Web文本分类中的几种阈值策略分析与比较
- 格式:doc
- 大小:121.00 KB
- 文档页数:4

收稿日期:2009202210 基金项目:江苏省科技攻关项目(B E2006357) 作者简介:金春霞(1973-),女,汉族,陕西兴平人,淮阴工学院讲师,硕士,主要从事计算机应用、信息处理、数据挖掘方向研究,E 2mail :jcxbzn @.3联系人:周海岩(1957-),男,汉族,河南虞城人,淮阴工学院教授,主要从事信息安全、数据挖掘、人工智能、智能决策等方向研究,E 2mail :zhy_5703@.第30卷第3期 长春工业大学学报(自然科学版) Vol 130No.32009年06月 Journal of Changchun University of Techonology (Natural Science Edition ) J un 12009基于机器学习的Web 文本分类技术及算法金春霞, 周海岩3(淮阴工学院计算机工程系,江苏淮安 223003)摘 要:提出了一种基于机器学习的Web 文本自动分类的信息检索解决方案。
采用层次约束法完成文本自动抓取功能,文本频度与词条频度相结合的文本特征选择算法实现特征提取,并采用特征加权技术进一步提高文本分类性能。
该算法不仅实现中文文本的自动分类,有效地提高Web 信息检索的精度,而且能大大降低人工二次浏览筛选的工作量,还可用于电子政务和电子商务信息的自动分类。
关键词:网络蜘蛛;特征选择;文本分类;特征加权;朴素贝叶斯中图分类号:TP391.1 文献标识码:A 文章编号:167421374(2009)0320347205Study on Web text categorization and algorithmbased on machine learningJ IN Chun 2xia , ZHOU Hai 2yan 3(Depart ment of Computer Engineering ,Huaiyin Instit ute of Technology ,Huai ’an 223003,China )Abstract :A solution for web text categorization information ret rieval based on machine learning is p ut forward.We adopt level const raint to realize text 2crawled f unction ,and apply t he feat ure selections f rom t he combination of document f requency and term frequency to f ulfill t he feat ure extraction.The feat ures are weighted to imp rove t he performance of text categorization.The algorit hm can realize automatic Chinese text categorization ,imp rove t he precisio n of web information ret rieval and greatly decrease t he amount of work for browsing and filtering.It can also be used for t he automatic categorizatio n of E 2government and E 2co mmerce information.Key words :network spider ;feat ure selectio n ;text categorization ;feat ure weight ;Naive Bayes.0 引 言 随着因特网的快速发展,网上信息浩如烟海,互联网上的中文网页信息数以亿计,如何利用计算机技术快速有效地获取有价值的信息已是中文信息检索领域急需解决的关键问题。


1 文本聚类研究现状1 文本聚类研究现状Internet 已经发展为当今世界上最大的信息库和全球范围内传播信息最主要的渠道。
随着Internet 的大规模普及和企业信息化程度的提高,各种资源呈爆炸式增长。
在中国互联网络信息中心(CNNIC)2007 年 1 月最新公布的中国互联网络发展状况统计报告中显示,70.2% 的网络信息均以文本形式体现。
对于这种半结构或无结构化数据,如何从中获取特定内容的信息和知识成为摆在人们面前的一道难题。
近年来,文本挖掘、信息过滤和信息检索等方面的研究出现了前所未有的高潮。
作为一种无监督的机器学习方法,聚类技术可以将大量文本信息组成少数有意义的簇,并提供导航或浏览机制。
文本聚类的主要应用点包括:(1) 文本聚类可以作为多文档自动文摘等自然语言处理应用的预处理步骤。
其中比较典型的例子是哥伦比亚大学开发的多文档自动文摘系统Newsblaster[1] 。
该系统将新闻进行聚类处理,并对同主题文档进行冗余消除、信息融合、文本生成等处理,从而生成一篇简明扼要的摘要文档。
(2) 对搜索引擎返回的结果进行聚类,使用户迅速定位到所需要的信息。
比较典型的系统有Infonetware Real Term Search 。
Infonetware 具有强大的对搜索结果进行主题分类的功能。
另外,由Carrot Search 开发的基于Java 的开源Carrot2 搜索结果聚合聚类引擎2.0 版也是这方面的利用,Carrot2 可以自动把自然的搜索结果归类( 聚合聚类) 到相应的语义类别中,提供基于层级的、同义的以及标签过滤的功能。
(3) 改善文本分类的结果,如俄亥俄州立大学的Y.C.Fang 等人的工作[2] 。
(4) 文档集合的自动整理。
如Scatter/Gather[3] ,它是一个基于聚类的文档浏览系统。
2 文本聚类过程文本聚类主要依据聚类假设:同类的文档相似度较大,非同类的文档相似度较小。

聚类识别阈值-概述说明以及解释1.引言1.1 概述聚类是一种常用的数据分析方法,用于将数据集划分为具有相似特征的数据簇。
在聚类分析中,阈值是一个关键的参数,用于确定数据点之间的相似性和差异性。
通过设置合适的阈值,可以有效地识别出不同的数据簇,并提供有价值的信息用于决策和预测。
聚类算法的目标是通过最大化簇内的相似性和最小化簇间的相似性来使得聚类结果更加准确。
阈值在聚类识别中扮演着重要的角色,它可以用来区分簇内和簇间的相似性。
当相似性超过阈值时,数据点将被划分到同一个簇内;而当相似性低于阈值时,则被划分到不同的簇内。
选择合适的阈值对于聚类分析的准确性和稳定性至关重要。
如果阈值过小,可能会导致过多的簇被合并为一个簇,造成信息的丢失;反之,如果阈值过大,可能会导致簇内的差异性过大,无法准确地识别不同的数据簇。
因此,研究和确定合适的聚类识别阈值对于提高聚类分析的质量和效果具有重要意义。
通过深入研究聚类算法的原理和方法,结合实际应用场景,可以找到合适的阈值选择策略,从而在聚类识别中取得更好的结果。
本文将深入探讨聚类的概念和应用,聚类算法的原理和方法,以及阈值在聚类识别中的作用。
进一步地,本文将总结研究结果并强调阈值的重要性,同时对未来研究方向进行展望。
1.2文章结构1.2 文章结构本文主要分为引言、正文和结论三个部分。
下面详细介绍每个部分的内容。
引言部分主要包括概述、文章结构和目的三个方面。
概述部分旨在介绍聚类识别阈值的重要性和研究背景,强调其在实际应用中的价值。
文章结构部分(即本节内容)则是对本文内容进行概括性的介绍,指导读者了解全文结构和各部分的主要内容。
目的部分则明确了本文的研究目标和意义,以及对读者的启示。
接下来是正文部分,主要划分为三个小节。
2.1 聚类的概念和应用将简单介绍聚类方法以及其在数据挖掘领域中的应用。
2.2 聚类算法的原理和方法将详细介绍常见的聚类算法原理,包括K-means、层次聚类和密度聚类等,并给出其优缺点。

lda 最小概率阈值-概述说明以及解释1.引言1.1 概述概述部分的内容:引言部分旨在介绍本文所讨论的主题,即LDA最小概率阈值。
本文将介绍LDA的基本原理以及最小概率阈值的概念,并探讨最小概率阈值在LDA中的具体应用。
LDA是一种广泛应用于自然语言处理、信息检索和主题建模等领域的文本分析技术。
它能够将一系列文档中的词语通过统计的方法进行主题分类,并且能够反映出每个主题在各个文档中的分布情况。
通过LDA,我们可以发现文本数据中的隐藏主题,并从中获取有关该主题的信息。
然而,现实应用中,LDA并不是完美的,它存在一些问题。
其中一个问题就是在进行主题分类时,有些主题的概率可能非常低。
这意味着,这些主题在文本中的出现可能是噪音或者无关紧要的信息。
因此,为了提高LDA的准确性和鲁棒性,研究者们提出了最小概率阈值的概念。
最小概率阈值是指在使用LDA模型进行主题分类时,设置一个阈值,只有当某个主题的概率大于等于该阈值时,才将其视作有效的主题。
通过设置最小概率阈值,可以过滤掉那些低概率的主题,从而提高LDA模型的分析结果的可信度。
本文将进一步探讨最小概率阈值在LDA中的应用。
我们将介绍如何选择最小概率阈值的方法,以及该阈值对LDA模型结果的影响。
同时,我们也会讨论最小概率阈值在实际应用中的一些挑战和限制。
在正文部分,我们将首先介绍LDA的基本原理,包括LDA模型的构建过程和参数估计方法。
然后,我们将详细解释最小概率阈值的概念,包括其定义、选择方法以及对LDA模型结果的影响。
最后,我们将探讨最小概率阈值在LDA中的具体应用,并给出一些实例。
通过本文的研究,我们希望读者能更好地理解LDA最小概率阈值的概念和应用,在实际问题中能够有效地利用该技术来提高主题分类的准确性和可靠性。
1.2 文章结构本篇文章主要围绕着LDA最小概率阈值展开讨论,文章结构如下:第一部分是引言部分,主要包括三个方面:概述、文章结构和目的。
在概述部分,会简要介绍LDA(Latent Dirichlet Allocation)的概念和背景。

文本分析中的情感分类方法教程情感分类是文本分析中一项重要的任务,旨在将文本内容进行情感分类,即判断出文本表达的情感倾向。
情感分类在舆情监测、社交媒体分析、用户评论分析等领域有着广泛的应用。
本文将介绍几种常用的情感分类方法。
一、基于词典的情感分类方法基于词典的情感分类方法是一种简单且有效的方法。
该方法的核心思想是通过构建情感词典,将文本中的情感词与词典进行匹配,根据匹配结果确定文本的情感分类。
具体步骤包括:1. 构建情感词典:收集一定量的带有情感倾向的词汇,将其标注为正面或负面情感。
2. 对文本进行分词:使用中文分词工具或英文分词工具将文本分解为单词或词语。
3. 匹配情感词:对文本中的每一个词进行情感词匹配,将匹配到的情感词进行统计。
4. 确定情感分类:根据文本中正面情感词和负面情感词的数量进行判断,数量大于某个阈值则判定为正面情感,数量小于某个阈值则判定为负面情感。
基于词典的情感分类方法的优点是简单易懂,不需要大量的训练数据。
然而,由于其依赖于情感词典的质量和覆盖率,当遇到新领域或新词汇时可能存在一定的缺陷。
二、基于机器学习的情感分类方法基于机器学习的情感分类方法是一种较为常用且较为准确的方法。
该方法通过利用机器学习算法,从标注有情感倾向的训练集中学习情感分类模型,并使用该模型对新文本进行情感分类。
具体步骤包括:1. 数据准备:采集一定量的带有情感倾向的文本数据,并根据情感进行标注。
2. 特征提取:将文本数据转化为机器学习算法可用的特征表示。
常用的特征包括词袋模型、tf-idf特征、n-gram特征等。
3. 模型训练:使用带有标注的数据集训练情感分类模型,常用的机器学习算法包括朴素贝叶斯、支持向量机、决策树等。
4. 模型评估:使用未标注的测试集评估训练得到的情感分类模型的性能。
5. 模型应用:使用训练好的模型对新文本进行情感分类。
基于机器学习的情感分类方法相比基于词典的方法在分类准确度上有较大提升,但需要较多的训练数据和一定的机器学习知识。

1. 技术背景分类问题是人类所面临的一个非常重要且具有普遍意义的问题。
将事物正确的分类,有助于人们认识世界,使杂乱无章的现实世界变得有条理。
自动文本分类就是对大量的自然语言文本按照一定的主题类别进行自动分类,它是自然语言处理的一个十分重要的问题。
文本分类主要应用于信息检索,机器翻译,自动文摘,信息过滤,邮件分类等任务。
文本分类的一个关键问题是特征词的选择问题及其权重分配。
在搜索引擎中,文本分类主要有这些用途:相关性排序会根据不同的网页类型做相应的排序规则;根据网页是索引页面还是信息页面,下载调度时候会做不同的调度策略;在做页面信息抽取的时候,会根据页面分类的结果做不同的抽取策略;在做检索意图识别的时候,会根据用户所点击的url所属的类别来推断检索串的类别等等。
2. 自动分类的原理和步骤在分类的时候首先会遇到文档形式化表示的问题,文档模型有3种:向量空间模型,布尔模型和概率模型,其中我们常用的是向量空间模型。
向量空间模型的核心描述如下:∙文档(Document):文本或文本中的片断(句子或段落)。
∙特征项(T erm):文档内容用它所包含的基本语言单位来表示,基本语言单位包括字、词、词组、短语、句子、段落等,统称为特征项。
∙特征项权重(Term Weight):不同的特征项对于文档D的重要程度不同,用特征项Tk附加权重Wk 来进行量化,文档D可表示为(T1,W1;T2,W2;…;Tn,Wn)∙向量空间模型(Vector Space Model):对文档进行简化表示,在忽略特征项之间的相关信息后,一个文本就可以用一个特征向量来表示,也就是特征项空间中的一个点;而一个文本集可以表示成一个矩阵,也就是特征项空间中的一些点的集合。
∙相似度(Similarity):相似度Sim(D1,D2)用于度量两个文档D1和D2之间的内容相关程度。
当文档被表示为文档空间的向量,就可以利用欧氏距离、内积距离或余弦距离等向量之间的距离计算公式来表示文档间的相似度。

!"!""#年第$!期福建电脑%&’文本挖掘三种技术的比较王一蕾林世平(福州大学数学与计算机科学学院,福建福州#("""!)【摘要】文章介绍了%&’挖掘的有关理论)从%&’文本挖掘的定义、%&’文本挖掘任务、功能等方面加以阐述)然后重点比较了%&’文本挖掘的三种技术(朴素贝叶斯方法(*+,-&.+/&0)、12最近邻接参照分类算法(12*&+3&04*&,56’73)、学习一阶规则算法(8,30493:&3;<:=>4,-&?&+3<&3))的分类效果。
最后)概述了%&’文本挖掘的用途和前景。
【关键词】%&’文本挖掘特征表示特征提取分类@3A !,B >C@3A !,B :C D,E $>F E +35D+G H I75<@3A >C J 4@3A !,B :C I75A C K 注:基金项目:福州大学科技发展基金资助项目(!""!2LM 2!$)、福建省自然科学基金资助项目(N"$$"""O )、福建省教育厅科研基金项目(PNQ Q Q )R A !S B >C E $J T8A !S )>C U -U J 4,T8A !,)>CR A >B :C EV,E $V I E $40,D A :):I C R A >B :I C 4S 40,D A :):I C R A >S B :I CR A >B :C E R A >C "GS R A G S B >C T8A G ):C4,R A >,C "G %-R A G I B >,C T8A G ):CSI$、引言随着;<4&3<&4及其相关技术的飞速发展)%%%已成为最大的信息集聚地。

Web文本分类技术研究和应用的开题报告1.项目背景和研究目的随着互联网的普及,Web上的文本信息呈现爆炸式增长,对理解和利用这些信息成为一项重要的挑战。
文本分类是将文本归类于特定类别的过程,这些类别可以是新闻、博客、商品评论等。
Web文本分类是指将Web上的文本信息进行分类。
其应用涉及到许多领域,如文本挖掘、情感分析、广告推荐等。
本研究的目的是研究Web文本分类的技术,探究如何将这些技术应用到实际应用中。
具体包括以下几个方面:1)调研Web文本分类技术的最新研究进展和研究现状;2)分析Web文本分类所涉及的技术,如特征提取、模型选择、算法优化等;3)建立Web文本分类模型并优化模型性能;4)应用Web文本分类技术到实际应用中,如文本分类、情感分析等。
2.研究内容和方法2.1 研究内容1)Web文本分类的技术和方法:调研Web文本分类技术的最新研究进展和研究现状,分析Web文本分类所涉及的技术和方法,如特征提取、模型选择、算法优化等。
2)Web文本分类模型的构建:根据所调研的Web文本分类技术和方法,建立Web文本分类模型并优化模型性能。
3)Web文本分类技术的应用:将Web文本分类技术应用到实际应用中,如文本分类、情感分析、广告推荐等。
2.2 研究方法1)文献调研法:调研Web文本分类技术的最新研究进展和研究现状。
2)实验研究法:建立Web文本分类模型,优化模型性能。
评价模型的性能指标,如准确率、召回率、F1值等。
3)案例分析法:将Web文本分类技术应用到实际应用中,如文本分类、情感分析、广告推荐等。
分析不同应用下Web文本分类的效果和优化方案。
3.预期成果1)研究Web文本分类技术的最新研究进展和研究现状,包括其所涉及的技术和方法,如特征提取、模型选择、算法优化等。
2)建立Web文本分类模型,并实现模型的优化,提高模型的性能。
3)将Web文本分类技术应用到实际应用中,如文本分类、情感分析、广告推荐等。

threshold class 阈值类-概述说明以及解释1.引言1.1 概述概述部分的内容可以描述阈值类的基本概念和其在现实生活中的重要性。
阈值类是一种在数据分析和机器学习中十分常见的概念。
它主要是基于一种特定的阈值或界限来对数据进行分类或决策。
也就是说,当数据超过或达到某个预定的阈值时,就会被归为一类,否则归为另外一类。
阈值类的概念在各个领域都有广泛的应用,比如金融、医疗、市场营销等。
在金融领域,阈值类被广泛应用于风险评估和预警系统中。
银行在贷款审批过程中,可以根据客户的收入、信用记录等因素设定一个最低阈值,超过该阈值则予以贷款,否则拒绝。
这种阈值类的应用可以有效地降低风险,保护金融机构的利益。
在医疗领域,阈值类经常用于疾病的诊断和治疗决策中。
医生根据血压、血糖等指标设定一些临界值,一旦患者的指标超过或达到了这些阈值,就可能意味着患者存在某种疾病或需要采取一些治疗措施。
通过阈值类的应用,可以及时发现和治疗疾病,保护患者的健康。
在市场营销领域,阈值类被广泛用于客户分群和个性化营销中。
根据客户的购买行为、兴趣偏好等设定一些阈值,可以将客户分为不同的群体,从而有针对性地进行推荐和营销活动,提高市场营销的精准度和效果。
总之,阈值类在不同领域中起着重要的作用,它能够帮助我们对数据进行分类、决策和预测。
对阈值类的研究和应用有助于提高我们对复杂问题的理解和解决能力。
本文将深入探讨阈值类的定义、应用场景和特点,希望能为读者提供有益的参考和启发。
1.2 文章结构文章结构部分应包括对整篇文章的组织和内容进行概括和归纳的描述。
该部分主要介绍了文章的章节设置和各章节的内容安排。
文章结构部分的内容可以按如下方式进行编写:文章结构部分旨在向读者介绍整篇文章的组织结构,从而使读者能够更好地理解和掌握文章的内容。
本文分为引言、正文和结论三大部分。
在引言部分,我们首先对阈值类这一概念进行了概述,介绍了其在现实生活中的应用以及其特点。
WEB文本模糊分类及其预处理的研究与实现随着Internet的迅速发展,尤其是World Wide Web的全球普及,Web上信息资源已涵盖了社会生活的各个方面,网络信息过载问题日益突出。
处理海量数据的一个重要方法就是将它们分类。
网页的自动分类是信息检索领域的一个很重要的研究方向。
通过自动分类不仅仅可以将网页按照类别信息分别建立相应的数据库,提高搜索引擎的查全率和查准率,而且可以建立自动的分类信息资源,为用户提供分类信息目录。
论文系统阐述并实现了一套Web文本分类的技术。
主要研究工作包括:(1)Web文本预处理,这里先对天网数据的特点对其解压缩特点做了详细介绍,针对其特点进行解压缩,作为后续工作的准备材料。
然后,详细介绍HTML Parser这一工具包,对如何使用HTML Parser提取Web 文本进行各种信息的流程做了介绍,并使用HTML Parser对已有数据进行解析。
(2)中文分词,首先简单介绍常用的中文分词算法,并对它们进行了比较,本系统使用的是常用的最大匹配分词算法。
然后介绍未登录词的识别,采用将命名实体和新词一体化识别策略对未登录词进行识别,这是本人的工作重点之一。
实验证明,系统实现的分词算法可以达到很好的分词效果,在准确性和速度上基本上都满足了文本分类的需要。
(3)文本特征向量的提取。
介绍特征项权重计算常用的方法TF*IDF,分析TF*IDF存在的几点不足,针对其不足,提出将TF*IDF与χ2统计,以及特征项的类内频率结合,然后重新计算文本特征向量的权重,形成训练文本。
在实现分类之后对改进的特征项提取方法做了实验验证,结果证实该法确实能提高分类准确率。
(4)使用双隶属度模糊SVM方法进行文本训练和文本分类。
介绍SVM的基本理论、目前SVM方法在文本分类中的应用情况,以及模糊支持向量机理论。
根据模糊支持向量机在文本分类上的特点,系统提出一种改进的模糊支持向量机:双隶属度模糊支持向量机,之后针对实际使用情况提出了更进一步的改进算法——双隶属度多类模糊支持向量机,从而将其扩展到多类分类上。
定价策略中的价格阈值分析价格阈值分析在定价策略中扮演着至关重要的角色。
其通过研究消费者对不同价格水平的反应,帮助企业确定最佳定价点,从而实现市场份额增长和利润最大化。
本文将从概念解释、价格阈值分析方法和案例研究三个方面进行论述,以帮助读者更好地理解价格阈值分析对定价策略的重要性。
一、概念解释价格阈值是指消费者对产品或服务价格有明确心理期望的底线。
一旦价格超过消费者的价格阈值,他们很可能会感到不满并减少购买数量或转向其他竞争对手。
价格阈值因产品属性、市场环境和个体差异而有所不同。
在定价策略中,企业需要通过价格阈值分析来确定消费者对某一产品或服务的价格敏感性,从而制定合适的定价策略。
二、价格阈值分析方法1.市场调研法:通过调查问卷、深度访谈等方式来了解消费者对产品价格的接受程度。
根据消费者对不同价格水平的态度和购买意愿,可以分析出价格阈值的范围和变化趋势。
2.定价实验法:通过设计不同价格水平的实验条件,观察消费者在不同价格下的购买行为。
通过观察实验结果,可以确定产品价格阈值的具体数值。
3.竞争对手分析法:通过研究市场上其他竞争对手的定价策略和产品销售情况,推测消费者对产品价格的敏感程度。
借助竞争对手的市场反馈信息,可以更准确地确定产品的价格阈值。
三、案例研究以某咖啡连锁店为例,该连锁店希望通过价格阈值分析来确定咖啡的最佳定价点。
首先,他们进行了市场调研,通过问卷调查了解消费者对不同价格咖啡的态度。
调研结果显示,消费者认为高于30元的咖啡价格过高,购买意愿较低。
其次,连锁店进行了定价实验。
他们在不同的门店设置了三个价格水平的咖啡,分别是20元、30元和40元。
通过观察实验结果,发现价格为30元时,销售量最大,消费者对该价格有较高接受度,因此可以确定30元为咖啡的价格阈值。
最后,连锁店进行了竞争对手分析。
他们发现在同一商圈内,其他竞争对手的咖啡价格普遍在20元至35元之间,而销售情况最好的门店定价在30元附近。
________________________________________________ 作者简介:李晓黎(1979- ) 女 硕士研究生,研究领域:网上数据挖掘。
Web文本分类中的几种阈值策略分析与比较 李子久
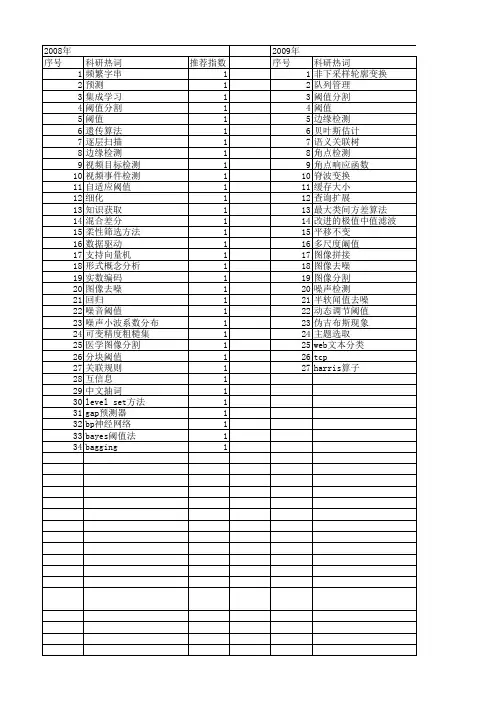
摘 要 本文主要针对中文网页,分析比较了文本分类中的关于类别阈值的几种策略,分别是: 位置截尾法(RCut)、比例截尾法(PCut)、最优截尾法(SCut)以及改进型截尾法(RTCut),主要实验结果有: RTCut的效果最佳;PCut具有一定的复杂度,不适合在线文本处理;SCut具有一定的不稳定性;而Rcut性能最差, 并且使用英文文本和中文文本评测这几种阈值策略的结果是一致的。 关键词 文本分类 阈值 分类算法 特征选取 中图分类号 TP18 文献标识码 A
1. 引言 随着web信息量的激增,人们需要自动的文本分类技术来实现对web信息资源的规划及利用。目前,文本分类是信息检索和数据挖掘领域的热门话题,它通过训练一定的文本集合得到类别与未知文本的映射规则,即计算出文本与类别的相关度,再采取一定的阈值策略决定文本的类别归属。不同的分类算法以及阈值策略都会对分类的结果产生一定的影响。但是,目前文本分类的研究热点主要集中在KNN、贝叶斯、支持向量机等分类算法上,人们往往忽视了分类中阈值策略的重要性。阈值的确定是文本分类中的一个重要的步骤,文献[1]提出了4种阈值策略:位置截尾法(RCut)、比例截尾法(PCut)、最优截尾法(SCut)以及改进型截尾法(RTCut),并且针对英文文本比较了上述四种阈值策略的优劣。实验结果表明:RTCut的效果最佳;PCut具有一定的复杂度,不适合在线文本处理;SCut具有一定的不稳定性;而Rcut性能最差。 与英文网页不同的是,中文网页使用汉字,词与词之间没有间隔,不像英语单词之间存在空格符,所以需要在文本分类之前对中文文本进行切词处理,并且切词的准确与否将很大程度的影响分类的效果。所以,本文采用了一个中文网页数据集,对RTCut、RCut、PCut、SCut这四种阈值策略在中文网页上的性能进行评测。
2. 阈值策略 首先介绍一下文本分类中常用的阈值策略,然后依据分类器的性能,讨论一下各个策略的优劣。 2.1位置截尾法(RCut) RCut方法将文本与每个类别的相似度排序,然后将文本指定给前t个类别。参数t即可以由用户指定,也可以通过预定初始值,然后给出测试文本,使用分类器进行分类,再根据分类的准确程度调整初始值。这种策略考虑到了分类器全局的性能,当t=1时,多用这种方法来将文本指定到单一类别当中[2]。 2.2比例截尾法(PCut) PCut通过将所有测试文本与某一类别的相似度按照由高到低的顺序排序,然后将前kj个 文本确定为该类别,这里
mxcPkjj)( (1) 2
训练文本总数的训练文本数量类别jjccP)( (2)
m是类别数量,jc代表类别j,)(jcP是类别jc的先验概率,可以通过公式(2)计算得
到。 PCut考虑到了全局的分类性能,主要以x为参数,它的值可以通过分类的准确程度来调整,这种确定方法类似于RCut中t值的确定方法。目前,一些分类器,如:贝叶斯、DTree、kNN和LLSF等方法采用了PCut阈值策略[3]。 2.3最优截尾法(SCut) SCut针对某一类别,计算所有测试文本与该类别的相似度。根据最优化该类别分类器的性能来调整相应的阈值,然后将确定的阈值应用到新的待分类文本上。RCut和PCut阈值策略是平均所有分类器的性能,采用t或x作为参数;而SCut只优化某一类别的性能,并不保证所有类别分类结果达到最优。SCut多被用于Ripper、FOIL、Winnow、EG、kNN、LLSF和Rocchio等分类算法[4]。 2.4改进型截尾法(RTCut) 文献[1]中提出了一种新的阈值策略,即改进型截尾法,这种方法修改了RCut和SCut的不足,并将二者结合起来确定类别的阈值,使查全率和查准率达到一定的平衡。在RTCut中,需要预先确定每个类的最优截尾阈值,新的阈值通过公式(3)计算:
1)|'(max)|()|()|('dcsdcsdcrdcfCc (3)
这里,d是待分类文本,)|(dcr是RCut中类别c的排列位置,)|(dcs是类别c的最优截尾阈值,而)|(dcf是类别c的新阈值。
3. 实验结果及其分析 3.1实验设置 为了系统的比较RCut、PCut、SCut以及RTCut这四种阈值策略,作者设计了一个中文网页分类系统,方案如下: (1)数据集 中文网页数据集是实现中文文本分类的前提和基础,为此,作者从中央财经网上人工获取了一个新闻网页语料库,通过中文文本分类器将各新闻信息分门别类,以用于在网上发布。该语料集包括5180个训练文本和615个测试文本,分为财政、经济、贸易、证券、科技5个大类,每个类别平均有1000个训练文本。 (2)数据抽取 利用netspider获取目标网页以后,需要对Html文件进行解析,按照一定的抽取规则抽取需要的数据项,系统中主要使用的抽取方法是将Html文本转换为一棵具有层次结构的HTML树,利用树结构来表示网页中的标记关系。 (3)特征选取 DF即文本频度,它表示在训练集中包含某个特征项t的文本数。这种衡量特征项重要程度的方法基于这样一个假设:DF较小的特征项对分类结果的影响较小。这种方法优先取DF较大的特征项,而DF较小的特征项将被剔除。即特征项按照DF值排序。DF是最简单的特征项 3
选取方法,而且该方法的计算复杂度低,能够胜任大规模的分类任务[5],所以该文本分类系统采用DF作为特征选取的标准。 (4)分类算法 系统中分类器所使用的分类算法为kNN,通过如下公式计算: kNNdjjiijibcdydxSimcxp),(),(),( (4)
其中,x为新文本的特征向量,p表示x属于类jc的权重,id为经过kNN方法训练、已归类的文本特征向量,),(jicdy为类别属性函数,即,如果id属于类jc,那么函数值为1,否则为0,jb为预先计算得到的jc的最优截尾阈值,),(idxSim为x与id的相似度,通过公式(5)计算:
dxdxdxCos),( (5)
(5)评估指标: 分类系统的基本评测指标是准确率和查全率。 准确率是所有判断的文本中与人工分类结果吻合的文本所占的比率。如公式(6)所示:
实际分类的文本数分类的正确文本数准确率)(precision (6)
查全率是人工分类结果应有的文本中分类系统吻合的文本所占的比率。如公式(7)所示:
应有文本数分类的正确文本数查全率)(recall (7)
准确率和查全率反映了分类质量的两个不同方面,两者必须综合考虑,不可偏废,因此,存在F1 测试值[6],其数学公式如下:查全率准确率查全率准确率测试值21F (8) 系统中采用微平均(Micro-avg)和宏平均(Macro-avg)作为分类器的评估标准,其中 微平均主要是考察单一类别的性能,而宏平均则是考察分类器的整体性能。 3.2实验结果及其分析 图1显示了采用kNN分类方法得到的RCut、PCut、SCut以及RTCut的微平均recall-precision曲线图,图2是相应的宏平均指标曲线。其中,RCut中t取值为1,2,3…,Pcut中x=0.5,1,2,3…,而RTCut则利用精度的提高来调整阈值,并且Scut在图中以点的形式描述。图中画出了一条平衡线,线上准确率和查全率得到等值,并且平衡线的附近可以得到最优的F1值。 4
图100.20.40.60.8100.20.40.60.81Micro-avg RecallMicro-avgPrecisionPCutRTCutRCutbreak-even-lineSCut 图200.20.40.60.8100.20.40.60.81Macro-avg RecallMacro-avgPrecisionPCutRTCutRCutbreak-even-lineSCut
从图1和图2可以看出:1)Scut具有一定的不稳定性;2)Pcut由于考虑了分类器的全局类别信息,所以具有较好的性能,但是并不适合在线处理;3)Rcut性能要弱于RTCut 和Pcut,而RTCut由于综合了Scut和Rcut的优点,所以在文本分类的过程中,较好的提高了分类的精度。论文得到的实验结果同文献[1]的实验结果基本一致。因此,这几种阈值策略在普通英文文本和中文网页下表现出的性能是一致的。
参考文献 1.Yiming Yang.A Study on Thresholding Strategies for Text Categorization[C].In:Proceedings of ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’01),2001 2.T.Joachims.Text Categorization with Support Vector Machines:Learning with Many Relevant Features.In European Conference on Machine Learning(ECML),pages 137-142,Berlin,1998.Springer. 3.D.Lewis.An evaluation of phrasal and clustered representations on a text categorization task.In 15th Ann Int ACM SIGIR Conference on Research and Development in Information (SIGIR’92),page
37-50,1992. 4.W.Hersh,C.Buckley,T.Leone,and D.Hickman.Ohsumed:an interactive retrieval evaluateon and new large text collection for research.In Proceedings of ACM SIGIR’94,pages 192-201,1994. 5.单松巍,冯是聪,李晓明. 几种典型特征选取方法在中文网页分类上的效果比较.计算机工程与应用2003.22 6.冯是聪,单松巍,张志刚等$一个中文网页数据集及其分类体系[C].见:海峡两岸技术交流会,南京,2002-10:121-129