编译原理Chapt2
- 格式:ppt
- 大小:611.50 KB
- 文档页数:76

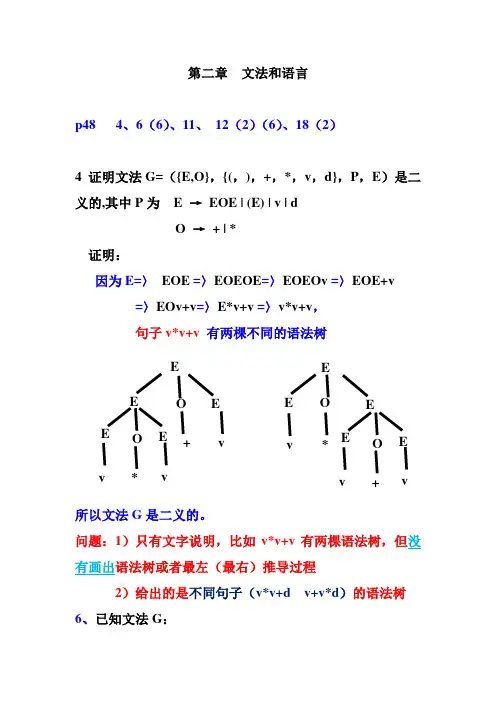
第二章 文法和语言p48 4、6(6)、11、 12(2)(6)、18(2)4 证明文法G=({E,O},{(,),+,*,v ,d},P ,E )是二义的,其中P 为 E → EOE | (E) | v | d O → + | * 证明:因为E=〉 EOE =〉EOEOE =〉EOEOv =〉EOE+v=〉EOv+v =〉E*v+v =〉v*v+v , 句子v*v+v 有两棵不同的语法树所以文法G 是二义的。
问题:1)只有文字说明,比如v*v+v 有两棵语法树,但没有画出语法树或者最左(最右)推导过程2)给出的是不同句子(v*v+d v+v*d )的语法树 6、已知文法G :EEEE OO v*v+ vE EE E O O v+v* v〈表达式〉∷=〈项〉|〈表达式〉+〈项〉〈项〉∷=〈因子〉|〈项〉*〈因子〉〈因子〉∷=(〈表达式〉)| i试给出下述表达式的推导及语法树(6)i+i*i推导过程:〈表达式〉=〉〈表达式〉+〈项〉E=〉E+T =〉〈表达式〉+〈项〉*〈因子〉=〉E+ T*F=〉〈表达式〉+〈项〉* i =〉E+ T*i=〉〈表达式〉+ 〈因子〉* i =〉E+F*i=〉〈表达式〉+ i* i =〉E+i*i=〉〈项〉+ i* i =〉T +i*i=〉〈因子〉+ i* i =〉F +i*i=〉i +i*i =〉i +i*i 共8步推导语法树:〈表达式〉+〈因子〉〈项〉i 〈因子〉i〈项〉〈项〉〈因子〉i*11、一个上下文无关文法生成句子abbaa的推导树如下:(1)给出该句子相应的最左推导和最右推导(2)该文法的产生式集合P可能有哪些元素?(3)找出该句子的所有短语、简单短语、句柄。
(1)最左推导:S=〉ABS=〉aBS=〉aSBBS=〉aBBS=〉abBS=〉abbS =〉abbAa=〉abbaa最右推导:S =〉ABS=〉ABAa=〉ABaa=〉ASBBaa=〉ASBbaa=〉ASbbaa=〉Abbaa=〉abbaa(2)该文法的产生式集合P可能有下列元素:S→ABS | Aa|εA→a B→SBB|b(3)因为字符串中的各字符有相对的位置关系,为了能相互区别,给相同的字符标上不同的数字。




编译原理简明教程第二版什么是编译原理?编译原理是计算机科学中的一门重要课程,它研究的是如何将高级程序设计语言(如C、Java)编写的程序转化为机器能够理解和执行的指令。
编译原理主要包括以下几个方面的内容:1.词法分析:将源代码转化为一系列的词法单元,例如标识符、关键字、运算符等。
2.语法分析:通过创建语法树,检查源代码是否符合语法规则。
3.语义分析:对语法树进行分析,检查程序中的语义错误。
4.优化技术:对源代码进行优化,提高程序的执行效率。
5.目标代码6.:将优化后的源代码转化为与目标机器相关的指令,7.可执行文件。
编译过程编译过程可以分为三个阶段:前端、优化和后端。
前端前端负责词法分析、语法分析和语义分析等工作。
具体过程如下:1.词法分析:将源代码划分为一个个词法单元。
这些词法单元是编程语言中的基本语义单位,例如标识符、关键字、运算符等。
词法分析的结果是一个词法单元序列。
2.语法分析:根据语法规则检查词法单元序列是否符合语法。
语法分析的结果是一个语法树。
3.语义分析:对语法树进行静态语义检查,确保程序的语义正确。
语义分析的结果是一个语义树。
优化优化阶段对语义树进行优化,提高程序的执行效率。
常见的优化技术包括常量折叠、循环展开和死代码删除等。
优化的目标是提高程序的执行速度、减少程序的内存占用和提高程序的可读性。
后端后端负责目标代码目标代码是针对具体的目标机器的,可以是汇编代码、机器码,或者是中间表示形式(如LLVM的字节码)。
目标代码的过程中,需要进行寄存器分配、指令选择和代码布局等工作。
编译器的实现编译器的实现可以基于手写的,也可以使用编译器工具(例如Flex和Bison)辅助完成。
手写实现编译器的优点是可以更好地理解和掌握编译原理的各个方面。
而使用编译器工具可以减少编写代码的工作量,提高编译器的开发效率。
无论是手写实现还是使用编译器工具,编译器的核心功能都是通过前端、优化和后端三个阶段来完成的。

第二章文法和语言本章讲述目前广泛使用的上下文无关文法。
即用上下文无关文法作为程序设计语言语法的描述工具。
阐明语法的一个工具是文法。
本章将介绍文法和语言的概念。
本章重点:上下文无关文法及其句型分析中的有关问题。
第一节文法的直观概念当我们表述一种语言时,无非是说明这种语言的句子,如果语言只含有有穷多个句子,则只需列出句子的有穷集就行了,但对于有无穷句子的语言来讲,存在着如何给出它的有穷表示的问题。
以自然语言为例,人们无法列出全部句子,但是人们可以给出一些规则,用这些规则来说明(或者定义)句子的组成结构,比如:“我是大学生”。
是汉语的一个句子。
汉语句子可以是由主语后随谓语而成,构成谓语的是动词和直接宾语,我们采用EBNF来表示这种句子的构成规则:〈句子〉∷=〈主语〉〈谓语〉〈主语〉∷=〈代词〉|〈名词〉〈代词〉∷=我|你|他〈名词〉∷=王明|大学生|工人|英语〈谓语〉∷=〈动词〉〈直接宾语〉〈动词〉∷=是|学习〈直接宾语〉∷=〈代词〉|〈名词〉“我是大学生”的构成符合上述规则,而“我大学生是”不符合上述规则,我们说它不是句子。
这些规则成为我们判别句子结构合法与否的依据。
一旦有了一组规则以后,我们可以按照如下方式用它们去推导或产生句子。
我们开始去找∷=左端的带有〈句子〉的规则并把它表示成∷=右端的符号串,这个动作表示成:〈句子〉⇒〈主语〉〈谓语〉,然后在得到的串〈主语〉〈谓语〉中,选取〈主语〉或〈谓语〉,再用相应的规则∷=右端代替之。
比如,选取了〈主语〉,并采用规则〈主语〉∷=〈代词〉,那么得到:〈主语〉〈谓语〉⇒〈代词〉〈谓语〉,重复做下去,我们得到句子:“我是大学生”的全部动作过程是:〈句子〉⇒〈主语〉〈谓语〉⇒〈代词〉〈谓语〉⇒我〈谓语〉⇒我〈动词〉〈直接宾语〉⇒我是〈直接宾语〉⇒我是〈名词〉⇒我是大学生符号⇒的含义是,使用一条规则,代替⇒左边的某个符号,产生⇒右端的符号串。
显然,按照上述办法,不仅生成“我是大学生”这样的句子,还可以生成“王明是大学生”,“王明学习英语”,“我学习英语”,“他学习英语”,“你是工人”,“你学习王明”等几十个句子。

第2章习题解答1.文法G[S]为:S->Ac|aBA->abB->bc写出L(G[S])的全部元素。
[答案]S=>Ac=>abc或S=>aB=>abc所以L(G[S])={abc}==============================================2. 文法G[N]为:N->D|NDD->0|1|2|3|4|5|6|7|8|9G[N]的语言是什么?[答案]G[N]的语言是V+。
V={0,1,2,3,4,5,6,7,8,9}N=>ND=>NDD.... =>NDDDD...D=>D......D===============================================3.已知文法G[S]:S→dAB A→aA|a B→ε|bB问:相应的正规式是什么?G[S]能否改写成为等价的正规文法?[答案]正规式是daa*b*;相应的正规文法为(由自动机化简来):G[S]:S→dA A→a|aB B→aB|a|b|bC C→bC|b也可为(观察得来):G[S]:S→dA A→a|aA|aB B→bB|ε===================================================================== ==========4.已知文法G[Z]:Z->aZb|ab写出L(G[Z])的全部元素。
[答案]Z=>aZb=>aaZbb=>aaa..Z...bbb=> aaa..ab...bbbL(G[Z])={a n b n|n>=1}===================================================================== =========5.给出语言{a n b n c m|n>=1,m>=0}的上下文无关文法。


