数据分析期末试题及答案
一、人口现状.sav数据中是1992年亚洲各国家和地区平均寿命(y)、按购买力计算的人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)的数据,试用多元回归分析的方法分析各国家和地区平均寿命与人均GDP、成人识字率、一岁儿童疫苗接种率的关系。(25分)
解:
1.通过分别绘制地区平均寿命(y)、按购买力计算的人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)之间散点图初步分析他们之间的关系
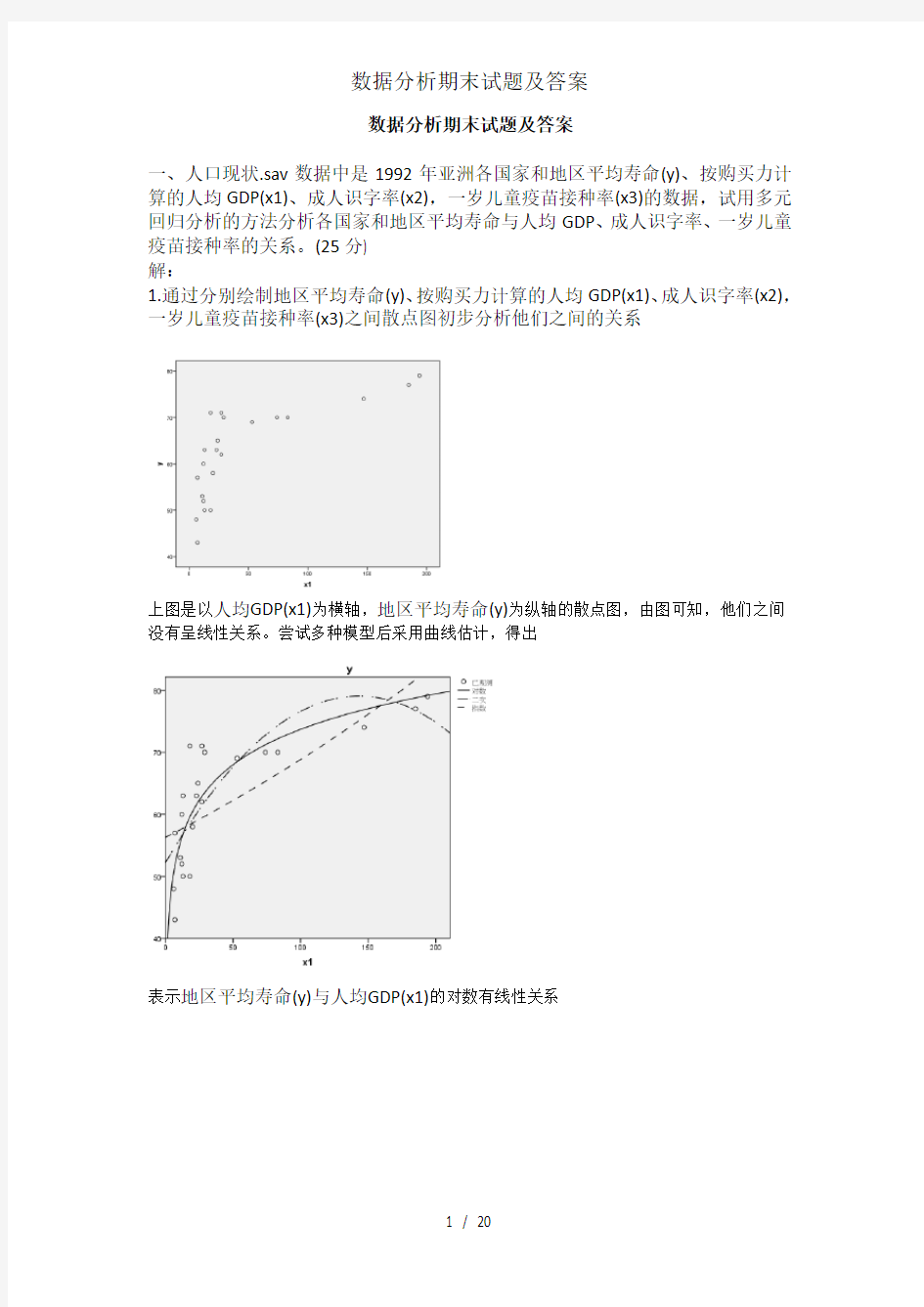
上图是以人均GDP(x1)为横轴,地区平均寿命(y)为纵轴的散点图,由图可知,他们之间没有呈线性关系。尝试多种模型后采用曲线估计,得出
表示地区平均寿命(y)与人均GDP(x1)的对数有线性关系
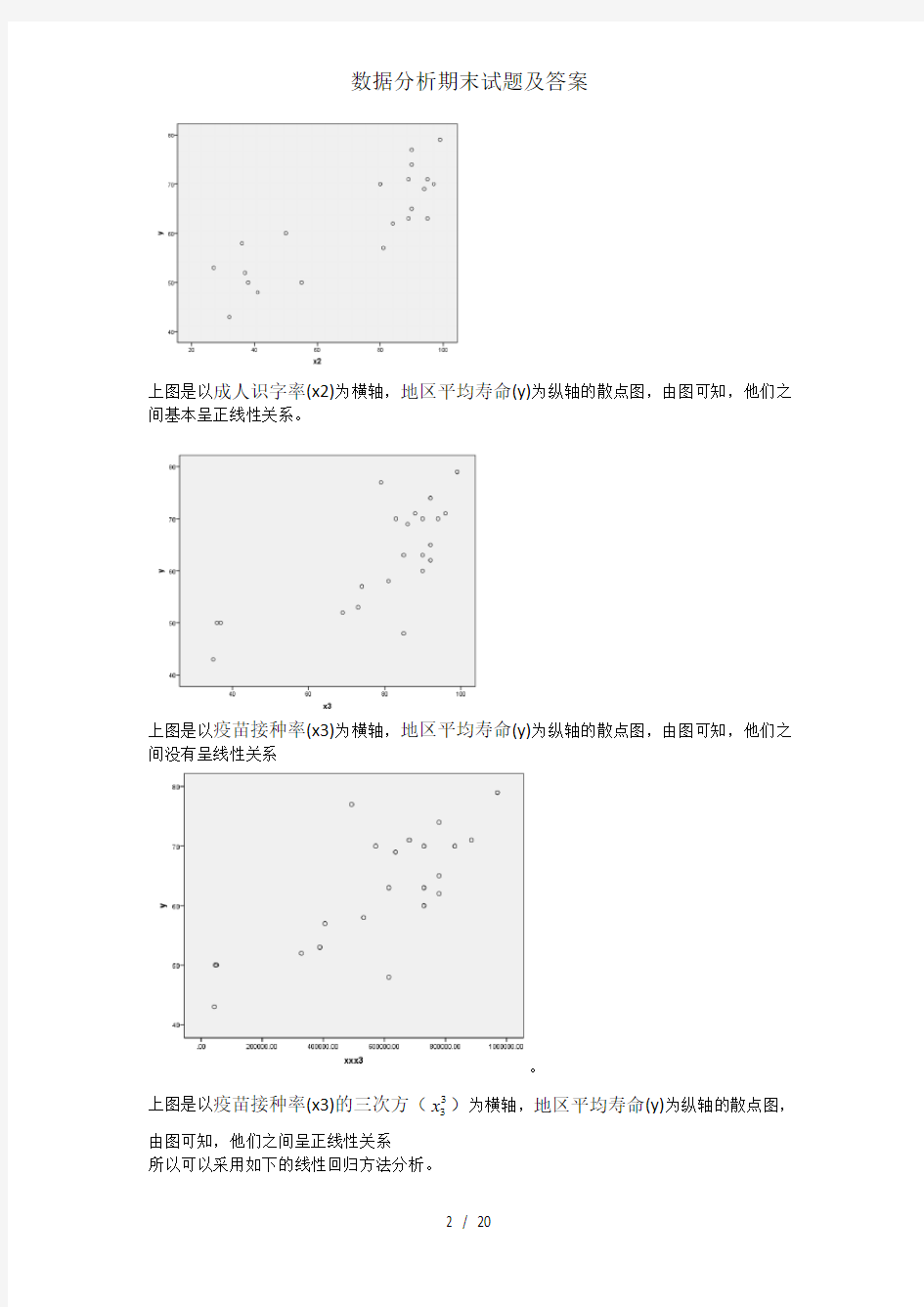
上图是以成人识字率(x2)为横轴,地区平均寿命(y)为纵轴的散点图,由图可知,他们之间基本呈正线性关系。
上图是以疫苗接种率(x3)为横轴,地区平均寿命(y)为纵轴的散点图,由图可知,他们之间没有呈线性关系
。
x)为横轴,地区平均寿命(y)为纵轴的散点图,上图是以疫苗接种率(x3)的三次方(3
3
由图可知,他们之间呈正线性关系
所以可以采用如下的线性回归方法分析。
2.线性回归
先用强行进入的方式建立如下线性方程
设Y=β0+β1*(Xi1)+β2*Xi2+β3*
X+εi i=1.2 (24)
3i
其中εi(i=1.2……22)相互独立,都服从正态分布N(0,σ^2)且假设其等于方差
R值为0.952,大于0.8,表示两变量间有较强的线性关系。且表示平均寿命(y)的95.2%的信息能由人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)一起表示出来。
建立总体性的假设检验
提出假设检验H0:β1=β2=β3=0,H1,:其中至少有一个非零
得如下方差分析表
上表是方差分析SAS输出结果。由表知,采用的是F分布,F=58.190,对应的检验概率P值是0.000.,小于显著性水平0.05,拒绝原假设,表示总体性假设检验通过了,平均寿命(y)与人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)之间有高度显著的的线性回归关系。
做独立性的假设检验得出参数估计表
2=β3=0:H1:β1、β2、β3不全为零
由表知,
β1=33.014,β1=0.072,β2=0.169,β3=0.178,以β1=0.072为例,表示当成人
识字率(x2),一岁儿童疫苗接种率(x3)不变时,,人均GDP(x1)每增加一个单位,平
均寿命(y)就增加0.072个单位。
基于以上结果得出年平均寿命(y)与人均GDP(x1)、成人识字率(x2),一岁儿童疫苗
接种率(x3)之间有显著性的线性关系有回归方程
Y=33.014+0.072*X1+ 0.169*X2+ 0.178*X3
β1、β2、β3对应得p值分别为0.000,0.000,0.002,对应的概率p值都小于0.05,
表示它们的单独性的假设检验没通过,即该模型是最优的,所以不用采用逐步回
归的方式分析。
对原始数据进行残差分析
未标准化的残差RES_1
-7.53964
-3.57019
-3.42221
-2.89835
-2.30455
-2.17263
-2.05862
-1.37142
-1.17048
-.43890
-.17260
-.03190
.94655
1.42896
1.61252
1.61590
2.10139
3.01856
3.02571
3.49808
4.60737
5.29645
以X1为横轴,RES_1为纵轴画出如下散点图
由上图可以看出,该残差图中各点分布近似长条矩形,所以模型拟合较好,即该线性回归模型比较合理。
同理可以得出RES_1与X2、X3的散点图,
由上图可以看出,该残差图中各点分布近似长条矩形,所以模型拟合较好,即该线性回归模型比较合理。
由上图可以看出,该残差图中各点分布近似长条矩形,所以模型拟合较好,即该线性回归模型比较合理。
误差项的正态性检验
数据(RES_1)标准化残差ZRES_1
由图可以看出,散点图近似的在一条直线附近,则可以认为数据来自正太分布总体
二、诊断发现运营不良的金融企业是审计核查的一项重要功能,审计核查的分类失败会导致灾难性的后果。下表列出了66家公司的部分运营财务比率,其中33家在2年后破产Y=0,另外33家在同期保持偿付能力(Y=1)。请用变量X1(未分配利润/总资产),X2(税前利润/总资产)和X3(销售额/总资产)拟合一个Logistic 回归模型,并根据模型给出实际意义的分析,数据见财务比率.sav(25分)。 解:
整体性的假设检验 提出假设性检验
H0:回归系数i β=0(i=1,2,3),H1:不都为0 建立logistic 模型:
)}
0{1}
0{ln(
=-=Y p Y p =3
213210X X X ββββ+++
分类表a,b
已观测 已预测
Y
百分比校正
1
步骤 0
Y
0 0 33 .0 1
0 33
100.0
上表显示了logistic分析的初始阶段方程中只有常数项时的错判矩阵,其中33家在2年后破产(y=0),但模型均预测为错误,正确率为0%,另外33家在同期保持偿付能力(Y=1),正确率为100%,所以模型总的预测正确率为50%。
由上表得知,如果变量X1(未分配利润/总资产),X2(税前利润/总资产)进入方程,概率p值都为0.000,小于显著性水平0.05,本应该是拒绝原假设,X1,X2是可以进入方程的。而X3(销售额/总资产)进入方程,概率p值为0.094,大于显著性水平0.05,本应该是接受原假设,X3(销售额/总资产)是不能进入方程的,但这里的解释变量的筛选策略为enter,是强行进入方程的。
用强行全部进入
-2倍的对数似然函数值越小表示模型的拟合优度越高,这里的值是5.791,比较小,表示模型的拟合优度还可以,而且Nagelkerke R 方为0.969,与0相比还是比较大的,所以拟合度比较高
上表显示了logistic 分析的初始阶段方程中只有常数项时的错判矩阵,其中33家在2年后破产(y=0),但模型预测出了32家,正确率为97%,另外33家在同期保持偿付能力(Y=1),模型预测出了32家,正确率为97%,所以模型总的预测正确率为97%,较之前的有很大的提高。
上表给出了方程中变量的系数。由表得出
160
.5,180.0,336.0,334.10,3210===-=ββββ
以
1β为例,表示控制变量X2(税前利润/总资产)和X3(销售额/总资产)不变,X1(未分
配利润/总资产)每增加一个单位,)}
0{1}
0{ln(
=-=Y p Y p 增加0.336分单位
模型方程:
)}
0{1}
0{ln(
=-=Y p Y p = 4.160X3X2180.00.336X1-10.334-++
Logistic 回归方程: P{Y=0}=
)4.160X3X2180.00.336X1--10.334ex p(1)4.160X3X2180.00.336X1--10.334ex p(+++++
由表得知,X1到X3对应的概率p 值都大于0.05,接受原假设,表示X1到X3对Y 都没有显著性影响。所以用下述方法改进。
用向前步进(wald )
-2倍的对数似然函数值越小表示模型的拟合优度越高,这里的值是9.472,比之前的5.791要大,表示拟合优度降低,表示用向前的方法并没有比进入的方法好
而且从上表知道总的预测百分比为97%,没有变化,所以这一步较之前的强行进入的方法没什么优化,也就是没什么必要用向前的方法做。
所以有最优的一个Logistic 回归模型为 模型方程:
)}
0{1}
0{ln(
=-=Y p Y p = 4.160X3X2180.00.336X1-10.334-++
Logistic 回归方程: P{Y=0}=
)4.160X3X2180.00.336X1--10.334ex p(1)4.160X3X2180.00.336X1--10.334ex p(+++++
三、为了研究几个省市的科技创新力问题,现在取了2005年8个省得15个科技指标数据,试用因子分析方法来分析一个省得科技创新能力主要受到哪些潜在因素的影响。数据见8个省市的科技指标数据.sav ,其中各个指标的解释如下:(25分)
X1:每百万人科技活动人员数(人/万人)
X2: 从事科技活动人员中科学技术、工程师所占比重(%) X3 :R&D 人员占科技胡哦哦的呢人员的比重(%) X4:大专以上学历人口数占总人口数的比例(%) X5 :地方财政科技拨款占地方财政支出的比重(%) X6:R&D 经费占GDP 比重(%)
X7:R&D 经费中挤出研究所占比例(%) X8:人均GDP(元/人)
X9:高科技产品出口额占商品出口额的比重(%) X10: 规模以上产业增加值中高技术产业份额(%)
X11 :万名科技人员被国际三大检索工具收录的论文数(篇/百万人) X12 :每百万人口发明专利的授权量(件/百万人)
X13:发明专利申请授权量占专利申请授权量的比重(%)X14 :万人技术市场成交合同金额(万元/万人)
X15 :财政性教育经费支出占GDP比重(%)
解:
所占的比例相差很大,取值范围差异大,所以不大适合做协方差的矩阵分析。所以应该采用相关矩阵的方法分析如下:
上表是15个变量间的相关系数矩阵,可以看出相关系数都比较高,比如X1(每百万人科技活动人员数(人/万人))和X2(从事科技活动人员中科学技术、工程师所占比重(%))的相关系数0.859,接近1,呈较强的的线性相关性,所以能够从中提取公因子,适合做因子分析
由表可知,前两个因子的特征根值很高,累积方差贡献率为分别为85.608(>=80%即可),对解释原有变量的贡献很大,第3个以后的因子特征根值都很小,对解释原有变量的贡献很校,可以忽略,因此提取第一和第二个因子比较合适,基本
能表达所有信息。有特征值1λ=11.136 2λ=1.706
上表是因子载荷矩阵A
以X1,X5,X10为例,有因子分析模型
1X =0.9731F -0.1582F +1ε;
5X =0.4821F +0.4972F +2ε;
10X =0.6111F +0.6372F +3ε;
因为5X ,和10X ,变量在1F ,2F 上都有较大的相差不大的载荷,几乎都受它们的共同影响,因子间的差异性没有表示出来,不方便进行因子命名,所以要进行正交旋转(拉大因子间的差异性)
对A 做方差最大的正交旋转,得到正交旋转矩阵]926
.0379
.0379.0926.0[
-=Γ
上表为旋转后的因子载荷矩阵
以X1,X5,X10为例,有因子分析模型
1X =0.9601F -0.2232F +1ε;
5X =0.2581F +0.6422F +2ε; 10X =0.3251F +0.8212F +3ε;
在第一公因子
1F 对应的列中,正载荷主要是
X1,X2,X3,X4,X6,X7,X11,X12,X13,X14,X15,其载荷分别是0.960……,所以1F 可视为高科技因子;
在第二公共因子2F 对应的列中,正载荷主要是,X5,X10其载荷是0.642,0.821,
所以2F可视为非该科技因子;
有公共因子1F,2F的得分矩阵如下:
F1的得分:
-0.90012
-0.79770
-0.47026
-0.45750
-0.00373
0.12888
0.25514
2.24528
得分越高表示科技越高
F2的得分
-1.31413
-1.28805
-0.53602
-0.02641
0.33279
0.39734
1.00045
1.43403
得分越低表示分高科技成分越高
四、湖南省某白酒厂开发了一种新的白酒,想在本省上市,考虑到公司的现状:生产能力小,营销实力不强,在全省范围内没有系统的营销网络。公司收集了某年度湖南省各地区的经济发展和消费水平指标,并选取了与白酒消费相关的6个代表性指标,即x1:总人口(万人),x2:人均国民生产总值,x3:职工年平均工资(元),x4:平均每人每年现金收入(元),x5:平均每人每年消费性支出(元),x6:平均每人每年储蓄(元)。具体数据见消费情况数据.sav,试通过聚类分析的方法,根据该厂的特点选择营销区域。(25分)
解:采用谱系聚类
用组间连接的方法表示类间距
用平方euclidean距离表示类内距
4 5 9 1980793.584 3 0 8
5 4 10 2623309.85
6 0 0 6
6 4 13 3255590.170 5 0 8
7 2 6 3308180.240 0 0 10
8 4 5 3465565.259 6 4 9
9 4 7 4201756.054 8 0 11
10 2 3 7220817.310 7 0 11
11 2 4 11895008.673 10 9 12
12 2 14 18646365.736 11 0 13
13 1 2 36090072.422 0 12 0
上表是谱系聚类的聚类表,由表可知,第一步是是将5和8分为一小类,然后到3阶和11分为一类,这样将各变量分为一类,然后将最相似的聚为一类,再将已聚合的小类按其相似性再聚合,随着相似性的减弱,最后将一切子类聚合成一个大类,从而得到如下谱系图
x1:总人口(万人),x2:人均国民生产总值,x3:职工年平均工资(元),x4:平均每人每年现金收入(元),x5:平均每人每年消费性支出(元),x6:平均每人每年储蓄(元)。
由上面的树状图可知,
若分为3类,则有
第一类:长沙(特点,X1总人口最多,X2国民生产总值,X3工年平均工资(元),x4:平均每人每年现金收入(元),x5:平均每人每年消费性支出(元)等都是最高的,表示长沙的人们对白酒的购买力最强,所以可以在长沙加大销售量,将此地作为最主要的销售地)
第二类:湘西(特点:特点,X1总人口最少X2国民生产总值最低,X3工年平均工资很低,X4均每人每年现金收入低,x5:平均每人每年消费性支出很低表示湘西的人们对白酒的购买力最弱,表示在此地销售量最小)
第三类:其他(相对均匀,适量的进行销售)
若分为4类,则有
第一类:长沙(预计销售量最多)
第二类:株洲,湘潭,岳阳(预计销售量次之)
第三类:其他(预计销售量较少)
第四类:湘西(预计销售量很小)
数据分析期末试题及答案 一、人口现状.sav数据中是1992年亚洲各国家和地区平均寿命(y)、按购买力计算的人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)的数据,试用多元回归分析的方法分析各国家和地区平均寿命与人均GDP、成人识字率、一岁儿童疫苗接种率的关系。(25分) 解: 1.通过分别绘制地区平均寿命(y)、按购买力计算的人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)之间散点图初步分析他们之间的关系 上图是以人均GDP(x1)为横轴,地区平均寿命(y)为纵轴的散点图,由图可知,他们之间没有呈线性关系。尝试多种模型后采用曲线估计,得出 表示地区平均寿命(y)与人均GDP(x1)的对数有线性关系
上图是以成人识字率(x2)为横轴,地区平均寿命(y)为纵轴的散点图,由图可知,他们之间基本呈正线性关系。 上图是以疫苗接种率(x3)为横轴,地区平均寿命(y)为纵轴的散点图,由图可知,他们之间没有呈线性关系 。 x)为横轴,地区平均寿命(y)为纵轴的散点图,上图是以疫苗接种率(x3)的三次方(3 3 由图可知,他们之间呈正线性关系 所以可以采用如下的线性回归方法分析。
2.线性回归 先用强行进入的方式建立如下线性方程 设Y=β0+β1*(Xi1)+β2*Xi2+β3* X+εi i=1.2 (24) 3i 其中εi(i=1.2……22)相互独立,都服从正态分布N(0,σ^2)且假设其等于方差 R值为0.952,大于0.8,表示两变量间有较强的线性关系。且表示平均寿命(y)的95.2%的信息能由人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)一起表示出来。 建立总体性的假设检验 提出假设检验H0:β1=β2=β3=0,H1,:其中至少有一个非零 得如下方差分析表 上表是方差分析SAS输出结果。由表知,采用的是F分布,F=58.190,对应的检验概率P值是0.000.,小于显著性水平0.05,拒绝原假设,表示总体性假设检验通过了,平均寿命(y)与人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)之间有高度显著的的线性回归关系。
《数据库原理》课程考试模拟题四 一、单项选择题(在每小题的四个备选答案中选出一个正确答案。本题共16分,每小题1分) 1. 在数据库中,下列说法()是不正确的。 A.数据库中没有数据冗余 B.数据库具有较高的数据独立性 C.数据库能为各种用户共享 D.数据库加强了数据保护 2. 按照传统的数据模型分类,数据库系统可以分为( )三种类型。 A.大型、中型和小型 B.西文、中文和兼容 C.层次、网状和关系 D.数据、图形和多媒体 3. 在数据库的三级模式结构中,( )是用户与数据库系统的接口,是用户用到的那部分数据的描述。 A.外模式 B.内模式 C.存储模式D.模式 4. 下面选项中不是关系的基本特征的是( )。 A. 不同的列应有不同的数据类型 B. 不同的列应有不同的列名 C. 没有行序和列序 D. 没有重复元组 5. SQL语言具有两种使用方式,分别称为交互式SQL和( )。 A.提示式SQL B.多用户SQL C.嵌入式SQL D.解释式SQL 6. 设关系模式R(ABCD),F是R上成立的FD集,F={A→B,B→C},则(BD)+为( )。 A.BCD B.BC C.ABC D.C 7. E-R图是数据库设计的工具之一,它适用于建立数据库的( )。 A.概念模型 B.逻辑模型 C.结构模型 D.物理模型 8. 若关系模式R(ABCD)已属于3NF,下列说法中( )是正确的。 A.它一定消除了插入和删除异常 B.仍存在一定的插入和删除异常C.一定属于BCNF D.A和C都是 9. 解决并发操作带来的数据不一致性普遍采用( )。 A.封锁技术 B.恢复技术 C.存取控制技术 D.协商 10. 数据库管理系统通常提供授权功能来控制不同用户访问数据的权限,这主要是为了实现数据库的( )。 A.可靠性 B.一致性 C.完整性 D.安全
《数据库原理与应用》 一.单项选择题(每题1分,共20分) 1.目前市场上常见的DBMS 90%以上都是基于( C )数据模型的。 A.层次B.网状C.关系D.面向对象 2.E-R图是在数据库设计中用来表示( A )的一种常用方法。 A.概念模型B.逻辑模型C.物理模型D.面向对象模型 3.( C )是数据库中全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图。 A.外模式B.内模式C.模式D.概念模式 4.( B )也称存储模式,是数据库物理结构和存储方式的描述,是数据在数据库内部的表示方式。 A.外模式B.内模式C.模式D.概念模式 5.数据库的概念模型独立于( A )。 A.具体的机器和DBMS B.E-R图C.信息世界D.现实世界 6.在数据库中存储的是( C )。 A.数据B.数据库模型C.数据以及数据之间的联系D.信息 7.规范化理论是关系数据库进行逻辑设计的理论依据,根据这个理论,关系数据库中的关系必须满足:其每一个属性都是( B )。 A.互不相关的B.不可分解的C.长度可变得D.互相关联的 8.在数据模型中有“型”和“值(或实例)”两个对应的概念。其中数据库的模式是一个( D )的概念,是一个相对()的概念,而数据库在某一时刻的状态则是一个()的概念,是一个相对()的概念。 A.型;变化;值;不变B.值;不变;型;变化 C.值;变化;型;不变D.型;不变;值;变化 9.关系表A的属性个数为5,元组个数为10;关系表B的属性个数为6,元组个数为20. 则A与B的笛卡尔积A×B的属性有( D )个,元组个数有()个。 A.30;200B.11;30 C.30;30D.11;200 10.父亲和子女的亲生关系属于( B )的关系。 A.1:1B.1:n C.m:n D.不一定 11.在SQL语言中,删除关系表中的一个属性列,要用动词( D ),删除关系表中的一行或多行元组,要用动词()。 A.delete,delete B.drop,drop C.delete,drop D.drop,delete 12.在SQL语言中,为关系模式增加一个属性要用动词(B),为关系表增加一行或多行元组要用动词()。 A.insert,insert B.add,insert C.insert,add D.add,add 13.实体完整性约束和SQL语言中的( A )相对应。 A.primary key B.foreign key C.check D.都不是 14.参照完整性约束和SQL语言中的( B )相对应。 A.primary key B.foreign key C.check D.都不是 15.在我们的学生-课程数据库中,SC表上建立了两个外码约束,被参照表是Student表和Course表,则最适当的说法是: A.Student表中的学生号Sno不能随意取值B.Course表中的课程号Cno不能随意取值 C.SC表中学生号Sno不能随便D.SC表中学生号Sno、课程号Cno均不能随意取值 16.如果在学生-课程数据库中的SC表上建立了参照完整性约束: Foreign Key (Sno)References Student(Sno), Foreign Key (Cno)References Course(Cno), 则( D )操作可能会违背该完整性约束。 A.在Student表上增加一行记录B.在Course表上增加一行记录 C.在SC表上删除一行记录D.更新SC表上的记录 17.关系R(X,Y,Z),函数依赖集FD={Y→Z,XZ→Y},则关系R是( C )。 A.1NF B.2NF C.3NF D.BCNF 18、表之间一对多关系是指_B_____。 A.一张表与多张表之间的关系B.一张表中的一个记录对应另一张表中的多个记录 C.一张表中的一个记录对应多张表中的一个记录D.一张表中的一个记录对应多张表中的多个记录 19、SQL的SELECT语句中,“HAVING条件表达式”用来筛选满足条件的(D) A.列B.行C.关系D.分组 20、SQL语言中INSERT、DELETE、UPDA TE实现哪类功能 D 。 A.数据查询B.数据控制C.数据定义D.数据操纵 二.填空题(每空1分,共18分): 1.从历史发展看来,数据管理技术经历了人工管理、文件管理和数据库管理三个阶段。 2.在SQL语言中,用符号—代表单个字符,用符号% 代表0到多个字符。 3.在SQL语言中,为了使查询的结果表中不包含完全相同的两个元组,应在select的后面加上关键词distinct 。 4、在SQL语句中,与表达式“工资BETWEEN 1210 AND 1240”功能相同的表达式是工资>=1210 and 工资<=1240 。 第 1 页/共 4 页
数据库期末考试试题及答案 一、选择题(每题1分,共20分) 1(在数据管理技术的发展过程中,经历了人工管理阶段、文件系统阶段和数据库系统阶段。 在这几个阶段中,数据独立性最高的是( A )阶段。 A. 数据库系统 B. 文件系统 C. 人工管理 D.数据项管理 2(数据库三级视图,反映了三种不同角度看待数据库的观点,用户眼中的数据库称为(D)。 A. 存储视图 B. 概念视图 C. 内部视图 D. 外部视图 3(数据库的概念模型独立于(A)。 A. 具体的机器和DBMS B. E-R图 C. 信息世界 D. 现实世界 4(数据库中,数据的物理独立性是指(C)。 A. 数据库与数据库管理系统的相互独立 B. 用户程序与DBMS的相互独立 C. 用户的应用程序与存储在磁盘上的数据库中的数据是相互独立的 D. 应用程序与数据库中数据的逻辑结构相互独立 5(关系模式的任何属性(A)。 A. 不可再分 B. 可再分 C. 命名在该关系模式中可以不惟一 D.以上都不是 6(下面的两个关系中,职工号和设备号分别为职工关系和设备关系的关键字: 职工(职工号,职工名,部门号,职务,工资) 设备(设备号,职工号,设备名,数量) 两个关系的属性中,存在一个外关键字为( C )。
A. 职工关系的“职工号” B. 职工关系的“设备号” C. 设备关系的“职工号” D. 设备关系的“设备号” 7(以下四个叙述中,哪一个不是对关系模式进行规范化的主要目的( C )。 A. 减少数据冗余 B. 解决更新异常问题 C. 加快查询速度 D. 提高存储空间效率 8(关系模式中各级范式之间的关系为( A )。 A. B. C. D. 9(保护数据库,防止未经授权或不合法的使用造成的数据泄漏、非法更改或破坏。这是指 数据的( A )。 A. 安全性 B.完整性 C.并发控制 D.恢复 10(事务的原子性是指( B )。 A. 事务一旦提交,对数据库的改变是永久的 B. 事务中包括的所有操作要么都做,要么都不做 C. 一个事务内部的操作及使用的数据对并发的其他事务是隔离的 D. 事务必须使数据库从一个一致性状态变到另一个一致性状态 11(下列哪些运算是关系代数的基本运算( D )。 A. 交、并、差 B. 投影、选取、除、联结 C. 联结、自然联结、笛卡尔乘积 D. 投影、选取、笛卡尔乘积、差运算 12(现实世界“特征” 术语, 对应于数据世界的( D )。 A(属性 B. 联系 C. 记录 D. 数据项 13(关系模型中3NF是指( A )。 A.满足2NF且不存在传递依赖现象 B.满足2NF且不存在部分依赖现象
数据分析练习题 第 小组 姓名: 练习一: 1、老师在计算学期总平均分的时候按如下标准:作业占100%、测验占30%、期中占35%、期末考试占35% x 小关 = . x 小兵 = . 2、结果如下表:(单位:小时) 求这些灯泡的平均使用寿命? . x = .小时 3、在一个样本中,2出现了x 1次,3出现了x 2次,4出现了x 3次,5出现了x 4次,则这个样本的平均数为 . 4、某人打靶,有a 次打中x 环,b 次打中y 环,则这个人平均每次中靶 环。 5、某校为了了解学生作课外作业所用时间的情况,对学生作课外作业所用时间进行调查,下表是该校初二某班50名学生某一天做数学课外作业所用时间的情况统计表 (1)、第二组数据的组中值是多少? (2)、求该班学生平均每天做数学作业所用时间 答:(1)组中值为: . (2)解: 6、某公司有15名员工,他们所在的部门及相应每人所创的年利润如下表该公司每人所创年利润的平均数是多少万元?
7、为调查居民生活环境质量,环保局对所辖的50个居民区进行了噪音(单位:分贝)水平的调查,结果如下图,求每个小区噪音的平均分贝数。 8、某公司销售部有营销人员15人,销售部为了制定某种商品的销售金额,统计了这15个人的销售量如下(单位:件) 1800、510、250、250、210、250、210、210、150、210、150、120、120、210、150 求这15个销售员该月销量的中位数和众数。 假设销售部负责人把每位营销员的月销售定额定为320件,你认为合理吗?如果不合理,请你制定一个合理的销售定额并说明理由。 练习二: 1. 数据8、9、9、8、10、8、99、8、10、7、9、9、8的中位数是 ,众数是 2. 一组数据23、27、20、18、X 、12,它的中位数是21,则X 的值是 . 3. 数据92、96、98、100、X 的众数是96,则其中位数和平均数分别是( ) A.97、96 B.96、96.4 C.96、97 D.98、97 4. 如果在一组数据中,23、25、28、22出现的次数依次为2、5、3、4次,并且没有其他的数据, 则这组数据的众数和中位数分别是( ) A.24、25 B.23、24 C.25、25 D.23、25 请你根据上述数据回答问题: (1).该组数据的中位数是什么? (2).若当气温在18℃~25℃为市民“满意温度”,则我市一年中达到市民“满意温度”的大约有多少天? 60 噪音/分贝 80 70 50 40 90
一、单选题(共 10 道试题,共 50 分。)V 1. SQL Server中,保存着每个数据库对象的信息的系统表是()。 A. sysdatabases B. Syscolumns C. Sysobjects D. Syslogs 满分:5 分 2. 在存在下列关键字的SQL语句中,不可能出现Where子句的是()。 A. Update B. Delete C. Insert D. Alter 满分:5 分 3. 在查询语句的Where子句中,如果出现了“age Between 30 and 40”,这个表达式等同于()。 A. age>=30 and age<=40 B. age>=30 or age<=40 C. age>30 and age<40 D. age>30 or age<40 满分:5 分 4. 如果要在一管理职工工资的表中限制工资的输入围,应使用()约束。 A. PDRIMARY KEY B. FOREIGN KEY C. unique D. check 满分:5 分 5. 记录数据库事务操作信息的文件是()。 A. 数据文件 B. 索引文件 C. 辅助数据文件 D. 日志文件 满分:5 分 6. 要查询XSH数据库CP表中产品名含有“冰箱”的产品情况,可用()命令。 A. SELECT * FROM CP WHERE 产品名称LIKE ‘冰箱’ B. SELECT * FROM XSH WHERE 产品名称LIKE ‘冰箱’ C. SELECT * FROM CP WHERE 产品名称LIKE ‘%冰箱%’ D. SELECT * FROM CP WHERE 产品名称=‘冰箱’ 满分:5 分 7. 储蓄所有多个储户,储户能够在多个储蓄所存取款,储蓄所与储户之间是()。 A. 一对一的联系 B. 一对多的联系 C. 多对一的联系 D. 多对多的联系 满分:5 分
2004-2005学年第二学期期末考试 C 2002级计算机科学与技术专业《数据库原理与应用》课程试题 :1分)一、选择题(15分,每空1.在数据库中,产生数据不一致的根本原因是____。 A.数据存储量太大 B.没有严格保护数据 C.未对数据进行完整性控制 D.数据冗余 2.相对于其他数据管理技术,数据库系统有①、减少数据冗余、保持数据的一致性、②和③的特点。 ①A.数据统一 B.数据模块化 C.数据结构化 D.数据共享 ②A数据结构化 B.数据无独立性 C.数据统一管理 D.数据有独立性 ③A.使用专用文件 B.不使用专用文件 C.数据没有安全与完整性保障 D.数据有安全与完整性保障 3.关系运算中花费时间可能最长的运算是____。 A.投影 B.选择 C.笛卡尔积 D.除 4.关系数据库用①来表示实体之间的联系,关系的数学定义是②。 ①A.层次模型 B.网状模型 C.指针链 D.二维表格数据 ②A.若干域(domain)的集合 B.若干域的笛卡尔乘积(Cartesian product) C.若干域的笛卡尔乘积的子集 D.若干元组(tuple)的集合 5.集合R与S的连接可以用关系代数的5种基本运算表示为________。 A.R-(R-S) B.σ (R×S) F C.空 D.空 6.在关系代数中,对一个关系做投影操作后,新关系的元组个数____原来关系的元组个数。A.小于 B.小于或等于 C.等于 D.大于 7.下列SQL语句中,创建关系表的是____。 A.ALTER B.CREATE C.UPDATE D.INSERT 8.关系数据库设计中的陷阱(pitfalls)是指________。 A.信息重复和不能表示特定信息 B.不该插入的数据被插入 C.应该删除的数据未被删除 D.应该插入的数据未被插入 9.数据库的____是为了保证由授权用户对数据库所做的修改不会影响数据一致性的损失。 A.安全性 B.完整性 C.并发控制 D.恢复 .事务是数据库进行的基本工作单位。如果一个事务执行成功,则全部更新提交;如果一个事务10.
SPSS在教育研究中的应用某大学学生对本校的满意度调查 学院:教育学院 专业:课程与教学论 学号:201411000156 姓名:李平 2014年12月13日
目录 一、研究问题的提出 (3) 二、研究内容与方法 (3) (一) 研究内容 (3) (二) 研究方法 (3) 三、调查对象及人数 (4) 四、问卷分析 (5) (一)回收情况 (5) (二)信度分析 (5) 五、数据统计与分析 (6) (一)数据输入 (6) (二)数据分析 (7) 1.描述统计 (7) (1)多选题描述统计 (7) (2)单选题描述统计 (9) 2.推断统计 (12) (1)独立样本T检验 (12) (2)单一样本T检验 (15) (3)单因素方差分析 (17) (4) X2检验 (21) 3.相关分析 (22) (1)变量间相关分析 (22) (2)维度间相关分析 (23) 六、结论 (27) 七、附录 (28)
一、研究问题的提出 学生的学校生活和成长密切相关。我们通过对他们的大学生活满意度的调查结果向有关部门提出建议,并希望能引起学校对这一系列问题的关注,最终希望大学生对其大学的满意度有所提升,大学生是一个庞大的群体,特别是近几年,随着高校的扩招,我国越来越多人能够上大学。上大学是很多人的梦想,他们都憧憬着大学校园的生活,然而当他们进了大学后才发现大学生活并非所想的美好,取而代之的却是对校园生活的不满,大学生是十分宝贵的人才资源,他们对校园生活的体验和感受,与他们的更好的学习。 二、研究内容与方法 (一)研究内容 了解学生对于学校的师资水平、环境、日常管理等各方面的满意度。 (二)研究方法 1.问卷编制 本研究采用自编问卷,问卷共由两部分组成:基本情况部分包括被调查者的性别、年级等,问卷主体部分包括师资水平、学校环境、日常管理三大维度,细分为12个三级指标(见表2-1),问卷采用五点制计分法,即“非常满意”、“满意”、“一般”、“不满意”、“非常不满意”,分别赋值5分、4分、3分、2分、1分。 表2-1 某大学学生对本校的满意度测评指标体系 一 级指标 二级指标(潜在变量)三级指标(观测变量) 对自己师资水平对教师教学方法、对教师工作态 度、对教师人品修养、对师资配备 学校的意学校环境对学习环境、对就餐环境、对居住 环境、对校园绿化环境 满度指数日常管理对专业课时安排、对收费标准、对 奖、助学金制度、对学校治安
期末考试卷(卷) 课程名称:数据库考试方式:开卷()闭卷(√) 、本试卷共4 页,请查看试卷中是否有缺页。 2、考试结束后,考生不得将试卷、答题纸带出考场。 1、以下(a )内存区不属于SGA。 A.PGA B.日志缓冲区 C.数据缓冲区 D.共享池 2、d )模式存储数据库中数据字典的表和视图。 (A.DBA B.SCOTT C.SYSTEM D.SYS 3、Oracle 中创建用户时,在若未提及DEFAULT TABLESPACE 关键字,Oracle 就将 c )则(表空间分配给用户作为默认表空间。A.HR B.SCOTT C.SYSTEM D.SYS
4、a )服务监听并按受来自客户端应用程序的连接请求。(A.OracleHOME_NAMETNSListener B.OracleServiceSID C.OracleHOME_NAMEAgent D.OracleHOME_NAMEHTTPServer 5、b )函数通常用来计算累计排名、移动平均数和报表聚合等。(A.汇总B.分析C.分组D.单行 6、b)SQL 语句将为计算列SAL*12 生成别名Annual Salary (A.SELECT ename,sal*12 …Annual Salary? FROM emp; B.SELECT ename,sal*12 “Annual Salary” FROM emp; C.SELECT ename,sal*12 AS Annual Salary FROM emp; D.SELECT ename,sal*12 AS INITCAP(“Annual Salary”) FROM emp; 7、锁用于提供(b )。 A.改进的性能 B.数据的完整性和一致性 C.可用性和易于维护 D.用户安全 8、( c )锁用于锁定表,允许其他用户查询表中的行和锁定表,但不允许插入、更新和删除行。 A.行共享B.行排他C.共享D.排他 9、带有( b )子句的SELECT 语句可以在表的一行或多行上放置排他锁。 A.FOR INSERT B.FOR UPDATE C.FOR DELETE D.FOR REFRESH
数据库期末考试试题 ━━━━━━━━━━━━━━━ 一、填空共30题(共计30分) ━━━━━━━━━━━━━━━ 第1题(分)题号:2385 ORDER BY 子句实现的是【1】. 答案: =======(答案1)======= 排序 第2题(分)题号:2374 如果列上有约束,要删除该列,应先删除【1】 答案: =======(答案1)======= 相应的约束 第3题(分)题号:2394 在每次访问视图时,视图都是从【1】中提取所包含的行和列. 答案: =======(答案1)======= 基表 第4题(分)题号:2372
1.在增加数据文件时,如果用户没有指明文件组,则系统将该数据文件增加到【1】文件组.答案: =======(答案1)======= 主 第5题(分)题号:2371 查看XSCJ数据库信息的存储过程命令是【1】 答案: =======(答案1)======= sp_helpdb 第6题(分)题号:2392 创建视图定义的T-SQL语句的系统存储过程是【1】. 答案: =======(答案1)======= sp_helptext 第7题(分)题号:2379 1.表的外键约束实现的是数据的【1】完整性. 答案: =======(答案1)======= 参照 第8题(分)题号:2390 要进行模糊匹配查询,需要使用【1】关键字来设置查询条件.
答案: =======(答案1)======= LIKE 第9题(分)题号:2380 定义标识列的关键字是【1】. 答案: =======(答案1)======= identity 第10题(分)题号:2383 在进行多表查询是,必须设置【1】条件. 答案: =======(答案1)======= 连接 第11题(分)题号:2363 联系两个表的关键字称为【1】 答案: =======(答案1)======= 外键 第12题(分)题号:2382 用【1】字句可以实现选择行的运算. 答案:
数据分析方法课程设计
题目概述: 3、调查美国50个州7种犯罪率,得结果列于表1,其中给出的是美国50个州每100 000 个人中七种犯罪的比率数据。这七种犯罪是:murder(杀人罪),rape(强奸罪),robbery(抢劫罪),assault(斗殴罪),burglary(夜盗罪),larceny(偷盗罪),auto(汽车犯罪)。
1)基于变量()的观测值,求样本协 方差矩阵S和样本相关系数矩阵R; 2)分别从S和R。出发做主成分分析: (1)求样本主成分的贡献率、累计贡献率和各个样本主成分; (2)在两种情况下,你认为应该保留几个主成分,其意义如何解释?(提示:要求累计贡献率达到80%以上)就此题而言,你认为基于S和R的分析结果哪个更 合理? (3)按第一主成分得分将美国50个州排序,结果如何? (4)作以第一主成分得分为横坐标,第二主成分得分为纵坐标的散点图。 L快速聚类和类平均距离谱系聚3)对表1的美国50个州七种犯罪的比率数据,分别试用 2.5 类法将美国50个州分4类,并对聚类结果进行分析和比较。从聚类结果看,你认为哪种分类方法好? 问题一 采用sas得到样本协方差矩阵S:
样本相关系数矩阵R: 问题二 1、从R进行主成分分析: (1)、求样本主成分的贡献率、累计贡献率和各个样本主成分。 贡献率: (2)累计贡献率到达80%以上,需保留三个主成分,前三个成分的累计贡献率已达到86.9%。
由此三个主成分: PRIN1=0.300279murder+ 0.431759 rape+0.396875 robbery+0.396652assault+ 0.440157 burglary +0.357360arceny +0.295177auto PRIN2=-0.629174muder-0.169435rape+0.042247robbery-0.343528asault+0.203341bur glary+ 0.402319larceny+0.502421auto PRIN3=0.178245muder-0.2442rape+0.495861robbery-0.06951asault- 0.2099burglary- 0.5392larceny+0.568auto 从S进行主成分分析: 贡献率: 特征向量: 累计贡献率:第一个成分贡献率已达到87.36%。主成分表达式: PRIN1=0.000864muder+0.008773rape+0.056993robbery+0.059196asault+ 0.465346burglary+0.872863larceny+0.121384auto 分析: 由于第一主成分对所有变量都有近似相等的载荷,因此可认为第一主成分是对所有犯罪率的总度量。第二主成分在变量auto和larceny上有高的正载荷,而在变量murder和assault上有高的负载荷;在burglary上存在小的正载荷,而在rape上存在小的负载荷。可以认为,这个主成分是用于度量暴力犯罪在犯罪性质上占的比重。第三主成分很难给出明显的解释。在依PRIN1排序的结果表中,排在前面的PRIN1值较小的州犯罪率较低,即北达科他NORTH DAKOTA(PRIN1= -3.96408)州犯罪率最低,PRIN1值较大的州,犯罪率较高,即内华达NEV ADA(PRIN1= 5.26699)州犯罪率最高。在依PRIN2排序的结果表35.4中,排在前面的PRIN2值较小州的暴力犯罪性质比重较大。
《数据库原理》课程考试模拟题四 、单项选择题(在每小题的四个备选答案中选出一个正确答案。本题共 )是不正确的。 B .数据库具有较高的数据独立性 D ?数据库加强了数据保护 2.按照传统的数据模型分类,数据库系统可以分为 ()三种类型 .西文、中文和兼容 .数据、图形和多媒体 是用户 与数据库系统的接口,是用户用到的那部 C .存储模式 D .模 ) ° B. 不同的列应有不同的列名 没有重复元组 SQL 和 ( ) ° C .嵌入式SQL D .解释式SQL 6. 设关系模 式 R (ABCD ) F 是R 上成立的FD 集,F={A ^B, B -C},则(BD )+为( ) 7. E-R 图是数据库设计的工具之一,它适用于建立数据库的 ( ) ° A .概念模型 B .逻辑模型 C .结构模型 D .物理模型 8. 若关系模式R (ABCD 已属于3NF,下列 说法中( ) 是正确的。 10. 数据库管理系统通常提供授权功能来控制不同用户访问数据的权限,这主要是为了实 现数据库的( ) ° 11. 一个事务一旦完成全部操作后,它对数据库的所有更新应永久地反映在数据库中,不 会丢失。这是指事务的( ) ° A.原子性 B. 一致性 C. 隔离性 D. 持久性 12. 在数据库中,软件错误属于() ° A.事务故障 B. 系统故障 C. 介质故障 D. 活锁 1.在数据库中,下列说法( A .数据库中没有数据冗余 C .数据库能为各种用户共享 A .大型、中型和小型 B C.层次、网状和关系 D 3. 在数据库的三级模式结构中,() 分数据的描述。 A .外模式 B .内模式 式 4. 下面选项中不是关系的基本特征的是 ( A.不同的列应有不同的数据类型 C.没有行序和列序 D. 5. SQL 语言具有两种使用方式,分别称为交互式 A.提示式SQL B .多用户SQL A . BCD B . BC C . ABC 16分,每小题1分) A .它一定消除了插入和删除异常 B C. 一定属于BCNF D 9. 解决并发操作带来的数据不一致性普遍采用 A .封锁技术 B .恢复技术 .仍存在一定的插入和删除异常 .A 和 C 都是 () ° C .存取控制技术 D .协商 A .可靠性 B . 一致性 C .完整性 D .安全性
数据库程序设计试题 1一、判断题(每题1分,共10分) 1、DB、DBMS、DBS三者之间的关系是DBS包括DB和DBMS。( ) 2、数据库的概念结构与支持其的DB的DBMS有关。( ) 3、下列式子R∩S=R—(R—S)成立。( ) 4、数据存储结构改变时逻辑结构不变,相应的程序也不变,这是数据库系统的逻辑独立 性。() 5、关系数据库基本结构是三维表。( ) 6、在嵌入式SQL语句中,主语句向SQL语句提供参数,主要用游标来实现。( ) 7、规范化的投影分解是唯一的。( ) 8、不包含在任何一个候选码中的属性叫做非主属性。( ) 9、在 Transact-SQL 语句的WHERE子句中,完全可以用IN子查询来代替OR逻辑表达式。 ( ) 10、封锁粒度越大,可以同时进行的并发操作越大,系统的并发程度越高。() 二、填空题(每空0.5分,共10分) 1、两个实体间的联系有联系,联系和联系。 2、select命令中,表达条件表达式用where子句,分组用子句,排序用 子句。 3、数据库运行过程中可能发生的故障有、和三类。 4、在“学生-选课-课程”数据库中的三个关系如下: S(S#,SNAME,SEX,AGE),SC(S#,C#,GRADE),C(C#,CNAME,TEACHER)。 现要查找选修“数据库技术”这门课程的学生姓名和成绩,可使用如下的SQL语句:SELECT SNAME,GRADE FROM S,SC,C WHERE CNAME= 数据库技术AND S.S#=SC.S# AND。 5、管理、开发和使用数据库系统的用户主要有、、 。 6、关系模型中可以有三类完整性约束:、 和。 7、并发操作带来数据不一致性包括三类:丢失修改、和。 8、事务应该具有四个属性:原子性、、隔离性和持续性。 9、数据库运行过程中可能发生的故障有事务故障、和三类。 10、在“学生-选课-课程”数据库中的三个关系如下:S(S#,SNAME,SEX,AGE),SC(S#,C#,GRADE),C(C#,CNAME,TEACHER)。 现要查找选修“数据库技术”这门课程的学生姓名和成绩,可使用如下的SQL语句:SELECT SNAME,GRADE FROM S,SC,C WHERE CNAME= ‘数据库技术’AND S.S#=SC.S# AND。 11、数据库设计包括、、逻辑结构设计、物理结构设计、数据库实施、数据库运行和维护。 12、MS SQL Server提供多个图形化工具,其中用来启动、停止和暂停SQL Server的图形 化工具称为_________。 13 、SELECT语句中进行查询 , 若希望查询的结果不出现重复元组 , 应在SELECT子 句中使用____________保留字。 14、如果一个关系不满足2NF,则该关系一定也不满足__________(在1NF、2NF、3NF 范围内)。 15、数据库的物理设计主要考虑三方面的问题:______、分配存储空间、实现存取路径。 三、单选题(每题1分,共20 分) 1、在SQL中,关系模式称为() A、视图 B、对象 C、关系表 D、存储文件 2、要保证数据库逻辑数据独立性,需要修改的是( )
命题方式:单独命题 佛山科学技术学院2008—2009学年第一学期 《数据分析》课程期末考试试题A卷专业、班级:姓名:学号:
共 3 页第 2 页
共 3 页第3 页
一(1)SAS界面包括 输出框,日志框,编辑器 (2)在非数值变量后面家上”$”符号. (3) 自由格式输入数据应加上”@@”标记. (4) 三均值的计算公式 ^ M=1/4Q1+1/2M+1/4Q3 二 程序: data t1; input x@@; cards; 100.00 107.57 112.42 96.21 121.58 107.21 117.16 116.19 101.37 109.78 112.83 104.37 105.40 109.50 111.60 112.10 113.50 112.40 proc univariate plot normal; run; proc capability graphics normal; histogram x/normal; qqplot x/normal(….); run; (1)由上图可知道 均值:109.510556 方差:40.5703938 变异系数:5.81632451 峰度:0.05978054 偏度:-0.3324812 (2) 中位数: 上四分位数: 下四分位数: 四分位极差: (3)做出直方图、QQ图、茎叶图、箱线图 直方图:
QQ图 茎叶图:
箱线图: (4)进行正态性W 检验(取05.0=α). 由上图可以知道Wo=0.978265,P=0.9304>05.0=α; 故不能拒绝原假设Ho,所以是高度显著的。 三 data t2; input x1-x4; cards ; 16.7 26.7 6.4 35.0 18.2 28.0 3.2 29.7 16.7 26.7 2.1 34.9 18.1 26.7 4.3 31.5 16.7 26.0 3.0 32.7 18.1 30.2 7.0 34.9 20.2 30.5 4.8 34.4 20.2 29.5 5.5 36.2 21.5 31.5 5.8 36.5 18.8 30.6 5.4 35.4 21.6 27.8 5.4 34.1 21.3 29.5 5.8 35.8 proc corr cov pearson ; run ; (1)计算协方差矩阵,Pearson 相关矩阵; 协方差矩阵:
一、选择题(每题1分,共20分) 1.在数据管理技术的发展过程中,经历了人工管理阶段、文件系统阶段和数据库系统阶段。在这几个阶段中,数据独立性最高的是( A )阶段。 A. 数据库系统 B. 文件系统 C. 人工管理 D.数据项管理 2.数据库三级视图,反映了三种不同角度看待数据库的观点,用户眼中的数据库称为(D)。 A. 存储视图 B. 概念视图 C. 内部视图 D. 外部视图 3.数据库的概念模型独立于(A)。 A.具体的机器和DBMS B. E-R图 C. 信息世界 D. 现实世界 4.数据库中,数据的物理独立性是指(C)。 A. 数据库与数据库管理系统的相互独立 B. 用户程序与DBMS的相互独立 C. 用户的应用程序与存储在磁盘上的数据库中的数据是相互独立的 D. 应用程序与数据库中数据的逻辑结构相互独立 5.关系模式的任何属性(A)。 A. 不可再分 B. 可再分 C. 命名在该关系模式中可以不惟一 D.以上都不是 6.下面的两个关系中,职工号和设备号分别为职工关系和设备关系的关键字: 职工(职工号,职工名,部门号,职务,工资) 设备(设备号,职工号,设备名,数量) 两个关系的属性中,存在一个外关键字为( C )。 A. 职工关系的“职工号” B. 职工关系的“设备号” C. 设备关系的“职工号” D. 设备关系的“设备号” 7.以下四个叙述中,哪一个不是对关系模式进行规X化的主要目的( C )。 A. 减少数据冗余 B. 解决更新异常问题 C. 加快查询速度 D. 提高存储空间效率 8.关系模式中各级X式之间的关系为( A )。 A. B. C. D. 9.保护数据库,防止未经授权或不合法的使用造成的数据泄漏、非法更改或破坏。这是指数据的( A )。 A. 安全性 B.完整性 C.并发控制 D.恢复 10.事务的原子性是指( B )。 A. 事务一旦提交,对数据库的改变是永久的 B. 事务中包括的所有操作要么都做,要么都不做 C. 一个事务内部的操作及使用的数据对并发的其他事务是隔离的 D. 事务必须使数据库从一个一致性状态变到另一个一致性状态 11.下列哪些运算是关系代数的基本运算( D )。 A. 交、并、差 B. 投影、选取、除、联结 C. 联结、自然联结、笛卡尔乘积 D. 投影、选取、笛卡尔乘积、差运算
一、选择题 1、下面(_B___)描述是正确的。 A、视图是一种常用的数据库对象,使用视图不可以简化数据操作。 B、使用视图可以提高数据库的安全性。 C、视图和表一样是由数据构成的。 D、视图必须从多个数据表中产生才有意义。 2、下面(__D__)组命令,将变量count值赋值为1。 A、DIM @count int SELECT @count=1 B、DIM count=1 int C、DECLARE count int SELECT count=1 D、DECLARE @count int SELECT @count=1 3、你要为一个向全世界出口产品的物流公司开发一个数据库。这个公司有关销售信息的资料都存储在一个名为sales的表格内。消费者的名字都被存放一个名为Customers的数据库内。以下是创建表格的脚本代码。 CREATE TABLE Customers ( CustomerID int NOT NULL, CustomerName varchar (30) NOT NULL, ContactName varchar (30) NULL, Phone varchar (20) NULL, Country varchar (30) NOT NULL) 通常每个国家只有1,2名顾客。然而, 有些国家有多达20 名顾客。公司的营销部门想要对超过10个顾客的国家做广告。 你要为营销部门创建一个包含这些国家的名单列表。你应该使用哪个代码? ( A ) A. SELECT Country FROM Customers GROUP BY Country HAVING COUNT (Country) > 10 B. SELECT TOP 10 Country FROM Customers C. SELECT TOP 10 Country FROM Customers FROM (SELECT DISTINCT Country FROM Customers) AS X GROUP BY Country HAVING COUNT(*) > 10 D. SET ROWCOUNT 10 SELECT Country , COUNT(*) as “NumCountries”
《生意参谋数据分析师》考试 1、 单选题 分值: 1 王家杂货铺的掌柜在复盘上月数据时发现客服小甲有12个咨询是没回复;如果小甲上个月总共有100个咨询量,那么他当时的回复率是多少? A: 0.12 B: 0.58 C: 0.82 D: 0.88 答案解析:"参考章节:店铺客服转化率诊断本题考点:客服回复率答案解析:客服回复率是指客服对于咨询他的客户进行回复的百分占比,如果有100个咨询量,其中12个没有回复,那么回复率就是(10 0-12)/100=88%" 2、 单选题 分值: 1 小芳根据数据分析发现主推宝贝标题里很多关键词没有带来访客数和转化率,于是想要替换这些关键词,她应该替换什么关键词进去? A: 从生意参谋的搜索词里面找到自己叶子类目的相关性强转化率高流量大的核心关键词,如果标题里没有的,就可以找出来替换进去。 B: 看看别人标题都用什么词,自己没有的,加进来 C: 加类目大词进来引流量 D: 选一些长尾词转化率高
答案解析:参考章节:快速优化标题提升手淘搜索流量本题考点:优质关键词寻找和标题优化答案解析:生意参谋—市场—搜索排行—搜索词里面找到自己叶子类目的相关性强转化率高流量大的核心关键词。 3、 单选题 分值: 1 小明是吹风机类目的商家,他想做类目趋势对比表,为此他需要收集近几年的相关数据作为参考? A: 近5年 B: 近4年 C: 近3年 D: 近2年 答案解析:参考章节:品类罗盘—商品年度规划(一)本题考点:市场趋势表格制作试题解析:在大数据的背景下,我们做类目数据对比时,会去抓取近3年子类目数据为参考维度。 4、 单选题 分值: 1 小明店铺的无线首页,模块1跳转店内爆款,每天点击量200,模块2跳转店内新品,每天点击量80;因为新品数据良好,有次爆款潜力,小明决定交换模块1和模块2跳转商品! A: 正确 B: 错误 答案解析:参考章节:页面效果如何提升?本题考点:页面数据分析答案解析:根据页面板块的点击数、点击率、转化率等数据来确定优化方向 5、 单选题 分值: 1 为了尽量减少花费,小李想选择免费方法实现新品破0 ;以下那种破0 方法不是免费的?