherently bursty protocols like TCP,we can improve short-term fairness and responsiveness by exploiting information about the protocol’s congestion control behavior.3.2.2Flow proportional shareOne of the key properties of a centralized token bucket is that it retains inter-flow fairness inherent to transport protocols such as TCP.Given the prevalence of TCP in the Internet,and espe-cially in modern cloud-based services,we design aflow propor-tional share(FPS)limiter that uses domain-specific knowledge about TCP to emulate a centralized limiter without maintaining de-tailed packet arrival rates.Each FPS limiter uses a token bucket for rate limiting—thus,each limiter has a local rate limit.Un-like GTB,which renews tokens at the global rate,FPS dynami-cally adjusts its local rate limit in proportion to a set of weights computed every estimate interval.These weights are based upon the number of liveflows at each limiter and serve as a proxy for demand;the weights are then used to enforce max-min fairness be-tween congestion-responsiveflows[6].The primary challenge in FPS is estimating TCP demand.In the previous designs,each rate limiter estimates demand by measuring packets’sizes and the rate at which it receives them;this accurately reflects the byte-level demand of the traffic sources.In contrast, FPS must determine demand in terms of the number of TCPflows present,which is independent of arrival rate.Furthermore,since TCP always attempts to increase its rate,a singleflow consuming all of a limiter’s rate is nearly indistinguishable from10flows doing the same.2However,we would like that a10-flow aggregate receive 10times the weight of a singleflow.Our approach to demand estimation in FPS is shown in Fig-ure2.Flow aggregates are in one of two states.If the aggregate under-utilizes the allotted rate(local limit)at a limiter,then all con-stituentflows must be bottlenecked.In other words,theflows are all constrained elsewhere.On the other hand,if the aggregate ei-ther meets or exceeds the local limit,we say that one or more of the constituentflows is unbottlenecked—for theseflows the lim-iter is the bottleneck.We calculateflow weights with the function FPS-E STIMATE.Ifflows were max-min fair,then each unbottle-neckedflow would receive approximately the same rate.We there-fore count a weight of1for every unbottleneckedflow at every limiter.Thus,if allflows were unbottlenecked,then the demand at each limiter is directly proportional to its currentflow count.Set-ting the local weight to this number results in max-min fair alloca-tions.We use the computed weight on line10of FPS-E STIMATE to proportionally set the local rate limit.limit−localdemand 10locallimit←idealweight·limitfair share of an unbottleneckedflow is20Kbps,the bottlenecked flow counts for half the weight of an unbottleneckedflow.Local arrival rate<local rate limit.When allflows at the limiter are bottlenecked,there is no unbottleneckedflow whose rate can be used to compute the weight.Since theflow aggregate is unable to use all the rate available at the limiter,we compute a weight that, based on current information,sets the local rate limit to be equal to the local demand(line9of FPS-E STIMATE).A limiter may oscillate between the two regimes:entering the second typically returns the system to thefirst,since the aggregate may become unbottlenecked due to the change in local rate limit. As a result,the local rate limit is increased during the next alloca-tion,and the cycle repeats.We note that this oscillation is necessary to allow bottleneckedflows to become unbottlenecked should ad-ditional capacity become available elsewhere in the network;like the estimator,we apply an EWMA to smooth this oscillation.We have proved that FPS is stable—given stable input demands,FPS remains at the correct allocation of weights among limiters once it arrives in that state.(We include the proof in the Appendix.)It remains an open question,however,whether FPS converges under all conditions,and if so,how quickly.Finally,TCP’s slow start behavior complicates demand estima-tion.Consider the arrival of aflow at a limiter that has a current rate limit of zero.Without buffering,theflow’s SYN will be lost and theflow cannot establish its demand.Thus,we allow bursting of the token bucket when the local rate limit is zero to allow a TCP flow in slow start to send a few packets before losses occur.When the allocator detects nonzero input demand,it treats the demand as a bottleneckedflow for thefirst estimate interval.As a result,FPS allocates rate to theflow equivalent to its instantaneous rate during the beginning of slow start,thus allowing it to continue to grow. 4.EV ALUATION METHODOLOGYOur notion of a good distributed rate limiter is one that accurately replicates centralized limiter behavior.Traffic policing mecha-nisms can affect packets andflows on several time scales;partic-ularly,we can aim to emulate packet-level behavior orflow-level behavior.However,packet-level behavior is non-intuitive,since applications typically operate at theflow level.Even in a single limiter,any one measure of packet-level behaviorfluctuates due to randomness in the physical system,though transport-layerflows may achieve the same relative fairness and throughput.This im-plies a weaker,but tractable goal of functionally equivalent behav-ior.To this end,we measure limiter performance using aggregate metrics over real transport-layer protocols.4.1MetricsWe study three metrics to determine thefidelity of limiter de-signs:utilization,flow fairness,and responsiveness.The basic goal of a distributed rate limiter is to hold aggregate throughput across all limiters below a specified global limit.To establishfidelity we need to consider utilization over different time scales.Achievable throughput in the centralized case depends critically on the traffic mix.Differentflow arrivals,durations,round trip times,and proto-cols imply that aggregate throughput will vary on many time scales. For example,TCP’s burstiness causes its instantaneous throughput over small time scales to vary greatly.A limiter’s long-term be-havior may yield equivalent aggregate throughput,but may burst on short time scales.Note that,since our limiters do not queue packets,some short-term excess is unavoidable to maintain long-term throughput.Particularly,we aim to achieve fairness equal to or better than that of a centralized token bucket limiter.Fairness describes the distribution of rate acrossflows.We em-ploy Jain’s fairness index to quantify the fairness across aflow set[20].The index considers kflows where the throughput offlow i is x i.The fairness index f is between0and1,where1is com-pletely fair(allflows share bandwidth equally):f=“P k i=1x i”20 25005000 7500 10000 12500 15000 051015R a t e (K b p s )Time (sec)(a)Centralized token bucket. 051015Time (sec)(b)Global token bucket. 051015Time (sec)(c)Global random drop. 051015Time (sec)Aggregate Departures Limiter 1 Departures Limiter 2 Departures(d)Flow proportional share.Figure 3:Time series of forwarding rate for a centralized limiter and our three limiting algorithms in the baseline experiment—3TCP flows traverse limiter 1and 7TCP flows traverse limiter 2.0 0.05 0.1 0.15 0.2 0.25 51015R e l a t i v e f r e q u e n c yForwarding rate (Mbps)(a)CTB 1sec.51015Forwarding rate (Mbps)(b)GTB 1sec. 51015Forwarding rate (Mbps)(c)GRD 1sec. 51015Forwarding rate (Mbps)(d)FPS 1sec.0 0.0150.03 0.045 0.06 0.075 51015R e l a t i v e f r e q u e n c yForwarding rate (Mbps)(e)CTB 0.1sec. 51015Forwarding rate (Mbps)(f)GTB 0.1sec. 5 1015Forwarding rate (Mbps)(g)GRD 0.1sec. 5 1015Forwarding rate (Mbps)(h)FPS 0.1sec.Figure 4:Delivered forwarding rate for the aggregate at different time scales—each row represents one run of the baseline experi-ment across two limiters with the “instantaneous”forwarding rate computed over the stated time period.5.EV ALUATIONOur evaluation has two goals.The first is to establish the ability of our algorithms to reproduce the behavior of a single limiter in meeting the global limit and delivering flow-level fairness.These experiments use only 2limiters and a set of homogeneous TCP flows.Next we relax this idealized workload to establish fidelity in more realistic settings.These experiments help achieve our second goal:to determine the effective operating regimes for each design.For each system we consider responsiveness,performance across various traffic compositions,and scaling,and vary the distribution of flows across limiters,flow start times,protocol mix,and traffic characteristics.Finally,as a proof of concept,we deploy our lim-iters across PlanetLab to control a mock-up of a simple cloud-based service.5.1BaselineThe baseline experiment consists of two limiters configured to enforce a 10-Mbps global limit.We load the limiters with 10un-bottlenecked TCP flows;3flows arrive at one limiter while 7ar-rive at the other.We choose a 3-to-7flow skew to avoid scenarios that would result in apparent fairness even if the algorithm fails.The reference point is a centralized token-bucket limiter (CTB)servicing all 10flows.We fix flow and inter-limiter round trip times (RTTs)to 40ms,and token bucket depth to 75,000bytes—slightly greater than the bandwidth-delay product,and,for now,use a loss-free communication fabric.Each experiment lasts 60seconds (enough time for TCP to stabilize),the estimate interval is 50ms,and the 1-second EWMA parameter is 0.1;we consider alternative values in the next section.Figure 3plots the packet forwarding rate at each limiter as well as the achieved throughput of the flow aggregate.In all cases,the aggregate utilization is approximately 10Mbps.We look at smaller time scales to determine the extent to which the limit is enforced.Figure 4shows histograms of delivered “instantaneous”forward-ing rates computed over two different time periods,thus showing whether a limiter is bursty or consistent in its limiting.All de-signs deliver the global limit over 1-second intervals;both GTB and GRD,however,are bursty in the short term.By contrast,FPS closely matches the rates of CTB at both time scales.We believe this is because FPS uses a token bucket to enforce local limits.It appears that when enforcing the same aggregate limit,the forward-ing rate of multiple token buckets approximates that of a single token bucket even at short time scales.Returning to Figure 3,the aggregate forwarding rate should be apportioned between limiters in about a 3-to-7split.GTB clearly fails to deliver in this regard,but both GRD and FPS appear ap-proximately correct upon visual inspection.We use Jain’s fairness index to quantify the fairness of the allocation.For each run of an experiment,we compute one fairness value across all flows,ir-respective of the limiter at which they arrive.Repeating this ex-periment 10times yields a distribution of fairness values.We use quantile-quantile plots to compare the fairness distribution of each。