
ORACLE的SQL问题性能优化经验总结
1.SQL 执行计划查看
使用PLSQL 可以看到SQL的执行计划,执行计划有四个执行方案:
默认的是ALL ROWS
如果对ALL ROWS 的执行计划不满意的话,我们可以选择Rule 规则查看。
如果Rule 规则的执行计划比较满意,我们就可以考虑使用如下方案进行优化:
1)检查SQL中对应数据表的分析时间,语句如下:
Select * from all_tables where table_name in (‘xxx’,’xxx’)
重点检查LAST_ANAL YZED 和NUM_ROWS 字段
如果分析时间太早,或者行数相差太大(包括行数为0实际不为0的情况)
有必要重新进行表分析。
2)如果表分析仍然无法凑效,则需要考虑使用hint的方式
就是在SQL的开始的中的select 语句部分加上/*+rule */ ,然后再进行测试。
2.执行计划分析
如果使用RULE 仍然没有好的执行计划,那么就要对SQL语句进行分析。
1)检查Table Access Full 全表扫描部分
查看数据表的数量是否很大,对大表的全表扫描是非常致命的;
2)检查Index Full Scan 全索引扫描部分
查看对应数据表的数量是否很大,对大表的全索引扫描只是比全表扫描好一点;
3)仔细对照使用的到的索引,是否有过滤性很差的索引
有部分索引的过滤能力很差,比如tb_cm_serv 的prod_id , tb_ba_subscription 的
联合索引(state,stat_date) 之类的,要注意大部分联合索引只能用到前面的确定条
件部分,后面的部分如果没有确定条件是不能用到的。
4)检查能否去掉不必要的排序
对于distinct ,union ,order by 这些语句,对SQL的性能影响很大,如果怀疑结果集
很大再排序导致SQL慢的情况,可以把这些排序部分去掉再观察SQL性能是否有
所改善,如果有改善的话,可以和开发商量能否修改写法、去掉排序部分。
5)局部分析
MBOSS的SQL语句,有很多都是非常复杂的,嵌套和union很多重,一下子看执
行计划容易一般很晕。此时可以通过执行计划进行
3.索引选用方法
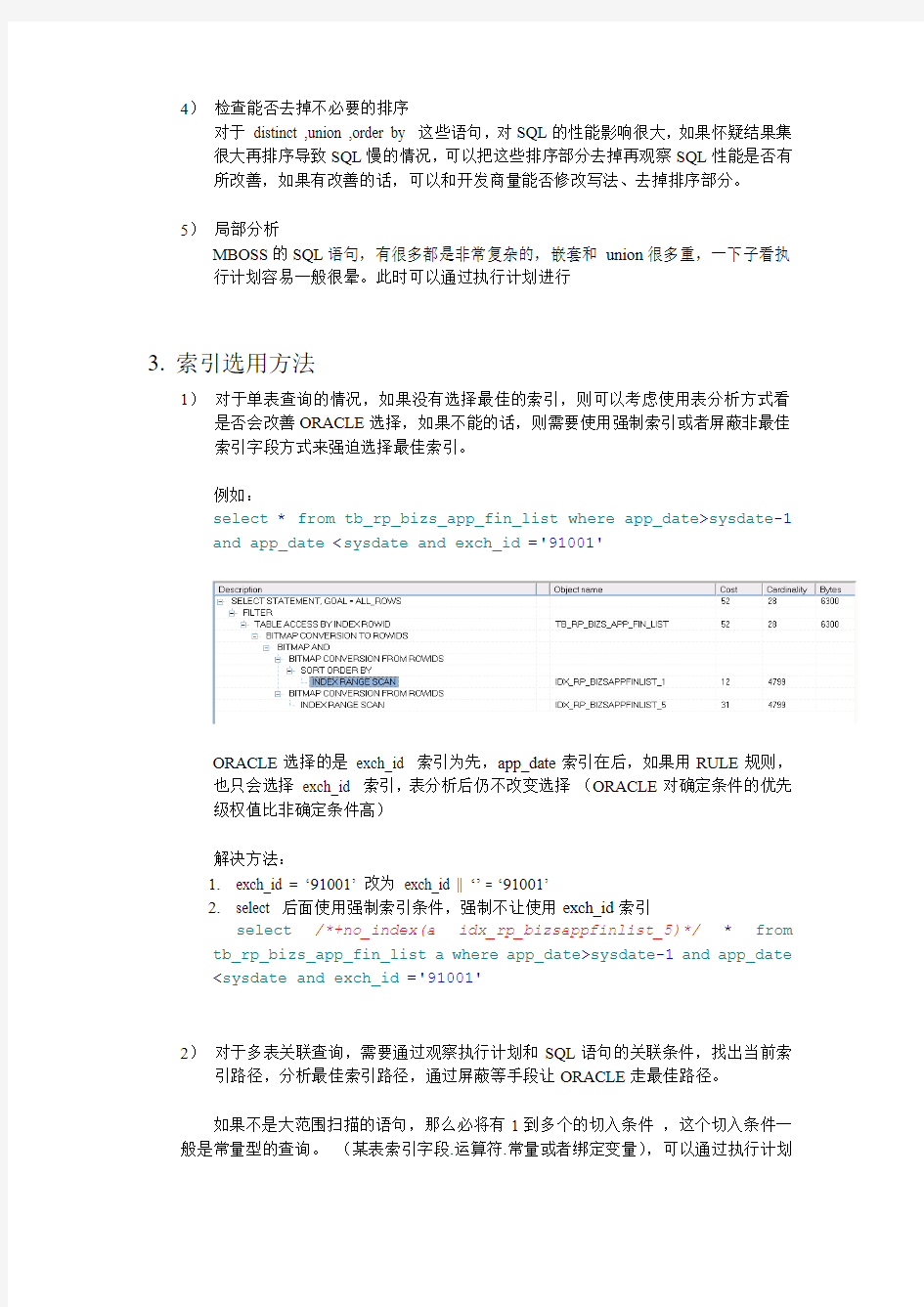
1)对于单表查询的情况,如果没有选择最佳的索引,则可以考虑使用表分析方式看是否会改善ORACLE选择,如果不能的话,则需要使用强制索引或者屏蔽非最佳
索引字段方式来强迫选择最佳索引。
例如:
select * from tb_rp_bizs_app_fin_list where app_date>sysdate-1
and app_date ORACLE选择的是exch_id 索引为先,app_date索引在后,如果用RULE规则, 也只会选择exch_id 索引,表分析后仍不改变选择(ORACLE对确定条件的优先 级权值比非确定条件高) 解决方法: 1.exch_id = ‘91001’改为exch_id || ‘’ = ‘91001’ 2.select 后面使用强制索引条件,强制不让使用exch_id索引 select/*+no_index(a idx_rp_bizsappfinlist_5)*/* from tb_rp_bizs_app_fin_list a where app_date>sysdate-1and app_date 2)对于多表关联查询,需要通过观察执行计划和SQL语句的关联条件,找出当前索引路径,分析最佳索引路径,通过屏蔽等手段让ORACLE走最佳路径。 如果不是大范围扫描的语句,那么必将有1到多个的切入条件,这个切入条件一般是常量型的查询。(某表索引字段.运算符.常量或者绑定变量),可以通过执行计划 和SQL语句来寻找第一索引切入。不过,如果被切入的索引不幸是state=’B0A’, org_id=’91001’ ,prod_id=1 ,XXXid=0 ,city_id=’200’之类的话,那么从切入点开始,语句就进入了大范围扫描状态,里面的n重循环就更加没戏了,赶紧想办法找更好的切入点把。 如果切入点没有问题,那么就要通过执行计划和SQL语句,把ORACLE对每个表的索引路径总结出来。 例如: SELECT s.subs_code, a.action_id, b.action_name, TO_CHAR(s.stat_date, 'YYYYMMDDHH24MISS'), s.cust_id, s.req_id FROM tb_pm_action b, tb_ba_action a, tb_pm_action_relation r, tb_ba_subscription s WHERE s.serv_id = 0 and r.city_id = s.native_code and a.city_id = r.city_id and b.city_id = a.city_id and s.native_code = :3 AND s.cust_id = :anCustId AND (s.stat NOT IN ('S0Z', 'S0C', 'S0R', 'S0X') or s.stat = 'S0Z'AND S.STAT_DATE > SYSDATE - 1 / 48) AND a.subs_id = s.subs_id AND a.action_id = b.action_id AND r.state = 'S0A' AND r.relate_type = 'ART001' AND r.relate_action_id = :anActionId AND r.action_id = a.action_id 执行计划: 我们可以通过执行计划看到 ORACLE 对这个SQL的索引路径是 Tb_ba_subscription s s.serv_id = 0 / s.cust_id = :anCustId =》 tb_pm_action_relation r r.relate_action_id = :anActionId =》 tb_ba_action a a.subs_id = s.subs_id /r.action_id = a.action_id =》 tb_pm_action b a.action_id = b.action_id 这个路径的问题在第一切入点: Tb_ba_subscription s s.serv_id = 0 这个切入点的过滤能力太差,会影响SQL的执行 所以SQL优化建议中,需要改为 s.serv_id + 0 =0 ,把 s.serv_id = 0 这个切入点屏蔽掉 当然,除了屏蔽方式外,通过表分析等都可以让ORACLE选择其他执行计划,不过ORACLE的CBO索引算法不是万能的,如果表分析也无法搞定,那就只能修改SQL的写法了。 3)对于全表扫描或者使用弱索引的数据表,如果发现更强的查询条件,但是该条件对 应字段没有索引,则需要考虑建立索引 例如: delete from TB_CM_DYNBILL where object_id = :serv_id and dynbill_type = 'SERV' 这里明显需要建立object_id 索引,否则只能全表扫描 Oracle SQL的优化 标签:oraclesql优化date数据库subquery 2009-10-14 21:18 18149人阅读评论(21) 收藏举报分类: Oracle Basic Knowledge(208) SQL的优化应该从5个方面进行调整: 1.去掉不必要的大型表的全表扫描 2.缓存小型表的全表扫描 3.检验优化索引的使用 4.检验优化的连接技术 5.尽可能减少执行计划的Cost SQL语句: 是对数据库(数据)进行操作的惟一途径; 消耗了70%~90%的数据库资源;独立于程序设计逻辑,相对于对程序源代码的优化,对SQL语句的优化在时间成本和风险上的代价都很低; 可以有不同的写法;易学,难精通。 SQL优化: 固定的SQL书写习惯,相同的查询尽量保持相同,存储过程的效率较高。 应该编写与其格式一致的语句,包括字母的大小写、标点符号、换行的位置等都要一致 ORACLE优化器: 在任何可能的时候都会对表达式进行评估,并且把特定的语法结构转换成等价的结构,这么做的原因是 要么结果表达式能够比源表达式具有更快的速度 要么源表达式只是结果表达式的一个等价语义结构 不同的SQL结构有时具有同样的操作(例如: = ANY (subquery) and IN (subquery)),ORACLE会把他们映射到一个单一的语义结构。 1 常量优化: 常量的计算是在语句被优化时一次性完成,而不是在每次执行时。下面是检索月薪大于2000的的表达式: sal > 24000/12 sal > 2000 sal*12 > 24000 如果SQL语句包括第一种情况,优化器会简单地把它转变成第二种。 优化器不会简化跨越比较符的表达式,例如第三条语句,鉴于此,应尽量写用常量跟字段比较检索的表达式,而不要将字段置于表达式当中。否则没有办法优化,比如如果sal上有索引,第一和第二就可以使用,第三就难以使用。 2 操作符优化: 优化器把使用LIKE操作符和一个没有通配符的表达式组成的检索表达式转换为一个“=”操作符表达式。 例如:优化器会把表达式ename LIKE 'SMITH'转换为ename = 'SMITH' 优化器只能转换涉及到可变长数据类型的表达式,前一个例子中,如果ENAME 字段的类型是CHAR(10),那么优化器将不做任何转换。 一般来讲LIKE比较难以优化。 其中: ~~IN 操作符优化: 优化器把使用IN比较符的检索表达式替换为等价的使用“=”和“OR”操作符的检索表达式。 例如,优化器会把表达式ename IN ('SMITH','KING','JONES')替换为 ename = 'SMITH' OR ename = 'KING' OR ename = 'JONES‘ oracle 会将 in 后面的东西生成一存中的临时表。然后进行查询。 如何编写高效的SQL: 当然要考虑sql常量的优化和操作符的优化啦,另外,还需要: 1 合理的索引设计: 例:表record有620000行,试看在不同的索引下,下面几个SQL的运行情况:语句A SELECT count(*) FROM record WHERE date >'19991201' and date <'19991214‘and amount >2000 语句B sql语句(mysql优化)绝对经典 误区1:count(1)和count(primary_key) 优于count(*) 很多人为了统计记录条数,就使用count(1) 和count(primary_key) 而不是count(*) ,他们认为这样性能更好,其实这是一个误区。对于有些场景,这样做可能性能会更差,应为数据库对count(*) 计数操作做了一些特别的优化。 误区2:count(column) 和count(*) 是一样的 这个误区甚至在很多的资深工程师或者是DBA 中都普遍存在,很多人都会认为这是理所当然的。实际上,count(column) 和count(*) 是一个完全不一样的操作,所代表的意义也完全不一样。count(column) 是表示结果集中有多少个column字段不为空的记录,count(*) 是表示整个结果集有多少条记录 误区3:select a,b from … 比select a,b,c from …可以让数据库访问更少的数据量 这个误区主要存在于大量的开发人员中,主要原因是对数据库的存储原理不是太了解。实际上,大多数关系型数据库都是按照行(row)的方式存储,而数据存取操作都是以一个固定大小的IO单元(被称作block 或者page)为单位,一般为4KB,8KB… 大多数时候,每个IO单元中存储了多行,每行都是存储了该行的所有字段(lob等特殊类型字段除外)。 所以,我们是取一个字段还是多个字段,实际上数据库在表中需要访问的数据量其实是一样的。当然,也有例外情况,那就是我们的这个查询在索引中就可以完成,也就是说当只取a,b两个字段的时候,不需要回表,而c这个字段不在使用的索引中,需要回表取得其数据。在这样的情况下,二者的IO量会有较大差异。(覆盖索引) 误区4:order by 一定需要排序操作 我们知道索引数据实际上是有序的,如果我们的需要的数据和某个索引的顺序一致,而且我们的查询又通过这个索引来执行,那么数据库一般会省略排序操作,而直接将数据返回,因为数据库知道数据已经满足我们的排序需求了。实际上,利用索引来优化有排序需求的SQL,是一个非常重要的优化手段。延伸阅读:MySQL ORDER BY 的实现分析,MySQL 中GROUP BY 基本实现原理以及MySQL DISTINCT 的基本实现原理。(order by null) ORACLE优化总结和注意事项 本文档中对优化方法进行详述,并对在优化过程中发现的一些问题进行总结。列出ORACLE的一些注意事项 注意事项: 1.安装的过程中,请务必进行正确安装。 2.当安装过程中出现错误的时候,最好清除原有遗留信息,进行重装,否则在数据库运行 的过程中可能会出现各种诡异的问题。 3.当数据库安装的过程中如果有警告信息,请记录下来,存档,方便排查数据库问题 4.安装的过程中请选择OLTP的数据模板Transaction Processing 5.安装过程中文件的创建 Controlfile、Datafiles、Redo Log Groups如果条件允许,最好分别放于不同的磁盘上。其中Controlfile和Redo Log Groups要尽量保证放在不同的磁盘上 6.其中Redo Log Groups重做日志组最好建5组以上,每个文件大小在1G以上,最大不超 过3G,避免出现进行check_point的时候造成buffer wait 导致数据库宕机 7.检查/etc/hosts文件 配置最后一行信息,将当前的主机名和ip配对起来,避免应用服务连接数据库导致的性能损耗 8.安装完成后,请启动数据库确保数据库基本安装成功 步骤: sqlplus /nolog connect /as sysdba startup//启动数据库实例 exit//退出sqlplus lsnrctl start//启动监听 emctl start dbconsole 上述步骤如果执行完,没有报错,则说明数据库基本安装正确,并可正常运行。如果执行上述操作的时候出现了问题,则说明数据库安装的过程中出现了某些问题,即使数据库实例当前可以启动连接,但是在以后稳定服务的过程中也是有可能会出现一些数据库问题的。 配置OCI连接 因为当前应用服务采用OCI连接的方式,因此在运行应用服务之前要配置OCI的连接条件 1、需求软件: 如果应用服务是跟ORACLE数据库安装在一台机器上,则不需要额外软件,直接进入第2步即可 如果应用服务是跟ORACLE数据库分开部署,则需要在部署应用服务的机器上安装一个客户端(精简客户端即可大小几M)需要从官方网站下载三个文件instantclient-basic-linux-x86-64-10.2.0.3-20070103.zip instantclient-sqlplus-linux-x86-64-10.2.0.3-20070103.zip instantclient-jdbc-linux-x86-64-10.2.0.3-20070103.zip 解压到同一个目录中,同时在该目录下新建一个文件tnsnames.ora文件,文件中添加以下内容 # Generated by Oracle configuration tools. HMS = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = 10.10.15.61)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = hms) ) ) (Oracle管理)如何优化SQL语句以提高Oracle执 行效率 (1)选择最有效率的表名顺序(只在基于规则的优化器中有效): Oracle的解析器按照从右到左的顺序处理FROM子句中的表名,FROM子句中写在最后的表(基础表drivingtable)将被最先处理,在FROM子句中包含多个表的情况下,你必须选择记录条数最少的表作为基础表。如果有3个以上的表连接查询,那就需要选择交叉表(intersectiontable)作为基础表,交叉表是指那个被其他表所引用的表。 (2)WHERE子句中的连接顺序: Oracle采用自下而上的顺序解析WHERE子句,根据这个原理,表之间的连接必须写在其他WHERE条件之前,那些可以过滤掉最大数量记录的条件必须写在WHERE子句的末尾。(3)SELECT子句中避免使用‘*’: Oracle在解析的过程中,会将‘*’依次转换成所有的列名,这个工作是通过查询数据字典完成的,这意味着将耗费更多的时间。 (4)减少访问数据库的次数: Oracle在内部执行了许多工作:解析SQL语句,估算索引的利用率,绑定变量,读数据块等。(5)在SQL*Plus,SQL*Forms和Pro*C中重新设置ARRAYSIZE参数,可以增加每次数据库访问的检索数据量,建议值为200。 (6)使用DECODE函数来减少处理时间: 使用DECODE函数可以避免重复扫描相同记录或重复连接相同的表。 (7)整合简单,无关联的数据库访问: 如果你有几个简单的数据库查询语句,你可以把它们整合到一个查询中(即使它们之间没有关系)。 (8)删除重复记录: 最高效的删除重复记录方法(因为使用了ROWID)例子:DELETEFROMEMPEWHEREE.ROWID>(SELECTMIN(X.ROWID) SQL 性能监控及SQL 语句优化 性能监控 作为SQL的数据库服务器,我们可以将其比作一个人,而SQL则是他的心脏,管理员就是他的大脑。要监控心脏是否健康首先要看他这个人是否健康。这两者是相辅相成的,少了一方都是不健康的。 数据库服务器的性能监视器 性能监视器 性能工具的介绍 性能监视器是一种简单而功能强大的可视化工具,用于实时收集系统状态并从日志文件中查看性能数据。 使用性能监视器可以: 获得对诊断系统问题和规划系统资源增长有用的性能数据、了解工作负载及其对系统资源的影响、观察工作负载和资源使用情况的变化和趋势,以便计划未来的升级、通过监视结果来测试配置变化、诊断问题并确定需要优化的组件或进程。 现在,可以开始选择这些对象和要监视的计数器了。 https://www.doczj.com/doc/0313189149.html, 应用程序性能计数器有关https://www.doczj.com/doc/0313189149.html, 应用程序性能计数器的大部分信息最近已被合并到一个题为“改善 .NET 应用程序的性能和伸缩性”的综合文档中。下表描述了一些可用于监视和优化 https://www.doczj.com/doc/0313189149.html, 应用程序(包括 Reporting Services)性能的重要计数器。 除了上表中介绍的这些核心监视要素之外,在您试图诊断 https://www.doczj.com/doc/0313189149.html, 应用程序具有的特定性能问题时,下表中的性能计数器也可对您有所帮助。 Reporting Services 性能计数器 Reporting Services 包括一组它自己的性能计数器,用于收集有关报告处理和资源消耗方面的信息。可通过 Windows 性能监视器工具中出现的两个对象来监视实例和组件的状态和活动:MSRS 2005 Web Service 和 MSRS 2005 Windows Service 对象。 MSRS 2005 Web Service 性能对象包括一组用来跟踪 Report Server 处理过程的计数器,这些处理过程通常通过在线交互式报告浏览操作而引发。这些计数器在https://www.doczj.com/doc/0313189149.html, 停止该 Web 服务后被重设。下表列出了可用于监视 Report Server 性能的计数器,并描述了它们的目的。 性能对象:RS Web Service OracleSQL性能优化方法 Oracle性能优化方法(SQL篇) (1) 1综述 (2) 2表分区的应用 (2) 3访咨询Table的方式 (3) 4共享SQL语句 (3) 5选择最有效率的表名顺序 (5) 6WHERE子句中的连接顺序. (6) 7SELECT子句中幸免使用’*’ (6) 8减少访咨询数据库的次数 (6) 9使用DECODE函数来减少处理时刻 (7) 10整合简单,无关联的数据库访咨询 (8) 11删除重复记录 (8) 12用TRUNCATE替代DELETE (9) 13尽量多使用COMMIT (9) 14运算记录条数 (9) 15用Where子句替换HA VING子句 (9) 16减少对表的查询 (10) 17通过内部函数提高SQL效率 (11) 18使用表的不名(Alias) (12) 19用EXISTS替代IN (12) 20用NOT EXISTS替代NOT IN (13) 21识不低效执行的SQL语句 (13) 22使用TKPROF 工具来查询SQL性能状态 (14) 23用EXPLAIN PLAN 分析SQL语句 (14) 24实时批量的处理 (16) 1综述 ORACLE数据库的性能调整是个重要,却又有难度的话题,如何有效地进行调整,需要通过反反复复的过程。在数据库建立时,就能依照顾用的需要合理设计分配表空间以及储备参数、内存使用初始化参数,对以后的数据库性能有专门大的益处,建立好后,又需要在应用中不断进行应用程序的优化和调整,这需要在大量的实践工作中不断地积存体会,从而更好地进行数据库的调优。 数据库性能调优的方法 ●调整内存 ●调整I/O ●调整资源的争用咨询题 ●调整操作系统参数 ●调整数据库的设计 ●调整应用程序 本文针对应用程序的调整,来讲明对数据库性能如何进行优化。 2表分区的应用 关于海量数据的表,能够考虑建立分区以提高操作效率。建立分区一样以关键字为分区的标志,也能够以其他字段作为分区的标志,但效率不如关键字高。建立分区的语句在建表时能够进行讲明: create table TABLENAME( SQL Server 系统性能调优解决方案 前言 近几年,医药流通市场经历了激烈的震荡,导致行业逐步成熟和企业的快速变革,差异化经营成为众多医药流通的竞争选择。时空产品在中国医药流通企业的发展过程中得到了广泛且深入应用,大量的客户化开发和定制支撑了企业管理中横向和纵向的变化,很好的适应了企业在发展过程中不断变化的需求。 对于数据库管理系统的使用,很多用户都面临着一个很棘手的问题:系统效率下降。产生效率下降的因素是多方面: 1.硬件问题 2.软件问题 3.实施问题 正因为产生效率下降的因素很多,所以如何去查找原因成为我们首要关注的问题,时空公司也处在积极探索过程中。时空公司在解决一些客户问题的过程中积累了一些方法和思路,归纳总结后呈现给体系内的技术人员,本方案就系统效率调整所必需的基础知识、方法、技巧等几个方面进行阐述,从而让技术人员能够快速定位问题,解决问题,为合作伙伴提供优质,快捷的服务。 索引简介 索引是根据数据库表中一个或多个列的值进行排序的结构。索引提供指针以指向存储在表中指定列的数据值,然后根据指定的排序次序排列这些指针。数据库使用索引的方式与使用书的目录很相似,通过搜索索引找到特定的值,然后跟随指针到达包含该值的行。 索引键:用于创建索引的列。 索引类型 ?聚集索引: 聚集索引基于数据行的键值在表内排序和存储这些数据行。由于数据行按基于聚集索引键的排序次序存储,因此聚集索引对查找行很有效。每个表只能有一个聚集索引,因为数据行本身只能按一个顺序存储。数据行本身构成聚集索引的最低级别(叶子节点)。只有当表包含聚集索引时,表内的数据行才按排序次序存储。如果表没有聚集索引,则其数据行按堆集方式存储。 聚集索引对于那些经常要搜索范围值的列特别有效。使用聚集索引找到包含第一个值的行后,便可以确保包含后续索引值的行在物理相邻。例如:如果应用程序执行的一个查询经常检索某一日期范围内的记录,则使用聚集索引可以迅速找到包含开始日期的行,然后检索表中所有相邻的行,直到到达结束日期。这样有助于提高此类查询的性能。同样,如果对从表中检索的数据进行排序时经常要用到某一列,则可以将该表在该列上聚集(物理排序),避免每次查询该列时都进行排序,从而节省成本。 ?非聚集索引 非聚集索引具有完全独立于数据行的结构。非聚集索引的最低行包含非聚集索引的键值,并且每个键值项都有指针指向包含该键值的数据行。数据行不按基于非聚集键的次序存储。如 ORACLE 数据库性能优化 参考书目: 《ORACLE 9i Database Performance Tuning Guide and Reference》《ORACLE 9i Database Reference》 《ORACLE 9i SQL Reference》 《ORACLE 9i Database Administrator’s Guide》 一、数据库实例创建过程参数确定 在创建数据库实例过程中,需要确定以下几个参数: 1. 数据块大小(DB_BLOCK_SIZE) 该参数指明了ORACLE所处理的数据存贮于数据文档以及SGA内存中的数据块大小。 该参数的可选择的范围为:4k,8k,16k,32k,64k。对于OLTP系统而言,取值可以为4K或8K,对于DSS系统而言,则可以取较大的数据,如32K或64K 建议统一取8K(即8192) 说明 DB_BLOCK_SIZE的大小将影响创建表时的EXTENT的大小。例如指定db_block_size=16K,某表空间的EXTENT MANAGEMENT 为local autoallocate,则其系统将extent的大小最小指定为1M.所以将可能导致空间的浪费。 2. 字符集(Character set) 该参数确定数据库以何种字符集来存贮CHAR以及V ARCHAR、V ARCHAR2等字符类型的值。对于ORACLE数据字典中的字符(如表及字段的COMMENT 内容)具有同样的作用。因此需要考虑如字符集的使用。对于国际项目,因为数据库中的comment内容(包括表及字符、存贮过程中的中文字符等内容)可能性需要以中文存贮,而用户业务数据使用的字符可能性是使用本地的语言,基于此,该参数需要选择支持UNICODE的字符编码的字符集。目前ORACLE9i支持以下二种UNICODE字符集: ?UTF8 ?AL32UTF8 建议统一取AL32UTF8 (O管理)ORACLESL性能优化(内部培训资料) ORACLESQL性能优化系列(一) 1.选用适合的ORACLE优化器 ORACLE的优化器共有3种: a.RULE(基于规则) b.COST(基于成本) c.CHOOSE(选择性) 设置缺省的优化器,可以通过对init.ora文件中OPTIMIZER_MODE参数的各种声明,如RULE,COST,CHOOSE,ALL_ROWS,FIRST_ROWS.你当然也在SQL句级或是会话(session)级对其进行覆盖. 为了使用基于成本的优化器(CBO,Cost-BasedOptimizer),你必须经常运行analyze命令,以增加数据库中的对象统计信息(objectstatistics)的准确性. 如果数据库的优化器模式设置为选择性(CHOOSE),那么实际的优化器模式将和是否运行过analyze命令有关.如果table已经被analyze过,优化器模式将自动成为CBO,反之,数据库将采用RULE形式的优化器. 在缺省情况下,ORACLE采用CHOOSE优化器,为了避免那些不必要的全表扫描(fulltablescan),你必须尽量避免使用CHOOSE优化器,而直接采用基于规则或者基于成本的优化器. 2.访问Table的方式 ORACLE采用两种访问表中记录的方式: a.全表扫描 全表扫描就是顺序地访问表中每条记录.ORACLE采用一次读入多个数据块(databaseblock)的方式优化全表扫描. b.通过ROWID访问表 你可以采用基于ROWID的访问方式情况,提高访问表的效率,,ROWID包含了表中记录的物理位置信息..ORACLE采用索引(INDEX)实现了数据和存放数据的物理位置(ROWID)之间的联系.通常索引提供了快速访问ROWID的方法,因此那些基于索引列的查询就可以得到性能上的提高. 3.共享SQL语句 为了不重复解析相同的SQL语句,在第一次解析之后,ORACLE将SQL语句存放在内存中.这块位于系统全局区域SGA(systemglobalarea)的共享池(sharedbufferpool)中的内存可以被所有的数据库用户共享.因此,当你执行一个SQL语句(有时被称为一个游标)时,如果它和之前的执行过的语句完全相同,ORACLE就能很快获得已经被解析的语句以及最好的执行路 Oracle SQL性能优化方法探讨 Oracle性能优化方法(SQL篇) (1) 1综述 (2) 2表分区的应用 (2) 3访问Table的方式 (3) 4共享SQL语句 (3) 5选择最有效率的表名顺序 (5) 6WHERE子句中的连接顺序. (6) 7SELECT子句中幸免使用’*’ (6) 8减少访问数据库的次数 (6) 9使用DECODE函数来减少处理时刻 (7) 10整合简单,无关联的数据库访问 (8) 11删除重复记录 (8) 12用TRUNCATE替代DELETE (9) 13尽量多使用COMMIT (9) 14计算记录条数 (9) 15用Where子句替换HAVING子句 (9) 16减少对表的查询 (10) 17通过内部函数提高SQL效率 (11) 18使用表的不名(Alias) (12) 19用EXISTS替代IN (12) 20用NOT EXISTS替代NOT IN (13) 21识不低效执行的SQL语句 (13) 22使用TKPROF 工具来查询SQL性能状态 (14) 23用EXPLAIN PLAN 分析SQL语句 (14) 24实时批量的处理 (16) 1综述 ORACLE数据库的性能调整是个重要,却又有难度的话题,如何有效地进行调整,需要通过反反复复的过程。在数据库建立时,就能依照顾用的需要合理设计分配表空间以及存储参数、内存使用初始化参数,对以后的数据库性能有专门大的益处,建立好后,又需要在应用中不断进行应用程序的优化和调整,这需要在大量的实践工作中不断地积存经验,从而更好地进行数据库的调优。 数据库性能调优的方法 ●调整内存 ●调整I/O ●调整资源的争用问题 ●调整操作系统参数 ●调整数据库的设计 ●调整应用程序 本文针对应用程序的调整,来讲明对数据库性能如何进行优化。 2表分区的应用 关于海量数据的表,能够考虑建立分区以提高操作效率。建 1.ORACLE的优化器共有3种 A、RULE (基于规则) b、COST (基于成本) c、CHOOSE (选择性) 设置缺省的优化器,可以通过对init.ora文件中OPTIMIZER_MODE参数的各种声明,如RULE,COST,CHOOSE,ALL_ROWS,FIRST_ROWS 。你当然也在SQL句级或是会话(session)级对其进行覆盖。 为了使用基于成本的优化器(CBO,Cost-Based Optimizer) ,你必须经常运行analyze 命令,以增加数据库中的对象统计信息(object statistics)的准确性。 如果数据库的优化器模式设置为选择性(CHOOSE),那么实际的优化器模式将和是否运行过analyze 命令有关。如果table已经被analyze过,优化器模式将自动成为CBO ,反之,数据库将采用RULE 形式的优化器。 在缺省情况下,ORACLE采用CHOOSE优化器,为了避免那些不必要的全表扫描(full table scan) ,你必须尽量避免使用CHOOSE优化器,而直接采用基于规则或者基于成本的优化器。 2.访问Table的方式 ORACLE 采用两种访问表中记录的方式: A、全表扫描 全表扫描就是顺序地访问表中每条记录。ORACLE采用一次读入多个数据块(database block)的方式优化全表扫描。 B、通过ROWID访问表 你可以采用基于ROWID的访问方式情况,提高访问表的效率,ROWID包含了表中记录的物理位置信息。ORACLE采用索引(INDEX)实现了数据和存放数据的物理位置(ROWID)之间的联系。通常索引提供了快速访问ROWID的方法,因此那些基于索引列的查询就可以得到性能上的提高。 3.共享SQL语句 为了不重复解析相同的SQL语句,在第一次解析之后,ORACLE将SQL语句存放在内存中。这块位于系统全局区域SGA(system global area)的共享池(shared buffer pool)中的内存可以被所有的数据库用户共享。因此,当你执行一个SQL语句(有时被称为一个游标)时,如果它和之前的执行过的语句完全相同,ORACLE就能很快获得已经被解析的语句以及最好的执行路径。ORACLE的这个功能大大地提高了SQL 的执行性能并节省了内存的使用。 可惜的是ORACLE只对简单的表提供高速缓冲(cache buffering),这个功能并不适用于多表连接查询。 数据库管理员必须在init.ora中为这个区域设置合适的参数,当这个内存区域越大,就可以保留更多的语句,当然被共享的可能性也就越大了。 当你向ORACLE提交一个SQL语句,ORACLE会首先在这块内存中查找相同的语句。这里需要注明的是,ORACLE对两者采取的是一种严格匹配,要达成共享,SQL语句必须完全相同(包括空格,换行等)。 数据库管理员必须在init.ora中为这个区域设置合适的参数,当这个内存区域越大,就可以保留更多的语句,当然被共享的可能性也就越大了。 共享的语句必须满足三个条件: A、字符级的比较:当前被执行的语句和共享池中的语句必须完全相同。 B、两个语句所指的对象必须完全相同: C、两个SQL语句中必须使用相同的名字的绑定变量(bind variables)。 4.选择最有效率的表名顺序(只在基于规则的优化器中有效) ORACLE的解析器按照从右到左的顺序处理FROM子句中的表名,因此FROM子句中写在最后的表(基础表driving table)将被最先处理。在FROM子句中包含多个表的情况下,你必须选择记录条数最少的表作为基础表。当ORACLE处理多个表时,会运用排序及合并的方式连接它们。首先,扫描第一个表(FROM子句中最后的那个表)并对记录进行派序,然后扫描第二个表(FROM子句中最后第二个表),最后将所有从第二个表中检索出的记录与第一个表中合适记录进行合并。 如果有3个以上的表连接查询,那就需要选择交叉表(intersection table)作为基础表,交叉表是指 基本的Sql 编写注意事项 尽量少用IN 操作符,基本上所有的IN 操作符都可以用EXISTS 代替。 不用NOT IN操作符,可以用NOT EXISTS或者外连接+替代。 Oracle 在执行IN 子查询时,首先执行子查询,将查询结果放入临时表再执行主查询。而EXIST则是首先检查主查询,然后运行子查询直到找到第一个匹配项。NOT EXISTS:匕NOT IN效率稍高。但具体在选择IN或EXIST操作时,要根据主子表数据量大小来具体考虑。 不用“<>”或者“ !=”操作符。对不等于操作符的处理会造成全表扫描,可以用“ <” or “>”代替。 Where子句中出现IS NULL或者IS NOT NULL时,Oracle会停止使用索引而执行全表扫描。可以考虑在设计表时,对索引列设置为NOT NULL这样就可以用其他操作来取代判断NULL的操作。 当通配符“ %”或者“ _”作为查询字符串的第一个字符时,索引不会被使用。 对于有连接的列“ || ”,最后一个连接列索引会无效。尽量避 免连接,可以分开连接或者使用不作用在列上的函数替代。 如果索引不是基于函数的,那么当在Where子句中对索引列使用函数时,索引不再起作用。 Where子句中避免在索引列上使用计算,否则将导致索引失效而进行全表扫描。 对数据类型不同的列进行比较时,会使索引失效。 用“ >=”替代“ >”。 UNION操作符会对结果进行筛选,消除重复,数据量大的情况 下可能会引起磁盘排序。如果不需要删除重复记录,应该使用UNION ALL。 Oracle从下到上处理Where子句中多个查询条件,所以表连接语句应写在其他Where条件前,可以过滤掉最大数量记录的条件必须写在Where子句的末尾。 Oracle从右到左处理From子句中的表名,所以在From子句中包含多个表的情况下,将记录最少的表放在最后。(只在采用RBO 优化时有效,下文详述) Order By 语句中的非索引列会降低性能,可以通过添加索引的方式处理。严格控制在Order By 语句中使用表达式。 不同区域出现的相同的Sql 语句,要保证查询字符完全相同, 以利用SGA共享池,防止相同的Sql语句被多次分析。多利用内部函数提高Sql 效率。 当在Sql 语句中连接多个表时,使用表的别名,并将之作为每列的前缀。这样可以减少解析时间。 需要注意的是,随着Oracle 的升级,查询优化器会自动对Sql 语句进行优化,某些限制可能在新版本的Oracle 下不再是问题。尤其是采用CBO (Cost-Based Optimization ,基于代价的优化方式)时。 我们可以总结一下可能引起全表扫描的操作: ORACLE的优化器共有3种 A、RULE (基于规则) b、COST (基于成本) c、CHOOSE (选择性) 设置缺省的优化器,可以通过对init.ora文件中OPTIMIZER_MODE参数的各种声明,如RULE,COST,CHOOSE,ALL_ROWS,FIRST_ROWS 。你当然也在SQL句级或是会话(session)级对其进行覆盖。 为了使用基于成本的优化器(CBO, Cost-Based Optimizer) ,你必须经常运行analyze 命令,以增加数据库中的对象统计信息(object statistics)的准确性。 如果数据库的优化器模式设置为选择性(CHOOSE),那么实际的优化器模式将和是否运行过analyze命令有关。如果table已经被analyze过,优化器模式将自动成为CBO ,反之,数据库将采用RULE形式的优化器。 在缺省情况下,ORACLE采用CHOOSE优化器,为了避免那些不必要的全表扫描(full table scan) ,你必须尽量避免使用CHOOSE优化器,而直接采用基于规则或者基于成本的优化器。 2.访问Table的方式 ORACLE 采用两种访问表中记录的方式: A、全表扫描 全表扫描就是顺序地访问表中每条记录。ORACLE采用一次读入多个数据块(database block)的方式优化全表扫描。 B、通过ROWID访问表 你可以采用基于ROWID的访问方式情况,提高访问表的效率, ROWID 包含了表中记录的物理位置信息。ORACLE采用索引(INDEX)实现了数据和存放数据的物理位置(ROWID)之间的联系。通常索引提供了快速访问ROWID的方法,因此那些基于索引列的查询就可以得到性能上的提高。 3.共享SQL语句 为了不重复解析相同的SQL语句,在第一次解析之后,ORACLE将SQL语句存放在存中。这块位于系统全局区域SGA(system global area)的共享池(shared buffer pool)中的存可以被所有的数据库用户共享。因此,当你执行一个SQL语句(有时被称为一个游标)时,如果它和之前的执行过的语句完全相同, ORACLE就能很快获得已经被解析的语句以及最好的执行路径。ORACLE的这个功能大提高了SQL的执行性能并节省了存的使用。 可惜的是ORACLE只对简单的表提供高速缓冲(cache buffering),这个功能并不适用于多表连接查询。 y物理模型CheckList (Oracle,性能) 1. 系统级优化 数据库参数配置 合理分配SGA及其内部参数(经验值如下): SGA=phy*(60%-80%) Share pool=SAG*45% DB Cache=SGA*45% Log Buffer: 1~3M 注:Oracle9i在Windows下有bug,是由Windows下的SGA最大 值有2G的限制造成的 注意调整process和open cursor参数,这两个参数直接影响 数据库的session量 分离表和索引:将表和索引建立在不同的表空间,决不要将 不属于Oracle内部系统的对象存放到SYSTEM表空间。同 时,确保数据表空间和索引表空间置于不同的硬盘,减少I/O 竞争; 如果是企业版数据库,大表可以考虑采取分区存储措施,提 高系统的性能; 优化Export和Import工作:使用较大的BUFFER(比如10MB , 10,240,000)可以提高EXPORT和IMPORT的速度 定期分析查询计划,提高数据库的性能; 2. 索引相关 要对经常查询的字段建立索引,但是由于索引管理的开销, 在增删改操作频繁的情况下避免建立不必要的索引; 对于只读或者接近只读的场合,如数据仓库,对于势值比较 小的列可以考虑使用bitmap索引; 如果索引是建立在多个列上, 只有在它的第一个列(leading column)被where子句引用时,优化器才会选择使用该索引. 3. SQL相关 Oracle的From子句表的顺序:记录越多的表放在越前面 (左); Oracle的where子句表达式的顺序:过滤掉最大数目记录的条 件放到where子句的末尾; Select子句中避免使用‘*’,增加了查询表的列的开销; 在执行结果等效的情况下,使用Truncate代替Delete; 为了在查询过程中要尽量使用索引,对于like语句避免使用 右匹配或者中间匹配的模糊查询; 将过滤条件尽可能放到Where子句中,而不是放到Having子 句中; 在SQL语句中,要减少对表的查询,特别是在含有子查询的 SQL子句中; 使用表的别名可以减少解析的时间并避免引起歧义; 使用exists替代in; 用NOT EXISTS替代NOT IN; 通常情况下,采用表连接的方式比exists更有效率; 当提交一个包含一对多表信息(比如部门表和雇员表)的查询 个人理解,数据库性能最关键的因素在于IO,因为操作内存是快速的,但是读写磁盘是速度很慢的,优化数据库最关键的问题在于减少磁盘的IO,就个人理解应该分为物理的和逻辑的优化,物理的是指oracle产品本身的一些优化,逻辑优化是指应用程序级别的优化物理优化: 一、优化内存 V$ROWCACHE视图结构 3.管理员可以通过下述语句来查看数据缓冲区的使用情况 select name,value from v$sysstat where name in ('db block gets', 'consistent gets ', 'physical reads'); 数据缓冲区使用命中率(physical reads除以db block gets加consistent gets之和)一定要小于10%,否则需要增加数据缓冲区大小 4.管理员可以通过执行下述语句,查看日志缓冲区的使用情况 select name,value from v$sysstat where name in ('redo entries','redo log space requests') 根据查询出的结果可以计算出日志缓冲区的申请失败率:requests除以entries 申请失败率应该解决与0,否则说明日志缓冲区开设太小,需要增加Oracle数据库的日志缓冲区 二、物理I/0的优化 1.在磁盘上建立数据文件前首先运行磁盘碎片整理程序 为了安全地整理磁盘碎片,需关闭打开数据文件的实例,并且停止服务。如果有足够的连续磁盘空间建立数据文件,那么就容易避免数据文件产生碎片。 2.不要使用磁盘压缩(Oracle文件不支持磁盘压缩) 3.不要使用磁盘加密 理解Oracle的日志机制 ? Oracle的日志是用来记录用户对数据库的改变,这样,当出现服务器硬件故障或者用户错误而丢失数据时,可以通过重做这些日志来恢复已提交的事务,Oracle日志机制包含以下组件: ?日志缓存SGA的一部分,用于缓存服务器进程产生的日志,包括DML和DDL; ? LGWR进程这个后台进程负责将日志缓存的数据写到联机日志文件,每个实例只有一个; ?数据库检查点检查点用于同步数据文件和日志文件,一个检查点事件的完成,代表在这个事件开始之前发生的所有对数据文件的改变都已实际记录到了数据文件,数据库在这个时间点是一致的,在实例恢复的时候,只有在最后一个检查点之后的日志才需要重做; ?联机日志文件用于存放从日志缓存中写出的日志数据,每个数据库最少需要两个日志文件,当前日志文件填满以后,发生日志切换,然后才可以继续写下一个日志文件; ?日志归档LGWR写满所有组的联机日志文件以后,会回头再写第一个组的日志文件,在非归档模式下,被重用的日志文件中的日志会被丢弃,在归档模式下,日志文件被重用前会被ARC0进程复制到归档日志文件; ? 一些可选的日志机制,如归档和Standby,因为附加的I/O会降低系统的性能,同时提供了可靠的灾难恢复能力,不建议因这些性能的下降而关闭生产系统的归档功能。 调整日志缓存 ? 日志缓存的管理机制可以类似理解成一个漏斗,日志数据不断地从漏斗上方加入,然后偶尔打开漏斗下方的开关将加入的数据清空,这个开关就是LGWR进程,为了日志缓存有空间容纳不断加进来的日志数据,LGWR在下面列出的任何一个条件下都会执行写出日志缓存的操作: ?应用程序发出Commit命令时; ?三秒间隔已到时; ?日志缓存三分之一满时; ?日志缓存达到1M时; ?数据库检查点发生时; ? 测量日志缓存的性能通过服务器进程放置日志条到日志缓存时发生等待的次数和时间来测量; Select Name, Value From V$sysstat Where Name In ('redo entries', 'redo buffer allocation retries','redo log space requests'); redo entries 服务器进程放进日志缓存的日志条的总数量; redo buffer allocation retries 服务器放置日志条时必须等待然后再重试的次数; redo log space requests LGWR进程写出日志缓存时等待日志切换的次数; 这个查询用于计算日志缓存重试率,这个比率应该小于百分之一; Select Retries.Value / Entries.Value "Redo log Buffer Retry Ratio" From V$sysstat Entries, V$sysstat Retries Where https://www.doczj.com/doc/0313189149.html, = 'redo entries' And https://www.doczj.com/doc/0313189149.html, = 'redo buffer allocation retries'; 这个查询用来显示哪些会话的LGWR正在进行写等待; ORACLE SQL性能优化 我要讲的题目是Oracle SQL性能优化,只是Oracle性能优化中的一项。Oracle的性能优化包含很多方面,比如调整物理存取,调整逻辑存取,调整内存使用,减少网络流量等。这里选择SQL性能优化是因为这部分内容我们测试人员最容易接触到,另外开发人员写SQL脚本时有时很随意,不知不觉就会造成程序性能上的下降。 1.选择最有效率的表名顺序(只在基于规则的优化器中有效) ORACLE的解析器按照从右到左的顺序处理FROM子句中的表名,因此FROM子句中写在最后的表(基础表 driving table)将被最先处理. 在FROM子句中包含多个表的情况下,你必须选择记录条数最少的表作为基 础表.当ORACLE处理多个表时, 会运用排序及合并的方式连接它们.首先,扫描第一个表(FROM子句中最后的那个表)并对记录进行派序,然后扫描 第二个表(FROM子句中最后第二个表),最后将所有从第二个表中检索出 的记录与第一个表中合适记录进行合并. 例如: 表 TAB1 16,384 条记录 表 TAB2 1 条记录 选择TAB2作为基础表 (最好的方法) select count(*) from tab1,tab2 执行时间0.96秒 选择TAB2作为基础表 (不佳的方法) select count(*) from tab2,tab1 执行时间26.09秒 如果有3个以上的表连接查询, 那就需要选择交叉表(intersection table)作为基础表, 交叉表是指那个被其他表所引用的表. 例如: EMP表描述了LOCATION表和CATEGORY表的交集. SELECT * FROM LOCATION L , CATEGORY C, EMP E WHERE E.EMP_NO BETWEEN 1000 AND 2000 AND E.CAT_NO = C.CAT_NO AND E.LOCN = L.LOCN 将比下列SQL更有效率 SELECT * FROM EMP E , LOCATION L , CATEGORY C WHERE E.CAT_NO = C.CAT_NO AND E.LOCN = L.LOCN AND E.EMP_NO BETWEEN 1000 AND 2000 2.WHERE子句中的连接顺序. ORACLE采用自下而上的顺序解析WHERE子句,根据这个原理,表之间的连接必须写在其他WHERE条件之前, 那些可以过滤掉最大数量记录的条件必须写在WHERE子句的末尾.OracleSQL的优化
sql语句(mysql优化)绝对经典
ORACLE优化总结和注意事项
2020年(Oracle管理)如何优化SQL语句以提高Oracle执行效率
SQL监控及性能优化
OracleSQL性能优化方法
SQL2019系统性能优化解决方案共12页文档
ORACLE 性能优化
( O管理)ORACLESL性能优化(内部培训资料)
Oracle SQL性能优化方法研究
ORACLE性能优化31条
oraclesql优化笔记
Oracle性能优化
Oracle性能优化
Oracle性能优化总结
oracle性能调优-管理oracle日志之Oracle日志运行机制
oracle性能优化简介
相关主题
文本预览