
Excel回归分析结果的详细阐释
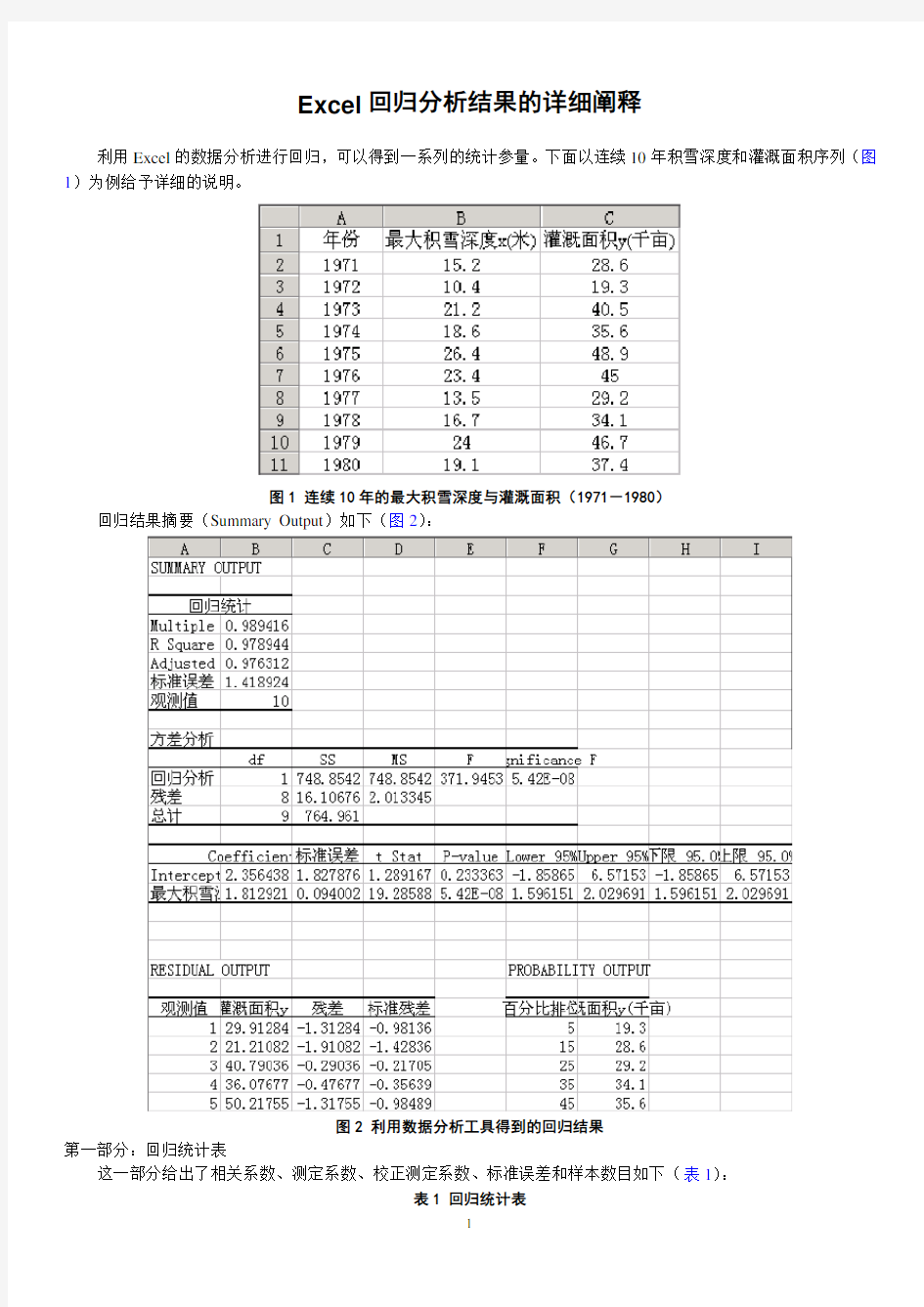
利用Excel的数据分析进行回归,可以得到一系列的统计参量。下面以连续10年积雪深度和灌溉面积序列(图1)为例给予详细的说明。
图1 连续10年的最大积雪深度与灌溉面积(1971-1980)
回归结果摘要(Summary Output)如下(图2):
图2 利用数据分析工具得到的回归结果
第一部分:回归统计表
这一部分给出了相关系数、测定系数、校正测定系数、标准误差和样本数目如下(表1):
表1 回归统计表
逐行说明如下:
Multiple 对应的数据是相关系数(correlation coefficient),即R=0.989416。 R Square 对应的数值为测定系数(determination coefficient),或称拟合优度(goodness of fit),它是相关系数的平方,即有R 2=0.9894162=0.978944。
Adjusted 对应的是校正测定系数(adjusted determination coefficient),计算公式为
1
)
1)(1(12-----=m n R n R a
式中n 为样本数,m 为变量数,R 2为测定系数。对于本例,n =10,m =1,R 2=0.978944,代入上式得
976312.01
110)
978944.01)(110(1=-----
=a R
标准误差(standard error )对应的即所谓标准误差,计算公式为
SSe 1
1
--=
m n s
这里SSe 为剩余平方和,可以从下面的方差分析表中读出,即有SSe=16.10676,代入上式可得
418924.110676.16*1
1101
=--=
s
最后一行的观测值对应的是样本数目,即有n =10。
第二部分,方差分析表
方差分析部分包括自由度、误差平方和、均方差、F 值、P 值等(表2)。
表2 方差分析表(ANOVA )
逐列、分行说明如下:
第一列df 对应的是自由度(degree of freedom ),第一行是回归自由度dfr ,等于变量数目,即dfr=m ;第二行为残差自由度dfe ,等于样本数目减去变量数目再减1,即有dfe=n -m -1;第三行为总自由度dft ,等于样本数目减1,即有dft=n -1。对于本例,m =1,n =10,因此,dfr=1,dfe=n -m -1=8,dft=n -1=9。
第二列SS 对应的是误差平方和,或称变差。第一行为回归平方和或称回归变差SSr ,即有
8542.748)?(SSr 1
2=-=∑=n
i i i y y
它表征的是因变量的预测值对其平均值的总偏差。
第二行为剩余平方和(也称残差平方和)或称剩余变差SSe ,即有
10676.16)?(SSe 1
2=-=∑=n
i i i y
y
它表征的是因变量对其预测值的总偏差,这个数值越大,意味着拟合的效果越差。上述的y 的标准误差即由SSe 给出。
第三行为总平方和或
称总变差SSt ,即有
它表示的是因变量对其平均值的总偏差。容易验证748.8542+16.10676=764.961,即有
SSt SSe SSr =+
而测定系数就是回归平方和在总平方和中所占的比重,即有
978944.0961
.7648542
.748SSt SSr 2===
R 显然这个数值越大,拟合的效果也就越好。
第四列MS 对应的是均方差,它是误差平方和除以相应的自由度得到的商。第一行为回归均方差MSr ,即有
8542.7481
8542
.748dfr SSr MSr ===
第二行为剩余均方差MSe ,即有
013345.28
10676
.16dfe SSe MSe ===
显然这个数值越小,拟合的效果也就越好。
第四列对应的是F 值,用于线性关系的判定。对于一元线性回归,F 值的计算公式为
2222
1dfe )
1(1
1
R
R R m n R F -=---=
式中R 2=0.978944,dfe=10-1-1=8,因此
9453.371978944
.01978944
.0*8=-=
F
第五列Significance F 对应的是在显著性水平下的F α临界值,其实等于P 值,即弃真概率。所谓“弃真概率”即模型为假的概率,显然1-P 便是模型为真的概率。可见,P 值越小越好。对于本例,P =0.0000000542<0.0001,故置信度达到99.99%以上。
第三部分,回归参数表
回归参数表包括回归模型的截距、斜率及其有关的检验参数(表3)。
表3 回归参数表
第一列Coefficients 对应的模型的回归系数,包括截距a =2.356437929和斜率b =1.812921065,由此可以建立回归模型
i i x y
8129.13564.2?+= 或
961
.764)(SSr 1
2=-=∑
=n
i i i y y
i i i x y ε++=8129.13564.2
第二列为回归系数的标准误差(用a s ?或b s ?表示),误差值越小,表明参数的精确度越高。这个参数较少使用,
只是在一些特别的场合出现。例如L. Benguigui 等人在When and where is a city fractal ?一文中将斜率对应的标准误差值作为分形演化的标准,建议采用0.04作为分维判定的统计指标(参见EPB2000)。
不常使用标准误差的原因在于:其统计信息已经包含在后述的t 检验中。
第三列t Stat 对应的是统计量t 值,用于对模型参数的检验,需要查表才能决定。t 值是回归系数与其标准误差的比值,即有
a a s a t ?=
,b b s
b t ?=
根据表3中的数据容易算出:
289167.1827876
.1356438
.2==
a t ,28588.19094002.0812921.1==
b t 对于一元线性回归,t 值可用相关系数或测定系数计算,公式如下
1
12
---=
m n R
R t
将R=0.989416、n =10、m =1代入上式得到
28588.191
110989416.01989416.02
=---=
t
对于一元线性回归,F 值与t 值都与相关系数R 等价,因此,相关系数检验就已包含了这部分信息。但是,对于多元线性回归,t 检验就不可缺省了。
第四列P value 对应的是参数的P 值(双侧)。当P<0.05时,可以认为模型在α=0.05的水平上显著,或者置信度达到95%;当P <0.01时,可以认为模型在α=0.01的水平上显著,或者置信度达到99%;当P <0.001时,可以认为模型在α=0.001的水平上显著,或者置信度达到99.9%。对于本例,P=0.0000000542<0.0001,故可认为在α=0.0001的水平上显著,或者置信度达到99.99%。P 值检验与t 值检验是等价的,但P 值不用查表,显然要方便得多。
最后几列给出的回归系数以95%为置信区间的上限和下限。可以看出,在α=0.05的显著水平上,截距的变化上限和下限为-1.85865和6.57153,即有
57153.685865.1≤≤-a
斜率的变化极限则为1.59615和2.02969,即有
02969.259615.1≤≤b
第四部分,残差输出结果
这一部分为选择输出内容,如果在“回归”分析选项框中没有选中有关内容,则输出结果不会给出这部分结果。
残差输出中包括观测值序号(第一列,用i 表示),因变量的预测值(第二列,用i y ?表示),残差(residuals ,
第三列,用e i 表示)以及标准残差(表4)。
表4 残差输出结果
预测值是用回归模型
i i x y
8129.13564.2?+= 计算的结果,式中x i 即原始数据的中的自变量。从图1可见,x 1=15.2,代入上式,得
118129.13564.2?x y
+=91284.292.15*8129.13564.2=+= 其余依此类推。
残差e i 的计算公式为
i i i y
y e ?-= 从图1可见,y 1=28.6,代入上式,得到
31284.191284.296.28?111-=-=-=y
y e 其余依此类推。
标准残差即残差的数据标准化结果,借助均值命令average 和标准差命令stdev 容易验证,残差的算术平均值为0,标准差为1.337774。利用求平均值命令standardize(残差的单元格范围,均值,标准差)立即算出表4中的结果。当然,也可以利用数据标准化公式
)
var(*i i i z z z z -=
i
i z
z σ-=
逐一计算。将残差平方再求和,便得到残差平方和即剩余平方和,即有
10676.16)?(1
21
2
=-==∑∑==n
i i i n i i y
y e SSe 利用Excel 的求平方和命令sumsq 容易验证上述结果。
以最大积雪深度x i 为自变量,以残差e i 为因变量,作散点图,可得残差图(图3)。残差点列的分布越是没有趋势(没有规则,即越是随机),回归的结果就越是可靠。
用最大积雪深度x i 为自变量,用灌溉面积y i 及其预测值i y ?为因变量,作散点图,可得线性拟合图(图4)。
图3 残差图
图4 线性拟合图
第五部分,概率输出结果
在选项输出中,还有一个概率输出(Probability Output)表(表5)。第一列是按等差数列设计的百分比排位,第二列则是原始数据因变量的自下而上排序(即从小到大)——选中图1中的第三列(C列)数据,用鼠标点击自下而上排序按钮,立即得到表5中的第二列数值。当然,也可以沿着主菜单的“数据(D)→排序(S)”路径,打开数据排序选项框,进行数据排序。
用表5中的数据作散点图,可以得到Excel所谓的正态概率图(图5)。
表5 概率输出表
图5 正态概率图
【几点说明】
第一,多元线性回归与一元线性回归结果相似,只是变量数目m≠1,F值和t值等统计量与R值也不再等价,因而不能直接从相关系数计算出来。
第二,利用SPSS给出的结果与Excel也大同小异。当然,SPSS可以给出更多的统计量,如DW值。在表示方法上,SPSS也有一些不同,例如P Value(P值)用 Sig.(显著性)表征,因为二者等价。只要
能够读懂Excel的回归摘要,就可以读懂SPSS回归输出结果的大部分内容。
更多相关资料,请参考https://www.doczj.com/doc/0411702377.html,