
《云计算与大数据实验》实验报告
实验一熟悉常用的Linux操作和Hadoop操作
学号 201710610 姓名:分数
实验目的:熟练使用Linux常用命令
Linux设置静态ip地址
搭建NTP服务器
实验环境:
Centos6.5
1.实验内容与完成情况:
在Jack文件夹执行命令unmame和uname-r来查看系统名称和版本号
2.ifconfig命令查看linux系统的网卡信息
3.ls命令,查看当前目录下的文件夹和文件。
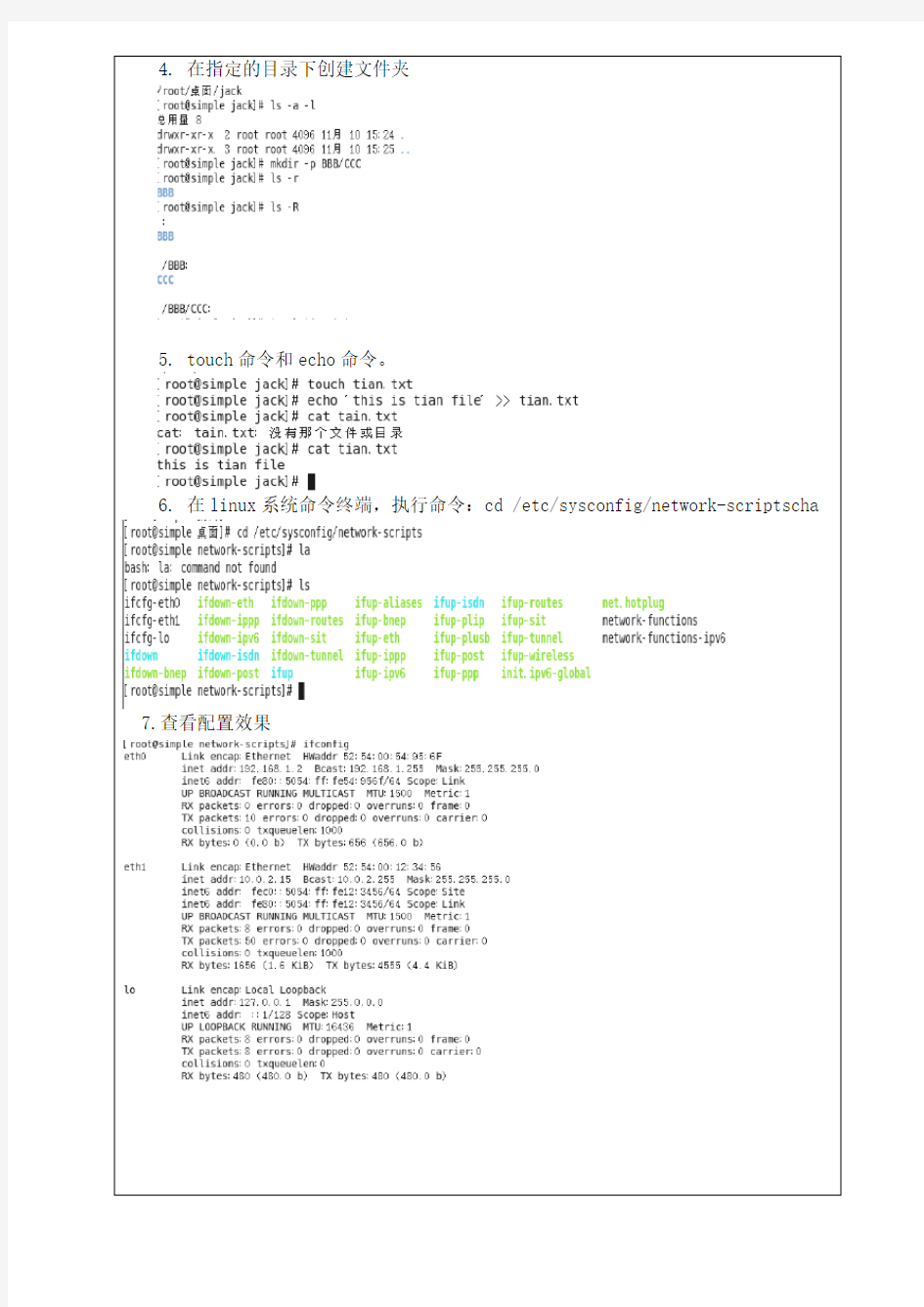
4.在指定的目录下创建文件夹
5.touch命令和echo命令。
6.在linux系统命令终端,执行命令:cd /etc/sysconfig/network-scriptscha
7.查看配置效果
7.安装ntp服务器:
8.修改ntp服务器配置文件:
9.ntp服务器采用upd协议开放端口:
出现的问题:
1.指令格式出现混淆,空格在实验中注意不到,导致指令报错。
2.
解决方案(列出遇到的问题和解决办法,列出没有解决的问题):
1.注意查看指令格式,在具体实验操作中要仔细认真。
Hadoop测试题 一.填空题,1分(41空),2分(42空)共125分 1.(每空1分) datanode 负责HDFS数据存储。 2.(每空1分)HDFS中的block默认保存 3 份。 3.(每空1分)ResourceManager 程序通常与NameNode 在一个节点启动。 4.(每空1分)hadoop运行的模式有:单机模式、伪分布模式、完全分布式。 5.(每空1分)Hadoop集群搭建中常用的4个配置文件为:core-site.xml 、hdfs-site.xml 、mapred-site.xml 、yarn-site.xml 。 6.(每空2分)HDFS将要存储的大文件进行分割,分割后存放在既定的存储块 中,并通过预先设定的优化处理,模式对存储的数据进行预处理,从而解决了大文件储存与计算的需求。 7.(每空2分)一个HDFS集群包括两大部分,即namenode 与datanode 。一般来说,一 个集群中会有一个namenode 和多个datanode 共同工作。 8.(每空2分) namenode 是集群的主服务器,主要是用于对HDFS中所有的文件及内容 数据进行维护,并不断读取记录集群中datanode 主机情况与工作状态,并通过读取与写入镜像日志文件的方式进行存储。 9.(每空2分) datanode 在HDFS集群中担任任务具体执行角色,是集群的工作节点。文 件被分成若干个相同大小的数据块,分别存储在若干个datanode 上,datanode 会定期向集群内namenode 发送自己的运行状态与存储内容,并根据namnode 发送的指令进行工作。 10.(每空2分) namenode 负责接受客户端发送过来的信息,然后将文件存储位置信息发 送给client ,由client 直接与datanode 进行联系,从而进行部分文件的运算与操作。 11.(每空1分) block 是HDFS的基本存储单元,默认大小是128M 。 12.(每空1分)HDFS还可以对已经存储的Block进行多副本备份,将每个Block至少复制到 3 个相互独立的硬件上,这样可以快速恢复损坏的数据。 13.(每空2分)当客户端的读取操作发生错误的时候,客户端会向namenode 报告错误,并 请求namenode 排除错误的datanode 后,重新根据距离排序,从而获得一个新的的读取路径。如果所有的datanode 都报告读取失败,那么整个任务就读取失败。14.(每空2分)对于写出操作过程中出现的问题,FSDataOutputStream 并不会立即关闭。 客户端向Namenode报告错误信息,并直接向提供备份的datanode 中写入数据。备份datanode 被升级为首选datanode ,并在其余2个datanode 中备份复制数据。 NameNode对错误的DataNode进行标记以便后续对其进行处理。 15.(每空1分)格式化HDFS系统的命令为:hdfs namenode –format 。 16.(每空1分)启动hdfs的shell脚本为:start-dfs.sh 。 17.(每空1分)启动yarn的shell脚本为:start-yarn.sh 。 18.(每空1分)停止hdfs的shell脚本为:stop-dfs.sh 。 19.(每空1分)hadoop创建多级目录(如:/a/b/c)的命令为:hadoop fs –mkdir –p /a/b/c 。 20.(每空1分)hadoop显示根目录命令为:hadoop fs –lsr 。 21.(每空1分)hadoop包含的四大模块分别是:Hadoop common 、HDFS 、
HADOOP表操作 1、hadoop简单说明 hadoop 数据库中的数据是以文件方式存存储。一个数据表即是一个数据文件。hadoop目前仅在LINUX 的环境下面运行。使用hadoop数据库的语法即hive语法。(可百度hive语法学习) 通过s_crt连接到主机。 使用SCRT连接到主机,输入hive命令,进行hadoop数据库操作。 2、使用hive 进行HADOOP数据库操作
3、hadoop数据库几个基本命令 show datebases; 查看数据库内容; 注意:hadoop用的hive语法用“;”结束,代表一个命令输入完成。 usezb_dim; show tables;
4、在hadoop数据库上面建表; a1: 了解hadoop的数据类型 int 整型; bigint 整型,与int 的区别是长度在于int; int,bigint 相当于oralce的number型,但是不带小数点。 doubble 相当于oracle的numbe型,可带小数点; string 相当于oralce的varchar2(),但是不用带长度; a2: 建表,由于hadoop的数据是以文件有形式存放,所以需要指定分隔符。 create table zb_dim.dim_bi_test_yu3(id bigint,test1 string,test2 string)
row format delimited fields terminated by '\t' stored as textfile; --这里指定'\t'为分隔符 a2.1 查看建表结构: describe A2.2 往表里面插入数据。 由于hadoop的数据是以文件存在,所以插入数据要先生成一个数据文件,然后使用SFTP将数据文件导入表中。
Linux基本命令 一、实训目的 ●掌握Linu各类命令的使用方法; ●熟悉Linx操作环境 二、实训内容 练习使用Linux常用命令,达到熟练应用的目的 三、实训步骤 子项目1.文件和目录类命令的使用 利用root用户登录到系统,进入字符界面。 1)用pwd命令查看当前所在目录。 2)用ls命令列出此目录下的文件和目录。 3)用-a选项列出此目录下包括隐藏文件在内的所有文件和目录。 4)用man命令查看ls命令的使用手册 5)在当前目录下,创建测试目录test mkdir test 6)利用ls命令列出文件和目录,确认test目录创建成功 7)进入test目录,利用pwd查看当前工作目录。cd /root/test pwd 8)利用touch命令,在当前目录创建一个新的空文件newfile。touch newfile 9)利用cp命令复制系统文件/etc/profile到当前目录下 cp /etc/profile /root/test 10)复制文件profile到一个新的文件profile.bak,作为备份 cp /etc/profile profile.bak 11)用ll命令以长格的形式列出当前目录下的所有文件,注意比较每个文件的长度和创建时 间的不同 12)用less命令分屏查看文件profile的内容,注意练习less命令的各个子命令,如b、p、q等,并对then 关键字查找。less /etc/profile 13)用grep命令在profile文件中对关键字then进行查询,并与上面的结果比较。 grep then /etc/profle 14)给文件profile创建一个软连接lnsprofile和一个硬链接lnhprofile ln -s profile lnsprofile(创建软连接) ln profile lnhprofile(创建硬链接) 15)一长格形式显示文件profile、lnsprofile和lnhprofile的详细信息。注意比较3个文件链接数的不同。
1 linux常用操作命令 linux系统中通过命令来提高自己的操作能力,下面由小编为大家整理了linux常用操作命令的相关知识,希望大家喜欢! linux常用操作命令一、常用指令 ls 显示文件或目录 -l 列出文件详细信息l(list) -a 列出当前目录下所有文件及目录,包括隐藏的a(all) mkdir 创建目录 -p 创建目录,若无父目录,则创建p(parent) cd 切换目录 touch 创建空文件 2 echo 创建带有内容的文件。
cat 查看文件内容 cp 拷贝 mv 移动或重命名 rm 删除文件 -r 递归删除,可删除子目录及文件 -f 强制删除 find 在文件系统中搜索某文件 wc 统计文本中行数、字数、字符数 grep 在文本文件中查找某个字符串rmdir 删除空目录 3 tree 树形结构显示目录,需要安装tree包
pwd 显示当前目录 ln 创建链接文件 more、less 分页显示文本文件内容head、tail 显示文件头、尾内容 ctrl+alt+F1 命令行全屏模式 linux常用操作命令二、系统管理命令 stat 显示指定文件的详细信息,比ls更详细who 显示在线登陆用户 whoami 显示当前操作用户 hostname 显示主机名 4 uname 显示系统信息
top 动态显示当前耗费资源最多进程信息 ps 显示瞬间进程状态ps -aux du 查看目录大小du -h /home带有单位显示目录信息 df 查看磁盘大小df -h 带有单位显示磁盘信息 ifconfig 查看网络情况 ping 测试网络连通 netstat 显示网络状态信息 man 命令不会用了,找男人如:man ls clear 清屏 alias 对命令重命名如:alias showmeit="ps -aux" ,另外解除使用unaliax showmeit 5 kill 杀死进程,可以先用ps 或top命令查看进程的id,然
Hadoop 练习题姓名:分数: 单项选择题 1.下面哪个程序负责HDFS数据存储。 a)NameNode b)Jobtracker c)Datanode √ d)secondaryNameNode e)tasktracker 2.HDfS中的block默认保存几份? a)3份√ b)2份 c)1份 d)不确定 3.下列哪个程序通常与NameNode在一个节点启动? a)SecondaryNameNode b)DataNode c)TaskTracker d)Jobtracker√ 4.Hadoop作者 a)Martin Fowler b)Kent Beck c)Doug cutting√ 5.HDFS默认Block Size a)32MB b)64MB√ c)128MB 6.下列哪项通常是集群的最主要的性能瓶颈 a)CPU b)网络 c)磁盘√ d)内存
7.关于SecondaryNameNode哪项是正确的? a)它是NameNode的热备 b)它对内存没有要求 c)它的目的是帮助NameNode合并编辑日志,减少NameNode启动时间√ d)SecondaryNameNode应与NameNode部署到一个节点 8.一个gzip文件大小75MB,客户端设置Block大小为64MB,请我其占用几个Block? a) 1 b)2√ c) 3 d) 4 9.HDFS有一个gzip文件大小75MB,客户端设置Block大小为64MB。当运行mapreduce 任务读取该文件时input split大小为? a)64MB b)75MB√ c)一个map读取64MB,另外一个map读取11MB 10.HDFS有一个LZO(with index)文件大小75MB,客户端设置Block大小为64MB。当运 行mapreduce任务读取该文件时input split大小为? a)64MB b)75MB c)一个map读取64MB,另外一个map读取11MB√ 多选题: 11.下列哪项可以作为集群的管理工具 a)Puppet√ b)Pdsh√ c)Cloudera Manager√ d)Rsync + ssh + scp√ 12.配置机架感知的下面哪项正确 a)如果一个机架出问题,不会影响数据读写√ b)写入数据的时候会写到不同机架的DataNode中√ c)MapReduce会根据机架获取离自己比较近的网络数据√ 13.Client端上传文件的时候下列哪项正确 a)数据经过NameNode传递给DataNode b)Client端将文件以Block为单位,管道方式依次传到DataNode√ c)Client只上传数据到一台DataNode,然后由NameNode负责Block复制工作 d)当某个DataNode失败,客户端会继续传给其它DataNode √
Hadoop 集群基本操作命令 列出所有Hadoop Shell支持的命令 $ bin/hadoop fs -help (注:一般手动安装hadoop大数据平台,只需要创建一个用户即可,所有的操作命令就可以在这个用户下执行;现在是使用ambari安装的dadoop大数据平台,安装过程中会自动创建hadoop生态系统组件的用户,那么就可以到相应的用户下操作了,当然也可以在root用户下执行。下面的图就是执行的结果,只是hadoop shell 支持的所有命令,详细命令解说在下面,因为太多,我没有粘贴。) 显示关于某个命令的详细信息 $ bin/hadoop fs -help command-name (注:可能有些命令,不知道什么意思,那么可以通过上面的命令查看该命令的详细使用信息。例子: 这里我用的是hdfs用户。) 注:上面的两个命令就可以帮助查找所有的haodoop命令和该命令的详细使用资料。
创建一个名为 /daxiong 的目录 $ bin/hadoop dfs -mkdir /daxiong 查看名为 /daxiong/myfile.txt 的文件内容$ bin/hadoop dfs -cat /hadoop dfs -cat /user/haha/part-m-00000 上图看到的是我上传上去的一张表,我只截了一部分图。 注:hadoop fs <..> 命令等同于hadoop dfs <..> 命令(hdfs fs/dfs)显示Datanode列表 $ bin/hadoop dfsadmin -report
$ bin/hadoop dfsadmin -help 命令能列出所有当前支持的命令。比如: -report:报告HDFS的基本统计信息。 注:有些信息也可以在NameNode Web服务首页看到 运行HDFS文件系统检查工具(fsck tools) 用法:hadoop fsck [GENERIC_OPTIONS]
新手刚刚接触Linux的时候可能处处感到不便,不过没有关系,接触新的事物都有这样的一个过程,在你用过Linux一段时间后,你就会逐渐了解Linux其实和Windows一样容易掌握。 由于操作和使用环境的陌生,如果要完全熟悉Linux的应用我们首先要解决的问题就是对Linux常用命令的熟练掌握。本章我们就来介绍Linux的常用基本命令。 Linux常用命令 1.Linux命令基础 Linux区分大小写。在命令行(shell)中,可以使用TAB键来自动补全命令。即可以输入命令的前几个字母,然后按TAB键,系统自动补全命令,若不止一个,则显示出所有和输入字母相匹配的命令。 按TAB键时,如果系统只找到一个和输入相匹配的目录或文件,则自动补全;若没有匹配的内容或有多个相匹配的名字,系统将发出警鸣声,再按一下TAB键将列出所有相匹配的内容(如果有的话)以供用户选择。 首先启动Linux。启动完毕后需要进行用户的登录,选择登陆的用户不同自然权限也不一样,其中―系统管理员‖拥有最高权限。 在启动Linux后屏幕出现如下界面显示:Red Hat Linux release 9 (Shrike) Kernel 2.4.20.8 on an i686
login: 输入:root(管理员名)后,计算机显示输口令(password:),输入你的口令即可。当计算机出现一个―#‖提示符时,表明你登录成功! 屏幕显示Linux提示符:[root@localhost root]#_ 这里需要说明的是―Red Hat Linux release 9 (Shrike)‖表示当前使用的操作系统的名称及版本。―2.4.20.8‖表示Linux操作系统的核心版本编号。―i686‖表示该台电脑使用的CPU的等级。 下面我们来介绍常用基本命令 一,注销,关机,重启 注销系统的logout命令 1,Logout 注销是登陆的相对操作,登陆系统后,若要离开系统,用户只要直接下达logout命令即可: [root@localhost root]#logout
3.6 误) 3.7Hadoop支持数据的随机读写。(错) (8) NameNode负责管理metadata,client端每次读写请求,它都会从磁盘中3.8 读取或则会写入metadata信息并反馈client端。(错误) (8) NameNode本地磁盘保存了Block的位置信息。(个人认为正确,欢迎提出其它意见) (9) 3.9 3.10 3.11DataNode通过长连接与NameNode保持通信。(有分歧) (9) Hadoop自身具有严格的权限管理和安全措施保障集群正常运行。(错误)9 3.12 3.13 3.14Slave节点要存储数据,所以它的磁盘越大越好。(错误) (9) hadoop dfsadmin–report命令用于检测HDFS损坏块。(错误) (9) Hadoop默认调度器策略为FIFO(正确) (9) 100道常见Hadoop面试题及答案解析 目录 1单选题 (5) 1.1 1.2 1.3 1.4 1.5 1.6 1.7下面哪个程序负责HDFS数据存储。 (5) HDfS中的block默认保存几份? (5) 下列哪个程序通常与NameNode在一个节点启动? (5) Hadoop作者 (6) HDFS默认Block Size (6) 下列哪项通常是集群的最主要瓶颈: (6) 关于SecondaryNameNode哪项是正确的? (6) 2 3多选题 (7) 2.1 2.2 2.3 2.4 2.5 下列哪项可以作为集群的管理? (7) 配置机架感知的下面哪项正确: (7) Client端上传文件的时候下列哪项正确? (7) 下列哪个是Hadoop运行的模式: (7) Cloudera提供哪几种安装CDH的方法? (7) 判断题 (8) 3.1 3.2 3.3 Ganglia不仅可以进行监控,也可以进行告警。(正确) (8) Block Size是不可以修改的。(错误) (8) Nagios不可以监控Hadoop集群,因为它不提供Hadoop支持。(错误) 8 3.4如果NameNode意外终止,SecondaryNameNode会接替它使集群继续工作。(错误) (8) 3.5Cloudera CDH是需要付费使用的。(错误) (8) Hadoop是Java开发的,所以MapReduce只支持Java语言编写。(错 8
Hadoop命令大全 Hadoop配置: Hadoop配置文件core-site.xml应增加如下配置,否则可能重启后发生Hadoop 命名节点文件丢失问题:
1、列出所有Hadoop Shell支持的命令 $ bin/hadoop fs -help 2、显示关于某个命令的详细信息 $ bin/hadoop fs -help command-name 3、用户可使用以下命令在指定路径下查看历史日志汇总 $ bin/hadoop job -history output-dir 这条命令会显示作业的细节信息,失败和终止的任务细节。 4、关于作业的更多细节,比如成功的任务,以及对每个任务的所做的尝试次数等可以用下面的命令查看 $ bin/hadoop job -history all output-dir 5、格式化一个新的分布式文件系统: $ bin/hadoop namenode -format 6、在分配的NameNode上,运行下面的命令启动HDFS: $ bin/start-dfs.sh bin/start-dfs.sh脚本会参照NameNode上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上启动DataNode守护进程。 7、在分配的JobTracker上,运行下面的命令启动Map/Reduce: $ bin/start-mapred.sh bin/start-mapred.sh脚本会参照JobTracker上${HADOOP_CONF_DIR}/slaves 文件的内容,在所有列出的slave上启动TaskTracker守护进程。 8、在分配的NameNode上,执行下面的命令停止HDFS: $ bin/stop-dfs.sh bin/stop-dfs.sh脚本会参照NameNode上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上停止DataNode守护进程。 9、在分配的JobTracker上,运行下面的命令停止Map/Reduce: $ bin/stop-mapred.sh bin/stop-mapred.sh脚本会参照JobTracker上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上停止TaskTracker守护进程。 10、启动所有 $ bin/start-all.sh 11、关闭所有 $ bin/stop-all.sh DFSShell 10、创建一个名为 /foodir 的目录 $ bin/hadoop dfs -mkdir /foodir 11、创建一个名为 /foodir 的目录 $ bin/hadoop dfs -mkdir /foodir 12、查看名为 /foodir/myfile.txt 的文件内容 $ bin/hadoop dfs -cat /foodir/myfile.txt
(1)基于虚拟机的Linux操作系统的使用 1.启动VMware Workstation应用程序,启动Windows以后,选择开始—程序——VMware—VMware Workstation,出现如图7—1所示窗口。 2.选择File—Open选择安装好的Linux虚拟机文件,或者直接单击Start this virtual machine 启动Linux操作系统。 3.启动系统后需要输入用户名和密码,如图7—2所示,用户名为“root”,密码为“jsjxy308”。 4.启动终端,成功进入系统后,选择“应用程序”—“系统工具”—“终端”。 5.在终端中执行Linux 命令,终端运行以后,就可以在这里输入Linux命令,并按回车键执行。 (2)文件与目录相关命令的使用 1.查询/bin目录,看一看有哪些常用的命令文件在该目录下: ll /bin 2.进入/tmp目录下,新建目录myshare: cd /tmp mkdir myshare ls –ld myshare/ 3.用pwd命令查看当前所在的目录: pwd 4.新建testfile文件: touch testfile ls -l 5.设置该文件的权限模式: chomd 755 testfile ls -l testfile 6.把该文件备份到/tmp/myshare目录下,并改名为testfile.bak: cp testfile myshare/testfile.bak ls -l myshare/ 7.在/root目录下为该文件创建1个符号连接: ln -s /tmp/testfile /root/testfile.ln ls -l /root/testfile.ln 8.搜索inittab 文件中含有initdefault字符串的行: cat /etc/inittab | grep initdefault (3)磁盘管理与维护命令的使用 1)Linux 下使用光盘步骤 1.确认光驱对应的设备文件: ll /dev/cdrom 2.挂载光盘: mout -t iso9600/dev/cdrom test/dir 1.查询挂载后的目录: ll /media/cdrom 2.卸载光盘: umount /dev/cdrom 2)Linux下USB设备的使用
Hadoop命令大全 (2010-04-19 22:10:17) 1、列出所有Hadoop Shell支持的命令 $ bin/hadoop fs -help 2、显示关于某个命令的详细信息 $ bin/hadoop fs -help command-name 3、用户可使用以下命令在指定路径下查看历史日志汇总 $ bin/hadoop job -history output-dir 这条命令会显示作业的细节信息,失败和终止的任务细节。 4、关于作业的更多细节,比如成功的任务,以及对每个任务的所做的尝试次数等可以用下面的命令查看 $ bin/hadoop job -history all output-dir 5、格式化一个新的分布式文件系统: $ bin/hadoop namenode -format 6、在分配的NameNode上,运行下面的命令启动HDFS: $ bin/start-dfs.sh bin/start-dfs.sh脚本会参照NameNode上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上启动DataNode守护进程。 7、在分配的JobTracker上,运行下面的命令启动Map/Reduce: $ bin/start-mapred.sh bin/start-mapred.sh脚本会参照JobTracker上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上启动TaskTracker守护进程。 8、在分配的NameNode上,执行下面的命令停止HDFS: $ bin/stop-dfs.sh bin/stop-dfs.sh脚本会参照NameNode上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上停止DataNode守护进程。 9、在分配的JobTracker上,运行下面的命令停止Map/Reduce: $ bin/stop-mapred.sh bin/stop-mapred.sh脚本会参照JobTracker上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上停止TaskTracker守护进程。 DFSShell 10、创建一个名为/foodir 的目录 $ bin/hadoop dfs -mkdir /foodir 11、创建一个名为/foodir 的目录 $ bin/hadoop dfs -mkdir /foodir 12、查看名为/foodir/myfile.txt 的文件内容 $ bin/hadoop dfs -cat /foodir/myfile.txt DFSAdmin 13、将集群置于安全模式 $ bin/hadoop dfsadmin -safemode enter 14、显示Datanode列表
基本MapReduce模式计数与求和基本MapReduce模式计数与求和 问题陈述: 有许多文档,每个文档都有一些字段组成。需要计算出每个字段在所有文档中的出现次数或者这些字段的其他什么统计值。例如,给定一个log文件,其中的每条记录都包含一个响应时间,需要计算出平均响应时间。 解决方案: 让我们先从简单的例子入手。在下面的代码片段里,Mapper每遇到指定词就把频次记1,Reducer一个个遍历这些词的集合然后把他们的频次加和。 1.class Mapper 2. method Map(docid id, doc d) 3. for all term t in doc d do 4. Emit(term t, count 1) 5. 6.class Reducer 7. method Reduce(term t, counts [c1, c2,...]) 8. sum = 0 9. for all count c in [c1, c2,...] do 10. sum = sum + c 11. Emit(term t, count sum) 复制代码 这种方法的缺点显而易见,Mapper提交了太多无意义的计数。它完全可以通过先对每个文档中的词进行计数从而减少传递给Reducer的数据量: [size=14.166666030883789px] 1. 1 class Mapper 2. 2 method Map(docid id, doc d) 3. 3 H = new AssociativeArray 4. 4 for all term t in doc d do 5. 5 H{t} = H{t} + 1
Hadoop FS Shell命令大全 您的评价: 收藏该经验 调用文件系统(FS)Shell命令应使用 bin/hadoop fs
红帽linux常用操作命令 1.查看硬件信息 # uname -a # 查看内核/操作系统/CPU信息 # head -n 1 /etc/issue # 查看操作系统版本 # cat /proc/cpuinfo # 查看CPU信息 # hostname # 查看计算机名 # lspci -tv # 列出所有PCI设备 # lsusb -tv # 列出所有USB设备 # lsmod # 列出加载的内核模块 # env # 查看环境变量资源 # free -m # 查看内存使用量和交换区使用量# df -h # 查看各分区使用情况 # du -sh # 查看指定目录的大小 # grep MemTotal /proc/meminfo # 查看内存总量 # grep MemFree /proc/meminfo # 查看空闲内存量 # uptime # 查看系统运行时间、用户数、负载# cat /proc/loadavg # 查看系统负载磁盘和分区 # mount | column -t # 查看挂接的分区状态 # fdisk -l # 查看所有分区 # swapon -s # 查看所有交换分区 # hdparm -i /dev/hda # 查看磁盘参数(仅适用于IDE设备) # dmesg | grep IDE # 查看启动时IDE设备检测状况网络# ifconfig # 查看所有网络接口的属性 # iptables -L # 查看防火墙设置 # route -n # 查看路由表 # netstat -lntp # 查看所有监听端口 # netstat -antp # 查看所有已经建立的连接 # netstat -s # 查看网络统计信息进程
Hadoop面试题目及答案(附目录) 选择题 1.下面哪个程序负责HDFS 数据存储。 a)NameNode b)Jobtracker c)Datanode d)secondaryNameNode e)tasktracker 答案C datanode 2. HDfS 中的block 默认保存几份? a)3 份b)2 份c)1 份d)不确定 答案A 默认3 份 3.下列哪个程序通常与NameNode 在一个节点启动? a)SecondaryNameNode b)DataNode c)TaskTracker d)Jobtracker 答案D 分析:hadoop 的集群是基于master/slave 模式,namenode 和jobtracker 属于master,datanode 和tasktracker 属于slave,master 只有一个,而slave 有多个SecondaryNameNode 内存需求和NameNode 在一个数量级上,所以通常secondaryNameNode(运行在单独的物理机器上)和NameNode 运行在不同的机器上。 JobTracker 和TaskTracker JobTracker 对应于NameNode,TaskTracker 对应于DataNode,DataNode 和NameNode 是针对数据存放来而言的,JobTracker 和TaskTracker 是对于MapReduce 执行而言的。mapreduce 中几个主要概念,mapreduce 整体上可以分为这么几条执行线索:jobclient,JobTracker 与TaskTracker。 1、JobClient 会在用户端通过JobClient 类将应用已经配置参数打包成jar 文件存储到hdfs,并把路径提交到Jobtracker,然后由JobTracker 创建每一个Task(即MapTask 和ReduceTask)并将它们分发到各个TaskTracker 服务中去执行。 2、JobTracker 是一个master 服务,软件启动之后JobTracker 接收Job,负责调度Job 的每一个子任务task 运行于TaskTracker 上,并监控它们,如果发现有失败的task 就重新运行它。一般情况应该把JobTracker 部署在单独的机器上。 3、TaskTracker 是运行在多个节点上的slaver 服务。TaskTracker 主动与JobTracker 通信,接收作业,并负责直接执行每一个任务。TaskTracker 都需要运行在HDFS 的DataNode 上。 4. Hadoop 作者 a)Martin Fowler b)Kent Beck c)Doug cutting 答案C Doug cutting 5. HDFS 默认Block Size a)32MB b)64MB c)128MB 答案:B 6. 下列哪项通常是集群的最主要瓶颈 a)CPU b)网络c)磁盘IO d)内存 答案:C 磁盘 首先集群的目的是为了节省成本,用廉价的pc 机,取代小型机及大型机。小型机和大型机
50个最受欢迎的Hadoop面试问题 您是否打算在大数据和数据分析领域找到工作?您是否担心破解Hadoop面试? 我们整理了一份方便的Hadoop面试问题清单。您可能具有关于软件框架的丰富知识,但是在短短的15分钟面试环节中无法测试所有这些知识。因此,面试官会问您一些特定的大数据面试问题,他们认为这些问题易于判断您对主题的了解。 立即注册:Hadoop基础在线培训课程 Hadoop面试的前50名问答 当前,与大数据相关的工作正在增加。五分之一的大公司正在迁移到大数据分析,因此现在是时候开始申请该领域的工作了。因此,我们不需再拖延地介绍Hadoop面试的前50名问答,这将帮助您完成面试。 Hadoop基本面试问题 这些是您在大数据采访中必将面对的最常见和最受欢迎的大数据Hadoop采访问题。通过准备这些Hadoop面试问题,无疑会给您带来竞争优势。 首先,我们将重点关注人们在申请Hadoop相关工作时遇到的常见和基本的Hadoop 面试问题,无论其职位如何。
1. Hadoop框架中使用了哪些概念? 答:Hadoop框架在两个核心概念上起作用: ?HDFS:Hadoop分布式文件系统的缩写,它是一个基于Java的文件系统,用于可扩展和可靠地存储大型数据集。HDFS本身在主从架构上工作,并以块 形式存储其所有数据。 ?MapReduce:这是用于处理和生成大型数据集的编程模型以及相关的实现。 Hadoop作业基本上分为两个不同的任务作业。映射作业将数据集分解为键 值对或元组。然后,reduce作业获取map作业的输出,并将数据元组合并 为较小的元组集。 2.什么是Hadoop?命名Hadoop应用程序的主要组件。 答:Hadoop是“大数据”问题的解决方案。Hadoop被描述为提供许多用于存储和处理大数据的工具和服务的框架。当难以使用传统方法进行决策时,它在大数据分析和制定有效的业务决策中也起着重要作用。 Hadoop提供了广泛的工具集,可以非常轻松地存储和处理数据。以下是Hadoop的所有主要组件:
Hadoop基本操作指令 假设Hadoop的安装目录HADOOP_HOME为/home/admin/hadoop,默认认为Hadoop环境已经由运维人员配置好直接可以使用 启动与关闭 启动Hadoop 1. 进入HADOOP_HOME目录。 2. 执行sh bin/start-all.sh 关闭Hadoop 1. 进入HADOOP_HOME目录。 2. 执行sh bin/stop-all.sh 文件操作 Hadoop使用的是HDFS,能够实现的功能和我们使用的磁盘系统类似。并且支持通配符,如*。 查看文件列表 查看hdfs中/user/admin/aaron目录下的文件。 1. 进入HADOOP_HOME目录。 2. 执行sh bin/hadoop fs -ls /user/admin/aaron 这样,我们就找到了hdfs中/user/admin/aaron目录下的文件了。 我们也可以列出hdfs中/user/admin/aaron目录下的所有文件(包括子目录下的文件)。 1. 进入HADOOP_HOME目录。 2. 执行sh bin/hadoop fs -lsr /user/admin/aaron 创建文件目录 查看hdfs中/user/admin/aaron目录下再新建一个叫做newDir的新目录。 1. 进入HADOOP_HOME目录。 2. 执行sh bin/hadoop fs -mkdir /user/admin/aaron/newDir 删除文件 删除hdfs中/user/admin/aaron目录下一个名叫needDelete的文件 1. 进入HADOOP_HOME目录。 2. 执行sh bin/hadoop fs -rm /user/admin/aaron/needDelete 删除hdfs中/user/admin/aaron目录以及该目录下的所有文件