
SPSS在生物统计学中的应用
——实验指导手册
实验三:参数估计
一、实验目的与要求
1.理解参数估计的概念
2.熟悉区间估计的概念与操作方法
二、实验原理
1. 参数估计的定义
●参数估计(parameter estimation)是根据从总体中抽取的样本估计总体分布中的未知参数的方法。
它是统计推断的一种基本形式,是数理统计学的一个重要分支,分为点估计和区间估计两部分。
●点估计(point estimation):又称定值估计,就是用实际样本指标数值作为总体参数的估计值。
当总体的性质不清楚时,我们须利用某一量数(样本统计量)作为估计数,以帮助了解总体的性质,如:样本平均数乃是总体平均数μ的估计数,当我们只用一个特定的值,亦即数线上的一个点,作为估计值以估计总体参数时,就叫做点估计。
?点估计的数学方法很多,常见的有“矩估计法”、“最大似然估计法”、“最小二乘估计法”、
“顺序统计量法”等。
?点估计的精确程度用置信区间表示。
●区间估计(interval estimation)是从点估计值和抽样标准误出发,按给定的概率值建立包含待估计参数的
区间。其中这个给定的概率值称为置信度或置信水平(confidence level),这个建立起来的包含待估计函数的区间称为置信区间,指总体参数值落在样本统计值某一区内的概率
●置信区间(confidence interval)是指在某一置信水平下,样本统计值与总体参数值间误差范围。置信区间
越大,置信水平越高。划定置信区间的两个数值分别称为置信下限(lower confidence limit,lcl)和置信上限(upper confidence limit,ucl)
2. 参数估计的基本原理
统计分析的目的就是由样本推断总体,参数估计即是实现这一目的的方法之一。
3. 参数估计的方法
参数估计的结果,常用点估计值(样本均值)+置信区间(置信下限、置信上限)来表示。
三、实验内容与步骤
1. 单个总体均值的区间估计
打开数据文件“描述性统计(100名女大学生的血清蛋白含量).sav”
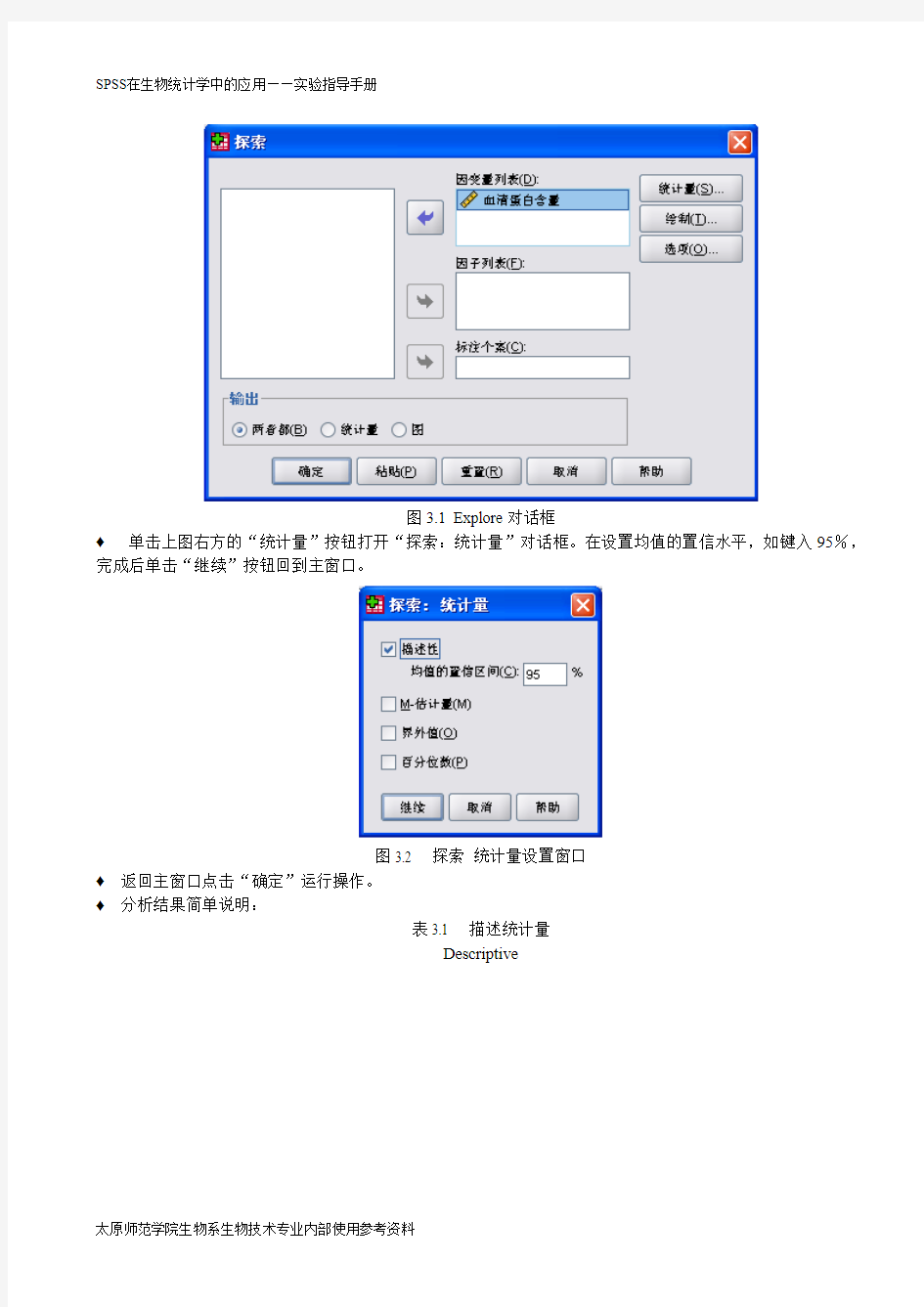
选择菜单【分析】—>【描述统计】—>【探索】”,打开图3.1探索(Explore)对话框。
?从源变量清单中将“血清蛋白含量”变量移入因变量列表(Dependent List)框中。
图3.1 Explore对话框
?单击上图右方的“统计量”按钮打开“探索:统计量”对话框。在设置均值的置信水平,如键入95%,完成后单击“继续”按钮回到主窗口。
图3.2 探索统计量设置窗口
?返回主窗口点击“确定”运行操作。
?分析结果简单说明:
表3.1 描述统计量
Descriptive
?如上表显示。从上表“ 95%Confidence Interval for Mean ”中可以得出,女大学生区间估计(置信度为95%)为:(72.4932,74.0848),其中lower Bound 表示置信区间的下限,Upper Bound表示置信区间的上限。点估计是:73.2890。
说明女大学生血清蛋白含量总体水平有平百分之九十五的机率落72.4932g/L和74.0848g/L之间,总体水平低于72.4932g/L和高于74.0848g/L的可能性小于百分之五。
2.两个总体均值之差的区间估计
【课本例14-2 】现有两组饲料喂猪的料重比数据如下。
饲料A 3.08 2.73 3.03 2.95 2.21 3.03 2.86 3.13 2.59 2.89
饲料B 3.43 3.04 3.37 3.29 2.46 3.37 3.19 2.89 3.49
要求对饲料A喂猪的平均料重比与饲料B喂猪的平均料重比之差进行区间估计,预设的置信度为95%。
?打开SPSS,打开数据文件:“两组饲料喂猪的料重比数据.xls”。
?计算两总体均值之差的区间估计,采用“独立样本T 检验”方法。选择菜单“【分析】→【比较均值】
→【独立样本T检验】”,
图3.3 “独立样本T检验”菜单选择
打开“独立样本T检验”对话框。
?变量选择
(1)从源变量清单中将“料重比”变量移入检验变量框中。表示要求该变量的均值的区间估计。
从源变量清单中将“饲料”变量移入分组变量框中。表示总体的分类变量。
图3.4 独立样本T检验对话框
?定义分组单击定义组按钮,打开Define Groups 对话框。在Group1 中输入A,在Group2 中输入B(A表示饲料A,B表示饲料B)。
图3.5 定义组define groups设置窗口
完成后单击“继续”按钮返回到“独立样本T检验”对话框。
?确定置信水平
单击“独立样本T检验”对话框右上方的“选项”按钮,弹出“独立样本T检验:选项”对话框,
图3.6 “独立样本T检验:选项”对话框
确定置信区间为95%,单击“继续”按钮返回到“独立样本T检验”对话框。
?计算结果单击“确定”按钮,输出结果如下图所示。
(1)Group Statistics(分组统计量)表
分别给出不同总体下的样本容量、均值、标准差和平均标准误。从该表中可以看出,A饲料的平均增重为2.8500,B饲料的平均增重为3.1700。
表3.2 分组统计量
(2)Independent Sample Test (独立样本T 检验)表
表3.3 独立样本T检验结果
结果说明,在当前抽样方式下,由样本均数差值-.32000(A饲料的平均增重2.8500与B饲料的平均增重3.1700之差。)估计两种饲料喂猪的总体增重水平差值有95%的可能性在-.61399与-.02601之间。
T检验结果:
⑴方差同质性检验:F值为0.275,其概率P=0.670>0.05,表明两未知总体方差差异不显著,可按照等方差假设进行检验。(Levene检验统计量W服从自由度为 1=k-1, 2=N-k的F分布。)
⑵检验:t 值为-2.296,其概率P=0.035<0.05,表明B饲料增重效果显著地好于A饲料。
⑶置信区间为-.61399与-.02601,推断总体参数的差异为0的可能性很小。
实验四:t检验
一、实验目的与要求
1. 理解t 检验的基本原理和用途
2. 熟练掌握T检验的SPSS操作
3. 学会利用T检验方法解决身边的实际问题
二、实验原理
●有三类t 检验可用:
?独立样本t 检验(双样本t 检验)。利用成组设计获取样本数据,比较一个变量中两组个案的
均值,以推断两组个案所在总体的差异是否显著。提供了每组的描述统计和Levene 方差相等
性检验,以及相等和不等方差t 值和均值差分的95% 置信区间。
?配对样本t 检验(相关t 检验)。利用配对设计获取成对样本数据,比较单个组的两个变量的
均值。此检验还用于匹配对或个案控制研究设计。输出包括检验变量的描述统计、变量之间的
相关性、配对差分的描述统计、t 检验和95% 置信区间。
?单样本t 检验。将一个变量的均值与已知值或假设值进行比较。检验变量的描述统计随t 检
验一起显示。检验变量的均值和假设的检验值之间差的95% 置信区间是缺省输出的一部分。
三、实验演示内容与步骤
㈠独立样本t 检验
在“实验三”内容里“2.两个总体均值之差的区间估计”中,已完成独立样本t检验的操作,大家可重复其操作步骤,以熟练操作步骤。
应记住独立样本t检验的数据结构,可在SPSS中创建数据文件,也可以在EXCEL中创建数据文件。
独立样本t检验的重点在于先根据方差齐性检验的结果,确定方差的同质性,再选择t检验的结果。
㈡配对样本t 检验
【课本例5.7 】在研究饮食中缺乏维生素E 与肝中维生素A 的关系时,将试验动物按性别、体重等配成8对,并将每对中的两头试验动物用随机分配法分配在正常饲料组和维生素E 缺乏组,然后将试验动物杀死,测定其肝中的维生素A 的含量,其结果如下表,试检验两组饲料对试验动物肝脏中维生素A 含量的作用是否有显著差异。
正常饲料组35502000300039503800375034503050维生素E 缺乏组24502400180032003250270025001750
?打开SPSS,打开数据文件:“课本5.7配对设计资料.xls”。
?选择菜单“【分析】→【比较均值】→【配对样本T检验】”,弹出“配对样本T检验”对话框,
图4.1 “配对样本T检验”菜单选择
图4.2 “配对样本T检验”对话框
Paired-Samples T Tes
如图4.2所示,将两个配对变量移入右边的成对变量Pair Variables列表框中。移动的方法是先选择其中的一个配对变量,再选择第二个配对变量,接着单击中间的箭头按钮。
?选项按钮的用于设置置信度选项,这里保持系统默认的95%
?在主对话框中单击ok按钮,执行操作。
?在输出视图中看分析结果
表4.1 两组饲料饲养后样本肝中的维生素A 的含量的描述统计量
表3.4给出了两组饲料饲养后样本肝中的维生素A 的含量的均值、标准差、均值标准误差。
表3.5给出了两组饲料饲养后样本肝中的维生素A 的含量的相关系数。
表4.3 配对样本t检验结果
表4.3给出了配对样本t检验结果,包括配对变量差值的均值、标准差、均值标准误差以及差值的95%置信
度下的区间估计。当然也给出了最为重要的t统计量和p值。
?结果显示p=0.004<0.01,表明,维生素E缺乏组肝中的维生素A 的含量极显著地低于正常饲料
组,造成肝中的维生素A 的含量低的原因是饲料中缺乏维生素E。
?置信区间为355.821与1269.179,推断总体参数的差异为0的可能性极小。
㈢单样本t 检验(单个总体均值的假设检验)
【课本例5.1 】按照规定,100g罐头番茄汁中的平均维生素C含量不得少于21mg/g,现从工厂的产品中随机抽取17个罐头,其100g番茄汁中的维生素C含量记录如下:
维生素c含
1625212023211915132317202918221622
量
,问这批罐头是否符合规定要求。
?打开SPSS,打开数据文件:“课本例题5.1单样本t检验资料.xls”。
?判断检验类型该例属于“小样本、总体标准差σ未知。假设形式为:
H0:μ=μ0,H1 :μ≠μ0
?判断分布类型因不知道番茄汁中的平均维生素C含量是否服从正态分布,先按照“实验二描述性统计:频率”的方法,对数据进行描述性统计。
选择菜单“【分析】—>【描述统计】—>【频率】”。弹出如图 2.7 所示“频率”对话框,在“频率:统计量”、“频率:图表”、“频率:格式”三个对话框中选择“均值”、“标准差”、“方差”、“均值的标准误”、“偏度”、“峰度”、“直方图-带正态曲线”后,点击【继续】继续返回“频率”对话框,点击
【确定】后,在弹出的“结果输出”视图中显示上述各项选择的对应结果如下:
表4.4 描述统计:频率
从表4.4和图4.3可知,茄汁中的平均维生素C含量是基本服从正态分布的,可以采用基于正态分布的T检验进行分析。
?软件程序操作选择菜单“【分析】→【比较均值】→单样本T检验”,
图4.4 “单样本T检验”菜单选择
弹出One-Sample T Test 对话框。从源变量清单中将“维生素C含量”向右移入“检验变量Test Variables”框中。
图4.5 “单样本T检验”对话框
one-sample T test
在“检验值Test Value”框里输入一个指定值(即假设检验值,本例中假设为21),T 检验过程将对每个检验变量分别检验它们的平均值与这个指定数值相等的假设。
?“One-Sample T Test”窗口中“确定”按钮,输出结果如下表所示。
(1)“One-Sample Statistics”(单个样本的统计量)表分别给出样本的容量、均值、标准差和平均标准误。本例中,产品数量均值为20.00。
表4.5 单样本统计量
(2)“One-Sample Test”(单个样本的检验)表
表4.6 单样本T检验结果
表中的t 表示所计算的T 检验统计量的数值,本例中为-1.035。表中的“df”,表示自由度,本例中为16。表中的“Sig”(双尾T 检验),表示统计量的P-值,并与双尾T检验的显著性的大小进行比较:Sig.=0.316>0.05,说明这批样本的平均维生素C含量与21无显著差异。表中的“Mean Difference”,表示均值差,即样本均值与检验值21之差,本例中为-1.000。表中的“95%Confidence Internal of the Difference”,样本均值与检验值偏差的95%置信区间为(-3.05,1.05),置信区间包括数值0,推断总体参数的偏差接近于0,产品符合要求。
云南师范大学2010~2011学年下学期期末统一考试 高级生物统计学实验(期末) 试卷 学院 专业 年级 学号 姓名 考试方式(闭卷或开卷): 闭卷 考试时量:60分钟 试卷编号(B 卷): 题号 一 二 三 四 五 总分 评卷人 得分 一、下表为某种动物在不同温度下的代谢率的变化,试比较温度对其代谢率 有无影响?并对SSR 法其进行多重比较 温度(℃) 代谢率(mlO 2/g.h ) -5 2.78 3.80 4.87 4.68 5.51 5.67 5.10 2.79 2.60 3.14 4.26 3.72 3.48 2.86 3.37 3.32 4.35 4.59 4.66 4.83 5.16 -5 -5 -5 -5 -5 -5 .00 .00 .00 .00 .00 .00 .00 5.0 5.0 5.0 5.0 5.0 5.0 5.0
ANOVA 数据 7.1972 3.598 5.684 .012 11.39718.633 18.593 20 Between Groups Within Groups Total Sum of Squares df Mean Square F Sig. 经但因素方差分析的:f=5.684, p=0.012,差异显著,说明多有作用, 数据 Duncan a 7 3.2643 7 4.32577 4.6300 1.000.484 温度231Sig. N 12Subset for alpha = .05 Means for groups in homogeneous subsets are displayed. Uses H armonic Mean Sample Size = 7.000. a. 二、为调查红绿色盲是否与性别有关,某单位调查结果如下: 色盲 非色盲 男 32 168 女 13 232 问红绿色盲是否与性别有关? 三、试用交互误差图比较不同季节某种动物的胃长(cm )的变化?并绘制出其在 95%置信带 季节 胃长(cm )
生物统计学期末考试题 一名词解释(每题2分,共10分) 1.生物统计学期末考试题 2.样本:从总体中抽出的若干个体所构成的集合称为样本 3.方差:用样本容量n来除离均差平方和,得到的平方和,称为方差 4.标准差:方差的平方根就是标准差 5.标准误:即样本均数的标准差,是描述均数抽样分布的离散程度及衡量均数抽样误差大小的尺度, 反映的是样本均数之间的变异。 6.变异系数:将样本标准差除以样本平均数,得出的百分比就是变异系数 7.抽样:通常按相等的时间间隔对信号抽取样值的过程。 8.总体参数:所谓总体参数是指总体中对某变量的概括性描述。 9.样本统计量:样本统计量的概念很宽泛(譬如样本均值、样本中位数、样本方差等等),到现在 为止,不是所有的样本统计量和总体分布的关系都能被确认,只是常见的一些统计量和总体分布之间 的关系已经被证明了。 10.正态分布:若随机变量X服从一个数学期望为μ、标准方差为σ2的高斯分布, 正态分布又名 高斯分布 11.假设测验:又称显著性检验,就是根据总体的理论分布和小概率原理,对未知或不完全知道的总 体提出两种彼此对立的假设,然后由样本的实际结果,经过一定的计算,做出在一定概率意义上应该 接受的那种假设的推断。 12.方差分析:又称“变异数分析”或“F检验”,用于两个及两个以上样本均数差别的显著性检验。 13.小概率原理:一个事件如果发生的概率很小的话,那么它在一次试验中是几乎不可能发生的,但 在多次重复试验中几乎是必然发生的,数学上称之小概率原理。 15.决定系数:决定系数定义为相关系数r的平方 16.随机误差:在实际相同条件下,多次测量同一量值时,其绝对值和符号无法预计的测量误差。 17.系统误差:它是在一定的测量条件下,对同一个被测尺寸进行多次重复测量时,误差值的大小和 符号(正值或负值)保持不变;或者在条件变化时,按一定规律变化的误差 二. 判断题(每题2分,共10分) 1. 在正态分布N(μ ;σ)中,如果σ相等而μ不等,则曲线平移, ( ) 2. 如果两个玉米品种的植株高度的平均数相同,我们可以认为这两个玉米品种是来自同一总体() 3. 当我们说两个处理平均数有显著差异时,则我们有99%的把握肯定它们来自不同总体. 4小概率原理是指小概率事件在一次试验中可以认为不可能发生() 5 激素处理水稻种子具有增产效应,现在在5个试验区内种植经过高、中、低三种剂量的激素处理的水稻种此试验称为三处理五重复试验() 6.系统误差是不可避免的,并且可以用来计算试验精度。() 7.精确度就是指观察值与真值之间的差异。() 8. 实验设计的三个基本原则是重复、随机、局部控制。() 9. 正交试验设计就是从全部组合的处理中随机选取部分组合进行试验。() 10.如果回归方程Y=3+1.5X的R2=0.64,则表明Y的总变异80%是X造成。() 三. 简答题(每题5分共20分) 1. 完全随机试验设计与随机区组试验设计有什么不同? 2. 什么是小概率原理?在统计推断中有何 作用? 3. 什么是多重比较中的FISHER氏保护测验?4. 样本的方差计算中,为什么要离均差平方和 除以n-1而不是除以n? 5. 如果两个变量X和Y的相关系数小于0.5,是否它们就没有显著相关性? 6. 单尾测验与双尾测验有何异同?
重庆西南大学 2012 至 2013 学年度第 2 期 生物统计学 试题(A ) 试题使用对象: 2011 级 专业(本科) 命题人: 考试用时 120 分钟 答题方式采用: 闭卷 说明:1、答题请使用黑色或蓝色的钢笔、圆珠笔在答题纸上书写工整. 2、考生应在答题纸上答题,在此卷上答题作废. 一:判断题;(每小题1分,共10分 ) 1、正确无效假设的错误为统计假设测验的第一类错误。( ) 2、标准差为5,B 群体的标准差为12,B 群体的变异一定大于A 群体。( ) 3、一差异”是指仅允许处理不同,其它非处理因素都应保持不变。( ) 4、30位学生中有男生16位、女生14位,可推断该班男女生比例符合1∶1 (已知84.321,05.0=χ)。 ( ) 5、固定模型中所得的结论仅在于推断关于特定的处理,而随机模型中试验结论则将用于推断处理的总体。( ) 6、率百分数资料进行方差分析前,应该对资料数据作反正弦转换。( ) 7、比较前,应该先作F 测验。 ( ) 8、验中,测验统计假设H 00:μμ≥ ,对H A :μμ<0 时,显著水平为5%,则测验的αu 值为1.96( ) 9、行回归系数假设测验后,若接受H o :β=0,则表明X 、Y 两变数无相关关系。 ( ) 10、株高的平均数和标准差为30150±=±s y (厘米),果穗长的平均数和标准差为s y ±1030±=(厘米),可认为该玉米的株高性状比果穗性状变异大。 ( ) 二:选择题;(每小题2分,共10分 ) 1分别从总体方差为4和12的总体中抽取容量为4的样本,样本平均数分别为3和2,在95%置信度下总体平均数差数的置信区间为( )。 A 、[-9.32,11.32] B 、[-4.16,6.16]
生物统计学考试题及答案
重庆西南大学 2012 至 2013 学年度第 2 期 生物统计学 试题(A ) 试题使用对象: 2011 级 专 业(本科) 命题人: 考试用时 120 分钟 答题方式采用: 一:判断题;(每小题1分,共10分 ) 1、正确无效假设的错误为统计假设测验的第一类错误。( ) 2、标准差为5,B 群体的标准差为12,B 群体的变异一定大于A 群体。( ) 3、一差异”是指仅允许处理不同,其它非处理因素都应保持不变。( ) 4、30位学生中有男生16位、女生14位,可推断该班男女生比例符合1∶1(已 知84.321,05.0=χ)。 ( ) 5、固定模型中所得的结论仅在于推断关于特定的处理,而随机模型中试验结论则将用于推断处理的总体。( ) 6、率百分数资料进行方差分析前,应该对资料数据作反正弦转换。( ) 7、比较前,应该先作F 测验。 ( ) 8、验中,测验统计假设H 00:μμ≥ ,对H A :μμ<0 时,显著水平为5%,则测验的αu 值为1.96( ) 9、行回归系数假设测验后,若接受H o :β=0,则表明X 、Y 两变数无相关关系。( ) 10、株高的平均数和标准差为30150±=±s y (厘米),果穗长的平均数和标准差为s y ±1030±=(厘米),可认为该玉米的株高性状比果穗性状变异大。 ( ) 二:选择题;(每小题2分,共10分 ) 1分别从总体方差为4和12的总体中抽取容量为4的样本,样本平均数分别为3和2,在95%置信度下总体平均数差数的置信区间为( )。
A 、[-9.32,11.32] B 、[-4.16,6.16] C 、[-1.58,3.58] D 、都不是 2、态分布不具有下列哪种特征( )。 A 、左右对称 B 、单峰分布 C 、中间高、两头低 D 、概率处处相等 3、一个单因素6个水平、3次重复的完全随机设计进行方差分析,若按最小显著差数法进行多重比较,比较所用的标准误及计算最小显著差数时查表的自由度分别为( )。 A 、 2MSe/6 , 3 B 、 MSe/6 , 3 C 、 2MSe/3 , 12 D 、 MSe/3 , 12 4、已知),N(~x 2σμ,则x 在区间]96.1,[σμ+-∞的概率为( )。 A 、0.025 B 、0.975 C 、0.95 D 、0.05 5、 方差分析时,进行数据转换的目的是( )。 A. 误差方差同质 B. 处理效应与环境效应线性可加 C. 误差方差具有正态性 D. A 、B 、C 都对 三、简答题;(每小题6分,共30分 ) 1、方差分析有哪些步骤? 2、统计假设是?统计假设分类及含义? 3、卡方检验主要用于哪些方面? 4、显著性检验的基本步骤? 5、平均数有哪些?各用于什么情况? 四、计算题;(共4题、50分) 1、进行大豆等位酶Aph 的电泳分析,193份野生大豆、223份栽培大豆等位基因型的次数列于下表。试分析大豆Aph 等位酶的等位基因型频率是否因物种而不同。( 99 .52 05.0,2=χ, 81 .7205.0,3=χ)(10分) 野生大豆和栽培大豆Aph 等位酶的等位基因型次数分布 物 种 等位基因型 1 2 3 野生大豆 29 68 96
第一章 统计数据的收集与整理 1.1 算术平均数是怎样计算的?为什么要计算平均数? 答:算数平均数由下式计算:,含义为将全部观测值相加再被观测值的个数 除,所得之商称为算术平均数。计算算数平均数的目的,是用平均数表示样本数据的集中点, 或是说是样本数据的代表。 1.2 既然方差和标准差都是衡量数据变异程度的,有了方差为什么还要计算标准差? 答:标准差的单位与数据的原始单位一致,能更直观地反映数据地离散程度。 1.3 标准差是描述数据变异程度的量,变异系数也是描述数据变异程度的量,两者之间有什么不同? 答:变异系数可以说是用平均数标准化了的标准差。在比较两个平均数不同的样本时所得结果更可靠。 1.4 完整地描述一组数据需要哪几个特征数? 答:平均数、标准差、偏斜度和峭度。 1.5 下表是我国青年男子体重(kg )。由于测量精度的要求,从表面上看像是离散型数据,不要忘记,体重是通过度量得到的,属于连续型数据。根据表中所给出的数据编制频数分布表。 66 69 64 65 64 66 68 65 62 64 69 61 61 68 66 57 66 69 66 65 70 64 58 67 66 66 67 66 66 62 66 66 64 62 62 65 64 65 66 72 60 66 65 61 61 66 67 62 65 65 61 64 62 64 65 62 65 68 68 65 67 68 62 63 70 65 64 65 62 66 62 63 68 65 68 57 67 66 68 63 64 66 68 64 63 60 64 69 65 66 67 67 67 65 67 67 66 68 64 67 59 66 65 63 56 66 63 63 66 67 63 70 67 70 62 64 72 69 67 67 66 68 64 65 71 61 63 61 64 64 67 69 70 66 64 65 64 63 70 64 62 69 70 68 65 63 65 66 64 68 69 65 63 67 63 70 65 68 67 69 66 65 67 66 74 64 69 65 64 65 65 68 67 65 65 66 67 72 65 67 62 67 71 69 65 65 75 62 69 68 68 65 63 66 66 65 62 61 68 65 64 67 66 64 60 61 68 67 63 59 65 60 64 63 69 62 71 69 60 63 59 67 61 68 69 66 64 69 65 68 67 64 64 66 69 73 68 60 60 63 38 62 67 65 65 69 65 67 65 72 66 67 64 61 64 66 63 63 66 66 66 63 65 63 67 68 66 62 63 61 66 61 63 68 65 66 69 64 66 70 69 70 63 64 65 64 67 67 65 66 62 61 65 65 60 63 65 62 66 64 答:首先建立一个外部数据文件,名称和路径为:E:\data\exer1-5e.dat 。所用的SAS 程序和计算结果如下: proc format; value hfmt 56-57='56-57' 58-59='58-59' 60-61='60-61' 62-63='62-63' 64-65='64-65' 66-67='66-67' 68-69='68-69' 70-71='70-71' 72-73='72-73' 74-75='74-75'; run; n y y n i i ∑== 1
第三章 几种常见的概率分布律 3.1 有4对相互独立的等位基因自由组合,问有3个显性基因和5个隐性基因的组合有多少种?每种的概率是多少?这一类型总的概率是多少? 答:代入二项分布概率函数,这里φ=1/2。 ()75218.02565621562121!5!3!838 3 5 == ??? ??=??? ????? ??=p 结论:共有56种,每种的概率为0.003 906 25(1/256 ),这一类型总的概率为 0.218 75。 3.2 5对相互独立的等位基因间自由组合,表型共有多少种?它们的比如何? 答:(1) 5 4322345 5 414143541431041431041435434143??? ??+??? ????? ??+??? ????? ??+??? ????? ??+??? ????? ??+??? ??=?? ? ??+ 表型共有1+5+10+10+5+1 = 32种。 (2) ()()()()()()6 976000.0024114165 014.0024 1354143589 087.002419 104143107 263.0024127 104143105 395.0024181 5414353 237.002412434355 43 2 2 3 4 5 541322314==??? ??==?=??? ????? ??==?=??? ????? ??==?=??? ????? ??==?=??? ????? ??===??? ??=隐隐显隐显隐显隐显显P P P P P P 它们的比为:243∶81(×5)∶27(×10)∶9(×10)∶3(×5)∶1 。 3.3 在辐射育种实验中,已知经过处理的单株至少发生一个有利突变的概率是φ,群体中至少出现一株有利突变单株的概率为P a ,问为了至少得到一株有利突变的单株,群体n 应多大? 答: 已知φ为单株至少发生一个有利突变的概率,则1―φ为单株不发生一个有利突变的概率为: ()()() ()()φφφ--= -=--=-1lg 1lg 1lg 1lg 11a a a n P n P n P
统计选择题 1,由于(1,研究对象本身的性质)造成我们所遇到的各种统计数据的不齐性。 2,研究某一品种小麦株高,因为该品种小麦是个极大的群体,其数量甚至于是个天文数字,该体属于(4,无限总体) 3,从总体中(2,随机抽出)一部分个体称为样本。 4,用随机抽样方法从总体中获得一个样本的过程称为(3,抽样) 5,身高,体重,年龄这一类数据属于(3,连续型数据;1,度量数据) 6,每10个中男性人数,每亩麦田中杂草株数,喷洒农药后每100只害虫中死虫数等,这一类数据属于(1,离散型数据;2,计数数据) 7,把频数按其组值的顺序排列起来,称为(3,频数分布) 8,以组值作为一个边,相应的频数为另一个边,做成的连续矩形图称为(2,直方图)9,绘制(4,多边形图)的方法是在坐标平面内点上各点(中值,频数),以线段连接各点,最高和最低非零频数点与相邻零频数点相连。 10,累积频数图是根据(3,累积频数表)直接绘出的。 11,样本数据总和除以样本含量,称为(算数平均数 12,已知样本平方和为360,样本含量为10,以下4种结果中(2,6.0)是正确的标准差。 13,概率的古典定义是(2,基本事件数与事件总数之比) 14,下面第(2,概率是事物所固有的特性) 15,对于事件A和B,P(A∪B)等于(2,P(AB)) 16,对于事件A和事件B,P(A|B)等于(P(AB)/P(B)) 17,对于任意事件A和B,P(AB)等于(P(B)P(B|A)) 18,下述(3随机试验中所输入的变量)项称为随机变量 19,关于连续型随机变量,有以下4种提法,其中(1,可取某一区间内的任何数值)20,总体平均数可以用以下4种符号中的一种表示,它是(2,μ) 21,样本标准差可以用以下4种符号中的一种表示,它是(1,s) 22,在养鱼场中,A鱼塘的面积占10%,A鱼塘中鱼的发病率为1%,问从养鱼场中任意捕捞一条鱼,它既是A鱼塘,又是生病的鱼的概率是(4,0.003) 23,以下4点是描述连续型随机变量特征的,其中(2,f(x)=lim △x→0P(x 第一章 填空 1.变量按其性质可以分为(连续)变量和(非连续)变量。 2.样本统计数是总体(参数)的估计值。 3.生物统计学是研究生命过程中以样本来推断(总体)的一门学科。 4.生物统计学的基本内容包括(试验设计)和(统计分析)两大部分。 5.生物统计学的发展过程经历了(古典记录统计学)、(近代描述统计学)和(现代推断统计学)3个阶段。 6.生物学研究中,一般将样本容量(n ≥30)称为大样本。 7.试验误差可以分为(随机误差)和(系统误差)两类。 判断 1.对于有限总体不必用统计推断方法。(×) 2.资料的精确性高,其准确性也一定高。(×) 3.在试验设计中,随机误差只能减小,而不能完全消除。(∨) 4.统计学上的试验误差,通常指随机误差。(∨) 第二章 填空 1.资料按生物的性状特征可分为(数量性状资料)变量和(质量性状资料)变量。 2. 直方图适合于表示(连续变量)资料的次数分布。 3.变量的分布具有两个明显基本特征,即(集中性)和(离散性)。 4.反映变量集中性的特征数是(平均数),反映变量离散性的特征数是(变异数)。 5.样本标准差的计算公式s=( )。 判断题 1. 计数资料也称连续性变量资料,计量资料也称非连续性变量资料。(×) 2. 条形图和多边形图均适合于表示计数资料的次数分布。(×) 3. 离均差平方和为最小。(∨) 4. 资料中出现最多的那个观测值或最多一组的中点值,称为众数。(∨) 5. 变异系数是样本变量的绝对变异量。(×) 单项选择 1. 下列变量中属于非连续性变量的是( C ). A. 身高 B.体重 C.血型 D.血压 2. 对某鱼塘不同年龄鱼的尾数进行统计分析,可做成( A )图来表示. A. 条形 B.直方 C.多边形 D.折线 3. 关于平均数,下列说法正确的是( B ). A. 正态分布的算术平均数和几何平均数相等. B. 正态分布的算术平均数和中位数相等. C. 正态分布的中位数和几何平均数相等. D. 正态分布的算术平均数、中位数、几何平均数均相等。 4. 如果对各观测值加上一个常数a ,其标准差( D )。 A. 扩大√a 倍 B.扩大a 倍 C.扩大a 2倍 D.不变 5. 比较大学生和幼儿园孩子身高的变异度,应采用的指标是( C )。 A. 标准差 B.方差 C.变异系数 D.平均数 第三章 12 2--∑∑n n x x )( 《生物统计学》复习题 一、填空题(每空1分,共10分) 1.变量之间的相关关系主要有两大类:( 因果关系),(平行关系 ) 2.在统计学中,常见平均数主要有(算术平均数)、(几何平均数 )、(调和平均数) 3.样本标准差的计算公式( 1)(2--= ∑n X X S ) 4.小概率事件原理是指(某事件发生的概率很小,人为的认为不会发生 ) 5.在标准正态分布中,P (-1≤u ≤1)=(0。6826 ) (已知随机变量1的临界值为0.1587) 6.在分析变量之间的关系时,一个变量X 确定,Y 是随着X 变化而变化,两变量呈因果关系,则X 称为(自变量),Y 称为(依变量) 二、单项选择题(每小题1分,共20分) 1、下列数值属于参数的是: A 、总体平均数 B 、自变量 C 、依变量 D 、样本平均数 2、 下面一组数据中属于计量资料的是 A 、产品合格数 B 、抽样的样品数 C 、病人的治愈数 D 、产品的合格率 3、在一组数据中,如果一个变数10的离均差是2,那么该组数据的平均数是 A 、12 B 、10 C 、8 D 、2 4、变异系数是衡量样本资料 程度的一个统计量。 A 、变异 B 、同一 C 、集中 D 、分布 5、方差分析适合于, 数据资料的均数假设检验。 A 、两组以上 B 、两组 C 、一组 D 、任何 6、在t 检验时,如果t = t 0、01 ,此差异是: A 、显著水平 B 、极显著水平 C 、无显著差异 D 、没法判断 7、 生物统计中t 检验常用来检验 A 、两均数差异比较 B 、两个数差异比较 C 、两总体差异比较 D 、多组数据差异比较 8、平均数是反映数据资料 性的代表值。 A 、变异性 B 、集中性 C 、差异性 D 、独立性 9、在假设检验中,是以 为前提。 A 、 肯定假设 B 、备择假设 C 、 原假设 D 、有效假设 10、抽取样本的基本首要原则是 考试轮次:2017-2018学年第一学期期末考试试卷编号 考试课程:[120770] 生物统计与实验设计命题负责人曾汉元 适用对象:生物与食品工程学院生物科学专业2015级审查人签字 考核方式:上机考试试卷类型:A卷时量:150分钟总分:100分 注意:答案中要求保留必要的计算和推理过程,全部答案保存为一个Word文档,文件名 为学号最后两位数+姓名。考试结束后不要关机。提交答卷后,请到主机看一下是否提交成功。第1题12分,第3题5分,第10题13分,其余的题各10分。 1、下表为某大学96位男生的体重测定结果(单位:kg),请根据资料分别计算以下指标:(1)算术平均数;(2)几何平均数;(3)中位数;(4)众数;(5)极差;(6)方差;(7)标准差;(8)变异系数;(9)标准误。(10) 绘制各体重分布柱形图。 66 69 64 65 64 66 70 64 59 67 66 66 60 66 65 61 61 66 67 68 62 63 70 65 64 66 68 64 63 60 60 66 65 61 61 66 59 66 65 63 58 66 66 68 64 65 71 61 62 69 70 68 65 63 66 65 67 66 74 64 70 64 59 67 66 66 60 66 65 61 61 66 67 68 62 63 70 65 64 66 68 64 63 60 60 66 65 61 61 66 59 66 65 63 58 66 2、已知1000株水稻的株高服从正态分布N(97,3 2),求: (1)株高在94cm以上的概率? (2)株高在90~99cm之间的概率? (3)株高在多少cm之间的中间概率占全体的99%? 3.已知某批30个小麦样品的平均蛋白质含量为14.5%,σ=2.50%,试进行95%置信度下的蛋白质含量的区间估计和点估计。 4、有一大麦杂交组合,F2代的芒性状表型有钩芒、长芒和短芒三种,观察计得其株数依次分别为348、11 5、157,试检验其比率是否符合9:3:4的理论比率。 5、某医院用某种中药治疗7例再生障碍性贫血患者,现将血红蛋白含量(g/L)变化的数据列在下面,假定资料满足各种假设测验所要求的前提条件,问:治疗前后之间的差别有无显著性意义? 患者编号 1 2 3 4 5 6 7 治疗前血红蛋白含量65 75 50 76 65 72 68 治疗后血红蛋白含量82 112 125 85 80 105 128 一、名词解释(8个小题,每小题2分,共16分) 1.完全随机设计 2.重复 3.试验处理 4.独立性检验 5.Ⅰ型错误 6.自由度 7.标准正态分布 8.交互作用 二、单项选择题(从下列各题四个备选答案中选出一个正确答案,并将其代号写在答题纸相应位置处。答案错选或未选者,该题不得分。14个小题,每小题1分,共14分) 1.在生物统计中,样本容量记为n 。关于大样本描述正确的是( ) A. n<20 B. n<30 C. n>20 D. n>30 2.关于系统误差描述正确的是( ) A.由许多人力无法控制的偶然因素综合作用造成的差异,在试验中难以消除。 B.由许多人力无法控制的偶然因素综合作用造成的差异,在试验中可以消除。 C.由试验处理间非试验条件的不同所造成的差异,在试验中可以消除。 D.由试验处理间非试验条件的不同所造成的差异,在试验中难以消除。 3.在多个处理比较的试验研究中,当处理数大于3时,各处理重复数的估计原则是( ) A. df e ≥5 B. df e ≥12 C. df e ≥20 D. df e ≥30 4.关于计数资料描述正确的是( ) A.计数资料的观察值只能是整数,它们之间的变异是连续的。 B.计数资料的观察值不一定是整数,它们之间的变异是连续的。 C.计数资料的观察值只能是整数,它们之间的变异是不连续的。 D.计数资料的观察值不一定是整数,它们之间的变异是不连续的。 5.在直线回归分析中,回归自由度等于 ( ) A.1 B.2 C.3 D.4 6.某猪场用80头猪检验某种疫苗是否有预防效果。注射疫苗的44头中有 12头发病,32头未发病;未注射的36头中有22头发病,14头未发病。在进行独立性检验时,其注射疫苗组的理论发病数为( ) A.18.7 B.25.3 C.15.3 D.20.7 7.研究发现,在标准化饲养管理条件下,某种家禽出壳重与上市重的直线回归方程为 (单位:g )。如果该家禽出壳重每增加1g ,则上市重增加( ) A.580.8 g B.22.2 g C.558.6 g D.603 g 8.决定系数r 2的取值范围是( ) A.-1,1 B. -1,0 C.0,1 D.-∞,+∞ 9.可估计和减少试验误差的手段是( ) A. 局部控制 B. 随机 C. 重复 D. 唯一差异原则 10.在单因素试验资料的方差分析中,总变异是指( ) A.全部测量值与各组均数之间的差异。 x y 2.228.580?+= 《生物统计学》第三版课后作业答案(李春喜、姜丽娜、邵云、王文林编着) 第一章概论(P7) 习题1.1 什么是生物统计学?生物统计学的主要内容和作用是什么? 答:(1)生物统计学(biostatistics)是用数理统计的原理和方法来分析和解释生物界各种现象和实验调查资料,是研究生命过程中以样本来推断总体的一门学科。 (2)生物统计学主要包括实验设计和统计推断两大部分的内容。其基本作用表现在以下四个方面:①提 供整理和描述数据资料的科学方法;②确定某些性状和特性的数量特征;③判断实验结果的可靠性; ④提供由样本推断总体的方法;⑤提供实验设计的一些重要原则。 习题1.2 解释以下概念:总体、个体、样本、样本容量、变量、参数、统计数、效应、互作、随机误差、系统误差、准确性、精确性。 答:(1)总体(populatian)是具有相同性质的个体所组成的集合,是研究对象的全体。 (2)个体(individual)是组成总体的基本单元。 (3)样本(sample)是从总体中抽出的若干个个体所构成的集合。 (4)样本容量(sample size)是指样本个体的数目。 (5)变量(variable)是相同性质的事物间表现差异性的某种特征。 (6)参数(parameter)是描述总体特征的数量。 (7)统计数(statistic)是由样本计算所得的数值,是描述样本特征的数量。 (8)效应(effection)试验因素相对独立的作用称为该因素的主效应,简称效应。 (9)互作(interaction)是指两个或两个以上处理因素间的相互作用产生的效应。 (10)实验误差(experimental error)是指实验中不可控因素所引起的观测值偏离真值的差异,可以分为随 机误差和系统误差。 (11)随机误差(random)也称抽样误差或偶然误差,它是有实验中许多无法控制的偶然因素所造成的实验 结果与真实结果之间产生的差异,是不可避免的。随机误差可以通过增加抽样或试验次数降低随机误差,但不能完全消。 (12) 系统误差(systematic)也称为片面误差,是由于实验处理以外的其他条件明显不一致所产生的倾 向性的或定向性的偏差。系统误差主要由一些相对固定的因素引起,在某种程度上是可控制的,只要试验工作做得精细,在试验过程中是可以避免的。 (13) 准确性(accuracy)也称为准确度,指在调查或实验中某一实验指标或性状的观测值与其真值接 近的程度。 (14) 精确性(precision)也称精确度,指调查或实验中同一实验指标或性状的重复观测值彼此接近程 度的大小。 (15)准确性是说明测定值堆真值符合程度的大小,用统计数接近参数真值的程度来衡量。精确性是反映 多次测定值的变异程度,用样本间的各个变量间变异程度的大小来衡量。 习题1.3 误差与错误有何区别? 答:误差是指实验中不可控制因素所引起的观测值偏离真值的差异,其中随机误差只可以设法降低,但不能避免,系统误差在某种程度上可控制、可克服的;而错误是指在实验过程中,人为的作用所引起的差错,是完全可以避免的。 第二章实验资料的整理与特征数的计算(P22、P23) 《生物统计学》期末考试试卷 一 单项选择(每题3分,共21分) 1.设总体服从),(2 σμN ,其中μ未知,当检验0H :220σσ=,A H :220σσ≠时,应选 择统计量________。 A. 2 (1)n S σ- B. 2 20(1)n S σ- X X 2.设123,,X X X 是总体2 ( , )N μσ的样本,μ已知,2 σ未知,则下面不是统计量的是_____。 A. 123X X X +- B. 41i i X μ=-∑ C. 2 1X σ+ D. 4 2 1 i i X =∑ 3.设随机变量~(0,1)X N ,X 的分布函数为()x Φ,则( 2)P X >的值为_______。 A. ()212-Φ???? B. ()221Φ- C. ()22-Φ D. ()122-Φ 4.假设每升饮水中的大肠杆菌数服从参数为μ的泊松分布,则每升饮水中有3个大肠杆菌的概率是________。 A.63e μ μ- B.36e μ μ- C.36e μ μ- D. 316 e μ μ- 5.在假设检验中,显著性水平α的意义是_______。 A. 原假设0H 成立,经检验不能拒绝的概率 B. 原假设0H 不成立,经检验不能拒绝的概率 C. 原假设0H 成立,经检验被拒绝的概率 D. 原假设0H 不成立,经检验被拒绝的概率 6.单侧检验比双侧检验的效率高的原因是________。 A .单侧检验只检验一侧 B .单侧检验利用了另一侧是不可能的这一已知条件 C .单侧检验计算工作量比双侧检验小一半 D. 在同条件下双侧检验所需的样本容量比单侧检验高一倍 7.比较身高和体重两组数据变异程度的大小应采用_____。 A .样本平均数 B. 样本方差 C. 样本标准差 D. 变异系数 2.2试计算下列两个玉米品种10个果穗长度(cm)的标准差和变异系数,并解释所得结果。24号:19,21,20,20,18,19,22,21,21,19; 金皇后:16,21,24,15,26,18,20,19,22,19。 【答案】1=20,s1=1.247,CV1=6.235%;2=20,s2=3.400,CV2=17.0%。 2.3某海水养殖场进行贻贝单养和贻贝与海带混养的对比试验,收获时各随机抽取50绳测其毛重(kg),结果分别如下: 单养50绳重量数据:45,45,33,53,36,45,42,43,29,25,47,50,43,49,36,30,39,44,35,38,46,51,42,38,51,45,41,51,50,47,44,43,46,55,42,27,42,35,46,53,32,41,4,50,51,46,41,34,44,46; 第三章概率与概率分布 3.3已知u服从标准正态分布N(0,1),试查表计算下列各小题的概率值: (1)P(0.3<u≤1.8);(2)P(-1<u≤1);(3)P(-2<u≤2);(4)P(-1.96<u≤1.96; (5)P(-2.58<u≤2.58)。 【答案】(1)0.34617;(2)0.6826;(3)0.9545;(4)0.95;(5)0.9901。 3.4设x服从正态分布N(4,16),试通过标准化变换后查表计算下列各题的概率值: (1)P(-3<x≤4);(2)P(x<2.44);(3)P(x>-1.5);(4)P(x≥-1)。 【答案】(1)0.4599;(2)0.3483;(3)0.9162;(4)0.8944。 3.5水稻糯和非糯为一对等位基因控制,糯稻纯合体为ww,非糯纯合体为WW,两个纯合亲本杂交后,其F1为非糯杂合体Ww。 (1)现以F1回交于糯稻亲本,在后代200株中试问预期有多少株为糯稻,多少株为非糯稻?试列出糯稻和非糯稻的概率; (2)当F1代自交,F2代性状分离,其中3/4为非糯,1/4为糯稻。假定F2代播种了2000株,试问糯稻株有多少?非糯株有多少? 课后答案网https://www.doczj.com/doc/0310065199.html,1=42.7,R=30,s1=7.078,CV1=16.58%;2=52.1,R=30,s2=6.335,CV2=12.16%。 第四章统计推断 课后答案网https://www.doczj.com/doc/0310065199.html,=0=21g,4.5接受HA:≠0;95%置信区间:(19.7648,20.2352)。 4.6核桃树枝条的常规含氮量为2.40%,现对一桃树新品种枝条的含氮量进行了10次测定,其结果为:2.38%、2.38%、2.41%、2.50%、2.47%、2.41%、2.38%、2.26%、2.32%、2.41%,试问该测定结果与常规枝条含氮量有无差别。 【答案】t=-0.371,接受H0:=0=2.40%。 4.7检查三化螟各世代每卵块的卵数,检查第一代128个卵块,其平均数为47.3粒,标准差为2 5.4粒;检查第二代69个卵块,其平均数为74.9粒,标准差为4 6.8粒。试检验两代每卵块的卵数有无显著差异。 【答案】u=-4.551,否定H0:1=2,接受HA:1≠2。 4.8假说:“北方动物比南方动物具有较短的附肢。”为验证这一假说,调查了如下鸟翅长(mm)资料:北方的:120,113,125,118,116,114,119;南方的:116,117,121,114,116,118,123,120。试检验这一假说。 【答案】t=-0.147,接受H0:1=2。 4.9用中草药青木香治疗高血压,记录了13个病例,所测定的舒张压(mmHg)数据如下:序 生物统计学各章题目 一 填空 1.变量按其性质可以分为(连续)变量和(非连续)变量。 2.样本统计数是总体(参数)的估计值。 3.生物统计学是研究生命过程中以样本来推断(总体)的一门学科。 4.生物统计学的基本内容包括(试验设计)和(统计分析)两大部分。 5.生物统计学的发展过程经历了(古典记录统计学)、(近代描述统计学)和(现 代推断统计学)3个阶段。 6.生物学研究中,一般将样本容量(n ≥30)称为大样本。 7.试验误差可以分为(随机误差)和(系统误差)两类。 判断 1.对于有限总体不必用统计推断方法。(×) 2.资料的精确性高,其准确性也一定高。(×) 3.在试验设计中,随机误差只能减小,而不能完全消除。(∨) 4.统计学上的试验误差,通常指随机误差。(∨) 二 填空 1.资料按生物的性状特征可分为(数量性状资料)变量和(质量性状资料)变 量。 2. 直方图适合于表示(连续变量)资料的次数分布。 3.变量的分布具有两个明显基本特征,即(集中性)和(离散性)。 4.反映变量集中性的特征数是(平均数),反映变量离散性的特征数是(变异数)。 5.样本标准差的计算公式s=( )。 判断题 1. 计数资料也称连续性变量资料,计量资料也称非连续性变量资料。(×) 2. 条形图和多边形图均适合于表示计数资料的次数分布。(×) 3. 离均差平方和为最小。(∨) 4. 资料中出现最多的那个观测值或最多一组的中点值,称为众数。(∨) 5. 变异系数是样本变量的绝对变异量。(×) 单项选择 1. 下列变量中属于非连续性变量的是( C ). A. 身高 B.体重 C.血型 D.血压 2. 对某鱼塘不同年龄鱼的尾数进行统计分析,可做成( A )图来表示. A. 条形 B.直方 C.多边形 D.折线 3. 关于平均数,下列说法正确的是( B ). 12 2--∑∑n n x x )( 最新生物统计学期末复习题库及答案 填空 1.变量按其性质可以分为(连续)变量和(非连续)变量. 2.样本统计数是总体(参数)的估计值. 3.生物统计学是研究生命过程中以样本来推断(总体)的一门学科. 4.生物统计学的基本内容包括(试验设计)和(统计分析)两大部分. 5.生物统计学的发展过程经历了(古典记录统计学)、(近代描述统计学)和(现代推断统计学)3个阶段. 6.生物学研究中,一般将样本容量(n ≥30)称为大样本. 7.试验误差可以分为(随机误差)和(系统误差)两类. 判断 1.对于有限总体不必用统计推断方法.(×) 2.资料的精确性高,其准确性也一定高.(×) 3.在试验设计中,随机误差只能减小,而不能完全消除.(∨) 4.统计学上的试验误差,通常指随机误差.(∨) 第二章 填空 1.资料按生物的性状特征可分为(数量性状资料)变量和(质量性状资料)变量. 2. 直方图适合于表示(连续变量)资料的次数分布. 3.变量的分布具有两个明显基本特征,即(集中性)和(离散性). 4.反映变量集中性的特征数是(平均数),反映变量离散性的特征数是(变异数). 5.样本标准差的计算公式s=( ). 判断题 1. 计数资料也称连续性变量资料,计量资料也称非连续性变量资料.(×) 2. 条形图和多边形图均适合于表示计数资料的次数分布.(×) 3. 离均差平方和为最小.(∨) 4. 资料中出现最多的那个观测值或最多一组的中点值,称为众数.(∨) 5. 变异系数是样本变量的绝对变异量.(×) 单项选择 1. 下列变量中属于非连续性变量的是( C ). A. 身高 B.体重 C.血型 D.血压 2. 对某鱼塘不同年龄鱼的尾数进行统计分析,可做成( A )图来表示. A. 条形 B.直方 C.多边形 D.折线 3. 关于平均数,下列说法正确的是( B ). A. 正态分布的算术平均数和几何平均数相等. B. 正态分布的算术平均数和中位数相等. C. 正态分布的中位数和几何平均数相等. D. 正态分布的算术平均数、中位数、几何平均数均相等. 4. 如果对各观测值加上一个常数a ,其标准差( D ). A. 扩大√a 倍 B.扩大a 倍 C.扩大a 2倍 D.不变 5. 比较大学生和幼儿园孩子身高的变异度,应采用的指标是( C ). A. 标准差 B.方差 C.变异系数 D.平均数 12 2--∑∑n n x x )( 。 第一章概论 解释以下概念:总体、个体、样本、样本容量、变量、参数、统计数、效应、互作、随机误差、系统误差、准确性、精确性。 第二章试验资料的整理与特征数的计算习题 2.1 某地100 例30 ~40 岁健康男子血清总胆固醇(mol · L -1 ) 测定结果如下: 4.77 3.37 6.14 3.95 3.56 4.23 4.31 4.71 5.69 4.12 4.56 4.37 5.39 6.30 5.21 7.22 5.54 3.93 5.21 6.51 5.18 5.77 4.79 5.12 5.20 5.10 4.70 4.74 3.50 4.69 4.38 4.89 6.25 5.32 4.50 4.63 3.61 4.44 4.43 4.25 4.03 5.85 4.09 3.35 4.08 4.79 5.30 4.97 3.18 3.97 5.16 5.10 5.85 4.79 5.34 4.24 4.32 4.77 6.36 6.38 4.88 5.55 3.04 4.55 3.35 4.87 4.17 5.85 5.16 5.09 4.52 4.38 4.31 4.58 5.72 6.55 4.76 4.61 4.17 4.03 4.47 3.40 3.91 2.70 4.60 4.09 5.96 5.48 4.40 4.55 5.38 3.89 4.60 4.47 3.64 4.34 5.18 6.14 3.24 4.90 计算平均数、标准差和变异系数。 【答案】=4.7398, s=0.866, CV =18.27 % 2.2 试计算下列两个玉米品种10 个果穗长度(cm) 的标准差和变异系数,并解释所得结果。 24 号:19 ,21 ,20 ,20 ,18 ,19 ,22 ,21 ,21 ,19 ; 金皇后:16 ,21 ,24 ,15 ,26 ,18 ,20 ,19 ,22 ,19 。 【答案】 1 =20, s 1 =1.247, CV 1 =6.235% ; 2 =20, s 2 =3.400, CV 2 =17.0% 。 2.3 某海水养殖场进行贻贝单养和贻贝与海带混养的对比试验,收获时各随机抽取50 绳测其毛重(kg) ,结果分别如下: 单养50 绳重量数据:45 ,45 ,33 ,53 ,36 ,45 ,42 ,43 ,29 ,25 ,47 ,50 ,43 ,49 ,36 ,30 ,39 ,44 ,35 ,38 ,46 ,51 ,42 ,38 ,51 ,45 ,41 ,51 ,50 ,47 ,44 ,43 ,46 ,55 ,42 ,27 ,42 ,35 ,46 ,53 ,32 ,41 ,48 ,50 ,51 ,46 ,41 ,34 ,44 ,46 ; 混养50 绳重量数据:51 ,48 ,58 ,42 ,55 ,48 ,48 ,54 ,39 ,58 ,50 ,54 ,53 ,44 ,45 ,50 ,51 ,57 ,43 ,67 ,48 ,44 ,58 ,57 ,46 ,57 ,50 ,48 ,41 ,62 ,51 ,58 ,48 ,53 ,47 ,57 ,51 ,53 ,48 ,64 ,52 ,59 ,55 ,57 ,48 ,69 ,52 ,54 ,53 ,50 。 试从平均数、极差、标准差、变异系数几个指标来评估单养与混养的效果,并给出分析结论。【答案】 1 =4 2 . 7, R=30, s 1 =7 . 078, CV 1 =16 . 58% ; 2 =52.1,R=30 ,s 2 =6.335, CV 2 =12.16% 。生物统计学期末复习题库及答案
《生物统计学》复习题及答案
生物统计学考试试卷及答案
生物统计学模拟试题4
李春喜生物统计学第三版课后作业答案
《生物统计学》期末考试试卷
生物统计学(第四版)答案 1—6章
生物统计学各章题目(含答案)
最新生物统计学期末复习题库及答案
最新生物统计学课后习题解答-李春喜
相关主题
文本预览