web文本挖掘
- 格式:ppt
- 大小:1.58 MB
- 文档页数:89


数据挖掘的方法有哪些
数据挖掘的方法主要包括以下几种:
1.分类:用于将数据分为不同的类别或标签,包括决策树、逻辑回归、支持向量机等。
2.聚类:将数据分为不同的组或簇,根据数据的相似性进行分组,包括k均值聚类、层次聚类等。
3.关联规则:寻找数据中的相关联关系,包括频繁模式挖掘、关联规则挖掘等。
4.异常检测:寻找数据中与正常模式不符的异常值,包括离群点检测、异常检测等。
5.预测建模:利用历史数据进行模型建立,用于预测未来事件的可能性,包括回归模型、时间序列分析等。
6.文本挖掘:从非结构化文本数据中提取有用信息,如情感分析、主题建模等。
7.图像和视觉数据挖掘:从图像和视频数据中提取特征和模式,用于图像处理、目标识别等。
8.Web挖掘:从互联网上的大量数据中发现有价值的信息,包括网页内容挖掘、链接分析等。
9.时间序列分析:研究时间维度上数据的相关性和趋势,包括ARIMA模型、周期性分析等。
10.集成学习:通过结合多个单一模型获得更好的预测性能,如随机森林、Adaboost等。
这些方法常常结合使用,根据具体问题和数据来选择合适的方法。

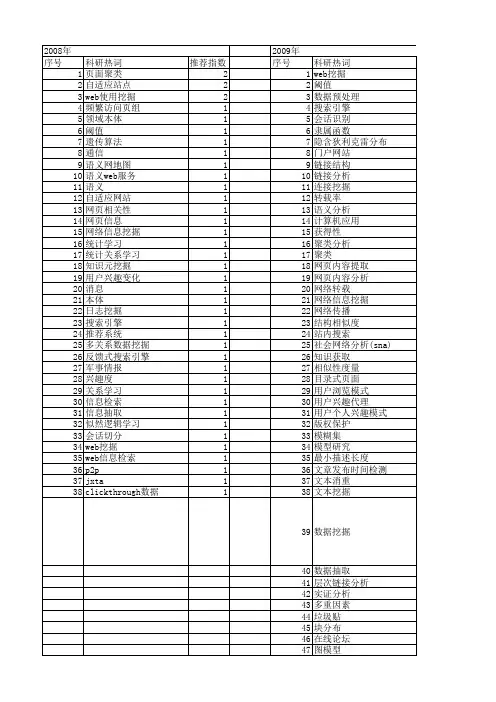
爱考机构-北大考研-计算机科学技术研究所研究生导师简介-杨建武_副研究员杨建武副研究员杨建武,男,1973年7月出生,博士,副研究员。
2002年7月毕业于北京大学计算机研究所,获博士学位。
主讲课程:·课程名称:文本挖掘技术·教学对象:北京大学信息科学技术学院研究生研究方向·信息检索、文本挖掘、SGML/XML主要研究工作面向互联网内容安全的Web挖掘技术研究。
获得信息产业部电子信息产业发展基金(“以智能信息分析处理为核心的数据挖掘软件平台”)、国家自然科学基金(“基于核矩阵学习的半结构化文本挖掘研究”)以及方正集团的课题资助。
主持研发的“方正智思”信息检索与智能分析产品已被广泛应用于国务院新闻办、中宣部等国家重要部门的互联网舆情分析预警系统等大型项目之中。
主要科研成果、专利、奖励:·《ASemi-StructuredDocumentModelForTextMining》计算机科学技术学报(JCST英文刊)2002.9·《半结构化数据相似搜索的索引技术研究》计算机学报2002.11·《基于规范划分集的并行循环计算划分》软件学报2003.3·《基于核矩阵学习的XML文档相似度量方法》软件学报2006.5·IntegratingElementKernelandTermSemanticsforSimilarity-BasedXMLDocumentClusteringWI'05·UsingProportionalTransportationSimilaritywithlearnedelementsemanticsforXMLdocumentclusteri ng.WWW2006·Manifold-rankingbasedtopic-focusedmulti-documentsummarization.IJCAI’07·SingleDocumentSummarizationwithDocumentExpansion.AAAI2007·Towardsaniterativereinforcementapproachforsimultaneousdocumentsummarizationandkeywordext raction.ACL2007·CollabSum:ExploitingMultipleDocumentClusteringforCollaborativeSingleDocumentSummarizati ons.SIGIR2007·LearninginformationdiffusionprocessontheWeb.WWW’07申请专利10多项,其中2项已获授权:·一种对半结构化文档集进行文本挖掘的方法专利,2004.8·一种基于快速排序算法的快速分页排序方法专利,2006.10奖励:·2004年度北京大学优秀博士论文。

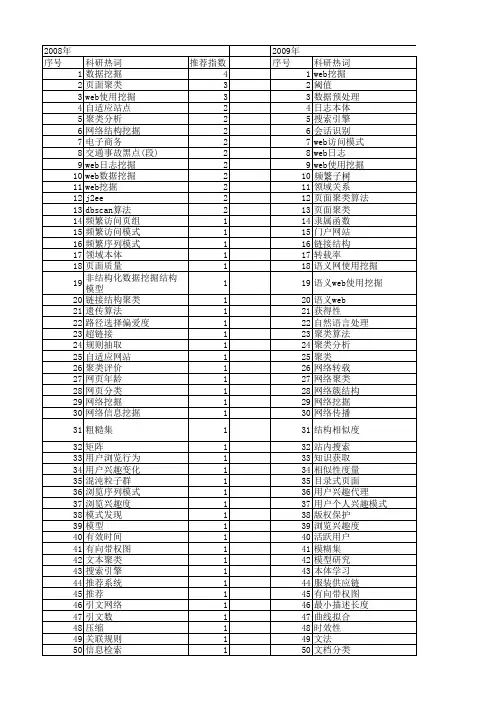

基于文本挖掘的分类与聚类技术
夏咏梅
【期刊名称】《情报探索》
【年(卷),期】2005(000)003
【摘要】从基于文本挖掘理论和实践两方面,探讨了文本的分类与聚类的理论、技术及两者之间的区别,讨论了聚类与分类技术在文本挖掘过程中的重要作用,通过所列举的自动分类与聚类的应用实例,能给读者的实际工作以一定的借鉴.
【总页数】3页(P65-67)
【作者】夏咏梅
【作者单位】南京大学信息管理系,江苏,210098
【正文语种】中文
【中图分类】G2
【相关文献】
1.基于层次聚类算法的WEB文本挖掘技术研究 [J], 吕岚
2.基于文本挖掘的计算机漏洞自动分类技术研究 [J], 邢翀
3.基于层次聚类算法的WEB文本挖掘技术探索 [J], 吕岚
4.基于自然语言处理技术的电力文本挖掘与分类 [J], 魏焱;杜斌;邓旭阳;何杰
5.基于文本挖掘的计算机漏洞自动分类技术分析 [J], 乔毅弘
因版权原因,仅展示原文概要,查看原文内容请购买。


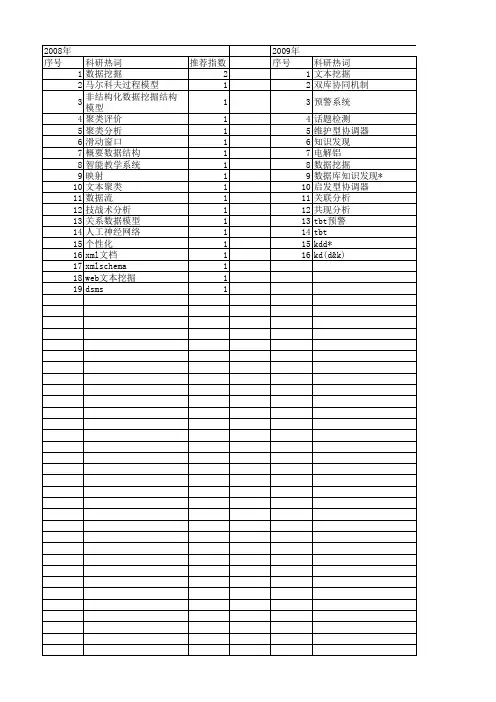
从大量数据中提取知识的过程
从大量数据中提取知识的过程通常称为数据挖掘。
数据挖掘是一个计算机科学术语,读音shùjùwājué,意思一般是指从大量
的数据中通过算法搜索隐藏于其中信息的过程。
数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。
数据挖掘分为有指导的数据挖掘和无指导的数据挖掘。
有指导的数据挖掘是利用可用的数据建立一个模型,这个模型是对一个特定属性的描述。
无指导的数据挖掘是在所有的属性中寻找某种关系。
具体而言,分类、估值和预测属于有指导的数据挖掘;关联规则和聚类属于无指导的数据挖掘。
数据挖掘简要分为:频繁模式挖掘(Frequent Pattern Mining)、序列挖掘(Sequence Mining)、数据流挖掘(Data Stream Mining)、文本挖掘(Text Mining)、Web挖掘(Web Minging)、图挖掘(Graph Mining)和时空数据挖掘(Temporal-spatial Mining)等,具体地:
数据流挖掘是针对数据流的数据挖掘,数据特点是数据随时间变化快且数据量大。

数据挖掘是20世纪90年代中期兴起的决策支持新技术,是基于大规模数据库的决策支持系统的核心,它是从数据库中发现知识的核心技术。
数据挖掘能够对数据库中的数据进行分析,以获得对数据更加深入的了解。
数据挖掘技术经历了三个演变时期。
第一时期称为机器学习时期,在这时期人们将已知的并且已经成功解决的事例输入计算机,由计算机对输入的事例进行总结产生相应的规则,在把总结出来的这些规则应用于实践;第二时期称为神经网络技术时期,这一时期人们关注的重点主要是在知识工程领域,向计算机输入代码是知识工程的重要特征,然而,专家们在这方面取得的成果并不理想,因为它投资大、效果差。
第三时期称为KDD时期,即数据挖掘现阶段所处的时期。
它是在20世纪80年代神经网络理论和机器学习理论指导下进一步发展的成果。
当时的KDD全称为数据库知识发现。
它一般是指从样本数据中寻找有用信息或联系的全部方法,如今人们已经接受这个名称,并用KDD这个词来代替数据挖掘的全部过程。
这里我们需要指出的是数据挖掘只是整个KDD过程中的一个重要过程。
数据仓库技术的发展促进了数据挖掘的发展,因为数据仓库技术为数据挖掘提供了原动力。
但是,数据仓库并不是数据挖掘的唯一源泉,数据挖掘不但可以从数据库中提取有用的信息,而且还可以从其它许多源数据中挖掘有价值的信息。
数据挖掘(Data Mining,DM),也称数据库中知识发现(knowlegde discovery in database,KDD),就是从大量的、不完全的、有噪声的、模糊的及随机的实际数据中提取隐含在其中的、未知的、但又是潜在有用的信息和知识的过程。
现在与之相应的有很多术语,如数据分析、模式分析、数据考古等。
我们从数据挖掘的定义中可以看出它包含了有几层意义:所使用的样本数据一般要求是有代表性的、典型的、可靠的;在样本数据中发现的规律是我们需要的;在样本数据中发现的规律能够被我们理解、接受、运用。
数据挖掘过程从数据库中发现知识,简称KDD,是20世纪80年代末开始的,现在人们把KDD 过程可定义为从数据集中识别出有效的、新颖的、潜在有用的,以及最终可以理解的模式的高级处理过程[14]。
面向Web的数据挖掘技术[摘要] 随着internet的发展,web数据挖掘有着越来越广泛的应用,web数据挖掘是数据挖掘技术在web信息集合上的应用。
本文阐述了web数据挖掘的定义、特点和分类,并对web数据挖掘中使用的技术及应用前景进行了探讨。
[关键词] 数据挖掘web挖掘路径分析电子商务一、引言近年来,数据挖掘引起了信息产业界的极大关注,其主要原因是存在大量数据,可以广泛使用,并且迫切需要将这些数据转换成有用的信息和知识。
数据挖掘是面向发现的数据分析技术,通过对大型的数据集进行探查。
可以发现有用的知识,从而为决策支持提供有力的依据。
web目前已成为信息发布、交互和获取的主要工具,它是一个巨大的、分布广泛的、全球性的信息服务中心。
它涉及新闻、广告、消费信息、金融管理、教育、政府、电子商务和其他许多信息服务。
面向web的数据挖掘就是利用数据挖掘技术从web文档及web服务中自动发现并提取人们感兴趣的、潜在的有用模型或隐藏的信息。
二、概述1.数据挖掘的基本概念数据挖掘是从存放在数据库、数据仓库、电子表格或其他信息库中的大量数据中挖掘有趣知识的过程。
数据挖掘基于的数据库类型主要有: 关系型数据库、面向对象数据库、事务数据库、演绎数据库、时态数据库、多媒体数据库、主动数据库、空间数据库、遗留数据库、异质数据库、文本型、internet 信息库以及新兴的数据仓库等。
2.web数据挖掘web上有少量的数据信息,相对传统的数据库的数据结构性很强,即其中的数据为完全结构化的数据。
web上的数据最大特点就是半结构化。
所谓半结构化是相对于完全结构化的传统数据库的数据而言。
由于web的开放性、动态性与异构性等固有特点,要从这些分散的、异构的、没有统一管理的海量数据中快速、准确地获取信息也成为web挖掘所要解决的一个难点,也使得用于web的挖掘技术不能照搬用于数据库的挖掘技术。
因此,开发新的web挖掘技术以及对web文档进行预处理以得到关于文档的特征表示,便成为web挖掘的重点。