
一次Linux下testdisk+gdisk恢复XFS文件系统及数据的经历
硬盘之前状况,用gdisk进行硬盘分区(SATA标准,3.6T容量),1.6T+2.0T两个分区,然后用mkfs.xfs格式化分区,最后结果就是,GPT分区表+两个XFS文件系统的硬盘(/dev/sdb,/dev/sdb1,/dev/sdb2)
我已无法确定引起这次硬盘错误的原因,但我确实这么做过:
原因一,从另一个硬盘的/home挂载点复制了大量数据到/dev/sdb1,然后我就将硬盘的数据线和电源线都拔掉了,这个动作在系统运行和关闭的两种情况下都做过,(SATA 硬盘是否安全的支持热插拔?)
原因二,在这次准备复制数据的之前,我没有将硬盘固定,也没有平放在台面(有一点斜度),然后开机,(胡乱的猜想着斜坡加载技术)
下面进入正题:
1,硬盘错误引起分区无法读取,挂载,开始纳闷哪里出了问题
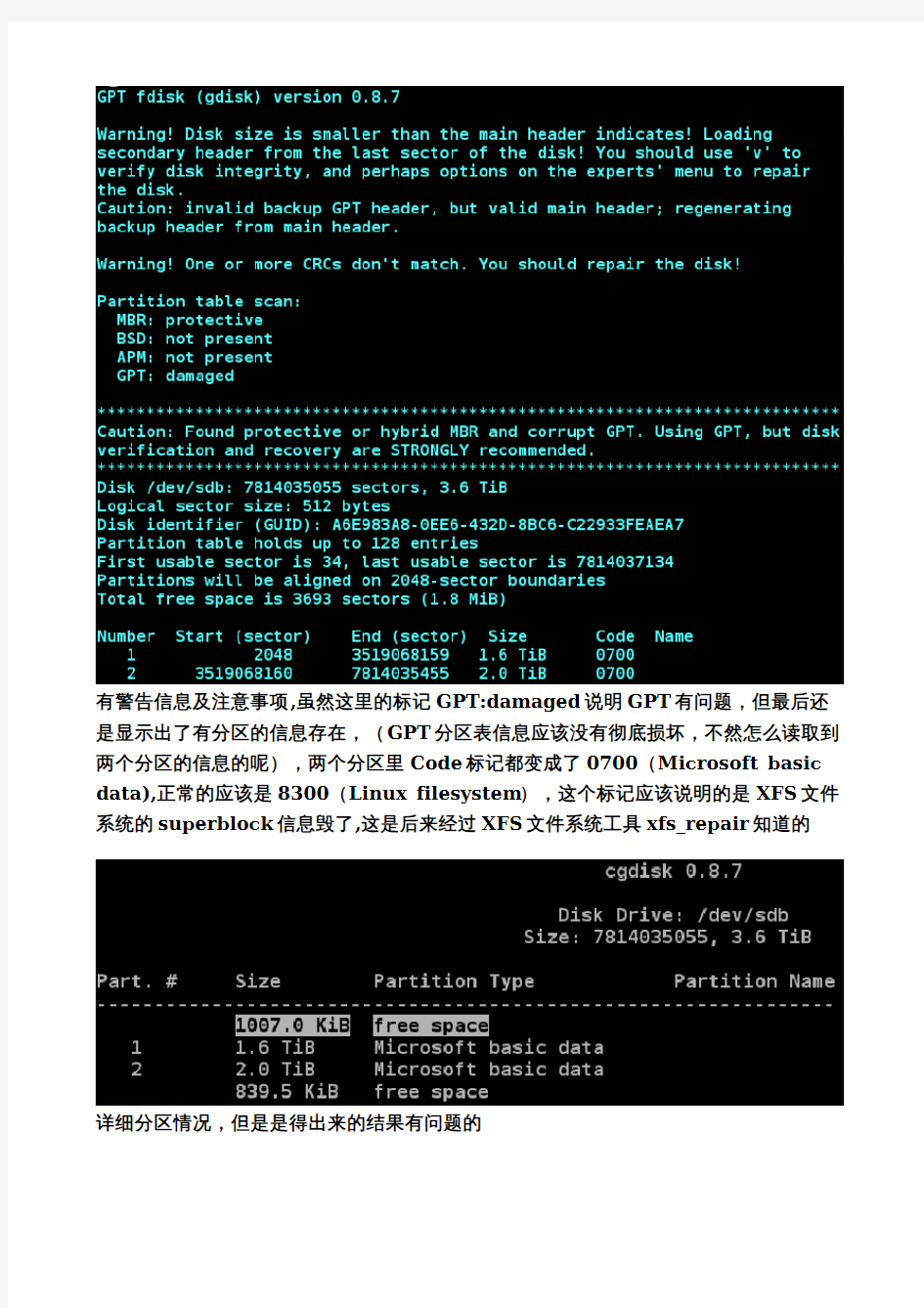
2,运行gdisk -l /dev/sdb,显示如下
有警告信息及注意事项,虽然这里的标记GPT:damaged说明GPT有问题,但最后还是显示出了有分区的信息存在,(GPT分区表信息应该没有彻底损坏,不然怎么读取到两个分区的信息的呢),两个分区里Code标记都变成了0700(Microsoft basic data),正常的应该是8300(Linux filesystem),这个标记应该说明的是XFS文件系统的superblock信息毁了,这是后来经过XFS文件系统工具xfs_repair知道的
详细分区情况,但是是得出来的结果有问题的
gdisk检测到五个问题,(惊讶,这么多的问题)
3,进行到这里,我着急了,于是寻求帮助
首先,尝试了xfs_repair /dev/sdb,这个命令进行了几次,因为中途中断过,这个修复时间是比较长的,几小时(差不多3,4小时?)后得到的结果却是无法检测验证到有效的备份superblock信息,(失败,心都凉了)
然后,找到testdisk工具,大略的看了下说明就上手做(英文实在是差,仔细地看也不明白),第一次进行Analyse后,完全不知道做什么,就直接退出
然后就去测试查看,运行lsblk,gdisk,没有任何改变,(此刻是没抱什么希望的),输出的日志文件testdisk.log也完全看不懂,但我在日志文件里看到了有XFS这三个
字母的身影,(此时心中还是有一丝喜悦的)
4,继续网上搜索,寻求答案,(辛辛苦苦建立的文件数据啊,那个心情真是无奈啊)
使用testdisk进行第二次Analyse(分析目前分区结构及搜寻丢失的分区),经过6小时的分析与搜索后,我大胆的进行了第二个动作,转换分区类型,(当时的想法是inode及data block里记录的信息应该是不会丢失或被覆盖的),于是我选择了Linux reserved(谷歌翻译了一下,“Linux保留”,这里是没有Linux filesystem 的,找来找去也没找到更合适的了),再进入子菜单选择了XFS(还有
XFS2,XFS3,XFS4,这里是比较疑惑的,网上没有找到任何答案),至此点击写入,然后退出。再一次阅读testdisk.log文件,(这里有点小插曲,我在主文件侠里找不到testdisk.log文件,进行whereis testdisk.log搜寻,这个文件怎么会跑
到/usr/src/linux-3.10.3-1-ARCH/testdisk.log这里了呢)?
5,testdisk.log文件内容如下:
这里是系统的一些相关信息
这里是选择了EFI GPT选项后得出的结果,在这里就分析出了当前的分区结构,只有一个Linux Reserved分区类型的分区,(这里的这个分析是不是肯定的)
这里是应该是选择了Analyse选项后再点击quick search得到的,大概是两段内容,第一,对于分区1文件系统的标记搜索,成功,(这个标记是什么,superblock?,不是损毁了吗?)。第二,对于分区2文件系统的标记搜索,在这里搜索到了很多标记,但是在比对数据(能这样表达吗)时却出现了问题,(这里应该就是为什么会耗时6小时的原因),因为数据的信息标记超出了磁盘的整个容量,(这会是什么原因造成的呢)
这里是搜索完成后得到无法恢复分区2文件系统的信息
这里是这次使用testdisk最后的结果日志,只找到了丢失的分区1文件系统,然后进行了分区类型的改变和确定写入。
6,经过上步的尝试,(说实话,心里很忐忑),使用lsblk查找,还是找不
到/dev/sdb1,于是运行gdisk
虽然看到不想看到的信息,但是No problems found一句让我有些惊喜,继续
作出决定,重写分区表信息7,喜出望外的结果
检测出/dev/sdb/sdb1
成功挽回文件!(兴奋啊)8,疑问与猜想
GPT分区表已经修复好,分区1的类型为Linux reserved(并不是未出问题之前的Linux filesystem),成功检测到/dev/sdb1的文件系统是XFS。已经挽回了数据,虽然并没有完整的修复,但现在没有空闲的磁盘来备份这些数据,所以这里就没敢继续往下尝试恢复了
疑问一:能不能直接使用gdisk的重新建立分区表的功能,使用testdisk好像最主要的作用就是做了分区的搜索,然后做了个分区类型的转换(这步是否可用其它工具完成)?
疑问二:XFS文件系统的superblock到底有没有损毁,如果没有损毁,怎么就检测不到分区文件系统信息,如果损毁了又是怎么恢复的,因为尝试运行了xfs_repair,检测到磁盘最后一个扇区也验证不了备份的superblock。superblock有没有彻底恢复,如果是彻底恢复的,为什么不能正确的检测到分区2的信息,如果并不是完整的superblock,又何以能够读取分区1的作息?
疑问三:总觉得这里的Linux reserved怪怪的,难道它在磁盘里的记录信息与Linux filesystem是兼容的?这个记录信息与XFS文件系统的superblock有没有关系?
疑问四:运行dd if=/dev/sdb of=/dev/sdax,会是什么结果?
猜想疑问一:阅读了鸟哥的私房菜基础篇里的ext2文件系统的那一章节,对文件系统(ext2,ext3,ext4,XFS)有这么个了解,记录整个磁盘分区情况的是GPT分区表,记录分区文件系统信息的是superblock,记录文件系统里的文件信息的是inode,记录文件系统里的文件实际数据的是block,这里的inode与block是否有独特的标记,是否可写这样一个程序,直接读取到磁盘里的inode来找到block
从而搜索出文件信息
猜想疑问二:说到这里当然还有一些疑问,这里的思维有些乱。GPT磁盘在开始区域
记录着保留的MBR信息,GPT信息及superblock信息,这些是怎么记录下来的,因为这个区域没有进行文件系统格式化,磁盘的整个磁盘的最小单位是sector(扇区),进行分区文件系统格式化后,磁盘用来记录信息的最小单位是block吗,那么
默认256bytes的inode又是个什么,superblock信息为什么会记录在第一个
分区以前未格式化的区域?
此篇小记说明:以上信息仅针对本人使用的系统环境,其中有一小部份表达的信息无法
用图片来比对,因为一开始没想要写此记,所以一些信息的截图就忽略了,特别是
xfs_repair这个环节。
最后作个提醒:硬盘发生错误,在系统运行期间无法自动fsck导致系统无法成功启动
或无法检测分区读取数据信息(非启动盘)后,绝不能再对硬盘进行任何写操作,慎用fsck,切记,切记,这样,自己就能最有把握的将数据拯救出来!
在互联网普及的时代,数据显得尤为重要。数据备份是对数据进行再存储,是一个数据导出动作,以防数据丢失。而数据恢复则与数据备份是两个相反方向的行为,是将不小心丢失的数据重新导回电脑端。数据备份与恢复系统哪个品牌好呢? 铱迅数据备份备份与恢复系统,是业界针对大数据量环境的应急接管平台,其利用磁盘级CDP技术,可实现IO级别的细颗粒度实时备份,将备份窗口、数据丢失降到较低。并且可以实现任意时间点的数据挂载与演练,能够快速响应业务系统的接管需求,对应用实现连续保护。 软硬件一体化配置 数据备份与恢复系统集备份服务器,操作系统、备份软件、磁盘阵列融于一体;并可加载铱迅容灾平台的虚拟化软件模块,备份容灾一机实现。 多方位的数据备份支持
备份存储服务器 软件模块 软件部分的服务器端内置在硬件中,采用Web界面提供设备、客户端、备份数据及管理员的管理;客户端由多个功能模块构成,安装在需要备份的服务器或PC上,依据数据保护的对象和等级不同,客户端授权划分为多个类型;更有扩展功能软件包,支持异地数据灾备等功能。
铱迅数据备份与恢复系统采用软硬件一体化配置,以持续数据保护技术(CDP)为核心,具备实时备份、定时备份等功能,整合了USB Key、密码口令等多因子安全身份验证安全模块,可以为数据库、文件、应用、操作系统提供安全、有效、完整的数据保护。 多方位备份 跨平台支持各类桌面电脑、服务器及小型机;支持Windows、Linux、Unix等操作系统及VMware ESX(i)、Hyper-V等虚拟化系统;支持Oracle/SQL Server/My SQL/DB2/Sybase及国产数据库等多种数据库;支持双机、虚拟机等服务器架构;支持LAN-Base、LAN-Free等备份方式;提供手动备份、定时备份、实时备份等备份策略设置;提供数据库、文件、应用及操作系统的多方位保护。 简易化操作 数据自动集中备份到黑方的存储空间中。基于Web界面统一管理平台,提供备份设备、备份客户端、备份数据的集中管理,将IT 技术人员的专业性数据备份恢复工作简化为普通工作人员即可轻松掌握并自动完成的简单工作。 CDP实时备份和恢复 创新性CDP持续数据保护技术,数据备份与恢复准确到秒,连续实时捕获所需备份文件的数据变化,并自动保存变化的数据和时间戳(即表示数据变化的时间节点),在此基础上可以实现过去任意时间点的数据恢复。有效解决定时备份、准CDP备份的时间窗口问题。 功能简介 核心技术 铱迅数据备份与恢复系统以持续数据保护(CDP)为核心技术精髓,并结合升级加密、数据压缩、数据同步等诸多先进技术,来实现可靠、安全、多面、有效的数据备份与恢复。
6苏州大学学报(工科版)第30卷 图1I-IDFS架构 2HDFS与LinuxFS比较 HDFS的节点不管是DataNode还是NameNode都运行在Linux上,HDFS的每次读/写操作都要通过LinuxFS的读/写操作来完成,从这个角度来看,LinuxPS是HDFS的底层文件系统。 2.1目录树(DirectoryTree) 两种文件系统都选择“树”来组织文件,我们称之为目录树。文件存储在“树叶”,其余的节点都是目录。但两者细节结构存在区别,如图2与图3所示。 一二 Root \ 图2ItDFS目录树围3LinuxFS目录树 2.2数据块(Block) Block是LinuxFS读/写操作的最小单元,大小相等。典型的LinuxFSBlock大小为4MB,Block与DataN-ode之间的对应关系是固定的、天然存在的,不需要系统定义。 HDFS读/写操作的最小单元也称为Block,大小可以由用户定义,默认值是64MB。Block与DataNode的对应关系是动态的,需要系统进行描述、管理。整个集群来看,每个Block存在至少三个内容一样的备份,且一定存放在不同的计算机上。 2.3索引节点(INode) LinuxFS中的每个文件及目录都由一个INode代表,INode中定义一组外存上的Block。 HDPS中INode是目录树的单元,HDFS的目录树正是在INode的集合之上生成的。INode分为两类,一类INode代表文件,指向一组Block,没有子INode,是目录树的叶节点;另一类INode代表目录,没有Block,指向一组子INode,作为索引节点。在Hadoop0.16.0之前,只有一类INode,每个INode都指向Block和子IN-ode,比现有的INode占用更多的内存空间。 2.4目录项(Dentry) Dentry是LinuxFS的核心数据结构,通过指向父Den姆和子Dentry生成目录树,同时也记录了文件名并 指向INode,事实上是建立了<FileName,INode>,目录树中同一个INode可以有多个这样的映射,这正是连
数据备份及恢复标准流程
索引 一Outlook Express篇 (3) 二Foxmail篇 (5) 三Office Outlook篇 (7) 四操作系统篇 (8) 五数据库篇 (9) 六数据灾难恢复篇 (10)
一、Outlook Express篇 Outlook Express是WIN9X自带的邮件收发软件,它拥有相当多的用户,但由于其是随系统安装而来的,再加上WIN9X的极不稳定,重装系统后将丢失OE中的很多个性设置,甚至于收发的邮件,因此,在系统正常时备份相关的信息是必要的。本文以OE5.0以上版本为例介绍。 1.存储文件夹的改变 在OE的工具-选项-维护-存储文件夹中可以改变邮件的存放位置,这里必须把邮件存放在其它分区中如E:\MAIL中,或改变HKEY_CURRENT_USER\Software\Microsoft\OutlookExpress中的Store Root,可以导出这个注册表分支,存放在E:\MAIL中。 2.邮件规则的备份 OE的一个强大功能就是其邮件规则,这样可以有选择性的收取邮件,将不用的邮件直接在服务器上删除,这些规则可以在脱机状态下设定,而不象FOXMAIL的远程邮箱管理必须在线执行,这样并没有节省在线的时间。 在OE中设置了邮件规则(在工具-邮件规则-邮件中进行设置)后,在注册表中的HKEY-CURRENT-USER\Identities\{9ACEA700-E70A-11D3-9796-A034DB516564}\Software\Microsoft\Outlook Express\5.0\Rules\Mail保存你的该项设置,当然各人{}中的内容可能不同;你的机子上OE中有多个标识,这里将会有几个{}。 3.个性化的签名 在工具-选项-签名中可以设定自已个性化的签名,而且对不同帐号自动添加不同的签名,如用于投稿的帐号,要添加自己的通信地址,这样可以收到稿费。在新闻中发帖子,要
数据备份与恢复 摘要 近年来,以计算机和网络为基础的信息产业获得了空前的发展,人们对数 据的安全性越来越重视。数据备份和灾难恢复逐渐成为了热点问题。由于各种客观原因,人们无法预测何时、何地会发生何种程度的灾难,也不不可能完全防止、控制其发生。但高性能的数据备份和灾难恢复方案能充分保护系统中有价值的信息。保证灾难发生时系统任然正常工作。 引言 随着以计算机为基础的电子信息技术在社会各方面越来越广泛的深入应用,各种工作逐步走上了办公自动化网络管理的发展道路,大量的管理信息系统和专用办公软件被开发并投入使用,这对规范管理、提高工作效率起到了良好的促进作用。在实际工作中,信息系统和管理软件从开始投入使用起,就将随着工作的开展和时间的推移,持续记录并积累大量的数据。工作中的许多重要的决策就是以这些日常积累的数据为基础的。但信息系统在提供方便和高效的同时,在运行中却常常会出现一些意料之外的问题,如人为误操作、硬件损毁、电脑病毒侵袭、断电或其它意外原因造成网络系统瘫痪、数据丢失,给企业、单位和管理人员带来难以弥补的损失。避免这种损失的最佳途径就是建立可靠的数据备份恢复系统,但是大部分应用人员只是在受到损失后才意识到了数据备份的重要性。
目录 一、背景 (3) 二、解决方案 (3) 三、什么是数据备份与恢复? (4) 四、需要备份的数据对象 (5) 五、备份设备 (6) 六、备份类型(或备份模式) (6) 七、备份窗口 (7) 八、备份介质 (7) 九、备份系统的逻辑结构和部署 (8) 十、恢复操作系统 (10)
一、背景 有专业机构的研究数据表明:丢失300MB的数据对于市场营销部门就意味着13万元人民币的损失,对财务部门意味着16万的损失,对工程部门来说损失可达80万。而丢失的关键数据 如果15天内仍得不到恢复, 企业就有可能被淘汰出局。 实际上,我们很多企业和组 织已有了前车之鉴,一些重 要的企业内曾经不止一次地 发生过灾难性的数据丢失事 故,造成了很大的经济损失, 在这种情况下,数据备份就 成为日益重要的措施,我们 必须对系统和数据进行备份!通过及时有效的备份,系统管理者就可以高枕无忧了。所以,对信息系统环境内的所有服务器、PC进行有效的文件、应用数据库、系统备份越来越迫切。 二、解决方案 基于磁盘备份篇: 企业数据主要分为结构化数据和非结构化数据。结构化数据,即行数据,存储在数据库里。非结构化数据包括所有格式的办公文档、文本、图片、XML、HTML、各类报表、图像和音频/视频信息等。专业的备份系统可同时备份结构化数据和非结构化数据,。目前市面上常见基于磁盘的备份系统类型可分为两种:备份软件+通用硬件存储平台(服务器、NAS存储、磁盘阵列柜)和存储一体柜。基于磁带备份篇:
第二章Btrfs文件系统 2.1 Btrfs文件系统简介 Btrfs(B-tree file system,B-tree文件系统)是针对Linux开发的一个新的CoW (copy-on-write,写时复制)文件系统。它最初是由甲骨文公司在2007年着手开始开发的,并在2014年8月正式发布其稳定版。开发Btrfs的目的在于解决Linux 文件系统中缺少池、快照、校验和以及集成的跨多设备访问等问题,目标在于实现Linux的规模化存储。规模化不仅仅是指解决存储问题,也意味着通过简洁的界面提供对存储的管控和管理能力,让大家能看到已使用的内容并使它更可靠。 2.2 Btrfs文件系统新特性 ?基于扩展的文件存储 ?文件大小上限16EiB ?小文件和索引目录的高效空间利用 ?动态索引节点分配 ?支持快照可写和快照只读 ?子卷(分离内部文件系统的根) ?支持数据和元数据的校验和 ?压缩(gzip和LZO) ?整合的多设备支持 ?支持文件条块化、文件镜像和文件条块化+镜像三种部署方案 ?高效的增量备份 ?后台消除进程支持查找和修复冗余副本上的文件错误 ?支持在线文件系统碎片整理和离线文件系统检查 ?Btrfs文件系统对RAID 5/RAID 6加强支持,在linux 3.19中添加了许多漏洞修补 2.3 Btrfs在linux内核的各版本中的变化 ● 3.0 Btrfs实现自动碎片整理、数据校验和检查,并且提升了部分性能 ● 3.2 BTRFS:更快的数据清理、tree roots自动备份、详细的错误消息、 元数据手动检查
● 3.3 BTRFS:支持不同RAID级别之间restriping,改善了平衡和调试工 具 ● 3.4 Btrfs文件系统大量改进:修复与数据恢复工具、元数据区块大于4KB、 性能改进、更好的错误处理 ● 3.5 Btrfs:I/O故障统计和一些不明显的提升 I/O故障统计支持新增:I/O故障、CRC故障和生成的元数据块跟踪检查每个驱动器,Btrfs 检查并返回驱动器状态,将在未来的btrfs-progs中包含,即:btrfs device stats。 ● 3.6 Btrfs:子卷配额、配额组、快照差别、跨子卷复制 ● 3.7 更新Btrfs文件系统,加快fsync()系统调用,移除单目录硬链接限制, 支持chattr per-file NOCOW,允许关闭使用nodatacow选项的文件数据写时复制 ● 3.9 Btrfs文件系统实验性支持RAID5和6。嵌入RAID特性可以让文件系统 摆脱复杂的底层存储阵列细节,例如因为文件系统自己知道数据备份数据存放在哪里,它自己就可以在发生磁盘损坏时恢复数据。嵌入RAID也有助于提高了文件系统对数据错误的容忍度,例如可以使用校验和,甚至也可以在元数据和数据上分别使用不同的RAID模式。这层抽象也意味着无法使用mdadm工具,因而必须整体恢复存储卷,比较耗时。 ● 3.10 Btrfs文件系统支持skinny extent,quota也进行了一些重建 ● 3.11例行的Btrfs和XFS文件系统bug修正和性能改进,F2FS修正了Linux 3.10中发现的一个性能退化bug,首次加入高性能并行分布式文件系统 Lustre ● 3.12 小幅改善了F2FS、XFS和Btrfs文件系统 ● 3.13 Btrfs和F2FS文件系统改进 ● 3.14 F2FS及BTRFS文件系统改进 ● 3.16 Btrfs及XFS文件系统的重大更新 ● 3.19 Btrfs文件系统改进RAID5 / RAID6支持
减少ZFS文件系统ARC缓存的方法减少ZFS文件系统ARC缓存的方法 1. ARC缓存简介 ZFS文件系统是Solaris 11系统的默认文件系统,ZFS文件系统简介可见附录。 ZFS使用在内存中建立缓存的方式来提升性能,这种做法在海量数据时尤为有效。ZFS的缓存使用ARC(Adjustable Replacement Cache)算法,它是基于IBM的Megiddo和Modha提出的ARC 淘汰算法演化而来的。所以这个缓存通常被称为ARC缓存。 Solaris系统中有两个内核参数来限制ARC缓存的大小: zfs_arc_min:确定ARC缓存的最小大小,设置单位为字节。默认64MB。 zfs_arc_max:确定ARC缓存的最大大小,设置单位为字节。默认在内存少于4 GB的系统上为物理内存的75%,在内存大于4 GB的系统上为物理内存减去1 GB。 这两个内核参数都是使用容量单位来设定的,并不能根据物理内存的大小来自动调节,所以在Solaris 11.2系统上增加了一个内核参数,使用百分比来设定: user_reserve_hint_pct:设置留给应用程序的物理内存百分比。查阅Oracle官方文档,并没有给出详细的说明,经试验,默认值应为0,且zfs_arc_min、zfs_arc_max参数依然有效,即user_reserve_hint_pct参数确定的ARC缓存占用量低于zfs_arc_min时,取zfs_arc_min的容量;高于zfs_arc_max时,取zfs_arc_max的容量。该参数在Solaris 11.2之前的系统中不存在。 2. 内存占用情况及产生的问题 使用以下命令可以查看内存使用明细: echo “::memstat” | mdb -k 在一台16GB的机器上,进行大量IO操作后(充分建立缓存),运行以上命令,如下图:
系统运维管理备份与恢复管理(Ⅰ) 版本历史 编制人: 审批人:
目录 目录 (2) 一、要求容 (3) 二、实施建议 (3) 三、常见问题 (4) 四、实施难点 (4) 五、测评方法 (4) 六、参考资料 (5)
一、要求容 a)应识别需要定期备份的重要业务信息、系统数据及软件系统等; b)应建立备份与恢复管理相关的安全管理制度,对备份信息的备份方式、备份频度、存储介质和保存期等进行规定; c)应根据数据的重要性和数据对系统运行的影响,制定数据的备份策略和恢复策略,备份策略须指明备份数据的放置场所、文件命名规则、介质替换频率和将数据离站运输的方法; d)应建立控制数据备份和恢复过程的程序,记录备份过程,对需要采取加密或数据隐藏处理的备份数据,进行备份和加密操作时要求两名工作人员在场,所有文件和记录应妥善保存; e)应定期执行恢复程序,检查和测试备份介质的有效性,确保可以在恢复程序规定的时间完成备份的恢复; f)应根据信息系统的备份技术要求,制定相应的灾难恢复计划,并对其进行测试以确保各个恢复规程的正确性和计划整体的有效性,测试容包括运行系统恢复、人员协调、备用系统性能测试、通信连接等,根据测试结果,对不适用的规定进行修改或更新。 二、实施建议 制定数据备份的规定,包括备份的策略、计划和容等信息,备份策略的制定要结合本身数据量多少、数据更新时间等要求进行制定,对备份的数据要进行定期的恢复性测试,保证该备份的可用性。数据的恢复管理不仅仅是灾难恢复的计划,应当针对不同的数据恢复要求和恢复的容制定多种适当的恢复策略,并定期对策略的有效性进行测试。
三、常见问题 多数公司没有对备份的数据进行恢复性测试。 四、实施难点 数据的恢复性测试需要建立测试的环境,投入较大;如果在原有系统上进行测试,应当不影响系统的正常运行,并确保原有系统能够快速的恢复。 五、测评方法 形式访谈,检查。对象系统运维负责人,系统管理员,数据库管理员,网络管理员,备份和恢复管理制度文档,备份和恢复策略文档,备份和恢复程序文档,备份过程记录文档,检查灾难恢复计划文档。 实施 a)应访谈系统管理员、数据库管理员和网络管理员,询问是否识别出需要定期备份的业务信息、系统数据及软件系统,主要有哪些;对其的备份工作是否以文档形式规了备份方式、频度、介质、保存期等容,数据备份和恢复策略是否文档化,备份和恢复过程是否文档化,对特殊备份数据(如数据)的操作是否要求人员数量,过程是否记录备案; b)应访谈系统管理员、数据库管理员和网络管理员,询问是否定期执行恢复程序,周期多长,系统是否按照恢复程序完成恢复,如有问题,是否针对问题进行恢复程序的改进或调整其他因素; c)应访谈系统运维负责人,询问是否根据信息系统的备份技术措施制定相应的灾难恢复计划,是否对灾难恢复计划进行测试并修改,是否对灾难恢复计划定期进行审查并更新,目前的灾难恢复计划文档为第几版; d)应检查备份和恢复管理制度文档,查看是否对备份方式、频度、介质、保存期等容进行规定; e)应检查数据备份和恢复策略文档,查看其容是否覆盖数据的存放场所、文
数据备份与恢复方案 2016年8月 目录 1概述 (1) 2备份需求 (1) 3策略 (1) 3.1备份环境 (1) 3.2备份节点 (1) 3.3备份方案概述 (1) 3.4数据恢复概述 (2) 4方案 (2) 5可能遇到情况及解决方法 (5)
1概述 随着公司信息化系统建设的不断推进,我们对信息系统的实时性要求也会越来越高,系统运行遇到故障时尽快恢复服务对公司的正常运营至关重要; 为最大限度保障云盘用户数据安全性,同时为了能在不可预计灾难情况下,保证云盘的安全快速恢复工作,所以需要对云盘进行数据备份与恢复工作。 方案主要内容:数据备份是指通过软件自动执行或手工操作将服务器重要文件及数据保存到磁盘柜和磁带等存储设备上。主要目的是减少及避免由于服务器软硬件故障造成的数据丢失,确保公司信息系统出现故障时在最短的时间内恢复运行并且重新提供服务。 云盘环境 采用双节点方式部署: 服务器:2台物理服务器均安装CentOS 7.0系统与云盘软件。 数据存储:2台服务器分别为:db_master与db_slave,各挂载3T的FC-SAN存储。 2备份需求 对2台云盘服务器数据进行备份,并验证恢复,保证数据安全性。 3策略 3.1备份环境 需要1台服务器安装CV备份服务器,分别为云盘服务器上安装CV控制台,因考虑备份服务器存放备份文件,故CV备份服务器挂载存储需要大于7T(云盘服务器存储为:800G磁盘+3T存储)。 3.2备份节点 2台生产环境云盘服务器都需要备份/data/data_all、/lefsdata、/usr/local/lefos,同时做好标记,区分开主服务器与副服务器的/data/data_all、/lefsdata、/usr/local/lefos。 3.3备份方案概述 将2台生产服务器安装CV客户端,从CV服务器中检测云盘服务器。检测到后,拷贝数据到CV服务器指定目录下。 3.4数据恢复概述 数据恢复时对应主、副服务器,从CV服务器上进行相关操作,将备份的主服务器与副服务器的/data/data_all、/lefsdata、/usr/local/lefos传输回备份服务器目录位置,检测拷贝后文件的所有者与所有组、权限是否正确,重启所有服务。
一次Linux下testdisk+gdisk恢复XFS文件系统及数据的经历 硬盘之前状况,用gdisk进行硬盘分区(SATA标准,3.6T容量),1.6T+2.0T两个分区,然后用mkfs.xfs格式化分区,最后结果就是,GPT分区表+两个XFS文件系统的硬盘(/dev/sdb,/dev/sdb1,/dev/sdb2) 我已无法确定引起这次硬盘错误的原因,但我确实这么做过: 原因一,从另一个硬盘的/home挂载点复制了大量数据到/dev/sdb1,然后我就将硬盘的数据线和电源线都拔掉了,这个动作在系统运行和关闭的两种情况下都做过,(SATA 硬盘是否安全的支持热插拔?) 原因二,在这次准备复制数据的之前,我没有将硬盘固定,也没有平放在台面(有一点斜度),然后开机,(胡乱的猜想着斜坡加载技术) 下面进入正题: 1,硬盘错误引起分区无法读取,挂载,开始纳闷哪里出了问题 2,运行gdisk -l /dev/sdb,显示如下
有警告信息及注意事项,虽然这里的标记GPT:damaged说明GPT有问题,但最后还是显示出了有分区的信息存在,(GPT分区表信息应该没有彻底损坏,不然怎么读取到两个分区的信息的呢),两个分区里Code标记都变成了0700(Microsoft basic data),正常的应该是8300(Linux filesystem),这个标记应该说明的是XFS文件系统的superblock信息毁了,这是后来经过XFS文件系统工具xfs_repair知道的 详细分区情况,但是是得出来的结果有问题的
gdisk检测到五个问题,(惊讶,这么多的问题) 3,进行到这里,我着急了,于是寻求帮助 首先,尝试了xfs_repair /dev/sdb,这个命令进行了几次,因为中途中断过,这个修复时间是比较长的,几小时(差不多3,4小时?)后得到的结果却是无法检测验证到有效的备份superblock信息,(失败,心都凉了) 然后,找到testdisk工具,大略的看了下说明就上手做(英文实在是差,仔细地看也不明白),第一次进行Analyse后,完全不知道做什么,就直接退出 然后就去测试查看,运行lsblk,gdisk,没有任何改变,(此刻是没抱什么希望的),输出的日志文件testdisk.log也完全看不懂,但我在日志文件里看到了有XFS这三个
1 理论知识 1.1 概念 1.1.1 全局统一命名空间的定义 全局统一命名空间将磁盘和内存资源集成一个单一的虚拟存储池,对上层用户屏蔽了底层的物理硬件。 1.1.2 GlusterFS的定义 GlusterFS是一套可扩展的开源群集文件系统,并能够轻松地为客户提供全局命名空间、分布式前端以及高达数百PB级别的扩展性。 1.1.3 元数据的定义 元数据,是用来描述一个给定的文件或是区块在分布式文件系统中所处的位置。注:元数据时网络附加存储解决方案在规模化方面的致命弱点,因其所有节点都必须不断与服务器(或集群组)保持联系以延续真个群集的元数据,故增加了额外的开销,致使硬件在等待响应元数据请求过程中而效率低下。 1.2 数据定位技术 Gluster通过其自有的弹性Hash算法可计算出文件在群集中每个节点的位置, 而无需联系群集内的其他节点,从而降低了追踪元数据的变化而带来额外的开销。 1.2.1 数据访问流程 - 根据输入的文件路径和文件名计算hash值 - 根据hash值在群集中选择子卷(存储服务器),进行文件定位 - 对所选择的子卷进行数据访问 1.2.2 Davies-Meyer算法 Gluster使用Davies-Meyer算法计算文件名的hash值,获得一个32位整数,算法特点如下: - 非常好的hash分布性
- 高效率的计算 1.3 Gluster的架构 1.3.1 存储服务器(Brick Server) - 存储服务器主要提供基本的数据存储功能 - 最终通过统一调度策略分布在不同的存储服务器上(通过Glusterfsd来处理数据服务请求) - 数据以原始格式直接存储于服务器本地文件系统(EXT3/EXT4/XFS/ZFS 等) 1.3.2 客户端和存储网关(NFS/Samba)
计算机化系统数据备份与恢复管理规范 数据备份与恢复管理规范 第一章总则 第一条为规范公司电子数据备份与恢复管理工作,合理存储历史数据及保证数据的安全性,保证信息的数据可靠性,保证业务系统数据的完整性和可用性,,保障公司正常的知识产权利益和技术资料的储备,对重要信息实施备份保护;防止因硬件故障、意外断电、病毒等因素造成数据的丢失,并在信息被损坏或丢失时能够及时恢复,使用备份数据恢复被损坏或丢失的业务数据,特制订本规范。 第二条本规范适用于公司电子信息系统的数据备份与管理,公司项目管理部承担了电子数据备份与恢复工作,因此,负责本规范的执行。 第三条定义 3.1 电子数据:也称数据电文,是指以电子、光学、磁或者类似手段生成、发送、接收或者储存的信息。 3.2 电子签名:是指电子数据中以电子形式所含、所附用于识别签名人身份并表明签名人认可其中内容的数据。 3.3 数据审计跟踪:是一系列有关计算机操作系统、应用程序及用户操作等事件的记录,用以帮助从原始数据追踪到有关的记录、报告或事件,或从记录、报告、事件追溯到原始数据。 3.4 数据可靠性:是指数据的准确性和可靠性,用于描述存储的所有数据值均处于客观真实的状态。 第二章第二章授权管理 第四条研究院分析所的电子数据一般来源于电子系统,数据采集、修改、备份、恢复和管理均由质量管理部授权的系统管理员(系统管理员担任)、分析所所长和检验员完成;为确保电子数据的真实、有效,针对不同的人员,授权操作,设置相应的访问权限。 第五条一级管理员(系统管理员担任):经质量管理部负责人授权的人员,具有系统的所有访问权限。有权建立二级管理员和三级管理员账户,如电脑系统时间、系统日志、操作员权限、增减登录帐户和初始登录帐户密码等,对所有使用的应用软件进行进行原名称安装、修复、备份和卸载,必须使用和验证应用软件为仪器供应商提供的正版软件,保留证书,重装和更换电脑、系统升级应进行风险评估,通过质量管理部门批准;对系统和应用软件采集的电子数据进行备份和恢复,对下级人员没有权限的内容设置成灰色不能使用,下级人员没有
在我上一篇文章中,我编了一份使用频率位居前50位的Unix命令清单。我提到的所有命令都适用于Unix最为流行的三个版本:Solaris、AIX和HP-UX操作系统。在本文中,我将引导您回顾Unix这些版本的发展史,讨论他们一些根本的区别,在文章最后部分还将以表格的形式对其常用命令进行对比。 Sun的Solaris操作系统 Solaris操作系统是Sun的Unix版本,它实际上是承袭于SunOS,而SunOS的历史则可追溯至1992年。起初SunOS是基于BSD Unix的,而SunOS的5.0及其之后的更高版本都是基于Unix SVR4的(更名为Solaris操作系统)。 其中究竟有什么奥妙?让我们进一步往前追溯。SunOS的1.0版本发布于1983年,支持Sun-1和Sun-2系统。1985年推出了2.0版本——让其声名卓著的是虚拟文件系统(VFS)和网络文件系统(NFS)。到了1987年,AT&T公司和Sun公司共同宣布,他们将基于SVR4合作开发一个旨在合并System V和BSD的项目,并对外发布。2.4版本的Solaris是Sun SparcX86操作系统的第一个版本。而SunOS的最后一次发布则是在1994年9月的4.1.4版本。Solaris 7则是第一个64位Ultra Sparc的版本,它能为Solaris的文件系统元数据记录提供本地支持。2002年推出的Solaris 9增添了对Solaris 卷标管理器和Linux的支持。2005年首次推出的Solaris 10有许多创新之处,其中包括了对其新ZFS文件系统、Solaris容器和逻辑域的支持。 目前Solaris的最高版本为10,其最新一次发布是在2008年10月。创新之一就是支持半虚拟化,在Solaris 10中基于Xen环境客户可以只用半虚拟化技术。 基本区别和特征 Solaris免费、开源,并通过OpenSolaris操作系统进行分布。Solaris基于Unix操作系统,相对于HP-UX或AIX而言,它的命令行更多。坦率地讲,相对于HP-UX中的系统管理器(SAM)或AIX中的系统管理界面工具(SMIT)Solaris都没有任何可比性。Solaris 操作系统能在Sparc和X86环境下运行。也配有最新的文件系统ZFS,近年来在这方面已取得了极大的进步,包括目前将其作为ROOT文件系统的能力。ZFS具有成为最佳全方位Unix文件系统的潜质。Solaris操作系统有许多方法来执行虚拟化,包括容器区、xVM服务器、逻辑域和硬件分区。 惠普的HP-UX HP-UX操作系统最初是在System V第三版的基础上研发出来的。它最初完全用于PA-RISC HP 9000平台。HP-UX的第一版发布于1984年。第九版采用了基于字符的图形用户界面(GUI)和SAM管理系统。发布于1995年的第十版改变了系统文件和目录结构的布局,而这一点与AT&T公司的SVR4极为相似。第十一版发布于1997年,同时也
系统备份及恢复 推荐的系统备份策略。系统需要备份的内容: ERDB ( 系统的控制组态内 容): c:\Program files\Honeywell\Experion PKS\Engineering Tools\System\Er Server 实时数据 库 (操作组态内容): C:\ Program files\Honeywell\ Experion PKS\Server\Data 操作流程图(包括子图): 用户自定 Station 设置文 件: C:\ Program files \Honeywell\ Experion PKS\Client\Station\*.stn \system\R**\*.stb QB 设置文件: 用户自定义目录 报表文件(自由格式报表或Excel报表) : 用户自定义目录 事件或历史数据文件及归档文件 (可选择备份或不 备): C: \Program files \honeywell\ Experion PKS\Server\Archive 用户自定义文件: 用户自定义目录 1系统备份介质建议: 移动硬盘 / 刻录光盘 / 磁带 / 远程网络计算机硬盘 1.1 ERDB备份(主Server:ServerB) Upload and Update Dbadmin – Backup Database 生成主*.bak 文件 Control Builder—File-Export生成project 备份文件. Snapshot/Checkpoint files — C:\Honeywell\Engineering Tools\System\ER\CPM***.snapshot 将以上生成的三类文件拷贝到备份目标盘er目录下 1.2 Server 数据库 (Server同步情况下, 只需备份一个 Server) C:\Program files\Honeywell\Experion PKS\Server\Data 目录到备份目标 盘。(不一定能直接copy, 与后台Service有关)。 bckbld –out filename –tag cda / backup function.(使用pntbld filename恢 复组态内容) 1.3 操作流程图(包括子图) 操作流程图(包括子图)备份到目标盘. 1.5 Station 设置文件(两台Server分别备份,并作标记) C:\Honeywell\Client\Station\*.stn 拷贝到备份目标盘station目录下 1.6QB 设置文件 (备份正式使用的那份文件) 用户自定义目录下*.qdb 文件拷贝到备份目标盘qckbld目录下 . 1.7 报表文件(自由格式报表或Excel报表) : C:\Honeywell\Server\Report 下自由格式报表或用户Excel 报表文件拷贝到备份目标盘Report目录下 1.8事件及历史数据文件和归档文件 (可选择备份或不备): C:\honeywell\Server\data ,Archive 和evtarchive目录拷贝到备份目标盘Archive目录下. 1.9 用户自定义文件备份到目标盘 2 使用备份恢复系统(适用于冗余Server) 2.1 ServerA 系统恢复(ServerB 工作正常情况下) ServerA 重新安装操作系统和PKS软 件 设置Servera与Serverb冗余 使ServerA 处于Backup 状态 在Station中(非ServerA station)作Server同步, 恢复Server实时数据库 在ServerB 中 Dbadmin--Recover Secondary Database ServerB中的流程图拷贝到ServerA响应目录下 备份盘中ServerA的Station目录下*.stn文件拷贝回ServerA 中: C:\Honeywell\Client\Station 目录覆盖同名文件. 备份盘中ServerA的qckbld目录中*.qdb文件恢复到ServerA相应目录中 报表文件文件恢复到ServerA相应目录中 历史数据文件从ServerB C:\honeywell\Server\Archive 目录拷贝到ServerA相应Archive目
目录 第1章数据备份与恢复 (2) 1.1 数据库备份方案背景 (2) 1.2 备份与恢复概述 (2) 1.3 数据库备份与恢复所要达到的目标 (2) 第2章数据备份方案 (3) 2.1 备份工具的选取 (3) 2.2 数据备份方案 (3) 2.3 备份实施需求 (3) 2.4 数据备份的几种方式 (4) 第3章数据恢复方案 (5) 3.1 数据恢复的几种方式 (5) 第4章相关参数以及备份恢复示例 (6) 4.1.1 相关参数 (6) 4.1.2 数据备份恢复示例 (7) 第1页
第1章数据备份与恢复 1.1 数据库备份方案背景 随着电子化进程的飞速发展和信息技术的广泛应用,数据越来越成为企业、事业单位日常运作中不可缺少的部分和领导决策的依据。但是,计算机的使用有时也会给人们带来烦恼,那就是计算机数据非常容易丢失和遭到破坏。有专业机构的研究数据表明:丢失300MB的数据对于市场营销部门就意味着13万元人民币的损失,对财务部门意味着16万的损失,对工程部门来说损失可达80万。而丢失的关键数据如果15天内仍得不到恢复,企业就有可能被淘汰出局。随着计算机系统越来越成为企业不可或缺的数据载体,如何利用数据备份来保证数据安全也成为我们迫切需要研究的一个课题。 1.2 备份与恢复概述 备份与恢复是我们使用数据库中不可缺少的部分,也是我们在使用数据库时会经常碰到的问题,当我们使用一个数据库时,总希望数据库的内容是可靠的、正确的,但由于计算机系统的故障(硬件故障、软件故障、网络故障、进程故障和系统故障)影响数据库系统的操作,影响数据库中数据的正确性,甚至破坏数据库,使数据库中全部或部分数据丢失。因此当发生上述故障后,希望能重新建立一个完整的数据库,该处理称为数据库恢复。 1.3 数据库备份与恢复所要达到的目标 备份仅仅是数据保护的手段,“备份数据必须能够迅速、正确的进行恢复”才是真正的目地,换句话说,企业规划备份架构时应该以恢复为最终目的进行构架,当意外发生时、当用户端提出恢复需求时,备份数据要能快速、可靠的恢复,如此的备份才是值得信赖的备份,才有其存储的意义。
了解Linux默认文件系统的发展历史 目前的大部分Linux 文件系统都默认采用ext4 文件系统,正如以前的Linux 发行版默认使用ext3、ext2 以及更久前的ext。 对于不熟悉Linux 或文件系统的朋友而言,你可能不清楚ext4 相对于上一版本ext3 带来了什么变化。你可能还想知道在一连串关于替代的文件系统例如Btrfs、XFS 和ZFS 不断被发布的情况下,ext4 是否仍然能得到进一步的发展。 在一篇文章中,我们不可能讲述文件系统的所有方面,但我们尝试让你尽快了解Linux 默认文件系统的发展历史,包括它的诞生以及未来发展。 我仔细研究了维基百科里的各种关于ext 文件系统文章、kernel 的wiki 中关于ext4 的条目以及结合自己的经验写下这篇文章。 ext 简史 MINIX 文件系统 在有ext 之前,使用的是MINIX 文件系统。如果你不熟悉Linux 历史,那么可以理解为MINIX 是用于IBM PC/AT 微型计算机的一个非常小的类Unix 系统。Andrew Tannenbaum 为了教学的目的而开发了它,并于1987 年发布了源代码(以印刷版的格式!)。 IBM 1980 中期的PC/AT,MBlairMartin,CC BY-SA 4.0 虽然你可以细读MINIX 的源代码,但实际上它并不是自由开源软件(FOSS)。出版Tannebaum 著作的出版商要求你花69 美元的许可费来运行MINIX,而这笔费用包含在书籍的费用中。尽管如此,在那时来说非常便宜,并且MINIX 的使用得到迅速发展,很快超过了Tannebaum 当初使用它来教授操作系统编码的意图。在整个20 世纪90 年代,你可以发现MINIX 的安装在世界各个大学里面非常流行。而此时,年轻的Linus Torvalds 使用MINIX 来开发原始Linux 内核,并于1991 年首次公布,而后在1992 年12 月在GPL 开源协议下发布。
F A N U C系统数据备份 与恢复
一、FANUC系统数据备份与恢复 (一)概述 FANUC数控系统中加工程序、参数、螺距误差补偿、宏程序、PMC程序、PMC数据,在机床不使用是是依靠控制单元上的电池进行保存的。如果发生电池时效或其他以外,会导致这些数据的丢失。因此,有必要做好重要数据的备份工作,一旦发生数据丢失,可以通过恢复这些数据的办法,保证机床的正常运行。 FANUC数控系统数据备份的方法有两种常见的方法: 1、使用存储卡,在引导系统画面进行数据备份和恢复; 2、通过RS232口使用PC进行数据备份和恢复。 (二)使用存储卡进行数据备份和恢复 数控系统的启动和计算机的启动一样,会有一个引导过程。在通常情况下,使用者是不会看到这个引导系统。但是使用存储卡进行备份时,必须要在引导系统画面进行操作。在使用这个方法进行数据备份时,首先必须要准备一张符合FANUC系统要求的存储卡(工作电压为5V)。具体操作步骤如下: 1、数据备份: (1)、将存储卡插入存储卡接口上(NC单元上,或者是显示器旁边); (2)、进入引导系统画面;(按下显示器下端最右面两个键,给系统上电); (3)、调出系统引导画面;下面所示为系统引导画面: (4)、在系统引导画面选择所要的操作项第4项,进入系统数据备份画面;(用UP或DOWN键)
(5)、在系统数据备份画面有很多项,选择所要备份的数据项,按下YES键,数据就会备份到存储卡中; (6)、按下SELECT键,退出备份过程; 2、数据恢复: (1)、如果要进行数据的恢复,按照相同的步骤进入到系统引导画面; (2)、在系统引导画面选择第一项SYSTEM DATA LOADING; (3)、选择存储卡上所要恢复的文件; (4)、按下YES键,所选择的数据回到系统中; (5)、按下SELECT键退出恢复过程; (三)使用外接PC进行数据的备份与恢复 使用外接PC进行数据备份与恢复,是一种非常普遍的做法。这种方法比前面一种方法用的更多,在操作上也更为方便。操作步骤如下: 1、数据备份: (1)、准备外接PC和RS232传输电缆; (2)、连接PC与数控系统; (3)、在数控系统中,按下SYSTEM功能键,进入ALLIO菜单,设定传输参数(和外部PC匹配); (4)、在外部PC设置传输参数(和系统传输参数相匹配); (5)、在PC机上打开传输软件,选定存储路径和文件名,进入接收数据状态; (6)、在数控系统中,进入到ALLIO画面,选择所要备份的文件(有程序、参数、间距、伺服参数、主轴参数等等可供选择)。按下“操作”菜单,进入到操作画面,再按下“PUNCH”软键,数据传输到计算机中; 2、数据恢复: (1)、外数据恢复与数据备份的操作前面四个步骤是一样的操作;
XFS文件系统的描述数据观察 EXT家族的dumpe2fs去观,而XFS家族用xfs_info去观察 [root@study ~]# xfs_info挂载点|装置文件名 [root@study ~]# df - - T /boot FilesystemType1K-blocksUsedAvailableUse%Mounted on /dev/vda2xfs1038336 133704 904632 13% /boot # 没错!可以看得出来是 xfs 文件系统的!来观察一下内容吧! [root@study ~]# xfs_info /dev/vda2 1 meta-data=/dev/vda 2 isize=256 agcount=4, agsize=65536 blks 2 = sectsz=512 attr=2, projid32bit=1 3 = crc=0 finobt=0 4 data = bsize=4096blocks=262144, imaxpct=25 5 = sunit=0swidth=0blks 6 naming =version 2 bsize=4096 ascii-ci=0 ftype=0 7 log =internal bsize=4096 blocks=2560, version=2 8 = sectsz=512 sunit=0 blks, lazy-count=1 9 realtime =none extsz=4096blocks=0, rtextents=0 ?第1 行里面的isize指的是inode的容量,每个有256bytes 这么大。至于agcount则是前面谈到的储存区群组(allocation group) 的个数,共有4 个,agsize则是指每个储存区群组具有65536 个block 。配合第4 行的block 设定为4K,因此整个档案系统的容量应该就是4*65536*4K 这么大! ?第2 行里面sectsz指的是逻辑磁区(sector) 的容量设定为512bytes 这么大的意思。 ?第4 行里面的bsize指的是block 的容量,每个block 为4K 的意思,共有262144 个block 在这个档案系统内。 ?第5 行里面的sunit与swidth与磁碟阵列的stripe 相关性较高。这部份我们底下格式化的时候会举一个例子来说明。 ?第7 行里面的internal 指的是这个登录区的位置在档案系统内,而不是外部设备的意思。且占用了4K * 2560 个block,总共约10M 的容量。 ?第9 行里面的realtime区域,里面的extent 容量为4K。不过目前没有使用。 磁盘与目录的容量 df:列出文件系统的整体磁盘使用量; [root@study ~]#df [- - ahikHTm] [ 目录或文件名] ] 选项与参数: -a :列出所有的文件系统,包括系统特有的/proc等文件系统; -k:以 KBytes 的容量显示各文件系统; -m:以 MBytes 的容量显示各文件系统; -h:以人们较易阅读的 GBytes, MBytes, KBytes 等格式自行显示; -H:以 M=1000K 取代 M=1024K 的进位方式; -T:连同该 partition的filesystem名称 (例如xfs) 也列出; -i:不用磁盘容量,而以inode的数量来显示