R. Automatic camera calibration and scene reconstruction with scale-invariant features
- 格式:pdf
- 大小:5.29 MB
- 文档页数:11

双目立体相机自标定方案的研究一、双目立体相机自标定原理双目视觉是通过两个摄像机从不同的角度拍摄同一物体,根据两幅图像重构出物体。
双目立体视觉技术首先根据已知信息计算出世界坐标系和图像坐标系的转换关系,即世界坐标系和图像坐标系的透视投影矩阵,将两幅图像上对应空间同一点的像点匹配起来,建立对应点的世界坐标和图像坐标的转换关系方程,通过求解方程的最小二乘解获取空间点的世界坐标系,实现二维图像到三维图像的重构。
重构的关键问题是找出世界坐标系和图像坐标系的转换关系--透视投影矩阵。
透视投影矩阵包含了图像坐标系和相机坐标系的转换关系,即相机的内参(主要是相机在两坐标轴上的焦距和相机的倾斜角度),以及相机坐标系和世界坐标系的转换关系,即相机的外参(主要是相机坐标系和世界坐标系的平移、旋转量)。
相机标定的过程就是确定相机内参和相机外参的过程。
相机自标定是指不需要标定块,仅仅通过图象点之间的对应关系对相机进行标定的过程。
相机自标定技术不需要计算出相机的每一项参数,但需要求出这些参数联系后生成的矩阵。
二、怎样提高摄像机自标定精确度?方法一、.提高估算基本矩阵F传统的相机自标定采用的是kruppa方程,一组图像可以得到两个kruppa方程,在已知3对图像的条件下,就可以算出所有的内参数。
在实际应用中,由于求极点具有不稳定性,所以采取基本矩阵F分解的方法来计算。
通过矩阵的分解求出两相机的投射投影矩阵,进而实现三维重构。
由于在获取图像过程中存在摄像头的畸变,环境干扰等因素,对图像会造成非线性变化,采用最初提出的线性模型计算 f 会产生误差。
非线性的基本矩阵估计方法得到提出。
近年来非线性矩阵的新发展是通过概率模型降低噪声以提高估算基本矩阵的精度。
方法二、分层逐步标定法。
该方法首先对图像做射影重建,再通过绝对二次曲线施加约束,定出仿射参数和摄像机参数。
由于它较其他方法具有较好的鲁棒性,所以能提高自标定的精度。
方法三、利用多幅图像之间的直线对应关系的标定法。
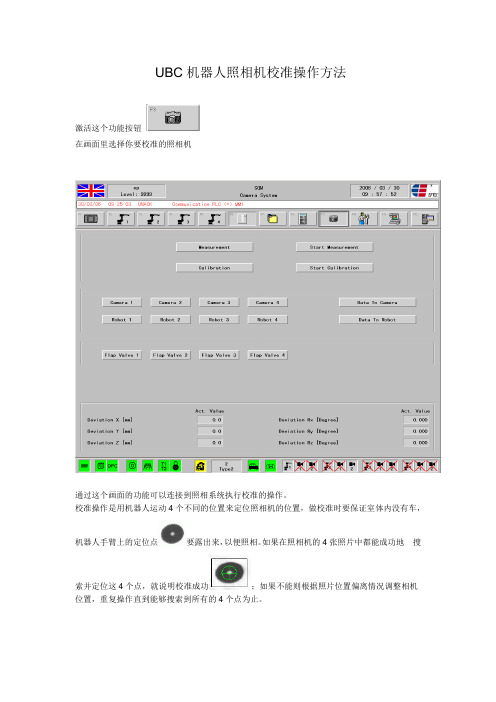
UBC机器人照相机校准操作方法
激活这个功能按钮
在画面里选择你要校准的照相机
通过这个画面的功能可以连接到照相系统执行校准的操作。
校准操作是用机器人运动4个不同的位置来定位照相机的位置,做校准时要保证室体内没有车,
机器人手臂上的定位点要露出来,以便照相。
如果在照相机的4张照片中都能成功地搜
索并定位这4个点,就说明校准成功;如果不能则根据照片位置偏离情况调整相机位置,重复操作直到能够搜索到所有的4个点为止。
操作控制按钮如下:(不限于校准)。

An Implementation of Camera Calibration AlgorithmsMeredith DrennanDepartment of Electrical and Computer EngineeringClemson UniversityAbstractCamera calibration is an important preprocessing step in computer vision applications. This paper seeks to provide an introduction to camera calibration procedures. It also discusses an implementation of automating point correspondences in known planar objects. Finally, results of a new implementation of Zhang’s calibration procedure are compared to other open source implementation results.1.IntroductionComputer vision is inherently plagued by the loss of dimensionality incurred when capturing a 3D photo in a 2D image. Camera calibration is an important step towards recovering three-dimensional information from a planar image. Over the past twenty years several algorithms have proposed solutions to the problem of calibration. Among the most popular are Roger Tsai’s algorithm [5], Direct Linear Transformation (DLT), and Zhang’s algorithm[6]. The focus of this paper is on Zhang’s algorithm because it is the basis behind popular open source implementations of camera calibration i.e. Intel’s Open CV and Matlab’s calibration toolkit [1].2.MethodsCalibration relates known points in the world to points in an image, in order to do so one must first acquire a series of known world points. The most common method is to use known planar objects at different orientations with respect to the camera to develop an independent series of data points. The calibration object chosen in this implementation is a 6x6 checkerboard with the corner points as the known world points. Most corner detector algorithms for camera calibration use edge detection to find the structure of the checkerboard, fit lines to the data points and compute the intersection of the lines in order to find the corners. This technique can be very accurate, providing in some cases accuracy of better than one tenth of a pixel but requires complicated line fitting algorithms. The implementation used here is based on feature detection by pinpointing windows with high variances in the X and Y directions. The points corresponding to the 36 highest variances (6x6 checkerboard implies 36 corners) are then chosen as the corner points. A simple image masking technique is used to ensure that no corner is detected twice. This is a much simpler implementation but experimental results show that accuracy is lost (see results section).The corners may be transformed into world points by assuming an origin at the top left corner of the checkerboard and then imposing the constant distance of each square between neighboring corners.Once a series of world points have been developed the homography matrix must be computed. This matrix becomes essentially a3x3 matrix relating world points to image points. The homography (H) can then be processed into intrinsic parameter (A), rotation, and translation matrices. We may assume that Z = 0 without loss of generality because a planar object is used to perform the calibration [6].The steps to compute the homography and intrinsic parameter matrices are as follows:sm = H M(1)Where m = [u, v, 1]T in the image plane coordinates and M = [x, y, 1]T in the model plane coordinates. From equation 1, the homography may be determined to within a scale factor (s).Computing the homography matrix takes the following form (from [2]): [x 1, y 1, 1, 0, 0, 0, -u 1x 1, -u 1y 1, -u 1,0, 0, 0, x 1, y 1, 1, -v 1x 1, -v 1y 1, -v1(2)x n , y n , 1, 0, 0, 0, -u n x n , -u n y n , -u n ,0, 0, 0, x n , y n , 1, -v n x n , -v n y n , -v n ]h’ = 0 Where h’ is a 9x1 column vector to be reshaped into the 3x3 homography H . By stacking this equation for n points in an image, the over-determined system can be solved using the eigen vector associated with the second smallest eigen value found via the SVD.Note that equation 2 introduced a matrix whose elements have various units, some of pixels, some meters, and some pixels*meters. It is important to normalize this matrix in order to achieve more stable results in the output.The following normalization matrix is used [4](3)where w and h are the image width and height respectively.Once H has been calculated the value of matrix B is estimatedB =(4)B is a symmetric 3x3 matrixLet b = [B11 B12 B22 B13 B23 B33] (5) andVij = [h i h ji , h i1h j2+h i2h j1, h i2h j2, h i3h j1+h i1h j3,h i3h j2+h i2h j3, h i3h j3](6)G =(15)The intrinsic matrix, A can then be found by denormalizing A’A = N-1A’ (16)For more information on the preceding algorithms see [3], [4], [6]. Further calculations can be done to find the rotation and translation matrices corresponding to each image and the first and second order distortion coefficients as described in [6].3.ResultsCode has been written in C++ in order to test the accuracy of the algorithms for feature detection and Zhang’s method discussed previously. As a baseline, the same camera (Dynex DX-WEB1C webcam) was also calibrated using two common open source implementations of Zhang’s calibration; Matlab’s toolkit available on the web [2], and Intel’s Open CV implementation. The number of input images to all three calibration tools has been kept constant at three. Using Blepo’s demo implementation of the Open CV code requires a nine square by six checkerboard input while both Matlab and the author’s version received the same 6x6 checkerboard images, therefore roughly the same data was fed to all three versions.A.Corner DetectionUsing a standard feature detection algorithm which searches for areas of high variances in X and Y directions, accuracy can be obtained at an average of within 2.2 pixels with a standard deviation of 1.4. While this is clearly not as accurate as calibration tools which use line fitting techniques, the prime advantage of this method of corner detection is simplicity.Figure 1 Checkerboard Variances and CornersFigure 1 shows an output of the feature detection on a standard checkerboard. Lines in gray mark areas of high variance in the X direction, and lines in white indicate areas of high variance in the Y direction. The points in blue mark the possible corners.A standard sort algorithm finds the areas of highest variance. Two techniques are used to ensure that a corner is not detected twice, first the image is fed to a Canny edge detector in order to reduce the number of possible corners. Then an image mask ensures that no other pointwithin 15 pixels is marked as a corner.Figure 2 Corners FoundB.Calibration AlgorithmOnce the corners have been detected, the calibration algorithm performs a series of steps as indicated in the methods section. The outputof the calibration is an intrinsic parameter matrix (A ) whose elements are described below andcompared to Matlab and Open CV results.Figure 1 Principle PointFigure 1 shows the observed principle point according to each implementation. All shown estimations are reasonable as the expected principle point would be at the center. Forreference purposes a pink square is drawn at the center of the image.The matrix A also contains values of α and β, where α/ β is the ratio of pixel width to height and is equal to 1 for most standard cameras. For the given camera this ratio averages at .9998 in Open CV, and .9919 in Matlab, whereas the mean ratio of the author’s implementation equals 1.53. While this parameter provides a large drawback to the use of this software as a calibration tool, it is important to note that both Matlab and Open CV perform optimization after the initial calculations based on Zhang’s method which use apriori knowledge of typical camera values such as α/ β ~1, [1] therefore future work can provide much better results.Implementation α/β Open CV 0.9998 Matlab0.9919 Author’s Version1.536Figure 2 Aspect Ratio ComparisonOne advantage to the use of the software developed by the author and describedthroughout this paper over other open source calibration tools is the capability of displaying not only the intrinsic matrix A, but also rotation, translation, and homography matrices for each image as well as focal length. This may not be important to a casual user, but it has thepotential to help guide those who are developing their own calibration software.Disclaimer: the focal length, rotation, and translation matrices are not calculated using Zhang’s method but are the result of anincomplete implementation of Tsai’s algorithm the author developed prior to implementing Zhang’s algorithm. See [5] for more detail. 4. ConclusionsThis paper describes a novel implementation of Zhengyou Zhang’s calibration algorithm with automatic feature detection to find the corners of the calibration object. The accuracy of which is reasonable although not as impressive as the currently available open source software. Future work can be done to improve this byimplementing optimization algorithms such as gradient descent or Levenberg-Marquardt. One advantage to the author’s calibrationimplementation as described throughout this paper is its ability to display intermediate matrices for guidance to those users who are developing their own calibration software. 5. References[1] Bouguet, Jean-Yves, (2008) Camera Calibration Toolbox for Matlab/bouguetj/calib_doc/[2] Boyle, Roger, Vaclav Hlavac, and Milan Sonka (1999) Image Processing, Analysis, and Machine Vision Second Edition. PWS Publishing.[3] Hanning, Tobais and Rene Schone (2007) Additional Constraints for Zhang's Closed Form Solution of the Camera Calibration Problem. University of Passau Technical Report.http://www.fim.uni-passau.de/fileadmin/files/forschung/mip-berichte/MIP-0709.pdf[4] Teixeira,Lucas Marcello Gattass, and Manuel Fernandez. Zhang's Calibration: Step by Stephttp://www.tecgraf.puc-rio.br/~mgattass/calibration/zhang_latex/zhang.pdf[5] Tsai, Roger Y (1987) A Versatile Camera Calibration Technique for High Accuracy 3D Machine Vision Metrology Using Off the Shelf Cameras and LensesIEEE Journal of Robotics and Automation Vol. RA-3 No 4 pp.323-346/bouguetj/calib_doc/papers/T sai.pdf[6] Zhang,Zhengyou. (1999) A Flexible New Technique for Camera Calibration. Microsoft Research Technical Report。


Camera-Assisted XY Calibration(CXC)User ManualBackgroundThe conventional standard for calibrating XY offsets on dual extruders,IDEX machines,and tool changers has been to print calibration line patterns and adjust the offset such that the lines match up.However,many printers are only capable of calibrating with PLA,requiringfilament switches.Furthermore,machines that are capable of calibrating other materials require waiting for the bed to heat to an acceptable temperature.This can take a significant amount of time for bed temps at80C+.The CXC eliminates the need for all of this by utilizing a camera and software to assist in quickly and easily calibrating the XY offsets with a higher degree of accuracy than existing standard methods*.*The calibration accuracy is limited by your machine’s minimum manual jog resolution.For example,if the minimum manual jog resolution on your printer is0.1mm,the maximum error when aligning one nozzle to the software’s crosshair will be up to+/-0.05mm.Since nozzles are aligned in pairs,the worst case maximum error is+/-0.1mm,however it is likely that your calibration accuracy will be better than this worst case scenario.RequirementsThe CXC was designed to be printer agnostic,however,to do so,your printer and setup must fulfill three requirements:1.Windows operating system2.Ability to jog the gantry in steps of0.1mm or less and read the position3.Ability to override XY calibration values(or tune offsets in the slicer)●USB camera module●High brightness white LEDs●Adjustable focus,short focal length lens●Integrated magnet for adhering to spring steel build plates●Reusable,washable adhesive stickers for non-steel build plates●4x M3mounting holes*●2m long USB cable***Early versions may have holes for M2.5or2-28thread rolling screws**Early versions may come with a short cable plus an additional USB extender●Software can be downloaded here●Superimposed crosshair&circle help align the center of the nozzle●The camera exposure can be adjusted with a slider●The camera zoom can be adjusted with a slider●The camera connection can be refreshed with the refresh button●Flexible parameters to accommodate any printer type regardless of how theprinter calculates and uses the offsets●Detailed tool-tips on all parameters●Automatic saving of parameters●Settings for IDEX,dual extruders and tool changers1.Download and extract the software.Run“setup.exe”to install the software.2.Connect the CXC to a laptop or PC USB port3.Determine whether the magnet will work on your printer,or if you need toattach the reusable adhesive pad-if the latter,attach it over the magnet4.Run the software5.Select the“Generic”profile6.Adjust the offset inversion parameters if necessary*7.Hit“Start”and follow the instructions to complete calibration8.Print the verification model to ensure nozzle alignment**9.Enter your printer and parameters into the shared parameter spreadsheet*** *Not necessary for most printer types-see Custom Profile&Printer section for more details and check here to see a list of parameters on user tested printers**Optional-Printing the verification model is only recommended forfirst time calibrations of your printer to ensure settings are correct***Optional-this spreadsheet will getfilled out over time by our user base so we can share parameter settings to the community1.Download and extract the software.Run“setup.exe”to install the software.2.Connect the CXC to a laptop or PC USB port3.Determine whether the magnet will work on your printer,or if you need toattach the reusable adhesive pad-if the latter,attach it over the magnet4.Run the software5.Select the“Generic”profile6.Adjust the offset inversion parameters if necessary*7.Enter the physical Nozzle Distance if required on your printer*8.Select the Left or Right origin parameters if necessary*9.Hit“Start”and follow the instructions to complete calibration10.Print the verification model to ensure nozzle alignment**11.Enter your printer and parameters into the shared parameter spreadsheet*** *Not necessary for most printer types-see Custom Profile&Printer section for more details and check here to see a list of parameters on user tested printers**Optional-Printing the verification model is only recommended forfirst time calibrations of your printer to ensure settings are correct***Optional-this spreadsheet will getfilled out over time by our user base so we can share parameter settings to the communityQuick Start-TOOL CHANGER1.Download and extract the software.Run“setup.exe”to install the software.2.Connect the CXC to a laptop or PC USB port3.Determine whether the magnet will work on your printer,or if you need toattach the reusable adhesive pad-if the latter,attach it over the magnet4.Run the software5.Select the“Tool Changer”property*6.Hit“Start”and follow the instructions to complete calibration**7.Print the verification model to ensure nozzle alignment***8.Enter your printer and parameters into the shared parameter spreadsheet**** *The CXC has been tested to work with the E3D tool changers.If you have a different tool changer you may need to adjust other parameters-see Custom Profile&Printer section for more details and check here to see a list of parameters on user tested printers**For the E3D system,T0will correspond to the probe location,while T1-T4correspond to the actual extruders***Optional-Printing the verification model is only recommended forfirst time calibrations of your printer to ensure settings are correct****Optional-this spreadsheet will getfilled out over time by our user base so we can share parameter settings to the communityWe’ve created a brief Quick Start document for E3D Tool Changers here.Custom Profile&PrinterFor printers that do not work with the generic profiles,there are some important parameters in the software to explain.For a spreadsheet of user tested and contributed printer parameters-see here.If you need to modify parameters for your printer,we encourage you to comment in the spreadsheet,or reach out to us at************************so we can keep track of this for our user base.IDEX Settings Non-IDEX(Dual)SettingsTo understand the additional non-IDEX parameters observe the picture below(from the Snapmaker Artisan).The“Default Offset”refers to our physical“Nozzle Distance”. This is the theoretical X offset between the nozzles.In many dual extrusion printers, the X Offset you enter into the machine follows a similar equation to the one below. In these instances the“Nozzle Distance”in our CXC software can be left at zero.However,some printers remove the“Default Offset”or the“Nozzle Distance”from the offset before being entered into the printer settings.In these cases,the X Offset follows the formula below.For these printers,we need to know the“Default Offset”or the“Nozzle Distance”ahead of time so the CXC software can calculate the correct number to enter into the printer settings.A detailed explanation of each parameter is documented in the table below.These descriptions are also present in the software as hoverable tool-tips.Invert X-Axis Inverts the calculated X offset.Some printers may want their enteredoffset to represent the actual,physicaloffset and will compensate thedifference infirmware.Other printersmay want the entered offset torepresent the distance the machineneeds to compensate for on all travels.For example,if the right extruder is+0.1mm relative to the left,someprinters may expect an entered offset of+0.1mm and will subtract0.1mm from allX moves.For other systems,the enteredoffset may need to be-0.1mm,indicating that X moves for the rightextruder need to be compensated bythis amount.This is off by default.Invert Y-Axis Inverts the calculated Y offset.Some printers may want their enteredoffset to represent the actual,physicaloffset and will compensate thedifference infirmware.Other printersmay want the entered offset torepresent the distance the machineneeds to compensate for on all travels.For example,if the right extruder is+0.1mm relative to the left,someprinters may expect an entered offset of+0.1mm and will subtract0.1mm from allY moves.For other systems,the enteredoffset may need to be-0.1mm,indicating that Y moves for the rightextruder need to be compensated bythis amount.This is off by default.Nozzle Distance Used in the offset calculations for dualextruder machines,this is ignored forIDEX printers.This value is commonly found in theslicer,user manual,or through technicalsupport.Some machines require removing thenozzle distance from the entered offset.For example,if the rightnozzle is+0.2mm relative to the left andhas a25mm nozzle distance,someprinters may expect+0.2mmas the entered offset,while othersrequire entering+25.2mm whichincludes the nozzle distance.For the latter scenario,leave the"Physical Offset"value at0.Left Origin Select this if your machine's origin is onthe left side(ie.moving left is a negativevalue while moving right is a positivevalue).This does not necessarily correspondwith the physical home location ofthe extruders and is driven by themachine coordinates.This is used to determine whether thenozzle distance should be subtractedor added during the offset calculations.Left Origin is typically the default onmost machines.Right Origin Select this if your machine's origin is onthe right side(ie.moving left is apositive value while moving right is anegative value).This does not necessarily correspondwith the physical home location ofthe extruders and is driven by themachine coordinates.This is used to determine whether thenozzle distance should be subtractedor added during the offset calculations.Left Origin is typically the default onmost machines.VerificationThere are many ways to verify XY offset calibrations.We prefer to print a calibration cube rather than line patterns,as the latter are fragile and not100%representative ofa real multi-material or multi-color print.●Calibration Cube-Left Extruder●Calibration Cube-Right ExtruderIf you do want to run a line pattern,we have a custom line pattern that you can use to run your verification.You are also welcome to use your own,or run the built-in calibration routine if your printer has one.We suggest printing ours with125%flow,ata slow speed like20mm/s.●Line Pattern-Left Extruder●Line Pattern-Right ExtruderBoth of thesefiles are only necessary for thefirst time you are calibrating and getting familiar with the process.You may need to re-run these if you have to change parameters like offset inversion.TroubleshootingIssue ResolutionOffset values do not match real life observations from verification printsBelow are some common reasons why your offset values may be incorrect.You did not clear existing XY offsetvalues from your printer and themachine is using these values tocompensate for moves performedduring calibration.You did not home the gantry afterclearing existing XY offsets and the machine is using the previous offsets.Your CXC moved during calibration.Instead of moving the right extruder directly to the absolute location of the left extruder,you incrementally stepped the extruder over.This can stackup error and should be avoided.Your machine is expecting inverted offset values.See the explanation in the Custom Profile&Printer section. You may not have the correct nozzle distance or origin type specified.See the explanation in the Custom Profile&Printer section.Re-running calibration is giving differentoffset values.If calibration is done correctly,you should be able to obtain the same XY offset values repeatably.You have existing XY offset values or you the values are different from what they were the last time you calibrated.You did not home the gantry after modifying offsets,but you did home the gantry after modifying offsets thefollowing time.Your CXC moved during calibration. Order of operations is critical during calibration-homing must always occur after changing of XY offset calibrationvalues.Software is not installing The software setup downloads andinstalls publishedfiles from our Githubpage.This is required for auto update tofunction.Therefore when you run“setup.exe”it requires an internetconnection.If you need to install thesoftware on an offline computer run the“.application”file instead.Once yourmachine is online again it will be able toauto update.If your machine is alwaysoffline,auto updates will not work andyou will need to update the softwaremanually upon software releases.For further troubleshooting or questions not answered in this document,contact us at************************。

科学网摄像机标定(camera calibration)笔记一作用建立3D到2D的映射关系,一旦标定后,对于一个摄像机内部参数K(光心焦距变形参数等,简化的情况是只有f错切=0,变比=1,光心位置简单假设为图像中心),参数已知,那么根据2D投影,就可以估计出R t;空间3D点所在的线就确定了,根据多视图(多视图可以是运动图像)可以重建3D。
如果场景已知,则可以把场景中的虚拟物体投影到2D图像平面(DLT,只要知道M即可)。
或者根据世界坐标与摄像机坐标的相对关系,R,T,直接在Wc位置渲染3D图形,这是AR的应用。
因为是离线的,所以可以用手工定位点的方法。
二方法1 Direct linear transformation (DLT) method2 A classical approach is "Roger Y. Tsai Algorithm".It is a2-stage algorithm, calculating the pose (3D Orientation, andx-axis and y-axis translation) in first stage. In secondstage it computes the focal length, distortion coefficients and the z-axis translation.3 Zhengyou Zhang's "a flexible new technique for cameracalibration" based on a planar chess board. It is based on constrains on homography.4个空间:世界,摄像机(镜头所在位置),图像(原点到镜头中心位置距离f),图像仿射空间(最终成像空间),这些空间原点在不同应用场合可以假设重合。
多功能一体机常用功能中英文对照1. 打印 - Print2. 复印 - Copy3. 扫描 - Scan4. 传真 - Fax5. 网络打印 - Network Printing6. 双面打印 - Duplex Printing7. 彩色打印 - Color Printing8. 黑白打印 - Black and White Printing9. 打印照片 - Photo Printing10. 打印文件 - Document Printing11. 自动文稿来排字 - Auto Drafting12. 打印素描 - Print Sketch13. 独立复印 - Standalone Copying14. 自动双面复印 - Automatic Duplex Copying15. 调整复印大小 - Resize Copying16. 复印文件 - Document Copying17. 复印照片 - Photo Copying18. 高分辨率扫描 - High-Resolution Scanning20. 扫描到网络文件夹 - Scan to Network Folder21. 扫描到USB - Scan to USB23. 扫描至PDF - Scan to PDF24. 传真文件 - Fax Documents25. 传真电子邮件 - Fax to Email26. 传真转发 - Forward Fax27. 密集打印 - Batch Printing28. 无线打印 - Wireless Printing29. 移动打印 - Mobile Printing30. 直接打印 - Direct Printing31. 远程打印 - Remote Printing32. 打印蓝图 - Print Blueprints33. 打印表格 - Print Spreadsheets34. 电子文件处理 - Electronic Document Handling35. 自动文档进给器 - Automatic Document Feeder36. 多页扫描 - Multi-Page Scanning37. 快速打印 - Quick Printing38. 自动航道选择 - Automatic Tray Selection39. 多功能控制面板 - Multi-Function Control Panel40. 高速打印 - High-Speed Printing41. 即插即用 - Plug and Play42. 自动开关机 - Auto Power On/Off43. 省电模式 - Power Saving Mode44. 耗材管理 - Supplies Management45. 打印预览 - Print Preview46. 快速拷贝 - Quick Copy47. 自动排序 - Automatic Sorting48. 自动双面扫描 - Automatic Duplex Scanning50. 打印明信片 - Print Postcards51. 对接多个设备 - Connect Multiple Devices52. 打印邮件 - Print Emails53. 打印备忘录 - Print Memos54. 自动校正 - Automatic Calibration55. 光盘打印 - Print on CDs/DVDs56. 快速扫描 - Quick Scanning57. 多种扫描模式 - Multiple Scanning Modes58. 传真存储 - Fax Storage59. 传真重传 - Fax Resend60. 电子邮件传真 - Email to Fax61. 电子文件转换 - Electronic File Conversion62. 打印讲义 - Print Handouts63. 防止用纸堵塞 - Paper Jam Prevention64. 自动补充纸张 - Automatic Paper Tray Refilling65. 快速替换墨盒 - Quick Ink Cartridge Replacement66. 打印通知 - Print Notifications67. 自动修复图像 - Automatic Image Correction68. 增强扫描质量 - Enhance Scanning Quality69. 打印多种纸张 - Print on Various Paper Types70. 打印宣传册 - Print Brochures71. 多种文件格式支持 - Support for Multiple File Formats72. 手机远程打印 - Mobile Remote Printing73. 网络共享 - Network Sharing74. 互联网打印 - Internet Printing75. 网络扫描 - Network Scanning76. 网络传真 - Network Faxing77. 即时打印 - Instant Printing78. 打印车票 - Print Tickets79. 打印发票 - Print Invoices80. 打印证件照 - Print ID Photos81. 快速打印照片 - Quick Photo Printing82. 打印贺卡 - Print Greeting Cards83. 自动识别纸张类型 - Automatic Paper Type Recognition84. 打印商业文件 - Print Business Documents85. 打印合同 - Print Contracts86. 打印报告 - Print Reports87. 多种打印设置 - Multiple Printing Settings88. 打印计划 - Print Schedules89. 自动封装文件 - Auto File Packaging90. 自动拍摄扫描 - Auto Capture Scanning91. 打印日记 - Print Journals92. 高质量打印 - High-Quality Printing93. 故障诊断 - Troubleshooting94. 打印密度调节 - Print Density Adjustment95. 碳粉调节 - Toner Adjustment96. 过滤扫描结果 - Filter Scanning Results97. 打印美术作品 - Print Artwork98. 打印季报表格 - Print Quarterly Reports99. 打印发表的文章 - Print Published Articles。
Automatic Camera Calibration and Scene Reconstruction with Scale-Invariant FeaturesJun Liu and Roger HubboldDepartment of Computer Science,University of ManchesterManchester,M139PL,United Kingdom{jun,roger}@Abstract.The goal of our research is to robustly reconstruct general3D scenes from2D images,with application to automatic model gener-ation in computer graphics and virtual reality.In this paper we aim atproducing relatively dense and well-distributed3D points which can sub-sequently be used to reconstruct the scene structure.We present novelcamera calibration and scene reconstruction using scale-invariant featurepoints.A generic high-dimensional vector matching scheme is proposedto enhance the efficiency and reduce the computational cost whilefindingfeature correspondences.A framework for structure and motion is alsopresented that better exploits the advantages of scale-invariant features.In this approach we solve the“phantom points”problem and this greatlyreduces the possibility of error propagation.The whole process requiresno information other than the input images.The results illustrate thatour system is capable of producing accurate scene structure and realistic3D models within a few minutes.1IntroductionThe possibility of being able to acquire3D information from2D images has at-tracted considerable attention in recent years.It offers promising applications in such areas as archaeological conservation,scene-of-crime analysis,architec-tural design,movie post-processing,to name but a few.The idea of automatic reconstruction from images is intriguing because,unlike other techniques which usually require special devices to obtain the data(ser scanner,ultrasound), the digital images are readily available.Although reconstructing3D models from 2D images is a very difficult problem,recent years have seen several theoretical breakthroughs,and a few systems have already been built.However,most of the systems only work under restrictive conditions,and are not readily applicable to more general cases.One of the most important stages of scene reconstruction is structure from motion(SfM),which determines the camera poses and scene structure based on image information alone.Feature points arefirst extracted from each input image,and they are tracked to provide information about the relations between the images.Therefore,feature extraction and tracking act as a starting point for scene reconstruction,and their performance largely determines the overall relia-bility of the reconstruction algorithm.Two of the most popular feature tracking G.Bebis et al.(Eds.):ISCV2006,LNCS4291,pp.558–568,2006.c Springer-Verlag Berlin Heidelberg2006Automatic Camera Calibration and Scene Reconstruction559 algorithms are the Harris corner detector[1]followed by Sum of Squared Differ-ence(SSD)matching[2,3,4,5],and the Kanade-Lucas-Tomasi(KLT)tracker [6,7].These algorithms work well when the baseline(i.e.viewpoint change be-tween images)is relatively small and the appearance of the features doesn’t change much across subsequences.However,this condition does not hold when the input data is a sequence of“sparse”images instead of a“dense”video stream, or where the appearances of the features change significantly with respect to the viewpoint.Therefore,a more robust feature tracking method is desirable to form a good foundation for the scene reconstruction problem.The Scale Invariant Feature Transformation(SIFT),first proposed by Lowe[8, 9],extracts distinctive features which act as descriptors of local image patches. These features are largely invariant to image scale and rotation,and partially in-variant(i.e.robust)to affine distortion,change in3D viewpoint,addition of noise and change in illumination.SIFT has become well-accepted by the computer vi-sion community.A recent evaluation by Mikolajczyk and Schmid[10]suggested that the SIFT-based descriptors performed the best among many other local de-scriptors,in terms of distinctiveness and robustness to various changes in viewing conditions.Successful applications of the SIFT algorithm have been reported in the areas of object recognition[8,9],panorama stitching[11]and augmented reality[12].Due to the invariant properties of SIFT,it can potentially tackle the problem of wide baseline matching and matching between significantly changing features. There is,however,very little literature about the application of SIFT in such areas as camera calibration and scene reconstruction.A similar but different work to ours is by Gordon and Lowe[12],where SIFT features are extracted and matched to relate any two images from an image sequence.In this paper we propose a more complete algorithm for SIFT feature matching and SfM computation.Our system is different from others in that we not only use SIFT features for camera pose estimation,but also their reconstructed3D positions for scene analysis.The rest of the paper is organised as follows:Section2introduces a new fea-ture matching algorithm based on SIFT,which improves the efficiency without compromising its accuracy.Section3discusses a novel framework for SfM,with the advantage that it can match features from non-adjacent images,thus solv-ing the problem of“phantom points”and making the system less prone to error propagation.Section4shows some experimental results to validate our method and Section5concludes our work.2A New Approach for SIFT Feature Matching2.1Related WorkThe SIFT algorithm computes,for each keypoint,its location in the image as well as a distinctive128-dimension descriptor vector associated with it.Matching a keypoint to a database of keypoints is usually done by identifying its nearest neighbour in that database.The nearest neighbour is defined as the keypoint560J.Liu and R.Hubboldwith minimum Euclidean distance to the descriptor vector.To reduce the number of spurious matches,the ratio R of the distance of the closest neighbour D to that of the second closest neighbour D is computed.The matches with a ratio greater than a certain threshold (0.8is suggested by Lowe)are discarded.Due to the high dimensionality of the keypoints,the matching process is rela-tively expensive.The naive exhaustive search has a complexity of O (nmd )where n is the number of keypoints in the database,m is the number of keypoints to be matched,and d is the dimension of the descriptor vector.The best algo-rithms,such as a k -d tree,provide no speedup over exhaustive search for more than about 10dimensional spaces [9].Therefore,two approximate matching al-gorithms have been proposed,namely Best-Bin-First(BBF)[13]and PCA-SIFT[14].The BBF algorithm is very similar to the k -d tree algorithm,except that the BBF algorithm restricts the search step so that it sets an absolute time limit on the search.As a result,the BBF algorithm returns a nearest neighbour at a high probability.However,our experiment shows that as the number of keypoints and the dimension increases,the BBF algorithm provides no significant speedup over the standard matching method.PCA-SIFT,on the other hand,reduces the dimensionality based on Principal Component Analysis.Both algorithms incur a certain amount of loss of correct matches.In our system SIFT is applied to act as a starting point for structure &motion and camera calibration,so it is desirable that the data is as noise-free as possible.2.2Problem SpecificationA formal specification of the matching problem is first outlined.Suppose we have in the database n points P ={P 0,P 1,...,P n −1},each of which comprises of a d dimensional descriptor vector [V 0,V 1,...,V d −1].We want to match m points P ={P 0,P 1,...P m −1},each with a descriptor vector of the same dimension [V 0,V 1,...,V d −1],to the database,in order to obtain a set of matched pairs S ={(P ,P )|P ↔P ,P ∈P ,P ∈P }.A matched pair (P i ,P j )has the property that P i is the nearest neighbour of P j in the database P ,i.e.,∀P k ∈P D(P i ,P j )≤D(P k ,P j )(1)where D(P i ,P j )is the Euclidean distance between the two descriptor vectors associated with the two keypoints.Furthermore,if P k is the second nearest neighbour to P j in the database,then another constraint should be satisfied that D(P i ,P j )/D(P k ,P j )≤thr(2)where thr is the threshold value,normally 0.8.This thresholding is designed to make sure that the match is distinctive enough from other possible matches,so as to discard many spurious matches.2.3The AlgorithmHere we present a new method which improves the efficiency without compromis-ing its accuracy.Our algorithm first performs a Principal Component AnalysisAutomatic Camera Calibration and Scene Reconstruction561 (PCA)on the two sets of keypoints P and P ,or more specifically,on the descrip-tor vectors associated with them.PCA is essentially a multivariate procedure which rotates the data such that maximum variabilities are projected onto the axes.In our case,the descriptor vector setsV={(V i0,V i1,...V i d−1)|P i∈P}(3)V ={(V j0,V j1,...V j d−1)|P j∈P }(4) are transformed intoV={( V i, V i1,... V i d−1)|P i∈P}(5)V ={( V j, V j1,... V j d−1)|P j∈P }(6)with V0and V 0representing the dimension of the greatest amount of varia-tion, V1and V 1representing the dimension of the second greatest amount of variation,and so on.The next step is that for every keypoint P j in P ,two initial full Euclidean distances between P j and thefirst two elements in P,P0and P1,are computed. These initial distances,D(P j,P0)and D(P j,P1),are compared,with the smaller one assigned to the nearest distance Nd,and the bigger one assigned to second nearest distance Snd.After the initialisation,the comparison continues,but without the necessity to compute the full Euclidean distance for each keypoint in P.Suppose now we want to test the keypoint P i and see whether it is a nearer neighbour to P j than the current nearest one.We start by computing the difference of the vector in thefirst dimension D2←( V j0− V i0)2,and compare it with the nearest distance squared Nd2.If D2≥Nd2,which indicates that P i cannot become the nearer neighbour,then it is unnecessary to compute the rest of the dimensions. If D2<Nd2,then the process continues by adding the difference of the vec-tor in the second dimension,D2←D2+( V j1− V i1)2.The aim of this method is to avoid unnecessary computations in the dimensional space,i.e.,to more quickly discard any keypoint which is unlikely to be the nearest neighbour.If, after going though all the dimensions d,D2<Nd2still holds,then we iden-tify P i as the new nearest neighbour by assigning Nd to Snd,and assigning D to Nd.The process continues until it reaches the end of the list P n−1.Thefinal stage is to compute the ratio R of the distance of the nearest neighbour Nd to that of the second nearest neighbour Snd:R=Nd/Snd.If R is below a certain threshold thr,then the matched pair is added to the set S,otherwise there is no reliable match.The role PCA plays here is to re-arrange the order of the dimensions so that the ones with larger variation come before the ones with smaller variation.This allows this algorithm to execute more quickly,i.e. to discard faster the keypoint which is not the nearest neighbour.562J.Liu and R.Hubbold2.4Experimental ResultsWe use an experimental setup where we match 2sets of keypoints of same size.This assumption is valid when the SIFT algorithm is applied to camera calibra-tion,in which case the number of keypoints detected for each frame does not vary very much.The number of keypoints is in a range from 250to 4000.We use Pollefeys’Castle sequence[15]to illustrate the algorithm.Two images are randomly selected from the Castle Sequence,from which the SIFT algorithm can detect up to around 4200keypoints for each image.Then a random subset of the detected keypoints is selected and matched using the standard exhaustive search algorithm as well as our new algorithm.In this experiment 8different image pairs are tested,and each pair is matched 3times with a certain number of keypoints selected.The average time spent on keypoint matching is compared and the result is shown in Figure 1.The result suggests that for the cases whereFig.1.Efficiency comparison between the standard exhaustive search algorithm and our improved algorithmthe number of keypoints is less than 1000,the performance of our algorithm is only slightly worse than the standard algorithm.This is because the PCA com-putation in our algorithm introduces an overhead,which offsets the speedup for modest point sets.However,our algorithm significantly outperforms the original one when the number of keypoints exceeds 3000.Therefore,our algorithm is ideal for a large keypoint database,as it greatly improves the efficiency while preserving the accuracy.3A Novel Framework for Structure from Motion 3.1The “Phantom Points”ProblemThe classical SfM only relates an image to the previous one.It is implicitly assumed that once a point is out of frame or occluded,it will not reappear.Although this is true for many sequences,the assumption does not always hold.Imagine a cer-tain point becomes occluded for several frames in the middle of the sequence,butAutomatic Camera Calibration and Scene Reconstruction563 becomes visible again for the rest of the sequence.The classical SfM method will generate two different3D points although they are supposed to be the same3D point.Here we coin the term phantom points,referring to points which the algo-rithm generates,but which do not really exist separately.The“phantom points”problem has so far not been properly addressed in the computer vision literature. Unfortunately,the problem often occurs in real image sequences,where there are foreground occlusions,or the camera moves back and forth.3.2A New Framework for SfMWe start by extracting the keypoints from thefirst image and inserting them into a list of vectors.Each keypoint P has three properties associated with it: its location in the image,coord,its feature vector,fvec,and the frame number of the image which it is from,fnum.After inserting the keypoints of thefirst image,the list is illustrated in Figure2(a)(with fnum marked):(a)(b)Fig.2.(a):Adding thefirst frame:(1)Features are extracted with SIFT,each of which contains the information of its location in the image coord,its feature vector fvec,and the frame number of the image which it is from fnum.Here only fnum is illustrated;(2)The keypoints are inserted at the back of the list.(b):Adding the second frame: (1)Features are extracted,which are matched to the list;(2)For those whichfind a match,we extend the vector and move the pair(3)to the front of the list;(4)For those which cannotfind a match,we insert them at the front of the list.The keypoints from the second image are extracted and matched with the method described in Section2.3.For those which do not match any keypoints in Frame0,we simply insert them at the front of the list.For those which do match,we extend the vector and move the pair to the front of the list,which is illustrated in Figure2(b).From the matched pairs a fundamental matrix F is computed.Based on F, spurious matches(the ones which do not adhere to the epipolar constraint) are detected.The false matches are,however,not removed from the list as in traditional methods.Instead,false matches are split:we remove the last item from the vector and insert it at the front of the list(See Figure3(a)).This way the keypoints that SIFT detects are utilised to the maximum:the falsely matched keypoints are given another chance to match the keypoints from later frames.564J.Liu and R.Hubbold(a)(b)Fig.3.(a):Rejecting outliers:outliers are detected based on the computed fundamen-tal matrix F.If a pair is detected as an outlier,then the algorithm(1)removes the unmatched features and(2)insert it at the front of the list.(b)Adding the third frame: (1)Features are extracted,and(2)matched to the last item of each vector.Note that the keypoints from Frame2can be matched to both those from Frame1and those from Frame0.The initial poses and structure are computed the same way as the traditional method.When a new view is available,the extracted keypoints are compared to the last item of each vector in the list.Again the outliers are“discarded”by splitting the matches rather than removing them.Figure3(b)shows,as an example,the status of the list after adding Frame2.Note that the keypoints from Frame2can be matched to both those from Frame1and those from Frame0. This is important because the matching is no longer restricted to adjacent frames. The framework described here natively solves the“phantom points”problem. 4Experimental ResultsOur SfM framework has been tested with the dinosaur sequence[16](see Fig-ure5(b))from the Robotics Group,University of Oxford.Our work is different from theirs[16]in that we do not require any prior knowledge of the input se-quence,i.e.we do not need to know whether it is a turntable sequence or not. To provide a comparison,wefirst reconstruct the sequence with the traditional(a)(b)parison of the reconstruction with the traditional method and our method (view from the top).(a):With the traditional method,severe“phantom points”lead to misalignment of the tail.(b):There are no“phantom points”with our method;thus the shape of the tail is consistent.Automatic Camera Calibration and Scene Reconstruction565(a)(b)Fig.5.Image sequences used in the comparison of the reprojection error.(a)Castle sequence,3samples of28images;(b)Dinosaur sequence,3samples of37images.(a)(b)parison of mean reprojection error between subsequence merging and our method:(a)Castle sequence and(b)Dinosaur sequence(a)(b)(c)(d)Fig.7.Meshed model of the Dinosaur sequence:(a)front view,(b)side view,(c)top view and(d)back view.The model comprises of more than6000robustly tracked and well-distributed3D points.With our system the whole reconstruction process(from the initial input images to thefinal output model)requires less than10minutes. method,where the features from current frame only relate to the previous adja-cent frame.To better illustrate the reconstruction of feature points,we generate a novel view from the top of the dinosaur.From Figure4(a)it is obvious that this method suffers from the“phantom points”problem:the tail of the dinosaur exhibits slight misalignment,although the dinosaur is supposed to have only one integral tail.Note that the misalignment effect is exaggerated by error propaga-tion in camera auto-calibration.The sequence is then tested with our new SfM framework,where features from current frame are matched to those from all the previous frames,and the result is shown in Figure4(b).Quantitative assessment was carried out to validate the advantages of our proposed SfM framework.Two publicly available image sequences were chosen:566J.Liu and R.Hubbold(a)(b)(c)(d)(e)(f)(g)Fig.8.(a)A challenging test case consisting of9images,each of which is1024×679 in resolution.This small set of images involve complicated camera movements includ-ing scaling and wide baseline translation.The surface point reconstruction viewed(b) from the front and(c)from the top illustrates that our system performs well in linking the widely separated frames into a consistent scene structure.In(d)a reference image is selected and a textured model is viewed from the front.We move the viewpoint to somewhere very different from the original ones and a novel view is shown in(e)from the very left and(f)from the top(textured with a different reference image).The straightness of lines demonstrates the accurate recovery of the depth information.We further analyse the quality of reconstruction by super-imposing the triangular meshes onto the textured model.The zoomed-in details are shown in(g).Meshes are more refined in complicated areas than in plain areas.This is desirable because the compu-tational resources are better distributed,biasing towardsfine recognisable details in both scene reconstruction and model rendering.The reconstructionfinishes within5 minutes on a2GHz processor.Automatic Camera Calibration and Scene Reconstruction567 the Castle sequence[15](see Figure5(a))and the Dinosaur sequence[16](see Figure5(b)).A commonly used criterion to analyse the quality of reconstruc-tion is the“reprojection error”,which is the geometric Euclidean distance(or L2 norm)between the projection of the reconstructed3D point and the measured image point.In our experiments the mean reprojection error for all the recon-structed3D points is used as an indication for the quality of the SfM methods. Our results are compared to the results using subsequence merging[17,18].Even though the subsequence merging technique performs well in constraining the overall mean reprojection error,it still shows moderate signs of error propa-gation.Results in Figures6(a)and6(b)suggest that our method is significantly less prone to error propagation compared to the subsequence merging technique. It is also interesting to see that our method performs surprisingly well for the Dinosaur sequence,considering the fact that it is a turntable sequence involving frequent self-occlusions.The ability to relate non-adjacent frames is important for pose estimation,as it results in projection matrices in a more consistent projective framework.Figure7shows the reconstructed model of the Dinosaur sequence.Our system recovers6105surface points which are subsequently meshed using Cocone[19]. Several views are taken from positions very different from the original viewpoints and the results indicate that the model structure is accurately reconstructed.The whole reconstruction process requires no user intervention andfinishes within 10minutes on a2GHz processor.Our system was further tested with photos taken with a Nikon D70s digital camera.Figure8shows our reconstruction of a sculptured memorial.5Conclusions and Future WorkWe have presented a scene reconstruction system based on scale-invariant feature points.Our system is carefully designed such that the features from non-adjacent frames can be matched efficiently.We solve the“phantom points”problem and greatly reduce the chance of error propagation.Experimental results show that relatively dense and well-distributed surface points can be recovered.Our system assigns refined and detailed meshes to complicated areas,but coarse and simple meshes to plain areas.This is desirable because the computational resources are better distributed,biasing towardsfine recognisable details in both scene reconstruction and model rendering.Future work includes a more sophisticated meshing scheme and inclusion of edge information to better represent the scene structure.References[1]Harris,C.J.,Stephens,M.:A combined corner and edge detector.In:Proceedingsof4th Alvey Vision Conference.(1988)147–151[2]Zhang,Z.,Deriche,R.,Faugeras,O.,Luong,Q.T.:A robust technique for match-ing two uncalibrated images through the recovery of the unknown epipolar geom-etry.AI78(1-2)(1995)87–119568J.Liu and R.Hubbold[3]Fitzgibbon,A.W.,Zisserman,A.:Automatic3D model acquisition and generationof new images from video sequences.In:EUSIPCO.(1998)1261–1269[4]Pollefeys,M.,Gool,L.V.,Vergauwen,M.,Cornelis,K.,Verbiest,F.,Tops,J.:Image-based3D acquisition of archaeological heritage and applications.In:Pro-ceedings of the2001conference on Virtual reality,archeology,and cultural her-itage.(2001)255–262[5]Gibson,S.,Hubbold,R.J.,Cook,J.,Howard,T.L.J.:Interactive reconstruction ofvirtual environments from video puters and Graphics27(2003) 293–301[6]Lucas,B.D.,Kanade,T.:An iterative image registration technique with an ap-plication to stereo vision(DARPA).In:Proceedings of the1981DARPA Image Understanding Workshop.(1981)121–130[7]Shi,J.,Tomasi,C.:Good features to track.In:CVPR.(1994)593–600[8]Lowe,D.G.:Object recognition from local scale-invariant features.In:ICCV.(1999)1150[9]Lowe,D.G.:Distinctive image features from scale-invariant keypoints.IJCV60(2)(2004)91–110[10]Mikolajczyk,K.,Schmid,C.:A performance evaluation of local descriptors.TPAMI02(2005)257[11]Brown,M.,Lowe,D.G.:Recognising panoramas.In:ICCV.(2003)1218–1225[12]Gordan,I.,Lowe,D.G.:Scene modelling,recognition and tracking with invariantimage features.In:ISMAR.(2004)110–119[13]Beis,J.S.,Lowe,D.G.:Shape indexing using approximate nearest-neighboursearch in high-dimensional spaces.In:CVPR.(1997)1000[14]Ke,Y.,Sukthankar,R.:PCA-SIFT:A more distinctive representation for localimage descriptors.In:CVPR.(2004)506–513[15]Pollefeys,M.,Gool,L.V.,Vergauwen,M.,Verbiest,F.,Cornelis,K.,Tops,J.,Koch,R.:Visual modeling with a hand-held camera.IJCV59(3)(2004)207–232 [16]Fitzgibbon,A.W.,Cross,G.,Zisserman,A.:Automatic3D model construction forturn-table sequences.In Koch,R.,Gool,L.V.,eds.:Proceedings of SMILE Work-shop on Structure from Multiple Images in Large Scale Environments.Volume 1506.(1998)154–170[17]Gibson,S.,Cook,J.,Howard,T.L.J.,Hubbold,R.J.,Oram,D.:Accurate cameracalibration for off-line,video-based augmented reality.In:ISMAR.(2002)37 [18]Repko,J.,Pollefeys,M.:3D models from extended uncalibrated video sequence:addressing key-frame selection and projective drift.In:Fifth International Con-ference on3-D Digital Imaging and Modeling.(2005)150–157[19]Dey,T.K.,Goswami,S.:Provable surface reconstruction from noisy samples.In:Proceedings of20th ACM-SIAM Symposium on Computational Geometry.(2004) 330–339。