data services应用记录
- 格式:docx
- 大小:1.50 MB
- 文档页数:27

iis 日志记录webservice的方法(原创实用版4篇)《iis 日志记录webservice的方法》篇1在IIS 中记录WebService 的日志,可以通过以下步骤实现:1. 打开IIS 管理器,找到要记录日志的WebService。
2. 在WebService 的属性窗口中,选择“日志记录”选项卡。
3. 在“日志记录”选项卡中,选择“记录所有请求”或“记录选定请求”选项。
这将决定是否记录WebService 的所有请求或仅记录特定的请求。
4. 在“日志格式”下拉菜单中,选择所需的日志格式。
常见的日志格式包括“XML”和“文本”。
5. 在“记录目标”下拉菜单中,选择要将日志记录到的目标。
可以选择本地计算机、共享目录或其他计算机。
6. 单击“应用”按钮以保存更改并关闭属性窗口。
完成以上步骤后,IIS 将开始记录WebService 的请求和响应,并将其存储在指定的日志文件中。
《iis 日志记录webservice的方法》篇2在IIS 中记录WebService 的日志,可以通过以下步骤实现:1. 打开IIS 管理器,找到要记录日志的WebService。
2. 在WebService 的属性窗口中,选择“日志记录”选项卡。
3. 在“日志记录”选项卡中,选择“记录所有请求”或“记录选定请求”选项。
这将决定是否记录WebService 的所有请求或仅记录特定的请求。
4. 在“日志记录”选项卡中,选择要记录的日志级别。
例如,选择“详细”级别以记录所有请求的详细信息。
5. 在“日志记录”选项卡中,选择要记录的日志文件。
例如,选择“Application log”以将日志记录到应用程序日志文件中。
6. 保存更改并关闭属性窗口。
《iis 日志记录webservice的方法》篇3在IIS 中记录WebService 的日志,可以通过以下步骤实现:1. 打开IIS 管理器,找到要记录日志的WebService。

服务器日志文件管理如何查看服务器运行记录服务器日志文件是记录服务器运行状态和活动的重要文件,通过查看服务器日志文件可以了解服务器的运行情况、故障排查、性能优化等。
在服务器管理中,查看服务器日志文件是一项必不可少的工作。
本文将介绍如何管理服务器日志文件以及如何查看服务器的运行记录。
一、服务器日志文件管理1. 日志文件的作用服务器日志文件是记录服务器活动的文件,包括系统日志、应用程序日志、安全日志等。
通过分析日志文件可以及时发现问题、排查故障、优化性能,保证服务器的正常运行。
2. 日志文件的种类常见的服务器日志文件包括系统日志、应用程序日志、访问日志、安全日志等。
不同类型的日志文件记录了不同方面的信息,管理员需要根据需要查看相应的日志文件。
3. 日志文件的存储位置在Linux系统中,日志文件通常存储在/var/log目录下,不同的日志文件有不同的存储路径。
管理员可以通过查看配置文件或者查看系统日志配置来了解日志文件的存储位置。
4. 日志文件的轮转为了避免日志文件过大占用过多磁盘空间,通常会对日志文件进行轮转。
日志文件轮转可以按照时间、大小等条件进行,管理员可以根据需要配置日志文件的轮转规则。
5. 日志文件的清理定期清理日志文件是服务器管理的重要工作之一。
过多的日志文件不仅会占用磁盘空间,还会影响服务器性能。
管理员可以编写脚本定期清理过期的日志文件,保持服务器的良好状态。
二、查看服务器运行记录1. 查看系统日志系统日志是记录系统运行状态和事件的重要日志文件,可以通过查看系统日志了解服务器的运行情况。
在Linux系统中,可以使用命令如cat、tail、grep等来查看系统日志文件,如/var/log/messages、/var/log/syslog等。
2. 查看应用程序日志除了系统日志,应用程序日志也是了解服务器运行情况的重要依据。
不同的应用程序会生成不同的日志文件,管理员可以查看相应的应用程序日志来了解应用程序的运行状态。
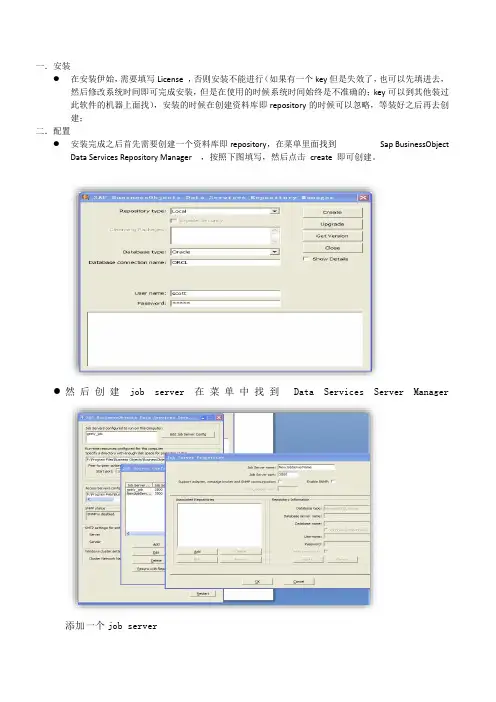
一.安装●在安装伊始,需要填写License ,否则安装不能进行(如果有一个key但是失效了,也可以先填进去,然后修改系统时间即可完成安装,但是在使用的时候系统时间始终是不准确的;key可以到其他装过此软件的机器上面找),安装的时候在创建资料库即repository的时候可以忽略,等装好之后再去创建;二.配置●安装完成之后首先需要创建一个资料库即repository,在菜单里面找到Sap BusinessObjectData Services Repository Manager ,按照下图填写,然后点击create 即可创建。
●然后创建job server 在菜单中找到Data Services Server Manager添加一个job server●之后就可以打开Data Services Designer进行设计开发了。
在designer里开发的job 保存在了第一步创建的资料库(Repository)里。
●在开始菜单中找到Date Services Management Console用户名密码默认为 admin●进入之后选择“Administrator”进行配置和管理在Management 里找到Repositories ,添加一个资料库(配置信息是第一步创建的资料库),配置完毕后就会出现资料库信息,已经创建的job 列表。
然后在Batch里找到相应的job进行配置或调试或监控。
以下图例总结了dataservices各组件之间的关系●在抽取数据的时候的步骤如下:1.上图中首先创建一个projects2.再创建一个job3.在datastores里创建数据库链接,然后把job中所用到的tables 以及functions导入进来4.在job里创建工作流、数据流等。
●在从一个表抽出数据到另一张表时,如果需要做一些数据转换,那么如图:首先选中需要改变的字段,在下面的mapping 中写下转换条件即可。

DataServices培训总结-操作手册目录一、DS简介 (2)二、DS数据加载方式 (2)三、DS进行数据抽取模型开发的基本过程 (3)四、DS创建数据源系统和目标系统的数据存储 (3)1、Oracle数据库作为数据源系统 (3)2、ECC作为数据源系统 (4)3、HANA数据库作为目标系统 (5)五、全量加载过程 (5)1、创建Project和Job (5)2、导入源表的元数据到资源库 (6)3、创建Data Flow (6)4、设置源表和目标表 (7)5、手工执行Job (7)六、基于表比较的增量加载 (8)1、在Job下定义工作流 (8)2、在工作流中定义数据流 (8)3、加入Table_Comparison控件 (9)4、设置Table_Comparison控件 (9)七、基于时间戳的增量加载 (10)1、在Job下定义工作流 (10)2、定义Script控件 (10)3、定义处理新增数据的数据流和处理更新数据的数据流 (11)八、DS中常用控件介绍 (13)1、Key_Generation (13)2、Case (13)3、Merge (14)4、Validation (15)5、设置过滤器和断点 (15)九、定义Job定期执行 (16)1、登录Data Services Management Console (16)2、定义Batch Job Schedules (17)十、其他注意事项 (18)一、DS简介SAP BusinessObjects Data Services是通过SAP HANA认证的ETL工具。
采用数据批量处理的方式,定期执行后台作业,将数据从多个业务系统中抽取出来,并进行必要的处理(转换,合并,过滤,清洗),然后再加载到HANA数据库中。
DS的组件之间的关系:◆Management Consol:管理控制台是网页版DS管理工具,可以进行一些系统配置和定义Job执行◆Designer:Designer是一个具有易于使用的图形用户界面的开发工具。

DataServices培训总结-操作手册目录一、DS简介 (3)二、DS数据加载方式 (4)三、DS进行数据抽取模型开发的基本过程 (5)四、DS创建数据源系统和目标系统的数据存储 (6)1、Oracle数据库作为数据源系统 (6)2、ECC作为数据源系统 (6)3、HANA数据库作为目标系统 (7)五、全量加载过程 (8)1、创建Project和Job (8)2、导入源表的元数据到资源库 (8)3、创建Data Flow (8)4、设置源表和目标表 (9)5、手工执行Job (10)六、基于表比较的增量加载 (11)1、在Job下定义工作流 (11)页脚内容12、在工作流中定义数据流 (11)3、加入Table_Comparison控件 (12)4、设置Table_Comparison控件 (13)七、基于时间戳的增量加载 (13)1、在Job下定义工作流 (13)2、定义Script控件 (14)3、定义处理新增数据的数据流和处理更新数据的数据流 (15)八、DS中常用控件介绍 (16)1、Key_Generation (16)2、Case (17)3、Merge (18)4、Validation (19)5、设置过滤器和断点 (20)九、定义Job定期执行 (21)1、登录Data Services Management Console (21)2、定义Batch Job Schedules (22)十、其他注意事项 (24)页脚内容2一、DS简介SAP BusinessObjects Data Services是通过SAP HANA认证的ETL工具。
采用数据批量处理的方式,定期执行后台作业,将数据从多个业务系统中抽取出来,并进行必要的处理(转换,合并,过滤,清洗),然后再加载到HANA数据库中。
DS的组件之间的关系:Management Consol:管理控制台是网页版DS管理工具,可以进行一些系统配置和定义Job执行页脚内容3Designer:Designer是一个具有易于使用的图形用户界面的开发工具。

Data Services 入门指南第一章 Data Services产品套件概述第一节 Data Services 和 Business Objects 产品套件Business Objects产品套件通过专业的终端用户工具在一个单独的,可信的商务智能平台上提供了非常深刻的研究和探讨。
整个平台由Data Services支持。
在Data Services的顶层,Business Objects设计了最可靠的,扩展的和可管理的BI平台,该平台支持业界集成度最好的报表,查询和分析,绩效管理仪表盘,记分板和应用程序。
真正的数据集成组合了批量抽取,转换及加载(ETL)技术和跨越多个扩展的企业应用之间的实时双向的数据流。
通过创建一个关系数据仓库并智能地组合使用对来自企业ERP系统和其他数据源的数据的直接实时访问和批量数据访问方法,BusinessObjects开发了一个功能强大的,高性能数据集成的产品,它允许充分平衡你的ERP和企业应用的基础设施以满足多种业务使用。
Business Objects提供了一个批量和实时数据集成系统来驱动目前新一代的分析和供应链管理应用。
使用Business Objects高可扩展性的数据集成解决方案,企业可以维护与客户,供应商,员工和合作方的一个实时的在线的对话,给他们提供交易和业务分析需要的关键信息。
第二节 Data Services产品优点使用Data Services来开发批量和实时使用的企业数据集成。
通过Data Services:可以创建一个单独的用于批量和实时数据移动的基础架构从而获得一个更快的更低成本的实现。
企业可以在独立于任何单独的系统的前提下将数据作为企业资产来管理。
集成多个系统的数据并将这些数据重新用于许多其他目的。
可以选择使用预打包的数据解决方案已获得快速的部署和快的投资回报。
这些解决从业务操作系统抽取历史的和日常的数据并在一个开放的关系数据库中缓存这些数据。

clientdetailsservice使用场景ClientDetailsService 是 Spring Security 提供的接口,用于加载和验证客户端的信息。
它主要用于在客户端请求访问受保护的资源时,验证客户端的身份和权限。
ClientDetailsService 的使用场景包括:1. 授权服务器:在 OAuth2 的授权服务器中,需要使用ClientDetailsService 来加载和验证客户端的信息。
授权服务器使用 ClientDetailsService 来验证客户端的身份和权限,判断客户端是否有权限访问受保护的资源。
2. 客户端管理系统:在客户端管理系统中,可以使用ClientDetailsService 加载和管理客户端的信息。
通过ClientDetailsService,可以对客户端的信息进行增删改查操作,包括添加新的客户端、更新客户端信息、删除客户端等。
3. 受保护资源服务:在受保护资源服务中,可以使用ClientDetailsService 来验证客户端的信息。
受保护资源服务可以通过 ClientDetailsService 来判断请求是否来自合法的客户端,以确保只有授权过的客户端能够访问受保护的资源。
4. 自定义授权逻辑:在一些特殊的情况下,可能需要根据自己的业务逻辑来进行客户端的验证和授权。
可以实现自定义的ClientDetailsService,来实现自定义的客户端验证逻辑。
总之,ClientDetailsService 是一个用于加载和验证客户端信息的接口,在 OAuth2 授权过程的授权服务器和资源服务中,以及客户端管理系统中都可以使用它来管理和验证客户端的身份和权限。

userdetailservice和clientdetailservice摘要:一、概述userdetailservice和clientdetailservice二、userdetailservice功能与实现1.获取用户详细信息2.用户身份验证3.用户权限管理三、clientdetailservice功能与实现1.客户端信息管理2.客户端权限控制3.客户端安全策略四、应用场景与实际案例五、总结与展望正文:一、概述userdetailservice和clientdetailservice在当今互联网应用中,userdetailservice和clientdetailservice变得越来越重要。
它们分别是用户详情服务和客户端详情服务,主要负责处理用户和客户端的相关信息和权限管理。
本文将详细介绍这两种服务的内容、功能及实现方式。
二、userdetailservice功能与实现1.获取用户详细信息UserDetailsService接口的核心方法是loadUserByUsername,该方法负责根据用户名获取用户的详细信息。
在实际应用中,这一功能通常通过调用数据库或其他数据存储方式来实现。
loadUserByUsername方法的实现需要保证安全性,确保只有合法用户能够获取到其他用户的详细信息。
2.用户身份验证UserDetailsService还负责用户身份验证。
在用户登录时,它会将输入的用户名和密码与数据库中存储的信息进行比对,验证用户身份。
如果验证成功,UserDetailsService会返回用户的详细信息;如果验证失败,它会返回null。
3.用户权限管理UserDetailsService还负责管理用户的权限。
通过分析用户角色、角色对应的权限等信息,为用户分配相应的权限。
这一功能在实际应用中通常通过角色-权限映射来实现。
三、clientdetailservice功能与实现1.客户端信息管理ClientDetailsService接口的核心方法是loadClientByClientId,该方法负责根据客户端ID获取客户端的详细信息。

DataServices培训总结-操作手册目录一、DS简介 (2)二、DS数据加载方式 (2)三、DS进行数据抽取模型开发的基本过程 (3)四、DS创建数据源系统和目标系统的数据存储 (3)1、Oracle数据库作为数据源系统 (3)2、ECC作为数据源系统 (4)3、HANA数据库作为目标系统 (5)五、全量加载过程 (5)1、创建Project和Job (5)2、导入源表的元数据到资源库 (6)3、创建Data Flow (6)4、设置源表和目标表 (7)5、手工执行Job (7)六、基于表比较的增量加载 (8)1、在Job下定义工作流 (8)2、在工作流中定义数据流 (8)3、加入Table_Comparison控件 (9)4、设置Table_Comparison控件 (9)七、基于时间戳的增量加载 (10)1、在Job下定义工作流 (10)2、定义Script控件 (10)3、定义处理新增数据的数据流和处理更新数据的数据流 (11)八、DS中常用控件介绍 (13)1、Key_Generation (13)2、Case (13)3、Merge (14)4、Validation (15)5、设置过滤器和断点 (15)九、定义Job定期执行 (16)1、登录Data Services Management Console (16)2、定义Batch Job Schedules (17)十、其他注意事项 (18)一、DS简介SAP BusinessObjects Data Services是通过SAP HANA认证的ETL工具。
采用数据批量处理的方式,定期执行后台作业,将数据从多个业务系统中抽取出来,并进行必要的处理(转换,合并,过滤,清洗),然后再加载到HANA数据库中。
DS的组件之间的关系:◆Management Consol:管理控制台是网页版DS管理工具,可以进行一些系统配置和定义Job执行◆Designer:Designer是一个具有易于使用的图形用户界面的开发工具。

DataWare 双机容错软件维护手册1.DataWare 双机容错的基本架构双机容错的目的在于确保数据数据的安全性以及系统永不停机(Non-stop),采用豪威所自行研发的DataWare 软件能够轻易的达成系统永不停机的状况,若能够搭配本公司的智能型磁盘阵列系统,更能够有效的将数据数据的安全性提升至最高。
一般来说,DataWare 双机容错软件的机本架构共分成两种模式:1.双机互备援(Dual Active)、2.双机热备份(Hot Standby)。
1.1双机互备援(Dual Active)基本简介所谓双机互备援意指两台服务器均为工作服务器,在正常情况下,两台工作服务器均为信息系统提供支持,并相互监视对方的运作状况。
当一台服务器出现异常造成不能支持信息系统正常运作时,另一服务器则会主动接管(Take Over)异常服务器的工作,继续支持信息的运作,从而确保信息系统能够不间断地运行,而达到不停机的功能(Non-Stop),但正常运行服务器的负载(Loading)会有所增加。
此时必须尽快将异常机修复以缩短正常机负载持续时间,当异常服务器经过维修恢复正常后,系统管理员通过管理命令,可以将正常服务器所接管的工作切换回已被修复的异常服务器1.2双机互备援(Dual Active)切换时机-系统软件或应用软件造成服务器当机。
-服务器未当机,但系统软件或应用软件工作不正常。
-服务器内SCSI 卡损坏,造成服务器与磁盘阵列无法存取数据。
-服务器内硬件损坏,造成服务器当机。
-服务器不正常关机。
1.3双机热备份(Hot Standby)基本简介所谓双机热备份就是一台服务器为工作服务器(Primary Server),另一台服务器为备援服务器(Standby Server),在系统正常情况下,工作服务器为信息系统提供支持,备援服务器监视工作服务器的运行情况(工作服务器也同时监视备援服务器是否正常,有时备援服务器因某种原因出现异常,工作服务器可尽早通知系统管理工作人员解决,确保下一次切换的可靠性)。

概念:主数据服务MDS把主数据组织成模型。
每个模型只包含一个数据域,即:以有意义的方式组织数据,如产品或客户信息。
在每一个模型中,可以配置一组与MDS数据库中对象相对应的对象:•实体:与数据库表对应的一组相关数据。
•属性:与表列对应的一个实体属性。
•基于域的属性:链接到另一个实体属性(通常对应列的外键)的属性。
•属性组:属性的集合,用于在MDS接口中将数据分组。
•成员:与数据库表中某行对应的一个实体记录。
叶和合并成员支持显式的层次结构。
叶成员在层次结构中处于最低水平。
一个合并成员既可以是叶成员的父亲也可以是其他的合并成员。
集合成员是集合的一部分。
•属性值:一个成员的具体数据值(对应于数据库表中的某一行的值)。
•层次:分层组织的成员。
派生层次是基于域属性的关系。
明确的层次结构根据用户的要求将数据分组。
•集合:一个用户定义的成员子集。
•业务规则:以SQL表达式形式存储的作用于导入数据的业务逻辑,。
•订购视图:显示访问主数据的系统信息。
把MDS当作前端应用程序,让您存储和管理SQL Server数据库中的数据。
应用程序自动管理表结构、关系、约束、权限和其他数据库组件,让您专注于数据本身。
入门篇:配置MDSMaster Data Services,也称为MDS,是SQL Server 2008 R2 增加的关键商业智能(BI)特性之一。
Master Data Services 的基本目标是为企业信息提供单个权威来源。
然后这个信息可以被其它应用和数据使用,这样您的环境中每一个应用便都是使用相同信息的同一份权威副本。
需要先安装Master Data Services 才能使用它。
安装要求使用64 位服务器,因为MDS 安装程序只支持64 位。
您还需要Windows PowerShell 1.0 或以上版本。
要启动安装过程,您需要打开SQL Server 2008 R2 DVD,然后进入MasterDataServices\x64\1033_ENU 文件夹。
为什么微软要推 Data Services微软在 .NET 3.5 SP1 平台上,推了一组新的数据访问 Framework,叫做 Data Services。
微软怕程序员太闲吗?为什么要创造 Data Services?Web Service 和 WCF 不就很好用了吗?本帖整理一些研讨会及网络上大内高手的观点,并提供一个可在 VS 2008 SP1 上执行的示例给大家下载参考;但本帖不提供 step by step 实作教学,因为网络上已经有一堆这种文章了 (参考本帖最下面的「参考文件」第 6、第 7 点的文章,照着用 VS 2008 + SP1 操作,即可达成本帖提供下载的示例)。
.NET 的 WCF 3.5,有一个很重要的新功能,是对 REST (Representational State Transfer) 的支持。
听说一些知名大型网站,及 RoR 阵营,都开始逐渐抛弃 Web Service,改提供 REST 的服务。
所以微软这边也不能闲着,也搞了一套 Data Services 来支持 REST 的概念。
所谓的 REST,如同字面上的意思,是要让开发人员和应用程序 (当然也包括异质平台的应用程序),能以简单到不能再简单的方式,去访问和撷取网络上的数据和资源。
怎么个简单法?REST 用最单纯的 URL 网址,就让一般客户、应用程序能直接访问、写入远程主机上的数据库。
此外,微软实作 REST 的 Data Services,亦有一套安全控管、存取权限控管的机制,不必担心安全性的问题。
相对于微软的 WCF Service 要做一些设定,以及过去大家常用的 Web Service,此二者和 REST、 Data Services 比较起来,相对就显得较复杂、不够弹性,且 Web Service 还有最为人垢病的 performance 问题。
过去如果你是一间公司的 MIS,当 A 部门的员工需要某些数据,你可能会随手写一支 Web Service 开放这些数据给别人使用;过不久 B 部门的主管又需要别的数据,你可能就再写另一支 Web Service,开放另一台主机数据库中的数据给别人使用。
dts 同步原理
DTS同步原理
DTS(Data Transformation Services)是一种数据同步技术,用于将数据从一个系统复制到另一个系统。
它基于日志文件的读取和解析,实现了高效准确的数据同步。
本文将以人类的视角,用简洁明了的语言描述DTS同步原理。
DTS同步的核心是日志文件的读取和解析。
每个系统都会生成日志文件,记录了系统的操作和变化。
DTS通过读取源系统的日志文件,并解析其中的操作记录,来获取源系统的数据变化。
DTS将解析到的数据变化应用到目标系统中。
它根据解析到的操作记录,比对源系统和目标系统的数据差异,然后在目标系统中执行相应的操作,如插入、更新或删除数据,以实现数据的同步。
DTS还具备增量同步的能力。
它会周期性地读取源系统的日志文件,并将解析到的新的操作记录应用到目标系统中。
这样,只有最新的数据变化才会被同步,大大提高了同步效率。
DTS还支持数据过滤和转换。
它可以根据用户的需求,选择性地同步特定的数据,或对数据进行转换和格式化,以适应目标系统的要求。
总结起来,DTS同步原理是通过读取和解析日志文件,获取数据变
化,并将其应用到目标系统中,以实现数据的准确高效同步。
它具备增量同步和数据转换的功能,可以满足不同系统间数据同步的需求。
希望本文能够以清晰明了的语言,让读者更好地理解DTS同步原理。
我们尽力保证文章的流畅度和自然度,避免让读者感觉像是机器生成的,而是真人叙述的故事。
终端服务的日志监控和登录日志记录的方式1.系统日志监控:终端服务一般会生成大量的系统日志,包括启动/关闭日志、错误日志、警告日志、信息日志等。
管理员可以通过监控这些系统日志来了解系统的运行状况和异常情况。
可以使用日志管理工具来收集和分析这些日志,比如将日志导入到ELK(Elasticsearch + Logstash + Kibana)等集中式日志管理系统中,进行实时监控和分析。
2.安全日志监控:终端服务的安全日志主要包括登录日志、访问控制日志、权限变更日志等。
管理员可以根据这些安全日志来监控用户的登录行为、权限变更情况等,以及检测潜在的安全威胁。
可以使用日志审计工具来实时监控和分析这些安全日志,比如使用OSSEC(开源入侵检测系统)等。
3.命令行日志监控:终端服务的命令行日志包括用户执行的系统命令、应用程序命令等。
通过监控这些命令行日志,管理员可以了解用户的操作行为,并及时发现异常操作或错误操作。
可以通过开启终端服务的命令行日志功能,并使用命令行监控工具来实时监控和记录这些命令行日志,比如使用Auditd。
终端服务的登录日志记录主要是为了追踪用户的登录行为,包括登录时间、登录账号、登录IP等信息。
通过登录日志的记录,管理员可以了解用户的登录情况,及时发现异常登录行为,比如登录次数异常、登录IP异常等。
可以通过以下几种方式实现登录日志的记录:1.系统日志记录:终端服务一般会将登录相关的信息写入系统日志,比如通过syslogd或rsyslogd将登录信息写入/var/log/auth.log等文件。
管理员可以定期检查这些系统日志来了解用户的登录行为。
2.安全日志记录:安全日志一般会包含用户登录的信息,可以通过安全日志审计工具来记录和分析用户的登录行为。
可以配置终端服务的安全日志审计规则,比如使用OSSEC进行实时监控和记录用户的登录行为。
3.登录日志管理工具:可以使用专门的登录日志管理工具来记录和管理终端服务的登录日志,这些工具可以提供更多的功能,比如、过滤、报警等。
abap cds 加法ABAP(Advanced Business Application Programming)是SAP系统的开发语言,广泛应用于SAP系统的开发。
CDS(Central Data Services)是SAP中用于存储和管理数据的数据库。
在ABAP中,我们可以使用CDS进行数据存储、查询和更新等操作。
下面是一个简单的示例,展示如何在ABAP中使用CDS进行加法操作。
首先,我们需要创建一个数据对象来存储加法的结果。
在ABAP中,可以使用以下语句创建一个数据对象:DATA: result TYPE i.在这个例子中,我们创建了一个整数类型的数据对象“result”,用于存储加法的结果。
接下来,我们可以使用以下语句从CDS中读取数据:SELECT sum( table1~amount ) INTO result FROM table1.在这个例子中,我们从名为“table1”的表中读取了所有记录的“amount”字段的总和,并将结果存储到“result”变量中。
最后,我们可以使用以下语句将结果输出到屏幕上:WRITE: / 'Total amount:', result.在这个例子中,我们将结果输出到屏幕上。
完整的ABAP代码如下所示:REPORT my_report.DATA: result TYPE i.SELECT sum( table1~amount ) INTO result FROM table1. WRITE: / 'Total amount:', result.在这个例子中,我们创建了一个名为“my_report”的报表,从名为“table1”的表中读取了所有记录的“amount”字段的总和,并将结果输出到屏幕上。
这是一个非常简单的示例,展示了如何在ABAP中使用CDS进行加法操作。
在实际应用中,我们可以根据需要使用更复杂的查询和操作,例如连接多个表、筛选数据、排序等。
DataServices®训总结-操作手册目录一、DS简介 (2)二、DS数据加载方式 (2)三、DS进行数据抽取模型开发的基本过程 (3)四、DS创建数据源系统和目标系统的数据存储 (3)1、Oracle数据库作为数据源系统 (3)2、ECC作为数据源系统 (4)3、HANA数据库作为目标系统 (5)五、全量加载过程 (5)1、创建Project 和Job (5)2、导入源表的元数据到资源库 (6)3、创建Data Flow (6)4、设置源表和目标表 (7)5、手工执行Job (7)六、基于表比较的增量加载 (8)1、在Job下定义工作流 (8)2、在工作流中定义数据流 (8)3、加入Table_Comparison 控件 (9)4、设置Table_Comparison 控件 (9)七、基于时间戳的增量加载 (10)1、在Job下定义工作流 (10)2、定义Script控件 (10)3、定义处理新增数据的数据流和处理更新数据的数据流 (11)八、DS中常用控件介绍 (13)1、Key_Generation (13)2、Case (13)3、Merge (14)4、Validation (15)5、设置过滤器和断点 (15)九、定义Job定期执行 (16)1、登录Data Services Management Console (16)2、定义Batch Job Schedules (17)十、其他注意事项 (18)、DS简介SAP BusinessObjects Data Service舞通过SAP HANA认证的ETL工具。
采用数据批量处理的方式,定期执行后台作业,将数据从多个业务系统中抽取出来,并进行必要的处理(转换,合并,过滤,清洗),然后再加载到HANA数据库中。
DS的组件之间的关系:Management Consol:管理控制台是网页版DS管理工具,可以进行一些系统配置和定义Job执行DesignemDesigner是一个具有易于使用的图形用户界面的开发工具。
一.安装●在安装伊始,需要填写License ,否则安装不能进行(如果有一个key但是失效了,也可以先填进去,然后修改系统时间即可完成安装,但是在使用的时候系统时间始终是不准确的;key可以到其他装过此软件的机器上面找),安装的时候在创建资料库即repository的时候可以忽略,等装好之后再去创建;二.配置●安装完成之后首先需要创建一个资料库即repository,在菜单里面找到Sap BusinessObjectData Services Repository Manager ,按照下图填写,然后点击create 即可创建。
●然后创建job server 在菜单中找到Data Services Server Manager添加一个job server●之后就可以打开Data Services Designer进行设计开发了。
在designer里开发的job 保存在了第一步创建的资料库(Repository)里。
●在开始菜单中找到Date Services Management Console用户名密码默认为 admin●进入之后选择“Administrator”进行配置和管理在Management 里找到Repositories ,添加一个资料库(配置信息是第一步创建的资料库),配置完毕后就会出现资料库信息,已经创建的job 列表。
然后在Batch里找到相应的job进行配置或调试或监控。
以下图例总结了dataservices各组件之间的关系●在抽取数据的时候的步骤如下:1.上图中首先创建一个projects2.再创建一个job3.在datastores里创建数据库链接,然后把job中所用到的tables 以及functions导入进来4.在job里创建工作流、数据流等。
●在从一个表抽出数据到另一张表时,如果需要做一些数据转换,那么如图:首先选中需要改变的字段,在下面的mapping 中写下转换条件即可。
当然,也可以写where 条件等(例如在where 里可以这样写:CHECKINOUT.CHECKTIME IS NOT NULL and USERINFO.SSN is not null AND ERID IS NOT nulland CHECKINOUT.CHECKTIME >= $ld_date AND ERID = ERID )。
下列图例描述了主要对象之间的关系三.多用户开发配置首先需要创建一个中央资源库,然后每个成员通过自己的本地资源库链接到中央资源库,每个成员把开发的内容保存到中央资源库中,当需要修改中央资源库中的内容时,需要check out ,这时别人只能浏览,修改完成之后check in 即可;中央资源库会保留各个历史版本。
●在数据库上创建一个用户作为中心资源库的用户。
●使用Sap BusinessObjects Data Services Repository Manager创建一个中央资源库(在repository type 里选择central);注:可以创建安全的和非安全的中央资源库,按需要创建,一般是创建安全的。
●打开Data Services Managerment Console 在Management里的Repositories里添加创建的中央资源库。
这时Central Repositories里就出现了刚创建的中央资料库。
●在users 里创建用户。
创建用户时在role选项中要选择Muti-User Administrator ,该角色不能用在非安全中央资源库,它是Administrator的一个子集。
用它能够添加或移除中央资源库、管理用户和用户组、预览中央资源库报告。
●在Central Repositories里找到相应的中央资源库,在users and Groups里创建相应的用户和组。
●用本地资源库登到录Date Services Designer。
在 Tools菜单中点击CentralRepositories ,添加中央资源库。
●之后就可以用了四.JobA batch job can contain the following objects:●Data flowso Sourceso Transformso Targets●Work flows●Scripts●Conditionals●Try/catch blocks●While Loops五.Try/catchtrybeginstepsendcatch(integer_constants)beginstepsend六.开发中的命名规范七.scirptScripts are single-use objects used to call functions and assign values to variables in a work flow.For example, you can use the SQL function in a script to determine the most recent update time for a table and then assign that value to a variable. You can then assign the variable to a parameter that passes into a data flow and identifies the rows to extract from a source.A script can contain the following statements:•Function calls•If statements•While statements•Assignment statements•OperatorsThe basic rules for the syntax of the script are as follows:•Each line ends with a semicolon (;).•Variable names start with a dollar sign ($).•String values are enclosed in single quotation marks (').•Comments start with a pound sign (#).•Function calls always specify parameters even if the function uses no parameters.For example, the following script statement determines today's date and assigns the value to the variable $TODAY:$TODAY = sysdate();You cannot use variables unless you declare them in the work flow that calls the script.八.脚本语法简要说明jobs 和work flows 可以用脚本定义逻辑流程的细节步骤,可以用来调用函数(存储过程),可以给变量赋值。
在创建的脚本对象或者是自定义函数中必须以分号(;)结尾。
注释语句必须用井号(#)开头。
表达式表达式是常量、符合、函数及变量的一个组合,用来计算指定数据类型的值,可以用在script 里面或是其他的data flow对象中。
因为表达式能够用在data flow 对象中使用,所以通常包含列名; Data Service 脚本语言对于列名和表名没有特定的语法,例如,你可以用类似于start_date 列在Mapping选项卡中作为输出,指定到输出的某一列上,但是start_date 列,必须要在schema in 中存在;如图:如果在schema in中出现了相同名字的字段,并且该字段在表达式中使用,那么在使用的时候就需要加上表的前缀;例如:这里的hire_date在schema in 的employees表和emp_ds引号的使用与在sql语句用的语法一样。
例如,如果引一些特殊字符(非字母),需要用双引号括起来;转义字符,如果在常量里面用到了单引号(’)或是反斜杠(\),那么需要用转义字符进行转义,DS里的转义字符是反斜杠;如关于字符串左右的空格问题,DS是用rtrim 或 rtrim_blank函数解决的;变量名变量名必须以$符号开头,如 $return_infolocal(局部)变量必须在使用之的job或work flow里定义;globa(全局)变量必须在使用之的job级别定义;返回值用 RETURN(expression)来返回;其中expression定义了返回的值;用在自定义函数中的局部变量必须用智能编辑器定义(自定义函数创建:tools→custom function →右键 new (可以填写注释));如图:在打开的自定义函数的编辑器中,首先在选择左边的 Variables 选项卡,然后在parameter 里的return上右击选择属性,可以修改返回值类型;然后在此菜单下可以创建相应的变量。
最后在右边的编辑框里输入相应的函数逻辑即可(在此可以用之前的函数,也就是在左边的选项卡functions里的相应函数;注意:这里面定义的变量只能在这里面使用。
可以在下列的地方使用函数•Transforms (Query, Case, SQL)•Script objects•Conditionals•other custom functions编辑一个存在的函数,可以到刚才的画面中的functions 标签中找到;如:JOB服务器每一个job服务器必须和一个本地资料库关联;多用户开发:多用户开发决定了你开发的方式以及管理应用不同阶段的方式;如果想成功使用多用户开发环境,你必须要保持本地库和中央库的连贯;下面介绍几个相应的概念:最高级别对象:不依赖于层级对象中的任何一个对象,例如:JOB1由Work flow1 和Data flow1组成,那么job1是最高级别的对象;对象依赖:在层级最高级别对象至下的相应对象。
例如刚才那种情况,Work flow1 和Data flow1都依赖job1对象,Data flow1依赖Work flow1.对象版本:一个对象版本是一个对象的一个实例,每次你添加或check in 一个对象到中央库,软件就会创建这个对象的新的版本。
最后或最近创建的版本就是对象最终的版本;中央资料库和本地资料库;中央资料库只是各个本地资料库资料的一个存放地,多个用户可以上传在本地资料库中的信息,也可以从中下载这些信息,如果要修改这些信息,那么必须check out 到本地资料库。