TURBO编译码及仿真
- 格式:doc
- 大小:724.05 KB
- 文档页数:22

电子信息类实践课III 通信系统仿真题目Turbo码的编译码算法仿真专业学号姓名日期注:本报告仅供参考1、课程设计目的(黑体小三,段前段后个一行)通过完成在在衰落信道下采用不同调制信号进行Turbo码编译码的编程实现,进一步了解了Turbo码的编码解码过程,以及在不同调制方式不同信道下的性能比见。
通过对卷积和交织器的设计,深入了解卷积和交织的作用。
以及熟悉了通信仿真的整体流程。
2、课程设计内容具体叙述课程设计的主要内容和原理。
表1 主要课程设计内容列表在进行本次Turbo仿真时,采用了两种不同编程方式。
在程序一中是直接调用matlab Communications System Toolbox中的Turbo编码和解码工具箱,通过配置参数进行仿真。
而在程序二中则根据Turbo码编译码原理编写。
如果程序一更像是一个黑匣子,只能知道通过编解码模块前、后的数据,而具体做了哪些则不得而知。
a.编码图1 Turbo码编码器结构典型的Turbo码编码器结构框图如图所示:由两个反馈的编码器通过一个交织器并行连接而成。
如果必要,由成员编码器输出的序列经过删余阵,从而可以产1生一系列不同码率的码。
例如,对于生成矩阵为g=[g1,g2]的(2,1,2)卷积码通过编码后,如果进行删余,则得到码率为1/2的编码输出序列;如果不进行删余,得到的码率为1/3。
一般情况下,Turbo码成员编码器是RSC编码器。
原因在于递归编码器可以改善码的比特误码率性能。
通俗理解1/2码率就是信号中有一半都是“无用信号”,这些“无用信号”就是两个分量编码器的生成的校验码,而删余则是各删除一部分校验码,把剩下的再和信息比特合在一块,形成编码好的矩阵。
b.译码图2 Turbo译码结构Turbo码获得优异性能的根本原因之一是使用了迭代译码,通过与分量编码器对应的分量译码器之间软信息的交换来提高译码性能。
对于 Turbo 码这样的并行级联码,如果分量译码器的输出为硬判决,则不可能实现分量译码器之间软信息的交换,从而限制了系统性能的进一步提高。

Turbo码原理及仿真1993 年C.Berrou、A.GIavieux 和P.Thitimajshiwa 首先提出了称之为Turbo 码的并行级联编译码方案。
Turbo码性能取决于码的距离特性。
线性码的距离分布同于重量分布,如果低重量的输入序列经编码得到的还是低重量的输出序列,则距离特性变坏。
该特性对于块码来说不存在问题;然而对于卷积码,则是个非常严重的问题。
因为卷积码的距离特性是影响误码率的一个非常重要的因素。
在Turbo码中,利用递归系统卷积码(RSC)编码器作为成员码时,低重量的输入序列经过编码后可以得到高重量的输出序列。
同时交织器的使用,也能加大码字重量。
实际上,Turbo码的目标不是追求高的最小距离,而是设计具有尽可能少的低重量码字的码。
Turbo 码由两个递归系统卷积码(RSC)并行级联而成。
译码采用特有的迭代译码算法。
1 Turbo码编码原理編码M 2 Turbo典型的Turbo码编码器结构框图如图2所示:由两个反馈的编码器(称为成员编码器)通过一个交织器I并行连接而成。
如果必要,由成员编码器输出的序列经过删余阵,从而可以产生一系列不同码率的码。
例如,对于生成矩阵为g=[g1,g2]的(2,1, 2)卷积码通过编码后,如果进行删余,则得到码率为1/2的编码输出序列;如果不进行删余,得到的码率为1/3。
一般情况下,Turbo码成员编码器是RSC编码器。
原因在于递归编码器可以改善码的比特误码率性能。
32编码图了 Tbrtw 码怕码曙方案中使用的Turbo 码为1/3码率的并行级联码,它的编码器由两个相同的码率为 1/2的RSC 编码器及交织器组成,如图4所示。
由于与非递归卷积码相比,递归卷积码产生的码字重量更大,所以这里采用了两个相同的系统递归卷积码(RSC)。
信息序列分成相同的两路,第一路经过 RSC 编码器1,输出系统码A及校验码C 2。
另一路先通过交织器进行交织,使信息序列在1帧内重新排列顺序,然后经过 RSC 编码器2得到系统码和对应的校验码,由于该系统码和A 实际上都是原信息序列,只是排列顺序不同,在接收端完全可以通过对进行交织得到,因此在传输过程中可以省去,而只保留对应的校验位q。

Turbo码的编译码原理及仿真内容摘要:Turbo 码是巧妙地将两个简单分量码通过伪随机交织器并行级联来构造具有伪随机特性的长码,并通过在两个输入/输出(SISO)译码器之间进行多次迭代实现了伪随机译码。
目前Turbo 码的大部分研究致力于在获得次优性能的情况下减小译码复杂度和时延,从而得到可实现的Turbo码系统。
Turbo码具有极其广阔的应用前景,是信道编码界的一个重大突破,被称为二十一世纪的纠错编码。
本文介绍了Turbo 码的产生背景,研究意义,研究现状(编译码技术、Turbo码的设计和分析、Turbo码在CDMA系统中的研究及应用、面向分组的Turbo码、Turbo码与其它通信技术的结合),编码原理、译码原理及Turbo码的性能仿真及设计。
通过对Turbo编译码原理的介绍及性能仿真的波形、频谱图的结果,本文对系统进行性能分析,并作了进一步的改进和调试。
仿真结果证明了整个设计系统的正确性。
由频谱特性可以看出:Turbo码不仅能够有效地抵御加性高斯噪声,而且具有很强的抗衰落和抗干扰特性。
可以看出,Turbo码在现代通信中具有较大的优越性和重要作用。
关键词:turbo码编码译码仿真Turbo Code principle And SimulationAbstract: The Turbo code is ingeniously two simple component code by pseudo random interleaver parallel cascade constructs has random characteristic of long code, and through the two input / output ( SISO ) decoder between iteration realized pseudorandom decoding. At present, most of research devoted to the Turbo code in obtaining suboptimal performance in the absence of reducing decoding complexity and delay, thus can realize Turbo code system. Turbo code has extremely broad application prospect, is the channel coding community a major breakthrough, known as the twenty-first Century error correction coding.This paper introduces the Turbo code generation background, research significance, research status ( compiled code technology, design of Turbo code and Turbo code analysis, in the CDMA system research and application, a packet-oriented Turbo code, Turbo code and other communications technologies ), encoding, decoding principle of principle and performance simulation of Turbo codes and design.Based on the Turbo compiler code principle introduction and performance simulation waveform, the result of spectrum, the system performance analysis, and made a further improvement and debugging. The simulation results prove that the design scheme is correct. The spectral character can see: Turbo code can not only effectively against the Gauss noise, but also has strong resistance to fading and interference properties. As can be seen, the Turbo code in modern communication has more advantages and important role.Keywords: the turbo code encoding decoding simulation目录前言 (1)1 绪论 (2)1.1T URBO码的研究背景及发展 (2)1.2本文的论文结构安排 (4)2 TURBO码的编码原理 (5)2.1T URBO码的编码器的组成 (5)2.2T URBO码的删余矩阵 (6)2.3T URBO码的交织器 (7)2.4本章小结 (9)3 TURBO码的译码原理 (9)3.1T URBO码的译码结构 (9)3.2T URBO码的LOG-MAP算法 (11)3.3SOVA译码算法 (13)3.4各种译码算法的比较 (14)3.5本章小结 (15)4 TURBO码的性能仿真及设计 (15)4.1T URBO码仿真系统的实现 (15)4.2T URBO码的仿真结果及分析 (19)4.2.1 不同码率对Turbo码的性能影响 (19)4.2.2 不同译码算法对Turbo 码的性能影响 (19)4.2.3 迭代次数 (20)4.2.4 交织长度 (21)4.3本章小结 (22)5 结束语 (22)参考文献 (24)Turbo码的编译码原理及仿真前言随着社会、经济的快速发展,Turbo码的应用越来越广泛。

卷积码(或者Turbo码)的交织与解交织的仿真编程和仿真实验一、实验目的实现卷积码(或者Turbo码)的交织与解交织的仿真编程和仿真实验,观察交织编码分别在白噪声信道和衰落信道下系统误码率的影响,分析原因。
二、实验原理信道编码中采用交织技术,可打乱码字比特之间的相关性,将信道中传输过程中的成群突发错误转换为随机错误,从而提高整个通信系统的可靠性。
交织编码根据交织方式的不同,可分为线性交织、卷积交织和伪随机交织。
其中线性交织编码是一种比较常见的形式。
所谓线性交织编码器,是指把纠错编码器输出信号均匀分成m个码组,每个码组由n段数据构成,这样就构成一个n×m的矩阵。
这里把这个矩阵称为交织矩阵。
如图1所示,数据以a11,a12,…,a1n,a21,a22,…,a2n,…,aij,…,am1,am2,…,amn(i=1,2,…,m;j=1,2,…,n)的顺序进入交织矩阵,交织处理后以a11,n21,…,am1,a12,a22,…,am2,…,a1n,a2n,…,amn的顺序从交织矩阵中送出,这样就完成对数据的交织编码,如图1所示。
还可以按照其他顺序从交织矩阵中读出数据,不管采用哪种方式,其最终目的都是把输入数据的次序打乱。
如果aij只包含1个数据比特,称为按比特交织;如果aij包含多个数据比特,则称为按字交织。
接收端的交织译码同交织编码过程相类似。
图 1 交织编码矩阵一般来说,如果有n个(m,k)码,排成,n×m矩阵,按列交织后存储或传送,读出或接收时恢复原来的排列,若(m,k)码能纠t个错误,那么交织后就可纠m个错误。
对纠正信道传输过程中出现的突发错误效果明显,如图2所示。
图2 交织编码示例GSM中使用这种比特交织器。
其交织方式为将信道编码后的每20ms的数据块m=456b拆分到8组中,每组57b,然后这每组57 b分配到不同的Burst中三、实验流程卷积交织解卷积交织四、源程序1、交织程序1)卷积交织function [aa]=jiaozhi(bb,n)%jiaozhi.m 卷积交织函数n=28; %分组长度%bb 卷积交织前原分组序列%aa 卷积交织后分组序列%序号重排方式:cc=[ 1 23 17 11 5 17 21; 8 2 24 18 12 6 28; 15 9 3 25 19 13 7; 22 16 10 4 26 20 14 ];%交织矩阵bb=[ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28];for i=1:naa(i)=bb(cc(i));end(2)循环等差交织function [aa]=jiaozhi_nocnv(bb,n)%jiaozhi_nocnv.m 循环等差交织函数n=28; %分组长度%bb 循环等差交织前原分组序列%aa 循环等差交织后还原分组序列%序号重排方式:bb=[ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 ]; j=1;for i=1:nj=rem(j+5-1,n)+1; %序号重排方式迭代算法aa(n+1-i)=bb(j);end2、解交织程序(1)解卷积交织function [bb]=jiejiaozhi(aa,n)%jiejiaozhi.m 解卷积交织函数n=28;% 分组长度%aa 解卷积交织前原分组序列%bb 解卷积交织后分组序列%序号重排方式:cc=[ 1 23 17 11 5 27 21; 8 2 24 18 12 6 28; 15 9 3 25 19 13 7 ;22 16 10 4 26 20 14 ]; aa=[ 1 8 15 22 23 2 9 16 17 24 3 10 11 18 25 4 5 12 19 26 27 6 13 20 21 28 7 14 ]; for i=1:nbb(cc(i))=aa(i);end(2)解循环等差交织function [bb]=jiejiaozhi_nocnv(aa,n)%jiaozhi_nocnv.m 解循环等差交织函数n=28;% 分组长度%aa 解循环等差交织前原分组序列%bb 解循环等差交织后还原分组序列%序号重排方式:aa=[ 1 24 19 14 9 4 27 22 17 12 7 2 25 20 15 10 5 28 23 18 13 8 3 26 21 16 11 6];j=1;for i=1:nj=rem(j+5-1,n)+1; %序号重排方式迭代算法bb(j)=aa(n+1-i);End交织码通常表示为(M,N),分组长度L=MN,交织方式用M行N列的交织矩阵表示。

PCCC码(Turbo码)的编码和译码算法目录一、概述 .................................................................... 1 二、PCCC码的编码算法 ........................................................................... ......................................... 3 三、 PCCC码的译码算法 ........................................................................... (13)一、概述虽然软判决译码、级联码和编码调制技术都对信道码的设计和发展产生了重大影响,但是其增益与Shannon 理论极限始终都存在2~3dB 的差距。
因此,在Turbo 码提出以前,信道截止速率R0 一直被认为是差错控制码性能的实际极限,shannon 极限仅仅是理论上的极限,是不可能达到的。
根据shannon 有噪信道编码定理,在信道传输速率R 不超过信道容量C 的前提下,只有在码组长度无限的码集合中随机地选择编码码字并且在接收端采用最大似然译码算法时,才能使误码率接近为零。
但是最大似然译码的复杂性随编码长度的增加而加大,当编码长度趋于无穷大时,最大似然译码是不可能实现的。
所以人们认为随机性编译码仅仅是为证明定理存在性而引入的一种数学方法和手段,在实际的编码构造中是不可能实现的。
在1993 年于瑞士日内瓦召开的国际通信会议(1CC,93)上,两位任教于法国不列颠通信大学的教授C.Berrou、A.Glavieux 和他们的缅甸籍博士生P.thitimajshima 首次提出了一种新型信道编码方案――Turbo 码,由于它很好地应用了shannon 信道编码定理中的随机性编、译码条件,从而获得了几乎接近shannon 理论极限的译码性能。

Turbo编译码技术的软件仿真
Turbo码是一类新的纠错码,具有并行级联的编码结构,使用了软输入软输
出迭代译码策略,在计算机仿真中获得了近Shannon限的优异性能,被认为是信
道编码发展过程中的一个里程碑。
由于Turbo码是在计算机仿真中发现的,所以长时间缺乏理论基础。
并且Turbo码使用了复杂的编码和译码技术,对Turbo码的研究非常困难。
理论研究和计算机仿真是研究Turbo码的两个重要手段。
计算机仿真不仅可以验证Turbo码理论的合理性,还可以对Turbo码设计产生实际的指导作用。
本文首先介绍了Turbo码产生的背景、仿真研究的意义及研
究现状。
其次,介绍了Turbo码编译码结构和基本原理,比较了常用的Turbo译码算法。
最后,使用软件构造了一个Turbo编译码仿真系统,对不同参数对Turbo码性能的影响进行了分析,得到了一些结论,并对实际使用中Turbo码的设计提出了一些
建议。



暑期实习报告——Turbo码的编译码原理及仿真研究一、研究背景 (2)二、研究内容 (2)三、研究过程及结果 (2)1.卷积码及交织器 (2)(一)研究AWGN信道 (2)<实例1> (2)(二)卷积码 (3)<实例2> (4)(三)交织器 (5)<实例3> (5)2.Turbo码编码 (7)3. Turbo码译码 (8)<实例4> (9)<1>不同迭代次数对Turbo码性能的影响: (11)<2>不同交织长度对Turbo码性能的影响: (13)<3>不同码率对Turbo码性能的影响: (15)四、Turbo码的应用 (17)1.Turbo 码在直扩(CDMA) 系统中的研究及应用 (17)2.Turbo码在3G中的应用 (17)(一)RSC 编码器的设计 (18)(二)交织长度的选择 (18)(三)译码器的设计 (18)3.Turbo 码与其它通信技术的结合 (18)五、收获与感悟 (19)一、研究背景Turbo码通过对子码的伪随机交织实现大约束长度的编码,具有接近随机编码的特性,采用迭代译码取得了中等的译码复杂度,它的误码性能逼近了Shannon极限。
Turbo码相对以前的编码方式大大提高了功率的利用率,因此特别适用于信噪比受限的信道,同时Turbo 码在衰落信道中也具有很好的编译码性能。
二、研究内容1.学习卷积码原理及交织器设计,进行相关仿真分析。
2.阅读Turbo码相关文献资料,进行Turbo码编码仿真。
3.学习Turbo译码算法,进行Turbo码译码仿真,并分析不同码率、不同交织长度、不同迭代次数下的性能。
三、研究过程及结果1.卷积码及交织器(一)研究AWGN信道<实例1>clear allt=0:0.001:10;x=sin(2*pi*t);snr=20;y=awgn(x,snr);subplot(2,1,1);plot(t,x);title('正弦信号x')subplot(2,1,2);plot(t,y);title('叠加了高斯白噪声的正弦信号')z=y-x;var(z)ans =0.0098。

一种新的TURBO码编译码器结构的研究及其在AWGN信道中的性
能仿真
TURBO码是第三代移动通信系统中使用信道编码的技术,对其编译码器的研究有着非常重要的意义。
在系统的设计过程中,根据SCCC和PCCC的不同原理,搭建了各自相应的系统模型。
并采用适当的模块分割,把整体系统的设计分解成对各个子模块的研究,并给出了相应的子模块仿真。
最后通过对两个系统的仿真,获得了如下的结论:通过增加交织长度,选择好的交织器,采用合适的迭代系统卷积码(RSC)编码器结构,应用好的译码算法以及增加迭代次数可以获得性能优良的TURBO码。
本论文的主要工作包括:1.首先简单介绍了TURBO码的提出,发展状况以及其应用价值。
2.详细讨论了三类TURBO码(串行级联卷积码(SCCC),并行级联卷积码(PCCC)和混合级联卷积码(HCCC)的编码器与译码器结构,原理。
3.论述了TURBO码编译码中的关键技术。
并深入讨论了译码算法。
4.在此基础上,用使用SIMULINK平台搭建了在AWGN信道下SCCC和PCCC的通信系统模型。
5.统计了大量的仿真数据,绘制出相应不同参数条件下的SCCC 和PCCC的性能曲线。
从而得出影响SCCC和PCCC的性能的参数条件。
并验证了TURBO码中的迭代循环译码,PCCC错误平层等理论。
本设计应用MATLAB中的SIMULINK仿真工具对TURBO的性能做出了仿真,证明TURBO码具有较低误码率,具有很高的实用价值。
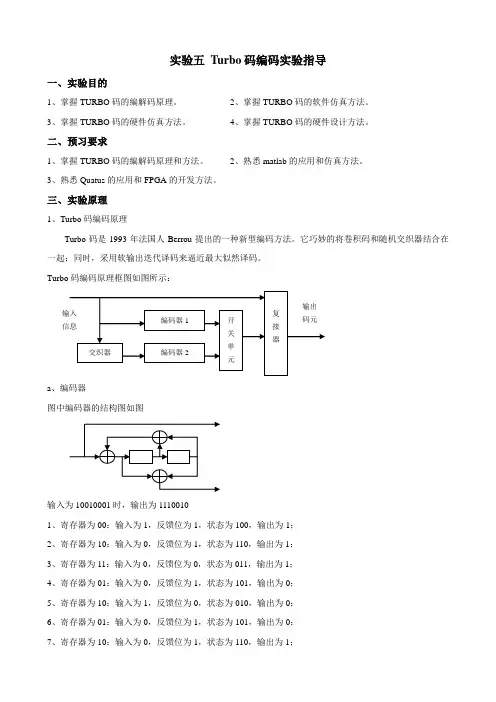
实验五Turbo码编码实验指导一、实验目的1、掌握TURBO码的编解码原理。
2、掌握TURBO码的软件仿真方法。
3、掌握TURBO码的硬件仿真方法。
4、掌握TURBO码的硬件设计方法。
二、预习要求1、掌握TURBO码的编解码原理和方法。
2、熟悉matlab的应用和仿真方法。
3、熟悉Quatus的应用和FPGA的开发方法。
三、实验原理1、Turbo码编码原理Turbo码是1993年法国人Berrou提出的一种新型编码方法。
它巧妙的将卷积码和随机交织器结合在一起;同时,采用软输出迭代译码来逼近最大似然译码。
Turbo码编码原理框图如图所示:a、编码器图中编码器的结构图如图输入为10010001时,输出为11100101、寄存器为00:输入为1,反馈位为1,状态为100,输出为1;2、寄存器为10:输入为0,反馈位为1,状态为110,输出为1;3、寄存器为11:输入为0,反馈位为0,状态为011,输出为1;4、寄存器为01:输入为0,反馈位为1,状态为101,输出为0;5、寄存器为10:输入为1,反馈位为0,状态为010,输出为0;6、寄存器为01:输入为0,反馈位为1,状态为101,输出为0;7、寄存器为10:输入为0,反馈位为1,状态为110,输出为1;8、寄存器为11:输入为1,反馈位为1,状态为111,输出为0;图中,两个方框为移位寄存器,⊕为异或器。
b、交织器交织可以将长的突发错误分散到每个行码中去。
以最常用的交织器-行列交织器为例,它的交织方式是采用行顺序写入、列顺序读出的方式,而解交织列顺序写入,行顺序读出。
交织时,输入序列为:a11 a12 a13 a14a21 a22 a23 a24a31 a32 a33 a34a41 a42 a43 a44通过行列交织后变为:a11 a21 a31 a41a12 a22 a32 a42a13 a23 a33 a43a14 a24 a34 a44上述序列为四组长度为四的码组。
Turbo码迭代译码方法的改进及性能仿真分析的开题报告一、选题背景与意义随着通信技术的快速发展,可靠的数据传输成为了现代通信的基础,而编码技术在数据传输过程中起到了非常重要的作用。
通信中最常见的编码方式是纠错编码,其中最具代表性的是卷积码和Turbo码。
Turbo码是一种误码率性能非常卓越的编码方式,是1993年由Berrou等人提出的,经过多年的发展,已成为现代通信中的重要编码方式。
Turbo码利用迭代译码的方法,通过多次反复迭代来逐步改进码字的译码性能,因此Turbo码的解调精度比传统卷积码高出很多。
Turbo码的迭代译码方法有很大的改进空间,可以通过一些方法来提高其译码性能,同时还可以通过性能仿真来评估这些方法的效果,并找出最佳的优化方案。
因此,本文将探讨Turbo码迭代译码方法的改进及性能仿真分析。
二、研究内容和思路本文将从以下几个方面对Turbo码迭代译码方法进行改进和优化:1. 码内交织(Interleaving):采用不同的交织方式来优化Turbo码的译码性能。
2. 偏置因子(Bias Factor):优化偏置因子的设置,提高译码准确度。
3. 迭代次数和停止准则:通过合理的迭代次数和停止准则来优化Turbo码的译码性能。
在以上基础上,通过性能仿真来评估所提出的改进方法的正确性和有效性,并找出最佳的优化方案。
三、预期成果本文预期达到以下几个方面的成果:1. 研究并提出Turbo码迭代译码方法的改进和优化方案。
2. 在Matlab等仿真工具中实现所提出的改进方案,进行性能仿真,并通过仿真结果来证明改进方案的有效性。
3. 分析不同参数对Turbo码译码性能的影响,并提出优化方案。
四、研究难点和挑战1. 码内交织和偏置因子的设置:选择合适的交织方式和优化偏置因子的设置对Turbo码的译码性能有着很大的影响,需要进行充分的实验和分析。
2. 迭代次数和停止准则的确定:为了得到最优的Turbo码译码性能,需要寻找最合适的迭代次数和停止准则,这需要进行大量的实验和分析。
Turbo码性能分析与仿真王会王忠(四川大学通信工程系,成都610065)摘要:本文介绍了一种新型差错控制编码——Turbo码,在对其原理分析的基础上,简单介绍了它的译码算法,并且实现了其中两种算法Log-MAP算法和SOV A算法的性能仿真,对不同译码算法下Turbo码的性能进行了分析比较。
关键词:差错编码;Turbo码;交织器;迭代译码;1 引言1948年,现代数字通信的奠基人Shannon在信道编码定理中指出,只要随机编码的码长足够大,就可以进行无限逼近信道容量C的通信并使错误概率任意小。
他证明:对于平稳离散无记忆有噪声信道,如果数据源的速率R低于信道容量C时,则一定存在一种编码方法,使当平均码字长度足够长时,用最大似然译码可达到任意小的错误概率。
但随机编码的译码复杂度随码长指数增长以致于不可实现。
自香农之后,人们不懈地向逼近信道容量的方向努力。
纠错编码理论的发展正是沿着这二条基本路线:一是构造长码;另一是在人们所能接受的范围内,如何实现最大似然译码。
1993年C.Berrou等人提出的Turbo码通过对子码的伪随机交织实现大约束长度的编码,具有接近随机编码的特性,采用迭代译码取得了中等的译码复杂度,它的误码性能在10-5数量级上逼近了Shannon极限。
并行级联递归系统卷积码(Turbo-code)的提出为编码研究带来新的曙光,其基本思想是利用短码来构造长码,在译码时,它使用一种全新的译码思想——迭代译码,将长码化成短码,从而以较小复杂度来获得接近最大似然译码的性能,突破了传统码的约束,真正挖掘了级联码的潜力,获得接近香农极限的性能。
Turbo码自提出之日起就成为信息论与编码界工作者的热切关注的热点,本文给出了Turbo码基本原理的介绍及其性能的仿真。
2 编译码原理图1中给出了Turbo码编码器的一般性结构。
图中d k是输入进行编码的数据块,加入尾随比特的作用是使在一个数据块编码结束之后,保证成员编码器的寄存器回到全零状态,这样的Turbo码就等同于线性分组码,从而通过分析这类分组码的特性来计算Turbo码的译码性能上界,对其性能进行估计与分析。
Turbo 编译码实验一、实验目的1、了解Turbo 码的基本原理。
2、熟悉Turbo 编码演算程序。
3、掌握Turbo 码的编码规则。
二、实验内容1、对信号源模块24位NRZ 码进行Turbo 编码。
2、Turbo 码译码还原。
三、实验仪器1、信号源模块 一块2、信道编码模块 一块3、数字存储示波器 一台四、实验原理1、Turbo 码Turbo 码是一种特殊的链接码,性能接近信息理论上能够达到的最好性能,在编码理论上是带有革命性的进步,但是其解码运算非常复杂。
Turbo 码的编码器在两个并联或串联的分量码(component code )编码器之间增加一个交织器(interleaver ),使之具有很大的码组长度,能在低信噪比条件下得到接近理想的性能。
Turbo 码的译码器有两个分量码译码器,译码在两个分量译码器之间进行迭代译码,故整个译码过程类似涡轮(turbo )工作,所以又形象的称为Turbo 码。
2、Turbo 编码下图28-1为Turbo 码的一种基本结构。
RSCC交织器b ib ic ic i ’RSCCb i ’图28-1 Turbo 码编码器上图中,Turbo 码编码器由一对递归系统卷积码RSCC (Recursive Systematic Convolution Code )编码器和一个交织器组成。
交织器的形式为矩阵交织器,由6×4比特的存储器构成,如下表28-1所示。
表28-1 交织器原理图a11a12a13a14a21a22a23a24a31a32a33a34a41a42a43a44a51a52a53a54a61a62a63a64信号码元按行的方向输入存储器中,再按列的方向输出。
例如,输入码元序列是:a11 a12 a13 a14 a21 a22 a23 a24 a31 a32 a33 a34 a41 a42 a43 a44 a51 a52 a53 a54 a61 a62 a63 a64 ,则输出码元序列是:a11 a21 a31 a41 a51 a61 a12 a22 a32 a42 a52 a62 a13 a23 a33 a43 a53 a63 a14 a24 a34 a44 a54 a64。
目录一、简述信道编码 (3)1.信道编码的原理 (3)2.信道编码的码型 (3)2.1分组码 (3)2.2 卷积码 (4)2.3 格型码 (4)2.4 Turbo 码 (4)二、Turbo码介绍 (5)1.Turbo的提出 (5)2. Turbo码编译码原理 (5)3. Turbo码仿真建模 (7)4.仿真结果分析 (9)三、总结 (12)四、参考文献 (12)一、简述信道编码1.信道编码的原理上了信息论与编码这门课我们知道,图像信号信源压缩编码的目的就是要去掉图像中的空间冗余和时间冗余,从而降低了总的数据率,提高了信息量的效率。
这样,容许保证一定图像质量的数字信号能以较少的数据量快速传输出去。
与此同时,经信源编码的去冗余而提高信源的信息熵(每个符号的平均信息量)后,数字信号的抗干扰能力明显下降了,这是不言而喻的,因为未压缩之前每个符号的信息量很低。
因此,压缩后的数字信号很容易受到传输通道中引入的噪声、多径反射和衰落等的影响而造成接收端发生程度不同的误码,有的甚至无法恢复出原始数据。
为解决这个问题,信道编码应运而生了。
所谓信道编码就是为提高信息传输可靠性而进行的编码(在信源编码的基础上以降低传输的信息量为代价来提高可靠性)。
信道编码可以检测、纠正由于传输造成的误码,所以这种编码也常称为差错控制编码。
信道编码是数字通信系统中的重要组成部分,其作用是完成检错纠错,码形变换的任务,从而提高传输信道的可靠性。
信道编码的原理简言之就是要使传输符号间具有某种特定的关系,通常将要传输的信息分组,根据某种规则,使每组信息映射(映射是数学上的一个术语,源于集合论,映射又称为变换,意思是两个集中的元素有某种对应关系。
)到一组信道符号,这组符号相互之间具有某种特定关系,即使其中某些符号在传输中会出错,也会发现这些错误,并进一步纠正它们。
显然,要实现信源具有检错和纠错能力,必需按一定的规则在信源编码的基础上再增加一些冗余码元(又称监督码),使这些冗余码元与被传信息码元之间建立一定的关系,发送端完成这个任务的过程称为纠错编码。
Turbo码的编译码原理及MATLAB仿真摘要纠错码技术作为改善数字通信可靠性的一种有效手段,在数字通信的各个领域中获得极为广泛的应用。
Turbo码是并行级联递归系统卷积码,在接近Shannon限的低信噪比下能获得较低的误码率,现已被很多系统所采用。
本文分析了Turbo码编码译码的原理,为了使Turbo码仿真更容易,研究并建立了基于Matlab中Simulink通信模块的Turbo码仿真模型。
使用所建立的模型进行仿真,结果表明,在信噪比相同的情况下,交织长度越大、迭代次数越多、译码算法越优,Turbo码性能越好,设计实际系统时,应综合考虑各因素。
关键词:Turbo码;Simulink仿真;交织长度;迭代次数AbstractAs an effective means to improve the reliability of digital communication, error correcting code technology is widely used in the field of digital communication.Turbo code is a parallel concatenated recursive systematic convolutional code, which can obtain lower bit error rate in the low SNR near Shannon limit,which is now used by many systems.In this paper,the principle of Turbo coding and decoding is analyzed,in order to make the Turbo Code simulation easier,a Turbo code simulation model based on Simulink module of Matlab is studied. Simulation result using the established model shows that the longer interleaving length,the more iteration times and the better decoding algorithm bring the better Turbo code performance with the same SNR value.Keywords:Turbo code;Simulink simulation;Interleaving length;Iteration times;引言根据Shannon[1]有噪信道编码定理,在信道传输速率R不超过信道容量C的前提下,只有在码组长度无限的码集合中随机地选择编码码字并且在接收端采用最大似然译码算法时,才能使误码率接近为零。
课程设计论文题目turbo码编译码及Matlab仿真学院物理科学与技术学院专业通信工程年级2010学生姓名学号指导教师二○一三年六月第1章绪论纠错码技术在过去的八年中发生了翻天覆地的改变。
从1993 年,Turbo 码被C.Berrou 等人提出以来,Turbo 码就以其优异的性能和相对简单可行的编译码算法吸引了众多研究者的目光.Turbo 码的实质是并行级联的卷积码,它与以往所有的码的不同之处在于它通过一个交织器的作用,达到接近随机编码的目的.它所采用的迭代译码策略,使得译码复杂性大大降低。
它采用两个子译码器通过交换称为外信息的辅助信息,相互支持,从而提高译码性能。
外信息的交换是在迭代译码的过程中实现的,前一次迭代产生的外信息经交换后将作为下一次迭代的先验信息。
人们将Turbo 码中子译码器互换信息以相互支持的思想称为“Turbo 原理”。
这种思想可运用于其他场合,如信道均衡,码调制,多用户检测,信源、信道联合译码等。
日前Turbo码的研究尚缺少理论基础支持,但是在各种恶劣条件下(即低SNR情况下),提供接近Shannon 极限的通信能力已经通过模拟证明。
但Turbo码也存在着一些急待解决的问题,例如译码算法的改进、复杂性的降低、译码延时的减小。
作为商用3G 移动通信系统的关键技术之一,Turbo 码也将逐渐获得较好的理论支持并且得到进一步开发和完善。
第2章 Turbo 码编码原理2.1 Turbo 码的编码结构Turbo 码的典型编码器如图1所示,Turbo 码编码器主要由分量编码器、交织器复接器组成。
分量码一般选择为递归系统卷积(RSC ,Recursive Systematic Convolutional )码,当然也可以是分组码(BC , Block Code )、非递归卷积(NRC ,Non-Recursive Convolutional )码以及非系统卷积(NSC ,Non-Systematic Convolutional )码,但从后面的分析将看到,分量码的最佳选择是递归系统卷积码。
通常两个分量码采用相同的生成矩阵,当然分量码也可以是不同的。
{u{}k c图1 Turbo 码的编码器结构以分量码为RSC 为例,分量编码器为递归系统卷积码(RSC )编码器。
第一个RSC 之前不使用交织器,后续的每个RSC 之前都有一个交织器与之对应。
一个Turbo 编码器中原则上可采用多个RSC ,但通常只选用2个,因为过多的RSC 分量编码器将使得译码非常复杂而难以实现。
通常的Turbo码编码器中,长度为N 的信息序列{}k u 在送入第一个分量编码器的同时作为系统输出{}sk x 直接送至复接器,同时{}k u 经过一个N 位交织器,形成一个新序列{}'k u (长度与内容没变,但比特位置经过重新排列。
{}k u 与{}'k u 分别传送到两个分量码编器(RSC1与RSC2)。
一般情况下,两个分量码编码器的结构相同,生成分量码校验序列{}p k x 1和{}p k x 2。
{}k u {}'k u 与未编码的信息序列{}s k x 经过复接后,生成Turbo 码序列{}k c ,将编码序列调制后,即可发射进入信道传输。
2.2 递归系统卷积码(RSC )纠错编码是将k 位的输入信息码元编成n 位的输出信道码元,在编码中,可以采用一定的算法,使输出码元中的k 位与输入码元一致。
这样,输入码元与输出码元有明显的对应关系,这种码称为系统码[。
系统码中一致的这k 位数据称为信息位,输出码元其余的n -k 位称为校验位,不满足这种关系的码称为非系统码。
同样的,卷积码可以分为系统卷积(SC ,Systematic Convolutional )码与非系统卷积(NSC ,Non-Systematic Convolutional )码两大类。
以下图2的(2,1,2)卷积码为例,设时刻k 的输入码元为k d ,输出码元为k X 和k Y ,则输出码元与输入码元的关系为k X图2∑-=---=++=10121K i i k i k k k k d g d d d X (2-1)∑=--=+=022i i k i k k k d g d d Y (2-2)式中,i g 1—1G 的系数,i g 2—2G 的系数。
非递推系统卷积码,约束长度K =3,但码生成多项式为Gl=4,G2=5。
它的输出码元与输入码元的关系为k k d X = (2-3)∑-=--=+=1022K i i k i k k k d g d d Y (2-4)系统码的结构比非系统码的简单,模2加法器和连线的数量都比非系统码的要少。
RSC 码是由一个NSC 码编码器通过反馈,并使k X 等于输入信息比特kd 而构成的。
对RSC 编码器,移位寄存器输入不再是数据比特k d ,而是一个新的二元变量k a 。
如果k X =k d ,输出k Y 为式(2-4),其中k d 由代替k a ,而k a 由下式递推计算∑-=-+=11K i i k i k k a r d a (2-5)式中i i g r 1= (2-6)式(2-5)可写为∑-=-=10K i i k i k a r d (2-7)下面讨论为什么选择RSC 编码器作为Turbo 码的子编码器。
首先,RSC 码具有系统码的优点。
因为系统码在从码字恢复出信息序列时无需求逆,这一特性使用户在译码时无需变换码字而直接对接收的码序列进行译码。
所以,RSC 码对于NSC 码而言译码简单、快速。
其次,还可以从Turbo 码重量分布的角度给予解释。
通过观察递归卷积码与非递归卷积码的低重量信息序列所产生的码字的分布情况,可以发现二者之间有明显的不同,低重量的输入信息序列经过非递归卷积编码器之后,只能产生低重量的监督码元序列,低重量码字的增加将严重影响Turbo 码的性能,而低重量的信息序列经过递归卷积编码之后,输出的监督码元的重量分布在一个很宽的范围之内,这是由其反馈特性所造成的。
因此,用非递归卷积码所构造的Turbo 码的性能比较差,Turbo 码需要递归卷积码实现。
最后,从差错控制编码的相关文献中也可知,在对比实验中,非系统卷积码(NSC )的BER 性能在高信噪比时比约束长度相同的非递归系统码要好,而在低信噪比时情况却正好相反[13]。
递归系统卷积(RSC )码综合了NSC 码和系统码的特性,虽然它与NSC 码具有相同的trellis 结构和自由距离,但是在高码率()32≥R 的情况下,对任何信噪比,它的性能均比等效的NSC 码要好。
由于系统递归卷积码具有以上特点,并且能改善误码率,所以通常选择RSC 码作为Turbo 码的子编码器。
NSC 的可由生成算子[]1111=g 和[]1012=g 来描述,也可将其表示为矩阵形式[]21,g g G =.RSC 可以表示为[]12,1g g G =。
NSC 中的第一个支路输出被反馈到了输入端,从而引起了生成矩阵形式上的变化。
RSC 的矩阵表达式中,1对应着输出的系统信息序列,2g 对应着编码器的前馈输出,1g 对应着反馈到输入端的成分。
研究指出RSC 的原始生成多项式的基础上加上适当的反馈,往往能获得好码,因为应用了反馈之后,可以获得最大长度的编码序列,根据分组码的知识,我们知道这给码序列增加了随机性,从而能获得更好的误比特率。
2.3 交织器交织器其实是通信系统中进行数据处理而采用的一种技术,交织器从其本质上来说就是一种实现最大限度的改变信息结构而不改变信息内容的器件,也就是使在信道传输过程中所突发产生集中的错误最大限度的分散化,不规则化[。
我们设X 为交织器的输入,Y 为交织器的输出,I 就是交织器,所以()X I Y =。
一般的应用交织器往往都是有延时的,我们有必要引入一个新的概念:交织器的延时,它是指在时刻i ,输出的i y 与此时此刻或以前的输入()i j x j <有关,且()i i I ≤,用式子来表示就是()0≥-=i I i δ,相应的()()i I i ti -=≤≤0min min δ为交织器的最小延时。
交织器是Turbo 码编码器主要的组成部分,也是Turbo 码的重要特征之一。
线性码的纠错译码性能实质上是由码字的重量分布决定的,Turbo码也是线性码,所以其性能也是由码字重量分布决定的,由于交织器实际上决定了Turbo码的重量分布,所以,给定了卷积编码器后,Turbo码的性能主要是由交织器决定的。
在低SNR时,交织器的大小将直接影响着Turbo码的差错性能。
因为交织长度大时,两个子编码器接收的输入序列的相关性就可以很低,就越有利于译码迭代,从而使得迭代结果越准确。
在高SNR时,是Turbo 码的低重量码字、最小汉明距离或距离谱决定着它可以达到的BER性能,所以交织器的设计显著的影响着低重量码字或距离谱,重量分布是反映纠错码性能的重要指标,所谓具有好的重量分布,就是要尽量减少低重量的码字的数量。
如果没有交织器的作用,Turbo码的两个子编码器的输入就相同。
如果其中一个经编码后产生低重量的码字,那么该序列在经过第二个字编码器输出后也会产生低重量的码字。
反之,加入交织器,由于交织器对输入序列进行了置换,使得数据在进入第二个编码器之前被打乱,也就改变了原来信息的排列方式,所以Turbo码的两个子编码器同时产生低重量输出的可能性就更小了,也就是说交织器减小了Turbo码产生低重量码字的概率,从而可以使Turbo码有比较好的纠错性能[15]。
在Turbo码中,交织器的这种使输入码元符号的顺序尽可能随机分布的作用,将使码元符号之间的相关性减弱,使进入各个子译码器的信息序列之间不相关。
这种去相关的结果使得各个子译码器可以彼此独立的工作。
彼此独立进行译码的结果是,软判决信息可以互相利用,判决结果也因此逐渐准确。
从而,使Turbo码译码器的性能远远好于其它类型的译码器,包括其他类型的级联译码器。
但是,由于交织器的存在,使得Turbo码存在一定的时延,数据帧越长,延时越大。
而且交织器的长度会对Turbo码的译码性能有很大的影响,交织深度越大,译码的误码率越低,传输质量越高。
所以,对于那些允许有较大时延的业务,Turbo码的作用就可以得到充分的发挥。
但是,对于那些不允许有较大时延的业务,Turbo码的应用却受到了限制。
仿真用来如下三个寄存器的递归卷积编码器,生成多项式表示为g[1 0 1 1,1 1 0 1]⊕⊕图3第3章 Turbo码译码3.1 Turbo码的译码结构通常情况下,Turbo码编码器使用两个分量RSC,编码输出包含了信息序列(在译码端常常被称为系统信息或系统比特)和两个分量RSC编码器输出的校验信息序列。