spss练习作业具体步骤要点
- 格式:doc
- 大小:401.00 KB
- 文档页数:13

spss实验指导书第一次课:SPSS统计软件学习(1):建立数据模板实验目的与要求:1、实验目的:学习掌握数据模板的建立的方式方法2、每个学生能够把自己实习小组的调查问卷录入SPSS二、实验用仪器与设备:PC机;SPSS统计软件;网络系统三、实验方法与步骤1、教师讲明本次课的学习内容和要求2、每个学生根据实验指导书把自己实习小组的调查问卷录入SPSS,建立数据模板四、实验步骤与参考资料一、在SPSS建立一个数据模板(即把一份调查问卷的问题录到SPSS上)1、在SPSS中定义问卷上的每一个问题的内容和含义问卷每一个问题一个变量。
所谓在SPSS建立一个数据模板,其实质就是在SPSS中V ariable View页面定义问卷上的每一个问题或变量。
其内容包括定义或选择确定变量名、变量类型(type)、变量标签和值标签(label)、缺失值形式(missing value)、变量的列格式(column format)、变量对齐方式、变量测度方式(Measure) 1)定义变量名:即问卷中每一题的关键词2)定义变量类型(type):有三种基本类型:数值型、字符型和日期型。
一般后面的值标签即问题答案选项录入的是数值就是数值型、录入的是文字就是字符型、录入的是日期就是日期型。
3)定义变量长度:一般采用默认值即可4) 定义小数位数:后面的值标签即问题答案选项录入的数值如是整数就选择0,否则按实际小数位数定5)定义变量标签(label):定义问题或问题提要即调查问卷中该问题或概要6)定义值标签(V alue Labels):定义问题答案选项。
这需要点击下拉菜单,在对话框里录入。
7)定义变量缺失值(Missing Value):一般默认为空格8)定义变量的列格式(column format)即显示宽度;9)定义变量对齐方式:采用一般默认即可10)定义变量测度方式(Measure):Scale,数据型测量方式,一般问题答案属定距、定比变量如身高、体重,工资、年龄等选择这种测量方式;Ordinal,排序型测量方式。

SPSS作业8:二项Logistic回归分析为研究和预测某商品消费特点和趋势,收集到以往胡消费数据.数据项包括是否购买,性别,年龄和收入水平。
这里采用Logistic回归的方法,是否购买作为被解释变量(0/1二值变量),其余各变量为解释变量,且其中性别和收入水平为品质变量,年龄为定距变量。
变量选择采用Enter方法,性别以男为参照类,收入以低收入为参照类。
(一)基本操作:(1)选择菜单Analyz e-Regression-Binary Logistic;(2)选择是否购买作为被解释变量到Dependent框中,选其余各变量为解释变量到Covariates框中,采用Enter方法,结果如下:消费的二项Logistic分析结果(一)(强制进入策略)Categorical Variables CodingsFrequency Parameter coding (1) (2)收入低收入132 .000 .000中收入144 1.000 。
000高收入155 。
000 1。
000性别男191 。
000女240 1.000分析:上表显示了对品质变量产生虚拟变量的情况,产生的虚拟变量命名为原变量名(编码)。
可以看到,对收入生成了两个虚拟变量名为Income(1)和Income(2),分别表示是否中收入和是否高收入,两变量均为0时表示低收入;对性别生成了一个虚拟变量名为Gedder(1),表示是否女,取值为0时表示为男。
消费的二项Logistic 分析结果(二)(强制进入策略)Block 0: Beginning BlockClassification Table a,bObserved Predicted是否购买 Percentage Correct不购买购买Step 0是否购买不购买 269 0 100。
购买162。
0 Overall Percentage62。
4a 。
Constant is included in the model 。

SPSS操作步骤及解析SPSS(Statistical Package for the Social Sciences)是一种用于数据分析的统计软件包。
它可以进行数据整理、描述统计分析、统计推断、回归分析、因子分析、聚类分析等各种统计分析。
下面是SPSS的操作步骤及解析。
1.数据导入:在SPSS中,数据可以以多种格式导入,如Excel文件、CSV文件、数据库导入等等。
点击“文件”按钮,然后选择“导入数据”选项。
在出现的对话框中选择要导入的文件,然后按照指示逐步完成导入过程。
3.描述统计分析:描述统计分析是指对数据进行基本的统计描述,包括计数、平均数、标准差、最小值、最大值等等。
点击“统计”按钮,在出现的下拉菜单中选择“描述统计”选项。
在打开的对话框中,选择要统计的变量,然后点击“确定”按钮即可生成统计描述。
4.数据转换:数据转换是指通过运算或者函数对数据进行转换,以得到更有意义的变量或者指标。
点击“转换”按钮,在出现的下拉菜单中选择“计算变量”选项。
在打开的对话框中,输入要进行的运算或者函数,然后点击“确定”按钮即可生成新的变量。
5.统计推断:统计推断是指通过样本数据对总体数据进行推断性统计分析。
点击“分析”按钮,在出现的下拉菜单中选择“统计推断”选项。
根据具体需求选择适当的统计方法,如t检验、方差分析、相关分析等等。
在打开的对话框中选择变量,并进行相应的设置,然后点击“确定”按钮即可生成推断性分析结果。
6.回归分析:回归分析是指通过对自变量和因变量之间的关系进行建模,预测因变量的取值。
点击“分析”按钮,在出现的下拉菜单中选择“回归”选项。
在打开的对话框中选择要进行回归分析的变量,然后进行相应的设置,如回归方法、模型选择等等,最后点击“确定”按钮即可生成回归分析结果。
7.图表制作:总结:。

实习一SPSS数据文件的建立和整理建立数据文件的SPSS命令1.定义变量2.录入数据3.保存数据文件4.双录入核对常见的数据预处理命令1.文件合并(merge files)(1) 增加观测值(Add Cases)合并e1.sav和e2.sav(2) 增加变量(Add Variables)em1.sav和em2.sav2.增减变量和观察单位3.排序与编秩4.选择观察单位(select cases)5.数据文件的拆分(split file)6.建立新变量(compute)7.重新赋值(recode)8.其它常见命令1.数值变量的统计描述操作步骤:Analyze→Descriptive Statistics→Frequencies→Statistics:Quartiles,Mean,Median,Std.deviation,Variance,Range,Minimum,Maximum Analyze→Descriptive Statistics→Descriptives→Options:Mean,Std.deviation,Variance,Range,Minimum,Maximum 结果输出:Descriptives:Mean,Std.deviation,Median,Variance,Quartiles,Range ,Minimum,Maximum2.分类变量的统计描述操作步骤:Analyze→Descriptive Statistics→Frequencies→Display frequency tables结果输出:Frequencies:Frequency,Percent,Valid Percent,Cumulative Percent3.正态性检验操作步骤:(未校正)Analyze→Nonparametric tests→1-Sample K-S→Test Distribution: Normal结果输出:Kolmogorov-Smirnov Z,Asymp. Sig. (2-tailed)操作步骤:(校正)Analyze→Descriptive Statistics→Explore→Plots: Normality plots with test结果输出:Kolmogorov-Smirnov Z,Asymp. Sig. (2-tailed)1.t检验(1)单样本均数的t检验操作步骤:Analyze→Compare Means→One-Sample T test结果输出:One-Sample Statistics:mean、std.deviation、std.error mean One-Sample Test:t、df、sig(2-tailed)(2)两个样本均数比较的t检验操作步骤:Analyze→ Compare Means→Independent Samples T test结果输出:group statistics:mean、std.deviation、std.error meanLevene's Test for Equality of Variances:F、sigt-test for Equality of Means:t、df、sig(2-tailed)(3)配对设计的t检验操作步骤:Analyze→ Compare Means→Paired Samples T test结果输出:paired samples statistics:mean、std.deviation、std.error mean paried samples test:t、df、sig(2-tailed)2.秩和检验(1)配对设计的秩和检验操作步骤:Analyze→Nonparametric tests→2 related samples结果输出:Test Statistics:Z、Asymp. Sig. (2-tailed)(2)两样本比较的秩和检验操作步骤:Analyze→Nonparametric tests→2 independent samples结果输出:Test Statistics:Z、Asymp. Sig. (2-tailed)实习六分类变量的假设检验1.成组设计四格表资料的х2检验和确切概率法操作步骤:Data → Weight cases: 频数变量Analyze → Descriptive Statistics → CrosstabsRow(s): 分组变量;Column(s): 结局变量选Chi-squareCounts中选Observed、Expected; 在Percentages中选Row结果输出:Crosstabultion(四格表)Chi-Square Tests:Pearson Chi-Square: Value、df、Sig. (n≥40,且E≥5)Continuity Correction: Value、df、Sig. (n≥40,但有1<E<5)Fisher’s Exact Test: Sig. (n≤40, 或E≤1)2.R×C列联表资料的 2检验同1;两个无序分类变量可计算关联系数在Nominal中选Contingency coefficient3.配对设计四格表资料的х2检验操作步骤:Data → Weight cases: 频数变量Analyze → Descriptive Statistics → CrosstabsRow(s): 分组变量;Column(s): 结局变量选McNemar结果输出:Crosstabultion(四格表)Chi-Square Tests:McNemar Test: Exact Sig.4.频数分布拟合优度检验操作步骤:Data → Weight cases: 频数变量Analyze →Nonparametric Tests→ 1-sample K-S (Poisson)结果输出:Kolmogorov-Smirnov Z、sig.5.单向有序分类变量的秩和检验操作步骤:Data → Weight cases: 频数变量Analyze →Nonparametric Tests→ 2 Independent Samples(两个样本)k Independent Samples(多个样本)结果输出:Z(两个样本) / Chi-Square(多个样本)、sig.实习九直线相关与回归1.相关操作步骤:Graphs → Scatter/Dot → Simple scatterAnalyze → Correlate → Bivariate(Correlation coefficients中选Pearson,等级相关选Spearman)结果输出:Correlation: correlation coefficient、Sig. (2-tailed)2.回归操作步骤:Graphs → Scatter/Dot → Simple scatterAnalyze → Regression → linear结果输出:Model Summary: R、R SquareANOV A: Sum of Squares、df、Mean Square、F、Sig.Coefficients: Unstandardized Coefficients (B、Std. Error)、t、Sig.实习十、十一多组数值变量比较的假设检验1. 单因素方差分析操作步骤:Analyze → General Linear Model → UnivariateDependent Variable: 测量指标;Fixed Factor(s): 分组变量选Descriptive statistics、Homogeneity testsPost hoc test for: 分组变量选方法S-N-K / Bonferroni / Turkey / Dunnett结果输出:Descriptive statistics: mean、std.deviation、NLevene’s Test of Equality of Error Variances: F、df、Sig.Tests of Between-Subjects Effects: Type III Sum of Squares、df、Mean Square、F、Sig.Post Hoc Tests: Multiple Comparisons: Mean Difference、Std.Error、SigHomogeneous Subsets: Subset2.协方差分析操作步骤:(1) Analyze → General Linear Model → UnivariateDependent Variable: 测量指标;Fixed Factor(s): 分组变量Covariate(s):协变量选Custum → Model: 分组变量、协变量、分组变量*协变量(2) Analyze → General Linear Model → UnivariateDependent Variable: 测量指标;Fixed Factor(s): 分组变量Covariate(s):协变量选Custum → Model: 分组变量、协变量选Descriptive statistics、Homogeneity tests、Parameter estimatesDisplay means for: 分组变量结果输出:(1)Tests of Between-Subjects Effects(分组变量*协变量): F、Sig.(2) Descriptive statistics: mean、std.deviation、NLevene’s Test of Equality of Error Variances: F、df、Sig.Tests of Between-Subjects Effects(分组变量和协变量):Type III Sum of Squares、df、Mean Square、F、Sig.Parameter Estimates: BEstimated Marginal Means: Mean、std.deviation3.Kruskal-Walls秩和检验操作步骤:Analyze → Nonparametric Tests → K Independent SamplesTest Variable List: 测量指标;Grouping Variable: 分组变量→ Define Range结果输出:Chi-square、df、Sig.4.随机区组设计的方差分析操作步骤:Analyze → General Linear Model → UnivariateDependent Variable: 测量指标;Fixed Factor(s): 分组变量、区组变量选Custum → Model: 分组变量、区组变量Display Means for: 分组变量、区组变量结果输出:Tests of Between-Subjects Effects: Type III Sum of Squares、df、Mean Square、F、Sig.Estimated Marginal Means:mean、std.deviation5.Friedman秩和检验操作步骤:Analyze → Nonparametric Tests → K Related SamplesTest Variable: 各处理组的测量指标;结果输出:Chi-square、df、Sig.。
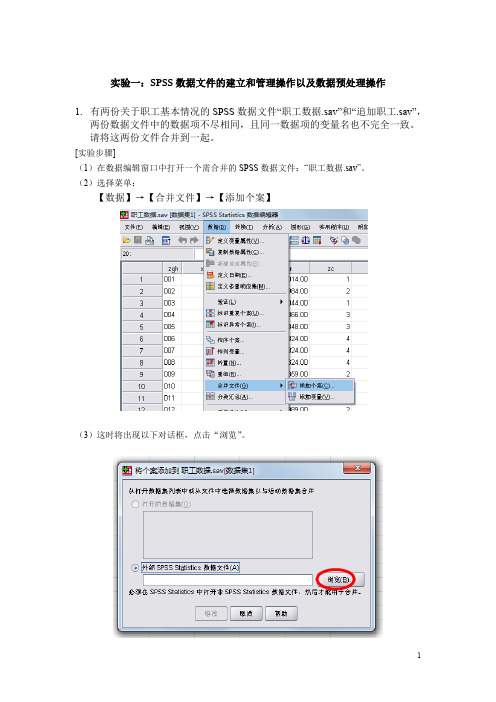
实验一:SPSS数据文件的建立和管理操作以及数据预处理操作1.有两份关于职工基本情况的SPSS数据文件“职工数据.sav”和“追加职工.sav”,两份数据文件中的数据项不尽相同,且同一数据项的变量名也不完全一致。
请将这两份文件合并到一起。
[实验步骤](1)在数据编辑窗口中打开一个需合并的SPSS数据文件:“职工数据.sav”。
(2)选择菜单:【数据】→【合并文件】→【添加个案】(3)这时将出现以下对话框,点击“浏览”。
(4)打开需进行纵向合并处理的SPSS数据文件“追加职工.sav”。
按“继续”后,显示纵向合并数据文件窗口。
(如下图)(5)对话框右边【新的活动数据集中的变量】框中显示的变量名是两个数据文件中的同名变量,对话框左边【非成对变量】框中显示的变量名是两个文件中的不同名变量。
其中,变量名后面的【*】表示该变量是当前数据编辑窗口中(“职工数据.sav”)的变量,【+】表示该变量是(2)“追加职工.sav”中指定的磁盘文件中的变量。
SPSS默认这些变量的含义不同,且不放入合并后的新文件中。
如果不接受这种默认,可选择其中的两个变量名并按【对】按钮指定配对,表示虽然它们的名称不同但数据含义是相同的,可进入合并后的数据文件中。
本题中,显然职称zc(*)和职称zc1(+)两个变量名需要按【对】按钮指定配对。
方法是:按住“Ctrl键”,同时鼠标点zc(*)和zc1(+),然后按【对】按钮,这时【新的活动数据集中的变量】框中出现“zc&zc1”变量名。
(6)把【非成对变量】框中显示的其他变量名全部标记,按右向箭头。
(7)按【确定】,完成操作。
2.根据“住房状况调查.sav”数据,通过数据排序功能分析本市户口和外地户口家庭的住房面积情况。
(按升序排列)[实验步骤](1)在数据编辑窗口中打开SPSS数据文件:“住房状况调查.sav”。
(2)选择菜单:【数据】→【排序个案】(3)指定主排序变量“户口状况”到【排序依据】框中,并选择【排序顺序】框中的选项指出该变量按升序还是降序排序。

spss基本操作完整版SPSS(Statistical Package for the Social Sciences)是一款广泛应用于数据分析和统计建模的软件。
它提供了一系列强大的功能和工具,可以帮助用户处理和分析大量的数据,从而得到准确的结果并支持决策制定。
本文将介绍SPSS的基本操作,并分享一些常用功能的使用方法。
一、数据导入与编辑在使用SPSS进行数据分析之前,首先需要导入要分析的数据,并对其进行编辑和整理。
下面介绍SPSS中的数据导入与编辑的基本操作。
1. 导入数据打开SPSS软件后,点击菜单栏中的"文件"选项,再选择"打开",然后选择要导入的数据文件(一般为Excel、CSV等格式)。
点击"打开"后,系统将自动将数据导入到SPSS的数据视图中。
2. 数据编辑在数据视图中,我们可以对导入的数据进行编辑,例如添加变量、删除无效数据、更改数据类型等操作。
双击变量名或者右键点击变量名,可以对变量属性进行修改。
通过点击工具栏上的"变量视图"按钮,可以进入变量视图进行更复杂的编辑。
二、数据清洗与处理数据清洗和处理是数据分析的重要步骤,它们能够提高数据的质量和可靠性。
下面介绍SPSS中的数据清洗与处理的基本操作。
1. 缺失值处理在实际的数据分析过程中,往往会遇到一些数据缺失的情况。
SPSS 提供了处理缺失值的功能,例如可以使用平均值或众数填补缺失值,也可以剔除含有缺失值的样本。
2. 数据筛选与排序当数据量较大时,我们通常需要根据一定的条件筛选出符合要求的数据进行分析。
SPSS提供了数据筛选和排序的功能,可以按照指定的条件筛选数据,并可以按照某个或多个变量进行数据排序。
三、统计分析SPSS作为统计分析的重要工具,提供了丰富的统计分析功能,下面介绍部分常用的统计分析方法。
1. 描述统计描述统计是对数据进行整体概述的统计方法,包括计数、求和、平均值、中位数、标准差、最大值、最小值等指标。
SPSS作业04_F值和T值、标准差和标准误、回归分析基本概念、拟合优度
回归分析
1、通常⽤来评价商业中⼼经营好坏的⼀个综合指标是单位⾯积的营业额,它是单位时间内(通常为⼀年)的营业额与经营⾯积的⽐值。
对单位⾯积营业额的影响因素的指标有单位⼩时车流量、⽇⼈流量、居民年平均消费额、消费者对商场的环境、设施及商品的丰富程度的满意度评分。
这⼏个指标中车流量和⼈流量是通过同时对⼏个商业中⼼进⾏实地观测⽽得到的。
⽽居民年平均消费额、消费者对商场的环境、设施及商品的丰富程度的满意度评分是通过随机采访顾客⽽得到的平均值数据。
下表中存放了从某市随机抽取的20个商业中⼼有关指标的数据,利⽤该数据完成下列⼯作
(1)研究变量间的相关程度。
(其余6个变量与“单位⾯积年营业额”间的相关程度,其余6个变量之间的相关程度);
(2)由(1)的结论建⽴“单位⾯积年营业额”与和其线性相关程度最⾼的变量的⼀元线性回归⽅程;
(3)采⽤逐步回归⽅法建⽴“单位⾯积年营业额”的预测公式。
表20个商业中⼼有关指标的数据
2、试⽤SPSS对地区⼈均GDP与第⼆产业⽐重、第三产业⽐重以及地理位置进⾏LOGISTIC 回归分析。
实验一:SPSS数据文件的建立和管理操作以及数据预处理操作1.有两份关于职工基本情况的SPSS数据文件“职工数据.sav”和“追加职工.sav”,两份数据文件中的数据项不尽相同,且同一数据项的变量名也不完全一致。
请将这两份文件合并到一起。
[实验步骤](1)在数据编辑窗口中打开一个需合并的SPSS数据文件:“职工数据.sav”。
(2)选择菜单:【数据】→【合并文件】→【添加个案】(3)这时将出现以下对话框,点击“浏览”。
(4)打开需进行纵向合并处理的SPSS数据文件“追加职工.s av”。
按“继续”后,显示纵向合并数据文件窗口。
(如下图)(5)对话框右边【新的活动数据集中的变量】框中显示的变量名是两个数据文件中的同名变量,对话框左边【非成对变量】框中显示的变量名是两个文件中的不同名变量。
其中,变量名后面的【*】表示该变量是当前数据编辑窗口中(“职工数据.sav”)的变量,【+】表示该变量是(2)“追加职工.sav”中指定的磁盘文件中的变量。
SPSS默认这些变量的含义不同,且不放入合并后的新文件中。
如果不接受这种默认,可选择其中的两个变量名并按【对】按钮指定配对,表示虽然它们的名称不同但数据含义是相同的,可进入合并后的数据文件中。
本题中,显然职称zc(*)和职称zc1(+)两个变量名需要按【对】按钮指定配对。
方法是:按住“Ctrl键”,同时鼠标点zc(*)和zc1(+),然后按【对】按钮,这时【新的活动数据集中的变量】框中出现“zc&zc1”变量名。
(6)把【非成对变量】框中显示的其他变量名全部标记,按右向箭头。
(7)按【确定】,完成操作。
2.根据“住房状况调查.sav”数据,通过数据排序功能分析本市户口和外地户口家庭的住房面积情况。
(按升序排列)[实验步骤](1)在数据编辑窗口中打开SPSS数据文件:“住房状况调查.sav”。
(2)选择菜单:【数据】→【排序个案】(3)指定主排序变量“户口状况”到【排序依据】框中,并选择【排序顺序】框中的选项指出该变量按升序还是降序排序。
spss作业一酸奶口味方差分析
不同品牌酸奶口味大比拼——用 SPSS 做方差分析。
今天来一起玩一个超有趣的游戏!这个游戏和平时爱喝的酸奶有关。
你们都知道,超市里有好多不同品牌的酸奶,味道也都不一样。
有的甜甜的,有的带点酸酸的感觉,还有的会有特别的水果味。
那到底哪个品牌的酸奶口味更好?今天就用一个很厉害的工具,叫 SPSS,来找出答案!
想象一下,把市面上常见的三个品牌的酸奶,分别是 A 牌、B 牌和 C 牌,都买回来。
然后找来好多好多小朋友,让他们都尝一尝这三种酸奶。
每个小朋友尝完之后,都要给这三种酸奶的口味打分,满分是 10 分。
比如说,小明尝了 A 牌酸奶,他觉得甜甜的,口感滑滑的,就给打了 8 分;尝了 B 牌酸奶,他觉得有点太酸,就给打了 6 分;尝了 C 牌酸奶,他感觉有浓浓的草莓味,可好喝,就给打了 9 分。
像这样,好多小朋友都给出了自己的分数。
现在,就把这些分数都收集起来,放到 SPSS 这个神奇的工具里。
SPSS 就像一个超级聪明的小脑袋瓜,它能帮分析这些分数。
它会看看这三个品牌的酸奶,它们得到的分数有没有很大的差别。
要是 A 牌酸奶的平均分比 B 牌和 C 牌都高好多,那就说明大部分小朋友都觉得A 牌酸奶口味更好;要是三个品牌的平均分都差不多,那就说明这三个品牌的酸奶口味大家觉得都差不多好。
通过 SPSS 的分析,就能清楚地知道,到底哪个品牌的酸奶在口味上更受大家欢迎。
就好像一场酸奶口味的大比拼,最后能找出冠军酸奶品牌!是不是特别好玩?以后再去买酸奶,就知道选哪个口味更棒!。
例题和SPSS电脑实验(一)SPSS统计分析软件在Analyze子菜单Descriptive Statistics给出计量资料三个基本统计分析过程:Frequencies、Descriptives和Explore。
【实验2-1】用例2-1资料编制血红蛋白的频数表。
建立1列102行的数据集li0201.sav。
2.操作步骤(1)找出最大值与最小值Analyze→Descriptive Statistics→Descriptives ,“血红蛋白”→Variable(s)框→OK,即可得到其最大值(maximum)173 g/L及最小值(Minimum)103g/L。
(2)分组段Transform→Recode into Different Variables,“血红蛋白”→Numeric Variable→Output框,在Name框中键入“组段”→Change→Old andnew Values,选中Old Value栏内的Range选项,在框中输入“103”,在through框中输入“109.9”;在New Value栏内,选中Value,在其框内输入“103”→Add,这样就在Old-New框中增加了“103 thru 109.9-103”,同理,设置其他组段区间,直到“159 thru165.9-159”,最后增加“166 thru 173-166”,Continue→OK,如此建立了新变量“组段”,并增加到原始数据集中。
(3)呈现频数表Analyze→Description Statistics→Frequencies,“组段”→Variable(s)框中,选中Display frequency tables→OK,即可得到频数表。
3.主要结果见图2-9。
图2-9 某地102名成年男性的血红蛋白(g/L)的频数表【实验2-2】用例2-1的资料求其均数。
操作步骤同实验2-1中(1),得均数(mean )为136.87 g/L 。
第 1 页 共 13 页 一、调查问卷 二、用SPSS Statistics软件进行描述统计分析 1、某地区经济增长率的时间序列图形。 解:第一步:数据来源,如图1
图1 某地区经济增长率xls截图 图2 Spss软件制作过程截图 第二步:将数据输入SPSS软件之中,如图2,制作某地区经济增长率的时间序列图形,如图3。
图3某地区1990—2012年经济增长率的时间序列图 第三步,从图中可以看出,某地区随时间的变化经济增长率变化趋势较大。
2、用SPSS Statistics进行描述统计分析 解:第一步,按照题目中的要求,随机选取了148个数据,如图4部分数据: 第 2 页 共 13 页
图4 Spss随机数据截图 第二步,根据要求,对上月工资进行描述统计分析,主要包括描述数据的集中趋势、离散程度(见表1),绘制直方图(见图5)。 表1 上月工资描述统计表(单位:元)
图5 上月工资直方图 集中趋势 离散趋势 均值 2925 极小值 1500 中值 2900 极大值 4800 众数 2900 全距 3300 和 432900 标准差 496.364 偏度 0.165 峰度 1.238 数据总计 148 第 3 页 共 13 页
第三步,分析数据的统计分布状况。 首先,从集中趋势来,上个月平均工资2925元,其中众数和中数也都在2900元,这说明大部分工资水平在2900左右。 其次,从离散趋势来看,最高工资4800元,最低工资1500元,最高工资和最低工资相差3300元,标准差为496.364,相差较大。 最后,从直方图来看和评述统计表来看,工资在2900元以上的占多数。可以的该地区整体工资水平大于平均值的占多数,该地区工资水平相对较高。 峰度为1.238,偏度为0.165符合正态分布。
三、用SPSS Statistics软件进行参数估计和假设检验及回归分析 1、计算总体中上月平均工资95%的置信区间(见表3)。 解:总体中上月平均工资分布未知,但是样本容量大于30,且已知标准误,所以通过SPSS分析得出总体中上月平均工资95%的置信区间,见表3, 假设; H0:总体中上月平均工资95%的不在此在此区间 H1:总体中上月平均工资95%的在此区间 表3 总体中上月平均工资95%的置信区间 均值95%的置信区间 下限 2844.37 Sig.(双侧)
上限 3005.63 0.000
答,总体中上月平均工资095的置信区间为[2844.37,3005.63],p=0.000<0.01,作出这样的推论正确的概率为0.95,错误的概率为0.05。 2、检验能否认为总体中上月平均工资等于2000元。 解:在本案例中,要检验样本中上月平均工资与总体中上月平均工资(为已知值:2000元)是否存在差异,即某一样本数据与某一确定均值进行比较。虽然不知道总体分布是否正态,但样本较大(N>30),可以运用单样本T检验.通过SPSS检验结果见(表4 、表5) 设; Ho:2000
H1:2000 其中,μ表示总体中上月平均工资 表4 单个样本统计量 N 均值 标准差 均值的标准误 上月工资 148 2925.00 496.364 40.801
表5 单个样本检验 t df Sig.(双侧) 均值差值 检验值 上月工资 22.671 147 0.000 925.000 2000
答:作出结论,均值差值为925,t=22.671,p=0.000<0.01,所以拒绝原假设,接受备择假设,即否认总体中上月的平均工资等于2000元。 第 4 页 共 13 页
3、检验能否认为男生的平均工资大于女生 解:两个样本均来自于正态分布的总体且男女上月工资独立,可以进行独立样本T检验,(见表6、表7) 表6 组统计量
性别 N 均值 标准差 均值的标准误 上月工资 男生 73 3156.16 442.840 51.831
女生 75 2700.00 441.129 50.937
假设1:H0:2221
H1:2221 其中,代表女生总体方差代表男生总体方差,2221 从表7中方差方程的 Levene 检验可以看出,F=0.101,P=0.751>0.05,所以不能拒绝原假设,可以认为两组数据无显著差异,所以应该选择方差相等下的T检验。 表7独立样本检验
假设2: H0:21 H1:21 其中μ1代表男生总体平均数,μ2代表女生总体平均数,下同 作出结论:从表6、表7中可以看出,男生有73人,平均工资3156.16元,女生75人,平均工资2700.00元。t=6.277,且p=0.000<0.001 所以拒绝原假设,接受备择假设,差异极显著。根据表6,可以最后得出结论,男生平均工资大于女生的结论。 4、一些学者认为,由于经济不景气,学生的平均工资今年和去年相比没有显著提高。检验这一假说。 解: 根据题意可知,需要进行相关样本T检验,设: H0:μ1≤μ2 H1;μ1>μ2 同上 表8 相关样本T检验 均值 标准差 均值标准误 T df 相关系数 sig 上月工资 2925 496.364 40.801 去年同月工资 2721.62 447.296 36.767 上月工资&去年同月工资 203.378 183.101 15.501 13.531 147 0.93 0.000
通过表8可知,t=13.531,P=0.000<0.01,所以拒绝原假设,接受备择假设,即学生的平均工资今年和去年相比有显著提高。
方差方程的 Levene 检验 T检验 F Sig. t df Sig.(双侧) 均值差值 标准误差值 上月工资 假设方差相等 0.101 0.751 6.277 146 0.000 456.164 72.667
假设方差不相等 6.277 145.859 0.000 456.164 72.670 第 5 页 共 13 页
5、方差分析。 (1)使用单因素方差分析的方法检验:能否认为不同学科的上月平均工资相等。如果不能认为全相等,请做多重比较。 解:第一步,提出假设,H0:不同学科上月的平均工资是相同的 H1:至少有两门学科上个月的平局工资是相同的 经过SPSS软件计算,见表9, 表9 三门学科上月工资水平方差分析表
平方和 df 均方 F 显著性 组间 372977.879 2 186488.939 0.754 0.472
组内 3.584E7 145 247203.601
总数 3.622E7 147
第二步,决策,F=0.754,P=0.472>0.05,接受H0,拒绝 H1,三者之间没有显著性差异。可以认为不同学科上月工资水平相同。 第三步,多重比较,经过Levene检验(见表10),p=0.724,方差没有显著性差异,方差齐性,经过LSD检验(见表11),P值均大于0.05,所以可以得出同样的结论,三门学科的上月工资水平没有差异。 表10 方差齐性检验
Levene 统计量 df1 df2 显著性 .323 2 145 0.724 表11 多重比较
(I) 学科 (J) 学科 均值差 (I-J) 标准误 显著性 95% 置信区间 下限 上限 LSD 1 2 -112.348 99.458 .261 -308.92 84.23 3 -111.912 108.528 .304 -326.41 102.59 2 1 112.348 99.458 .261 -84.23 308.92 3 .436 98.038 .996 -193.33 194.20 3 1 111.912 108.528 .304 -102.59 326.41 2 -.436 98.038 .996 -194.20 193.33
(2)在方差分析中同时考虑学科和性别因素,用双因素方差分析模型分析学科和性别对上月平均工资的影响。
解: 第一步,提出假设,H0:性别和学科对上月工资水平没有影响 H1:性别和学科同时对上月工资水平有影响 第二步,经过SPSS计算,见表12, 第 6 页 共 13 页
表12主体间效应的检验 源 df 均方 F Sig.
校正模型 5 1603013.899 8.071 .000
性别 1 7202158.042 36.263 .000
学科 2 153037.863 .771 .465
性别 * 学科 2 7642.822 .038 .962
总计 148
第三步,作出决策 性别因素P=0.000<0.01,在0.01水平上差异显著,所以拒绝原假设,接受备择假设,即性别因素对工资水平有显著性影响,和前面结果一致。 学科因素P=0.465>0.05,在0.05水平上差异不显著,所以接受原假设,拒绝备择假设,即学科因素对上月工资水平没有影响,和前面结果一致。 性别 * 学科p=0.962>0.05,在0.05水平上差异不显著,所以接受原假设,拒绝备择假设,即学科和性别因素同时对上月工资水平没有影响。
6、非参数检验。 (1)用非参数检验方法检验能否认为男生和女生上月工资的中位数相等。 解:第一步,采用wilcoxon符号秩检验中位数 ,选择的原设与备择假设如下: H0:男生与女生上月工资的中位数相等; H1:男生与女生上月工资的中位数不相等 。 第二步,通过SPSS软件计算,见表13、14 表13 检验男女生上月工资中位数是否相等wilcoxon秩和检验中秩和的计算结果
N 秩均值 秩和 上月工资 男生 73 94.67 6911.00
女生 75 54.87 4115.00
总数 148
表14 wilcoxon秩和检验的检验统计量和p值 上月工资 Mann-Whitney U 1265.000 Wilcoxon W 4115.000 Z -5.663 渐近显著性(双侧) .000
精确显著性(双侧) .000
精确显著性(单侧) .000
点概率 .000