FSL-C08
- 格式:pdf
- 大小:670.91 KB
- 文档页数:20

飞思卡尔半导体文件编号:AN3266应用笔记第 1版,5/2006RS08使用向导by: Vincent KoSystems Engineering Microcontroller DivisionRS08是飞思卡尔推出的超低成本 8位 MCU 内核,本文主要介绍 RS08平台。
第一部分为用户提供使用 RS08的基本信息,第二部分包括沿用技术和概念的应用示例。
RS08介绍本部分通过介绍 RS08架构、编程模式、指令集等来帮助用户了解 RS08平台;一般会以 MC9RS08KA2为基准,通过参考实例的方式来作介绍,有必要的话,也会提供飞思卡尔 HC08和 S08平台的交叉参考。
目录1 RS08介绍 (1)1.1 RS08架构............................................................2 1.2 RS08指令集........................................................6 1.3 内存分页结构......................................................15 1.4 MCU 复位...............................................................16 1.5 等待模式............................................................17 1.6 停止模式.............................................................17 1.7 子程序调用 (18)1.8 中断..................................................................19 2 模拟 ADC 应用实例 ........................................................22 2.1 执行.......................................................................22 2.2 校准...................................................................27 2.3 测量结果 .. (28)附录 A 程序实例 (30)This document contains information on a new product under development.Freescale reserves the right to change or discontinue this product without notice. ©Freescale Semiconductor, Inc., 2007. All rights reserved. General Business Information1.1 RS08架构RS08平台是专为超低成本的应用而设计。
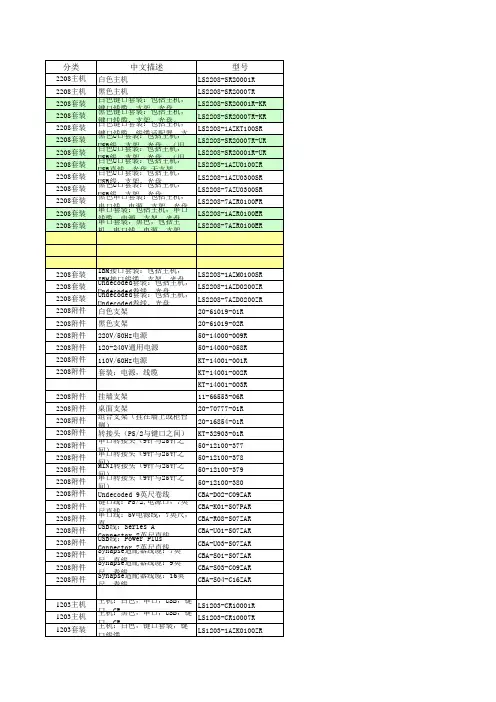
分类2208主机 2208主机 2208套装 2208套装 2208套装 2208套装 2208套装 2208套装 2208套装 2208套装 2208套装 2208套装 2208套装 2208套装 2208套装 2208套装 2208套装 2208套装 2208套装 2208附件 2208附件 2208附件 2208附件 2208附件 2208附件 2208附件 2208附件 2208附件 2208附件 2208附件 2208附件 2208附件 2208附件 2208附件 2208附件 2208附件 2208附件 2208附件 2208附件 2208附件 2208附件 1203主机 1203主机 1203套装 白色主机 黑色主机中文描述型号LS2208-SR20001R LS2208-SR20007R白色键口套装:包括主机,键口线缆,支架,光盘。
(旧PN:LS2208-1Azk0100S) LS2208-SR20001R-KR 黑色键口套装:包括主机,键口线缆,支架,光盘。
(旧PN:LS2208-7AZK0100S) LS2208-SR20007R-KR 白色键口套装:包括主机,键口线缆,线缆适配器,支架,光盘 LS2208-1AZKT100SR 黑色U口套装:包括主机,USB线,支架,光盘。
(旧PN:LS2208-7AZU0100s) LS2208-SR20007R-UR 白色U口套装:包括主机,USB线,支架,光盘。
(旧PN:LS220-1AZU0100S) LS2208-SR20001R-UR 白色U口套装:包括主机,USB直线,光盘,无支架 LS2208-1AZU0100ZR 白色U口套装:包括主机,USB线,支架,光盘 LS2208-1AZU0300SR 黑色U口套装:包括主机,USB线,支架,光盘 LS2208-7AZU0300SR 黑色串口套装:包括主机,串口线,电源,支架,光盘 LS2208-7AZR0100FR 串口套装:包括主机,串口线缆,电源,支架,光盘 LS2208-1AZR0100ER 串口套装,黑色,包括主机,串口线,电源,支架,光盘 LS2208-7AZR0100ER 串口套装:包括主机,NIX线,支架,光盘 LS2208-7AZR0800SR 串口套装:包括主机,NIX线,支架,光盘 LS2208-1AZR0800SR 黑色串口套装:包括主机,串口直线,支架,110V电源,光盘 LS2208-7AZR0100DR IBM接口套装:包括主机,IBM接口线缆,支架,光盘 LS2208-1AZM0100SR Undecoded套装:包括主机,Undecoded卷线,光盘 LS2208-1AZD0200ZR Undecoded套装:包括主机,Undecoded卷线,光盘 LS2208-7AZD0200ZR 白色支架 黑色支架 220V/50Hz电源 120-240V通用电源 110V/60Hz电源 套装:电源,线缆 挂墙支架 桌面支架 转接头(PS/2与键口之间) 20-61019-01R 20-61019-02R 50-14000-009R 50-14000-058R KT-14001-001R KT-14001-002R KT-14001-003R 11-66553-06R 20-70777-01R KT-32903-01R组合支架(挂在墙上或柜台侧) 20-16854-01R 串口转接头(9针与25针之间) 50-12100-377 串口转接头(9针与25针之间) 50-12100-378 MINI转接头(9针与25针之间) 50-12100-379 串口转接头(9针与25针之间) 50-12100-380 Undecoded 9英尺卷线 CBA-D02-C09ZAR 键口线:PS/2,电源口,7英尺直线 CBA-K01-S07PAR 串口线:5V电源线,7英尺,直 CBA-R08-S07ZAR USB线:Series A Connector,7英尺直线 CBA-U01-S07ZAR USB线:Power Plus Connector,7英尺直线 CBA-U03-S07ZAR Synapse适配器线缆:7英尺,直线 CBA-S01-S07ZAR Synapse适配器线缆:9英尺,卷线 CBA-S03-C09ZAR Synapse适配器线缆:16英尺,卷线 CBA-S04-C16ZAR 主机:白色,串口,USB,键口,CR LS1203-CR10001R 主机:黑色,串口,USB,键口,CR LS1203-CR10007R 主机:白色,键口套装,键口线缆 LS1203-1AZK0100ZR1203套装 1203套装 1203套装 1203套装 1203套装 1203套装 1203套装 1203套装 1203套装 1203套装 1203套装 1203套装 1203套装 1203套装 1203套装 1203套装 1203套装 1203套装 1203套装 1203附件 1203附件 1203附件 1203附件 1203附件白色键口套装:主机,7英尺键口直线,支架,光盘 LS1203-1AZK0100SR 黑色键口套装:主机,7英尺键口直线,支架,光盘 LS1203-7AZK0100SR 白色键口套装:主机,7英尺键口直线,光盘 LS1203-7AZK0100ZR 白色U口套装:主机,7英尺USB直线,支架,光盘 LS1203-1AZU0100SR 黑色U口套装:主机,7英尺USB直线,支架,光盘 LS1203-7AZU0100SR 白色U口套装:主机,7英尺USB直线,光盘 LS1203-1AZU0100ZR 黑色U口套装:主机,7英尺USB直线,光盘 LS1203-7AZU0100ZR 白色EMEA串口套装:主机,7英尺串口直线,支架,电源,光盘 LS1203-1AZR0100ER 黑色EMEA串口套装:主机,7英尺串口直线,支架,电源,光盘 LS1203-7AZR0100ER 白色EMEA串口套装:主机,7英尺串口直线,电源,光盘 LS1203-1AZR0100BR 黑色EMEA串口套装:主机,7英尺串口直线,电源,光盘 LS1203-7AZR0100BR 白色US串口套装:主机,7英尺串口直线,电源,光盘 LS1203-1AZR0100AR 白色AP串口套装:主机,7英尺串口直线,电源,光盘 LS1203-1AZR0100CR 白色US串口套装:主机,7英尺串口直线,支架,电源,光盘 LS1203-1AZR0100DR 白色AP串口套装:主机,7英尺串口直线,支架,电源,光盘 LS1203-1AZR0100FR 黑色US串口套装:主机,7英尺串口直线,电源,光盘 LS1203-7AZR0100AR 黑色AP串口套装:主机,7英尺串口直线,电源,光盘 LS1203-7AZR0100CR 黑色US串口套装:主机,7英尺串口直线,支架,电源,光盘 LS1203-7AZR0100DR 黑色AP串口套装:主机,7英尺串口直线,支架,电源,光盘 LS1203-7AZR0100FR 110V/60Hz电源 套装:电源,线缆 KT-14001-001R KT-14001-002R套装:电源 250VAC, 5.2VDC,1A KT-14001-003R 免提支架-白色 免提支架-黑色 20-73951-01R 20-73951-07R性能指数接近LS2208,提供更经济、便捷的条码识别效率。

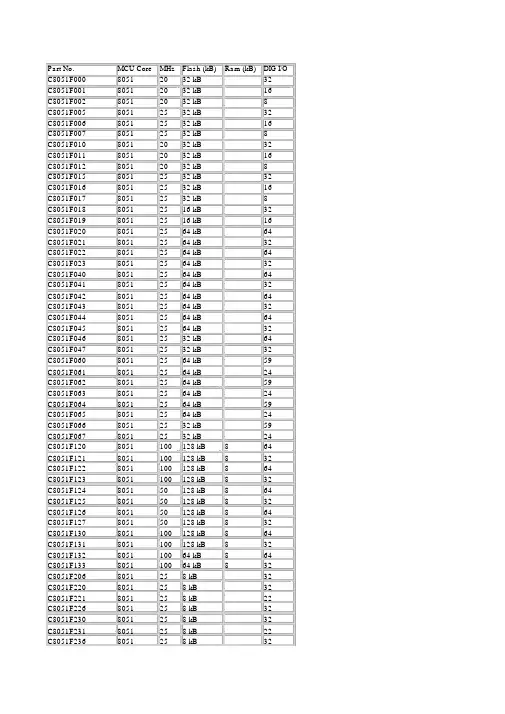
Part No. MCU Core MHz Flash (kB) Ram (kB) DIG I/O C8051F000 8051 20 32 kB 32C8051F001 8051 20 32 kB 16C8051F002 8051 20 32 kB 8C8051F005 8051 25 32 kB 32C8051F006 8051 25 32 kB 16C8051F007 8051 25 32 kB 8C8051F010 8051 20 32 kB 32C8051F011 8051 20 32 kB 16C8051F012 8051 20 32 kB 8C8051F015 8051 25 32 kB 32C8051F016 8051 25 32 kB 16C8051F017 8051 25 32 kB 8C8051F018 8051 25 16 kB 32C8051F019 8051 25 16 kB 16C8051F020 8051 25 64 kB 64C8051F021 8051 25 64 kB 32C8051F022 8051 25 64 kB 64C8051F023 8051 25 64 kB 32C8051F040 8051 25 64 kB 64C8051F041 8051 25 64 kB 32C8051F042 8051 25 64 kB 64C8051F043 8051 25 64 kB 32C8051F044 8051 25 64 kB 64C8051F045 8051 25 64 kB 32C8051F046 8051 25 32 kB 64C8051F047 8051 25 32 kB 32C8051F060 8051 25 64 kB 59C8051F061 8051 25 64 kB 24C8051F062 8051 25 64 kB 59C8051F063 8051 25 64 kB 24C8051F064 8051 25 64 kB 59C8051F065 8051 25 64 kB 24C8051F066 8051 25 32 kB 59C8051F067 8051 25 32 kB 24C8051F120 8051 100 128 kB 8 64C8051F121 8051 100 128 kB 8 32C8051F122 8051 100 128 kB 8 64C8051F123 8051 100 128 kB 8 32C8051F124 8051 50 128 kB 8 64C8051F125 8051 50 128 kB 8 32C8051F126 8051 50 128 kB 8 64C8051F127 8051 50 128 kB 8 32C8051F130 8051 100 128 kB 8 64C8051F131 8051 100 128 kB 8 32C8051F132 8051 100 64 kB 8 64C8051F133 8051 100 64 kB 8 32C8051F206 8051 25 8 kB 32C8051F220 8051 25 8 kB 32C8051F221 8051 25 8 kB 22C8051F226 8051 25 8 kB 32C8051F230 8051 25 8 kB 32C8051F231 8051 25 8 kB 22C8051F236 8051 25 8 kB 32C8051F300-GS 8051 25 8 kB 8 C8051F301-GM 8051 25 8 kB 8 C8051F301-GS 8051 25 8 kB 8 C8051F302-GM 8051 25 8 kB 8 C8051F302-GS 8051 25 8 kB 8 C8051F303-GM 8051 25 8 kB 8 C8051F303-GS 8051 25 8 kB 8 C8051F304-GM 8051 25 4 kB 8 C8051F304-GS 8051 25 4 kB 8 C8051F305-GM 8051 25 2 kB 8 C8051F305-GS 8051 25 2 kB 8 C8051F310 8051 25 16 kB 29 C8051F311 8051 25 16 kB 25 C8051F312 8051 25 8 kB 29 C8051F313 8051 25 8 kB 25 C8051F314 8051 25 8 kB 29 C8051F315 8051 25 8 kB 25 C8051F316 8051 25 16 kB 21 C8051F317 8051 25 16 kB 21 C8051F320 8051 25 16 kB 25 C8051F321 8051 25 16 kB 21 C8051F326 8051 25 16 kB 15 C8051F327 8051 25 16 kB 15 C8051F330-GM 8051 25 8 kB 17 C8051F330-GP 8051 25 8 kB 17 C8051F331 8051 25 8 kB 17 C8051F332 8051 25 4 kB 17 C8051F333 8051 25 4 kB 17 C8051F334 8051 25 2 kB 17 C8051F335 8051 25 2 kB 17 C8051F336 8051 25 16 kB 17 C8051F337 8051 25 16 kB 17 C8051F338 8051 25 16 kB 21 C8051F339 8051 25 16 kB 21 C8051F340-GQ 8051 50 64 kB 40 C8051F341-GQ 8051 50 32 kB 40 C8051F342-GM 8051 50 64 kB 25 C8051F342-GQ 8051 50 64 kB 25 C8051F343-GM 8051 50 32 kB 25 C8051F343-GQ 8051 50 32 kB 25 C8051F344-GQ 8051 25 64 kB 40 C8051F345-GQ 8051 25 32 kB 40 C8051F346-GM 8051 25 64 kB 25 C8051F346-GQ 8051 25 64 kB 25 C8051F347-GM 8051 25 32 kB 25 C8051F347-GQ 8051 25 32 kB 25 C8051F348-GQ 8051 25 32 kB 40 C8051F349-GM 8051 25 32 kB 25 C8051F349-GQ 8051 25 32 kB 25 C8051F34A-GM 8051 50 64 kB 25 C8051F34A-GQ 8051 50 64 kB 25 C8051F34B-GM 8051 50 32 kB 25 C8051F34B-GQ 8051 50 32 kB 25C8051F34D-GQ 8051 50 64 kB 25 C8051F350 8051 50 8 kB 17 C8051F351 8051 50 8 kB 17 C8051F352 8051 50 8 kB 17 C8051F353 8051 50 8 kB 17 C8051F360 8051 100 32 kB 39 C8051F361 8051 100 32 kB 29 C8051F362 8051 100 32 kB 25 C8051F363 8051 100 32 kB 39 C8051F364 8051 100 32 kB 29 C8051F365 8051 100 32 kB 25 C8051F366 8051 50 32 kB 29 C8051F367 8051 50 32 kB 25 C8051F368 8051 50 16 kB 29 C8051F369 8051 50 16 kB 25 C8051F370-A-GM 8051 50 16 kB 1 21 C8051F371-A-GM 8051 50 16 kB 1 21 C8051F374-A-GM 8051 50 8 kB 1 21 C8051F375-A-GM 8051 50 8 kB 1 21 C8051F380-GQ 8051 50 64 kB 40 C8051F381-GM 8051 50 64 kB 25 C8051F381-GQ 8051 50 64 kB 25 C8051F382-GQ 8051 50 32 kB 40 C8051F383-GM 8051 50 32 kB 25 C8051F383-GQ 8051 50 32 kB 25 C8051F384-GQ 8051 50 64 kB 40 C8051F385-GM 8051 50 64 kB 25 C8051F385-GQ 8051 50 64 kB 25 C8051F386-GQ 8051 50 32 kB 40 C8051F387-GM 8051 50 32 kB 25 C8051F387-GQ 8051 50 32 kB 25 C8051F388-GQ 8051 50 64 kB 40 C8051F389-GM 8051 50 64 kB 25 C8051F389-GQ 8051 50 64 kB 25 C8051F38A-GQ 8051 50 32 kB 40 C8051F38B-GM 8051 50 32 kB 25 C8051F38B-GQ 8051 50 32 kB 25 C8051F38C-GM 8051 50 16 kB 25 C8051F38C-GQ 8051 50 16 kB 25 C8051F390-A-GM 8051 50 16 kB 1 21 C8051F391-A-GM 8051 50 16 kB 1 21 C8051F392-A-GM 8051 50 16 kB 1 17 C8051F393-A-GM 8051 50 16 kB 1 17 C8051F394-A-GM 8051 50 8 kB 1 21 C8051F395-A-GM 8051 50 8 kB 1 21 C8051F396-A-GM 8051 50 8 kB 1 17 C8051F397-A-GM 8051 50 8 kB 1 17 C8051F398-A-GM 8051 50 4 kB 1 17 C8051F399-A-GM 8051 50 4 kB 1 17 C8051F410 8051 50 32 kB 24 C8051F411 8051 50 32 kB 20 C8051F412 8051 50 16 kB 24 C8051F413 8051 50 16 kB 20C8051F500-AQ 8051 50 64 kB 40 C8051F500-IM 8051 50 64 kB 40 C8051F500-IQ 8051 50 64 kB 40 C8051F501-AM 8051 50 64 kB 40 C8051F501-AQ 8051 50 64 kB 40 C8051F501-IM 8051 50 64 kB 40 C8051F501-IQ 8051 50 64 kB 40 C8051F502-AM 8051 50 64 kB 25 C8051F502-AQ 8051 50 64 kB 25 C8051F502-IM 8051 50 64 kB 25 C8051F502-IQ 8051 50 64 kB 25 C8051F503-AM 8051 50 64 kB 25 C8051F503-AQ 8051 50 64 kB 25 C8051F503-IM 8051 50 64 kB 25 C8051F503-IQ 8051 50 64 kB 25 C8051F504-AM 8051 50 32 kB 40 C8051F504-AQ 8051 50 32 kB 40 C8051F504-IM 8051 50 32 kB 40 C8051F504-IQ 8051 50 32 kB 40 C8051F505-AM 8051 50 32 kB 40 C8051F505-AQ 8051 50 32 kB 40 C8051F505-IM 8051 50 32 kB 40 C8051F505-IQ 8051 50 32 kB 40 C8051F506-AM 8051 50 32 kB 25 C8051F506-AQ 8051 50 32 kB 25 C8051F506-IM 8051 50 32 kB 25 C8051F506-IQ 8051 50 32 kB 25 C8051F507-AM 8051 50 32 kB 25 C8051F507-AQ 8051 50 32 kB 25 C8051F507-IM 8051 50 32 kB 25 C8051F507-IQ 8051 50 32 kB 25 C8051F508-AM 8051 50 64 kB 33 C8051F508-IM 8051 50 64 kB 33 C8051F509-AM 8051 50 64 kB 33 C8051F509-IM 8051 50 64 kB 33 C8051F510-AM 8051 50 32 kB 33 C8051F510-IM 8051 50 32 kB 33 C8051F511-AM 8051 50 32 kB 33 C8051F511-IM 8051 50 32 kB 33 C8051F520-C-AM 8051 25 8 kB 6 C8051F520-C-IM 8051 25 8 kB 6 C8051F521-C-AM 8051 25 8 kB 6 C8051F521-C-IM 8051 25 8 kB 6 C8051F523-C-AM 8051 25 4 kB 6 C8051F523-C-IM 8051 25 4 kB 6 C8051F524-C-AM 8051 25 4 kB 6 C8051F524-C-IM 8051 25 4 kB 6 C8051F526-C-AM 8051 25 2 kB 6 C8051F526-C-IM 8051 25 2 kB 6 C8051F527-C-AM 8051 25 2 kB 6 C8051F527-C-IM 8051 25 2 kB 6 C8051F530-C-AM 8051 25 8 kB 16 C8051F530-C-AT 8051 25 8 kB 16C8051F530-C-IT 8051 25 8 kB 16 C8051F531-C-AM 8051 25 8 kB 16 C8051F531-C-AT 8051 25 8 kB 16 C8051F531-C-IM 8051 25 8 kB 16 C8051F531-C-IT 8051 25 8 kB 16 C8051F533-C-AM 8051 25 4 kB 16 C8051F533-C-AT 8051 25 4 kB 16 C8051F533-C-IM 8051 25 4 kB 16 C8051F533-C-IT 8051 25 4 kB 16 C8051F534-C-AM 8051 25 4 kB 16 C8051F534-C-AT 8051 25 4 kB 16 C8051F534-C-IM 8051 25 4 kB 16 C8051F534-C-IT 8051 25 4 kB 16 C8051F536-C-AM 8051 25 2 kB 16 C8051F536-C-AT 8051 25 2 kB 16 C8051F536-C-IM 8051 25 2 kB 16 C8051F536-C-IT 8051 25 2 kB 16 C8051F537-C-AM 8051 25 2 kB 16 C8051F537-C-AT 8051 25 2 kB 16 C8051F537-C-IM 8051 25 2 kB 16 C8051F537-C-IT 8051 25 2 kB 16 C8051F540-AM 8051 50 16 kB 25 C8051F540-AQ 8051 50 16 kB 25 C8051F540-IM 8051 50 16 kB 25 C8051F540-IQ 8051 50 16 kB 25 C8051F541-AM 8051 50 16 kB 25 C8051F541-AQ 8051 50 16 kB 25 C8051F541-IM 8051 50 16 kB 25 C8051F541-IQ 8051 50 16 kB 25 C8051F542-AM 8051 50 16 kB 18 C8051F542-IM 8051 50 16 kB 18 C8051F543-AM 8051 50 16 kB 18 C8051F543-IM 8051 50 16 kB 18 C8051F544-AM 8051 50 8 kB 25 C8051F544-AQ 8051 50 8 kB 25 C8051F544-IM 8051 50 8 kB 25 C8051F544-IQ 8051 50 8 kB 25 C8051F545-AM 8051 50 8 kB 25 C8051F545-AQ 8051 50 8 kB 25 C8051F545-IM 8051 50 8 kB 25 C8051F545-IQ 8051 50 8 kB 25 C8051F546-AM 8051 50 8 kB 18 C8051F546-IM 8051 50 8 kB 18 C8051F547-AM 8051 50 8 kB 18 C8051F547-IM 8051 50 8 kB 18 C8051F550-AM 8051 50 32 kB 18 C8051F550-IM 8051 50 32 kB 18 C8051F551-AM 8051 50 32 kB 18 C8051F551-IM 8051 50 32 kB 18 C8051F552-AM 8051 50 32 kB 18 C8051F552-IM 8051 50 32 kB 18 C8051F553-AM 8051 50 32 kB 18 C8051F553-IM 8051 50 32 kB 18C8051F554-IM 8051 50 16 kB 18 C8051F555-AM 8051 50 16 kB 18 C8051F555-IM 8051 50 16 kB 18 C8051F556-AM 8051 50 16 kB 18 C8051F556-IM 8051 50 16 kB 18 C8051F557-AM 8051 50 16 kB 18 C8051F557-IM 8051 50 16 kB 18 C8051F560-AM 8051 50 32 kB 25 C8051F560-AQ 8051 50 32 kB 25 C8051F560-IM 8051 50 32 kB 25 C8051F560-IQ 8051 50 32 kB 25 C8051F561-AM 8051 50 32 kB 25 C8051F561-AQ 8051 50 32 kB 25 C8051F561-IM 8051 50 32 kB 25 C8051F561-IQ 8051 50 32 kB 25 C8051F562-AM 8051 50 32 kB 25 C8051F562-AQ 8051 50 32 kB 25 C8051F562-IM 8051 50 32 kB 25 C8051F562-IQ 8051 50 32 kB 25 C8051F563-AM 8051 50 32 kB 25 C8051F563-AQ 8051 50 32 kB 25 C8051F563-IM 8051 50 32 kB 25 C8051F563-IQ 8051 50 32 kB 25 C8051F564-AM 8051 50 16 kB 25 C8051F564-AQ 8051 50 16 kB 25 C8051F564-IM 8051 50 16 kB 25 C8051F564-IQ 8051 50 16 kB 25 C8051F565-AM 8051 50 16 kB 25 C8051F565-AQ 8051 50 16 kB 25 C8051F565-IM 8051 50 16 kB 25 C8051F565-IQ 8051 50 16 kB 25 C8051F566-AM 8051 50 16 kB 25 C8051F566-AQ 8051 50 16 kB 25 C8051F566-IM 8051 50 16 kB 25 C8051F566-IQ 8051 50 16 kB 25 C8051F567-AM 8051 50 16 kB 25 C8051F567-AQ 8051 50 16 kB 25 C8051F567-IM 8051 50 16 kB 25 C8051F567-IQ 8051 50 16 kB 25 C8051F568-AM 8051 50 32 kB 33 C8051F568-IM 8051 50 32 kB 33 C8051F569-AM 8051 50 32 kB 33 C8051F569-IM 8051 50 32 kB 33 C8051F570-AM 8051 50 32 kB 33 C8051F570-IM 8051 50 32 kB 33 C8051F571-AM 8051 50 32 kB 33 C8051F571-IM 8051 50 32 kB 33 C8051F572-AM 8051 50 16 kB 33 C8051F572-IM 8051 50 16 kB 33 C8051F573-AM 8051 50 16 kB 33 C8051F573-IM 8051 50 16 kB 33 C8051F574-AM 8051 50 16 kB 33 C8051F574-IM 8051 50 16 kB 33C8051F575-IM 8051 50 16 kB 33 C8051F580-AM 8051 50 128 kB 8 40 C8051F580-AQ 8051 50 128 kB 8 40 C8051F580-IM 8051 50 128 kB 8 40 C8051F580-IQ 8051 50 128 kB 8 40 C8051F581-AM 8051 50 128 kB 8 40 C8051F581-AQ 8051 50 128 kB 8 40 C8051F581-IM 8051 50 128 kB 8 40 C8051F581-IQ 8051 50 128 kB 8 40 C8051F582-AM 8051 50 128 kB 8 25 C8051F582-AQ 8051 50 128 kB 8 25 C8051F582-IM 8051 50 128 kB 8 25 C8051F582-IQ 8051 50 128 kB 8 25 C8051F583-AM 8051 50 128 kB 8 25 C8051F583-AQ 8051 50 128 kB 8 25 C8051F583-IM 8051 50 128 kB 8 25 C8051F583-IQ 8051 50 128 kB 8 25 C8051F584-AM 8051 50 96 kB 8 40 C8051F584-AQ 8051 50 96 kB 8 40 C8051F584-IM 8051 50 96 kB 8 40 C8051F584-IQ 8051 50 96 kB 8 40 C8051F585-AM 8051 50 96 kB 8 40 C8051F585-AQ 8051 50 96 kB 8 40 C8051F585-IM 8051 50 96 kB 8 40 C8051F585-IQ 8051 50 96 kB 8 40 C8051F586-AM 8051 50 96 kB 8 25 C8051F586-AQ 8051 50 96 kB 8 25 C8051F586-IM 8051 50 96 kB 8 25 C8051F586-IQ 8051 50 96 kB 8 25 C8051F587-AM 8051 50 96 kB 8 25 C8051F587-AQ 8051 50 96 kB 8 25 C8051F587-IM 8051 50 96 kB 8 25 C8051F587-IQ 8051 50 96 kB 8 25 C8051F588-AM 8051 50 128 kB 8 33 C8051F588-IM 8051 50 128 kB 8 33 C8051F589-AM 8051 50 128 kB 8 33 C8051F589-IM 8051 50 128 kB 8 33 C8051F590-AM 8051 50 96 kB 8 33 C8051F590-IM 8051 50 96 kB 8 33 C8051F591-AM 8051 50 96 kB 8 33 C8051F591-IM 8051 50 96 kB 8 33 C8051F700-GQ 8051 25 15 kB 54 C8051F701-GQ 8051 25 15 kB 54 C8051F702-GQ 8051 25 16 kB 54 C8051F703-GQ 8051 25 16 kB 54 C8051F704-GM 8051 25 15 kB 39 C8051F704-GQ 8051 25 15 kB 39 C8051F705-GM 8051 25 15 kB 39 C8051F705-GQ 8051 25 15 kB 39 C8051F706-GM 8051 25 16 kB 39 C8051F706-GQ 8051 25 16 kB 39 C8051F707-GM 8051 25 16 kB 39 C8051F707-GQ 8051 25 16 kB 39C8051F709-GQ 8051 25 8 kB 54 C8051F710-GQ 8051 25 8 kB 54 C8051F711-GQ 8051 25 8 kB 54 C8051F712-GM 8051 25 8 kB 39 C8051F712-GQ 8051 25 8 kB 39 C8051F713-GM 8051 25 8 kB 39 C8051F713-GQ 8051 25 8 kB 39 C8051F714-GM 8051 25 8 kB 39 C8051F714-GQ 8051 25 8 kB 39 C8051F715-GM 8051 25 8 kB 39 C8051F715-GQ 8051 25 8 kB 39 C8051F716-GM 8051 25 16 kB 29 C8051F717-GM 8051 25 16 kB 20 C8051F760 8051 25 32 kB 8 —C8051F761 8051 25 32 kB 8 —C8051F762 8051 25 32 kB 8 —C8051F765 8051 25 32 kB 8 —C8051F766 8051 25 32 kB 8 —C8051F767 8051 25 32 kB 8 —C8051F800-GM 8051 25 16 kB 17 C8051F800-GU 8051 25 16 kB 17 C8051F801-GM 8051 25 16 kB 17 C8051F801-GU 8051 25 16 kB 17 C8051F802-GM 8051 25 16 kB 17 C8051F802-GU 8051 25 16 kB 17 C8051F803-GS 8051 25 16 kB 13 C8051F804-GS 8051 25 16 kB 13 C8051F805-GS 8051 25 16 kB 13 C8051F806-GM 8051 25 16 kB 17 C8051F806-GU 8051 25 16 kB 17 C8051F807-GM 8051 25 16 kB 17 C8051F807-GU 8051 25 16 kB 17 C8051F808-GM 8051 25 16 kB 17 C8051F808-GU 8051 25 16 kB 17 C8051F809-GS 8051 25 16 kB 13 C8051F810-GS 8051 25 16 kB 13 C8051F811-GS 8051 25 16 kB 13 C8051F812-GM 8051 25 8 kB 17 C8051F812-GU 8051 25 8 kB 17 C8051F813-GM 8051 25 8 kB 17 C8051F813-GU 8051 25 8 kB 17 C8051F814-GM 8051 25 8 kB 17 C8051F814-GU 8051 25 8 kB 17 C8051F815-GS 8051 25 8 kB 13 C8051F816-GS 8051 25 8 kB 13 C8051F817-GS 8051 25 8 kB 13 C8051F818-GM 8051 25 8 kB 17 C8051F818-GU 8051 25 8 kB 17 C8051F819-GM 8051 25 8 kB 17 C8051F819-GU 8051 25 8 kB 17 C8051F820-GM 8051 25 8 kB 17 C8051F820-GU 8051 25 8 kB 17 C8051F821-GS 8051 25 8 kB 13C8051F823-GS 8051 25 8 kB 13 C8051F824-GS 8051 25 8 kB 13 C8051F825-GS 8051 25 8 kB 13 C8051F826-GS 8051 25 8 kB 13 C8051F827-GS 8051 25 8 kB 13 C8051F828-GS 8051 25 8 kB 13 C8051F829-GS 8051 25 8 kB 13 C8051F830-GS 8051 25 4 kB 13 C8051F831-GS 8051 25 4 kB 13 C8051F832-GS 8051 25 4 kB 13 C8051F833-GS 8051 25 4 kB 13 C8051F834-GS 8051 25 4 kB 13 C8051F835-GS 8051 25 4 kB 13 C8051F850-C-GM8051 25 8 kB 16 C8051F850-C-GU 8051 25 8 kB 18 C8051F851-C-GM8051 25 4 kB 16 C8051F851-C-GU 8051 25 4 kB 18 C8051F852-C-GM8051 25 2 kB 16 C8051F852-C-GU 8051 25 2 kB 18 C8051F853-C-GM8051 25 8 kB 16 C8051F853-C-GU 8051 25 8 kB 18 C8051F854-C-GM8051 25 4 kB 16 C8051F854-C-GU 8051 25 4 kB 18 C8051F855-C-GM8051 25 2 kB 16 C8051F855-C-GU 8051 25 2 kB 18 C8051F860-C-GS 8051 25 8 kB 13 C8051F861-C-GS 8051 25 4 kB 13 C8051F862-C-GS 8051 25 2 kB 13 C8051F863-C-GS 8051 25 8 kB 13 C8051F864-C-GS 8051 25 4 kB 13 C8051F865-C-GS 8051 25 2 kB 13 C8051F901-GM 8051 25 8 kB 16C8051F901-GU 8051 25 8 kB 16C8051F902-GM 8051 25 8 kB 16C8051F902-GU 8051 25 8 kB 16C8051F911-GM 8051 25 16 kB 16C8051F911-GU 8051 25 16 kB 16C8051F912-GM 8051 25 16 kB 16C8051F912-GU 8051 25 16 kB 16C8051F920-GM 8051 25 32 kB 24C8051F920-GQ 8051 25 32 kB 24 C8051F921-GM80512532 kB16C8051F930-GQ 8051 25 64 kB 24C8051F931-GM 8051 25 64 kB 16 C8051F960-B-GM 8051 25 128 kB 8 57 C8051F960-B-GQ 8051 25 128 kB 8 57 C8051F961-B-GM 8051 25 128 kB 8 34C8051F962-B-GM 8051 25 128 kB 8 57 C8051F962-B-GQ 8051 25 128 kB 8 57 C8051F963-B-GM 8051 25 128 kB 8 34 C8051F964-B-GM 8051 25 64 kB 8 57C8051F964-B-GQ 8051 25 64 kB 8 57 C8051F965-B-GM 8051 25 64 kB 8 34 C8051F966-B-GM 8051 25 32 kB 8 57 C8051F966-B-GQ 8051 25 32 kB 8 57 C8051F967-B-GM 8051 25 32 kB 8 34 C8051F968-B-GM 8051 25 16 kB 57 C8051F968-B-GQ 8051 25 16 kB 57 C8051F969-B-GM 8051 25 16 kB 34 C8051F970-A-GM 8051 25 32 kB 8 43 C8051F971-A-GM 8051 25 32 kB 8 28 C8051F972-A-GM 8051 25 32 kB 8 19 C8051F973-A-GM 8051 25 16 kB 4 43 C8051F974-A-GM 8051 25 16 kB 4 28 C8051F975-A-GM 8051 25 16 kB 4 19C8051F980-GM 8051 25 8 kB 16 C8051F981-GM 8051 25 8 kB 16 C8051F982-GM 8051 25 4 kB 16 C8051F983-GM 8051 25 4 kB 16 C8051F985-GM 8051 25 2 kB 16 C8051F986-GM 8051 25 8 kB 17 C8051F986-GU 8051 25 8 kB 17 C8051F987-GM 8051 25 8 kB 17 C8051F987-GU 8051 25 8 kB 17C8051F988-GM 8051 25 4 kB 17 C8051F988-GU 8051 25 4 kB 17 C8051F989-GM 8051 25 4 kB 17 C8051F989-GU 8051 25 4 kB 17 C8051F990-GM 8051 25 8 kB 16 C8051F991-GM 8051 25 8 kB 16 C8051F996-GM 8051 25 8 kB 17 C8051F996-GU 8051 25 8 kB 17 C8051F997-GM 8051 25 8 kB 17 C8051F997-GU 8051 25 8 kB 17Communications Timers (16- PCA Internal I2C; SPI; UART bit) Channels Osc4 5 ±20%I2C; SPI; UART 4 5 ±20% I2C; SPI; UART 4 5 ±20% I2C; SPI; UART 4 5 ±20% I2C; SPI; UART 4 5 ±20% I2C; SPI; UART 4 5 ±20% I2C; SPI; UART 4 5 ±20% I2C; SPI; UART 4 5 ±20% I2C; SPI; UART 4 5 ±20% I2C; SPI; UART 4 5 ±20% I2C; SPI; UART 4 5 ±20% I2C; SPI; UART 4 5 ±20% I2C; SPI; UART 4 5 ±20% I2C; SPI; UART 4 5 ±20% EMIF; I2C; SPI; UART; 2 x UART 5 5 ±20% EMIF; I2C; SPI; UART; 2 x UART 5 5 ±20% EMIF; I2C; SPI; UART; 2 x UART 5 5 ±20% EMIF; I2C; SPI; UART; 2 x UART 5 5 ±20% CAN; EMIF; I2C; SPI; UART; 2 x UART 5 6 ±2% CAN; EMIF; I2C; SPI; UART; 2 x UART 5 6 ±2% CAN; EMIF; I2C; SPI; UART; 2 x UART 5 6 ±2% CAN; EMIF; I2C; SPI; UART; 2 x UART 5 6 ±2% CAN; EMIF; I2C; SPI; UART; 2 x UART 5 6 ±2% CAN; EMIF; I2C; SPI; UART; 2 x UART 5 6 ±2% CAN; EMIF; I2C; SPI; UART; 2 x UART 5 6 ±2% CAN; EMIF; I2C; SPI; UART; 2 x UART 5 6 ±2% CAN; EMIF; I2C; SPI; UART; 2 x UART 5 6 ±2% CAN; I2C; SPI; UART; 2 x UART 5 6 ±2% CAN; EMIF; I2C; SPI; UART; 2 x UART 5 6 ±2% CAN; I2C; SPI; UART; 2 x UART 5 6 ±2% EMIF; I2C; SPI; UART; 2 x UART 5 6 ±2%I2C; SPI; UART; 2 x UART 5 6 ±2% EMIF; I2C; SPI; UART; 2 x UART 5 6 ±2%I2C; SPI; UART; 2 x UART 5 6 ±2% EMIF; I2C; SPI; UART; 2 x UART 5 6 ±2% EMIF; I2C; SPI; UART; 2 x UART 5 6 ±2% EMIF; I2C; SPI; UART; 2 x UART 5 6 ±2% EMIF; I2C; SPI; UART; 2 x UART 5 6 ±2% EMIF; I2C; SPI; UART; 2 x UART 5 6 ±2% EMIF; I2C; SPI; UART; 2 x UART 5 6 ±2% EMIF; I2C; SPI; UART; 2 x UART 5 6 ±2% EMIF; I2C; SPI; UART; 2 x UART 5 6 ±2% EMIF; I2C; SPI; UART; 2 x UART 5 6 ±2% EMIF; I2C; SPI; UART; 2 x UART 5 6 ±2% EMIF; I2C; SPI; UART; 2 x UART 5 6 ±2% EMIF; I2C; SPI; UART; 2 x UART 5 6 ±2% SPI; UART 3 —±20% SPI; UART 3 —±20% SPI; UART 3 —±20% SPI; UART 3 —±20% SPI; UART 3 —±20% SPI; UART 3 —±20% SPI; UART 3 —±20%I2C; UART 3 3 ±2% I2C; UART 3 3 ±2% I2C; UART 3 3 ±2% I2C; UART 3 3 ±2% I2C; UART 3 3 ±20% I2C; UART 3 3 ±20% I2C; UART 3 3 ±20% I2C; UART 3 3 ±20% I2C; UART 3 3 ±20% I2C; UART 3 3 ±20% I2C; UART 3 3 ±20% I2C; UART 3 3 ±20% I2C; SPI; UART 4 5 ±2% I2C; SPI; UART 4 5 ±2% I2C; SPI; UART 4 5 ±2% I2C; SPI; UART 4 5 ±2% I2C; SPI; UART 4 5 ±2% I2C; SPI; UART 4 5 ±2% I2C; SPI; UART 4 5 ±2% I2C; SPI; UART 4 5 ±2% I2C; SPI; UART; USB 4 5 ±1.5% I2C; SPI; UART; USB 4 5 ±1.5% UART; USB 2 —±1.5% UART; USB 2 —±1.5% I2C; SPI; UART 4 3 ±2% I2C; SPI; UART 4 3 ±2% I2C; SPI; UART 4 3 ±2% I2C; SPI; UART 4 3 ±2% I2C; SPI; UART 4 3 ±2% I2C; SPI; UART 4 3 ±2% I2C; SPI; UART 4 3 ±2% I2C; SPI; UART 4 3 ±2% I2C; SPI; UART 4 3 ±2% I2C; SPI; UART 4 3 ±2% I2C; SPI; UART 4 3 ±2% EMIF; I2C; SPI; UART; 2 x UART; USB 4 5 ±1.5% EMIF; I2C; SPI; UART; 2 x UART; USB 4 5 ±1.5% I2C; SPI; UART; USB 4 5 ±1.5% I2C; SPI; UART; USB 4 5 ±1.5% I2C; SPI; UART; USB 4 5 ±1.5% I2C; SPI; UART; USB 4 5 ±1.5% EMIF; I2C; SPI; UART; 2 x UART; USB 4 5 ±1.5% EMIF; I2C; SPI; UART; 2 x UART; USB 4 5 ±1.5% I2C; SPI; UART; USB 4 5 ±1.5% I2C; SPI; UART; USB 4 5 ±1.5% I2C; SPI; UART; USB 4 5 ±1.5% I2C; SPI; UART; USB 4 5 ±1.5% EMIF; I2C; SPI; UART; 2 x UART; USB 4 5 ±1.5% I2C; SPI; UART; USB 4 5 ±1.5% I2C; SPI; UART; USB 4 5 ±1.5% I2C; SPI; UART; 2 x UART; USB 4 5 ±1.5% I2C; SPI; UART; 2 x UART; USB 4 5 ±1.5% I2C; SPI; UART; 2 x UART; USB 4 5 ±1.5% I2C; SPI; UART; 2 x UART; USB 4 5 ±1.5%EMIF; I2C; SPI; UART; 2 x UART; USB 4 5 ±1.5% I2C; SPI; UART; USB 4 5 ±1.5% I2C; SPI; UART 4 3 ±2% I2C; SPI; UART 4 3 ±2% I2C; SPI; UART 4 3 ±2% I2C; SPI; UART 4 3 ±2% EMIF; I2C; SPI; UART 4 6 ±2% I2C; SPI; UART 4 6 ±2% I2C; SPI; UART 4 6 ±2% EMIF; I2C; SPI; UART 4 6 ±2% I2C; SPI; UART 4 6 ±2% I2C; SPI; UART 4 6 ±2% I2C; SPI; UART 4 6 ±2% I2C; SPI; UART 4 6 ±2% I2C; SPI; UART 4 6 ±2% I2C; SPI; UART 4 6 ±2% I2C; 2 x I2C; SPI; UART 6 3 ±2% I2C; 2 x I2C; SPI; UART 6 3 ±2% I2C; 2 x I2C; SPI; UART 6 3 ±2% I2C; 2 x I2C; SPI; UART 6 3 ±2% I2C; 2 x I2C; SPI; UART; 2 x UART; USB 6 5 ±1.5% I2C; 2 x I2C; SPI; UART; 2 x UART; USB 6 5 ±1.5% I2C; 2 x I2C; SPI; UART; 2 x UART; USB 6 5 ±1.5% I2C; 2 x I2C; SPI; UART; 2 x UART; USB 6 5 ±1.5% I2C; 2 x I2C; SPI; UART; 2 x UART; USB 6 5 ±1.5% I2C; 2 x I2C; SPI; UART; 2 x UART; USB 6 5 ±1.5% I2C; 2 x I2C; SPI; UART; 2 x UART; USB 6 5 ±1.5% I2C; 2 x I2C; SPI; UART; 2 x UART; USB 6 5 ±1.5% I2C; 2 x I2C; SPI; UART; 2 x UART; USB 6 5 ±1.5% I2C; 2 x I2C; SPI; UART; 2 x UART; USB 6 5 ±1.5% I2C; 2 x I2C; SPI; UART; 2 x UART; USB 6 5 ±1.5% I2C; 2 x I2C; SPI; UART; 2 x UART; USB 6 5 ±1.5% I2C; 2 x I2C; SPI; UART; 2 x UART 6 5 ±1.5% I2C; 2 x I2C; SPI; UART; 2 x UART 6 5 ±1.5% I2C; 2 x I2C; SPI; UART; 2 x UART 6 5 ±1.5% I2C; 2 x I2C; SPI; UART; 2 x UART 6 5 ±1.5% I2C; 2 x I2C; SPI; UART; 2 x UART 6 5 ±1.5% I2C; 2 x I2C; SPI; UART; 2 x UART 6 5 ±1.5% I2C; 2 x I2C; SPI; UART; 2 x UART; USB 6 5 ±1.5% I2C; 2 x I2C; SPI; UART; 2 x UART; USB 6 5 ±1.5% I2C; 2 x I2C; SPI; UART 6 3 ±2% I2C; 2 x I2C; SPI; UART 6 3 ±2% I2C; 2 x I2C; SPI; UART 6 3 ±2% I2C; 2 x I2C; SPI; UART 6 3 ±2% I2C; 2 x I2C; SPI; UART 6 3 ±2% I2C; 2 x I2C; SPI; UART 6 3 ±2% I2C; 2 x I2C; SPI; UART 6 3 ±2% I2C; 2 x I2C; SPI; UART 6 3 ±2% I2C; 2 x I2C; SPI; UART 6 3 ±2% I2C; 2 x I2C; SPI; UART 6 3 ±2% I2C; SPI; UART 4 6 ±2% I2C; SPI; UART 4 6 ±2% I2C; SPI; UART 4 6 ±2% I2C; SPI; UART 4 6 ±2%CAN; EMIF; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; EMIF; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; EMIF; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; EMIF; I2C; LIN; SPI; UART 4 6 ±0.5% EMIF; I2C; SPI; UART 4 6 ±0.5% EMIF; I2C; SPI; UART 4 6 ±0.5% EMIF; I2C; SPI; UART 4 6 ±0.5% EMIF; I2C; SPI; UART 4 6 ±0.5% CAN; EMIF; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; EMIF; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; EMIF; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; EMIF; I2C; LIN; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% CAN; EMIF; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; EMIF; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; EMIF; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; EMIF; I2C; LIN; SPI; UART 4 6 ±0.5% EMIF; I2C; SPI; UART 4 6 ±0.5% EMIF; I2C; SPI; UART 4 6 ±0.5% EMIF; I2C; SPI; UART 4 6 ±0.5% EMIF; I2C; SPI; UART 4 6 ±0.5% CAN; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; I2C; LIN; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% CAN; EMIF; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; EMIF; I2C; LIN; SPI; UART 4 6 ±0.5% EMIF; I2C; SPI; UART 4 6 ±0.5% EMIF; I2C; SPI; UART 4 6 ±0.5% CAN; EMIF; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; EMIF; I2C; LIN; SPI; UART 4 6 ±0.5% EMIF; I2C; SPI; UART 4 6 ±0.5% EMIF; I2C; SPI; UART 4 6 ±0.5% LIN; SPI; UART 3 3 ±0.5% LIN; SPI; UART 3 3 ±0.5% SPI; UART 3 3 ±0.5% SPI; UART 3 3 ±0.5% LIN; SPI; UART 3 3 ±0.5% LIN; SPI; UART 3 3 ±0.5% SPI; UART 3 3 ±0.5% SPI; UART 3 3 ±0.5% LIN; SPI; UART 3 3 ±0.5% LIN; SPI; UART 3 3 ±0.5% SPI; UART 3 3 ±0.5% SPI; UART 3 3 ±0.5% LIN; SPI; UART 3 3 ±0.5% LIN; SPI; UART 3 3 ±0.5%LIN; SPI; UART 3 3 ±0.5% SPI; UART 3 3 ±0.5% SPI; UART 3 3 ±0.5% SPI; UART 3 3 ±0.5% SPI; UART 3 3 ±0.5% LIN; SPI; UART 3 3 ±0.5% LIN; SPI; UART 3 3 ±0.5% LIN; SPI; UART 3 3 ±0.5% LIN; SPI; UART 3 3 ±0.5% SPI; UART 3 3 ±0.5% SPI; UART 3 3 ±0.5% SPI; UART 3 3 ±0.5% SPI; UART 3 3 ±0.5% LIN; SPI; UART 3 3 ±0.5% LIN; SPI; UART 3 3 ±0.5% LIN; SPI; UART 3 3 ±0.5% LIN; SPI; UART 3 3 ±0.5% SPI; UART 3 3 ±0.5% SPI; UART 3 3 ±0.5% SPI; UART 3 3 ±0.5% SPI; UART 3 3 ±0.5% I2C; LIN; SPI; UART 4 6 ±0.5% I2C; LIN; SPI; UART 4 6 ±0.5% I2C; LIN; SPI; UART 4 6 ±0.5% I2C; LIN; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% I2C; LIN; SPI; UART 4 6 ±0.5% I2C; LIN; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% I2C; LIN; SPI; UART 4 6 ±0.5% I2C; LIN; SPI; UART 4 6 ±0.5% I2C; LIN; SPI; UART 4 6 ±0.5% I2C; LIN; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% I2C; LIN; SPI; UART 4 6 ±0.5% I2C; LIN; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% CAN; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; I2C; SPI; UART 4 6 ±0.5% CAN; I2C; SPI; UART 4 6 ±0.5% I2C; LIN; SPI; UART 4 6 ±0.5% I2C; LIN; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5%CAN; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; I2C; SPI; UART 4 6 ±0.5% CAN; I2C; SPI; UART 4 6 ±0.5% I2C; LIN; SPI; UART 4 6 ±0.5% I2C; LIN; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% CAN; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; I2C; SPI; UART 4 6 ±0.5% CAN; I2C; SPI; UART 4 6 ±0.5% CAN; I2C; SPI; UART 4 6 ±0.5% CAN; I2C; SPI; UART 4 6 ±0.5% I2C; LIN; SPI; UART 4 6 ±0.5% I2C; LIN; SPI; UART 4 6 ±0.5% I2C; LIN; SPI; UART 4 6 ±0.5% I2C; LIN; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% CAN; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; I2C; SPI; UART 4 6 ±0.5% CAN; I2C; SPI; UART 4 6 ±0.5% CAN; I2C; SPI; UART 4 6 ±0.5% CAN; I2C; SPI; UART 4 6 ±0.5% I2C; LIN; SPI; UART 4 6 ±0.5% I2C; LIN; SPI; UART 4 6 ±0.5% I2C; LIN; SPI; UART 4 6 ±0.5% I2C; LIN; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% I2C; SPI; UART 4 6 ±0.5% CAN; EMIF; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; EMIF; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; EMIF; I2C; SPI; UART 4 6 ±0.5% CAN; EMIF; I2C; SPI; UART 4 6 ±0.5% EMIF; I2C; LIN; SPI; UART 4 6 ±0.5% EMIF; I2C; LIN; SPI; UART 4 6 ±0.5% EMIF; I2C; SPI; UART 4 6 ±0.5% EMIF; I2C; SPI; UART 4 6 ±0.5% CAN; EMIF; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; EMIF; I2C; LIN; SPI; UART 4 6 ±0.5% CAN; EMIF; I2C; SPI; UART 4 6 ±0.5% CAN; EMIF; I2C; SPI; UART 4 6 ±0.5% EMIF; I2C; LIN; SPI; UART 4 6 ±0.5% EMIF; I2C; LIN; SPI; UART 4 6 ±0.5%EMIF; I2C; SPI; UART 4 6 ±0.5% CAN; EMIF; I2C; LIN; SPI; UART; 2 x 6 12 ±0.5% UCAN;RTEMIF; I2C; LIN; SPI; UART; 2 x 6 12 ±0.5% UCAN;RTEMIF; I2C; LIN; SPI; UART; 2 x 6 12 ±0.5% UCAN;RTEMIF; I2C; LIN; SPI; UART; 2 x 6 12 ±0.5% UARTEMIF; I2C; SPI; UART; 2 x UART 6 12 ±0.5% EMIF; I2C; SPI; UART; 2 x UART 6 12 ±0.5% EMIF; I2C; SPI; UART; 2 x UART 6 12 ±0.5% EMIF; I2C; SPI; UART; 2 x UART 6 12 ±0.5% CAN; I2C; LIN; SPI; UART; 2 x UART 6 12 ±0.5% CAN; I2C; LIN; SPI; UART; 2 x UART 6 12 ±0.5% CAN; I2C; LIN; SPI; UART; 2 x UART 6 12 ±0.5% CAN; I2C; LIN; SPI; UART; 2 x UART 6 12 ±0.5% I2C; SPI; UART; 2 x UART 6 12 ±0.5% I2C; SPI; 2 x UART 6 12 ±0.5% I2C; SPI; UART; 2 x UART 6 12 ±0.5% I2C; SPI; UART; 2 x UART 6 12 ±0.5% CAN; EMIF; I2C; LIN; SPI; UART; 2 x 6 12 ±0.5% U RT 6 12 ±0.5%C A N; EMIF; I2C; LIN; SPI; UART; 2 xU RT 6 12 ±0.5% C A N; EMIF; I2C; LIN; SPI; UART; 2 xU RT 6 12 ±0.5%C A N; EMIF; I2C; LIN; SPI; UART; 2 xUART 6 12 ±0.5% EMIF; I2C; SPI; UART; 2 x UARTEMIF; I2C; SPI; UART; 2 x UART 6 12 ±0.5% EMIF; I2C; SPI; UART; 2 x UART 6 12 ±0.5% EMIF; I2C; SPI; UART; 2 x UART 6 12 ±0.5% CAN; I2C; LIN; SPI; UART; 2 x UART 6 12 ±0.5% CAN; I2C; LIN; SPI; UART; 2 x UART 6 12 ±0.5% CAN; I2C; LIN; SPI; UART; 2 x UART 6 12 ±0.5% CAN; I2C; LIN; SPI; UART; 2 x UART 6 12 ±0.5% I2C; SPI; UART; 2 x UART 6 12 ±0.5% I2C; SPI; UART; 2 x UART 6 12 ±0.5% I2C; SPI; UART; 2 x UART 6 12 ±0.5% I2C; SPI; UART; 2 x UART 6 12 ±0.5% CAN; EMIF; I2C; LIN; SPI; UART; 2 x 6 12 ±0.5% U RT 6 12 ±0.5%C A N; EMIF; I2C; LIN; SPI; UART; 2 xUART 6 12 ±0.5% EMIF; I2C; SPI; UART; 2 x UARTEMIF; I2C; SPI; UART; 2 x UART 6 12 ±0.5% CAN; EMIF; I2C; LIN; SPI; UART; 2 x 6 12 ±0.5% UCAN;RTEMIF; I2C; LIN; SPI; UART; 2 x 6 12 ±0.5% UARTEMIF; I2C; SPI; UART; 2 x UART 6 12 ±0.5% EMIF; I2C; SPI; UART; 2 x UART 6 12 ±0.5% EMIF; I2C; SPI; UART 4 3 ±2% EMIF; I2C; SPI; UART 4 3 ±2% EMIF; I2C; SPI; UART 4 3 ±2% EMIF; I2C; SPI; UART 4 3 ±2% I2C; SPI; UART 4 3 ±2% I2C; SPI; UART 4 3 ±2% I2C; SPI; UART 4 3 ±2% I2C; SPI; UART 4 3 ±2% I2C; SPI; UART 4 3 ±2% I2C; SPI; UART 4 3 ±2% I2C; SPI; UART 4 3 ±2% I2C; SPI; UART 4 3 ±2%。

LAD RoadmapsQ1 2010Henry SUN–LAD Product MarketingIntel ConfidentialIntel?? Ethernet Client/Entry Server Roadmap –Q1’10liconGbE MACPHYPCIe x1 MSI-X 802.1AS IEEE 1588 GbEPHY6x6mmGbE PHY6x6mmPCI-e/SMBusPHYinterface 802.3az EEE E LAN SiNC-SI lt1W VirtualizationGbEPHYGbEPHY6x6mmPCIe/SMBusPHY interface Platform Power Savings Intel?? vPro 802.1AS IEEE 1588 802.1aeiSVR Intel??vPro Intel RPAT 802.1AS IEEE 1588 802.1aeGb00GbE PHYGLCI Intel??AMT 802.1aeGbE PHY6x6mmPCIe/SMBusPHY interface Platform Power Savings Intel?? vPro 802.1AS IEEE 1588 802.1aeGbEPHY6x6mmPCI-e/SMBusPHYinterface 802.3az EEE iSVR Intel??RPAT 802.1AS IEEE 1588 10/110/100 PHY5x5mmLCIinterface Single 3.3v railsupplylt300mWPowerormsMobileDesktoplt300mW PowerPlatfoEntry ServerWorkstationIntel??AtomIntel?? Ethernet Server Silicon Roadmap –Q1’1010GbE iWARPPCIe x8 XAUIRDMAKernelBypass5??secLatency0GbEDl10GBT2525Dual10GbE -KR SFI XAUI KX4updatedRDMA Kernel Bypass 5 ??sec LatencyN Si10Dual 10GbE -XAUI KX4PCIe Gen2 x8 I/OAT VMDq SR-IOVFCoE offloads Flow Director iSCSIIPSec/802.1ae IEEE 1588 802.1AS Virtualization DCBDual 10G Base-T25x25mmPin compatible w/ PowervillePCIe Gen2 x8 x4 lt 10W I/OAT VMDq SR-IOV iSCSI Virtualization DCBDual GbEPCIe x4 x2 x1 I/OAT VMDq SR-IOVIPsec/802.1ae IEEE 1588 802.1AS iSCSILANEDual GbEPCIe x4 x2 x1 I/OAT VMDq iSCSISR-IOV IEEE 1588 802.1ASDual GbE 25x25mmPin compatible w/ TwinvilleDual GbE17x17mmPin compatible w/ Barton Hillsupdated1GbMACPHY GbEQuad GbE17x17mmGbEcopperSerDESPCIeGen2x4x2x1Quad GbE 17x17mmPin compatible w/ Barton HillsGbE copper SerDES PCIe Gen2 x4 x2 x1 I/OAT VMDq SR-IOV EEE iSCSI Dual GbE 17x17mmupdatedEdblmsMissionCriticalPCIe x1 MSI-X IEEE 1588 802.1AS NC-SI lt1W iSCSI VirtualizationGbE copper SerDES PCIe Gen2 x4 x2x1I/OAT VMDq iSCSI VirtualizationVirtualizationBarton Hills can be used as an early sample vehicleExpandableEfficient PerformanceWorkstationPlatformEmbeddedIntel?? Ethernet –Embedded Silicon Roadmap Q1’10Dual 10GbE MACPCIe x8 x4 I/OAT VMDq iSCSI VirtualizationD ual 10GbE -KR SFIXAUIKX41010GbEGbEDual 10GbE -XAUI KX4PCIeGen2 x8 Virtualization I/OAT VMDq SR-IOV FCoE offloads Flow Director iSCSIIPS/8021IEEE15888021ASDCBDual 10GbE-Base-T 25x25mmPin compatible w/ PowervillePCIeGen2 x8 x4lt 10W I/OAT VMDq SR-IOV DCBFCoE offloads Security iSCSI VirtualizationQuad GbE 17x17mmCopper SerDES SGMII PCIeGen2 x4 x2 QuadQuadPortPortIPSec/802.1ae IEEE 1588 802.1AS DCByQuad GbE 17x17mmPin compatible w/ Barton HillsCSDESSGMIIPCIG242x1 I/OAT VMDq IEEE1588/802.1AS iSCSI VirtualizationGbEGbECopper SerDES SGMII PCIeGen2 x4 x2 x1 I/OAT VMDq SR-IOV EEE iSCSI IEEE1588/802.1AS VirtualizationDual GbE17x17mmCopper SerDES SGMIIPCIe Gen2 x4 x2 x1 iSCSI VirtualizationI/OAT VMDq IEEE 1588/802.1ASDual GbEPCIe x4 x2 x1I/OAT iSCSI VirtualizationDualDualPortPortGbEGbEDual GbE 25x25mm or 17x17mmPin compatible w/ 10GbE TwinvillePin compatible w/ Barton HillsCopper SerDES SGMII PCIeGen2 x4 x2 x1 I/OAT VMDq SR-IOV EEE IEEE1588/802.1AS VirtualizationDual GbEPCIe x4 x2 x1 VirtualizationI/OAT VMDq iSCSIDual GbEPCIe x4 x2 x1 I/OAT VMDq SR-IOV iSCSI IPSec 802.1ae IEEE 1588/ 802.1AS VirtualizationGbE MACPHYPCIe x1SingleSinglePortPortGbEPHY6x6mmGbE MACPHYPCIe x1 RSSMSI-X IEEE 1588 802.1AS NC-SI lt1W VirtualizationGbE MACPHYPCIex1 lt1WGbE PHYIntel??AMTPortPortGbEGbEGbE PHYLow TDPGbE PHYGLCI Intel??AMT 802.1aeGbE PHY6x6mmPCIe/SMBusPHY interface Platform Power SavingsIntel??vPro 802.1AS IEEE 1588 802.1aeGbE PHY6x6mmPCI-e/SMBusPHYinterface 802.3az EEE iSVR IEEE 1588 Intel??vPro Intel RPAT 802.1AS 802.1aePowerville Quad GbE ControllerSingle die 1000BASE-T Quad port MAC/PHY??Power: 4.2W Max 4x1G Base-T ??Package: 25mm Dual Twinville compatible17mm Quad Barton Hills CompatibleNC-SISMBusPCIe v2.0 5GT/s x4/x2/x1Optimized for Virtualization??16 transmit and 16 receive queues per port??VMDq support 8 VMs??PCI-SIG SR-IOV I/O Virtualization 8 Virtual function/portPCIeQueue Management ampDMAMgmtOS2BMCpUnified networking ??iSCSI acceleration and remote bootOut of Band management support BMCI/FInterfacesNCSISMBPathroghampMCT PoerSMBQ0TXRX…QnQ0TXRX…QnQ0TX RX…QnQ0TXRX…Qn??Interfaces: NC-SI SMB Path rough amp MCTP over SMB??Host to BMC amp BMC to Network pass-through ??Inventory monitoring and device configuration Energy efficiency FIFOFIFOGbE MACFIFOFIFOGbE MACFIFOFIFOGbE MACFIFOFIFOGbE MACVirtual Ethernet Bridge??EEE –Energy Efficient Ethernet ??Platform power efficient synchronizationIEEE 1588/802.1as support S:2H’10P:Q1’111000 SerDes/PHYSerDes1000SerDes/PHYSerDesPHYSerDesPHYSerDes1000 SerDes/1000 SerDes/S: 2H10 P:Q111Base TSGMIIBase TSGMIIBase TSGMIIBase TSGMIITwinville Dual10GBASE-T ControllerPCIEGen25GT/sX8NCSI/SMBusSingle-die 10GBASE-T dual port MAC/PHY??3-speed 10G/1000/100BASE-T??Low power lt10W Max –No active HS??Package:25mmDualPowervillecompatibleIPMIPCI-E Gen2 5GT/sX8NC-SI/SMBusOS-2-BMCPackage: 25mm Dual Powerville compatible??Base features from Niantic Adv ManageabilityOptimized for Virtualization??64 transmit and 64 receive queues per portVMDqsupport64VMsPCIe withSR-IOVIPMIPass-ThroughQ1Q2Qm…Q0Q2Qn…??VMDq support 64 VMs??PCI-SIG I/O Virtualization 64 Virtual function/portUnified networking ??DCB: Priority grouping Priority flow control DCBxFCoEiSCSITCPFCoEiSCSITCPVirtual Ethernet Bridge??FCoE Initiator with HW acceleration??iSCSI acceleration and remote bootIPSec amp LinkSec security OutofBandmanagementsupportBMCI/FFCoE iSCSI TCP Acceleration10GbE MACIPSec/LinkSecFCoE iSCSI TCP Acceleration10GbE MACIPSec/LinkSecOut of Band management support BMC I/F??Interfaces: NC-SI SMB Path rough amp MCTP over SMB??Host to BMC amp BMC to Networkpass-through ??Inventory monitoring and device configurationIEEE1588/8021assupport10G/1000/100BASE-TPHY10G/1000/100BASE-TPHYIEEE 1588/802.1as support S: Q2’10 P: Q1’11To RJ-45 Port 0To RJ-45 Port 1OEM Adapter Updates for Q1’10??Iron Pond Sampling updated to March and Production updatedtoQ2’10updated to Q2 ’10??Bartonville updated production date toFeb ’10BtillQSddfd??Bartonville QS dropped fromroadmapBase:Intel??82576-KawelaBase:Intel??82599EB-NianticIntel?? Ethernet Network Adapter Roadmap –Q1’10OEM –Shipping PCI-Express Adapters10Gigabit10/100/1000 Mbps PCI ExpressBase:Intel??82575EB-ZoarBase: Intel?? 82576-KawelaPCIex4 x2 x1 I/OAT VMDq SR-IOV iSCSI IPsec/802.1ae IEEE 1588 802.1AS Base: Intel?? 82599EB -NianticPCIeGen2 x8 I/OAT VMDq SR-IOV iSCSI FCoEoffloads DCB Flow Director IPSec/802.1ae IEEE 1588 802.1ASDual Port–E10G42BTDASpring Fountain DADual Port –E1G42ETG1P20 Portville DTQuad Port –E1G44ETG1P20 Portville QT –No SR-IOVBase: Intel?? 82575EB -ZoarPCIex4 x2 x1 I/OAT VMDqBase: Intel?? 82598EB -OplinPCIex8 x4 I/OAT VMDqDual Port–EXPX9502CX4G1P5 Cedar CoveBase: Intel?? 82571GB –Ophir or Intel?? 82572GI-RimonPCIex4x2x1I/OATiSCSIQuad Port –EXPI9404PTG1P20 SpringportDualPort–E10G42AFDAGP5 Long CovePCIex4 x2 x1 I/OAT iSCSIQuad Port–EXPI9404PTG1P20Kirkwood -Intel?? 82571GB –OphirQuad Port–EXPI9404PTLSP20Kirkwood LP -Intel?? 82571GB –OphirDual Port–EXPI9402PTG2P20RedwaterStd Bracket -Intel??82571GB –OphirDual Port–EXPI9402PTG2L20RedwaterLP Bracket -Intel??82571GB–OphirSilPtEXPI9400PTG2P20GldIl??822GIRiSingle Port–E10G41AT2G1P5 Copper Pond 2Base: Intel?? 82576 -KawelaPCIex4 x2 x1 I/OAT VMDq SR-IOV iSCSIIPsec/802.1ae IEEE 1588 802.1AS Base: Intel?? 82599EB -NianticPCIeGen2 x8 I/OAT VMDq SR-IOV iSCSI FCoE offloads DCB Flow Director IPSec/802.1ae IEEE 1588 802.1ASDual Port –E1G42EFG1P20Std Bracket LPShipSilPE10G41BFSRX20SR1SiFtiSR1Single Port –EXPI9400PTG2P20 Glyndon-Intel?? 82572GI –RimonBase: Intel?? 82571GB –Ophir or Intel?? 82572GI-RimonPCIex4 x2 x1 I/OAT iSCSIBase: Intel?? 82598EB -OplinPCIex8 x4 I/OAT VMDqiSCSIFiberOpticServerAdaptersQuadPortEXPI9404PFG1P20BoltonIntel??82571GBOph irpSingle Port –E10G41BFSRX520-SR1Spring Fountain SR1Dual Port–E10G42BFSRX520-SR2 Spring Fountain SR2Dual Port –E10G42BFDAX520-DA2 Spring Fountain LR1AdaptersQuad Port –EXPI9404PFG1P20Bolton -Intel?? 82571GB –Ophir Dual Port –EXPI9402PFG2P20 Bretona -Intel?? 82571GB –OphirSingle Port–EXPI9400PFG2P20SheepsheadBay -Intel?? 82572GI -RimonDual Port–EXPX9502FXSRGP5Green Fountain SRSingle Port SR –EXPX9501FXSRGP5 Bellefontaine SRIntel?? Ethernet Network Adapter Roadmap –Q1’10OEM –Shipping Legacy amp Desktop Adapters10/100/1000 Mbps PCI-X10 Gigabit10/100/1000 Mbps PCI ExpressQuad Port –PWLA8494GTG1P20 Kingsport 3Intel?? 82546B–AnvikDualPort–PWLA8492GTG2L20LPBracketDoubleBarrowDual PortPWLA8492GTG2L20LP Bracket Double BarrowDual Port –PWLA8492GTG2P20Std Bracket Dbl BarrowIntel?? 82546GB –AnvikIISingle Port -PWLA8490MTG1P20Std Bracket EversonSingle Port -PWLA8490MTG1L20LP Bracket EversonIntel?? 82545GM -AttlaFiberOpticDual Port -PWLA8492MFG3P20Std Bracket Dbl EldridgeDual Port-PWLA8492MFG3L20LP Bracket Dbl EldridgeIntel?? 82546GB –AnvikIISingle Port-PWLA8490MFG1P20Std BracketBaldrySilPtPWLA8490MFG1L20LPBktBldOpticServerAdaptersSingle Port-PWLA8490MFG1L20 LP Bracket BaldrySingle Port -PWLA8490LXG1P20Std Bracket BaldryLXIntel?? 82545GM -AttlaSingle Port -PWLA8391GTG3P20Std Bracket Stebbins 2Single Port -PWLA8391GTG3L20LP Bracket Stebbins 2Intel?? 82541PI–Tabor IIISingle Port –EXPI9301CTG1P20Std Bracket LP ShipIntel?? 82571GB-OphirIntel??10 Gigabit AT2 Server Adapter PCIe 10GbE BASE-T Copper Server AdapterCopper Pond IIKey MessagesDual speed: 10GBASE-T and1000BASE-TpIndustry Leading / Standards BasedDistance to 100 MetersMeets PCIePower EnvelopeLow Profile Form FactorIntel?? Ethernet Server Adapter X520-SR1SR2 LR1Spring Fountain SR amp LRProduct FeaturesKMProduct FeaturesBrand NameIntel?? Ethernet Server Adapter X520-SR1 SR2Intel?? Ethernet Server AdapterX520-LR1Product Code/sE10G41BFSR E10G41BFSRG1P5 Single PortSRE10G42BFSR E10G42BFSRG1P5 Dl Pt SRKey MessagesPCIe 2 Gen 25Gt/sConsolidates network infrastructureUnifies LAN and StoragenetworksE10G42BFSR E10G42BFSRG1P5 Dual Port SRE10G41BFLR Single Port LRNOTE: These two boards DO ship with optics installedSpeed/Ports1GbE/10GbE-Fiber / Single amp Dual PortEthernet ControllerIntel?? 82599ES 10 Gigabit Ethernet Controller NianticFCoE offloads and iSCSI accelerationAdvanced I/O virtualization accelerationBandwidth for more Virtual MachinesPluggable OpticsConnector amp Cable MediumLC Fiber OpticSlot type Maximum Bus Speed amp Slot WidthPCI Express 2.0 5.0 GT/s X 8 ConnectorNew lower pricingSupport Slot HeightsLow Profile amp Full HeightCabling TypeMMF 62.5/50um up to 300m SR SMF up to 10km LRO/S SupportWindows??Server 2003 Standard Enterprise Data Center Server 2008 Windows XP Vista Windows 7 2H’09 Linux RHEL SuSe Fedora FreeBSD Solaris Solaris Open Source ESX EFIPower ConsumptionSingle Port SR –6.7 WDual Port SR –10.0 WSingle Port LR –6.7 WOther Featured TechnologiesDesigned for Multi-coreProcessors:MSI/MSI-X and Direct Cache Access Flow Director up to 128 TX RX physical queues per portOptimized for Virtualization:Intel?? Virtualization Technology for Connectivity VT-c VMDq 2 w/64VM’s Unified Networking over Ether net:iSCSI Remote Boot FCoE Unified Networking over Ethernet:iSCSI Remote Boot FCoE hardware accelerationNew security features:IPSec LinkSecoffloadsIntel?? Ethernet Server Adapter X520-DA2Spring Fountain DAProduct FeaturesKMProduct FeaturesBrand NameIntel?? Ethernet Server Adapter X520-DA2ProductCode/sE10G42BTDA Retail Dual PortE10G42BTDAG1P5 OEM Gen Dual PortNOTE: This board does NOT ship with optics installed must be purchased separatelyKey MessagesPCIe2 Gen 2 5Gt/sUnifies LAN and Storage networksFCoE offloads and iSCSI accelerationpurchased separatelyIntel Optics Accessory KitsE10GSFPSRE10GSFPLRSpeed/Ports1GbE/10Gbps –Copper DA or Fiber / Dual PortEthernet ControllerIntel?? 82599ES 10 Gigabit Ethernet Controller NianticAdvanced I/O virtualization accelerationBandwidth for more Virtual MachinesSupports Pluggable OpticsDual port SFP twinaxcopper adapterConnector amp Cable MediumSFP Direct Attached Copper Cable Twin AxialIntel Optics also supported Purchase separatelySlot type Maximum Bus Speed amp Slot WidthPCI Express 2.0 5.0 GT/s X 8 ConnectorLow cost 10GbE connections for Data Center in rack applicationsSupport Slot HeightsLow Profile amp Full HeightCabling TypePassive Cable: 2 pair shielded “twin axial” cable1–10m MMF 62.5/50um up to 300m SR SMF up to 10km LRO/S SupportWindows??Server 2003 Standard Enterprise Data Center Server O/S SupportWindows??Server 2003 Standard Enterprise Data Center Server 2008 Windows XP Vista Windows 7 2H’09 Linux RHEL SuSe Fedora FreeBSD Solaris Solaris Open Source ESX EFIPower Consumption Dual Port –7.9 WOth Ftd ThliDid f MltiPMSI/MSIX d Dit Ch Other Featured TechnologiesDesigned for Multi-core Processors:MSI/MSI-X and Direct Cache Access Flow Director up to 128 TX RX physical queues per portOptimized for Virtualization:Intel?? Virtualization Technology for Connectivity VT-c VMDq 2 w/64VM’s Unified Networking over Ethernet:iSCSI Remote Boot FCoE hardware accelerationNew security features:IPSecLinkSecoffloadsNew security features:IPSec LinkSecoffloadsIntel?? Ethernet SFP SR amp LR OpticsProduct FeaturesBrand NameIntel?? Ethernet SFP SR amp LR OpticsBrand NameIntel?? Ethernet SFP SR amp LR OpticsProduct Code/sE10GSFPSR–SFP SR OpticsE10GSFPLR –SFP LR Optics1000BASE-SX 1G Ethernet10GBASE-SR/SW 10G Ethernet –E10GSFPSR1000BASELX 1G Etht10GBASELR/LW 10G Etht E10GSFPLR1000BASE-LX 1G Ethernet10GBASE-LR/LW 10G Ethernet –E10GSFPLR??Hot-pluggable SFPfootprint??Supports rate selectable 1.25 Gb/s or 9.95 to 10.3 Gb/3 bit rates??Power dissipation lt 1W??RoHS-6 compliant lead-free??Commercial temperature range 0C-70C degrees??Single 3.3V power supply??Maximum link length of 300m on 2000MHZ-km MMF SR??Maximum link length of 10km LR??Uncooled850nm VCSEL laserSR??Uncooled1310nm DFB laser LR??Receiver limiting electrical interface??DuplexLC connector??SFF-8431 IEEE 802.3-2005Intel?? Ethernet Network Adapter Roadmap –Q1’10OEM -In Development / Planning10Gb VMDq SR-IOV iSCSI Virtualization FCoE DCBDT/QT CopperTwinville10GBASE-T PCIe 2.0/Gen 2 I/OAT VMDqSR-IOV iSCSI Virtualization DCBSingle Port –E10G41BTG1P5X520-T1 Iron PondDualPortE10G42BTG1P5X520T2IronPondupdatedNewDual Port–E10G42BTG1P5X520-T2 Iron PondIntel?? 82599EB -NianticNew10/100/1000 Mbps PCIe 2.0 5GT/s I/OAT VMDq VirtualizationQuad Port –E1G44HTG1P20I340-T4 Bartonville CopperIntel?? 82580EB -Barton HillsDual Port –E1G42HTG1P20I340-T2 Bartonville CopperIntel?? 82580DB -Barton Hills1Gb VMDq SR-IOV iSCSI Virtualization EEEDT/QT CopperPowervilleNew10Gb10Gb VMDq SR-IOV iSCSI Virtualization FCoE DCBPCIe 2.0DA4 Quad Port Direct Attach10Gb VMDq SR-IOV iSCSI Virtualization FCoE DCB PCIe Gen 3DA4 Quad Port DirectAttachIl??8299EBNiiNewNewFiberOpticServer AdaptersIntel?? 82599EB -NianticIntel?? 82599EB -NianticNew1Gb1Gb VMDq SR-IOV iSCSI Virtualization EEEDF/QF FiberTwinvilleIntel?? Ethernet Server Adapter X520-T1/T2Iron PondX520T1/T2Iron PondProduct FeaturesBrand NameIntel?? Ethernet Server Adapter X520-T1Intel?? Ethernet Server Adapter X520-T2Pdt Cd/E10G42BT Rtil Dl PtKey MessagesPCIe 2 Gen 2 5Gt/sConsolidates network infrastructureUnifiesLANandStoragenetworksProduct Code/sE10G42BT Retail Dual PortE10G41BTG1P5 OEM Gen SinglePortE10G42BTG1P5 OEM Gen Dual PortSpeed/Ports1000BASE-T/10GBASE-T Copper -Single Dual PortEthernet ControllerIntel?? Ethernet 82599ES 10 Gigabit Ethernet ControllerUnifies LAN and Storage networksFCoE offloads and iSCSI accelerationAdvanced I/O virtualization accelerationBandwidth for more Virtual Machines10GBASE-TSingleandDualPortEthernet ControllerIntel?? Ethernet 82599ES 10 Gigabit Ethernet ControllerConnector amp Cable MediumRJ-45 CopperSlot type Maximum Bus Spee.。

空管缩略语大全(总17页) -CAL-FENGHAI.-(YICAI)-Company One1-CAL-本页仅作为文档封面,使用请直接删除空中交通管制缩略语大全(ICAO English)A Amber 琥珀色(南北向主航路)A/A Air-to-air 空对空AAL Above Aerodrome Level 高出机场平面ABM Abeam 正切ABN Aerodrome beacon 机场灯标ABT About 关于ABV Above …以上AC Altocumulus 高积云ACAC Airborne collision avoidance system 机载防撞系统ACC Area control center 区域管制中心ACCID Notification of an aircraft accident 航空器失事通知ACFT Aircraft 航空器ACK Acknowledge 承认,收悉CAN Aircraft classification number 航空器等级序号AD Aerodrome 机场ADA Advisory area 咨询区ADF Automatic direction-finding equipment 自动定向设备ADIZ Air defense identification zone 防空识别区ADR Advisory route 咨询航路ADS Address 收电地址ADVS Advisory service 咨询服务ADZ Advise 通知AEIS Aeronautical en-route information service 航空的航路情报服务AER Approach end runway 跑道的进近端AERADIO Air radio 航空无线电AES Aerodrome emergency services 机场紧急服务AFB Air force base 空军基地AFCS Automatic flight control system 飞行自动控制系统AFIS Aerodrome flight information service 机场飞行情报服务AFL Above field level 高于场面AFM Affirmative 是的,对的AFS Aeronautical fixed service 航空固定服务AFTN Aeronautical fixed telecommunication network航空固定电信网A/G Air to ground 空对地AGA Aerodromes, air routes and ground aids机场、航路和地面助航设施AGL Above ground level 高出地面AGN Again 再,再次AIREP Air report 空中报告ALA Alighting area 着陆区,降落区ALR Alerting 告警ALS Approach lighting system 进近灯光系统ALT Altitude 海拔高度ALTN Alternate 备降,备分AM Amplitude modulation 调幅AMA Area minimum altitude 区域最低高度AMDT Amendment 修订AMS Aeronautical mobile service 航空移动服务AMSL Above mean sea level 高出平均海平面AOC Airport obstacle chart 机场障碍物图AOR Area of responsibility 责任区APCH Approach 进近APP Approach control 进近管制APRX Approximate 大约APU Auxiliary power unit 辅助动力装置APV Approve 批准ARO Air traffic services reporting office 空中交通服务报告室ARP Airport reference point 机场基准点ARQ Automatic error correction 自动误差纠正ARR Arrival 到达ARSA Airport radar service area 机场雷达服务区ARSR Air route surveillance radar 空中航路监视雷达AS Altostratus 高层云ASC Ascend to 上升ASDA Accelerate-stop distance available 可用加速停止距离ASPH Asphalt 沥青ASR Airport surveillance radar 机场监视雷达ATA Actual time of arrival 实际到达时间ATC Air traffic control 空中交通管制ATD Actual time of departure 实际离场时间ATF Aerodrome traffic frequency 机场交通频率ATFM Air traffic flow management 空中交通流量管理ATIS Automatic terminal information service 自动终端情报服务ATM Air traffic management 空中交通管理ATN Aeronautical telecommunication network 航空电信网ATS Air traffic service 空中交通服务ATZ Aerodrome traffic zone 机场交通地带AUTH Authorized 授权AUW All up weight 起飞全重AUX Auxiliary 辅助的AVBL Available 有用的,可用性AVG Average 平均AWY Airway 航路AZM Azimuth 方位(角)B Blue 兰色(南北向辅航路)BA Braking action 刹车效应BASE Cloud base 云底BC Back course 后航道BCN Beacon 灯标BCST Broadcast 广播BDRY Boundary 边界BFR Before 在…之前BGN Begin 开始BKN Broken 裂云BLDG Building 建筑物BLW Below …以下BRG Bearing 方位(角)BTL Between layers 云层之间,云层飞行BTN Between 在…之间BYD Beyond 超过C Degrees Celsius (Centigrade) 摄氏度CAAC Civil aviation administration of China 中国民用航空总局CAB Civil Aeronautics Board (美国)民用航空委员会CAT Clear air turbulence 晴空颠簸CAT Category 分类,类别CB Cumulonimbus 积雨云CEIL Ceiling 云高CGL Circling guidance light(s) 盘旋引导灯CH Channel 波道CHG Change 改变、换CIV Civil 民用CK Check 检查,校核CL Center line 中心线CLBR Calibration 校正CLG Calling 呼叫CLR Clear, clearance 放行,放行许可CLSD Closed 关闭CM Centimeter 厘米CMB Climb to 爬升至CNL Cancel or cancelled 取消CNS Communication, navigation and surveillance 通信、导航和监视COM Communications 通信CONC Concrete 混凝土COND Condition 条件,状况CONT Continue(s) 连续,连续的COORD Coordinates 坐标COP Change-over point 转换点COR Correct or correction 正确,更正CORR Corridor 走廊CPU Central processing unit 计算机中央处理系统CRP Compulsory reporting point 强制性位置报告点CRT Cathode ray tube 阴极射线管CRZ Cruise 巡航CTA Control area 管制区CTL Control 管制,控制CTN Caution 注意CTR Control zone 管制地带CWY Clearway 净空道DA Decision altitude 决断高度DCKG Docking 停靠DCT Direct 直线进近,直飞DEG Degree 度DEP Depart/departure 起飞或离场DEPT Department 部门DES Descend to 下降DEST Destination 目的地DEV Deviation 偏航,偏离DFTI Distance from touchdown indicator 离接地距离指示器DH Decision height 决断高DIST Distance 距离DIV Divert, diverting 改航,转向DLA Delay 延误DME Distance measuring equipment 测距仪DP Dew point temperature 露点DPT Depth 深度DR Dead reckoning 推测DRG During 在…期间DS Dust storm 尘暴DSB Double sideband 双边带DUR Duration 持续期,持续时间DVOR Doppler VOR 多普勒全向信标EAT Expected approach time 预计进近时间EET Expected elapsed time 预计航程(经过)时间EFC Expected further clearance 预计进一步放行许可ELEV Elevation 标高EM Emission 发射,发讯EMERG Emergency 紧急,应急ENG Engine 发动机ERR Error 错误EST Estimate 预计,估计ETA Estimated time of arrival 预计到达时间ETD Estimated time of departure 预计离场时间ETE Estimated time enroute 预计航路飞行时间ETO Estimated time over 预计飞越时间EXC Except 除…..之外EXP Expect 预期,希望EXTD Extend 延长、延伸F Degrees Fahrenheit 华氏(度)FAA Federal Aviation Administration 联邦航空局(美)FAC Facilities 设施,设备FAF Final approach fix 最后进近定位点FAP Final approach point 最后进近点FAS Final approach segment 最后进近航段FAX Facsimile transmission 传真FC Funnel cloud 漏斗云FCST Forecast 预报FCT Friction coefficient 摩擦系数FG Fog 雾FIC Flight information center 飞行情报中心FIR Flight information region 飞行情报区FIS Flight information service 飞行情报服务FISA Automated Flight information service 自动飞行情报服务FL Flight level 飞行高度FLD Field 机场,场地FLG Flashing 闪光,照明弹FLT Flight 飞行,飞行航班FM From 自,从FM Frequency modulation 调频FMS Flight management system 飞行控制系统FMU Flight management unit 流量管理单位FNA Final approach 最后进近FPL Filed flight plan 申报的飞行计划FPM Feet per minute 英尺/分FPR Flight plan route 飞行计划路线FR Fuel remaining 剩余油量FREQ Frequency 频率FSL Full stop landing 全停着陆FSS Flight service station 飞行服务站FST First 第一FT Feet 英尺G Green 绿色(东西向主航路)GA General aviation 通用航空GCA Ground controlled approach (radar) 地面管制进近(雷达)GEO Geographic or true 地理的或真的GMT Greenwich mean time 地面管制GP Glide path 下滑道GPS Global positioning system 全球定位系统GRADU Gradually 逐渐地GS Glide slope 下滑坡度GS Ground speed 地速GWT Gross weight 全重H24 24 hour service 24小时服务HBN Hazard beacon 危险信标HC Critical height 临界高HDF High frequency direction finding station 高频定向台HDG Heading 航向HEL Helicopter 直升机HF High frequency (3-30 MHz) 高频HGT Height 高HJ Sunrise to sunset 日出至日没,昼间服务HLDG Holding 等待HN Sunset to sunrise 日没日出至,夜间服务HPA Hectopascal 百帕HS During hours of scheduled operations 按航班开放HIS Horizontal situation indicator 水平状态指示仪HST High speed taxiway turn-off 高速转出滑行道HX Irregular service 非定时服务Hz Hertz (cycles per second) 赫兹(每分钟周数)IAC Instrument approach chart 仪表进近图IAF Initial approach fix 起始进近定位点IAL Instrument approach and landing chart 仪表进近和着陆图IAP Instrument approach procedure 仪表进近程序IAR Intersection of air routes 航路交叉点IAS Indicated airspeed 指示空速IATA International air transport association 国际航空运输协会IBN Identification beacon 识别灯标ICAO International Civil Aviation Organization 国际民航组织IDENT Identification 识别,认别标志IF Intermediate approach fix 中间进近定位点IFR Instrument flight rules 仪表飞行规则IGS Instrument guiding system 仪表引导系统ILS Instrument landing system 仪表着陆系统IM Inner marker 内指点标IMC Instrument meteorological conditions 仪表气象条件IMG Immigration 入境,移民IMPT Important 重要INBD Inbound 进场,向台INFO Information 资料,情报INOP Inoperative 不工作INP If not possible 如不可能INPR In progress 在进行中INS Inertial navigation system 惯性导航系统INT Intersection 交叉点,联络道INTER Intermittent 间断的INTL International 国际的INTRG Interrogator 询问器INTRP Interrupted 中断,干扰IR Ice on runway 跑道积冰IS Island 岛屿ISA International standard atmosphere 国际标准大气JTST Jet stream 高空激流KG Kilogram 公斤KHz Kilohertz 千赫KM Kilometer 公里KMH Kilometer(s) per hour 公里/时KT Knots 海里/时KW Kilowatt 千瓦L Locator (Compass) 示位台LAT Latitude 纬度LB Pound 磅LCT Local time 当地时间LDA Landing distance available 可用着陆距离LDG Landing 着陆LDI Landing direction indicator 着陆方向指示器LEN Length 长度LF Low frequency 低频(30-300千赫)LGT Light, lighting 灯,灯光LIH Light intensity high 高强度灯LIL Light intensity low 低强度灯LIM Light intensity medium 中强度灯LLZ Localizer 航向道LMM Locator middle marker 示位台中指点标LOM Locator outer marker 示位台外指点标LONG Longitude 经度LORAN LORAN(long range air navigation system)罗兰(远程导航系统)LT Local time 当地时LVL Level 水平,层M Meters 米MAA Maximum authorized altitude 批准的最大高度MAG Magnetic 磁的MAINT Maintenance 维修,维护MAP Aeronautical maps and charts 航空地图和航图MAPT Missed approach point 复飞点MAR Marine (At sea) 在海上,在海洋MAX Maximum 最大的MB Millibar 毫巴MBZ Mandatory broadcast zone 强制广播区MCA Minimum crossing altitude 最低穿越高度MDA Minimum descent altitude 最低下降高度MDF Medium frequency direction-finding station 中频定向台MEA Minimum en-route altitude 最低航路高度MER True height above MSL 高出平均海平面的真高MET Meteorological 气象的METAR Aviation routine weather report (in aeronautical meteorological code)航空例行天气预报(用航空气象电码)MF Medium frequency 中频(300-3000赫兹)MHA Minimum holding altitude 最低等待高度MHz Megahertz 兆赫MID Mid-point (related to RVR) 中间点(关于跑道视程)MIL Military 军用,军事MIN Minutes 分钟MKR Marker radio beacon 无线电指点信标MLS Microwave landing system 微波着陆系统MM Middle marker 中指点标MM Millimeter 毫米MOA Military operating area 军事活动区MOC Minimum obstacle clearance (required) 最小超障余度(要求的)MOD Moderate 中度MOV Move, movement 活动,运动MPH Miles per hour 英里/小时MPS Meters per second 米/秒MPW Maximum permitted weight 最大允许重量MRA Minimum reception altitude 最低接受高度MRG Medium range 中程MS Minus 减,负MSA Minimum sector altitude 最低扇区高度MSG Message 电报MSL Mean sea level 平均海平面MT Mountain 山MTOW Maximum take-off weight 最大起飞重量MTWA Maximum total weight authorized 最大允许全重N Night, north or northern 夜间,北或北方NA Not authorized 不允许,不批准NAT North Atlantic 北大西洋NAV Navigation 导航NAVAID Navigational aid 导航设施NB Northbound 向北飞行的NC No change 无变化NCRP Non-compulsory reporting point 非强制性位置报告点NDB Non-directional radio beacon 无方向性信标NE Northeast 东北NEB North-eastbound 向东北飞的NEG No, negative 不,不是,不正确的NGT Night 夜,夜晚NIL None 没有NM Nautical miles 海里NML Normal 正常NOF International NOTAM office 国际航行通告室NAP Noise abatement procedure 消噪音程序NOTAM Notice to airman 航行通告NR Number 号码,数NW North-west 西北NWB North-westbound 向西北方向飞的NXT Next 下一个,下次OAC Oceanic area control center 海洋管制中心OAS Obstacle assessment surface 障碍物评价面OBS Observe, observed, observation 观测,观察OBST Obstruction 障碍物OCA Oceanic control area 海洋管制区OCA Obstacle clearance altitude 超障高度OCS Obstacle clearance surface 超障面OM Outer marker 外指点标OPN Open 开放OPR Operator, operate, operative 经营人,报务员,运行OPS Operations 运行,运转O/R On request 按要求,按申请OTS Out of service 不工作OVNGT Overnight 过夜PALS Precision approach light system 精密进近灯光系统PANS-OPS Procedures for air navigation services—aircraft operations航行服务程序-航空器运行PAPI Precision approach path indicator 精密进近航径指示器PAR Precision approach radar 精密进近雷达PARL Parallel 平行PCN Pavement classification number 道面等级序号PCZ Positive control zone 绝对管制地带PERM Permanent 永久的PJE Parachute jumping exercise 跳伞训练PLN Flight plan 飞行计划PN Prior notice required 需事先通知POB Persons on board 机上人员PRKG Parking 停机PROB Probability 概率,可能性PROC Procedure 程序PROP Propeller aircraft 螺旋桨航空器PROV Provisional 临时的,暂时的PS Plus 加、正PSG Passing 过往,经过PSGR Passenger 旅客PSN Position 位置PTN Procedure turn 程序转弯PWR Power 电源,功率QDM Magnetic bearing to facility 向台磁方位QDR Magnetic bearing from facility 背台磁方位QFU Magnetic orientation of runway 跑道磁向QTE True bearing 真方位QUAD Quadrant 象限R Red 红色(东西向辅航路)R Radar, right 雷达,右RA Radio altimeter 无线电高度表RAC Rules of the air and air traffic services空中规则和空中交通服务RAG Runway arresting gear 跑道制动装置RAI Runway alignment indicator 对准跑道指示器RB Rescue boat 救生艇RCA Reaching cruising altitude 到达巡航高度RCC Rescue co-ordination center 救援协调中心RCF Radio communication failure 无线电通讯失效RCL Runway centerline 跑道中心线RCLM Runway centerline markings 跑道中心线标志RCLR Recleared 再放行RDL Radial 径向线REC Receive, receiver 收,收到,接收REDL Runway edge light(s) 跑道边灯REF Reference 参阅REG Registration 登记,注册REIL Runway end identification lights 跑道端识别灯RENL Runway end light(s) 跑道端灯REP Reporting point 报告点REQ Request 请求RF Radio facility 无线电设施RFLG Refueling 加油(燃料)RH Right hand 右手(边)RL Report leaving 脱离报告RLCE Request level change en-route 请求在航路上改变高度层RLLS Runway lead-in lighting system 跑道引进灯光系统RMK Remarks 附注,备注RNAV Area navigation 区域导航/领航ROC Rate of climb 上升率,爬升率ROD Rate of descent 下滑率,下降率RPM Revolutions per hour 每分钟的转数RSCD Runway surface condition 跑道道面情况RSR En-route surveillance radar 航路监视雷达RTE Route 航路RTF Radiotelephony 无线电话RTG Radiotelegraphy 无线电报RTHL Runway threshold light(s) 跑道入口灯RTR Remote transmitter/receiver 遥控发射机/接收机RTS Return to service 恢复工作RTT Radio teletypewriter 无线电传打字机RTZL Runway touchdown zone light(s) 跑道接地带灯RVR Runway visual range 跑道视程RVV Runway visibility values 跑道能见度数值RWY Runway 跑道S South 南、南纬SAR Search and rescue 搜寻与援救SB Southbound 向南飞SDBY Stand by 等待,备份SE Southeast 东南SEB South-eastbound 向东南飞SEC Seconds 秒SECT Sector 扇区SELCAL Selective call system 选择呼叫系统SER Service 服务,工作SFC Surface 表面,道面SID Standard instrument departure 标准仪表离场SKED Schedule 定期SLW Slow 慢SMC Surface movement control 地面活动管制SMR Surface movement radar 地面活动雷达SN Snow 雪SNOWTAM Snow NOTAM 雪情通告SRA Special rules area 特殊规则区SRA Surveillance radar approach 监视雷达进近SRE Surveillance radar element 地面管制进近(GCA)的监视雷达部分SRG Short range 短程SSB Single sideband 单边带SSR Secondary surveillance radar 二次监视雷达SST Supersonic transport 超音速运输机STA Strait in approach 直线进近STAR Standard terminal arrival 标准终端进场STD Standard 标准STN Station 站,站位STNR Stationary 静止的STWL Stopway light(s) 停止道灯SUP Supplement 增补,补充SUPPS Regional supplementary procedures 地区补充程序SW Southwest 西南SWB South-westbound 向西南飞SWY Stopway 停止道T Temperature 温度TA Transition altitude 过度高度TAF Aerodrome forecast 机场天气预报TAIL Tail wind 顺风TAR Terminal area surveillance radar 终端区监视雷达TAS True airspeed 真空速TCA Terminal control area 终端管制区TDO Tornado 龙卷风TDZ Touchdown zone 接地区TEMPO Temporary 临时TEND Trend forecast 趋势预报TFC Traffic 交通TGL Touch-and-go landing 连续起落TGS Taxiing guidance system 滑行引导系统THR Threshold 跑道入口TKOF Take-off 起飞TMA Terminal control area 终端管制区TNA Turn altitude 转弯高度TML Terminal 终端,终端机场TOC Top of climb 爬升顶点TODA Take-off distance available 可用起飞距离TORA Take-off run available 可用起飞滑跑距离TP Turning point 转弯点TR Track 航迹,轨迹TRA Temporary reserved airspace 临时备用空域TRL Transition level 过度高度层TROP Tropopause 对流层顶TT Teletypewriter 电传打字机TURB Turbulence 颠簸TVOR Terminal VOR 终端甚高频全向信标TWR Tower 塔台TWY Taxiway 滑行道TWYL Taxiway-link 滑行联络道TXT Text 电文TYP Type of aircraft 机型TYPH Typhoon 台风UAA Upper advisory area 高空咨询区UAB Until advised by…直到由…通知UAC Upper area control center 高空区域管制中心UAD Upper advisory route 高空咨询航路UAR Upper air route 高空航路UFN Until further notice 直至进一步通知UGT Urgent 紧急UHF Ultra high frequency (300-3000MHz) 超高频(300-3000兆赫)UIC Upper information center 高空情报中心UIR Upper flight information region 高空飞行情报区UNL Unlimited 无限制U/S Unserviceable 不能使用USB Upper sideband 上边带UTA Upper control area 高空管制区UTC Coordinated universal time 协调世界时UWY Upper airway 高空航路VAC Visual approach chart 目视进近图VAR Magnetic variation 磁差VASIS Visual approach slope indicator system 目视进近坡度指示系统VDF VHF direction finding station 甚高频定向台VDP Visual descent point 目视下降点VFR Visual flight rules 目视飞行规则VHF Very high frequency (30-300MHz) 甚高频VIP Very important person 要客VIS Visibility 能见度VLF Very low frequency 甚低频VMC Visual meteorological conditions 目视气象条件VNAV Vertical navigation 垂直导航VOLMET Meteorological information for aircraft in flight供飞行中航空器用的气象情报VOR VHF Omnidirectional range 甚高频全向信标VSP Vertical speed 垂直速度VTOL Vertical take-off and landing 垂直起降VV Vertical visibility 垂直能见度W West, white 西,白色WAC World Aeronautical Chart 世界航图(1:1000,000)WB Westbound 向西飞WDI Wind direction indicator 风向指示器WEF With effect from 自xx起生效WIE With immediate effect 立即生效WIP Work in progress 工程在进行中WO Without 没有WPT Way-point 航路点WRNG Warning 警告,报警WS Wind shear 风切变WT Weight 重量WX Weather 天气X Cross 交叉,十字XNG Crossing 穿越Y Yellow 黄色YDS Zulu time 格林尼治平时Z Coordinated universal time 协调世界时。

D2008型电子称重仪表技术说明书2012年02月简化版●使用前请仔细阅读本产品说明书●请妥善保管本产品说明书,以备查阅宁波柯力传感科技股份有限公司目录第一章技术参数 (1)第二章秤台调试步骤指南 (2)第三章安装联接 (2)第一节、仪表与数字传感器的连接 (2)第二节、仪表与大屏幕的连接使用 (3)第三节、仪表与电脑的连接使用 (3)第四节、仪表与蓄电池的连接使用 (3)第四章数字传感器调试 (3)第一节修改传感器通信地址和秤台数字传感器组秤 (3)第二节修改数字传感器通讯角位 (4)第三节压角识别秤台各角位下的数传地址 (5)第四节查看各角位内码 (6)第五节角差修正 (6)第五章标定调试 (7)第一节标定 (7)第二节分度值自动切换和标定线性 (9)第三节标定误差的修正 (10)第六章其他操作 (10)第一节密码管理 (10)第二节日期时间设置 (11)第三节定时关机 (11)第三节系统测试 (11)第四节PC通讯参数设置 (13)第五节打印参数设置 (13)第六节自定义打印格式设置 (15)第七节仪表文本信息输入与文本信息删除 (15)第六章信息提示 (16)附录A: 通信协议 (16)附录B:称重单格式示例: (19)▲!传感器与仪表的连接必须可靠,传感器的屏蔽线必须可靠接地。
连接线不允许在仪表通电的状态下进行插拔,防止静电损坏仪表或传感器。
▲!传感器和仪表都是静电敏感设备,在使用中必须切实采取防静电措施,严禁在秤台上进行电焊操作或其他强电操作,在雷雨季节,必须落实可靠的避雷措施,防止因雷击造成传感器和仪表的损坏,确保操作人员的人身安全和称重设备及相关设备的安全运行。
第一章技术参数1、型号:适用于D2008型(08FA/08FP/08FP1)不锈钢壳+橡胶按键、D2008型(08FB/08FBP/08FBP1)不锈钢壳+金属按键、D2008型(08FJ)不锈钢壳+橡胶按键、D2008型(09FA/09FP1/09FP) 不锈钢壳+橡胶按键、D10(A、P1) 塑料壳+薄膜按键、D11、D11(P、P1) 塑料壳+薄膜按键2、数字传感器接口:通信方式RS485信号传输距离在接12数字传感器情况下可接至30米,如需更长,请与本公司联系传输波特率9600、19200 bps激励电源DC12V数字接口能力最多可接16个数字传感器3、显示:7位LED数码管,7个状态指示符。


HCS08/RS08集成开发环境设计与实现中文摘要HCS08/RS08集成开发环境设计与实现中文摘要Freescale公司于2004年开始推出的新一代8位MCU HCS08系列及其简化版本的RS08系列产品,目前已经有200多个型号上市。
该系列MCU新引入的BDM功能,为嵌入式开发提供了全新的调试手段。
目前,国内使用该系列MCU,其开发工具依赖进口,本课题目标是自主开发HCS08/RS08集成开发环境。
开发HCS08/RS08集成开发环境内容包括:编程调试器、硬件评估系统、各芯片最小系统、PC方软件等。
开发难点主要有:编程调试器的通用性、汇编及C语言源程序级调试及USB设备驱动程序的开发。
通过测量目标芯片的频率实现稳定的通信,在此基础上实现编程调试器的通用性。
涵盖HCS08/RS08各型号产品的测试目标板有效地验证了编程调试器的性能。
对代码编译后的list文件和dbg文件进行分析,设计相应的数据结构,实现了代码的单步调试和断点调试。
PC方程序完成对代码的编辑、编译和对目标文件的分析。
论文还详细描述了开发USB设备驱动程序所涉及的相关基础知识以及具体过程,实现了一个完整的USB设备驱动程序。
关键词:HCS08/RS08系列微控制器,USB,编程调试器,BDM作者:叶旺胜指导老师:王宜怀ABSTRACT The Design and Implementation of HCS08/RS08 Embeded Developing PlatformThe Design and Implementation of HCS08/RS08 EmbededDeveloping PlatformABSTRACTFreescale’s new generation MCUs HCS08 and its simplify version RS08 provide more than 200 types products. BDM technology inside them can help developer to promote their work. But many native users depend on foreign platforms to develop,so we design and implement HCS08/RS08 develop platform by us.The system include such as programmer and debug pod, hardware test system,PC host software etc.To support all kinds of MCUs of HCS08/RS08 and provide tools to debugC&ASM code are the most challengeable jobs as well as USB’s device dirver.By measurement the frequence of target MCU so the host can communicate to target stably,and we bring forward the programmer&debugger pod to support all kind of MCUs of HCS08/RS08. The hardware test boards including all kinds of HCS08/RS08 MCUs can test and verify the quality of the pod. The suitable data struct help to step in/out the code and make the breakpoint to debug code through analyse the list file and the dbg file. The paper also describes in detail the coherent knowledge of the device driver, bring forward the USB device driver for the programmer and debugger pod.Key Word:HCS08/RS08 series MCUs,USB,programmer and debugger,BDMWritten by Ye WangshengSupervised by Wang Yihuai目录第一章概述 (1)1.1 HCS08和RS08系列MCU概述 (1)1.2 嵌入式开发平台的基本功能 (3)1.3 系统开发的必要性 (4)1.4 本文工作 (5)1.5 本文结构 (6)第二章设计方案及技术基础 (7)2.1 设计方案 (7)2.2 BDM调试模式 (7)2.2.1调试方法的历史回顾 (8)2.2.2 HCS08/RS08和HC08调试方法的比较 (9)2.2.3 BDM通信协议 (10)2.2.4 BDM指令的组织 (13)2.2.5 BDM的进入方式 (15)2.3 USB通用串行总线 (15)2.3.1 USB基本概念 (16)2.3.2 USB的数据格式 (16)2.3.3 USB事务 (19)2.3.4 USB传输 (20)2.3.5 USB标准设备请求 (22)2.3.6 USB的设备状态 (24)2.3.7 USB设备和主机 (25)2.4 小结 (26)第三章硬件设计 (27)3.1 芯片选型 (27)3.2 基本系统的电路设计 (28)3.2.1 电源电路 (28)3.2.2 时钟电路 (28)3.2.3 复位电路 (29)3.3 BDM接口设计 (30)3.4 编程调试器电路设计 (30)3.5 USB接口设计 (32)3.6 目标板设计 (32)3.7 小结 (33)第四章 MCU方软件设计 (34)4.1总体设计 (34)4.2 USB模块设计 (34)4.2.1 USB初始化 (35)4.2.2 USB设备枚举 (35)4.2.3 USB数据传输 (38)4.3 BDM功能模块设计 (40)4.3.1 目标机频率测试 (40)4.3.2 收发1字节的BDM实现 (41)4.3.3目标机复位 (43)4.3.4 收发例程选择 (43)4.3.5 BDM指令实现 (44)4.3.6 目标机擦除及写入 (44)4.3.7 调试 (45)4.4 小结 (48)第五章 PC方软件设计 (49)5.1 总体设计 (49)5.2 目标芯片库 (50)5.3 擦除、写入功能的实现 (51)5.4 目标代码分析 (52)5.5 调试功能实现 (53)5.5.1 dbg文件结构 (53)5.5.2 调试方式 (55)5.5.3 变量数据的获取与处理 (59)5.6 小结 (63)第六章 USB驱动程序设计 (64)6.1 Windows驱动模型 (64)6.1.1 WDM概述 (64)6.1.2 WDM的重要概念和数据结构 (66)6.1.3 WDM驱动程序的组成 (69)6.2 USB设备驱动实现 (69)6.2.1 USB即插即用功能的实现 (70)6.2.2 USB驱动程序接口 (71)6.3 小结 (77)第七章开发体会与总结 (78)7.1 体会 (78)7.2 总结 (79)参考文献 (80)附录A JB8芯片USB模块寄存器 (82)HCS08/RS08集成开发环境设计与实现第一章概述第一章概述Freescale(中文译名飞思卡尔,其前身为Motorola半导体部)公司的MCU系列产品在业界一直享有盛誉,其新推出的HCS08系列和RS08系列MCU是新一代高性价比,高集成度的8位MCU,兼容传统的HC08 MCU指令,具有更多的寻址方式,更高的时钟频率,更强的省电性能和更多层次的低功耗工作模式。


DATA SHEETFortiSwitch ™ Secure Access FamilyHighlights§Designed for installations from desktops to wiring closets§Ideal for SD-Branch deployments §Centralized security and accessmanagement from FortiGate interfaces with FortiLink§Optimal for converged network environments; enabling voice, data, and wireless traffic to be delivered across a single network§Supports non-FortiLink deployments through onboard GUI, API, or command line configuration§Up to 48 ports in a compact 1 RU form factor§Stackable up to 300 switches per FortiGate, depending on model§Supports Wire-speed switching and Store and Forward forwarding modeThe FortiSwitch TM Secure Access Family deliversoutstanding security, performance, and manageability. Secure, Simple, and Scalable, FortiSwitch is the right choice for threat-conscious businesses of all sizes. Tightly integrated into the Fortinet Security Fabric via FortiLink, FortiSwitch can be managed directly from the familiar FortiGate interface. This single pane of glass management provides complete visibility and control ofusers and devices on the network regardless of how they connect. This makes the FortiSwitch ideal for SD-Branch deployments with applications that range from desktop to data center aggregation, enabling businesses to converge their security and network access.Security Fabric Integration through FortiLinkFortiLink is an innovative proprietary management protocol that allows our FortiGate Next Generation Firewall toseamlessly manage any FortiSwitch. FortiLink enables the FortiSwitch to become a logical extension of the FortiGate, integrating itdirectly into the Fortinet Security Fabric. This management option reduces complexity and decreases management costs as network security and access layer functions are enabled and managed through a single console. FortiLink integration enables centralized policy management, including role-based access and control, making it easy to implement and manage. This control and manageability make FortiSwitch ideal for SD-Branch deployments.Product OfferingsFS-108E, 108E-POE, 108E-FPOE, 124E, 124E-POE, 124E-FPOE, 148E, 148E-POE, 224D-FPOE, 224E, 224E-POE, 248D,248E-POE, 248E-FPOE, 424D, 424D-POE, 424D-FPOE, 448D, 448D-POE, 448D-FPOE, 424E-FIBER, M426E-FPOE, 424E, 424E-POE, 424E-FPOE, 448E, 448E-POE, 448E-FPOE,524-D, 524D-FPOE, 548D, 548D-FPOECloud Management OptionFortiGate CloudDATA SHEET | FortiSwitch™ Secure Access FamilyFeaturesLAG support for FortiLink Connection YesActive-Active Split LAG from FortiGate to FortiSwitches for Advanced Redundancy Yes (with FS-2xx, 4xx, 5xx)FORTISWITCH2XXD, 4XXD, 5XXD SERIESFORTISWITCH2XXE, 4XXE SERIESFORTISWITCH1XXE SERIES Layer 2Jumbo Frames Yes Yes YesAuto-negotiation for Port Speed and Duplex Yes Yes YesMDI/MDIX Auto-crossover Yes Yes YesIEEE 802.1D MAC Bridging/STP Yes Yes YesIEEE 802.1w Rapid Spanning Tree Protocol (RSTP)Yes Yes YesIEEE 802.1s Multiple Spanning Tree Protocol (MSTP)Yes Yes YesSTP Root Guard Yes Yes YesSTP BPDU Guard Yes Yes YesEdge Port / Port Fast Yes Yes YesIEEE 802.1Q VLAN Tagging Yes Yes YesPrivate VLAN Yes Yes NoIEEE 802.3ad Link Aggregation with LACP Yes Yes YesUnicast/Multicast traffic balance over trunking port (dst-ip, dst-mac, src-dst-ip, src-dst-mac, src-ip, src-mac)Yes Yes YesIEEE 802.1AX Link Aggregation Yes Yes Yes Spanning Tree Instances (MSTP/CST)15/115/115/1IEEE 802.3x Flow Control and Back-pressure Yes Yes YesIEEE 802.3 10Base-T Yes Yes YesIEEE 802.3u 100Base-TX Yes Yes YesIEEE 802.3z 1000Base-SX/LX Yes Yes YesIEEE 802.3ab 1000Base-T Yes Yes YesIEEE 802.3ae 10 Gigabit Ethernet4xx and 5xx Family N/A N/ADATA SHEET | FortiSwitch™ Secure Access FamilyFeaturesTelnet / SSH Yes Yes Yes HTTP / HTTPS Yes Yes Yes SNMP v1/v2c/v3Yes Yes Yes SNTP Yes Yes Yes Standard CLI and Web GUI Interface Yes Yes YesDATA SHEET | FortiSwitch ™ Secure Access Family5FeaturesAdditional RFC and MIB SupportRFC 2571 Architecture for Describing SNMP Yes Yes Yes DHCP ClientYes Yes Yes RFC 854 Telnet Server Yes Yes Yes RFC 2865 RADIUSYes Yes Yes RFC 1643 Ethernet-like Interface MIB Yes Yes Yes RFC 1213 MIB-IIYes Yes Yes RFC 1354 IP Forwarding Table MIBYes Yes Yes RFC 2572 SNMP Message Processing and Dispatching Yes Yes Yes RFC 1573 SNMP MIB II Yes Yes Yes RFC 1157 SNMPv1/v2c Yes Yes Yes RFC 2030 SNTPYes Yes Yes RFC 6933 Entity MIB (Version 4)Yes Yes Yes RFC 3621 Power Ethernet MIBYes Yes Yes RFC 3433 Entity Sensor Management Information BaseYes Yes Yes RFC 2819 Remote Network Monitoring Management Information BaseYes Yes Yes RFC 2787 Definitions of Managed Objects for the Virtual Router Redundancy Protocol Yes Yes Yes RFC 2620 RADIUS Accounting Client MIB Yes Yes Yes RFC 2618 RADIUS Authentication Client MIB Yes Yes Yes RFC 2576 Coexistence between SNMP versions Yes Yes Yes RFC 2573 SNMP Applications Yes Yes Yes RFC 2571 SNMP Frameworks Yes Yes Yes RFC 2233 Interface MIB Yes Yes Yes RFC 1493 Bridge MIBYes Yes Yes RFC 3289 Management Information Base for the Differentiated Services Architecture Yes Yes -RFC 2934 Protocol Independent Multicast MIB for IPv4Yes Yes -RFC 2932 IPv4 Multicast Routing MIBYes Yes -RFC 2674 Definitions of Managed Objects for Bridges with Traffic Classes, Multicast Filtering and Virtual LAN ExtensionsYesYes -RFC 2362 Protocol Independent Multicast-Sparse Mode (PIM-SM)Yes Yes -RFC 2328 OSPF v2Yes Yes -RFC 1850 OSPFv2 MIB Yes Yes -RFC 1724 RIPv2 MIBYes Yes -RFC 3289 Management Information Base for the Differentiated Services Architecture YesYes-RFC 2934 Protocol Independent Multicast MIB for IPv4Yes (4XX/5XX only)Yes (4XX only)-RFC 2932 IPv4 Multicast Routing MIBYes (4XX/5XX only)Yes (4XX only)-RFC 2674 Definitions of Managed Objects for Bridges with Traffic Classes, Multicast Filtering and Virtual LAN ExtensionsYesYes -RFC 2362 Protocol Independent Multicast-Sparse Mode (PIM-SM)Yes (4XX/5XX only)Yes (4XX only)-RFC 2328 OSPF v2Yes Yes -RFC 1850 OSPFv2 MIB Yes Yes -RFC 1724 RIPv2 MIBYesYes-DATA SHEET | FortiSwitch ™ Secure Access Family6Specifications* Fortinet Warranty Policy:/doc/legal/EULA.pdfFortiSwitch 108E FortiSwitch 108E-POE FortiSwitch 108E-FPOEDATA SHEET | FortiSwitch ™ Secure Access Family7* Fortinet Warranty Policy: /doc/legal/EULA.pdfSpecificationsFortiSwitch 124E FortiSwitch 124E-POEFortiSwitch 124E-FPOEDATA SHEET | FortiSwitch™ Secure Access Family8* Fortinet Warranty Policy: /doc/legal/EULA.pdfSpecificationsFortiSwitch 148E FortiSwitch 148E-POEDATA SHEET | FortiSwitch ™ Secure Access Family9Specifications* Fortinet Warranty Policy:/doc/legal/EULA.pdfFortiSwitch 224D-FPOE FortiSwitch 224EFortiSwitch 224E-POEDATA SHEET | FortiSwitch ™ Secure Access Family10Specifications* Fortinet Warranty Policy:/doc/legal/EULA.pdfFortiSwitch 248E-POEFortiSwitch 248E-FPOEFortiSwitch 248D11* Fortinet Warranty Policy:/doc/legal/EULA.pdfFortiSwitch 424D-FPOEFortiSwitch 424DFortiSwitch 424D-POE12* Fortinet Warranty Policy:/doc/legal/EULA.pdfFortiSwitch 448D-FPOEFortiSwitch 448DFortiSwitch 448D-POEFORTISWITCH-424E-FIBER* Fortinet Warranty Policy: /doc/legal/EULA.pdfFortiSwitch 424E-Fiber FortiSwitch M426E-FPOE1314* Fortinet Warranty Policy:/doc/legal/EULA.pdfFortiSwitch 424E-FPOEFortiSwitch 424EFortiSwitch 424E-POE15FORTISWITCH 448E-FPOE48x GE RJ45 and 4x 10GE SFP+ portsNote: SFP+ ports are compatible with 1 GE SFP 1* Fortinet Warranty Policy: /doc/legal/EULA.pdfFortiSwitch 448E-FPOEFortiSwitch 448E FortiSwitch 448E-POE16*FS-524D, FS-524D-FPOE, FS-548D, FS-548D-FPOE Power Supply Units are Hot-Swappable** Fortinet Warranty Policy: /doc/legal/EULA.pdfFortiSwitch 548D-FPOE FortiSwitch 548DFortiSwitch 524D-FPOE FortiSwitch 524DProduct SKU DescriptionFortiSwitch 108E FS-108E Layer 2 FortiGate switch controller compatible switch with 8 GE RJ45 + 2 SFP ports, line AC and PSE dual powered. Fanless. FortiSwitch 108E-POE FS-108E-POE Layer 2 FortiGate switch controller compatible PoE+ switch with 8 GE RJ45 + 2 SFP ports,4 port PoE with maximum 65 W PoE limit. Fanless.FortiSwitch 108E-FPOE FS-108E-FPOE Layer 2 FortiGate switch controller compatible PoE+ switch with 8 GE RJ45 + 2 SFP ports,8 port PoE with maximum 130 W PoE limit. Fanless.FortiSwitch 124E FS-124E Layer 2 FortiGate switch controller compatible switch with 24 GE RJ45 + 4 SFP ports. Fanless.FortiSwitch 124E-POE FS-124E-POE Layer 2 FortiGate switch controller compatible PoE+ switch with 24 GE RJ45 + 4 SFP ports, 12 port PoE with maximum 185 W limit. FortiSwitch 124E-F-POE FS-124E-FPOE Layer 2 FortiGate switch controller compatible PoE+ switch with 24 GE RJ45 + 4 SFP ports, 24 port PoE with maximum 370 W limit. FortiSwitch 148E FS-148E Layer 2 FortiGate switch controller compatible switch with 48 GE RJ45 + 4 SFP ports.FortiSwitch 148E-POE FS-148E-POE Layer 2 FortiGate switch controller compatible PoE+ switch with 48 GE RJ45 + 4 SFP ports, 24 port PoE with maximum 370 W limit. FortiSwitch 224D-FPOE FS-224D-FPOE Layer 2/3 FortiGate switch controller compatible PoE+ switch with 24 GE RJ45 + 4 SFP ports,24 port PoE with maximum 370 W limit.FortiSwitch 224E FS-224E Layer 2/3 FortiGate switch controller compatible switch with 24 GE RJ45 + 4 SFP ports. Fanless.FortiSwitch 224E-POE FS-224E-POE Layer 2/3 FortiGate switch controller compatible PoE+ switch with 24 GE RJ45 + 4 SFP ports,12 port PoE with maximum 180 W limit.FortiSwitch 248D FS-248D Layer 2/3 FortiGate switch controller compatible switch with 48 GE RJ45 + 4 SFP ports.FortiSwitch 248E-POE FS-248E-POE Layer 2/3 FortiGate switch controller compatible PoE+ switch with 48 GE RJ45 + 4 SFP ports,24 port PoE with maximum 370 W limit.FortiSwitch 248E-FPOE FS-248E-FPOE Layer 2/3 FortiGate switch controller compatible PoE+ switch with 48 GE RJ45 + 4 SFP ports,48 port PoE with maximum 740 W limit.FortiSwitch 424D FS-424D Layer 2/3 FortiGate switch controller compatible switch with 24 GE RJ45 + 2x 10 GE SFP+ ports.FortiSwitch 424D-POE FS-424D-POE Layer 2/3 FortiGate switch controller compatible PoE+ switch with 24 GE RJ45 + 2x 10 GE SFP+ ports,24 port PoE with maximum 185 W limit.FortiSwitch 424D-FPOE FS-424D-FPOE Layer 2/3 FortiGate switch controller compatible PoE+ switch with 24 GE RJ45 + 2x 10 GE SFP+ ports,24 port PoE with maximum 370 W limit.FortiSwitch 448D FS-448D Layer 2/3 FortiGate switch controller compatible switch with 48 GE RJ45 + 4x 10 GE SFP+ ports.FortiSwitch 448D-POE FS-448D-POE Layer 2/3 FortiGate switch controller compatible PoE+ switch with 48 GE RJ45 + 4x 10 GE SFP+ ports,48 port PoE with maximim 370 W limit.FortiSwitch 448D-FPOE FS-448D-FPOE Layer 2/3 FortiGate switch controller compatible PoE+ switch with 48 GE RJ45 + 4x 10 GE SFP+ ports,48 port PoE with maximum 740 W limit.FortiSwitch 424E-Fiber FS-424E-Fiber Layer 2/3 FortiGate switch controller compatible switch with 24x GE SFP and 4x 10 GE SFP+ UplinksFortiSwitch M426E-FPOE FS-M426E-FPOE Layer 2/3 FortiGate switch controller compatible PoE+/UPoE switch with 16x GE RJ45, 8x 2.5 RJ45, 2x 5 GE RJ45 and4x 10 GE SFP+, 24 port PoE with maximum 420 W limit.FortiSwitch 424E FS-424E Layer 2/3 FortiGate switch controller compatible switch with 24 GE RJ45, 4x 10 GE SFP + ports.FortiSwitch 424E-POE FS-424E-POE Layer 2/3 FortiGate switch controller compatible switch with 24 GE RJ45, 4x 10 GE SFP + ports,24 port PoE with maximum 283.5 W limit.FortiSwitch 424E-FPOE FS-424E-FPOE Layer 2/3 FortiGate switch controller compatible switch with 24 GE RJ45, 4x 10 GE SFP + ports,24 port PoE with maximum 433.7 W limit.FortiSwitch 448E FS-448E Layer 2/3 FortiGate switch controller compatible switch with 48 GE RJ45, 4x 10 GE SFP + ports.FortiSwitch 448E-POE FS-448E-POE Layer 2/3 FortiGate switch controller compatible switch with 48 GE RJ45, 4x 10 GE SFP + ports, 48 port PoE with maximum 421 W limit.FortiSwitch 448E-FPOE FS-448E-FPOE Layer 2/3 FortiGate switch controller compatible switch with 48 GE RJ45, 4x 10 GE SFP + ports, 48 port PoE with maximum 772 W limit.FortiSwitch 524D FS-524D Layer 2/3 FortiGate switch controller compatible switch with 24 GE RJ45, 4x 10 GE SFP+ and 2x 40 GE QSFP+ ports. FortiSwitch 524D-FPOE FS-524D-FPOE Layer 2/3 FortiGate switch controller compatible PoE+ switch with 24 GE RJ45, 4x 10 GE SFP+, 2x 40 GE QSFP+ ports,24 port PoE with maximum 400 W limit.FortiSwitch 548D FS-548D Layer 2/3 FortiGate switch controller compatible switch with 48 GE RJ45, 4x 10 GE SFP+ and 2x 40 GE QSFP+ ports. FortiSwitch 548D-FPOE FS-548D-FPOE Layer 2/3 FortiGate switch controller compatible PoE+ switch with 48 GE RJ45, 4x 10 GE SFP+ and 2x 40 GE QSFP+ ports,48 port PoE with maximum 750 W limit.FortiSwitch Cloud Management License*FC-10-WMSC1-190-02-DD FortiSwitch Cloud Management License subscription 1 Year Contract.17AccessoriesFortiSwitch Advanced Features License FS-SW-LIC-200SW License for FS-200 Series Switches to activate Advanced Features.FS-SW-LIC-400SW License for FS-400 Series Switches to activate Advanced Features.FS-SW-LIC-500SW License for FS-500 Series Switches to activate Advanced Features.External Redundant AC Power Supply FRPS-740Redundant AC power supply for up to 2 units: FS-224D-FPOE, FS-248D-FPOE, FS-424D-FPOE, FS-448D-POE and FS-424D-POE. Redundant AC Power Supply FS-PSU-150AC power supply for FS-548D and FS-524D.FS-PSU-600AC power supply for FS-524D-FPOE.**FS-PSU-900AC power supply for FS-548D-FPOE.*** When managing a FortiSwitch with a FortiGate via FortiGate Cloud, no additional license is necessary.** Provides additional PoE capacity.For details of Transceiver modules, see the Fortinet Transceivers datasheet.Note that all PoE FortiSwitches are Alternative-A. Copyright © 2020 Fortinet, Inc. All rights reserved. Fortinet®, FortiGate®, FortiCare® and FortiGuard®, and certain other marks are registered trademarks of Fortinet, Inc., and other Fortinet names herein may also be registered and/or common law trademarks of Fortinet. All other product or company names may be trademarks of their respective owners. Performance and other metrics contained herein were attained in internal lab tests under ideal conditions, and actual performance and other results may vary. Network variables, different network environments and other conditions may affect performance results. Nothing herein represents any binding commitment by Fortinet, and Fortinet disclaims all warranties, whether express or implied, except to the extent Fortinet enters a binding written contract, signed by Fortinet’s General Counsel, with a purchaser that expressly warrants that the identified product will perform according to certain expressly-identified performance metrics and, in such event, only the specific performance metrics expressly identified in such binding written contract shall be binding on Fortinet. For absolute clarity, any such warranty will be limited to performance in the same ideal conditions as in Fortinet’s internal lab tests. Fortinet disclaims in full any covenants, representations, and guarantees pursuant hereto, whether express or implied. Fortinet reserves the right to change, modify, transfer, or otherwise revise this publication without notice, and the most current version of the publication shall be applicable. Fortinet disclaims in full any covenants, representations, and guarantees pursuant hereto, whether express or implied. Fortinet reserves the right to change, modify, transfer, or otherwise revise this publication without notice, and the most current version of the publication shall be applicable.FST-PROD-DS-SW3FS-SA-DAT-R38-202007。
M IDYEAR U PDATE2006ToolStick Development PlatformThe USB ToolStick platform is a fully contained evaluation and development system in a USB stick that demonstrates Silicon Labs’ easy-to-use develop-ment tools. Using only a PC with a USB port, designers can fully experience the Silicon Labs software development environment in conjunction with the MCU on-chip debugging hardware that allows full, non-intrusive access to the CPU, peripherals and memory. Buy online at /ToolStickPrecision Mixed-Signal MCUsSmall Form Factor Mixed-Signal MCUsUSB Mixed-Signal MCUsEasily update legacy RS-232 and RS-485 designs to USB. The CP210x single-chip CP2103-EBBuy online at /USBEthernet802.15.4/ZigBee TM Development KitsSilicon Labs offers 802.15.4 and ZigBee development kits that allow customers to focus on application development rather than hardware selection. These kits include all the hardware and software needed to immediately begin developing 802.15.4 or ZigBee network solutions.•Demonstration GUI– Graphical representation of 13 ZigBee topologies– Three demo applications to monitor data from any of the networked devices: temperature, received signal strength indicator (RSSI) and thumbwheel (analog)•802.15.4 MAC-level application development •ZigBee application development•Silicon Labs Integrated Development Environment (IDE)Buy online at /ZigBeeZigBee-2.4-DKPower over Ethernet Voice Reference DesignThis reference design includes the PoE-VOICE-EB Reference Design Board which contains an IEEE 802.3af compliant Power over Ethernet circuit, 8 kHz voice/speech sampling system and an IEEE 802.3 embedded Ethernet connection. The board provides a hardware platform for evaluating and developing software for embedded systems that use the C8051F340 as the main controller, the CP2201 as the Ethernet controller and the Si3400as the PoE controller. The reference design software uses the TCP/IP Configuration Wizard,which generates starter firmware based on the industry standard CMX™ Micronet Stack.Buy online at /EthernetPoE-Voice-EBCAN Mixed-Signal MCUsCP2120 SPI-I 2C Bridge and GPIO Port ExpanderThe CP2120 allows an SPI master to communicate as an I 2C master device. The chip includes a 4-wire slave SPI bus, bridge control logic, a bi-directional I 2C bus interface and 8 general purpose input/output pins. The CP2120 Evaluation Kit demonstrates the SPI-I 2C fixed functionality and requires absolutely no code development. Buy online at /CP2120CP2120EKBuy Online 16 mm16 mm12 mm12 mm9 mm9 mm9 mm9 mm5 mm5 mm4 mm4 mm3 mm3 mm©2006, Silicon Laboratories Inc. Silicon Laboratories and the Silicon Labs logo are trademarks of Silicon Laboratories Inc. All other product or service names are the property of their perspective owners. PG, 5000, Oct 06 , Rev EMicrocontroller Development ToolsDevelopment KitsComplete development/prototyping system includes the following:•Prototyping/demonstration board• USB adapter for in-system programming and debugging • Silicon Laboratories IDE • MCU configuration wizard Buy online at /DevKitsIntegrated Development EnvironmentThird Party Tool SupportA broad range of third-party compilers and development tools are available, including a free Small Device C Compiler (SDCC) supported by App Note 198, “Integrating SDCC 8051 Tools into the Silicon Labs IDE.”Flash programming and source-level debug of OMF-51 object files is fully supported.Design Support at /MCUSilicon Laboratories ’Reference Designs, Application Notes and source code examples address a wide range of applications and markets. Visit our website at /MCU for complete access to all of our design resources.Product Support at /supportMCU User’s Forum: where C8051F MCU users can share experiences and technical questions with other users.Microcontroller support email: Americas:mcuapps@Europe and Asia:eumcuapps@Development Kit or IDE support email: mcutools@400 West Cesar Chavez Austin, TX 78701512.416.8500877.444.3032 (toll free)Fax: 512.416.96694 kB C compiler included Source code editor Project managerKeil 8051 macro assembler and linker Flash programmerSupports full-speed, non-intrusive, in-circuit debug logic Source-level debugVariable watch window Real-time breakpointsConditional memory watchpoints Memory and register inspect/modify Supports third-party development tools Single-step and animated execution modesPricing and availability: /sales6.5 mm6.5 mm。
Part No.MCU Core MHz Flash (kB)Ram (kB)DIG I/O EFM32G200F16-QFN32ARM Cortex-M33216 kB824 EFM32G200F32-QFN32ARM Cortex-M33232 kB824 EFM32G200F64-QFN32ARM Cortex-M33264 kB1624 EFM32G210F128-QFN32ARM Cortex-M332128 kB1624 EFM32G222F128-QFP48ARM Cortex-M332128 kB1637 EFM32G222F32-QFP48ARM Cortex-M33232 kB837 EFM32G222F64-QFP48ARM Cortex-M33264 kB1637 EFM32G230F128-QFN64ARM Cortex-M332128 kB1656 EFM32G230F32-QFN64ARM Cortex-M33232 kB856 EFM32G230F64-QFN64ARM Cortex-M33264 kB1656 EFM32G232F128-QFP64ARM Cortex-M332128 kB1653 EFM32G232F32-QFP64ARM Cortex-M33232 kB853 EFM32G232F64-QFP64ARM Cortex-M33264 kB1653 EFM32G280F128-QFP100ARM Cortex-M332128 kB1686 EFM32G280F32-QFP100ARM Cortex-M33232 kB886 EFM32G280F64-QFP100ARM Cortex-M33264 kB1686 EFM32G290F128-BGA112ARM Cortex-M332128 kB1690 EFM32G290F32-BGA112ARM Cortex-M33232 kB890 EFM32G290F64-BGA112ARM Cortex-M33264 kB1690 EFM32G840F128-QFN64ARM Cortex-M332128 kB1656 EFM32G840F32-QFN64ARM Cortex-M33232 kB856 EFM32G840F64-QFN64ARM Cortex-M33264 kB1656 EFM32G842F128-QFP64ARM Cortex-M332128 kB1653 EFM32G842F32-QFP64ARM Cortex-M33232 kB853 EFM32G842F64-QFP64ARM Cortex-M33264 kB1653 EFM32G880F128-QFP100ARM Cortex-M332128 kB1686 EFM32G880F32-QFP100ARM Cortex-M33232 kB886 EFM32G880F64-QFP100ARM Cortex-M33264 kB1686 EFM32G890F128-BGA112ARM Cortex-M332128 kB1690 EFM32G890F32-BGA112ARM Cortex-M33232 kB890 EFM32G890F64-BGA112ARM Cortex-M33264 kB1690 EFM32GG230F1024-QFN64ARM Cortex-M3481024 kB12856 EFM32GG230F512-QFN64ARM Cortex-M348512 kB12856 EFM32GG232F1024-QFP64ARM Cortex-M3481024 kB12853 EFM32GG232F512-QFP64ARM Cortex-M348512 kB12853 EFM32GG280F1024-QFP100ARM Cortex-M3481024 kB12886 EFM32GG280F512-QFP100ARM Cortex-M348512 kB12886 EFM32GG290F1024-BGA112ARM Cortex-M3481024 kB12890 EFM32GG290F512-BGA112ARM Cortex-M348512 kB12890 EFM32GG295F1024-BGA120ARM Cortex-M3481024 kB12893 EFM32GG295F512-BGA120ARM Cortex-M348512 kB12893 EFM32GG330F1024-QFN64ARM Cortex-M3481024 kB12853 EFM32GG330F512-QFN64ARM Cortex-M348512 kB12853 EFM32GG332F1024-QFP64ARM Cortex-M3481024 kB12850 EFM32GG332F512-QFP64ARM Cortex-M348512 kB12850 EFM32GG380F1024-QFP100ARM Cortex-M3481024 kB12883 EFM32GG380F512-QFP100ARM Cortex-M348512 kB12883 EFM32GG390F1024-BGA112ARM Cortex-M3481024 kB12887 EFM32GG390F512-BGA112ARM Cortex-M348512 kB12887 EFM32GG395F1024-BGA120ARM Cortex-M3481024 kB12893EFM32GG840F1024-QFN64ARM Cortex-M3481024 kB12856 EFM32GG840F512-QFN64ARM Cortex-M348512 kB12856 EFM32GG842F1024-QFP64ARM Cortex-M3481024 kB12853 EFM32GG842F512-QFP64ARM Cortex-M348512 kB12853 EFM32GG880F1024-QFP100ARM Cortex-M3481024 kB12886 EFM32GG880F512-QFP100ARM Cortex-M348512 kB12886 EFM32GG890F1024-BGA112ARM Cortex-M3481024 kB12890 EFM32GG890F512-BGA112ARM Cortex-M348512 kB12890 EFM32GG895F1024-BGA120ARM Cortex-M3481024 kB12893 EFM32GG895F512-BGA120ARM Cortex-M348512 kB12893 EFM32GG940F1024-QFN64ARM Cortex-M3481024 kB12853 EFM32GG940F512-QFN64ARM Cortex-M348512 kB12853 EFM32GG942F1024-QFP64ARM Cortex-M3481024 kB12850 EFM32GG942F512-QFP64ARM Cortex-M348512 kB12850 EFM32GG980F1024-QFP100ARM Cortex-M3481024 kB12883 EFM32GG980F512-QFP100ARM Cortex-M348512 kB12883 EFM32GG990F1024-BGA112ARM Cortex-M3481024 kB12887 EFM32GG990F512-BGA112ARM Cortex-M348512 kB12887 EFM32GG995F1024-BGA120ARM Cortex-M3481024 kB12893 EFM32GG995F512-BGA120ARM Cortex-M348512 kB12893 EFM32LG230F128G-E-QFN64ARM Cortex-M348128 kB3256 EFM32LG230F256G-E-QFN64ARM Cortex-M348256 kB3256 EFM32LG230F64G-E-QFN64ARM Cortex-M34864 kB3256 EFM32LG232F128G-E-QFP64ARM Cortex-M348128 kB3253 EFM32LG232F256G-E-QFP64ARM Cortex-M348256 kB3253 EFM32LG232F64G-E-QFP64ARM Cortex-M34864 kB3253 EFM32LG280F128G-E-QFP100ARM Cortex-M348128 kB3286 EFM32LG280F256G-E-QFP100ARM Cortex-M348256 kB3286 EFM32LG280F64G-E-QFP100ARM Cortex-M34864 kB3286 EFM32LG290F128G-E-BGA112ARM Cortex-M348128 kB3290 EFM32LG290F256G-E-BGA112ARM Cortex-M348256 kB3290 EFM32LG290F64G-E-BGA112ARM Cortex-M34864 kB3290 EFM32LG295F128G-E-BGA120ARM Cortex-M348128 kB3293 EFM32LG295F256G-E-BGA120ARM Cortex-M348256 kB3293 EFM32LG295F64G-E-BGA120ARM Cortex-M34864 kB3293 EFM32LG330F128G-E-QFN64ARM Cortex-M348128 kB3253 EFM32LG330F256G-E-QFN64ARM Cortex-M348256 kB3253 EFM32LG330F64G-E-QFN64ARM Cortex-M34864 kB3253 EFM32LG332F128G-E-QFP64ARM Cortex-M348128 kB3250 EFM32LG332F256G-E-QFP64ARM Cortex-M348256 kB3250 EFM32LG332F64G-E-QFP64ARM Cortex-M34864 kB3250 EFM32LG360F128G-E-CSP81ARM Cortex-M348128 kB3265 EFM32LG360F256G-E-CSP81ARM Cortex-M348256 kB3265 EFM32LG360F64G-E-CSP81ARM Cortex-M34864 kB3265 EFM32LG380F128G-E-QFP100ARM Cortex-M348128 kB3283 EFM32LG380F256G-E-QFP100ARM Cortex-M348256 kB3283 EFM32LG380F64G-E-QFP100ARM Cortex-M34864 kB3283 EFM32LG390F128G-E-BGA112ARM Cortex-M348128 kB3287 EFM32LG390F256G-E-BGA112ARM Cortex-M348256 kB3287 EFM32LG390F64G-E-BGA112ARM Cortex-M34864 kB3287EFM32LG395F256G-E-BGA120ARM Cortex-M348256 kB3293 EFM32LG395F64G-E-BGA120ARM Cortex-M34864 kB3293 EFM32LG840F128G-E-QFN64ARM Cortex-M348128 kB3256 EFM32LG840F256G-E-QFN64ARM Cortex-M348256 kB3256 EFM32LG840F64G-E-QFN64ARM Cortex-M34864 kB3256 EFM32LG842F128G-E-QFP64ARM Cortex-M348128 kB3253 EFM32LG842F256G-E-QFP64ARM Cortex-M348256 kB3253 EFM32LG842F64G-E-QFP64ARM Cortex-M34864 kB3253 EFM32LG880F128G-E-QFP100ARM Cortex-M348128 kB3286 EFM32LG880F256G-E-QFP100ARM Cortex-M348256 kB3286 EFM32LG880F64G-E-QFP100ARM Cortex-M34864 kB3286 EFM32LG890F128G-E-BGA112ARM Cortex-M348128 kB3290 EFM32LG890F256G-E-BGA112ARM Cortex-M348256 kB3290 EFM32LG890F64G-E-BGA112ARM Cortex-M34864 kB3290 EFM32LG895F128G-E-BGA120ARM Cortex-M348128 kB3293 EFM32LG895F256G-E-BGA120ARM Cortex-M348256 kB3293 EFM32LG895F64G-E-BGA120ARM Cortex-M34864 kB3293 EFM32LG940F128G-E-QFN64ARM Cortex-M348128 kB3253 EFM32LG940F256G-E-QFN64ARM Cortex-M348256 kB3253 EFM32LG940F64G-E-QFN64ARM Cortex-M34864 kB3253 EFM32LG942F128G-E-QFP64ARM Cortex-M348128 kB3250 EFM32LG942F256G-E-QFP64ARM Cortex-M348256 kB3250 EFM32LG942F64G-E-QFP64ARM Cortex-M34864 kB3250 EFM32LG980F128G-E-QFP100ARM Cortex-M348128 kB3283 EFM32LG980F256G-E-QFP100ARM Cortex-M348256 kB3283 EFM32LG980F64G-E-QFP100ARM Cortex-M34864 kB3283 EFM32LG990F128G-E-BGA112ARM Cortex-M348128 kB3287 EFM32LG990F256G-E-BGA112ARM Cortex-M348256 kB3287 EFM32LG990F64G-E-BGA112ARM Cortex-M34864 kB3287 EFM32LG995F128G-E-BGA120ARM Cortex-M348128 kB3293 EFM32LG995F256G-E-BGA120ARM Cortex-M348256 kB3293 EFM32LG995F64G-E-BGA120ARM Cortex-M34864 kB3293 EFM32TG108F16-QFN24ARM Cortex-M33216 kB417 EFM32TG108F32-QFN24ARM Cortex-M33232 kB417 EFM32TG108F4-QFN24ARM Cortex-M332 4 kB217 EFM32TG108F8-QFN24ARM Cortex-M3328 kB217 EFM32TG110F16-QFN24ARM Cortex-M33216 kB417 EFM32TG110F32-QFN24ARM Cortex-M33232 kB417 EFM32TG110F4-QFN24ARM Cortex-M332 4 kB217 EFM32TG110F8-QFN24ARM Cortex-M3328 kB217 EFM32TG210F16-QFN32ARM Cortex-M33216 kB424 EFM32TG210F32-QFN32ARM Cortex-M33232 kB424 EFM32TG210F8-QFN32ARM Cortex-M3328 kB224 EFM32TG222F16-QFP48ARM Cortex-M33216 kB437 EFM32TG222F32-QFP48ARM Cortex-M33232 kB437 EFM32TG222F8-QFP48ARM Cortex-M3328 kB237 EFM32TG225F16-BGA48ARM Cortex-M33216 kB437 EFM32TG225F32-BGA48ARM Cortex-M33232 kB437 EFM32TG225F8-BGA48ARM Cortex-M3328 kB237 EFM32TG230F16-QFN64ARM Cortex-M33216 kB456EFM32TG230F32-QFN64ARM Cortex-M33232 kB456 EFM32TG230F8-QFN64ARM Cortex-M3328 kB256 EFM32TG232F16-QFP64ARM Cortex-M33216 kB453 EFM32TG232F32-QFP64ARM Cortex-M33232 kB453 EFM32TG232F8-QFP64ARM Cortex-M3328 kB253 EFM32TG822F16-QFP48ARM Cortex-M33216 kB437 EFM32TG822F32-QFP48ARM Cortex-M33232 kB437 EFM32TG822F8-QFP48ARM Cortex-M3328 kB237 EFM32TG825F16-BGA48ARM Cortex-M33216 kB437 EFM32TG825F32-BGA48ARM Cortex-M33232 kB437 EFM32TG825F8-BGA48ARM Cortex-M3328 kB237 EFM32TG840F16-QFN64ARM Cortex-M33216 kB456 EFM32TG840F32-QFN64ARM Cortex-M33232 kB456 EFM32TG840F8-QFN64ARM Cortex-M3328 kB256 EFM32TG842F16-QFP64ARM Cortex-M33216 kB453 EFM32TG842F32-QFP64ARM Cortex-M33232 kB453 EFM32TG842F8-QFP64ARM Cortex-M3328 kB253 EFM32WG230F128-QFN64ARM Cortex-M448128 kB3256 EFM32WG230F256-QFN64ARM Cortex-M448256 kB3256 EFM32WG230F64-QFN64ARM Cortex-M44864 kB3256 EFM32WG232F128-QFP64ARM Cortex-M448128 kB3253 EFM32WG232F256-QFP64ARM Cortex-M448256 kB3253 EFM32WG232F64-QFP64ARM Cortex-M44864 kB3253 EFM32WG280F128-QFP100ARM Cortex-M448128 kB3286 EFM32WG280F256-QFP100ARM Cortex-M448256 kB3286 EFM32WG280F64-QFP100ARM Cortex-M44864 kB3286 EFM32WG290F128-BGA112ARM Cortex-M448128 kB3290 EFM32WG290F256-BGA112ARM Cortex-M448256 kB3290 EFM32WG290F64-BGA112ARM Cortex-M44864 kB3290 EFM32WG295F128-BGA120ARM Cortex-M448128 kB3293 EFM32WG295F256-BGA120ARM Cortex-M448256 kB3293 EFM32WG295F64-BGA120ARM Cortex-M44864 kB3293 EFM32WG330F128-QFN64ARM Cortex-M448128 kB3253 EFM32WG330F256-QFN64ARM Cortex-M448256 kB3253 EFM32WG330F64-QFN64ARM Cortex-M44864 kB3253 EFM32WG332F128-QFP64ARM Cortex-M448128 kB3250 EFM32WG332F256-QFP64ARM Cortex-M448256 kB3250 EFM32WG332F64-QFP64ARM Cortex-M44864 kB3250 EFM32WG360F128G-A-CSP81ARM Cortex-M448128 kB3265 EFM32WG360F256G-A-CSP81ARM Cortex-M448256 kB3265 EFM32WG360F64G-A-CSP81ARM Cortex-M44864 kB3265 EFM32WG380F128-QFP100ARM Cortex-M448128 kB3283 EFM32WG380F256-QFP100ARM Cortex-M448256 kB3283 EFM32WG380F64-QFP100ARM Cortex-M44864 kB3283 EFM32WG390F128-BGA112ARM Cortex-M448128 kB3287 EFM32WG390F256-BGA112ARM Cortex-M448256 kB3287 EFM32WG390F64-BGA112ARM Cortex-M44864 kB3287 EFM32WG395F128-BGA120ARM Cortex-M448128 kB3293 EFM32WG395F256-BGA120ARM Cortex-M448256 kB3293 EFM32WG395F64-BGA120ARM Cortex-M44864 kB3293 EFM32WG840F128-QFN64ARM Cortex-M448128 kB3256EFM32WG840F256-QFN64ARM Cortex-M448256 kB3256 EFM32WG840F64-QFN64ARM Cortex-M44864 kB3256 EFM32WG842F128-QFP64ARM Cortex-M448128 kB3253 EFM32WG842F256-QFP64ARM Cortex-M448256 kB3253 EFM32WG842F64-QFP64ARM Cortex-M44864 kB3253 EFM32WG880F128-QFP100ARM Cortex-M448128 kB3286 EFM32WG880F256-QFP100ARM Cortex-M448256 kB3286 EFM32WG880F64-QFP100ARM Cortex-M44864 kB3286 EFM32WG890F128-BGA112ARM Cortex-M448128 kB3290 EFM32WG890F256-BGA112ARM Cortex-M448256 kB3290 EFM32WG890F64-BGA112ARM Cortex-M44864 kB3290 EFM32WG895F128-BGA120ARM Cortex-M448128 kB3293 EFM32WG895F256-BGA120ARM Cortex-M448256 kB3293 EFM32WG895F64-BGA120ARM Cortex-M44864 kB3293 EFM32WG940F128-QFN64ARM Cortex-M448128 kB3253 EFM32WG940F256-QFN64ARM Cortex-M448256 kB3253 EFM32WG940F64-QFN64ARM Cortex-M44864 kB3253 EFM32WG942F128-QFP64ARM Cortex-M448128 kB3250 EFM32WG942F256-QFP64ARM Cortex-M448256 kB3250 EFM32WG942F64-QFP64ARM Cortex-M44864 kB3250 EFM32WG980F128-QFP100ARM Cortex-M448128 kB3283 EFM32WG980F256-QFP100ARM Cortex-M448256 kB3283 EFM32WG980F64-QFP100ARM Cortex-M44864 kB3283 EFM32WG990F128-BGA112ARM Cortex-M448128 kB3287 EFM32WG990F256-BGA112ARM Cortex-M448256 kB3287 EFM32WG990F64-BGA112ARM Cortex-M44864 kB3287 EFM32WG995F128-BGA120ARM Cortex-M448128 kB3293 EFM32WG995F256-BGA120ARM Cortex-M448256 kB3293 EFM32WG995F64-BGA120ARM Cortex-M44864 kB3293 EFM32ZG108F16-QFN24ARM Cortex-M0+2416 kB417 EFM32ZG108F32-QFN24ARM Cortex-M0+2432 kB417 EFM32ZG108F4-QFN24ARM Cortex-M0+24 4 kB217 EFM32ZG108F8-QFN24ARM Cortex-M0+248 kB217 EFM32ZG110F16-QFN24ARM Cortex-M0+2416 kB417 EFM32ZG110F32-QFN24ARM Cortex-M0+2432 kB417 EFM32ZG110F4-QFN24ARM Cortex-M0+24 4 kB217 EFM32ZG110F8-QFN24ARM Cortex-M0+248 kB217 EFM32ZG210F16-QFN32ARM Cortex-M0+2416 kB424 EFM32ZG210F32-QFN32ARM Cortex-M0+2432 kB424 EFM32ZG210F4-QFN32ARM Cortex-M0+24 4 kB224 EFM32ZG210F8-QFN32ARM Cortex-M0+248 kB224 EFM32ZG222F16-QFP48ARM Cortex-M0+2416 kB437 EFM32ZG222F32-QFP48ARM Cortex-M0+2432 kB437 EFM32ZG222F4-QFP48ARM Cortex-M0+24 4 kB237 EFM32ZG222F8-QFP48ARM Cortex-M0+248 kB237Communications Timers (16-bit)PCAChannelsInternalOscADC 1I2C; SPI; 2 x USART2—±2%12-bit, 4-ch., 1 Msps I2C; SPI; 2 x USART2—±2%12-bit, 4-ch., 1 Msps I2C; SPI; 2 x USART2—±2%12-bit, 4-ch., 1 Msps I2C; SPI; 2 x USART2—±2%12-bit, 4-ch., 1 Msps I2C; SPI; 2 x USART3—±2%12-bit, 4-ch., 1 Msps I2C; SPI; 2 x USART3—±2%12-bit, 4-ch., 1 Msps I2C; SPI; 2 x USART3—±2%12-bit, 4-ch., 1 Msps I2C; SPI; 3 x USART3—±2%12-bit, 8-ch., 1 Msps I2C; SPI; 3 x USART3—±2%12-bit, 8-ch., 1 Msps I2C; SPI; 3 x USART3—±2%12-bit, 8-ch., 1 Msps I2C; SPI; 3 x USART3—±2%12-bit, 8-ch., 1 Msps I2C; SPI; 3 x USART3—±2%12-bit, 8-ch., 1 Msps I2C; SPI; 3 x USART3—±2%12-bit, 8-ch., 1 Msps I2C; SPI; UART; 3 x USART3—±2%12-bit, 8-ch., 1 Msps I2C; SPI; UART; 3 x USART3—±2%12-bit, 8-ch., 1 Msps I2C; SPI; UART; 3 x USART3—±2%12-bit, 8-ch., 1 Msps I2C; SPI; UART; 3 x USART3—±2%12-bit, 8-ch., 1 Msps I2C; SPI; UART; 3 x USART3—±2%12-bit, 8-ch., 1 Msps I2C; SPI; UART; 3 x USART3—±2%12-bit, 8-ch., 1 Msps I2C; SPI; 3 x USART3—±2%12-bit, 8-ch., 1 Msps I2C; SPI; 3 x USART3—±2%12-bit, 8-ch., 1 Msps I2C; SPI; 3 x USART3—±2%12-bit, 8-ch., 1 Msps I2C; 3 x USART3—±2%12-bit, 8-ch., 1 Msps I2C; SPI; 3 x USART3—±2%12-bit, 8-ch., 1 Msps I2C; SPI; 3 x USART3—±2%12-bit, 8-ch., 1 Msps I2C; SPI; UART; 3 x USART3—±2%12-bit, 8-ch., 1 Msps I2C; SPI; UART; 3 x USART3—±2%12-bit, 8-ch., 1 Msps I2C; SPI; UART; 3 x USART3—±2%12-bit, 8-ch., 1 Msps I2C; SPI; UART; 3 x USART3—±2%12-bit, 8-ch., 1 Msps I2C; SPI; UART; 3 x USART3—±2%12-bit, 8-ch., 1 Msps I2C; SPI; UART; 3 x USART3—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART;4—±2%12-bit, 8-ch., 1 MspsUSB2 x I2C; I2S; SPI;3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI;3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART;4—±2%12-bit, 8-ch., 1 MspsUSB2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI;3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 MspsI2C; I2S; SPI2—±2%—I2C; I2S; SPI2—±2%—I2C; I2S; SPI2—±2%—I2C; I2S; SPI2—±2%—I2C; I2S; SPI; 2 x USART2—±2%12-bit, 2-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 2-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 2-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 2-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 4-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 4-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 4-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 4-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 4-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 4-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 4-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 4-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 4-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 8-ch., 1 MspsI2C; I2S; SPI; 2 x USART2—±2%12-bit, 8-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 8-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 8-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 8-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 4-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 4-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 4-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 4-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 4-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 4-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 8-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 8-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 8-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 8-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 8-ch., 1 Msps I2C; I2S; SPI; 2 x USART2—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI;3 x USART4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI;3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 2 x UART; 3 x USART4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; SPI; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps 2 x I2C; I2S; 2 x UART; 3 x USART; USB4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 Msps2 x I2C; I2S; SPI; 2 x UART;3 x USART; USB 4—±2%12-bit, 8-ch., 1 MspsI2C; I2S; SPI2—±2%—I2C; I2S; SPI2—±2%—I2C; I2S; SPI2—±2%—I2C; I2S; SPI2—±2%—I2C; I2S; SPI2—±2%12-bit, 2-ch., 1 Msps I2C; I2S; SPI2—±2%12-bit, 2-ch., 1 Msps I2C; I2S; SPI2—±2%12-bit, 2-ch., 1 Msps I2C; I2S; SPI2—±2%12-bit, 2-ch., 1 Msps I2C; I2S; SPI2—±2%12-bit, 4-ch., 1 Msps I2C; I2S; SPI2—±2%12-bit, 4-ch., 1 Msps I2C; I2S; SPI2—±2%12-bit, 4-ch., 1 Msps I2C; I2S; SPI2—±2%12-bit, 4-ch., 1 Msps I2C; I2S; SPI2—±2%12-bit, 4-ch., 1 Msps I2C; I2S; SPI2—±2%12-bit, 4-ch., 1 Msps I2C; I2S; SPI2—±2%12-bit, 4-ch., 1 Msps I2C; I2S; SPI2—±2%12-bit, 4-ch., 1 MspsADC 2DAC TempSensor DebugInterfaceOther PackageTypePackageSize—12-bit, 1-ch.TRUE SW Low Power; RTC QFN326x6 mm—12-bit, 1-ch.TRUE SW Low Power; RTC QFN326x6 mm—12-bit, 1-ch.TRUE SW Low Power; RTC QFN326x6 mm—12-bit, 1-ch.TRUE SW AES; Low Power; RTC QFN326x6 mm—12-bit, 1-ch.TRUE SW AES; Low Power; RTC QFP487x7 mm—12-bit, 1-ch.TRUE SW AES; Low Power; RTC QFP487x7 mm—12-bit, 1-ch.TRUE SW AES; Low Power; RTC QFP487x7 mm—12-bit, 2ch.TRUE SW AES; Low Power; RTC QFN649x9 mm—12-bit, 2ch.TRUE SW AES; Low Power; RTC QFN649x9 mm—12-bit, 2ch.TRUE SW AES; Low Power; RTC QFN649x9 mm—12-bit, 1-ch.TRUE SW AES; Low Power; RTC QFP6410x10 mm—12-bit, 1-ch.TRUE SW AES; Low Power; RTC QFP6410x10 mm—12-bit, 1-ch.TRUE SW AES; Low Power; RTC QFP6410x10 mm—12-bit, 2ch.TRUE SW AES; Low Power; RTC QFP10014x14 mm—12-bit, 2ch.TRUE SW AES; Low Power; RTC QFP10014x14 mm—12-bit, 2ch.TRUE SW AES; Low Power; RTC QFP10014x14 mm—12-bit, 2ch.TRUE SW AES; Low Power; RTC BGA11210x10 mm—12-bit, 2ch.TRUE SW AES; Low Power; RTC BGA11210x10 mm—12-bit, 2ch.TRUE SW AES; Low Power; RTC BGA11210x10 mm—12-bit, 2ch.TRUE SW AES; LCD; Low Power;RTCQFN649x9 mm—12-bit, 2ch.TRUE SW AES; LCD; Low Power;RTCQFN649x9 mm—12-bit, 2ch.TRUE SW AES; LCD; Low Power;RTCQFN649x9 mm—12-bit, 1-ch.TRUE SW AES; LCD; Low Power;RTCQFP6410x10 mm—12-bit, 1-ch.TRUE SW AES; LCD; Low Power;RTCQFP6410x10 mm—12-bit, 1-ch.TRUE SW AES; LCD; Low Power;RTCQFP6410x10 mm—12-bit, 2ch.TRUE SW AES; LCD; Low Power;RTCQFP10014x14 mm—12-bit, 2ch.TRUE SW AES; LCD; Low Power;RTCQFP10014x14 mm—12-bit, 2ch.TRUE SW AES; LCD; Low Power;RTCQFP10014x14 mm—12-bit, 2ch.TRUE SW AES; LCD; Low Power;RTCBGA11210x10 mm—12-bit, 2ch.TRUE SW AES; LCD; Low Power;RTCBGA11210x10 mm—12-bit, 2ch.TRUE SW AES; LCD; Low Power;RTCBGA11210x10 mm—12-bit, 2ch.TRUE ETM; SW AES; Low Power; RTC QFN649x9 mm—12-bit, 2ch.TRUE ETM; SW AES; Low Power; RTC QFN649x9 mm—12-bit, 2ch.TRUE ETM; SW AES; Low Power; RTC QFP6410x10 mm—12-bit, 2ch.TRUE ETM; SW AES; Low Power; RTC QFP6410x10 mm—12-bit, 2ch.TRUE ETM; SW AES; Low Power; RTC QFP10014x14 mm—12-bit, 2ch.TRUE ETM; SW AES; Low Power; RTC QFP10014x14 mm—12-bit, 2ch.TRUE ETM; SW AES; Low Power; RTC BGA11210x10 mm—12-bit, 2ch.TRUE ETM; SW AES; Low Power; RTC BGA11210x10 mm—12-bit, 2ch.TRUE ETM; SW AES; Low Power; RTC BGA1207x7 mm—12-bit, 2ch.TRUE ETM; SW AES; Low Power; RTC BGA1207x7 mm—12-bit, 2ch.TRUE ETM; SW AES; Low Power; RTC QFN649x9 mm—12-bit, 2ch.TRUE ETM; SW AES; Low Power; RTC QFN649x9 mm—12-bit, 2ch.TRUE ETM; SW AES; Low Power; RTC QFP6410x10 mm—12-bit, 2ch.TRUE ETM; SW AES; Low Power; RTC QFP6410x10 mm—12-bit, 2ch.TRUE ETM; SW AES; Low Power; RTC QFP10014x14 mm—12-bit, 2ch.TRUE ETM; SW AES; Low Power; RTC QFP10014x14 mm—12-bit, 2ch.TRUE ETM; SW AES; Low Power; RTC BGA11210x10 mm—12-bit, 2ch.TRUE ETM; SW AES; Low Power; RTC BGA11210x10 mm—12-bit, 2TRUE ETM; SW AES; Low Power; RTC BGA1207x7 mm。
FSL 08系列单片机开发及C语言编程简介 张明峰 2007年10月 于上海 1. CodeWarrior中建立新项目 运行CodeWarrior(CW)集成开发平台,如图1-1所示在File菜单下点击New,弹出建立新项目的模板对话框,见图1-2。
一般的简便做法是在图1-2对话框左面的选择列表中选择“HC(S)08 New Project Wizard”,然后在右面的项目名“Project Name”输入条中,输入你要建立的新项目名字,再在“Location”一栏中用 确定项目存放的文件夹路经,完成后按“OK”进入下一步。
你也可以在图1-2对话框左侧列表中选择“Empty Project”,这样生成的项目不包含任何文件,你必须在CodeWarrior中自己添加所有相关的文件内容。我想除非有特殊理由,实际项目开发过程中很少采用这种麻烦的方式来建立自己的项目。
接下去是选择项目开发所用的编程语言,见图1-3。最常用的当然是C语言编程。有时因具体项目要求,除了C编程外还需要编写独立的汇编语言模块,那就再加选汇编工具(Assembly)。C++编程在免费版和标准版CW下都不支持,只有在专业版下才可以使用。编程语言选择完毕后按“Next”。
图1-1 图1-2 图1-3 FSL 08系列单片机开发及C语言编程简介
张明峰 2007年10月 于上海 这时将出现如图1-4的对话框,让你选择项目开发对应的MCU型号。在CW5.x版本下支持几乎所有的HC08和大部分HCS08单片机型号。在最新的CW6.x中,增加了飞思卡尔最低端的8位机(RS08系列)和低端32位处理器(Coldfire V1系列)的支持,但HC08系列的有些型号没有被包含在内。由于HC08为比较老的产品系列,已经不推荐在新项目设计中选用,因此影响不会太大。对于新用户来说,请尽量直接安装CW6.x或以后推出的更新版本。
以典型的9S08系列为例,当你选择了一个MCU型号后,在图1-4右侧会显示出所有针对该型号芯片可用的项目调试场景。其中: “Full Chip Simulator”是芯片全功能模拟仿真,即无需任何目标系统的硬件资源,直接在你的PC机上模拟运行单片机的程序,在模拟运行过程中可以观察调试程序的各项控制和运行流程,分析代码运行的时间,观察各种变量,等等。CW提供了功能强大的模拟激励功能,可以在模拟运行时模拟一些外部事件的输入,配合程序调试; “P&E Multilink/Cyclone Pro”是基于P&E公司的硬件调试工具实现实时在线硬件调试。实际就是我们经常说的BDM调试。BDM调试是基于芯片本身内含的在线调试功能,可实现程序下载,单步/全速运行,可以设若干个断点,可以观察和修改任意寄存器或RAM内存空间。BDM几乎是开发飞思卡尔8位(9S08和RS08系列)、16位(9S12系列)和32位(Coldfire V1系列)单片机的标准调试模式,运用最为广泛; “SofTec HCS08”是另外一家SofTec公司提供的硬件调试工具,国内使用较少; “HCS08 Serial Monitor”是基于芯片串口的监控调试开发模式。由于开发效率较低,现在几乎无人使用。
注意不同系列,不同型号的芯片,或不同版本的CW,其所对应或支持的开发场景可能不同,在图1-4的项目建立模板中都可以显现出来。用户点击选择某一项场景后,该场景将在项目建立完成后作为首选配置。你可以在稍后调试过程中随意切换开发场景,不必太在意在这里的选择。
到此你如果按“Finish”,整个项目建立过程将完成,剩下的一些项目设定将自动用缺省配置。如果你要自己选择调整,则按“Next”进入下一步,往项目中添加现成的文件,见图1-5。
图1-4 FSL 08系列单片机开发及C语言编程简介 张明峰 2007年10月 于上海 如果你以前编写了很多代码文件现在想重复利用,那么可以通过图1-5对话框左面的文件树选择对应的文件,按中间的“Add”逐个添加到右侧的“Project Files”列表中。若加错了就用“Remove”把列表中的文件移除。注意此列表下方的两个选项:“Copy files to project”选择是否将所选的文件拷贝到现在的项目文件夹中。如果你准备在新的项目中修改这些文件,就选择拷贝,以免把原始的文件改变后而影响先前的一些项目;“Create main.c/main.asm file”选择是否在本项目中生成全新的main.c或main.asm文件,一般的项目开发都需要生成新的main文件。按用户自己的要求和目的自由选取。建议大家保留默认的选择状态。如果没有什么现成的文件需要加入,就直接按“Next”进入下一步,选择处理器专家(Processor Expert或简称PE)。
PE是CW集成开发平台内带的可实现芯片内部各种资源模块配置并自动生成相关代码的一个软件工具。不过只有专业版的CW才支持该功能。通过PE,用户可以快速实现芯片初始化代码的自动生成工作,而且PE还提供了大量的软件库可供用户开发时嵌入或调用。因为8位单片机结构和功能相对简单,实现的控制项目复杂度也不是很高,故一般情况下8位机开发我们都不需要PE的介入,自己直接编写程序代码即可。关于PE的详细介绍将耗费大量的文字,这里按下不提。所以在图1-6的对话框中选择“None”,并直接按“Next”进入下一步。
这是项目建立模板的最后一步。在这一步你可以决定有关C/C++的一些编译和代码生成模式,见图1-7。 启动代码选择。所有C编译器会自动生成一些启动代码。单片机复位后的指令运行将首先执行这些启动代码,然后再进入到你自己的程序模块main函数。这些启动代码主要完成堆栈指针初始化、全局和静态变量自动清零
图1-5 图1-6 图1-7 FSL 08系列单片机开发及C语言编程简介
张明峰 2007年10月 于上海 或赋初值、调用main函数等。ANSI标准初始化“ANSI startup code”即完成上述工作,是项目开发的标准选择;最小初始化“Minimal startup code”除了初始化堆栈指针外就直接调用main函数,代码最少,进入main函数最快,但变量的清零和赋初值必须由用户自己编写代码实现。在这里请大家特别注意,即最小初始化将不会对全局或静态变量自动清零,这一点在单片机编程中有时非常重要。在实际产品中当单片机出现异常复位程序重新开始运行时,我们往往希望原先的控制过程得以延续,因此一些关键变量的内容要在复位后保留而不能不分青红皂白地一概清零。选择最小初始化代码可以实现这一特殊要求,但还有更合理更高级的方法,将在后面介绍prm文件时详细说明。 编译内存模式选择。“Tiny”模式是指所有程序不超过64KB,RAM变量不超过内存地址最前面的256字节(有时也被称作第0页);“Small”模式程序空间一样不超过64KB,但RAM不限于第0页,可以覆盖整个64K地址空间。如果你选择的芯片有超过第0页空间的RAM并想在设计中充分利用,就应该选择该缺省的“Small”模式。 浮点运算库选择。当你的程序设计决定用浮点运算时就应该选择加入浮点运算库。浮点运算库有两种:一是标准浮点float和双精度浮点double都用32位精度表示,换句话说float和double都看成是float。这样做的目的是减少代码量,提高运算速度;另一种是double用64位精度表示,毋庸置疑其运算精度将增加,但代码量也将增加,运算时间也会更长。用户可以按实际计算需求酌情选取。如果设计中无需浮点运算,就选择“None”。
全部选择完成并确认后,按“Finish”,恭喜你:你的项目已经成功建立,可以开始编写你自己的代码,调试你的目标系统了。完成后的项目范例如图1-8,其中: Sources栏目下包含所有你的原程序文件,可以是C,也可以是asm,或C++。你可以在此栏下点击鼠标右键在弹出菜单中选择“Add Files”添加其他源程序文件; Includes栏目下包含本项目所有被引用的头文件。你可以自己编写项目相关的头文件并添加到本栏目下; Libs栏目所包含的是本项目开发用到的代码库,可以是目标代码型式或C源程序型式; Project Setting下放的全是项目的配置文件。Startup Code下是刚才建项目时自动生成的启动文件,你可以打开观察具体的程序代码,也可以在必要时自己添加或修改这些启动代码;Link Files下的三个文件分别是:用于编程器下载的代码文件格式配置(bbl文件)、机器代码连接定位用的内存说明和配置文件
图1-8 FSL 08系列单片机开发及C语言编程简介 张明峰 2007年10月 于上海 (prm文件)、生成的目标代码在内存中的映射文件(map文件)。其中prm文件最为关键,将在稍后重点专门介绍。
2. CodeWarrior中项目的基本管理和设定 现在项目已经成功建立,应该可以开始编写自己的代码了。但在写代码之前,先了解一下CW中最基本的项目管理和设定的方法还是很有必要。
在图1-8中项目窗口的右上角有一些小图标,这些图标代表了项目开发管理的最基本功能:
该图标可以即时改变目标单片机型号和开发调试场景。按下这一图标,将弹出图1-4所示的对话框,可以按照前面针对新项目建立模板的介绍,改变目标单片机的型号,或设定不同的当前目标开发调试场景。对于调试场景的改变,也可以直接点击当前场景右边的下拉菜单按纽,直接用鼠标点击选择所需的新场景,如图2-1;
该图标完成项目配置选项设定。点击该图标会弹出一个对话框,里面所含的内容非常繁杂,这里只解释几个日常使用时最常用的选项配置:
1. 最终目标代码类型设定(Target Setting)。在这里你可以选择最终编译连接生成的代码直接用于单片机程序运行(Link for HC08),或将各个源代码文件编译连接生成一个库文件(Libmaker for HC08)。这些选择可以通过图2-2所示的下拉菜单选择;
图2-1 图2-2 图2-3