a Departmento de Informática,
- 格式:pdf
- 大小:157.25 KB
- 文档页数:12

Informa tica元数据库解析Informa tica所有的元数据信息均以数据库表的方式存到了元数据库中。
当然Infa本身工具提供了很多的人性化的功能,使我们在开发时可以很方便的进行操作,但人们的需求总是万变的,需要方便的取到自己需要的信息,那就需要我们对他的元数据库有很深的了解。
Informa tica通过表和视图给我们提供着所有的信息,在此将通过一个系列的帖子,将大部分常见的,且非常有用的表及视图介绍一下。
基于这些东西,我们即可以根据不同的需求查出自己需要的数据,也可以开发一些辅助的Infa应用程序。
OPB_ATT R:INFORMA TICA(Designe r,Workflo w等)设计时及服务器设置的所有属性项的名称,当前值及该属性项的简要说明例如:ATTR_NA ME:Tracing LevelATTR_VA LUE:2ATTR_CO MMENT:Amounto fdetai linthe sessio nlog用途:可以通过该表快速查看到设计或设置时碰到的一些属性项的用途与说明OPB_ATT R_CATE GORY:INFORMA TICA各属性项的分类及说明例如:CATEGOR Y_NAME:Filesan dDirec toriesDESCRIP TION:Attribu tesrel atedto filena mesand direct oryloc ations用途:查看上表所提的属性项的几种分类及说明OPB_CFG_ATTR:WORKFLO WMANAG ER中的各个Folder下的Sess ionCon figura tion的配置数据,每个配置对应表中一组Config_Id相同的数据,一组配置数据共23条例如:ATTR_ID:221ATTR_VA LUE:$PMBadFi leDir用途:查看所有的SessionC onfigu ration的配置项及值,并方便的进行各个不同Folder间的配置异同比较OPB_CNX:WORKFLO WMANAG ER中关于源、目标数据库连接的定义,包括RelationalC onnect ion,QueueCo nnecti on,LoaderC onnect ion等例如:OBJECT_NAME:Orace_S ourceUSER_NA ME:oralUSER_PA SSWORD:`?53S{$+*$*[X]CONNECT_STRIN G:Oratest用途:查看在WorkFlowMa nager中进行配置的所有连接及其配置数据OPB_CNX_ATTR:上表所记录的所有数据库连接的一些相关属性值,一种属性值一条数据。

2020年6月英语六级阅读真题及答案2020年6月英语六级阅读真题及答案Section ADirections: In this section, there is a short passagewith 5 questions or incomplete statements. Read the passage carefully. Then answer the questions or complete the statements in the fewest possible words. Please write your answers on Answer Sheet 2.Questions 47 to 51 are based on the following passage.How good are you at saying "no"? For many, it'ssurprisingly difficult. This is especially true of editors, who by nature tend to be eager and engaged participants in everything they do. Consider these scenarios:It's late in the day. That front-page package you've been working on is nearly complete; one last edit and it's finished. Enter the executive editor, who makes a suggestion requiring a more-than-modest rearrangement of the design and the addition of an information box. You want to scream: "No! It's done!" What do you do?The first rule of saying no to the boss is don't say no. She probably has something in mind when she makes suggestions, and it's up to you to find out what. The second rule is don't raise the stakes by challenging her authority. That issue is already decided. The third rule is to be ready to citeoptions and consequences. The boss's suggestions might be appropriate, but there are always consequences. She might not know about the pages backing up that need attention, or aboutthe designer who had to go home sick. Tell her she can have what she wants, but explain the consequences. Understand what she's trying to accomplish and propose a Plan B that will make it happen without destroying what you've done so far.Here's another case. Your least-favorite reporter suggests a dumb story idea. This one should be easy, but it's not. If you say no, even politely, you risk inhibitingfurther ideas, not just from that reporter, but from others who heard that you turned down the idea. This scenario is common in newsrooms that lack a systematic way to filter story suggestions.Two steps are necessary. First, you need a system for how stories are proposed and reviewed. Reporters can tolerate rejection of their ideas if they believe they were given a fair hearing. Your gut reaction (本能反应) and dismissive rejection, even of a worthless idea, might not qualify as systematic or fair.Second, the people you work with need to negotiate a "What if ...?" agreement covering "What if my idea is turned down?" How are people expected to react? Is there an appeal process? Can they refine the idea and resubmit it? By anticipating "What if...?" situations before they happen, you can reach understanding that will help ease you out of confrontations.47. Instead of directly saying no to your boss, you should find out __________.48. The author's second warning is that we should avoid running a greater risk by __________.49. One way of responding to your boss's suggestion is to explain the __________ to her and offer an alternative solution.50. To ensure fairness to reporters, it is important toset up a system for stories to __________.51. People who learn to anticipate "What if...?"situations will be able to reach understanding and avoid__________.参考答案47. what is in your boss's mind48. challenging our boss's anthority49. possible consequences50. be proposed and reviewed51. feeling uneasy about the confrontationsSection BDirections: There are 2 passages in this section. Each passage is followed by some questions or unfinished statements. For each of them there are four choices marked A), B), C) and D). You should decide on the best choice and mark the corresponding letter on Answer Sheet 2 with a single line through the centre.Passage OneQuestions 52 to 56 are based on the following passage.At the heart of the debate over illegal immigration lies one key question: are immigrants good or bad for the economy? The American public overwhelmingly thinks they're bad. Yetthe consensus among most economists is that immigration, both legal and illegal, provides a small net boost to the economy. Immigrants provide cheap labor, lower the prices ofeverything from farm produce to new homes, and leave consumers with a little more money in their pockets. So whyis there such a discrepancy between the perception of immigrants' impact on the economy and the reality?There are a number of familiar theories. Some argue that people are anxious and feel threatened by an inflow of new workers. Others highlight the strain that undocumented immigrants place on public services, like schools, hospitals, and jails. Still others emphasize the role of race, arguing that foreigners add to the nation's fears and insecurities. There's some truth to all these explanations, but they aren't quite sufficient.To get a better understanding of what's going on,consider the way immigration's impact is felt. Though its overall effect may be positive, its costs and benefits are distributed unevenly. David Card, an economist at UC Berkeley, notes that the ones who profit most directly from immigrants' low-cost labor are businesses and employers – meatpacking plants in Nebraska, for instance, or agricultural businessesin California. Granted, these producers' savings probably translate into lower prices at the grocery store, but howmany consumers make that mental connection at the checkout counter? As for the drawbacks of illegal immigration, these, too, are concentrated. Native low-skilled workers suffer mostfrom the competition of foreign labor. According to a study by George Borjas, a Harvard economist, immigration reduced the wages of American high-school dropouts by 9% between 1980-2000.Among high-skilled, better-educated employees, however, opposition was strongest in states with both high numbers of immigrants and relatively generous social services. What worried them most, in other words, was the fiscal (财政的)burden of immigration. That conclusion was reinforced by another finding: that their opposition appeared to soften when that fiscal burden decreased, as occurred with welfare reform in the 1990s, which curbed immigrants' access to certain benefits.The irony is that for all the overexcited debate, the net effect of immigration is minimal. Even for those most acutely affected – say, low-skilled workers, or California residents – the impact isn't all that dramatic. "The unpleasant voices have tended to dominate our perceptions," says Daniel Tichenor, a political science professor at the University of Oregon. "But when all those factors are put together and the economists calculate the numbers, it ends up being a net positive, but a small one." Too bad most people don't realize it.注意:此部分试题请在答题卡2上作答。

2014年普通高等学校招生全国统一考试 (天津卷)英语第二部分:阅读理解(共20小题,每小题2.5分,满分50分)AA Guide to the UniversityFoodThe TWU Cafeteria is open 7am to 8 pm. It serves snacks(小吃), drinks, ice cream bars and meals. You can pay with cash or your ID cards. You can add meal money to your ID cards at the Front Desk. Even if you do not buy your food in the cafeteria, you can use the tables to eat your lunch, to have meetings and to study.If you are on campus in the evening or lat at night, you can buy snacks, fast food, and drinks in the Lower Cafélocated in the bottom level of the Douglas Centre. This area is often used for entertainment such as concerts, games or TV watching.RelaxationThe Globe, located in the bottom level of McMillan Hall, is available for relaxing, studying, cooking, and eating. Monthly activities are held here for all international students. Hours are 10 am to 10 pm, closed on Sundays.HealthLocated on the top floor of Douglas Hall, th e Wellness Centr e is committed t o physical, emotional and social health. A doctor and nurse is available if you have health questions or need immediate medical help or personal advice. The cost of this is included in your medical insuranc e. Hours are Monday to Friday, 9 am to noon and 1;00 to 4;30 pm.Academic SupportAll student s have access to the Writing Centre on the upper floor of Douglas Hall. Here, qualified volunteer s will work with you on written work, grammar, vocabulary, and other academic skills. You can sign up for an appointme nt on the sign-up sheet outside the door two 30 –minute appointments per week maximum. This service is free.TransportationThe TWU Express is a shuttle(班车) service. The shuttle transports students between campus and the shopping centre, leaving from the Mattson Centre. Operation hours are between 9am and 3pm. Saturdays only. Round trip fare is $1.36. What can you do in the TWU Cafeteria?A. Do homework and watch TVB. Buy drinks and enjoy concertsC. have meals and meet with friendsD. Add money to your ID and play chess37. Where and when can you cook your own food?A. The Globe, FridayB. The Lower Café, SundayC. The TWU Cafeteria, FridayD. The McMillan Hall, Sunday.38. The Guide tells us that the Wellness Centre______.A. is open six days a weekB. offers services free of chargeC. trains students in medical careD. gives advice on mental health39. How can you seek help from the Writing Centre?A. By applying onlineB. By calling the centreC. By filling in a sign-up formD. By going to the centre directly40. What is the function of TWU Express?A. To carry students to the lecture halls.B. To provide students with campus toursC. To take students to the Mattson Centre.D. To transport students to and from the stores.【篇章导读】这是一篇广告。
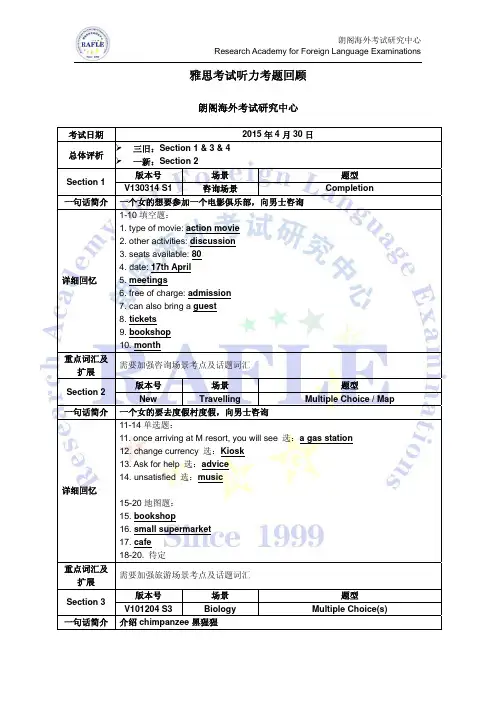
雅思考试听力考题回顾朗阁海外考试研究中心考试日期 2015年4月30日总体评析 三旧:Section 1 & 3 & 4 一新:Section 2Section 1版本号场景题型V130314 S1 咨询场景Completion一句话简介一个女的想要参加一个电影俱乐部,向男士咨询详细回忆1-10填空题:1. type of movie: action movie2. other activities: discussion3. seats available: 804. date: 17th April5. meetings6. free of charge: admission7. can also bring a guest8. tickets9. bookshop10. month重点词汇及扩展需要加强咨询场景考点及话题词汇Section 2 版本号场景题型New Travelling Multiple Choice / Map一句话简介一个女的要去度假村度假,向男士咨询详细回忆11-14单选题:11. once arriving at M resort, you will see 选:a gas station12. change currency 选:Kiosk13. Ask for help 选:advice14. unsatisfied 选:music15-20地图题:15. bookshop16. small supermarket17. cafe18-20. 待定重点词汇及扩展需要加强旅游场景考点及话题词汇Section 3版本号场景题型V101204 S3 Biology Multiple Choice(s)一句话简介介绍chimpanzee黑猩猩详细回忆21-26单选题:21. What is the best time to observe the chimpanzees? 什么时候好观察它们?选:A. 它们look for food的时候A. looking for food C. eating food22. Why do the chimpanzees wave to them? 大猩猩招手是为了?选:C. to show their dominance23. Where do their behaviors come from, various ways? 它从哪里学来的本领?选:B. imitating humanA. imitating their parentsB. imitating humanC. genetic24. How do the chimpanzees open the nutshell to get the food? 如何开食物的壳获取果实?选:C. hit with stonesA. throw to the wallB. hit with stickC. hit with stones25. What do the chimpanzees use leaves to do? 用树叶是为了?选:to protect head dry (from the rain)26. What do the students think the research result is? 对这次参观的感受?选:A. 研究的结果invalidA. invalidB. interestingC. imaginable27-30多选题:(5选2)27-28. What is the future research direction? 下次学生还想了解这个动物的哪些方面?选:A. adult relationship和B. feeding young animals29-30. What tools do they need to bring next time? 下次去做研究还要带些什么东西?选:B. measuring equipment和D. video camera (not camera) binoculars A. fruit (banana) B. measuring equipment D. video camera (not camera) binocularsSection 4版本号场景题型V130829 S4 Biology Completion一句话简介仿生学,从自然中加以运用的东西/ Bio-mimicry人类模仿生物进行仿生设计详细回忆31-40填空题:31. Arctic (Eskimo) people(北极人) copy the hunting skill spider.32. silk which is stronger than steel(蜘蛛丝组成的绳子比同样粗细的steel还要有力)33. finer than human hair application(比人的hair还要有韧性)34. environmentally friendly equipment for fishing(应用到fishing中做渔网)35. treat sports (athlete) injures36. medical stitches: self-dissolving (removal) pain(应用到医疗中,给患者带来更少的pain)37. Problem: noise of a train(解决noise)Owl: artificial skill38. vibration on plane and end of a tunnel(解决火车出tunnel时的多普勒效应)39. 利用仿生学增加boots的摩擦力 / skating boards used by Olympic40. reduce the loss of energy(减少energy损失)重点词汇及扩展补充自然和动物相关的背景单词,比如owl猫头鹰,蜘蛛spider等。

LuaInterface:Scripting CLR with LuaFabio Mascarenhas1,Roberto Ierusalimschy11Departamento de Inform´a tica,PUC-RioRua Marquˆe s de S˜a o Vicente,225–22453-900Rio de Janeiro,RJ,Brasilmascarenhas@,roberto@inf.puc-rio.brAbstract.In this paper we present LuaInterface,a library for scripting CLR with Lua. Common Language Runtime aims to provide interoperability among objects writtenin several different languages.LuaInterface is a library for the CLR that lets Lua script objectsin any language that runs in the CLR.It gives Lua the capabilities of a full CLS consumer.TheCommon Language Specification is a subset of the CLR with rules for language interoperability,and languages that can use CLS-compliant libraries are called CLS consumers.Applicationsmay also use LuaInterface to embed a Lua interpreter and use Lua as a language for configu-ration scripts or for extending the application.LuaInterface is part of the project forintegration of Lua into Common Language Infrastructure.1.IntroductionThe Framework aims to provide interoperability among several different languages through its Common Language Runtime(CLR)[13].The CLR specification is being turned into ISO and ECMA standards[14],and implementations for non-Windows platforms already exist[17,18].Visual Basic, JScript,C#,J#,and C++already have compilers for the CLR,written by Microsoft,and compilers for several other languages are under development[2].Lua is a scripting language designed for to be simple,portable,to have a small footprint,and to be easily embeddable into other languages[8,10].Scripting languages are often used for connecting components written in other languages to form applications(“glue”code).They are also used for building prototypes,and as languages for configurationfiles.The dynamic nature of these languages allows the use of components without previous declaration of types and without the need for a compilation phase. Nevertheless,they perform extensive type checking at runtime and provide detailed information in case of errors.The combination of these features can increase developer productivity by a factor of two or more [16].This work presents LuaInterface,a library for the CLR that allows Lua scripts to access the object model of the CLR,the Common Type System(CTS),turning Lua into a scripting language for components written in any language that runs in the CLR.LuaInterface is part of the project for integration of Lua into the CLR[9].LuaInterface provides all the capabilities of a full CLS consumer.The Common Language Spec-ification(CLS)is a subset of the CLR that establishes a set of rules to promote language interoperability. Compilers that generate code capable of using CLS-compliant libraries are called CLS -pilers that can produce new libraries or extend existing ones are called CLS extenders.A CLS consumer should be able to call any CLS-compliant method or delegate,even methods named after keywords of the language;to call distinct methods of a type with the same name and signature but from different interfaces; to instantiate any CLS-compliant type,including nested types;and to read and write any CLS-compliant property and access any CLS-compliant event[14,CLI Partition I Section7.2.2].With LuaInterface,Lua scripts can instantiate CTS types,access theirfields,and call their methods (both static and instance),all using the standard Lua syntax.CLR applications can run Lua code,acess Lua data,call Lua functions,and register CLR methods as functions.Applications can use Lua as a language for their configuration scripts or as an embedded scripting language,and Lua cripts can glue together different components.Besides these consumer facilities there is also a limited support for dynamically creating new CTS types,but it will not be covered in this paper.Lua is dynamically typed,so it needs no type declarations to instantiate or use CLR objects.It checks at runtime the correctness of each instantiation,field access,or method call.LuaInterface makes extensive use of the reflexive features of the CLR,without the need of preprocessing or creating stubs for each object that needs to be accessed.Its implementation required no changes to the Lua interpreter: the interpreter is compiled to an unmanaged dynamic linked library and the CLR interfaces with it using P/Invoke.The rest of this paper is structured as follows:Section2shows how applications can use LuaIn-terface and the methods it exposes,with examples.Section3describes particular issues of the implemen-tation,with basic performance measurements.Section4presents some related work and comments on their strengths and drawbacks relative to LuaInterface,and Section5presents some conclusions and future developments.2.Interfacing Lua and the CLRAs an embeddable language,Lua has an API that lets an application instantiate a Lua interpreter,run Lua code,exchange data between the application and the interpreter,call Lua functions,and register functions so they can be called from Lua[11].LuaInterface wraps this API into a class named Lua,which provides methods to execute Lua code,to read and write global variables,and to register CLR methods as Lua functions.Auxiliary classes provide methods to access Lua tables’(associative arrays)fields and to call Lua functions.LuaInterface also has the capabilities of a full CLS consumer,so Lua code can instantiate CLR objects and access their their properties and methods.Functions arefirst-class values in Lua,so Lua objects are just tables,and functions stored infields are their methods.By convention,these functions receive afirst argument called self that holds a reference to the table.There is syntactic sugar for accessingfields and methods.The dot(.)operator is used forfields,with obj.field="foo"meaning obj["field"]="foo",for example.The colon (:)operator is used to call methods.A method call like obj:foo(arg1,arg2)is syntactic sugar for obj["foo"](obj,arg1,arg2),that is,the object goes as thefirst argument to the call.2.1.The API wrapperApplications start a new Lua interpreter by instantiating an object of class Lua.Multiple instances may be created,and they are completely independent.Methods DoFile and DoString execute a Lua source file and a Lua chunk,respectively.Access to global variables is through the class indexer,indexed by vari-able name.The indexer returns Lua values with the equivalent CTS value type:nil as null,numbers as System.Double(the Lua interpreter uses doubles to represent all numbers),strings as System.String, and booleans as System.Boolean.The following C#code shows the usage of these methods: //Start a new Lua interpreterLua lua=new Lua();//Run Lua chunkslua.DoString("num=2");//create global variable’num’lua.DoString("str=’a string’");//Read global variables’num’and’str’double num=(double)lua["num"];string str=(string)lua["str"];//Write to global variable’str’lua["str"]="another string";The indexer returns Lua tables as LuaTable objects,which have their own indexers to read and write tablefields,indexed by name or by numbers(arrays in Lua are just tables indexed by numbers).They work just like the indexers in class Lua.Lua functions are returned as LuaFunction objects.Their call method calls the corresponding function and returns an array with the function’s return values.LuaInterface converts CLR values passed to Lua(either as a global or as an argument to a function) into the appropriate Lua types:numeric values to Lua numbers,strings to Lua strings,booleans to Lua booleans,null to nil,LuaTable objects to the wrapped table,and LuaFunction objects to the wrapped function.2.2.Loading CTS types and instantiating objectsScripts need a type reference to instantiate new objects.They need two functions to get a type reference. First they should use load assembly,which loads the specified assembly,making its types available to be imported as type references.Then they should use import type,which searches the loaded assemblies for the specified type and returns a reference to it.The following excerpt shows how these functions work.load_assembly("System.Windows.Forms")load_assembly("System.Drawing")Form=import_type("System.Windows.Forms.Form")Button=import_type("System.Windows.Forms.Button")Point=import_type("System.Drawing.Point")StartPosition=import_type("System.Windows.Forms.FormStartPosition")Notice how scripts can use import type to get type references for structures(Point)and enumerations(FormStartPosition),as well as classes.Scripts call static methods through type references,using the same syntax of Lua objects.For example,Form:GetAutoScaleSize(arg)calls the GetAutoScaleSize method of class Form. LuaInterface does lookup of static methods dynamically by the number and type of arguments.Scripts also read and write to staticfields and non-indexed properties through type references,also with the same syntax of Lua objects.For example,var=Form.ActiveForm assigns the value of the ActiveForm property of class Form to the variable var.LuaInterface treats enumeration values asfields of the corresponding enumeration type.LuaInteface converts arguments to the parameter type not the original Lua type.For example,a number passed to a C#method expecting a System.Int32value is converted to System.Int32,not to System.Double.LuaInterface coerces numerical strings into numbers,numbers into strings and Lua functions into delegates.The same conversions apply tofields and non-indexed properties,with values converted to thefield type or property type,respectively.To instantiate a new CTS object a script calls the respective type reference as a function.Thefirst constructor that matches the number and type of the parameters is used.The following example extends the previous example to show some of the discussed features:form1=Form()button1=Button()button2=Button()position=Point(10,10)start_position=StartPosition.CenterScreen2.3.Accessing other CTS typesOnly numeric values,strings,booleans,null,LuaTable instances and LuaFunction instances have a mapping to a basic Lua type that LuaInterface uses when passing them from the CLR to Lua.LuaIn-terface passes all other objects as references stored inside an userdata value(an userdata is a Lua type for application-specific data).Scripts read and write an object’sfields and non-indexed properties asfields of Lua objects,and call methods as methods Lua objects.To read and write indexed properties(including indexers)they must use their respective get and set methods(usually called get PropertyName and set PropertyName).The same considerations about method matching and type coercion that apply for accessing static members apply for accessing instance members.The following Lua code extends the previous examples to show how to access properties and methods:button1.Text="OK"button2.Text="Cancel"button1.Location=positionbutton2.Location=Point(button1.Left,button1.Height+button1.Top+10) form1.Controls:Add(button1)form1.Controls:Add(button2)form1.StartPosition=start_positionform1:ShowDialog()The three previous examples combined,when run,show a form with two buttons,on the center of the screen.Scripts can register Lua functions as event handlers by calling the event’s Add pseudo-method.The call takes a Lua function as the sole argument,and automatically converts this function to a Delegate instance with the appropriate signature.It also returns the created delegate,allowing deregistration through the event’s Remove pseudo-method.The following Lua code extends the previous examples to add event handlers to both buttons:function handle_mouseup(sender,args)print(sender:ToString().."MouseUp!")button1.MouseUp:Remove(handler1)endhandler1=button1.MouseUp:Add(handle_mouseup)handler2=button2.Click:Add(exit)--exit is a standard Lua function Scripts can also register and deregister handlers by calling the object’s add and remove methods for the event(usually called add EventName and remove EventName).LuaInterface passes any exception that occurs during execution of a CLR method to Lua as an error,with the exception object as the error message(Lua error messages are not restricted to strings).Lua has mechanisms for capturing and treating those errors.LuaInterface also provides a shortcut for indexing single-dimension arrays(either to get or set values),by indexing the array reference with a number,for example,arr[3].For multidimensional arrays scripts should use the methods of class Array instead.2.4.Additional full CLS consumer capabilitiesThe features already presented cover most uses of LuaInterface,and most of the capabilities of a full CLS consumer.The following paragraphs present the features that cover the rest of the needed capabilities.Lua offers only call-by-value parameters,so LuaInterface supports out and ref parameters using multiple return values(functions in Lua can return any number of values).LuaInterface returns the values of out and ref parameters after the method’s return value,in the order they appear in the method’s signature. The method call should ommit out parameters.The standard method selection of LuaInterface uses thefirst method that matches the number and type of the call’s arguments,so some methods of an object may never be selected.For those cases, LuaInterface provides the function get method bysig.It takes an object or type reference,the method name,and a list of type references corresponding to the method parameters.It returns a function that,when called,executes the desired method.If it is an instance method thefirst argument to the call must be the receiver of the method.Scripts can also use get method bysig to call instance methods of the CLR numeric and string types.There is also a get constructor bysig function that does the same thingfor constructors.It takes as parameters a type reference that will be searched for the constructor and zero or more type references,one for each parameter.It returns a function that,when called,instantiates an objectof the desired type with the matching constructor.If a script wants to call a method with a Lua keyword as its name the obj:method(...) syntax cannot be used.For a method named function,for example,the script should call it usingobj["function"](obj,...).To call distinct methods with the same name and signature,but belonging to different interfaces, scripts can prefix the method name with the interface name.If the method is called foo,for example,andits interface is IFoo,the method call should be obj["IFoo.foo"](obj,...).Finally,to get a reference to a nested type a script can call import type with the nested type’s name following the containing type’s name,like in import_type("ContainingType+NestedType").3.Implementation of LuaInterfaceWe wrote LuaInterface mostly in C#,with a tiny(less than30lines)stub in C.The current version uses Lua version5.0.The C#code is platform-neutral,but the stub must be changed depending on the standard calling convention used by the CLR on a specific platform.The implementation assumes the existence of a DLL or shared library named lua.dll containing the implementation of the Lua API plus the stub code, and a library named lualib.dll containing the implementation of the Lua library API.3.1.Wrapping the Lua APILuaInterface accesses the Lua API functions through Platform/Invoke(P/Invoke for short),the CLR’s native code interface.Access is straightforward,with each function exported by the Lua libraries correspondingto a static method in LuaInterface’s C#code.For example,the following C prototype:void lua_pushstring(lua_State*L,const char*s);when translated to C#is:static extern void lua_pushstring(IntPtr L,string s);P/Invoke automatically marshalls basic types from the CLR to C.It marshalls delegates as function pointers,so passing methods to Lua is almost straightforward,for care must be taken so the CLR garbage collector will not collect the delegates.In Windows there is also a conflict of function calling conventions. The C compilers use CDECL calling convention by default(caller cleans the stack)while the Microsoft.NET compilers use STDCALL as default(callee cleans the stack),so we wrote a tiny stub C stub which exports a function that receives an explicit STDCALL function pointer and passes it to the Lua interpreter wrapped inside a CDECL function.Implementing the Lua wrapper class and its methods that deal with Lua standard types was easy once the Lua API was fully available to C#programs.The API has functions to convert Lua numbers to Cdoubles and C doubles to Lua numbers.It also has functions to convert Lua strings to C strings(char*)and C strings to Lua strings,and functions to convert Lua booleans to C booleans(integers)and C booleans to Lua booleans.The Lua class’indexer just calls these functions when numbers,strings and booleans are involved.The indexer returns tables and functions as LuaTable and LuaFunction instances,respec-tively,containing a Lua reference(an integer),and CLR applications access or call them through the ap-propriate API functions.When the CLR garbage collector collects the instances LuaInterface removes their Lua references so the interpreter may collect them.3.2.Passing CLR objects to LuaLua has a data type called userdata that lets an application pass arbitrary data to the interpreter and later retrieve it.When an application creates a new userdata the intrepreter allocates space for it and returns a pointer to the allocated space.The application can attach functions to an userdata to be called when it is garbage-collected,indexed as a table,called as a function,or compared to other values.When LuaInterface needs to pass a CLR object to Lua it stores the object inside a list(to keep the CLR from collecting it),creates a new userdata,stores the index(in the list)of the object inside this userdata, and passes the userdata instead.A reference to the userdata is also stored,with the same index,inside a Lua table.This table is used if the object was already passed earlier,to reuse the already created userdata instead of creating another one(avoiding aliasing).This table stores weak references so the interpreter can eventually collect the userdata.When the interpreter collects it the original object must be removed from the list.This is done by the userdata’sfinalizer function.ing CLR objects from LuaWhen a script calls a CLR method,such as obj:foo(arg1,arg2),the Lua interpreterfirst converts the call to obj["foo"](arg1,arg2),which is an indexing operation(obj["foo"])followed by a call to the value returned by it.The indexing operation for CLR objects is implemented by a Lua function.It checks if the method is already in the object type’s method cache.If it is not,the function calls a C#function which returns a delegate to represent the method and stores it in the object type’s method cache.When the interpreter calls the delegate for a method itfirst checks another cache to see if this method has been called before.This cache stores the MethodBase object representing the method(or one of its overloaded versions),along with a pre-allocated array of arguments,an array of functions to get the arguments’values from Lua with the correct types,and an array with the positions of out and ref parameters (so the delegate can return their values).If there is a method in the cache the delegate tries this methodfirst. If the cache is empty or the call fails due to a wrong signature,the delegate checks all overloaded versions of the method one by one tofind a match.If itfinds one it stores the method in the cache and calls it, otherwise it throws an exception.To readfields LuaInterface uses the same C#function that returns the method delegate,but now it returns the value of thefield.Non-indexed properties and events use this same technique,but events return an object used for registration/deregistration of event handlers.This object implements the event’s Add and Remove pseudo-methods.LuaInterface uses another C#function to treat assignment tofields and non-indexed properties.It retrieves the object from the userdata,uses reflection to try tofind a property orfield with the given name and,if found,converts the assigned value to the property type orfield type and stores it.Type references returned by the import type function are instances of class Type,with their own assignment and indexing functions.They search for static members only,but otherwise work just like the assignment and indexing functions of normal object instances.When a script calls a type reference to instantiate a new object,LuaInterface calls a function which searches the type’s constructors for a matching one,instantiating an object of that type if itfinds a match.3.4.Performance of CLR method callsWe ran simple performance tests to gauge the overhead of calling a CLR method from a Lua script.On average the calls werefive times slower than calling the same method from C#using reflection(with MethodBase.Invoke).Most of the overhead is from P/Invoke:each P/Invoke call generates from ten to thirty CPU instructions plus what is needed for security checking and argument marshalling[15]. One call is needed for each argument of the method plus one for the receiver,one for the delegate,one for each returned value,and one call to get the number of arguments passed to the method.The rest of the overhead(afifth of the call’s time,approximately)is from Lua itself,as each method call is also a Lua function call which checks a Lua table(the method cache).Implementing this cache in C#just makes performance worse(by a factor of2.5),as three more P/Invoke calls are needed to get the receiver of the method,the method’s name and then returning the delegate.Removing the second level of caching so every method call needs to match the arguments against the method’s overloaded versions and their parameters worsens the performance by a factor of three.The naive implementation(no caching at all)is much worse(by about two orders of magnitude),as each method call involves the creation of a new delegate.4.Related WorkThe LuaPlus distribution[12]has some of the features of LuaInterface.It provides a managed C++wrapper to the Lua API that is similar to LuaInterface’s API wrapper,with methods to run Lua code,to read and write Lua globals,and to register delegates(with a specific signature)as Lua functions.Arbitrary CLR objects may be passed to the interpreter as userdata,but Lua scripts cannot access their properties and methods,and applications cannot register methods with arbitrary signatures as Lua functions.LuaOrb is a library,implemented in C++,for scripting CORBA objects and implementing CORBA interfaces[5,6].As LuaInterface,LuaOrb uses reflection to access properties and to call methods of CORBA objects.Registering Lua tables as implementations of CORBA interfaces is done through CORBA’s Dynamic Server Interface,which has no similar in CLR,although a similar feature was implemented for LuaInterface by runtime code generation through Reflection.Emit.LuaJava is a scripting tool for Java that allows Lua scripts to access Java objects and create Java objects from Lua tables[3,4].LuaJava uses an approach very similar to the one in LuaInterface to access Java objects,using Java reflection tofind properties and methods and Java’s native code API to acess the Lua C API.It uses dynamic generation of bytecodes to create Java objects from tables,generating a class that delegates attribute access and method calling to the Lua table.This class is loaded by a custom class loader.The CLR’s Reflection.Emit interface made this task much easier,with its utility classes and methods for generating and loading Intermediate Language(IL)code.Microsoft’s Script for Framework[7]is a set of script engines that a CLR application can host.It provides two engines by default,a Visual Basic engine and a JScript engine.Scripts have full access to CTS classes and the application can make its objects available to them.The scripts are compiled to CLR’s Intermediate Language(IL)before they are executed,instead of being directly executed by a separate interpreter like LuaInterface does with Lua scripts.ActiveState’s PerlNET[1]gives access to Perl code from the CLR.It packages Perl classes and modules as CTS classes,with their functions and methods visible to other objects.This is accomplished by embedding the interpreter inside the runtime,and using proxies to interface the CLR objects with Perl code. This is very similar to the approach used by LuaInterface,but the types generated by LuaInterface are kept on memory and recreated on each execution instead of being exported to an autonomous assembly on disk.Other scripting languages have compilers for the CLR in several stages of development,such as SmallTalk(S#),Python,and Ruby[2].When these compilers are ready these languages may also be used to script CLR applications,but only prototypes are available yet.5.Conclusions and Future WorkThis paper presented LuaInterface,a library that gives Lua scripts full access to CLR types and objects and allows CLR applications to run Lua Code,turning Lua into a glue language for CLR applications. LuaInterface gives Lua the capabilities of a full CLS consumer.We implemented the library in C#so it is platform-neutral,except for a small C ers can compile the C code(the Lua interpreter and the stub)in all the platforms where the CLR is available,with minimal changes to the stub code.The Lua interpreter was designed to be easily embeddable,and with the CLR’s P/Invoke library access to the interpreter was straightforward.We created an object-oriented wrapper to the C API functionsto provide a more natural interface for CLR applications.Performance of method calls from Lua is still poor when compared with reflection,although Lu-aInterface caches method calls.They were aboutfive times slower,on average.Most of the overhead comes from costly P/Invoke function calls.What we learned during the course of this project:•The extensibility of Lua made it easy to implement the full CLS consumer capabilities without any changes to the interpreter or language,and without the need for a preprocessor;•Lua’s dynamic typing and the CLR’s reflection are crucial for the lightweight approach to integra-tion that was used in this project,as the correctness of operations may be checked by the library at runtime;•Reflection is not the performance bottleneck for the library,as we initially thought it would be;•P/Invoke is very easy to use and very clean,but much slower than we thought,and became the bottleneck of the library.The CLR documentation could give more emphasis to the performance penalties of using P/Invoke.LuaInterface is an ongoing project.There is room for improvements with more CLR extension features,as well as further optimization for method calls,reducing the use of P/Invoke or not using it at all.One possible optimization is to reduce the number of P/Invoke calls necessary for each operation.This requires extensions to the API(new C functions).Another optimization is to do a full port of the Lua interpreter to managed code.Both are being considered for future work.References[1]ActiveState.PerlNET— components using the Perl Dev Kit,2002.Available at http:///ASPN/Downloads/PerlNET.[2] Languages,2003.Available at /dotnetlanguages.html.[3]C.Cassino and R.Ierusalimschy.LuaJava—Uma Ferramenta de Scripting para Java.In Simp´o sioBrasileiro de Linguagens de Programac¸˜a o(SBLP’99),1999.[4]C.Cassino,R.Ierusalimschy,and N.Rodriguez.LuaJava—A Scripting Tool for Java.Techni-cal report,1999.Available at http://www.tecgraf.puc-rio.br/˜cassino/luajava/ index.html.[5]R.Cerqueira,C.Cassino,and R.Ierusalimschy.Dynamic Component Gluing Across Different Com-ponentware Systems.In International Symposium on Distributed Objects and Applications(DOA’99), 1999.。

Versus:a Model for a Web RepositoryJo˜a o P.Campos M´a rio J.SilvaXLDB Research GroupDepartamento de Inform´a ticaFaculdade de Ciˆe ncias da Universidade de LisboaCampo Grande,1749-016Lisboa,Portugal[jcampos,mjs]@di.fc.ul.ptAbstractWeb data warehouses can prove useful to applications that process large amounts of Web data.Versus is a model for a Repository for Web data management applications,supporting ob-ject versioning and distributed operation.Versus applications control the distribution,and the integration of data.This paper presents the design of Versus and our prototype implementation.Keywords:Web data repository,versioning,distributed database.1IntroductionThe Web is a great personal enhancement tool,but the amount of data available is so vast that its true potential can only be harnessed with tools specialized in aiding usersfind,sort,filter, summarize and mine this data.To handle large amounts of information,applications need bandwidth.With today’s limi-tations,applications wouldn’t be able to solve user queries in due time,because it would take them too long to download the data.Pre-fetching the information(anticipating user interaction)and storing it would be a rea-sonable solution:getting a copy of all the needed information is very expensive(both on time and bandwidth usage),but saved data can then be reused by several applications and users.A Web robot can be used to seek,download and store large portions of Web contents. However available Web robots are either expensive and proprietary[1,8],outdated[9],or both [16].Solutions for storing collected Web data are tightly coupled with the robots used,and, being proprietary,are not readily available for usage by other applications.In addition,to efficiently implement Web applications that deal with Web data,we may need scalable storage,capable of holding large amounts of data,with a high throughput.The motivation for this work is that we couldn’tfind a storage offering high performance meta-data management(like serverlessfilesystems[2]do for data)with an interface to manage web meta-data.Our goal is to provide support for automatically perform the following functions: Retrieval of large quantities of data from the Web.This may represent a huge compu-tational effort,requiring advanced techniques to address scale problems.Applications retrieving and saving data are usually built tightly coupled with the storage system used.Hence,the storage framework for Web data should be highly scalable,allowing the distri-bution of the loading processes among a network of processors.Manage meta-data about Web resources.Most applications built on Web data require both the documents retrieved from the Web and the meta-data available about these documents,such as the URL where the document was retrieved,its last modification date,or MIME-type.The storage system must provide methods for storing and retrieving these meta-data elements along with the documents.Save historic data.History may be relevant.While some applications won’t care about old unavailable documents,some others might be interested in looking at how a portion of the Web was some time ago.The storage must provide access methods enabling user applications to specify what they want to see in respect to time.This paper presents an implementable model for a Web data repository satisfying these functional and architectural requirements and the implementation of a working prototype that serves as its proof of concept.Versus is the name used for the model developed for storing and managing Web data.In the text,we also designate the developed prototype system as Versus.The paper is organized as follows:next section presents some work related with Versus; section3presents the Versus model for a distributed repository;section4details our prototype implementation and section5presents the conclusions and future work.2Related WorkVersion models are a powerful means of representing evolution of objects over time.The empha-sis on versioning systems research was on supporting Computer Aided Design(CAD)systems. The design process is slow:complex objects are developed by teams of designers,each of whom designs independent parts.Parts are integrated to form the whole.Eventually some parts are redrawn and some parts are reused from previous projects.Web data collection is similar to CAD engineering design:data is collected at different times (due to bandwidth constraints)and may be related(through the link structure)or integrated with other data to form complex objects,like pages or sites.Some parts(pages)of the collected Web may be revised,recollected and related with old(already stored)parts.The Web grows everyday,revealing new pages to integrate in the global picture.Version models provide semantic extensions to support the organization of engineering data [14],including unified concepts for managing and structuring information changing over time. Versus uses some of the defined concepts,such as workspaces,versions and check-out/check-in operations.Web-based Distributed Authoring and Versioning(WebDAV)is a set of extensions to the HTTP protocol that enable users to collaboratively edit and managefiles on remote Web servers [18,13].WebDAV implements long lasting locks,preventing two users from writing the same resource without merging changes.WebDAV servers are not designed for holding the amount of data we aim to hold with Versus.A WebDAV interface could,in principle,be developed for Versus.Web repositories are data stores designed to hold Web data.Most were developed to sup-port search engines,storing the data needed to build indexes or compute rankings.Some implementations hold large portions of the Web,and their architecture is designed to hold the entire visible Web.WebBase[10]is a repository of web pages designed for maintaining a large shared repository of data downloaded from the Web.The main focus of WebBase is optimizing data access,storing all the meta-data in a separate database management system.From our experiments we found that meta-data management can be a bottleneck to the system perfor-mance.We couldn’tfind details about how WebBase manages meta-data other than it is saved on a relational database(is it centralized or distributed?)WebBase is specifically tailored for supporting a Web crawler.AIDE[7,3]is a difference engine that allows users to track changes on Internet pages; WebGUIDE[6]is a system for exploring the changes storage system,offering a navigational tool to analyze the differences in Web pages over time.The difference engine is supported by a centralized versioning repository that stores versions of documents so that they are available for comparison in the future.Data is saved in this repository in Revision Control System(RCS) [17]format.Meta-data is saved in a relational database.The Internet Archive[12,4,15]goal is to build an Internet library for offering access to collections in digital format.The main focus is on long term preservation of selected contents and offering access to collected items.We have presented other research on topics related to Versus.A comparison between Versus and the systems presented is out of the scope of this paper and is of little practical interest as they all have a small overlap with Versus with respect to functionality.3Versus ModelProcessing large quantities of information in a Web data-warehouse involves integration of data from multiple sources,indexing,summarizing and mining Web data.The key for scaling up these heavy data processing operations lies in distributing the load among several processors, parallelizing the tasks to perform.However,this distribution must be supported by a storage system that can cope with the new complexities introduced,such as partitioning the work into units,physical distribution of data and scheduling work units among the processors,provisioning of methods for accessing distributed data and,finally,the fusion of the independently processed parts to form coherent views.Our approach is based in a versions and workspaces model for data,enabling paralleliza-tion of applications processing large collections of Web pages.Versus follows this approach, supporting concurrent updates,versioning and distribution.3.1A Typical Usage ScenarioOne example of an application with high data interaction is a distributed Web crawler.In a typical implementation,each thread,running on a separate processor,is responsible for collect-ing documents from certain parts of the Web;in the end,the crawler delivers an integrated archive with the collected documents.The running context of such an application is depicted in Figure1.Each thread,when initializing,would get from the storage server the roots of the crawl(the pages where to start looking for links).Crawling the Web consists of iteratively downloading pages,extracting the links referencing other pages,downloading these pages and so on.During the crawl,threads would exchange data through the repository’s storage server to ensure that each document is not processed more than once.When each of the threadsfinishes, it uploads the documents obtained to the repository’s storage server,making them available to other applications.3.2RequirementsWe identified the following main requirements for a web data repository:•Support partitioning of the work into disjoint units that can be processed concurrently;•Support concurrent updates to disjoint subsets of the data;•Support integration of results from processed units;•Enabling threads working on separate units to exchange information so that applications can avoid duplicate processing;HighBandwidthStorageServerProcessingNodesFigure 1:Running context of applications using Versus.The storage server holdsdata to be shared by the several transactions of the running application.Eachtransaction runs in a processing node and has an associated storage,where dataprocessed locally is kept.The time lost in data transfer between the processingnodes and the storage server is compensated by parallel data processing.•Support storage of large amounts of data,ultimately archiving a very large portion of theentire Web;•Enable reading of stored information while other transactions process updates;•Support periodic partial updates to stored information,refreshing stale data items whilemaintaining their relationships to other items;•Reuse storage when new documents are equal to a previously collected version;•Enable views over past states of data,providing the time dimension in stored data.3.3AssumptionsThe design of Versus is based on the following assumptions:rmation spaces can be partitioned into disjoint subsets that can be processed with ahigh degree of independence;2.The performance overhead introduced by intra-thread communication for synchronizationof the non independent part of the computation is largely compensated by the parallel execution of the threads.3.Applications provide the repository with a function to partition the data into processingunits and a function to reconcile conflicting data generated within different units.Independence among working units is application specific.Assumption 2implicitly states that Versus is most suited for applications that can profit from parallel processing.3.4ConceptsWe now present the main concepts of the Versus model.Archive WorkspaceThreadDataThreadDataCheck out Check inGroupWorkspacePrivateWorkspacesDataApplication451Figure2:Versus supports three classes of workspaces:archive,group and pri-vate workspaces.Thefigure depicts an archive workspace holding a data set partitioned in several subsets.Applications check-out to the group workspace only the data sets they will use.Threads concurrently check-out subsets of the data,process them,and check them back in.3.4.1WorkspacesWorkspaces are well bounded and independent environments where application threads can apply transactions to subsets of the data to be processed,minimizing interaction with other data subsets being processed by other clients.We define three kinds of workspaces:private,group and archive.Private workspace:provides storage to application threads.Private workspaces are inde-pendent of one another,and may reside in different processors.Each parallel thread that accesses the repository and generates results for an application should instantiate a private workspace of its own.Group workspace:integrates partial results generated by clients on private workspaces.Each application(possibly with several threads of execution)processing archived data should instantiate a group workspace.Conflicts may arise when consolidating data from several private workspaces into a group workspace.Versus handles the conflicts using the methods provided by the application that generated them.Archive workspace:stores data permanently.It keeps version history for the data and is able to reconstruct earlier views of data.The archive workspace is an append only storage: data stored in the archive workspace can’t be updated or deleted.Data is passed from one workspace to another via check-out and check-in operations through the following steps(seefigure2):1.When an application is started,it instantiates a new group workspace,checking-out datait will need from the archive workspace;2.The application forks n parallel threads;3.Each of the parallel threads starts its own private workspace and checks out one of thedata subsets;4.Whenfinished with one subset,the thread checks in the results into the group workspaceand restarts with another data subset;5.When the applicationfinishes,the results in the group workspace are checked-in into thearchive workspace.3.4.2LayersVersus sees its data as a collection of objects that can be versioned,organizing them in layers.A layer is a storage unit capable of holding one single version of each object stored in a workspace. Each workspace may contain objects from several layers.Each workspace has an active layer.All objects that are added to the workspace are as-sociated to the active layer.Workspaces can’t save objects in layers other then the active layer.A Versus repository may be set to increment the active layer number automatically or manually.If set to automatically increase the layer number,the current layer is incremented whenever a new version of an object that already exists in the current layer is added;then the new version is added to the new layer.If the repository is set to manually increment the current layer number,then any addition of an object that already exists in that layer is denied and an error is raised.Layers are represented by integers monotonically incremented in a repository,they store the time dimension of data,showing the partial order of object manipulation operations within the repository;for example,in a manually incremented repository,one application knows that any two objects stored in the same layer are contemporary,meaning that they were both inserted into the repository when that layer was the active layer.3.4.3VersionsVersion models allow the storage of several instances of the same objects as saved in different instants over time.This is very useful for storing the evolution of the state of objects,enabling applications to see views of the represented world at different points in time.As the Web can’t (and shouldn’t)be represented at once,saved representations of it can’t be easily refreshed. The application of the version model to Web data is very useful because it allows the refreshing of parts of the represented data known to be stale,maintaining coherence between fresh and non fresh data.Furthermore,applications can choose to work with different views over data: for instance,a search engine built on top of the repository may use the latest available version of each document,while a web difference engine can choose to read all versions of a document to track how it was changed.Versus assumes that if any two versions have the same id,then they both are versions of the same object.As all versions have an associated layer number,which is unique for every version of any given object,two versions of one object have distinct layer numbers,and the order of the layer numbers can be used to derive which of these is the oldest version.3.4.4Objects and AssociationsVersus is designed to process webs of objects that can be viewed as labeled graphs,where nodes are object instances and edges are associations between them.Edge labels denote association types.Objects saved in a Versus repository are modeled as having an associated name,a property set and a stream of data.Streams of data are to be saved in afilesystem,and their management is external to Versus.An object o is represented in Versus as a tuple o(name,{properties},stream). The object name is the identifier of an object and can’t be changed.Objects may be related to each other by oriented,typed associations,modeling the rich associations that exist in the real world between objects.A relationship R of type t from objecta to objectb is represented as a tuple R(a,b,t),where a is the anchor of the relation,b its target and t is the association type.3.4.5Partition and Data UnitsA partition of a workspace is defined as the division of the workspace into disjoint subsets.We call each of the subsets forming the partition a strict data unit,or simply a strict unit.3.4.6PredicatesWhen checking out data from one workspace to another,applications specify the disjoint subset of the data(objects and versions)to be checked out.If applications had to enumerate the objects to check-out one by one,they would have to know in advance the objects’identifiers.This may turn out impossible to some applications. In Versus,applications specify sets of objects to check-out using predicates.A predicate is a function P red A that,given an object o returns true when o belongs to A.P red A is not a belongs-to operation.The application of a predicate to all objects in the workspace defines the unit.On check-out,the repository tests the supplied predicate against candidate objects and returns those that satisfy the predicate.For instance,if one thread wants to perform a transaction on all objects whose identifier starts with letter d,it provides a function to the repository that returns true if an object starts with d and false otherwise.The repository then evaluates that function on all objects of the workspace tofind out which are to be checked-out.Predicates must be defined by Versus applications because only applications have the knowl-edge of how their data can be processed in independent subsets.Predicates defined over one workspace must obey to two invariant conditions:1.No object in a workspace can satisfy two different predicates simultaneously.2.Every object in a workspace will satisfy a predicate for the lifetime of all applications thatoperate on the workspace.Invariant2implies that predicates can’t depend on object attributes that are updated by the application and should be functions of object properties that are invariant(such as the name).3.4.7Strict Data UnitsA strict data unit represents a set of data that can be checked out by a transaction.Partitions vary according to the predicates given.As predicates are application defined,the size of the data units is application dependent.The minimum check-out granularity is ultimately a single object.Invariant1implies that data units defined by a partition are disjoint.The union of all strict data units in a workspace always represents a set of objects contained in the workspace.3.4.8Working unitsA working unit is a container used to check-out a strict data unit from one workspace to another and checking the results of the operations executed on the objects of the working unit back in.A valid working unit definition would consist in creating a data unit for each letter and making all objects whosefirst letter of their identifier match the working unit letter part of the corresponding data unit.This definition would always generate26working units(one for each letter),independently of being applied to an empty workspace or to a workspace with thousands of objects to partition.This working unit definition complies with both repository invariants:tt t t tiii)check-out of the working unit containing the circles data unit;iii)private workspace objects are updated and three new objects(a circle,a cross and a square)are inserted;iv)data is checked back in the original group workspace.an object with a given identifier will only match one starting letter;and as the identifier will always have the samefirst letter,it will always belong to the same data unit and will be always checked out to the same working unit.3.4.9Loose Data UnitsA loose data unit is a strict data unit plus all objects for which there is a relationship between versions belonging to the strict data unit and other versions added to the working unit.Objects can only be added to a working unit if they satisfy the predicate defining the strict data unit that originated it,or if they are directly related with objects in the strict data unit.Figure3represents the relationship between working units and workspaces.At check-out, a working unit is identical to the strict working unit:all the checked out objects satisfy the predicate originating the unit.At check-in,there might be objects(like the new square in the example of Figure3)that don’t satisfy the predicate(“is a circle?”in the example).Loose data units are the data units in this condition.3.5OperationsSo far we have seen that,to update an object,an application checks out the working unit that contains the object into a private workspace,modifies the object and then checks the working unit back in.The intuition behind this mode of operation is that if we have a massive processing on a large collection of objects,we can make it concurrently by copying the objects into separate data stores,have them manipulated while isolated from the collection,and then reconcile them with the collection.We now present the semantics of these operations on workspaces.3.5.1Operations on data and conflict generationAddition of new objects to a working unit while isolated would be very restricted if this were possible only with objects within the strict data unit checked out.For example,consider a crawler collecting pages from the Web,working on a private workspace that checked out a working unit for all objects of a given site;if,when downloading one of the Web pages itfinds a link to some page on another site,how would it save that reference?Not within the partition, because it doesn’t satisfy the predicate.It would not be able to check-out the proper working unit either,because it can’t handle two working units at a time.To mitigate this problem,we allow for data that doesn’t belong to the current strict data unit(the one previously checked out)to be conditionally inserted within the working unit, enlarging it into a loose data unit.Insertion is allowed for objects that,albeit not belonging to the strict working unit,are directly associated with objects that are within the strict working unit.On the other hand,insertion is always allowed for objects belonging to the strict working unit.Inserting or updating object belonging to the working unit does not generate conflicts as objects in data units are checked out to one workspace at a time,no two parallel threads concur to use the same objects.However,conditional insertion of objects that don’t belong to the strict working unit may generate conflicts,because two parallel processes might insert the same object while isolated.When reconciling the data,conflicts must be automatically resolved by an application-supplied code.3.5.2Check-outTransactions check-out a data unit from one workspace,called the source workspace,into an-other,called the target workspace.They determine what to check-out by applying the predicate associated with the working unit to the source workspace.The check-out operation for a given unit defined by a predicate takes one argument,the source workspace to check-out,and generates two workspaces:the source workspace after the check-out and the target workspace.The check-out operation is defined only if the unit to check-out is not already in use.The only modification to the source workspace is that the unit is added to the set of units currently in use.The target workspace will contain all the objects of the source workspace that satisfy the predicate,plus all the relationships from the source workspace where both the anchor and target objects are checked out.Check-out doesn’t copy relationships from objects that belong to the checked out unit to objects that don’t belong to the corresponding unit at the target workspace.Hence,threads working on the target workspace don’t have access to these relationships.Applications that require access to these relationships should define a partition that generates units big enough to contain them.Transactions can only check-out data from one working unit at a time.As check-out doesn’t copy relationships involving objects outside the strict data unit to the more private workspace, applications operating on the private workspace will only see relationships among objects in the workspace.3.5.3Conflict resolutionImplementation of a conflict resolution policy in the repository would force all the applications to use it,even if it is not appropriate to their needs.To satisfy the specific needs of Web applications the model defines a conflict manager interface that applications must implement to solve the conflicts while saving conflicting data.Figure4:Class model for the data handled by the repository.Versus applications must implement a conflict management function,that,given two can-didate objects,decide which should be saved in the repository.The result may be one third object generated by merging the two candidates.The decision is application driven.3.5.4Check-inApplying an operation to the data in one workspace is equivalent to partitioning the workspace, checking out each of the data units,applying the operation to each of the working units and then checking them in.As this is true for operations that don’t need to see relations between objects in different partitions,the repository is suited for serving applications for loading large amounts of data,allowing the parallelization of the process.The reintegration of working units’data previously checked out from a workspace has to consider the existence of new data that might conflict with the already existing data.Check-in is a function that takes two workspaces W and W x and returns a third workspace, resulting from checking W x into W .Its effects are:1.The resulting set of objects consists of those objects created before the check-out plus:•Objects created before check-out that belong to the strict unit,but were updatedduring isolated operations;•Objects identified by the resolution of conflicts between new objects and those thatexisted before and don’t belong to the unit;•The remaining objects,those created after check-out,that satisfy the predicate.2.The resulting relationships are all the relationships that existed before the check-out,minus relationships from updated versions,plus new relationships.3.The lock created when the unit was checked out is released.3.6Data ModelFigure4shows the UML class model of the data handled in a Versus repository.We have the following main classes:。

Audi A3Audi A3 SportbackA u d i A 3 y A u d i A 3 S p o r t b a c kA la vanguardia de la técnica www.audi.esEl contenido del presente catálogo tiene carácter meramente informativo, y por tanto tiene como único objetivo constituir un elemento orientativo y de ayuda para facilitar información general, no particular, ni específica, sobre los vehículos a los que se refiere.En consecuencia, los datos obrantes en el presente catálogo no deben tomarse en consideración para la eventual decisión de adquisición de un vehículo . Para ello, para concertar y/o clarificar alguno o varios de los datos citados en el mismo, así como para formalizar un pedido concreto, o para cualquier otra cuestión que sea de su interés, le rogamos contacte con alguno de los Concesionarios Oficiales Audi al objeto de que le informen pormenorizada-mente sobre las especiales características, equipamiento de serie, opcionales, precio, datos, campañas, promociones, disponibilidad de unidades, plazo de entrega, período de fabricación, etc. de los vehículos aquí referenciados.Le recordamos que la compañía fabricante y/o Volkswagen-Audi España, S.A. efectúan constantes mejoras en sus vehículos a fin y efecto de adaptarlos a las necesidades específicas de los clientes así como al objeto de incorporar en los mismos, en la medida de lo posible, los avances técnicos disponibles en cada momento.Es por ello por lo que los equipamientos, datos y características de los vehículos aquí referenciados son los disponibles generalmente a la fecha de edición de este catálogo y, por tanto, deben entenderse sin perjuicio de aquellas particularidades que pueden existir en cada caso atendiendo a la disponibilidad de modelos y al mercado al que va dirigido.Este vehículo y todos sus componentes así como los recambios originales, han sido diseñados y fabricados atendiendo a la Normativa Legal destinada a prevenir y reducir al mínimo la repercusión en el Medio Ambiente, mediante la utilización y valoración de materiales reciclados/reciclables, adoptando las medidas dirigidas a conseguir un adecuado reciclado para la conservación y mejora de la calidad ambiental.A fin de cumplir con los objetivos de descontaminación y fomento del reciclado y reutilización de componentes de los vehículos al final de su vida útil, se ha creado en España una extensa Red de Centros Autorizados, bajo la denominación de SIGRAUTO (para consultas www.sigrauto.es), que garantizan su adecuado tratamiento medioambiental, a los cuales deberá dirigirse para la entrega, sin desmontaje previo de componentes del vehículo. El Centro Autorizado facilitará el Certificado de Destrucción para obtener la baja en la DGT.Este catálogo de producto ha sido confeccionado con fibra de papel sin cloro.AUDI AG 85045 Ingolstadt www.audi.esVálido desde octubre de 2008Impreso en Alemania 833/1204.38.61。


西班牙语-常用缩略词adj.形容词adj.-f.形容词和阴性名词adj.-f.pl. 形容词和阴性名词复数adj.-m.形容词和阳性名词adj.-m.pl. 形容词和阳性名词复数adj.-s.形容词和名词adv.副词(al.)德语词汇amb.两可性名词Amér.拉丁美洲方言Amér.C.中美洲方言Amér.M.南美洲方言And.(西班牙)安达卢西亚方言Antill.安的列斯群岛方言(ár.)阿拉伯语词汇Ar. (西班牙)阿拉贡方言Arg.阿根廷方言art.冠词Ast.(西班牙)阿斯图里亚斯方言aum.指大词aux.助动词Bol.玻利维亚方言Cat.(西班牙)卡塔卢尼亚方言Col.哥伦比亚方言com.两性名词conj.连接词C.Rica哥斯达黎加方言Cub.古巴方言Chil.智利方言(chin.)汉语词汇dem.指示的dim.指小词Dom.多米尼加方言Ecuad.厄瓜多尔方言Filip.菲律宾方言(fr.)法语词汇galic.(西班牙语中的)法语词汇(gr.)希腊语词汇Guat危地马拉方言Hond.洪都拉斯方言impers.无人称动词indet.不定的(ingl.)英语词汇interj.感叹词interr.疑问的intr.不及物动词invar.不变化的irreg.不规则的(ital.)意大利语词汇(jap.)日语词汇(lat.)拉丁文词汇m.阳性名词Méx.墨西哥方言Mur.(西班牙)穆尔西亚方言Nicar.尼加拉瓜方言n.p.专有名词p.a.现在分词Pan.巴拿马方言Parag.巴拉圭方言Per.秘鲁方言pers.人称的pl.复数(port.)葡萄牙语词汇pos.物主的P.P.过去分词Pr.读音为Pref.词首prep.前置词prnl.人称代词补语动词pwn.代词P.Rico波多黎各方言reí.关系的RiopL(南美洲)拉普拉塔河流域方言(rus.)俄语词汇s.名词Sal.(西班牙)萨拉曼卡方言Salv.萨尔瓦多方言Sant.(西班牙)桑坦德方言sing.单数superl.最高级的tr.及物动词(tur.)土耳其语词汇U.m.c.多用作U.m.en pl. 多用复数形式Urug.乌拉圭方言U.t.c.也用作U.t.en pl.也用复数Venez.委内瑞拉方言【口】口语【俗】俗语【引】引伸词义【转】转义【貶】贬义【讽】讽剌语【谑】戏谑语【集】锒合名词【雅】委婉叙法【文】文学用语【诗】诗歌用语【新】新词,新义【古】古词,古义【罕】罕用义【法】法律,法学【哲】哲学【逻】逻辑学【军】军事【商】商业,财贸【剧】戏剧,剧场【乐】音乐【骑】骑术【猎】狩猎【美】美术【纹】纹章学【宗】宗教【神】神学【希神】希腊神话【罗神】罗马神话【数】数学【理】物理【天】天文学【电】电工,电讯,无线电【化】化学【生】生物学【植】植物,植物学【动】动物,动物学【农】农业【医】医学,医药【解】解剖学【地】地理【质】地质【技】工程技术【机】机械工程【矿】矿业,矿物【冶】冶金【空】航空,飞机【海】航海,舰船【建】建筑【木】木工【石】石工【泥】泥水工【测】测绘【摄】摄影【印】印刷,书业【纺】纺织染adv. adverbio/adverbial 副词adv. a. adverbio de afirmación 确定副词adv. c. adverbio de cantidad 数量副词advers. adversativo/adversativa 转折连接副词adv. interrog. adverbio interrogativo 疑问副词adv. l. adverbio de lugar 地点副词adv. lat. adverbio latino 拉丁语系副词adv. m. adverbio de modo 模式副词adv. neg. adverbio de negación 否定副词adv. ord. adverbio de orden 顺序副词adv. t. adverbio de tiempo 时间副词AERON. aeronáutica 航空学afirm. afirmativo/afirmativa 确定al. alemán/alemana 德语词汇ALBA?. alba?ilería 水泥工ALG. álgebra 代数学amb. ambiguo 模糊amer. americanismo 美系ANAT. anatomía 细胞ant. antiguo/antigua 古代aprox. aproximado/aproximadamente 大约ár. árabe 阿拉伯语ARIT. aritmética 算术ARQUEOL. arqueología 考古学ARQUIT. arquitectura 建筑学art. artículo 条款ART. arte 美术ASTROL. Astrología星卜术ASTRON. astronomía 星象学ASTRONáUT. Astronáutica航天学aux. auxiliar 辅助BACTER. Bacteriología 病毒学BIOL. biología 生物学BIOQUíM. Bioquímica生物化学BOT. botánica 植物学cant. cantidad 数量card. cardinal 基数, 点CARP. carpintería 木工cat. catalán/catalana 加泰罗尼亚CIN. cinematografía 电影CIR. cirugía 外科col. coloquial 口语com. común (genero) 双性(语法上)COM. comercio 贸易comp. comparativo/comparative对比的conc. concesivo/concesiva 让步的cond. condicional 条件的conj. Conjugación变位conj. Conjuncion 连接词contr.contracción 缩约cop. copulativo 连接的d. C. después de Cristo 公元后def. defectivo 缺位的(动词)dem. demostrativo 指示DEP. deportes 体育DER. derecho 法律desp. despectivo 贬义的dim. diminutivo 指小词,缩小的distr. distributivo/distributiva 关系的disy. disyuntivo/disyuntiva 选择性的连接词ECOL. ecología 生态学ECON. economía 经济ej. ejemplo 例子ELECTR. electricidad 电ELECTRóN. electrónica 电器ESC. escultura 雕塑ESTAD. estadística 概率etc. etcétera 等等excl. exclamativo/exclamación 惊叹的expr.expresión 语词f. femenino (sustantivo) 阴性FILOS. filosofía 哲学FIS. Física物理FON fonética 语音fr francés法语GENéT genética 基因GEOG geografía地理学GEOL geología地质学GEOM geometría 几何学GRAM gramática 语法HISTOL histología组织学ingl inglés/inglesa 组织学ilat ilativa 因果关系的impers impersonal无人称IMPR imprenta 印刷indef indefinido 不定的indet indeterminado 未定的INFORM informática 计算机interj interjección 感叹词interrog interrogativo/interrogativa疑问intr intransitivo 不及物的irón irónico/irónica 讽刺的irreg irregular 不规则的it italiano/italiana 意大利语lat latín/latino/latina 拉丁语LING lingüística 语言LIT literatura 文学loc locución 固定词组loc adj locución adjetiva形容词固定词组loc adv locución adverbial副词固定词组loc conjunt locución conjuntiva连接词固定词组loc prepos locución prepositiva 前置词固定词组m masculino (sustantivo) 阳性MAR marina 航海MAT matemáticas 数学MEC mecánica 工械MED medicina 药品METAL metalurgia 治金METEOR meteorología 气象学MéTR métrica 格律学MICROBIOL microbiología 微生物学MIL milicia 军事MIN minería 采矿MINER Mineralogía 矿物学MIT mitología 神话MúS música 音乐n nombre/neutro名称/中性n.p nombre propio独有名称NUMISM numismática 钱币学onomat onomatopeya 拟声OPTóptica 眼科ORTOGR Ortografía 正字法p.p participio pasado过去分词PALEONT paleontología 古生物学PAT patología病理学p.ej por ejemplo举例pers persona/personal 个人化PINT pintura 颜料pl plural 复数poét poético/poética 诗歌POL política 政治POS posesivo 拥有的pref prefijo 前缀词prep preposición 前置词prnl pronominal (verbo) 代词的pron pronombre 代词PSICOL psicología心理学PSIQUIAT psiquiatría 心理学QUIM química 化学reg regular 有规则的REL religión 宗教relat relativo 关系词RET retórica 修辞学s sustantivo/siglo 名词/世纪sing singular 单数SOCIOL Sociología社会学suf sufijo 后缀词sup superlativo 最高级别的t tiempo 时间TECNOL Tecnología科技TEOL teología 神学TOPOG topografía 测绘学tr transitivo 及物的TV televisión 电视v verbo 动词vulg vulgar 粗俗的ZOOL Zoología动物学。
Journal of Leshan Normal University第39卷第2期圆园24年2月Vol.39熏No.2Feb .熏2024DOI:10.16069/ki.51-1610/g4.2024.02.012学报中国故事7篇,其中1篇为唐传奇《离魂记》,未标作者,仅注明“Cuento de la dinast侏a Tang”(唐代故事),这就在一定程度上印证了卡萨雷斯笔下的“无知”。
另外,译文隐去了故事发生地点—衡州,男主人公“王宙”的名字有所出入—“WangChu”。
尽管如此,故事的大体情节与原文基本一致。
《离魂记》的选录也开启了唐传奇西译之路。
《奇幻文学选集》之后,20世纪四五十年代,唐传奇最重要的译者是西班牙汉学家黄玛赛(Marcela de Juan,1905—1981),她编译多部中国文学西译专集,以诗歌、短篇故事为主,其中,故事集主要包括《中国古代传统故事》(Cuentos chinos de tradición antigua,1948)、《中国故事家选集》(A ntología de cuentistas chinos,1948)与《古镜记与其他中国故事》(El espejo antiguo y otros cuentos chinos,1954)。
《中国故事家选集》共7篇故事,其中,5篇唐传奇:《薛伟》《崔书生》《枕中记》《李娃传》《古镜记》。
《古镜记与其他中国故事》共8篇,其中,2篇唐传奇:《古镜记》《枕中记》。
她在前言中如此评论《古镜记》:“这则带有童话意蕴的寓言展示了中国当时的社会状况。
这些以蛇、鱼的身形出现的怪物,象征了山匪与令人生厌的官兵。
”[3]10此译本在1983年、1987年与1988年再版,在西语世界影响深远。
黄玛赛从汉语直译,译风精准且善用中西比较视野,读者接受度高,进一步拓展了唐传奇在西语世界的传播。
20世纪60年代,卡雷罗·比希尼娅(Carreno Virginia)从英语转译《中国女士:中国古典故事》(Damas de China.Historias de la China Clásica, 1963),也在布宜诺斯艾利斯出版,选译《任氏传》《李娃传》《昆仑奴》等唐传奇篇目。
2014年中国农业银行秋季招聘考题英语单元试卷含解答英语单元Directions A word or phrase is missing in each of the sentences below. Four answer choices are given below each sentence. Select the best answer to complete the sentence. Then, mark the letter (A), (B), (C), or (D) on your answer sheet. 12. Her vast market analysis knowledge and contacts within the industry make Adrienne Reston an incredible _______ for our company’s marketing department.A) research B) resource C) resort D) response13. If you don’t keep the meat i n the refrigerator on such a hot day, it may ____.A) go out B) go away C) go off D) go down14. Women have ____ equal say in affairs at home.A) any B) some C) / D) an15. Will you see to ____ that my birds are looked after well while I’m away?A) them B) yourself C)it D) me16. Can we do our work better with ____ money and ____ people?A) lesser, few B) less, fewer C) little, less D) few, less Directions A word or phrase is missing in each of the sentences below. Four answer choices are given below each sentence. Select the best answer to complete the sentence. Then, mark the letter (A), (B), (C), or (D) on your answer sheet. Questions 17-19 refer to the following article.Calling all Koi lovers!The GMAC Convention Center will 17._____ a Koi Convention May 22-25 from 9-9. Admission is $10.There will be a variety of Koi from Japan on 18._____ with more than a dozen varieties and sizes of Koi on sale.A special Koi breeding class will be held on Sunday at 2 p.m. Class is 19._____ to15 participants.To sign up for the workshops or for more information, please visit gmac /koi.17. A) holding B) have held C)&nb sp;be holding D) been holding18. A) display B) showing C) present D) available19. A) restrict B) restricts C) restricted D) restricting Directions In this part you will read a selection of texts, such as magazine and newspaper articles, letters, and advertisements. Each text is followed by several questions. Select the best answer for each question and mark the letter (A), (B), (C), or (D) on your answer sheet.Questions 20-24 refer to the following letter and order form.22 Baker AvenueSt. Francis, Minnesota 55070November 23, 2011Home Care Products1147 Bear Lake BoulevardMinneapolis, Minnesota 55440To Whom It May Concern,I have received your spring 2012 catalogue and would like to place my order. Enclosed is the order form from the catalogue. I have also enclosed a personal check for $222.00. I have chosen your home delivery #2 choice, which is by the US Postal Service.I understand that my check will cover both the cost of the goods and the delivery.I have always enjoyed your products and look forward to more high-quality and attractive ones form you again. I’m especially impressed with this year’s Princess line of bedding.Yours truly,Mrs. Judy PascawHome Care Products1147 Bear Lake BoulevardMinneapolis, Minnesota 55440Tel: (952) 443-1717 Fax: (952) 443-1718homecareproductsORDER FORMItem Catalogue Number Number Price per Item TotalPrincess blanket P141 1 $72.50 $72.50Princess sheet P142 2 $30.00 $60.00Princess pillow slip P143 3 $15.00 $45.00Land O’Lakes vase D337 1 $44.50 $44.50Grand Total$222.0020. For which holiday did Mrs. Pascaw probably place her order?A) Independence DayB) ChristmasC) Mother’s DayD) Valentine’s Day21. Which of the following did Mrs. Pascaw NOT send to Home Care Products?A) A checkB) An order formC) A letterD) A request for a catalogue22. Which of the following can we assume from the letter?A) Home Care Products does not accept credit cardsB) Delivery of products requires an additional charge.C) There were at least two delivery choices.D) Mrs. Pascaw is a first-time customer.23. Which item was the cheapest per unit?A) The blanketB) The sheetsC) The pillowD) The vase24. Which category of home product was the bulk of Mrs. Pascaw’s order?A) BeddingB) DecorationC) GardeningD) Toiletries参照解答:英语单元12-16 BCDCB17-19 CAC20-24 BDCCA。
托业易错知识1. information about the department’s expenditures is available in the monthly report.A) DetailB) DetailsC) DetailingD) Detailed选 D 不选 A 确有 detail informaion 这种说法,不过 detailed information 是更正式,更传统的说法2. Ms. Rogers failed to carry out her duties in a professional and acceptable manner.(A) believably(B) impossibly(C) repeatedly(D) realisticallyC 再三地 Rogers 女士再三地没有以专业和礼貌的方式完成她的职责。
3. It’s recommended that any woman over the age of 50 annually the Breast Cancer Screening Center.(A) visit(B) visits(C) visited(D) visitingA 不选B it’s recommended that sb (should) do sth 这是个固定句型,和建议、要求、主张recommend,suggest, demand, require,insist, order 一样的用法。
以前的知识有很多都忘记了。
要加强复习。
4. The council a monument in Civic Square, honoring the soldiers who fought and died in World War .(A) extracted(B) located(C) commissioned(D) persuadedC 相当于 erect 竖立5. There are lots of interesting tourist sites, souvenir shops and restaurantswalking distance of the conference center.(A) on(B) at(C) across精品文库(D) withinD6. Watson beachside offers members of its Elite Club fantastic services and great discounts in its network of resorts.(A) altogether(B) everywhere(C) beyond(D) alongsideB7. One member of the board expressed about the company’s plan to expand into Southeast Asia.(A) reservations(B) possibilities(C) responses(D) qualitiesA8. How do you know Japanese? I lived in Tokyo for a few months.How well is your Japanese? I can only speak a little.9. attending a conference on regional development today, the mayor will hold a press conference to discuss the election.(A) According to(B) Seeing as(C) Instead of(D) Due toC10. The attorney’s to the shipping company is to sue the port authorities for causing a loss of profit.(A) judgment(B) recommendation(C) activity(D) progressionB11. The beachside resort only capacity in the busy vacation period from the end of May to the beginning of August.(A) sets(B) reaches(C) makes欢迎下载2精品文库(D) providesB12. The new exhibition at Wharton Gallery on Foxton Street the work of local artist Ravi Ashankar.(A) elaborates(B) showcases(C) pictures(D) occupiesB elaborates 详细阐述 showcases 展示13. The surveillance() of personal communication is only when it assists in matters of national security.(A) permitting(B) Permissive(C) Permissible(D) permissionC permissive 许可的,自由的 permissible 可允许的14. If you come across any errors in the article during proofreading, please report to the managing editor.(A) It(B) Itself(C) Them(D) themselvesC15. Few of the survey indicated that they would be willing to participate in an in-depth interview afterwards.(A) Respond(B) Responses(C) Responsive(D) respondentsD they would be 所以前面是指人16. The civic library stocks a wide range of materials, including books, DVDs and CDs.(A) educate(B) Educated(C) Education(D) Educational欢迎下载 3精品文库D17. Many professional athletes have no education to once they retire.(A) go back to(B) Move forward on(C) Fall back on(D) Go ahead withC 无法生活18. It’s hard for some people to respect their boss because they have a problem with .(A) Authorization(B) Authorities(C) Authors(D) AuthorityD19. I am genuinely looking forward to our new CEO.(A) have meeting(B) Have met(C) Meet(D) MeetingD20. I need to get the proposal back which I you last week.(A) Lent(B) Borrowed(C) Wrote(D) ReadA21. My boss by the general manager.(A) is intimidated(B) Has intimidated(C) Is intimidating(D) intimidatesA22. It looks like you could use some help for the conference.(A) Prepare(B) Prepared(C) Preparation(D) PreparingD欢迎下载 4精品文库23. Contrary to popular belief, significant revenue does not always into profit.(A) Transcend(B) Transport(C) Translate(D) TransgressC transgress 违反24. There are both advantages and disadvantages driving a car to work.(A) With(B) On(C) Of(D) InC25. Someone is going to have to the blame for losing that file.(A) Take(B) Make(C) Have(D) FindA 接受责难26. How did you find the service in the hotel?A) I used a GPS device.B) It left a lot to be desired.C) I was stayed there for 3 days.选 B 这题有两个知识点1. 问题不是问“你怎么找到这家酒店的服务的”而是问“你觉得这家酒店的服务怎么样?”How do you find sth= How do you think about sth2. Leave a lot to be desired 意思是“还有许多需要改进的地方” leave nothing to be desire d 意思是“完美无缺”27. Who’s responsible for restocking the company letterhead?A) I mailed it this morning like you asked.B) Jane bought her stockings the other day.C) Have we run out already?选 C 。
UNIT7 A1. It is a most extraordinary thing, but I never read a patent medicine advertisement without being forced to draw the conclusion that I am suffering from the particular disease said in the ad and dealt with in its most deadly from这是一个最不寻常的事,但我从来不读,而无需被迫得出这样的结论,我患有特定疾病的专利药品广告,在广告中说,在其最致命的处理从2. The diagnosis seems in every case to correspond exactly with all the sensations thatI have ever felt.看病的诊断似乎在任何情况下,所有的感觉,我曾经觉得完全一致。
3.I sat for a while, frozen with horror; and then, in the listlessness of despair, I again turned over the pages.我坐了一会儿,冻结与恐怖;然后,在绝望的精神萎靡,我再次一翻。
4.I felt rather hurt about this at first; it seemed somehow to be a sort of slight.我觉得有点受伤的关于这方面的第一个,不知怎么的,似乎是一种轻微。
5.I thought what an interesting case I must be from a medical point of view, what an acquisition I should be to a class!我想我必须是一个有趣的案例,从医学的角度来看,我应该是一类什么样的收购!B1.He gradually realized that2.No not from talking about sports3.Led to the death of the child's4.Beginning is the name of a small staff5.He had helped her。
号: 1671 - 8127 (2009 ) 02 - 0061 - 02液体表面张力现象错误认识的大气压反推法刘伟民,张国昌(商丘师范学院物理与信息工程系, 河南商丘476000)摘要:从理论、反推和实际计算三方面对一种液体表面张力现象展开推证; 最终证实: 底面平整物体被缓慢离水面时受到的阻力,并非大气压力作用,而是液体表面张力作用的结果.关键词:大气压力;底面;平整;液体表面张力中图分类号: O4 文献标识码: A引言液体表面张力系数的测定,是高等学校物理学专业或理工科必开实验之一,也是中学常见实验. 关于实验的研究已有多篇文献报道[ 1 - 3 ] ,在此不再赘述. 学生在进行该实验时,难免有一些错误认识.平铺上一块面积很大的玻璃板,日常生活经验告诉我们,在保持玻璃板水平的前提下,当试图把玻璃水面时,能明显感觉到其下方存在有阻力; 洗脸盆放入水中,用一只手去把它拿离水面时,也能感觉有阻碍作用;平面物体越大,这种感觉越明显. 对于此类现象,许多学生认为是一种大气压力作用. 实以证明,这是一种液体表面张力现象. 我们以生活中使用最多的能够自由悬浮在水面上的普通光盘对象,并从三方面对该问题展开讨论.理论推证如图1所示,用粗线表示光盘的水平侧视图,箭头表示大气压的作用. 由中学物理知识可知,光盘底面大气压作用. 产生上文中错误认识的主要原因是学生对气的作用特点没有真正搞懂. 可能的解释是学生把此现象与生活中某些现象混淆,比如厨房常用的吸盘式挂钩,它的基原理是用力按压吸盘将其内部气体挤空,此时内部可视为状态,在外部大气压力作用下,挂钩被固定在光滑平整墙壁显然,本实验中,光盘只是自由悬浮在水池中,根据连通器大气压能够贯通整个容器,故此现象不能解释为大气压力图 1 光盘所受大气压作用示意图反推计算法通过计算也可证明上述观点不正确. 经测量可知所用光盘的外直径为12 c m ,内直径为1. 5 c m ,若只有上表面受到大气压作用,则在通常条件下,设大气压和底面别用p 和s表示,并设由此产生的向下作用力大小为F1 ,则( 1) F1= PS式中, P = 1101 ×105 Pa, S =π×[ ( 12 ) 2 - ( 3 ) 2 ] ×10 - 4 m22 4= 1 , 11 ×10 - 2 m2稿日期: 2008 - 11 -11金项目:商丘师范学院青年骨干教师资助项目( 20080922 )者简介:刘伟民( 1978 - ) ,男,河南焦作人,商丘师范学院讲师,主要从事多孔材料及物理实验教学与研究.所以, F1 = 1112 ×10 N3设重力常数g取10N / Kg,则此过程大致相当于从水面上提起质量M = 112 Kg的物体,很显然,实际过程远没有如此困难.3 实际表面张力计算底面平整的金属薄片竖直浸入水中,使其底边保持水平,在垂直往上提拉过程中会受到方向朝下的表面张力f作用,且该表面张力的大小与金属薄片的底面周长成正比[ 4 ] 46 - 49 . 回到本实验中,即相当于把金属薄片的底面做成圆环平面状, 而且表面张力只发生在光盘平面的最外侧和最内侧界面上. 则由相关理论可得:f =σπ(D1 + D2 )( 2)式中σ为水的表面张力系数, D1 和D2 分别为实验所用光盘的外直径和内直径. 且D1 = 12 cm , D2 = 115 cm ,查表可知, 20 ℃时,σ≈70 ×10 - 3 N ·m - 1 ,则f = 70 ×10 - 3 ×π×( 1315 ×10 - 2 ) = 0103N即实际的作用力很小,远没有达到( 1 )式中量值. 在如此小作用力下,人仍然可以感觉到阻力的存在,作者认为可以有如下解释:首先向上提拉的过程必须非常缓慢,如果以一个很快的速度瞬间将光盘提拉出水面,对这种阻力的感觉就不太明显;再者,采用同样的速度,缓慢把光盘竖直拿离粗糙度非常高的桌面(若太光滑,光盘在放到桌面上时可能会将内部气体排空,即会类似于吸盘原理) ,或者把光盘放在一个水平平面支架上,再与拿离水面的情况进行对比实验,特别注意体会提拉过程刚开始用力瞬间两者的不同,并重复多次,会明显感觉到两者的差异性,而这种差异正是表面张力存在的表现.4 结论由上述讨论可知,底面平整物体拿离水面时,的确存在一定阻力,但该阻力并非大气压作用结果,而是物体底面与液体之间表面张力作用的表现. 从中也发现,对于学生在实验过程中的模糊认识,教师可根据实际情况,采用反推法进行提示和说明. 使学生既掌握了新知识,又更正和巩固了已学内容,同时提高了实验教学效果.参考文献:[ 1 ]魏杰,张拥军,李超. 一种测量液膜高度的方法[ J ]. 大学物理, 2005 , 24 (1 ): 33 - 34.[ 2 ]李高斌,韩立新,戴永侠. 关于液体表面张力的几个问题的实验探究[ J ]. 物理教师, 2007 , 28 (9 ) : 32 -34.[ 3 ]徐崇,刘哲语,郇维亮. 液体表面张力系数测量实验的改进[ J ]. 大学物理实验, 2005 , 18 ( 4 ) : 7 - 10.[ 4 ]钱锋,潘人培. 大学物理实验(修改版) [M ]. 北京:高等教育出版社, 2005.[责任编辑冯喜忠]A D isp r o o f to a K in d o f W r o n g U n d e r s ta n d in g a b o u t L iq u idS u r f a c e T e n s io n P h e n om e n o n U s in g A tm o s p h e r ic P r e s s u r eL IU W e i - m in, ZHAN G Guo - chang(D epa r t m en t of Physics and Infor m a tion E ng ineering, S hangqiu Teachers College, S hangqiu 476000, Ch ina)A b s t r a c t: The de mon stra tion wa s ca rried ou t upon a k ind of liqu id su if ace ten sion p henom enon r e sp ective ly f r om th r ee m ethod s such as t he o r y, d is2 p r oof and p r actica l calcu la tion. The r e su lts ind ica te tha t the re sistance wh ich p eop le p e r ce ived when they tran sf e r ob jec ts w ith f la t underside sl o w l y f r o m wa te r su rf ace was no t due to a t mo sp h eric p r e ssu r e bu t f r om liqu id su r f a ce ten sion.K e y w o r d s: a t mo sp heric p r e ssu r e; unde rside; f la t; liqu id su rf ace ten sion。
Requirements Processes: An Experience ReportJulio Cesar Sampaio do Prado Leite a, Soeli T. Fiorini a, Amador Durán b, Beatriz Bernárdez b, JuanSánchez Díaz c and Emilio Insfrán Pelozo ca Departmento de Informática, Pontifícia Universidade Católica do Rio de Janeiro, Brasil {julio,soeli}@inf.puc-rio.brb Departmento de Lenguajes ySistemas Informáticos,Universidad de Sevilla, España{amador,beat}@.esc Departmento de SistemasInformáticos y Computación,Universidad Politécnica deValencia, España{jsanchez,einsfran}@dsic.upv.es AbstractProcesses are certainly a key element in software management. Defining and using processes is believed to be an important factor towards quality. Our paper describes a general process language and the experience on its use by two different research teams with two different requirements processes. The process language is the basic representation for a process reuse repository implemented as a web application. The web application was used in order to describe a process for requeriments management and a process for interface generation based on requirements information. We present both processes as well as an evaluation of the prototype. Our results are a confirmation of the importance of process reuse and of the possibility of sharing requirements information by publication, on the web, of requeriments processes.Keywords: requirements engineering, requirements process, process reuse, requirements management, interface1IntroductionIn the last few years, a large number of new techniques and methods in different areas, have presented the process perspective as a new form of visualizing and improving production, business or support operations in organizations. In terms of organizational theory, there is a shift from the functional perspective to a cross-function one, based on processes. This trend is substantially enforced as globalization of the economy introduced the need for quality standards, and those are fundamentally based on process oriented audits. That is, to meet quality standards, organizations need to document and follow well-defined processes.The quality movement has reached software engineering. Standards, following the pioneers CMM (Capability Maturity Model) [1] and ISO 9000, have emerged and most of them are centered on processes. Software process is the cornerstone of software quality. No quality can be achieved if the software development organization does not follow established and well-defined processes.The first ideas about software process were geared towards automation. Defining software processes as programs could lead to greater automation in software construction. Today there are several environments that implement processes in an automated fashion, however, as researchers found out, automating processes is not a trivial endeavor. As such, as in organizations, software engineering has also started to use the notion of process without relying in automation. The possibility of establishing process description and communicating these descriptions to others has been seen as an important managing tool for software engineers.The growing interest in Process Engineering was an evolution of studies focused on products which verified that the quality of the developed software has a strong relation with the process which is used to elaborate it. In 1984, at the First International Workshop on Software Processes –(ISPW) a group of researchers learned about the new subject on process technology, which emerged. Afterwards, more than twenty workshops and conferences have been held (ICSP, IPTW, EWSPT, FEAST and PROFES).Nowadays, attempting to improve processes, many companies try to reach levels of process maturity [2], based on their improvement and definition. However, those improvements are expensive, and they rely on the involvement of managers and teams, process data, people who know process modeling, training, and cultural change. Several factors, imposing difficulties, make companies spend long periods of time to define some processes [2], and some of them give up in the middle of the maturity process. A frequently mentioned process to accelerate this within a company is to replicate one organizational process reusable in other projects. At this point, the process descriptions are very important because they allow the knowledge to be reused.Our paper reports on results from this standpoint. For us, processes are task descriptions that have a fixed objective and are informative on how humans, using different resources can accomplish an objective. Particularly we are interested in processes for requirements engineering. Working on software processes, Fiorini [3] has identified problems with existing software description languages and on the effective reuse of software process information. In order to meliorate the problems Fiorini has proposed an environment and a process language that enables a more complete description of processes as well as guide and facilitate their reuse.In this context, we are presenting two different proposals of requirements engineering process. One focused on requirements management and the other on interface generation from user requirements. Both are results of research experience on requirements engineering and were performed by different research groups. As such, we see our article as contributing to the dissemination of processes and evaluating Fiorini´s proposal.The rest of this paper is organized as follows. In section 2, the process definition language used in the experiences is defined. In section 3, the web tool developed for supporting the process definition tasks is presented. In sections 4 and 5, two experiences of process definition are reported. In section 6 some observations from the experiences are described. Finally, in section 7 some conclusions are presented and future work is pointed out.2The Process Description Language (ROpl)A process modeling language is a formal notation used to express process models. A process model is the description of a process, expressed in a process modeling language [4]. The language we are using, ROpl, is a process description language geared towards reuse [5]. The language is a strong typed description language that focus on the enumeration of atributes for a given process. It is a static language and has no interpreter for its semantics. The grammar is defined in XML[6], a meta language for ROpl, allowing us to specify the structure of ROpl. As such, the information concerning ROpl structure can be sent/received and processed on the Web in an even way. Because the processes naturally have a hierarchical structure, we adopted XML, taking the advantage of its benefits to work with documents structuring.The XML’s DTD (Document Type Definition) contains or points out at the declarative marks, which define a grammar or set of rules to a certain class of documents. Since ROpl has three major types: usual process, pattern process and standard process, its DTD has three different representation for a process.Following we provide an overall description of the three process types and the operands of each type. See [5] for more details.2.1 Standard ProcessIt is a standard (for example, CMM or ISO) in a form of process. It is a base for process definition, according to specifics process improvement and quality assurance standards. It has a normative finality.A standard process pattern is organized around the idea of section, sub-section and item. The structure of a standard process is described below, where, as in DTD specifications, the comma means sequence. Other features such as attributes or cardinality or have been omitted for the sake of readability.Process-Standard :=Name, Keywords, Objective, Applicability, Type, Description, Author, Version, Representation, Where-to-Find, Adaptation, Artifacts, Concepts, Actors, SectionSection :=Name, Objective, Description, Sub-SectionSub-Section :=Name, Reference, Objective, Description, Representation, Training, Verification, Metrics, Tool, ItemItem :=Name, Reference, Pre-Condition, Input, Description, Constraint, Output, Post-Condition, Pre-Condition, Input, Recommendation, Constraint, Output, Post-Condition, Use-Pattern 2.2 Process PatternIt is a process that deals with problems related to processes. According to the definition of patterns, it can not be new or hypothetical [7] [8].A process pattern is organized around the idea of community, family and individual. That is, a process is composed of macro activities which are composed of micro activities. The structure of a process pattern is described below, using the same notation that was used for describing the structure of standard processes.Process-Community :=Name, Keywords, Origin, Objective, Classification, Problem, Context, Cause, Representation, Artifacts, Family-Process, Individual-ProcessProcess-Family :=Id, Context, Cause, Control , Related-Pattern, Representation, Family-SolutionFamily-Solution :=Name, Pre-Condition , Input , Recommendation, Constraint, Output, Pos-Condition, Use-PatternProcess-Invididual :=Id, Context, Cause, Control , Related-Pattern, Representation, Individual-Solution Individual-Solution :=Name, Pre-Condition , Input , Recommendation, Constraint, Output, Pos-Condition2.3 Usual ProcessIt is any existing process that is neither a standard nor a pattern. It is not a standard process because it does not have the normative finality and it is not a process pattern because it has not been tested (applied) a considerable number of times to solve one recurrent problem.An usual process has 3 abstraction levels: the process, the macro activity and the detailed activity. That is, a process is composed of macro activities which are composed of detailed activities. Its structure is defined as follows:Process :=Concept, Actor, Verification, Metrics, Training, Method, Tool, Templates, Police, Artifacts, Name, Author, Classification, Type, Objective, Description, Pre-Condition, Pos-Condition, Macro-Representation, Micro-Representation, Conformance, Characteristics, Macro-ActivityMacro-Activity :=Name, Description, Pre-Condition, Input, Output, Previous-Activity, Pos-Condition, Constraint, Actor-in-Charge, Method, Tool, Micro-ActivityMicro-Activity :=Name, Description, Pre-Condition, Input, Output, Previous-Activity, Pos-Condition, Constraint, Actor-in-Charge, Method, ToolBesides the three basic types, we also have a type called solution process which is an instance of either the framework 1or of any other process (pattern, usual or standard), or of the combination of those.However, accomplishing the mapping and documentation of processes is an arduous and painstaking job, particularly in large organizations, because it involves people who are expected to supply information regarding the manner in which they perform their activities.Given this context, it is important that the infrastructure to support process description and further use be functional and ease to use. Based on a process reuse architecture [3], Figure 1, a Web tool was developed, RPS (http://www.re.les.inf.puc-rio.br/soeli), in order to provide this infrastructure.Figure 1: Process Reuse Architecture1“A process framework models the behavior of the processes in a given domain. A process framework is defined as a reusable process. Its kernel models the common activities among the processes of the domain. Hot -spots model the specific and flexible parts of the processes of the domain and they are specified during the instantiation of the framework. The hotspots are activities or other elements of the process (techniques, tools...), that define characteristics or specific paths of a solution process (process instance). The hotspots are instanced by the process engineer, redefining the description of activities or elements, both on the macro and detailed levels. The framework itself will have to be represented as a process, identifying the parts that are hot spots and common activities. The instantiation of one processes framework generates a solution process. ”[3]. See also Figure 1.3The Web Tool (RPS)RPS is a Web tool designed to provide support for the edition and retrieval of process information. The tool uses ROpl as its basis. Figure 2 shows the main menu with two types of selection: by the menu on the left or by the chart, where you have the possibility of reusing a framework or reuse directly patterns, standards or processes. The menu on the left give the option of a) data entry (cadastro), for cataloguing new processes, b) view a process (consulta), to visualize in HTML a given chosen process, or c) access control (utilitários), for managing access and passwords.Figure 2: RPS main PageSeveral different pages are available according to the function requested. The processes are stored as XML [6] files and are prettyprinted using XSL (Extensible Stylesheet Language) [6], which makes possible different presentation styles for processes. Depending on the type of reuse (Figure 1) a special path of the flow below is followed, that implies that there different possibilities of re-using the information stored in the data base.RPS is a prototype and as such has several limitations, however we believe that it opens an avenue of opportunities regarding the research of how processes are presented, their languages and the reusepossibilities of processes. Our initial results [5] were very positive. On the next two sections we detail two different processes and a respective assessment of the tool for each process.4First Experience: Requirements Management ProcessThe first experience took place at the Departmento de Lenguajes y Sistemas Informáticos at the Universidad de Sevilla and was driven by two members of the local Requirements Engineering Research Group. The goal was to describe a detailed process for Requirements Management (RM), taking the approach described in [9] as a basis and focusing on requirements change management. The RM process was initially modeled using UML activity diagrams [10], as shown in Figure 3 and Figure 4.Figure 3: Requirements Engineering Process OverviewIn Figure 3 a context diagram for Requirements Engineering (RE) is presented. Following RPS, RE was defined as an usual process, and Requirements Development (RD) and Requirements Management (RM) as macro activities. In Figure 4, a detailed description of the RM macro activity is displayed.The former approach was defining RM as a process itself, but the structure shown in Figure 4 was eventually chosen in order to maximize reuse of already defined processes. The reason of this choice was that all RM defined processes in the repository were at the macro activity level, and the current implementation of the web tool do not allow changing the abstraction level (process, macro activity or detailed activity) of an asset.The next decision to be made was to choose the reuse strategy from the three possible options (see the right part of Figure 2, there a flowchart details the types of reuse the tool supports). The framework reuse strategy was initially discarded after some attempts because the only available framework in the web tool process repository, a framework for RE, was too general and we found an usual process asset that was much closer to our approach. So, the free partial reuse strategy was finally chosen, achieving a high reuse ratio, although some translation work was needed, since the reuse processes was initially described in Portuguese and the target language was English.Figure 4: Activity diagram for Requirements Management5Second experience: Semi-Automatic User Interface Generation from User RequirementsThe second case study used to evaluate the tool is about a semi-automatic user interface generation method. This process is based on user requirements. The case study is organized as follows: first, our user interface generation method, and second each phase and activity is explained in detail. Finally the experience of using the tool for the process definition is reported. When a software product is designed and implemented, it is very important to assure that the user requirements have been properly represented. To achieve this objective, a guided software production process is needed, starting from the initial requirements engineering activities and through to the resultant software product. In this section, a methodological approach for generating user interfaces corresponding to the user requirements is introduced. As opposed to other proposals, we defend the idea of having a process with a high degree of automation where the generation of user interfaces corresponding to precise user requirements has a methodological guidance. Furthermore, a corresponding visual tool, which allows us to almost completely automate the entire process, has been implemented. A detailed discussion about the tool can be found in [11]. An important contribution of the method is that it automatically generates an inter–form model of navigation which is based on the relationships include and extend specified among the use cases. The introduction of this navigation feature makes possible to use the generated interfaces in web environments.In short, this section presents both a methodological proposal and the associated support tool, which backs it up, within the field of requirements engineering. They are based on the Unified Modeling Language (UML [10]), extended by the introduction of Message Sequence Charts (MSC) [12]. As we view MSCs as extended UML Sequence Diagrams by adding the needed stereotypes, the approach can be considered UML-compliant from the notational point of view.A clear, precise iterative process allows us to derive user interface prototypes in a semi-automatic way from scenarios. Furthermore, a formal specification of the system is generated and represented through state transition diagrams. These diagrams describe the dynamic behavior of both the interface and control objects associated to each use case or each MSC. The method has four main steps: the first two steps require analyst assistance to some degree, whereas the last two steps make the process of scenario validation fully automated by means of prototyping5.1Description of the ProposalIn this section we present precise method or process to guide the generation of user interfaces corresponding to the user requirements, according to the ideas introduced in section 4 and using the UML diagrams class model, state transition diagrams and message sequence charts. Figure 1 shows a schematic representation of the activities contained in the proposed method. As we have commented above, the first two activities, namely scenario representation and synthesis of use cases, are manual activities which the analyst must carry out. The last two, specification generation and generation of prototypes, are totally automatic.Figure 5: Schematic Representation of the MethodFigure 5 also fixes the order in which these activities should be performed. The process begins at the scenario representation stage where a use case model is created. The next stage consists of describing use cases by means of MSC. During the stage of specification generation, a state transition diagram (STD [13]) for the class User Interface and another STD for the Control Object are automatically obtained from a given MSC. Lastly, the final stage consists of automatically generating the user interface prototypes as well. The method is iterative; in consequence, the prototyping is used to validate and enrich the initial requirements.5.2Tool utilizationWe have considered as “usual process” the describe method in the last section. We can define four macro activities: use case model construction, use cases synthesis, specification generation and user interface generation. Each macro activity can be decomposed in detailed activities. We shall now proceed to explain the macro activity “use cases synthesis” in detail.This macro activity can be decomposed in tow detailed activities: message sequence chart construction and message sequence chart labeling. The former detailed activity can be described as follow. Once we have obtained the Use Case Model, we need to work with the involved use case information to undertake the process of designing a software system. To do this, use cases must be formally described: the formal definition of a use case is achieved by using a graphic, non-ambiguous language, such as MSC. In this phase, which is a manual one, the use case templates are used as help so that the analyst can detect the events sent by the actors and by the classes of problem domain. In each MSC, besides the participating actors (initiator, supporting actors), one class for the user interface and one class that acts as control object are introduced, according to the initial Objectory proposal [14] and according to the UML approaches for a software production process [15].The last detailed activity also can be described in the sequel manner. An important piece of data that must be introduced in this step, is constituted by the labels that will appear in the user interface to identify relevant pieces of information. When following the flow of events specified in the MSC, a given piece of information enters or exits the user interface object, the analyst must specify the corresponding label, that will play a basic role in the process of generating the user interface.Apart from the labels, information about the type of the arguments of each event specified in the diagram must be introduced. The allowed types are the basic data-valued types (number, Boolean, character, strings, enumerated) and the object-valued types corresponding to the system classes. The types of the event arguments together with the class attributes are used in the process of the interface generation.6ConclusionsWe have briefly presented an infrastructure for process reuse and detailed the ROpl, a process language proposed to cast processes for reuse. The infrastructure is supported by a web application that provides editing, retrieving and visualization mechanisms. In order to gain more understanding on requeriments processes as well as on the effectiveness of the prototype tool, we conducted two experiences with two different research groups. We detail below the final remarks of each research group. We end the section enumerating further work.The first experience at the Universidad de Sevilla was highly positive. The search facilities were a key aspect, and the facet-based schema has proved to be extremely useful. The reuse guideline for frameworks was also very useful, especially because it offered a broad view of the framework, its activities and some guides for making reuse decisions. The flexible view of the concept of framework was also a positive aspect, since any activity in a framework can be reused or not, not only hot spots, although some of them are strongly recommended but no one is considered as mandatory.One of the drawbacks was the strictly sequential model of processes and the lack of an standard graphical representation of processes. It would be interesting to have a richer model in which processes could be ordered in a more flexible way. Other found problem was the strict level hierarchy, in which an item initially created at one level (process, macro activity or activity) cannot be changed to an upper or lower level and, in the case of detailed activities, they must be reused together with their parent macro activity, not isolated.From the point of view of “Universidad Politécnica de Valencia”, we have encountered a powerful mechanism of process definition and reutilization, but we have only fully exploded the former characteristic, process definition. There is a coherent classification of process types: standard, pattern, usual and solution. The variable level of granularity in process definition and decomposition (macro and detailed activities) let us employ the desire level of abstraction and detail.In the other hand, there are also negative aspects. There is not a graphical notation to depict process and activities dependency. The precedence process relation is very restrictive. Finally, there is not a view model or users and users groups. Any user can access to all database. We have not found a privacy policy and information protection.Regarding future work, we understand that different issues vary in terms of effort needed and maturity over time. The short term issues are those related to the tool, like: better user interface, language customization, privacy and security, and of course a more stable platform. Requiring more effort would be things related to the language concept itself, for instance, during the first experience, it was found as interesting the possibility of having more than 3 levels of abstraction. It would be nice if recursive composition could be applied when defining a process, i.e. if a process could be defined as recursively composed by other process, having as many depth levels as necessary. In terms of long term we would be interested in auditing and populating the repository together with a more robust tool. Collaborations like the one presented in this paper, we believe, will foster the possibility of improving the repository as well as provide a larger user base for testing the tool.References[1] Paulk, C.M., Curtis, B., Chrissis, M. B., Weber, V.C.: Capability Maturity Model for Software, Ver. 1.1, Software EngineeringInstitute, Carnegie Mellon University, CMU/SEI-93-TR-24, ESC-TR-93-177, 1993.[2] SEI, Process Maturity Profile of the Software Community 1999 Year End Update, SEMA 3.00, Carnegie Mellon University,March, 2000.[3] Fiorini, S. T., Leite, J. C. S. P., Lucena, C. P.: Process Reuse Architecture, Klaus R. Dittrich, Andreas Geppert, Moira C.Norrie (Eds.): Advanced Information Systems Engineering, 13th International Conference, CaiSE 2001, Interlaken, Switzerland, June 4-8, 2001, Proceedings. Lecture Notes in Computer Science 2068 Springer 2001, pp. 284-298.[4] Finkelstein, A., Kamer, J., Nuseibech, B.: Software Process Modelling and Tecnology, Research Studies Press Ltda, 1994[5] Fiorini, S. T., Arquitetura para Reutilização de Processos de Software (Software Process Reuse Architecture), PhD Thesis, Departamento de Informática, Pontifícia Universidade Católica do Rio de Janeiro, April, 2001.[6] /TR/REC-xml and /Style/XSL/[7] Coplien, J. O.: Software Patterns, SIGS Books & Multimedia, USA, 1996.[8]Gamma, E., Helm, R., Johnson, R., e Vlissides, J.: Design Patterns: Elements of Reusable Object-Oriented Design, Addison-Wesley, 1995.[9]Wiegers, Karl E., Software Requirements, Microsoft Press, 1999.[10] Booch G; Rumbaugh J; Jacobson I, The unified modeling language, Addison-Wesley. 1999.[11] Sánchez J; Pastor O; Fons J; From user requirements to user interfaces: a methodological approach, Klaus R. Dittrich,Andreas Geppert, Moira C. Norrie (Eds.): Advanced Information Systems Engineering, 13th International Conference, CAiSE 2001, Interlaken, Switzerland, June 4-8, 2001, Proceedings. Lecture Notes in Computer Science 2068 Springer 2001, pp. 60-75.[12] ITU: Recommendation Z. 120: Message Sequence Chart (MSC). ITU, Geneva, 1996.[13] Harel D.: State Charts: a visual formalism for complex systems, Science of Computer Programming, 8(3), 231-274. 1987.[14] Jacobson I et al. Object-Oriented Software Engineering: A use case driven approach. New-York ACM Press, 1992.[15] Jacobson I; Booch G; Rumbaugh J. The Unified Software Development Process. Addison-Wesley, 1999.。