关于使用spss软件制作完全随机分组数据处理的图文演示
- 格式:ppt
- 大小:671.50 KB
- 文档页数:20

利用SPSS产生随机数字的常用方法作者简介徐州医学院公共卫生学院流行病与卫生统计学教研室(221002)金英良黄水平赵华硕在医学研究中,科研工作者常常需要把研究对象进行随机分组,实现不同处理因素实验顺序的随机化或在总体中随机抽取部分样本作为研究。
以上问题均涉及到统计学中随机化的问题,其目的主要是减少偏性,提高均衡性,是统计学能够得出客观推断的前提。
实现随机化的主要方法有两种,即随机数字表和计算机的随机数发生器。
所谓的随机数发生器就是通过一定的算法,对事先选定的随机种子做复杂运算,用产生的结果来近似地模拟完全随机数,这种随机数被称作伪随机数〔1〕。
一些医学文献或书籍常常只是简单提及SPSS 产生随机数字的菜单操作命令,没有作为重要知识点进行讲解。
笔者主要介绍如何利用SPSS 13·0统计分析软件产生随机数字的常用方法。
利用随机数生成函数生成随机数字在SPSS统计软件中,利用随机数生成函数生成一列随机数字的方法是调用Transform菜单下的compute子菜单,如图1所示。
在Function group列表中列出了可以实现各种功能的函数,这里我们选择RandomNumbers,立刻会在其下面的Functions and SpecialVar-iables子对话框中会提供了一系列随机数生成函数列表。
不同函数表示各自所产生的随机数字符合特定的分布,如t分布、F分布和Poisson分布等函数,当我们选取相应函数时,其左侧对话框内会有相应的函数功能英文介绍说明。
这里我们以常用的正态分布函数为例进行讲解。
软件所生成的随机数个数与数据库中的记录数相同,这里我们事先建立NO变量,并输入从1到10作为要进行随机化的记录编号。
在ComputeVariable对话框下的TargetVariable框中输入随机数的变量名,这里我们定义为random,然后选取Functions and SpecialVariables子对话框下的Rv.Norma,l点击按钮,在Numeric Expression表达式框内会出现函数表达式两个问号分别代表我们要定义的正态分布均数和标准差,这里我们以输入均数=100,标准差=10为例,最后点击OK按钮提交,结果在SPSS13.0数据窗口中的random变量一列会产生一组随机数字,见图2。



手把手教你SPSS实现随机抽样的两种方法我们在进行科学研究时,常常会强调一个非常重要的概念——“随机化”。
随机化的过程主要分为两大类:随机抽样和随机分组,它们在样本选取和分组方案中占有至关重要的地位。
随机化按照数学概率的原理,使研究对象有同等的机会被抽中或被分配到某一处理组,结果不受人为因素的干扰和影响。
如果没有遵循随机化的原则,抽取了一个有偏的样本,或者分组不均衡,这样即使得出了结论,也无法推论到总体,因此随机化是提高样本代表性及组间均衡性的重要方法,随机化过程的优劣直接关系到研究结果的可靠性。
随机化的概念虽然早已深入人心,但是在具体的随机化操作过程中,很多研究者往往误把“随便”“随意”当成“随机化”,从而形成“伪随机化”的假象,归根结底还是因为大家并不清楚到底该如何有效的实现随机化。
为此,小咖打算专门用几期的内容,向大家分别介绍一下随机抽样和随机分组的内容以及软件实现过程。
随机抽样随机抽样,即遵循随机化原则,保证总体中每个个体都有独立的、已知的、非零的概率被抽中作为研究对象。
若样本量足够大,数据代表性好,随机化效果好,调查结果则会更可靠,可以将抽样结果推论到总体。
常用的随机抽样方法主要包括简单随机抽样、系统抽样、分层抽样、整群抽样和多阶段抽样。
1. 简单随机抽样(也叫单纯随机抽样,simple random sampling)简单随机抽样是最简单、最基本的抽样方法。
它是从总体N个样本的抽样框中,不考虑样本之间的任何关系,完全随机地依次地抽取n 个样本,构成一个抽样样本。
它的特点是:每个样本被抽中的概率相等,样本之间完全独立,彼此没有一定的关联性和排斥性。
简单随机抽样方法是其它各种抽样形式的基础,通常用在总体之间差异程度较小,且总体数量有限、数目不是太大的情况下。
如果总体数量太大,编号工作就较为繁重,抽到的样本也较为分散,导致资料收集困难。
2. 系统抽样(也叫机械抽样或等距抽样,systematic sampling)系统抽样就是先将总体(N)的各个样本按照一定的顺序进行排列,根据抽样容量(n)的要求来确定抽样间隔(K=N/n),然后在第一组中随机确定一个起点,从该起点开始机械地每间隔K个距离依次抽取样本,直到抽够n个样本为止。

用SPSS实现完全随机设计多组比较秩和检验的多重比较用SPSS实现完全随机设计多组比较秩和检验的多重比较一、引言在实证研究中,为了探讨不同处理或干预对某个变量的影响,常常需要进行多组比较。
多组比较的目的是确定是否存在差异以及差异的大小。
秩和检验是一种用于比较两组或多组样本之间差异的非参数方法,具有一定的优势。
二、方法以SPSS软件为例,我们可以利用其提供的功能实现完全随机设计多组比较秩和检验的多重比较。
以下是具体的步骤:1. 数据准备首先,需要准备好用于分析的数据。
假设有n个处理组,每个处理组有m个观测值。
可以将数据按照处理组进行分类整理,每个处理组的观测值放在一列中。
2. 数据输入打开SPSS软件,创建一个新的数据文件,并将之前准备好的数据输入。
确保每个处理组的观测值对应正确。
3. 非参数检验选择菜单栏中的“分析-非参数检验-维尔科克森-曼-惠特尼U 检验”或“分析-非参数检验-克鲁斯卡尔-华里斯H检验”,根据实验需要选择适当的检验方法。
4. 设置选项在弹出的对话框中,将要比较的变量选择到“因子”框中,将处理组变量选择到“因子标签”框中。
选择需要进行多重比较的处理组,点击“组间对比”按钮。
5. 多重比较在“组间对比”对话框中,选择想要进行多重比较的处理组。
可以点击“加入全部对比”按钮将所有处理组两两比较,也可以手动选择需要比较的处理组。
点击“确定”进行多重比较。
6. 结果输出SPSS将会输出多重比较的结果,包括均值、标准误差、t值、p值等统计指标。
根据p值判断处理组之间是否存在显著差异。
三、示例为了更好地理解上述方法,我们通过一个假想的实验来展示如何使用SPSS进行完全随机设计多组比较秩和检验的多重比较。
假设研究人员想要比较四种不同药物对降压效果的影响。
他们随机地将30名患有高血压的参与者分为四个处理组,分别接受A药物、B药物、C药物和D药物的治疗。
每个处理组的参与者分别测量他们的血压值。
现在,研究人员想要确定这些药物在降压效果上是否有显著差异。

SPSS聚类分析过程聚类的主要过程一般可分为如下四个步骤:1.数据预处理(标准化)2.构造关系矩阵(亲疏关系的描述)3.聚类(根据不同方法进行分类)4.确定最佳分类(类别数)SPSS软件聚类步骤1. 数据预处理(标准化)→Analyze →Classify →Hierachical Cluster Analysis →Method 然后从对话框中进行如下选择从Transform Values框中点击向下箭头,此为标准化方法,将出现如下可选项,从中选一即可:标准化方法解释:None:不进行标准化,这是系统默认值;Z Scores:标准化变换;Range –1 to 1:极差标准化变换(作用:变换后的数据均值为0,极差为1,且|x ij*|<1,消去了量纲的影响;在以后的分析计算中可以减少误差的产生。
);Range 0 to 1(极差正规化变换/ 规格化变换);2. 构造关系矩阵在SPSS中如何选择测度(相似性统计量):→Analyze →Classify →Hierachical Cluster Analysis →Method 然后从对话框中进行如下选择常用测度(选项说明):Euclidean distance:欧氏距离(二阶Minkowski距离),用途:聚类分析中用得最广泛的距离;Squared Eucidean distance:平方欧氏距离;Cosine:夹角余弦(相似性测度;Pearson correlation:皮尔逊相关系数;3. 选择聚类方法SPSS中如何选择系统聚类法常用系统聚类方法a)Between-groups linkage 组间平均距离连接法方法简述:合并两类的结果使所有的两两项对之间的平均距离最小。
(项对的两成员分属不同类)特点:非最大距离,也非最小距离b)Within-groups linkage 组内平均连接法方法简述:两类合并为一类后,合并后的类中所有项之间的平均距离最小C)Nearest neighbor 最近邻法(最短距离法)方法简述:用两类之间最远点的距离代表两类之间的距离,也称之为完全连接法d)Furthest neighbor 最远邻法(最长距离法)方法简述:用两类之间最远点的距离代表两类之间的距离,也称之为完全连接法e)Centroid clustering 重心聚类法方法简述:两类间的距离定义为两类重心之间的距离,对样品分类而言,每一类中心就是属于该类样品的均值特点:该距离随聚类地进行不断缩小。



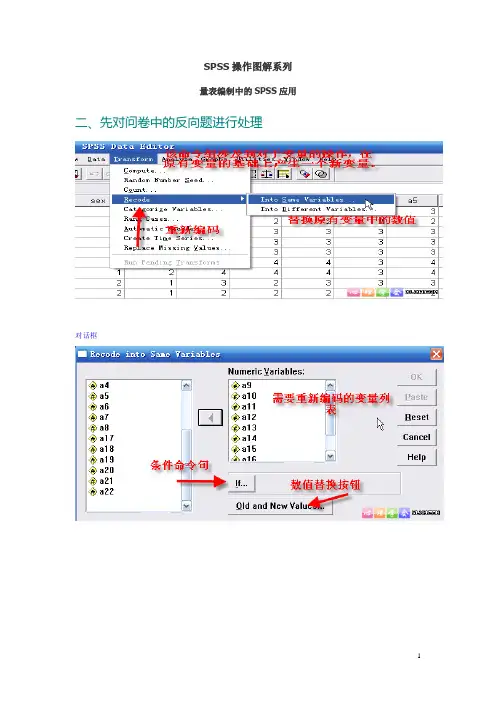
SPSS操作图解系列量表编制中的SPSS应用二、先对问卷中的反向题进行处理对话框三、计算量表的总分菜单选择对话框结果四、进行项目分析(一)题总相关的计算:使用皮尔逊积差相关(一般要求达0.4以上)(二)菜单选择对话框(二)计算题项区分度:使用高低分组T检验(独立样本),假设检验要达到显著水平!1、进行高低分组(1)对记录进行排序,找到高低分组的临界分数点。
(一般为27%或者33%)菜单选择结果(2)产生一个新的分组变量菜单选择对话框结果(3)独立样本T检验菜单选择对话框结果五、因素分析,构建量表结构效度!菜单选择对话框结果KMO和球形检验的结果表明原始数据适合进行因素分析!考虑到第五个因素中只有两个题项,因此可以删除这两个题项,并进行第二次的因素分析。
直到结果满意为止。
此处操作略~~另:因素分析仅仅为手段,重要的是要根据一定的理论进行因素命名。
只有命名的结果和一定的理论相符,我们才可以认为该量表具有良好的结构效度!五、信度分析:使用内部一致性系数(克隆巴赫)菜单选择对话框结果SPSS操作图解系列SPSS程序的基本操作流程一、数据定义(data definition)使计算机能够正确的辨认量化的数据,并对于数据赋予正确的意义。
变量名称指定(变量标签)、变量数值的标签、变量的格式类型、遗漏值的设定。
数据定义必需与编码表配合,将适当的变量名称与数据的意义加以标注,并设定适当的遗漏值,方能使后续的数据处理与分析能够正确有效的进行。
二、数据转换(data transformation)进行数据分析前的一些校正与转换的工作反向题的反向计分,出生年月变量转变成年龄的新变量的创造。
废卷处理、数据备份、遗漏值的补漏检查等作业,也是在此一阶段进行。
SPSS软件提供的观察值选择、重新编码或四则运算等指令,都能协助转换工作的进行。
一旦转换完成后,此一数据库已可称为干净的(clean and clear)的数据。
观察值的选择:四则混合运算(创造出新的变量)重新编码:在原来变量基础上直接替换数值(反向题的记分转换)三、资料分析(data analysis)依操作者的指令,进行各种的统计分析或统计图表的制作。

⽅差分析的SPSS操作第五节⽅差分析的SPSS操作⼀、完全随机设计的单因素⽅差分析1.数据采⽤本章第⼆节所⽤的例1中的数据,在数据中定义⼀个group变量来表⽰五个不同的组,变量math表⽰学⽣的数学成绩。
数据输⼊格式如图6-3(为了节省空间,只显⽰部分数据的输⼊):图6-3 单因素⽅差分析数据输⼊将上述数据⽂件保存为“6-6-1.sav”。
2.理论分析要⽐较不同组学⽣成绩平均值之间是否存在显著性差异,从上⾯数据来看,总共分了5个组,也就是说要解决⽐较多个组(两组以上)的平均数是否有显著的问题。
从要分析的数据来看,不同组学⽣成绩之间可看作相互独⽴,学⽣的成绩可以假设从总体上服从正态分布,在各组⽅差满⾜齐性的条件下,可以⽤单因素的⽅差分析来解决这⼀问题。
单因素⽅差分析不仅可以检验多组均值之间是否存在差异,同时还可进⼀步采取多种⽅法进⾏多重⽐较,发现存在差异的究竟是哪些均值。
3.单因素⽅差分析过程(1)主效应的检验假如我们现在想检验五组被试的数学成绩(math)的均值差异是否显著性,可依下列操作进⾏。
①单击主菜单Analyze/Compare Means/One-W ay Anova…,进⼊主对话框,请把math选⼊到因变量表列(Dependent list)中去,把group选⼊到因素(factor)中去,如图6-4所⽰:图6-4:One-Way Anova主对话框②对于⽅差分析,要求数据服从正态分布和不同组数据⽅差齐性,对于正态性的假设在后⾯⾮参数检验⼀章再具体介绍;One-Way Anova可以对数据进⾏⽅差齐性的检验,单击铵钮Options,进⼊它的主对话框,在Homogeneity-of-variance项上选中即可。
设置如下图6-5所⽰:图6-5:One-Way Anova的Options对话框点击Continue,返回主对话框。
③在主对话框中点击OK,得到单因素⽅差分析结果4.结果及解释(1)输出⽅差齐性检验结果Test of Homogeneity of VariancesMATHLevene Statistic df1 df2 Sig.1.238 4 35 .313上表结果显⽰,Levene⽅差齐性检验统计量的值为1.238,Sig=0.313>0.05,所以五个组的⽅差满⾜⽅差齐性的前提条件,如果不满⾜⽅差齐性的前提条件,后⾯⽅差分析计算F统计量的⽅法要稍微复杂,本章我们只考虑⽅差齐性条件满⾜的情况。
统计课spss操作流程图Made by:从前有一个叫钟锦然的烟酒生根据老师上课内容做的,如果出入,请各位同学多多指正目录:1对一组数据进行正态性检验操作(P66 例5-6): (2)2对一组数据进行单样本T检验操作(P66 例5-6): (3)3对一组配对样本进行配对样本差值正态性检验(P69 例5-9): (4)4配对样本T检验操作(P69 例5-9): (5)5两样本计量资料的T检验操作(P82 第9题): (7)6多组计量资料的假设检验的操作(P151 例9-2): (11)7计数资料的卡方检验操作: (17)8成组秩和检验操作(P104,例7-2) (20)9配对秩和检验操作(P107,例7-4) (22)10多组样本秩和检验操作(P105,例7-3) (24)11单样本卡方检验的操作(P111,例7-7) (32)12单样本比较秩和检验(上课无,旧教材P141,例9-2): (38)13单向反应变量有序列联表的秩和检验操作(P143,例9-4): (41)1对一组数据进行正态性检验操作(P66 例5-6):1.1点击‘探索’后的页面,正态性描述在绘制当中选择2对一组数据进行单样本t检验操作(P66 例5-6):2.1点击后的操作界面:2.2输出结果如下:3对一组配对样本进行配对样本差值正态性检验(P69 例5-9):3.1差值计算操作:3.2点击计算变量后操作界面如下:3.3再重复正态性检验。
4配对样本t检验操作(P69 例5-9):4.1点击后操作界面如下:4.2输出结构如下:5两样本计量资料的t检验操作(P82 第9题):5.1在进行t检验之前,要对两样本进行正态性检验,其操作如下:5.2输出结果如下:5.3对两样本进行录入,如下,其中要注意SPSS对数据的管理要求:5.4点击后操作界面如下:5.5在录入两组样本数据时要注意5.6进行两样本t检验如下:5.7点击后操作界面如下:5.8输出结果:组统计量分组N 均值标准差均值的标准误生存时间草蒿素10 33.7000 18.84469 5.95921 溶媒组10 48.9000 33.30148 10.530856多组计量资料的假设检验的操作(P151 例9-2):6.1对数据进行正态性检验:6.2付值界面:6.3数据录入情况:6.4对数据进行正态性检验:6.5输出结果:6.6方差分析,看总的数据是否有差异:6.7输出数据:6.8SPSS对方差齐性检验、方差齐的组间比较和方差不齐的组间比较进行打包,操作如下:6.9结果输出:6.10方差齐的组间比较,结果输出:7计数资料的卡方检验操作:7.1对两行两列四个表进行数据录入时的数据管理要求:7.1.1数据录入如下:7.1.2对频数进行加权,目的是有别于计量资料:7.2卡方检验:7.2.1数据输出:8成组秩和检验操作(P104,例7-2)1.检验成组数据是否符合正态分布,不符合就用成组秩和检验。