
成都空气污染指数API的建模与预测
20085728 刘童超
【目录】
1..数据来源与数据预处理 (2)
1.1数据来源 (2)
1.2离群点和缺失值的检验..................................................................... 错误!未定义书签。
2.直观分析和相关分析 (4)
2.1直观分析和特征分析 (4)
2.2相关分析 (6)
2.3平稳性检验 (7)
3.liu(t)序列的零均值处理 (8)
3.1数据的零均值化 (8)
3.2零均值过程的检验 (8)
4.模型的识别和初步定阶 (8)
5.模型的参数估计 (9)
6.模型的检验 (10)
6.1参数的显著性检验 (10)
6.2模型的适用性检验 (11)
7.模型的预测 (12)
7.1对序列liu1(t)的预测 (12)
7.2对序列liu(t)的预测 (12)
【附录及参考文献】 (13)
附录1.零均值化处理后的数据 (13)
参考文献: (14)
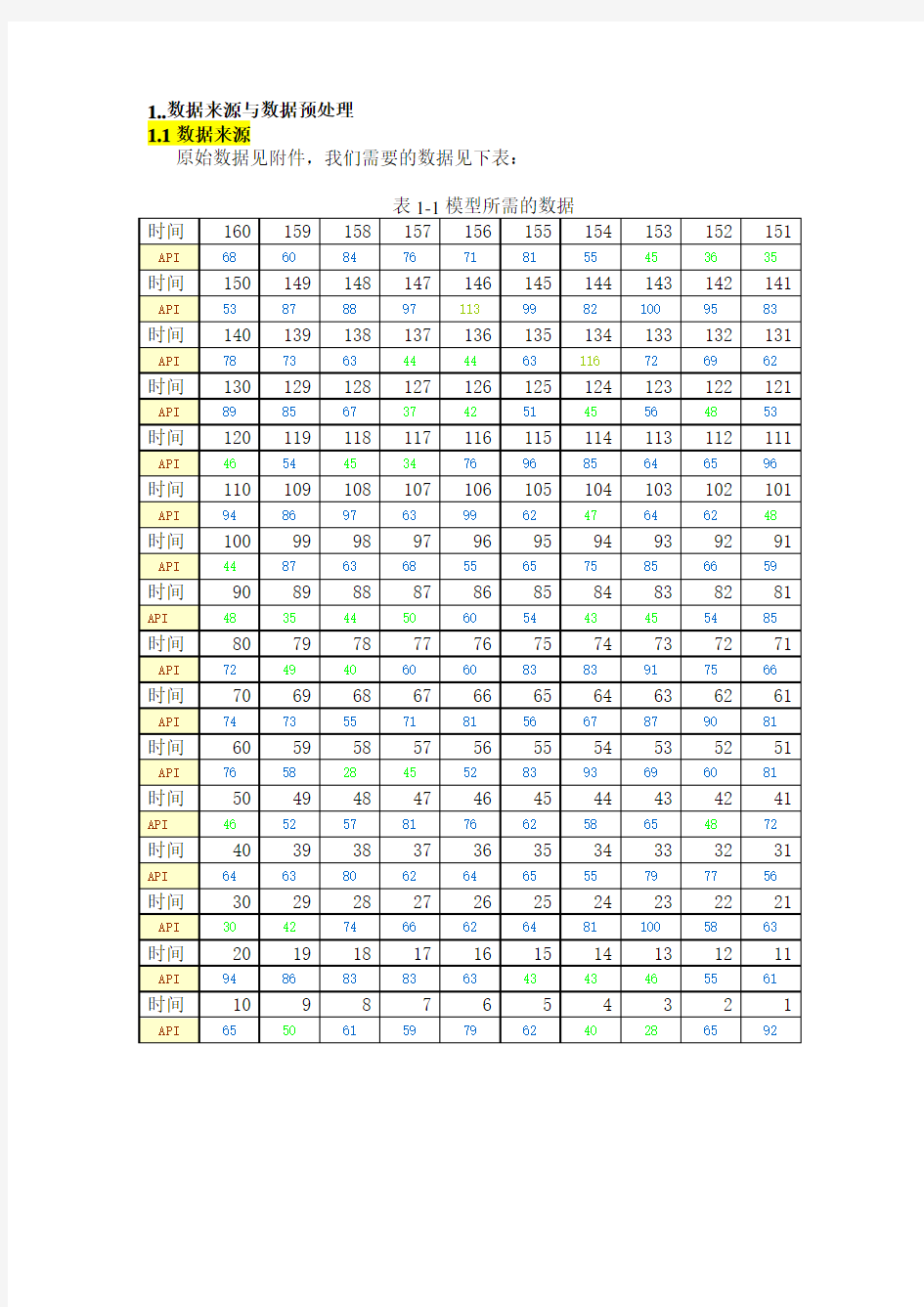
1..数据来源与数据预处理
1.1数据来源
原始数据见附件,我们需要的数据见下表:
此处一共160个数据,其中1~150用来建立模型,我们称为样本,151~160用来检验预测值与真实值的误差,我们成为检验值。其中的时间的意义是:t=1代表日期2010-5-30,t=2代表日期2010-5-31,t=3代表日期2010-6-1,以此类推,t=160代表日期2010-11-4。
数据中的API 为空气污染指数,我国目前采用的空气污染指数(API )分为五个等级,API ≤50,说明空气质量为优,相当于国家空气质量一级标小准;50
由SPSS 分析出来的结果见表1-2
由表1-2可以看出,数据个数为150个,没有缺失值。t X =66.41,t S =18.07 数值与平均值的距离见图1-1
图1- 1
由图1-1可以看出,对任意时间t ,t 1t X X +-都在-t S 与t S 之间,所以我们可以得
出结论,该数据没有离群点。
综上所述,需要建模的数据正常——既没有离群点,也没有缺失值。
2.直观分析和相关分析
2.1直观分析和特征分析
在eviews软件中,我们将该数据命名为liu(t)。用eviews画出的折线图如图2-1
图2- 1
通过eviews画出的柱状统计图见图2-2
X=66.4,中位数为64,最大值为116,由以上图表可以看出:样本liu(t)的均值
t
S=18.69,偏度为0.24,峰度为2.54,由于相伴概率最小值为28,样本标准差
t
为0.256,大于0.05,所以我们接受数据服从正态分布的假设,故认为原数据是正态分布数据。
检验样本是否服从正态分布也可以用用P-P图和Q-Q图来检验,SPSS做出
的PP图见图2-3
P-P图基本是一条直线,说明它的分布对称,服从正态分布,进一步验证了以上的结论。
2.2相关分析
在eviews中作出自相关系数和偏相关系数图,结果见图2-4
自相关系数图和偏相关系数图两侧的虚线之心水平α=0.05的置信带,称为barlett线,意思是如果系数落在barlett线内,我们可以认为该系数等于零。
由图2-4可以看出,两阶以后的自相关系数和偏相关系数基本都落在barlett 线内,所以我们可以认为该数据平稳,为了进一步说明这个问题,我们在进行一次单位根检验以验证该数据的平稳性。
2.3平稳性检验
在eviews中执行view→Unite root test.检验结果如图2-5
图2- 5
由上图可以得知,t统计量的值时-6.95,小于显著性水平下的临界值,拒绝
原假设,也就是说序列liu(t)不存在单位根,该系统是平稳的,进一步验证了2.2的结果,也证明由图2-1推断出来的季节性是不存在的。
由上图知,其中的检验式为:liu()0.4898(1)32.31t liu t ?=--+ (2-1) 3.liu(t)序列的零均值处理 3.1数据的零均值化
对于均值非零的数据,一般有两种处理方法,一是建立非中心化的ARMA 模型,将序列的均值作为一个参数估计,但是需要估计的参数要比中心化的ARMA 模型多一个,于是在这里我们采用另一种方法,用样本均值t X 作为样本均值u 的估计,即零均值处理,下面是具体过过程。
新序列liu1(t)=liu(t)-t X =liu(t)-66.4。零均值化后的序列数据见附录1. 3.2零均值过程的检验
在对liu (1)序列执行命令“view →Descriptive Statistics →Histogram and Stats ”得到柱状统计图,结果见图3-1
图3- 1
因为时间序列liu(1)的均值t X 为-0.165,标准差t S 为18,样本均值t X 落在0±2t S 当中,所以我们接受均值为0的原假设,表明序列liu(1)已经是一个零均值序列。
4.模型的识别和初步定阶
时间序列liu1(t)的自相关系数和偏相关系数见图4-1
由上图可以看到,样本的自相关系数1ρ较大,而其余的自相关系数都落在barlett 线以内,而且
11
2222
11221
2)20.518)0.20242)0.2024(2)
k k ρρρ+=+?≈<
+=≥(4-1)
当k>1时,自相关函数都落在该范围内,所以时间序列liu1(t)在1步后是截尾的,因此可以用MA (1)模型进行拟合。
对于偏相关系数,我们也可以看出,只有11?较大,其余都很小,且大于一阶
的样本偏相关系数几乎都满足0.1633kk ?≤
=≈,虽然16,16?为-0.166,其绝对值略大于0.1633,但由于简约性原则,我们仍然认为其偏相关系数在一
步之后截尾的,因此可以用AR (1)来对数据拟合。
根据Box-Jenkins 建模方法,一般初步设定的模型是ARMA(n ,n-1),即自回归的阶数比移动平均的阶数高一阶,于是这里我们将初步模型定为ARMA (2,1)。
5.模型的参数估计
参数的估计一般有三种方法:矩估计;最小二乘估计;极大似然估计。但是由于矩估计太简单,精度低,只实用于做初估计,而极大似然估计计算量非常大,特别是对于ARMA 模型,似然函数公式十分复杂,所以我们这里采用最小二乘估计。
利用eviews 软件可以得到各个模型中的参数的最小二乘估计和剩余平方和和AIC 值,ARMA(2,1)模型结果如表5-1
AR (2)模型最恰当。 6.模型的检验
6.1参数的显著性检验
该模型参数检验的目的是看是否有系数显著为零。在eviews 命令窗口中输入“ls liu1 ar(1) ar(2)”便得到参数检验的结果,详细结果见图6-1
图6- 1
由2?的相伴概率可以看出,我们应该接受2?=0的原假设,令2?=0,继续用AR(1)拟合数据,参数检验的结果如图6-2
由相伴概率和单位根可以看到,利用AR(1)模型对序列liu1(t)进行拟合比较恰当。
6.2模型的适用性检验
对AR (1)进行适用性检验,残差序列的样本自相关系数如图6-3
图6- 3
从自相关系数值可以看出,几乎所有0.160(1)
k k ρ<
=≥ (6-1)
但13ρ=-0.167,170.177ρ=,28ρ=0.25不满足式子6-1,这说明序列liu1(t)中还有少量的自相关信息没有被提出出来,这也是该模型的不足。 由图6-2所得到的系数可知,时间序列liu1(t)的模型为:
liu1(t)=ε
(t)+0.517850?liu1(t-1) (6-2)
原序列liu(t)的模型为:
liu(t)=liu1(t) +66.41 (6-3)
7.模型的预测
7.1对序列liu1(t)的预测
对于t=151到160的数据,利用差分形式进行预测时间序列liu1(t),即:liu1(t)=0.517850 liu1(t-1) (t=151,152……160)
其预测值见表7-1
对原始时间序列liu(t)的预测采用公式6-3
即:liu(t)=liu1(t) +66.41
其详细值见表7-2
残差图如下:
图7- 1
由残差图可见,该模型不是非常的拟合原数据,其实,这种结果其实在8.2进行使用性检验时就应该预料到,还有,在四步预测之后,预测数据就趋于一个定值,这与实际情况已经矛盾了,所以该模型不能用来做长期预测。不过由于API的划分是[0,50]为一级空气的标准,(50,100]为二级空气的标准,所以预测的空气质量等级并没有改变,这也是该模型的可取之处。
【附录及参考文献】
附录1.零均值化处理后的数据
参考文献:
[1]王沁.时间序列分析及其应用.四川.西南交通大学出版社.2008
[2]潘红宇.时间序列分析.北京.对外经济大学出版社.2006
[3]王振龙.应用时间序列分析.北京.科学出版社.2007
Eviews 时间序列分析实例 时间序列是市场预测中经常涉及的一类数据形式, 绍。通过第七章的学习,读者了解了什么是时间序列, 、指数平滑法实例 所谓指数平滑实际就是对历史数据的加权平均。它可以用于任何一种没有明显函数规 律,但确实存在某种前后关联的时间序列的短期预测。 由于其他很多分析方法都不具有这种 特点,指数平滑法在时间序列预测中仍然占据着相当重要的位置。 (―)一次指数平滑 一次指数平滑又称单指数平滑。它最突出的优点是方法非常简单, 甚至只要样本末期的 平滑值,就可以得到预测结果。 一次指数平滑的特点是: 能够跟踪数据变化。 这一特点所有指数都具有。 预测过程中添 加最新的样本数据后, 新数据应取代老数据的地位, 老数据会逐渐居于次要的地位, 直至被 淘汰。这样,预测值总是反映最新的数据结构。 一次指数平滑有局限性。第一,预测值不能反映趋势变动、季节波动等有规律的变动; 第二,这种方法多适用于短期预测, 而不适合作中长期的预测;第三, 由于预测值是历史数 据的均值,因此与实际序列的变化相比有滞后现象。 指数平滑预测是否理想,很大程度上取决于平滑系数。 Eviews 提供两种确定指数平滑 系数的方法:自动给定和人工确定。 选择自动给定,系统将按照预测误差平方和最小原则自 动确定系数。如果系数接近 1,说明该序列近似纯随机序列,这时最新的观测值就是最理想 的预测值。 出于预测的考虑,有时系统给定的系数不是很理想, 用户需要自己指定平滑系数值。平 滑系数取什么值比较合适呢? 一般来说,如果序列变化比较平缓,平滑系数值应该比较小, 比如小于0.1; 如果序列变化比较剧烈, 平滑系数值可以取得大一些, 如0.3?0.5。若平滑系 数值大于0.5才能跟上序列的变化,表明序列有很强的趋势,不能采用一次指数平滑进行预 测。 [例1]某企业食盐销售量预测。现在拥有最近连续 30个月份的历史资料(见表 I ), 试预测下一月份销售量。 表 某企业食盐销售量 单位:吨 解:使用对数据进行分析,第一步是建立工作文件和录入数据。有关操作在本 理和一些分析实例。本节的主要内容是说明如何使用 Eviews 软件进行分析。 本书第七章对它进行了比较详细的介 并接触到有关时间序列分析方法的原
成都空气污染指数API的建模与预测 20085728 刘童超 【目录】 1..数据来源与数据预处理 (2) 1.1数据来源 (2) 1.2离群点和缺失值的检验..................................................................... 错误!未定义书签。 2.直观分析和相关分析 (4) 2.1直观分析和特征分析 (4) 2.2相关分析 (6) 2.3平稳性检验 (7) 3.liu(t)序列的零均值处理 (8) 3.1数据的零均值化 (8) 3.2零均值过程的检验 (8) 4.模型的识别和初步定阶 (8) 5.模型的参数估计 (9) 6.模型的检验 (10) 6.1参数的显著性检验 (10) 6.2模型的适用性检验 (11) 7.模型的预测 (12) 7.1对序列liu1(t)的预测 (12) 7.2对序列liu(t)的预测 (12) 【附录及参考文献】 (13) 附录1.零均值化处理后的数据 (13) 参考文献: (14)
1..数据来源与数据预处理 1.1数据来源 原始数据见附件,我们需要的数据见下表:
此处一共160个数据,其中1~150用来建立模型,我们称为样本,151~160用来检验预测值与真实值的误差,我们成为检验值。其中的时间的意义是:t=1代表日期2010-5-30,t=2代表日期2010-5-31,t=3代表日期2010-6-1,以此类推,t=160代表日期2010-11-4。 数据中的API 为空气污染指数,我国目前采用的空气污染指数(API )分为五个等级,API ≤50,说明空气质量为优,相当于国家空气质量一级标小准;50
实验一ARMA 模型建模 一、实验目的 学会检验序列平稳性、随机性。学会分析时序图与自相关图。学会利用最小二乘法等方法对ARMA 模型进行估计,以及掌握利用ARMA 模型进行预测的方法。学会运用Eviews 软件进行ARMA 模型的识别、诊断、估计和预测和相关具体操作。 二、基本概念 1平稳时间序列: 定义:时间序列{zt}是平稳的。如果{zt}有有穷的二阶中心矩,而且满足: (a)ut= Ezt =c; (b)r(t,s) = E[(zt-c)(zs-c)] = r(t-s,0) 则称{zt}是平稳的。 2 AR 模型: AR 模型也称为自回归模型。它的预测方式是通过过去的观测值和现在的干扰值的线性组合预测。具有如下结构的模型称为P 阶自回归模型,简记为AR(P)。 x t = 0 + 1x t-1 + 2x t-2 + + p x t- p + t p0 E(t) = 0,Var(t) = 2 ,E(t s) = 0,s t Ex = 0,s t 3 MA 模型: MA 模型也称为滑动平均模型。它的预测方式是通过过去的干扰值和现在的干扰值的线性组合预测。具有如下结构的模型称为Q 阶移动平均回归模型,简记为MA(q)。 x t= +t-1t-1 -2t-2 - -q t-q q0 E() = 0,Var( ) = 2, E( ) = 0, s t 4 ARMA 模型: ARMA模型:自回归模型和滑动平均模型的组合,便构成了用于描述平稳随机过程的自回归滑动平均模型ARMA。具有如下结构的模型称为自回归移动平均回归模型,简记为ARMA(p,q)。 x t= 0 + 1x t-1 + + p x t- p+ t- 1t-1 - - q t-q
eviews教程第25章时间序列截面数据模型 (3) 对转换后变量使用OLS (X 包括常数项和回归 量x ) (25.12) 其中。 EViews在输出中给 出了由(3)得到的的参数估计。使用协方差矩阵的标准估计量计算 标准差。 EViews给出了随机影响的估计值。计算公式为: (25.13) 得到的是的最优线性无偏预测值。最后, EViews 给出了加权和不加权的概括统计量。加权统计量来自(3)中的 GLS 估计方程。未加权统计量来自普通模型的残差,普通模型中包括 (3)中的参数和估计随机影响: (25.14) 三、截面加权当残差具有截面异方差性和 同步不相关时最好进行截面加权回归: (25.15) EViews进行FGLS ,并且从一阶段Pool 最小 二乘回归得出。估计方差计算公式为: (25.16) 其中是OLS 的拟合值。估计系数值和协方差矩阵 由标准GLS 估计量给出。四、SUR 加权当残差具有截 面异方差性和同步相关性时,SUR 加权最小二乘是可行的GLS 估计量: (25.17) 其中是同步相关的对称阵: (25.18) 一般项,在所有的t 时为常 数。 EViews估计SUR 模型时使用的是由一阶段Pool 最小二乘回归得到: (25.19) 分母中的最大值函数是为了解决向下加权协方差项产 生的不平衡数据情况。如果缺失值的数目可渐进忽略,这种方法生成 可逆的的一致估计量。模型的参数估计和参数协方差矩阵计 算使用标准的GLS 公式。五、怀特(White )协方差估计在Pool 估计中可计算怀特的异方差性一致协方差估计(除了SUR 和 随机影响估计)。EViews 使用堆积模型计算怀特协方差矩阵: (25.20) 其中K 是估计参数总数。这种方差估计量足以解释各截面 成员产生的异方差性,但不能解释截面成员间同步相关的可能。 * * 第二十五章时间序列/截面数据模型在经典计量经济学模型 中,所利用的数据(样本观测值)的一个特征是,或者只利用时间序
Eviews时间序列分析实例 时间序列是市场预测中经常涉及的一类数据形式,本书第七章对它进行了比较详细的介绍。通过第七章的学习,读者了解了什么是时间序列,并接触到有关时间序列分析方法的原理和一些分析实例。本节的主要内容是说明如何使用Eviews软件进行分析。 一、指数平滑法实例 所谓指数平滑实际就是对历史数据的加权平均。它可以用于任何一种没有明显函数规律,但确实存在某种前后关联的时间序列的短期预测。由于其他很多分析方法都不具有这种特点,指数平滑法在时间序列预测中仍然占据着相当重要的位置。 (-)一次指数平滑 一次指数平滑又称单指数平滑。它最突出的优点是方法非常简单,甚至只要样本末期的平滑值,就可以得到预测结果。 一次指数平滑的特点是:能够跟踪数据变化。这一特点所有指数都具有。预测过程中添加最新的样本数据后,新数据应取代老数据的地位,老数据会逐渐居于次要的地位,直至被淘汰。这样,预测值总是反映最新的数据结构。 一次指数平滑有局限性。第一,预测值不能反映趋势变动、季节波动等有规律的变动;第二,这种方法多适用于短期预测,而不适合作中长期的预测;第三,由于预测值是历史数据的均值,因此与实际序列的变化相比有滞后现象。 指数平滑预测是否理想,很大程度上取决于平滑系数。Eviews提供两种确定指数平滑系数的方法:自动给定和人工确定。选择自动给定,系统将按照预测误差平方和最小原则自动确定系数。如果系数接近1,说明该序列近似纯随机序列,这时最新的观测值就是最理想的预测值。 出于预测的考虑,有时系统给定的系数不是很理想,用户需要自己指定平滑系数值。平滑系数取什么值比较合适呢?一般来说,如果序列变化比较平缓,平滑系数值应该比较小,比如小于0.l;如果序列变化比较剧烈,平滑系数值可以取得大一些,如0.3~0.5。若平滑系数值大于0.5才能跟上序列的变化,表明序列有很强的趋势,不能采用一次指数平滑进行预测。 [例1]某企业食盐销售量预测。现在拥有最近连续30个月份的历史资料(见表l),试预测下一月份销售量。 表1 某企业食盐销售量单位:吨 解:使用Eviews对数据进行分析,第一步是建立工作文件和录入数据。有关操作在本
时间序列分析实验指导 A
统计与应用数学学院
随着计算机技术的飞跃发展以及应用软件的普及,对高等院校的实验教学提出了越来越高的要求。为实现教育思想与教学理念的不断更新,在教学中必须注重对大学生动手能力的培训和创新思维的培养,注重学生知识、能力、素质的综合协调发展。为此,我们组织统计与应用数学学院的部分教师编写了系列实验教学指导书。 这套实验教学指导书具有以下特点: ①理论与实践相结合,书中的大量经济案例紧密联系我国的经济发展实际,有利于提高学生分析问题解决问题的能力。 ②理论教学与应用软件相结合,我们根据不同的课程分别介绍了SPSS SAS、MATLAB、EVIEWS等软件的使用方法,有利于提高学生建立数学模型并能正确求解的能力。 这套实验教学指导书在编写的过程中始终得到财经大学教务处、实验室管理处以及统计与应用数学学院的关心、帮助和大力支持,对此我们表示衷心的感谢! 限于我们的水平,欢迎各方面对教材存在的错误和不当之处予以批评指正。 统计与数学模型分析实验中心 2007年2月
实验一EVIEWS中时间序列相关函数操作................. -1 -实验二确定性时间序列建模方法 ........................ -10 -实验三时间序列随机性和平稳性检验. (21) 实验四时间序列季节性、可逆性检验.................. -25 -实验五ARMA模型的建立、识别、检验................ -34 - 实验六ARMA模型的诊断性检验...................... -37 -实验七ARMA模型的预测............................ -38 -实验八复习ARMA建模过程 .......................... -40 -实验九时间序列非平稳性检验........................ -42 -
在对时间序列Y、X1进行回归分析时需要考虑Y与X1之间是否存在某种切实的关系,所以需要进行协整检验。 1.1利用eviews创建时间序列Y、X1: 打开eviews软件点击file-new-workfile,见对话框又三块空白处workfile structuretype处又三项选择,分别是非时间序列unstructured/undate,时间序列dated-regularfrequency,和不明英语balance panel。选择时间序列dated-regular frequency。在datespecification中选择年度,半年度或者季度等,和起始时间。右下角为工作间取名字和页数。 点击ok。 在所创建的workfile中点击object-new object,选择series,以及填写名字如Y,点击OK。 将数据填写入内。 1.2对序列Y进行平稳性检验: 此时应对序列数据取对数,取对数的好处在于可将间距很大的数据转换为间距较小的数据。 具体做法是在workfile y的窗口中点击Genr,输入logy=log(y),则生成y的对数序列logy。 再对logy序列进行平稳性检验。 点击view-United root test,test type选择ADF检验,滞后阶数中lag length 选择SIC检验,点击ok得结果如下: Null Hypothesis: LOGY has a unit root Exogenous: Constant
Lag Length: 0 (Automatic based on SIC, MAXLAG=1) t-StatisticProb.* Augmented Dickey-Fuller test statistic- 2." ."09959 Test critical values:1% level- 4."602226 5% level- 3."026225 10% level - 2."0013 当检验值Augmented Dickey-Fuller test statistic的绝对值大于临界值绝对值时,序列为平稳序列。 若非平稳序列,则对logy取一阶差分,再进行平稳性检验。直到出现平稳序列。假设Dlogy和DlogX1为平稳序列。 1.3对Dlogy和DlogX1进行协整检验 点击窗口quick-equation estimation,输入DLOGY C DLOGX1,点击ok,得到运行结果,再点击proc-make residual series进行残差提取得到残差序列,再对残差序列进行平稳性检验,若残差为平稳序列,则Dlogy与Dlogx1存在协整关系。
实验一ARMA 模型建模 一、实验目的 学会检验序列平稳性、随机性。学会分析时序图与自相关图。学会利用最小二乘法等方法对ARMA 模型进行估计,以及掌握利用ARMA 模型进行预测的方法。学会运用Eviews 软件进行ARMA 模型的识别、诊断、估计和预测和相关具体操作。 二、基本概念 1 平稳时间序列: 定义:时间序列{zt}是平稳的。如果{zt}有有穷的二阶中心矩,而且满足: (a )ut= Ezt =c; (b )r(t,s) = E[(zt-c)(zs-c)] = r(t-s,0) 则称{zt}是平稳的。 2 AR 模型: AR 模型也称为自回归模型。它的预测方式是通过过去的观测值和现在的干扰值的线性组合预测。具有如下结构的模型称为P 阶自回归模型,简记为AR(P)。 ? ???? ??
11222 0()0(),()0,t t t t q t q q t t t s x E Var E s t εμεθεθεθεθεεσεε---?=+----? ≠??===≠?L , 4 ARMA 模型: ARMA 模型:自回归模型和滑动平均模型的组合, 便构成了用于描述平稳随机过程的自回归滑动平均模型ARMA 。具有如下结构的模型称为自回归移动平均回归模型,简记为ARMA(p,q)。 ? ???? ??
时间序列分析 实验指导 4 2 -2 -4 50100150200250 数学与统计学院
目录 实验一 EVIEWS中时间序列相关函数操作···························- 1 - 实验二确定性时间序列建模方法 ····································- 8 - 实验三时间序列随机性和平稳性检验 ···························· - 17 - 实验四时间序列季节性、可逆性检验 ···························· - 20 - 实验五 ARMA模型的建立、识别、检验···························· - 25 - 实验六 ARMA模型的诊断性检验····································· - 28 - 实验七 ARMA模型的预测·············································· - 29 - 实验八复习ARMA建模过程·········································· - 31 - 实验九时间序列非平稳性检验 ····································· - 33 -
实验一 EVIEWS中时间序列相关函数操作 【实验目的】熟悉Eviews的操作:菜单方式,命令方式; 练习并掌握与时间序列分析相关的函数操作。 【实验内容】 一、EViews软件的常用菜单方式和命令方式; 二、各种常用差分函数表达式; 三、时间序列的自相关和偏自相关图与函数; 【实验步骤】 一、EViews软件的常用菜单方式和命令方式; ㈠创建工作文件 ⒈菜单方式 启动EViews软件之后,进入EViews主窗口 在主菜单上依次点击File/New/Workfile,即选择新建对象的类型为工作文件,将弹出一个对话框,由用户选择数据的时间频率(frequency)、起始期和终止期。选择时间频率为Annual(年度),再分别点击起始期栏(Start date)和终止期栏(End date),输入相应的日期,然后点击OK按钮,将在EViews 软件的主显示窗口显示相应的工作文件窗口。 工作文件窗口是EViews的子窗口,工作文件一开始其中就包含了两个对象,一个是系数向量C(保存估计系数用),另一个是残差序列RESID(实际值与拟合值之差)。 ⒉命令方式 在EViews软件的命令窗口中直接键入CREATE命令,也可以建立工作文件。命令格式为:CREATE 时间频率类型起始期终止期 则菜单方式过程可写为:CREATE A 1985 1998 ㈡输入Y、X的数据 ⒈DATA命令方式 在EViews软件的命令窗口键入DATA命令,命令格式为: DATA <序列名1> <序列名2>…<序列名n>
河南财经政法大学应用时间序列分析实验手册 应用时间序列分析 实验手册
目录 目录 (2) 第一章Eviews的基本操作 (3) 第二章时间序列的预处理 (6) 一、平稳性检验 (6) 二、纯随机性检验 (13) 第三章平稳时间序列建模实验教程 (14) 一、模型识别 (14) 二、模型参数估计 (18) 三、模型的显著性检验 (21) 四、模型优化 (23) 第四章非平稳时间序列的确定性分析 (24) 一、趋势分析 (24) 二、季节效应分析 (39) 三、综合分析 (44) 第五章非平稳序列的随机分析 (50) 一、差分法提取确定性信息 (50) 二、ARIMA模型 (63) 三、季节模型 (68)
第一章Eviews的基本操作 The Workfile(工作簿) Workfile 就像你的一个桌面,上面放有许多Objects,在使用Eviews 时首先应该打开该桌面,如果想永久保留Workfile及其中的内容,关机时必须将该Workfile存到硬盘或软盘上,否则会丢失。 (一)、创建一个新的Workfile 打开Eviews后,点击file/new/workfile,弹出一个workfile range对话框(图1)。 图1 该对话框是定义workfile的频率,该频率规定了workfile中包含的所有objects频率。也就是说,如果workfile的频率是年度数据,则其中的objects也是年度数据,而且objects数据范围小于等于workfile的范围。 例如我们选择年度数据(Annual),在起始日(Start date)、终止日(End date)分别键入1970、1998,然后点击OK,一个新的workfile就建立了(图2)。 图2
统计分析报告 基于eviews软件的湖北省人均GDP时间序列模型构建与预测 姓名:刘金玉 学院:经济管理学院 学号:20121002942 指导教师:李奇明 日期:2014年12月14日
基于eviews软件的湖北省人均GDP时间序列 模型构建与预测 1、选题背景 改革开放以来,中国的经济得到飞速发展。1978年至今,中国GDP年均增长超过9%。中国的经济实力明显增强。2001年GDP超过1.1万亿美元,排名升到世界第六位。外汇储备已达2500亿美元。市场在资源配置中已经明显地发挥基础性作用。公有、私有、外资等多种所有制经济共同发展的格局基本形成。宏观调控体系初步建立。我国社会生产力、综合国力、地区发展、产业升级、所有制结构、商品供求等指标均反映出我国经济运行质量良好,为实现第三步战略。在全国的经济飞速发展的大环境下,各省GDP的增长也是最能反映其经济发展状况的指标。而人均 GDP 是最能体现一个省的经济实力、发展水平和生活水准的综合性指标,它不仅考虑了经济总量的大小,而且结合了人口多少的因素,在国际上被广泛用于评价和比较一个地区经济发展水平。尤其是我们这样的人口大国,用这一指标反映经济增长和发展情况更加准确、深刻和富有现实意义。深入分析这一指标对于反映我国经济发展历程、探讨增长规律、研究波动状况,制定相应的宏观调控政策有着十分重要的意义。 本文是以湖北省人均GDP作为研究对象。湖北省人均GDP的增长速度在上世纪90年代增长率有下滑的趋势(见表1)。进入21世纪,继东部沿海地区先发展起来,并涌现出环渤海、长三角、珠三角等城市群,以及中共中央提出“西部大开发”的战略后,中部地区成了“被遗忘的区域”,中部地区经济发展严重滞后于东部沿海地区,为此,中共中央提出了“中部崛起”的重大战略决策。自2004年提出“中部崛起”的重要战略构思后,山西、河南、安徽、湖北、湖南、江西六个省都依托自己的资源和地理优势来扩大地区竞争力,湖北省尤为突出。那么,研究湖北省人均GDP的统计规律性和变动趋势,对于了解湖北省的经济增长规律以及地方政策的制定有特别重要的意义。因此本文试图以湖北省1978-2013年人均GDP 历史数据为样本,通过ARMA 模型对样本进行统计分析,以揭示湖北省人均GDP变化的内在规律性,建立计量经济模型,并在此基础上进行短期外推预测,作为湖北未来几年经济发展的重要参考依据。
在 Eviews中对时间序列进行预测的详细步骤 、输入数据 1.1打开Eviews6.0,按照如图所示打开工作表创建框 giit Ob j e ct Frsc Qmck OgtiQns; T indoitf Help N?w卜Vorkfile. . I Open 卜 EiV* A-S-.- Trograirt 7ert File Import Fr izit Print S毗up Ruiiu ,.. Eli t Dated - regular uency v V/orkfile structure t/pe
1.2在右上角的data specification框中输入起止年份(start data和end data) Irregular D^ted and Panel worhfilejs may be made from Unstructured uwrkfiles by latwr speciFyiny date andjar otkier id ent fi er series? Cancel Date spe cifit 日tiori
1.3输入数据:在输入框中输入data gdp (本文采用的数据为1990—2012年的GDP 值)。当然,data后面可以输入任何你想要定义的“英文名字” 输入data gdp后注意按回车键,弹出表格窗口后在其中输入数据(也可复制进去数据:ctrl+v键)
、平稳性检验 2.1在打开的数据窗口中点击View—Correlogram (1) 在弹出的窗口中直接点OK即可J CorrelaE^^> Specifica??? X Correlogram of ?oo1st difference Lags to include 12
时间序列计量经济学模型 一.企业景气指数和企业家信心指数 1.1建立工作文件并录入数据,如图1所示 图1 这是企业景气指数和企业家信心指数的原始数据,prosperity代表企业景气指数,confidence代表企业家信心指数。 1.2平稳性检验 1.2.1平稳性的图示判断(图2)
图2 从图中可以看出企业景气指数和企业家信心指数这两序列都是非平稳的。 1.2.2样本自相关图判断 点击主界面Quick\Series Statistics\Correlogram...,在弹出的对话框中输入prosperity,点击OK就会弹出Correlogram Specification对话框,选择Level,并输入要输出的阶数(一般默认为24),点击OK,即可得到prosperity的样本相关函数图,如图3所示。
图3 从上述样本相关函数图,可以看到企业景气指数(prosperity)的样本相关函数是缓慢的递减趋于零的,但随着时间的推移,在0附近波动并呈发散趋势。所以,通过企业景气指数(prosperity)的样本相关图,可初步判定该企业景气指数(prosperity)时间序列非平稳。 同理得:confidence的样本相关函数图,如图4所示
图4 从上述样本相关函数图,可以看到企业家信心指数(confidence)的样本相关函数是缓慢的递减趋于零的,但随着时间的推移,在0附近波动并呈发散趋势。所以,通过企业家信心指数(confidence)的样本相关图,可初步判定该企业家信心指数(confidence)时间序列非平稳。 1.2.3单位跟检验 单位跟检验((ADF检验 检验)) (1)企业景气指数(prosperity) 采用ADF检验对prosperity序列进行平稳性的单位根检验。点击主界面Quick\Series Statistics\Unit Root Test...,在弹出的Series对话框中输入prosperity,点击OK,就会出现Unit Root Test对话框,如图5所示。
时间序列分析实验指导统计与应用数学学院
前言 随着计算机技术的飞跃发展以及应用软件的普及,对高等院校的实验教学提出了越来越高的要求。为实现教育思想与教学理念的不断更新,在教学中必须注重对大学生动手能力的培训和创新思维的培养,注重学生知识、能力、素质的综合协调发展。为此,我们组织统计与应用数学学院的部分教师编写了系列实验教学指导书。 这套实验教学指导书具有以下特点: ①理论与实践相结合,书中的大量经济案例紧密联系我国的经济发展实际,有利于提高学生分析问题解决问题的能力。 ②理论教学与应用软件相结合,我们根据不同的课程分别介绍了SPSS、SAS、MATLAB、EVIEWS等软件的使用方法,有利于提高学生建立数学模型并能正确求解的能力。 这套实验教学指导书在编写的过程中始终得到安徽财经大学教务处、实验室管理处以及统计与应用数学学院的关心、帮助和大力支持,对此我们表示衷心的感谢! 限于我们的水平,欢迎各方面对教材存在的错误和不当之处予以批评指正。 统计与数学模型分析实验中心 2007年2月
目录 实验一 EVIEWS中时间序列相关函数操作·错误!未定义书签。实验二确定性时间序列建模方法·····错误!未定义书签。实验三时间序列随机性和平稳性检验···错误!未定义书签。实验四时间序列季节性、可逆性检验···错误!未定义书签。实验五 ARMA模型的建立、识别、检验··错误!未定义书签。实验六 ARMA模型的诊断性检验·····错误!未定义书签。实验七 ARMA模型的预测········错误!未定义书签。实验八复习ARMA建模过程·······错误!未定义书签。实验九时间序列非平稳性检验······错误!未定义书签。