
word可以直接另存为 htm,但即使是另存为 html 也会有大量的废代码。以前我一般用 dreamweaver 的 clean up html 来处理,先处理 word 特有标签,然后删除一些 font,b,span 等。进一步,在 editplus 里面用正则进行处理,最后得到我想要的干净的html 代码。当然最完美的办法就是拷贝文字出来,自己用文本编辑器书写htm标签,:)
今天又看到lifehacker这几种word 2 clean htm方法:
1.使用这个HTML Tidy Library Project开源软件来处理。
2.微软官方站点也有个Office 2000 HTML Filter 2.0工具,可以用来处理掉word2000转html时出现的多余代码。
3.使用这个Word HTML Cleaner 在线工具来处理。只能处理word2000以下版本。
4.有人给出了正则表达式(其实,上面的各种软件也都是用正则来解决的)
删除不需要的标签
<[/]?(font|span|xml|[ovwxp]:w+)[^>]*?>
- replace any matches with the empty string
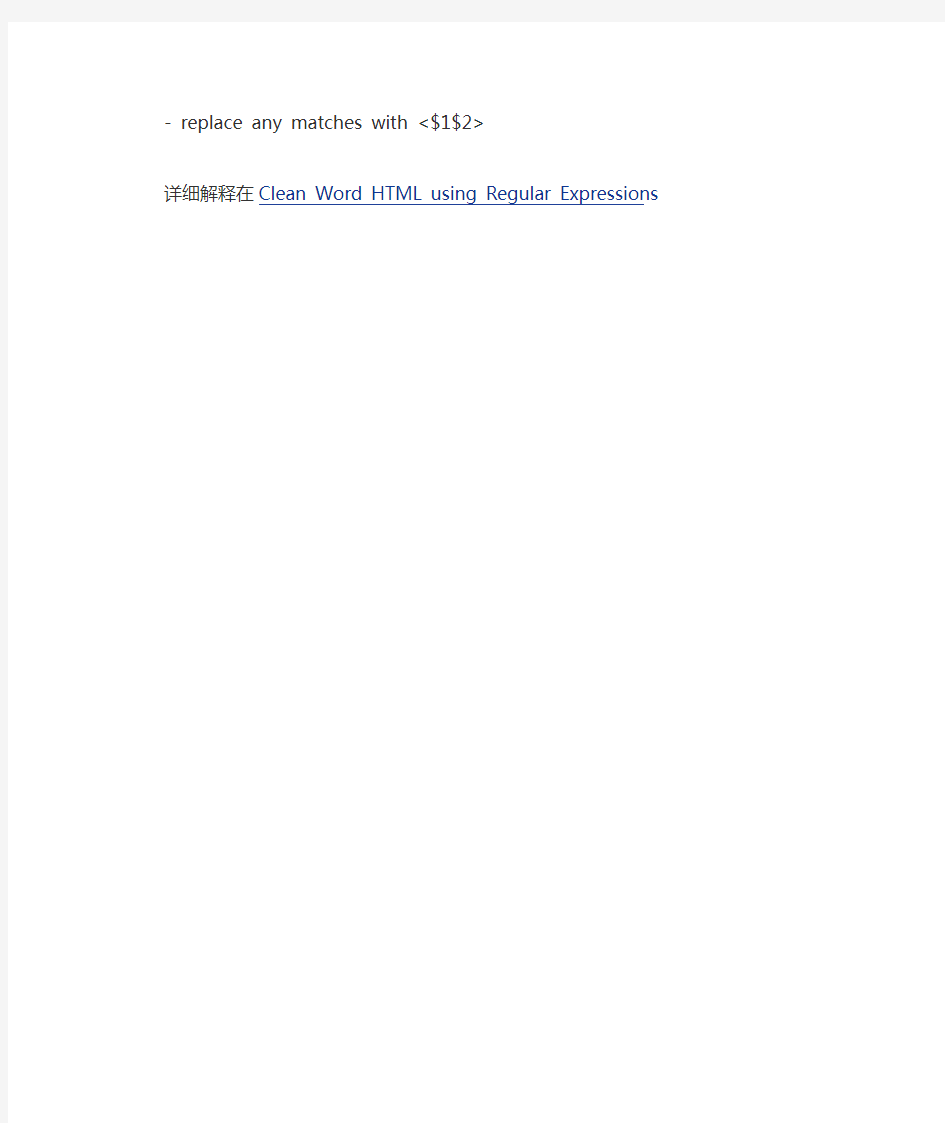
删除class,style...等不需要的属性
<([^>]*)(?:class|lang|style|size|face|[ovwxp]:w+)=(?:'[^']*'|""[^""] *""|[^>]+)([^>]*)>
- replace any matches with <$1$2>
详细解释在Clean Word HTML using Regular Expressions
竭诚为您提供优质文档/双击可除 为什么我用word文档转换成html格式 后表格边框不见了 篇一:word格式转换html 将word格式的文件转换成html格式的网页文件详细步骤: 1、首先建立一个word文档,并在上面编辑好自己想要创建网页的内容,如下图: 2、点击“文件”下拉菜单,并在下拉菜单中选择“另存为”命 令 3、页面出现下图所示的窗口, 4、点击保存类型中的三角形下拉菜单,得到下图所示的窗口 , 5、选择“网页文件(*html,*htm)”命令,给文件命名为“教育.html”并点击“保存”;即完成了“word”转换成“html”网页格式(为什么我用word文档转换成html格式后表格边框不见了)的过程:
7、寻找下图两个文件,双击打开后缀名为html的文件,如这里的“教育.html”文件,即可看到我们转换的html网页了。 篇二:word转html后的变化 word文档转换为html文档后的变化 办公软件 palign="left">当用户将word文档存为web页时,word 会关闭文档,然后用超文本标记语言(html)格式保存,但是因为html不支持某些word功能,转换时word会更改或取消内容,因此应先用word格式保存文档。特别是当文档还要当作word文档使用时。本人通过实践和搜集,对word文档转换成html时发生的变化列出如下表,希望能给广大网页设计爱好者一点帮助。 篇三:word文档格式html制作规则 word文档格式html制作规则 一、制作要求 文书制作应当完整、准确、规范,符合相关要求。 除有特别要求的文书外,文书尺寸统一使用a4 (210mm*297mm)纸张印制。 1、文书使用3号黑体; 2、文书名称使用2号宋体; 3、表格内文字使用5号仿宋。需加盖公章的制作式文
JavaToHtml 为了方便在blog中粘贴源代码,特意找了这方面的工具(本来琢磨自己写,可惜能力有限,再次受打击了~~~) JavaToHtml开源,Eclipse Plugin 大家都知道读源代码很累,读乱七八糟的源代码那就想吐了,所以格式化源代码还是很有必要的,不信看看下面的例子。 格式化后的漂亮效果: import java.util.Vector; public class Stack
} } 下面是原版的: import java.util.Vector; public class Stack
C# Word转PDF、TXT、图片、HTML 使用MS Word时,用户点击“文档”-“另存为”,即可将新建的或现有的Word文档保存为PDF、TXT、HTML 等格式文档。如何通过编程的方式实现Word的转换功能呢? 在C#中对文档进行转换,我们需要使用到Interop.Word或其他第三方类库。使用Interop.Word,需要安装Microsoft Office,各种配置十分麻烦。本文为大家介绍使用免费版的Spire.Doc组件实现Word文档格式转换。 该组件提供的可用于格式转换的方法有: 下载Spire.Doc后,引用Spire.Doc.dll到Visual Studio,并在程序开头添加以下命名空间即可。 using System; using Spire.Doc; using System.Drawing; 然后,就可以通过下面的代码进行格式转换:
一,Word转PDF //初始化Document实例 Document doc = new Document(); //加载Word文档 doc.LoadFromFile("个人简历.docx"); //保存为PDF doc.SaveToFile("个人简历.pdf", FileFormat.PDF); 二,Word转HTML //初始化Document实例 Document doc = new Document(); //加载Word文档 doc.LoadFromFile("个人简历.docx"); //保存为HTML doc.SaveToFile("个人简历.html", FileFormat.Html); 三,Word转TXT //初始化Document实例 Document doc = new Document(); //加载Word文档 doc.LoadFromFile("个人简历.docx"); //保存为Text文档 doc.SaveToFile("个人简历.txt", FileFormat.Txt);
*本事例主要讲了如下几点: * 1:将图片转换为BASE64加密字符串. * 2:将图片流转换为BASE64加密字符串. * 3:将BASE64加密字符串转换为图片. * 4:在jsp文件中以引用的方式和BASE64加密字符串方式展示图片. 首先看工具类: import ; import ; import ; import ; import ; import ; import ; import ; import ; /** * @author IluckySi 1
* @since */ public class ImageUtil { private static BASE64Encoder encoder = new ; private static BASE64Decoder decoder = new ; /** * 将图片转换为BASE64加密字符串. * @param imagePath 图片路径. * @param format 图片格式. * @return */ public String convertImageToByte(String imagePath, String format) { File file = new File(imagePath); BufferedImage bi = null; ByteArrayOutputStream baos = null; String result = null;
try { bi = ImageIO.read(file); baos = new ByteArrayOutputStream(); ImageIO.write(bi, format == null ? "jpg" : format, baos); byte[] bytes = baos.toByteArray(); result = encoder.encodeBuffer(bytes).trim(); "将图片转换为BASE64加密字符串成功!"); } catch (IOException e) { "将图片转换为BASE64加密字符串失败: " + e); } finally { try { if(baos != null) { baos.close(); baos = null; } } catch (Exception e) { "关闭文件流发生异常: " + e); } 3
将Word文档转换成图片PDF的办法 很多人都想把Word文档转换成图片格式的PDF文档,保证无法拷贝文档里的文字,以保护知识产权,但是苦于找不到合适的办法。网上有可以完成这个任务的软件,但是要收费,效果也不好。经探索,我总结出了以下较为便捷(而且绝对免费)的转换方法,不需特别的软件,只需要Word和Adobe Acrobat两种基本软件就可以得到效果很好的图片PDF文档。 第一步:在word软件里利用“另存为”或虚拟打印机把word 文档转换成非图片格式的PDF文档。这个比较简单,不细说。 第二步:在Adobe Acrobat Pro里打开菜单栏的“文件”—“导出”—“图像”—“JPEG”,把PDF转换成一张一张的jpg图片, 版式阅读软件,云签章,可信时间戳
全部放在同一个文件夹下。 第三步:在Adobe Acrobat Pro里打开菜单栏的“文件”—“创建PDF”—“组合文件到单个PDF”,点“添加文件”,选择“添加文件夹”,选择刚才存放JPG图片的文件夹,往下操作就变成图片PDF了。 注意事项:生成JPG图片时可以设置图片质量,不要把图片质量设太高,否则体积太大、速度太慢。有一半的质量,转换之后每张图片几百K,看起来效果就很好了。 躬行文件转换迁移系统为各类应用系统提供长期驻留的文档格式转换服务,可采用实时、批量或套转方式将各种格式文档转换为PDF或OFD文件,支持的格式包括但不限于微软Office办公文档系列、WPS、PDF、XPS、图片、RTF、HTML网页等。内置多种转换引擎,支持集群配置,可有效应对高精度、大数据量、高速度、高可靠性要求的文档转换需求。支持以WebApi方式调用。 河南省躬行信息科技有限公司位于郑州高新技术开发区,是一家以信息技术为核心的高科技企业。公司以信息安全技术为特色,秉承"优质服务,互利共赢"的理念,提供软件与系统开发、信息安全保密、Web应用安全等开发和咨询服务。期待您的详询。 版式阅读软件,云签章,可信时间戳
. Word转html存在域代码丢失。 Aspose ,jacob,poi都无法解决 在使用jocob转换成html时域代码会被包裹 可以统一提取出来转换成latex ,latex转换成图片,解决word域代码丢失问题 private void processFormula(List
标签。 为了显示美观,对关键字加粗显示,即在关键字左右加标签。比如: public 对单行注释文本用绿色显示,可以使用标签,形如: //这是我的单行注释! 注意:如果“//”出现在字符串中,则注意区分,不要错误地变为绿色。 不考虑多行注释的问题(/* .... */ 或 /** .... */) 你的任务是:编写程序,把给定的源文件转化为相应的html表达。 【输入、输出格式要求】 与你的程序同一目录下,存有源文件 a.txt,其中存有标准的java源文件。
要求编写程序把它转化为b.html。 例如:目前的 a.txt 文件与 b.html 文件就是对应的。可以用记事本打开b.html查看转换后的内容。用浏览器打开b.html则可以看到显示的效果。 注意:实际评测的时候使用的a.txt与示例是不同的。 【注意】 请仔细调试!您的程序只有能运行出正确结果的时候才有机会得分! 请把所有类写在同一个文件中,调试好后,存入与【考生文件夹】下对应题号的“解答.txt”中即可。 相关的工程文件不要拷入。 请不要使用package语句。 源程序中只能出现JDK1.5中允许的语法或调用。不能使用1.6或更高版本。 a.txt // 我的工具类 public class MyTool { public static void main(String[] args) { int a = 100; int b = 20; if(a>b && true) System.out.println(a); else System.out.println("this! //aaa//kkk"); // 测试注释显示是否正确 } } 代码 package com; import java.io.BufferedReader; import java.io.BufferedWriter;
https://www.doczj.com/doc/0f7935859.html,/itedu/200707/126842_3.html 一、表达式的组成 1、数字 2、运算符:+ - / * ^ % = 3、圆括号 4、变量 二、运算符优先级 由高到低分别为:+-(正负号)、^、*/%、+-、= 优先级相等的运算符按照从左到右的顺序计算 三、关键技术点 1、确定运算的优先级,从高到低分别为:原子元素表达式,包括数字和变量;括号表达式;一元表达式,取数的负数;指数表达式;乘、除、取模表达式;加、减表达式;赋值表达式。 2、对于每一级别的运算,都由一个方法实现,在方法中先完成比自己高一级别的运算,再处理本级别的运算。因此,在计算整个表达式的主方法中,只需要调用最低级别的运算的实现方法即可。 3、确定表达式中的分隔符,(+、-、*、/、%、^、=、(、)、)。利用这些分隔符将表达式分成多段,每一段叫做一个token,分隔符也算token。 4、用长度为26的int数组vars存储变量的值。 5、Character的isWhitespace方法判断字符是否为空白符,用于去掉表达式中的空白符。 6、Character的isLetter方法判断字符是否为字母,用于提取表达式中的变量 7、Character的isDigit方法判断字符是否为数字,用于获取表达式中的数字 四、演示实例 /** *//** * 文件名ExpressionParser.java */ package book.oo.String; /** *//** * 表达式解析器 * @author joe * */
public class ExpressionParser ...{ //4种标记类型 public static final int NONE_TOKEN = 0; //标记为空或者结束符 public static final int DELIMITER_TOKEN = 1; //标记为分隔符 public static final int VARIABLE_TOKEN = 2; //标记为变量 public static final int NUMBER_TOKEN = 3; //标记为数字 //4种错误类型 public static final int SYNTAX_ERROR = 0; //语法错误 public static final int UNBALPARENS_ERROR = 1; //括号没有结束错误 public static final int NOEXP_ERROR = 2; //表达式为空错误 public static final int DIVBYZERO_ERROR = 3; //被0除错误 //针对4种错误类型定义的4个错误提示 public static final String[] ERROR_MESSAGES = ...{"Syntax Error", "Unbalanced " + "Parentheses", "No Expression Present", "Division by Zero"}; //表达式的结束标记 public static final String EOE = ""\0"; private String exp; //表达式字符串 private int expIndex; //解析器当前指针在表达式中的位置 private String token; //解析器当前处理的标记 private int tokenType; //解析器当前处理的标记类型 private double[] vars = new double[26]; //变量数组 /** * */ public ExpressionParser() { } /** * 解析一个表达式,返回表达式的值 */ public double evaluate(String expStr) throws Exception { double result; this.exp = expStr; this.expIndex = 0; //获取第一个标记 this.getToken(); if (this.token.equals(EOE)) { //没有表达式异常
Java 将PDF 转为Word、图片、SVG、XPS、Html、PDF/A 本文将介绍通过Java编程来实现PDF文档转换的方法。包括: PDF转为Word PDF转为图片 PDF转为Html PDF转为SVG 将PDF每一页转为单个的SVG 将一个包含多页的PDF文档转为一个SVG PDF转为XPS PDF转为PDF/A 使用工具:Free Spire.PDF for Java(免费版) Jar文件获取及导入: 方法1:通过官网下载jar文件包。下载后,解压文件,并将lib文件夹下的Spire.Pdf.jar文件导入Java程序。 方法2:可通过maven仓库安装导入。参考导入方法。 Java代码示例 【示例1】PDF 转Word PdfDocument pdf = new PdfDocument("test.pdf"); pdf.saveToFile("ToWord.docx",FileFormat.DOCX); 【示例2】PDF转图片 支持的图片格式包括Jpeg, Jpg, Png, Bmp, Tiff, Gif, EMF等。这里以保存为Png格式为例。 import com.spire.pdf.*; import javax.imageio.ImageIO; import java.awt.image.BufferedImage; import java.io.File; import java.io.IOException; public class PDFtoimage { public static void main(String[] args) throws IOException { PdfDocument pdf = new PdfDocument("test.pdf");
java html内容生成word文件实现代码 https://www.doczj.com/doc/0f7935859.html, 编辑:kepeer 来源:转载 处理HTML标签我用的是Jsoup组件,生成word文档这方面我用的是Jacob组件。 有兴趣的朋友可以去Google搜索一下这两个组件。大致思路如下: 先利用jsoup将得到的html代码“标准化”(Jsoup.parse(String html))方法,然后利用FileWiter 将此html内容写到本地的template.doc文件中,此时如果文章中包含图片的话,template.doc 就会依赖你的本地图片文件路径,如果你将图片更改一个名称或者将路径更改,再打开这个template.doc,图片就会显示不出来(出现一个叉叉)。为了解决此问题,利用jsoup组件循环遍历html文档的内容,将img元素替换成${image_自增值}的标识,取出img元素中的src 此时你的html内容会变成如下格式:(举个示例) 代码如下复制代码
测试消息1 ${image_1}