
第2章 S P S S数据文件的建立与编辑
数据管理是SPSS的重要组成部分,也是对数据进行统计分析的基础。在对数据分析之前
必须先建立数据文件,将收集到的各种信息、数据输入计算机中。SPSS具有建立数据文件的功
能,在SPSS中建立数据文件分两步:一是在变量视图(V ariable V iew)中建立数据文件的格式(定
义变量名、类型、宽度等),另一个是在数据视图(Data V iew)中,向建立好格式的数据文件中输
入数据。现以某单位人事档案工资表为例说明建立数据文件的基本方法。
表2.1 某单位人事档案工资表
编号姓名性别出生年月职称婚否工资奖金
(x1)(x2)(x3)(x4)(x5)(x6)(x7)(x8)
0101李莉娟 女 01/12/78助 工 F230.5030.00
0102王万宏 男 12/23/60高 工 T500.0050.00
0103张华卫 男 07/01/70工程师 T240.0060.00
0104赵 斌 男 11/05/54高 工 T350.0080.00
0105梁 萍 女 03/12/79助 工 F210.0020.00
0201王兰香 女 11/23/78工 人 F230.0034.00
0202黄丽丽 女 05/12/67工程师 T350.0040.00
0203王永歌 男 06/29/72助 工 F240.0025.00
0204许艳艳 女 02/28/64高 工 F490.0030.00
0205李建辉 男 04/12/68工程师 T340.0040.00
2.1建立数据文件
执行“开始”|“程序”|“SPSS FOR WINDOWS”|“SPSS FOR WINDOWS”命令,启
动SPSS或双击桌面上的快捷图标即可启动SPSS软件并显示数据编辑窗口(DA TE EDITOR)。
数据编辑窗口有两个标签,一个是变量视图(V ariable V iew),另一个是数据视图(Data V iew)。
变量视图用于定义和编辑变量的数据格式,数据视图用于输入数据。
⒈定义数据文件格式
单击V ariable View(变量视图)标签,打开变量视图窗口,系统出现定义变量的10种选项,
功能如下:
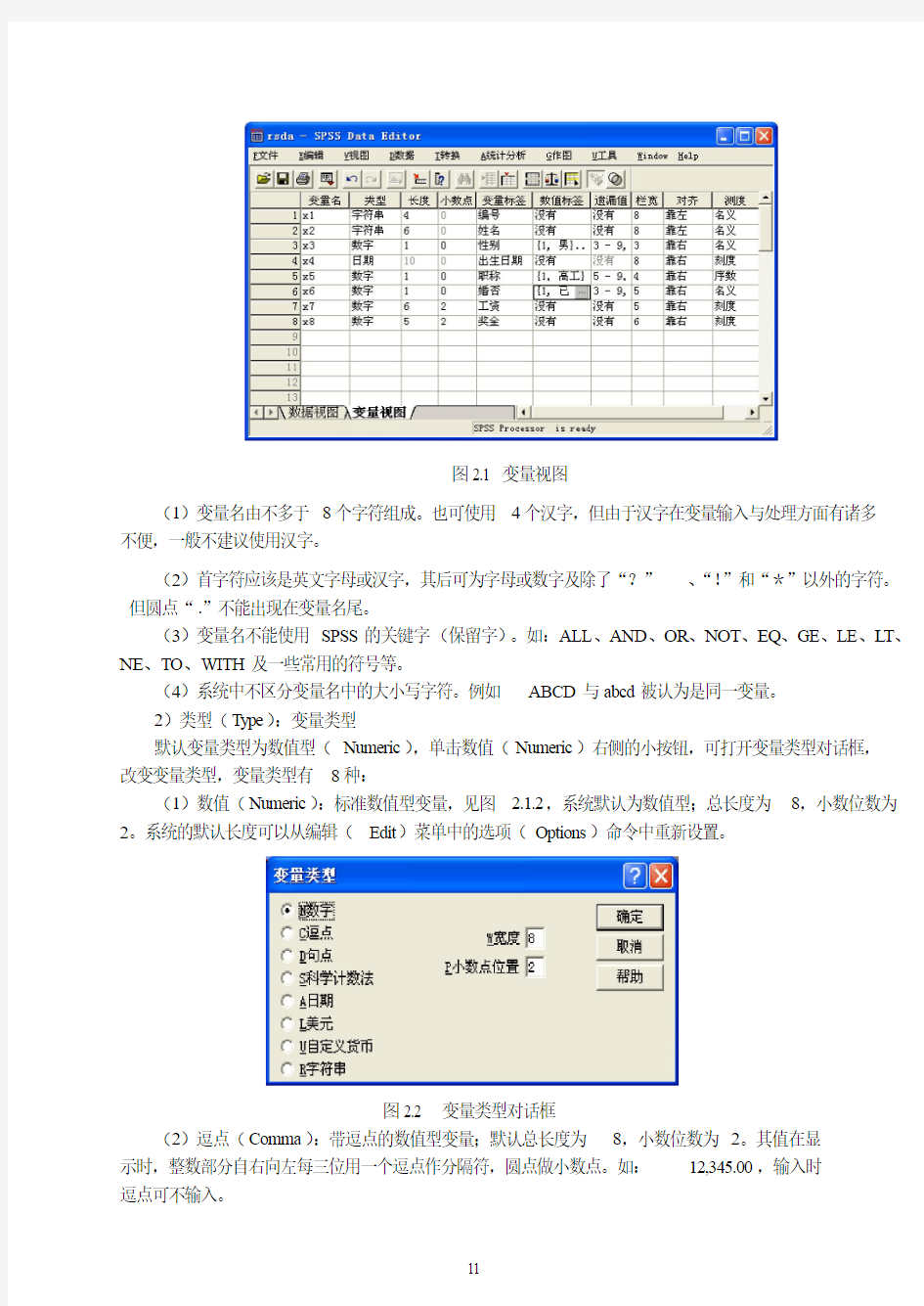
1)变量名(Name):
变量名栏,在该栏输入变量名。本例,定义x1、x2 、x3、x4、x5、x6、x7、x8等8个变量为变量命名,见图2.1,变量命名应该遵循如下原则:
图2.1 变量视图
(1)变量名由不多于8个字符组成。也可使用4个汉字,但由于汉字在变量输入与处理方面有诸多不便,一般不建议使用汉字。
(2)首字符应该是英文字母或汉字,其后可为字母或数字及除了“?”、“!”和“*”以外的字符。但圆点“.”不能出现在变量名尾。
(3)变量名不能使用SPSS的关键字(保留字)。如:ALL、AND、OR、NOT、EQ、GE、LE、L T、NE、TO、WITH及一些常用的符号等。
(4)系统中不区分变量名中的大小写字符。例如ABCD与abcd被认为是同一变量。
2)类型(Type):变量类型
默认变量类型为数值型(Numeric),单击数值(Numeric)右侧的小按钮,可打开变量类型对话框,改变变量类型,变量类型有8种:
(1)数值(Numeric):标准数值型变量,见图2.1.2,系统默认为数值型;总长度为8,小数位数为
2。系统的默认长度可以从编辑(Edit)菜单中的选项(Options)命令中重新设置。
图2.2 变量类型对话框
(2)逗点(Comma):带逗点的数值型变量;默认总长度为8,小数位数为2。其值在显
示时,整数部分自右向左每三位用一个逗点作分隔符,圆点做小数点。如:12,345.00,输入时
逗点可不输入。
(3)句点(Dot ):带圆点的数值型变量;默认总长度为8,小数位数为2。显示时与逗点
(Comma )相反,其值在显示时,整数部分自右向左每三位用一个圆点作分隔符,逗点做小数点。
(4)科学记数法(Scientific Notation ):科学记数法;默认总长度为8,小数位数为2。对
于很大或很小的数据用此方法表示,指数的字母可以用E ,也可用D ,也可省略,如:12345可输入为1.2345E4、12345、1.2345D4、1.2345E+4、1.2345+4,但显示值为1.2345E+04
(5)日期(Date ):日期型变量,有27种表示方法,见表2.2和图2.3;
表2.2 日期型变量格式 格式
说明 格式 说明
dd-mmm-yyyy 日日-月月月-年年年年
dd-mmm-yy 日日-月月月-年年
mm/dd/yyyy 月月/日日/年年年年
mm/dd/yy 月月/日日/年年
dd.mm.yy 日日.月月.年年
yydd 年年日数
y yyydd 年年年年日数
qQyyyy 季度Q 年年年年
qQyy 季度Q 年年
mMmyyyy 月份年年年年
mMmyy 月份年年
wWWKyyyy 周数WK 年年年年
wWWKyy 周数WK 年年 MONDA Y ,TUESDA Y… 星期几 MON,TUE,WED…… 星期几的缩写JANUARY ,FEB… 月份 JAN,FEB,NAR 月份缩写 dd-mmm-yyyy hh:mm 日日月月月-年年年年 时时:分分 dd-mmm-yyyy hh:mm:ss 日日-月月月-年年年年 时时:分分:秒秒 dd-mmm-yyyy hh:mm:ss.ss 日日-月月月-年年年年 时时:分分:秒秒.百分秒 hh:mm 时时:分分 hh:mm:ss 时时:分分:秒秒 hh:mm:ss.ss 时时:分分:秒秒.百分秒 ddd:hh:mm 日数:时时:分分 ddd hh:mm:ss 日数:时时:分分:秒秒
ddd hh:mm:ss.ss 日数:时时:分分:秒秒.百分
秒
图2.3 变量类型对话框日期格式
(6)货币型(Dollar ):货币型变量,默认总长度为8,小数位数为2,其值在显示时有效
数字前有“$”,用逗点做分隔符。输入时可不带“$”,系统自动加上。如输入12345.67系统自动显示:$12,345.67有12种表示方法,见表2.3和图2.4 ;
图2.4 变量类型对话框美元格式表2.1.3 贷币型变量格式
格式位数总长度小数格式
数
总长度小数位
$ #
$ # #
$ # # # $# # #.# # $#, # # # $ #,# # #.# # 2
3
4
7
6
9
2
2
$ # # # ,# # #
$ # # # ,# # #.# #
$ # # #,# # #,# # #
$ # # # ,# # # .# # #.# #
$ # # # ,# # # ,# # #,# # #
$ # #,# # #,# # #,# # #.# #
8
11
12
15
16
19
2
2
2
(7)自定义型(Custom currency):自定义型变量,是一种由用户利用编辑(Edit)菜单的选项(Options)功能定义的,一般用于货币符号等的设置,见图2.5;
图2.5 变量类型对话框自定义货币格式
其中:CCA、CCB、CCC、CCD、CCD、CCE是用户自己定义的5种自定义格式,CC为自英文定义货币型的首字母,A-E为编号。如定义CCA的格式为¥1,234.56RMB等。可在编辑(Edit)菜单的选项(Options)命令中,打开货币(Currency)选项卡,进行设置,其中全部数值(All V alues)用于设置首(前缀)(Prefix)、尾(后缀)(Suffix)字符,负数(Negative V alue)栏用于设置负数的首(Prefix)尾(Suffix)字符,系统默认负数的首字符是“-”。小数点分隔符(Decimal Separator)栏用于设置小数点的符号,默认为圆点(Period),也可定义为逗号(Comma)。
图2.6 选项对话框
(8)字符型(String):字符型变量。
有任何可以显示的字符组成,可以是汉字或字符,宽度1-255,作为常量时应用单引号“’”、双引号“””括起。注意应为英文引号。
一般地,为便于数据统计,变量类型应定义为数值型。
3)宽度(Width)与小数位数(Decimals)。
根据每个变量数据的大小(最大数)及保留小数点的位数,定义变量的总宽度,小数点位数。总宽度包括小数点位数,但不包括小数点本身。如:12345.67。宽度定义为7位,2位小数。应该再次强调的是宽度是变量内容的宽度,而不是变量本身的宽度。本例中,定义性别数值型、小数为0.
4)变量标签(Label)。为了便于标示变量,对变量的含义进行进一步说明常常需要用汉字表示,变量的内容,如X3变量的标签为“性别”。其最大长度为255个字符。给变量加上标签后,在数据窗口鼠标指向变量时,变量名下会显示标签。在对数据分析后出现的结果输出窗口中凡是出现变量名的地方均用变量标签来表示。
5)数值标签(V alues):。
对X3(性别)及X5(职称)变量,对变量的可能取值进行进一步的说明,通常仅对分类变量的取值指定值标签。当变量值是有限数据时,对这些数据输入时尽量用代码输入,以加快输入速度、方便数据处理。如性别中“男”可输入“1”(或M),“女”可输入“2”(或F),职称也与此类似。结果输出时为了便于识别,可以使用数值标签,定义输入值的含义。默认没有数值标签(None),要改变,可按以下步骤:
(1)单击None后的小按钮,弹出数值标签(V alue Label)对话框,在上面的“数值”(V alue)栏中输入变量值,如“1”,在下面的数值标签(V alue Label)栏中输入标签如“男”,单击“Add”按钮,同理可输入其他数值说明。X3中“1”为“男”,“2”为“女”。
(2)单击确定按钮
这样凡是在结果中性别是“1”的地方都会用“男”代替,性别是2的地方都会用“女”代
替。见图2.7
图2.7 数值标签对话框
如要在数据视图中显示变量值用数值标签表示,则可执行“视图(V iew)菜单|数值标签(V alue label)”命令,如对性别变量值标签定义完毕后,则输入1时将显示“男”,2时显示“女”,也可通过单击“值”标签右侧的按钮,在弹出的下拉列表框中进行选择其他值,用于对输入值的修改。但变量中存放的数值仍然是其原值,这里是1和2。
6):缺失值(Missing),缺失值有二种类型
一种是用户定义的缺失值。由于调查数据资料时(如测量人群生长发育情况),某项数据(如身高)没有调查,数据收集错误(调查表上填写数据错误,如身高误写为300CM),或输入数据完毕后发现一些数据不符合逻辑等。可以将这些数据定义为遗漏值或称缺失值、缺省值,对数据进行分析时,系统将不分析这些数据,使该项其他数据有效,用户可以定义以下3种缺失值。
(1)没有缺失值(No missing values)无需定义缺省值,即除了默认的缺省值外,不设缺省值,这是默认方式。
(2)离散的缺失值(Discrete miss values):可定义1~3个离散的单一数为缺失值;如有效范围为1-7 ,缺失值可定义为0,8,9
(3)范围加离散的缺失值(Range plus one optional discrete miss): 定义指定某一范围为缺失值,同时指定另外一个不在这一范围内的离散单一数为缺失值,如可定义性别中3-9及0为缺失值,见图2.8。
图2.8设置遗漏值
另一种是系统缺失值,指在数据输入时某项数据由于没有输入(如按回车键跳过某项数据)或输入不合逻辑的数据(如数值型数据输入一个英文字符),系统默认缺省值为“.”。系统缺省值不需定义。
缺失值定义后,在进行数据统计时默认不参加计算。这样会产生数据例数不一的情况,对数值型及日期型数据,为保持数据完整性,系统提供了5种不同替代缺省值的方法。
(1)选择主菜单的“数据转换(Transform)=> 替换缺省值(Replace Missing V alues…)”命令,打开替换缺省值对话框。
(2)在左侧变量列表框中选择要转换缺省值的变量,方法与Windows中选择文件方法类似,要选择一个变量单击某变量,要选择多个连续变量,可单击第一个变量,然后按Shift键后单击最后一个变量,或用鼠标拖动的方法选择;要选择多个不连续变量,可单击第一个变量,然后按Ctrl键后单击其他要选择的变量。
(3)变量选择完后,单击对话框中间的右向箭头按钮。将选择变量选择到新变量(New variables)框中,
(4)在名称和方法框(Name and Method)选择新变量名称和方法
默认变量名为变量名后加下划线表示。如X8,新变量为X8_1。
默认方法(Method)为使用该变量的均数替代缺省值,在可以使用其他。X8_1变量中数值为将缺省值用均数替换,其他值不变。替代缺省值(Replace Missing V alues)的方法(Method)可以是(图2.9):
l Series mean,将缺省值替代为均数(默认)。
l Mean of nearby points,用邻近点有效数值的均数替换缺省值。
l Median of nearby points ,用邻近点有效数值的中位数替代缺省值。
l Linear Interpolation,用线性插值法替代缺省值。如果序列的第一个或最后一个值是缺省值,则不被替代。
l Linear trend at points:用点的趋势替换缺省值。当前序列将根据与从1到n的变量进行回归,缺省值将被替换成预测值。
图2.9替代遗漏值
7)栏宽(Columns): 定义变量值的列显示宽度,默认宽度为8,用户根据需要可进行调整。
8)对齐(Align): 字符对齐方式,有三种选择项:
靠左(Left)向左对齐;靠右(Right)向右对齐;居中(center)居中对齐。默认字符型数据左对齐,其他数据为向右对齐,用户可单击右侧的下拉列表中选择一种对齐方式。
9)测度:(Measure)数据测度选项,
测度是指按照某种法则给现象、事物或事件分派一定得数字或符号,通过测度来刻划事物的特征或属性。有三种类型选择:
(1)刻度型(Scale),定比测度或比率测度,为连续型变量,表示间隔测度的变量和表示比值的变量,如身高、体重等。
(2)序数(Ordinal):定序测度或顺序测度,为有序分类变量,用于表示有顺序的等级变量,如文化程度,职称,考试排名等。变量值可以是数值型,也可以是字符型;
(3)名义型((Nominal):定类测度,或名义测度,为标称变量,是分类变量的一种,可以是数值型变量,也可以是字符型变量,如:性别、宗教信仰,党派等,没有顺序大小之分。
测度的确定与许多统计分析过程以及图形过程有密切关系。在这些过程中系统需要区分变量是定比测度或分类变量。后两种只作为分类变量对待。如该统计过程没有要求,则按系统默认数值型自动按刻度型(Scale),字符型自动按名义测度(Nominal)也可。
本例,x3(性别)可定义为名义型(Nominal)类型变量。X5(职称)为Ordinal型变量。见图2.1.
2、数据录入
将变量定义完毕,单击窗口下端的数据视图(Data V iew)标签,定义的变量会自动出现在窗口上端,将表2.1.1中的数据依次录入。
图2.10 据视图中数据
①在定义变量之后,数据编辑窗口形成了一个数据文件的二维表格,表格的顶部标有定义的变量名,表格的左侧有观察值(case)的序号(黑色的说明已输入数据,灰色的说明没有数据被输入)。
②一个变量名和一个观察量序号就对应了二维表格中的一个单元格。输入数据时可按变量(列式)输入数据,也可按察序号(记录、行式)输入数据,默认按变量输入数据,
③输入数据时,单击鼠标左键,把插入点定位到第一个单元格,使该单元格为当前操作的单元格,输入该变量的第一个值,按回车键;当前操作单元格下移到同变量下一个单元格,输入第二个值,以此方法把该变量值输完。如按观察序号(记录)输入数据,可在一个单元格输完数据后按“T ab”键,输入同一观察序号(记录)的下一变量值,输入数据时,可利用上、下、左、右光标键,或单击鼠标将光标移到插入点定位到某一单元格,并在其中输入或编辑数据。
3、文件的保存
第一次保存文件时,单击文件(File)菜单中的保存(Save)命令或工具上的保存按钮,系统会弹出另存为(Save Data As)对话框,如图2.11 ,系统给出14种保存的格式供选择,分述如下(括号内为扩展名):
图2.11另存为对话框
⑴SPSS(*.sav):SPSS for Windows建立的数据文件;
⑵SPSS7.0(*.sav):SPSS for Windows7.0建立的数据文件;
⑶SPSS/PC+(*.sys):SPSS/PC或SPSS/PC plus建立的数据文件;
⑷SPSS portable(*.por):一种ASCⅡ码文件;
⑸T ab-delimited(*.dat):是用ASCⅡ码写的数据文件;
⑹Fixed ASCⅡ(*.dat):混合ASCⅡ码数据格式文件;
⑺Excel(*.xls):Excel的数据格式文件;
⑻1-2-3 Rel3.0(*.wk3):Lotus3.0版本的数据格式文件;
⑼1-2-3 Rel2.0(*.wk1):Lotus2.0版本的数据格式文件;
⑽1-2-3 Rel1.0(*.wks):Lotus1.0版本的数据格式文件;
⑾Sylk(*.slk):多种扩展电子表格的文件;
⑿dBASEⅡⅢ Ⅳ(*.dbf):dBASEⅡⅢⅣ版本的文件。
本例中,选择SPSS 数据文件格式SPSS(*.sav),并选择路径(可事先在C盘建立一个名为自己名字如DA T A命名的文件夹,也可单击该窗口中的“新建”按钮)和文件名“RSDA.SA V”,单击对话框中的“Save”即可,数据编辑窗口标题栏上出现文件名。数据保存时可单击变量(V ariables)按钮打开保存变量(SA VE AS V ARIABLES)对话框。在保留(KEEP)列可选择需要保存的变量(打X号),也可选择“保存所有”(KEEP ALL)变量或“去除所有”(DROP ALL)变量的保存。单击“继续”(CONTINUE)返回“另存为”(SA VE AS)对话框。
如果是一个保存过的数据文件,要存盘文件,单击保存命令不会弹出另存为对话框,要换名存盘,可选择“File“(文件)菜单中的“Save Data”另存为命令,打开另存为对话框。
⒊文件的打开
单击“文件”(File)菜单中的“打开”(Open)子菜单,选择“数据”(Data)选项,出现“数据文件”(Open File)对话框,如图2.12,对话框中出现12种选项,分述如下(括号内为
扩展名):
图2.12 打开文件
⑴SPSS(*.sav):SPSS for Windows建立的数据文件,默认文件类型;
⑵SPSS/PC+(*.sys):SPSS/PC或SPSS/PC plus建立的数据文件;
⑶Systat(*.syd):美国疾病控制中心编写的流行病学分析软件;
⑷Sytat(*.sys): 美国疾病控制中心编写的流行病学分析软件;
⑸SPSS portable(*.por): 一种ASCⅡ码文件;
⑹Excel(*.xls):Excel的数据格式文件;
⑺Lotus(*.w*):Lotus文件;
⑻Sylk(*.slk): 多种扩展电子表格的文件;
⑼dBASE (*.dbf):dBASE文件;
⑽T ext(*.txt):纯文本文件;
⑾Data(*.dat):Data文件;
⑿All files(*.*): 所有文件。
本例中选择Spss(*.sav),给出路径名(如C盘DA T A文件夹)及文件名后(RSDA.SA V),单击对话框中的“Open”(打开)选项,即可打开目的文件。
如要打开最近打开过的数据文件,可以在FILE(文件)菜单下端的最近使用过的数据文件(RECENT USED DA T A)菜单中选择。打开其他文件(程序文件、结果文件)可在最近使用过的文件(RECENT USED FILE)中选择。
2.2数据文件的编辑与管理
对数据进行处理时,一种统计分析方法需要数据具有一定的数据格式,因此需要对原来数据文件进行编辑加工,它包括变量的增加和删减、观察值的增加和修改,数据的定位、排序、对数据进行转换或重新编码等。
⒈增加新的变量(I n s e r t V a r i a b l e)
(1)如果要在某一处增加一个新变量,可先切换到变量视图(V ariable View),然后把插入点定位于该处。
(2)单击数据(Data)菜单中的插入变量命令(Insert V ariable)。如单击X5(职称)变
量行的任一个单元格,然后单击Data菜单中的Insert V ariable子菜单命令,系统自动插入一个新的变量,默认插入的第一个变量名为var00001,如插入第二个变量则为var00002,用户可以定义其名字(Name)类型(Type)、宽度(Width)等项目。变量插入后在数据视图输入数据,见图2.13,如为var00001,更名为age(年龄)。
图2.13 插入变量
(3)也可在数据视图中用类似方法插入变量,但默认类型为数值型(Numeric),需到变量视图(V ariable view)修改其类型(Type)、宽度(Width)等格式。
(4)如要增加多个同格式变量,可先选中原变量(如X8),选择编辑(Edit)菜单中的复制(Copy)变量命令,将变量格式复制到剪切板,然后单击编辑(Edit)菜单中的粘贴变量(Paste V ariable)项,打开粘贴变量(Paste V ariable)对话框,
2、修改变量格式
要修改变量名(Name)、类型(Type)、宽度(Width)、小数位(Decimals)等格式可单击V ariable View(变量视图)标签,单击需修改格式单元格进行修改。如可将X3(性别)类型变为“STRING”(字符)型。
图2.14 粘贴变量
3、删除变量
(1)在变量视图中单击待删变量的序号(位于变量行首),此时整个变量列被选中,呈反象显示(黑底白字)
(2)然后单击编辑(Edit)菜单中的清除(CLEAR)命令或按键盘中的Delete键,该
列即被删除。
(3)也可在数据视图中单击变量名,选中变量列,执行编辑(EDIT)菜单中的剪切(CUT)命令或清除(CLEAR)命令,或按DEL键删除变量。
变量删除后其中的数据将一起被删除,因此删除时要确认。
4、移动变量位置
(1)在变量视图中(V ariable V iew)中单击要移动变量所在行的行号(如X5前的5),选中要移动的变量行。
(2)将鼠标指向变量名前的行号(5)的拖动到需要的位置(X8下面最后处),则将变量移动到需要的位置。
(3)数据视图(Data V iew)中单击变量名,选中变量列,拖动鼠标到目标位置处。
5、浏览数据
(1)在数据视图中,看到输入的数据,如果变量或观察值在一个窗口显示不完全,可使用垂直及水平滚动条移动到所需位置(或P AGEUP、P AGEDOWN)。
(2)当变量较多时,由于移动使一般位于前面的标志变量(如编号、姓名)移出屏幕之外,可选中这些变量(方法是在数据视图中⒌通过拖动鼠标选定变量),再单击鼠标右键,在弹出的快捷菜单中选择锁定选定的列(PIN SELECTED COLUMNS)命令,则这些列将不移出屏幕之外。运用同样的方法,选择UNDO PINNING(撤消锁定)则可取消锁定。
(3)单击视图(VIEW)菜单中的数据(DA T A)命令或按CTRL+T,可转换到数据视图,此时“视图|数据”(VIEW| DA T A)菜单变为“视图|变量”(VIEW|V ARIABLE),单击它(或按CTRL+T)可转换为变量视图。
(4)执行视图|字体(VIEW|FONT)命令,打开字体对话框,可改变显示字符的字体、字号、字型等。
(5)执行“视图|网格”(VIEW |GRID LINES)命令(前面有“√”为选定),可“设置或取消”栅格。
(6)执行“视图|数值标签”(VIEW |V ALUE LABELS)命令(前面有“√”为选定),可“设置或取消”数值标签的显示,如上例设置性别变量中的1…男,2…女数值标签。如选定,则性别栏中的变量值为“1”的地方显示为“男”、“2”的地方显示为“女”。
图2.15视图菜单
6、观察值的修改
如果数据输入错误,单击该单元格,激活这个单元格,使它成为当前操作单元格,可重新输入数据;双击该单元格,可修改单元格中内容。可用上下左右光标键或垂直滚动条、水平滚动条来查找要修改的数据,也可直接搜索某一观察序号(记录)。记录号在数据编辑窗口的左端为流水号是输入数据时系统自动产生的,用户不需建立。对观察值的修改同样也可使用复制粘贴的方法,操作之前。需选定需要操作的单元格。
1)选定单元格
(1)选定一个单元格在该单元格上单击鼠标左键。如单击观测值号则选定该行观测值。
(2)选定连续多个单元格先选定一个单元格,然后再在最后一个单元格上按SHIFT 键同时单击鼠标左键,则可选定两个单元格之间的矩形区域。也可用鼠标拖动的方法选定一矩形区域。先选定第一个观测值行号再按SHIFT键单击最后一个观测值号则选定几行观测值。
(3)选定不连续的几行观测值。先选定第一个观测值行号,按CTRL键选定其他观测值行号,则几行观测值被选定。
2)复制单元格或观测值
(1)选定需要复制的单元格或观测值
(2)单击编辑(EDIT)菜单中的复制(COPY)命令;单击鼠标右键,从快捷菜单中选择复制(COPY)命令;使用Ctrl+C快捷键
将选定内容复制到剪贴板。
(3)选定数量相等的的单元格或观测值行。执行编辑(EDIT)菜单中的粘贴(Paste)
命令、单击右键从弹出的快捷菜单中选择粘贴(Paste)命令,执行Ctrl+V快捷命令。
图2.16复制观测值
3)移动单元格或观测值
与复制同执行操作时将复制(COPY)换成剪切(CUT)即可。
7、案例定位(G o T o C a s e)
如果数据量很大,查找某一个观察值就很有必要。例如,想要查找第8号观察值,操作如下:
(1)单击数据(Data)菜单中的案例定位(GO TO CASE)子菜单,系统出现案例定位对
话框。见图2.17
图2.17 案例定位
输入要查找的观察值的编号8
(2)单击确定按钮(OK),系统就会定格在第8个观察值和行头。
8、在指定变量中查找数据
(1)打开数据文件RSDA.SA V,单击鼠标左键,将插入点定位于需要查找数据的变量如
X2(姓名)列的任意单元格。
(2)选择主菜单中的“(编辑)Edit”|“查找(Find)”命令,打开“在变量中查找数据
X2”(find data in variable X2)对话框,见图2.18。
(3)在查找(FIND)文本框中输入要查找的数据,如“王兰香”。单击找下一个(FIND NEXT)
则向下寻找符合条件的数据,如找到则将鼠标定位于该记录,单击找下一个(FIND NEXT)继
续查询下面符合条件的记录。如没有找到则显示“没有找到”(NO FIND),记录找到后可对其进行编辑。
图.2.18 查找数据
9、增加新的观察值(I n s e r t C a s e)插入案例。
图2.19 插入案例
如果要在第5号观察值之前插入一个新的观察值,操作如下:
先单击需要插入观察值(5号)的所在行任一单元格,然后执行数据(Data)菜单中的插入观察值(Insert Case)子菜单,系统自动在当前位置插入一行空白的观察值,原来的观察值自动下移,在新观察值上录入数据,见图2.19。
10、删除一个观察值行(D e l e t e C a s e)
(1)将插入点定位到需要删除的观测值行序号上(如5号观察值),选定该行观察值(2)执行(编辑)Edit菜单中的(剪切)Cut命令或(清除)CLEAR命令或按Delete键,该行即被删除。
(3)如没有选定行号而是选定多个单元格则仅删除选定的单元格中数据而不删除该观察值。
图 2.20 删除观测值
11、数据的排序(S o r t C a s e s)
在对数据进行分析时,有时需要按某个或某几个变量值对数据重新排列。可用排序命令如在RSDA.SA V文件中,按X3(性别),X7(工资)进行排序。
(1)选择数据(Data)菜单中排序观测值(Sort Cases)命令,打开排序观测值(Sort Cases)对话框,见图.2.21。
(2)对话框的左侧是可供选择的排序变量,双击第1个排序变量如X3进入右侧对话框,再选择(双击)第二个排序变量X7进入右侧对话框。
(3)对每一个排序变量都有两种排序方式可供选择:递增(Ascending)为按升序排序;递减(Descending)为按降序排序。本例X3(性别)按升序,即先1(男)后2(女),X7(工资)按降序(高工资在前,低工资在后),单击OK按钮。
(4)可看到先按第一排序变量(性别)的值进行排列,当第一变量值相同时再按第二变
量(工资)的值进行排列。排序之前需先保存原始数据。
图.2.21 案例排序
12、数据的行列互换(T r a n s p o s e)
数据分析之前的重要步骤是对数据进行整理成需要的格式,以适应数据分析的要求,有时需要将数据中的数据原来以行(列)方向排列的数据转换成按列(行)方向排列的数据。操作步骤:
(1)在进行操作之前,为便于说明问题,在X1变量前新增加一个变量X0(新变量)其值为y1-y10。字符型,宽度3位。
(2)执行“数据菜单|行列转置(Data|Transpose)”,打开行列转置(Transpose)对话框(见图2.22)。
图 2.22 行列转置
(3)从源变量清单中选择转置变量,进入变量(V ariables)框中,这里我们选择x7(工资)、X8(奖金)两变量进入右侧的变量(V ARIABLES)框。
(4)选择名称变量进入名称变量(NAME V ARIABLE)框,这里我们选择X0,然后单击确定按钮。则会出现如图2.23结果:
图2.23 行列转置后的数据文件
产生的新数据会在第一列出现一个case_lbl新变量,用于存放原来数据的变量名,如图3.7如不事先定义新变量,则变量名默认为V AR0001、V AR0002…等,可用同样方法将数据再转换回原来的排列方式。需要注意的是转换变量需是同类型的变量,字符型变量不能转置。若变量类型不同则会用系统缺省值(.)替代。
13、数据文件的拆分(S p l i t F i l e)
文件的拆分相当于统计学中的分组,即将数据按一个或几个分组变量分成一些统计分析的组,有时在对数据进行分析时需要按不同类别对某一变量进行分组分析。例如,要用FREQUENCES命令求不同性别职工的平均工资,因为该命令只能对整个变量进行分析,不能分组,因此在进行分析之前须按X3(性别)对该数据进行拆分。但“拆分”并不是将一个数据文件拆分为两个或若干个独立的数据文件,仍然是一个文件,文件拆分后启动一个对拆分后的各分组数据进行统计分析的过程,按给定的拆分变量(如:X3(性别))进行排序,以便对不同性别分别进行分析。从表面上看,拆分效果与数据分类整理(排序)结果相同。
文件拆分基本步骤:
(1)执行“数据菜单|拆分文件”(Data|Split File)子菜单”命令,打开拆分文件(Split File)对话框,见图2.24。
(2)系统默认的是对数据文件中所有观测值(Analyze all cases)进行分析,为了按不同组别(性别)对观测值进行分析,可选择比较分组(Compare groups)选项。也可选择以分组形式输出(Organize output by Groups),两者区别是输出格式的不同。前者将分组变量安置在同一表格里比较层叠输出,后者将按每一分组变量单独输出。
图2.24 拆分文件对话框
(3)选择分组变量X3(性别)进入“按…分组”(Groups Based on)对话框,说明按X3(性别)作为分组的依据。在“按…分组”(Groups Based on)对话框下面有两个选择项:
文件已经排序(File is already sorted)是指数据文件已经按所选择的变量排序,如数据文件已经排序则选择此项。
按组变量排序文件(Sort the file by grouping variables)是指按分组变量对数据文件进行分类排序,我们选择后者对数据按X3(性别)排序。
(4)单击OK(确定)即可完成对数据文件的拆分,结果见图2.25。根据前面叙述可选择分析所有观测值(Analyze all cases)来取消拆分。
图2.25 拆分结果
14、数据文件的合并(M e r g e F i l e s)
合并数据文件包括两种方式:纵向合并和横向合并,从外部数据文件中增加观测值到当前数据文件中(Add Cases),称为纵向合并,即增加观测值;从外部数据文件中增加变量到当前数据文件中(Add V ariables),称为横向合并,即增加变量。
1)增加观测值(Add Cases):假设有另外一个数据文件RSDA2.sav(如图2.26),录入了另外10名职工数据,为便于统计分析,需要把RSDA2.sav中的数据增加到RSDA..SA V中,这里我们为了说明,可把RSDA.SA V另存一份名为RSDA2.SA V。在RSDA文件中新增加一个变量XX,内容与X8相同(可采用复制/粘贴命令)。在RSDA2.SA V文件中将X1,X2分别更名
XX1,XX2。合并文件具体操作如下:
图2.26 增加变量菜单
(1)单击数据(Data)菜单中的合并文件(Merge Files)子菜单,然后选择增加观察值(Add
Cases)命令,弹出增加观察值读文件(Add Cases:Read File)对话框,如图2.27。
图2.27 读取增加观测值文件对话框
(2)选择需合并的文件,RSDA2.sav,单击打开,弹出Add Cases From RSDA2(添加来自RSDA2的文件)对话框,如图2.28。
在对话框的左侧为不匹配变量(Unpaired V ariables),列出分属两个文件的不成对变量名,即变量名和类型不相匹配的变量,其中用[*]标记表示工作文件,用[+]标记的属于外部文件,带“<”的为字符变量,右侧为新工作表文件(V ariables in New Working Data File)列出匹配变量,只有相同的变量(变量名、类型等)才能合并到一起。
(3)如果两文件的变量名不同,类型相同,是一种类型的数据,如X1、X2与XX1、XX2变量,增加观测值时,应将两者(X1、XX1)同时选中(按CTRL单击变量名),单击配对(Pair)按钮,将它们移至新数据文件中的变量(V ariables in New W orking Data File 框)中,合并后的新文件变量列表里二者的观测值将合并到工作文件(rsda.sav)x1变量中。
同理可合并X2、XX2变量。新工作表变量宽度为工作文件(rsda.sav)数据宽度,如工作文件的数据宽度小于外部文件的数据宽度,则外部文件的观测值不会显示出来,而以“*”
代替。
图2.28 选择合并数据变量
(4)对左侧不匹配变量,可以对其更名,方法是选中需更名的变量,如X1单击更名(Rename)按钮,打开更名(Rename)对话框,输入新的变量名。也可对匹配变量更名,方法是选中右侧变量,但击左向按钮,将其选择到左侧框中。然后对其更名。更名后再移到新工
广东技术师范学院实验报告 学院:计算机科学学 院 专业:物联网工程班级: 12物 联网 成绩: 姓名:邓文龙学号:08 组别:组员: 实验地点:工业中心204 实验日期:2014.03.26 指导教师签名: 实验5项目名称:文件系统管理 1、实验目的 理解Linux系统中的文件系统基本结构,掌握各种访问和管理文件以及文件系统的基本命令。 2、实验内容 2.1 文件系统管理的基本概念 文件系统(file system)是指操作系统中用于管理文件信息的软件机构。借用维基百科里面关于文件系统的解释(https://www.doczj.com/doc/0818262611.html,/wiki/文件系统):计算机的文件系统是一种存储和组织计算机数据的方法,它使得对其访问和查找变得容易,文件系统使用文件和树形目录的抽象逻辑概念代替了硬盘和光盘等物理设备使用数据块的概念,用户使用文件系统来保存数据不必关心数据实际保存在硬盘(或者光盘)的地址为多少的数据块上,只需要记住这个文件的所属目录和文件名。在写入新数据之前,用户不必关心硬盘上的那个块地址没有被使用,硬盘上的存储空间管理(分配和释放)功能由文件系统自动完成,用户只需要记住数据被写入到了哪个文件中。 文件系统既要建立在一定的物理存储设备上,但却是一个逻辑上的概念。对用户来说,关于文件的各种操作及访问都需要通过文件系统进行,文件系统成为用户和存储设备之间的一个重要界面。本实验主要讨论在Linux系统中文件以及文件系统管理的各种操作。 文件系统管理主要包括两大部分的内容,一部分是结合文件系统的基本特性,对文件系统作必要的设置,监控文件系统的基本使用状态,另一部分则是对文件的各类管理操作。这些都是从软件层面上对文件系统进行管理。部分最基本的shell命令已经之前的实验中有所介绍。 2.2文件系统 2.2.1文件系统的层次结构(补充教材6.4.1节) 文件系统表达了一种组织文件的方式。一般地,UNIX文件系统采用的都是一种所谓树状的层次结构,称为“根文件系统”。如下图所示,树根以“/”表示,
数据管理技术选择题精选 数据管理技术的基本概念 数据[date(DB)]:是对现实世界中客观事物的符号化表示,可以用数字来表示的数据是数值数据,如年龄、身高、价格等;用非数字形式来表示的数据是非数值数据如文字、图像、声音等。P4 数据类型:数字型(数量、价格)、文本型(姓名、地址)、日期型(出生日期、生产日期)、逻辑 型(是否学生)、OLE型(照片、音乐)。P32 1. (1)用一组数据“姓名:赵明,所教学科:语文,出生日期:1970-10-2”来描述教师信息,其中 “姓名D(出生日期C)”数据可设置为 (2)用一组数据“CD编号:A001,CD名称:黄河,价格(元):27,数量(片):100,唱片公司: 新力”来描述CD唱片销售信息,其中“CD编号D(价格B)”数据可设置为 (3)用一组数据"姓名:赵明,任教年级:高一,教师照片:"来描述教师信息,其中"教师 照片"数据在Access中可设置为A A. OLE对象型 B.数字型 C.日期/时间型 D.文本型 数据库(DB):按照某种模型组织起来的,可以被用户或应用程序共享的、大量且互相关联的数据集合P8 常见的数据库:Foxpro、Access、SQL、Oraclet等P12 2.下列属于数据库管理系统的是A A.SQL Server B.Windows C.旅游线路.xls D.中国邮编区号.mdb 数据库管理系统(DBMS):对数据库中的数据进行管理和控制的软件。P8 3. 4.数据库管理系统B(数据库A/数据D)的英文名称缩写是 A.DB B.DBMS C.DOC D.DATA 统一管理数据库中的数据资源要使用C A.表格管理系统 B.文件管理系统 C.数据库管理系统 D.Windows资源管理系统 数据管理技术发展的三个阶段:①人工管理阶段②文件系统阶段③数据库系统阶段P7 5. 6.数据管理技术经历了三个阶段,分别是D A.数据库系统、多媒体系统和超媒体阶段 B.文件系统、数据库系统和超媒体阶段 C.文件系统、数据库系统和多媒体系统阶段 D.人工管理、文件系统和数据库系统阶段数据管理技术的最初阶段是A A.人工管理 B.文件系统 C.超文本管理 D.数据库系统 数据库应用系统:针对某个特定目标,建立在数据库管理系统之上的计算机应用系统。P92 7.用Access编制的“校运会资料管理系统”属于A A.数据库应用系统 B.系统软件 C.数据库 D.数据库管理系统
《数据库技术》上机实验 实验三数据库及数据库表的创建与管理 一、实验目的 熟悉和掌握数据库的创建和连接方法; 熟悉和掌握数据表的建立、修改和删除; 加深对表的实体完整性、参照完整性和用户自定义完整性的理解。 二、实验软件平台 Windows XP/7/8/10操作系统; 安装了SQL SERVER 三、实验内容 背景材料:在以下实验中,使用学生-课程数据库(school),它描述了学生的基本信息、课程的基本信息及学生选修课程的基本信息。(要求使用命令的方式创建) 1.创建学生-课程数据库create database school Sno:char(9) Sname: varchar(6) Ssex:char(2) Sage:tinyint Sdept:char(2) Sno为主键,姓名不能为空,性别只能取男或女,年龄大于等于0。 Cno为主键,课程名不能为空,先行课可以为空,学分大于等于0 Sno:char(9) Cno:varchar(3) grade: float 主键是课程号和学号思考?成绩可以为空么?为什么? 5.将以上创建表S、C、SC的SQL命令以.SQL文件的形式保存在磁盘上。[文件操作的方 式直接保存即可,这部分不用写在“四实验结果”中] 温馨提示:到这部分内容做完为止,可以用数据库的备份功能将所建好的数据库及数据库表完全备份下来,下周的实验课程会利用这个表结构。或者直接保存题5的SQL语句也可以,下次课直接执行这些sql文件,也可以达到保存的目的。 6.在表S上增加“出生日期”属性列。 7.删除表S的“年龄”属性列。 8.删除表SC,利用磁盘上保存的.SQL文件重新创建表SC。 9.修改C表,将学分的约束改为0到5之间 10.修改S表的性别的类型,设置为char(1),并将约束改为0和1
一、单选题 1、对于离散空间最佳的内插方法 是: A.整体内插法 B.局部内插法 C.移动拟合法 D.邻近元法 2、下列能进行地图数字化的设备 是: A.打印机 B.手扶跟踪数字化仪 C.主 机 D.硬盘 3、有关数据处理的叙述错误的 是: A.数据处理是实现空间数据有序化的必要过程 B.数据处理是检验数据质量的关键环节 C.数据处理是实现数据共享的关键步骤 D.数据处理是对地图数字化前的预处理 4、邻近元法 是: A.离散空间数据内插的方法 B.连续空间内插的方法 C.生成DEM的一种方法 D.生成DTM的一种方法 5、一般用于模拟大范围内变化的内插技术是: A.邻近元法 B.整体拟合技术 C.局部拟合技术 D.移动拟合法 6、在地理数据采集中,手工方式主要是用于录入: A.属性数据 B.地图数据 C.影象数 据 D.DTM数据
7、要保证GIS中数据的现势性必须实时进行: A.数据编辑 B.数据变换 C.数据更 新 D.数据匹配 8、下列属于地图投影变换方法的 是: A.正解变换 B.平移变换 C.空间变 换 D.旋转变换 9、以信息损失为代价换取空间数据容量的压缩方法是: A.压缩软件 B.消冗处理 C.特征点筛选 法 D.压缩编码技术 10、表达现实世界空间变化的三个基本要素是。 A. 空间位置、专题特征、时间 B. 空间位置、专题特征、属性 C. 空间特点、变化趋势、属性 D. 空间特点、变化趋势、时间 11、以下哪种不属于数据采集的方式: A. 手工方式 B.扫描方式 C.投影方 式 D.数据通讯方式 12、以下不属于地图投影变换方法的是: A. 正解变换 B.平移变换 C.数值变 换 D.反解变换 13、以下不属于按照空间数据元数据描述对象分类的是: A. 实体元数据 B.属性元数据 C.数据层元数据 D. 应用层元数据 14、以下按照空间数据元数据的作用分类的是: A. 实体元数据 B.属性元数据 C. 说明元数据 D. 分类元数据 15、以下不属于遥感数据误差的是: A. 数字化误差 B.数据预处理误差 C. 数据转换误差 D. 人工判读误差
管理数据库复习题 一.单项选择(在每小题的四个备选答案中,选出一个正确的答案,将其标号填入括号内。每题1分,共30分) 1.是存储在计算机内有结构的数据的集合。 A.数据库系统 B.数据库 C.数据库管理系统 D.数据结构 2.数据库系统与文件系统的主要区别是_______。 A.数据库系统复杂,而文件系统简单 B.文件系统不能解决数据冗余和数据独立性问题,而数据库系统可以解决 C.文件系统只能管理程序文件,而数据库系统能够管理各种类型的文件 D.文件系统管理的数据量较少,而数据库系统可以管理庞大的数据量 3.数据库的概念模型独立于_______。 A.具体的机器和DBMS B.E-R图 C.信息世界D.现实世界 4.数据库的基本特点是_______ 。 A.数据结构化B.数据独立性 C.数据冗余大,易移植D.统一管理和控制 5.的数据独立性最高。 A.文件系统B.数据库 C.手工处理D.其他 6.数据库中,数据的物理独立性是指_______。 A.数据库与数据库管理系统的相互独立 B.用户程序与DBMS的相互独立 C.用户的应用程序与存储在磁盘上数据库中的数据是相互独立的 D.应用程序与数据库中数据的逻辑结构相互独立 7.关系模型中的关系模式至少是_______。 A.1NF B.2NF C.3NF D.BCNF 8.在关系DB中,任何二元关系模式的最高范式必定是 A.1NF B.2NF C.3NF D.BCNF 9.在关系模式中,如果属性A和B存在1对1的联系,则说_______。
A.A→B B.B→A C.A← →B D.以上都不是 10.数据库系统的核心是 A.数据库B.数据库管理系统 C.数据模型D.软件工具 11.候选关键字中的属性称为__________。 A.非主属性B.主属性C.复合属性D.关键属性 12.关系模式中各级模式之间的关系为 A.3NF∈2NF∈1NF B.3NF∈1NF∈2NF C.1NF∈2NF∈3NF D.2NF∈1NF∈3NF 13.SQL语言使用最频繁的语句是。 A .SELECT B.INSERT C .UPDATE D.DELETE 14.SQL语言具有两种使用方式,分别称为交互式SQL和。 A.提示式SQL B.多用户SQL C.嵌入式SQL D.解释式SQL 15 。下列SQL语句中,修改表结构的是。 A.ALTER B.CREATE C.UPDA TE D.INSERT 16.对关系模型叙述错误的是。 A.建立在严格的数学理论、集合论和谓词演算公式的基础之上 B.微机DBMS绝大部分采取关系数据模型 C.用二维表表示关系模型是其一大特点 D.不具有连接操作的DBMS也可以是关系数据库系统 17.关系模型中,一个关键字是。 A.可由多个任意属性组成 B.至多由一个属性组成 C.可由一个或多个其值能唯一标识该关系模式中任何元组的属性组成 D.以上都不是 18.同一个关系模型的任意两个元组值。 A.不能全同B.可全同 C.必须全同D.以上都不是
实验一、数据文件的编辑与整理 在SPSS中,数据文件的编辑、整理等功能被集中在了Data和Transform两个 菜单项中,这两个菜单的内容如下所示: Data 菜单项 Transform 菜单项 2.1 进一步整理数据文件--Data 菜单 【Sort Cases 对话框】 例2.1 对数据集li1_1.sav 按group 升序,x 降序的次序排列。 解:选择菜单Data==>Sort Cases,系统弹出Sort Cases 对话框,该对话框并不复杂,其中比较特殊的是下方的Sort Order 单选钮,有升序和降序两种选择。请注意,该单选钮是和上方的Sort By 框一起使用的,具体方法如下: 1. 确认升序单选钮被选择,将Group 选入Sort By 框; 2. 选择降序单选钮,将x 选入Sort By 框。 【Merge Files 对话框】 用于对数据文件进行合并。有纵向合并和横向合并两种。 纵向合并——增加观测量到当前数据;Data==>Merge File ==> Add Cases 横向合并——增加变量到当前数据文件。Data==>Merge File ==> Add Variables 【Aggregate 对话框】 用于对数据进行分类汇总,所谓分类汇总就是按指定的分类变量对观测值进行分组,对每组记录的各变量值求指定的描述统计量,结果可以存入新数据文件,也可以替换当前数据文件。
例2.2 计算Li1_1.sav中两组的血磷值标准差。 解:该题完全可以用更简单的方法完成,这里只是演示一下汇总对话框的用法。 1.Break Variables框:Group 2.Aggregate Variables框:x 3.Function钮:(Standard deviation单选钮:Continue钮) 4.Replace working data file单选钮:选中 5. OK 【 Select Cases 对话框】 很多时候我们不需要分析全部的数据,而是按某种要求分析其中的一部分(比如只分析男性的身高、只对前200个数据进行分析以了解大概情况),这时使用Select Cases对话框可以大大简化工作。 该对话框界面如下所示: z All cases单选钮:和下面的4个单选钮为一组,选中它则分析所 有的记录; z If condition is satisfied单选钮:只分析满足条件的记录; z If按钮:和If单选钮一起使用,单击后弹出If对话框; z Random sample of cases单选钮:从原数据中随机抽样; z Sample按钮:和Random单选钮一起使用,可以设定按百分比抽取记录,或者精确设定从前若干个记录中抽取多少个记录; z Based on time or case range单选钮:基于记录序号来选择记录; z Range按钮:和Based单选钮一起使用,用于输入记录序号范围; z Use filter variable单选钮:使用筛选指示变量来选择记录,必需在下面选入一个筛选指示变量,该变量取值为非0的记录将被选中,进入以 后的分析; z Filtered单选钮:和下面的Deleted单选钮为一组,表示未被选中的记录只是被隔离,这些记录的记录号会被加上斜杠以示区别; z Deleted单选钮:未被选中的记录将被删除,一般不要使用。
《数据库原理》实验报告 题目:实验一 数据库和表的创建与管理学号姓名班级日期 2016.10.15 一.实验内容、步骤以及结果 1.利用图形用户界面创建,备份,删除和还原数据库和数据表 (1)创建SPJ数据库,初始大小为10MB,最大为50MB,数据库自动增长,增长 方式是按5%比例增长;日志文件初始为2MB,最大可增长到5MB,按1MB 增长。数据库的逻辑文件名和物理文件名均采用默认值。 (2)在SPJ数据库中创建如图2.1-图2.4的四张表
(3)备份数据库SPJ(第一种方法):备份成一个扩展名为bak的文件。(提示: 最好先删除系统默认的备份文件名,然后添加自己指定的备份文件名)
(4)备份数据库SPJ(第二种方法):将SPJ数据库定义时使用的文件(扩展名为 mdf,ldf的数据文件、日志文件等)复制到其他文件夹进行备份。 (5) 删除已经创建的工程项目表(J表)。 (6) 删除SPJ数据库。(可以在系统默认的数据存储文件夹下查看此时SPJ数据库对应的mdf,ldf文件是否存在) (7) 利用备份过的bak备份文件还原刚才删除的SPJ数据库。(还原数据库) (8) 利用备份过的mdf,ldf的备份文件还原刚才删除的SPJ数据库。(附加) (9) 将SPJ数据库的文件大小修改为100MB。
(10) 修改S表,增加一个联系电话的字段sPhoneNo,数据类型为字符串类型。 2. 利用SQL语言创建和删除数据库和数据表 (1) 用SQL语句创建如图2.5-图2.7要求的数据库Student,初始大小为20MB,最大为100MB,数据库自动增长,增长方式是按10M兆字节增长;日志文件初始为2MB,最大可增长到5MB,按1MB增长。数据库的逻辑文件名和物理文件名,日志文件名请自定义。
实验二空间数据处理(三) ——ArcGIS的数据编辑目的 (1)掌握矢量数据的编辑 内容 (1)掌握矢量数据的编辑方法; (2)几何数据和属性数据两部分内容的编辑; (3)练习数据属性表的基本编辑、表连接等。 基本概念介绍 1.ArcMap中的数据编辑 数据编辑是纠正数据错误的重要手段,包括几何数据和属性数据的 编辑。几何数据的编辑主要是针对图形的操作(图形编辑),包括平行 线复制、缓冲区生成、镜面反射、图层合并、结点操作和拓扑修改等。 属性数据的编辑包括图形要素属性的添加、删除、修改、复制、粘贴、 属性表导出等。 在ArcMap中,编辑操作由编辑器工具条来控制。该工具条有几个重 要的控件: (1)编辑器下拉菜单:菜单中有用于启动、停止和存储编辑对话过程的一些 命令同时还提供了几种编辑操作、捕捉选项以及编辑选项。 (2)编辑工具:这一工具用于选择要编辑的要素。 (3)草图工具:这是编辑空间要素的主要工具。允许数字化新的要素或修改 已有要素的形状。该工具进行的实际操作由编辑草图属性列表所控制。 (4)编辑草图属性列表:从下拉列表中,选择想要进行的编辑操作。所列出 的任务将根据编辑的要素类的改变而变化。 (5)属性对话框:在这个窗口中可以编辑选中要素的属性值。 2. 理解表格结构 表是数据库的结构物,它包括了行和列。行(或称为记录)代表一
个特征,如高速公路、湖等;列(或称为域),描述了特征的属性,例 如长度、深度等。每个表格的基本格式相同,即有行和列组成。一些表 格,诸如要素类的缺省属性表都有预先设置的字段。例如多边形coverage 有四个标准的字段即面积、周长、coverage#和coverage-id。一个线性 shapefile仅有一列名为shape的缺省列,其他字段完全由用户定义。 每个表格必须有唯一字段名,但字段的数据格式可以有多种。一般 来说,可以存储数字、文字、日期。在ArcCatalog还支持特定格式,包括 短整形、长整形、浮点型、双精度型、日期型、object-id和BLOB。 3.图形编辑 (一)、基本步骤 进入ArcMap工作环境,打开已有的地图文档或新建地图文档后,进 行数据编辑一般需要经过下列5个步骤: (1)加载编辑数据 单击文件菜单下的添加数据命令,选择需要加载的数据层。 (2)打开编辑工具 在工具栏的空白处点击右键,选择编辑器,出现编辑器工具条。 (3)进入编辑状态 单击编辑器下的开始编辑命令,使数据层进入编辑状态。 (4)执行数据编辑 在创建要素窗口中选择当前编辑任务的目标数据层,然后选择编辑 构造工具命令,对要素进行编辑。 (5)结束数据编辑 单击编辑器下的停止编辑命令,选择是否保存编辑结果,结束编辑。 (二)、本编辑练习 (1)加载编辑数据 在开始——打开ArcMap10,单击文件菜单下的添加数据命令, 在data2\Basicedit\下:按shift+左键选择需要加载的数据层(,,,)。
实验一数据文件的建立与编辑 一、实验目的与实验要求 1.熟悉SPSS的工作界面 2.掌握数据的录入、数据文件的编辑和操作 二、SPSS的基本工作界面及基本操作介绍 SPSS的全称是:Statistical Program for Social Sciences,即社会科学统计程序。该软件是公认的最优秀的统计分析软件包之一。 下面以SPSS 14为例,介绍基本的SPSS界面,并详细讲解数据录入,数据文件的编辑和操作这方面的基础知识。 1.SPSS中的主要窗口 SPSS软件最基本的窗口是Data Editor和Output两个窗口。另外还有一个Syntax窗口。 在SPSS中,操作界面实际上起的就是“操作界面”的作用。当你用对话框选定某项操作,单击“OK”后,SPSS就将你的选择在Syntax窗口中翻译成程序语句,然后提交系统执行。如果单击“Paste”按钮,SPSS就不将生成的程序语句提交执行,而是传送到程序编辑窗中供你折腾。“Paste”按钮在几乎所有的SPSS对话框中都存在,它是专门为编程准备的,作用是把过程语句粘贴到Syntax窗口上。不光SPSS,SAS等其它软件也是这么做的。 (1)数据编辑窗口 数据编辑窗口最上方标有“SPSS Data Editor”。在SPSS for Windows 启动后屏幕显示在主画面上的激活窗口即是该数据编辑窗。 在数据编辑器的二维表格中每行都是数据文件的一个记录,在统计学中称作“一个概率事件”。在SPSS的菜单或帮助信息中用“Cases”这个单词表示。每个Cases是由变量的一定的值组成的,是一个事件,或者说是对一个被观察对象的各种特征的实测值组成的。因此相对应变量来说可以称之为“观测值”。单元格中的数据即是某个观测值中的一个值,因此可以称之为变量值,也可以称之为某个观测值,在Help信息中往往使用Case这个单词。
第二章数据库的建立与管理 一、选择题 1.ACCESS的数据库类型是( C ). A.层次数据库 B.网状数据库 C.关系数据库 D.面向对象数据库 2.ACCESS数据库的文件拓展名是( A ). A..mdb B..exe C..bnp D..doc 3. 退出ACCESS时可以使用的快捷键是( D ). A.Alt+F B.Alt+X C.Ctrl+S D.Alt+F4 4.代表ACCESS图标的是( D ). 5.下列不能退出ACCESS操作是( D ). A.单击ACCESS窗口标题栏右端的“关闭”按钮 B.双击ACCESS标题栏左端的控制菜单图标 C.单击ACCESS标题栏左端的控制菜单图标,从弹出的菜单中 选择“关闭”命令 D.选择“文件”菜单中的“关闭”命令 6.下列( C )不是ACCESS主窗口的组成部分。 A.标题栏 B.工具栏 C.任务栏 D.状态栏 7.( D )位于ACCESS主窗口的最底部,用于显示数据库管理系 统进行数据管理时的工作状态. A.标题栏 B.工具栏 C.菜单栏 D.状态栏 8.( B )包含ACCESS中的常用工具,可以在不使用菜单命令的
情况下,直接单击相应的命令图标来执行命令. A.标题栏 B.工具栏 C.菜单栏 D.状态栏 9. ACCESS数据库设计窗口中的菜单栏不包括( D ). A.文件 B.视图 C.编辑 D.数据 10.下列( B )不是打开菜单的方法. A.使用鼠标单击菜单名 B.按“Ctrl+字母”组合键 C.按“Alt+字母”组合键 D.按F10键 11.下列关于菜单项的说法错误的是( C ). A.深色的菜单项表示当前命令可用 B.浅色的菜单项表示当前命令不可用 C.带省略号(……)的菜单项表示鼠标指向它时弹出一个子菜 单 D.带有符号( ^)的菜单项表示当前命令有效 12. ACCESS数据库设计视图窗口不包括( D ). A.命令按钮组 B.对象类别按钮组 C.对象成员集合 D.关系编辑窗口 13.下列不能启动ACCESS的操作是( C ). A.从“开始”菜单的“所有程序”子菜单中选择“Microsoft Office Access”命令 B.双击桌面上的ACCESS快捷方式图标 C.单击以.mdb为后缀的数据库文件 D.右击以.mdb为后缀的数据库文件,在弹出的快捷菜单中选
第二部分空间数据的编辑与处理 一、误差或错误的检查与编辑 通过矢量数字化或扫描数字化所获取的原始空间数据,都不可避免的存在着错误或误差,属性数据在建库输入时,也难免会存在错误,所以,对图形数据和属性数据进行一定的检查、编辑是很有必要的。 图形数据和属性数据的误差主要包括以下几个方面: 1、空间数据的不完整或重复:主要包括空间点、线、面数据的丢失或重复、区域中心点的遗漏、栅格数据矢量化时引起的断线等; 2、空间数据位置的不准确:主要包括空间点位的不准确、线段过长或过短、线段的断裂、相邻多边形结点的不重合等; 图5-4 数字化几种误差示例 3、空间数据的比例尺不准确; 4、空间数据的变形; 5、空间属性和数据连接有误; 6、属性数据不完整; 图5-4是几种数字化误差的示例。 为发现并有效消除误差,一般采用如下方法进行检查: 1、叠合比较法,是空间数据数字化正确与否的最佳检核方法,按与原图相同的比例尺用把数字化的内容绘在透明材料上,然后与原图叠合在一起,在透光桌上仔细的观察和比较。一般,对于空间数据的比例尺不准确和空间数据的变形马上就可以观察出来,对于空间数据的位置不完整和不准确则须用粗笔把遗漏、位置错误的地方明显地标注出来。如果数字化的范围比较大,分块数字化时,除检核一幅(块)图内的差错外还应检核已存入计算机的其它图幅的接边情况; 2、目视检查法,指在屏幕上用目视检查的方法,检查一些明显的数字化误差与错误,如图所示,包括线段过长或过短、多边形的重叠和裂口、线段的断裂等; 3、逻辑检查法,如根据数据拓扑一致性进行检验,将弧段连成多边形,进行数字化误差的检查。有许多软件已能自动进行多边形结点的自动平差。另外,对属性数据的检查一般也最
第6单元文件系统的管理 一、填空题 1.加密文件系统提供了用于在NTFS卷上存储加密文件的核心文件加密技术。 2.共享权限分读取、写入、完全控制。 3.创建共享文件夹用户必须属于Administrators、Server Operators、Power Users等用户组的成员。 4.分布式文件系统为整个网络上的文件系统资源提供了一个逻辑树结构。 5.共享用户身份有以下3种:读者、参与者、共有者。 6.复制拓扑用来描述DFS各服务器之间复制数据的逻辑连接,一般有交错拓扑、集散拓扑、没有拓扑。 7.FAT指的是文件分配表,包括FAT16和FAT32两种。 8.NTFS是一个特别为网络和磁盘配额、文件加密等管理安全特性设计的磁盘格式。 9.NTFS文件夹的B-Tree结构使得用户在访问较大文件夹中的文件时,速度甚至比访问卷中较小文件夹中的文件还快。 10.不管是共享权限还是NTFS权限都有累加性。 11.不管是共享权限还是NTFS权限都遵循拒绝权限优先于其他权限的规则。 12.DFS支持两种DFS命名空间,基于域和独立命名空间。 二、选择题
1.下列(C )不属于Windows Server 2008 DFS复制拓扑。 A.交错拓扑 B.集散拓扑 C.环形拓扑 D.没有拓扑 2.目录的“可读”意味着(D )。 A.可在该目录下建立文件 B.可从该目录充删除文件 C.可以从一个目录转到另一个目录 C.可以查看该目录下的文件 3.(C )属于共享命名管道的资源。 A.driveletter$ B.ADMIN$ C.IPC$ D.PRINT$ 4.卷影副本内的文件只可以读取,不可以修改,而且每个磁盘最多只可以有(B )个卷影副本。 A.256 B.64 C.1024 D.8 5.要启用磁盘配额管理,Windows Server 2008驱动器必须(B )。 A.使用FAT16或FAT32文件系统 B.只使用NTFS C.使用NTFS或FAT32文件系统 C.只使用FAT32文件系统 6.Windows Server 2008 不支持以下(D )文件系统。 A.FAT16 B.FAT32 C.NTFS D.EXT2 7.下面(D )不属于NTFS权限。 A.读取 B .写入 C.修改 D.创建 8.FAT16最大可以管理(B )磁盘分区。 A.1G B.2G C.4G D.8G 9.从安全角度考虑,Windows Server 2008应当采用的文件格式系统
实验二 SPSS数据录入与编辑 一、实验目的 通过本次实验,要求掌握SPSS的基本运行程序,熟悉基本的编码方法、了解如何录入数据和建立数据文件,掌握基本的数据文件编辑与修改方法。 二、实验性质 必修,基础层次 三、主要仪器及试材 计算机及SPSS软件 四、实验内容 1.录入数据 2.保存数据文件 3.编辑数据文件 五、实验学时 2学时(可根据实际情况调整学时) 六、实验方法与步骤 1.开机 2.找到SPSS的快捷按纽或在程序中找到SPSS,打开SPSS 3.认识SPSS数据编辑窗 4.按要求录入数据 5.联系基本的数据修改编辑方法 6.保存数据文件 7.关闭SPSS,关机。 七、实验注意事项 1.实验中不轻易改动SPSS的参数设置,以免引起系统运行问题。 2.遇到各种难以处理的问题,请询问指导教师。
3.为保证计算机的安全,上机过程中非经指导教师和实验室管理人员 同意,禁止使用移动存储器。 4.每次上机,个人应按规定要求使用同一计算机,如因故障需更换, 应报指导教师或实验室管理人员同意。 5.上机时间,禁止使用计算机从事与课程无关的工作。 八、上机作业 一、定义变量 1. 试录入以下数据文件,并按要求进行变量定义。 1)对性别(Sex)设值标签“男=0;女=1”。 2)正确设定变量类型。其中学号设为数值型;日期型统一用“mm/dd/yyyy“型号;生活费用货币型。 3)变量值宽统一为10,身高与体重、生活费的小数位2,其余为0。
2.试录入以下数据文件,保存为“数据1.sav”。
实验三统计图的制作与编辑 一、实验目的 通过本次实验,了解如何制作与编辑各种图形。 二、实验性质 必修,基础层次 三、主要仪器及试材 计算机及SPSS软件 四、实验内容 1.条形图的绘制与编辑 2.直方图的绘制与编辑 3.饼图的绘制与编辑 五、实验学时 2学时 六、实验方法与步骤 1.开机; 2.找到SPSS的快捷按纽或在程序中找到SPSS,打开SPSS; 3.按要求完成上机作业; 4. 关闭SPSS,关机。 七、实验注意事项 1.实验中不轻易改动SPSS的参数设置,以免引起系统运行问题。 2.遇到各种难以处理的问题,请询问指导教师。 3.为保证计算机的安全,上机过程中非经指导教师和实验室管理人员同意,禁止使用移动存储器。 4.每次上机,个人应按规定要求使用同一计算机,如因故障需更换,应报指导教师或实验室管理人员同意。
目的: 运用书面的文件系统,减少单纯口头传达所产生的错误和风险,提供正确操作和监控的依据,明确职工必须遵守的程序和规程,并能追溯每批产品的历史,保证药品生产的全过程符合GMP要求。 范围: 生产管理和质量文件系统。 责任: 软件管理员负责编制; 主管质量的副总负责审核; 由总经理审核批准; 公司所有部门及人员执行。 内容: 1.总则:文件是从事药品生产活动和质量保证活动的依据和准则。 药品生产质量管理文件涉及到GMP各个方面,贯穿于药品生产的一切活动中。文件系统管理包括文件的建立与审批、分发与回收、文件的归档与保存、文件的销毁及文件的培训等方面。 建立健全药品生产质量管理文件,并按规定严格执行,才能保证药品生产的全过程有章可循,有据可查,有监控,有复核,杜绝生产中的混淆、污染和差错,确保药品生产的
2.文件系统:(见附表1) 3.文件系统的管理 文件系统的管理是指文件系统的编制、审批、颁发、培训、执行、归档、修订直至销毁的全过程的管理活动。 3.1文件的编号 3.3.1编号的方法 编号由公司代号、部门代号、文件类别编号、亚类别编号、文件顺序号五部分组成。 A ) 公司代号 由“天光药业” “天光”二字的汉语拼音的第一个大写字母组成,即“TG ”。 C )文件类别编号 技术性文件和管理性文件编号编制方法 公司代码(★)-部门代号(■)+类别编号(O )+ 亚类别编号(□)-文件顺序号(△) 表示方法:★-■O □-△ 文件所附附件编号均为该文件编号后+附件顺序号◇ 表示方法:★-■O □-△◇ 检验记录文件编号编制方法公司代码(★)-部门代号(■)+类别编号(O )+亚类别编号(□)-文件顺序号(△) 表示方法:★-■O □-△ D )类别 a)技术性文件类别:
大数据技术与应用 网络与交换技术国家重点实验室 交换与智能控制研究中心 程祥 2016年9月
提纲-大数据存储和管理1. 分布式文件系统 1.1 概述 1.2 典型分布式文件系统 1.3 HDFS 2. 分布式数据库 2.1 概述 2.2 NoSQL 2.3 HBase 2.4 MongoDB(略) 2.5 云数据库(略)
1.1 概述 ?定义:相对于本地文件系统,分布式文件系统是一种通过网络实现文件在多台主机上进行分布式存储的文件系统。 ?分布式文件系统一般采用C/S模式,客户端以特定的通信协议通过网络与服务器建立连接,提出文件访问请求。 ?客户端和服务器可以通过设置访问权限来限制请求方对底层数据存储块的访问。
1.2 典型的分布式文件系统 ?NFS (Network File System) 由Sun微系统公司作为TCP/IP网上的文件共享系统开发,后移植到Linux等其他平台。其接口都已经标准化。 ?AFS (Andrew File System) 由卡耐基梅隆大学信息技术中心(ITC)开发,主要用于管理分部在不同网络节点上的文件。AFS与 NFS不同,AFS提供给用户的是一个完全透明,永远唯一的逻辑路径(NFS需要物理路径访问)。
1.2 典型的分布式文件系统(续) ?GFS(Google File System) 由Google开发,是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普通硬件上,并提供容错功能。 ?HDFS(Hadoop Distributed File System) HDFS是Apache Hadoop项目的一个子项目,是一个高度容错的分布式文件系统,设计用于在低成本硬件上运行,适合存储大数据,GFS的开源版本。
实验3-1、空间数据库管理及属性编辑 一、实验目的 1. 利用ArcCatalog 管理地理空间数据库,理解Personal Geodatabse 空间数据库模型的有关概念。 2. 掌握在ArcMap中编辑属性数据的基本操作。 3. 掌握根据GPS数据文件生成矢量图层的方法和过程。 4. 理解图层属性表间的连接(Join)或关联(Link)关系。 二、实验准备 预备知识: ArcCatalog 用于组织和管理所有GIS 数据。它包含一组工具用于浏览和查找地理数据、记录和浏览元数据、快速显示数据集及为地理数据定义数据结构。 基本概念:要素数据集、要素类 数据文件:National.mdb ,GPS.txt (GPS野外采集数据)。 软件准备:ArcGIS Desktop 9.x ---ArcCatalog 三、实验内容与主要过程 第1步启动ArcCatalog 打开一个地理数据库 当ArcCatalog打开后,点击按钮(连接到文件夹). 建立到包含练习数据的连接 在ArcCatalog窗口左边的目录树中, 点击上面创建的文件夹的连接图标旁的(+)号,双击个人空间数据库-National.mdb。打开它。
在National.mdb 中包含有2 个要素数据集、1个关系类和1 个属性表。 第2步预览地理数据库中的要素类 在ArcCatalog窗口右边的数据显示区内,点击“预览”选项页切换到“预览”视图界面。在目录树中,双击数据集要素集-“WorldContainer”,点击要素类-“Countries94”激活它。 在此窗口的下方,“预览”下拉列表中,选择“表格”。现在,你可以看到Countries94的属性表。查看它的属性字段信息。 第3步创建缩图,并查看元数据
第二章 SPSS数据文件的建立与管理 2.1 SPSS数据文件 2.1.1 SPSS数据文件的特点: SPSS是一个有别于其他文件的特殊格式的文件,SPSS数据文件是一种有结构的数据文件,它由数据结构和内容两部分组成,其中的数据结构记录数据变量的名称、类型、变量宽度、小数位数、变量名标签、变量值标签、缺失值、显示宽度、对齐方式和度量尺度等必要信息,数据的内容才是那些待分析的具体数据。 基于上述特点,建立SPSS数据文件时应完成两项任务,即描述数据的结构和录入编辑数据。 2.1.2 SPSS数据的组织方式 (1)原始数据的组织方式 数据编辑窗口中的一行称为一个个案或记录(Case),所有个案组成SPSS数据文件的内容。数据编辑窗口的一列称为一个变量(Variable),每个变量都有一个名字,称为变量名,它是访问和分析SPSS每个变量的唯一标志。 SPSS数据文件的结构就是对每个变量及相关特征的描述。 (2)频数数据的组织方式 例: 职称年龄段 35岁以下(1)36-49岁 (2) 50岁以上 (3) 教授(1)0158副教授(2)10202讲师(3)20101助教(4)3520 频数数据的组织方式 职称年龄段人数 110 1215 138
2110 2220 232 3120 3210 331 4135 422 430 2.2 SPSS数据的结构和定义方法 SPSS数据的结构是对SPSS每列变量及其相关属性的描述,主要包括变量名、数据类型、变量宽度、变量名标签、变量值标签、显示宽度、缺失值、对齐方式、度量尺度等信息。 变量名(Variable name) 变量名是变量访问和分析的唯一标志。在定义SPSS数据结构时应首先给出每列变量的变量名。变量的命名规则如下: 1.首字符应以英文字母开头,后面可以跟除了!、?、*之外的字母或数字。下划线、圆点不能为变量名的最后一个字符。SPSS允许用汉字作为变量名。 2.变量名的字符个数最好不多于8个;变量名不区分大小写字母。 3. SPSS有默认的变量名,以字母“VAR”开头,后面补足5位数字,如VAR00001,VAR00012等。变量名不能与SPSS内部特有的具有特定含义的保留字同名,如ALL,BY,AND,NOT,OR等。 4.变量名最好与其代表的数据含义相对应,每个变量名必须具有唯一性。 数据类型(Type) 数据类型是指每个变量取值的类型。SPSS中有三种基本数据类型:数值型、字符型和日期型。 数值型 (1)标准型(Numeric) (2)科学记数法型(Scientific Notation) (3)逗号型(Comma)
实验2 数据库的创建和管理 学号: 2011193158 姓名:韩江玲 一、实验目的: 1、掌握使用企业管理器创建SQL Server数据库的方法; 2、掌握使用T-SQL语言创建SQL Server数据库的方法; 3、掌握附加和分离数据库的方法; 4、掌握使用企业管理器或存储过程查看SQL数据库属性的方法; 5、熟悉数据库的收缩、更名和删除; 6、掌握使用企业管理器或sp_dboption存储过程修改数据库选项的方法。 二、实验内容和步骤: 本次实验所创建数据库(包括数据库文件和事务日志)存放位置都为“D:\TestDB”。因此首先在D盘下新建文件夹TestDB。 1. 数据库的创建 创建数据库的过程实际上就是为数据库设计名称、设计所占用的存储空间和文件存放位置的过程。 实验内容1:使用SQL Server企业管理器创建一个数据库,具体要求如下: 1)数据库名称为Test1。 2)主要数据文件:逻辑文件名为Test1_Data1,物理文件名为Test1_Data1.mdf,初始容量为1MB,最大容量为10MB,递增量为1MB。 3)次要数据文件:逻辑文件名为Test1_Data2,物理文件名为Test1_Data2.ndf,初始容量为1MB,最大容量为10MB,递增量为1MB。 4)事务日志文件:逻辑文件名为Test1_Log,物理文件名为Test1_Log.ldf,初始容量为1MB,大容量为5MB,递增量为1MB。其他选项为默认值。 注:我在创建数据库的时候,系统要求主文件(Test1_data1和Test1_data2)的大小不能小于3MB,所以在本例中我设置的主文件的初始大小均为3MB
地理信息系统原理 1)熟悉并认识ArcMap 图形用户操作界面。 2)了解地理数据是如何进行组织及基于“图层”进行显示的。 3)掌握一些专用术语。 4)通过浏览与地理要素关联的数据表,了解地理数据是如何与其属性信息进行 连接的。 5)掌握GIS两中基本简单查询操作,加深对其实现原理的理解。 6)初步了解设置图层显示方式-图例的使用。在以前学习Mapinfo的基础上,掌握图层的基本用法。 二、实验准备 1.在计算机中选择一个合适的驱动器,并建立一个目录,如在D:\下建立 一个名为GIS 的目录,即D:\GIS\(为与其它同学区别,所建目录也可以 加上你名字的字母,如D:\lfchGIS\) ,该目录为后期的工作空间,除软 件自带的数据外,以后所有实习提供的数据都存放在该目录下。 2.软件准备:ArcGIS Desktop 9.x 。 3.资料准备:Redlands市土地利用及街区矢量数据 4.知识准备: (1)理解GIS的三种角度 1) GIS就是空间数据库:GIS 是一个包含了用于表达通用GIS 数据模型(要素、栅格、拓扑、网络等等)的数据集的空间数据库。 2)GIS就是地图:从空间可视化的角度看:GIS 是一套智能地图,同时也是用于显示地表上的要素和要素间关系的视图。底层的地理信息可以用各种地图的方式进行表达,而这些表现方式可以被构建成“数据库的窗口”,来支持查询、分析和信息编辑。 3) GIS是空间数据处理分析工具集:从空间处理的角度看,GIS 是一套用来从现有的数据集获取新数据集的信息转换工具。这些空间处理功能从已有数据集提取信息,然后进行分析,最终将结果导入到数据集中。 (2)主要原理:查询数据(两种最基本的查询)
密级: 硕士学位论文 基于元数据的文件系统管理工具的设计与实现 作者姓名:陈德清 指导教师: 石京燕副研究员 中国科学院高能物理研究所 学位类别: 工程硕士 学科专业: 计算机技术 培养单位: 中国科学院高能物理研究所 2014年4月
Design and Implementation of File System Management Tool Based on Metadata By Deqing Chen A Dissertation Submitted to University of Chinese Academy of Sciences In partial fulfillment of the requirement For the degree of Master of Computer Technology Institute of High Energy Physics, Chinese Academy of Sciences April, 2014
研究生学位论文声明 本人郑重声明:所呈交的学位论文,是本人在导师指导下独立进行研究工作所取得的成果,除文中已经注明引用的内容外,本学位论文的研究成果不包含任何他人享有著作权的内容。对本论文所涉及的研究工作做出贡献的其他个人和集体,均已在文中以明确方式标明。 签名:_____________日期:_____________ 关于学位论文使用授权的说明本人完全了解中国科学院高能物理研究所“关于中国科学院高能物理所研究生论文及研究成果使用权的规定”(2001)高发研生字第315号文件,即:高能物理研究所拥有在著作权法规定范围内学位论文的使用权,其中包括:(1)已获学位的研究生必须按规定提交学位论文,高能物理研究所可以采用影印、缩印或其他复制手段保存研究生上交的学位论文;(2)为教学和科研目的,高能物理研究所可以将公开的学位论文作为资料在图书馆、资料室等场所供科研人员阅读,或在所内网站供科研人员浏览部分内容;(3)根据《中华人民共和国学位条例暂行实施办法》,向国家图书馆等相关部门报送可以公开的学位论文。 签名:_____________日期:_____________