Oracle 11gR2 概念 第9章 数据并发性和一致性
- 格式:pdf
- 大小:926.12 KB
- 文档页数:43



oracle 11g rac 原理Oracle 11g RAC(Real Application Clusters)是Oracle数据库的一种高可用解决方案,它允许多个节点共享同一个数据库实例,以提供更高的可用性和可扩展性。
以下是Oracle 11g RAC 的原理:1. 共享存储:Oracle 11g RAC需要使用共享存储来存储数据库的数据文件、控制文件和日志文件。
共享存储通常是通过网络连接到多个节点,因此所有节点可以同时访问存储中的数据。
2. 共享连接:Oracle 11g RAC使用Cluster Interconnect来提供节点之间的高速连接。
Cluster Interconnect是一个专用的高速网络,用于节点之间的通信,以确保数据的一致性和互操作性。
3. 共享缓存:每个节点都有自己的SGA(System Global Area)用来缓存数据库的数据块。
Oracle 11g RAC使用Cache Fusion技术来确保所有节点的缓存数据的一致性。
当一个节点需要访问另一个节点的数据时,它可以直接从其他节点的缓存中读取数据,而不需要访问磁盘。
4. 共享处理:Oracle 11g RAC使用Global Cache Service(GCS)和Global Enqueue Service(GES)来协调多个节点上的并发事务。
GCS负责管理缓存数据的锁定和共享,以保证数据的一致性,而GES负责处理并发事务之间的资源请求和释放。
5. 自动故障转移:Oracle 11g RAC具有自动故障转移功能,当某个节点宕机时,自动将该节点上的数据库实例转移到其他节点上,以保证服务的连续性。
故障转移是通过Clusterware软件来实现的,它可以监控节点的状态,并在节点失效时自动触发故障转移操作。
总的来说,Oracle 11g RAC通过共享存储、共享连接、共享缓存和共享处理来实现多个节点之间的数据共享和并发访问。

一、概述Oracle数据库是目前全球使用最广泛的关系型数据库管理系统之一,它提供了强大的数据管理和处理功能,被广泛应用于企业级应用中。
Oracle数据库实例是Oracle数据库的核心概念之一,它在Oracle数据库运行过程中起着至关重要的作用。
本文将深入探讨Oracle数据库实例的概念、特点及其在数据库运行中的作用。
二、Oracle数据库实例的概念1. Oracle数据库实例的定义Oracle数据库实例是指在数据库启动时,Oracle进程和内存结构的集合。
它包括了一系列的进程和内存结构,用于管理数据库的数据访问、事务处理、共享资源控制等功能。
2. Oracle数据库实例的特点(1)独立性:每个数据库实例都是相互独立的,它们可以在同一服务器上运行,也可以在不同的服务器上运行。
(2)并发性:Oracle数据库实例能够处理大量的并发访问请求,保证了数据库的高效运行。
(3)持久性:Oracle数据库实例是持久的,一旦启动,它将一直运行,直到被关闭或者服务器宕机。
三、Oracle数据库实例的组成1. 进程:Oracle数据库实例包括了多个关键进程,如后台进程、前台进程等,用于处理用户的请求、管理数据缓冲池、执行SQL语句等。
2. 内存结构:Oracle数据库实例的内存结构包括了SGA(System Global Area)和PGA(Program Global Area),SGA用于存储全局共享的数据和控制信息,PGA用于存储每个进程私有的数据和控制信息。
四、Oracle数据库实例的作用1. 数据访问管理:Oracle数据库实例负责管理用户的数据访问请求,包括读取数据、更新数据、删除数据等操作。
2. 事务处理:Oracle数据库实例支持ACID(原子性、一致性、隔离性、持久性)事务功能,保证了数据库的数据完整性和一致性。
3. 共享资源控制:Oracle数据库实例负责管理数据库中的共享资源,如锁、缓存等,保证了多个用户之间对数据库的安全访问。
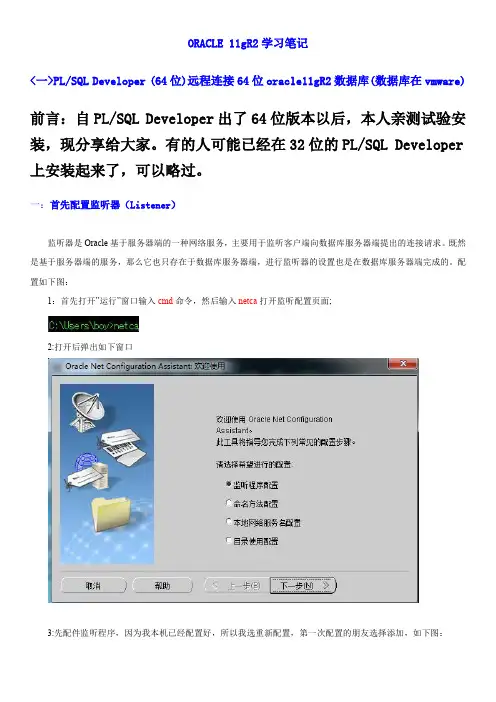
ORACLE11gR2学习笔记<一>PL/SQL Developer(64位)远程连接64位oracle11gR2数据库(数据库在vmware)前言:自PL/SQL Developer出了64位版本以后,本人亲测试验安装,现分享给大家。
有的人可能已经在32位的PL/SQL Developer 上安装起来了,可以略过。
一:首先配置监听器(Listener)监听器是Oracle基于服务器端的一种网络服务,主要用于监听客户端向数据库服务器端提出的连接请求。
既然是基于服务器端的服务,那么它也只存在于数据库服务器端,进行监听器的设置也是在数据库服务器端完成的。
配置如下图:1:首先打开”运行”窗口输入cmd命令,然后输入netca打开监听配置页面;2:打开后弹出如下窗口3:先配件监听程序,因为我本机已经配置好,所以我选重新配置,第一次配置的朋友选择添加,如下图:二:然后配件本地网络服务名本地服务名是基于Oracle客户端的网络配置,所以,如果客户端需要连接数据库服务器进行操作,则需要配置该客户端,其依附对象可以是任意一台欲连接数据库服务器进行操作的PC机,也可以是数据库服务器自身。
1:配置如下图注意:因为我创建的数据库是ORCL,所以选择ORCL;注意:这里的主机名与端口号必须与数据库服务器端监听器配置的主机名和端口号相同。
3:最后打开Net Manage检查下前面所做的配置如下图:注意:如果有修改,最后别忘记点下保存网络配置;二:安装pl/sql developer(x64)和instantclient-basic-windows.x64-11.2.0.4.0.zip 1:首先去网上下这个两个软件,然后先解压instantclient-basic-windows.x64-11.2.0.4.0.zip(下载64位版本)到客户端任意磁盘的根目录,如图,然后在oracle服务端拷贝一份tnsnames.ora(C:\app\product\11.2.0\dbhome_1\NETWORK\ADMIN)到C:\instantclient_11_2目录下,打开编辑如下:2:安装64位版本PL/SQL Developer,安装过程这里省略;3:配置PL/SQL Developer,打开工具-->首选项-->连接,然后配置如图:(第一次打开软件先点取消登陆)注意:Oracle主目录名也可以为:OraDb11g_home1三:配置操作系统(本人是windows7x64)环境变量1:添加环境变量NLS_LANG=AMERICAN_AMERICA.ZHS16GBKTNS_ADMIN=C:\instantclient_11_22:在系统环境变量中配置Path,添加instantclient的路径,即C:\instantclient_11_2如图;到此PL/SQL Developer就全部配置完成了,我截图给大家看下:<二>干净地卸载oracle数据库1:步骤如下图:<三>oracle监听器1:启动监听器-lsnrctl start LISTENER;//listener是监听器的名字,如果没有指定监听器的名字,则该命令将启动默认的监听器。


Oracle实用教程(Oracle11G版)第10章事务、锁、闪回第10章事务、锁、闪回和Undo表空间10. 1 事务10. 2 锁10.3 闪回操作10.4 Undo表空间10. 1 事务10.1.1 事务的概念在现实生活中,事务随处可见,如银行交易、股票交易、网上购物、库存品控制等。
在所有这些例子中,事务的成功取决于这些相互依赖的行为是否能够被成功地执行,是否互相协调。
其中的任何一个失败都将取消整个事务,系统返回到事务处理之前的状态。
下面使用一个简单的例子来帮助理解事务。
向公司数据库添加一名新的雇员(见图10.1)。
10.1.1 事务的概念(1)原子性。
原子性意味着每个事务都必须被认为是一个不可分割的单元。
假设一个事务由两个或者多个任务组成,其中的语句必须同时成功才能认为事务是成功的。
如果事务失败,系统将会返回到事务以前的状态。
(2)一致性。
不管事务是完全成功完成还是中途失败,当事务使系统中的所有数据处于一致的状态时存在一致性。
参照前面的例子,一致性是指如果从系统中删除了一个雇员,则所有和该雇员相关的数据,包括工资数据和组的成员资格也要被删除。
(3)隔离性。
隔离性是指每个事务在它自己的空间发生,和其他发生在系统中的事务隔离,而且事务的结果只有在它完全被执行时才能看到。
即使在这样的一个系统中同时发生了多个事务,隔离性原则保证某个特定事务在完全完成之前,其结果是看不见的。
(4)持久性。
持久性意味着一旦事务执行成功,在系统中产生的所有变化将是永久的。
即使系统崩溃,一个提交的事务仍然存在。
当一个事务完成,数据库的日志已经被更新时,持久性就开始发生作用。
大多数RDBMS产品通过保存所有行为的日志来保证数据的持久性,这些行为是指在数据库中以任何方法更改数据。
10.1.2 事务处理(1)连接到数据库,并开始执行第一条DML语句;(2)前一个事务结束或者执行一条自动提交事务的语句。
发生如下事件时,Oracle认为事务结束。

/category/db/orcl/basic/ any question please contact martin.tian@Previous NextView PDF 15 Process Architecture Previous NextView PDF 第15章进程体系结构This chapter discusses the processes in an Oracle database. 本章讨论 Oracle 数据库中的进程。
This chapter contains the following sections: 本章包括如下各节:∙Introduction to Processeso Multiple-Process Oracle Database Systemso Types of Processes∙Overview of Client Processeso Client and Server Processeso Connections and Sessions∙Overview of Server Processeso Dedicated Server Processeso Shared Server Processes∙Overview of Background Processeso Mandatory Background Processeso Optional Background Processeso Slave Processes ∙进程简介o多进程 Oracle 数据库系统o进程类型∙客户端进程概述o客户端和服务器进程o连接和会话∙服务器进程概述o专用服务器进程o共享服务器进程∙后台进程概述o强制性后台进程o可选后台进程o从属进程Introduction to Processes 进程简介A process is a mechanism in an operating system that can run a series of steps. The mechanism depends on the operating system. For example, on Linux an Oracle background process is a Linux process. On Windows, anOracle background process is a thread of execution within a process. 进程是在操作系统中可以运行一系列步骤的机制。


Previous NextView PDF 11 Physical Storage Structures Previous NextView PDF 第11章物理存储结构This chapter describes the primary physical database structures of an Oracle database. Physical structures are viewable at the operating system level. 本章介绍了 Oracle 数据库的主要物理数据库结构。
物理结构可以在操作系统级别查看。
This chapter contains the following sections: 本章包含以下各节:∙Introduction to Physical Storage Structureso Mechanisms for Storing Database Fileso Oracle Automatic Storage Management (Oracle ASM)o Oracle Managed Files and User-Managed Files∙Overview of Data Fileso Use of Data Fileso Permanent and Temporary Data Fileso Online and Offline Data Fileso Data File Structure∙Overview of Control Fileso Use of Control Fileso Multiple Control Fileso Control File Structure∙Overview of the Online Redo Logo Use of the Online Redo Logo How Oracle Database Writes to the Online Redo Logo Structure of the Online Redo Log ∙物理存储结构简介o用于存储数据库文件的机制o Oracle 自动存储管理(Oracle ASM)o Oracle 管理的文件和用户管理的文件∙数据文件的概述o使用数据文件o永久和临时数据文件o联机和脱机数据文件o数据文件结构∙控制文件的概述o使用控制文件o多个控制文件o控制文件结构∙联机重做日志概述o使用联机重做日志o Oracle 数据库如何写入到联机重做日志o联机重做日志的结构Introduction to Physical Storage Structures 物理存储结构简介One characteristic of an RDBMS is the independence of logical data structures such as tables, views, and indexes from physical storagestructures. Because physical and logical structures are separate, you can manage physical storage of data without affecting access to logicalstructures. For example, renaming a database file does not rename thetables stored in it. RDBMS 的特点之一是逻辑数据结构(如表、视图和索引)与物理存储结构的独立性。

Oracle 11gR2 DataGuard教程(Physical Standby Database)目录第1章理论基础 (4)1.1概述 (4)1.2日志发送 (4)1.2.1使用ARCH进程 (4)1.2.2使用LGWR进程的SYNC(同步)方式 (4)1.2.3使用LGWR进程的ASYNC(异步)方式 (5)1.3日志接收 (6)1.4日志应用 (6)1.5数据保护模式 (7)1.5.1最大保护(Maximum Protection) (7)1.5.2最高可用性(Maximum Availability) (7)1.5.3最高性能(Maximum Performance) (8)1.5.4修改数据保护模式 (8)第2章配置 (8)2.1配置参数说明 (8)2.1.1独立参数 (8)2.1.2主库参数 (10)2.1.3备库参数 (15)2.2环境介绍 (17)2.2.1主库环境 (17)2.2.2备库环境 (17)2.3配置过程 (18)2.3.1主库配置 (18)2.3.2备库配置 (21)2.3.3复制数据库 (23)2.4其他问题 (24)第3章角色切换 (25)3.1S WITCH O VER (25)3.1.1准备工作 (25)3.1.2主库切换为新备库 (25)3.1.3备库切换为新主库 (25)3.1.4新备库应用日志 (26)3.2F AIL O VER (26)第1章理论基础1.1概述DataGuard至少需要两个数据库,一个以READ WRITE(读写)模式打开,进行在线事务处理,角色称为Primary Database(主库),一个以READ ONLY(只读)模式打开,接收重做日志并重新应用,角色称为Standby Database(备库)。
用户连接主库进行事务处理,更改操作被记录在联机重做日志和归档重做日志中,这些日志通过网络发送给备库并在备库上重新应用,最终实现主备库数据同步。
Previous NextView PDF 9 Data Concurrency and ConsistencyPrevious NextView PDF 第9章数据并发性和一致性This chapter explains how Oracle Database maintains consistent data in amultiuser database environment.本章介绍了在多用户数据库环境中,Oracle数据库如何维护一致的数据。
This chapter contains the following sections: 本章包含以下各节:∙Introduction to Data Concurrency and Consistency o Multiversion Read Consistencyo Locking Mechanismso ANSI/ISO Transaction Isolation Levels∙Overview of Oracle Database Transaction Isolation Levels o Read Committed Isolation Levelo Serializable Isolation Levelo Read-Only Isolation Level∙Overview of the Oracle Database Locking Mechanism o Summary of Locking Behavioro Use of Lockso Lock Modeso Lock Conversion and Escalationo Lock Durationo Locks and Deadlocks∙Overview of Automatic Lockso DML Lockso DDL Lockso System Locks∙Overview of Manual Data Locks∙Overview of User-Defined Locks ∙数据并发和一致性介绍o多版本读一致性o锁定机制o ANSI/ISO 事务隔离级别∙Oracle 数据库事务隔离级别概述o读提交隔离级别o可串行化隔离级别o只读隔离级别∙数据库锁定机制概述o锁定行为总结o使用锁o锁模式o锁转换和锁升级o锁持续时间o锁和死锁∙自动锁的概述o DML锁o DDL锁o系统锁∙手动数据锁概述∙用户定义的锁的概述Introduction to Data Concurrency and Consistency 数据并发和一致性介绍In a single-user database, a user can modify data without concern for other users modifying the same data at the same time. However, in a multiuser database, statements within multiple simultaneous transactions 在单用户的数据库中,用户可以修改数据,而不用担心其他用户在同一时间修改相同的数据。
但是,在一个多用户的数据库中,多个事务内的语句可以同时更新相同的数据。
同时执行的多个事务必须产生有意义且一致的结果。
can update the same data. Transactions executing simultaneously mustproduce meaningful and consistent results. Therefore, a multiuserdatabase must provide the following:因此,多用户数据库必须提供以下功能:∙Data concurrency, which ensures that users can access data atthe same time∙数据并发性,确保多个用户可以同时访问数据∙Data consistency, which ensures that each user sees a consistent view of the data, including visible changes made by the user's own transactions and committed transactions of other users ∙数据一致性,确保每个用户看到数据的一致的视图,包括可以看到用户自己的事务所做的更改,和其他用户已提交的事务所做的更改。
To describe consistent transaction behavior when transactions run concurrently, database researchers have defined a transaction isolationmodel called serializability. A serializable transaction operates in an environment that makes it appear as if no other users were modifyingdata in the database. 为描述当多个事务同时运行时的事务一致性行为,数据库研究人员定义了一种称为可串行性的事务隔离模型。
可串行化事务在一种使其看起来好像没有其他用户正在修改数据库中的数据的环境中运作。
While this degree of isolation between transactions is generally desirable,running many applications in serializable mode can seriously compromise application throughput. Complete isolation of concurrently runningtransactions could mean that one transaction cannot perform an insertion into a table being queried by another transaction. In short, real-world considerations usually require a compromise between perfect transaction isolation and performance. 虽然事务之间的这种隔离度好像不错,但在可序列化模式下运行许多应用程序可能会严重影响应用程序吞吐量。
对并发运行事务的完全隔离可能意味着一个事务无法在某个正在被另一个事务查询的表上执行插入操作。
简而言之,现实的考虑通常需要在完美的事务隔离性和性能之间的一个折衷。
Oracle Database maintains data consistency by using a multiversion consistency model and various types of locks and transactions. In this way, the database can present a view of data to multiple concurrent users, with each view consistent to a point in time. Because different versions of data blocks can exist simultaneously, transactions can read the version of data committed at the point in time required by a query and return results that are consistent to a single point in time. Oracle 数据库通过使用多版本一致性模型和各种类型的锁和事务,来维护数据的一致性。
通过这种方式,数据库可以向多个并发用户呈现一个数据的视图,每个视图都在某个时间点上是一致的。
因为不同版本的数据块可以同时存在,事务可以读取在某个查询请求时间点上的已提交版本数据,并返回符合一个单一时间点的结果。
See Also: 另见:Chapter 5, "Data Integrity" and Chapter 10, "Transactions"第 5 章,"数据完整性"和第 10 章,"事务" Multiversion Read Consistency 多版本读一致性In Oracle Database, multiversioning is the ability to simultaneously materialize multiple versions of data. Oracle Database maintains multiversion read consistency, which means that database queries have the following characteristics: 在Oracle数据库中,多版本即同时实现数据的多个版本的能力。
Oracle 数据库维护多版本读取一致性,这意味着数据库查询具有以下特征:∙Read-consistent queries ∙读一致查询The data returned by a query is committed and consistent withrespect to a single point in time.查询所返回的数据已提交的,且关于某个单一时间点一致。
Important: 重要:Oracle Database never permits dirty reads, which occur when a transaction reads uncommitted data in another transaction. Oracle 数据库绝不允许脏读。
当一个事务读取了另一个事务中未提交的数据时,会发生脏读。
To illustrate the problem with dirty reads, suppose one transaction updates a column value without committing. A second transaction reads the updated and dirty (uncommitted) value. The first session rolls back the transaction so that the column has its old value, but the second transaction proceeds using the updated value, corrupting the database. Dirty reads compromise data integrity, violate foreign keys, and ignore unique constraints. 为说明脏读的问题,假设一个事务更新某列的值,但不提交。