
实验报告
系部计算机系I班级I I学号I I姓名课程名称—数据结构I实验日期实验名称回文判断成绩
实验目的:
掌握栈的基本操作:入栈、出栈等在链式或顺序存储结构上的实现。
实验条件:PC机一台、VC++6.0编译环境
实验内容与算法思想:
内容:
输入一字符串判断其是否为回文。
算法思想:
1. 算法中主要用到的函数
①void mai n() //主函数
②int push_seqstack(Seqstack *s,char x) // 进栈
③in t pop_seqstack(Seqstack *s) // 出栈
④int gettop_seqstack(Seqstack *s) 〃取栈顶元素
⑤int Ishuiwe n( char *s) 〃判断是否是回文
2. 函数之间的调用关系
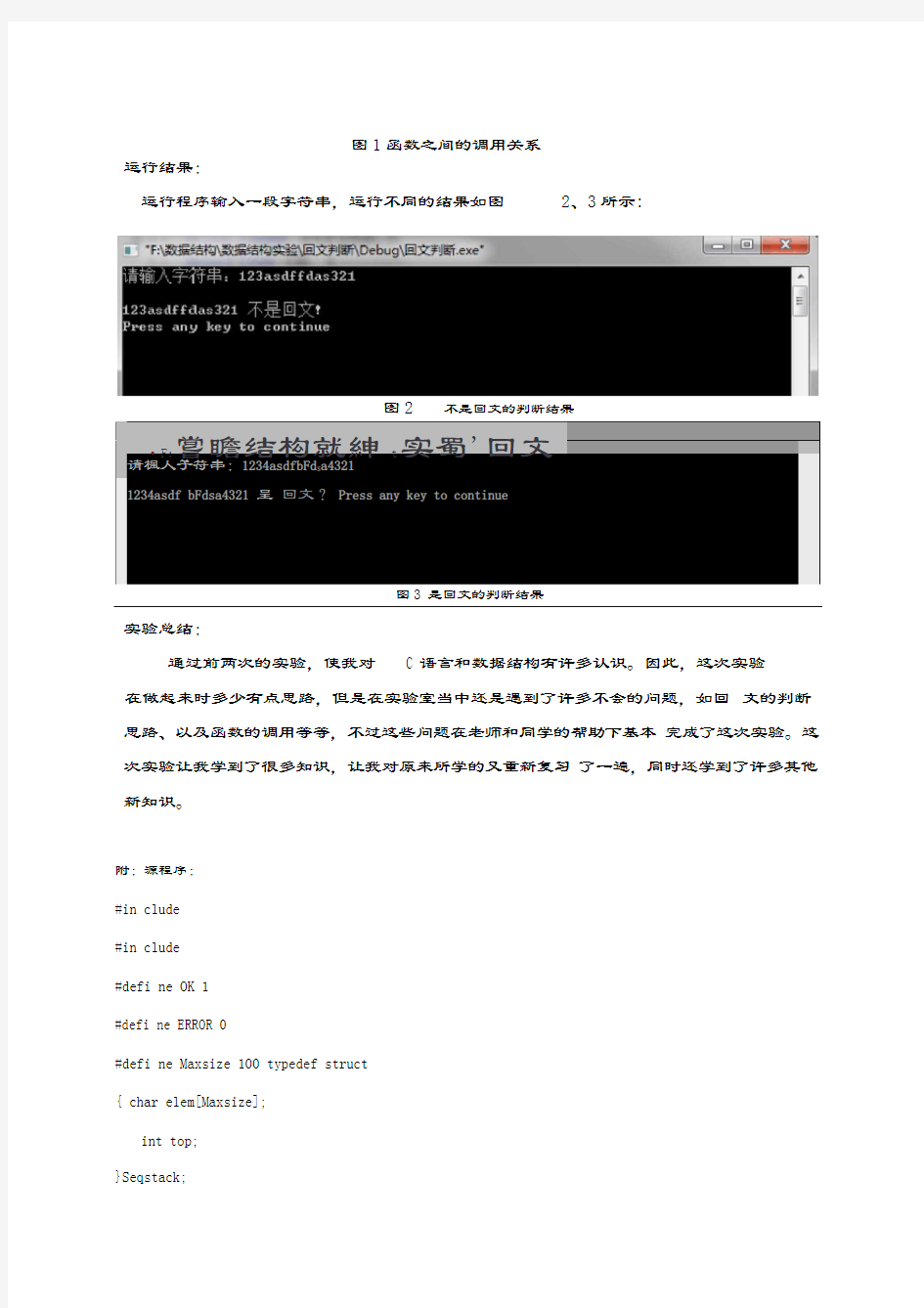
函数之间的调用关系如图1所示:
图1函数之间的调用关系
运行结果:
运行程序输入一段字符串,运行不同的结果如图2、3所示:
图2 不是回文的判断结果
实验总结:
通过前两次的实验,使我对C语言和数据结构有许多认识。因此,这次实验
在做起来时多少有点思路,但是在实验室当中还是遇到了许多不会的问题,如回文的判断思路、以及函数的调用等等,不过这些问题在老师和同学的帮助下基本完成了这次实验。这次实验让我学到了很多知识,让我对原来所学的又重新复习了一遍,同时还学到了许多其他新知识。
附:源程序:
#in clude
#in clude
#defi ne OK 1
#defi ne ERROR 0
#defi ne Maxsize 100 typedef struct
{ char elem[Maxsize];
int top;
}Seqstack;
void init_seqstack(Seqstack *s) // 初始化 {
s->top=-1;
}
int push_seqstack(Seqstack *s,char x) // 进栈 {
if(s->top==Maxsize-1)
return ERROR;
}
else
{ s->top++; s->elem[s->top]=x; return OK; }
}
int pop_seqstack(Seqstack *s)
// 出栈 { char x;
if(s->top==-1)
return ERROR;
else
{ x=s->elem[s->top]; s->top--;
}
return x;
f( 栈已满 *********** !\n") printf(
栈已空 ********** !\n")
int gettop_seqstack(Seqstack *s)
{ char x; if(s->top==-1)
return ERROR;
}
else
x=s->elem[s->top]; return x;
}
int Ishuiwen(char *s)
//判断是否是回文 {
Seqstack *STK,stack; char *p;
int n; n=strlen(s);
STK=&stack;
init_seqstack(STK); push_seqstack(STK,'#'); if(n%2==0)
{ p=s+n/2;
while(s!=p)
{ push_seqstack(STK,*s);
s++;
}
}
else
{ p=s+(n+1)/2;
while(s!=p-1)
//取栈顶元素
printf(" **********
栈已满 *********** !\n")
{ push_seqstack(STK,*s);
s++;
}
while(STK->top!=-1 &&
gettop_seqstack(STK)!='#')
{ if(*p!=pop_seqstack(STK))
return ERROR;
p++;
}
return OK;
}
void main()
{ char s[100];
printf(" 请输入字符串: ");
gets(s);
int x;
x=Ishuiwen(s);
if(x==1)
printf("%s 是回文 !\n",s);
else
printf("%s 不是回文 !\n",s);
设线性表A中有n个字符,试设计程序判断字符串是否中心对称,例如xyzyx和xyzzyx都是中心对称的字符串。 #include
void push(listack *& s,elemtype e) { listack *p; p=(listack*)malloc(sizeof(listack)); p->data=e; p->next=s->next; s->next=p; } int pop(listack *&s,elemtype &e) { listack *p; if(s->next==NULL) return 0; p=s->next; e=p->data; s->next=p->next; free(p); return 1; } int gettop(listack *s,elemtype &e) { if(s->next==NULL) return 0; e=s->next->data; return 1; } int judge(char *str) { listack *s;elemtype e; initstack(s); char *p=str; while(*p!='#') { push(s,*p); p++; } while(!stackempty(s)) { pop(s,e); if(e!=*str) return 0; str++; } return 1;
实验报告 系部计算机系I班级I I学号I I姓名课程名称—数据结构I实验日期实验名称回文判断成绩 实验目的: 掌握栈的基本操作:入栈、出栈等在链式或顺序存储结构上的实现。 实验条件:PC机一台、VC++6.0编译环境 实验内容与算法思想: 内容: 输入一字符串判断其是否为回文。 算法思想: 1. 算法中主要用到的函数 ①void mai n() //主函数 ②int push_seqstack(Seqstack *s,char x) // 进栈 ③in t pop_seqstack(Seqstack *s) // 出栈 ④int gettop_seqstack(Seqstack *s) 〃取栈顶元素 ⑤int Ishuiwe n( char *s) 〃判断是否是回文 2. 函数之间的调用关系 函数之间的调用关系如图1所示:
图1函数之间的调用关系 运行结果: 运行程序输入一段字符串,运行不同的结果如图2、3所示: 图2 不是回文的判断结果 实验总结: 通过前两次的实验,使我对C语言和数据结构有许多认识。因此,这次实验 在做起来时多少有点思路,但是在实验室当中还是遇到了许多不会的问题,如回文的判断思路、以及函数的调用等等,不过这些问题在老师和同学的帮助下基本完成了这次实验。这次实验让我学到了很多知识,让我对原来所学的又重新复习了一遍,同时还学到了许多其他新知识。 附:源程序: #in clude
R语言判别分析实验报告 班级:应数1201 学号: 姓名:麦琼辉 时间:2014年11月28号 1 实验目的及要求 1)了解判别分析的目的和意义; 2)熟悉R语言中有关判别分析的算法基础。 2 实验设备(环境)及要求 个人计算机一台,装有R语言以及RStudio并且带有MASS包。 3 实验内容 企业财务状况的判别分析 4 实验主要步骤 1)数据管理:实验对21个破产的企业收集它们在前两年的财务数据,对25个 财务良好的企业也收集同一时期的数据。数据涉及四个变量:CF_TD(现金/总债务);NI_TA(净收入/总资产);CA_CL(流动资产/流动债务);CA_NS (流动资产/净销售额),一个分组变量:企业现状(1:非破产企业,2:破产企业)。 2)调入数据:对数据复制,然后在RStudio编辑器中执行如下命令。 case5=read.table(‘clipboard’,head=T) head(case5) 3)Fisher判别效果(等方差,线性判别lda):采用Bayes方式,即先验概率 为样本例数,相关的RStudio程序命令如下所示。 library(MASS) ld=lda(G~.,data=case5);ld #线性判别 ZId=predict(ld) addmargins(table(case5$G,ZId$class)) 4)Fisher判别效果(异方差,非线性判别--二次判别qda):再次采用Bayes 方式,相关的RStudio程序命令如下所示。
library(MASS) qd=qda(G~.,data=case5);qd #二次判别 Zqd=predict(qd) addmargins(table(case5$G ,Zqd$class)) 5 实验结果 表1 线性判别lda 效果 原分类 新分类 1 2 合计 1 24 1 25 2 3 18 21 合计 27 19 46 符合率 91.30% 由表1和表2可知,qda (二次判别---非线性判 别)的效果比lda (一次判别)要好。 6 实验小结 通过本次实验了解了判别分析的目的和意义,并熟悉R 语言中有关判别分析的算法基础。 表2 二次判别qda 效果 原分类 新分类 1 2 合计 1 24 1 25 2 2 19 21 合计 26 20 46 符合率 93.50%
2.7.1.1 练习1 回文数的猜想 1输入一个数 2一个数,加上是这个数的倒序数,得出结果 3判断是否为回文数,是就退出,否则返回第2步骤 回文数:1336331、9559 典型:输入1735 1753+3571=5324 5324+4235=9559 9559就是一个回文数 程序解答过程: 1设计出各函数功能,便于调用 2编码,解答 各函数功能: 输入数据:int input(void) 对数据取逆序:int reverse(int data) 判断回文数:int ispalin(int data) 溢出判断:int isover(int data //palin.c #include
int reverse(int data) { int res=0; for(;data>0;data=data/10)//取得data的的逆序 res=res*10+data%10;//data%10取得data最后一位数字 return res; } int ispalin(int data) { return data==reverse(data); } int isover(int data) { return data<=0||reverse(data)<=0;//当data大小越界,即超过2^31-1,变成负数 } int main() { int data=input(); int i; for(i=0;!isover(data);data+=reverse(data)) { if(!ispalin(data)) printf("[%d]:%d+%d=%d\n",++i,data,reverse(data),data+reverse(data)); else { printf("Palin:%d\n",data); return 0; } } printf("Can not find Palin!\n"); return 0; } 知识:unsigned int:2^32-1 int : 2^31-1 超过了最大值会越界,越界的数会变成负数
回文判断实验二
洛阳理工学院实验报告 系别计算机系班级B13053 学号B13053235 姓名李登辉 2 课程名称数据结构实验日期2014.3.28 实验名称栈和队列的基本操作成绩 实验目的: 熟悉掌握栈和队列的特点,掌握与应用栈和队列的基本操作算法,训练和提高结构化程序设计能力及程序调试能力。 实验条件: 计算机一台,Visual C++6.0
实验内容: 1.问题描述 利用栈和队列判断字符串是否为回文。称正读与反读都相同的字符序列为“回文”序列。要求利用栈和队列的基本算法实现判断一个字符串是否为回文。栈和队列的存储结构不限。 2.数据结构类型定义 typedef struct { char elem[MAX]; int top; }SeqStack; 顺序栈 3.模块划分 void InitStack(SeqStack *S):栈初始化模块, int Push(SeqStack *S,char x,int cnt):入栈操作 int Pop(SeqStack * S,char * x):出栈操作 void InitQuene(SeqQuene *Q):队列初始化 int EnterQuene(SeqQuene *Q,char x,int cnt):入队操作 int DeleteQuene(SeqQuene *Q,char *x,int cnt):出队操作 void main():主函数 4.详细设计 #include
R语言判别分析实验报 告 GE GROUP system office room 【GEIHUA16H-GEIHUA GEIHUA8Q8-
R语言判别分析实验报告 班级:应数1201 学号: 姓名:麦琼辉 时间:2014年11月28号 1 实验目的及要求 1)了解判别分析的目的和意义; 2)熟悉R语言中有关判别分析的算法基础。 2 实验设备(环境)及要求 个人计算机一台,装有R语言以及RStudio并且带有MASS包。 3 实验内容 企业财务状况的判别分析 4 实验主要步骤 1)数据管理:实验对21个破产的企业收集它们在前两年的财务数据,对25个财 务良好的企业也收集同一时期的数据。数据涉及四个变量:CF_TD(现金/总债务);NI_TA(净收入/总资产);CA_CL(流动资产/流动债务);CA_NS(流动资产/净销售额),一个分组变量:企业现状(1:非破产企业,2:破产企业)。 2)调入数据:对数据复制,然后在RStudio编辑器中执行如下命令。
case5=read.table(‘clipboard’,head=T) head(case5) 3)Fisher判别效果(等方差,线性判别lda):采用Bayes方式,即先验概率为 样本例数,相关的RStudio程序命令如下所示。 library(MASS) ld=lda(G~.,data=case5);ld #线性判别 ZId=predict(ld) addmargins(table(case5$G,ZId$class)) 4)Fisher判别效果(异方差,非线性判别--二次判别qda):再次采用Bayes方 式,相关的RStudio程序命令如下所示。 library(MASS) qd=qda(G~.,data=case5);qd #二次判别 Zqd=predict(qd) addmargins(table(case5$G,Zqd$class)) 5 实验结果 表1 线性判别lda效果 原分类新分类
回文串实验报告 课程名称:数据结构 实验名称:单链表 学生姓名:杜克强 学生学号: 201207092427
实验一回文串的基本操作及其应用 一、实验目的 1、掌握栈和队列的顺序存储结构和链式存储结构,以便在实际中灵活应用。 2、掌握栈和队列的特点,即后进先出和先进先出的原则。 3、掌握栈和队列的基本运算,如:入栈与出栈,入队与出队等运算在顺序 存储结构和链式存储结构上的实现。 二、实验内容和要求 [问题描述] 对于一个从键盘输入的字符串,判断其是否为回文。回文即正反序相同。如“abba”是回文,而“abab”不是回文。 [基本要求] (1)数据从键盘读入; (2)输出要判断的字符串; (3)利用栈的基本操作对给定的字符串判断其是否是回文,若是则输出“Yes”,否则输出“No”。 [测试数据] 由学生任意指定。 三、实验步骤 1.需求分析 本演示程序用C语言编写,完成对一个字符串是否是回文字符串的判断 ①输入一个任意的字符串; ②对输入的字符串进行判断是否为回文串;
③输出判断结果; ④测试数据: A.依次输入“abccba”,“asddas”等数据; B.输出判断结果“Yes”,“No”等 四、算法设计 1、算法思想: 把字符串中的字符逐个分别存储到队列和堆栈中,然后逐个出队和出栈并比较出队列的数据元素和退栈的数据元素是否相等,若相等则是会文,否则不是。 2、模块设计 (1)int Palindrome_Test()判断字符序列是否为回文串; (2)Status main()主函数; (3)Status CreatStack(SqStack &S)创建一个栈; (4)Status Push(SqStack &S,SElemType e)入栈; (5)Status Pop(SqStack &S ,SElemType &e)出栈; (6)Status CreatQueue(LinkQueue &Q)创建一个队列; (7)Status EnQueue(LinkQueue &Q,QElemType e)入队; (8)Status DeQueue(LinkQueue &Q,QElemType &e)出队;
R语言判别分析实验报告 The latest revision on November 22, 2020
R语言判别分析实验报告 班级:应数1201 学号: 姓名:麦琼辉 时间:2014年11月28号 1实验目的及要求 1)了解判别分析的目的和意义; 2)熟悉R语言中有关判别分析的算法基础。 2实验设备(环境)及要求 个人计算机一台,装有R语言以及RStudio并且带有MASS包。 3实验内容 企业财务状况的判别分析 4实验主要步骤 1)数据管理:实验对21个破产的企业收集它们在前两年的财务数据,对25 个财务良好的企业也收集同一时期的数据。数据涉及四个变量:CF_TD(现金/总债务);NI_TA(净收入/总资产);CA_CL(流动资产/流动债务); CA_NS(流动资产/净销售额),一个分组变量:企业现状(1:非破产企业,2:破产企业)。 2)调入数据:对数据复制,然后在RStudio编辑器中执行如下命令。 case5=read.table(‘clipboard’,head=T) head(case5) 3)Fisher判别效果(等方差,线性判别lda):采用Bayes方式,即先验概 率为样本例数,相关的RStudio程序命令如下所示。 library(MASS) ld=lda(G~.,data=case5);ld#线性判别 ZId=predict(ld) addmargins(table(case5$G,ZId$class)) 4)Fisher判别效果(异方差,非线性判别--二次判别qda):再次采用
Bayes 方式,相关的RStudio 程序命令如下所示。 library(MASS) qd=qda(G~.,data=case5);qd#二次判别 Zqd=predict(qd) addmargins(table(case5$G,Zqd$class)) 5实验结果 表1线性判别lda 效果 原分类 新分类 12合计 1 24 1 25 2 3 18 21 合计 27 19 46 符合率 91.30% 由表1和表 2可知,qda (二次判别---非线 性判别)的效果比lda (一次判别)要好。 6实验小结 通过本次实验了解了判别分析的目的和意义,并熟悉R 语 言中有关判别分析的算法基础。 表2二次判别qda 效果 原分类 新分类 12合计 1 24 1 25 2 2 19 21 合计 26 20 46 符合率 93.50%
求回文子串O(n) manacher算法 回文串定义:“回文串”是一个正读和反读都一样的字符串,比如“level”或者“noon”等等就是回文串。 回文子串,顾名思义,即字符串中满足回文性质的子串。 经常有一些题目围绕回文子串进行讨论,比如HDOJ_3068_最长回文,求最长回文子串的长度。朴素算法是依次以每一个字符为中心向两侧进行扩展,显然这个复杂度是O(N^2)的,关于字符串的题目常用的算法有KMP、后缀数组、AC自动机,这道题目利用扩展KMP 可以解答,其时间复杂度也很快O(N*logN)。但是,今天笔者介绍一个专门针对回文子串的算法,其时间复杂度为O(n),这就是manacher算法。 大家都知道,求回文串时需要判断其奇偶性,也就是求aba和abba的算法略有差距。然而,这个算法做了一个简单的处理,很巧妙地把奇数长度回文串与偶数长度回文串统一考虑,也就是在每个相邻的字符之间插入一个分隔符,串的首尾也要加,当然这个分隔符不能再原串中出现,一般可以用‘#’或者‘$’等字符。例如: 原串:abaab 新串:#a#b#a#a#b# 这样一来,原来的奇数长度回文串还是奇数长度,偶数长度的也变成以‘#’为中心的奇数回文串了。 接下来就是算法的中心思想,用一个辅助数组P记录以每个字符为中心的最长回文半径,也就是P[i]记录以Str[i]字符为中心的最长回文串半径。P[i]最小为1,此时回文串为Str[i]本身。 我们可以对上述例子写出其P数组,如下
新串:# a # b # a # a # b # P[] : 1 2 1 4 1 2 5 2 1 2 1 我们可以证明P[i]-1就是以Str[i]为中心的回文串在原串当中的长度。 证明: 1、显然L=2*P[i]-1即为新串中以Str[i]为中心最长回文串长度。 2、以Str[i]为中心的回文串一定是以#开头和结尾的,例如“#b#b#”或“#b#a#b#”所以L减去最前或者最后的‘#’字符就是原串中长度的二倍,即原串长度为(L-1)/2,化简的P[i]-1。得证。 依次从前往后求得P数组就可以了,这里用到了DP(动态规划)的思想,也就是求P[i]的时候,前面的P[]值已经得到了,我们利用回文串的特殊性质可以进行一个大大的优化。我先把核心代码贴上: for(i=1;i
《Java语言》课程作业 (第一次) 题目第8题 学院计算机学院专业 班别 学号 姓名陈聪 2015年4月22日
一、课程题目 8、题目:回文素数 回文素数是指一个数同时为素数和回文数。例如:131是一个素数,同时也是一个回文数。数字313和757也是如此。编写程序,显示前100个回文素数,每行显示10个数并且准确对齐,如下所示: 2 3 5 7 11 101 131 151 181 191 313 353 373 383 727 757 787 797 919 929 ……. …. …. ………………. [选题人数:3] 二、题目分析与设计 1、题目的需求:编写程序,显示前100个回文素数,每行显示10个数并且准确对齐。 2、制定对应程序的功能: (1)将2以后的素数挑选出来,直到显示完前100个回文素数:利用for循环。 (2)判断挑选出来的素数是否为回文数:通过将原素数倒置再与原素数比较来判断。 (3)输出回文素数,同时判断是否要换行,通过确定位数来使回文素数准确 对齐。 3、(1)程序功能层次图: (2)程序结构流程图:
4、所使用的开发环境:Eclipse (1)判断一个数是否为素数: i=2; while(i while(s!=0) { b=b*10+s%10; s=s/10; } (3)判断素数是否为回文数并输出: if(a==b) { n++; if(n%10==0) System.out.printf("%8d\n",a); else System.out.printf("%8d",a); } 三、测试分析 1、题目的需求:编写程序,显示前100个回文素数,每行显示10个数并且准确对齐。因此本程序不需要构建测试数据。 2、运行程序的结果如下: 所得到的前一百个回文素数与预计结果一致,格式正确,每行显示10个数并且准确对齐。 附录:源代码 package hui; public class huiwen{ public static void main(String args[]){ int a,b,s; 实验二栈和队列的基本操作及其应用 一、实验目的 1、掌握栈和队列的顺序存储结构和链式存储结构,以便在实际中灵活应用。 2、掌握栈和队列的特点,即后进先出和先进先出的原则。 3、掌握栈和队列的基本运算,如:入栈与出栈,入队与出队等运算在顺序 存储结构和链式存储结构上的实现。 二、实验内容 本次实验提供4个题目,每个题目都标有难度系数,*越多难度越大,学生 可以根据自己的情况任选一个! 题目一:回文判断(*) [问题描述] 对于一个从键盘输入的字符串,判断其是否为回文。回文即正反序相同。如 “abba”是回文,而“abab”不是回文。 [基本要求] (1)数据从键盘读入; (2)输出要判断的字符串; (3)利用栈的基本操作对给定的字符串判断其是否是回文,若是则输出 “Yes”,否则输出“No”。 [测试数据] 由学生任意指定。 题目二:顺序栈和循环队列基本操作(*) [基本要求] 1、实现栈的基本操作 六项基本操作的机制是:初始化栈:init_stack(S);判断栈空:stack_empty(S);取栈顶元素:stack_top(S,x);入栈:push_stack(S,x);出栈:pop_stack(S);判断栈满:stack_full(S) 2、实现队列的基本操作 六项基本操作的机制是:初始化队列:init_queue(Q);判断队列是否为空:queue_empty(Q);取队头元素:queue_front(Q,x);入队:enqueue(Q,x);出队:outqueue(Q,x);判断队列是否为满:queue_full(Q) [测试数据] 由学生任意指定。 题目三:商品货架管理(**) [问题描述] 商店货架以栈的方式摆放商品。生产日期越近的越靠近栈底,出货时从栈顶取货。一天营业结束,如果货架不满,则需上货。入货直接将商品摆放到货架上,则会使生产日期越近的商品越靠近栈顶。这样就需要倒货架,使生产日期越近的越靠近栈底。 [基本要求] 设计一个算法,保证每一次上货后始终保持生产日期越近的商品越靠近栈底。 [实现提示] 可以用一个队列和一个临时栈作为周转。 [测试数据] 由学生任意指定。 三、实验前的准备工作 1、掌握栈的逻辑结构和存储结构。 2、熟练掌握栈的出栈、入栈等操作。 3、掌握队列的逻辑结构和存储结构。 4、熟练掌握队列的出队、入队等操作 四、实验报告要求 1、实验报告要按照实验报告格式规范书写。 *2、写出算法设计思路。 3、实验上要写出多批测试数据的运行结果。 4、结合运行结果,对程序进行分析。 题目四:Rails(ACM训练题) Description There is a famous railway station in PopPush City. Country there is incredibly hilly. The station was built in last century. Unfortunately, funds were extremely limited that time. It was possible to establish only a surface track. Moreover, it turned out that the 一、实验目的及要求: 1、目的 用SPSS软件实现判别分析及其应用。 2、内容及要求 用SPSS对实验数据利用Fisher判别法和贝叶斯判别法,建立判别函数并判定宿州、广安等13个地级市分别属于哪个管理水平类型。 二、仪器用具: 三、实验方法与步骤: 准备工作:把实验所用数据从Word文档复制到Excel,并进一步导入到SPSS 数据文件中,同时,由于只有当被解释变量是属性变量而解释变量是度量变量时,判别分析才适用,所以将城市管理的7个效率指数变量的变量类型改为“数值(N)”,度量标准改为“度量(S)”,以备接下来的分析。 四、实验结果与数据处理: 表1 组均值的均等性的检验 Wilks 的 Lambda F df1df2Sig. 综合效率标准指数.582264.000 经济效率标准指数.406264.000 结构效率标准指数.954264.218 社会效率标准指数.796264.001 人员效率标准指数.342264.000 发展效率标准指数.308264.000 环境效率标准指数.913264.054 表1是对各组均值是否相等的检验,由该表可以看出,在的显著性水平上我们不能拒绝结构效率标准指数和环境效率标准指数在三组的均值相等的假设,即认为 除了结构效率标准指数和环境效率标准指数外,其余五个标准指数在三组的均值是有显著差异的。 表2 对数行列式 group秩对数行列式 16 26 36 汇聚的组内6 打印的行列式的秩和自然对数是组协方差矩阵的秩和自然对数。 表3 检验结果 箱的 M F近似。 df142 df2 Sig..000 对相等总体协方差矩阵的零假设进行检验。 以上是对各组协方差矩阵是否相等的Box’M检验,表2反映协方差矩阵的秩和行列式的对数值。由行列式的值可以看出,协方差矩阵不是病态矩阵。表3是对各总体协方差阵是否相等的统计检验,由F值及其显著水平,在的显著性水平下拒绝原假设,认为各总体协方差阵不相等。 1)Fisher判别法: 图一 回文判断实验报告 一.实验题目:回文判断 二.实验目的: 对于一个从键盘输入的字符串,判断其是否为回文。回文即正反序相同。如“abba”是回文,而“abab”不是回文。 三.实验需求: 1.数据从键盘读入; 2.输出要判断的字符串; 3.利用栈的基本操作对给定的字符串判断其是否是回文,若是则输出“Yes”否则输出“No” 四.主要实现函数 (1)建立顺序栈存储结构 typedef struct { } (2)初始化 int initstack(Sqstack &s,int maxsize) (3)入栈 int enstack(Sqstack &s, char e) (4)出栈 int popstack(Sqstack &s,char &e) (5)判断是否为回文 int main() { int r; //用于判断是否为回文 Sqstack L,Q; //定义两个栈 initstack(L,20); initstack(Q,20); int l; //用于记录输入字符的长度cout<<"请输入字符串长度"; cin>>l; if(l<=0)exit(1); cout<<"输入字符"< . 数据结构实验报告判断回文数 级班: 内序号班: 名生姓学: 教师导指: 时间: 201124月年10日 一、实验目的'. . 熟悉栈和队列的各项操作,区别栈和队列的操作原理。 二、实验内容 利用栈的操作完成读入的一个以*结尾的字符序列是否是回文序列的判断。 回文序列即正读与反读都一样的字符序列,例如:43211234*是回文序列,而789678*不是。三、数据结构及算法思想 算法思想:从键盘上读取一个字符,同时存储在顺序栈与链队列之中,直到字符序列的最后一个字符为*停止插入。在程序中设置了一个标志位flag,将输入的序列分别做入栈、出栈、入队、出队操作,若出栈与出队的数据完全一致,则将flag标志为1,否则为零。Flag为1,则表示该序列是回文序列,否则,为非回文序列。 四、模块划分 1.对各个模块进行功能的描述 (1)void InitStack(SeqStack *S):栈初始化模块,即初始化一个空栈,随后对该空栈进行数据的写入操作; (2)int Push(SeqStack *S,char x,int cnt):入栈操作,即给空栈中写入数据,数据长度有宏定义给出; (3)int Pop(SeqStack * S,char * x):出栈操作,即将栈中的数据输出,由于栈的操作是先进后出,因此,出栈的数据是原先输入数据的逆序; (4)void InitQuene(SeqQuene *Q):队列初始化,即初始化一个空队列,最后对该空队列进行数据的写入操作; (5)int EnterQuene(SeqQuene *Q,char x,int cnt):入队操作,即给空队列中写入数据,数据长度一样有宏定义给出; (6)int DeleteQuene(SeqQuene *Q,char *x,int cnt):出队操作,即将队列中的数据输出,由于队列的操作是先进先出,因此,出队的数据室原先输入数据的正序; (7)void main():主函数,用于调用前面的模块,进行出队数据与出栈数据的比较,判断输入的序列是否是回文序列。 2.模块之间关系及其相互调用的图示 '. . 福建农林大学实验报告 实验一 Java开发环境 一、实验目的: 1、掌握分支、循环语句的使用。 二、实验内容: 1、用循环语句打印一个99乘法表。 2、判断回文数(逆序排列后得到的数和原数相同)。 三、实验要求: 1、打印的乘法表应该呈现阶梯状。 2、给定一个1-99999之间的整型数,程序可以判断它的位数,并判断是否是回文数。 3、实验报告给出完整代码。 四、算法描述及实验步骤 先定义两个变量i和j然后初始化值为1,由于题目的条件,所以i<+9而j<=I,然后经过输出语句System.out.print (j+"*"+i+"="+i*j+" ");可将i和j值进行相乘,最后用输出语句改变下格式就可以了。 五、调试过程及实验结果 1 算出来的并没有按照表格输出 改System.out.println (" "); 中println后的ln就可以改变换行了, 2 六、总结 通过第一小题的练习,让我加强了对for循环语句和输出函数的使用。 经过第二小题的练习,我懂得了什么是回文数,并且用.reverse(),反转字符串来反转,然后将反转后的数字和之前的数字进行比较。 七、附录(代码): 9*9乘法表: class Test{ public static void main (String[] args) { for(int i=1;i<=9;i++) { for(int j=1;j<=i;j++) { System.out.print (j+"*"+i+"="+i*j+" "); } System.out.println (" "); } } } 判断回文数: class Test { public static void main(String[] args) { String str = "1234554321"; boolean huiwenshu = new StringBuilder(str).reverse().toString().equals(str); System.out.println (str); System.out.println(huiwenshu); } } 页眉 2015——2016学年第一学期 实验报告 课程名称:多元统计分析 实验项目:判别分析 设计性□验证性□实验类别:综合性□√专业班级: 姓名:学号: 实验地点:统计与金融创新实验室(新60801) 实验时间: 指导教师:曹老师成绩: 数学与统计学院实验中心制页脚 一、实验目的统计《spss 让学生掌握判别分析的基本步骤和分析方法;学习 的内容,掌握一般判别分析与逐分析从入门到精通》P307-P320步判别分析方法。 二、实验内容,掌》应用《胃病患者的测量数据》和《表征企业类型的数据.sav、1统计分析从spss握一般判别分析与逐步判别分析方法。数据来源于《章的数据。入门到精通数据文件》第12的数据进行分析,数据见文件《何晓群多元统计2、参考教材例4-2 》中的例4-2new。)分析(数据三、实验方案(程序设计说明) 四、程序运行结果1. (1) 分析案例处理摘要未加权案例N 百分比 93.3 14 有效 6.7 缺失或越界组代码1 .0 至少一个缺失判别变量0 .0 排除的缺失或越界组代码还有至少0 一个缺失判别变量6.7 合计1 100.0 15 合计 组统计量 1 N(列表状态)类别均值标准差有效的未加权的已加权的5.000 188.60 57.138 5 铜蓝蛋白5.000 16.502 5 150.40 蓝色反应胃癌患者5.000 5.933 5 尿吲哚乙酸13.80 5.000 13.323 5 中性琉化物20.00 4.000 47.500 4 铜蓝蛋白156.25 4.000 118.75 14.104 4 蓝色反应萎缩性胃炎4.000 1.732 4 尿吲哚乙酸7.50 4.000 8.386 4 中性琉化物14.50 5.000 33.801 5 铜蓝蛋白151.00 5.000 13.012 5 蓝色反应121.40 其他胃病5.000 1.871 5 尿吲哚乙酸5.00 5.000 5 中性琉化物8.00 7.314 14.000 14 铜蓝蛋白165.93 46.787 14.000 14 蓝色反应131.00 20.203 合计14.000 14 8.86 5.318 尿吲哚乙酸14.000 10.726 14 数学实验报告判别分析 一、实验目的 要求熟练掌握运用SPSS软件实现判别分析。 二、实验内容 已知某研究对象分为3类,每个样品考察4项指标,各类观测的样品数分别为7,4,6;另外还有2个待判样品分别为 第一个样品: =-=-== 18,214,316,456 x x x x 第二个样品: ==-== 192,217,318,4 3.0 x x x x 运用SPSS软件对实验数据进行分析并判断两个样品的分组。 三、实验步骤及结论 1.SPSS数据分析软件中打开实验数据,并将两个待检验样本键入,作为样本18和样本19。 2.实验分析步骤为: 分析→分类→判别分析 3.得到实验结果如下: (1)由表1,对相等总体协方差矩阵的零假设进行检验,Sig值为0.022<0.05,则拒绝原假设,则各分类间协方差矩阵相等。 由表2可得,函数1所对应的特征值贡献率已达到99.6%,说明样本数据均向此方向投影就可得到效果很高的分类,故只取函数1作为投影函数,舍去函数2不做分析。 表3为典型判别式函数的Wilks的Lambda检验,此检验中函数1的Wilks Lambda检验sig值为0.022<0.05,则拒绝原假设,说明函数1判别显著。 表4为求得的各典型函数判别式函数系数,由此表可以求得具体函数,得y=9.240+0.010x1+0.543x2+0.047x3-0.068x4。 由表5给出的组质心处的函数值,可以得到函数1的置信坐标为(-1.846,0.616,1.744)。 (2)关于两个待判样本的分组方法: 将样本1的因变量数据代入方程 y=9.240+0.010x1+0.543x2+0.047x3-0.068x4 求得y1=-1.498,分别减去上表中-1.846,0.616,1.744,取绝对值得0.348,0.882,0.246,则样本1为第1组; 同理可得,y2=1.571,分别减去上表中-1.846,0.616,1.744,取绝对值得 3.417,0.955,0.173,则样本2为第3组。 贝叶斯判别部分如下: 表6 表7为贝叶斯判别分析得到的分类函数系数表,可以得到3个分组各自的函数: y1=-223.305-0.074x1-19.412x2+4.549x3+1.582x4 y2=-199.884-0.045x1-18.097x2+4.661x3+1.414x4 y3=-190.041-0.040x1-17.457x2+4.720x3+1.377x4 将两组样本数据分别代入3个方程: 代入样本1得 y1=410.431,y2=207.594,y3=207.309 代入样本2得 y1=186.519,y2=191.765,y3=192.139 绝对回文数 Time Limit:10000MS Memory Limit:65536K Total Submit:30 Accepted:16 Description 绝对回文数,即其十,二进制均为回文,输入一个n值(<=100000),判断其是否为绝对回文数(二进制最前面的0不能算) ,若不是,输出”no”(不包括引号),若是,请按格式十进制值(二进制值),比如n=99时,其为绝对回文数,则输出99(1100011) 。 Input 一个n值。 Output 一行,按文中要求输出相应结果。 Sample Input 99 Sample Output 99(1100011) Source ?var ? i,j,n,l,l2:longint; ? a,b:array[1..100] of longint; ? bbt,flag:boolean; ?begin ? readln(n); ? l:=0; j:=n; ? while j<>0 do begin ? inc(l); ? a[l]:=j mod 10; j:=j div 10; ? end; ? l2:=0; j:=n; ? while j<>0 do begin ? inc(l2); ? b[l2]:=j mod 2; j:=j div 2; ? end; ? flag:=true; bbt:=true; ? for i:=1 to l div 2 do if a[i]<>a[l-i+1] then begin ? bbt:=false; break; ? end; ? if not bbt then flag:=false; ? bbt:=true; ? for i:=1 to l2 div 2 do if b[i]<>b[l2-i+1] then begin ? bbt:=false; break; ? end; ? if not bbt then flag:=false; ? if flag then begin ? for i:=1 to l do write(a[i]); write('('); ? for i:=1 to l2 do write(b[i]); ? writeln(')'); ? end ? else writeln('no'); ?end. 实验二栈和队列 一、实验目的 1、掌握栈和队列的顺序存储结构和链式存储结构,以便在实际中灵活应用。 2、掌握栈和队列的特点,即后进先出和先进先出的原则。 3、掌握栈和队列的基本运算,如:入栈与出栈,入队与出队 等运算在顺序存储结构和链式存储结构上的实现。 二、实验内容 1.请简述栈的基本特性和栈的几种基本操作的机制 栈是限定仅在表位进行插入或删除操作的线性表,栈的修改是按照后进先出的原则进行的,根据这种特性进行回文判断。 [问题描述] 对于一个从键盘输入的字符串,判断其是否为回文。回文即正反序相同。如“abba”是回文,而“abab”不是回文。 [基本要求] (1)数据从键盘读入; (2)输出要判断的字符串; (3)利用栈的基本操作对给定的字符串判断其是否是回文,若是则输出“该字符串是回文”,否则输出“该字符串不是回文”。 [测试数据] 由学生任意指定。 2.设计简单的程序实现用栈判断回文 #include typedef struct{ char *base; char *top; int stacksize; }SqStack; void InitStack(SqStack &S){ S.base =(char *)malloc(STACK_INIT_SIZE * sizeof(char)); if(!S.base)exit(0); S.top = S.base; S.stacksize = STACK_INIT_SIZE; } void Push(SqStack &S,char e){ if(S.top - S.base >= S.stacksize){ S.base = (char *) realloc (S.base,(S.stacksize + STACKINCREMENT) * sizeof(char)); if(!S.base) printf("存储分配失败!"); S.top = S.base + S.stacksize; S.stacksize += STACKINCREMENT; } *S.top++ = e; } char Pop(SqStack &S,char &e){ if(S.top == S.base) { printf("该栈为空!"); printf("\n"); e = 'E'; }else{ e = *--S.top;数据结构实验二(栈和队列)
判别分析实验报告spss
回文判断实验报告
数据结构C语言版判断回文数试验报告
用循环语句打印一个乘法表判断回文数(逆序排列后得到数和原数相同)
多元统计分析实验报告判别分析
判别分析实验报告
1004 绝对回文数
用栈和队列判断回文
相关主题
文本预览