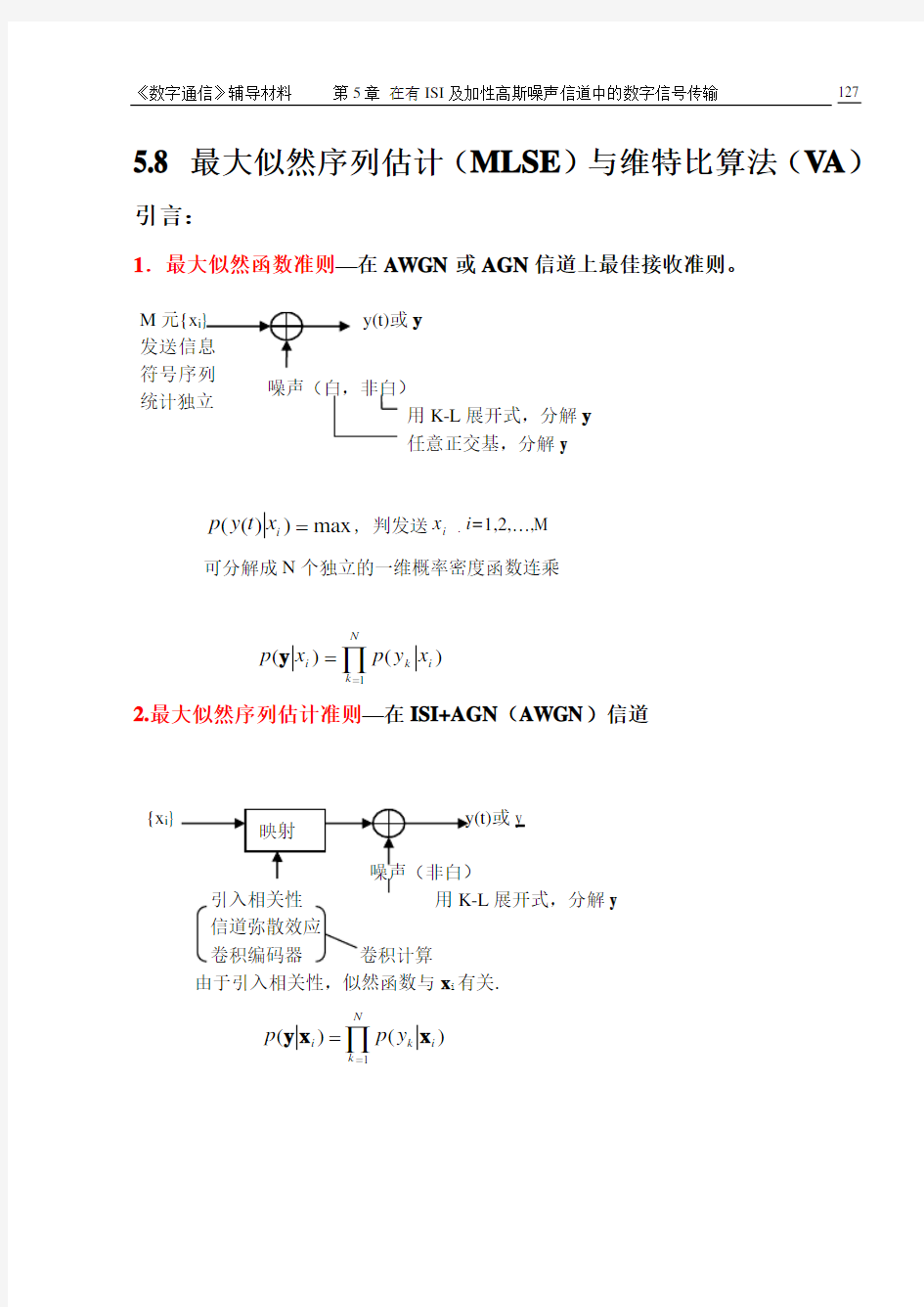

5.8 最大似然序列估计(MLSE )与维特比算法(V A )
引言:
1.最大似然函数准则—在AWGN 或AGN 信道上最佳接收准则。
∏==
N
k i k
i x y
p x p 1
)()(y
2.最大似然序列估计准则—在ISI+AGN (AWGN )信道
或y
.
{x i 噪声(白,非白)
用K-L 展开式,分解y 任意正交基,分解y
y(t)或y
max ))((=i x t y p , 判发送i x . i=1,2,…,M
可分解成N 个独立的一维概率密度函数连乘
M 元{x i 统计独立
展开式,分解y
一 最佳接收准则及性能指数
1. 系统模型
2.最佳接收准则——ML 函数准则——MLSE 准则 求似然函数:
在N 维复信号空间中,利用K -L 展开式,在标准正交基(){}t f n 上
()()∑
=∞→=N
k k k N t f z t z 1,lim
特点:k r 的均值与)(t h 所覆盖的若干连续符号(即序列I p )有关。 原因:信道)(t h 弥散效应使相邻符号之间引入相关性。 所以:k r 的统计特性与序列I p 有关。 则似然函数为
1(()|)(|)(|)
N
k k p r t p p r ===∏p N p p I r I I
???
? ?????? ?
?--=
∑∑∏
=-=N
k n
n
k n k
k N
k k
h
I r 12
1
21
exp 21
λπλ
}n I
()()()t z nT t h I t r n
n +-=∑
问题:在非白噪声及ISI 中的最佳接收
{I n ()k k N z λ,0~ 统计独立高斯变量
()(),lim
1
t f r t r k
N
k k
N ∑=∞
→= ??
?
?
?∑-n
k n k n k h I N r λ,~ 统计独立高斯变量 式中, ∑+=-n
k n
k n k z h
I r
接收信号能量 也可写成:
()()()
2
1
1
1|2n N
n
k k p r t I h t nT dt λ∞
-∞
=????
=
-
--??????
∑?
N p r I ()12,,...,N r r r =N r , ()12,,...,P I I I =P I
按照MLSE 准则,对给定接收信号r (t ), 当 ()|max p =N p r I ,判p I
即最佳估计序列 {}12?,,...,p P I I I =I 是取遍所有序列后使ML 最大的序列。 3.性能指标
使似然函数()
|p N p r I 最大,等价于使积分值为最小。
定义:性能指数
()()()2
P n n
J r t I h t nT dt ∞
-∞
=--∑?
I
()()()2
**2Re n n r t dt I r t h t nT dt ∞
∞
-∞
-∞??=
--???
?∑?
?
**
()()n m n
m
I I h t nT h t mT dt ∞
-∞+--∑∑?
故, MLSE 准则等价于()J P I 最小。
()J P I 可简化为: ()**2Re n n n m n m n n m
J I y I I x -??
=-+ ???∑∑∑P I
最佳估计时, min )?(=p
J I 式中,
dt nT t h t r y n )()(*-=
?
∞
∞
- 为MF 在nT t = 时输出 ?
∞
∞
-+=
dt nT t h t h x n )()(* 为MF(或信道)自相关函数
MF 输出y n
相关函数x n-m
注:()()()x t h t h t *=*-,()()()h t g t c t =*。 二.维特比算法(V A )
1.性能指数()N J I 的递推算法
设发送序列(复) {}12,,...,N I I I =N I 总长度为N 收:最佳估计序列 {
}
12,,...,N
I I I ∧
∧∧∧
=N I 使min J ∧??
= ???
N I
**111
2Re min N N N n n m n n m n n m J I y I I x ∧∧∧∧-===????
=-+= ? ?????∑∑∑N I
可分解为递推形式:
(1) ()
11?--N N J I (2) 1
11
**11
1
1
2
**0
????()2Re()????2Re()2Re()N N N n n n m n m
n n m N N N N n N n N
n N L
J I y I I x I y I I x I x ----==--==-=-+-++∑∑∑∑
N I (A)
证明:
1
1
1
11
11
2
11
1
1
????2()()???????N
N n
n N
m m N n m
n m N N N N n m n m
N N
m N m N n n N
n m m n I
I I I x I
I x I x I I x I I x -*
*==-==----*
*
*---=====++=+++∑∑∑∑∑∑()
1
??2
Re()N N n N n n N L
I I x -*-=-∑
N n N n x x *
--=(自相关函数)
L N n L n N -≥∴≤-
(1) (2)
其中,设信道(T x +ch)的冲激响应h (t )持续时间为[0, LT ](支撑),则自相关函数(或T x +ch +MF 的响应)持续时间为[-LT, LT ] (支撑)。
(A)式可表示为:
1
2
110
??????()()2Re()2Re()N N N N N N N
N n N n N n N L
J J I y I I x I x -**---=-=-++∑
I I (A1) 对子序列I k 进行估计时(换个时间下标),性能指数
()
**111
????2Re k k k
k n n n m n m n n m J I y I I x -===??=-+
???∑∑∑k I (A2) 对子序列I k+1 进行估计时,性能指数:(将(A )式中N →k+1, N-1→k )
()(
)
12
*
*
011
111
11??()()??Re 2Re 2k
n k k k k n
k n k L
k k I
y I
I
x I x k
J J J δ+++++-+=+-+++=-∑
k k I I (A3) 或
11??()()k k k k k J J J δ+++=I I (性能指数增量) k 值的确定: k=L,L+1,…,N
最大值k max =N ,由发送序列最大长度所确定
最小值k min =L ,由信道响应的长度所确定。(因为ISI 覆盖了L 个符号,只有在k L ≥后,才有可能做出正确的估计) (A3)式就是性能指数的递推算法。
为了从概念上更清晰地说明和简明地表达V A
定义:估计序列状态121()
????{...}, ,1,....,k k L k L k k
L I I I I k L L N σ-+-+-==+个等于信道响应的长度,,,, k σ表示t=kT 时刻,包括当前及其前列符号在内的L 个符号(即ISI 所覆盖
的符号)估计值所有可能取值的组合。
若符号为M 元,则每个状态取值组合共有M L 个。
例如,M=2,L=2,则k σ共有4个取值组合。显然,正确估计只能是其中某一个。状态k σ中取值组合可简称为状态取值(或状态元素),用节点0表示。
因此,一般讲,对长度为L 的M 元符号序列,每一个状态共有M L 个节点。
1∧I 2∧
I k σ
00 01 10 11
M L 个节点
k σ k
长度为N (N>L )的序列N
I ?经历了(N-L+1)个状态。 {}
1211???????,,...,,,...,...,N L L N L N I I I I I I +-+=I
L σ 1+L σ N σ
(N-L+1)个状态
定义:状态转移—从一个状态k σ过渡到下一个状态1+k σ,记为()1,+k k σσ,将
“状态k σ”及“状态转移()1,+k k σσ”引入(A3)式,性能指数11?()k k J ++I 可改写为
()()()1111,;+++++=k k k k k k k y B P P σσσσ, []1,-∈N L k (A4)
上式即为性能指数递推算法简洁形式,即V A 。
2.Trellis 图及最佳估计的几何解释。 1) Trellis 图
由前面分析可以看出:
由(A1)式计算性能指数)?(N J I ,并寻找其最小值,来获得对发送符号序列的最佳估计^
N I 的算法,等价于(A4)式的递推算法。
因此,最佳估计N
I ?应满足:
,1,?
??()min{(...)}()N
N N N L L N N N P P J σσσ+==I I I 为最小值 (A5) 或
()()1
1;,1??()min N N N N N L k k k k L P P B y σσσ-++=??=+????
∑I I (A6) 或
()(){}
1
1;,1?(1)?()lim
min k N N
N L k k k k L N P P B y σσσ+++=→-=+I I ( A7)
(A7)式所表示的求最佳估计序列N
I ?的递推算法,可以用Trellis 图加以几何解释。 L σ k σ 1+k σ
N σ
L L k k 11++k k )N N
图解说明:
● 每一个状态,共有M L 个节点(o )
● ()1,;1++k k k y B σσ为“分支度量(长度)”或“状态转移度量(长度)”,表示从
1+→k k σσ时,各节点的性能指数增量。 ● ()k k P σ为“路径度量(长度)”。
表示从初始状态L σ开始直到状态k σ,各节点性能指数的累加值。 2)最佳估计的几何解释:
(即,在Trellis 图中,寻求最佳N
I ?的几何解释)
a)最佳
N
I?由全程最短路径所确定。
按(A5)式,最佳^
N
I等价于全程最短路径)
?(
N
N
P I所连接各状态相应节点所
表示的符号序列。
b)求全程最短路径的方法:计算—累加—比较、取舍
即:在状态转移中,累加分支长度,再比较、取舍,直到最后一个状态为止。
具体地说,
按(A6)(A7)式,求全程最短路径可由逐段最短路径累加来实现。
即状态每转移一次,计算在新状态下各节点的累加路径,再舍去各节点中较长的路径,只保留其中最短路径(叫“幸存路径”)。各状态下的最短路径叫“局部最短路径”。这种在状态转移过程中通过计算、累加、比较、取舍方法寻求最短路径的过程延续到最后一个状态
N
。再比较各节点的幸存路径,即可找到全程最短路径。
3)说明几点:
--关于全程最短路径与局部最短路径的关系。
●“全程最短路径”的唯一性。
当发送序列很长,N很大,全程最短路径是唯一的,它对应着最佳估计
N
I?。
●“局部最短路径“的分离性。
局部最短路径在若干个状态转移过程中,不一定与全程最短路径相吻合,或同时存在几个相等的局部“最短”路径。因此,在若干个状态转移过程中,不一定能确定真正符合全程的最短路径。
原因:信道噪声的随机性。
当噪声样本序列比较短时,它的统计特性不平稳,带有较大的随机性;
当噪声样本序列足够长时,它的统计特性才比较平稳。
●离合长度的随机性。
总的来看,局部最短路径与全程最短路径“时分”、“时合”,分离或合并的长度是随机的。它取决于信道的条件、信噪比等因素。当信道条件差,或信噪比较低时,分离的长度就增加。在极端情况下,分离现象直到最终状态时,也不能消除,这时接收的错误概率比较大。路径
4)估计
I?的具体方法:
N
●要实时估计,不能最终估计。
在实际应用中,不可能等找出全程最短路径之后,再确定
I?,因为这需
N 要庞大的存储器,而且也不满足通信实时性的要求。
●要截取足够长度进行估计。
由于“分离现象”的存在,必须截取足够长度的接收信号序列进行估计。
●截取长度要固定,不宜随机。
分离长度虽然是随机的,但不宜采用随机截取方式进行估计。因为随机截取进行估计将增加设备复杂性。
通常,截取足够的固定长度q(“截取深度”或“判决深度”),选q 5L 时,一般MLSE性能损失很小
3 .V A小结
--V A是寻求全程最佳(最短)路径的计算过程(递推算法)
“最佳路径”等价于MLSE准则,或MAP准则。
--更一般讲,
V A是在加性无记忆噪声中估计马尔可夫链状态序列的一种递推最佳求解方法。(故也适合于Trellis码的解码)
注:马氏过程:无后效应,随机过程的当前状态只与前一状态有关,而与其它时刻的状态无关。
马氏链:状态和时间参数都是离散的马氏过程。
V A 的算法过程归纳如下:
1)建立相应的存储单元
k 时间指数 ()k k P σ
路径长度
()1,;1++k k k y B σσ分支长度
2)建立初始状态:k =L ,计算()L L P σ 3)递推运算:
● 计算分支长度()1,;1++k k k y B σσ
● 计算路径长()()()1,;111+++++=k k k k k K k y B P P σσσσ ● 求最短路径(幸存路径)
{}1
1
1
1
1
??()min ()k k k k k P P σ+++++=I I
k=L,L +1,…, N -1 存储幸存路径11?()k k P ++I 及相应的最佳估计序列1?k +I 在q k ≥时,开始输出最佳估计序列。
重复上述递推运算直到K=N-1为止,即可得到最佳估计序列:
{}
121?????,,...,N N N I I I I =I -,
三. 最佳接收机结构
{I k }?{k
I
四 举例。
1.实序列估计的V A
假定发送符号序列为实序列:1,2,{}N N N a a a =I =a
则性能指数为:(由(A )式)
1
11
1
2
01
11
????????()222N N N N N n
n
n m n m
N N N n N n N n n m n N L
J a
y a a x
a
y a a x a x ------====-=-+-++∑∑∑∑
a
● 计算分支长度
()21;,11111101????22k
k k k k k k n k n k n k L
B y a
y a a
x a x σσ++++++-+=+-=-++∑
● 计算路径长度
()()()1,;111+++++=k k k k k k k y B P P σσσσ
● 求最短路径
{}1
1111?
?()min ()k k k k k P P σ+++++=I I k=L,L +1,…, N -1 当k=L 时,初始路径为
()1
11
???2L L L
L L n n n m n m n n m P a
y a a x σ-====-+∑∑∑ 11???{,,,}k k L k k a
a
a σ-+-= 由L 个符号组成
当k=L , 11???{,,,}k L L L a
a
a σσ-==
2.系统的条件及分析
【条件】: 设二元数字传输系统,M=2
信道响应长度为LT ,L=2, {h 0,h 1,…h L }
信道自相关函数长度(2L+1)T, {x -L …x -1,x 0,x 1…x L }
x 0=1, x +1=x -1=0.5, x +2=x -2=-0.25 (自相关函数对称性)
发送序列长度N=7, {}1,2,...N N a a a =a
匹配滤波器输出样值y n :
y 1=1.5,y 2=2.0,y 3 =0.5 y 4 =1.0 y 5 =-1.5 y 6 =-3.0 y 7=0.5
【分析】: 状态11???{,,,}k k L k k a
a
a σ-+-= k=L,L +1,…, N -1 2=L ,k σ∴由2个符号组合而成
2=M , ∴每一个状态共有M L =22=4个节点
例如,{}2120 00 1??, 1 01 1L a
a σσ??
????
===????????
考察相邻两个状态的转移情况(从1+→k k σσ)
k T (k +1)T 21∧
∧a a k σ 1+k σ 32∧
∧
a a
0 0 0 0
0 1 0 1 1 0 1 0 1 1 1 1 ),;(11++k k k y B σσ ()k k P σ ()11++k k P σ
可以看出:
● 每一状态中,都有4个节点(00,01,10,11) ● 从前一状态(k σ)看:
每一节点都分别通过2个分支转移到下一状态的相应的2个节点 共同点: 上分支—表示后续符号为0 下分支—表示后续符号为1 ● 从后一状态(1+k σ)看:
每一个节点都分别通过2个分支与前一状态的相应2个节点相联系。
每个状态中4个节点有相应的4个路径长度(幸存路径):
()()()()11,10,01,00k k k k P P P P
2个状态各节点间有相应的8个分支长度 ()1,;1++k k k y B σσ
()()()()10,11,00,10,10,0100,00;11.;11.;11.;11.++++++++k k k k k k k k k k k k y B y B y B ,y B ()()()()11,11,01,10,11,01,01,00;11.;11.;11.;11.++++++++k k k k k k k k k k k k y B y B y B y B
3.V A 的计算举例
设二元符号“0”“1”分别用电平“-1”和“+1”表示:
“0”——(-1) “1”——(+1)
1)建立初始状态:k=L=2
{}212 1 11 +1??, 1 11 +1a a σ--??
??-??
==??+-????+??
计算()22σP :
()()()()()2
2
2
221
11
112211012121122011220121???2?????????? 2?? 22n n n m n m n n m P a
y a a x a
y a y a a x a a x a a x a a x a
y a y x a a x σ-===-=-+=-+++++=-+++∑∑∑
()()()()()()()()()()()()2222002 1.5 2.0210.510
012 1.5 2.0210.501021.5 2.0210.521121.5 2.0210.54
P P P P =---++==--++-==--+-==-+++=-
2)递推运算
计算()3,2;33,2σσy B
()2
2
2,33;2,3333330
133312210????()22???? 22n n n B y a y a a x a x a
y a a x a x x σσ-==-+∑+=-+++
2,33;2,32,33;12
????( )( ,)B y B y a a a a σσ=
()()()()()()()()()()()()()()()()()2,33;
2,33;2,33;2,33;
2,33;2,33;00,0020.520.250.512.500,0120.520.250.510.501,1020.520.250.510.501,1120.520.250.511.510,0020.520.250.513.510,0
120.520.25B y B y B y B y B y B y =----+==-+-+=-=---++==-+++==-----+==-+-()()()()()()()2,33;2,33;0.51 1.511,1020.520.250.51 1.511,1120.520.250.510.5
B y B y -+=-=----++==-+-++=
计算()33σP
()()()3,2;33,22233σσσσy B P P +=
设 u —上支路, d —下支路 幸存路径
()()()()()()()()()()()()()()()()()()()()()()()()
.35.0411,1111115
.15.1011,0101115.25.1410,1111105.05.0010,0101105.0)5.1(201,1010015
.9)5.0(1001,0000015.55.3200,1010005.125.21000,000000;33,223;33,223;33,223;33,223;33,223;33,223;33,223;33,223-=+-=+==+=+=-=+-=+==+=+==-+=+==-+=+==+=+==+=+=y B P P y B P P y B P P y B P P y B P P y B P P y B P P y B P P d u d u d u d u
()
003()013P
()103P ()
113P
● 求状态3σ中各节点的幸存路径(最短路径)
)}(),(m in{)(333333σσσd u P P P =
5.5)00()}00(),00(m in{)00(3333===d d u P P P P
5.0)01()01(33==d P P 5.2)10()10(33-==d P P 5.3)11()11(33-==d P P
在Trellis 图中,两状态转移中各节点的最短路径(即幸存路径)用实线表示,而非最短路径(舍去路径)用虚线表示。 ● 令k =3,4,5,6
重复上述的V A 递推运算过程,计算出4σ,5σ,6σ,7σ各状态中各个节点的最短路径(幸存路径),如图所示。
4.寻求最佳估计序列{}7127????a a a =,,,a
1) 根据局部最短路径,经过比较、舍取、递推,即可确定全程最短路径,
即最佳路径。
2) 由最佳路径所连接的各状态中的各节点即可找到最佳估计序列。
由图可见,最佳路径所连接的各节点为:
{}{
}{}{}{}{}11,,11,,11,,11,,11,,11,+----++--+++ 因此,1234567???????1, 1, 1, 1, 1, 1, 1a
a a a a a a =+=+=-=+=-=-=+ {}7?1,1,1,1,1,1,1∴=++-+--+a
或
{}7?1101001=a
5.关于判决深度
由图可见,在3σ时,局部最短路径()5.3113-=P ,与全程最短路径在该状态的值
()5.2103-=P 不吻合。换言之,在状态3σ时,局部最短路径通过节点(11),而
全程最短路径通过节点(10),两者是分离的。只有到4σ时才重新合并。因此,当被估计序列很长时,必须选取足够大的判决深度(L q 5≥)。
2σ 3σ 4σ 5σ 6σ 7σ
(00) -1-1 +
全程最短路径 (最佳路径)
(01) -1+1
(10) +1-1 +
(11) +1+1
-4 -3.5 -4 +0.5 +8 -1.5 ),;(323σσy B
),;(767σσy B
)(22σP )(33σP )(44σP )(55σP )(66σP )(77σP
(n,k,N)卷积码的维特比译码算法实现#include
这篇文章简单描述一下Viterbi算法——一年之前我听过它的名字,直到两周之前才花了一点时间研究了个皮毛,在这里做个简单检讨。先用一句话来简单描述一下:给出一个观测序列o1,o2,o3 …,我们希望找到观测序列背后的隐藏状态序列s1, s2, s3, …;Viterbi以它的发明者名字命名,正是这样一种由动态规划的方法来寻找出现概率最大的隐藏状态序列(被称为Viterbi路径)的算法。这里需要抄一点有关隐马可夫序列(HMM,Hidden Markov Model)的书页来解释一下观测序列和隐藏状态序列。 首先从最简单的离散Markov过程入手,我们知道,Markov随机过程具有如下的性质:在任意时刻,从当前状态转移到下一个状态的概率与当前状态之前的那些状态没有关系。所以,我们可以用一个状态转移概率矩阵来描述它。假设我们有n个离散状态S1, S2,…Sn,我们可以构造一个矩阵A,矩阵中的元素aij表示从当前状态Si下一时刻迁移到Sj状态的概率。 但是在很多情况下,Markov模型中的状态是我们观察不到的。例如,容器与彩球的模型:有若干个容器,每个容器中按已知比例放入各色的彩球(这样,选择了容器后,我们可以用概率来预测取出各种彩球的可能性);我们做这样的实验,实验者从容器中取彩球——先选择一个容器,再从中抓出某一个球,只给观察者看球的颜色;这样,每次取取出的球的颜色是可以观测到的,即o1, o2,…,但是每次选择哪个容器是不暴露给观察者的,容器的序列就组成了隐藏状态序列S1, S2,…Sn。这是一个典型的可以用HMM描述的实验。
HMM有几个重要的任务,其中之一就是期望通过观察序列来猜测背后最有可能的隐藏序列。在上面的例子中,就是找到我们在实验中最有可能选择到的容器序列。Viterbi正是用来解决这个问题的算法。HMM另外两个任务是:a) 给定一个HMM,计算一个观测序列出现的可能性;b)已知一个观测序列,HMM参数不定,如何优化这些参数使得观测序列的出现概率最大。解决前一个问题可以用与Viberbi结构非常类似的Forward算法来解决(实际上在下面合二为一),而后者可以用Baum-Welch/EM算法来迭代逼近。 从Wiki上抄一个例子来说明Viterbi算法。 假设你有一个朋友在外地,每天你可以通过电话来了解他每天的活动。他每天只会做三种活动之一——Walk, Shop, Clean。你的朋友从事哪一种活动的概率与当地的气候有关,这里,我们只考虑两种天气——Rainy, Sunny。我们知道,天气与运动的关系如下: Rain y Sunn y Wal k 0.1 0.6 Sho p 0.4 0.3 Clea n 0.5 0.1
【时间简“识”】 说明:本文摘自于经管之家(原人大经济论坛) 作者:胖胖小龟宝。原版请到经管之家(原人大经济论坛) 查看。 1.带你看看时间序列的简史 现在前面的话—— 时间序列作为一门统计学,经济学相结合的学科,在我们论坛,特别是五区计量经济学中是热门讨论话题。本月楼主推出新的系列专题——时间简“识”,旨在对时间序列方面进行知识扫盲(扫盲,仅仅扫盲而已……),同时也想借此吸引一些专业人士能够协助讨论和帮助大家解疑答惑。 在统计学的必修课里,时间序列估计是遭吐槽的重点科目了,其理论性强,虽然应用领域十分广泛,但往往在实际操作中会遇到很多“令人发指”的问题。所以本帖就从基础开始,为大家絮叨絮叨那些关于“时间”的故事!
Long long ago,有多long?估计大概7000年前吧,古埃及人把尼罗河涨落的情况逐天记录下来,这一记录也就被我们称作所谓的时间序列。记录这个河流涨落有什么意义?当时的人们并不是随手一记,而是对这个时间序列进行了长期的观察。结果,他们发现尼罗河的涨落非常有规律。掌握了尼罗河泛滥的规律,这帮助了古埃及对农耕和居所有了规划,使农业迅速发展,从而创建了埃及灿烂的史前文明。 好~~从上面那个故事我们看到了 1、时间序列的定义——按照时间的顺序把随机事件变化发展的过程记录下来就构成了一个时间序列。 2、时间序列分析的定义——对时间序列进行观察、研究,找寻它变化发展的规律,预测它将来的走势就是时间序列分析。 既然有了序列,那怎么拿来分析呢? 时间序列分析方法分为描述性时序分析和统计时序分析。 1、描述性时序分析——通过直观的数据比较或绘图观测,寻找序列中蕴含的发展规律,这种分析方法就称为描述性时序分析 ?描述性时序分析方法具有操作简单、直观有效的特点,它通常是人们进行统计时序分析的第一步。
5.8 最大似然序列估计(MLSE )与维特比算法(V A ) 引言: 1.最大似然函数准则—在AWGN 或AGN 信道上最佳接收准则。 ∏== N k i k i x y p x p 1 )()(y 2.最大似然序列估计准则—在ISI+AGN (AWGN )信道 或y . {x i 噪声(白,非白) 用K-L 展开式,分解y 任意正交基,分解y y(t)或y max ))((=i x t y p , 判发送i x . i=1,2,…,M 可分解成N 个独立的一维概率密度函数连乘 M 元{x i 统计独立 展开式,分解y
一 最佳接收准则及性能指数 1. 系统模型 2.最佳接收准则——ML 函数准则——MLSE 准则 求似然函数: 在N 维复信号空间中,利用K -L 展开式,在标准正交基(){}t f n 上 ()()∑ =∞→=N k k k N t f z t z 1,lim 特点:k r 的均值与)(t h 所覆盖的若干连续符号(即序列I p )有关。 原因:信道)(t h 弥散效应使相邻符号之间引入相关性。 所以:k r 的统计特性与序列I p 有关。 则似然函数为 1(()|)(|)(|) N k k p r t p p r ===∏p N p p I r I I ??? ? ?????? ? ?--= ∑∑∏ =-=N k n n k n k k N k k h I r 12 1 21 exp 21 λπλ }n I ()()()t z nT t h I t r n n +-=∑ 问题:在非白噪声及ISI 中的最佳接收 {I n ()k k N z λ,0~ 统计独立高斯变量 ()(),lim 1 t f r t r k N k k N ∑=∞ →= ?? ? ? ?∑-n k n k n k h I N r λ,~ 统计独立高斯变量 式中, ∑+=-n k n k n k z h I r
第七章 平稳时间序列预测法 基本内容 一、概述 1、 时间序列{}t y 取自某一个随机过程,如果此随机过程的随机特征不随时间变化,则我们称 过程是平稳的;假如该随机过程的随机特征随时间变化,则称过程是非平稳的。 2、 宽平稳时间序列的定义:设时间序列{}t y ,对于任意的t ,k 和m ,满足: ()()m t t y E y E += ()()k m t m t k t t y y y y ++++=,cov ,cov 则称{}t y 宽平稳。 3、Box-Jenkins 方法是一种理论较为完善的统计预测方法。他们的工作为实际工作者提供了对时间序列进行分析、预测,以及对ARMA 模型识别、估计和诊断的系统方法。使ARMA 模型的建立有了一套完整、正规、结构化的建模方法,并且具有统计上的完善性和牢固的理论基础。 4、ARMA 模型三种基本形式:自回归模型(AR :Auto-regressive ),移动平均模型(MA : Moving-Average )和混合模型(ARMA :Auto-regressive Moving-Average )。 (1) 自回归模型AR(p):如果时间序列{}t y 满足t p t p t t y y y εφφ+++=-- (11) 其中{}t ε是独立同分布的随机变量序列,且满足: ()0=t E ε,()02>=εσεt Var 则称时间序列{}t y 服从p 阶自回归模型。或者记为()k t t y y B -=φ。 平稳条件:滞后算子多项式()p p B B B φφφ++-=...11的根均在单位圆外,即 ()0=B φ的根大于1。 (2) 移动平均模型MA(q):如果时间序列{}t y 满足q t q t t t y -----=εθεθε...11 则称时间序列{}t y 服从q 阶移动平均模型。或者记为()t t B y εθ=。 平稳条件:任何条件下都平稳。 (3) ARMA(p,q)模型:如果时间序列{}t y 满足 q t q t t p t p t t y y y -------+++=εθεθεφφ (1111) 则称时间序列{}t y 服从(p,q)阶自回归移动平均模型。或者记为()()t t B y B εθφ=。
2010年12月(上) Viterbi 译码的Matlab 实现 张慧 (盐城卫生职业技术学院,江苏盐城 224006) [摘要]本文主要介绍了Viterbi 译码是一种最大似然译码算法,是卷积编码的最佳译码算法。本文主要是以(2,1,2)卷积码为例,介 绍了Viterbi 译码的原理和过程,并用Matlab 进行仿真。[关键词]卷积码;Viterbi 译码 1卷积码的类型 卷积码的译码基本上可划分为两大类型:代数译码和概率译码,其中概率译码是实际中最常采用的卷积码译码方法。 2Viterbi 译码 Viterbi 译码是由Viterbi 在1967年提出的一种概率译码,其实质是最大似然译码,是卷积码的最佳译码算法。它利用编码网格图的特殊结构,降低了计算的复杂性。该算法考虑的是,去除不可能成为最大似然选择对象的网格图上的路径,即,如果有两条路径到达同一状态,则具有最佳量度的路径被选中,称为幸存路径( surviving path )。对所有状态都将进行这样的选路操作,译码器不断在网格图上深入,通过去除可能性最小的路径实现判决。较早地抛弃不可能的路径降低了译码器的复杂性。 为了更具体的理解Viterbi 译码的过程,我们以(2,1,2)卷积码为例,为简化讨论,假设信道为BSC 信道。译码过程的前几步如下:假定输入数据序列m ,码字U ,接收序列Z ,如图1所示,并假设译码器确知网格图的初始状态。 图1 时刻t 1接收到的码元是11,从状态00出发只有两种状态转移方向,00和10,如图a 所示。状态转换的分支量度是2;状态转换的分支径量度是0。时刻t 2从每个状态出发都有两种可能的分支,如图b 所示。这些分支的累积量度标识为状态量度┎a ,┎b ,┎c ,┎d ,与各自的结束状态相对应。同样地,图c 中时刻t 3从每个状态出发都有两个分支,因此,时刻时到达每个状态的路径都有两条,这两条路径中,累积路径量度较大的将被舍弃。如果这两条路径的路径量度恰好相等,则任意舍弃其中一条路径。到各个状态的幸存路径如图d 所示。译码过程进行到此时,时刻t 1和t 2之间仅有一条幸存路径,称为公共支(com-mon stem )。因此这时译码器可以判决时刻t 1和t 2之间的状态转移是00→10;因为这个状态转移是由输入比特1产生的,所以译码器输出1作为第一位译码比特。由此可以看出,用实线表示输入比特0,虚线表示输入比特1,可以为幸存路径译码带来很大的便利。注意,只有当路径量度计算进行到网格图较深处时,才产生第一位译码比特。在典型的译码器实现中,这代表了大约是约束长度5倍的译码延迟。 图2幸存路径选择 在译码过程的每—步,到达每个状态的可能路径总有两条,通过比较路径量度舍弃其中一条。图e 给出了译码过程的下一步:在时刻t 5到达各个状态的路径都有两条,其中一条被舍弃;图f 是时刻t 5的幸存路径。注意,此例中尚不能对第二位输入数据比特做出判决,因为在时刻t 2离开状态10的路径仍为两条。图g 中的时刻t 6同样有路径合并,图h 是时刻t 6的幸存路径,可见编码器输出的第二位译码比特是1,对应了时刻t 2和t 3之间的幸存路径。译码器在网格图上继续上述过程,通过不断舍弃路径直至仅剩一条,来对输入数据比特做出判决。 网格图的删减(通过路径的合并)确保了路径数不会超过状态数。对于此例的情况,可证明在图b 、d 、f 、h 中,每次删减后都只有4条路径。而对于未使用维特比算法的最大似然序列彻底比较法,其可能路径数(代表可能序列数)是序列长度的指数函数。对于分支字长为L 的二进制码字序列,共有2L 种可能的序列。下面我们用Matlab 函数viterbi (G,k,channel_output )来产生输入序列经Viterbi 译码器得到的输出序列,并将结果与输入卷积码编码器的信息序列进行比较。在这里,G =g ,k=k0,channel_output=output 。用Matlab 函数得到的译码输出为10011100110000111,这与我们经过理论分析得出的结果是一致的。 我们用subplot 函数将译码器最终的输出结果与(下转第261页) 250
编号: 《DSP技术与应用》课程论文卷积码的维特比译码的分析与实现 论文作者姓名:______ ______ 作者学号:___ ______ 所在学院: 所学专业:_____ ___ 导师姓名职称:__ _ 论文完成时间: _
目录 摘要: (1) 0 前言 (2) 1 理论基础 (2) 1.1信道理论基础 (2) 1.2差错控制技术 (3) 1.3纠错编码 (4) 1.4线性分组码 (5) 2 卷积码编码 (7) 2.1 卷积码概要 (7) 2.2 卷积码编码器 (8) 2.3卷积码的图解表示 (8) 2.4 卷积码的解析表示 (11) 3 卷积码的译码 (14) 3.1 维特比译码 (15) 3.2 代数译码 (17) 3.3 门限译码 (18) 4 维特比译码器实现 (18) 4.1 TMS320C54 系列DSP概述 (18) 4.2 Viterbi译码器的DSP实现 (19) 4.3 实现结果 (21) 5 结论 (21) 参考文献 (22) II
卷积码的维特比译码的分析与实现 摘要: 针对数据传输过程中的误码问题,本文论述了提高数据传输质量的一些编码及译码的实现问题。自P.Elias 首次提出卷积码编码以来,这一编码技术至今仍显示出强大的生命力。在与分组码同样的码率R 和设备复杂性的条件下,无论从理论上还是从实际上均己证明卷积码的性能至少不比分组码差,且实现最佳和准最佳译码也较分组码容易。目前,卷积码已广泛应用在无线通信标准中,其维特比译码则利用码树的重复性结构,对最大似然译码算法进行了简化。本文所做的主要工作: 首先对信道编码技术进行了研究,根据信道中可能出现的噪声等问题对卷积码编码方法进行了主要阐释。 其次,对卷积码维特比译码器的实现算法进行了研究,完成了译码器的软件设计。 最后,结合实例,采用DSP芯片实现卷积码的维特比译码算法的仿真和运行。 关键词: 卷积码维特比译码DSP Convolutional codes and Viterbi decoding analysis and realization Zhang Yi-Fei (School of Physics and Electronics, Henan University, Henan Kaifeng 475004, China) Abstract: Considering the error bit problem during data transmission,this thesis discussed some codings and decoders,aiming at enhancing transmission performance. From P.Elias first gave the concept of convolutional code, it has show its’ great advantage. Under the same condition and the same rate of block code, the performance of convolutional code is better than block code, and it’s easier to implement the best decoding.Convolutional codes have been widely used in wireless communication standards, the V iterbi decoding using the repetitive structure of the code tree, the maximum likelihood decoding algorithm has been simplified. Major work done in this article: First, the channel coding techniques have been studied, the main interpretation of the convolutional code encoding method according to the channel may be noise and other issues. Secondly, the convolutional code V iterbi decoder algorithm has been studied, the software design of the decoder. Finally, with examples, simulation and operation of the DSP chip convolutional codes, Viterbi decoding algorithm. 1
BUPT 卷积码编码及Viterbi译码 班级:07114 学号:070422 姓名:吴希龙 指导老师:彭岳星 邮箱:FusionBupt@https://www.doczj.com/doc/0819153843.html,
1. 序言 卷积码最早于1955年由Elias 提出,稍后,1957年Wozencraft 提出了一种有效地译码方法即序列译码。1963年Massey 提出了一种性能稍差但是比较实用的门限译码方法,使得卷积码开始走向实用化。而后1967年Viterbi 提出了最大似然译码算法,它对存储级数较小的卷积码很容易实现,被称作Viterbi 译码算法,广泛的应用于现代通信中。 2. 卷积码编码及译码原理 2.1 卷积码编码原理 卷积码是一种性能优越的信道编码,它的编码器和解码器都比较易于实现,同时还具有较强的纠错能力,这使得它的使用越来越广泛。卷积码一般表示为(n,k,K)的形式,即将k 各信息比特编码为n 个比特的码组,K 为编码约束长度,说明编码过程中相互约束的码段个数。卷积码编码后的n 各码元不经与当前组的k 个信息比特有关,还与前K-1个输入组的信息比特有关。编码过程中相互关联的码元有K*n 个。R=k/n 是编码效率。编码效率和约束长度是衡量卷积码的两个重要参数。典型的卷积码一般选n,k 较小,但K 值可取较大(>10),以获得简单而高性能的卷积码。 卷积码的编码描述方式有很多种:冲激响应描述法、生成矩阵描述法、多项式乘积描述法、状态图描述,树图描述,网格图描述等。 2.1.1 卷积码解析表示法 卷积码的解析表示发大致可以分为离散卷积法,生成矩阵法,码多项式法。下面以离散卷积为例进行说明。 卷积码的编码器一般比较简单,为一个具有k 个输入端,n 个输出端,m 级移位寄存器的有限状态有记忆系统。下图所示为(2,1,7)卷积码的编码器。 若输入序列为u =(u 0u 1u 2u 3……), 则对应两个码字序列c ①=(c 0①c 1①c 2①c 3①……)和c ②=(c 0②c 1②c 2②c 3② ……) 相应的编码方程可写为c ①=u ?g ①,c ②=u ?g ②,c=(c ①,c ②)。 “?” 符号表示卷积运算,g ①,g ②表示编码器的两个冲激响应,即编码器的输出可以由输入序列和编码器的两个冲击响应卷积而得到,故称为卷积码。这里的冲激响应指:当输入为[1 0 0 0 0 … … ]序列时,所观察到的两个输出序列值。由于上图K 值为7,故冲激响应至
卷积码编码维特比译码实验设计报告 SUN 一、实验目的 掌握卷积码编码和维特比译码的基本原理,利用了卷积码的特性, 运用网格图和回溯以得到译码输出。 二、实验原理 1.卷积码是由连续输入的信息序列得到连续输出的已编码序列。其编码器将k个信息码元编为n个码元时,这n个码元不仅与当前段的k个信息有关,而且与前面的(m-1)段信息有关(m为编码的约束长度)。 2.一般地,最小距离d表明了卷积码在连续m段以内的距离特性,该码可以在m个连续码流内纠正(d-1)/2个错误。卷积码的纠错能力不仅与约束长度有关,还与采用的译码方式有关。 3. 维特比译码算法基本原理是将接收到的信号序列和所有可能的发送信号序列比较,选择其中汉明距离最小的序列认为是当前发送序列。卷积码的Viterbi 译码是根据接收码字序列寻找编码时通过网格图最佳路径的过程,找到最佳路径即完成了译码过程,并可以纠正接收码字中的错误比特。 4.所谓“最佳”, 是指最大后验条件概率:P( C/ R) = max [ P ( Cj/ R) ] , 一般来说, 信道模型并不使用后验条件概率,因此利用Beyes 公式、根据信道特性出结论:max[ P ( Cj/ R) ]与max[ P ( R/ Cj) ]等价。考虑到在系统实现中往往采用对数形式的运算,以求降低运算量,并且为求运算值为整数加入了修正因子a1 、a2 。令M ( R/ Cj) = log[ P ( R/ Cj) ] =Σa1 (log[ P( Rm/ Cmj ) ] + a2) 。其中, M 是组成序列的码字的个数。因此寻找最佳路径, 就变成寻找最大M( R/ Cj) , M( R/ Cj) 称为Cj 的分支路径量度,含义为发送Cj 而接收码元为R的似然度。 5.卷积码的viterbi译码是根据接收码字序列寻找编码时通过网格图最佳路径的过程,找到最佳路径即完成了译码过程并可以纠正接收码字中的错误比特。 三、实验代码 #include<> #include "" #define N 7 #include "" #include <> #include<> #define randomize() srand((unsigned)time(NULL)) encode( unsigned int *symbols, /*编码输出*/ unsigned int *data, /*编码输入*/ unsigned int nbytes, /*nbytes=n/16,n为实际输入码字的数目*/ unsigned int startstate /*定义初始化状态*/
Viterbi算法 Viterbi算法是一种动态规划算法,用来寻找由观测信息产生(Observed Event)的最可能隐状态序列(Viterbi路径),这种方法通常用在隐马尔可夫模型中。向前算法是一个类似的算法,用来计算一串观测事件发生的概率。这些算法都属于信息论的范畴。 这个算法做一连串的假设。首先,观测事件和隐事件必须处于序列中。这个序列通常是关于时间的。第二,这两个序列需要对应,一个观测事件的实例必须与一个隐事件相关联。第三,计算在特定时间点t的最可能隐序列必须只依赖于位于t的观测事件,和t-1处的最可能序列。这些假设在一阶隐马尔可夫模型中都要被满足。 Viterbi路径和Viterbi算法同时遵循寻找单一最可能观测解释的相关动态规划算法。例如,在统计分析中的动态规划算法能应用于寻找一个字符串的单个最相似上下文无关推导,即“Viterbi推导”。 Viterbi算法是由Andrew Viterbi 在1967年提出的,是一种用于有噪声的数据链路中错误纠正的模型,并广泛应用在卷积码的解码中,例如CDMA/GSM数字蜂窝,拨号调制解调器,卫星通信,深空通信和802.11无线局域网等。现在也广泛的应用在语言理解,关键词匹配,计算机语言学,生物信息学等。例如,在语音理解中,听觉信号被认为是观测事件的序列,文字串被认为是“潜在的原因”。Viterbi算法能够找到对应听觉信号的最可能文字序列。 概要 前面提到的假设可以被如下概括。Viterbi算法在一个状态机的假设上做操作。也就是说,在任何时间系统被抽象为一些状态。这些状态是有限的,尽管很大。每个状态被表示为一个节点。多个状态的序列(路径)往往都能产生同一个给定的状态,但其中只有一条是最可能产生这个状态的,被称作“生存路径”。这是一个最基础的假设,因为这个算法会检测所有的可能路径并只保留一个最可能的路径。这种策略并不需要计算所有的路径,只需要一个状态一个路径而已。 第二个关键的假设是前一个状态到一个新状态的转移被一个递增的度量描述,通常是一个数字。这种转移是从实践中计算而来的。第三个假设是事件在一个路径上是累加的。所以整个算法的关键是计算每个状态的数值。当发生了一个事件,算法结合上一个可能状态与转换产生的增量度量,并从中选择一个最优的,据此来检测向前的新状态。增量度量由事件触发,并由旧状态与新状态间的转换决定。例如,在数据交换中,可能发生一半的符号由奇状态转换,而另一半由偶状态开始转换。同时,在很多例子中,状态转换图是不连续的。一个简单的例子,一个汽车有三个状态,向前,停止和向后,状态从向前倒向后是不允许的。他必须先进入停止状态。在计算出增量度量和和状态度量后,只有最好的幸存,而其他的被舍弃。这种基础算法有一个改进,允许向前搜索和向后搜索。
时间序列分析预测EXCEL操作 一、长期趋势(T)的测定预测方法 线性趋势→:: 用回归法 非线性趋势中的“指数曲线”:用指数函数LOGEST、增长函数GROWTH(针对指数曲线) 多阶曲线(多项式):用回归法 (一)回归模型法-------长期趋势(线性或非线性)模型法: 具体操作过程:在EXCEL中点击“工具”→“数据分析”→“回归”→分别在“Y值输入区域”和“X值输入区域”输人数据和列序号的单元格区域一选择需要的输出项目,如“线性拟合图”。回归分析工具的输出解释: 计算结果共分为三个模块: 1)回归统计表: Multiple R(复相关系数R):R2的平方根,又称为相关系数,它用来衡量变量xy之间相关程度的大小。R Square(复测定系数R2 ):用来说明用自变量解释因变量变差的程度,以测量同因变量y的拟合效果。Adjusted R Square (调整复测定系数R2):仅用于多元回归才有意义,它用于衡量加入独立变量后模型的拟合程度。当有新的独立变量加入后,即使这一变量同因变量之间不相关,未经修正的R2也要增大,修正的R2仅用于比较含有同一个因变量的各种模型。 标准误差:又称为标准回归误差或叫估计标准误差,它用来衡量拟合程度的大小,也用于计算与回归有
关的其他统计量,此值越小,说明拟合程度越好。 2)方差分析表:方差分析表的主要作用是通过F检验来判断回归模型的回归效果。 3)回归参数:回归参数表是表中最后一个部分: ?Intercept:截距a ?第二、三行:a (截距) 和b (斜率)的各项指标。 ?第二列:回归系数a (截距)和b (斜率)的值。 ?第三列:回归系数的标准误差 ?第四列:根据原假设Ho:a=b=0计算的样本统计量t的值。 第五列:各个回归系数的p值(双侧) 第六列:a和b 95%的置信区间的上下限。 (二)使用指数函数LOGEST和增长函数GROWTH进行非线性预测 在Excel中,有一个专用于指数曲线回归分析的LOGEST函数,其线性化的全部计算过程都是自动完成的。如果因变量随自变量的增加而相应增加,且增加的幅度逐渐加大;或者因变量随自变量的增加而相应减少,且减少的幅度逐渐缩小,就可以断定其为指数曲线类型。 具体操作过程: 1.使用LOGEST函数计算回归统计量 ①打开“第3章时间数列分析与预测.xls”工作簿,选择“增长曲线”工作表如下图所示。 ②选择E2:F6区域,单击工具栏中的“粘贴函数”快捷键,弹出“粘贴函数”对话框,在“函数分类”中选择 “统计”,在“函数名”中选择“LOGEST”函数,则打开LOGEST对话框,如下图11.20所示。
7 平稳时间序列预测法 7.1 概述 7.2 时间序列的自相关分析 7.3 单位根检验和协整检验 7.4 ARMA模型的建模 回总目录 7.1 概述 时间序列取自某一个随机过程,则称: 一、平稳时间序列 过程是平稳的――随机过程的随机特征不随时间变化而变化过程是非平稳的――随机过程的随机特征随时间变化而变化回总目录 回本章目录 宽平稳时间序列的定义: 设时间序列 ,对于任意的t,k和m,满足: 则称宽平稳。 回总目录
回本章目录 Box-Jenkins方法是一种理论较为完善的统计预测方法。 他们的工作为实际工作者提供了对时间序列进行分析、预测,以及对ARMA模型识别、估计和诊断的系统方 法。使ARMA模型的建立有了一套完整、正规、结构 化的建模方法,并且具有统计上的完善性和牢固的理 论基础。 ARMA模型是描述平稳随机序列的最常用的一种模型; 回总目录 回本章目录 ARMA模型三种基本形式: 自回归模型(AR:Auto-regressive); 移动平均模型(MA:Moving-Average); 混合模型(ARMA:Auto-regressive Moving-Average)。回总目录 回本章目录 如果时间序列满足 其中是独立同分布的随机变量序列,且满足:
则称时间序列服从p阶自回归模型。 二、自回归模型 回总目录 回本章目录 自回归模型的平稳条件: 滞后算子多项式 的根均在单位圆外,即 的根大于1。 回总目录 回本章目录 如果时间序列满足 则称时间序列服从q阶移动平均模型。或者记为。 平稳条件:任何条件下都平稳。
三、移动平均模型MA(q) 回总目录 回本章目录 四、ARMA(p,q)模型 如果时间序列 满足: 则称时间序列服从(p,q)阶自回归移动平均模型。 或者记为: 回总目录 回本章目录 q=0,模型即为AR(p); p=0,模型即为MA(q)。 ARMA(p,q)模型特殊情况: 回总目录 回本章目录 例题分析 设 ,其中A与B 为两个独立的零均值随机变量,方差为1;
什么是时间序列预测法? 一种历史资料延伸预测,也称历史引伸预测法。是以所能反映的社会经济现象的发展过程和规律性,进行引伸外推,预测其发展趋势的方法。 时间序列,也叫时间数列、历史复数或。它是将某种的数值,按时间先后顺序排到所形成的数列。时间序列预测法就是通过编制和分析时间序列,根据时间序列所反映出来的发展过程、方向和趋势,进行类推或延伸,借以预测下一段时间或以后若干年内可能达到的水平。其内容包括:收集与整理某种社会现象的历史资料;对这些资料进行检查鉴别,排成数列;分析时间数列,从中寻找该社会现象随时间变化而变化的规律,得出一定的模式;以此模式去预测该社会现象将来的情况。 时间序列预测法的步骤 第一步收集历史资料,加以整理,编成时间序列,并根据时间序列绘成。时间序列分析通常是把各种可能发生作用的因素进行分类,传统的分类方法是按各种因素的特点或影响效果分为四大类:(1)长期趋势;(2)季节变动;(3);(4)不规则变动。 第二步分析时间序列。时间序列中的每一时期的数值都是由许许多多不同的因素同时发生作用后的综合结果。 第三步求时间序列的长期趋势(T)季节变动(s)和不规则变动(I)的值,并选定近似的数学模式来代表它们。对于数学模式中的诸未知参数,使用合适的技术方法求出其值。 第四步利用时间序列资料求出长期趋势、季节变动和不规则变动的数学模型后,就可以利用它来预测未来的值T和季节变动值s,在可能的情况下预测不规则变动值I。然后用以下模式计算出未来的时间序列的预测值Y: 加法模式T+S+I=Y 乘法模式T×S×I=Y 如果不规则变动的预测值难以求得,就只求和季节变动的预测值,以两者相乘之积或相加之和为时间序列的预测值。如果经济现象本身没有季节变动或不需预测分季分月的资料,则长期趋势的预测值就是时间序列的预测值,即T=Y。但要注意这个预测值只反映现象未来的发展趋势,即使很准确的在按时间顺序的观察方面所起的作用,本质上也只是一个的作用,实际值将围绕着它上下波动。 []
动态规划:卷积码的Viterbi译码算法 学院:网研院?姓名:xxx 学号:xxx一、动态规划原理 动态规划(dynamic programming)是运筹学的一个分支,是求解决策过程(decision process)最优化的数学方法。动态规划算法通常用于求解具有某种最优性质的问题。在这类问题中,可能会有许多可行解,每一个解都对应于一个值,我们希望找到具有最优值的解。动态规划算法与分治法类似,其基本思想也是将待求解问题分解成若干个子问题,先求解子问题,然后从这些子问题的解得到原问题的解。与分治法不同的是,适合于用动态规划求解的问题,经分解得到子问题往往不是互相独立的。若用分治法来解这类问题,则分解得到的子问题数目太多,有些子问题被重复计算了很多次。如果我们能够保存已解决的子问题的答案,而在需要时再找出已求得的答案,这样就可以避免大量的重复计算,节省时间。 动态规划程序设计是对解最优化问题的一种途径、一种方法,而不是一种特殊算法。不象搜索或数值计算那样,具有一个标准的数学表达式和明确清晰的解题方法。动态规划程序设计往往是针对一种最优化问题,由于各种问题的性质不同,确定最优解的条件也互不相同,因而动态规划的设计方法对不同的问题,有各具特色的解题方法,而不存在一种万能的动态规划算法,可以解决各类最优化问题。 二、卷积码的Viterbi译码算法简介 在介绍维特比译码算法之前,首先了解一下卷积码编码,它常常与维特比译码结合使用。(2,1,3)卷积码编码器是最常见的卷积码编码器,在本次实验中也使用了(2,1,3)卷积码编码器,下面介绍它的原理。 (2,1,3)卷积码是把信源输出的信息序列,以1个码元为一段,通过编码器输出长为2的一段码段。该码段的值不仅与当前输入码元有关,而且也与其之前的2个输入码元有关。如下图所示,输出out1是输入、第一个编码器存储的值和第二个编码器存储的值逻辑加操作的结果,输出out2是输入和第二个编码器存储的值逻辑加操作的结果。 (2,1,3)卷积码编码器
卷积码的维特比译码原理及仿真 摘 要 本课程设计主要解决对一个卷积码序列进行维特比(Viterbi)译码输出,并通过Matlab 软件进行设计与仿真,并进行误码率分析。 实验原理 QPSK :QPSK 是英文QuadraturePhaseShiftKeying 的缩略语简称, 意为正交相移键控,是一种数字调制方式。四相相移键控信号简称“QPSK ”。它分为绝对相移和相对相移两种。 卷积码:又称连环码,是由伊莱亚斯(P.elias)于1955年提出来的一种非分组码。积码将k 个信息比特编成n 个比特,但k 和n 通常很小,特别适合以串行形式进行传输,时延小。卷积码是在一个滑动的数据比特序列上进行模2和操作,从而生成一个比特码流。卷积码和分组码的根本区别在于,它不是把信息序列分组后再进行单独编码,而是由连续输入的信息序列得到连续输出的已编码序列。卷积码具有误码纠错的能力,首先被引入卫星和太空的通信中。NASA 标准(2,1,6)卷积码生成多项式为: 346 1345 6 2()1()1g D D D D D g D D D D D =++++=++++ 其卷积编码器为: 输入序列 + + 输出c1 输出c2 图1.1 K=7,码率为1/2的卷积码编码器
维特比译码:采用概率译码的基本思想是:把已接收序列与所有可能的发送序列做比较,选择其中码距最小的一个序列作为发送序列。如果接收到L 组信息比特,每个符号包括v 个比特。接收到的Lv 比特序列与2L 条路径进行比较,汉明距离最近的那一条路径被选择为最有可能被传输的路劲。当L 较大时,使得译码器难以实现。维特比算法则对上述概率译码做了简化,以至成为了一种实用化的概率算法。它并不是在网格图上一次比较所有可能的2kL 条路径(序列),而是接收一段,计算和比较一段,选择一段最大似然可能的码段,从而达到整个码序列是一个最大似然值得序列。 下面以图2.1的(2,1,3)卷积码编码器所编出的码为例,来说明维特比解码的方法和运作过程。为了能说明解码过程,这里给出该码的状态图,如图2.2所 示。维特比译码需要利用图来说明移码过程。根据卷积码画网格的方法,我们可以画出该码的网格图,如图2.3所示。该图设接收到的序列长度为8,所以画8个时间单位,图中分别标以0至7。这里设编码器从a 状态开始运作。该网格图的每一条路径都对应着不同的输入信息序列。由于所有可能输入信息序列共有2kL 个,因而网格图中所有可能的路径也为2L 条。这里节点a=00,b=10,c=01,d=11。 m j m j-1 m j-2 输出序列 m 1,m 2,…m j ,… y 1j y 2j 输入序列 00 a d 10 c b 11 00 11 01 01 10 图2.1 (2,1,3)卷积码编码器 图2.2 (2,1,3)卷积码状态图
一种卷积码维特比译码算法的软件实现Ξ 张海勇1) 刘文予1) 芦东昕2) 吴 畏2) (华中科技大学电子与信息工程系1) 武汉 430074) (中兴通讯股份有限公司2) 深圳 518057) 摘 要 提出了数字通信系统中一种卷积码译码的软件实现方案,该方案应用软件技术实现了卷积码维特比译码器功能,在程序实现中充分利用了卷积码的特性,运用蝶形运算,周期性的回溯以得到译码输出。在程序设计上采用了一些宏定义等处理方法,可以提升运算速度,是一种软件方法的前向纠错编码技术。 关键词:卷积码 维特比译码算法 蝶形运算 回溯 中图分类号:TP31 A Soft w are Implementation of Viterbi Decoding Algorithm Zhang H aiyong1) Liu Wenyu1) Lu Dongxin2) Wu Wei2) (Dept.of Electronics&Information Engineering1),HUST,Wuhan430074) (ZTE Corporation2),Shenzhen518057) Abstract:A software implementation of a channel coding technology is presented,which realizes the functions of convolution2 al coding and Viterbi decoding.According to convolutional codes feature,this software uses butterfly algorithm which is defined as a macro,periodically traces back to get the decoding output,we also use some other methods in the program,can speed up the al2 gorithm,which belongs to a forward error correction coding technology. K ey w ords:convolutional code,Viterbi decoding algorithm,butterfly algorithm,trace back Class number:TP31 卷积码是由伊莱亚斯(Elias)于1954年首先提出来的。它充分利用了各组之间的相关性,本组的信息元不但决定本组的监督元,而且也参与决定以后若干组的监督元。同时在译码过程中,不但从该时刻所收到的码组中提取译码信息,而且还利用以后若干时刻内所收到的码组来提取有关信息。无论从理论上还是实际上均已证明其性能不差于分组码。在一些采用了前向纠错的系统里,如GS M/CDM A通信系统、卫星与空间通信系统里广泛采用了卷积码[1]。 卷积码译码器的设计是由高性能的复杂译码器开始的,如最初的序列译码,随着译码约束长度的增加,译码错误概率可达到非常小。后来慢慢地向低性能的简单译码器演化,对不太长的约束长度,维特比(V iterbi)算法是非常实用的。维特比算法是一种最大似然的译码方法。当编码约束度不太大(小于等于10)或者误码率要求不太高(约10-5)时[2],它的设备比较简单,用硬件译码计算速度很快。本文将给出一种用软件实现卷积码维特比译码算法的设计方法,针对译码中计算量最多的蝶形运算,采用宏定义的方式,并在计算度量长度时采用双数组计算,能够加快译码计算速度。 1 卷积码编码器的参数分析 卷积码把信源输出的信息序列以每段k0个码元进行分段,通过编码器输出长为n0的一个码段,该段(n0-k0)个校验元不仅与本段信息元有关,还与其前面m段信息元有关。卷积码可以用(n0,k0,K)表示,其中(K=m+1)为约束长度,串联的移位寄存器的数目以m表示,一个信息 Ξ收到本文时间:2004年12月2日