EViews统计分析在计量经济学中的应用第章综合案例
- 格式:ppt
- 大小:2.91 MB
- 文档页数:84

影响农作物产量的相关因素分析一研究问题探究农业生活中农作物产量与种植面积,播种面积,受灾面积,农用物资投入量之间的关系,以便采取措施更好的提高农作物产量。
资料来源中国统计局官网2014说明:解释变量:播种面积 x1受灾面积 x2农用物资投入量 x3被解释变量:农作物产量 y确立所求一元线性回归方程为:Y=c+a1*x1+a2*x2+a3*x3二、模型分析(1)在Eviews中新建工作簿,输入相关数据,得出相应散点图如下:(2)通过Eviews软件计算,得出估计模型的参数结果如下:Y=-30483.39+0.411650*x1-0.045030*x2+0.009793*x3 (3)经济意义检验:X1的系数是正数,表明播种面积与农作物产量成正相关,x2的系数为负,说明受灾面积与农作物产量成负相关x3的系数为正,说明农用物资投入量与农作物产量成正相关。
所以该回归方程的系数的符号与经济理论和人们的经验期望值相一致。
(4)统计检验1.拟合优度检验R^2=0.932342^2=0.906969计算结果表明,估计的样本回归方程较好的拟合了样本观测值。
2.F-检验提出检验的原假设为H0:a1=a2=a3=0对立假设为H1:a1 a2 a2至少有一个不等于零F-statistic=36.74695对于给定的显著性水平α=0.05,查出分子自由度为3,分母自由度为8的F分布侧分位数F0.05(3,8)=4.07。
因为F=36.74695>4.07,所以否定H0,总体回归方程是显著,即播种面积,受灾面积,农用物资投入量与农作物产量之间存在显著的线性关系。
3.t-检验提出检验的原假设为H0:a1=0 a2=0 a3=0由表的t的统计量为a1的t-statistic=2.601174a2 的t-statistic=-0.604389a3的t-statistic=4.685807对于给定的显著性水平α=0.05,查出自由度为8的t分布双侧分位数t0.05/2(8)=2.306.因为t1=2.601174>2.306,所以否定H0,a1显著不等于零,即可认为播种面积对农作物产量有显著影响;|t2| =0.604389<2.306,所以不否定H0,a1=0,即受灾面积对农作物产量没有显著的影响,于是,在建立回归模型时,x2可以不作为解释变量进入模型。
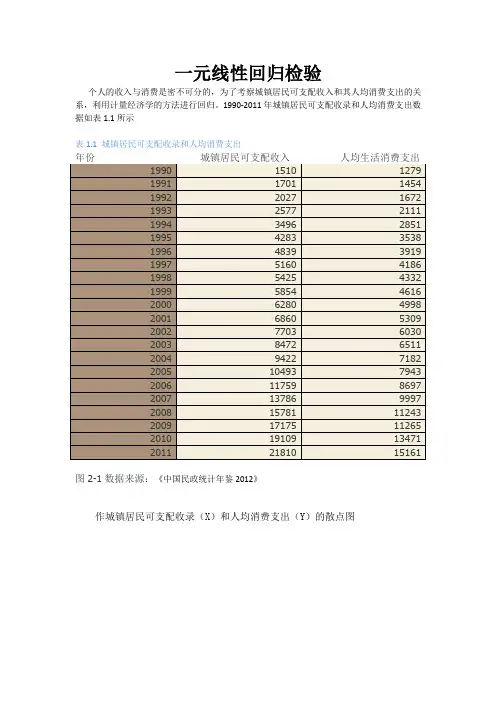
一元线性回归检验个人的收入与消费是密不可分的,为了考察城镇居民可支配收入和其人均消费支出的关系,利用计量经济学的方法进行回归。
1990-2011年城镇居民可支配收录和人均消费支出数据如表1.1所示表1.1 城镇居民可支配收录和人均消费支出图2-1数据来源:《中国民政统计年鉴2012》作城镇居民可支配收录(X)和人均消费支出(Y)的散点图图2. 2从散点图可以看出居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)大体呈现为线性关系,所以建立的计量经济模型为如下线性模型:12i i i Y X u ββ=++三、估计参数假定所建模型及随机扰动项i u 满足古典假定,可以用OLS 法估计其参数。
运用计算机软件EViews 作计量经济分析十分方便。
利用EViews 作简单线性回归分析的步骤如下:1、建立工作文件首先,双击EViews 图标,进入EViews 主页。
在菜单一次点击File\New\Workfile图2-3选择数据类型和起止日期。
时间序列提供起止日期(年、季度、月度、周、日),非时间序列提供最大观察个数。
本例中在Start Data 里输入1990,在End data 里输入2011,见图2-3。
单击OK 后屏幕出现Workfile 工作框,如图2-4所示。
图2-4二、输入和编辑数据建立或调入工作文件以后,可以输入和编辑数据。
在主菜单上单击Quick→Empty Group(见图2-5)图2-5再用方向键将光标移到每一列的顶部之后,输入各个变量名,回车后输入数据(见图2-7)。
另外数据还可以从Excel中直接复制到空组。
然后为每个时间序列取序列名。
单击数据表中的SER01,在数据组对话框中的命令窗口输入该序列名称,如本例中输入X,回车后Yes。
采用同样的步骤修改序列名Y(见图2-8)。
数据输入操作完成。
图2-8数据输入完毕,单击工作文件窗口工具条的Save或单击菜单兰的File→Save将数据存入磁盘。


计量经济学eviews实验报告计量经济学Eviews实验报告引言:计量经济学是经济学中的一个重要分支,它通过运用统计学和数学方法来分析经济现象,并建立经济模型来预测和解释经济变量之间的关系。
Eviews是一种流行的计量经济学软件,它提供了丰富的数据分析和模型建立工具,被广泛应用于经济学研究和实证分析。
一、数据收集与处理在进行计量经济学实验之前,首先需要收集相关的经济数据。
这些数据可以来自于各种来源,如经济统计局、金融机构或者自行收集。
然后,我们需要对数据进行处理,包括数据清洗、转换和整理,以便于后续的分析和建模。
二、描述性统计分析描述性统计分析是计量经济学中的第一步,它通过计算数据的均值、方差、相关系数等统计量来描述数据的基本特征。
在Eviews中,我们可以使用各种命令和函数来进行描述性统计分析,比如mean、var、cor等。
通过描述性统计分析,我们可以对数据的分布和变化情况有一个初步的了解。
三、回归分析回归分析是计量经济学中最常用的方法之一,它用于研究一个或多个自变量对一个因变量的影响。
在Eviews中,我们可以使用OLS(Ordinary Least Squares)命令来进行回归分析。
首先,我们需要选择一个合适的回归模型,然后通过最小二乘法估计模型的参数。
通过回归分析,我们可以得到模型的拟合优度、参数估计值和统计显著性等信息,从而判断变量之间的关系和影响程度。
四、模型诊断与改进在进行回归分析之后,我们需要对模型进行诊断和改进。
模型诊断主要包括残差分析、异方差性检验和多重共线性检验等。
在Eviews中,我们可以使用DW (Durbin-Watson)统计量来检验残差的自相关性,使用Breusch-Godfrey检验来检验异方差性,使用VIF(Variance Inflation Factor)来检验多重共线性。
如果模型存在问题,我们可以通过引入其他变量、转换变量或者使用其他的回归方法来改进模型。

计量经济学论文(eviews分析)计量经济作业计量经济学论文(EViews分析)导言计量经济学是一门研究经济现象及其相互关系的学科,通过运用统计学方法和经济学理论,对经济数据进行分析和解释。
在本篇论文中,我们将运用EViews软件进行计量经济分析,以探讨某一经济问题的核心要素和关系。
第一部分:数据收集与描述性统计在这一部分中,我们将介绍数据的来源和收集方法,并进行描述性统计分析,以便了解数据的基本特征。
数据来源和收集方法我们收集了关于某国家的宏观经济数据,包括国内生产总值(GDP)、物价指数、失业率、人口数量等。
这些数据可以通过政府统计局、国际组织或经济学研究机构的报告来获取。
描述性统计分析在这一部分,我们将计算各个变量的平均值、标准差、最小值、最大值和偏度等统计指标,并绘制相应的直方图和散点图,以便对数据的分布和相关关系有更直观的了解。
第二部分:计量经济模型的建立与估计在这一部分中,我们将构建计量经济模型,并通过使用EViews软件进行参数估计,以分析各个变量之间的关系。
模型的建立根据我们对经济问题的研究目标和数据的特点,我们选择了某一计量经济模型,以解释变量Y与自变量X1、X2之间的关系。
在模型中,我们还考虑了可能的误差项。
参数估计使用EViews软件,我们可以通过最小二乘法对模型进行参数估计。
这将帮助我们确定各个变量的系数估计值,并评估其统计显著性。
模型诊断在参数估计后,我们将进行模型的诊断检验,以评估模型的拟合优度和误差项的符合性。
通过观察残差图和假设检验等方法,我们可以确定模型是否符合计量经济学的基本假设。
第三部分:计量经济模型的解释与预测在这一部分中,我们将解释计量经济模型的估计结果,并利用该模型进行未来情景的预测。
模型解释通过对模型中各个变量的系数估计进行解释,我们可以理解自变量与因变量之间的经济关系,并得出相应的经济学解释。
模型预测利用模型的参数估计结果和最新的经济数据,我们可以进行未来情景的预测。


资料范本本资料为word版本,可以直接编辑和打印,感谢您的下载计量经济学实验一 EViews 软件的基本操作地点:__________________时间:__________________说明:本资料适用于约定双方经过谈判,协商而共同承认,共同遵守的责任与义务,仅供参考,文档可直接下载或修改,不需要的部分可直接删除,使用时请详细阅读内容实验一 EViews 软件的基本操作1.1 实验目的了解EViews 软件的基本操作对象,掌握软件的基本操作。
1.2 实验内容以表1.1所列中国的GDP与消费的总量数据(1990~2000,亿元)为例,利用EViews 软件进行如下操作:(1)EViews 软件的启动(2)数据的输入、编辑与序列生成(3)图形分析与描述统计分析(4)数据文件的存贮、调用与转换表1.1数据来源:2004年中国统计年鉴,中国统计出版社1.3 实验步骤1.3.1 EViews的启动步骤进入Windows /双击EViews5快捷方式,进入EViews窗口;或点击开始/程序/EViews5/EViews5进入EViews窗口,如图1.1。
图1.1标题栏:窗口的顶部是标题栏,标题栏的右端有三个按钮:最小化、最大化(或复原)和关闭,点击这三个按钮可以控制窗口的大小或关闭窗口。
菜单栏:标题栏下是主菜单栏。
主菜单栏上共有7个选项: File,Edit,Objects,View,Procs,Quick,Options,Window,Help。
用鼠标点击可打开下拉式菜单(或再下一级菜单,如果有的话),点击某个选项电脑就执行对应的操作响应。
命令窗口:主菜单栏下是命令窗口,窗口最左端一竖线是提示符,允许用户在提示符后通过键盘输入EViews命令。
主显示窗口:命令窗口之下是EViews的主显示窗口,以后操作产生的窗口(称为子窗口)均在此范围之内,不能移出主窗口之外。
状态栏:主窗口之下是状态栏,左端显示信息,中部显示当前路径,右下端显示当前状态,例如有无工作文件等。

《计量经济学》实验报告一研究问题:1987~2007年间天津市国内生产总值与财政收入的关系改革开放以来,随着经济体制改革的深化和经济的快速增长,天津市生产总值和财政收入发生很大变化,天津市的财政收入1987年为55.87亿元,到2007年已增长到1204.64亿元,为1978年的21.56倍。
为了研究影响天津市财政收入增长的主要原因,分析财政收入增长的数量规律,预测天津市财政收入未来的增长趋势,需要建立计量经济模型。
理论描述:研究财政收入的影响因素离不开一些基本的经济变量。
大多数相关的研究文献中都把总税收、国内生产总值这两个指标作为影响财政收入的基本因素,还有一些文献中也提出了其他一些变量, 比如其他收入、经济发展水平等。
影响财政收入的因素众多复杂, 但是通过研究经济理论对财政收入的解释以及对实践的观察, 对财政收入影响的因素主要有总税收、国内生产总值、其他收入和就业人数等。
因此可以从以上方面分析各种因素对财政税收增长的具体影响。
为了分析天津市财政收入与国内生产总值的关系,选择天津市“财政收入”作为被解释变量(用Y表示),选择“国内生产总值”作为解释变量(用X表示)。
下表为由《中国统计年鉴》得到的1987~2007年的有关数据。
数据及来源:1987~2007年天津市生产总值与财政收入单位:亿元年份生产总值X 财政收入Y1987 220.63 55.871988 259.64 44.811989 283.34 46.491990 310.95 44.881991 342.75 58.091992 411.24 63.051993 536.10 74.961994 725.14 95.991995 917.65 117.341996 1099.47 137.451997 1235.28 169.121998 1336.38 186.55 1999 1450.06 206.89 2000 1639.36 244.81 2001 1840.10 304.52 2002 2150.76 375.92 2003 2578.03 451.74 2004 3110.97 502.17 2005 3697.62 725.81 2006 4359.15 926.33 20075018.261204.64资料来源:中国统计年鉴数据库为分析天津市生产总值(X )与财政收入(Y )的关系,作如图所示的散点图:从散点图可以看出天津市生产总值(X )与财政收入(Y )大体呈现为线性关系,为分析天津市生产总值对财政收入的推动作用为目的,可以建立如下简单线性回归模型 u XY t tt ++=ββ21利用EViews 作简单线性回归分析进行参数估计,回归结果如下表所示:可用规范的形式将参数估计和检验的结果写为:=∧YfXt20008.200804.763-+(20.76213) (0.009827) t =(-3.068472)(22.38813) R 2=0.963478 F=501.2283 n=21 回归结果图为:经济意义:所估计的参数∧β1=-63.70804,∧β2=0.220008,说明天津市国内生产总值每增加1元,平均说来可导致财政收入提高0.220008元。

eviews计量经济学实验报告EViews计量经济学实验报告引言:计量经济学是经济学的一个重要分支,它运用数学和统计学方法对经济现象进行定量分析和预测。
EViews是一种强大的计量经济学软件,它提供了丰富的数据处理、统计分析和模型建立功能,被广泛应用于学术研究和实际经济分析中。
本实验报告旨在通过使用EViews软件,对某一经济现象进行实证研究,从而展示EViews在计量经济学中的应用和价值。
数据收集与预处理:本实验选择了中国GDP和CPI数据作为研究对象,数据来源于国家统计局。
首先,我们从国家统计局的官方网站上下载了相应的数据集,并导入到EViews中。
然后,我们对数据进行了初步的预处理,包括缺失值处理、异常值处理和数据平滑等。
通过这些步骤,我们得到了一份完整、可靠的数据集,为后续的分析和建模打下了基础。
描述性统计与数据可视化:在进行进一步的分析之前,我们首先对数据进行了描述性统计和数据可视化。
通过EViews的统计功能,我们计算了GDP和CPI的均值、标准差、最大值和最小值等统计指标,以及相关系数和协方差等相关指标。
同时,我们还使用EViews的绘图功能,绘制了GDP和CPI的时间序列图、散点图和直方图等。
这些统计和图表可以直观地展示数据的分布和变化趋势,为后续的模型分析提供参考。
时间序列分析:在进行时间序列分析时,我们首先对GDP和CPI数据进行平稳性检验。
通过EViews的单位根检验和ADF检验,我们发现GDP和CPI序列都是非平稳的,即存在单位根。
为了消除非平稳性,我们对数据进行了差分处理。
通过一阶差分,我们得到了平稳的GDP和CPI序列。
接下来,我们对平稳序列进行了自相关和偏自相关分析,以确定合适的ARIMA模型。
通过EViews的自相关函数和偏自相关函数图,我们发现GDP序列可以拟合为ARIMA(1,1,0)模型,而CPI序列可以拟合为ARIMA(0,1,1)模型。
回归分析与模型评估:在进行回归分析时,我们选择了GDP作为因变量,CPI作为自变量,建立了线性回归模型。

我国限额以上餐饮企业营业额的影响因素分析班级:姓名:学号:指导老师:我国限额以上餐饮企业营业额的影响因素分析摘要:本文收集了1999 —2009共11年的相关数据,选取餐饮企业的数量、城镇居民人均年消费性支出、全国城镇人口数以及公路里程数作为解释变量构建模型,对我国限额以上餐饮企业营业额的影响因素进行分析。
并利用Eviews软件对模型进行参数估计和检验,且加以修正,最后根据模型的最终结果进行经济意义分析,然后提出自己的看法。
关键词:餐饮企业营业额、影响因素、计量分析一、研究背景近十年来,投资者进入餐饮企业的数量一直持递增趋势。
在他们进入一个行业之前,势必要对该行业的营业额、营业利润等进行估计,当这些因素的估计值能够达到他们的预期的时候,他们才会对其进行投资。
由于餐饮企业的营业额是影响投资者是否进入餐饮业的一个重要因素,那么对于我国餐饮企业的营业额问题的深入研究就相当的有必要,这有助于投资者作出合理的决策。
下面即进行了对我国限额以上餐饮企业营业额的计量模型研究。
二、变量的选取影响餐饮企业营业额的因素有很多,包括餐饮企业的数量、营业面积、从业人员、城镇居民人均年消费性支出、全国城镇人口数、餐饮企业的平均价格水平及公路里程数(表示交通状况),但综合考虑后,选取了其中的一部分变量(企业数、城镇居民人均年消费性支出、全国城镇人口数、公路里程数)进行研究,并对各个变量对餐饮企业营业额的影响进行预测。
1. 企业数本文认为餐饮企业营业额与餐饮企业的数量有关,并预测两者之间呈正相关2. 城镇居民人均年消费性支出本文认为餐饮企业营业额与城镇居民人均年消费性支出有关,并预测两者之间呈正相关3. 全国城镇人口数本文认为餐饮企业营业额与全国城镇人口数有关,并预测两者之间呈正相关4. 公路里程数本文认为餐饮企业营业额与公路里程数有关,并预测两者之间呈正相关三、相关数据:其中营业额(单位:亿元),企业数(单位:个),人均年消费性支出(单位:元),全国城镇人口数(单位:万人),公路里程数(单位:万公里)年度营业额企业数人均年消费性全国城镇人口公路里程(丫)(x1)支出(x2)数(x3) 数(x4)1999 3519559 3266 4615.9143748 135.2 2000 4052445 3508 4998 45906 140.3 2001 4898943 4132 5309.01 48064 169.8 2002 6242471 5021 6029.88 50212 176.5 200374700005935 6510.94 52376 181 2004 11605000 10067 7182.1 54283 187.1 2005 12602000 9922 7942.88 56212 334.5 2006 15736000 11822 8696.55 57706 345.7 2007 19072000 14070 9997.47 59379 358.4 2008 25928000 22523 11242.85 60667 373 2009 268640002069412264.5562186386.1四、模型的设定 先查看其散点图::灿1MM-23000- □11000- u1W0Q*1DOOO-□0 KOT12000-0 X KM*Q008000 •TOOthfk0 05000u 0 g0 y 01------------------------- 1 ----------------------- 1 ----------------------- XJE+OC1S4T20E+O7:]E+O0根据散点图,认为这四个解释变量基本和营业额 (丫)呈现线性关系,所以 假设模型为:丫=刃+ B 1*x1+ 仪*x2+ g*x3+ B 4*X 4+ 卩五、模型的估计根据相关数据,利用统计软件Eviews5对上述设定的模型进行最小二乘估 计,结果如下:Dependent Variable: Y Method Least SquaresDate : 12/06/11 Time: 21 06Sample 1999 2009 ncluded observations 11VariableCoefficient Std Error t-Statistic Prob.593.3221 75.15516 7.394629 0.00021834.992 299 6427 6.1123934 0.0009-98.66568 68.52235 -1439905 0.20003619.168 3080.442 1 174886 0.2B46-32033592444694 -1 3103310.2380^-squared 0 999109 Mean dependent var12544583Adjusted R^squared 0 998515 S.D. dependent var 8457726 S E. of regression 3259754 Akaike info criterion 28 52999 Sum squared resid 6 38E+11 Schwarz criterion 28 71085 _og likelihood -151.9149 F -statistic1681.475 Durbin-Watson stat 2 715880Prob(F-statistic) 0 000000由上述结果,可得初始的模型为:Y= — 3203359+593.3*x1+1835*x2— 98.7*x3+3619.2*x4六、模型的检验1.拟合优度和模型估计效果检验:n 52OX-xao ooU0X'OC£+«J 1CC+0?20E 神73X+O7OOE+09 10E+U7:0E+<J730E+<J7从回归的结果来看,模型拟合较好,丫变化的99.9%可由其他四个变量的变化来解释。
中国储蓄存款总额(Y,亿元)与GDP(元)数据如下表。 表1-1 年份 GDP 储蓄Y 1978 3645.2 210.6 1979 4062.6 281.0 1980 4545.6 399.5 1981 4889.5 523.7 1982 5330.5 675.4 1983 5985.6 892.5 1984 7243.8 1214.7 1985 9040.7 1622.6 1986 10274.4 2238.5 1987 12050.6 3081.4 1988 15036.8 3822.2 1989 17000.9 5196.4 1990 18718.3 7119.8 1991 21826.2 9141.6 1992 26937.3 11758.0 1993 35260.0 15203.5 1994 48108.5 21518.8 1995 59810.5 29662.3 1996 70142.5 38520.8 1997 78060.9 46279.8 1998 83024.3 53407.5 1999 88479.2 59621.8 2000 98000.5 64332.4 2001 108068.2 73762.4 2002 119095.7 86910.6 2003 134977.0 103617.3 2004 159453.6 119555.4 2005 183617.4 141051.0 2006 215904.4 161587.3 2007 266422.0 172534.2 2008 316030.3 217885.4 2009 340320.0 260771.7 2010 399759.5 303302.5 2011 468562.4 343635.9 2012 516282.1 399551.0 数据来源:《中国统计年鉴》,2013年 图1-1 解:
一、估计一元线性回归模型𝒀𝒊=𝟎𝜷^+𝟏𝜷^𝑮𝑫𝑷𝒕+𝓮𝒕 由经济理论知,储蓄存款总额受GDP影响,当GDP增加时,储蓄存款总额也随着增加,他们之间具有正向的同步变动趋势。储蓄存款总额除受GDP影响之外,还受到其他一些变量的影响及随机因素的影响,将其他变量及随机因素的影响均并到随机变量U中,根据X与Y的样本数据,作X与Y之间的散点图可以看出,他们的变化趋势是线性的,由此建立中国储蓄存款总额Y与GDP之间的一员线性回归模型。 𝑌𝑖=𝛽0+𝛽1𝑋1𝑖+𝑢𝑖