OPENCV训练图像集中文版
- 格式:pdf
- 大小:198.21 KB
- 文档页数:7

级联分类器训练引言级联分类器的工作主要包括两个阶段:训练和检测。
检测阶段被描述在一个常规的OpenCV 文件的objdetect 模块的文档里。
文档介绍了级联分类器的一些基本信息。
目前的指南描述了如何训练级联分类器:一个训练数据集和运行训练应用程序的准备。
重要的笔记在OpenCV里有两个应用程序可以用来训练级联分类器:opencv_haartraining和opencv_traincascade。
opencv_traincascade是一个较新的版本,用C++按照OpenCV 2.x API 的标准编写。
但这两个应用程序之间的主要区别是,opencv_traincascade同时支持Haar [Viola2001] 和LBP [Liao2007](局部二值模式)的特征。
相比于Haar特征,LBP特征是整数,所以用LBP训练和检测比用Haar特征快好几倍。
至于LBP和Haar的检测质量取决于训练:首先是训练数据集的品质还有训练参数。
训练一个和基于Haar的分类有几乎相同的质量的基于LBP的分类是有可能的。
opencv_traincascade和opencv_haartraining以不同的文件格式存储训练好的分类器。
值得注意的是,较新的级联检测接口(见objdetect模块的级联分类器类)两种格式都支持。
opencv_traincascade可以用旧格式保存(输出)训练好的级联。
但opencv_traincascade和opencv_haartraining无法在中断后以另一种格式加载(输入)一个分类器来进一步训练。
注意,opencv_traincascade应用程序可以使用TBB实现多线程。
在多核模式下使用,OpenCV 必须要用TBB来构建。
并且这有一些和训练相关的辅助工具。
·opencv_createsamples是用来准备正训练数据集和测试样本集的。
opencv_createsamples产生一个opencv_haartraining和opencv_traincascade都支持的格式的正样本数据集。

PythonOpenCV实现图⽚上输出中⽂OpenCV中在图⽚上输出中⽂⼀般需要借助FreeType库实现。
FreeType库是⼀个完全免费(开源)的、⾼质量的且可移植的字体引擎,它提供统⼀的接⼝来访问多种字体格式⽂件。
但使⽤FreeType需要下载库并重新编译,过程⿇烦⼀点。
在Python中,可以借助PIL(Python Imaging Library)模块实现,相对简单很多,需要做的只是对图像进⾏OpenCV格式和PIL格式的相互转换。
# -*- coding: utf-8 -*-import cv2import numpyfrom PIL import Image, ImageDraw, ImageFontif __name__ == '__main__':img_OpenCV = cv2.imread('01.jpg')# 图像从OpenCV格式转换成PIL格式img_PIL = Image.fromarray(cv2.cvtColor(img_OpenCV, cv2.COLOR_BGR2RGB))# 字体字体*.ttc的存放路径⼀般是: /usr/share/fonts/opentype/noto/ 查找指令locate *.ttcfont = ImageFont.truetype('NotoSansCJK-Black.ttc', 40)# 字体颜⾊fillColor = (255,0,0)# ⽂字输出位置position = (100,100)# 输出内容str = '在图⽚上输出中⽂'# 需要先把输出的中⽂字符转换成Unicode编码形式if not isinstance(str, unicode):str = str.decode('utf8')draw = ImageDraw.Draw(img_PIL)draw.text(position, str, font=font, fill=fillColor)# 使⽤PIL中的save⽅法保存图⽚到本地# img_PIL.save('02.jpg', 'jpeg')# 转换回OpenCV格式img_OpenCV = cv2.cvtColor(numpy.asarray(img_PIL),cv2.COLOR_RGB2BGR)cv2.imshow("print chinese to image",img_OpenCV)cv2.waitKey()cv2.imwrite('03.jpg',img_OpenCV)输出效果:字体 *.ttc的存放路径⼀般是: /usr/share/fonts/opentype/noto/可以使⽤locate指令查找本机上已经下载的字体:以上就是本⽂的全部内容,希望对⼤家的学习有所帮助,也希望⼤家多多⽀持。

Open Source Computer Vision Library by Gary R. Bradski, Vadim Pisarevsky, and Jean-Yves Bouguet, Springer, 1st ed. (June, 2006).视频处理例程(位于<opencv-root>/samples/c/目录中):色彩跟踪: camshiftdemo点跟踪: lkdemo动作分割: motempl边缘检测: laplace图像处理例程(位于<opencv-root>/samples/c/目录中):边缘检测: edge分割: pyramid_segmentation形态: morphology直方图: demhist距离转换: distrans椭圆拟合 fitellipseOpenCV 命名约定函数命名:cvActionTarget[Mod](...)Action = 核心功能(例如设定set, 创建create)Target = 操作目标(例如轮廓contour, 多边形polygon)[Mod] = 可选修饰词(例如说明参数类型)矩阵数据类型:CV_<bit_depth>(S|U|F)C<number_of_channels>S = 带符号整数U = 无符号整数F = 浮点数例: CV_8UC1 表示一个8位无符号单通道矩阵,CV_32FC2 表示一个32位浮点双通道矩阵.图像数据类型:IPL_DEPTH_<bit_depth>(S|U|F)例: IPL_DEPTH_8U 表示一个8位无符号图像.IPL_DEPTH_32F 表示一个32位浮点数图像.头文件:#include <>#include <>#include <>#include <> C程序实例关闭窗口:cvDestroyWindow("win1");改变窗口尺寸:cvResizeWindow("win1",100,100);直接获取键盘操作:key=cvWaitKey(10); .break;case 'i':...break;}}处理滚动条事件:定义滚动条handler:void trackbarHandler(int pos){printf("Trackbar ",pos);}注册handler:int trackbarVal=25;int maxVal=100;cvCreateTrackbar("bar1", "win1", &trackbarVal ,maxVal , trackbarHandler); 获取滚动条当前位置:int pos = cvGetTrackbarPos("bar1","win1");设定滚动条位置:cvSetTrackbarPos("bar1", "win1", 25);OpenCV基础数据结构图像数据结构IPL 图像:IplImage|-- int nChannels; 若不为NULL则表示需要处理的图像| |-- char *imageDataOrigin;它不是C++的构造函数.其他数据结构点:CvPoint p = cvPoint(int x, int y);CvPoint2D32f p = cvPoint2D32f(float x, float y);CvPoint3D32f p = cvPoint3D32f(float x, float y, float z);例如:=;=;长方形尺寸:CvSize r = cvSize(int width, int height);CvSize2D32f r = cvSize2D32f(float width, float height);带偏移量的长方形尺寸:CvRect r = cvRect(int x, int y, int width, int height);图像处理分配与释放图像空间分配图像空间:IplImage* cvCreateImage(CvSize size, int depth, int channels);size: cvSize(width,height);depth: IPL_DEPTH_8U, IPL_DEPTH_8S, IPL_DEPTH_16U,IPL_DEPTH_16S, IPL_DEPTH_32S, IPL_DEPTH_32F, IPL_DEPTH_64Fchannels: 1, 2, 3 or 4.注意数据为交叉存取.彩色图像的数据编排为b0 g0 r0 b1 g1 r1 ...举例:设定/获取兴趣通道:void cvSetImageCOI(IplImage* image, int coi); 读取存储图像从文件中载入图像:IplImage* img=0;img=cvLoadImage(fileName);if(!img) printf("Could not load image file: %s\n",fileName);Supported image formats: BMP, DIB, JPEG, JPG, JPE, PNG, PBM, PGM, PPM,SR, RAS, TIFF, TIF载入图像默认转为3通道彩色图像. 如果不是,则需加flag:img=cvLoadImage(fileName,flag);flag: >0 载入图像转为三通道彩色图像=0 载入图像转为单通道灰度图像<0 不转换载入图像(通道数与图像文件相同).图像存储为图像文件:if(!cvSaveImage(outFileName,img)) printf("Could not save: %s\n",outFileName);输入文件格式由文件扩展名决定.存取图像元素假设需要读取在i行j列像点的第k通道. 其中, 行数i的范围为[0, height-1], 列数j的范围为[0, width-1], 通道k的范围为[0, nchannels-1].间接存取: (比较通用, 但效率低, 可读取任一类型图像数据)对单通道字节图像:IplImage* img=cvCreateImage(cvSize(640,480),IPL_DEPTH_8U,1);CvScalar s;s=cvGet2D(img,i,j); = 111;imgA[i][j].g = 111;imgA[i][j].r = 111;多通道浮点图像:IplImage* img=cvCreateImage(cvSize(640,480),IPL_DEPTH_32F,3);RgbImageFloat imgA(img);imgA[i][j].b = 111;imgA[i][j].g = 111;imgA[i][j].r = 111;图像转换转为灰度或彩色字节图像:cvConvertImage(src, dst, flags=0);src = float/byte grayscale/color imagedst = byte grayscale/color imageflags = CV_CVTIMG_FLIP (flip vertically)CV_CVTIMG_SW AP_RB (swap the R and B channels)转换彩色图像为灰度图像:使用OpenCV转换函数:cvCvtColor(cimg,gimg,CV_BGR2GRAY); * +cimgA[i][j].g* +cimgA[i][j].r*;颜色空间转换:cvCvtColor(src,dst,code); CV_BGR2GRAY, CV_BGR2HSV, CV_BGR2Lab绘图命令画长方体:许多其他方法提供了更加方便的C++接口,其效率与OpenCV一样.OpenCV将向量作为1维矩阵处理.矩阵按行存储,每行有4字节的校整.分配矩阵空间:CvMat* cvCreateMat(int rows, int cols, int type);type: 矩阵元素类型. 格式为CV_<bit_depth>(S|U|F)C<number_of_channels>.例如: CV_8UC1 表示8位无符号单通道矩阵, CV_32SC2表示32位有符号双通道矩阵. 例程:CvMat* M = cvCreateMat(4,4,CV_32FC1);释放矩阵空间:CvMat* M = cvCreateMat(4,4,CV_32FC1);cvReleaseMat(&M);复制矩阵:CvMat* M1 = cvCreateMat(4,4,CV_32FC1);CvMat* M2;M2=cvCloneMat(M1);初始化矩阵:double a[] = { 1, 2, 3, 4,5, 6, 7, 8,9, 10, 11, 12 };CvMat Ma=cvMat(3, 4, CV_64FC1, a);另一种方法:CvMat Ma;cvInitMatHeader(&Ma, 3, 4, CV_64FC1, a);初始化矩阵为单位阵:CvMat* M = cvCreateMat(4,4,CV_32FC1);cvSetIdentity(M);间接存取矩阵元素:cvmSet(M,i,j,; Mb -> MccvDiv(Ma, Mb, Mc); Mb -> MccvAddS(Ma, cvScalar, Mc); Vb -> rescvCrossProduct(&Va, &Vb, &Vc);单矩阵操作:CvMat *Ma, *Mb;cvTranspose(Ma, Mb);视频序列操作从视频序列中抓取一帧OpenCV支持从摄像头或视频文件(A VI)中抓取图像.从摄像头获取初始化:CvCapture* capture = cvCaptureFromCAM(0); 在抓取动作都结束后再恢复帧图像.释放抓取源:cvReleaseCapture(&capture);注意由设备抓取的图像是由capture函数自动分配和释放的. 不要试图自己释放它.获取/设定帧信息获取设备特性:cvQueryFrame(capture); 用摄像头时不对,奇怪!!!.获取帧信息:float posMsec = cvGetCaptureProperty(capture, CV_CAP_PROP_POS_MSEC);int posFrames = (int) cvGetCaptureProperty(capture, CV_CAP_PROP_POS_FRAMES);float posRatio = cvGetCaptureProperty(capture, CV_CAP_PROP_POS_A VI_RATIO);获取所抓取帧在视频序列中的位置, 从首帧开始按[毫秒]算. 或者从首帧开始从0标号, 获取所抓取帧的标号. 或者取相对位置,首帧为0,末帧为1, 只对视频文件有效.设定所抓取的第一帧标号:不过似乎也不成功!!!存储视频文件初始化视频存储器:CvVideoWriter *writer = 0;int isColor = 1;int fps = 25;存储视频文件:IplImage* img = 0;int nFrames = 50;for(i=0;i<nFrames;i++){cvGrabFrame(capture);释放视频存储器:cvReleaseVideoWriter(&writer);。

OPENCV2基础(补充材料) OpenCV_tutorials翻译资料整理而来翻译材料出处: .cn/opencvdoc/[2014/10]目录一、Mat - 基本图像容器........................................................................ 错误!未定义书签。
二、OpenCV如何扫描图像、利用查找表和计时................................ 错误!未定义书签。
三、矩阵的掩码操作............................................................................... 错误!未定义书签。
四、使用OpenCV对两幅图像求和(求混合(blending)) .................. 错误!未定义书签。
五、改变图像的对比度和亮度............................................................... 错误!未定义书签。
六、图像平滑处理................................................................................... 错误!未定义书签。
七、腐蚀与膨胀(Eroding and Dilating) .................................................. 错误!未定义书签。
八、实现自己的线性滤波器................................................................... 错误!未定义书签。
九、给图像添加边界............................................................................... 错误!未定义书签。

学习opencv中⽂版教程——第⼆章学习opencv中⽂版教程——第⼆章所有案例,跑起来~~~然⽽并没有都跑起来。
我只把我能跑的都尽量跑了,毕竟看书还是很⽣硬,能运⾏能出结果,才⽐较好。
越着急,⼼越慌,越是着急,越要慢,越是陌⽣,越不能盲进。
否则更容易⾛错路。
看了⼀些东西发现都挺坑的,然后看了看书,发现书上写的也。
所以就把看书笔记,和跑动例程都来做⼀个整理。
关于如何配置,是重中之重然后是看书⼜看回到了这本学习opencv的⽩⾊装帧书上。
初试⽜⼑——显⽰图像例2-1#include "highgui.h"//1、int main(int argc,char **argv){ //2、IplImage* img = cvLoadImage(argv[1]);//3、cvNamedWindow("Example1", CV_WINDOW_AUTOSIZE);//4、cvShowImage("Example1", img);//5、cvWaitKey(0);//6、cvReleaseImage(&img);//7、cvDestroyWindow("Example1");//8、}1、⾼级GUI图像⽤户界⾯,包含媒体的输⼊输出,视频捕捉,图像视频的编解码,图形交互界⾯的接⼝。
GUI:Graphical User Interface 图形⽤户界⾯(接⼝)3、如果能明⽩主函数的参数情况,那么在命令⾏⾥⾯键⼊:opencv教程——显⽰图像 1.png 。
其中第⼀个参数要想展⽰的话是:argv[0]如果cout<<argv[0]将会是“opencv教程——显⽰图像”,所以argv[1] 是 “1.png”所以下⾯⼀同也给了⼀个⽬录结构,为了能在当前⽬录⾥⾯找到1.png这张图⽚。
如果找到的话,就加载这张图⽚,并且把图像信息赋给img。


学习OpenCV中文版教学设计前言本文是关于教学OpenCV计算机视觉库的教学设计。
计算机视觉是一项快速发展的领域,为了适应这一发展趋势,本教学设计注重培养学生的实践能力和理论知识。
同时,本教学设计采用中文版OpenCV库,具有较高的适用性和实用性。
教学目标本教学着重培养学生的理论知识和实践能力,主要包括以下几个方面:1.了解计算机视觉的基本概念和研究领域;2.掌握OpenCV的基本应用和编程思路;3.学会使用OpenCV进行图像处理、物体检测、目标跟踪等;4.学会将OpenCV应用到具体项目中,解决实际问题。
教学内容本教学分为三个阶段,分别是基础、进阶和应用阶段。
基础阶段第一章绪论本章主要介绍计算机视觉的基本概念,包括计算机视觉的定义、发展历程、研究领域、应用前景等。
同时介绍OpenCV的基本功能、编程环境、编程语言等。
第二章图像基础知识这一章节主要介绍如何采用OpenCV对图像进行读取、显示、存储。
同时介绍灰度图像和彩色图像的基本概念和处理方法。
第三章图像处理基础介绍一些常见的图像处理操作,如二值化、滤波、边缘检测、形态学操作等。
并使用OpenCV对图像进行处理,展示其效果。
第四章特征提取与描述介绍如何对图像进行特定特征提取,如SIFT、SURF等,讲解特征描述符的分类、应用和算法。
使用OpenCV对图像进行特征提取和描述。
进阶阶段第五章目标检测介绍如何使用OpenCV进行目标检测,包括Haar、LBP、HOG等常见算法。
并介绍检测器的训练方法和模型优化。
第六章目标跟踪介绍如何进行目标跟踪,讲解常用的跟踪算法,如KCF、TLD、MOSSE等。
同时使用OpenCV进行目标跟踪,并讲解其实现原理。
第七章视觉SLAM介绍基于视觉的SLAM技术,介绍其相关算法和实现流程。
使用OpenCV实现基于视觉的SLAM。
应用阶段第八章图像识别应用介绍OpenCV在图像识别领域的应用,包括人脸识别、车牌识别、文本识别等应用。

c++快速生成图像处理训练集csv文件程序工具:c++编辑器和编译器查看csv文件:Notepad++自定义函数void get_csv(const char* savefile_path, const char* picturefile_path,const char * form, int num, int index); 参数说明:savefile_path:保存csv文件路径picturefile_path:保存的图像路径form:图像格式num:图像数量index:图像编号程序如下#include<iostream>#include<fstream>using namespace std;void get_csv(const char* savefile_path, const char* picturefile_path,const char * form, int num, int index); int main() {get_csv("D:/document/opencv_data/trains/test.csv", "D:/document/opencv_data/trains/", "csv",10, 1);return 0;}void get_csv(const char* savefile_path, const char* picturefile_path, const char* form, int num, int index) { ofstream fd(savefile_path);if (fd.is_open()) {for (int i = 1; i <= num; i++) {fd <<picturefile_path<< i <<"."<<form<<","<<index<< endl;//输出的格式可以在这里修改}}fd.close();}程序输出结果如下。


学习OpenCV(中⽂版)学习OpenCV(中⽂版)【原书名】 Learning OpenCV: Computer Vision with the OpenCV Library【原出版社】 O'Reilly Media, Inc.【作 者】(美)Gary Bradski;Adrian Kaehler【译 者】于仕琪;刘瑞祯[同译者作品]【丛书名】清华⼤学出版社O'Reilly系列【出版社】清华⼤学出版社【书号】 9787302209935【上架时间】 2009-10-16【出版⽇期】 2009 年10⽉【开本】 16开【页码】 601 【版次】1-1详情查看:【内容简介】计算机视觉是在图像处理的基础上发展起来的新兴学科。
OpenCV是⼀个开源的计算机视觉库,是英特尔公司资助的两⼤图像处理利器之⼀。
它为图像处理、模式识别、三维重建、物体跟踪、机器学习和线性代数提供了各种各样的算法。
.本书由OpenCV发起⼈所写,站在⼀线开发⼈员的⾓度⽤通俗易懂的语⾔解释了OpenCV的缘起和计算机视觉基础结构,演⽰了如何⽤OpenCV和现有的⾃由代码为各种各样的机器进⾏编程,这些都有助于读者迅速⼊门并渐⼊佳境,兴趣盎然地深⼊探索计算机视觉领域。
本书可作为信息处理、计算机、机器⼈、⼈⼯智能、遥感图像处理、认知神经科学等有关专业的⾼年级学⽣或研究⽣的教学⽤书,也可供相关领域的研究⼯作者参考。
透过本书,您将置⾝于迅速发展的计算机视觉领域。
本书由⾃由开源OpenCV的发起⼈所著,介绍了计算机视觉,并通过实例演⽰了如何快速⽣成这样的应⽤——能使计算机“看到”并根据由此获取的数据做出决策。
计算机视觉⽆处不在,安全系统、制造检验系统、医学图像分析、⽆⼈机等都可以见到它的踪影。
它与Google Map和Google Earth紧密结合,它检查LCD屏幕上的像素,它确保衬衫上的每个针脚都能完全缝合。
OpenCV提供了⼀个简易好⽤的计算机视觉框架和⼀个丰富的库,后者包含500多个可实时运⾏视觉代码的函数。
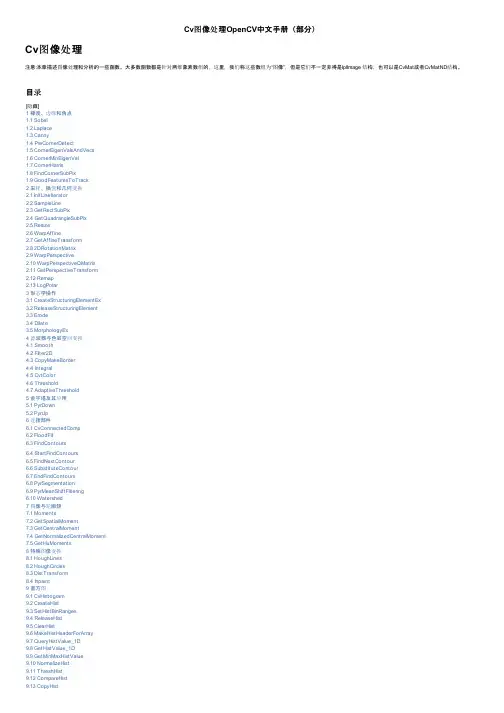
Cv图像处理OpenCV中文手册(部分)Cv图像处理注意:本章描述图像处理和分析的一些函数。
大多数函数都是针对两维象素数组的,这里,我们称这些数组为“图像”,但是它们不一定非得是IplImage 结构,也可以是CvMat或者CvMatND结构。
目录[隐藏]1 梯度、边缘和角点1.1 Sobel1.2 Laplace1.3 Canny1.4 PreCornerDetect1.5 CornerEigenValsAndVecs1.6 CornerMinEigenVal1.7 CornerHarris1.8 FindCornerSubPix1.9 GoodFeaturesToTrack2 采样、插值和几何变换2.1 InitLineIterator2.2 SampleLine2.3 GetRectSubPix2.4 GetQuadrangleSubPix2.5 Resize2.6 WarpAffine2.7 GetAffineTransform2.8 2DRotationMatrix2.9 WarpPerspective2.10 WarpPerspectiveQMatrix2.11 GetPerspectiveTransform2.12 Remap2.13 LogPolar3 形态学操作3.1 CreateStructuringElementEx3.2 ReleaseStructuringElement3.3 Erode3.4 Dilate3.5 MorphologyEx4 滤波器与色彩空间变换4.1 Smooth4.2 Filter2D4.3 CopyMakeBorder4.4 Integral4.5 CvtColor4.6 Threshold4.7 AdaptiveThreshold5 金字塔及其应用5.1 PyrDown5.2 PyrUp6 连接部件6.1 CvConnectedComp6.2 FloodFill6.3 FindContours6.4 StartFindContours6.5 FindNextContour6.6 SubstituteContour6.7 EndFindContours6.8 PyrSegmentation6.9 PyrMeanShiftFiltering6.10 Watershed7 图像与轮廓矩7.1 Moments7.2 GetSpatialMoment7.3 GetCentralMoment7.4 GetNormalizedCentralMoment7.5 GetHuMoments8 特殊图像变换8.1 HoughLines8.2 HoughCircles8.3 DistTransform8.4 Inpaint9 直方图9.1 CvHistogram9.2 CreateHist9.3 SetHistBinRanges9.4 ReleaseHist9.5 ClearHist9.6 MakeHistHeaderForArray9.7 QueryHistValue_1D9.8 GetHistValue_1D9.9 GetMinMaxHistValue9.10 NormalizeHist9.11 ThreshHist9.12 CompareHist9.13 CopyHist[编辑][编辑][编辑][编辑][编辑]9.13 CopyHist 9.14 CalcHist9.15 CalcBackProject9.16 CalcBackProjectPatch 9.17 CalcProbDensity 9.18 EqualizeHist 10 匹配10.1 MatchTemplate 10.2 MatchShapes 10.3 CalcEMD2梯度、边缘和角点Sobel使用扩展 Sobel 算子计算一阶、二阶、三阶或混合图像差分void cvSobel( const CvArr* src, CvArr* dst, int xorder, int yorder, int aperture_size=3 );src输入图像.dst输出图像.xorderx 方向上的差分阶数yordery 方向上的差分阶数aperture_size扩展 Sobel 核的大小,必须是 1, 3, 5 或 7。
级联分类器训练引言级联分类器的工作主要包括两个阶段:训练和检测。
检测阶段被描述在一个常规的OpenCV 文件的objdetect 模块的文档里。
文档介绍了级联分类器的一些基本信息。
目前的指南描述了如何训练级联分类器:一个训练数据集和运行训练应用程序的准备。
重要的笔记在OpenCV里有两个应用程序可以用来训练级联分类器:opencv_haartraining和opencv_traincascade。
opencv_traincascade是一个较新的版本,用C++按照OpenCV 2.x API 的标准编写。
但这两个应用程序之间的主要区别是,opencv_traincascade同时支持Haar [Viola2001] 和LBP [Liao2007](局部二值模式)的特征。
相比于Haar特征,LBP特征是整数,所以用LBP训练和检测比用Haar特征快好几倍。
至于LBP和Haar的检测质量取决于训练:首先是训练数据集的品质还有训练参数。
训练一个和基于Haar的分类有几乎相同的质量的基于LBP的分类是有可能的。
opencv_traincascade和opencv_haartraining以不同的文件格式存储训练好的分类器。
值得注意的是,较新的级联检测接口(见objdetect模块的级联分类器类)两种格式都支持。
opencv_traincascade可以用旧格式保存(输出)训练好的级联。
但opencv_traincascade和opencv_haartraining无法在中断后以另一种格式加载(输入)一个分类器来进一步训练。
注意,opencv_traincascade应用程序可以使用TBB实现多线程。
在多核模式下使用,OpenCV 必须要用TBB来构建。
并且这有一些和训练相关的辅助工具。
·opencv_createsamples是用来准备正训练数据集和测试样本集的。
opencv_createsamples产生一个opencv_haartraining和opencv_traincascade都支持的格式的正样本数据集。
OPENCV2基础(补充材料)OpenCV_tutorials翻译资料整理而来翻译材料出处:/opencvdoc/2.3.2/html/doc/tutorials/tutorial s.html[2014/10]目录一、Mat - 基本图像容器 (2)二、OpenCV如何扫描图像、利用查找表和计时 (9)三、矩阵的掩码操作 (18)四、使用OpenCV对两幅图像求和(求混合(blending)) (22)五、改变图像的对比度和亮度 (25)六、图像平滑处理 (30)七、腐蚀与膨胀(Eroding and Dilating) (37)八、实现自己的线性滤波器 (45)九、给图像添加边界 (49)十、Sobel 导数 (55)十一、霍夫线变换 (61)十二、直方图均衡化 (68)十三、仿射变换 (73)十四、Remapping 重映射 (81)一、 Mat - 基本图像容器目的从真实世界中获取数字图像有很多方法,比如数码相机、扫描仪、CT或者磁共振成像。
无论哪种方法,我们(人类)看到的是图像,而让数字设备来“看“的时候,则是在记录图像中的每一个点的数值。
比如上面的图像,在标出的镜子区域中你见到的只是一个矩阵,该矩阵包含了所有像素点的强度值。
如何获取并存储这些像素值由我们的需求而定,最终在计算机世界里所有图像都可以简化为数值矩以及矩阵信息。
作为一个计算机视觉库,OpenCV其主要目的就是通过处理和操作这些信息,来获取更高级的信息。
因此,OpenCV如何存储并操作图像是你首先要学习的。
Mat在2001年刚刚出现的时候,OpenCV基于C语言接口而建。
为了在内存(memory)中存放图像,当时采用名为IplImage的C语言结构体,时至今日这仍出现在大多数的旧版教程和教学材料。
但这种方法必须接受C语言所有的不足,这其中最大的不足要数手动内存管理,其依据是用户要为开辟和销毁内存负责。
虽然对于小型的程序来说手动管理内存不是问题,但一旦代码开始变得越来越庞大,你需要越来越多地纠缠于这个问题,而不是着力解决你的开发目标。
如何用OPENCV训练自己的分类器要用OpenCV训练自己的分类器,您需要以下步骤:1.收集和准备数据集:首先,您需要收集和准备一个包含不同类别图像的数据集。
确保每个类别包含足够数量的图像,以便训练分类器。
例如,如果您要训练一个猫狗分类器,那么您至少需要准备包含猫和狗图像的两个文件夹。
2.加载数据集:使用OpenCV中的图像处理函数,您可以加载图像数据集并将其准备成适合训练分类器的格式。
通常,这涉及将图像转换为灰度图像(如果您不需要颜色信息),调整图像大小,并将其转换为NumPy数组。
3.提取特征:一旦您准备好数据集,您需要选择适当的特征来描述图像中的内容。
对于分类器的训练,可以使用各种特征提取方法,例如颜色直方图、灰度共生矩阵、方向梯度直方图(HOG)等。
根据您的应用场景,选择一个或多个适合的特征提取方法,并将其应用于图像数据集中的每个图像。
4.标记数据:5.划分数据集:将数据集分为训练集和测试集是非常重要的,这样您可以在训练分类器后评估其性能。
一般来说,将大部分数据用于训练(例如80%),其余的用于测试。
确保训练集和测试集中的图像数量均匀分布,并且每个类别都有足够数量的图像。
6.训练分类器:7.评估分类器:一旦分类器训练完毕,您可以使用测试集上的数据来评估其性能。
计算分类器对测试集中图像的准确性、精确性、召回率等指标。
这将帮助您了解分类器的性能和潜在问题,并可根据需要进行优化。
8.调整参数和优化:如果分类器的性能不如预期,您可以尝试调整分类器的参数,例如特征提取方法、分类器模型、参数调整等。
通过多次迭代和优化,改进分类器的性能。
9.预测新数据:以上简要介绍了使用OpenCV训练自己的分类器的主要步骤。
请注意,这仅是一个概述,具体实现可能会根据您的需求和数据集而有所不同。
OpenCV在机器学习和计算机视觉领域有广泛的应用,它提供了强大的工具和函数来帮助您进行数据处理、特征提取、模型训练和分类预测等任务。
opencv中文教程OpenCV 是一个开源的计算机视觉库,支持许多图像和视频处理功能。
它是一种强大的工具,可用于图像增强、特征提取、目标检测等应用。
OpenCV 提供了丰富的函数和类,使得图像处理变得简单且高效。
下面是一些常用的功能和函数的示例:1. 图像读取和显示```import cv2img = cv2.imread("image.jpg") # 读取图像cv2.imshow("Image", img) # 显示图像cv2.waitKey(0) # 等待按键cv2.destroyAllWindows() # 关闭窗口```2. 图像灰度化```import cv2img = cv2.imread("image.jpg")gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转为灰度图像cv2.imshow("Gray Image", gray_img)cv2.waitKey(0)cv2.destroyAllWindows()```3. 图像边缘检测```import cv2import numpy as npimg = cv2.imread("image.jpg", 0)edges = cv2.Canny(img, 100, 200) # 边缘检测cv2.imshow("Edges", edges)cv2.waitKey(0)cv2.destroyAllWindows()```4. 目标检测```import cv2img = cv2.imread("image.jpg")cascade =cv2.CascadeClassifier("haarcascade_frontalface_default.xml") # 使用人脸识别级联分类器gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) faces = cascade.detectMultiScale(gray_img, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30)) # 检测人脸for (x, y, w, h) in faces:cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 2) # 绘制矩形框cv2.imshow("Detected Faces", img)cv2.waitKey(0)cv2.destroyAllWindows()```这些只是 OpenCV 的一小部分功能,它还提供了许多其他功能,如图像滤波、形态学操作、图像匹配等。
级联分类器训练引言级联分类器的工作主要包括两个阶段:训练和检测。
检测阶段被描述在一个常规的OpenCV 文件的objdetect模块的文档里。
文档介绍了级联分类器的一些基本信息。
目前的指南描述了如何训练级联分类器:一个训练数据集和运行训练应用程序的准备。
重要的笔记在OpenCV里有两个应用程序可以用来训练级联分类器:opencv_haartraining和opencv_traincascade。
opencv_traincascade是一个较新的版本,用C++按照OpenCV2.x API 的标准编写。
但这两个应用程序之间的主要区别是,opencv_traincascade同时支持Haar [Viola2001]和LBP[Liao2007](局部二值模式)的特征。
相比于Haar特征,LBP特征是整数,所以用LBP训练和检测比用Haar特征快好几倍。
至于LBP和Haar的检测质量取决于训练:首先是训练数据集的品质还有训练参数。
训练一个和基于Haar的分类有几乎相同的质量的基于LBP的分类是有可能的。
opencv_traincascade和opencv_haartraining以不同的文件格式存储训练好的分类器。
值得注意的是,较新的级联检测接口(见objdetect模块的级联分类器类)两种格式都支持。
opencv_traincascade可以用旧格式保存(输出)训练好的级联。
但opencv_traincascade和opencv_haartraining无法在中断后以另一种格式加载(输入)一个分类器来进一步训练。
注意,opencv_traincascade应用程序可以使用TBB实现多线程。
在多核模式下使用,OpenCV 必须要用TBB来构建。
并且这有一些和训练相关的辅助工具。
·opencv_createsamples是用来准备正训练数据集和测试样本集的。
opencv_createsamples产生一个opencv_haartraining和opencv_traincascade都支持的格式的正样本数据集。
输出的是一个以*.VEC为后缀的文件,它是一种包含图像的二进制格式。
·opencv_performance可用于评估分类器的质量,但是只能评估opencv_haartraining的训练。
它需要一个图像标记的集合,运行分类器并且报告性能,即找到的对象的数量,没有对象的数量,错误警报的数量等信息。
因为opencv_haartraining是一个过时的应用,只对opencv_traincascade进行进一步的讲解。
为opencv_traincascade准备训练数据时opencv_createsamples工具是必需的,所以它也将被详述。
opencv_createsamples工具一个opencv_createsamples工具提供了数据集的生成功能,写和读,用数据集这个术语作为训练集和测试集的统称。
训练数据准备为了训练我们需要一组样本。
有两种类型的样品:正和负。
负样本对应于非目标图像。
正样本对应于包含了被测物体的图像。
集负样本必须手动创建,而一组正样本由opencv_createsamples工具创建。
负样本负样品来自任意图像。
这些图像必须不包含被检测对象。
负样本被放在一个特殊的文件里。
这是一个在它的每一行包含一个负样本图像的文件名的文本文件(相对于描述文件的目录)。
这个文件必须手动创建。
注意,负样本和样本图像也被称为背景样本或背景样本图像,并在此文件中是可交换的。
被描述的图像可以具有不同的尺寸。
但每个图像应该是(但不一定)大于训练窗口的大小,因为这些图像被用来进行再次抽取,变成具有训练尺寸的负面图像。
描述文件的一个实例:目录结构:/imgimg1.jpgimg2.jpgbg.txt文件bg.txtimg/img1.jpgimg/img2.jpg正样本正样本用opencv_createsamples工具来创建。
他们可能是从一个包含对象的单帧图像或先前标记的图像的集合中创建。
请注意,你需要一个大的正样本数据集把它送给你之前提到的工具,因为它只适用于透视变换。
例如,你可能只需要一个正样本,像opencv标志这样的一个明显的规则物体,但对于面孔这样的,你绝对需要成百上千个正样本。
在面孔的这种情况下,你应该考虑所有的种族和年龄组,情绪又或者胡子的风格。
因此,一个单帧的物体图像可能包含公司徽标。
那么一大组的正样本被通过随机旋转从而给定的对象的图像创造,改变标志的强度以及放置标志的任意背景的数量和范围的随机性可以通过opencv_createsamples工具的命令行参数控制。
命令行参数:-vec<vec_file_name>输出文件的名字中包含正的训练样本。
-img<image_file_name>源对象的图像(如,公司标志)。
-bg<background_file_name>背景描述文件;列出了作为背景的随机扭曲版本的对象的图像。
-num<number_of_samples>产生正样本的数量-bgcolor<background_color>背景颜色(目前灰度图像被假定);背景颜色为透明色。
因为可能有压缩失真,颜色容错的数量可以通过-bgthresh被指定。
所有像素在bgcolor-bgthresh到bgcolor+bgthresh的范围内被认为是透明的。
-bgthresh<background_color_threshold>-inv如果指定,颜色取反。
-randinv如果指定,颜色将随机取反。
-maxidev<max_intensity_deviation>在最突出的样本像素的最大强度偏差。
-maxxangle<max_x_rotation_angle>-maxyangle<max_y_rotation_angle>-maxzangle<max_z_rotation_angle>给最大旋转角度一定的弧度。
-show有用的调试选项。
如果指定,每个样品将被显示。
按ESC键结束创建样本过程。
-w<sample_width>宽度(像素)的输出样本。
-h<sample_height>高度(像素)的输出样本。
-pngoutput使用此选项打开opencv_createsamples工具生成一个PNG样本集合和大量相关注释文件,而不是一个单一的vec(矢量)文件。
opencv_createsamples工具可以以多个模式工作,即:从一个单一的图像和一个背景的集合中创建训练集:以一个单一的VEC文件作为输出;以一个JPG图片集合和注释列表文件作为输出;以一个的PNG图像集合和相关的文件注释作为输出;将采集样品标记为VEC格式;显示vec文件的内容。
从一个单一的图片和背景的集合中创建训练集并以一个单一的VEC文件作为输出下面的程序是一个用来创建一个样本对象的实例:源图像被随机的绕着三个轴旋转。
选择的角度被-max?angle限制。
然后在[bg_color-bg_color_threshold; bg_color+bg_color_threshold]强度范围内的像素解释为透明。
白噪声添加到前景的强度上。
如果-inv参数被指定然后指定前景像素强度取反。
如果-randinv的值被指定随后指定算法随机选择是否在该样本上进行取反。
最后,得到的图像放置到从背景描述文件中任意抽取出的背景上,调整到所需的大小,通过-w和-h来指定随后存储到通过命令行选项指定的VEC 文件中。
创建训练集作为一个PNG图像的集合为了获得这种行为,-img,-bg,-info和-pngoutput键值应指定。
用-info的键值指定文件名,应包括至少一个水平层次的目录,该目录将作为训练集的顶层目录。
例如,调用opencv_createsamples如下所示:opencv_createsamples-img/home/user/logo.png-bg/home/user/bg.txt -info/home/user/annotations.lst-pngoutput-maxxangle0.1-maxyangle 0.1-maxzangle0.1输出将具有以下结构:/home/user/annotations/0001_0107_0099_0195_0139.txt0002_0107_0115_0195_0139.txt...neg/<background files here>pos/0001_0107_0099_0195_0139.png0002_0107_0115_0195_0139.png...annotations.lst在TXT格式的注释目录里包含样品中关于以下一个文件格式的对象包围盒的信息:Image filename:"/home/user/pos/0002_0107_0115_0195_0139.png" Bounding box for object1"PASperson"(Xmin,Ymin)-(Xmax,Ymax):(107, 115)-(302,254)创建测试集设置为JPG图像的集合这种变异的用法非常类似于上一个,但是以不同的格式产生输出;获得这样的行为-img,-bg和-info的值应指定。
例如,调用opencv_createsamples如下:opencv_createsamples-img/home/user/logo.png-bg/home/user/bg.txt -info annotations.lst-maxxangle0.1-maxyangle0.1-maxzangle0.1目录结构:info.datimg1.jpgimg2.jpg文件info.datimg1.jpg11401004545img2.jpg2100200505050302525将样品的标记集合变为VEC格式正样本也可以从之前的标记图像集合中获得。
这个系列是由一个类似背景描述文件的文本文件描述。
此文件的每一行对应一个图像。
该行的第一个元素是文件名。
其次是对象实例的数量。
下面的数字是对象的边界矩形的坐标(x,y,宽度,高度)。
描述文件的一个实例:目录结构:/imgimg1.jpgimg2.jpginfo.dat文件info.dat:img/img1.jpg11401004545img/img2.jpg2100200505050302525图像img1.jpg包含单独的对象实例的边框坐标:(140,100,45,45)。