搜索引擎的排名原理
- 格式:doc
- 大小:25.50 KB
- 文档页数:2

分类排名公式分类排名公式是指通过一定的算法和规则,将一组数据按照一定的标准进行排序和分类。
在互联网时代,分类排名公式被广泛应用于搜索引擎、电商平台、社交媒体等各个领域。
本文将从分类排名公式的基本原理、应用场景以及优化方法等方面进行阐述。
一、分类排名公式的基本原理分类排名公式的基本原理是将一组数据按照一定的规则进行排序和分类,以满足用户的需求。
常见的分类排名公式包括PageRank算法、TF-IDF算法、机器学习算法等。
1. PageRank算法PageRank算法是由Google创始人之一拉里·佩奇提出的一种用于网页排序的算法。
该算法通过分析网页之间的链接关系来确定网页的权重,从而进行排名。
具体而言,PageRank算法根据链接的数量和质量来评估网页的重要性,重要的网页通常具有更高的排名。
2. TF-IDF算法TF-IDF算法是一种用于文本排序的算法,通过计算一个词在文本中的出现频率和在整个文本集合中的逆文档频率,来评估该词的重要性。
具体而言,TF-IDF算法认为一个词在文本中出现的频率越高,且在其他文本中出现的频率越低,该词的重要性就越高,从而进行排名。
3. 机器学习算法机器学习算法是一种通过训练模型来进行分类和排序的算法。
该算法通过分析大量的样本数据,学习样本之间的关系和规律,从而对新的数据进行分类和排序。
常见的机器学习算法包括支持向量机、朴素贝叶斯、随机森林等。
分类排名公式在各个领域都有广泛的应用,下面列举几个常见的应用场景。
1. 搜索引擎排名搜索引擎通过分类排名公式对网页进行排序,使用户能够更快速、准确地找到所需的信息。
搜索引擎通过分析网页的关键词、链接关系、用户行为等因素,综合评估网页的重要性,从而进行排名。
2. 电商平台排名电商平台通过分类排名公式对商品进行排序,使用户能够更方便地找到所需的商品。
电商平台通过分析商品的销量、评价、价格等因素,综合评估商品的质量和吸引力,从而进行排名。

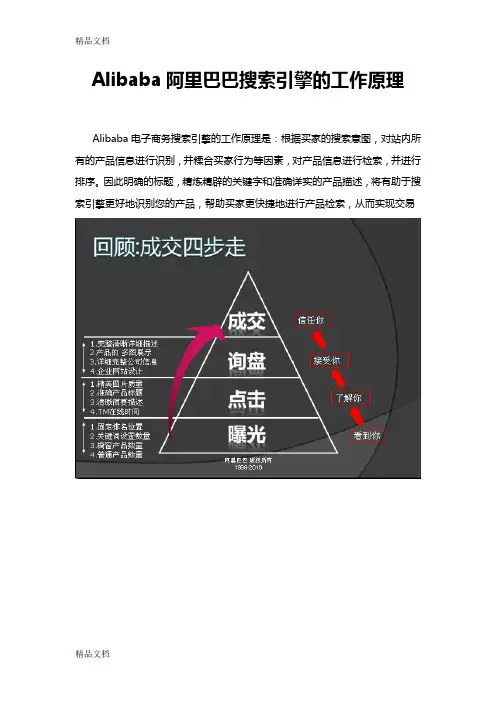
Alibaba阿里巴巴搜索引擎的工作原理Alibaba电子商务搜索引擎的工作原理是:根据买家的搜索意图,对站内所有的产品信息进行识别,并糅合买家行为等因素,对产品信息进行检索,并进行排序。
因此明确的标题,精炼精辟的关键字和准确详实的产品描述,将有助于搜索引擎更好地识别您的产品,帮助买家更快捷地进行产品检索,从而实现交易自由排序主要规则:(下面5点是按先后顺序排列的,一定要先完成匹配度,然后再完成完整度,再是专业度,再是买家喜好度,最后才是刷新)1、关键词的匹配度四重匹配,即关键词,产品名称,简要描述,详细描述四处都要含有同一个关键词例如:产品名称:Red 4G Digital MP3 player关键词:MP3更多关键词:MP3 player Digital MP3 player简要描述:Digital MP3 player ……详细描述:Digital MP3 player ……第一个关键词为MP3,产品名称及两个描述中都含有。
更多关键词为MP3 player,产品名称及两个描述中都含有。
更多关键词为Digital MP3 player,产品名称及两个描述中都含有。
按照上面的例子,我设置的3个关键词都达到了四重匹配,这样的话,这3个词就有机会排在前面。
2、产品信息的完整度所谓的完整度,也就是在发布产品或更新产品的完成率,凡是产品要填的内容,就一定不能空着,一定要保证产品的完整度。
完整度比重较大的几个点:a)产品名称产品名称中,一定不能含有标点符号,这样会影响排名。
建议用6个以内的单词来表示名称。
b)关键词c)产品属性d)图片e)交易条件3、产品的专业度所谓的专业度就是指产品的行业类目分类是否精准,产品的详细描述是否完整。
要点:详细描述字数要写的很多。
4、买家的喜好程度所谓的买家的喜好度是指,买家点击你产品的次数,也就是说,买家点击贵司产品的次数越多,就有机会优先排名。
5、更新建议您1周更新1-2次就可以了。

PageRank 通俗易懂解释一、引言在信息爆炸的今天,互联网已经成为我们获取和分享信息的主要渠道。
然而,随着网页数量的不断增加,如何快速找到高质量、相关的信息变得越来越困难。
为了解决这个问题,谷歌的创始人拉里·佩奇和谢尔盖·布林发明了一种名为PageRank 的算法。
本文将通过通俗易懂的方式,详细解释PageRank 的原理和应用。
二、PageRank 简介PageRank 是一种基于网页之间相互链接关系的排名算法,旨在对互联网上的网页进行重要性评估。
PageRank 的核心思想是:一个网页的重要性取决于它被其他重要网页链接的次数和质量。
换句话说,如果一个网页被很多高质量的网页链接,那么这个网页的重要性也会相应提高。
三、PageRank 原理1. 初始化:首先,我们需要为每个网页分配一个初始的PageRank 值。
通常,将所有网页的PageRank 值设置为相同的初始值,如1/N,其中N 是网页的总数。
2. 计算链接关系:接下来,我们需要计算网页之间的链接关系。
对于每个网页,我们可以统计指向它的链接数量和质量。
链接数量是指有多少其他网页链接到了当前网页,而链接质量则是指链接到当前网页的其他网页的重要性。
3. 更新PageRank 值:有了链接关系后,我们就可以根据PageRank 的核心思想来更新每个网页的PageRank 值。
具体来说,一个网页的新PageRank 值等于它所有链接的PageRank 值之和,再乘以一个衰减因子。
衰减因子的值通常为0.85,表示链接传递的权重会随着距离的增加而逐渐减小。
4. 迭代计算:重复步骤2 和3,直到PageRank 值收敛为止。
收敛是指连续两次计算得到的PageRank 值之间的差异小于某个预设的阈值。
四、PageRank 应用PageRank 算法最初是谷歌搜索引擎的核心组成部分,用于对搜索结果进行排序。
通过PageRank 分析,我们可以快速找到高质量、相关的信息。

搜索引擎的基本原理搜索引擎是一种能够帮助用户在互联网上找到所需信息的工具,它的基本原理是通过对互联网上的信息进行收集、整理和索引,然后根据用户输入的关键词进行匹配和排序,最终呈现给用户相关的搜索结果。
搜索引擎的基本原理涉及到信息检索、网页抓取、索引建立和搜索算法等方面。
首先,搜索引擎通过网络爬虫程序对互联网上的网页进行抓取和收集。
网络爬虫会按照一定的规则和算法,自动地访问和抓取网页上的内容,然后将这些内容存储到搜索引擎的数据库中。
这一过程需要考虑网页的质量、更新频率、页面结构等因素,以确保搜索引擎能够及时、全面地收集到互联网上的信息。
其次,搜索引擎会对收集到的网页内容进行索引建立。
索引是搜索引擎的重要组成部分,它是对网页内容的一种结构化存储和组织方式,能够快速地找到和定位到用户所需的信息。
索引建立的过程包括对网页内容进行分词、去除停用词、建立倒排索引等操作,以便于后续的搜索和匹配。
接着,搜索引擎会根据用户输入的关键词进行搜索和匹配。
搜索引擎的搜索算法会根据用户输入的关键词,在索引中找到相关的网页内容,并根据一定的排序算法对搜索结果进行排序。
搜索算法通常会考虑网页的相关性、权重、链接结构、用户行为等因素,以提供用户最相关和最有用的搜索结果。
最后,搜索引擎会将排序好的搜索结果呈现给用户。
用户可以通过搜索引擎的界面,查看搜索结果并点击进入相关的网页。
搜索引擎还会提供一些辅助功能,如相关搜索、搜索建议、筛选和排序等,以帮助用户更快地找到所需的信息。
总的来说,搜索引擎的基本原理包括网页抓取、索引建立、搜索算法和搜索结果呈现等方面。
通过这些基本原理,搜索引擎能够高效地帮助用户在互联网上找到所需的信息,成为人们日常生活和工作中不可或缺的工具。

PageRank算法1. PageRank算法概述PageRank,即⽹页排名,⼜称⽹页级别、Google左側排名或佩奇排名。
是Google创始⼈拉⾥·佩奇和谢尔盖·布林于1997年构建早期的搜索系统原型时提出的链接分析算法,⾃从Google在商业上获得空前的成功后,该算法也成为其他搜索引擎和学术界⼗分关注的计算模型。
眼下许多重要的链接分析算法都是在PageRank算法基础上衍⽣出来的。
PageRank是Google⽤于⽤来标识⽹页的等级/重要性的⼀种⽅法,是Google⽤来衡量⼀个站点的好坏的唯⼀标准。
在揉合了诸如Title标识和Keywords标识等全部其他因素之后,Google通过PageRank来调整结果,使那些更具“等级/重要性”的⽹页在搜索结果中另站点排名获得提升,从⽽提⾼搜索结果的相关性和质量。
其级别从0到10级,10级为满分。
PR值越⾼说明该⽹页越受欢迎(越重要)。
⽐如:⼀个PR值为1的站点表明这个站点不太具有流⾏度,⽽PR值为7到10则表明这个站点很受欢迎(或者说极其重要)。
⼀般PR值达到4,就算是⼀个不错的站点了。
Google把⾃⼰的站点的PR值定到10,这说明Google这个站点是很受欢迎的,也能够说这个站点很重要。
2. 从⼊链数量到 PageRank在PageRank提出之前,已经有研究者提出利⽤⽹页的⼊链数量来进⾏链接分析计算,这样的⼊链⽅法如果⼀个⽹页的⼊链越多,则该⽹页越重要。
早期的⾮常多搜索引擎也採纳了⼊链数量作为链接分析⽅法,对于搜索引擎效果提升也有较明显的效果。
PageRank除了考虑到⼊链数量的影响,还參考了⽹页质量因素,两者相结合获得了更好的⽹页重要性评价标准。
对于某个互联⽹⽹页A来说,该⽹页PageRank的计算基于下⾯两个基本如果:数量如果:在Web图模型中,如果⼀个页⾯节点接收到的其它⽹页指向的⼊链数量越多,那么这个页⾯越重要。

搜索引擎运作原理
搜索引擎是互联网上最常用的工具之
一,它能帮助用户快速找到所需的信息。
搜索引擎是一种计算机程序,它会搜索互联网上的信息,找到与用户输入的搜索词最相关的网站。
那么,搜索引擎是如何运作的呢?
搜索引擎的运作原理有三个主要步骤:索引、排序和搜索。
首先,索引的步骤是搜索引擎的核心,它包括收集网页信息和建立索引过程。
在收集网页信息的步骤中,搜索引擎会通过爬虫(又称蜘蛛或机器人)来搜索网络上的信息,将网页的内容和网址存入到数据库中,以备搜索时使用。
建立索引是搜索引擎的另一个重要步骤,在这一步骤中,搜索引擎会将网页的内容和网址建立索引,并将其存入数据库中。
排序是搜索引擎运作的第二个步骤,它的主要作用是根据搜索关键词对搜索结果进行排序,以便搜索用户能够快速找到信息。
搜索引擎会根据网页内容相关性、网页点击率等因素进行排序,将最相关的网页排在最前面,以便用户能够快速找到最相关的信息。
最后一步是搜索步骤,这是搜索引擎的最后一步。
当用户在搜索框中输入搜索词时,搜索引擎会查找包含搜索词的内容,并将搜索结果按照相关性排序显示出来。
用户输入的搜索词越准确,搜索结果越准确,搜索时间也会越短。
综上所述,搜索引擎的运作原理主要包括三个步骤:索引、排序和搜索。
搜索引擎将网页信息收集并建立索引,根据搜索词对搜索结果进行排序,并将结果显示出来。
搜索引擎的运作原理既简单又有效,它为网络用户提供了快速查找信息的便利条件。

百度搜索引擎的原理
百度搜索引擎是基于信息检索的技术原理进行工作的。
其核心原理主要分为网页爬取、网页索引和查询处理三个步骤。
首先,百度搜索引擎会使用爬虫程序自动收集互联网上的网页内容。
这些爬虫会从互联网上的一个个链接开始,逐个地访问网页并将其内容保存下来。
爬虫会遵循页面中的链接跳转到其他网页继续爬取。
通过这种方式,百度搜索引擎可以获取到大量的网页信息。
接下来,百度会对这些爬取到的网页进行索引。
索引是一个巨大的数据库,其中包含了所有爬取到的网页的信息。
为了提高检索效率,百度会对网页的文本内容进行处理和分析,提取出其中的关键词和主题。
这些关键词和主题会用作后续搜索的关键参数。
同时,百度还会记录网页的URL链接和其他相关信息,以便用户在搜索时能够快速找到。
最后,当用户在百度搜索框中输入关键词并提交时,百度会调用查询处理程序来处理用户的搜索请求。
查询处理程序会根据用户输入的关键词,在索引中寻找与之相关的网页信息。
百度会对这些网页进行排序,将与关键词相关性较高的网页排在前面。
同时,根据用户的搜索历史、位置和其他个人信息,百度还会提供个性化的搜索结果。
总结起来,百度搜索引擎的原理包括网页爬取、网页索引和查询处理三个步骤。
通过自动爬取网页内容并进行处理和索引,百度能够提供用户相关、准确的搜索结果。

seo搜索引擎优化原理很多人对SEO优化是什么感到好奇,每天更新文章,为什么网站排名可以提高。
今天,将介绍seo搜索引擎优化原理 1。
seo搜索引擎优化原理 1搜索引擎使用收集和捕获向用户显示,使用爬虫程序,通常被称为蜘蛛,网站搜索引擎优化优化是向网站发布有价值的内容,让蜘蛛捕获,让蜘蛛向用户显示,从而提高网站排名,获得流量。
二、信息过滤然而,当蜘蛛抓取内容时,它会过滤掉一些低质量的内容。
如果你的网站是低质量的内容。
重复内容,它将被搜索引擎直接过滤,排名自然无法提高。
一般来说,我们网站的内容需要做好以下几点:1。
及时性;2.可读性;3.价值。
满足这三点的内容是蜘蛛需要的,也是用户想知道的。
三、对数据库进行分类和存储搜索引擎蜘蛛将捕获的内容分类,存储在数据库中,建立索引链接,以便用户可以通过网站或关键字搜索找到内容。
四、给排名显示搜索引擎会根据用户的需求和内容的质量,对网站文章的内容进行合理的排序,并向用户展示。
搜索引擎有自己的排名算法,其核心是围绕用户展开。
搜索引擎会根据相关性和内容的参考价值来决定排名显示。
总结:搜索引擎的每个算法都围绕着用户展开。
如果我们想做好网站优化,提高网站排名,我们需要做好用户体验,以获得搜索引擎的信任,快速获得排名,获得更多的展示机会。
此外,为了做好网站优化工作,我们还需要注意百度算法,不要触摸算法,避免网站减少,搜索引擎优化是提高搜索引擎对网站的信任,以获得排名。
seo搜索引擎优化原理 2不管是国内的头条搜索、还是国外的谷歌搜索,搜索引擎的本质是一种应答机制。
它们的存在是为了发现、理解和组织互联网内容,以便为用户提出的问题提供最相关的结果。
因此,理解了搜索引擎的工作原理,就有助于自己网站的SEO优化。
搜索引擎主要通过三个功能来帮用户获取网页内容:•爬虫:在互联网上爬取内容,查看它们找到的每个 URL 的代码、内容。
•索引:存储和组织在爬取过程中发现的内容。
一旦页面在索引中,它就会在搜索中显示相关查询的结果。

简述搜索引擎的工作原理
搜索引擎是一个互联网工具,帮助用户在海量的网页中快速找到所需的信息。
它的工作原理可以简述为以下几个步骤:
1. 爬取网页:搜索引擎会通过网络爬虫程序从互联网上爬取网页内容。
爬虫根据预设的种子链接开始,在网页上解析并跟踪其他链接,逐层递归地将新的网页加入抓取队列。
2. 建立索引:搜索引擎将爬取到的网页内容进行处理,提取出网页的关键信息,并建立索引。
索引是搜索引擎的核心组件,它会将诸如网页标题、URL、正文、链接等信息存储在数据结构中,以便后续快速检索。
3. 处理用户查询:当用户输入查询关键词时,搜索引擎会从索引中查找与关键词相关的网页。
为了提供准确的搜索结果,搜索引擎会对用户的查询进行分析和处理,去除停用词、关键词扩展等操作,摘取核心信息。
然后,它会根据一系列算法计算每个网页与查询的相关性分数。
4. 返回搜索结果:根据相关性分数,搜索引擎将搜索结果排序,并显示给用户。
通常,搜索引擎会返回一系列标题和描述,同时提供链接到相关网页的便捷方式。
上述是搜索引擎的简要工作原理。
值得注意的是,搜索引擎的工作过程非常复杂,还涉及到反垃圾策略、用户反馈等细节。
每个搜索引擎都有自己独特的算法和技术,以提供更好的搜索体验。

搜狗快速排名原近年来,网络技术发展迅猛,网络上种类繁多的内容不断涌现,各种信息在网络上挥之不去。
用户每天都要面对大量的信息,在信息过多的情况下,如何去定位用户需要的信息成为一个重要的问题。
在这个背景下,搜索引擎排名成为网络信息定位的重要依据。
搜索引擎排名是指网络上的搜索引擎会按照一定的算法,将网络信息进行排名,以实现信息的筛选与定位。
例如,当用户在网页中输入一个关键词,搜索引擎会根据相关算法,将网页信息排序,以确定符合用户搜索意图的信息,给出对应的排名。
搜狗是一家著名的中国搜索引擎,也是其中一个强大的搜索引擎排名系统。
搜狗快速排名原是搜狗搜索引擎排名系统中的一种排名算法。
搜狗快速排名原的做法是,在每个搜索结果中,搜索引擎会根据网页内容的丰富性,结构的紧凑性,标题和描述的说明等,为每个网页打出一个分数,以确定每个网页的排名。
其中,网页内容的丰富性是搜索引擎最注重的指标,它代表了网页内容的完整性和丰富性,是网页内容评价的重要标准。
结构的紧凑性表示网页信息的组织和表达能力,紧凑的结构能够更好的把握网页信息的重点,以便于搜索引擎的抓取和检索。
此外,标题和描述的完备性也是网页内容评价的重要指标,标题和描述是网页内容的概括,将内容概括出来,能够帮助用户更快的定位网页内容。
搜狗快速排名原的算法优点显而易见:一方面,它通过网页内容的完整性、丰富性等参数,来筛选出搜索结果中优质的网页,从而帮助用户更快定位所需要的信息;另一方面,它可以通过不断的优化,根据不同的搜索术语来筛选出精准度更高的信息,从而满足用户不同需求。
搜狗快速排名原已经成为了搜索引擎排名的主流算法,它不仅被搜狗使用,也被其他搜索引擎使用,比如百度、Google等。
它的优点在于功能强大,操作简单,能够有效的过滤信息,满足用户不同的需求。
此外,它还能够保证网页排名的公平性,让每一个网页都能够得到公平的机会。
由此可见,搜狗快速排名原已经成为了搜索引擎信息定位的重要依据,它能够有效的把握信息的重点,并确保公平性,让用户能够更快的定位需要的信息,以满足不同的需求。
百度排名规则及算法总结要想百度给你网站排名,只有三种理由,第一你给百度钱了,第二你是百度旗下的公司或产品,第三你提供有价值的内容,提高了百度搜索的用户体验了。
除去这三个理由,你别想着要百度给你排名,那么我们围绕这三种理由,展开我们的分析。
百度竞价百度竞价主要是根据关键词出价获得排名的,对于百度竞价我了解的不是很多,大致我清楚,当你出价1元一个点击,排名在第三位,那么人家想要超过你,人家就得出价1元以上,原理是这个样子的。
通常情况下,百度付费的广告排名控制在第2-3是最好的状态,排名在第一,基本是竞争对手在点击你的网站。
所以控制在2-3是最佳的位置。
百度竞价最大的好处,就是排名时间块,马上投放广告,马上就有排名,所以不少的企业选择百度竞价做前期推广,而百度竞价的原理也非常简单,百度公司要赚钱生存,所以推出了这个百度付费推广的模式,通过他们的后台直接操作给你排名,你有排名可以赚到钱,但你得给他们钱,不可能永远依靠百度竞价来支撑,所以除了百度竞价,我们还可以这样去做。
百度旗下产品百度旗下产品非常多,能够参与排名的也非常多,比如百度文库、百度知道、百度百科、百度经验、百度百家等等,这些百度产品只是一个平台,百度官方人员从来不会编辑里面的内容,这些平台里面的内容都是由第三方企业或个人编辑而成,既然要我们来编辑,那么推广的机会就来了。
咱们还是先说说,他们排名算法以及规则吧。
百度旗下的产品是由百度自己开发而成,在排名上有很大的优势,优势在哪里呢,就是通过阿拉丁通道排名的,说白了就是走后门。
前面说到了付费竞价推广是通过后台直接给出排名,而百度旗下产品的平台与付费推广不一样,他们不属于推广,而是直接优先展示他们网站的排名。
展现的形式还是与普通网站自然排名展现的形式一样。
但是这种阿拉丁通道的排名也是有规则的,第一他们没有收录规则,基本是审核通过的内容直接收录,所以收不收录就看你的内容是否会审核。
但是他们的排名是有规则的,比如同一篇文章,在百度文库、各种BBS或者自己的博客上进行发布,最终你会发现排名在前的是百度文库;论权重新浪、搜狐等大型网站不比百度文库差,但是百度为了让自己旗下产品生存,获得流量,只有通过后门技术,直接用百度文库的页面来做排名。
搜索引擎的工作原理搜索引擎是一种用于在互联网上获取信息的工具,它通过收集、整理和索引网页上的信息,然后根据用户的搜索关键词提供相关的搜索结果。
下面将详细介绍搜索引擎的工作原理。
1. 网页抓取与索引搜索引擎首先需要从互联网上抓取网页,这个过程称为网络爬虫。
网络爬虫会按照一定的规则从一个网页开始,通过链接在网页间跳转,抓取页面上的内容,并将这些内容存储到搜索引擎的数据库中。
抓取的网页数据会经过一系列的处理和解析,提取出其中的文本、链接、标题、图片等信息。
这些信息将被用于后续的索引和搜索。
2. 网页索引搜索引擎会将抓取到的网页数据进行索引,建立一个包含关键词和对应网页的索引数据库。
索引的目的是为了加快搜索速度,当用户输入关键词进行搜索时,搜索引擎可以快速地在索引数据库中找到相关的网页。
索引的过程包括对网页内容进行分词和建立倒排索引。
分词是将网页的文本内容按照一定的规则切分成一个个的词语,去除停用词(如“的”、“是”等),并对词语进行归一化处理。
倒排索引则是将每个词语与包含该词语的网页进行关联,方便后续的搜索。
3. 搜索与排序当用户输入关键词进行搜索时,搜索引擎会将关键词与索引数据库中的词语进行匹配,并找到包含该关键词的网页。
搜索引擎会根据一定的算法对搜索结果进行排序,以提供用户最相关和有用的结果。
排序算法通常会考虑多个因素,如关键词在网页中的出现频率、关键词在标题或重要位置的出现、网页的权威性等。
同时,搜索引擎也会根据用户的搜索历史、地理位置等信息进行个性化推荐。
4. 搜索结果展示搜索引擎会将排序后的搜索结果展示给用户。
搜索结果通常包括网页的标题、摘要和URL等信息,以及相关的图片、视频等多媒体内容。
为了提供更好的用户体验,搜索引擎还会提供一些额外的功能,如搜索建议、相关搜索、筛选和排序选项等,以帮助用户更精确地找到所需信息。
5. 搜索引擎优化搜索引擎优化(SEO)是一种通过优化网页内容和结构,提高网页在搜索引擎中排名的技术。
百度搜索结果展示的基本原理我们在百度或者其它搜索引擎上输入一个关键词,点击查询,搜索引擎会从先到后列出大量的结果,看到这些结果,我们常会有疑问:这些结果是怎么来的呢?排序的标准又是什么呢?这个看似简单的问题,却是搜索引擎研究的核心难题之一。
为了解答这个疑问,马海祥特意写了这篇文章,为大家介绍一下百度搜索结果展示的基本工作原理:一、页面抓取原理搜索引擎在抓取到我们网站的前提是必须要有渠道,当你新建一个域名,新建了一个普通页面,页面没有经过任何人的访问,也没有任何地方出现过你的页面,那么搜索引擎是无法正确的抓取到你的页面的,有些页面或网站之所以什么都没有操作,搜索引擎也一样可以抓取和收录,其原因主要是通过以下几个渠道:1、链接渠道我们做外链的主要目的是什么,是传递权重还是能够更好的让搜索引擎通过这个链接来抓取我们的站点(具体可查看马海祥博客《外链对网站SEO优化到底有什么作用》的相关介绍)?这是大家都在考虑的一个问题,其实更重要的是让搜索引擎能够通过此链接正确的抓取到我们的网站,这也是SEOER都在说,现在新站建议做外链,老站就没必要的原因之一。
2、提交渠道80%的站点在建立以后会手动提交到搜索引擎,这是搜索引擎在收录到更多站点的一个重点渠道,当搜索引擎不知道你的站点存在的时候,你提交了你的站点,这就是直接告诉了搜索引擎,你的站点是存在的,值得搜索引擎的收录。
3、浏览器渠道百度曾报道,360浏览器可根据用户流量的网页进行收集和抓取,也就是说,当用户使用了360浏览器浏览了某一个未被360搜索引擎发现的站点,那么360浏览器将会记录这个网站,然后将这个网站放到搜索引擎去处理,同样,我想百度浏览器也会做类似的事情吧。
二、文章收录原理一些SEO初学者,刚接触百度收录的时候,总会问:为什么同时发布两篇文章,一篇被收录,还有一篇未收录?为何我在大型网站发布的软文未收录?等等收录问题,其实百度对网站文章收录这一点看的相对严格(具体可查看马海祥博客《百度收录网站文章的现状及原则依据》的相关介绍),所以我们在这一点不能掉以轻心。
搜索引擎的工作分为四个步骤第一步:爬行,搜索引擎通过特定的软件定律来跟踪网页的链接,从一个链接到另一个因此,这称为爬网。
第二步:获取存储空间,搜索引擎将通过蜘蛛跟踪链接爬网到网页,并将爬网数据存储在原始页面数据库中。
第三步:预处理,搜索引擎将爬虫爬回页面,进行各种步骤预处理。
步骤4:排名:用户在搜索框中输入关键字后,排名程序调用索引数据库数据,计算并向用户显示排名,排名过程直接与用户互动。
不同搜索引擎的结果基于该引擎的内部信息。
例如:某种搜索引擎没有这种信息,则无法查询结果。
扩展数据:定义搜索引擎包括四个部分:搜索器,索引器,搜索器和用户。
搜索器的功能是在Internet 上漫游,查找和收集信息。
索引器的功能是了解搜索者搜索到的信息,从中提取索引项,并用其表示文档并生成文档库的索引表。
检索器的功能是根据用户的查询快速检出索引数据库中的文档,评估文档与查询之间的相关性,对输出结果进行分类,实现用户相关性的反馈机制。
用户界面的功能是输入用户查询,显示查询结果并提供用户相关性的反馈机制。
起源所有搜索引擎的始祖都是1990年在蒙特利尔的麦吉尔大学(McGill University)的三名学生(艾伦·埃姆特(Elan Emtage)和彼得(Peter))Deutsch和Bill Wheelan发明了Archie(Archie常见问题解答)。
Alan emtage和其他人提出了开发一个可以使用文件名查找文件的系统的想法,因此创建了Archie。
Archie是第一个自动为Internet上匿名FTP站点的文件编制索引的程序,但它实际上还不是搜索引擎。
Archie是可搜索的FTP文件名的列表。
用户必须输入确切的文件名进行搜索,然后Archie会告诉用户哪个FTP地址可以下载文件。
受Archie的流行启发,内华达大学系统计算服务公司于1993年开发了gopher(gopher FAQ)搜索工具Veronica(Veronica FAQ)。
搜索引擎的基本⼯作原理了解搜索引擎的基本⼯作原理1.搜索引擎的概念在浩瀚的⽹络资源中,搜素引擎(Search Engine)是⼀种⽹上信息检索⼯具,它能帮助⽤户迅速⽽全⾯地找到所需要的信息。
我们这样对搜索引擎进⾏定义:搜索引擎是⼀种能够通过因特⽹接受⽤户的查询命令,并向⽤户提供符合其查询要求的信息资源⽹址的系统。
据统计,搜索引擎搜索仅次于电⼦邮件的应⽤。
⽬前⽹上⽐较有影响的中⽂搜索⼯具有:google、百度、北⼤天⽹、爱问(iask)、雅虎(yahoo!)、搜狗(sogou)、搜搜(soso)等搜索引擎。
英⽂的有:Yahoo! 、AltaVista、Excite、Infoseek、Lycos、Aol等。
另外还有专⽤搜索引擎,例如专门搜索歌曲和⾳乐的;专门搜索电⼦邮件地址、电话与地址及公众信息的;专门搜索各种⽂件的FTP搜索引擎等。
搜索引擎是指根据⼀定的策略,运⽤特定的计算机程序搜集互联⽹上的信息,在对信息进⾏组织和处理后,为⽤户提供检索服务的系统。
搜索引擎并不是真正的互联⽹,它搜索的实际上是预先整理好的⽹页索引数据库。
真正意义上的搜索引擎,通常指的是收集了互联⽹上⼏千万到⼏⼗亿个⽹页并对我那个也中的每⼀个词(即关键词)进⾏索引。
建⽴索引数据库的全⽂搜索引擎。
现在的搜索引擎已普遍使⽤超链分析技术,除了分析索引⽹页本⾝的内容,还分析索引所有指向该⽹页的链接的URL、Anchor、Text,甚⾄链接周围的⽂字。
所以,有时候,即使某个⽹页A中并没有出现某个词,⽐如“信息检索”,但如果有⽹页B⽤链接“信息检索”指向这个⽹页A,那么⽤户搜索“信息检索”时也能找到⽹页A。
⽽且,如果有越多的⽹页的“信息检索”链接指向⽹页A,那么⽹页A在⽤户搜索“信息检索”时也会被认为更相关,排序也会越靠前。
搜索引擎的原理,可以分为四步:从互联⽹上抓取⽹页、建⽴索引数据库、在索引数据库中搜索排序、对搜索结果进⾏处理和排序。
(1)、从互联⽹上抓取⽹页:利⽤能够从互联⽹上⾃动收集⽹页的蜘蛛系统程序,⾃动访问互联⽹,并沿着任何⽹页中所有URL爬到其他⽹页,重复这个过程,并把爬过的所有⽹页收集回来。
搜索引擎的排名原理
要了解搜索引擎优化,首先了解搜索引擎的基本工作原理。搜索引擎排名大致上可
以分为四个步骤。
1、 爬行和抓取
搜索引擎派出一个能够在网上发现新网页并抓取文件的程序,这个程序通常被称为
蜘蛛或机器人。搜索引擎蜘蛛从数据库中已知的网页开始出发,就像正常用户的浏
览器一样访问这些网页并抓取文件。
并且搜索引擎蜘蛛会跟踪网页上的链接,访问更多网页,这个过程就叫爬行。当通
过链接发现有新的网址时,蜘蛛将把新网址记录入数据库等待抓取。跟踪网页链接
是搜索引擎蜘蛛发现新网址的最基本方法,所以反向链接成为搜索引擎优化的最基
本因素之一。没有反向链接,搜索引擎连页面都发现不了,就更谈不上排名了。
搜索引擎蜘蛛抓取的页面文件与用户浏览器得到的完全一样,抓取的文件存入数据
库。
2、 索引
搜索引擎索引程序把蜘蛛抓取的网页文件分解、分析,并以巨大表格的形式存入数
据库,这个过程就是索引。在索引数据库中,网页文字内容,关键词出现的位置、
字体、颜色、加粗、斜体等相关信息都有相应记录。
搜索引擎索引数据库存储巨量数据,主流搜索引擎通常都存有几十亿级别的网页。
3、 搜索词处理
用户在搜索引擎界面输入关键词,单击“搜索”按钮后,搜索引擎程序即对输入的
搜索词进行处理,如中文特有的分词处理,对关键词词序的分别,去除停止词,判
断是否需要启动整合搜索,判断是否有拼写错误或错别字等情况。搜索词的处理必
须十分快速。
4、 排序
对搜索词进行处理后,搜索引擎排序程序开始工作,从索引数据库中找出所有包含
搜索词的网页,并且根据排名计算法计算出哪些网页应该排在前面,然后按一定格
式返回“搜索”页面。
排序过程虽然在一两秒之内就完成返回用户所要的搜索结果,实际上这是一个非常
复杂的过程。排名算法需要实时从索引数据库中找出所有相关页面,实时计算相关
性,加入过滤算法,其复杂程度是外人无法想象的。搜索引擎是当今规模最大、最
复杂的计算系统之一。
但是即使最好的搜素引擎在鉴别网页上也还无法与人相比,这就是为什么网站需要
搜索引擎优化。没有SEO的帮助,搜索引擎常常并不能正确返回最相关、最权威、
最有用的信息。