
一、Fisher 线性判别
Fisher 线性判别是统计模式识别的基本方法之一。它简单,容易实现,且计算量和存储量小,是实际应用中最常用的方法之一。Fisher 判别法Fisher 在1936年发表的论文中首次提出的线性判别法。Fisher 判别法的基本思想是寻找一个最好的投影,当特征向量x 从d 维空间映射到这个方向时,两类能最好的分开。这个方法实际上涉及到特征维数的压缩问题。
一维空间的Fisher 线性判别函数为:
2
1212
()()F m m J w S S -=
+ (1)
i m =
∑x N
1,i=1,2 (2)
2,1,)()(=--=∑∈i m x m x S T i x i i i
ξ (3)
其中,1m 和2m 是两个样本的均值,1S ,2S 分别为各类样本的的类内离散度。投影方向w 为:
)(211
m m S w w -=- (4)
12w S S S =+ (5)
在Fisher 判决函数中,分子反应了映射后两类中心的距离平方,该值越大,类间可分性越好;分母反应了两类的类内的离散度,其值越小越好;从总体上讲,()F J w 的值越大越好,在这种可分性评价标准下,使()F J w 达到最大值的w 即为最佳投影方向。
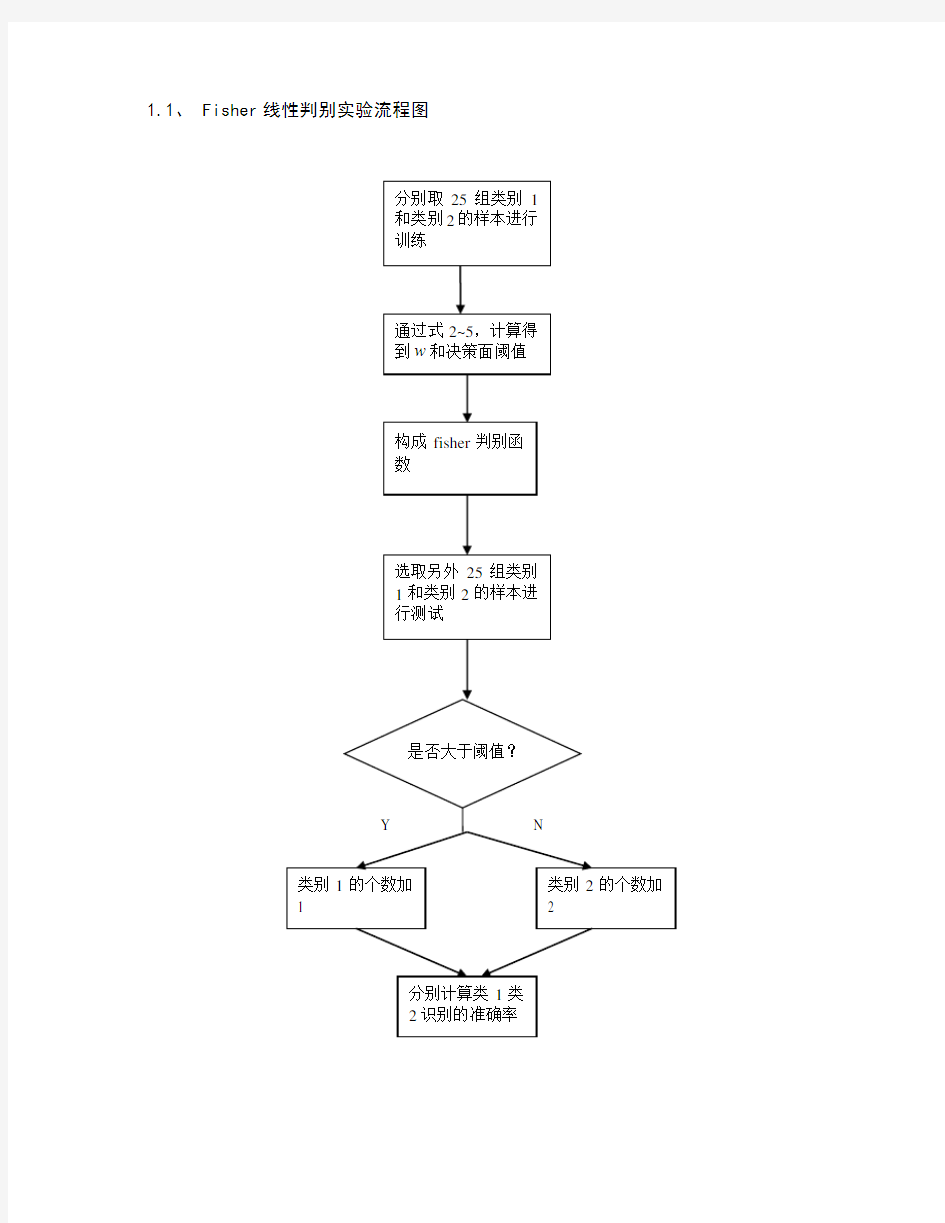
1.1、 Fisher线性判别实验流程图
1.2 Fisher线性判别mtalab代码
data=importdata('C:\Users\zzd\Desktop\data-ch5.mat'); data1=data.data;
data2=https://www.doczj.com/doc/068350036.html,bel;
sample1=data1(1:25,:);
sample2=data1(51:75,:);
sample=[sample1
sample2];
sp_l=data2(26:75);
test1=data1(26:50,:);
test2=data1(76:100,:);
test=[test1
test2];
lth=zeros(50,50);
sample_m1=mean(sample1);
sample_m2=mean(sample2);
m1=sample_m1';
m2=sample_m2';
sb=(m1-m2)*(m1-m2)';
s1=zeros(2);
for n=1:25
temp = (sample1(n,:)'-m1)*(sample1(n,:)'-m1)';
s1=s1+temp;
end;
s2=zeros(2);
for n=1:25
temp = (sample2(n,:)'-m2)*(sample2(n,:)'-m2)';
s2 = s2+temp;
end;
sw=s1+s2;
vw=inv(sw)*(m1-m2);
a_m1 = vw'*m1;
a_m2 = vw'*m2;
w0 = (a_m1+a_m2)/2;
for n=1:50
if(vw'*test(n,:)' - w0>0)
m1(n,:)=1;
else
m1(n,:)=2;
end;
end;
m1;
count1=0;
count2=0;
for n=1:25
if m1(n,:)==sp_l(n,:)
count1=count1+1;
else
n
end
if m1(n+25,:)==sp_l(25+n,:)
count2=count2+1;
else
n+25
end
end
class1_rate=count1/25
class2_rate=count2/25
plot(sample(1:25,1),sample(1:25,2),'r.'); hold on ;
plot(test(1:25,1),test(1:25,2),'b.');
plot(sample(26:50,1),sample(26:50,2),'m.'); plot(test(26:50,1),test(26:50,2),'g.');
x1 = [-2:0.01:4];
y1 = x1*vw(2)/vw(1);
plot(x1,y1);
1.3 Fisher线性判别实验运行结果class1_rate =
0.8000
class2_rate =
0.8400
二、近邻法
邻近法最初由Court 和Hart 于1968年提出的。它是一种理论上比较成熟的方
法,也是一种简单、有效、非参数的机器学习算法之一,并且取得了较好的效果.。其基本思想是在训练样本中找到测试样本的最近邻,然后根据这个最近邻样本的类别来决定测试样本的类别,如图1所示。邻近法算法所选择的邻居都是已经正确分类的对象。邻近法虽然从原理上也依赖于极限定理,但在类别决策时,只与最相邻的样本有关。
该算法在分类时的不足主要有:如果样本数目太少,样本的分布可能会带有很大的偶然性,不一定能很好地代表数据内的分布情况,此时就会影响最近邻法的性能。该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的最近邻点。
如果写成判别函数的形式,i w 类的判别函数可以写作:
1,...,(),
min ()k k i c
g x x i g x ω==
∈则 (6)
决策规则为各类的判别函数比较大小,即
1,...,(),
min ()k k i c
g x x i g x ω==
∈则 (7)
2.1 邻近法分类流程图
2.2 邻近法分类实验matlab代码
data=importdata('C:\Users\zzd\Desktop\data-ch5.mat');
data1=data.data;
data2=https://www.doczj.com/doc/068350036.html,bel;
sample1=data1(1:25,:);
sample2=data1(51:75,:);
sample=[sample1
sample2];
sp_l=data2(26:75);
test1=data1(26:50,:);
test2=data1(76:100,:);
test=[test1
test2];
% plot(test(:,1),test(:,2),'.');
lth=zeros(50,50);
for n=1:50
for i=1:50
lth(n,i)=((test(n,1)-sample(i,1))^2+(test(n,2)-sample(i,2))^2)^(1/2); end
end
lth=lth';
[a,b]=min(lth);
c1=0;c2=0;
for k=1:25
if b(k)<=25
c1=c1+1;
else
k
end
if b(k+25)>25
c2=c2+1;
else
k+25
end
end
class1_rate=c1/25
class2_rate=c2/25
figure
plot(sample(1:25,1),sample(1:25,2),'r.'); hold on ;
plot(test(1:25,1),test(1:25,2),'b.');
plot(sample(26:50,1),sample(26:50,2),'m.'); plot(test(26:50,1),test(26:50,2),'g.');
2.3 近邻法分类实验运行结果
class1_rate =
0.9600
class2_rate =
0.8800
三、实验总结
比较两类的分类结果可以得出:用fisher线性判别分析方法得到的类1类2的识别率分别是80%和84%;而用近邻法得到的识别率分别为96%和88%。因此近邻法的识别率要高于fisher线性判别,主要原因是这两种类型的点相对集中,有一定的规律,但是线性不可分,存在交叠的情况。
在这个分类实验中近邻法有着较高的识别率,但是如果对样本数目少或规律比较复杂的样本,选择近邻法得到的结果可能会大打折扣。因此要根据具体的应用场合来选择合适的分类方法。
模式识别实验报告
————————————————————————————————作者:————————————————————————————————日期:
实验报告 实验课程名称:模式识别 姓名:王宇班级: 20110813 学号: 2011081325 实验名称规范程度原理叙述实验过程实验结果实验成绩 图像的贝叶斯分类 K均值聚类算法 神经网络模式识别 平均成绩 折合成绩 注:1、每个实验中各项成绩按照5分制评定,实验成绩为各项总和 2、平均成绩取各项实验平均成绩 3、折合成绩按照教学大纲要求的百分比进行折合 2014年 6月
实验一、 图像的贝叶斯分类 一、实验目的 将模式识别方法与图像处理技术相结合,掌握利用最小错分概率贝叶斯分类器进行图像分类的基本方法,通过实验加深对基本概念的理解。 二、实验仪器设备及软件 HP D538、MATLAB 三、实验原理 概念: 阈值化分割算法是计算机视觉中的常用算法,对灰度图象的阈值分割就是先确定一个处于图像灰度取值范围内的灰度阈值,然后将图像中每个像素的灰度值与这个阈值相比较。并根据比较的结果将对应的像素划分为两类,灰度值大于阈值的像素划分为一类,小于阈值的划分为另一类,等于阈值的可任意划分到两类中的任何一类。 最常用的模型可描述如下:假设图像由具有单峰灰度分布的目标和背景组成,处于目标和背景内部相邻像素间的灰度值是高度相关的,但处于目标和背景交界处两边的像素灰度值有较大差别,此时,图像的灰度直方图基本上可看作是由分别对应于目标和背景的两个单峰直方图混合构成。而且这两个分布应大小接近,且均值足够远,方差足够小,这种情况下直方图呈现较明显的双峰。类似地,如果图像中包含多个单峰灰度目标,则直方图可能呈现较明显的多峰。 上述图像模型只是理想情况,有时图像中目标和背景的灰度值有部分交错。这时如用全局阈值进行分割必然会产生一定的误差。分割误差包括将目标分为背景和将背景分为目标两大类。实际应用中应尽量减小错误分割的概率,常用的一种方法为选取最优阈值。这里所谓的最优阈值,就是指能使误分割概率最小的分割阈值。图像的直方图可以看成是对灰度值概率分布密度函数的一种近似。如一幅图像中只包含目标和背景两类灰度区域,那么直方图所代表的灰度值概率密度函数可以表示为目标和背景两类灰度值概率密度函数的加权和。如果概率密度函数形式已知,就有可能计算出使目标和背景两类误分割概率最小的最优阈值。 假设目标与背景两类像素值均服从正态分布且混有加性高斯噪声,上述分类问题可以使用模式识别中的最小错分概率贝叶斯分类器来解决。以1p 与2p 分别表示目标与背景的灰度分布概率密度函数,1P 与2P 分别表示两类的先验概率,则图像的混合概率密度函数可用下式表示为
一、实验目的 使用数据挖掘中的分类算法,对数据集进行分类训练并测试。应用不同的分类算法,比较他们之间的不同。与此同时了解Weka平台的基本功能与使用方法。 二、实验环境 实验采用Weka 平台,数据使用Weka安装目录下data文件夹下的默认数据集iris.arff。 Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java 写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 三、数据预处理 Weka平台支持ARFF格式和CSV格式的数据。由于本次使用平台自带的ARFF格式数据,所以不存在格式转换的过程。实验所用的ARFF格式数据集如图1所示 图1 ARFF格式数据集(iris.arff)
对于iris数据集,它包含了150个实例(每个分类包含50个实例),共有sepal length、sepal width、petal length、petal width和class五种属性。期中前四种属性为数值类型,class属性为分类属性,表示实例所对应的的类别。该数据集中的全部实例共可分为三类:Iris Setosa、Iris Versicolour和Iris Virginica。 实验数据集中所有的数据都是实验所需的,因此不存在属性筛选的问题。若所采用的数据集中存在大量的与实验无关的属性,则需要使用weka平台的Filter(过滤器)实现属性的筛选。 实验所需的训练集和测试集均为iris.arff。 四、实验过程及结果 应用iris数据集,分别采用LibSVM、C4.5决策树分类器和朴素贝叶斯分类器进行测试和评价,分别在训练数据上训练出分类模型,找出各个模型最优的参数值,并对三个模型进行全面评价比较,得到一个最好的分类模型以及该模型所有设置的最优参数。最后使用这些参数以及训练集和校验集数据一起构造出一个最优分类器,并利用该分类器对测试数据进行预测。 1、LibSVM分类 Weka 平台内部没有集成libSVM分类器,要使用该分类器,需要下载libsvm.jar并导入到Weka中。 用“Explorer”打开数据集“iris.arff”,并在Explorer中将功能面板切换到“Classify”。点“Choose”按钮选择“functions(weka.classifiers.functions.LibSVM)”,选择LibSVM分类算法。 在Test Options 面板中选择Cross-Validatioin folds=10,即十折交叉验证。然后点击“start”按钮:
北京科技大学计算机与通信工程学院 模式分类第二次上机实验报告 姓名:XXXXXX 学号:00000000 班级:电信11 时间:2014-04-16
一、实验目的 1.掌握支持向量机(SVM)的原理、核函数类型选择以及核参数选择原则等; 二、实验内容 2.准备好数据,首先要把数据转换成Libsvm软件包要求的数据格式为: label index1:value1 index2:value2 ... 其中对于分类来说label为类标识,指定数据的种类;对于回归来说label为目标值。(我主要要用到回归) Index是从1开始的自然数,value是每一维的特征值。 该过程可以自己使用excel或者编写程序来完成,也可以使用网络上的FormatDataLibsvm.xls来完成。FormatDataLibsvm.xls使用说明: 先将数据按照下列格式存放(注意label放最后面): value1 value2 label value1 value2 label 然后将以上数据粘贴到FormatDataLibsvm.xls中的最左上角单元格,接着工具->宏执行行FormatDataToLibsvm宏。就可以得到libsvm要求的数据格式。将该数据存放到文本文件中进行下一步的处理。 3.对数据进行归一化。 该过程要用到libsvm软件包中的svm-scale.exe Svm-scale用法: 用法:svmscale [-l lower] [-u upper] [-y y_lower y_upper] [-s save_filename] [-r restore_filename] filename (缺省值:lower = -1,upper = 1,没有对y进行缩放)其中,-l:数据下限标记;lower:缩放后数据下限;-u:数据上限标记;upper:缩放后数据上限;-y:是否对目标值同时进行缩放;y_lower为下限值,y_upper为上限值;(回归需要对目标进行缩放,因此该参数可以设定为–y -1 1 )-s save_filename:表示将缩放的规则保存为文件save_filename;-r restore_filename:表示将缩放规则文件restore_filename载入后按此缩放;filename:待缩放的数据文件(要求满足前面所述的格式)。缩放规则文件可以用文本浏览器打开,看到其格式为: y lower upper min max x lower upper index1 min1 max1 index2 min2 max2 其中的lower 与upper 与使用时所设置的lower 与upper 含义相同;index 表示特征序号;min 转换前该特征的最小值;max 转换前该特征的最大值。数据集的缩放结果在此情况下通过DOS窗口输出,当然也可以通过DOS的文件重定向符号“>”将结果另存为指定的文件。该文件中的参数可用于最后面对目标值的反归一化。反归一化的公式为: (Value-lower)*(max-min)/(upper - lower)+lower 其中value为归一化后的值,其他参数与前面介绍的相同。 建议将训练数据集与测试数据集放在同一个文本文件中一起归一化,然后再将归一化结果分成训练集和测试集。 4.训练数据,生成模型。 用法:svmtrain [options] training_set_file [model_file] 其中,options(操作参数):可用的选项即表示的涵义如下所示-s svm类型:设置SVM 类型,默
HUNAN UNIVERSITY 人工智能实验报告 题目实验三:分类算法实验 学生姓名匿名 学生学号2013080702xx 专业班级智能科学与技术1302班 指导老师袁进 一.实验目的 1.了解朴素贝叶斯算法的基本原理; 2.能够使用朴素贝叶斯算法对数据进行分类 3.了解最小错误概率贝叶斯分类器和最小风险概率贝叶斯分类器 4.学会对于分类器的性能评估方法 二、实验的硬件、软件平台 硬件:计算机 软件:操作系统:WINDOWS 10 应用软件:C,Java或者Matlab 相关知识点: 贝叶斯定理: 表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率,其基本求解公式为:
贝叶斯定理打通了从P(A|B)获得P(B|A)的道路。 直接给出贝叶斯定理: 朴素贝叶斯分类是一种十分简单的分类算法,叫它朴素贝叶斯分类是因为这种方法的思想真的很朴素,朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。 朴素贝叶斯分类的正式定义如下: 1、设为一个待分类项,而每个a为x的一个特征属性。 2、有类别集合。 3、计算。 4、如果,则。 那么现在的关键就是如何计算第3步中的各个条件概率。我们可以这么做: 1、找到一个已知分类的待分类项集合,这个集合叫做训练样本集。 2、统计得到在各类别下各个特征属性的条件概率估计。即 3、如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导: 因为分母对于所有类别为常数,因为我们只要将分子最大化皆可。又因为各特征属性是条件独立的,所以有:
模式识别实验报告 姓名: 班级: 学号: 提交日期:
实验一 线性分类器的设计 一、 实验目的: 掌握模式识别的基本概念,理解线性分类器的算法原理。 二、 实验要求 (1)学习和掌握线性分类器的算法原理; (2)在MATLAB 环境下编程实现三种线性分类器并能对提供的数据进行分类; (3) 对实现的线性分类器性能进行简单的评估(例如算法使用条件,算法效率及复杂度等)。 三、 算法原理介绍 (1)判别函数:是指由x 的各个分量的线性组合而成的函数: 00g(x)w ::t x w w w =+权向量阈值权 若样本有c 类,则存在c 个判别函数,对具有0g(x)w t x w =+形式的判别函数的一个两类线性分类器来说,要求实现以下判定规则: 1 2(x)0,y (x)0,y i i g g ωω>∈?? <∈? 方程g(x)=0定义了一个判定面,它把两个类的点分开来,这个平面被称为超平面,如下图所示。
(2)广义线性判别函数 线性判别函数g(x)又可写成以下形式: 01 (x)w d i i i g w x ==+∑ 其中系数wi 是权向量w 的分量。通过加入另外的项(w 的各对分量之间的乘积),得到二次判别函数: 因为 ,不失一般性,可以假设 。这样,二次判别函数拥有更多 的系数来产生复杂的分隔面。此时g(x)=0定义的分隔面是一个二阶曲面。 若继续加入更高次的项,就可以得到多项式判别函数,这可看作对某一判别函数g(x)做级数展开,然后取其截尾逼近,此时广义线性判别函数可写成: 或: 这里y 通常被成为“增广特征向量”(augmented feature vector),类似的,a 被称为
《模式识别》实验报告 一、数据生成与绘图实验 1.高斯发生器。用均值为m,协方差矩阵为S 的高斯分布生成N个l 维向量。 设置均值 T m=-1,0 ?? ??,协方差为[1,1/2;1/2,1]; 代码: m=[-1;0]; S=[1,1/2;1/2,1]; mvnrnd(m,S,8) 结果显示: ans = -0.4623 3.3678 0.8339 3.3153 -3.2588 -2.2985 -0.1378 3.0594 -0.6812 0.7876 -2.3077 -0.7085 -1.4336 0.4022 -0.6574 -0.0062 2.高斯函数计算。编写一个计算已知向量x的高斯分布(m, s)值的Matlab函数。 均值与协方差与第一题相同,因此代码如下: x=[1;1]; z=1/((2*pi)^0.5*det(S)^0.5)*exp(-0.5*(x-m)'*inv(S)*(x-m)) 显示结果: z = 0.0623 3.由高斯分布类生成数据集。编写一个Matlab 函数,生成N 个l维向量数据集,它们是基于c个本体的高斯分布(mi , si ),对应先验概率Pi ,i= 1,……,c。 M文件如下: function [X,Y] = generate_gauss_classes(m,S,P,N) [r,c]=size(m); X=[]; Y=[]; for j=1:c t=mvnrnd(m(:,j),S(:,:,j),fix(P(j)*N)); X=[X t]; Y=[Y ones(1,fix(P(j)*N))*j]; end end
调用指令如下: m1=[1;1]; m2=[12;8]; m3=[16;1]; S1=[4,0;0,4]; S2=[4,0;0,4]; S3=[4,0;0,4]; m=[m1,m2,m3]; S(:,:,1)=S1; S(:,:,2)=S2; S(:,:,3)=S3; P=[1/3,1/3,1/3]; N=10; [X,Y] = generate_gauss_classes(m,S,P,N) 二、贝叶斯决策上机实验 1.(a)由均值向量m1=[1;1],m2=[7;7],m3=[15;1],方差矩阵S 的正态分布形成三个等(先验)概率的类,再基于这三个类,生成并绘制一个N=1000 的二维向量的数据集。 (b)当类的先验概率定义为向量P =[0.6,0.3,0.1],重复(a)。 (c)仔细分析每个类向量形成的聚类的形状、向量数量的特点及分布参数的影响。 M文件代码如下: function plotData(P) m1=[1;1]; S1=[12,0;0,1]; m2=[7;7]; S2=[8,3;3,2]; m3=[15;1]; S3=[2,0;0,2]; N=1000; r1=mvnrnd(m1,S1,fix(P(1)*N)); r2=mvnrnd(m2,S2,fix(P(2)*N)); r3=mvnrnd(m3,S3,fix(P(3)*N)); figure(1); plot(r1(:,1),r1(:,2),'r.'); hold on; plot(r2(:,1),r2(:,2),'g.'); hold on; plot(r3(:,1),r3(:,2),'b.'); end (a)调用指令: P=[1/3,1/3,1/3];
贝叶斯分类实验报告 篇一:贝叶斯分类实验报告 实验报告 实验课程名称数据挖掘 实验项目名称贝叶斯分类 年级 XX级 专业信息与计算科学 学生姓名 学号 1207010220 理学院 实验时间: XX 年 12 月 2 日 学生实验室守则 一、按教学安排准时到实验室上实验课,不得迟到、早退和旷课。 二、进入实验室必须遵守实验室的各项规章制度,保持室内安静、整洁,不准在室内打闹、喧哗、吸烟、吃食物、随地吐痰、乱扔杂物,不准做与实验内容无关的事,非实验用品一律不准带进实验室。 三、实验前必须做好预习(或按要求写好预习报告),未做预习者不准参加实验。四、实验必须服从教师的安排和指导,认真按规程操作,未经教师允许不得擅自动用仪器设备,特别是与本实验无关的仪器设备和设施,如擅自动用
或违反操作规程造成损坏,应按规定赔偿,严重者给予纪律处分。 五、实验中要节约水、电、气及其它消耗材料。 六、细心观察、如实记录实验现象和结果,不得抄袭或随意更改原始记录和数据,不得擅离操作岗位和干扰他人实验。 七、使用易燃、易爆、腐蚀性、有毒有害物品或接触带电设备进行实验,应特别注意规范操作,注意防护;若发生意外,要保持冷静,并及时向指导教师和管理人员报告,不得自行处理。仪器设备发生故障和损坏,应立即停止实验,并主动向指导教师报告,不得自行拆卸查看和拼装。 八、实验完毕,应清理好实验仪器设备并放回原位,清扫好实验现场,经指导教师检查认可并将实验记录交指导教师检查签字后方可离去。 九、无故不参加实验者,应写出检查,提出申请并缴纳相应的实验费及材料消耗费,经批准后,方可补做。 十、自选实验,应事先预约,拟订出实验方案,经实验室主任同意后,在指导教师或实验技术人员的指导下进行。 十一、实验室内一切物品未经允许严禁带出室外,确需带出,必须经过批准并办理手续。 学生所在学院:理学院专业:信息与计算科学班级:信计121
信息与通信工程学院 模式识别实验报告 班级: 姓名: 学号: 日期:2011年12月
实验一、Bayes 分类器设计 一、实验目的: 1.对模式识别有一个初步的理解 2.能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识 3.理解二类分类器的设计原理 二、实验条件: matlab 软件 三、实验原理: 最小风险贝叶斯决策可按下列步骤进行: 1)在已知 ) (i P ω, ) (i X P ω,i=1,…,c 及给出待识别的X 的情况下,根据贝叶斯公式计 算出后验概率: ∑== c j i i i i i P X P P X P X P 1 ) ()() ()()(ωωωωω j=1,…,x 2)利用计算出的后验概率及决策表,按下面的公式计算出采取i a ,i=1,…,a 的条件风险 ∑== c j j j i i X P a X a R 1 )(),()(ωω λ,i=1,2,…,a 3)对(2)中得到的a 个条件风险值) (X a R i ,i=1,…,a 进行比较,找出使其条件风险最小的 决策k a ,即()() 1,min k i i a R a x R a x == 则 k a 就是最小风险贝叶斯决策。 四、实验内容 假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为 正常状态:P (1ω)=; 异常状态:P (2ω)=。 现有一系列待观察的细胞,其观察值为x : 已知先验概率是的曲线如下图:
)|(1ωx p )|(2ωx p 类条件概率分布正态分布分别为(-2,)(2,4)试对观察的结果 进行分类。 五、实验步骤: 1.用matlab 完成分类器的设计,说明文字程序相应语句,子程序有调用过程。 2.根据例子画出后验概率的分布曲线以及分类的结果示意图。 3.最小风险贝叶斯决策,决策表如下: 结果,并比较两个结果。 六、实验代码 1.最小错误率贝叶斯决策 x=[ ] pw1=; pw2=; e1=-2; a1=; e2=2;a2=2; m=numel(x); %得到待测细胞个数 pw1_x=zeros(1,m); %存放对w1的后验概率矩阵 pw2_x=zeros(1,m); %存放对w2的后验概率矩阵
主观贝叶斯实验报告 学生姓名 程战战 专业/班级 计算机91 学 号 09055006 所在学院 电信学院 指导教师 鲍军鹏 提交日期 2012/4/26
根据初始证据E 的概率P (E )及LS 、LN 的值,把H 的先验概率P (H )更新为后验概率P (H/E )或者P(H/!E)。在证据不确定的情况下,用户观察到的证据具有不确定性,即0 作业6 编程题实验报告 (一)实验内容: 编程实现朴素贝叶斯分类器,假设输入输出都是离散变量。用讲义提供的训练数据进行试验,观察分类器在 121.x x m ==时,输出如何。如果在分类器中加入Laplace 平滑(取?=1) ,结果是否改变。 (二)实验原理: 1)朴素贝叶斯分类器: 对于实验要求的朴素贝叶斯分类器问题,假设数据条件独立,于是可以通过下式计算出联合似然函数: 12(,,)()D i i p x x x y p x y =∏ 其中,()i p x y 可以有给出的样本数据计算出的经验分布估计。 在实验中,朴素贝叶斯分类器问题可以表示为下面的式子: ~1*arg max ()()D i y i y p y p x y ==∏ 其中,~ ()p y 是从给出的样本数据计算出的经验分布估计出的先验分布。 2)Laplace 平滑: 在分类器中加入Laplace 平滑目的在于,对于给定的训练数据中,有可能会出现不能完全覆盖到所有变量取值的数据,这对分类器的分类结果造成一定误差。 解决办法,就是在分类器工作前,再引入一部分先验知识,让每一种变量去只对应分类情况与统计的次数均加上Laplace 平滑参数?。依然采用最大后验概率准则。 (三)实验数据及程序: 1)实验数据处理: 在实验中,所用数据中变量2x 的取值,对应1,2,3s m I === 讲义中所用的两套数据,分别为cover all possible instances 和not cover all possible instances 两种情况,在实验中,分别作为训练样本,在给出测试样本时,输出不同的分类结果。 2)实验程序: 比较朴素贝叶斯分类器,在分类器中加入Laplace 平滑(取?=1)两种情况,在编写matlab 函数时,只需编写分类器中加入Laplace 平滑的函数,朴素贝叶斯分类器是?=0时,特定的Laplace 平滑情况。 实现函数:[kind] =N_Bayes_Lap(X1,X2,y,x1,x2,a) 输入参数:X1,X2,y 为已知的训练数据; x1,x2为测试样本值; a 为调整项,当a=0时,就是朴素贝叶斯分类器,a=1时,为分类器中加入Laplace 平滑。 输出结果:kind ,输出的分类结果。 实验一Bayes 分类器设计 本实验旨在让同学对模式识别有一个初步的理解,能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识,理解二类分类器的设计原理。 1实验原理 最小风险贝叶斯决策可按下列步骤进行: (1)在已知)(i P ω,)(i X P ω,i=1,…,c 及给出待识别的X 的情况下,根据贝叶斯公式计算出后验概率: ∑== c j i i i i i P X P P X P X P 1 ) ()() ()()(ωωωωω j=1,…,x (2)利用计算出的后验概率及决策表,按下面的公式计算出采取i a ,i=1,…,a 的条件风险 ∑== c j j j i i X P a X a R 1 )(),()(ωω λ,i=1,2,…,a (3)对(2)中得到的a 个条件风险值)(X a R i ,i=1,…,a 进行比较,找出使其条件风险最小的决策k a ,即 则k a 就是最小风险贝叶斯决策。 2实验内容 假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为 正常状态:P (1ω)=0.9; 异常状态:P (2ω)=0.1。 现有一系列待观察的细胞,其观察值为x : -3.9847 -3.5549 -1.2401 -0.9780 -0.7932 -2.8531 -2.7605 -3.7287 -3.5414 -2.2692 -3.4549 -3.0752 -3.9934 2.8792 -0.9780 0.7932 1.1882 3.0682 -1.5799 -1.4885 -0.7431 -0.4221 -1.1186 4.2532 已知类条件概率密度曲线如下图: )|(1ωx p )|(2ωx p 类条件概率分布正态分布分别为(-2,0.25)(2,4)试对观察的结果进 行分类。 3 实验要求 1) 用matlab 完成分类器的设计,要求程序相应语句有说明文字。 2) 根据例子画出后验概率的分布曲线以及分类的结果示意图。 3) 如果是最小风险贝叶斯决策,决策表如下: 实验一 Bayes 分类器设计 【实验目的】 对模式识别有一个初步的理解,能够根据自己的设计对贝叶斯决策理论算法有一个深刻 地认识,理解二类分类器的设计原理。 【实验原理】 最小风险贝叶斯决策可按下列步骤进行: (1)在已知)(i P ω,)(i X P ω,i=1,…,c 及给出待识别的X 的情况下,根据贝叶斯公式计算出后验概率: ∑==c j i i i i i P X P P X P X P 1)()() ()()(ωωωωω j=1,…,x (2)利用计算出的后验概率及决策表,按下面的公式计算出采取i a ,i=1,…,a 的条件风险 ∑==c j j j i i X P a X a R 1)(),()(ωωλ,i=1,2,…,a (3)对(2)中得到的a 个条件风险值)(X a R i ,i=1,…,a 进行比较,找出使其条件风险最 小的决策k a ,即 ()()1,min k i i a R a x R a x ==L 则k a 就是最小风险贝叶斯决策。 【实验内容】 假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为 正常状态:P (1ω)=0.9; 异常状态:P (2ω)=0.1。 现有一系列待观察的细胞,其观察值为x : -3.9847 -3.5549 -1.2401 -0.9780 -0.7932 -2.8531 -2.7605 -3.7287 -3.5414 -2.2692 -3.4549 -3.0752 -3.9934 2.8792 -0.9780 0.7932 1.1882 3.0682 -1.5799 -1.4885 -0.7431 -0.4221 -1.1186 4.2532 已知类条件概率是的曲线如下图: )|(1ωx p )|(2ωx p 类条件概率分布正态分布分别为N (-2,0.25)、N (2,4) 试对观察的结果进行分类。 【实验要求】 1) 用matlab 完成基于最小错误率的贝叶斯分类器的设计,要求程序相应语句有说明 文字,要求有子程序的调用过程。 2) 根据例子画出后验概率的分布曲线以及分类的结果示意图。 3) 如果是最小风险贝叶斯决策,决策表如下: 最小风险贝叶斯决策表: 模式识别理论与方法 课程作业实验报告 实验名称:Generating Pattern Classes 实验编号:Proj01-01 规定提交日期:2012年3月16日 实际提交日期:2012年3月13日 摘要: 在熟悉Matlab中相关产生随机数和随机向量的函数基础上,重点就多元(维)高斯分布情况进行了本次实验研究:以mvnrnd()函数为核心,由浅入深、由简到难地逐步实现了获得N 个d维c类模式集,并将任意指定的两个维数、按类分不同颜色进行二维投影绘图展示。 技术论述: 1,用矩阵表征各均值、协方差2,多维正态分布函数: 实验结果讨论: 从实验的过程和结果来看,进一步熟悉了多维高斯分布函数的性质和使用,基本达到了预期目的。 实验结果: 图形部分: 图1集合中的任意指定两个维度投影散点图形 图2集合中的任意指定两个维度投影散点图形,每类一种颜色 数据部分: Fa= 9.6483 5.5074 2.4839 5.72087.2769 4.8807 9.1065 4.1758 1.5420 6.1500 6.2567 4.1387 10.0206 3.5897 2.6956 6.1500 6.9009 4.0248 10.1862 5.2959 3.1518 5.22877.1401 3.1974 10.4976 4.9501 1.4253 5.58257.4102 4.9474 11.3841 4.5128 2.0714 5.90068.2228 4.4821 9.6409 5.43540.9810 6.2676 6.9863 4.2530 8.8512 5.2401 2.7416 6.5095 6.1853 4.8751 9.8849 5.8766 3.3881 5.7879 6.7070 6.6132 10.6845 4.8772 3.4440 6.0758 6.6633 3.5381 8.7478 3.3923 2.4628 6.1352 6.9258 3.3907 《模式识别》实验报告 ---最小错误率贝叶斯决策分类 一、实验原理 对于具有多个特征参数的样本(如本实验的iris 数据样本有4d =个参数),其正态分布的概率密度函数可定义为 11 22 11()exp ()()2(2)T d p π-??=--∑-???? ∑x x μx μ 式中,12,,,d x x x ????=x 是d 维行向量,12,,,d μμμ????=μ 是d 维行向量,∑是d d ?维协方差矩阵,1-∑是∑的逆矩阵,∑是∑的行列式。 本实验我们采用最小错误率的贝叶斯决策,使用如下的函数作为判别函数 ()(|)(), 1,2,3i i i g p P i ωω==x x (3个类别) 其中()i P ω为类别i ω发生的先验概率,(|)i p ωx 为类别i ω的类条件概率密度函数。 由其判决规则,如果使()()i j g g >x x 对一切j i ≠成立,则将x 归为i ω类。 我们根据假设:类别i ω,i=1,2,……,N 的类条件概率密度函数(|)i p ωx ,i=1,2,……,N 服从正态分布,即有(|)i p ωx ~(,)i i N ∑μ,那么上式就可以写为 112 2 ()1()exp ()(),1,2,32(2)T i i d P g i ωπ-?? = -∑=???? ∑ x x -μx -μ 对上式右端取对数,可得 111()()()ln ()ln ln(2)222 T i i i i d g P ωπ-=-∑+-∑-i i x x -μx -μ 上式中的第二项与样本所属类别无关,将其从判别函数中消去,不会改变分类结果。则判别函数()i g x 可简化为以下形式 111 ()()()ln ()ln 22 T i i i i g P ω-=-∑+-∑i i x x -μx -μ 实验报告实验课程名称:模式识别 姓名:班级:学号: 注:1、每个实验中各项成绩按照5分制评定,实验成绩为各项总和 2、平均成绩取各项实验平均成绩 3、折合成绩按照教学大纲要求的百分比进行折合 ; 2015年4月 实验1 图像的贝叶斯分类 实验目的 将模式识别方法与图像处理技术相结合,掌握利用最小错分概率贝叶斯分类器进行图像分类的基本方法,通过实验加深对基本概念的理解。 实验仪器设备及软件 HP D538、MATLAB ( 实验原理 基本原理 阈值化分割算法是计算机视觉中的常用算法,对灰度图象的阈值分割就是先确定一个处于图像灰度取值范围内的灰度阈值,然后将图像中每个像素的灰度值与这个阈值相比较。并根据比较的结果将对应的像素划分为两类,灰度值大于阈值的像素划分为一类,小于阈值的划分为另一类,等于阈值的可任意划分到两类中的任何一类。此过程中,确定阈值是分割的关键。 对一般的图像进行分割处理通常对图像的灰度分布有一定的假设,或者说是基于一定的图像模型。最常用的模型可描述如下:假设图像由具有单峰灰度分布的目标和背景组成,处于目标和背景内部相邻像素间的灰度值是高度相关的,但处于目标和背景交界处两边的像素灰度值有较大差别,此时,图像的灰度直方图基本上可看作是由分别对应于目标和背景的两个单峰直方图混合构成。而且这两个分布应大小接近,且均值足够远,方差足够小,这种情况下直方图呈现较明显的双峰。类似地,如果图像中包含多个单峰灰度目标,则直方图可能呈现较明显的多峰。 上述图像模型只是理想情况,有时图像中目标和背景的灰度值有部分交错。这时如用全局阈值进行分割必然会产生一定的误差。分割误差包括将目标分为背景和将背景分为目标两大类。实际应用中应尽量减小错误分割的概率,常用的一种方法为选取最优阈值。这里所谓的最优阈值,就是指能使误分割概率最小的分割阈值。图像的直方图可以看成是对灰度值概率分布密度函数的一种近似。如一幅图像中只包含目标和背景两类灰度区域,那么直方图所代表的灰度值概率密度函数可以表示为目标和背景两类灰度值概率密度函数的加权和。如果概率密度函数形式已知,就有可能计算出使目标和背景两类误分割概率最小的最优阈值。 假设目标与背景两类像素值均服从正态分布且混有加性高斯噪声,上述分类问题可用模式识别中的最小错分概率贝叶斯分类器来解决。以1p 与2p 分别表示目标与背景的灰度分布概率密度函数,1P 与2P 分别表示两类的先验概率,则图像的混合概率密度函数用下式表示 1122()()()p x P p x P p x =+ 式中1p 和2p 分别为 … 212 1()21()x p x μσ--= 222 2()22()x p x μσ-- = 121P P += 1σ、2σ是针对背景和目标两类区域灰度均值1μ与2μ的标准差。若假定目标的灰度较亮, 模式识别实验报告-年月 ————————————————————————————————作者: ————————————————————————————————日期: 学院: 班级: 姓名: 学号: 2012年3月 实验一 Bay es分类器的设计 一、 实验目的: 1. 对模式识别有一个初步的理解,能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识; 2. 理解二类分类器的设计原理。 二、 实验条件: 1. PC 微机一台和MA TL AB 软件。 三、 实验原理: 最小风险贝叶斯决策可按下列步骤进行: 1. 在已知 ) (i P ω, )|(i X P ω,c i ,,1 =及给出待识别的X 的情况下,根据贝叶斯 公式计算出后验概率: ∑== c j j j i i i P X P P X P X P 1 ) ()|() ()|()|(ωωωωω c j ,,1 = 2. 利用计算出的后验概率及决策表,按下式计算出采取 i α决策的条件风险: ∑==c j j j i i X P X R 1) |(),()|(ωωαλα a i ,,1 = 3. 对2中得到的a 个条件风险值) |(X R i α(a i ,,1 =)进行比较,找出使条件 风险最小的决策k α,即: ) |(min )|(,,1X R X R k c i k αα ==, 则 k α就是最小风险贝叶斯决策。 四、 实验内容: (以下例为模板,自己输入实验数据) 假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为: 正常状态:)(1ωP =0.9; 异常状态:)(2ωP =0.1。 实验报告 课程名称:模式识别 学院:电子通信与物理学院专业:电子信息工程 班级:电子信息工程2013-3姓名: 学号: 指导老师: 实验一Bayes 分类器设计 本实验旨在让同学对模式识别有一个初步的理解,能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识,理解二类分类器的设计原理。 1实验原理 最小风险贝叶斯决策可按下列步骤进行: (1)在已知)(i P ω,)(i X P ω,i=1,…,c 及给出待识别的X 的情况下,根据贝叶斯公式计算出后验概率: ∑==c j i i i i i P X P P X P X P 1)()() ()()(ωωωωω j=1,…,x (2)利用计算出的后验概率及决策表,按下面的公式计算出采取i a ,i=1,…,a 的条件风险 ∑==c j j j i i X P a X a R 1)(),()(ωωλ,i=1,2,…,a (3)对(2)中得到的a 个条件风险值)(X a R i ,i=1,…,a 进行比较,找出使其条件风险最小的决策k a ,即 则k a 就是最小风险贝叶斯决策。 2实验内容 假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为 正常状态:P (1ω)=; 异常状态:P (2ω)=。 现有一系列待观察的细胞,其观察值为x : 已知类条件概率密度曲线如下图: )|(1ωx p )|(2ωx p 类条件概率分布正态分布分别为(-2,)(2,4)试对观察的结果进行分类。 3 实验要求 1) 用matlab 完成分类器的设计,要求程序相应语句有说明文字。 2) 根据例子画出后验概率的分布曲线以及分类的结果示意图。 3) 如果是最小风险贝叶斯决策,决策表如下: 最小风险贝叶斯决策表: 请重新设计程序,画出相应的后验概率的分布曲线和分类结果,并比较两个结果。 实验报告 实验课程名称:模式识别 :王宇班级:20110813 学号:2011081325 注:1、每个实验中各项成绩按照5分制评定,实验成绩为各项总和 2、平均成绩取各项实验平均成绩 3、折合成绩按照教学大纲要求的百分比进行折合 2014年6月 实验一、图像的贝叶斯分类 一、实验目的 将模式识别方法与图像处理技术相结合,掌握利用最小错分概率贝叶斯分类器进行图像分类的基本方法,通过实验加深对基本概念的理解。 二、实验仪器设备及软件 HP D538、MATLAB 三、实验原理 概念: 阈值化分割算法是计算机视觉中的常用算法,对灰度图象的阈值分割就是先确定一个处于图像灰度取值围的灰度阈值,然后将图像中每个像素的灰度值与这个阈值相比较。并根据比较的结果将对应的像素划分为两类,灰度值大于阈值的像素划分为一类,小于阈值的划分为另一类,等于阈值的可任意划分到两类中的任何一类。 最常用的模型可描述如下:假设图像由具有单峰灰度分布的目标和背景组成,处于目标和背景部相邻像素间的灰度值是高度相关的,但处于目标和背景交界处两边的像素灰度值有较大差别,此时,图像的灰度直方图基本上可看作是由分别对应于目标和背景的两个单峰直方图混合构成。而且这两个分布应大小接近,且均值足够远,方差足够小,这种情况下直方图呈现较明显的双峰。类似地,如果图像中包含多个单峰灰度目标,则直方图可能呈现较明显的多峰。 上述图像模型只是理想情况,有时图像中目标和背景的灰度值有部分交错。这时如用全局阈值进行分割必然会产生一定的误差。分割误差包括将目标分为背景和将背景分为目标两大类。实际应用中应尽量减小错误分割的概率,常用的一种方法为选取最优阈值。这里所谓的最优阈值,就是指能使误分割概率最小的分割阈值。图像的直方图可以看成是对灰度值概率分布密度函数的一种近似。如一幅图像中只包含目标和背景两类灰度区域,那么直方图所代表的灰度值概率密度函数可以表示为目标和背景两类灰度值概率密度函数的加权和。如果概率密度函数形式已知,就有可能计算出使目标和背景两类误分割概率最小的最优阈值。 假设目标与背景两类像素值均服从正态分布且混有加性高斯噪声,上述分类问题可以使用模 2015年12月 实验一 Bayes 分类器的设计 一、 实验目的: 1. 对模式识别有一个初步的理解,能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识; 2. 理解二类分类器的设计原理。 二、 实验条件: 1. PC 微机一台和MATLAB 软件。 三、 实验原理: 最小风险贝叶斯决策可按下列步骤进行: 1. 在已知)(i P ω,)|(i X P ω,c i ,,1 =及给出待识别的X 的情况下,根据贝叶斯公式计算出后验概率: ∑==c j j j i i i P X P P X P X P 1)()|() ()|()|(ωωωωω c j ,,1 = 2. 利用计算出的后验概率及决策表,按下式计算出采取i α决策的条件风险: ∑==c j j j i i X P X R 1) |(),()|(ωωαλα a i ,,1 = 3. 对2中得到的a 个条件风险值)|(X R i α(a i ,,1 =)进行比较,找出使条件风险最小的决策k α,即: )|(m i n )|(,,1X R X R k c i k αα ==, 则k α就是最小风险贝叶斯决策。 四、 实验内容: 假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为: 正常状态:)(1ωP =0.9; 异常状态:)(2ωP =0.1。 现有一系列待观察的细胞,其观察值为x : -3.9847 -3.5549 -1.2401 -0.9780 -0.7932 -2.8531 -2.7605 -3.7287 -3.5414 -2.2692 -3.4549 -3.0752 -3.9934 2.8792 -0.9780 0.7932 1.1882 3.0682 -1.5799 -1.4885 -0.7431 -0.4221 -1.1186 4.2532 )|(1ωx P )|(2ωx P 类条件概率分布正态分布分别为(-2,0.25)(2,4)。决策表为011=λ(11λ表示),(j i ωαλ的简写),12λ=6, 21λ=1,22λ=0。 试对观察的结果进行分类。 五、 实验程序及结果: 试验程序和曲线如下,分类结果在运行后的主程序中:统计学习_朴素贝叶斯分类器实验报告
模式识别实验报告
模式识别实验报告-实验一-Bayes分类器设计汇总
模式识别实验报告_2
《模式识别》实验报告-贝叶斯分类
哈尔滨工程大学模式识别实验报告
模式识别实验报告年月
实验一Bayes分类器设计
模式识别实验报告
模式识别基础实验报告
相关主题
文本预览