搜索引擎相关度算法分析
- 格式:doc
- 大小:49.50 KB
- 文档页数:14
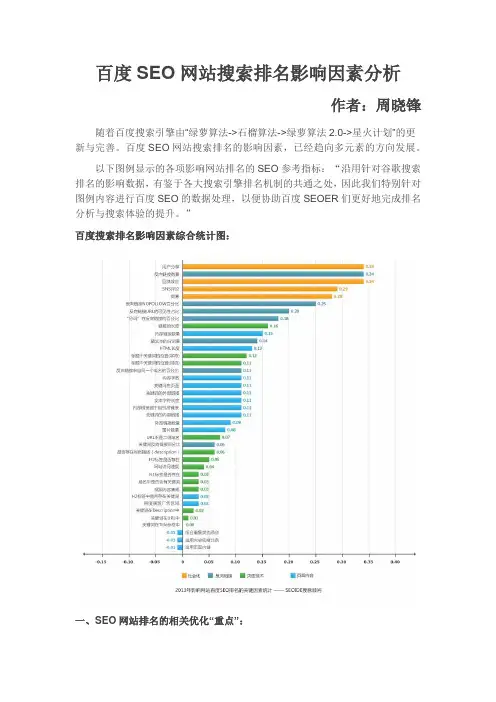
百度SEO网站搜索排名影响因素分析作者:周晓锋随着百度搜索引擎由“绿萝算法->石榴算法->绿萝算法2.0->星火计划”的更新与完善。
百度SEO网站搜索排名的影响因素,已经趋向多元素的方向发展。
以下图例显示的各项影响网站排名的SEO参考指标:“沿用针对谷歌搜索排名的影响数据,有鉴于各大搜索引擎排名机制的共通之处,因此我们特别针对图例内容进行百度SEO的数据处理,以便协助百度SEOER们更好地完成排名分析与搜索体验的提升。
”百度搜索排名影响因素综合统计图:一、SEO网站排名的相关优化“重点”:1、相比往年,今年针对网站外部链接的组成结构审查得更为严格。
2、现行搜索引擎算法规则在“品牌效应”面前似乎显得一无是处。
3、“用户推荐机制”对排名的影响呈几何倍数增长。
4、高质量的网站内容依然非常重要。
5、反向链接对网站排名的影响依旧名列前茅。
6、站内SEO正在体现搜索引擎对于页面技术支持的友好性。
7、聚合类内容的整合实现方式正在取替劣质的SEO伪原创内容。
8、百度站长平台强势推出,建立行之有效的误伤投诉以及拒绝链接通道。
9、百度搜索信任机制的建立,正在规范并过滤着绝大多数的劣质SEO排名。
二、站内SEO排名的优化影响因素解析:站内SEO的关键因素评点:图例统计主要呈现页面内容结构组成对于排名的影响,以往依靠于采集或网站自身权重建立的劣质内链作用正在迅速下降。
目前通过聚合类组成的内容主体则更受搜索引擎所喜爱,其表现于丰富的结构内容完成了以往关联机制类的页面体验,有利于用户体验的建立并为站内SEO集合权重进而为网站提供排名支撑的因素。
这里值得一提的是,现阶段百度针对搜索结果当中对于官网、V认证、百度分享、推荐等自身信任推荐体系的网站应用方面,有着一定比例的排名加成作用。
我们估且美其名曰为:搜索安全的信任体系,其发展势头正与用户体验的推荐并列自成一派。
《相关新闻详见:360推出的用户搜索评分方式》个中利与弊他日自有分晓。

hits 原理Hits 原理解析1. Hits 模型简介•Hits(Hyperlink-Induced Topic Search)模型是一种经典的链接分析算法。
•它通过分析网页之间的链接结构,评估网页的重要性,并获取相关的主题信息。
•Hits 模型广泛应用于搜索引擎的排名算法中,如谷歌的PageRank 算法。
2. 基本原理•主题相关性:Hits 模型认为,一个网页的重要性与其所包含的关键词相关性有关。
•链接结构:通过分析网页之间的链接结构,Hits 模型可以判断网页的权威性和可信度。
3. Hits 模型的工作流程•首先,Hits 模型需要构建一个网页之间的链接图。
•然后,通过迭代计算的方式,不断更新每个网页的权重,直到收敛。
•最后,根据网页的权重,对搜索结果进行排序和排名。
4. 迭代计算过程1.初始化:为每个网页赋予一个初始的权重值。
2.计算 Authority 值:根据网页之间的链接关系,更新每个网页的 Authority 值。
3.计算 Hub 值:根据网页之间的链接关系,更新每个网页的 Hub值。
4.归一化:对 Authority 值和 Hub 值进行归一化处理,使其和为1。
5.收敛判断:检查计算得到的 Authority 和 Hub 值是否与上一次计算相差足够小,如果是,则停止计算,否则返回第2步。
5. 评估网页重要性的指标•Authority 值:代表一个网页的主题相关性,即网页作为一个权威来源提供的信息质量。
•Hub 值:代表一个网页的链接质量,即网页提供的链接是否指向其他权威来源。
6. Hits 模型的特点•基于链接分析:Hits 模型通过分析网页之间的链接结构来评估网页的重要性。
•主题相关性:Hits 模型将主题相关性作为评估网页重要性的关键指标。
•迭代计算:Hits 模型通过迭代计算的方式,不断更新网页的权重,直到收敛为止。
7. 总结•Hits 模型是一种经典的链接分析算法,用于评估网页的重要性和获取相关的主题信息。

搜索引擎名词解释搜索引擎是一种用于帮助用户在互联网上查找特定信息的计算机程序。
用户通过输入关键词或短语,搜索引擎会在其索引中查找与该关键词相关的网页、图片、视频和其他在线资源,并将结果以列表或排名的方式展示给用户。
以下是一些与搜索引擎相关的名词解释:1. 搜索引擎算法:搜索引擎算法是用于决定特定搜索查询的结果排名的一组规则和计算方法。
搜索引擎公司会保密其算法的具体细节,以避免滥用和操纵。
2. 搜索引擎优化(SEO):搜索引擎优化是一系列技术和策略,旨在提高网站在搜索引擎的排名和可见性。
SEO包括关键词研究、网站结构优化、内容优化、链接建设等活动。
3. 搜索引擎广告(SEA):搜索引擎广告是一种广告形式,通过在搜索结果页面上以有偿方式展示广告,帮助企业推广产品和服务。
常见的搜索引擎广告平台有Google AdWords和百度推广。
4. 网络爬虫:网络爬虫是搜索引擎算法中的核心部分,用于浏览互联网上的网页并将其存储到搜索引擎的数据库中。
网络爬虫会按照事先设定的规则和指令自动访问网站,并提取页面“标题”、“描述”和关键词等信息。
5. 自然搜索结果:自然搜索结果也被称为有机搜索结果,是通过搜索引擎算法根据网页的相关性和权威性来排名的结果。
自然搜索结果不需要付费,是根据搜索引擎认为最合适的内容来展示给用户。
6. 人工智能搜索:人工智能搜索引擎是利用机器学习和自然语言处理等人工智能技术来改进搜索结果的搜索引擎。
通过分析用户的搜索历史和行为,人工智能搜索引擎可以为用户提供更个性化和准确的搜索结果。
7. 垂直搜索引擎:垂直搜索引擎是指针对特定领域或行业的搜索引擎,例如电商搜索引擎、旅游搜索引擎等。
相比于通用搜索引擎,垂直搜索引擎提供更专业和精准的搜索结果。
8. 元搜索引擎:元搜索引擎是一种同时查询多个其他搜索引擎并将结果整合展示给用户的搜索引擎。
元搜索引擎可以提供更全面的搜索结果,并帮助用户节省时间,避免在不同搜索引擎之间来回切换。

PageRank算法1. PageRank算法概述PageRank,即⽹页排名,⼜称⽹页级别、Google左側排名或佩奇排名。
是Google创始⼈拉⾥·佩奇和谢尔盖·布林于1997年构建早期的搜索系统原型时提出的链接分析算法,⾃从Google在商业上获得空前的成功后,该算法也成为其他搜索引擎和学术界⼗分关注的计算模型。
眼下许多重要的链接分析算法都是在PageRank算法基础上衍⽣出来的。
PageRank是Google⽤于⽤来标识⽹页的等级/重要性的⼀种⽅法,是Google⽤来衡量⼀个站点的好坏的唯⼀标准。
在揉合了诸如Title标识和Keywords标识等全部其他因素之后,Google通过PageRank来调整结果,使那些更具“等级/重要性”的⽹页在搜索结果中另站点排名获得提升,从⽽提⾼搜索结果的相关性和质量。
其级别从0到10级,10级为满分。
PR值越⾼说明该⽹页越受欢迎(越重要)。
⽐如:⼀个PR值为1的站点表明这个站点不太具有流⾏度,⽽PR值为7到10则表明这个站点很受欢迎(或者说极其重要)。
⼀般PR值达到4,就算是⼀个不错的站点了。
Google把⾃⼰的站点的PR值定到10,这说明Google这个站点是很受欢迎的,也能够说这个站点很重要。
2. 从⼊链数量到 PageRank在PageRank提出之前,已经有研究者提出利⽤⽹页的⼊链数量来进⾏链接分析计算,这样的⼊链⽅法如果⼀个⽹页的⼊链越多,则该⽹页越重要。
早期的⾮常多搜索引擎也採纳了⼊链数量作为链接分析⽅法,对于搜索引擎效果提升也有较明显的效果。
PageRank除了考虑到⼊链数量的影响,还參考了⽹页质量因素,两者相结合获得了更好的⽹页重要性评价标准。
对于某个互联⽹⽹页A来说,该⽹页PageRank的计算基于下⾯两个基本如果:数量如果:在Web图模型中,如果⼀个页⾯节点接收到的其它⽹页指向的⼊链数量越多,那么这个页⾯越重要。

相对于TF-IDF 而言,在信息检索和文本挖掘领域,BM25算法则更具理论基础,而且是工程实践中当仁不让的重要基线(Baseline)算法。
BM25在20世纪70年代到80年代被提出,到目前为止已经过去二三十年了,但是这个算法依然在很多信息检索的任务中表现优异,是很多工程师首选的算法之一。
今天我就来谈谈BM25算法的历史、算法本身的核心概念以及BM25的一些重要变种,帮助你快速掌握这个信息检索和文本挖掘的利器。
BM25的历史BM25,有时候全称是Okapi BM25,是由英国一批信息检索领域的计算机科学家开发的排序算法。
这里的“BM”是“最佳匹配”(Best Match)的简称。
BM25背后有两位著名的英国计算机科学家。
第一位叫斯蒂芬·罗伯逊(Stephen Robertson)。
斯蒂芬最早从剑桥大学数学系本科毕业,然后从城市大学(City University)获得硕士学位,之后从伦敦大学学院(University College London)获得博士学位。
斯蒂芬从1978年到1998年之间在城市大学任教。
1998年到2013年间在微软研究院剑桥实验室工作。
我们之前提到过,美国计算机协会ACM 现在每三年颁发一次“杰拉德·索尔顿奖”,用于表彰对信息检索技术有突出贡献的研究人员。
2000年这个奖项颁给斯蒂芬,奖励他在理论方面对信息检索的贡献。
BM25可谓斯蒂芬一生中最重要的成果。
另外一位重要的计算机科学家就是英国的卡伦·琼斯(Karen Sp?rck Jones)。
周一我们在TF-IDF 的文章中讲过。
卡伦也是剑桥大学博士毕业,并且毕生致力于信息检索技术的研究。
卡伦的最大贡献是发现IDF 以及对TF-IDF 的总结。
卡伦在1988年获得了第二届“杰拉德·索尔顿奖”。
BM25算法详解现代BM25算法是用来计算某一个目标文档(Document)相对于一个查询关键字(Query)的“相关性”(Relevance)的流程。

page rank算法的原理
PageRank算法是由谷歌创始人之一拉里·佩奇(Larry Page)
提出的,用于评估网页在搜索引擎中的重要性。
PageRank算法的原理可以概括为以下几点:
1. 链接分析:PageRank算法基于链接分析的思想,认为一个
网页的重要性可以通过其被其他重要网页所链接的数量来衡量。
即一个网页的重要性取决于其他网页对它的引用和推荐。
2. 重要性传递:每个网页都被赋予一个初始的权重值,然后通过不断迭代的计算过程,将网页的重要性从被链接的网页传递到链接的网页。
具体来说,一个网页的权重值由其被其他网页所链接的数量以及这些链接网页的权重值决定。
3. 随机跳转:PageRank算法引入了随机跳转的概念。
即当用
户在浏览网页时,有一定的概率会随机跳转到其他网页,而不是通过链接跳转。
这样可以模拟用户在浏览网页时的行为,并增加所有网页的重要性。
4. 阻尼因子:PageRank算法还引入了阻尼因子,用于调控随
机跳转的概率。
阻尼因子取值范围为0到1之间,通常取值为0.85。
阻尼因子决定了用户在浏览网页时选择跳转到其他网页
的概率。
通过以上原理,PageRank算法可以计算出各个网页的重要性
得分,从而在搜索引擎中按照重要性进行排序。



搜索引擎工作原理搜索引擎是一种用于帮助用户在互联网上查找信息的工具,通过收集、索引和展示网页内容,为用户提供相关的搜索结果。
搜索引擎的工作原理可以分为以下几个步骤:网页抓取、索引建立和搜索结果展示。
1. 网页抓取搜索引擎通过网络爬虫(也称为蜘蛛、机器人)自动访问互联网上的网页,并将网页内容下载到搜索引擎的服务器上。
爬虫按照一定的规则遍历网页,通过链接跳转和网页分析等方式获取更多的网页。
爬虫会定期访问已抓取的网页,以便更新搜索引擎的索引。
2. 索引建立在网页抓取后,搜索引擎会对网页内容进行处理和分析,提取出网页中的关键词、标题、摘要等信息,并将这些信息存储在索引数据库中。
索引数据库是搜索引擎的核心组成部分,它包含了大量的网页信息和相关的索引信息。
索引数据库会根据关键词的频率、位置和其他相关度因素对网页进行排序和分类。
3. 搜索结果展示当用户在搜索引擎中输入关键词进行搜索时,搜索引擎会根据用户的搜索词在索引数据库中进行匹配和排序。
搜索引擎会根据网页的相关度对搜索结果进行排序,并将最相关的网页展示给用户。
搜索引擎还会根据用户的搜索历史、地理位置和其他个性化因素对搜索结果进行调整和个性化推荐。
搜索引擎的工作原理涉及到多个技术和算法,以下是一些常用的技术和算法:1. 爬虫技术爬虫技术是搜索引擎获取网页内容的基础。
爬虫会按照一定的规则和策略遍历网页,通过链接跳转和网页分析等方式获取更多的网页。
爬虫还会处理网页中的链接,将新的网页添加到待抓取队列中。
爬虫的设计和实现需要考虑到网页的数量、抓取速度和网络资源的限制等因素。
2. 关键词匹配算法关键词匹配算法是搜索引擎对用户搜索词和网页内容进行匹配的核心算法。
关键词匹配算法会根据关键词的频率、位置和其他相关度因素对网页进行排序和分类。
常见的关键词匹配算法包括向量空间模型(VSM)、BM25和TF-IDF等。
3. 网页排名算法网页排名算法是搜索引擎对搜索结果进行排序的算法。

信息检索——BM25算法详解BM25算法,通常⽤来作搜索相关性平分。
⼀句话概况其主要思想:对Query进⾏语素解析,⽣成语素qi;然后,对于每个搜索结果D,计算每个语素qi与D的相关性得分,最后,将qi相对于D的相关性得分进⾏加权求和,从⽽得到Query与D的相关性得分。
BM25算法的⼀般性公式如下:其中,Q表⽰Query,qi表⽰Q解析之后的⼀个语素(对中⽂⽽⾔,我们可以把对Query的分词作为语素分析,每个词看成语素qi。
);d表⽰⼀个搜索结果⽂档;Wi表⽰语素qi的权重;R(qi,d)表⽰语素qi与⽂档d的相关性得分。
下⾯我们来看如何定义Wi。
判断⼀个词与⼀个⽂档的相关性的权重,⽅法有多种,较常⽤的是IDF。
这⾥以IDF为例,公式如下:其中,N为索引中的全部⽂档数,n(qi)为包含了qi的⽂档数。
根据IDF的定义可以看出,对于给定的⽂档集合,包含了qi的⽂档数越多,qi的权重则越低。
也就是说,当很多⽂档都包含了qi时,qi的区分度就不⾼,因此使⽤qi来判断相关性时的重要度就较低。
我们再来看语素qi与⽂档d的相关性得分R(qi,d)。
⾸先来看BM25中相关性得分的⼀般形式:其中,k1,k2,b为调节因⼦,通常根据经验设置,⼀般k1=2,b=0.75;fi为qi在d中的出现频率,qfi为qi在Query中的出现频率。
dl为⽂档d的长度,avgdl为所有⽂档的平均长度。
由于绝⼤部分情况下,qi在Query中只会出现⼀次,即qfi=1,因此公式可以简化为:从K的定义中可以看到,参数b的作⽤是调整⽂档长度对相关性影响的⼤⼩。
b越⼤,⽂档长度的对相关性得分的影响越⼤,反之越⼩。
⽽⽂档的相对长度越长,K值将越⼤,则相关性得分会越⼩。
这可以理解为,当⽂档较长时,包含qi的机会越⼤,因此,同等fi的情况下,长⽂档与qi的相关性应该⽐短⽂档与qi的相关性弱。
综上,BM25算法的相关性得分公式可总结为:从BM25的公式可以看到,通过使⽤不同的语素分析⽅法、语素权重判定⽅法,以及语素与⽂档的相关性判定⽅法,我们可以衍⽣出不同的搜索相关性得分计算⽅法,这就为我们设计算法提供了较⼤的灵活性。

相似度分析淘宝产品关键词相近技巧淘宝作为国内最大电商平台之一,在商品搜索方面有着强大的搜索引擎算法技术支撑,通过分析消费者搜索关键字与商品的相似度,为用户提供高质量的搜索结果,提供便捷购物体验。
本文将探讨如何分析淘宝产品关键词的相似度以及相近技巧。
一、相似度分析1.1 统计分析在淘宝商品搜索中,有两种统计分析方法可以帮助分析产品关键词的相似度:词频统计和TF-IDF算法。
词频统计在搜索排名上起到决定性作用,即搜索关键字在商品描述和商品标题的字数出现频次,词频越高则搜索排名越靠前。
TF-IDF算法则是通过统计搜索关键字在各个商品中出现的频率,同时考虑该词语在所有文档中的出现频率,从而计算得到每个词语的重要程度,依此对淘宝商品进行搜索排序。
1.2 相似度算法在淘宝搜索中,为了能够更准确地找到用户需要的商品,淘宝需要判断搜索关键字和商品标题、商品描述的关联程度,从而计算商品排名顺序。
常见的相似度算法有余弦相似度算法和Jaccard相似度算法。
余弦相似度算法是通过计算两个向量的夹角来衡量它们之间的相似性,值越接近1则说明两个向量越相似;值越接近0则说明两个向量越不相似。
在淘宝搜索中,夹角越小,则相似度越高,搜索结果也就越靠前。
Jaccard相似度算法是通过计算两个集合的交集与并集的比例来衡量它们之间的相似度,值越大表示相似度越高。
在淘宝搜索中,通过将搜索关键字和商品关键词所在集合进行比较,计算出相似度值,从而排出相关的商品。
二、相近技巧2.1 同义词在相似度分析中,同义词是重要的关键词相近技巧之一。
当消费者在搜索商品时,有时会使用同义词来替换原始搜索词汇,比如“手机”就可以替换成“智能手机”、“手机壳”、“苹果手机”等搜索词汇。
所以,商家在发布商品时,可以在标题或商品描述中使用更多的同义词,以避免在搜索时被漏掉。
2.2 词语组合在淘宝的搜索中,相近技巧也可以采用词语组合的方式。
就是在关键词前后增加相关的描述性词汇,比如“中国风”、“时尚”、“日式”、“北欧”等装饰词语,从而让搜索关键字更加具体化,增强商品的曝光度。
热词计算公式通常是指在搜索引擎优化(SEO)中,用于计算关键词热度的公式。
关键词热度是衡量一个关键词在搜索引擎中的搜索频率和竞争程度的指标。
热词计算公式可以帮助我们了解哪些关键词具有较高的搜索量和较低的竞争程度,从而为我们的网站或内容提供更好的排名机会。
常见的热词计算公式有以下几种:
1. 搜索量(Volume):搜索量是指某个关键词在一定时间内被搜索的次数。
这个数据可以通过搜索引擎的关键词规划工具(如Google关键词规划师、百度指数等)获取。
2. 竞争程度(Competition):竞争程度是指在某个特定行业中,有多少网站在针对同一个关键词进行优化。
竞争程度越高,说明这个关键词的竞争越激烈,排名的难度也越大。
竞争程度可以通过关键词规划工具或者直接在搜索引擎中查看搜索结果页的标题和描述来判断。
3. 相关度(Relevance):相关度是指一个关键词与其所指向的内容之间的相关性。
相关度越高,说明这个关键词与内容的匹配程度越好,用户在搜索这个关键词时,更容易找到他们想要的信息。
相关度可以通过分析关键词与内容的匹配程度、用户行为等因素来判断。
综合以上三个因素,我们可以得出一个热词的综合评分。
一般来说,搜索量大、竞争程度低、相关度高的关键词被认为是高热词,适合用于优化网站或内容。
pagerank算法原理PageRank算法是Google搜索引擎的核心算法,它是一种基于网络结构的技术,用于评估网页的重要性。
PageRank算法是由谷歌创始人拉里·佩奇和谷歌创始人朱利安·斯蒂芬森在1998年提出的,它是基于网页之间的链接关系来评估网页的重要性的。
PageRank算法的基本思想是,一个网页的重要性取决于它的链接数量和质量。
如果一个网页有很多的链接,那么它就被认为是重要的,而如果一个网页的链接数量很少,那么它就被认为是不重要的。
此外,一个网页的重要性还取决于它的链接质量,如果一个网页的链接来自一个重要的网页,那么它就被认为是重要的,而如果一个网页的链接来自一个不重要的网页,那么它就被认为是不重要的。
PageRank算法的实现原理是,首先,将网页的重要性定义为一个数字,称为PageRank值,PageRank值越高,表明网页的重要性越高。
其次,根据网页之间的链接关系,计算每个网页的PageRank 值。
最后,根据计算出的PageRank值,对网页进行排序,从而得到搜索结果。
PageRank算法的实现过程是,首先,将网页的重要性定义为一个数字,称为PageRank值,PageRank值越高,表明网页的重要性越高。
其次,根据网页之间的链接关系,计算每个网页的PageRank 值。
具体来说,PageRank值的计算是通过一个矩阵来实现的,矩阵中的每一行代表一个网页,每一列代表一个网页的链接,矩阵中的每一个元素代表一个网页的链接权重,即一个网页的重要性。
最后,根据计算出的PageRank值,对网页进行排序,从而得到搜索结果。
PageRank算法的优点是,它可以有效地评估网页的重要性,并且可以根据网页之间的链接关系来计算每个网页的PageRank值,从而得到更准确的搜索结果。
一、特征词库的类别的建立与更新众所周知,百度有特征词库,通过特征词库,可以对用户查询序列,进行判断。
例如:当用户搜索“天龙八部在线观看” 、“射雕英雄传在线观看” 、“鹿鼎记在线观看” 、“电视剧在线观看”时,由于这些待挖掘序列中的“天龙八部” 、“射雕英雄传” 、“鹿鼎记” 、“电视剧” 在需求特征词库中属于视频类需求的特征词,并且“在线观看” 这一关键词与上述视频类需求的特征词的共现频次达到一定阈值(共现阈值)时,根据关键词“在线观看” ,提取关键词“在线观看” 与视频需求类别的映射关系,并根据映射关系来建立或更新需求特征词库。
二、对词条的分类首先对查询序列进行切词处理获得切分后的词条,再通过诸如对词条进行语义分析或根据词条在需求特征词库中进行匹配查询等方式,来获得所述候选需求类别。
例如:用户的查询序列为“土豆上的热门影视剧” 时,通过对其进行切词处理,得到“土豆/热门/ 影视剧” ,由于影视剧一词具有明显的需求类别,诸如视频、下载、图片、演员介绍,再通过诸如对词条进行语义分析或根据所述词条在需求特征词库中进行匹配查询等方式,来获得候选需求类别。
当挖掘序列相对应的分类结果的用户累计点击次数超过预设点击阈值时,基于所述分类结果所对应的需求类别,提取待挖掘序列与需求类别的映射关系,并根据映射关系来建立或更新需求特征词库,例如,当待挖掘序列为“日本地震” 时,根据该待挖掘序列对应的分类结果,如视频类搜索结果、新闻类搜索结果、图片类搜索结果,若视频类搜索结果对应的用户累计点击次数为300,新闻类搜索结果对应的用户累计点击次数为25000,图片类搜索结果对应的用户累计点击次数为700,预设点击阈值为10000 时,将待挖掘序列对应的分类结果的用户累计点击次数与预设点击阈值进行比较,并根据高于所述预设点击阈值的分类结果所对应的需求类别,即新闻需求类别,提取该待挖掘序列与新闻需求类别间的所述映射关系,并根据映射关系来建立或更新需求特征词库。
搜索引擎优化的原理与方法随着互联网的快速发展,我们已经进入了一个全新的数字时代。
作为每个互联网用户最重要的工具,搜索引擎在我们的生活中扮演着越来越重要的角色。
无论是想要购物、旅游、咨询医生还是做研究,我们都离不开搜索引擎。
如今,在搜索引擎上排名靠前的网站会吸引更多的流量和潜在客户。
这就需要我们深入了解搜索引擎优化的原理与方法,为我们的网站流量和排名提供更好的解决方案。
一、搜索引擎优化的原理搜索引擎优化(Search Engine Optimization,简称 SEO)是指通过优化网站设计和内容等策略,使网站在搜索引擎中排名更靠前,进而提高网站的流量和曝光率的一种技术手段。
那么,搜索引擎是如何根据关键词来决定排名呢?在 SEO 中,搜索引擎主要通过抓取和分析网页来决定网站的排名。
搜索引擎会通过一些算法来判断网页的重要性,并根据这些算法来确定网站的排名。
为了提高网站的排名,在网站设计和内容方面需要考虑以下几个方面:1.内容网站的内容对于搜索引擎排名非常重要。
优秀的内容会增加网站的权重,提高网站的排名。
搜索引擎通常会根据内容的相关性、相关字数和完整性等因素来评估一个网站是否可信。
2.外部链接外部链接也是搜索引擎优化的核心要素之一。
一般来说,搜索引擎会根据外部链接来评估一个网站的权重和可信度。
如果一个网站有大量的外部链接,说明该网站受到了其他网站的信任和认可,因此搜索引擎会提高网站的排名。
3.网站结构网站结构对于搜索引擎排名也非常重要。
搜索引擎通常会通过链接来评估一个网站的结构。
合理的网站结构可以提高网站的质量和权重。
4.站点标志和元数据站点标志和元数据包括网站标题、描述和关键字等信息。
这些信息可以帮助搜索引擎更好地理解网站的内容和目的。
二、搜索引擎优化的方法SEO 的方法有很多种,下面我将介绍一些比较常见且有效的SEO 方法:1.关键词研究在进行 SEO 之前,需要对网站进行关键词研究。
我们需要了解用户在搜索引擎中使用哪些关键词,以及这些关键词的竞争情况。
搜索引擎相关度算法分析 相关性,是搜索引擎优化中的重点。但是对于相关性的搜索引擎工作原理,相信大部分的SEOER对于都缺乏了解。作为职业SEO对于搜索引擎算法的研究是必须的,虽然说,我们不可能知道搜索引擎算法的全部。但是只需要我们主流搜索引擎技术的方向,你就可以知道搜索引擎时代的脉搏。 相关度排序技术的产生主要是由搜索引擎的特点决定的。 首先,现代搜索引擎能够访问的Web网页数量已经达到上十亿的规模,哪怕用Hu只是搜索其中很少的一部分内容,基于全文搜索技术的搜索引擎也能返回成千上万的页面。即便这些结果网页都是用Hu所需要的,用Hu也没有可能对所有的网页浏览一遍,所以能够将用Hu最感兴趣的结果网页放于前面,势必可以增强搜索引擎用Hu的满意度。 其次,搜索引擎用Hu自身的检索专业能力通常很有限,在最为普遍的关键词检索行为中,用Hu一般只是键人几个词语。例如,Spink等曾对Excite等搜索引擎的近300位用Hu做过实验调查,发现人均输入的检索词为3.34个。国内部分学者也有相似的结论,发现90%左右的用Hu输入的中文检索单字为2~6个,而且2字词居多,约占58%,其次为4字词(约占18%)和3字词(约占14%)。过少的检索词事实上无法真正表达用Hu的检索需求,而且用Hu通常也不去进行复杂的逻辑构造,只有相当少的用Hu进行布尔逻辑检索、限制性检索和高级检索等方法,仅有5.24%的检索式中包含有布尔逻辑算符。国内的部分学者的研究结果也表明,约40%的用Hu不能正确运用字段检索或二次检索,80%左右的用Hu不能正确运用高级检索功能,甚至还发现用Hu缺乏动力去学习复杂的检索技能,多数用Hu都寄希望于搜索引擎能够自动地为他们构造有效的检索式。由于缺乏过去联机检索中常常具备的检索人员,因此,用Hu实际的检索行为与用Hu理想的检索行为存在事实上的差距,检索结果的不满意也是不奇怪的。正是由于这个特点,搜索引擎就必须设法将用Hu最想要的网页结果尽可能地放到网页结果的前面,这就是网页相关度排序算法在搜索引擎中为什么非常重要的原因。 现阶段的相关度排序技术主要有以下几种:一是基于传统信息检索技术的方式,它主要利用关键词本身在文档中的重要程度来对文档与用Hu查询要求的相关度做出测量,如利用网页中关键词出现的频率和位置。一般而言,检索出的网页文档中含有的查询关键词个数越多,相关性越大,并且此关键词的区分度越高;同时,查询关键词如果出现在诸如标题字段等重要位置上,则比出现在正文的相关度要大。二是超连分析技术,使用此技术的代表性搜索引擎有Google和Bai。和前者相比,它以网页被认可的重要程度作为检索结果的相关度排序依据。从设计思想上看,它更注重第三方对该网页的认可,如具有较大连入网页数的网页才是得到广泛认可的重要网页,而根据关键词位置和频率的传统方法只是一种网页自我认可的形式,缺乏客观性。最后还有一些其他方式,如由用Hu自由定义排序规则的自定义方式。北京大学的天网FTP搜索引擎就采用这种排序方式,它可以让用Hu选择诸如时间、大小、稳定性和距离等具体排序指标来对结果网页进行相关度排序。再如收费排名模式,它作为搜索引擎的一种主要赢利手段,在具有网络门Hu特点的大型搜索引擎中广为使用,但于担心影响搜索结果的客观性,这种方式不是它们的主流排序方式,而仅仅作为一个补充显示在付费搜索栏目中。 相关度排序技术主要依赖于超连分析技术实现。超连分析技术可以提供多种功能,其中的主要功能就是解决结果网页的相关度排序问题。它主要是利用网页间存在的各种超连指向,对网页之间的引用关系进行分析,依据网页连人数的多少计算该网页的重要度权值。一般认为,如果A网页有超连指向B网页,相当于A网页投了B网页一票,即A认可了B网页的重要性。深入理解超连分析算法,可以根据连接结构把整个Web网页文档集看成一个有向的拓扑图,其中每个网页都构成图中的一个结点,网页之间的连接就构成了结点间的有向边,按照这个思想,可以根据每个结点的出度和入度来评价网页的重要性。 对于超连分析技术,有代表性的算法主要是Page等设计的PageRank算法和Kleinberg创造的HITS算法。其中,PageRank算法在实际使用中的效果要好于HITS算法,这主要是由于以下原因:首先,PageRank算法可以一次性、脱机且独立于查询的对网页进行预计算以得到网页重要度的估计值,然后在具体的用Hu查询中,结合其他查询指标值,一起对查询结果进行相关性排序,从而节省了系统查询时的运算开销;其次,PageRank算法是利用整个网页集合进行计算的,不像HITS算法易受到局部连接陷阱的影响而产生“主题漂移”现象,所以现在这种技术广泛地应用在许多搜索引擎系统中,Google搜索引擎的广获成功也表明了以超连分析为特征的网页相关度排序算法日益成熟。 PageRank技术基于一种假设,即对于Web中的一个网页A,如果存在指向网页A的连接,则可以将A看成是一个重要的网页。PageRank认为网页的连入连接数可以反映网页的重要程度,但是由于现实中的人们在设计网页的各种超连时往往并不严格,有很多网页的超连纯粹是为了诸如网站导航、商业广告等目的而制作,显然这类网页对于它所指向网页的重要程度贡献程度并不高。但是,由于算法的复杂性,PageRank没有过多考虑网页超连内容对网页重要度的影响,只是使用了两个相对简单的方法:其一,如果一个网页的连出网页数太多,则它对每个连出网页重要度的认可能力降低;其二,如果一个网页由于本身连入网页数很低造成它的重要程度降低,则它对连出网页重要度的影响也相应降低。所以,在实际计算中,网页A的重要性权值正比于连入网页A的重要性权值,并且和连入网页A的连出网页数量呈反比。由于无法知道网页A自身的重要性权值,所以决定每个网页的重要权值需要反复迭代地进行运算才能得到。也就是说,一个网页的重要性决定着同时也依赖于其他网页的重要性.
——————————————————————————————————————— 【补充材料:搜索引擎的相关排序算法分析与优化】 WWW是一个巨大的潜在的知识库,它所拥有的web页已经从最初的几千个发展到至今的20多亿个(已被编入索引).随着网络规模的爆炸性增长,搜索引擎已经成了帮助人们寻找相关信息的重要工具.据纽约市场研究机构朱比特通信公司的调查分析,88%的网上用户使用搜索工具,成为除Email之外使用最多的互联网应用之一.但是由于Web数据本身具有分布、异质、动态、半结构或非结构等特征,这无疑给Web上的信息检索提出了挑战[1].目前的搜索引擎普遍存在着查全率和查准率不高的现象,任何一个简单的查询都至少返回数以万计的检索结果,而其中只有很少一部分与用户真正的检索要求有关.同时,由于搜索引擎数据量巨大,而用户的接受能力有限,查全率对搜索引擎来说基本失去了评价的意义.而前X个检索结果的查准率对于用户的检索目标更具意义[1].影响查准率的因素有很多,相关排序算法是其中的一个关键点。
1、相关排序的概念和存在的问题。 传统上,人们将信息检索系统返回结果的排序称为“相关排序”(RelevanceRanking),隐含其中各条目的顺序反映了结果和查询的相关程度.在搜索引擎中,其排序不是一个狭义的相关序,而是一种反映多种因素的综合统计优先序.在排序方面,搜索引擎目前存在的问题:(1)对于多数检索课题,要么输出的检索结果过载,记录数量达千条以上,给相关性判断带来困难;要么是零输出或输出量太少,造成过分的漏检.(2)在相关度方面,搜索引擎对相关度参数的选择、计量和算法各不相同.(3)由于搜索引擎是按照已定的相关度对检索结果进行排序,关键词检索返回结果的相关度排序方式单一,用户不能根据需要选择输入的排序方法,用户对结果的排序无能为力,因而用户基本上是在被动接受返回序列,这难免与用户的检索目标冲突,受到用户接受能力的限制,无疑会影响到检全率与检准率。
2、现有的排序算法。 现有的搜索引擎排序技术主要有PageRank算法和HITS算法.PageRank算法以“随机冲浪”模型为理论基础,而HITS算法使用Hub和Authority相互加强模型,二者都是利用了网页和超链组成的有向图,根据相互连接的关系进行递归运算. 2.1 PageRank算法。 LawrencePage和SergeyBrin描述了PageRank最初的算法,网页A页的PageRank值PR(A)=(1-d)+d(PR(T1)ΠC(T1)+…+PR(Tn)ΠC(Tn)),其中d为阻尼系数,且0网页的PageRank值决定了随机访问到这个页面的概率.用户点击页面内的链接概率,完全由页面上链接数量的多少决定的,这也是上面PR(Ti)ΠC(Ti)的原因.因此,一个页面通过随机冲浪到达的概率就是链入它的页面上的链接被点击概率的和,且阻尼系数的减低了这个概率.阻尼系数的引入,是因为用户不可能无限的点击链接,常常因无聊而随机跳入另一个页面. 由此可见,PageRank并不是将整个网站排等级,而是以单个页面计算的.页面A的PageRank值取决于那些连接到A页面的PageRank的递归值.PR(Ti)值并不是均等影响页面PR(A)的.在PageRank的计算公式里,T对于A的影响还受T的出站链接数C(T)的影响.这就是说,T的出站链接越多,A受T的这个连接的影响就越少.PR(A)是所有PR(Ti)之和.所以,对于A来说,每多增加一个入站链接都会增加PR(A).所有PR(Ti)之和乘以一个阻尼系数的,它的值在0到1之间.因此,阻尼系数的使用,减少了其它页面对当前页面A的排序贡献.另外,PageRank算法中对于向外链接的权值贡献是平均的,也就是不考虑不同链接的重要性.斯坦福大学计算机科学系Arvin的Arasu等科学家经过试验表明,PageRank算法计算效率还可以得到很大的提高 2.2 HITS算法。 HITS(Hyperlink-In的uce的TopicSearch)算法是利用HubΠAuthority的搜索方法,具体算法如下:将查询q提交给传统的基于关键字匹配的搜索引擎.搜索引擎返回很多网页,从中取前n个网页作为根集(RootSet),用S表示.S满足如下3个条件:S中网页数量相对较小;S中网页大多数是与查询q相关的网页;S中网页包含较多的权威网页.通过向S中加入被S引用的网页和引用S的网页,将S扩展成一个更大的集合T.以T中的Hub网页为顶点集V1,以权威网页为顶点集V2.V1中的网页到V2中的网页的超链接为边集E,形成一个二分有向图.对V1中的任一个顶点v,用h(v)表示网页v的Hub值,且h(v)收敛;对V2中的顶点u,用a(u)表示网页的Authority值.开始时h(v)=a(u)=1,对u执行I操作,修改它的a(u),对v执行O操作,修改它的h(v),然后规范化a(u)Πh(v),如此不断的重复计算下面的I操作和O操作,直到a(u).其中I操作:a(u)=∑h(v);O操作:h(v)=∑a(u). 每次迭代对a(u)、h(v)进行规范化处理:a(u)=a(u)Π∑[a(q)]2;h(v)=h(v)Π∑[h(q)]2.HITS算法可以获得比较好的查全率,输出一组具有较大Hub值的网页和具有较大权威值的网页.但在实际应用中,HITS算法有以下几个问题:由S生成T的时间开销是很昂贵的,由T生成有向图也很耗时,需要分别计算网页的AΠH值,计算量大;网页中广告等