
第3讲MATLAB数据建模方法(上):常用方法
作者:卓金武, MathWorks 中国
以数据为基础而建立数学模型的方法称为数据建模方法,包括回归、统计、机器学习、深度学习、灰色预测、主成分分析、神经网络、时间序列分析等方法,其中最常用的方法还是回归方法。本讲主要介绍在数学建模中常用几种回归方法的MATLAB实现过程。
根据回归方法中因变量的个数和回归函数的类型(线性或非线性)可将回归方法分为:一元线性、一元非线性、多元回归。另外还有两种特殊的回归方式,一种在回归过程中可以调整变量数的回归方法,称为逐步回归,另一种是以指数结构函数作为回归模型的回归方法,称为Logistic回归。本讲将逐一介绍这几个回归方法。
3.1 一元回归
3.1.1 一元线性回归
【例3-1】近10年来,某市社会商品零售总额与职工工资总额(单位:亿元)的数据见表3-1,请建立社会商品零售总额与职工工资总额数据的回归模型。
表3-1 商品零售总额与职工工资总额
回归方法建立他们之间的回归模型了,具体实现的MATLAB代码如下:
(1)输入数据
(2)采用最小二乘回归
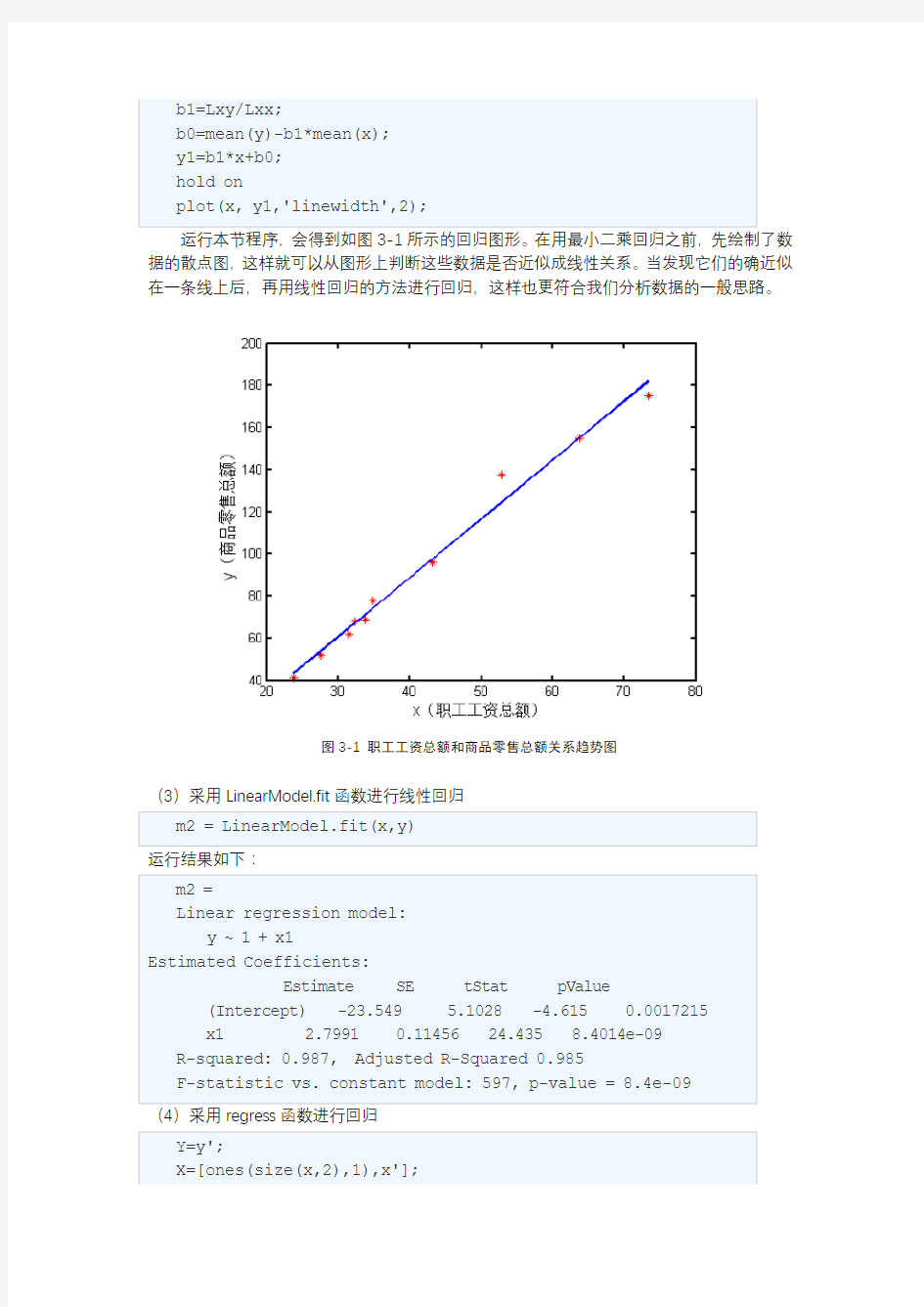
据的散点图,这样就可以从图形上判断这些数据是否近似成线性关系。当发现它们的确近似在一条线上后,再用线性回归的方法进行回归,这样也更符合我们分析数据的一般思路。
图3-1 职工工资总额和商品零售总额关系趋势图
(3)采用LinearModel.fit函数进行线性回归
运行结果如下:
(4)采用regress函数进行回归
运行结果如下:
只要根据自己的需要选用一种就可以了。函数LinearModel.fit 输出的内容为典型的线性回归的参数。关于regress ,其用法多样,MATLAB 帮助中关于regress 的用法,有以下几种:
b = regress(y,X)
[b,bint] = regress(y,X) [b,bint,r] = regress(y,X) [b,bint,r,rint] = regress(y,X)
[b,bint,r,rint,stats] = regress(y,X) [...] = regress(y,X,alpha) 输入y (因变量,列向量),X (1与自变量组成的矩阵)和(alpha ,是显著性水平, 缺省时默认0.05)。
输出01
??(,)b ββ=,bint 是01ββ,的置信区间,r 是残差(列向量),rint 是残差的置信区间,s 包含4个统计量:决定系数2R (相关系数为R ),F 值,F(1,n-2)分布大于F 值的概率p ,剩余方差2s 的值。2s 也可由程序sum(r.^2)/(n-2)计算。其意义和用法如下:2R 的值越接近1,变量的线性相关性越强,说明模型有效;如果满足1(1,2)F n F α--<,则认为变量y 与x 显著地有线性关系,其中1(1,2)F n α--的值可查F 分布表,或直接用MATLAB 命令finv(1-α,1, n-2)计算得到;如果p α<表示线性模型可用。这三个值可以相互印证。2s 的值主要用来比较模型是否有改进,其值越小说明模型精度越高。
3.1.2 一元非线性回归
在一些实际问题中,变量间的关系并不都是线性的,此时就应该用非线性回归。用用非线性回归首先要解决的问题是回归方程中的参数如何估计。下面通过一个实例来说明如何利用非线性回归技术解决实例的问题。
【例3-2】 为了解百货商店销售额x 与流通率(这是反映商业活动的一个质量指标,指每元商品流转额所分摊的流通费用)y 之间的关系,收集了九个商店的有关数据(见表3-2)。请建立它们关系的数学模型。
表3-2 销售额与流通费率数据
9
25.5 2.2
为了得到x与y之间的关系,先绘制出它们之间的散点图,如图3-2所示的“雪花”点图。由该图可以判断它们之间的关系近似为对数关系或指数关系,为此可以利用这两种函数形式进行非线性拟合,具体实现步骤及每个步骤的结果如下:
(1)输入数据
(2)对数形式非线性回归
运行结果如下:
运行结果如下:
在该案例中,选择两种函数形式进行非线性回归,从回归结果来看,对数形式的决定系数为0.973,而指数形式的为0.993,优于前者,所以可以认为指数形式的函数形式更符合y 与x之间的关系,这样就可以确定他们之间的函数关系形式了。
3.2 多元回归
【例3-3】某科学基金会希望估计从事某研究的学者的年薪Y与他们的研究成果(论文、著作等)的质量指标X1、从事研究工作的时间X2、能成功获得资助的指标X3之间的关系,为此按一定的实验设计方法调查了24位研究学者,得到如表3-3所示的数据(i为学者序
号),试建立Y 与123,,X X X 之间关系的数学模型,并得出有关结论和作统计分析。
表3-3 从事某种研究的学者的相关指标数据
他们之间的变化趋势,如何近似满足线性关系,则可以执行利用多元线性回归方法对该问题进行回归。具体步骤如下:
(1)作出因变量Y 与各自变量的样本散点图
作散点图的目的主要是观察因变量Y 与各自变量间是否有比较好的线性关系,以便选择恰当的数学模型形式。图7-3分别为年薪Y 与成果质量指标1X 、研究工作时间2X 、获
得资助的指标
3X 之间的散点图。从图中可以看出这些点大致分布在一条直线旁边,因此,
有比较好的线性关系,可以采用线性回归。绘制图3-3的代码如下:
Y 与x1的散点图 Y 与x2的散点图 Y 与x3的散点图
图3-3 因变量Y 与各自变量的样本散点图
(2)进行多元线性回归
这里可以直接使用regress 函数执行多元线性回归,具体代码如下:
运行后即得到结果如表3-4所示。
表3-4 对初步回归模型的计算结果
计算结果包括回归系数b=(0123,,,ββββ)=(18.0157, 1.0817, 0.3212, 1.2835)、回归系数的
30
35404550
5530
354045505530
35
40
45
50
55
置信区间,以及统计变量stats (它包含四个检验统计量:相关系数的平方2R ,假设检验统计量F,与F 对应的概率p ,2s 的值)。因此我们得到初步的回归方程为:
123?18.0157 1.08170.3212 1.2835y
x x x =+++
由结果对模型的判断:
回归系数置信区间不包含零点表示模型较好,残差在零点附近也表示模型较好,接着就是利用检验统计量R,F,p 的值判断该模型是否可用。
1)相关系数R的评价:本例R的绝对值为0.9542,表明线性相关性较强。
2)F 检验法:当1(,1)F
F m n m α->--,即认为因变量y 与自变量12,,,m x x x 之间
有显著的线性相关关系;否则认为因变量y 与自变量12,,,m x x x 之间线性相关关系不显著。
本例F=67.919>10.05(3,20)F -= 3.10。
3)p 值检验:若p α<(
α为预定显著水平)
,则说明因变量y 与自变量12,,,m x x x 之间显著地有线性相关关系。本例输出结果,p<0.0001,显然满足P<α=0.05。
以上三种统计推断方法推断的结果是一致的,说明因变量y 与自变量之间显著地有线性相关关系,所得线性回归模型可用。2s 当然越小越好,这主要在模型改进时作为参考。
3.3 逐步归回
【例3-4】 (Hald,1960)Hald 数据是关于水泥生产的数据。某种水泥在凝固时放出的热量Y (单位:卡/克)与水泥中4种化学成品所占的百分比有关:
3213:O Al CaO X ?
223:SiO CaO X ?
323234:O Fe O Al CaO X ??
242:SiO CaO X ?
在生产中测得12组数据,见表3-5,试建立Y 关于这些因子的“最优”回归方程。
表3-5 水泥生产的数据
对于例3-4中的问题,可以使用多元线性回归、多元多项式回归,但也可以考虑使用逐步回归。从逐步回归的原理来看,逐步回归是以上两种回归方法的结合,可以自动使得方程
的因子设置最合理。对于该问题,逐步回归的代码如下:
程序执行后得到下列逐步回归的窗口,如图3-4所示。
图3-4 逐步回归操作界面
在图3-4中,用蓝色行显示变量X1、X2、X3、X4均保留在模型中,窗口的右侧按钮上方提示:将变量X3剔除回归方程(Move X3 out),单击Next Step按钮,即进行下一步运算,将第3列数据对应的变量X3剔除回归方程。单击Next Step按钮后,剔除的变量X3所对应的行用红色表示,同时又得到提示:将变量X4剔除回归方程(Move X4 out),单击Next Step按钮,这样一直重复操作,直到“Next Step”按钮变灰,表明逐步回归结束,此时得到的模型即为逐步回归最终的结果。
3.4 Logistic回归
【例3-5】企业到金融商业机构贷款,金融商业机构需要对企业进行评估。评估结果
为0,1两种形式,0表示企业两年后破产,将拒绝贷款,而1表示企业2年后具备还款能力,可以贷款。在表3-6中,已知前20家企业的三项评价指标值和评估结果,试建立模型对其他5家企业(企业21-25)进行评估。
表3-6 企业还款能力评价表
对于该问题,很明显可以用Logistic模型来回归,具体求解程序如下:
得到的回归结果与原始数据的比较如图3-5所示。
图3-5 回归结果与原始数据的比较图
3.5 小结
本讲主要介绍数学建模中常用的几种回归方法。在使用回归方法的时候,首先可以判断自变量的个数,如果超过2个,则需要用到多元回归的方法,否则考虑用一元回归。然后判断是线性还是非线性,这对于一元回归是比较容易的,而对于多元,往往是将其他变量保持不变,将多元转化为一元再去判断是线性还是非线性。如果变量很多,而且复杂,则可以首先考虑多元线性回归,检验回归效果,也可以用逐步回归。总之,用回归方法比较灵活,根
据具体情景还是比较容易找到合适的方法的。
关于作者
卓金武,MathWorks中国高级工程师,教育业务经理,在数据分析、数据挖掘、机器学习、数学建模、量化投资和优化等科学计算方面有多年工作经验,现主要负责MATLAB校园版业务;曾2次获全国大学生数学建模竞赛一等奖,1次获全国研究生数学建模竞赛一等奖;专著3部:《MATLAB在数学建模中的应用》、《大数据挖掘:系统方法与实例分析》、《量化投资:MATLAB数据挖掘技术与实践》。
数据分析建模简介 观察和实验是科学家探究自然的主要方法,但如果你有数据,那么如何让这些数据开口说话呢?数据用现代人的话说即信息,信息的挖掘与分析也是建模的一个重要方法。 1.科学史上最有名的数据分析例子 开普勒三定律 数据来源:第谷?布拉赫(1546-1601,丹麦人),观察力极强的天文学家,一辈子(20年)观察记录了750颗行星资料,位置误差不超过0.67°。 观测数据可以视为实验模型。 数据处理:开普勒(1571-1630,德国人),身体瘦弱、近视又散光,不适合观天,但有一个非常聪明的数学头脑、坚韧的性格(甚至有些固执)和坚强的信念(宇宙是一个和谐的整体),花了16年(1596-1612)研究第谷的观测数据,得到了开普勒三定律。 开普勒三定律则为唯象模型。 2.数据分析法 2.1 思想 采用数理统计方法(如回归分析、聚类分析等)或插值方法或曲线拟合方法,对已知离散数据建模。 适用范围:系统的结构性质不大清楚,无法从理论分析中得到系统的规律,也不便于类比,但有若干能表征系统规律、描述系统状态的数据可利用。 2.2 数据分析法 2.2.1 基础知识 (1)数据也称观测值,是实验、测量、观察、调查等的结果,常以数量的形式给出; (2)数据分析(data analysis)是指分析数据的技术和理论; (3)数据分析的目的是把隐没在一大批看来杂乱无章的数据中的信息集中、萃取和提炼出来,以找出所研究对象的内在规律;
(4)作用:在实用中,它可帮助人们作判断,以采取适当行动。 (5)实际问题所涉及的数据分为: ①受到随机性影响(随机现象)的数据; ②不受随机性影响(确定现象)的数据; ③难以确定性质的数据(如灰色数据)。 (6)数理统计学是一门以收集和分析随机数据为内容的学科,目的是对数据所来自的总体作出判断,总体有一定的概率模型,推断的结论也往往一概率的形式表达(如产品检验合格率)。 (7)探索性数据分析是在尽量少的先验假定下处理数据,以表格、摘要、图示等直观的手段,探索数据的结构及检测对于某种指定模型是否有重大偏离。它可以作为进一步分析的基础,也可以对数据作出非正式的解释。 实验者常常据此扩充或修改其实验方案(作图法也该法的重要方法,如饼图、直方图、条形图、走势图或插值法、曲线(面)拟合法等)。 2.2.2 典型的数据分析工作步骤 第一步:探索性数据分析 目的:通过作图、造表、用各种形式的方程拟合、计算某些特征量等手段探索规律性的可能形式,即往什么方向和用何种方式去寻找和揭示隐含在数据中的规律性。 第二步:模型选定分析 目的:在探索性分析的基础上,提出一类或几类可能的模型(如进一步确定拟合多项式(方程)的次数和各项的系数)。 第三步:推断分析 目的:通常用数理统计或其它方法对所选定的模型或估计的可靠程度或精确程度作出推断(如统计学中的假设检验、参数估计、统计推断)。3.建模中的概率统计方法 现实世界存在确定性现象和随机现象,研究随机现象主要由随机数学来承担,随机数学包括十几个分支,但主要有概率论、数理统计、试验设计、贝叶
matlab常用操作备忘(1)2007-11-30 22:01:06 分类: 北京理工大学 20981 陈罡 帮助朋友做几个数据的卷积的仿真,一用才知道,呵呵,发现对不住偶的导师了。。。好多matlab的关键字和指令都忘记了。特意收集回顾一下: (1)管理命令和函数 addpath :添加目录到MATLAB搜索路径 doc :在Web浏览器上现实HTML文档 help :显示Matlab命令和M文件的在线帮助 helpwin helpdesk :help 兄弟几个 lookfor :在基于Matlab搜索路径的所有M文件中搜索关键字 partialpath:部分路径名 8*) path :所有关于路径名的处理 pathtool :一个不错的窗口路径处理界面 rmpath :删除搜索路径中指定目录 type :显示指定文件的内容 ver :版本信息 version :版本号 web :打开web页 what :列出当前目录吓所有的M文件 Mat文件和 Mex文件 whatsnew :显示readme文件 which :显示文件位置 (2)管理变量和工作区 clear :从内存中删除所有变量,clear x y z是删除某个变量 disp :显示文本或数组内容 length :数组长度(最长维数) load :重新载入变量(从磁盘上) mlock :锁定文件,防止文件被错误删除 munlock :解锁文件 openvar :在数组编辑器中打开变量 pack :整理内存空间 save :保存变量到文件 8*) size :数组维数
who whos :列出内存变量 workspace :显示工作空间窗口 (3)管理命令控制窗口(command窗口) clc :清空命令窗口 echo :禁止或允许显示执行过程 format :设置输出显示格式 home :光标移动到命令窗口左上角 more :设置命令窗口页输出格式 (4)文件和工作环境 cd :改变工作目录 copyfile :复制文件 delete :删除文件和图形对象 diary :把命令窗口的人机交互保存到文件 dir :显示目录 edit :编辑文本文件 fileparts :返回文件的各个部分 fullfile :使用指定部分建立文件全名 inmem :返回内存(伪代码区)的matlab函数名 ls :在unix系统中列出目录(win中亦可) matlabroot :根目录 mkdir :新建目录 open :打开文件 pwd :显示当前目录 tempdir :返回系统临时目录的名字 tempname :随机给出一个临时字符串(可用作文件名) ! :直接调用操作系统command命令 (5)启动和推出matlab matlabrc :Matlab的启动M文件 exit quit :退出Matlab startup :运行matlab启动文件 (6)程序设计 builtin :从可重载方法中调用内置函数 eval :执行包含可执行表达式的字符串
实验报告 实验题目: 0.618法的MATLAB实现学生姓名: 学号: 实验时间: 2013-5-13
一.实验名称: 0.618法求解单峰函数极小点 二.实验目的及要求: 1. 了解并熟悉0.618法的方法原理, 以及它的MATLAB 实现. 2. 运用0.618法解单峰函数的极小点. 三.实验内容: 1. 0.618法方法原理: 定理: 设f 是区间],[b a 上的单峰函数, ] ,[ ,)2()1(b a x x ∈, 且)2()1(x x <. 如果)()()2()1(x f x f >, 则对每一个],[)1(x a x ∈, 有)()()2(x f x f >; 如果)()()2()1(x f x f ≤, 则对每一个] ,[) 2(b x x ∈, 有)()()1(x f x f ≥. 根据上述定理, 只需选择两个试探点, 就可将包含极小点的区间缩短. 事实上, 必有 如果)()()2()1(x f x f >, 则],[)1(b x x ∈; 如果)()() 2()1(x f x f ≤, 则][)2(x a x ,∈. 0.618 法的基本思想是, 根据上述定理, 通过取试探点使包含极小点的区间(不确定区间)不断缩短, 当区间长度小到一定程度时, 区间上各点的函数值均接近极小值, 因此任意一点都可作为极小点的近似. 0.618 法计算试探点的公式: ). (618.0),(382.0k k k k k k k k a b a a b a -+=-+=μλ 2. 0.618法的算法步骤: ①置初始区间],[11b a 及精度要求0>L , 计算试探点1λ和1μ, 计算函数值)(1λf 和)(1μf . 计算公式是 ).(618.0 ),(382.011111111a b a a b a -+=-+=μλ 令1=k . ②若L a b k k <-, 则停止计算. 否则, 当)()(k k f f μλ>时, 转步骤③; 当)()(k k f f μλ≤时, 转步骤④. ③置k k a λ=+1, k k b b =+1, k k μλ=+1,)(618.01111++++-+=k k k k a b a μ, 计算函数值)(1+k f μ, 转步骤⑤.
学生学号实验课成绩 学生实验报告书 实验课程名称数据分析与建模 开课学院 指导教师姓名 学生姓名 学生专业班级 2015 —2016 学年第 1 学期
实验报告填写规范 1、实验是培养学生动手能力、分析解决问题能力的重要环节;实验报告是反映实验教学水 平与质量的重要依据。为加强实验过程管理,改革实验成绩考核方法,改善实验教学效果,提高学生质量,特制定本实验报告书写规范。 2、本规范适用于管理学院实验课程。 3、每门实验课程一般会包括许多实验项目,除非常简单的验证演示性实验项目可以不写实 验报告外,其他实验项目均应按本格式完成实验报告。在课程全部实验项目完成后,应按学生姓名将各实验项目实验报告装订成册,构成该实验课程总报告,并给出实验课程成绩。 4、学生必须依据实验指导书或老师的指导,提前预习实验目的、实验基本原理及方法,了 解实验内容及方法,在完成以上实验预习的前提下进行实验。教师将在实验过程中抽查学生预习情况。 5、学生应在做完实验后三天内完成实验报告,交指导教师评阅。 6、教师应及时评阅学生的实验报告并给出各实验项目成绩,同时要认真完整保存实验报 告。在完成所有实验项目后,教师应将批改好的各项目实验报告汇总、装订,交课程承担单位(实验中心或实验室)保管存档。
画出图形 由图x=4时,y最大等于1760000 (2)求关于所做的15%假设的灵敏性 粗分析: 假设C=1000 即给定r y=f(x)=(1500-100x)1000(1+rx)=-100000rx^2+1500000rx-100000x+1500000 求导,f’(x)=-200000rx+1500000r-100000,令f’(x)=0,可得相应x值,x=(15r-1)/2r Excel画出相应图形
大数据与建模 LG GROUP system office room 【LGA16H-LGYY-LGUA8Q8-LGA162】
1、SQL用于访问和处理数据库的标准的计算机语言。用来访问和操作数据库系统。SQL语句用于取回和更新数据库中的数据。SQL可与数据库程序系统工作。比如MS Access,DB2,Infermix,MS SQL Server,Oracle,Sybase以及其他数据库系统。SQL可以面向数据库执行查询,从数据库取回数据,在数据库中插入新的记录,更新数据库中的数据,从数据库删除记录,创建新数据库,在数据库中创建新表,在数据库中创建存储过程,在数据库中创建视图和设置表、存储过程和视图的权限等。 2、Hadoop是一个能够对大量数据进行分布式处理的软件框架。但是Hadoop是以一种可靠、高效、可伸缩的方式进行处理的。Hadoop是可好的,因为他假设计算单元和存户会失败,因此他维护多个工作数据副本,确保能够针对失败的节点重新分布处理。Hadoop是高效的,因为他以并行的方式工作,通过并行处理加快处理速度。Hadoop还是可伸缩的,能够处理PB级数据。此外,Hadoop
依赖于社区服务器,因此他的成本较低,任何人都可以使用。 3、HPCC(high performance computinggand communications)高性能计算与通信的缩写。1993年,由美国科学、工程技术联邦协调理事会向国会提交了“重大挑战项目”高性能计算与通信的报告,也就是被称为HPCC计划的报告,及美国总统科学战略项目,其目的是通过加强研究与开发解决一批重要的科学与技术挑战问题。HPCC是美国实施信息高速公路而上实施的计划,该计划的实施将耗资百亿美元,其主要目标要达到:开发可扩展的计算系统及相关软件,以支持太位级网络传输性能,开发千兆比特网络技术,扩展研究和教育机构及网络连接能力。 4、Strom是自由的开源软件,一个分布式的、容错的实时计算系统。Strom可以非常可靠的处理庞大的数据流,用于处理Hadoop的批量出具,Strom很简单,支持许多种编程语言,使用起来非常有趣。Strom由Twitter开元而来,其他知名的应用企业包括Groupon、淘宝、支付宝、阿里巴巴、乐元素、Admaster等等。Strom有许多应用领域:实时分析、在线机器学习、不停顿的计算,分布式RPC(员过程调用协议,一种通过网络
实验1 熟悉Matlb环境及基本操作 实验目的: 1.熟悉Matlab环境,掌握Matlab的主要窗口及功能; 2.学会Matlab的帮助使用; 3.掌握向量、矩阵的定义、生成方法和基本运算; 4.掌握Matlab的基本符号运算; 5.掌握Matlab中的二维图形的绘制和控制。 实验内容: 1.启动Matlab,说明主窗口、命令窗口、当前目录窗口、工作空间窗口、历史窗口、图形窗口、M文件编辑器窗口的功能。 2.实例操作Matlab的帮助使用。 3.实例操作向量、矩阵的定义、生成方法和基本运算。 4.实例操作Matlab的基本符号运算。 5.实例操作Matlab中的二维图形绘制和控制。 实验仪器与软件: 1.CPU主频在2GHz以上,内存在512Mb以上的PC; 2.Matlab 7及以上版本。 实验讲评: 实验成绩: 评阅教师: 年月日
实验1 熟悉Matlab环境及基本操作 一、Matlab环境及主要窗口的功能 运行Matlab安装目录下的matlab.exe文件可启动Matlab环境,其默认布局如下图: 其中, 1.主窗口的功能是:主窗口不能进行任何计算任务操作,只用来进行一些整体的环境参数设置,它主要对6个下拉菜单的各项和10个按钮逐一解脱。 2.命令窗口的功能是:对MATLAB搜索路径中的每一个M文件的注释区的第一行进行扫描,一旦发现此行中含有所查询的字符串,则将该函数名及第一行注释全部显示在屏幕上。 3. 历史窗口的功能是:历史窗口显示命令窗口中的所有执行过的命令,一方面可以查看曾经执行过的命令,另一方面也可以重复利用原来输入的命令行,可以从命令窗口中直接通过双击某个命令行来执行该命令,
实验一 MATLAB 基本操作及运算 一、 实验目的 二、 实验的设备及条件 三、 实验内容 1、 建立以下标量: 1) a=3 2) ,(j 为虚数单位) 3) c=3/2πj e 2、 建立以下向量: 1) Vb= 2.71382882????????-???? 2) Vc=[4 3.8 … -3.8 -4 ] (向量中的数值从4到-4,步长为-0.2) 3、 建立以下矩阵: 1) 3 333Ma ????=?????? Ma 为一个7×7的矩阵,其元素全为3. 2) 11191212921020100Mb ??????=??????
Mb 为一个10×10的矩阵. 3) 114525173238Mc ????=?????? 4、 使用题1中的变量计算下列等式的x,y,z 的值: 1) ((15)/6)111a x e --=+ 2) 2x π= 3) 3ln([()()]sin(/3))x b c b c a π=+-R ,其中R 表示复数实部。 5、 求解函数值22/(2.25)ct y e -=,其中c 取值见题1,t 的取值范围为题2中行 向量Vc 。 6、 使用题1和题3中所产生的标量和矩阵计算等式 1()()T Mx a Mc Mc Mc -=?? 其中*为矩阵所对应行列式的值,参考det 。 7、 函数的使用和矩阵的访问。 1) 计算矩阵Mb 每一列的和,结果应为行向量形式。 2) 计算整个矩阵Mb 的平均值。 3) 用向量[1 1…1] 替换Mb 的最上一行的值 4) 将矩阵Mb 的第2~5行,第3到9列的元素所构成的矩阵赋值给矩阵SubMb 。 5) 删除矩阵Mb 的第一行; 6) 使用函数rand 产生一个1×10的向量r ,并将r 中值小于0.5的元素设置为0。 8、 已知CellA (1, 1)=‘中国’,CellA (1,2)=‘北京’,CellA (2,1)是一个3乘3的单位阵,CellA (2, 2)=[1 2 3],试用MATLAB 创建一个2×2的细胞数组CellA 。 9、 已知结构数组student 中信息包含有姓名,学号,性别,年龄和班级,试用MATLAB 创建相应的结构数组student 。该数组包含有从自己学号开始连续5个同学的信息(如果学号在你后面的同学不足5个则往前排序),创建完成后查看自己的信息。
第九章最优化方法的MatIab实现 在生活和工作中,人们对于同一个问题往往会提出多个解决方案,并通过各方面的论证从中提取最佳方案。最优化方法就是专门研究如何从多个方案中科学合理地提取出最佳方案的科学。由于优化问题无所不在,目前最优化方法的应用和研究已经深入到了生产和科研的各个领域,如土木工程、机械工程、化学工程、运输调度、生产控制、经济规划、经济管理等,并取得了显著的经济效益和社会效益。 用最优化方法解决最优化问题的技术称为最优化技术,它包含两个方面的内容: 1)建立数学模型即用数学语言来描述最优化问题。模型中的数学关系式反映了最优化问题所要达到的目标和各种约束条件。 2)数学求解数学模型建好以后,选择合理的最优化方法进行求解。 最优化方法的发展很快,现在已经包含有多个分支,如线性规划、整数规划、非线性规划、动态规划、多目标规划等。 9.1 概述 利用Matlab的优化工具箱,可以求解线性规划、非线性规划和多目标规划问题。 具体而言,包括线性、非线性最小化,最大最小化,二次规划,半无限问题,线性、非线性方程(组)的求解,线性、非线性的最小二乘问题。另外,该工具箱还提供了线性、非线性最小化,方程求解,曲线拟合,二次规划等问题中大型课题的求解方法,为优化方法在工程中的实际应用提供了更方便快捷的途径。 9.1.1优化工具箱中的函数 优化工具箱中的函数包括下面几类: 1 ?最小化函数
2.方程求解函数 3.最小—乘(曲线拟合)函数
4?实用函数 5 ?大型方法的演示函数 6.中型方法的演示函数 9.1.3参数设置 利用OPtimSet函数,可以创建和编辑参数结构;利用OPtimget函数,可以获得o PtiOns优化参数。 ? OPtimget 函数 功能:获得OPtiOns优化参数。 语法:
时 间 内容提要授课详细内容实践训练 第一天业界主流的 数据仓库工 具和大数据 分析挖掘工 具 1.业界主流的基于Hadoop和Spark的大数据分析挖掘项目 解决方案 2.业界数据仓库与数据分析挖掘平台软件工具 3.Hadoop数据仓库工具Hive 4.Spark实时数据仓库工具SparkSQL 5.Hadoop数据分析挖掘工具Mahout 6.Spark机器学习与数据分析挖掘工具MLlib 7.大数据分析挖掘项目的实施步骤 配置数据仓库工具 Hadoop Hive和 SparkSQL 部署数据分析挖掘 工具Hadoop Mahout 和Spark MLlib 大数据分析 挖掘项目的 数据集成操 作训练 1.日志数据解析和导入导出到数据仓库的操作训练 2.从原始搜索数据集中抽取、集成数据,整理后形成规范 的数据仓库 3.数据分析挖掘模块从大型的集中式数据仓库中访问数 据,一个数据仓库面向一个主题,构建两个数据仓库 4.同一个数据仓库中的事实表数据,可以给多个不同类型 的分析挖掘任务调用 5.去除噪声 项目数据集加载 ETL到Hadoop Hive 数据仓库并建立多 维模型 基于Hadoop 的大型数据 仓库管理平 台—HIVE数 据仓库集群 的多维分析 建模应用实 践 6.基于Hadoop的大型分布式数据仓库在行业中的数据仓库 应用案例 7.Hive数据仓库集群的平台体系结构、核心技术剖析 8.Hive Server的工作原理、机制与应用 9.Hive数据仓库集群的安装部署与配置优化 10.Hive应用开发技巧 11.Hive SQL剖析与应用实践 12.Hive数据仓库表与表分区、表操作、数据导入导出、客 户端操作技巧 13.Hive数据仓库报表设计 14.将原始的日志数据集,经过整理后,加载至Hadoop + Hive 数据仓库集群中,用于共享访问 利用HIVE构建大型 数据仓库项目的操 作训练实践 Spark大数据 分析挖掘平 台实践操作 训练 15.Spark大数据分析挖掘平台的部署配置 16.Spark数据分析库MLlib的开发部署 17.Spark数据分析挖掘示例操作,从Hive表中读取数据并 在分布式内存中运行
实验一 MATLAB 基本操作 一、实验目的 1. 学习和掌握MA TLAB 的基本操作方法 2. 掌握命令窗口的使用 3. 熟悉MATLAB 的数据表示、基本运算 二、实验内容和要求 1. 实验内容 1) 练习MATLAB7.0或以上版本 2) 练习矩阵运算与数组运算 2. 实验要求 1) 每位学生独立完成,交实验报告 2) 禁止玩游戏! 三、实验主要软件平台 装有MATLAB7.0或以上的PC 机一台 四、实验方法、步骤及结果测试 1. 实验方法:上机练习。 2. 实验步骤: 1) 开启PC ,进入MA TLAB 。 2) 使用帮助命令,查找sqrt 函数的使用方法 答: help sqrt 3) 矩阵、数组运算 a) 已知 ??????????=987654321A ,???? ??????=963852741B ,求)2()(A B B A -?+ 答: A=[1, 2, 3; 4, 5, 6; 7, 8, 9]; B=[1, 4, 7; 2, 5, 8; 3, 6, 9]; (A+B)*(2*B-A) b) 已知?? ????-=33.1x ,??????=π24y ,求T xy ,y x T c) 已知??????????=987654321A ,???? ??????=300020001B ,求A/B, A\B. d) 已知???? ??????=987654321A ,求:(1) A 中第三列前两个元素;(2) A 中所有第二行元素;(3) A 中四个角上的元素;(4) 交换A 的第1、3列。(5) 交换A 的第1、2行。(6) 删除A 的第3列。
e) 已知[]321=x ,[]654=y ,求:y x *.,y x /.,y x \.,y x .^, 2.^x ,x .^2。 f) 给出x=1,2,…,7时,x x sin 的值。 3)常用的数学函数 a )随机产生一个3x3的矩阵A ,求:(1) A 每一行的最大、最小值,以及最大、最小值所在的列;(2) A 每一列的最大、最小值,以及最大、最小值所在的行;(3) 整个矩阵的最大、最小值;(4) 每行元素之和;(5) 每列元素之和;(6) 每行元素之积;(7) 每列元素之积。 b) 随机产生两个10个元素的向量x ,y 。(1) 求x 的平均值、标准方差。(2) 求x ,y 的相关系数。(3)对x 排序,并记录排序后元素在原向量中的位置。 4) 字符串操作函数 建立一个字符串向量(如‘ABc123d4e56Fg9’),然后对该向量做如下处理: (1) 取第1~5个字符组成的子字符串。 (2) 将字符串倒过来重新排列。 (3) 将字符串中的小写字母变成相应的大写字母,其余字符不变。 (4) 统计字符串中小写字母的个数。
数据分析和数据建模 大数据应用有几个方面,一个是效率提升,帮助企业提升数据处理效率,降低数据存储成本。另外一个是对业务作出指导,例如精准营销,反欺诈,风险管理以及业务提升。过去企业都是通过线下渠道接触客户,客户数据不全,只能利用财务数据进行业务运营分析,缺少围绕客户的个人数据,数据分析应用的领域集中在企业内部经营和财务分析。 大数据应用有几个方面,一个是效率提升,帮助企业提升数据处理效率,降低数据存储成本。另外一个是对业务作出指导,例如精准营销,反欺诈,风险管理以及业务提升。过去企业都是通过线下渠道接触客户,客户数据不全,只能利用财务数据进行业务运营分析,缺少围绕客户的个人数据,数据分析应用的领域集中在企业内部经营和财务分析。 数字时代到来之后,企业经营的各个阶段都可以被记录下来,产品销售的各个环节也被记录下来,客户的消费行为和网上行为都被采集下来。企业拥有了多维度的数据,包括产品销售数据、客户消费数据、客户行为数据、企业运营数据等。拥有数据之后,数据分析成为可能,企业成立了数据分析团队整理数据和建立模型,找到商品和客户之间的关联关系,商品之间关联关系,另外也找到了收入和客户之间的关联关系。典型的数据分析案例如沃尔玛啤酒和尿布、蛋挞和手电筒,Target的判断16岁少女怀孕都是这种关联关系的体现。
关联分析是统计学应用最早的领域,早在1846年伦敦第二次霍乱期间,约翰医生利用霍乱地图找到了霍乱的传播途径,平息了伦敦霍乱,打败了霍乱源于空气污染说的精英,拯救了几万人的生命。伦敦霍乱平息过程中,约翰医生利用了频数分布分析,建立了霍乱地图,从死亡案例分布的密集程度上归纳出病人分布同水井的关系,从而推断出污染的水源是霍乱的主要传播途径,建议移除水井手柄,降低了霍乱发生的概率。 另外一个典型案例是第二次世界大战期间,统计分析学家改造轰炸机。英美联盟从1943年开始对德国的工业城市进行轰炸,但在1943年年底,轰炸机的损失率达到了英美联盟不能承受的程度。轰炸军司令部请来了统计学家,希望利用数据分析来改造轰炸机的结构,降低阵亡率,提高士兵生还率。统计学家利用大尺寸的飞机模型,详细记录了返航轰炸机的损伤情况。统计学家在飞机模型上将轰炸机受到攻击的部位用黑笔标注出来,两个月后,这些标注布满了机身,有的地方标注明显多于其他地方,例如机身和侧翼。有的地方的标注明显少于其他地方,例如驾驶室和发动机。统计学家让军火商来看这个模型,军火商认为应该加固受到更多攻击的地方,但是统计学家建议对标注少的地方进行加固,标注少的原因不是这些地方不容易被击中,而是被击中的这些地方的飞机,很多都没有返航。这些标注少的地方被击中是飞机坠毁的一个主要原因。军火商按照统计学家的建议进行了飞机加固,大大提高了轰炸机返航的比率。以二战著名的B-17轰炸机为例,其阵亡率由26%降到了7%,帮助美军节约了几亿美金,大大提高了士兵的生还率。 一数据分析中的角色和职责 数据分析团队应该在科技部门内部还在业务部门内部一直存在争议。在业务部门内部,对数据场景比较了解,容易找到数据变现的场景,数据分析对业务提升帮助较大,容易出成绩。但是弊端是仅仅对自己部门的业务数据了解,分析只是局限独立的业务单元之内,在数据获取的效率上,数据维度和数据视角方面缺乏全局观,数据的商业视野不大,对公司整体业务的推动发展有限。业务部门的数据分析团队缺少数据技术能力,无法利用最新的大数据计算和分析技术,来实现数
大数据风控建模标准流程 一、风控建模标准过程 (一)数据采集汇总 2、评估数据真实性和质量,数据质量好的变量进入后续步骤 (二)模型设计 1、时间窗和好坏客户定义 时间窗:根据获取数据的覆盖周期,将数据分为用来建模的观察期数据,和后面用来验证表现的表现期数据; 好坏客户定义:分析客户滚动和迁移率,来定义什么程度逾期的为“坏客户”,例如定义M3为坏客户就是定义逾期3个月的才是坏 客户; 2、样本集切分和不平衡样本处理 样本集切分:切分为训练集和测试集,一般7/3或8/2比例; 不平衡样本:最理想样本为好坏各50%,实际拿到的样本一般坏 客户占比过低,采取过采样或欠采样方法来调节坏样本浓度。 3、模型选择 评分卡模型以逻辑回归为主。 (三)数据预处理及变量特征分析 1、变量异常值、缺失值处理:使用均值、众数等来平滑异常值,来填补缺失,缺失率过高的变量直接丢弃; 2、变量描述性统计:看各个变量的集中或离散程度,看变量的 分布是否对样本好坏有线性单调的相关性趋势; (四)变量筛选
1、变量分箱:变量取值归入有限个分组中,一般5个左右的分 箱数量,来参加后面的算法模型计算。分箱的原则是使得各箱内部 尽量内聚,即合并为一箱的各组坏样本率接近;使得相邻分箱的坏 样本率呈现单调趋势。从方法上一版采取先机器分箱,后人工微调。 2、定量计算变量对于识别坏样本的贡献度(WOE和IV) (1)WOE是统计一个变量的各分箱区间之间的好占总好比值坏 占总坏之比,不同分箱之间差异明显且比例成单调趋势,说明分箱 的区分度好; (2)IV是在WOE基础上进一步加权计算这个变量整体上对于区 分好坏样本的识别度,也就是变量影响因子。数越大说明用这个变 量进行区分的效果越好,但IV值过大容易引起模型过拟合,即模型 过于依赖单一变量,造成使用过程中平衡性健壮性不好; 3、计算变量之间的相关性或多重共线性,相关性高于0.5甚至0.7的两个变量里,就要舍弃一个,留下iv值较高的那个。例如 “近一个月查询次数”、“近三个月查询次数”、“近六个月查询 次数”这三个变量显然明显互相相关度高,只保留其中一个变量进 入模型即可。 (五)变量入模计算 1、以最终选定的若干变量,进入回归模型算法,机器自动计算 其中每一个X就是一种变量,这个计算就是为了算出每种变量的最终权重,也就是算出所有的b。 2、客户违约概率映射为客户分数。以上公式一旦计算确定,则 给出一个确定的客户,就可以算出其违约概率,下面公式是把概率 进一步再映射计算成一个客户总评分。 3、计算确定每种变量每个分箱所应该给的得分 某一变量在一个分箱的得分该组WOE 1、模型区分好坏客户能力评价
常用对象操作:除了一般windows窗口的常用功能键外。 1、!dir 可以查看当前工作目录的文件。!dir& 可以在dos状态下查看。 2、who 可以查看当前工作空间变量名,whos 可以查看变量名细节。 3、功能键: 功能键快捷键说明 方向左键Ctrl+B 光标向后移一个字符 方向右键Ctrl+F 光标向前移一个字符 Ctrl+方向右键Ctrl+R 光标向右移一个字符 Ctrl+方向左键Ctrl+L 光标向左移一个字符 home Ctrl+A 光标移到行首 End Ctrl+E 光标移到行尾 Esc Ctrl+U 清除一行 Del Ctrl+D 清除光标所在的字符 Backspace Ctrl+H 删除光标前一个字符 Ctrl+K 删除到行尾 Ctrl+C 中断正在执行的命令 4、clc可以命令窗口显示的内容,但并不清除工作空间。 二、函数及运算 1、运算符: +:加,-:减,*:乘,/:除,\:左除^:幂,‘:复数的共轭转置,():制定运算顺序。 2、常用函数表: sin( ) 正弦(变量为弧度) Cot( ) 余切(变量为弧度) sind( ) 正弦(变量为度数) Cotd( ) 余切(变量为度数) asin( ) 反正弦(返回弧度) acot( ) 反余切(返回弧度) Asind( ) 反正弦(返回度数) acotd( ) 反余切(返回度数) cos( ) 余弦(变量为弧度) exp( ) 指数 cosd( ) 余弦(变量为度数) log( ) 对数 acos( ) 余正弦(返回弧度) log10( ) 以10为底对数 acosd( ) 余正弦(返回度数) sqrt( ) 开方 tan( ) 正切(变量为弧度) realsqrt( ) 返回非负根 tand( ) 正切(变量为度数) abs( ) 取绝对值 atan( ) 反正切(返回弧度) angle( ) 返回复数的相位角
数据、模型与决策 3 线性规划问题的计算机求解及应用举例 第7题 (1)线性规划模型 (2)线性规划模型代数式 公司所做决策的变量是每种原料合金的数量,因此引入决策变量 i x 表示第i 种原料合金的数量()1,2,3,4,5,6i =。 建立此问题的数学模型为:
(1)线性规划模型 (2)线性规划模型代数式 公司所做决策的变量是每种原料数,因此引入决策变量 x表示第i i 种原料数() i=。 1,2,3,4 建立此问题的数学模型为:
线性规划模型代数式 车间所做决策的变量是(1,2,3)i A i =机床生产(1,2)j B j =零件数,因此引入决策变量ij x 表示加工(1,2)j B j =零件使用的(1,2,3)i A i =机床台数。 建立此问题的数学模型为: (1)线性规划模型 (2)使用sumproduct 函数
(1)线性规划模型 (2)线性规划模型代数式 公司所做决策可用网络配送图表示(如下图),图中节点123,,v v v 表示1、2、3三个工厂,节点4v 表示配送中心,节点567,,v v v 表示1、2、3三个仓库。每一条有向弧表示一条可能的运输路线,并给出了相应的单位运输成本,对运输量有限制的路线的最大运输能力也同时给出。 网络配送模型 引入变量ij f 表示由i v 经过路线(),i j v v 运输到j v 的产品属。问题的目
标是总运输成本最小化:
(1)线性规划模型 (2)线性规划模型代数式 医院所做决策的变量是每时段开始上班的人数,因此引入决策变量i x 表示第i 个时段上班的人数()1,2,3,4,5,6i =。 建立此问题的数学模型为:
实验一Matlab基本操作 题目: 1.利用基本矩阵产生 3x3 和15x8 的单位阵,全 1 阵,全0 阵,均匀分布的随 机阵([-1,1]之间),正态分布随机阵(方差4,均值1) 2.利用diag()函数和rot90()产生下列矩阵: 然后求解a 阵的逆矩阵aa 及b 阵的特征值和对应特征向量,并利用reshape 将 aa 阵变换成行向量。 3.产生一均匀分布在(-5,5)随机阵(50x2),精确到小数点后一位。 4.编程实现当α∈[-π,π],间隔为1o 时,求解正弦和余弦的值,并利用plot() 函数绘制正弦,余弦曲线。 5.利用rand 函数产生(0,1)间均匀分布的10x10 随机矩阵a,然后统计a 中大于等于0.6 的元素个数。 6.利用randn 函数产生均值为0,方差为 1 的10x10 正态分布随机阵,然后统计其 中大于-0.5,小于0.5 的元素个数。 7.编程实现下表功能: 8.有一矩阵a,找出矩阵中其值大于 1 的元素,并将他们重新排列成列向量b。9.在一保定市区9 月份平均气温变化测量矩阵temp_Baoding_sep 中(48x30),存在有奇异值(大于42o C,小于0o C),编程实现删除奇异值所在的行。 10.在给定的100x100 矩阵中,删除整行内容全为0 的行,删除整列内容全为0 的列。 程序: 1. %3X3矩阵 a1=eye(3) a2=ones(3) a3=zeros(3) a4=1-2*rand(3) a5=2*randn(3)+1 %15X8矩阵 b1=eye(15,8) b2=ones(15,8) b3=zeros(15,8) b4=1-2*rand(15,8) b5=2*randn(15,8)+1 运行结果:
[设计]罚函数法MATLAB程序 一、进退法、0.618法、Powell法、罚函数法的Matlab程序设计罚函数法(通用) function y=ff(x,k) y=-17.86*0.42*x(1)/(0.8+0.42*x(1))*(1-exp(- 2*(0.8+0.42*x(1))/3))*exp(-1.6)*x(2)-22. 99*x(1)/(0.8+x(1))*(1-exp(-2*(0.8+x(1))/3))*x(3)+k*(x(2)- (1.22*10^2*(9517.8*exp(-1 .6-2*0.42*x(1)/3)*x(2)+19035.6*exp(- 2*x(1)/3)*x(3)))/(1.22*10^2+9517.8*exp(-1.6-2 *0.42*x(1)/3)*x(2)+19035.6*exp(-2*x(1)/3)*x(3)))^2+k*(x(3)-exp(-0.8-2*x(1)/3)*x(3) -exp(-2.4-2*0.42*x(1)/3)*x(2))^2; % 主函数,参数包括未知数的个数n,惩罚因子q,惩罚因子增长系数k,初值x0,以及允许的误差r function G=FHS(x0,q,k,n,r,h,a) l=1; while (l) x=powell(x0,n,q,r(1),h,a); %调用powell函数 g(1)=ff1(x),g(2)=ff2(x) . . . g(p)=ffp(x); %调用不等式约束函数,将其值 %存入数组g h(1)=hh1(x),h(2)=hh2(x) . . . h(t)=hht(x); %调用等式约束函数,将其值%存入数组h for i=1:p
关于举办“大数据建模与分析挖掘应用”实战培训班的通知地点北京上海 时间12月 23-26 1月 12-15 一、课程简介 大数据建模与分析挖掘技术已经逐步地应用到新兴互联网企业(如电子商务网站、搜索引擎、社交网站、互联网广告服务提供商等)、银行金融证券企业、电信运营等行业,给这些行业带来了一定的数据价值增值作用。 本次课程面向有一定的数据分析挖掘算法基础的工程师,带大家实践大数据分析挖掘平台的项目训练,系统地讲解数据准备、数据建模、挖掘模型建立、大数据分析与挖掘算法应用在业务模型中,结合主流的Hadoop与Spark大数据分析平台架构,实现项目训练。 结合业界使用最广泛的主流大数据平台技术,重点剖析基于大数据分析算法与BI技术应用,包括分类算法、聚类算法、预测分析算法、推荐分析模型等在业务中的实践应用,并根据讲师给定的数据集,实现两个基本的日志数据分析挖掘系统,以及电商(或内容)推荐系统引擎。 本课程基本的实践环境是Linux集群,JDK1.8, Hadoop 2.7.*,Spark 2.1.*。 学员需要准备的电脑最好是i5及以上CPU,4GB及以上内存,硬盘空间预留50GB(可用移动硬盘),基本的大数据分析平台所依赖的软件包和依赖库等,讲师已经提前部署在虚拟机镜像(VMware镜像),学员根据讲师的操作任务进行实践。 本课程采用技术原理与项目实战相结合的方式进行教学,在讲授原理的过程中,穿插实际的系统操作,本课程讲师也精心准备的实际的应用案例供学员动手训练。 二、培训目标 1.本课程让学员充分掌握大数据平台技术架构、大数据分析的基本理论、机器学习的常用算法、国内外主流的大数据分析与BI商业智能分析解决方案、以及大数据分析在搜索引擎、广告服务推荐、电商数据分析、金融客户分析方面的应用案例。 2.本课程强调主流的大数据分析挖掘算法技术的应用和分析平台的实施,让学员掌握主流的基于大数据Hadoop和Spark、R的大数据分析平台架构和实际应用,并用结合实际的生产系统案例进
龙格库塔方法matlab实现~ function ff=rk(yy,x0,y0,h,a,b)%yy为y的导函数,x0,y0,为初值,h为步长,a,b为区间 c=(b-a)/h+1;i1=1; %c为迭代步数;i1为迭代步数累加值 y=y0;z=zeros(c,6); %z生成c行,5列的零矩阵存放结果; %每行存放c次迭代结果,每列分别存放k1~k4及y的结果 for x=a:h:b if i1<=c k1=feval(yy,x,y); k2=feval(yy,x+h/2,y+(h*k1)/2); k3=feval(yy,x+h/2,y+(h*k2)/2); k4=feval(yy,x+h,y+h*k3); y=y+(h/6)*(k1+2*k2+2*k3+k4); z(i1,1)=x;z(i1,2)=k1;z(i1,3)=k2;z(i1,4)=k3;z(i1,5)=k4;z(i1,6)=y; i1=i1+1; end end fprintf(‘结果矩阵,第一列为x(n),第二列~第五列为k1~k4,第六列为y(n+1)的结果') z %在命令框输入下列语句 %yy=inline('x+y'); %>> rk(yy,0,1,0.2,0,1) %将得到结果 %结果矩阵,第一列为x(n),第二列~第五列为k1~k4第六列为y(n+1)的结果 %z = % 0 1.0000 1.2000 1.2200 1.4440 1.2428 % 0.2000 1.4428 1.6871 1.7115 1.9851 1.5836 % 0.4000 1.9836 2.2820 2.3118 2.6460 2.0442 % 0.6000 2.6442 3.0086 3.0451 3.4532 2.6510 % 0.8000 3.4510 3.8961 3.9407 4.4392 3.4365 % 1.0000 4.4365 4.9802 5.0345 5.6434 4.4401
简介:本文档为《纵横向拉开档次法的MATLAB实现》,可适用于工程科技领域,主题内容包含globalxystdszxystdxy定义全局变量loadshuju原始数据xystd=zscore(shuju)数据无量纲处理xystdrow,符等。 global xystdsz xystd x y %定义全局变量 load shuju %原始数据 xystd= zscore (shuju); %数据无量纲处理 [xystdrow,xystdcol]=size(xystd); %----------区域知识创造能力评价---------- for tt=1:xystdcol xystdsz{tt}(:,:)=xystd{tt}(:,1:10); %提取区域知识创造能力指标无量纲值 end [xystdszrow,xystdszcol]=size(xystdsz); [xyrow,xycol]=size(xystdsz{1}); w0=zeros(1,xycol); for i=1:xycol w0(1,i)=1/xycol; % 优化初始值 end Aeq=[]; beq=[]; lb=zeros(1,xycol);ub=ones(1,xycol); %zeros生成零矩阵;ones生成全1阵。 options =optimset('largescale','off'); %优化函数,largescale大规模算法 [w,faval]=fmincon(@YHQU,w0,[],[],Aeq,beq,lb,ub,@fun,options ); %优化求权重;fmincon用来求解非线性多元函数最小值。 wqz1=w./sum(w); %权重归一化 for tt=1:xystdszcol z{tt}(:,1)=xystd{tt}(:,1:10)*wqz1'; % 求评价值 pxacz(:,tt)=px(z{tt}(:,1)) ; % 对评价值排序 end clear w0 w lb ub faval ; clear global xystdsz; %--------区域知识流动能力评价------------ for tt=1:xystdszcol xystdsz{tt}(:,:)=xystd{tt}(:,11:16); %提取区域知识流动能力指标无量纲值 end global xystdsz; [xystdszrow,xystdszcol]=size(xystdsz); [xyrow,xycol]=size(xystdsz{1}); w0=zeros(1,xycol); for i=1:xycol w0(1,i)=1/xycol; % 优化w初始值 end Aeq=[]; beq=[]; lb=zeros(1,xycol);ub=ones(1,xycol); options =optimset('largescale','off'); [w,faval]=fmincon(@YHQU,w0,[],[],Aeq,beq,lb,ub,@fun,options );