
21个必知数据科学题和答案
2016-03-10分类:其他
最近KDnuggets上发的“20个问题来分辨真假数据科学家”这篇文章非常热门,获得了一月的阅读量排行首位。
但是这些问题并没有提供答案,所以KDnuggets的小编们聚在一起写出了这些问题的答案。我还加了一个特别提问——第21问,是20个问题里没有的。
下面是答案。
Q1.解释什么是正则化,以及它为什么有用。
回答者:Matthew Mayo
正则化是添加一个调优参数的过程模型来引导平滑以防止过拟合。(参加KDnuggets文章《过拟合》)
这通常是通过添加一个常数到现有的权向量。这个常数通常要么是L1(Lasso)要么是L2(ridge),但实际上可以是任何标准。该模型的测算结果的下一步应该是将正则化训练集计算的损失函数的均值最小化。
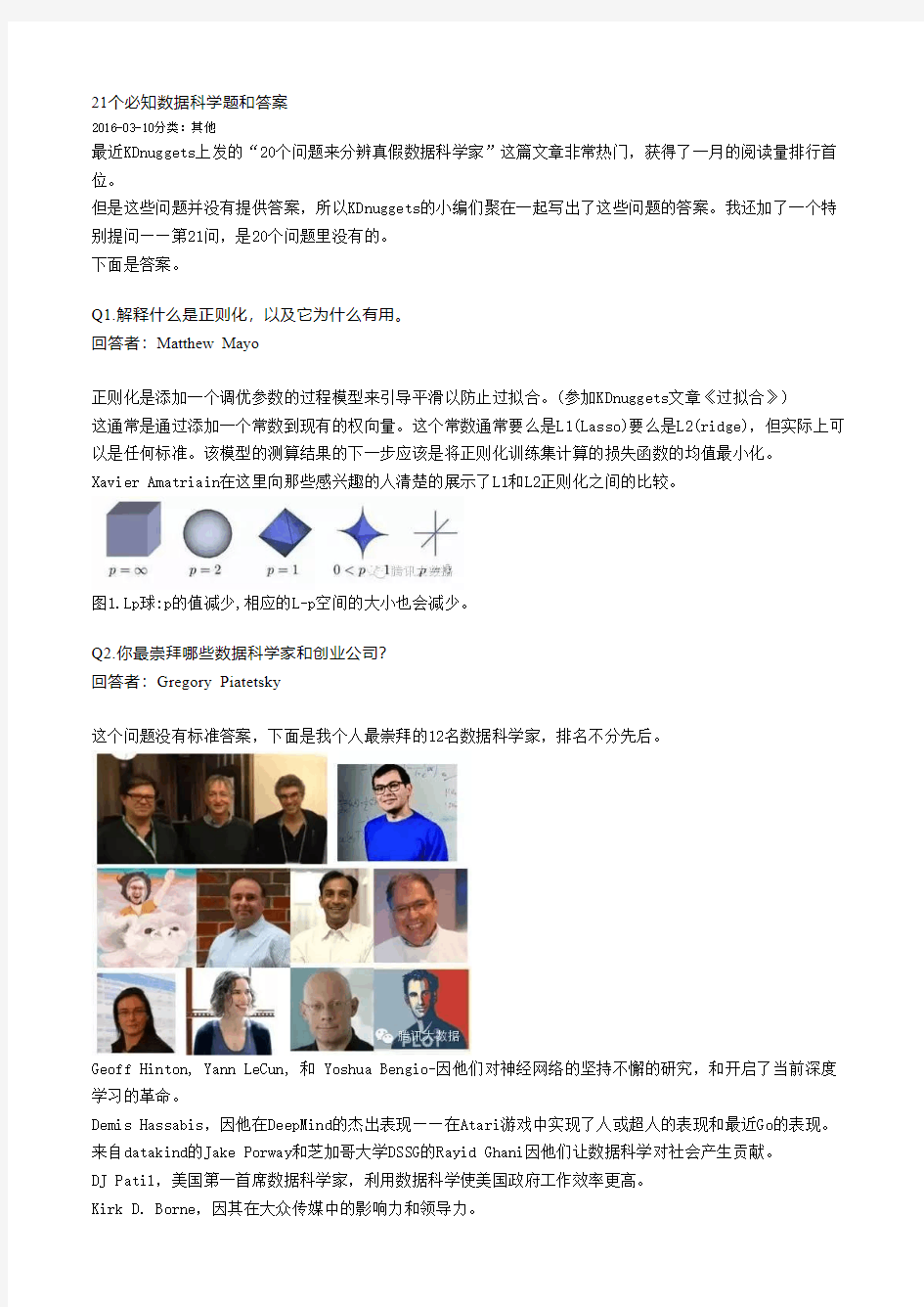
Xavier Amatriain在这里向那些感兴趣的人清楚的展示了L1和L2正则化之间的比较。
图1.Lp球:p的值减少,相应的L-p空间的大小也会减少。
Q2.你最崇拜哪些数据科学家和创业公司?
回答者:Gregory Piatetsky
这个问题没有标准答案,下面是我个人最崇拜的12名数据科学家,排名不分先后。
Geoff Hinton, Yann LeCun, 和 Yoshua Bengio-因他们对神经网络的坚持不懈的研究,和开启了当前深度学习的革命。
Demis Hassabis,因他在DeepMind的杰出表现——在Atari游戏中实现了人或超人的表现和最近Go的表现。来自datakind的Jake Porway和芝加哥大学DSSG的Rayid Ghani因他们让数据科学对社会产生贡献。
DJ Patil,美国第一首席数据科学家,利用数据科学使美国政府工作效率更高。
Kirk D. Borne,因其在大众传媒中的影响力和领导力。
Claudia Perlich,因其在广告生态系统的贡献,和作为kdd-2014的领头人。
Hilary Mason在Bitly杰出的工作,和作为一个大数据的明星激发他人。
Usama Fayyad,展示了其领导力,为KDD和数据科学设立了高目标,这帮助我和成千上万的人不断激励自己做到最好。
Hadley Wickham,因他在数据科学和数据可视化方面的出色的成果,包括dplyr,ggplot2,和RStudio。
数据科学领域里有太多优秀的创业公司,但我不会在这里列出它们,以避免利益冲突。
Q3.如何验证一个用多元回归生成的对定量结果变量的预测模型。
回答者:Matthew Mayo
模型验证方法:
如果模型预测的值远远超出响应变量范围,这将立即显示较差的估计或模型不准确。
如果值看似是合理的,检查参数;下列情况表示较差估计或多重共线性:预期相反的迹象,不寻常的或大或小的值,或添加新数据时观察到不一致。
利用该模型预测新的数据,并使用计算的系数(平方)作为模型的有效性措施。
使用数据拆分,以形成一个单独的数据集,用于估计模型参数,另一个用于验证预测。
如果数据集包含一个实例的较小数字,用对折重新采样,测量效度与R平方和均方误差(MSE)。
Q4.解释准确率和召回率。它们和ROC曲线有什么关系?
回答者:Gregory Piatetsky
这是kdnuggets常见问题的答案:精度和召回
计算精度和召回其实相当容易。想象一下10000例中有100例负数。你想预测哪一个是积极的,你选择200个以更好的机会来捕捉100个积极的案例。你记录下你预测的ID,当你得到实际结果时,你总结你是对的或错的。以下是正确或错误的四种可能:
TN/真阴性:例阴性且预测阴性
TP/真阳性:例阳性且预测阳性
FN/假阴性:例阳性而预测阴性
FP/假阳性:例阴性而预测阳性
意义何在?现在你要计算10000个例子中有多少进入了每一个bucket:
现在,你的雇主会问你三个问题:
1.你的预测正确率有几成?
你回答:确切值是(9760+60)除以10000=98.2%
2.你获得阳性的例子占多少比例?
你回答:召回比例为60除以100=60%
3.正值预测的百分比多少?
你回答:精确值是60除以200=30%
看一个维基上的精度和召回的优秀范例。
图4.精度和召回
ROC曲线代表了灵敏度(召回)与特异性(不准确)之间的关系,常用来衡量二元分类的性能。然而,在处理高倾斜度的数据集的时候,精度-召回(PR)曲线给出一个更具代表性的表现。见Quora回答:ROC曲线和精度-召回曲线之间的区别是什么?。
Q5.如何证明你对一个算法的改进确实比什么都不做更好?
回答者:Anmol Rajpurohit
我们会在追求快速创新中(又名“快速成名”)经常看到,违反科学方法的原则导致误导性的创新,即有吸引力的观点却没有经过严格的验证。一个这样的场景是,对于一个给定的任务:提高算法,产生更好的结果,你可能会有几个关于潜在的改善想法。
人们通常会产生的一个明显冲动是尽快公布这些想法,并要求尽快实施它们。当被问及支持数据,往往是共享的是有限的结果,这是很有可能受到选择偏差的影响(已知或未知)或一个误导性的全局最小值(由于缺乏各种合适的测试数据)。
数据科学家不让自己的情绪操控自己的逻辑推理。但是确切的方法来证明你对一个算法的改进确实比什么都不做更好将取决于实际情况,有几个共同的指导方针:
确保性能比较的测试数据没有选择偏差
确保测试数据足够,以成为各种真实性的数据的代表(有助于避免过拟合)
确保“受控实验”的原则,即在比较运行的原始算法和新算法的表现的时候,性能、测试环境(硬件等)方面必须是完全相同的。
确保结果是可重复的,当接近类似的结果出现的时候
检查结果是否反映局部极大值/极小值或全局极大值/最小值
来实现上述方针的一种常见的方式是通过A/B测试,这里面两个版本的算法是,在随机分割的两者之间不停地运行在类似的环境中的相当长的时间和输入数据。这种方法是特别常见的网络分析方法。
Q6.什么是根本原因分析?
回答者:Gregory Piatetsky
根据维基百科:
根本原因分析(RCA)是一种用于识别错误或问题的根源的解决方法。一个因素如果从problem-fault-sequence的循环中删除后,阻止了最终的不良事件重复出现,则被认为是其根源;而一个因果因素则影响一个事件的结果,但不其是根本原因。
根本原因分析最初用于分析工业事故,但现在广泛应用于其他领域,如医疗、项目管理、软件测试。
这是一个来自明尼苏达州的实用根本原因分析工具包。
本质上,你可以找到问题的根源和原因的关系反复问“为什么”,直到找到问题的根源。这种技术通常被称为“5个为什么”,当时涉及到的问题可能比5个更少或更多。
图 “5个为什么”分析实例,来自《根本原因分析的艺术》
Q7.你是否熟悉价格优化、价格弹性、库存管理、竞争情报?举例说明。
回答者:Gregory Piatetsky
这些问题属于经济学范畴,不会经常用于数据科学家面试,但是值得了解。
价格优化是使用数学工具来确定客户会如何应对不同渠道产品和服务的不同价格。
大数据和数据挖掘使得个性化的价格优化成为可能。现在像亚马逊这样的公司甚至可以进一步优化,对不同的游客根据他们的购买历史显示不同的价格,尽管有强烈的争论这否公平。
通常所说的价格弹性是指需求的价格弹性,是对价格敏感性的衡量。它的计算方法是:
需求的价格弹性=需求量变动%÷价格变动%。
同样,供应的价格弹性是一个经济衡量标准,显示了产品或服务的变化如何响应价格变化。
库存管理是一个企业在生产过程中使用的产品的订购、储存和使用的监督和控制,它将销售的产品和销售的成品数量进行监督和控制。
维基百科定义:
竞争情报:定义、收集、分析和分发有关产品、客户、竞争对手和所需环境的任何方面的情报,以支持管理人员和管理者为组织做出战略决策的环境。
像Google Trends, Alexa, Compete这样的工具可以用来确定趋势和分析你的竞争对手的网站。
下面是一些有用的资源:
竞争情报的报告指标by Avinash Kaushik
37款监视你的竞争对手的最好的营销工具from KISSmetrics
来自10位专家的10款最佳竞争情报工具
Q8.什么是统计检定力?
回答者:Gregory Piatetsky
维基百科定义二元假设检验的统计检定力或灵敏度为测试正确率拒绝零假设的概率(H0)在备择假设(H1)是真的。
换句话说,统计检定力是一种可能性研究,研究将检测到的效果时效果为本。统计能力越高,你就越不可能犯第二类错误(结论是没有效果的,然而事实上有)。
这里有一些工具来计算统计检定力。
Q9.解释什么是重抽样方法和它们为什么有用。并说明它们的局限。
回答者:Gregory Piatetsky
经典的统计参数检验比较理论抽样分布。重采样的数据驱动的,而不是理论驱动的方法,这是基于相同的样本内重复采样。
重采样指的是这样做的方法之一
估计样本统计精度(中位数、方差、百分位数)利用可用数据的子集(折叠)或随机抽取的一组数据点置换(引导)
在进行意义测试时,在数据点上交换标签(置换测试),也叫做精确测试,随机测试,或是再随机测试)利用随机子集验证模型(引导,交叉验证)
维基百科里关于bootstrapping, jackknifing。
见How to Check Hypotheses with Bootstrap and Apache Spark
这里是一个很好重采样统计的概述。
Q10.有太多假阳性或太多假阴性哪个相比之下更好?说明原因。
回答者:Devendra Desale
这取决于问题本身以及我们正在试图解决的问题领域。
在医学检验中,假阴性可能会给病人和医生提供一个虚假的安慰,表面上看它不存在的时候,它实际上是存在的。这有时会导致不恰当的或不充分的治疗病人和他们的疾病。因此,人们会希望有很多假阳性。
对于垃圾邮件过滤,当垃圾邮件过滤或垃圾邮件拦截技术错误地将一个合法的电子邮件信息归类为垃圾邮件,并影响其投递结果时,会出现假阳性。虽然大多数反垃圾邮件策略阻止和过滤垃圾邮件的比例很高,排除没有意义假阳性结果是一个更艰巨的任务。所以,我们更倾向于假阴性而不是假阳性。
Q11.什么是选择偏差,为什么它是重要的,你如何避免它?
回答者:Matthew Mayo
选择偏差,一般而言,是由于一个非随机群体样本造成的问题。例如,如果一个给定的样本的100个测试案例是一个60 / 20/ 15/ 5的4个类,实际上发生在在群体中相对相等的数字,那么一个给定的模型可能会造
成错误的假设,概率可能取决于预测因素。避免非随机样本是处理选择偏差最好的方式,但是这是不切实际的。可以引入技术,如重新采样,和提高权重的策略,以帮助解决问题。
Q12. 举例说明如何使用实验设计回答有关用户行为的问题。
回答者:Bhavya Geethika.
步骤1.制定研究问题
页面加载时间对用户满意度评级的影响有哪些?
步骤2.确定变量
我们确定原因和结果。独立变量——页面加载时间,非独立变量——用户满意评级
步骤3.生成假说
减少页面下载时间能够影响到用户对一个网页的满意度评级。在这里,我们分析的因素是页面加载时间。
图12.一个有缺陷的实验设计(漫画)
步骤4.确定实验设计
我们考量实验的复杂性,也就是说改变一个因素或多个因素,同时在这种情况下,我们用阶乘设计(2^k设计)。选择设计也是基于目标的类型(比较、筛选、响应面)和许多其他因素。
在这里我们也确定包含参与者/参与者之间及二者混合模型。如,有两个版本的页面,一个版本的购买按钮(行动呼吁)在左边,另一个版本的在右边。
包含参与者设计——所有用户组看到两个版本
参与者之间设计——一组用户看到版本A,娶她用户组看到版本B。
步骤5.开发实验任务和过程:
详细描述实验的步骤、用于测量用户行为的工具,并制定目标和成功标准。收集有关用户参与度的定性数据,以便统计分析。
步骤6.确定操作步骤和测量标准
操作:一个因素的级别将被控制,其他的将用于操作,我们还要确定行为上的标准:
在提示和行为发生之间的持续时间(用户点击购买了产品花了多长时间)。
频率-行为发生的次数(用户点击次数的一个给定的页面在一个时间)
持续-特定行为持续时间(添加所有产品的时间)
程度-行为发生时的强烈的冲动(用户购买商品有多快)
步骤7:分析结果
识别用户行为数据,假说成立,或根据观察结果反驳例子:用户满意度评级与页面加载时间的比重是多少。Q13“长”数据和“宽”数据有什么不同之处?
回答者:Gregory Piatetsky
在大多数数据挖掘/数据科学应用记录(行)比特性(列)更多——这些数据有时被称为“高”(或“长”)的数据。
在某些应用程序中,如基因组学和生物信息学,你可能只有一个小数量的记录(病人),如100,或许是20000为每个病人的观察。为了“高”工作数据的标准方法将导致过度拟合数据,所以需要特殊的方法。
图13.对于高数据和宽数据不同的方法,与表示稀疏筛查确切数据简化,by Jieping Ye。
问题不仅仅是重塑数据(这里是有用的R包),还要避免假阳性,通过减少特征找到最相关的数据。
套索等方法减少特性和稀疏覆盖在统计学习:套索和概括,由Hastie Tibshirani,Wainwright。(你可以免费下载PDF的书)套索等方法减少特性,在“统计学习稀疏”中很好地包含了:《套索和概括》
by Hastie, Tibshirani, and Wainwright(你可以免费下载PDF的书)
Q14你用什么方法确定一篇文章(比如报纸上的)中公布的统计数字是错误的或者是为了支持作者观点,而不是关于某主题正确全面的事实信息?
一个简单的规则,由Zack Lipton建议的:如果一些统计数据发表在报纸上,那么它们是错的。这里有一个更严重的答案,来自Anmol Rajpurohit:每一个媒体组织都有目标受众。这个选择很大地影响着决策,如这篇文章的发布、如何缩写一篇文章,一篇文章强调的哪一部分,如何叙述一个给定的事件等。
确定发表任何文章统计的有效性,第一个步骤是检查出版机构和它的目标受众。即使是相同的新闻涉及的统计数据,你会注意到它的出版非常不同,在福克斯新闻、《华尔街日报》、ACM/IEEE期刊都不一样。因此,数据科学家很聪明的知道在哪里获取消息(以及从来源来判断事件的可信度!)。
图14a:福克斯新闻上的一个误导性条形图的例子
图14b:如何客观地呈现相同的数据 来自5 Ways to Avoid Being Fooled By Statistics
作者经常试图隐藏他们研究中的不足,通过精明的讲故事和省略重要细节,跳到提出诱人的错误见解。因此,用拇指法则确定文章包含误导统计推断,就是检查这篇文章是否包含了统计方法,和统计方法相关的选择上的细节限制。找一些关键词如“样本”“误差”等等。虽然关于什么样的样本大小或误差是合适的没有完美的答案,但这些属性一定要在阅读结果的时候牢记。
首先,一篇可靠的文章必须没有任何未经证实的主张。所有的观点必须有过去的研究的支持。否则,必须明确将其区分为“意见”,而不是一个观点。其次,仅仅因为一篇文章是著名的研究论文,并不意味着它是使用适当的研究方向的论文。这可以通过阅读这些称为研究论文“全部”,和独立判断他们的相关文章来验证。最后,虽然最终结果可能看起来是最有趣的部分,但是通常是致命地跳过了细节研究方法(和发现错误、偏差等)。
理想情况下,我希望所有这类文章都发表他们的基础研究数据方法。这样,文章可以实现真正的可信,每个人都可以自由分析数据和应用研究方法,自己得出结果。
Q15解释Edward Tufte“图表垃圾”的概念。
回答者:Gregory Piatetsky
图标垃圾指的是所有的图表和图形视觉元素没有充分理解表示在图上的信息,或者没有引起观看者对这个信息的注意。
图标垃圾这个术语是由Edward Tufte在他1983年的书《定量信息的视觉显示》里提出的。
图15所示。Tufte写道:“一种无意的Necker错觉,两个平面翻转到前面。一些金字塔隐藏其他;一个变量(愚
蠢的金字塔的堆叠深度)没有标签或规模。”
图标垃圾的的这个例子是一个更现代的例子,很难理解excel使用者画出的柱状图,因为“工人”和“起重
机”掩盖了他们。
这种装饰的问题是,他们迫使读者更加困难而非必要地去发现数据的含义。
Q16你会如何筛查异常值?如果发现它会怎样处理?
回答者:Bhavya Geethika.
筛选异常值的方法有z-scores, modified z-score, box plots, Grubb's test,Tietjen-Moore测试
指数平滑法,Kimber测试指数分布和移动窗口滤波算法。然而比较详细的两个方法是:
Inter Quartile Range
An outlier is a point of data that lies over 1.5 IQRs below the first quartile (Q1) or
High = (Q3) + 1.5 IQR
Low = (Q1) - 1.5 IQR
Tukey Method
It uses interquartile range to filter very large or very small numbers. It is practically
Low outliers = Q1 - 1.5(Q3 - Q1) = Q1 - 1.5(IQR)
High outliers = Q3 + 1.5(Q3 - Q1) = Q3 + 1.5(IQR)
在这个区域外的任何值都是异常值
当你发现异常值时,你不应该不对它进行一个定性评估就删除它,因为这样你改变了数据,使其不再纯粹。
重要的是要在理解分析的背景下或者说重要的是“为什么的问题——为什么异常值不同于其他数据点?”
这个原因是至关重要的。如果归因于异常值错误,你可能把它排除,但如果他们意味着一种新趋势、模式或
显示一个有价值的深度数据,你应该保留它。
Q17如何使用极值理论、蒙特卡洛模拟或其他数学统计(或别的什么)正确估计非常罕见事件的可能性?回答者:Matthew Mayo.
极值理论(EVT)侧重于罕见的事件和极端,而不是经典的统计方法,集中的平均行为。EVT的州有3种分布模型的极端数据点所需要的一组随机观察一些地理分布:Gumble,f,和威布尔分布,也称为极值分布(EVD)1、2和3分别。
EVT的状态,如果你从一个给定的生成N数据集分布,然后创建一个新的数据集只包含这些N的最大值的数据集,这种新的数据集只会准确地描述了EVD分布之一:耿贝尔,f,或者威布尔。广义极值分布(GEV),然后,一个模型结合3 EVT模型以及EVD模型。
知道模型用于建模数据,我们可以使用模型来适应数据,然后评估。一旦发现最好的拟合模型,分析可以执行,包括计算的可能性。
Q18推荐引擎是什么?它如何工作?
回答者:Gregory Piatetsky
现在我们很熟悉Netflix——“你可能感兴趣的电影”或亚马逊——购买了X产品的客户还购买了Y的推荐。
你可能感兴趣的电影
这样的系统被称为推荐引擎或广泛推荐系统。
他们通常以下两种方式之一产生推荐:使用协作或基于内容的过滤。
基于用户的协同过滤方法构建一个模型过去的行为(以前购买物品,电影观看和评级等)并使用当前和其他用户所做的决定。然后使用这个模型来预测(或评级)用户可能感兴趣的项目。
基于内容的过滤方法使用一个项目的特点推荐额外的具有类似属性的物品。这些方法往往结合混合推荐系统。
这是一个比较,当这两种方法用于两个流行音乐推荐系统——Last.fm 和 Pandora Radio。(以系统推荐条目为例)
Last.fm创建一个“站”推荐的歌曲通过观察乐队和个人定期跟踪用户听和比较这些听其他用户的行为。最后一次。fm会跟踪不出现在用户的图书馆,但通常是由其他有相似兴趣的用户。这种方法充分利用了用户的行为,它是一个协同过滤技术。
Pandora用一首歌的属性或艺术家(400年的一个子集属性提供的音乐基因工程)以设定具有类似属性
的“站”,播放音乐。用户的反馈用来提炼的结果,排除用户“不喜欢”特定的歌曲的某些属性和强调用
户“喜欢”的歌的其他属性。这是一个基于内容的方法。
这里有一些很好的介绍Introduction to Recommendation Engines by Dataconomy 和an overview
of building a Collaborative Filtering Recommendation Engine by Toptal。关于推荐系统的最新研究,点击ACM RecSys会议。
Q19解释什么是假阳性和假阴性。为什么区分它们非常重要?
回答者:Gregory Piatetsky
在二进制分类(或医疗测试)中,假阳性是当一个算法(或测试)满足的条件,在现实中不满足。假阴性是当一个算法(或测试)表明不满足一个条件,但实际上它是存在的。
在统计中,假设检验出假阳性,也被称为第一类误差和假阴性- II型错误。
区分和治疗不同的假阳性和假阴性显然是非常重要的,因为这些错误的成本不一样。
例如,如果一个测试测出严重疾病是假阳性(测试说有疾病,但人是健康的),然后通过一个额外的测试将会确定正确的诊断。然而,如果测试结果是假阴性(测试说健康,但是人有疾病),然后患者可能会因此死去。
Q20你使用什么工具进行可视化?你对Tableau/R/SAS(用来作图)有何看法?如何有效地在一幅图表(或一个视频)中表示五个维度?
回答者:Gregory Piatetsky
有很多数据可视化的好工具。R,Python,Tableau和Excel数据科学家是最常用的。
这里是有用的KDnuggets资源:
可视化和数据挖掘软件
Python可视化工具的概述
21个基本数据可视化工具
前30名的社交网络分析和可视化工具
标签:数据可视化
有很多方法可以比二维图更好。第三维度可以显示一个三维散点图,可以旋转。您可以操控颜色、材质、形状、大小。动画可以有效地用于显示时间维度(随时间变化)。
这是一个很好的例子。
图20:五维虹膜数据的散点图,尺寸:花萼长度;颜色:萼片宽;形状:类;x-column:花瓣长度;y-column:花瓣宽度。
从5个以上的维度,一种方法是平行坐标,由Alfred Inselberg首先提出。
图20 b:平行坐标里的虹膜数据
另请参阅
Quora:高维数据可视化的最好方法是什么?
和
乔治·格林斯和他的同事们在High-Dimensional Visualizations 的开创性工作。
当然,当你有很多的维度的时候,最好是先减少维度或特征。
特别提问:解释什么是过拟合,你如何控制它
这个问题不是20问里面的,但是可能是最关键的一问来帮助你分辨真假数据科学家!
回答者:Gregory Piatetsky
过拟合是指(机器)学习到了因偶然造成并且不能被后续研究复制的的虚假结果。
我们经常看到报纸上的报道推翻之前的研究发现,像鸡蛋不再对你的健康有害,或饱和脂肪与心脏病无关。这个问题在我们看来是很多研究人员,特别是社会科学或医学领域的,经常犯下的数据挖掘的基本错误——过度拟合数据。
研究人员了测试太多假设而没有适当的统计控制,所以他们会碰巧发现一些有趣的事情和报告。不足为奇的是,下一次的效果,由于(至少一部分是)偶然原因,将不再明显或不存在。
这些研究实践缺陷被确定,由约翰·p·a·埃尼迪斯的在他的里程碑式的论文《为什么大多数发表的研究成果是错误的》(《公共科学图书馆·医学》杂志,2005年)中发表出来。埃尼迪斯发现,结果往往是被夸大的或不能被复制。在他的论文中,他提出了统计证据,事实上大多数声称的研究成果都是虚假的。
埃尼迪斯指出,为了使研究结果是可靠的,它应该有:
大型的样本和大量的结果
测试关系的数量更多,选择更少
在设计,定义,结果和分析模式几个方面有更大的灵活性
最小化偏差,依资金预算和其他因素考量(包括该科学领域的普及程度)
不幸的是,这些规则常常被违反,导致了很多不能再现的结果。例如,标准普尔500指数被发现与孟加拉国的黄油生产密切相关(从1981年至1993年)(这里是PDF)
若想看到更多有趣的(包括完全虚假)的结果,您可以使用一些工具,如谷歌的correlate或Tyler Vigen 的Spurious correlations。
可以使用几种方法来避免数据过拟合:
试着寻找最简单的假设
正规化(为复杂性添加一种处罚)
随机测试(使变量随机化,在这个数据上试试你的方法——如果它发现完全相同的结果,肯定有哪里出错了)嵌套交叉验证(在某种程度上做特征选择,然后在交叉验证外层运行整个方法)
调整错误发现率
使用2015年提出的一个突破
方法——可重复使用的保持法
好的数据科学是对世界理解的前沿科学,数据科学家的责任是避免过度拟合数据,并教育公众和媒体关于错误数据分析的危险性。
(文章出自“数盟社区”)
1.栈和队列的共同特点是(只允许在端点处插入和删除元素) 2.栈通常采用的两种存储结构是(线性存储结构和链表存储结构) 3.链表不具有的特点是(B) A.不必事先估计存储空间 B.可随机访问任一元素 C.插入删除不需要移动元素 D.所需空间与线性表长度成正比 4.用链表表示线性表的优点是(便于插入和删除操作) 5.在单链表中,增加头结点的目的是(方便运算的实现) 6.循环链表的主要优点是(从表中任一结点出发都能访问到整个链表) 7.线性表若采用链式存储结构时,要求内存中可用存储单元的地址(D) A.必须是连续的 B.部分地址必须是连续的 C.一定是不连续的 D.连续不连续都可以 8.线性表的顺序存储结构和线性表的链式存储结构分别是(随机存取的存储结构、顺序存取的存储结构) 9.具有3个结点的二叉树有(5种形态) 10.设一棵二叉树中有3个叶子结点,有8个度为1的结点,则该二叉树中总的 结点数为(13)(n 0 = n 2 +1) 11.已知二叉树后序遍历序列是dabec,中序遍历序列是debac,它的前序遍历序列是(cedba) 12.若某二叉树的前序遍历访问顺序是abdgcefh,中序遍历访问顺序是dgbaechf,则其后序遍历的结点访问顺序是(gdbehfca) 13.数据库保护分为:安全性控制、完整性控制、并发性控制和数据的恢复。
1.在计算机中,算法是指(解题方案的准确而完整的描述) 2.算法一般都可以用哪几种控制结构组合而成(顺序、选择、循环) 3.算法的时间复杂度是指(算法执行过程中所需要的基本运算次数) 4.算法的空间复杂度是指(执行过程中所需要的存储空间) 5.算法分析的目的是(分析算法的效率以求改进) 6.下列叙述正确的是(C) A.算法的执行效率与数据的存储结构无关 B.算法的空间复杂度是指算法程序中指令(或语句)的条数 C.算法的有穷性是指算法必须能在执行有限个步骤之后终止 D.算法的时间复杂度是指执行算法程序所需要的时间 7.数据结构作为计算机的一门学科,主要研究数据的逻辑结构、对各种数据结构进行的运算,以及(数据的存储结构) 8.数据结构中,与所使用的计算机无关的是数据的(C) A.存储结构 B.物理结构 C.逻辑结构 D.物理和存储结构 9.下列叙述中,错误的是(B) A.数据的存储结构与数据处理的效率密切相关 B.数据的存储结构与数据处理的效率无关 C.数据的存储结构在计算机中所占的空间不一定是连续的 D.一种数据的逻辑结构可以有多种存储结构 10.数据的存储结构是指(数据的逻辑结构在计算机中的表示) 11.数据的逻辑结构是指(反映数据元素之间逻辑关系的数据结构) 12.根据数据结构中各数据元素之间前后件关系的复杂程度,一般将数据结构分为(线性结构和非线性结构) 13.下列数据结构具有记忆功能的是(C) A.队列 B.循环队列 C.栈 D.顺序表 14.递归算法一般需要利用(栈)实现。 15.由两个栈共享一个存储空间的好处是(节省存储空间,降低上溢发生的机率)
数据库面试题 1 1. 在一个查询中,使用哪一个关键字能够除去重复列值? 答案:使用distinct关键字 2. 什么是快照?它的作用是什么? 答案:快照Snapshot是一个文件系统在特定时间里的镜像,对于在线实时数据备份非常有用。快照对于拥有不能停止的应用或具有常打开文件的文件系统的备份非常重要。对于只能提供一个非常短的备份时间而言,快照能保证系统的完整性。 3. 解释存储过程和触发器 答案: 存储过程是一组Transact-SQL语句,在一次编译后可以执行多次。因为不必重新编译Transact-SQL语句,所以执行存储过程可以提高性能。 触发器是一种特殊类型的存储过程,不由用户直接调用。创建触发器时会对其进行定义,以便在对特定表或列作特定类型的数据修改时执行。 4. SQL Server是否支持行级锁,有什么好处? 答案:支持动态行级锁定 SQL Server 2000动态地将查询所引用的每一个表的锁定粒度调整到合适的级别。当查询所引用的少数几行分散在一个大型表中时,优化数据并行访问的最佳办法是使用粒度锁,如行锁。但是,如果查询引用的是一个表中的大多数行或所有行,优化数据并行访问的最佳办法可以是锁定整个表,以尽量减少锁定开销并尽快完成查询。 SQL Serve 2000通过为每个查询中的每个表选择适当的锁定级别,在总体上优化了数据并发访问。对于一个查询,如果只引用一个大型表中的几行,则数据库引擎可以使用行级锁定;如果引用一个大型表的几页中的多行,则使用页级锁定;如果引用一个小型表中的所有行,则使用表级锁定。 5. 数据库日志干什么用,数据库日志满的时候再查询数据库时会出现什么情况。答案:每个数据库都有事务日志,用以记录所有事务和每个事务对数据库所做的修改。 6. 存储过程和函数的区别? 答案:存储过程是用户定义的一系列SQL语句的集合,涉及特定表或其它对象的任务,用户可以调用存储过程,而函数通常是数据库已定义的方法,它接收参数并返回某种类型的值并且不涉及特定用户表 7. 事务是什么? 答案:事务是作为一个逻辑单元执行的一系列操作,一个逻辑工作单元必须有四个属性,称为 ACID(原子性、一致性、隔离性和持久性)属性,只有这样才能成为一个事务: (1) 原子性 事务必须是原子工作单元;对于其数据修改,要么全都执行,要么全都不执行。
数据分析笔试题 一、编程题(每小题20分)(四道题任意选择其中三道) 有一个计费表表名jifei 字段如下:phone(8位的电话号码),month(月份),expenses (月消费,费用为0表明该月没有产生费用) 下面是该表的一条记录:64262631,201011,30.6 这条记录的含义就是64262631的号码在2010年11月份产生了30.6元的话费。 按照要求写出满足下列条件的sql语句: 1、查找2010年6、7、8月有话费产生但9、10月没有使用并(6、7、8月话费均在51-100 元之间的用户。 2、查找2010年以来(截止到10月31日)所有后四位尾数符合AABB或者ABAB或者AAAA 的电话号码。(A、B 分别代表1—9中任意的一个数字) 3、删除jifei表中所有10月份出现的两条相同记录中的其中一条记录。
4、查询所有9月份、10月份月均使用金额在30元以上的用户号码(结果不能出现重复) 二、逻辑思维题(每小题10分)须写出简要计算过程和结果。 1、某人卖掉了两张面值为60元的电话卡,均是60元的价格成交的。其中一张赚了20%, 另一张赔了20%,问他总体是盈利还是亏损,盈/亏多少? 2、有个农场主雇了两个小工为他种小麦,其中A是一个耕地能手,但不擅长播种;而B 耕地很不熟练,但却是播种的能手。农场主决定种10亩地的小麦,让他俩各包一半,于是A从东头开始耕地,B从西头开始耕。A耕地一亩用20分钟,B却用40分钟,可是B播种的速度却比A快3倍。耕播结束后,庄园主根据他们的工作量给了他俩600元工钱。他俩怎样分才合理呢? 3、1 11 21 1211 111221 下一行是什么? 4、烧一根不均匀的绳,从头烧到尾总共需要1个小时。现在有若干条材质相同的绳子,问如何用烧绳的方法来计时一个小时十五分钟呢?(绳子分别为A 、B、C、D、E、F 。。。。。来代替)
无领导小组讨论的经典面试题目及答案解析 沙漠求生记 一、内容 1、在炎热的八月,你乘坐的小型飞机在撒哈拉沙漠失事,机身严重撞毁,将会着火焚烧。 2、飞机燃烧前,你们只有十五分钟时间,从飞机中领取物品。 3、问题:在飞机失事中,如果你们只能从十五项物品中,挑选五项。在考虑沙漠的情况后,按物品的重要性,你们会怎样选择呢?请解释原因。 二、沙漠情况 1、飞机的位置不能确定,只知道最近的城镇是附近七十公里的煤矿小城。 2、沙漠日间温度是40度,夜间温度随时骤降至5度。 三、假设 1、飞机上生还人数与你的小组人数相同。你们装束轻便,只穿着短袖T恤、牛仔裤、运动裤和运动鞋,每人都有一条手帕。 2、全组人都希望一起共同进退。 3、机上所有物品性能良好。 四、物品清单 请从以下十五项物品中,挑选最重要的五项: 1、一支闪光信号灯(内置四个电池)
2、一把军刀 3、一张该沙漠区的飞行地图 4、七件大号塑料雨衣 5、一个指南针 6、一个小型量器箱(内有温度计、气压计、雨量计等) 7、一把45口径手枪(已有子弹) 8、三个降落伞(有红白相间图案) 9、一瓶维他命丸(100粒装) 10、十加仑饮用水 11、化妆镜 12、七副太阳眼镜 13、两加仑伏特加酒 14、七件厚衣服 15、一本《沙漠动物》百科全书 专家解题: 一位專家在沙漠研究求生問題,搜集了無數事件和生還者資料,得出以下結論: 1.化妝鏡: 在各項物品中,鏡子是獲救的關鍵.鏡子在太陽下可產生相等於七萬支燭光;如反射太陽光線,地平線另一端也可看見.只要有一面鏡,獲救機會有80%
2.外套1件: 人體內有40%是水份,流汗和呼吸會使水份消失,保持鎮定可減低脫水速度.穿外套能減低皮膚表面的水份蒸發.如沒有外套,維持生命的時間便減少一日. 3.四公升水: 如有以上兩項物品,可生存三天.水有助減低脫水速度.口渴時,飲水可使頭腦清醒. 但身體開始脫水時,飲水也沒有多大作用了. 4.手電筒: 電筒是在晚上最快最可靠的工具.有了化妝鏡和手電筒,24小時都可發出訊號;而且可用電筒作反光鏡和玻璃做訊號,亦可作引火點燃之用. 5.降落傘: 可用作遮蔭和發出訊號,用仙人掌做營桿,降落傘做營頂,可減低20度. 6.大摺刀: 可切碎仙人掌或切割營桿,也有其他用途,可排於較前位置. 7.膠雨衣: 可做(集水器),在地上掘一個洞,用雨衣蓋在上面,再在中間放一小石塊,使之成漏斗形.日夜溫度差距可使空氣的水份附在雨衣上:將雨衣上的水滴在電筒中儲存.這樣做一天可提取500毫升的水,但也可消耗兩倍可收集的水份. 8.手槍: 第二天之後,說話和行動已很困難.彈藥有時要做起火之用,而國際求救訊號是連續三個短的符號.無數事件是因為求生者不能作聲而沒有給發現.還有槍柄可作槌仔用. 9.太陽眼鏡: 在猛烈陽光下會有光盲症.用降落傘遮蔭可避免眼睛受損,但用太陽眼鏡更舒適. 10.紗布一箱: 沙漠濕度低,是最少傳染病的地方.,但身體脫水會使血液凝結. 有事例紀錄,有一男子身體內失去水份,而身上的衣服已撕破,倒在仙人掌和石上. 滿身傷口但無流血.後來獲救,飲水後傷口再度流血,紗布可當繩子或包紮保護之用. 11.指南針: 除用其反射面作發訊外,它並無用處,反而引誘了人離開失事地點的危機. 12.航空圖: 可用作起火或廁紙用,亦會引誘人走出沙漠. 13.書一本: 最大問題是脫水而非饑餓,打獵所得相等於失去水份,沙漠中也沒什麼動物可見.進食亦需要大量的水以幫助消化. 14.伏特加酒:劇烈的酒精會吸去人體水份,更可致命,它只能用作暫時降低體溫之用. 15.鹽片千片:人們過分高估鹽的用途.如血液內鹽份增加,同時也需要大量的水以降低身體內的含鹽量. 月球求生记
数据结构面试专题 1、常用数据结构简介 数据结构是指相互之间存在着一种或多种关系的数据元素的集合和该集合中数据元素间的关系组成。常用的数据有:数组、栈、队列、链表、树、图、堆、散列表。 1)数组:在内存中连续存储多个元素的结构。数组元素通过下标访问,下标从0开始。优点:访问速度快;缺点:数组大小固定后无法扩容,只能存储一种类型的数据,添加删除操作慢。适用场景:适用于需频繁查找,对存储空间要求不高,很少添加删除。 2)栈:一种特殊的线性表,只可以在栈顶操作,先进后出,从栈顶放入元素叫入栈,从栈顶取出元素叫出栈。应用场景:用于实现递归功能,如斐波那契数列。 3)队列:一种线性表,在列表一端添加元素,另一端取出,先进先出。使用场景:多线程阻塞队列管理中。 4)链表:物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表的指针地址实现,每个元素包含两个结点,一个是存储元素的数据域,一个是指向下一个结点地址的指针域。有单链表、双向链表、循环链表。优点:可以任意加减元素,不需要初始化容量,添加删除元素只需改变前后两个元素结点的指针域即可。缺点:因为含有大量指针域,固占用空间大,查找耗时。适用场景:数据量小,需频繁增加删除操作。 5)树:由n个有限节点组成一种具有层次关系的集合。二叉树(每个结点最多有两个子树,结点的度最大为2,左子树和右子树有顺序)、红黑树(HashMap底层源码)、B+树(mysql 的数据库索引结构) 6)散列表(哈希表):根据键值对来存储访问。 7)堆:堆中某个节点的值总是不大于或不小于其父节点的值,堆总是一棵完全二叉树。8)图:由结点的有穷集合V和边的集合E组成。 2、并发集合了解哪些? 1)并发List,包括Vector和CopyOnWriteArrayList是两个线程安全的List,Vector读写操作都用了同步,CopyOnWriteArrayList在写的时候会复制一个副本,对副本写,写完用副本替换原值,读时不需要同步。 2)并发Set,CopyOnWriteArraySet基于CopyOnWriteArrayList来实现的,不允许存在重复的对象。 3)并发Map,ConcurrentHashMap,内部实现了锁分离,get操作是无锁的。
数据库面试题:数据库的面试题及答案 疯狂代码 https://www.doczj.com/doc/19757054.html,/ ?:http:/https://www.doczj.com/doc/19757054.html,/DataBase/Article25003.html . 数据库切换日志的时候,为什么一定要发生检查点?这个检查点有什么意义? 答:触发dbwr的执行,dbwr会把和这个日志相关的所有脏队列写到数据文件里,缩短实例恢复所需要的时间。 2. 表空间管理方式有哪几种,各有什么优劣。 答:字典管理方式和本地管理方式,本地管理方式采用位图管理extent,减少字典之间的竞争,同时避免了碎片。 本地管理表空间与字典管理表空间相比,其优点如下: 1).减少了递归空间管理; 2).系统自动管理extents大小或采用统一extents大小; 3).减少了数据字典之间的竞争; 4).不产生回退信息; 5).不需合并相邻的剩余空间; 6).减少了空间碎片; 7).对临时表空间提供了更好的管理。 3. 本地索引与全局索引的差别与适用情况。 答:对于local索引,每一个表分区对应一个索引分区,当表的分区发生变化时,索引的维护由Oracle自动进行。对于global索引,可以选择是否分区,而且索引的分区可以不与表分区相对应。当对分区进行维护操作时 ,通常会导致全局索引的INVALDED,必须在执行完操作后REBUILD。Oracle9i提供了UPDATE GLOBAL INDEXES语句,可以使在进行分区维护的同时重建全局索引。 4. 一个表a varchar2(1),b number(1),c char(2),有100000条记录,创建B-Tree索引在字段a上,那么表与索引谁大?为什么? 答:这个要考虑到rowid所占的字节数,假设char总是占用2字节的情况,比较rowid,另外,table和index在segment free block的管理也有差别。 5. Oracle9i的data guard有几种模式,各有什么差别。 答:三种模式: 最大性能(maximize performance):这是data guard默认的保护模式。primay上的事务commit前不需要从standby上收到反馈信息。该模式在primary故障时可能丢失数据,但standby对primary的性能影响最小。 最大可用(maximize availability):在正常情况下,最大可用模式和最大保护模式一样;在standby不可用时 ,最大可用模式自动最大性能模式,所以standby故障不会导致primay不可用。只要至少有一个standby可用的情况下,即使primarydown机,也能保证不丢失数据。 最大保护(maximize protection):最高级别的保护模式。primay上的事务在commit前必须确认redo已经传递到至少一个standby上,如果所有standby不可用,则primary会挂起。该模式能保证零数据丢失。 6. 执行计划是什么,查看执行计划一般有哪几种方式。 答:执行计划是数据库内部的执行步骤: set autotrace on select * from table
从互联网巨头数据挖掘类招聘笔试题目看我们还差多少知识 1 从阿里数据分析师笔试看职业要求 以下试题是来自阿里巴巴招募实习生的一次笔试题,从笔试题的几个要求我们一起来看看数据分析的职业要求。 一、异常值是指什么?请列举1种识别连续型变量异常值的方法? 异常值(Outlier)是指样本中的个别值,其数值明显偏离所属样本的其余观测值。在数理统计里一般是指一组观测值中与平均值的偏差超过两倍标准差的测定值。 Grubbs’ test(是以Frank E. Grubbs命名的),又叫maximum normed residual test,是一种用于单变量数据集异常值识别的统计检测,它假定数据集来自正态分布的总体。 未知总体标准差σ,在五种检验法中,优劣次序为:t检验法、格拉布斯检验法、峰度检验法、狄克逊检验法、偏度检验法。 点评:考察的内容是统计学基础功底。 二、什么是聚类分析?聚类算法有哪几种?请选择一种详细描述其计算原理和步骤。 聚类分析(cluster analysis)是一组将研究对象分为相对同质的群组(clusters)的统计分析技术。聚类分析也叫分类分析(classification analysis)或数值分类(numerical taxonomy)。聚类与分类的不同在于,聚类所要求划分的类是未知的。 聚类分析计算方法主要有:层次的方法(hierarchical method)、划分方法(partitioning method)、基于密度的方法(density-based method)、基于网格的方法(grid-based method)、基于模型的方法(model-based method)等。其中,前两种算法是利用统计学定义的距离进行度量。 k-means 算法的工作过程说明如下:首先从n个数据对象任意选择 k 个对象作为初始聚类中心;而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止。一般都采用均方差(标准差)作为标准测度
大学生面试20个经典问题与答案 面试是大学生就业关键一关,要知己知彼,百战不殆。下面由首席大学生就业顾问、著名职业生涯规划专家:李震东老师向大家介绍面试问题及回答思路: 问题一:“请你自我介绍一下” 我就读于华南理工大学工商管理学院,我的专业是国际经济与贸易,此外还辅修了法学. 在校期间,除了学习课本,我比较喜欢参加一些课外活动.包括发传单,做家庭教师,参加各种比赛和项目.主要就是简历上介绍的那些. 我比较喜欢踢足球,看各种企业培训的讲座. 不知道您对哪些方面还需要进一步了解. 思路: 1、这是面试的必考题目。 2、介绍内容要与个人简历相一致。 3、表述方式上尽量口语化。 4、要切中要害,不谈无关、无用的内容。 5、条理要清晰,层次要分明。 6、事先最好以文字的形式写好背熟。 问题二:“谈谈你的家庭情况” 思路: 1、况对于了解应聘者的性格、观念、心态等有一定的作用,这是招聘单位问该问题的主要原因。 2、简单地罗列家庭人口。 3、宜强调温馨和睦的家庭氛围。 4、宜强调父母对自己教育的重视。 5、宜强调各位家庭成员的良好状况。 6、宜强调家庭成员对自己工作的支持。 7、宜强调自己对家庭的责任感。 问题三:最能概括你自己的三个词是什么? 思路:我经常用的三个词是:适应能力强,有责任心和做事有始终,结合具体例子向主考官解释,使他们觉得你具有发展潜力。 问题四:“你有什么业余爱好?” 思路: 1、业余爱好能在一定程度上反映应聘者的性格、观念、心态,这是招聘单位问该问题的主要原因。 2、最好不要说自己没有业余爱好。
3、不要说自己有那些庸俗的、令人感觉不好的爱好。 4、最好不要说自己仅限于读书、听音乐、上网,否则可能令面试官怀疑应聘者性格孤僻。 5、最好能有一些户外的业余爱好来“点缀”你的形象。 6、找一些富于团体合作精神的。这里有一个真实的故事:有人被否决掉,因为他的爱好是深海潜水。主考官说:因为这是一项单人活动,我不敢肯定他能否适应团体工作。 问题五:“你最崇拜谁?” 思路: 1、最崇拜的人能在一定程度上反映应聘者的性格、观念、心态,这是面试官问该问题的主要原因。 2、不宜说自己谁都不崇拜。 3、不宜说崇拜自己。 4、不宜说崇拜一个虚幻的、或是不知名的人。 5、不宜说崇拜一个明显具有负面形象的人。 6、所崇拜的人人最好与自己所应聘的工作能“搭”上关系。 7、最好说出自己所崇拜的人的哪些品质、哪些思想感染着自己、鼓舞着自己。 问题六:“你的座右铭是什么?” 思路: 1、座右铭能在一定程度上反映应聘者的性格、观念、心态,这是面试官问这个问题的主要原因。 2、不宜说那些医引起不好联想的座右铭。 3、不宜说那些太抽象的座右铭。 4、不宜说太长的座右铭。 5、座右铭最好能反映出自己某种优秀品质。 6、参考答案——“只为成功找方法,不为失败找借口”。 问题七:“谈谈你的缺点” 思路: 1、不宜说自己没缺点。 2、不宜把那些明显的优点说成缺点。 3、不宜说出严重影响所应聘工作的缺点。 4、不宜说出令人不放心、不舒服的缺点。 5、可以说出一些对于所应聘工作“无关紧要”的缺点,甚至是一些表面上看是缺点,从工作的角度看却是优点的缺点.。绝对不要自作聪明地回答“我最大的缺点是过于追求完美”,有的人以为这样回答会显得自己比较出色,但事实上,他已经岌芨可危了。 问题八:“谈一谈你的一次失败经历”
.栈通常采用的两种存储结构是______________________ .用链表表示线性表的优点是_______________________ 8.在单链表中,增加头结点的目的是___________________ 9.循环链表的主要优点是________________________- 12.线性表的顺序存储结构和线性表的链式存储结构分别是__________________________ 13.树是结点的集合,它的根结点数目是_____________________ 14.在深度为5的满二叉树中,叶子结点的个数为_______________ 15.具有3个结点的二叉树有(_____________________ 16.设一棵二叉树中有3个叶子结点,有8个度为1的结点,则该二叉树中总的结点数为____________________ 17.已知二叉树后序遍历序列是dabec,中序遍历序列是debac,它的前序遍历序列是____________________________ 18.已知一棵二叉树前序遍历和中序遍历分别为ABDEGCFH和DBGEACHF,则该二叉树的后序遍历为______________________ 19.若某二叉树的前序遍历访问顺序是abdgcefh,中序遍历访问顺序是dgbaechf,则其后序遍历的结点访问顺序是_______________________ 20.数据库保护分为:安全性控制、完整性控制、并发性控制和数据的恢复。 在计算机中,算法是指_______________________ 算法一般都可以用哪几种控制结构组合而成_____________________ .算法的时间复杂度是指______________________ 5. 算法的空间复杂度是指__________________________ 6. 算法分析的目的是__________________________
Student(S#,Sname,Sage,Ssex)学生表 S#:学号 Sname:学生姓名 Sage:学生年龄 Ssex:学生性别 Course(C#,Cname,T#)课程表 C#:课程编号 Cname:课程名称 T#:教师编号 SC(S#,C#,score)成绩表 S#:学号 C#:课程编号 score:成绩 Teacher(T#,Tname)教师表 T#:教师编号: Tname:教师名字 问题: 1、查询“001”课程比“002”课程成绩高的所有学生的学号 select a.S# from (select S#,score from SC where C#='001')a, (select s#,score from SC wh ere c#='002')b Where a.score>b.score and a.s# = b.s#; 2、查询平均成绩大于60分的同学的学号和平均成绩 select S#, avg(score) from sc group by S# having avg(score)>60 3、查询所有同学的学号、姓名、选课数、总成绩 select student.S#, student.Sname, count(sc.C#), sum(score) from student left outer join SC on student.S# = SC.S# group by Student.S#, Sname
4、查询姓‘李’的老师的个数: select count(distinct(Tname)) from teacher where tname like '李%'; 5、查询没有学过“叶平”老师可的同学的学号、姓名: select student.S#, student.Sname from Student where S# not in (select distinct(SC.S#) from SC,Course,Teacher where sc.c#=course.c# AND teacher.T#=course.T# AND Teahcer.Tname ='叶平'); 6、查询学过“叶平”老师所教的所有课的同学的学号、姓名:select S#,Sname from Student where S# in (select S# from SC ,Course ,Teacher where SC.C#=Course.C# and Teacher.T#=Course.T# and Teacher.Tname='叶平' group by S# having count(SC.C#)=(select count(C#) from Course,Teacher where Teacher.T#=Course.T# and Tname='叶平')); 7、查询学过“011”并且也学过编号“002”课程的同学的学号、姓名: select Student.S#,Student.Sname from Student,SC where Student.S#=SC.S# and SC.C#='001'and exists( Select * from SC as SC_2 where SC_2.S#=SC.S# and SC_2.C#='002'); 8、查询课程编号“002”的成绩比课程编号“001”课程低的所有同学的学号、姓名: Select S#,Sname
1、海量日志数据,提取出某日访问百度次数最多的那个IP。 首先是这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中。注意到IP是32位的,最多有个2^32个IP。同样可以采用映射的方法,比如模1000,把整个大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP(可以采用hash_map进行频率统计,然后再找出频率最大的几个)及相应的频率。然后再在这1000个最大的IP中,找出那个频率最大的IP,即为所求。 或者如下阐述: 算法思想:分而治之+Hash 1.IP地址最多有2^32=4G种取值情况,所以不能完全加载到内存中处理; 2.可以考虑采用“分而治之”的思想,按照IP地址的Hash(IP)24值,把海量IP日志分别存储到1024个小文件中。这样,每个小文件最多包含4MB个IP地址; 3.对于每一个小文件,可以构建一个IP为key,出现次数为value的Hash map,同时记录当前出现次数最多的那个IP地址; 4.可以得到1024个小文件中的出现次数最多的IP,再依据常规的排序算法得到总体上出现次数最多的IP; 2、搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。 假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。 典型的Top K算法,还是在这篇文章里头有所阐述, 文中,给出的最终算法是:
第一步、先对这批海量数据预处理,在O(N)的时间内用Hash表完成统计(之前写成了排序,特此订正。July、2011.04.27); 第二步、借助堆这个数据结构,找出Top K,时间复杂度为N‘logK。 即,借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比所以,我们最终的时间复杂度是:O(N)+ N’*O(logK),(N为1000万,N’为300万)。ok,更多,详情,请参考原文。 或者:采用trie树,关键字域存该查询串出现的次数,没有出现为0。最后用10个元素的最小推来对出现频率进行排序。 3、有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。 方案:顺序读文件中,对于每个词x,取hash(x)P00,然后按照该值存到5000个小文件(记为x0,x1,…x4999)中。这样每个文件大概是200k左右。 如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M。 对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树/hash_map 等),并取出出现频率最大的100个词(可以用含100个结点的最小堆),并把100个词及相应的频率存入文件,这样又得到了5000个文件。下一步就是把这5000个文件进行归并(类似与归并排序)的过程了。 4、有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个
校园招聘系列校园招聘系列之 校招经典面试问题汇编(含答案) 一、认识自我类 1、自我评价一下你自己,最大的优点以及最大的缺点,另外你的人生规划是什么? 答:我热爱生活,积极看待人生,对于很多东西都有旺盛的求知欲,愿意从任何人身上学习我不懂的东西,我也非常喜欢交朋友,乐于在一个团结友好的大团队之中开展工作。总的来说,热情,好学,以及良好的沟通协调能力是我的最大优势。当然我也有很多缺点,由于年龄的关系,我看一些问题不够深入,有时候未免做事情未免急躁,不过我能够虚心听取意见,相信在开展工作之时,能够发挥我的特长并且出色完成任务。 2、如果本单位无法给你解决户口问题,但是其他条件都能满足你,你是否还会来本公司工作? 答:我很喜欢贵单位,对于单位能够在各个方面最大程度的证明我的价值表示衷心的感谢。户口是我比较关注的问题,如果单位能够尽可能的帮助我解决这个后顾之忧,那么我就能够保证全心全意的投入到工作之中来,如果单位暂时有困难,我也表示理解。毕竟事业的发展空间对于我来说才是最重要的。我会好好权衡。
3、看你的简历中得知你有在大公司作intern的经历,为什么你在找正式工作的时候来我们这样一家小公司? 答:大公司有大公司的优势,小公司也有小公司的好处。对于一个刚毕业的学生来说,我需要学习的地方很多,而最最急需掌握的是独立处理问题的能力和承担一个项目的经验.在大公司中由于人员组织结构的复杂庞大以及井然有序,每个人各司其职,往往长年累月做的都是重复性的相同工作,难以接触到自己职责之外的事情,而小公司因为部门少,人事关系相对简单,每个人在挽成自己的本职工作之外,还有很多机会接触别人做的东西,这样只需要在短时间内就可以锻炼成为一个"多面手".有了在小公司的工作经验,不需要很长时间,我想我就可以独立策划一个项目并且出色的完成它.还有一点,大公司创造利润之后?配到每个员工头上的红利其实并不多;而小公司的利益都会切实的落实到每个职工身上,是那种所谓你能看得到摸的着的好处,这一点也是相当吸引我的。 4、请问你是否有男友?他/她和你不在一个城市工作,你如何解决这个问题? 答:是的,我有一个感情很稳定的男友,并且确实我们暂时不在一个地方。从我个人来讲,我确实很希望能有机会两个人在一个地方,不过我不认为这将是我事业前途的羁绊。如果我为了这份感情放弃一份我十分满意的工作,那将会令我和男友之间的?系变得非常沉重。这不是我所希望看到的,也不是我男友所希望看到的。我们希望能够各自拥有各自事业的发展空间,双方都是独立出色的个体,这将会使我们更加欣赏对方。
栈和队列的共同特点是__________________________ .栈通常采用的两种存储结构是______________________ .用链表表示线性表的优点是_______________________ 8.在单链表中,增加头结点的目的是___________________ 9.循环链表的主要优点是________________________- 12.线性表的顺序存储结构和线性表的链式存储结构分别是 __________________________ 13.树是结点的集合,它的根结点数目是_____________________ 14.在深度为5的满二叉树中,叶子结点的个数为_______________ 15.具有3个结点的二叉树有(_____________________ 16.设一棵二叉树中有3个叶子结点,有8个度为1的结点,则该二叉树中总的结点数为____________________ 17.已知二叉树后序遍历序列是dabec,中序遍历序列是debac,它的前序遍历序列是 ____________________________ 18.已知一棵二叉树前序遍历和中序遍历分别为ABDEGCFH和DBGEACHF,则该二叉树的后序遍历为______________________ 19.若某二叉树的前序遍历访问顺序是abdgcefh,中序遍历访问顺序是dgbaechf,则其后序遍历的结点访问顺序是_______________________ 20.数据库保护分为:安全性控制、完整性控制、并发性控制和数据的恢复。 在计算机中,算法是指_______________________ 算法一般都可以用哪几种控制结构组合而成_____________________ .算法的时间复杂度是指______________________ 5. 算法的空间复杂度是指__________________________ 6. 算法分析的目的是__________________________
数据分析师常见的7道笔试题目及答案 导读:探索性数据分析侧重于在数据之中发现新的特征,而验证性数据分析则侧重于已有假设的证实或证伪。以下是由小编J.L为您整理推荐的实用的应聘笔试题目和经验,欢迎参考阅读。 1、海量日志数据,提取出某日访问百度次数最多的那个IP。 首先是这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中。注意到IP是32位的,最多有个2^32个IP。同样可以采用映射的方法,比如模1000,把整个大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP(可以采用 hash_map进行频率统计,然后再找出频率最大的几个)及相应的频率。然后再在这1000 个最大的IP中,找出那个频率最大的IP,即为所求。 或者如下阐述: 算法思想:分而治之+Hash 1.IP地址最多有2^32=4G种取值情况,所以不能完全加载到内存中处理; 2.可以考虑采用“分而治之”的思想,按照IP地址的Hash(IP)24值,把海量IP日志分别存储到1024个小文件中。这样,每个小文件最多包含4MB个IP地址; 3.对于每一个小文件,可以构建一个IP为key,出现次数为value的Hash map,同时记录当前出现次数最多的那个IP地址; 4.可以得到1024个小文件中的出现次数最多的IP,再依据常规的排序算法得到总体上出现次数最多的IP; 2、搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。 假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。 典型的Top K算法,还是在这篇文章里头有所阐述, 文中,给出的最终算法是: 第一步、先对这批海量数据预处理,在O(N)的时间内用Hash表完成统计(之前写成了排序,特此订正。July、2011.04.27); 第二步、借助堆这个数据结构,找出Top K,时间复杂度为N‘logK。 即,借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比所以,我们最终的时间复杂度是:O(N) + N’*O(logK),(N为1000万,N’为300万)。ok,更多,详情,请参考原文。 或者:采用trie树,关键字域存该查询串出现的次数,没有出现为0。最后用10个元素的最小推来对出现频率进行排序。 3、有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。 方案:顺序读文件中,对于每个词x,取hash(x)P00,然后按照该值存到5000 个小文件(记为x0,x1,…x4999)中。这样每个文件大概是200k左右。 如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M。 对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树 /hash_map等),并取出出现频率最大的100个词(可以用含100 个结点的最小堆),并把
经典面试题及答案分析 人事主管最常用的面试题和最喜欢的答案 咨询题1: 假如我录取你,你认为你在这份工作上会待多久呢? a?这咨询题可能要等我工作一段时刻后,才干比较具体地回答。 b?—份工作至少要做3年、5年,才干学习到精华的部分。 c?那个咨询题蛮难回答的,可能要看当时的情形。 d?至少2年,2年后我打算再出国深造。 解答:挑选 b 最多, a 次之。 b 的回答能充分显示出你的稳定性,只是,这必须配合你的履历表上,之前的工作是否也有一致性。a的回答则是特别实际,有些人事主管因为观赏应征者的坦诚,可以同意如此的回答。 咨询题2:除了我们公司之外,你还应征了其它哪些公司呢? a?除了向贵公司如此的计算机外设产品公司外,我还应征了x饮料公司、x软件设计公 司及x化工公司。 b?因为是经过人才站,因此有不少公司与我联络,别胜枚举。 c?由于我只对计算机公司较感兴趣,所以除贵公司外,我还应征了x及x公司。 d?我别是很积极地想换工作,这半年多来陆陆续续寄了一些履历,公司名字别太记得。 解答:最理想的回答是c。c的回答能够显示出应征者的目标明确,关于自己的下一具工作应该在哪里,考虑得很清晰。 咨询题3:你希翼5 年后达到什么成就? a. 做一天和尚敲一天钟,尽人事听天命、顺其自然。 b?依我的灵巧及才能,晋升到部门经理是我的中期目标。 c. 自己独当一面开公司。 d. “全力以赴”是我的座右铭,希翼能随着经验的增加,被给予更多的职责及挑战。解答: 最理想的回答是d。 咨询题4:假如你离开现职,你认为你的老总会有什么反应? a. 很震惊,因为老总对我就是很信赖,我就如同他的左右手一样。 b. 还好吧,他似乎内心也有数,反正公司如今也别忙。 c. 他似乎适应了,反正他手下的人来来去去已是司空见惯。 d. 我想他一定会生气地破口大骂,他是一具相当情绪化的人。 解答:最理想的回答是a。面谈者想借此了解你和前(现)任主管的相处情形,以及你在主管心目中的地位怎么? 咨询题5:你什么原因想来我们公司工作? a. 要紧是这份工作的内容很吸引我。 b. 贵公司在业界颇出名的,听说治理也很人性化。 c. 我的大学同学在贵公司会计部工作,是他建议我来应征的。 d. 贵公司所处的产业,以及在业界的声誉、工作性质,都很吸引我。解答:最理想的回答是d。
一、单链表 目录 1.单链表反转 2.找出单链表的倒数第4个元素 3.找出单链表的中间元素 4.删除无头单链表的一个节点 5.两个不交叉的有序链表的合并 6.有个二级单链表,其中每个元素都含有一个指向一个单链表的指针。写程序把这个二级链表称一级单链表。 7.单链表交换任意两个元素(不包括表头) 8.判断单链表是否有环?如何找到环的“起始”点?如何知道环的长度? 9.判断两个单链表是否相交 10.两个单链表相交,计算相交点 11.用链表模拟大整数加法运算 12.单链表排序 13.删除单链表中重复的元素 首先写一个单链表的C#实现,这是我们的基石: public class Link { public Link Next; public string Data; public Link(Link next, string data) { this.Next = next; this.Data = data; } } 其中,我们需要人为地在单链表前面加一个空节点,称其为head。例如,一个单链表是1->2->5,如图所示: 对一个单链表的遍历如下所示: static void Main(string[] args) { Link head = GenerateLink(); Link curr = head; while (curr != null)
{ Console.WriteLine(curr.Data); curr = curr.Next; } } 1.单链表反转 这道题目有两种算法,既然是要反转,那么肯定是要破坏原有的数据结构的:算法1:我们需要额外的两个变量来存储当前节点curr的下一个节点next、再下一个节点nextnext: public static Link ReverseLink1(Link head) { Link curr = head.Next; Link next = null; Link nextnext = null; //if no elements or only one element exists if (curr == null || curr.Next == null) { return head; } //if more than one element while (curr.Next != null) { next = curr.Next; //1 nextnext = next.Next; //2 next.Next = head.Next; //3 head.Next = next; //4 curr.Next = nextnext; //5 } return head; } 算法的核心是while循环中的5句话 我们发现,curr始终指向第1个元素。 此外,出于编程的严谨性,还要考虑2种极特殊的情况:没有元素的单链表,以及只有一个元素的单链表,都是不需要反转的。