KMP算法思想
- 格式:doc
- 大小:366.00 KB
- 文档页数:30

2 KMP算法:KMP算法是由D.E.Knuth(克努特),J.H.Morris(莫里斯),V.R.Pratt(普拉特)等人共同提出的,该算法主要消除了主串指针(i指针)的回溯,利用已经得到的部分匹配结果将模式串右滑尽可能远的一段距离再继续比较,从而使算法效率有某种程度的提高,O(n+m)。
先从例子入手(p82):按Brute-Force算法i=i-j+2=2-2+2=2,j=1按Brute-Force算法i=i-j+2=2-1+2=3,j=1按Brute-Force算法i=i-j+2=8-6+2=4,j=1,但从已匹配的情况看,模式串在t[6]即“c”前的字符都是匹配的,再看已匹配的串“abaab”,t[1]t[2]与t[4]t[5]相同,那么,因为t[4]t[5]与原串s[6]s[7]匹配,所以t[1]t[2]必然与原串s[6]s[7]匹配,因此说t[3]可以直接与s[8]匹配,按KMP 算法i=8,j=3匹配成功。
从上例看出在匹配不成功时,主串指针i不动,j指针也不回到第一个位置,而是回到一个恰当的位置,如果这时让j指针回到第一个位置,就可能错过有效的匹配,所以在主串指针i不动的前提下,j指针回到哪个位置是问题的关键,既不能将j右移太大,而错过有效的匹配,另一方面,又要利用成功的匹配,将j右移尽可能地大,而提高匹配的效率,因此问题的关键是寻找模式串自身的规律。
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////。
和直接比较若不满足和直接比较所以:满足:,设1i i 12112111112121s ),2(;s )1(""")"2(""")"1(""""t t j k t t t t t t t t s s t t t t s s s s k j k j k j k j i j i m n <<====-+-+----+-////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////设s=” s 1 s 2 ... s n ”, t=” t 1 t 2 ... t m ”,在匹配过程中,当s i ≠ t j (1≤i ≤n-m+1,1≤j ≤m)时,存在(前面的j-1个字符已匹配):” s i-j+1 ... s i-1 ” =” t 1 t 2 ... t j-1 ” (1) 若模式中存在可互相重叠的最长的真子串,满足: ” t 1 t 2 ... t k-1 ”=”t j-k+1 t j-k+2 ... t j-1 ” (2) 其中真子串最短可以是t 1 ,即 t 1。
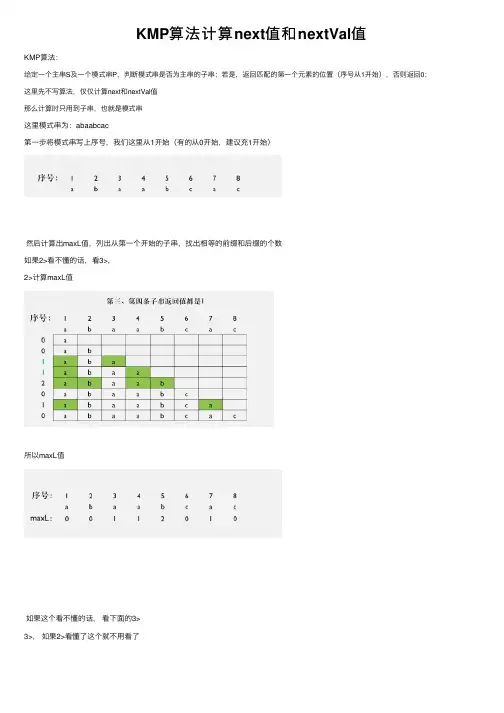
KMP算法计算next值和nextVal值
KMP算法:
给定⼀个主串S及⼀个模式串P,判断模式串是否为主串的⼦串;若是,返回匹配的第⼀个元素的位置(序号从1开始),否则返回0;这⾥先不写算法,仅仅计算next和nextVal值
那么计算时只⽤到⼦串,也就是模式串
这⾥模式串为:abaabcac
第⼀步将模式串写上序号,我们这⾥从1开始(有的从0开始,建议充1开始)
然后计算出maxL值,列出从第⼀个开始的⼦串,找出相等的前缀和后缀的个数
如果2>看不懂的话,看3>,
2>计算maxL值
所以maxL值
如果这个看不懂的话,看下⾯的3>
3>,如果2>看懂了这个就不⽤看了
依次类推4>计算next值
接下来将maxL复制⼀⾏,去掉最后⼀个数,在开头添加⼀个-1,向右平移⼀个格,然后每个值在加1的到next值
5>计算nextVal值,⾸先将第⼀个为0,然后看next和maxL是否相等(先计算不相等的)
当next和maxL不相等时,将next的值填⼊
当next和maxL相等时,填⼊对应序号为next值得nextVal值
所以整个nextVal值为:。

KMP算法以及优化(代码分析以及求解next数组和nextval数组)KMP算法以及优化(代码分析以及求解next数组和nextval数组)来了,数据结构及算法的内容来了,这才是我们的专攻,前⾯写的都是开胃⼩菜,本篇⽂章,侧重考研408⽅向,所以保证了你只要看懂了,题⼀定会做,难道这样思想还会不会么?如果只想看next数组以及nextval数组的求解可以直接跳到相应部分,思想总结的很⼲~~⽹上的next数组版本解惑先总结⼀下,⼀般KMP算法的next数组结果有两个版本,我们需要知道为什么会存在这种问题,其实就是前缀和后缀没有匹配的时候next数组为0还是为1,两个版本当然都是对的了,如果next数组为0是的版本,那么对于前缀和后缀的最⼤匹配长度只需要值+1就跟next数组是1的版本⼀样了,其实是因为他们的源代码不⼀样,或者对于模式串的第⼀个下标理解为0或者1,总之这个问题不⽤纠结,懂原理就⾏~~那么此处,我们假定前缀和后缀的最⼤匹配长度为0时,next数组值为1的版本,考研⼀般都是⽤这个版本(如果为0版本,所有的内容-1即可,如你算出next[5]=6,那么-1版本的next[5]就为5,反之亦然)~~其实上⾯的话总结就是⼀句话next[1]=0,j(模式串)数组的第⼀位下标为1,同时,前缀和后缀的最⼤匹配长度+1即为next数组的值,j所代表的的是序号的意思408反⼈类,⼀般数组第⼀位下标为1,关于书本上前⾯链表的学习⼤家就应该有⽬共睹了,书本上好多数组的第⼀位下标为了⽅便我们理解下标为1,想法这样我们更不好理解了,很反⼈类,所以这⾥给出next[1]=0,前缀和后缀的最⼤匹配长度+1的版本讲解前⾔以及问题引出我们先要知道,KMP算法是⽤于字符串匹配的~~例如:⼀个主串"abababcdef"我们想要知道在其中是否包括⼀个模式串"ababc"初代的解决⽅法是,朴素模式匹配算法,也就是我们主串和模式串对⽐,不同主串就往前移⼀位,从下⼀位开始再和模式串对⽐,每次只移动⼀位,这样会很慢,所以就有三位⼤神⼀起搞了个算法,也就是我们现在所称的KMP算法~~代码以及理解源码这⾥给出~~int Index_KMP(SString S,SString T,intt next[]){int i = 1,j = 1;//数组第⼀位下标为1while (i <= S.length && j <= T.length){if (j == 0 || S.ch[i] == T.ch[j]){//数组第⼀位下标为1,0的意思为数组第⼀位的前⾯,此时++1,则指向数组的第⼀位元素++i;++j; //继续⽐较后继字符}elsej = next[j]; //模式串向右移动到第⼏个下标,序号(第⼀位从1开始)}if (j > T.length)return i - T.length; //匹配成功elsereturn 0;}接下来就可以跟我来理解这个代码~~还不会做动图,这⾥就⼿画了~~以上是⼀般情况,那么如何理解j=next[1]=0的时候呢?是的,这就是代码的思路,那么这时我们就知道,核⼼就是要求next数组各个的值,对吧,⼀般也就是考我们next数组的值为多少~~next数组的求解这⾥先需要给出概念,串的前缀以及串的后缀~~串的前缀:包含第⼀个字符,且不包含最后⼀个字符的⼦串串的后缀:包含最后⼀个字符,且不包含第⼀个字符的⼦串当第j个字符匹配失败,由前1~j-1个字符组成的串记为S,则:next[j]=S的最长相等前后缀长度+1与此同时,next[1]=0如,模式串"ababaa"序号J123456模式串a b a b a anext[j]0当第六个字符串匹配失败,那么我们需要在前5个字符组成的串S"ababa"中找最长相等的前后缀长度为多少再+1~~如串S的前缀可以为:"a","ab","aba","abab",前缀只不包括最后⼀位都可串S的后缀可以为:"a","ba","aba","baba",后缀只不包括第⼀位都可所以这⾥最⼤匹配串就是"aba"长度为3,那么我们+1,取4序号J123456模式串a b a b a anext[j]04再⽐如,当第⼆个字符串匹配失败,由前1个字符组成的串S"a"中,我们知道前缀应当没有,后缀应当没有,所以最⼤匹配串应该为0,那么+1就是取1~~其实这⾥我们就能知道⼀个规律了,next[1]⼀定为0(源码所造成),next[2]⼀定为1(必定没有最⼤匹配串造成)~~序号J123456模式串a b a b a anext[j]014再再⽐如,第三个字符串匹配失败,由前两个字符组成的串S"ab"中找最长相等的前后缀长度,之后再+1~~前缀:"a"后缀:"b"所以所以这⾥最⼤匹配串也是没有的长度为0,那么我们+1,取1序号J123456模式串a b a b a anext[j]0114接下来你可以⾃⼰练练4和5的情况~~next[j]011234是不是很简单呢?⾄此,next数组的求法以及kmp代码的理解就ok了~~那么接下来,在了解以上之后,我们想⼀想KMP算法存在的问题~~KMP算法存在的问题如下主串:"abcababaa"模式串:"ababaa"例如这个问题我们很容易能求出next数组序号J123456模式串a b a b a anext[j]011234此时我们是第三个字符串匹配失败,所以我们的next[3]=1,也就是下次就是第⼀个字符"a"和主串中第三个字符"c"对⽐,可是我们刚开始的时候就已经知道模式串的第三个字符"a"和"c"不匹配,那么这⾥不就多了⼀步⽆意义的匹配了么?所以我们就会有kmp算法的⼀个优化了~~KMP算法的优化我们知道,模式串第三个字符"a"不和主串第三个字符"c"不匹配,next数组需要我们的next[3]=1,也就是下次就是第⼀个字符"a"和主串中第三个字符"c"对⽐,之后就是模式串第⼀个字符"a"不和"c"匹配,就是需要变为next[1]=0,那么我们要省去步骤,不就可以直接让next[3]=0么?序号J12345模式串a b a b anext[j]01123nextval[j]00那么怎么省去多余的步骤呢?这就是nextval数组的求法~~nextval的求法以及代码理解先贴出代码for (int j = 2;j <= T.length;j++){if (T.ch[next[j]] == T.ch[j])nextval[j] = nextval[next[j]];elsenextval[j] = next[j];}如序号J123456模式串a b a b a anext[j]011234nextval[j]0⾸先,第⼀次for循环,j=2,当前序号b的next[2]为1,即第⼀个序号所指向的字符a,a!=当前序号b,所以nextval[2]保持不变等于next[2]=1序号J123456模式串a b a b a anext[j]011234nextval[j]01第⼆次for循环,j=3,当前序号a的next[3]为1,即第⼀个序号所指向的字符a,a=当前序号a,所以nextval[3]等于nextval[1]=0序号J123456模式串a b a b a anext[j]011234nextval[j]010第三次for循环,j=4,当前序号b的next[4]为2,即第⼆个序号所指向的字符b,b=当前序号b,所以nextval[4]等于nextval[2]=1序号J123456模式串a b a b a anext[j]011234nextval[j]0101就是这样,你可以练练5和6,这⾥直接给出~~序号J123456模式串a b a b a anext[j]011234nextval[j]010104⾄此nextval数组的求法你也应该会了,那么考研要是考了,那么是不是就等于送分给你呢?⼩练习那么你试着来求⼀下这个模式串的next和nextval数组吧~~next[j]nextval[j]⼩练习的答案序号j12345模式串a a a a b next[j]01234 nextval[j]00004。

kmp算法概念KMP算法概念KMP算法是一种字符串匹配算法,它的全称是Knuth-Morris-Pratt 算法。
该算法通过预处理模式串,使得在匹配过程中避免重复比较已经比较过的字符,从而提高了匹配效率。
一、基本思想KMP算法的基本思想是:当模式串与文本串不匹配时,不需要回溯到文本串中已经比较过的位置重新开始匹配,而是利用已知信息跳过这些位置继续匹配。
这个已知信息就是模式串自身的特点。
二、next数组1.定义next数组是KMP算法中最核心的概念之一。
它表示在模式串中当前字符之前的子串中,有多大长度的相同前缀后缀。
2.求解方法通过观察模式串可以发现,在每个位置上出现了相同前缀和后缀。
例如,在模式串“ABCDABD”中,第一个字符“A”没有任何前缀和后缀;第二个字符“B”的前缀为空,后缀为“A”;第三个字符“C”的前缀为“AB”,后缀为“B”;第四个字符“D”的前缀为“ABC”,后缀为“AB”;第五个字符“A”的前缀为“ABCD”,后缀为“ABC”;第六个字符“B”的前缀为“ABCDA”,后缀为“ABCD”;第七个字符“D”的前缀为“ABCDAB”,后缀为“ABCDA”。
根据上述观察结果,可以得到一个求解next数组的方法:(1)next[0]=-1,next[1]=0。
(2)对于i=2,3,...,m-1,求解next[i]。
①如果p[j]=p[next[j]],则next[i]=next[j]+1。
②如果p[j]≠p[next[j]],则令j=next[j],继续比较p[i]和p[j]。
③重复执行步骤①和步骤②,直到找到满足条件的j或者j=-1。
(3)通过上述方法求解出所有的next值。
三、匹配过程在匹配过程中,文本串从左往右依次与模式串进行比较。
如果当前字符匹配成功,那么继续比较下一个字符;否则利用已知信息跳过一些位置继续进行匹配。
具体地:(1)如果当前字符匹配成功,则i和j都加1。
(2)如果当前字符匹配失败,则令j=next[j]。

KMP算法详解KMP 算法详解KMP 算法是⼀个⼗分⾼效的字符串查找算法,⽬的是在⼀个字符串 s 中,查询 s 是否包含⼦字符串 p,若包含,则返回 p 在 s 中起点的下标。
KMP 算法全称为 Knuth-Morris-Pratt 算法,由 Knuth 和 Pratt 在1974年构思,同年 Morris 也独⽴地设计出该算法,最终由三⼈于1977年联合发表。
举⼀个简单的例⼦,在字符串 s = ababcabababca 中查找⼦字符串 p = abababca,如果暴⼒查找,我们会遍历 s 中的每⼀个字符,若 s[i] = p[0],则向后查询p.length() 位是否都相等。
这种朴素的暴⼒的算法复杂度为O(m×n),其中m和n分别是 p 和 s 的长度。
KMP 算法可以⽅便地简化这⼀查询的时间复杂度,达到O(m+n)。
1. PMT 序列PMT 序列是 KMP 算法的核⼼,即 Partial Match Table(部分匹配表)。
举个例⼦:char a b a b a b c aindex01234567PMT00123401PMT 的值是字符串的前缀集合与后缀集合的交集中最长元素的长度。
PMT[0] = 0: 字符串 a 既没有前缀,也没有后缀;PMT[1] = 0: 字符串 ab 前缀集合为 {a},后缀集合为 {b},没有交集;PMT[2] = 1: 字符串 aba 前缀集合为 {a, ab},后缀集合为 {ba, a},交集为 {a},交集元素的最长长度为1;PMT[3] = 2: 字符串 abab 前缀集合为 {a, ab, aba},后缀集合为 {bab, ab, b},交集为 {ab},交集元素的最长长度为2;…… 以此类推。
2. 算法主体现在我们已经知道了 PMT 序列的含义,那么假设在 PMT 序列已经给定的情况下,如何加速字符串匹配算法?tar 存储 s 的下标,从 0 开始,若 tar > s.length() - 1,代表匹配失败;pos 存储 p 的下标,从 0 开始,若 s[tar] != p[pos],则 pos ⾛到下⼀个可能匹配的位置。

KMP算法简介什么是KMP算法KMP算法(Knuth-Morris-Pratt算法)是一种用于字符串匹配的算法,用于在一个主串中查找一个模式串的出现位置。
它的特点是在匹配失败时,不回溯主串的指针,而是通过利用已经匹配过的信息,将模式串尽量地向后移动,从而提高匹配效率。
KMP算法的原理KMP算法的核心思想是利用模式串自身的特点,通过预处理模式串,构建一个部分匹配表(Partial Match Table),从而在匹配过程中可以根据已匹配的信息来决定下一步的匹配位置。
部分匹配表部分匹配表是一个与模式串对应的数组,用于存储模式串在每个位置上的最长相同前缀后缀的长度。
例如,对于模式串”ABCDABD”,其部分匹配表为:位置部分匹配值0 01 02 03 04 15 26 0KMP算法的匹配过程KMP算法的匹配过程可以简述为以下几个步骤:1.预处理模式串,构建部分匹配表;2.在主串中从左到右逐个字符进行匹配;3.如果当前字符匹配成功,则继续比较下一个字符;4.如果当前字符匹配失败,则根据部分匹配表,将模式串向右移动一定的距离,再次进行匹配;5.重复步骤3和4,直到模式串匹配完毕或者主串匹配完毕。
KMP算法的优势相较于朴素的字符串匹配算法,KMP算法具有以下优势:1.减少了不必要的字符比较次数,提高了匹配效率;2.通过预处理模式串,可以在匹配过程中根据已匹配的信息决定下一步的匹配位置,避免了回溯主串的指针。
KMP算法的应用KMP算法在字符串匹配中有着广泛的应用,例如:1.字符串查找:在一个文本中查找一个子串的出现位置;2.字符串替换:将一个文本中的某个子串替换为另一个字符串;3.DNA序列匹配:在生物信息学中,用于比对DNA序列的相似性。
KMP算法的压力测试为了验证KMP算法的效率和稳定性,我们进行了一系列的压力测试。
测试环境•操作系统:Windows 10•处理器:****************************•内存:16GB测试方法我们使用不同长度的主串和模式串进行匹配,记录下KMP算法的执行时间,并与朴素的字符串匹配算法进行对比。

深度剖析KMP,让你认识真正的NextKMP算法,想必大家都不陌生,它是求串匹配问题的一个经典算法(当然如果你要理解成放电影的KMP,请退出本页面直接登录各大电影网站,谢谢),我想很多人对它的理解仅限于此,知道KMP能经过预处理然后实现O(N*M)的效率,比brute force(暴力算法)更优秀等等,其实KMP算法中的Next函数,功能十分强大,其能力绝对不仅仅限于模式串匹配,它并不是KMP的附属品,其实它还有更多不为人知的神秘功能^_^先来看一个Next函数的典型应用,也就是模式串匹配,这个相信大家都很熟悉了:POJ 3461 Oulipo——很典型的模式串匹配问题,求模式串在目标串中出现的次数。
#include<cstdio>#include<iostream>#include<cmath>#include<cstring>#include<algorithm>using namespace std;#define MAX 1000001char t[MAX];char s[MAX];int next[MAX];inline void calnext(char s[],int next[]){int i;int j;int len=strlen(s);next[0]=-1;j=-1;for(i=1;i<len;i++){while(j>=0&&s[i]!=s[j+1])j=next[j];if(s[j+1]==s[i])//上一个循环可能因为j=-1而不做,此时不能知道s[i]与s[j+1]的关系。
故此需要此条件。
j++;next[i]=j;}}int KMP(char t[],char s[]){int ans=0;int lent=strlen(t);int lens=strlen(s);if(lent<lens)return 0;int i,j;j=-1;for(i=0;i<lent;i++){while(j>=0&&s[j+1]!=t[i])j=next[j];if(s[j+1]==t[i])j++;if(j==lens-1){ans++;j=next[j];}}return ans;}int main(){int testcase;scanf("%d",&testcase);int i;for(i=1;i<=testcase;i++){scanf("%s%s",s,t);calnext(s,next);printf("%d\n",KMP(t,s));}return 0;}—————————————————————————————————————————————POJ 2406 Power Strings这道题就比较有意思了,乍看之下,怎么看貌似都与KMP无关,呵呵,这就是因为你没有深入理解Next 的含义;我首先来解释下这道题的题意,给你一个长度为n的字符串,首先我们找到这样一个字符串,这个字符串满足长度为n的字符串是由这个字符串重复叠加得到并且这个字符串的长度要最小.,然后输出重复的次数。

KMP模式匹配算法KMP算法是一种字符串匹配算法,用于在一个主串中查找一个模式串的出现位置。
该算法的核心思想是通过预处理模式串,构建一个部分匹配表,从而在匹配过程中尽量减少不必要的比较。
KMP算法的实现步骤如下:1.构建部分匹配表部分匹配表是一个数组,记录了模式串中每个位置的最长相等前后缀长度。
从模式串的第二个字符开始,依次计算每个位置的最长相等前后缀长度。
具体算法如下:-初始化部分匹配表的第一个位置为0,第二个位置为1- 从第三个位置开始,假设当前位置为i,则先找到i - 1位置的最长相等前后缀长度记为len,然后比较模式串中i位置的字符和模式串中len位置的字符是否相等。
- 如果相等,则i位置的最长相等前后缀长度为len + 1- 如果不相等,则继续判断len的最长相等前后缀长度,直到len为0或者找到相等的字符为止。
2.开始匹配在主串中从前往后依次查找模式串的出现位置。
设置两个指针i和j,分别指向主串和模式串的当前位置。
具体算法如下:-当主串和模式串的当前字符相等时,继续比较下一个字符,即i和j分别向后移动一个位置。
-当主串和模式串的当前字符不相等时,根据部分匹配表确定模式串指针j的下一个位置,即找到模式串中与主串当前字符相等的位置。
如果找到了相等的位置,则将j移动到相等位置的下一个位置,即j=部分匹配表[j];如果没有找到相等的位置,则将i移动到下一个位置,即i=i+13.检查匹配结果如果模式串指针j移动到了模式串的末尾,则说明匹配成功,返回主串中模式串的起始位置;如果主串指针i移动到了主串的末尾,则说明匹配失败,没有找到模式串。
KMP算法的时间复杂度为O(m+n),其中m为主串的长度,n为模式串的长度。
通过预处理模式串,KMP算法避免了在匹配过程中重复比较已经匹配过的字符,提高了匹配的效率。
总结:KMP算法通过构建部分匹配表,实现了在字符串匹配过程中快速定位模式串的位置,减少了不必要的比较操作。

kmp next算法KMP算法(Knuth-Morris-Pratt Algorithm)是一种字符串匹配算法,它的核心思想是利用已经得到的匹配结果,尽量减少字符的比较次数,提高匹配效率。
本文将详细介绍KMP算法的原理、实现方法以及应用场景。
一、KMP算法的原理KMP算法的核心是构建next数组,用于指导匹配过程中的回溯操作。
next数组的定义是:对于模式串中的每个字符,记录它前面的子串中相同前缀和后缀的最大长度。
next数组的长度等于模式串的长度。
具体来说,KMP算法的匹配过程如下:1. 初始化主串指针i和模式串指针j为0。
2. 逐个比较主串和模式串对应位置的字符:- 若主串和模式串的字符相等,i和j同时后移一位。
- 若主串和模式串的字符不相等,根据next数组的值,将模式串指针j回溯到合适的位置,继续匹配。
二、KMP算法的实现KMP算法的实现可以分为两个步骤:构建next数组和利用next数组进行匹配。
1. 构建next数组:- 首先,next[0]赋值为-1,next[1]赋值为0。
- 然后,从第2个位置开始依次计算next[i],根据前一个位置的next值和模式串的字符进行判断:- 若前一个位置的next值为-1或模式串的字符与前一个位置的字符相等,则next[i] = next[i-1] + 1。
- 若前一个位置的next值不为-1且模式串的字符与前一个位置的字符不相等,则通过next数组的回溯操作,将模式串指针j回溯到合适的位置,继续判断。
2. 利用next数组进行匹配:- 在匹配过程中,主串指针i和模式串指针j会同时后移:- 若主串和模式串的字符相等,i和j同时后移一位。
- 若主串和模式串的字符不相等,则根据next数组的值,将模式串指针j回溯到合适的位置,继续匹配。
三、KMP算法的应用场景KMP算法在字符串匹配中有广泛的应用,特别是在大规模文本中的模式匹配问题上具有明显的优势。
以下是KMP算法的几个应用场景:1. 子串匹配:判断一个字符串是否是另一个字符串的子串。

字符串匹配kmp算法字符串匹配是计算机科学中的一个基本问题,它涉及在一个文本串中寻找一个模式串的出现位置。
其中,KMP算法是一种更加高效的算法,它不需要回溯匹配过的字符,在匹配失败的时候,根据已经匹配的字符和模式串前缀的匹配关系直接跳跃到下一次匹配的起点。
下面,我将详细介绍KMP算法原理及其实现。
1. KMP算法原理KMP算法的核心思想是:当模式串中的某个字符与文本串中的某个字符不相同时,根据已经匹配的字符和模式串前缀的匹配关系,跳过已经比较过的字符,从未匹配的字符开始重新匹配。
这个过程可以通过计算模式串的前缀函数(即next数组)来实现。
具体地,假设现在文本串为T,模式串为P,它们的长度分别为n和m。
当对于文本串T的第i个字符和模式串P的第j个字符(i和j都是从0开始计数的)进行匹配时:如果T[i]和P[j]相同,则i和j都加1,继续比较下一个字符;如果T[i]和P[j]不同,则j回溯到next[j](next[j]是P[0]到P[j-1]的一个子串中的最长的既是自身的前缀又是后缀的子串的长度),而i不会回溯,继续和P[next[j]]比较。
如果匹配成功,则返回i-j作为P在T中的起始位置;如果匹配失败,则继续执行上述过程,直到文本串T被遍历完或匹配成功为止。
2. KMP算法步骤(1)计算模式串的前缀函数next[j]。
next[j]表示P[0]到P[j-1]的一个子串中的最长的既是自身的前缀又是后缀的子串的长度。
具体计算方式如下:先令next[0]=-1,k=-1(其中k表示相等前缀的长度,初始化为-1),j=0。
从j=1向后遍历整个模式串P:如果k=-1或者P[j]=P[k],则next[j+1]=k+1,k=j,j+1;否则,令k=next[k],再次执行步骤2。
(2)使用next数组进行匹配。
从文本串T的第0个字符开始,从模式串P的第0个字符开始匹配,如果匹配失败,根据next数组进行回溯。

KMP算法KMP算法是一种用于字符串匹配的快速算法,全称为Knuth-Morris-Pratt算法,是由Donald Knuth、Vaughan Pratt和James Morris在1977年共同提出的。
该算法的核心思想是通过利用已经匹配过的部分来避免不必要的字符比较,从而提高匹配效率。
1.暴力匹配算法在介绍KMP算法之前,我们先来了解一下暴力匹配算法。
暴力匹配算法,又称为朴素匹配算法,是最基本的匹配方法,它的思想就是从主串的第一个字符开始,逐个比较主串和模式串的字符,直到匹配成功或者主串和模式串的所有字符都比较完毕。
具体算法如下:```暴力匹配(主串S,模式串P):i=0j=0n = length(S)m = length(P)while i < n and j < m:if S[i] == P[j]: // 匹配成功,继续比较下一个字符i++else: // 匹配失败,模式串向后移动一位i=i-j+1j=0if j == m: // 匹配成功return i - jelse: // 匹配失败return -1```暴力匹配算法的时间复杂度为O(n*m),其中n和m分别为主串和模式串的长度。
2.KMP算法的思想KMP算法的关键在于构建一个部分匹配表,通过这个表来确定模式串在匹配失败时应该移动的位置。
部分匹配表的定义如下:对于模式串P的前缀子串P[0:i],如果存在一个真前缀等于真后缀,则称其长度为i的真前缀的真后缀长度为部分匹配值。
假设有一个模式串P,我们定义一个部分匹配表next,其中next[i]表示在P[i]之前的子串(不包括P[i])中,有多大长度的相同前缀后缀。
例如,P="ABCDABD",则next[7]=2,因为在P[7]之前的子串中,"ABD"是长度为3的前缀,也是长度为3的后缀。
构建部分匹配表的算法如下:构建部分匹配表(P):m = length(P)next = [0] * m // 初始化部分匹配表j=0k=-1next[0] = -1while j < m - 1:if k == -1 or P[j] == P[k]: // P[j]表示后缀的单个字符,P[k]表示前缀的单个字符j++k++next[j] = kelse:k = next[k]```构建部分匹配表的时间复杂度为O(m),其中m为模式串的长度。
kmp算法[编辑本段]kmp算法-概述一种改进的字符串匹配算法,由 D.E.Knuth与V.R.Pratt和J.H.Morris同时发现,因此人们称它为克努特——莫里斯——普拉特操作(简称KMP算法)。
[编辑本段]kmp算法-学习介绍完全掌握KMP算法思想学过数据结构的人,都对KMP算法印象颇深。
尤其是新手,更是难以理解其涵义,搞得一头雾水。
今天我们就来面对它,不将它彻底搞懂,誓不罢休。
如今,大伙基本上都用严蔚敏老师的书,那我就以此来讲解KMP 算法。
(小弟正在备战考研,为了节省时间,很多课本上的话我都在此省略了,以后一定补上。
)严老的《数据结构》79页讲了基本的匹配方法,这是基础。
先把这个搞懂了。
80页在讲KMP算法的开始先举了个例子,让我们对KMP的基本思想有了最初的认识。
目的在于指出“由此,在整个匹配的过程中,i指针没有回溯,”。
我们继续往下看:现在讨论一般情况。
假设主串:s: ‘s(1) s(2) s(3) ……s(n)’; 模式串:p: ‘p(1) p(2) p(3)…..p(m)’把课本上的这一段看完后,继续现在我们假设主串第i个字符与模式串的第j(j<=m)个字符‘失配’后,主串第i个字符与模式串的第k(k<j)个字符继续比较此时,s(i)≠p(j), 有主串:S(1)……s(i-j+1)……s(i-1) s(i) ………….|| (相配) || ≠(失配)匹配串:P(1) ……. p(j-1) p(j)由此,我们得到关系式‘p(1) p(2) p(3)…..p(j-1)’= ’s(i-j+1)……s(i-1)’由于s(i)≠p(j),接下来s(i)将与p(k)继续比较,则模式串中的前(k-1)个字符的子串必须满足下列关系式,并且不可能存在k’>k 满足下列关系式:(k<j),‘p(1) p(2) p(3)…..p(k-1)’= ’s(i-k+1)s(i-k+2)……s(i-1)’即:主串:S(1)……s(i-k +1) s(i-k +2) ……s(i-1) s(i) ………….|| (相配) || || ?(有待比较)匹配串:P(1) p(2) ……p(k-1) p(k)现在我们把前面总结的关系综合一下有:S(1)…s(i-j +1)…s(i-k +1) s(i-k +2) ……s(i-1) s(i) ……|| (相配) || || || ≠(失配)P(1) ……p(j-k+1) p(j-k+2) ….... p(j-1) p(j)|| (相配) || || ?(有待比较)P(1) p(2) ……. p(k-1) p(k)由上,我们得到关系:‘p(1) p(2) p(3)…..p(k-1)’= ’s(j-k+1)s(j-k+2)……s(j-1)’接下来看“反之,若模式串中存在满足式(4-4)。
kmp 时间复杂度计算摘要:一、KMP 算法简介1.KMP 算法的概念2.KMP 算法的原理3.KMP 算法的作用二、KMP 算法的时间复杂度分析1.KMP 算法的时间复杂度公式2.KMP 算法时间复杂度分析的过程3.KMP 算法相对于其他字符串匹配算法的优势三、KMP 算法在实际应用中的案例1.KMP 算法在文本处理中的应用2.KMP 算法在信息检索中的应用3.KMP 算法在自然语言处理中的应用正文:一、KMP 算法简介KMP(Knuth-Morris-Pratt)算法是一种高效的字符串匹配算法,用于在一个主字符串中查找一个子字符串出现的位置。
该算法由Donald Knuth、Charles Morris 和Vaughan Pratt 于1977 年共同提出,其核心思想是利用子字符串的前缀与后缀信息来避免不必要的字符比较,从而提高匹配速度。
1.KMP 算法的概念:KMP 算法是一种滑动窗口法,通过构建一个“部分匹配表”(也称为“失效函数”或“next 数组”),实现字符串的高效匹配。
2.KMP 算法的原理:从主字符串的第一个字符开始,将其与子字符串的第一个字符进行比较。
若相等,继续比较后续字符;若不等,根据部分匹配表的值,将子字符串向右移动若干个字符,再次进行比较。
如此循环,直至找到匹配的子字符串或到达子字符串末尾。
3.KMP 算法的作用:KMP 算法可以在O(n) 的时间复杂度内完成主字符串与子字符串的匹配,其中n 为字符串的长度。
相较于O(n^2) 的暴力匹配算法,KMP 算法具有较高的效率。
二、KMP 算法的时间复杂度分析1.KMP 算法的时间复杂度公式:最优情况下,KMP 算法的时间复杂度为O(n),其中n 为字符串的长度。
最坏情况下,KMP 算法的时间复杂度为O(n^2),此时子字符串与主字符串的前缀完全相同。
2.KMP 算法时间复杂度分析的过程:分析KMP 算法的时间复杂度,需要考虑最优情况、最坏情况和平均情况。
改进的模式匹配算法的理论分析设T = t0 t1 … t s-1 t s t s+1 t s+2 … t s+j-1 t s+j t s+j+1 … t n-1P = p0 p1 p2 … p j-1 p m-1.若在匹配过程中出现了如下情况:t s t s+1t s+2… t s+j-1= p0p1p2… p j-1,(1)但t s+j ≠ p j.也就是说,在匹配过程出现了:T t0 t1 … t s-1t s t s+1t s+2… t s+j-1t s+j t s+j+1… t s+m-1 … t n-1‖ ‖ ‖ … ‖ ⨯P p0p1p2 … p j-1p j p j-1… p m-1则本次匹配失败.由朴素的模式匹配算法,我们需要下一趟匹配,即需要验证下式是否成立:t s+1t s+2… t s+j-1 t s+j … t s+m?= p0p1 … p j-2p j-1… p m-1(2)如果(2)式成立,则匹配成功,返回s+1;否则需要再下一趟的匹配:t s+2t s+3… t s+j-1t s+j… t s+m+1?= p0p1… p j-3p j-2 …p m-1 (2')以此类推.下面给出两个互逆的条件p0p1… p j-2 = p1p2 …p j-1 (3)p0p1… p j-2 ≠p1p2 …p j-1 (3')显然,这两个条件能且只能满足一个.下面并分情况讨论:【1】如果(3) 式成立,则由(1) (2) (3) 式,可以断定p0 p1 …p j-2 = t s+1 t s+2 … t s+j-1成立,即在(3)式条件下,对(2) 式的验证只需要从p j-和t s+j 开始逐个往后比较,而不必从p0 和t s+2 开始.1【2】如果(3') 式成立,则由(1) (2) (3') 式,可以断定p0 p1 …p j-2 ≠t s+1 t s+2 … t s+j-1成立,即在(3')式条件下,(2)式一定不能成立,应该直接进行下下次验证,即对(2') 进行验证.对于(2'),也引进两个互逆的条件p0p1… p j-3 = p2p3 …p j-1 (4)p0p1… p j-3 ≠p2p3 …p j-1 (4')这两个条件也是只能满足一个,分情况讨论:【2.1】如果(4) 式成立,则由(1) (2') (4),可以断定p0 p1 …p j-3 = t s+2 t s+3 … t s+j-1成立,即:对(2') 式的判断从p j-2和t s+j开始逐个往后比较,而不必从p0和t s+2开始.【2.2】如果(4')式成立,则由(1) (2') (4'),可断定p0 p1 …p j-3 ≠t s+2 t s+2… t s+j-1成立,即(2')一定不成立,应该开始再下一次的判断,即:t s+3 t s+4 … t s+j-1 t s+j … t s+m+2 ?= p0 p1 … p j-4 p j-3 …p m-1没必要再往下做了,下面把刚才的两次匹配过程总结一下,找出规律来:【1】如果(3) 式成立,则对(2)式的验证可以从p j-1和t s+j开始继续往后进行,而不必从p0和t s+1开始.【2】如果(3') 成立,则需要进行下下次匹配【见(2')式】:【3】如果(3') 和(4) 式成立,则对(2') 式的验证可以从p j-2和t s+j开始继续往后进行,而不必从p0和t s+1开始.【4】如果(3') 和(4') 式成立,则需要进行下下下次匹配:t s+3 t s+4 … t s+j-1 t s+j … t s+m+2 ?= p0 p1 … p j-4 p j-3 …p m-1由刚才总结的第【3】种情况,我们可以设想存在一个k,使得p0p1… p j-2 ≠p1p2 …p j-1 (3')p0p1… p j-3 ≠p2p3 …p j-1 (4')… … … …p0p1… p k ≠p j-k-1p j-k …p j-1 (5')p0p1… p k-1 = p j-k p j-k+1 …p j-1 (6)显然,如果这样的k 存在,则0 <= k < j-1(当k == 0 时,(6)式的左右都为空串).再由刚才总结的第【2】和【4】种情况可知:如果(3') (4') …(5') 都成立,哪些判断不用做了呢?这需要发现(2)、(2') 的变化规律.刚才,由(3') 式,则(2) 式不用再判断了;由(4') 式,则(2') 式不用再判断了.换句话说,根据(5') 式,●当k = j – 2时【(3')式成立】,(2)式不用判断了;●当k = j – 3时【(4')式成立】,(2')式不用判断了;●… …由此可以推出:当k时,下面的(7) 式不用判断了t s+j-k-1t s+j-k… t s+j-1t s+j… t s+j-k+m-2 ?= p0p1… p k p k+1… p m-1 (7)也就是说,当k 时,也就是(5') 成立时,(7) 式子不用判断了.此时需继续判断如下的(8) 式是否成立t s+j-k t s+j-k+1… t s+j-1t s+j… t s+j-k+m-1?= p0p1… p k-1p k… p m-1 (8)由(6) 式和(8) 式,再考虑到(1) 式并改写(1) 式t s t s+1… t s+j-k t s+j-k+1… t s+j-1= p0p1… p j-k p j-k+1 …p j-1(1)可以断定:p0 p1 …p k-1 = t s+j-k t s+j-k+1 … t s+j-1,因此,下次比较从p k和t s+j开始即可.综上:若在上述的失配情况下,且存在最大的正整数k,换句话说,当k = j-2, j-3, …, k 时,(5') 式都是成立的.但是,当k-1 时,(5') 不再成立,而(6) 式成立,则下一次的比较从p k和t s+j开始即可.那么,这样的k 是否存在?如何确定呢?下面把刚才的问题再次重述一下,从而明确我们要做的具体任务:若t s t s+1 t s+2 … t s+j-1 = p0 p1 p2 … p j-1,但t s+j p j,则本次匹配失败.则我们用一个next向量来确定k,也就是说,当模式P 中第j 个字符p j与目标T 中第s+j 个字符t s+j失配时,应当用模式P 中字符p k (next[j] = k)与目标T 中的t s+j继续进行比较.那么k 怎么求呢?下面介绍确定k 的方法.显然,k的取值是由(5') 和(6) 式确定.进一步发现,k的取值只与模式P有关,和目标T无关,因此把next向量称为模式的特征向量(描述了模式的一个特征,和主串无关).由上述分析可知,next[j] 的值可以按如s下的公式来计算:next[j]={−1,j=0;k,0<k<j−1,且使得p0p1…p k−1=p j−k p j−k+1…p j−1的最大整数k 0,其他情况.示例:若P = "abaabcac",则设在进行某一趟匹配比较时在模式P 的第j 位失配:●如果j > 0,那么在下一趟比较时模式串P的起始比较字符是p k,即p next(j),而目标串T 的指针不回溯,仍指向刚才失配的字符;●如果j = 0,则目标串T 的指针进一,模式串P 指针回到字符p0,继续进行下一趟匹配比较.上述两种情况就是KMP算法的核心内容。
从头到尾彻底理解KMP作者:July时间:最初写于2011年12月,2014年7月21日晚10点全部删除重写成此文,随后的半个多月不断反复改进。
后收录于新书《编程之法:面试和算法心得》第4.4节中。
1. 引言本KMP原文最初写于2年多前的2011年12月,因当时初次接触KMP,思路混乱导致写也写得混乱。
所以一直想找机会重新写下KMP,但苦于一直以来对KMP的理解始终不够,故才迟迟没有修改本文。
然近期因开了个算法班,班上专门讲解数据结构、面试、算法,才再次仔细回顾了这个KMP,在综合了一些网友的理解、以及算法班的两位讲师朋友曹博、邹博的理解之后,写了9张PPT,发在微博上。
随后,一不做二不休,索性将PPT 上的内容整理到了本文之中(后来文章越写越完整,所含内容早已不再是九张PPT 那样简单了)。
KMP本身不复杂,但网上绝大部分的文章(包括本文的2011年版本)把它讲混乱了。
下面,咱们从暴力匹配算法讲起,随后阐述KMP的流程步骤、next 数组的简单求解递推原理代码求解,接着基于next 数组匹配,谈到有限状态自动机,next 数组的优化,KMP的时间复杂度分析,最后简要介绍两个KMP的扩展算法。
全文力图给你一个最为完整最为清晰的KMP,希望更多的人不再被KMP折磨或纠缠,不再被一些混乱的文章所混乱。
有何疑问,欢迎随时留言评论,thanks。
2. 暴力匹配算法假设现在我们面临这样一个问题:有一个文本串S,和一个模式串P,现在要查找P在S中的位置,怎么查找呢?如果用暴力匹配的思路,并假设现在文本串S匹配到 i 位置,模式串P 匹配到 j 位置,则有:如果当前字符匹配成功(即S[i] == P[j]),则i++,j++,继续匹配下一个字符;如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 0。
相当于每次匹配失败时,i 回溯,j 被置为0。
理清楚了暴力匹配算法的流程及内在的逻辑,咱们可以写出暴力匹配的代码,如下:[cpp]view plaincopyprint?1.int ViolentMatch(char* s, char* p)2.{3.int sLen = strlen(s);4.int pLen = strlen(p);5.6.int i = 0;7.int j = 0;8.while (i < sLen && j < pLen)9.{10. if (s[i] == p[j])11. {12. //①如果当前字符匹配成功(即S[i] == P[j]),则i++,j++13. i++;14. j++;15. }16. else17. {18. //②如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 019. i = i - j + 1;20. j = 0;21. }22. }23. //匹配成功,返回模式串p在文本串s中的位置,否则返回-124. if (j == pLen)25. return i - j;26. else27. return -1;28.}举个例子,如果给定文本串S“BBC ABCDAB ABCDABCDABDE”,和模式串P“ABCDABD”,现在要拿模式串P去跟文本串S匹配,整个过程如下所示:1.S[0]为B,P[0]为A,不匹配,执行第②条指令:“如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 0”,S[1]跟P[0]匹配,相当于模式串要往右移动一位(i=1,j=0)2. S[1]跟P[0]还是不匹配,继续执行第②条指令:“如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 0”,S[2]跟P[0]匹配(i=2,j=0),从而模式串不断的向右移动一位(不断的执行“令i = i - (j - 1),j = 0”,i 从2变到4,j一直为0)3. 直到S[4]跟P[0]匹配成功(i=4,j=0),此时按照上面的暴力匹配算法的思路,转而执行第①条指令:“如果当前字符匹配成功(即S[i] == P[j]),则i++,j++”,可得S[i]为S[5],P[j]为P[1],即接下来S[5]跟P[1]匹配(i=5,j=1)4. S[5]跟P[1]匹配成功,继续执行第①条指令:“如果当前字符匹配成功(即S[i] == P[j]),则i++,j++”,得到S[6]跟P[2]匹配(i=6,j=2),如此进行下去5. 直到S[10]为空格字符,P[6]为字符D(i=10,j=6),因为不匹配,重新执行第②条指令:“如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 0”,相当于S[5]跟P[0]匹配(i=5,j=0)6. 至此,我们可以看到,如果按照暴力匹配算法的思路,尽管之前文本串和模式串已经分别匹配到了S[9]、P[5],但因为S[10]跟P[6]不匹配,所以文本串回溯到S[5],模式串回溯到P[0],从而让S[5]跟P[0]匹配。
KMP算法详解(转)此前一天,一位MS的朋友邀我一起去与他讨论快速排序,红黑树,字典树,B树、后缀树,包括KMP算法,唯独在讲解KMP算法的时候,言语磕磕碰碰,我想,原因有二:1、博客内的东西不常回顾,忘了不少;2、便是我对KMP算法的理解还不够彻底,自不用说讲解自如,运用自如了。
所以,特再写本篇文章。
由于此前,个人已经写过关于KMP算法的两篇文章,所以,本文名为:KMP算法之总结篇。
本文分为如下六个部分:第一部分、再次回顾普通的BF算法与KMP算法各自的时间复杂度,并两相对照各自的匹配原理;第二部分、通过我此前第二篇文章的引用,用图从头到尾详细阐述KMP算法中的next数组求法,并运用求得的next数组写出KMP算法的源码;第三部分、KMP算法的两种实现,代码实现一是根据本人关于KMP算法的第二篇文章所写,代码实现二是根据本人的关于KMP算法的第一篇文章所写;第四部分、测试,分别对第三部分的两种实现中next数组的求法进行测试,挖掘其区别之所在;第五部分、KMP完整准确源码,给出KMP算法的准确的完整源码;第六步份、一眼看出字符串的next数组各值,通过几个例子,让读者能根据字符串本身一眼判断出其next数组各值。
力求让此文彻底让读者洞穿此KMP算法,所有原理,来龙去脉,让读者搞个通通透透(注意,本文中第二部分及第三部分的代码实现一的字符串下标i从0开始计算,其它部分如第三部分的代码实现二,第五部分,和第六部分的字符串下标i 皆是从1开始的)。
第一部分、KMP算法初解1、普通字符串匹配BF算法与KMP算法的时间复杂度比较KMP算法是一种线性时间复杂的字符串匹配算法,它是对BF算法(Brute-Force,最基本的字符串匹配算法的)改进。
对于给的原始串S 和模式串P,需要从字符串S中找到字符串P出现的位置的索引。
BF算法的时间复杂度O(strlen(S) * strlen(T)),空间复杂度O(1)。
KMP算法(推导⽅法及模板)介绍克努斯-莫⾥斯-普拉特算法Knuth-Morris-Pratt(简称为KMP算法)可在⼀个主⽂本S内查找⼀个词W的出现位置。
此算法通过运⽤对这个词在不匹配时本⾝就包含⾜够的信息来确定下⼀个匹配将在哪⾥开始的发现,从⽽避免重新检查先前匹配的。
此算法可以在O(n+m)时间数量级上完成串的模式匹配操作,其改进在于:每当⼀趟匹配过程中出现字符⽐较不等时,不需回溯i的指针,⽽是利⽤已经得到的“部分匹配”的结果将模式向右“滑动”尽可能远的距离后,继续进⾏⽐较。
kmp的核⼼之处在于next数组,⽽为了⽅便理解,我先介绍KMP的思想KMP匹配当开始匹配时,如果匹配过程中产⽣“失配”时,指针i(原串的下标)不变,指针j(模式串的下标)退回到next[j] 所指⽰的位置上重新进⾏⽐较,并且当指针j退回⾄零时,指针i和指针j需同时加⼀。
即主串的第i个字符和模式的第⼀个字符不等时,应从主串的第i+1个字符起重新进⾏匹配。
简单来说,就是两个串匹配,如果当前字符相等就⽐较两个字符串的下⼀个字符,如果当前匹配不相等时,就让j(待匹配串的下标)回到next[j] 的位置,因为我们已经知道next数组的作⽤是利⽤已经得到的“部分匹配”的结果将模式向右“滑动”尽可能远的距离,如ababac与abac⽐较时i=4,j=4时不匹配,则利⽤next数组让j=2继续匹配⽽不⽤重新开始。
(⽬前先不⽤管next数组的值时如何得到的,只要明⽩它的作⽤即可,下⾯回介绍)所以我们可以写出kmp的代码int KMP(char str[],char pat[]){int lenstr=strlen(str);int lenpat=strlen(pat);int i=1,j=1;while(i<=lenstr){if(j==0 || str[i]==pat[j]) //匹配成功继续往后匹配++i,++j;elsej=next[j]; //否则根据next数组继续匹配if(j==lenpat) //说明匹配完成return 1;}return 0;}接下来就是关键的求next数组了next数组⾸先,next数组取决于模式串本⾝⽽与相匹配的主串⽆关,我们可以对其递推得到。
KMP字符串模式匹配详解来自CSDN A_B_C_ABC网友KMP字符串模式匹配通俗点说就是一种在一个字符串中定位另一个串的高效算法。
简单匹配算法的时间复杂度为O(m*n);KMP匹配算法。
可以证明它的时间复杂度为O(m+n).。
一.简单匹配算法先来看一个简单匹配算法的函数:int Index_BF ( char S [ ], char T [ ], int pos ){/*若串S中从第pos(S的下标0≤pos<StrLength(S))个字符起存在和串T相同的子串,则称匹配成功,返回第一个这样的子串在串S中的下标,否则返回-1 */int i = pos, j = 0;while ( S[i+j] != '\0'&& T[j] != '\0')if ( S[i+j] == T[j] )j ++;//继续比较后一字符else{i ++; j = 0;//重新开始新的一轮匹配}if ( T[j] == '\0')return i;//匹配成功返回下标elsereturn -1;//串S中(第pos个字符起)不存在和串T相同的子串}// Index_BF此算法的思想是直截了当的:将主串S中某个位置i起始的子串和模式串T 相比较。
即从j=0起比较S[i+j]与T[j],若相等,则在主串S中存在以i为起始位置匹配成功的可能性,继续往后比较( j逐步增1 ),直至与T串中最后一个字符相等为止,否则改从S串的下一个字符起重新开始进行下一轮的"匹配",即将串T向后滑动一位,即i增1,而j退回至0,重新开始新一轮的匹配。
例如:在串S=”abcabcabdabba”中查找T=” abcabd”(我们可以假设从下标0开始):先是比较S[0]和T[0]是否相等,然后比较S[1]和T[1]是否相等…我们发现一直比较到S[5]和T[5]才不等。
如图:当这样一个失配发生时,T下标必须回溯到开始,S下标回溯的长度与T 相同,然后S下标增1,然后再次比较。
如图:这次立刻发生了失配,T下标又回溯到开始,S下标增1,然后再次比较。
如图:这次立刻发生了失配,T下标又回溯到开始,S下标增1,然后再次比较。
如图:又一次发生了失配,所以T下标又回溯到开始,S下标增1,然后再次比较。
这次T中的所有字符都和S中相应的字符匹配了。
函数返回T在S中的起始下标3。
如图:二. KMP匹配算法还是相同的例子,在S=”abcabcabdabba”中查找T=”abcabd”,如果使用KMP匹配算法,当第一次搜索到S[5]和T[5]不等后,S下标不是回溯到1,T 下标也不是回溯到开始,而是根据T中T[5]==’d’的模式函数值(next[5]=2,为什么?后面讲),直接比较S[5]和T[2]是否相等,因为相等,S和T的下标同时增加;因为又相等,S和T的下标又同时增加。
最终在S中找到了T。
如图:KMP匹配算法和简单匹配算法效率比较,一个极端的例子是:在S=“AAAAAA…AAB“(100个A)中查找T=”AAAAAAAAAB”,简单匹配算法每次都是比较到T的结尾,发现字符不同,然后T的下标回溯到开始,S 的下标也要回溯相同长度后增1,继续比较。
如果使用KMP匹配算法,就不必回溯.对于一般文稿中串的匹配,简单匹配算法的时间复杂度可降为O (m+n),因此在多数的实际应用场合下被应用。
KMP算法的核心思想是利用已经得到的部分匹配信息来进行后面的匹配过程。
看前面的例子。
为什么T[5]==’d’的模式函数值等于2(next[5]=2),其实这个2表示T[5]==’d’的前面有2个字符和开始的两个字符相同,且T[5]==’d’不等于开始的两个字符之后的第三个字符(T[2]=’c’).如图:也就是说,如果开始的两个字符之后的第三个字符也为’d’,那么,尽管T[5]==’d’的前面有2个字符和开始的两个字符相同,T[5]==’d’的模式函数值也不为2,而是为0。
前面我说:在S=”abcabcabdabba”中查找T=”abcabd”,如果使用KMP匹配算法,当第一次搜索到S[5]和T[5]不等后,S下标不是回溯到1,T下标也不是回溯到开始,而是根据T中T[5]==’d’的模式函数值,直接比较S[5]和T[2]是否相等。
为什么可以这样?刚才我又说:“(next[5]=2),其实这个2表示T[5]==’d’的前面有2个字符和开始的两个字符相同”。
请看图:因为,S[4] ==T[4],S[3] ==T[3],根据next[5]=2,有T[3]==T[0],T[4] ==T[1],所以S[3]==T[0],S[4] ==T[1](两对相当于间接比较过了),因此,接下来比较S[5]和T[2]是否相等。
有人可能会问:S[3]和T[0],S[4]和T[1]是根据next[5]=2间接比较相等,那S[1]和T[0],S[2]和T[0]之间又是怎么跳过,可以不比较呢?因为S[0]=T[0],S[1]=T[1],S[2]=T[2],而T[0] != T[1], T[1] != T[2],==> S[0] != S[1],S[1] != S[2],所以S[1] != T[0],S[2] != T[0]. 还是从理论上间接比较了。
有人疑问又来了,你分析的是不是特殊轻况啊。
假设S不变,在S中搜索T=“abaabd”呢?答:这种情况,当比较到S[2]和T[2]时,发现不等,就去看next[2]的值,next[2]=-1,意思是S[2]已经和T[0]间接比较过了,不相等,接下来去比较S[3]和T[0]吧。
假设S不变,在S中搜索T=“abbabd”呢?答:这种情况当比较到S[2]和T[2]时,发现不等,就去看next[2]的值,next[2]=0,意思是S[2]已经和T[2]比较过了,不相等,接下来去比较S[2]和T[0]吧。
假设S=”abaabcabdabba”在S中搜索T=“abaabd”呢?答:这种情况当比较到S[5]和T[5]时,发现不等,就去看next[5]的值,next[5]=2,意思是前面的比较过了,其中,S[5]的前面有两个字符和T的开始两个相等,接下来去比较S[5]和T[2]吧。
总之,有了串的next值,一切搞定。
那么,怎么求串的模式函数值next[n]呢?(本文中next值、模式函数值、模式值是一个意思。
)三.怎么求串的模式值next[n]定义:(1)next[0]= -1 意义:任何串的第一个字符的模式值规定为-1。
(2)next[j]= -1 意义:模式串T中下标为j的字符,如果与首字符相同,且j的前面的1—k个字符与开头的1—k个字符不等(或者相等但T[k]==T[j])(1≤k<j)。
如:T=”abCabCad”则next[6]=-1,因T[3]=T[6](3)next[j]=k 意义:模式串T中下标为j的字符,如果j的前面k个字符与开头的k个字符相等,且T[j] != T[k](1≤k<j)。
即T[0]T[1]T[2]。
T[k-1]==T[j-k]T[j-k+1]T[j-k+2]…T[j-1]且T[j] != T[k].(1≤k<j);(4) next[j]=0 意义:除(1)(2)(3)的其他情况。
举例:01)求T=“abcac”的模式函数的值。
next[0]= -1 根据(1)next[1]=0 根据(4) 因(3)有1<=k<j;不能说,j=1,T[j-1]==T[0]next[2]=0 根据(4) 因(3)有1<=k<j;(T[0]=a)!=(T[1]=b)next[3]= -1 根据(2)next[4]=1 根据(3) T[0]=T[3]且T[1]=T[4]即下标01234T a b c a cnext-100-11若T=“abcab”将是这样:下标01234T a b c a bnext-100-10为什么T[0]==T[3],还会有next[4]=0呢,因为T[1]==T[4],根据(3)”且T[j] != T[k]”被划入(4)。
02)来个复杂点的,求T=”ababcaabc”的模式函数的值。
next[0]= -1 根据(1)next[1]=0 根据(4)next[2]=-1 根据(2)next[3]=0 根据(3)虽T[0]=T[2]但T[1]=T[3]被划入(4)next[4]=2 根据(3) T[0]T[1]=T[2]T[3]且T[2] !=T[4]next[5]=-1 根据(2)next[6]=1 根据(3) T[0]=T[5]且T[1]!=T[6]next[7]=0 根据(3)虽T[0]=T[6]但T[1]=T[7]被划入(4)next[8]=2 根据(3) T[0]T[1]=T[6]T[7]且T[2] !=T[8]即下标012345678T a b a b c a a b cnext-10-102-1102只要理解了next[3]=0,而不是=1,next[6]=1,而不是= -1,next[8]=2,而不是= 0,其他的好象都容易理解。
03)来个特殊的,求T=”abCabCad”的模式函数的值。
下标01234567T a b C a b C a dnext-100-100-14next[5]= 0 根据(3)虽T[0]T[1]=T[3]T[4],但T[2]==T[5]next[6]= -1 根据(2)虽前面有abC=abC,但T[3]==T[6]next[7]=4 根据(3)前面有abCa=abCa,且T[4]!=T[7]若T[4]==T[7],即T=” adCadCad”,那么将是这样:next[7]=0,而不是= 4,因为T[4]==T[7].下标01234567T a d C a d C a dnext-100-100-10如果你觉得有点懂了,那么练习:求T=”AAAAAAAAAAB”的模式函数值,并用后面的求模式函数值函数验证。
意义:next函数值究竟是什么含义,前面说过一些,这里总结。
设在字符串S中查找模式串T,若S[m]!=T[n],那么,取T[n]的模式函数值next[n],1.next[n]= -1表示S[m]和T[0]间接比较过了,不相等,下一次比较S[m+1]和T[0]2.next[n]=0表示比较过程中产生了不相等,下一次比较S[m]和T[0]。
3.next[n]= k >0但k<n,表示,S[m]的前k个字符与T中的开始k个字符已经间接比较相等了,下一次比较S[m]和T[k]相等吗?4.其他值,不可能。
四.求串T的模式值next[n]的函数说了这么多,是不是觉得求串T的模式值next[n]很复杂呢?要叫我写个函数出来,目前来说,我宁愿去登天。