公用数据库基因组表达谱数据挖掘策略及分析方法-李曦(达人学社)
- 格式:ppt
- 大小:9.81 MB
- 文档页数:73

第24期2020年12月No.24December,20200 引言近年来,国家对于人工智能的发展也越来越重视,2017年7月,国务院发布《新一代人工智能发展规划》,在该文件中明确指出了人工智能的发展对于教育行业发展的重要性。
2018年5月,教育部发布了《教育信息化2.0行动计划》,再次强调了发展智能教育的重要性,开启了智能教育时代。
2020年3月,美国高等教育信息化组织发布的《2020年地平线报告:教与学版》,再次强调了人工智能技术在教育中的重要作用。
1 数据来源与研究方法1.1 数据来源研究数据的收集来源于中国知网(CNKI )数据库,在高级检索页面中主题词设定为“人工智能”并含“教育”。
学科设定为“社会科学Ⅱ辑”中的社会科学理论与方法、社会科学及统计学、教育理论与教育管理、高等教育;“信息科技”中的无线电电子学、电信技术、计算机硬件技术、计算机软件及计算机应用和互联网技术。
时间跨度为2010年1月1日至2020年3月15日。
期刊来源选取“核心期刊”和“CSSCI ”。
共检索到914篇,剔除不符合主题的文献,共得到792篇作为研究样本。
1.2 研究方法本研究利用CiteSpace V 软件进行可视化分析,绘制了2010年以来国内人工智能教育的作者、机构合作图谱,关键词共现图谱等,对现有的文献进行定量和定性分析。
知识图谱是通过“图”和“谱”的双重特征与性质,基于科学知识对象显示其发展进程和结构关系,通过可视化知识图形和序列化的知识谱系,呈现知识元或知识群之间网络结构互动交叉演化或衍生等诸多复杂的关系。
本文除了采用文献研究法之外,还采用了对比分析法,通过对不同的文献进行对比分析,了解人工智能教育的应用现状以及特点。
摘 要:近年来,随着科技的发展,人工智能已经成为人们生活中不可忽略的一个部分。
在教育行业中,也有越来越多的教育单位选择使用人工智能技术开展教育工作,但是目前国内针对人工智能教育的应用却依旧存在一定的问题,亟待改善和解决。

264研究与探索Research and Exploration ·理论研究与实践中国设备工程 2024.01 (上)等领域不可或缺的工具。
狭义的知识图谱特指一类知识表示,本质上是一种大规模的语义网络;广义的知识图谱是大数据时代知识工程一系列技术的总称。
从狭义角度考察,此种大规模的语义网络包括实体、概念及其之间的各种关系,其中,语义网络是知识图谱的本质。
与传统的语义网络相比,知识图谱代表的语义网络规模巨大、语义丰富、质量精良、结构友好。
语义网络是一种以图形化的形式,通过点与边描述知识关系的方法。
图形中的点可以描述实体、概念和属性。
实体称为对象或实例,它是一切属性的物质基础,是有明确指代意义的。
概念又称类别、类,其是指一类人,这类人有相同的特征。
概念所对应的动词称为概念化和范畴化,概念化一般指识别文本中的相关概念的过程,例如,拉格朗日的中值思想;范畴化一般指实体形成类别的过程,如具有若干哲学思想的人们组成某个特定的哲学派别,则这一学派的形成就是典型范畴化的过程。
每个实体都有一定的属性值,包括数值、日期、文本等,知识图谱的推理即是建立在实体、属性与关系之上。
科学知识图谱在图书馆学情报学应用领域,包括识别学科领域热点、展示学科研究前沿、分析引用关系等。
2 CiteSpace 的主要学科基础理论从哲学、社会学、数据科学,数学等学科入手,可全面理解软件包含的学科基础知识。
2.1 科学革命的结构CiteSpace 设计灵感之一,是来源于托马斯•库恩的《科学革命的结构》。
库恩重塑了科学的真理形象,其“范式论”“不可通约论”为科学史研究提供了新的视角。
库恩思考的根本问题可以概括为“科学进步的机制是什么”。
这是需要借助科学史研究才能回答的问题,但传统的研究方法存在缺陷,而作者尝试从科学史的编著工作中找到突破口。
科学知识的历史不是简单增长过程,其中某个阶段必定会发生根本性的转变,新的科学观应以研究此类根本性转变为宗旨。

第28卷㊀第5期2023年10月㊀哈尔滨理工大学学报JOURNAL OF HARBIN UNIVERSITY OF SCIENCE AND TECHNOLOGY㊀Vol.28No.5Oct.2023㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀一种CCA -层次聚类的基因聚类算法林倩闽(厦门理工学院电气工程与自动化学院,福建厦门361024)摘㊀要:针对基因芯片技术带来的海量基因表达数据,为了充分挖掘其蕴含的生物信息和潜在的生物机制,提出一种基于CCA -层次聚类的基因聚类算法(CCA-Hc )㊂该算法在层次聚类的基础上引入典型相关分析,优化相似性矩阵计算方法㊂首先,利用典型相关分析方法结合基因的多个特征信息进行基因相关性度量,得到基因相似性矩阵㊂然后将该相似性矩阵作为层次聚类的邻近矩阵进行凝聚层次聚类㊂在Oryza sativa L.(水稻)的基因表达数据集上进行CCA-Hc 聚类效果测试实验,结果表明,与采用欧式距离的传统层次聚类算法(EUC-Hc )相比,CCA-Hc 的内部稳定性指标和生物功能性指标均优于EUC-Hc ,具有更佳的鲁棒性和聚类准确性,更有利于去发现基因间的共表达关系㊂关键词:基因表达数据;聚类算法;典型相关分析;层次聚类DOI :10.15938/j.jhust.2023.05.011中图分类号:TP391文献标志码:A文章编号:1007-2683(2023)05-0085-06A Gene Clustering Algorithm Based on the CCA-Hierarchical ClusteringLIN Qianmin(School of Electrical Engineering and Automation,Xiamen University of Technology,Xiamen 361024,China)Abstract :Aiming at the massive gene expression data brought by gene chip technology,in order to fully mine the biological information and potential biological mechanisms contained in it,this paper proposes a gene clustering algorithm based on CCA-hierarchical clustering (CCA-Hc).The algorithm introduces canonical correlation analysis on the basis of hierarchical clustering,and optimizes the calculation method of similarity matrix.First,the canonical correlation analysis method is used to measure the gene correlation by combining the multiple feature information of the gene,and the gene similarity matrix is obtained.Then the similarity matrix is used as the neighbor matrix of hierarchical clustering for agglomerative hierarchical clustering.The CCA-Hc clustering effect test experiment was performed on the gene expression dataset of Oryza sativa L.(rice).The results show that,compared with the traditional hierarchical clustering algorithm using Euclidean distance (EUC-Hc),CCA-Hc is superior to EUC-Hc in both internal stability index and biological functional index,and has better robustness and clustering accuracy.It is more conducive to discoveringthe co-expression relationship between genes.Keywords :gene expression data;clustering algorithm;canonical correlation analysis;hierarchical clustering㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀收稿日期:2022-06-08基金项目:福建省科技厅引导性项目(2019H0039);福建省中青年教师教育科研项目(JAT210341).通信作者:林倩闽(1992 ),女,硕士,助理实验师,E-mail:1023447133@.0㊀引㊀言随着高通量测序技术的不断快速发展,出现越来越多复杂度高㊁数据量大的生物数据㊂不同测序技术可以得到不同水平的生物数据,如通过基因组测序得到DNA 水平的生物数据,转录组测序得到RNA 水平的生物数据㊂基因表达数据是通过DNA微阵列技术(又称为基因芯片技术)检测得到,是不同细胞在不同条件下的基因动态表达水平[1]㊂基因是携带遗传物质的DNA片段,在不同细胞中会有不同的表达方向[2],从而可以控制不同的性状㊂为此基因表达数据蕴含着丰富且重要的生物机制,具有很大的研究价值㊂在基因表达数据分析中,聚类分析方法被广大研究者选用,用以发现具有相似表达行为的基因集,基因间的共表达㊁共调控关系等,对于推断未知的基因功能及在疾病诊断方面具有重要意义[2]㊂目前基因聚类算法根据聚类对象可以分为基于基因㊁基于样本聚类以及基于基因样本的双聚类[3-4]㊂根据聚类方式的不同,又可以分为以K-means算法[5]㊁K-MEDOIDS[6]为代表的基于分区的聚类算法,以BIRCH算法[7]㊁CURE算法[8]为代表的基于层次的聚类算法,以DBSCAN算法[9]㊁OPTICS算法[10]为代表的基于密度的聚类算法和以CLIQUE算法[11]为代表的基于网格的聚类算法㊂在对基因表达数据进行聚类分析时,主要是度量基因之间的相关性,把相关性程度高的基因聚在一起㊂很多基因聚类研究中把皮尔森相关系数㊁欧式距离㊁曼哈顿距离等作为相关性程度的度量方式[12]㊂这些度量方式是基于基因的整体表达水平进行的,即一个基因只由一个一维的数据矩阵表示㊂而在实际的的测序过程中,往往会在不同的细胞周期进行实验测量基因的表达水平,使得一个基因会有多组数据,每组数据代表该基因的一个特征㊂大部分的研究中采用求和的方式把基因多个特征的数据进行累加,进而分析基因之间的相关性㊂这种方法存在的问题是忽略了基因各个特征对表达水平的影响,从而对聚类结果造成影响㊂为了解决上述问题,本文把典型相关分析(Ca-nonical Correlation Analysis,CCA)引入到层次聚类中来,搭建出基于CCA-层次聚类的基因聚类算法(CCA-Hc)㊂典型相关分析是一种计算变量之间相关性的统计学分析方法,能结合变量的多个特征,得到变量的整体相关性[13]㊂利用典型相关分析度量基因之间的相关性,能充分考虑基因的多个特征信息,使得聚类结果中的基因集相似性程度更高㊂同时采用凝聚层次聚类,可以从聚类树状图中直观地分析聚类结果,从而整体上提高聚类效果㊂最后用GEO数据库上的基因数据集来验证CCA-Hc算法的有效性㊂1㊀CCA-Hc算法设计1.1㊀典型相关分析给定基因微阵列数据矩阵A nˑm=(G,T),n表示基因个数,m表示条件的种类数㊂每个基因可以看成是一个变量,使用典型相关分析方法分析变量相关性时,假设变量X有p个特征,变量Y有q个特征,pɤq,每个特征均对应m个不同条件的数据,则X=[x1, ,x p]T(1) Y=[y1, ,y q]T(2)变量X的数据矩阵为x11x12x13 x1mx21x22x23 x2mx31x32x33 x3m︙︙︙︙x p1x p2x p3 x pméëêêêêêêêùûúúúúúúú变量Y的数据矩阵为y11y12y13 y1my21y22y23 y2my31y32y33 y3m︙︙︙︙y q1y q2y q3 y qméëêêêêêêêùûúúúúúúú变量X和变量Y的协方差矩阵为ð=Cov(X,Y)=Var(X)Cov(X,Y)Cov(Y,X)Var(Y)()=ð11ð12ð21ð22()(3)变量X和变量Y的线性表达式记为U㊁V,表示为:U=a1x1+a2x2+ +a p x p=a T X(4) V=b1y1+b2y2+ +b q y q=b T Y(5)变量X和变量Y进行典型相关性分析时,可用这两个变量的线性表达式U㊁V之间相关系数的最大值来度量变量之间的相关性程度,即max a,b corr(U,V)=a Tð12b(a Tð11aˑb Tð22b)1/2(6)在求解上述最值表达式时,运用拉格朗日数乘法求解瑞利熵矩阵(ð-111ð12ð-122ð21)得到p个特征值,68哈㊀尔㊀滨㊀理㊀工㊀大㊀学㊀学㊀报㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀第28卷㊀记为λ1,λ2 λp ㊂这p 个特征值即变量X 和变量Y之间的典型相关系数㊂每一个相关系数再应用卡方检验进行显著性检验,得到p 个卡方检验p-value 值,记为p 1,p 2 p p ㊂为了更好地表示变量之间的典型相关程度,引入一个关于典型相关系数和p-value 值的权重函数W 来表示,定义为:W =ðp i =1λi I (log P i )ðp i =1I (log P i )(7)其中I (log P i )=0P >0.05-log PP ɤ0.05{这样每两个变量之间就能得到一个w 值来度量它们的相关性程度㊂对基因表达数据的n 个基因进行如上方法的典型相关分析后,最终得到一个n ˑn 的相似性矩阵㊂1.2㊀层次聚类目前常用的聚类算法有基于分区㊁基于层次㊁基于密度和基于网络4种类型[2],其中基于层次聚类的算法因原理通俗易懂㊁结果直观且精度高等优点而被广泛使用[14]㊂层次聚类分为自下而上的凝聚聚类和自上而下的分裂聚类两种[15],其中凝聚层次聚类运用最为广泛,同时凝聚层次聚类在无预先定义类别数的分类中具有明显优势[16]㊂故本文采用的是凝聚层次聚类,可以用树状图和嵌套簇图来表示,例如图1所示㊂图1㊀凝聚层次聚类的树状图和嵌套簇图Fig.1㊀Dendrogram and Nested Cluster Diagramfor Agglomerative Hierarchical Clustering下面介绍凝聚层次聚类的聚类过程:步骤1:视每一个数据点(如基因变量)为一个集群;步骤2:计算邻近矩阵,把类间距离最接近的两个集群进行合并;步骤3:重复步骤2,直到所有数据点合并完成㊂步骤2中的类间距离即两个集群之间的距离,传统的层次聚类类间距离计算方法有如下几种[17]:1)两个集群中距离最近的两个样本距离;2)两个集群中距离最远的两个样本距离;3)两个集群中所有样本之间的距离再求平均值;完成所有聚类步骤后会生产一个树状图(又叫聚类树)㊂采用不同的变量相关性程度度量方式和不同的类间距离计算方法都将对聚类结果造成影响㊂1.3㊀CCA-HC 算法传统的层次聚类算法其计算复杂度为O (n 3),由于在聚类过程中需要不断地重复计算类间距离㊁不断地更新邻近矩阵,从而消耗大量的时间与资源[18]㊂对于数据量庞大的基因微阵列数据,迫切需要对算法进行优化,降低复杂度㊂本文提出了一种基于CCA 和层次聚类的基因聚类算法(CCA-HC),优化相似性矩阵计算方法,把典型相关分析的输出作为层次聚类的输入,即把典型相关分析得到的相似性矩阵作为层次聚类的邻近矩阵㊂CCA-HC 在度量基因相关性程度时采用典型相关分析的方法,在层次聚类方式上选择自下而上的凝聚层次聚类㊂CCA-HC 充分利用了典型相关分析和层次聚类的优点,能够结合基因的多个特征来量化基因之间的相关性,使得聚类结果中的基因集相似性程度更高,也能自主选择集群数目以得到更佳的聚类效果[18]㊂2㊀实验与结果分析2.1㊀实验数据为了评价章节一中提出算法的聚类效果,在GEO 数据库上下载Oryza sativa L.(水稻)的基因表达数据集,得到的原始数据集共有45063个基因,样本数为41㊂由于原始数据集基因数庞大,对其计算分析时不论在存储空间还是计算程序上都提出了较高的要求,为此进行适当的数据预处理显得尤为重要㊂本文在数据预处理方面开展的主要工作有:把基因名未知的数据剔除;过滤掉样本表达量过低的基因;采用log2的对数函数对原始数据进行标准化处理等㊂经过如上处理后得到4564ˑ41的数据矩阵,用于后续的实验分析㊂预处理后的实验数据集78第5期林倩闽:一种CCA -层次聚类的基因聚类算法统计情况如表1所示㊂表1㊀预处理后的实验数据集统计情况表Tab.1㊀Statistical table of experimental dataset after preprocessing数据集基因数样本数基因功能类别Oryza sativa L.456441881.5㊀评价标准基因表达数据的聚类效果可以从聚类结果中同一集群的相关性程度以及聚类算法的稳定性等方面进行评价,用生物功能性指标和内部稳定性指标来描述㊂1.生物功能性指标生物同源性指标(biological homogeneity index, BHI)是用来评估聚类集群在生物功能意义上的同源性程度[19]㊂在基因本体(gene ontology,GO)数据库上下载水稻的基因功能类数据,可以得知每个水稻基因所对应的生物组织功能,用来分析同一聚类集群中的基因在功能上的相关性㊂BHI公式计算如下:BHI(K,B)=1KðK k=11nk(n k-1)ðiʂjɪC k I(B(i)=B(j))(8)式中:C为聚类结果中的任一集群;B为基因功能类集合,当基因i和基因j所对应的功能类存在交集,则I(B(i)=B(j))=1,否则为0㊂最终得到的BHI 是介于0~1的值,BHI值越大,表示基因聚类集群的生物功能相关性越大,聚类效果更佳[19]㊂2.内部稳定性指标内部稳定性指标在于评价聚类算法的鲁棒性,通过改变基因微阵列数据的某几列进行聚类,进而比较基于不同数据的聚类结果㊂优值系数(figure of merit,FOM)是内部稳定性指标中的一种,表示数据列改变后基因之间的平均群内方差[20]㊂FOM公式计算如下:FOM(l,K)=1NðK k=1ðiɪC k(l)dist(x i,l, x C k(l))(9)式中:FOM的取值范围是0到无穷大,FOM值越小表示该聚类算法的稳定性越好[20]㊂2.3㊀结果与分析为验证CCA-Hc的聚类效果,对比采用欧式距离的传统层次聚类算法(EUC-Hc),运用相同数据集进行实验㊂为了获得更加准确的聚类效果,本实验设置不同的聚类集群参数,确定聚类集群数目K 分别为2㊁4㊁6㊁7㊁9㊁11㊁12这7组实验,并通过BHI 和FOM指标对这7组实验的聚类结果进行评估, BHI和FOM指标值分别见表2和表3㊂表2㊀不同聚类集群数目下的BHI指标值Tab.2㊀BHI index values under different number of clusters 算法类型\集群数目CCA-Hc EUC-Hc差异率K=20.4660.233100.05%K=40.4630.34633.77%K=60.4670.37723.90%K=70.4670.41213.34%K=90.4650.4357.12%K=110.4640.4512.72%K=120.4630.456 1.48%表3㊀不同聚类集群数目下的FOM指标值Tab.3㊀FOM index values under different number of clusters算法类型\集群数目CCA-Hc EUC-Hc差异率K=22.6974.633-41.78%K=42.6974.298-37.26%K=62.6964.047-33.37%K=72.6963.995-32.52%K=92.6963.816-29.35%K=112.6953.693-27.03%K=12 2.695 3.636-25.89%㊀㊀表2中的差异率指的是CCA-Hc的BHI指标比EUC-Hc的BHI指标相差的百分比,同理可以计算表3中的差异率㊂根据表2和表3的实验指标数据发现,对于7组不同的聚类集群数目实验,本文提出的CCA-Hc 的BHI指标均高于EUC-Hc,FOM指标均低于EUC-Hc,这表明CCA-Hc的鲁棒性更好,聚类结果中同一集群的基因相关性更大,聚类效果更加显著㊂同时还发现,集群数目对CCA-Hc的影响较小,K选不同的值,BHI指标值稳定在0.463~0.467之间,FOM88哈㊀尔㊀滨㊀理㊀工㊀大㊀学㊀学㊀报㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀第28卷㊀指标值稳定在2.695~2.697之间,而集群数目对EUC-Hc 算法的影响相对比较明显㊂图2为CCA-Hc 在Oryza sativa L.数据集的聚类树状图,可以自行在所需的层级对树状图进行 剪枝 操作以获得合适的聚类效果[21]㊂图2㊀CCA-Hc 在Oryza sativa L.数据集的聚类树状图Fjg.2㊀Clustering dendrogram of CCA-Hc in Oryzasativa L.dataset3㊀结㊀论本文为了充分有效地挖掘基因表达数据所蕴含的生物机制,提出一种基于CCA -层次聚类的基因聚类算法(CCA-Hc)㊂把典型相关分析方法引入到凝聚层次聚类中来进行多特征基因的聚类分析,成为本文的创新之处㊂该算法利用典型相关分析方法度量基因之间的相关性程度,能够充分考虑基因的多个特征信息㊂同时采用凝聚层次聚类可自主选择聚类集群数目,直观显示聚类结果㊂基于Oryza sativa L.(水稻)的基因表达数据集,本文对比了CCA-Hc 和EUC-Hc 的聚类效果,使用BHI 和FOM 两个评价指标进行衡量,结果表明CCA-Hc 的鲁棒性和聚类准确性均更好,更有利于去探索基因表达数据潜在的生物机制㊂参考文献:[1]㊀欧阳玉梅.基因表达数据聚类分析技术及其软件工具[J].生物信息学,2010,8(2):104.OUYANG Yumei.Gene Expression Data Cluster Analysis Technology and Software Tools [J ].Bioinformatics,2010,8(2):104.[2]㊀高华成.基于数据降维框架的基因聚类算法[D].南京:南京邮电大学,2021.[3]㊀姚登举,詹晓娟,张晓晶.一种加权K -均值基因聚类算法[J ].哈尔滨理工大学学报,2017,22(2):112.YAO Dengju,ZHAN Xiaojuan,ZHANG Xiaojing.A Weighted K-Means Gene Clustering Algorithm[J].Jour-nal of Harbin University of Science and Technology,2017,22(2):112.[4]㊀方匡南,陈远星,张庆昭,等.双向聚类方法综述[J].数理统计与管理,2020,39(1):22.FANG Kuangnan,CHEN Yuanxing,ZHANG Qingzhao,et al.Review of Bidirectional Clustering Methods [J].Journal of Applied Statistics and Management,2020,39(1):22.[5]㊀吴明阳,张芮,岳彩旭,等.应用K-means 聚类算法划分曲面及实验验证[J].哈尔滨理工大学学报,2017(1):54.WU Mingyang,ZHANG Rui,YUE Caixu,et al.Appli-cation of K-means Clustering Algorithm for Surface Divi-sion and Experimental Verification[J].Journal of HarbinUniversity of Science and Technology,2017(1):54.[6]㊀LACKO D,HUYSMANS T,VLEUGELS J,et al.ProductSizing with 3D Anthropometry and K-medoids Clustering[J].Computer-Aided Design,2017:S0010448517301173.[7]㊀ZHANG T,RAMAKRISHNAN R,LIVNY M.BIRCH:ANew Data Clustering Algorithm and Its Applications[J].Data Mining and Knowledge Discovery,1997,1(2):141.[8]㊀FUSHIMI T,MORI R.High-Speed Clustering of Region-al Photos Using Representative Photos of Different Re-gions[C].2018IEEE /WIC /ACM International Confer-ence on Web Intelligence (WI),IEEE,2018:520.[9]㊀Al-MAMORY S O,KAMIL I S.A New Density BasedSampling to Enhance DBSCAN Clustering Algorithm[J].Journal of Computer Science,2019,32(4):315.[10]ANKERST M,BREUNIG M M,KRIEGEL H P,et al.OPTICS:Ordering Points to Identify the Clustering Struc-ture[C]//SIGMOD 1999,Proceedings ACM SIGMOD International Conference on Management of Data,June 1-3,1999,Philadelphia,Pennsylvania,USA.ACM,1999:2008,99.[11]王飞,王国胤,李智星,等.一种基于网格的密度峰值聚类算法[J ].小型微型计算机系统,2017(5):1034.WANG Fei,WANG Guoyin,LI Zhixing,et al.A Grid-based Density Peak Clustering Algorithm[J].Journal of98第5期林倩闽:一种CCA -层次聚类的基因聚类算法Chinese Computer Systems,2017(5):1034. [12]YAO J,CHANG C,SALMI M L,et al.Genome-scaleClusteranalysis of Replicated Microarrays Using ShrinkageCorrelation Coefficient[J].BMC Bioinformatics,2008,9:288.[13]HONG S,CHEN X,JIN L,et al.Canonical CorrelationAnalysis for RNA-seq Co-expression Networks[J].Nu-cleic Acids Res,2013,41(8):e95.[14]万静,郑龙君,何云斌,等.高维数据的高密度子空间聚类算法[J].哈尔滨理工大学学报,2020,25(4):84.WAN Jing,ZHENG Longjun,HE Yunbin,et al.High-Density Subspace Clustering Algorithm for High-Dimen-sional Data[J].Journal of Harbin University of Scienceand Technology,2020,25(4):84.[15]刘昊.基于聚类算法的生物分析软件的设计与实现[D].上海:复旦大学,2013.[16]乔锦荣,原新鹏,梁旭东,等.凝聚层次聚类方法在降水预报评估中的应用[J].干旱气象,2022,40(4):690.QIAO Jinrong,YUAN Xinpeng,LIANG Xudong,et al.Application of Agglomerative Hierarchical ClusteringMethod in Precipitation Forecast Evaluation[J].AridMeteorology,2022,40(4):690.[17]JASKOWIAK P A,CAMPELLO R J,COSTA I G.Onthe Selection of Appropriate Distances for Gene Expres-sion Data Clustering[J].BMC Bioinformatics,2014,15(2):1.[18]季姜帅,裴颂文.面向异质基因数据的智能层次聚类算法研究[J].小型微型计算机系统,2021,43(9):1808.JI Jiangshuai,PEI Songwen.Research on Intelligent Hi-erarchical Clustering Algorithm for Heterogeneous GeneticData[J].Journal of Chinese Computer Systems,2021,43(9):1808.[19]DATTA S,DATTA S.Methods for Evaluating ClusteringAlgorithms for Gene Expression Data Using a ReferenceSet of Functional Classes[J].BMC Bioinformatics,2006,7(1):1.[20]DATTA parisons and Validation of Statistical Clus-tering Techniques for Microarray Gene Expression Data[J].Bioinformatics,2003,19(4):459. [21]HULOT A,CHIQUET J,JAFFRÉZIC F,et al.Fast TreeAggregation for Consensus Hierarchical Clustering[J].BMC Bioinformatics,2020,21(1):12.(编辑:温泽宇)09哈㊀尔㊀滨㊀理㊀工㊀大㊀学㊀学㊀报㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀第28卷㊀。

`题目 iris数据集的KDD实验学院名称信息科学与技术学院专业名称计算机科学与技术学生姓名何东升学生学号201413030119 指导教师实习地点成都理工大学实习成绩二〇一六年 9月iris数据集的KDD实验第1章、实验目的及内容1.1 实习目的知识发现(KDD:Knowledge Discovery in Database)是从数据集中识别出有效的、新颖的、潜在有用的,以及最终可理解的模式的非平凡过程。
知识发现将信息变为知识,从数据矿山中找到蕴藏的知识金块,将为知识创新和知识经济的发展作出贡献。
该术语于1989年出现,Fayyad定义为"KDD"是从数据集中识别出有效的、新颖的、潜在有用的,以及最终可理解的模式的非平凡过程”。
KDD的目的是利用所发现的模式解决实际问题,“可被人理解”的模式帮助人们理解模式中包含的信息,从而更好的评估和利用。
1.2 算法的核心思想作为一个KDD的工程而言,KDD通常包含一系列复杂的挖掘步骤.Fayyad,Piatetsky-Shapiro 和Smyth 在1996年合作发布的论文<From Data Mining to knowledge discovery>中总结出了KDD包含的5个最基本步骤(如图).1: selection: 在第一个步骤中我们往往要先知道什么样的数据可以应用于我们的KDD工程中.2: pre-processing: 当采集到数据后,下一步必须要做的事情是对数据进行预处理,尽量消除数据中存在的错误以及缺失信息.3: transformation: 转换数据为数据挖掘工具所需的格式.这一步可以使得结果更加理想化.4: data mining: 应用数据挖掘工具.5:interpretation/ evaluation: 了解以及评估数据挖掘结果.1.3实验软件:Weka3-9.数据集来源:/ml/datasets/Iris第2章、实验过程2.1数据准备1.从uci的数据集官网下载iris的数据源2.抽取数据,清洗数据,变换数据3.iris的数据集如图Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。

第9卷第4期2011年12月生物信息学China Journal of Bioinformatics Vol.9No.4Dec.,2011收稿日期:2010-01-06;修回日期:2010-05-30.基金项目:安徽高校省级自然科学研究重点项目资助(KJ2008A089).作者简介:詹少华,男,教授,博士,研究方向:生物信息学与分子育种,E -mail :zhansh@wxc.edu.cn.*通讯作者:林毅,教授,博士生导师,E -mail :linyiahau@126.com.doi :10.3969/j.issn.1672-5565.2011.04.08利用VBA 查找核酸数据库DNA 保守序列詹少华1,尹艺林1,蔡永萍2,樊洪泓2,林毅2*(1.皖西学院生物与制药工程学院,六安237012;2.安徽农业大学生命科学学院,合肥230036)摘要:采用VBA 编写了查找核酸数据库保守序列的四个相关程序,“导入DNA 序列”程序可以将Fasta 格式的DNA 序列文本文件存放到Excel Sheet1的A 列中,保留每个序列的Gi 号,删除多余的注释部分;“整理DNA 序列”程序可以将DNA 序列Gi 号存放到A 列中,B 列为对应Gi 号的完整序列;“DNA 随机序列”程序可以产生DNA 随机序列;“发现DNA 保守序列”程序可以将随机序列与下载的DNA 序列比对,查找每一种随机序列的出现频率。
以大豆基因组序列为实例,说明了这些程序的应用方法。
该程序弥补了流行序列比对软件的不足,为PCR 设计引物、分析基因功能以及种质资源鉴定等方面提供新的工具。
关键词:VBA ;序列比对;保守序列;核酸数据库;大豆中图分类号:Q518.2文献标识码:A文章编号:1672-5565(2011)-04-299-04Searching conservative sequences in nuclear acid database by VBA programsZHAN Shao-Hua 1,YIN Yi-lin 1,CAI Yong-Ping 2,FAN Hong-Hong 2,LIN Yi 2*(1.Biological and Pharmacological Engineering Department ,West Anhui University ,Lu ’an ,Anhui 237012,China ;2.Life Science School ,Anhui Agricultural University ,Hefei Anhui 230036,China )Abstract :The four VBA (visual basic for application )programs were written for searching conservative sequences in nuclear acid database.The programs included importing -DNA -sequence ,sorting -DNA -sequence ,DNA -random -sequence and finding -DNA -conservative -sequence.The DNA sequences saved as fasta format in text file could be imported into column A of Excel Sheet1by the program of importing -DNA -sequence ,at same time ,the Gi numbers were reserved and the redundant notes were deleted.Then ,the Gi numbers were sorted into column A and corresponding DNA integrate sequences were arranged into column B by the program of sorting -DNA -se-quence.DNA random sequences could be made by the program of DNA -random -sequence.The program of find-ing -DNA -conservative -sequence could help us searching conservative sequences in DNA databases by align-ment with the DNA random sequences.As an example of the programs application ,the conservative sequences of soybean genome survey sequences were searched.The programs were the supplementary tools of prevalent sequence alignment software ,could contribute to design PCR primers ,to analyze the genes function ,and to identify breeding resource.Key words :Visual Basic for Application (VBA );Sequence alignment ;Conservative sequence ;Nuclear acid data-base ;Soybean序列比对是分子生物学中重要的分析方法,可用于探测新序列与已知序列的同源性,分析物种之间的亲缘关系[1],可以在此基础上设计引物进行PCR 扩增、预测新序列高级结构、功能和基因电子克隆。

表达谱数据的 GO分析和聚类分析王琼萍上海交通大学GO(gene ontology)是基因本体联合会(Gene Ontology Consortium)所建立的数据库。
GO 是多种生物本体语言中的一种,旨在建立一个能阐释各种物种的基因以及基因产物。
这个数据库最开始起源于三个模式生物的数据库:果蝇基因组数据库(Drosophila)、酵母基因组数据库(Saccharomyces Genome Database,SGD)、小鼠基因组数据库(Mouse GenomeDatabase,MGD)。
在这之后,在基因本体联合会成员的努力下,将GO 数据库扩展到了植物、动物、微生物等世界范围内各个主要的数据库。
GO 数据库建立了具有三层结构的定义方式来描述基因及其产物的生物学过程、细胞组分及分子功能,对不同信息源的信息进行整合,以DAG(有向无环图)结构组织起来作为多个分支,节点的高低也代表了每个节点的意义的广泛程度。
每个父项(parent terms)下包含若干子项(children terms),分支越远,匹配的GO 条目就越具体。
在这个层级结构中,一个生物学注释可以由一个基因集表示。
这个数据库的建立为基因功能数据挖掘提供了新的思路。
一套基因本体,其实也就是一套基因的树状结构。
GO 数据库及其序列分析程序的问世,使得差异基因的功能分析变得更加高效、准确。
目前,已经有很多可以供畜牧研究者免费使用的GO资源,如AmiGo,它可以分析一个基因的GO 术语,也可以分析多个基因。
另外,还有Onto express、DAVID、Gostat 等。
差异基因的GO 分析关键在于利用统计学方法进行基因富集,常用的方法是Fisher 的精确概率法或卡方检验。
Fisher 的精确概率法利用超几何分布(hypergeometric distribution)的原理推断每个基因集中差异表达基因的比例是否与整个基因芯片上差异表达基因的比例相同。

国内外信息资源管理学科对COVID -19的研究总结与思考基于CiteSpace 和VOSviewer 知识图谱的可视化计量分析杨㊀勇,杨友清(无锡职业技术学院图书馆,214121)摘㊀要:文章运用文献计量法和科学知识图谱法,基于CNKI 和Web of Science 数据库,借助Citespace 和VOSviewer 软件对国内外信息资源管理学科关于新冠疫情研究文献进行聚类㊁共现等可视化分析,得出新冠疫情期间国内外信息资源管理学科研究热点主要聚焦在公共危机预警㊁应急舆情分析㊁信息综合治理㊁知识服务质量㊁信息系统便利度等方面㊂总结出未来信息资源管理助力公共文化事业发展将持续增强㊁应对重大危机处理能力将得到有效提升㊁以人为本的服务理念将不断深入等趋势㊂关键词:信息资源管理学;COVID -19;知识图谱;公共文化事业;危机管理;图书馆服务引用本文格式:杨勇,杨友清.国内外信息资源管理学科对COVID -19的研究总结与思考 基于CiteSpace 和VOSviewer 知识图谱的可视化计量分析[J].大学图书情报学刊,2023(6):119-131.Research Summary and Reflection on COVID -19in Information Resource Management Disciplines at Home and Abroad :Visual Measurement Analysis Based on CiteSpace and VOSviewer Knowledge MapYANG Yong,YANG You-qing(Library of Wuxi Vocational and Technical College,Wuxi㊀214121,China)Abstract :This article uses the bibliometric method and scientific knowledge map method,based on CNKI and Webof Science databases,with the help of Citespace and VOSviewer software,to carry out clustering,co-occurrence and othervisual analysis of research literature on COVID-19pandemic in the field of information resource management at home and abroad.It is concluded that during the COVID-19period,the research hotspots of information resource managementat home and abroad mainly focus on public crisis early warning,emergency public opinion analysis,comprehensive information management,knowledge service quality,and information system convenience,and that in the future,information resources management will continue to enhance the development of public cultural undertakings,the ability todeal with major crises will be effectively improved,and the people-oriented service concept will continue to deepen.Key words :information resource management;COVID-19;knowledge graph;public cultural undertaking;crisismanagement;library service0㊀引言新型冠状病毒感染疫情( COVID -19 )爆发以来对各行各业正常运行造成重大影响,在这一背景下,信息资源管理学科基于自身对 信息管理 (包括信息提取方法㊁信息传递规律㊁信息组织理论㊁信息共享方案等问题)具有的天然优势,在各个层面展开了研究㊂本研究从国际国内视野出发,以CiteSpace 和VOSviewer 为分析工具,以中国期刊全文数据库(CNKI)和Web of Science(WOS)为数据来源平台,收集了2020年以来信息资源管理学科关于COVID -19的研究成果,进行文献定量分析和可视化处理,对信息资源管理学科关于COVID -19的研究脉络与研究热基金项目:2022年江苏省高校哲学一般项目 信息生态视域下高校图书馆健康信息服务困境及应对策略研究 (2022SJYB1046)9112023年11月第41卷第6期㊀㊀㊀㊀㊀㊀㊀㊀大学图书情报学刊Journal of Academic Library and Information Science㊀㊀㊀㊀㊀㊀㊀㊀Nov ,2023Vol.41No.6点问题进行深入剖析,以总结本领域对新冠疫情的研究状况,为信息资源管理学科应对重大突发公共卫生事件提供治理思路㊂1㊀数据来源与研究方法1.1㊀数据来源(1)CNKI 检索CNKI 包括了丰富的中文文献资源,收录了中文各个学科领域中最具权威性和影响力的学术论文,能比较全面地反映 COVID -19 国内研究现状㊂截至2022年9月30日,笔者以 COVID -19 新型冠状病毒肺炎 2019冠状病毒病 新冠肺炎 重大公共卫生事件 疫情 为题名和关键词在中国期刊全文数据库进行精准匹配,论文发表时间限定为2020年至今,学科限定于信息资源管理学科(包括 图书情报与数字图书馆 档案学㊁档案事业 两大学科),期刊来源不限㊂首次检索出541篇文献,手动剔除导读㊁资讯和评论等非学术研究文献,最终获得与本文主题相关的国内样本文献301篇㊂(2)WOS 检索WOS 在线数据库几乎包含全世界所有重要的研究论文,是全球获取学术信息的重要平台,检索结果具有一定的权威性和代表性,检索时间为2022年9月30日,基本检索条件为选择数据库为=(Web ofScience Core Collection ),TS 为=( COVID -19 or Corona Virus Disease 2019 or COVID -19Outbreak or novel coronavirus ),检索的语种=(英语),日期范围限定为=(2020年1月至2022年9月),文献类型为=(Article OR Review Article OR Proceeding Paper),SU 为=(Information Science Library Science),剔除与研究主题明显不符的文献,最终获得国外样本文献455篇㊂将检索结果记录存为download_txt 格式,设定为 全记录并且包含所引用的参考文献 进行输出㊂1.2㊀研究方法研究方法采用科学计量学方法和科学知识图谱法,借助基于JAVA 平台的VOSviewer 软件进行国家/地区㊁机构㊁关键词共现和聚类分析,利用Citespace 可视化分析工具软件进行国家/地区㊁机构㊁关键词排名和关键词突现分析㊂VOSviewer 通过主题聚类功能反映研究领域中的热点主题㊁新主题㊂CiteSpace 可视化软件利用中介中心性发现和衡量文献中节点的重要性㊂2㊀国内外信息资源管理学科对COVID -19研究的文献特征分析2.1㊀发文量和年份分析笔者通过对收集到的文献进行统计,国外信息资源管理学科总计发文455篇,国内301篇,为呈现发文趋势的明显变化,笔者以季度为时间段,绘制图1㊂可见,从2020年1月30日世界卫生组织将新冠疫情定义为构成 国际关注的突发公共卫生事件 (Public Health Emergency of International Concern,PHEIC )之后,国内外信息资源管理学科关于COVID -19的研究开始呈喷发态势㊂2020-3 2020-6 2020-9 2020-12 2021-3 2021-6 2021-9 2021-12 2022-3 2022-6 2022-99080706050403020100图1㊀国内外COVID -19研究发文量21杨㊀勇,杨友清.国内外信息资源管理学科对COVID -19的研究总结与思考 基于CiteSpace 和VOSviewer 知识图谱的可视化计量分析2.2㊀科研合作网络分析2.2.1㊀国外科研合作网络分析图2为VOSviewer软件绘制的信息资源管理学科对 新冠疫情 研究国家/地区科研合作网络,可见位于中心位置㊁节点较大的为中国㊁美国㊁英国和西班牙,此外,美国与其他国家合作关系紧密且广泛㊂表1为应用CiteSpace软件分析的国家/地区的发文数量及中心性排名情况㊂发文量排名前5位的国家/地区为美国(128篇)㊁中国(包括台湾省,87篇)㊁西班牙(48篇)㊁英国(41篇)㊁澳大利亚(27篇);中心性排名前5位的国家/地区为马来西亚(0.43)㊁中国(0.33)㊁美国(0.33)㊁英国(0.31)㊁澳大利亚(0.27)㊂图2㊀国外发文国家/地区合作网络表1㊀发文量、中心性前10位的国家/地区排名按发文量排名按中心性排名国家/地区发文量(篇)国家/地区中心性1USA128MALAYSIA0.43 2PEOPLES R CHINA74PEOPLES R CHINA0.33 3SPAIN48USA0.33 4ENGLAND41ENGLAND0.31 5AUSTRALIA27AUSTRALIA0.27 6INDIA23FRANCE0.19 7MALAYSIA16U ARAB EMIRATES0.18 8PAKISTAN15SPAIN0.13 9ITALY15NIGERIA0.12 10SOUTH KOREA13RUSSIA0.11㊀㊀对国外发文机构的分析结果(表2)显示,发文量排名前5的机构为:旁遮普大学㊁武汉大学㊁巴塞罗那大学㊁马德里康普顿斯大学㊁格拉纳达大学,前10位中有3所机构来自中国(另外2所为香港大学㊁华中科技大学)㊂根据中心性进行排名,前面分别为巴塞罗那大学㊁马德里康普顿斯大学㊁ESIC商学院㊁旁遮普大学和武汉大学㊂图3为应用VOSviewer软件绘制的国外 新冠疫情 研究机构科研合作密度可视化图,形成武汉大学㊁巴塞罗那大学等为中心的4个高密度科研合作区,可以看出中国在该领域具有一定的科研地位和国际竞争力㊂表2㊀国外发文量和中心性前10位的机构排名按发文量排名按中心性排名发文机构发文量(篇)国家/地区中心性1Univ Punjab6Univ Barcelona0.01 2Wuhan Univ6Univ Complutense Madrid0.01 3Univ Barcelona5ESIC Business&Mkt Sch0.01 4Univ Complutense Madrid5Univ Punjab0 5Univ Granada5Wuhan Univ0 6Univ Carlos III Madrid5Univ Granada0 7Univ Sydney4Univ Carlos III Madrid0 8Univ Tennessee4Univ Sydney0 9Univ Hong Kong4Univ Tennessee010Huazhong Univ Sci&Technol4Univ Hong Kong0121总第200期大学图书情报学刊2023年第6期图3㊀国外研究机构科研合作密度可视化图2.2.2㊀国内科研合作网络分析利用CiteSpace 软件对国内发文机构及发文作者进行分析,结果见表3㊂表3㊀国内发文机构及发文作者结果统计排名国家/地区发文量(篇)1南京大学信息管理学院142武汉大学信息管理学院83中国人民大学信息资源管理学院64中国科学院文献情报中心55中国科学院大学经济与管理学院图书情报与档案管理系56郑州大学信息管理学院47安徽大学管理学院48四川大学公共管理学院39中国科学院科技战略咨询研究院310中国医学科学院医学信息研究所33㊀国内外信息资源管理学科对对COVID -19研究脉络分析3.1㊀研究主题分析3.1.1㊀国外研究主题分析关键词是对文献主题和研究方向的自然表达,也是文献核心内容浓缩和提炼后的表述方式㊂通过对关键词的统计分析,一定程度上能够揭示国外信息资源管理学科对COVID -19的研究热点㊂笔者使用VOSviewer 软件对关键词进行分析,为追求结果的真实性,首先对相同意义的关键词进行合并,随后对频率ȡ2的关键词进行共现分析,结果见图4㊂表4反映了当前国外学者在 social media academic libraryfake news information technology academic library等有关国外COVID -19的主题上给予重点关注㊂在梳理国外信息资源管理学科对COVID -19研究文献内容的基础上,结合表4㊁图4所示关键词,得知当前国外信息资源管理学界关于COVID -19的研究主题可以归为两大类,即图书馆对COVID -19的干预研究㊁信息疫情相关研究㊂这两类研究主题分别具有代表性关键词,如表5所示㊂表4㊀国外发文量排名前10的关键词与中介中心性排名前10的关键词排名按发文量排名按中心性排名关键词发文量关键词中介中心性1social media62behavior 0.192impact 34organization 0.193model 28challenge 0.174academic library27adoption 0.165information 23model 0.156fake news23determinant 0.157communication 20information technology0.148management 19anxiety 0.149health 18communication 0.1310science18strategy0.12221杨㊀勇,杨友清.国内外信息资源管理学科对COVID -19的研究总结与思考 基于CiteSpace 和VOSviewer 知识图谱的可视化计量分析图4㊀国外研究关键词共现和聚类图表5㊀国外研究主题及其代表性关键词研究主题代表性关键词图书馆对COVID-19的干预研究information㊁identification㊁model㊁academic library㊁public library㊁communication technology㊁content analysis㊁sentiment analysis㊁covid-19vaccine㊁public opinion㊁twitter㊁epidemic信息疫情相关研究facebook㊁media㊁memory㊁fake news㊁twitter㊁social media㊁information㊁adoption㊁access㊁web㊁life㊁gratification㊁experience㊁literacy㊁dissemination㊁memory㊁ebola㊁conspiracy theory㊁information dissemination㊁information professional㊁rumor㊁health crisis㊁health information㊁risk communication㊁crisis communication㊀㊀(1)图书馆对COVID-19的干预研究图书馆对COVID-19的干预研究主要有五个维度:第一,提供高质量的健康信息资源㊂虽然健康问题并不是图书馆的核心使命,但公共卫生和公共图书馆的目标是互补的,两者都积极寻求影响民众健康的卫生信息资源,如相关疾病的预防和治疗信息[1]㊂鉴于此,图书馆可以免费提供可靠㊁高质量的健康信息,帮助用户了解自身健康问题[2]㊂第二,成为医疗卫生部门的重要合作者㊂2008年以来,美国国家医学图书馆(NLM)专门信息服务分部成立了灾害信息管理研究中心(DIMRC),支持专业图书馆员参与医疗部门的灾害救治工作㊂北德克萨斯大学(University of North Texas)图书馆和信息科学系开始为医疗部门信息专业人员提供关于灾害信息管理的课程[3]㊂第三,辨别虚假/错误信息㊂图书馆通过网站及时向外界公布虚假/错误信息,如英国特许图书馆和信息专业人员协会将有关COVID-19的所有错误信息公布在Newsguard网站上,并且提供COVID-19错误信息的跟踪服务,使图书馆在打击虚假信息方面发挥关键作用[4]㊂第四,在线图书馆服务㊂COVID-19期间图书馆纷纷关闭,以技术为中心的在线数字图书服务得到广泛关注[5]㊂在线数字服务包括举办教育研讨会㊁提供电子书㊁提供有声读物㊁提供数据库访问㊁组织虚拟展览㊁举办虚拟活动(作者读书分享会)㊁在线文献传递以及收集可靠的研究和学习参考资源[6-8]㊂塞尔维亚公共图书馆数据显示,COVID-19期间在线数字资料使用率增加了约130%,医学㊁法律㊁经济学等学科书籍最受关注[9]㊂第五,疫情期间新型学术图书馆员服务研究㊂传统学术图书馆员主要是线下利用自身专业技能为用户提供信息以支持其学习和研究[10]㊂COVID-19迫使学术图书馆员将服务重点从线下转移到仅在线上环境中提供信息资源[11]㊂虽然有学者认为提供在线信息资源服务已经不是新鲜事[12],但广泛提供在线服务是在COVID-19出现之后㊂美国大学与研究图书馆协会发布的‘远程学习图书馆服务标准“确定了几则COVID-19期间学术图书馆员新服务:其一,除了提供各种订阅数据库,还得掌握如何为读者提供图像㊁音频㊁视频和视听等资源;其二,学术图书馆员必须掌握如何运用电话㊁电子邮件㊁传真和其他信息通信技术工具与用户保持沟通;其三,学术图书馆员必须树立终生学习的目标,以应对疫情常态化带来的各种冲击㊂(2)信息疫情相关研究321总第200期大学图书情报学刊2023年第6期信息疫情(infodemic)相关研究焦点主要集中在以下几个方面:第一, 信息疫情 概念研究㊂2002年GuntherEysenbach 教授提出 信息流行病学 (infodemiology),该学科主要研究健康信息和错误信息的决定因素和分布情况,帮助医疗卫生人员和患者通过网络获得高质量的健康信息[13]㊂ 胎生 于 infodemiology 的infodemic 概念在学界尚未达成一致,关于 infodemic 本质特征的描述学者们基本保持一致,比如 infodemic 是与COVID -19相关的错误信息或虚假信息[14-15], infodemic 是COVID -19期间所产生的多余信息[16]㊂第二, 信息疫情 传播问题研究㊂其一,关于传播范围,不准确的信息可能比基于事实的信息传播得更远㊁更快㊁更深㊁更广泛[17]㊂其二,关于传播主体,一般主流平台的用户主体不太容易受到来自可疑来源信息传播的影响,比如quora(国外知乎)平台上的用户辨识虚假信息的能力比Facebook 上用户会强一些,甚至Facebook 是分享COVID -19虚假信息最常用的社交媒体[18]㊂其三,关于传播信息的选择,前1%的虚假新闻都与政治有关,其次是城市传说㊁商业㊁恐怖主义㊁科学㊁娱乐和自然灾害,表明虚假政治新闻比其他任何类别的虚假信息传播速度更快,传播范围更广,危害程度更大㊂其四,关于传播信息的缘由,学者认为虚假谣言信息比真实信息 更新颖 更有趣 更吸引人 ,从而激发人们转载分享虚假信息的欲望[19]㊂第三,应对 信息疫情 的策略研究㊂其一,有关法律法规㊂巴西参议院于2020年6月30日批准了第2630号法案‘巴西互联网自由㊁责任和透明度法“(BrazilianLawonFreedom ,ResponsibilityandTransparency on the Internet ),打击在互联网上传播有关COVID -19的虚假信息[20]㊂南非根据‘计算机滥用和网络犯罪法“(Computer Misuse and Cybercrimes Act ),规定 任何被判故意发布虚假信息的人都将被处以罚款或最高2年的监禁[21]㊂其二,关于具体措施,尼日利亚为了管理有关COVID -19虚假信息的传播,政府当局联合Facebook 实施事实核查试点项目,比如为尼日利亚疾病控制中心筛选信息㊂此外,畅通卫生医疗机构和公众的实时对话[22]㊁定期召开新闻发布会[23]㊁创建虚假错误信息预警系统[24]都成为有效预防infodemic 的措施㊂其三,关于用户信息素养提升,通过数据素养提升社会公众对数据的批判性理解,主要包括关注数据安全㊁保护数据隐私㊁讨论数据偏差㊁储存管理数据等[25];通过媒体和信息素养提升社会大众识别㊁理解和批判网络信息资源的能力[26]㊂3.1.2㊀国内 新冠疫情 研究主题分析笔者利用VOSviewer 软件对关键词进行共现分析,结果见图5㊂表6反映了当前国内学者在 应急服务 疫情防控 应急管理 信息服务 线上服务 阅读推广 等有关COVID -19的主题上给予重点关注㊂图5 国内研究关键词共现和聚类图421杨㊀勇,杨友清.国内外信息资源管理学科对COVID -19的研究总结与思考 基于CiteSpace 和VOSviewer 知识图谱的可视化计量分析表6㊀国内发文量与中介中心性排名前10的关键词排名按发文量排名按中心性排名关键词发文量关键词中介中心性1应急服务25图书馆0.38 2疫情防控23疫情防控0.32 3图书馆23线上服务0.32 4新冠疫情18阅读推广0.22 5应急管理7应急服务0.15 6突发事件7信息行为0.14 7信息服务7突发事件0.09 8线上服务6应急管理0.06 9开放获取5大数据0.06 10预印本4危机管理0.04㊀㊀通过梳理国内信息资源管理学科关于新冠疫情的研究文献内容,结合图5㊁表5所示,可以将当前国内信息资源管理学界有关 新冠疫情 的一级研究主题归为两大类,即突发公共卫生事件的反应机制研究和COVID-19期间信息资源管理学科的疫情防控研究,具体如图6所示㊂(1)突发公共卫生事件反应机制研究第一,突发公共卫生事件预警研究㊂其一,预警机制理论研究㊂增强社会风险意识㊁完善风险适时预警机制以及加强疾控知识管理等[27],同时应做到事前信息监测和预警㊁事中信息共享和决策㊁事后信息溯源和应用以及全过程信息管理[28]㊂其二,预警实践操作研究㊂构建不同预警防控措施条件下疫情发展时间模型,再依据相关模型计算选择较为理想的预警防控介入时间点及措施[29],或者采用 互联网+国家治理ң提升危机监测和预警能力ң破解突发性公共卫生事件 实践操作理论范式,以数据和科技的力量全方[30]图6㊀国内关于 新冠疫情 研究主题及其代表性关键词㊀㊀第二,突发公共卫生事件网络舆情研究㊂COVID-19发生以来,社交媒体上曾出现数次重大网络舆情事件,比如西安孕妇流产事件㊁兰州三岁小孩事件㊁郑州富士康疫情事件等,一度占据新浪热搜榜首位数小时,引起社会广泛关注,而这一过程是由公众需要了解事件真相的情绪所驱动的,对政府公信力造成严峻考验㊂信息资源管理学界2020年以来就对与COVID -19相关网络舆情给予重点关注,以期在复杂而多元化的信息中辨明真伪㊁把握方向㊁占领阵地,提升政府公信力[31]㊂其一,关于网络舆情演化研究㊂除了将重大疫情网络舆情演化分为四个阶段,即 突发㊁爆发㊁降温㊁失焦 [32],还可以划分为潜伏期㊁爆发期㊁衰退期三个阶段[33]㊂其二,疫情期间舆情风险评估研究㊂在网络舆情影响因素和发展演化规律的基础上,网络舆情风险评估指标体系可以从舆情发布者影响力㊁舆情热度㊁舆情强度㊁舆情扩散度四个维度进行评估[34];或者可以借助我国自然灾害预警等级的划分标准,舆情风险等级可以划分为一级(非常严重)㊁二级(比较严重)㊁三级(一般严重)㊁四级(轻微严重)[35]㊂其三,疫情期间舆情治理研究㊂相关部门应实时监控舆情演化动态,根据不同阶段舆情的主题和网民情感倾向制定治理策略,同时应加强官方媒体的效能发挥,注重权威媒体的强引导作用[36]㊂第三,突发公共卫生事件背景下信息管理问题研究㊂其一,公众信息需求研究㊂突发公共卫生事件导致的大范围实施管控措施,极大地刺激了公众的信息需求,因此建议信息部门应当借助社交媒体,以公众信息需求为导向[37],及时满足公众不同阶段的信息需521总第200期大学图书情报学刊2023年第6期求[38]㊂其二,信息协同研究㊂通过与信息㊁技术㊁环境交互构建突发公共卫生事件信息协同发布平台[39],提高信息传递效率,提升信息价值,获得协同效应[40]㊂其三,信息开放获取研究㊂政府需要在疫情信息公开工作中做出更多努力[41],在做好信息安全保护的前提下开展信息开放工作[42],这对推进我国突发公共卫生管理体系和能力现代化建设具有重要价值[43]㊂(2)COVID-19期间信息资源管理学科的疫情防控第一,应对COVID-19的图书馆智慧㊂其一,常规服务不间断[44]㊂持续提供全天候24小时网络信息资源在线服务,信息服务方式采用融合线上线下新模式㊂太原市图书馆开展多项以数字资源为核心的创新服务,比如网上读书会㊁线上观展㊁云讲坛以及网上借阅等;呼和浩特市图书馆开启 鸿雁快借 服务㊂其二,开展健康信息素养教育服务[45]㊂公民对健康信息的需求成为疫情防控常态化后新的增长点㊂比如贵州省图书馆编制‘健康知识手册“,四川省图书馆推出‘新型冠状病毒感染防护“指南㊁南方医科大学图书馆医学情报学教研室开展‘医学信息获取与管理“授课㊂其三,提供新冠肺炎专题文献追踪服务[46]㊂吉林省图书馆汇总并链接了9个新型冠状病毒感染专利数据库;湖南省图书馆全面收集和整理防疫抗疫过程中的社会动态㊁专家观点㊁国内外先进经验和经典案例,向党政机关提供决策咨询;军事科学院通过跟踪国内㊁国际最新科研进展推出新冠感染信息专题平台,及时提供专业㊁权威的国内外疫情研究进展和学术资料;武汉大学图书馆盘点和追踪全球发表的新冠感染抗疫文献成果,供相关研究参考㊂其四,图书馆社会记忆功能再加强[47]㊂比如福建省图书馆向社会征集抗 疫 文献资料;重庆图书馆征集抗疫文献资料,留存特殊 记疫 ;广州中医药大学揭牌全国首家抗疫文献馆,存留社会记 疫 ,增强战 疫 信心㊂第二,应对COVID-19的情报学智慧㊂其一,通过文献可视化剖析中国新冠疫情学术研究趋向㊂比如在新冠感染疫情期间,国内文献主题主要集中在疫情防控㊁经济舆情和医疗卫生3个方面[48],IncoPat及Innography数据库收录了新冠感染相关专利文献,得出中国新冠感染专利市场活跃[49]㊂其二,通过情报分析模型构建,助力疫情防控㊂一方面从信息特征和来源的角度分析用户信息偏好,从而优化社会化问答社区中健康信息的整体质量,保证用户获取的信息是可信㊁系统的[50]㊂另外,利用结构方程模型探索全球健康危机下公众的信息搜寻㊁加工行为与情感㊁认知的影响机制,为政府应急管理和个体自我调节提供决策依据[51]㊂第三,应对COVID-19的档案学智慧㊂其一, COVID-19期间疫情档案归档与管理研究㊂归档方法上,要从归档目标㊁归档主体㊁归档范围和归档方法四个层面入手[52];归档程序上,档案部门应重视协调沟通㊁加强统筹领导等[53];归档技术选择上,要扩大对大数据㊁区块链㊁云计算等技术的使用范围[54];在归档内容上,应扩大疫情档案收集的范围和类型[55]㊂其二,重大公共危机治理中档案工作参与机制研究㊂要建立健全基于公共危机治理时间序列的 事前-事中-事后 档案工作参与机制[56];构建横跨国家机关㊁医疗机构㊁科研院所㊁媒体组织的疫情档案工作四维响应体系[57];建成全国联动的专题数字档案馆,完善突发公共卫生事件记忆库[58]㊂其三,重大公共危机治理中档案学理论创新研究,具体理论有档案记忆观㊁ 档案与身份认同 档案多元论 社群档案 档案情感价值 等[59]㊂3.2㊀研究热点及演化分析3.2.1㊀国外研究热点及演化分析笔者使用VOSviewer软件生成关键词聚类密度视图,如图7所示,节点区域内的数量越多,权重越大,颜色呈现越趋向于红色;权重越小,颜色呈现越趋向于蓝色[60]㊂综合分析可见,科学计量(scientometrics)是国外信息资源管理学科参与COVID-19相关主题研究的主要研究方法;创新抗疫理念方法以实现人类社会可持续发展是研究关注的热点价值理念;数字媒体㊁流行病㊁人工智能㊁公众意见㊁公众健康㊁信息素养等是研究的热点问题㊂通过Citespace软件对关键词进行timezone(时区)布局可视化(见图8),可以发现国外信息资源管理学科有关COVID-19的研究热点问题㊂由图8可以看出,国外信息资源管理学科关于COVID-19研究热点呈现出显著的变化趋势,COVID-19初期(2020 2021年),学者们主要关注信息资源管理学科如何参与COVID-19治理,比如研究健康信息㊁社交媒体㊁虚假信息㊁信息行为等;2021 2022年,学者重点研究了COVID-19期间信息治理(主要内容包括信息疫情㊁信息传播㊁信息超载等)的机制和模式;2022年至今,学者们的研究突破了对COVID-19本身问题的研究,开始关注疫情期间如何保障公众的信息权利,实现个人价值,比如通过信息素养教育㊁充分尊重公众的意见与选择㊁对图书馆疫情期间服务质量进行评估等方式,保障公众均等获取信息的权利与自由㊂621杨㊀勇,杨友清.国内外信息资源管理学科对COVID-19的研究总结与思考 基于CiteSpace和VOSviewer知识图谱的可视化计量分析。
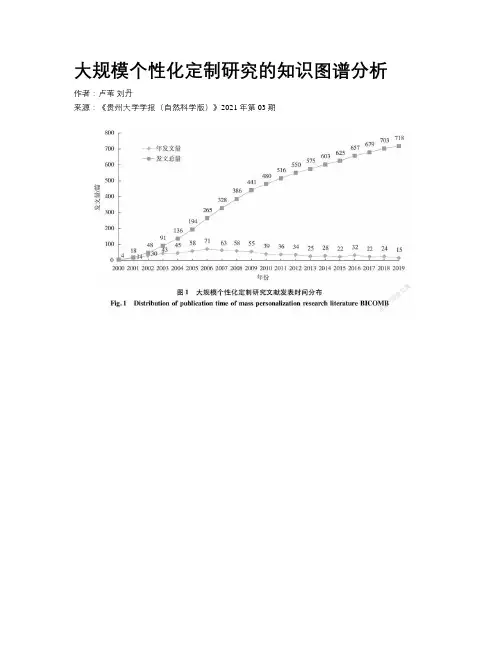
大规模个性化定制研究的知识图谱分析作者:卢苇刘丹来源:《贵州大学学报(自然科学版)》2021年第03期摘要:利用文献计量工具CiteSpace和书目共现分析系统(bibliographic items co-occurrence matrix builder,BICOMB)对2000—2020年CNKI数据库中收录的大规模个性化定制研究的相关文献进行可视化分析,绘制其关键词共现、知识聚类、時区图等图谱,归纳大规模个性化定制研究的关键技术和演变历程。
研究发现:大规模个性化定制领域已有一定的理论成果,并在服装、家电等行业进行了实践验证,但研究主要集中在配置设计和模块化上,前沿分支较少;其关键技术有客户需求获取、配置设计、产品平台以及模块化;明确其演化路径是以大规模定制为载体发展为智能制造下的特色分支,依托智能制造技术加深定制程度,实现真正意义上的大规模个性化定制。
关键词:大规模个性化定制;知识图谱;客户需求;智能制造中图分类号:TP305文献标志码:A随着经济的发展和消费水平的提升,多样化产品仍不能满足新一代消费者个性化需求,彰显个性的定制产品的需求越来越迫切,为应对这一需求,大规模个性化定制应运而生,其特点是以接近大规模生产的效率和成本满足客户的个性化需求。
1987年,大规模个性化定制的概念被提出[1],其核心是增加产品多样性和定制化,而不增加其成本,同时满足人们个性化需求的大规模生产[2]。
接着更多的研究集中在模块化、产品配置等方面,用以加快产品的成型[3]。
现今,大规模个性化定制与物联网、智能制造等技术相结合[4],以整体优化的思想,指导产生一批客户需求驱动型企业,给客户提供优质、高效、低成本的个性化产品。
大规模个性化定制在理论研究上取得一定的成果,但缺少对相关理论的梳理,对了解该领域的发展和研究概貌有一定的限制。
因此,利用知识图谱理清大规模个性化定制研究的阶段性成果,通过关键词共现、知识聚类和时区图等来了解该领域的现状、关键技术以及演变历程,以指导企业更好地应用这种新的生产模式,也为学者理解大规模个性化定制内涵和进行更加深入的研究提供参考。

DOI :10.15913/ki.kjycx.2024.02.012数智驱动下基于CiteSpace的智慧图书馆研究的知识图谱分析*蒋丽艳(东北师范大学图书馆,吉林 长春 130024)摘 要:以大数据、人工智能、数智驱动技术为核心的信息技术正助力着现代图书馆由传统模式向智慧方向转变。
通过运用先进CiteSpace 技术可视化的方法,对CNKI (中国知网)数据库中主题词是“智慧图书馆”、发文时间在2012-12-01—2022-12-01期间的论文进行统计和可视化分析。
通过对智慧图书馆各类型机构论文产出分布、高产机构论文产出分布及论文发表期刊分布图谱进行详细研究,以期为智慧图书馆的模式构建及实践路径提供强有力的借鉴。
关键词:CiteSpace ;智慧图书馆;知识图谱;可视化分析中图分类号:G250.7 文献标志码:A 文章编号:2095-6835(2024)02-0045-04——————————————————————————*[基金项目]吉林省教育科学“十四五”规划2023年度一般课题“创新驱动发展战略下吉林省校地文化深度融合协同育人机制研究”(编号:GH23790)信息技术的蓬勃发展,为智慧图书馆构建注入全新动力。
在大数据、数智驱动技术、人工智能快速发展的环境下,网络信息资源非常丰富,开放共享已经成为最主要的趋势。
先进的创新智慧技术已经成为智慧图书馆最主要的技术支撑,用数智驱动、云计算、物联网等特定的先进技术和全新的管理理念作为主要辅助,产生不受时空束缚且可被感知的新一代图书馆模式。
图书馆崭新的管理模式和服务能力因为智慧图书馆的出现而发生重要改变。
复合图书馆和数字图书馆全新发展理念与实践的延续、整合与升华的终极产物就是智慧图书馆,是目前图书馆的全新发展模式。
率先在欧美建立名为“Smart Library ”图书馆联盟的是加拿大渥太华,建立时间在2001年前后,是国外关于智慧图书馆的最早实践。


㊀收稿日期:2022-09-07基金项目:中央高校基本科研业务费专项资金资助项目(19JNQM25)ꎻ广州市哲学社会科学发展 十四五 规划课题(2021GZYB18)ꎻ深圳市哲学社会科学规划课题(SZ2022B014)作者简介:景秀丽(1979-)ꎬ女ꎬ辽宁营口人ꎬ博士ꎬ硕士生导师ꎬ副教授ꎬ研究方向:大数据ꎬ文本处理ꎬ电子商务等.㊀㊀辽宁大学学报㊀㊀㊀自然科学版第50卷㊀第2期㊀2023年JOURNALOFLIAONINGUNIVERSITYNaturalSciencesEditionVol.50㊀No.2㊀2023基于XGBoost算法的电商用户重复购买行为预测景秀丽1ꎬ史明曦2(1.暨南大学深圳旅游学院ꎬ广东深圳518052ꎻ2.圣路易斯华盛顿大学奥林商学院ꎬ美国密苏里州圣路易斯63130)摘㊀要:机器学习算法广泛应用于电商用户行为数据分析及商业预测.其中ꎬXGBoost算法作为一种常用的有监督机器学习算法ꎬ能够实现电商用户行为特征最优选择与行为模型构建㊁评估消费价值㊁预测重复购买行为概率㊁提高商业决策的精准性与可行性.本研究采用阿里云天池大数据竞赛 天猫复购预测 所提供的 双十一 电商购物节关联数据集中约42万电商平台用户产生的5500万条行为数据ꎬ基于促销活动情境完成特征构造ꎬ实现有监督分类学习.本研究实现了XGBoost算法的参数优化与数据特征值处理过程优化ꎬ完成了促销活动后6个月内电商用户重复购买行为的预测模型演算.结果表明:优化后的XGBoost算法能够比较精准地预测电商用户重复购买行为㊁评估在线用户潜在购买价值㊁实现精准营销以及真正促进促销活动的长期投资回报率提高.关键词:XGBoost算法ꎻ集成学习ꎻ特征工程ꎻ重购预测ꎻ精准营销中图分类号:TP391㊀㊀㊀文献标志码:A㊀㊀㊀文章编号:1000-5846(2023)02-0134-12RepurchasePredictionofE ̄CommerceUserBasedonXGBoostJINGXiu ̄li1ꎬSHIMing ̄xi2(1.ShenzhenTourismCollegeꎬJinanUniversityꎬShenzhen518053ꎬChinaꎻ2.OlinBusinessSchoolꎬWashingtonUniversityinSt.LouisꎬSt.Louis63130ꎬU.S.A)Abstract:㊀MachinelearningiswidelyusedinE ̄commerceuserbehavioranalysisandE ̄commerceplatformbusinessforecasts.XGBoostisacommonlyusedsupervisedensemblelearningalgorithm.Itcanbeusedtoconstructpreciseusersᶄbehaviormodelsꎬthusevaluatingcustomervalueꎬandpredictingtheirrepurchaseprobabilityꎬaswellasimprovingbusinessdecisionsᶄprecisionandfeasibility.Thisresearchadoptstheuserrepurchasedatasetrelatedtothe DoubleEleven shoppingeventofferedbyAlibabaTianchiꎬwhichcollectsupto55millionbehavioraldatageneratedby420thousandusersꎬconstructsfeaturesbasedonthepromotionbackgroundandconductssupervisedlearning.ThisresearchoptimizestheXGBoostparametertuningandfeature㊀㊀processingꎬandconstructsarepurchaseforecastmodelforspecificuser ̄sellerpairsonasix ̄monthperiodafterthepromotion.TheresultindicatesthattheoptimizedalgorithmXGBoostcanpreciselypredictE ̄commerceuserrepurchasebehaviorandbeusedinevaluatingusersᶄpotentialinrepurchaseꎬimprovingE ̄commerceplatformsᶄprecisionmarketingandtrulyimprovingthelong ̄termROI(ReturnonInvestment)ofpromotionevents.Keywords:㊀XGBoostꎻensemblelearningꎻfeatureengineeringꎻrepurchasepredictionꎻprecisionmarketing0㊀引言我国电子商务行业的发展历经二十多年ꎬ在线零售市场不断创新和扩展ꎬ推动了新经济业态的成长与进步.Statista全球统计数据库的«2021年电子商务报告»显示ꎬ中国是目前世界最大和渗透率最高的电子商务市场.国内各大在线零售平台发展迅速ꎬ在激烈竞争中为了吸引用户源和争夺市场份额ꎬ积极探索促销活动形式与种类ꎬ例如天猫淘宝的 双十一购物狂欢节 ㊁京东的 618 购物节等.多样化高频率的购物节给平台引流了大量新用户(促销活动中出现首次购买行为的用户)和短期高成交额.陈可旺[1]分析促销作为一种短期刺激性工具ꎬ虽然能够有效激发用户对特定商品服务进行立即购买的欲望ꎬ但是电商平台更需要锁定长期持续的有效收益.Rosenberg等[2]提出企业重视客户留存并且开发一个新客户所需的成本是维护一个老客户所需成本的6倍.陈龙[3]研究表明电商平台及商家有必要确定哪些用户有可能转化为重复购买者ꎬ并对这些潜在忠诚用户进行精准营销ꎬ降低促销成本ꎬ提高投资回报率.蔡一凡[4]做了用户聚类和特征选择的在线购买行为研究.张李义等[5]聚焦新消费者重复购买意向的预测研究.当前对用户重复购买行为预测方法主要有两类方法ꎬ一是以Pareto/NBD(Negativebinomialdistribution)㊁MBG(Modifiedbetageometric)/NBD为代表的概率模型ꎬ二是以决策树㊁逻辑回归㊁SVM(Supporvectormachine)为代表的机器学习模型[6].基于海量数据的机器学习算法为电商平台精准地把握消费者偏好需求㊁预测消费者行为㊁评估客户价值提供了有效分析方法ꎬ采用数据挖掘技术能够运用多维变量进行预测ꎬ结果更加客观真实[7].电商平台用户数据对象涵盖用户信息㊁商品信息㊁商家信息ꎬ用户在网站上浏览商品时产生的一系列在线行为数据(如登录㊁点击㊁收藏㊁购买㊁评论㊁咨询客服等)ꎬ并且实时在网站日志中进行同步ꎬ构成了海量丰富的大数据集.通过对大数据集进行分析ꎬ电商平台可以提取出用户的需求㊁偏好㊁购买能力等价值信息ꎬ完成重复购买行为预测模型设计[8].消费者重复购买的预测问题转化为消费者是否将重复购买的分类问题ꎬ运用机器学习中的分类算法进行有监督训练.例如Rahim等[9]基于RFM(Recencyꎬfrequencyꎬmonetaryvalue)模型研究客户重复购买行为ꎬ运用SVM算法和决策树算法对客户进行分类ꎬ准确率超过了97%.相比单种算法构建的预测模型ꎬ集成学习方法通过串行或并行的方式将多个弱监督模型进行组合ꎬ可以进一步提高模型预测的准确性ꎬ代表算法有随机森林算法和GBDT(Gradient ̄boosteddecisiontrees)算法等ꎻ或运用多模型融合策略ꎬ将不同类型算法训练出的模型以Stacking㊁Voting㊁Blending㊁Ranking等方法进行531㊀第2期㊀㊀㊀㊀㊀㊀景秀丽ꎬ等:基于XGBoost算法的电商用户重复购买行为预测㊀㊀融合ꎬ提高模型的准确率和泛化能力[10].胡晓丽等[11]基于集成学习对用户重购行为进行预测ꎬ引入 分段下采样 的方法解决类别不平衡问题ꎬ并用Stacking融合了RandomForest㊁XGBoost㊁LightGBM构建预测模型ꎬ结果表明ꎬStacking方法能够带来0.4%至2%的AUC(Areaunderthereceiveroperatingcharacteristiccurve)提升.吕泽宇等[12]使用了LightGBM和XGBoost两种方法构建模型ꎬ并用Hyperopt进行参数搜索ꎬ证明该方法只需少量特征即可达到较好的预测效果.基于先进的机器学习算法ꎬ引入特征工程设计ꎬ也是数据挖掘的关键技术之一.机器学习算法用于解决多个领域多个方向问题ꎬ学习效果如何很大程度上依赖于特征工程中提取的特征是否真正贴合业务需要ꎬ这一过程需要结合许多研究领域的专家知识.文献研究发现ꎬ针对电商购物节后消费者重复购买行为预测研究不多ꎬ通过提取特征值ꎬ结合促销活动变量对消费者行为产生的特殊影响ꎬ可构建更精准的重复购买预测模型.此外ꎬ运用天猫大数据平台提供的公开数据集ꎬ针对促销前和促销中的用户短期行为等数据维度提取更加详细的特征值ꎬ运用XGBoost集成学习算法构建电商购物节后新用户重复购买行为预测模型ꎬ提高预测能力.1㊀算法背景决策树算法在机器学习中常用于预测和分类ꎬ是一种有监督的机器学习方法.在数据复杂的情况下ꎬ使用单一决策树进行预测有时无法取得较好的效果.Kearns等[13]认为可通过集成学习将弱学习算法提升为强学习算法.集成算法主要有Bagging和Boosting两类.其中Boosting提升算法由Schapire[14]通过构造多项式级算法ꎬ率先提出验证Kearns弱学习算法提升的思路ꎬ其各个相互依赖的分类器串行ꎬ根据预测能力的不同ꎬ预测函数的权重也不同.陈凯等[15]研究表明ꎬ在训练的过程中增加对分类错误样本的学习权重ꎬ在迭代中能够不断调整和持续提高准确度ꎬ将各个基学习器进行加权集成输出最终结果.XGBoost算法全称eXtremeGradientBoostꎬ由Chen等[16]在经典Boosting算法GBDT的基础上改进提出ꎬ在计算速度上表现优秀.XGBoost的核心思想是采用向前分布算法ꎬ每轮迭代产生的弱分类器都在上一轮迭代的残差基础上继续训练ꎬ通过不断减小残差来实现回归和分类ꎬ并将CART(Classficationandregressiontree)分类回归树作为基学习器.XGBoost算法的目标函数由损失函数和复杂度函数相加而成ꎬ模型误差小ꎬ更加简单ꎬ可防止过拟合ꎬ使用梯度提升法可使目标函数最小化.其目标函数在经过泰勒二次展开后可以简化为Obj=-12ðTj=1Gj2Hj+λ+γT(1)式中:T为叶子节点数ꎻγ为学习率限制叶子节点个数ꎻλ为正则化参数限制叶子节点分数ꎻGj为一阶导数ꎻHj为二阶导数.在每棵树选择特征进行分裂时ꎬXGBoost使用的是贪心法ꎬ遍历特征计算每个节点的分裂收益ꎬ选择增益最大的特征进行分裂:Gain=12GL2HL+λ+GR2HR+λ-(GL+GR)2HL+HR+λ[]-γ(2)即用分割后的目标函数值减去分割前的目标函数值ꎬ当增益大于γ阈值时ꎬ树才分裂ꎬ这样目标函数在优化的同时也实现了预剪枝.当数据量极大时贪心算法十分耗费内存ꎬ对此XGBoost算法还提出了一种近似搜索方法ꎬ在难以精确搜索情况下运用全局近似或者局部近似选取候选分裂点ꎬ再从中选择最佳分裂点ꎬ结果同样具有准确性.通过调用Python开发环境的XGBoost工具包进行重复631㊀㊀㊀辽宁大学学报㊀㊀自然科学版2023年㊀㊀㊀㊀购买行为的预测.2㊀数据采集与分析2.1㊀数据集数据集来源于阿里云天池大数据平台 天猫复购预测大赛 的公开数据集.该数据集包含了424170名匿名用户的基本信息以及他们在 双十一购物狂欢节 前6个月以及 双十一购物狂欢节 当天的交互行为记录和购物记录ꎬ同时标记了这些用户在购物节后6个月是否有重复购买行为.数据集一共包括 用户信息表 用户行为日志表 用户-商家消费行为表 3张数据表ꎬ提供了 用户编号 用户年龄范围 用户性别 商品编号 商品类别编号 商品品牌编号 商家编号 行为时间 行为类型 9个属性.数据初筛发现ꎬ数据集的样本用户皆有过一次以上的购买记录ꎬ且 双十一购物狂欢节 期间都有首次进行消费的商家.用户信息表和用户行为表包含了所有样本用户的相关数据.为满足模型训练及测试的需求ꎬ天池大数据平台提供的数据集将样本用户分为数量相当的两部分ꎬ并分别归入电商用户行为模型的训练集和测试集之中.其中训练集中的label字段已经完成对用户的标签化ꎬ即标明用户在 双十一购物狂欢节 后是否会重复购买ꎬ用于有监督学习对模型进行分类训练ꎻ而测试集中的prob字段表示预测用户是否在促销活动后重复购买ꎬ在模型训练后对无标签对象进行预测.2.2㊀数据清洗2.2.1㊀缺失值处理原数据集用户信息表中的age_range(用户年龄范围)字段有92914条缺失值㊁gender(用户性别)字段有10426条缺失值ꎬ缺失值在属性中占比较大ꎬ使用均值替换法在已有数据中寻找缺失数据的最可能值.购买同一产品的用户群体往往具有相似的年龄和性别.对应数据处理流程包括:首先ꎬ在用户信息表中获取缺失年龄或性别属性用户对应的user_id(用户编号)ꎬ通过这些user_id在用户行为日志表中寻找属性值缺失用户购买过的所有商品的item_id(商品编号)ꎻ其次ꎬ在用户行为表中寻找购买过这些商品的其他用户的编号ꎬ通过用户信息表得到这些用户的年龄范围或性别属性ꎬ以此计算商品用户群的平均年龄范围或性别属性ꎻ最后ꎬ以所有已购商品的平均用户年龄和性别的平均值填补该用户缺失的年龄或性别属性.用户行为日志表中的brand_id(商品品牌编号)字段有91015个缺失值ꎬ但由于同一商家售卖同一类别的同一商品ꎬ其品牌应当是相同的ꎬ其中大部分的缺失值可以通过与item_id(商品编号)ꎬcat_id(商品类别编号)ꎬseller_id(商家编号)进行匹配找回.2.2.2㊀数据转换在特征构造过程中需要按照时间进行数据提取ꎬ而原字段 time_stamp 时间戳以mmdd标识ꎬ如5月11日记为 0511 的string类型数据ꎬ来记录用户在线行为发生时间ꎬ无法进行数学运算ꎬ因此在数据集成时对 time_stamp 时间戳进行转换并添加一个int类型的新字段 day ꎬ用来表示用户在线行为发生时间在从5月11日至11月11日这185d的时间周期内所处的位置ꎬ如将 0511 转化为 1 ꎬ将 1111 转化为 185 ꎬ这样就不必考虑每月天数之间的差异并可以按时间进行数据提取.3㊀特征工程特征工程即对原始数据进行一系列处理的工程ꎬ最大限度地提炼出特征ꎬ作为输入供模型和算731㊀第2期㊀㊀㊀㊀㊀㊀景秀丽ꎬ等:基于XGBoost算法的电商用户重复购买行为预测㊀㊀法使用.特征工程是对数据进行理解㊁表示和展示的过程ꎬ其在实际过程中要求尽可能地去除原始数据里的噪声ꎬ提炼出更加高效的特征以供预测模型调用解决问题.高质量特征对于提高模型的性能和精准度有很大意义.特征工程需要结合多学科知识ꎬ首先对电商用户重复购买行为的影响因素模型进行分析.用户自身属性方面ꎬ徐鹏鹏[17]构建结构方程模型研究用户重复购买电商品牌的影响因素ꎬ认为客户的个人特征㊁质量关注㊁感知价值㊁网购依赖及购物满意度会造成影响.商品属性方面ꎬ李海霞[18]根据环境心理学理论和社会交换理论ꎬ认为客户面对与商家在口碑㊁技术㊁人员㊁产品等服务接触时产生的刺激ꎬ会对社会关系及经济关系进行是否满意和信任的考量ꎬ从而决定是否重复购买.在用户与商家间的交互关系上ꎬ经典的RFM模型通过客户最近一次的消费时间㊁消费频度和消费金额对客户价值进行衡量.针对电商行业特点ꎬ李敏等[19]在RFM模型的基础上加入客户对商品满意度和关注度的考量ꎬ构建RFMSA(Recencyꎬfrequencyꎬmonetaryꎬstatisfactionꎬattention)模型对用户忠诚度进行分类.薛红松等[20]验证了电商客户重购行为和商家商品销量和排名符合幂律分布ꎬ重购行为倾向于在一定时期内集中发生ꎬ且随着购买次数增加ꎬ重购周期将缩短ꎬ状态趋向稳定.由此可见ꎬ当前针对电商用户重复购买行为影响因素的研究ꎬ很多学者尚未将商家推广促销和电商平台购物节活动等纳入具体分析.促销刺激可以加速新用户与商家产生交互关系ꎬ也增加了对新用户价值判断的难度.对新老客户重复购买意愿的不同特点ꎬ卢美丽等[21]考虑了购买强化效应ꎬ并验证受此影响顾客购买次数可呈幂律分布或广延指数分布ꎬ即可将客户分为易受促销影响的提升区顾客和已形成购物惯性的稳定区顾客.结合上述研究以及数据集提供的有限信息ꎬ本研究将在特征提取时构建4大类特征ꎬ即用户特征㊁商家特征㊁关系特征㊁促销特征.原数据集的可用特征维度较低ꎬ因此在提取原特征之外还需要通过对原属性进行分割和结合ꎬ构造出新的特征.商家特征考虑商家热度㊁口碑㊁产品对重复购买的影响ꎻ用户特征考虑其人口特征㊁网购依赖度㊁网购信任度㊁稳定忠诚度ꎻ交互特征考虑用户对商家的交互时间㊁交互频次ꎻ促销特征考虑商家的促销力度以及用户的价格敏感度.如图1所示.图1㊀特征工程设计3.1㊀用户特征用户特征是对用户个人属性和购物偏好的描述ꎬ包括人口特征㊁网购依赖度㊁网购信任度㊁稳定度ꎬ会对其是否重复购买造成影响.多数研究者会从原始数据集的用户信息表中提取用户人口特征数据ꎬ参照此方法ꎬ本研究基于所用数据集中的用户信息表提取用户年龄和性别数据ꎬ探究其对消费831㊀㊀㊀辽宁大学学报㊀㊀自然科学版2023年㊀㊀㊀㊀者的购买行为和购买偏好的影响作用ꎬ即将上述两类数据属性作为原特征进行提取[14].网购依赖度则体现用户是否为电商平台的重度使用者ꎬ主要考虑其活跃度和使用深度.用户行为日志表中记录了用户在促销活动前和促销活动中的6个月内在平台内点击㊁加入购物车㊁购买收藏的行为.用户各类行为频次越高ꎬ登录天数越多ꎬ说明其对平台越忠实ꎬ具有更高的维护价值.因此可以从行为日志表统计出用户的点击总次数㊁加入购物车总次数㊁购买总次数㊁收藏总次数㊁登录总天数㊁购买总天数作为特征.另一方面ꎬ相较于只在平台购买小部分类别产品的用户ꎬ部分用户对平台使用程度更深ꎬ运用平台满足其大部分购物需求ꎬ有更高的重复购买可能性.可以据此统计用户购买类别总数㊁购买品牌总数㊁购买不同商品总数这几个特征.网购信任度代表用户对电商产品可靠性的认知以及对性价比的敏感度.一些用户属于冲动型消费者ꎬ在电商平台上查询到喜欢的商品之后无需多做了解就能提交订单ꎻ一些用户属于理智型消费者ꎬ在选购商品时习惯货比三家ꎬ争取最大可能以更优惠的价格买到性价比高的商品.通过用户行为日志表可以计算用户购买行为和非购买行为所有操作的比例ꎬ即购买行为占比和非购买行为占比ꎬ以及非购买行为的购买转化率ꎬ计算公式为用户操作行为占比=用户某种操作行为总次数用户所有操作行为总次数(3)非购买行为转化率=购买行为次数各种非购买行为总次数(4)用户稳定度说明用户转移购买的难易程度.电商平台产品质量相对难以直接判断ꎬ一些高稳定度用户在积攒购物经验ꎬ找到自己满意的商家后ꎬ会倾向于在该商家进行持续的购买以节省搜寻试错成本ꎬ有更高的重复购买可能性.此处重复购买者指的是在某商家购买天数超过两天的用户ꎬ可以对用户购买商家总数㊁用户重复购买次数㊁用户重复购买商家总数㊁重复购买率进行统计计算ꎬ公式如下:用户重复购买率=所有重复购买过的商家所有购买过的商家(5)3.2㊀商家特征商家特征描述的是商家的形象和吸引力ꎬ商家的热度㊁口碑以及产品特征会对重复购买决策造成影响.商家热度反映商家的客户及潜在客户数量ꎬ商家的热度越高说明其吸引顾客完成订单的能力越强.可以构建出商家被点击总次数㊁被加入购物车总次数㊁被购买总次数㊁被收藏总次数等特征.商家口碑及其客户满意度是用户决定是否重复购买的关键因素.如果有更多用户在查看㊁加购㊁收藏商家商品ꎬ进行多重信息搜集和产品比较后ꎬ最终能够完成转化进行购买ꎬ说明商家在信誉㊁价格等方面能够让顾客信任ꎬ有较好的口碑ꎬ这也将增加再次购买的可能性.据此构造商家的点击购买转化率㊁加购购买转化率㊁收藏购买转化率.此外购买者总数和重复购买者总数也是商家口碑的一个重要考量因素ꎬ重复购买率越大ꎬ说明其客户满意度越高.可构建的特征有商家购买者总数㊁重复购买者总数㊁重复购买率.重复购买率的计算公式是重复购买率=重复购买者总数购买者总数(6)商家产品类型和特点也会影响用户在店内重复购买的意向ꎬ商家的产品种类越丰富ꎬ越能吸引931㊀第2期㊀㊀㊀㊀㊀㊀景秀丽ꎬ等:基于XGBoost算法的电商用户重复购买行为预测㊀㊀用户进行搜索.因此统计出商家种类总数㊁品牌总数㊁商品总数的特征ꎬ将商家对用户吸引力进一步量化.3.3㊀交互特征交互特征描述的是每条记录中指定用户和商家之间存在的关系ꎬ关系越强ꎬ再次购买的可能性越大.关系强度可以通过最近一次交互行为的时间㊁交互频次体现.最近一次行为发生的时间越相近ꎬ说明用户近期对商家越关注ꎬ因此要计算用户最近一次与商家发生交互行为距离 双十一狂欢购物节 促销活动的天数.而用户对商品进行点击㊁加入购物车㊁收藏等操作的频次越高ꎬ说明用户对商品和商家越关注ꎬ可以构造出特定用户在特定商户中的点击总次数㊁点击总天数㊁加购商家总次数㊁收藏商家总次数等相关特征.用户单次在商家内部购买的商品数量会影响消费者与商家之间的关系深度ꎬ用户对商家内的多种不同商品有购买意向会影响未来重购行为的发生概率.从用户行为日志表中可以构造出用户在商家的购买总件数㊁购买不同商品数㊁购买品牌数㊁购买类别数等特征.3.4㊀促销特征促销帮助商家吸引了更多新用户ꎬ所以有必要针对促销构建特征帮助判断新客户重复购买的可能性ꎬ主要观察商家的促销力度及用户的价格敏感度.当商家活动力度大时ꎬ可能会导致短期购买量大涨ꎬ但在活动后一段时间内客户由于反差过大而不愿再次购买.可以通过比较商家近期关注度与长期关注度进行观察ꎬ构造商家促销月被点击次数㊁被加购次数㊁被购买次数㊁被收藏次数ꎬ促销月被点击占比㊁被加购占比㊁被购买占比㊁被收藏占比特征.当用户价格敏感度高时ꎬ在促销的驱动下可能会在短期内活跃度提高ꎬ产生更多交互记录ꎬ而促销结束后可能受价格影响不选择重复购买.对此可以在用户行为日志表中构造一些趋势特征来对用户的促销敏感度进行衡量ꎬ如促销月用户点击㊁加入购物车㊁购买㊁收藏行为的次数ꎬ以及这4种行为的次数在所有对应行为次数中的占比ꎬ即用户促销月点击占比㊁加购占比㊁购买占比㊁收藏占比.最终一共提取了3类55个特征.促销月某行为占比=促销月(商家受到或用户进行)某行为次数(商家受到或用户进行)某行为总次数(7)通过对数据集直接分析ꎬ构造出来的特征往往在取值范围上存在着较大的落差.如果某一特征的量级过大㊁方差过大ꎬ很有可能导致该特征在模型训练时发挥主导作用ꎬ从而使得其他特征失效.为了避免这一情况发生ꎬ在模型训练之前对特征值进行均值归一化处理ꎬ使所有特征值呈服从均值为0㊁标准差为1的标准正态分布.运用Python中sklearn包的StandardScaler完成这一操作.4㊀模型构建训练与预测4.1㊀模型构建4.1.1㊀样本划分与比例调整通过Python程序中的XGBoost包和sklearn包对预测模型进行构建与训练.运用XGBoost算法进行有监督训练.阿里云天池大数据平台 天猫复购预测大赛 数据集提供了带有用户分类标签的训练表一共包含260864条数据ꎬ数据量较为充足ꎬ可以按照标准形式将样本划分为训练集和测试集ꎬ比例为7ʒ3.样本数据中的正样本ꎬ即重复购买用户样本为15952条ꎬ负样本ꎬ即非重复购买用户样041㊀㊀㊀辽宁大学学报㊀㊀自然科学版2023年㊀㊀㊀㊀本为244912条.样本数量正负样本比例约为1ʒ15ꎬ数量差距较大ꎬ存在类别不平衡的问题.严重的类别不均衡在机器学习的过程中可能会导致模型倾向样本数量多的类别ꎬ引起过拟合问题ꎬ影响模型预测结果的准确性ꎬ因此通过一定的采样策略ꎬ保证模型训练时正负样本比例协调.Python的XGBoost包为解决数据类别不均衡的问题提供了方法.如果只考虑模型的ROC(Receiveropertatingcharacteristiccurve)㊁AUC㊁召回率指标ꎬ而不关心样本为某一类别的概率大小ꎬ可以通过将Booster参数中的 scale_pos_weight 设置为数据负样本数量/正样本数量ꎬ为比例小的样本赋予更大的权重ꎬ改变样本在训练中的贡献ꎬ减弱类别数量不平衡的影响ꎬ即将 scale_pos_weight 的参数值设置为15.4.1.2㊀参数设置Python程序中的XGBoost包对学习目标参数eval_metric设置指定分类器训练情况的输出指标ꎬ再调用sklearn包中的metrics选择整个模型需要输出的评估指标.XGBoost一共有通用参数㊁Booster参数㊁学习目标参数3类.1)通用参数对模型宏观功能进行控制.Booster决定的是迭代所用的模型ꎬ有树模型和线性模型ꎬ本实验使用的是树模型gbtree.silent决定运行时是否输出信息ꎬ默认值0输出.nthread决定运行时使用的线程数ꎬ默认值为-1ꎬ代表自动获取最大值.2)Booster参数用于控制每一步Booster(树或回归)的生成ꎬ如表1所示.eta即学习率ꎬ决定每次迭代的收缩步长ꎬ参数值越大越难以收敛ꎬ因此将参数值设置为偏小值0.1ꎬ提升学习过程的精细化.min_child_weight为最小叶子节点样本权重和ꎬ当一个叶子节点的样本权重总和小于该参数值时则停止分裂ꎬ取值范围为[0ꎬ+ɕ)ꎬ取值越大越保守ꎬ可以防止过拟合ꎬ默认值为1.max_depth为树的最大深度ꎬ该值越大模型则越复杂ꎬ越容易导致过拟合ꎬ默认值为6.sub_sample控制构建每棵树时采用的样本比例ꎬ可以防止过拟合ꎬ取值于(0ꎬ1]之间ꎬ此处设为值0.8.colsample_bytree控制构建每棵树时随机抽取的特征占比ꎬ取值于(0ꎬ1]之间ꎬ此处设为值0.8.gamma指的是节点分裂要求的最小损失函数减少值ꎬ参数越大越能避免过拟合ꎬ默认值为0.alpha为控制复杂度的权重的L1正则化项ꎬ参数值越大越能避免过拟合ꎬ可以加快高维度数据的运算速度ꎬ此处设为值1.scale_pos_weight可在类别样本数不平衡时加快算法收敛速度ꎬ此处设为值15.表1㊀Booster参数初始值设置参数名参数值eta0.1min_child_weight1gamma0max_depth6sub_sample0.8colsample_bytree0.8alpha1scale_pos_weight153)学习目标参数ꎬ确定模型学习目标.objective确定需要被最小化的损失函数ꎬ由于研究的问题是二分类问题ꎬ并要求以概率的形式输出结果ꎬ因此将此参数设定为binary:logisticꎬ即二分类回归.eval_metric定义的是分类器的评估指标ꎬ可以同时添加多种指标ꎬ此处添加常用的auc㊁logloss(负对数似然函数值)㊁error(二分类错误率).seed为随机数种子ꎬ该参数值能使随机数据复现ꎬ此处设置为100.4.2㊀模型训练4.2.1㊀初始参数训练XGBoost包中的XGBoost.train()用于对分类器进行训练ꎬ参数主要包括params㊁dtrain㊁num_boost_round㊁evals=()㊁early_stopping_rounds.dtrain指的是被训练的数据.num_boost_round指的是141㊀第2期㊀㊀㊀㊀㊀㊀景秀丽ꎬ等:基于XGBoost算法的电商用户重复购买行为预测。
文章编号:1673-887X(2023)12-0103-03基于Web of Science核心合集数据库的智慧灌溉文献计量分析段正宇1,朱成立1,王策1,沈雨桐2(1.河海大学农业科学与工程学院,江苏南京211100;2.河海大学公共管理学院,江苏南京211100)摘要为梳理智慧灌溉发展历程,有效提升农业灌溉水有效利用系数,采用文献计量分析方法,基于Web of Science核心合集数据库中2012年—2022年发表的以“智慧灌溉”为研究主题的198篇文献,利用CiteSpace软件网络可视化分析功能,进行该领域文献计量分析。
研究发现:该领域发文量呈上升趋势,且2018年开始发文量陡增;发文主体为中国、印度、美国等农业大国;发文单位以大学、科学院等研究机构为主。
在作者/机构合作图谱中,网络整体密度低,反映出智慧灌溉领域研究团体分散,合作对象固定,尚未形成极具凝聚力的科研单位和核心作者群。
关键词共现频次聚类图谱中出现了高密度聚集,“模型”“物联网”“人工智能”等研究热点突出。
关键词智慧灌溉;物联网;传感器;CiteSpace;趋势分析中图分类号S275文献标志码A doi:10.3969/j.issn.1673-887X.2023.12.036Quantitative Analysis of Intelligent Irrigation Literature Basedon Web of Science Core Collection DatabaseDuan Zhengyu1,Zhu Chengli1,Wang Ce1,Shen Yutong2(1.College of Agricultural Science and Engineering,Hohai University,Nanjing211100,Jiangsu,China;2.College of Public Administration,Hohai University,Nanjing211100,Jiangsu,China)Abstract:In order to sort out the development process of intelligent irrigation and effectively improve the effective utilization coeffi‐cient of agricultural irrigation water,this paper adopted the bibliometric analysis method and based on198literatures on the research theme of"intelligent irrigation"published from2012to2022in the core database of Web of Science.Based on the network visual analysis function of CiteSpace software,the literature in this field is analyzed quantitatively.The results showed that the number of published papers in this field is on the rise,and the number of published papers has increased sharply since2018.The main authors are China,India,the United States and other major agricultural countries.The issuing units are mainly research institutions such as universities and academies of sciences.In the author or institution cooperation map,the overall density of the network is low,which reflects that the research group in the field of intelligent irrigation were scattered,the cooperation objects were fixed,and the re‐search units and core authors have not yet formed a very cohesive research unit.In the keyword co-occurrence frequency clustering graph,high-density clustering appeared,and research hotspots such as"model""Internet of things"and"artificial intelligence"were prominent.Key words:intelligent irrigation,Internet of Things,sensor,CiteSpace,trend analysis《联合国世界水资源开发报告2018》指出,全球水资源需求以每年1%的速度增长,增长速度未来20年将大幅加快[1]。