分布式事务处理入门
- 格式:pptx
- 大小:217.58 KB
- 文档页数:29

分布式事务的实现方法
分布式事务的实现方法有多种,以下是其中几种常见的方案:
1. 两阶段提交(XA 方案):事务管理器先询问各个数据库是否准备好了,每个要操作的数据库都回复事务管理器ok,那么就正式提交事务。
2. TCC方案:TCC的全称是:Try、Confirm、Cancel。
Try阶段是对各个服务的资源做检测以及对资源进行锁定或者预留;Confirm阶段是在各个服务中执行实际的操作;Cancel阶段是如果任何一个服务的业务方法执行出错,那么就需要进行补偿,即执行已经执行成功的业务逻辑的回滚操作。
一般来说,支付、交易等需要严格保证资金正确性的场景会使用TCC方案。
3. 可靠消息最终一致性方案:通过消息队列将分布式事务中的操作进行异步解耦,从而实现最终的一致性。
这种方式能够处理大量并发操作,但是可能会存在数据不一致的风险。
4. 最大努力通知方案:通过最大努力的方式将通知发送给其他服务,以实现分布式事务的一致性。
这种方式简单易行,但是可能会因为网络问题或者服务不可用等原因导致通知失败。
5. SAGA方案:SAGA是一种基于事务的分布式事务处理模型,它将一个分布式事务视为一系列本地事务的组合。
每个本地事务在一个单独的节点上执行,并且通过消息传递进行通信。
SAGA能够保证全局事务的最终一致性,同时具有较好的容错性和可恢复性。
以上是分布式事务的几种常见实现方案,每种方案都有其优缺点,需要根据具体的业务场景和需求来选择适合的方案。

分布式事务解决方案之TCCTCC(Try-Confirm-Cancel)是一种分布式事务解决方案,它通过将一个大事务分解为三个小事务来解决分布式系统中的一致性问题。
在TCC 中,每个小事务都有三个阶段:Try(尝试)、Confirm(确认)和Cancel(取消)。
Try阶段是指在执行事务之前,先尝试预留资源和锁定资源。
在这个阶段,应用程序会执行一些检查,验证所有需要的资源是否可用,并预留这些资源,以确保后续的事务操作可以成功执行。
Confirm阶段是指在Try阶段所有资源预留成功后,执行真正的事务操作。
在这个阶段,应用程序会执行真正的业务逻辑,对事务进行处理,并将事务状态从“预备”状态转变为“已提交”状态。
Cancel阶段是指在Try阶段出现错误或者其他异常情况时,回滚事务所做的操作。
在这个阶段,应用程序会执行撤销操作,释放之前预留的资源,并将事务状态从“预备”状态转变为“已撤销”状态。
TCC解决分布式事务的核心思想是通过拆分大事务为多个小事务,在每个小事务中保证数据一致性,并且通过确认和撤销操作来保证事务的最终一致性。
这种方式可以避免传统的二阶段提交等集中式事务管理方式的性能问题和可扩展性问题。
TCC的优点有以下几点:1. 高性能:TCC在Try阶段并不等待资源的释放,只是预留资源,因此在分布式事务场景下可以获得较好的性能。
2.可扩展性:TCC通过将事务拆分为多个小事务,可以将并发控制的粒度细化,提高系统的并发性能。
3.高可靠性:TCC通过确认和撤销操作来保证事务的最终一致性,即使在一些小事务失败的情况下,也可以通过取消操作恢复到事务开始之前的状态。
然而,TCC也存在一些缺点:1.代码复杂性:TCC需要开发者在每个小事务中手动编写确认和取消操作的逻辑,增加了代码的复杂性和开发难度。
2.并发控制问题:由于TCC采用乐观锁的方式来进行并发控制,所以存在并发冲突的问题。
开发者需要解决并发冲突的业务逻辑和异常处理。
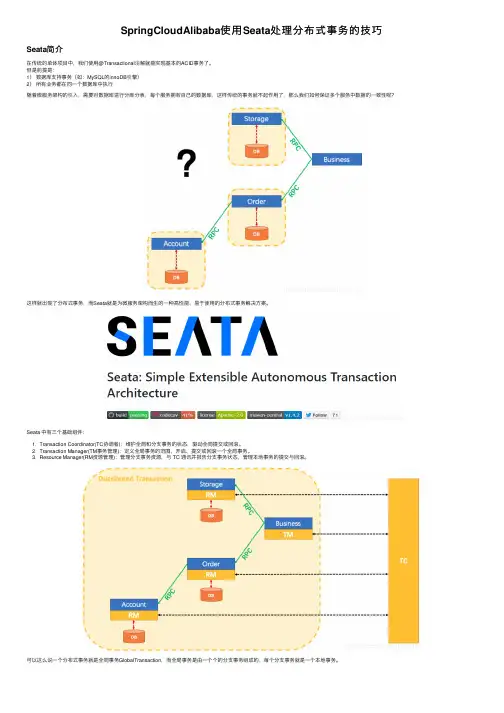
SpringCloudAlibaba使⽤Seata处理分布式事务的技巧Seata简介在传统的单体项⽬中,我们使⽤@Transactional注解就能实现基本的ACID事务了。
但是前提是:1)数据库⽀持事务(如:MySQL的innoDB引擎)2)所有业务都在同⼀个数据库中执⾏随着微服务架构的引⼊,需要对数据库进⾏分库分表,每个服务拥有⾃⼰的数据库,这样传统的事务就不起作⽤了,那么我们如何保证多个服务中数据的⼀致性呢?这样就出现了分布式事务,⽽Seata就是为微服务架构⽽⽣的⼀种⾼性能、易于使⽤的分布式事务解决⽅案。
Seata 中有三个基础组件:1. Transaction Coordinator(TC协调者):维护全局和分⽀事务的状态,驱动全局提交或回滚。
2. Transaction Manager(TM事务管理):定义全局事务的范围,开启、提交或回滚⼀个全局事务。
3. Resource Manager(RM资源管理):管理分⽀事务资源,与 TC 通讯并报告分⽀事务状态,管理本地事务的提交与回滚。
可以这么说⼀个分布式事务就是全局事务GlobalTransaction,⽽全局事务是由⼀个个的分⽀事务组成的,每个分⽀事务就是⼀个本地事务。
Seata的⽣命周期1. TM 要求 TC ⽣成⼀个全局事务,并由 TC ⽣成⼀个全局事务XID 返回。
2. XID 通过微服务调⽤链传播。
3. RM 向 TC 注册本地事务,将其注册到 ID 为 XID 的全局事务中。
4. TM 要求 TC 提交或回滚XID 对应的全局事务。
5. TC 驱动 XID 对应的全局事务对应的所有的分⽀事务提交或回滚。
Seata安装和配置startup -m standalone安装和配置Seatafile.conf主要是数据库的配置,配置如下registry.conf 是注册中⼼的配置另外conf⽬录中还需要⼀个脚本⽂件:nacos-config.sh ⽤于对nacos进⾏初始化配置在seata1.4.0中是没有的,需要⾃⾏创建,内容如下:#!/usr/bin/env bash# Copyright 1999-2019 Seata.io Group.## Licensed under the Apache License, Version 2.0 (the "License");# you may not use this file except in compliance with the License.# You may obtain a copy of the License at、## /licenses/LICENSE-2.0## Unless required by applicable law or agreed to in writing, software# distributed under the License is distributed on an "AS IS" BASIS,# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.# See the License for the specific language governing permissions and# limitations under the License.while getopts ":h:p:g:t:u:w:" optdocase $opt inh)host=$OPTARG;;p)port=$OPTARG;;g)group=$OPTARG;;t)tenant=$OPTARG;;u)username=$OPTARG;;w)password=$OPTARG;;)echo " USAGE OPTION: $0 [-h host] [-p port] [-g group] [-t tenant] [-u username] [-w password] " exit 1;;esacdoneurlencode() {for ((i=0; i < ${#1}; i++))dochar="${1:$i:1}"case $char in[a-zA-Z0-9.~_-]) printf $char ;;*) printf '%%%02X' "'$char" ;;esacdone}if [[ -z ${host} ]]; thenhost=localhostfiif [[ -z ${port} ]]; thenport=8848fiif [[ -z ${group} ]]; thengroup="SEATA_GROUP"fiif [[ -z ${tenant} ]]; thentenant=""fiif [[ -z ${username} ]]; thenusername=""fiif [[ -z ${password} ]]; thenpassword=""finacosAddr=$host:$portcontentType="content-type:application/json;charset=UTF-8"echo "set nacosAddr=$nacosAddr"echo "set group=$group"failCount=0tempLog=$(mktemp -u)function addConfig() {curl -X POST -H "${contentType}" "http://$nacosAddr/nacos/v1/cs/configs?dataId=$(urlencode $1)&group=$group&content=$(urlencode $2)&tenant=$tenant&username=$username&password=$password" >"${tempLog}" 2>/dev/null if [[ -z $(cat "${tempLog}") ]]; thenecho " Please check the cluster status. "exit 1fiif [[ $(cat "${tempLog}") =~ "true" ]]; thenecho "Set $1=$2 successfully "elseecho "Set $1=$2 failure "(( failCount++ ))fi}count=0for line in $(cat $(dirname "$PWD")/config.txt | sed s/[[:space:]]//g); do(( count++ ))key=${line%%=*}value=${line#*=}addConfig "${key}" "${value}"doneecho "========================================================================="echo " Complete initialization parameters, total-count:$count , failure-count:$failCount "echo "========================================================================="if [[ ${failCount} -eq 0 ]]; thenecho " Init nacos config finished, please start seata-server. "elseecho " init nacos config fail. "fi在seata的根⽬录,与conf同级的⽬录下,还需要config.txt 配置⽂件,默认也是没有的只需要对mysql的配置进⾏修改完整⽂件:transport.type=TCPtransport.server=NIOtransport.heartbeat=truetransport.enableClientBatchSendRequest=truetransport.threadFactory.bossThreadPrefix=NettyBosstransport.threadFactory.workerThreadPrefix=NettyServerNIOWorkertransport.threadFactory.serverExecutorThreadPrefix=NettyServerBizHandlertransport.threadFactory.shareBossWorker=falsetransport.threadFactory.clientSelectorThreadPrefix=NettyClientSelectortransport.threadFactory.clientSelectorThreadSize=1transport.threadFactory.clientWorkerThreadPrefix=NettyClientWorkerThreadtransport.threadFactory.bossThreadSize=1transport.threadFactory.workerThreadSize=defaulttransport.shutdown.wait=3service.vgroupMapping.my_test_tx_group=defaultservice.default.grouplist=127.0.0.1:8091service.enableDegrade=falseservice.disableGlobalTransaction=falseclient.rm.asyncCommitBufferLimit=10000client.rm.lock.retryInterval=10client.rm.lock.retryTimes=30client.rm.lock.retryPolicyBranchRollbackOnConflict=trueclient.rm.reportRetryCount=5client.rm.tableMetaCheckEnable=falseclient.rm.tableMetaCheckerInterval=60000client.rm.sqlParserType=druidclient.rm.reportSuccessEnable=falseclient.rm.sagaBranchRegisterEnable=falseclient.rm.tccActionInterceptorOrder=-2147482648mitRetryCount=5client.tm.rollbackRetryCount=5client.tm.defaultGlobalTransactionTimeout=60000client.tm.degradeCheck=falseclient.tm.degradeCheckAllowTimes=10client.tm.degradeCheckPeriod=2000client.tm.interceptorOrder=-2147482648store.mode=filestore.lock.mode=filestore.session.mode=filestore.publicKey=xxstore.file.dir=file_store/datastore.file.maxBranchSessionSize=16384store.file.maxGlobalSessionSize=512store.file.fileWriteBufferCacheSize=16384store.file.flushDiskMode=asyncstore.file.sessionReloadReadSize=100store.db.datasource=druidstore.db.dbType=mysqlstore.db.driverClassName=com.mysql.jdbc.Driverstore.db.url=jdbc:mysql://127.0.0.1:3306/seata?useUnicode=true&rewriteBatchedStatements=true er=rootstore.db.password=123456store.db.minConn=5store.db.maxConn=30store.db.globalTable=global_tablestore.db.branchTable=branch_tablestore.db.queryLimit=100store.db.lockTable=lock_tablestore.db.maxWait=5000store.redis.mode=singlestore.redis.single.host=127.0.0.1store.redis.single.port=6379store.redis.sentinel.masterName=xxstore.redis.sentinel.sentinelHosts=xxstore.redis.maxConn=10store.redis.minConn=1store.redis.maxTotal=100store.redis.database=0store.redis.password=xxstore.redis.queryLimit=100mittingRetryPeriod=1000server.recovery.asynCommittingRetryPeriod=1000server.recovery.rollbackingRetryPeriod=1000server.recovery.timeoutRetryPeriod=1000server.maxCommitRetryTimeout=-1server.maxRollbackRetryTimeout=-1server.rollbackRetryTimeoutUnlockEnable=falseserver.distributedLockExpireTime=10000client.undo.dataValidation=trueclient.undo.logSerialization=jacksonclient.undo.onlyCareUpdateColumns=trueserver.undo.logSaveDays=7server.undo.logDeletePeriod=86400000client.undo.logTable=undo_logpress.enable=truepress.type=zippress.threshold=64klog.exceptionRate=100transport.serialization=seatapressor=nonemetrics.enabled=falsemetrics.registryType=compactmetrics.exporterList=prometheusmetrics.exporterPrometheusPort=9898在conf⽬录中,使⽤Git Bash进⼊命令⾏,输⼊sh nacos-config.sh 127.0.0.1这是对Seata进⾏初始化配置,上图表⽰所有配置都成功设置了在nacos中可以看到出现了seata相关的配置接下来在seata数据库中,新建三个表drop table if exists `global_table`;create table `global_table` (`xid` varchar(128) not null,`transaction_id` bigint,`status` tinyint not null,`application_id` varchar(32),`transaction_service_group` varchar(32),`transaction_name` varchar(128),`timeout` int,`begin_time` bigint,`application_data` varchar(2000),`gmt_create` datetime,`gmt_modified` datetime,primary key (`xid`),key `idx_gmt_modified_status` (`gmt_modified`, `status`),key `idx_transaction_id` (`transaction_id`));drop table if exists `branch_table`;create table `branch_table` (`branch_id` bigint not null,`xid` varchar(128) not null,`transaction_id` bigint ,`resource_group_id` varchar(32),`resource_id` varchar(256) ,`lock_key` varchar(128) ,`branch_type` varchar(8) ,`status` tinyint,`client_id` varchar(64),`application_data` varchar(2000),`gmt_create` datetime,`gmt_modified` datetime,primary key (`branch_id`),key `idx_xid` (`xid`));drop table if exists `lock_table`;create table `lock_table` (`row_key` varchar(128) not null,`xid` varchar(96),`transaction_id` long ,`branch_id` long,`resource_id` varchar(256) ,`table_name` varchar(32) ,`pk` varchar(36) ,`gmt_create` datetime ,`gmt_modified` datetime,primary key(`row_key`));在项⽬相关的数据库中,新建表undo_log ⽤于记录撤销⽇志CREATE TABLE `undo_log` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`branch_id` bigint(20) NOT NULL,`xid` varchar(100) NOT NULL,`context` varchar(128) NOT NULL,`rollback_info` longblob NOT NULL,`log_status` int(11) NOT NULL,`log_created` datetime NOT NULL,`log_modified` datetime NOT NULL,`ext` varchar(100) DEFAULT NULL,PRIMARY KEY (`id`),UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;最后在bin⽬录中,启动命令⾏,执⾏seata-server.bat 启动Seata服务项⽬应⽤SeataSpringCloud项⽬中有两个服务:订单服务和库存服务,基本业务是:购买商品插⼊订单减少库存订单详情表DROP TABLE IF EXISTS `tb_order_detail`;CREATE TABLE `tb_order_detail` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '订单详情id ',`order_id` bigint(20) NOT NULL COMMENT '订单id',`sku_id` bigint(20) NOT NULL COMMENT 'sku商品id',`num` int(11) NOT NULL COMMENT '购买数量',`title` varchar(256) NOT NULL COMMENT '商品标题',`own_spec` varchar(1024) DEFAULT '' COMMENT '商品动态属性键值集',`price` bigint(20) NOT NULL COMMENT '价格,单位:分',`image` varchar(128) DEFAULT '' COMMENT '商品图⽚',PRIMARY KEY (`id`),KEY `key_order_id` (`order_id`) USING BTREE) ENGINE=MyISAM AUTO_INCREMENT=131 DEFAULT CHARSET=utf8 COMMENT='订单详情表';库存表DROP TABLE IF EXISTS `tb_stock`;CREATE TABLE `tb_stock` (`sku_id` bigint(20) NOT NULL COMMENT '库存对应的商品sku id',`seckill_stock` int(9) DEFAULT '0' COMMENT '可秒杀库存',`seckill_total` int(9) DEFAULT '0' COMMENT '秒杀总数量',`stock` int(9) NOT NULL COMMENT '库存数量',PRIMARY KEY (`sku_id`)) ENGINE=MyISAM DEFAULT CHARSET=utf8 COMMENT='库存表,代表库存,秒杀库存等信息';⽗项⽬定义了springboot、springcloud、springcloud-alibaba的版本<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.3.10.RELEASE</version><relativePath/> <!-- lookup parent from repository --></parent><dependencyManagement><dependencies><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-alibaba-dependencies</artifactId><version>0.9.0.RELEASE</version><type>pom</type><scope>import</scope></dependency><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-alibaba-dependencies</artifactId><version>2.2.1.RELEASE</version><type>pom</type><scope>import</scope></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-dependencies</artifactId><version>Hoxton.SR8</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement>⼦项⽬的依赖定义了nacos和seata客户端<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><scope>runtime</scope></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.3.2</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-seata</artifactId><exclusions><exclusion><groupId>io.seata</groupId><artifactId>seata-spring-boot-starter</artifactId></exclusion></exclusions></dependency><dependency><groupId>io.seata</groupId><artifactId>seata-spring-boot-starter</artifactId><version>1.2.0</version></dependency>⼦项⽬配置⽂件完整配置server:port: 8001spring:application:name: stock-servicecloud:nacos:discovery:server-addr: localhost:8848alibaba:seata:enabled: trueenable-auto-data-source-proxy: truetx-service-group: my_test_tx_groupregistry:type: nacosnacos:application: seata-serverserver-addr: 127.0.0.1:8848username: nacospassword: nacosconfig:type: nacosnacos:server-addr: 127.0.0.1:8848group: SEATA_GROUPusername: nacospassword: nacosservice:vgroup-mapping:my_test_tx_group: defaultdisable-global-transaction: falseclient:rm:report-success-enable: falsedatasource:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/eshop?serverTimezone=UTC&useUnicode=true&useSSL=false&characterEncoding=utf8 username: rootpassword: 123456库存服务定义了减库存的⽅法@RestControllerpublic class StockController {@Autowiredprivate IStockService stockService;@PutMapping("/stock")public ResponseEntity<Stock> reduceSkuStock(@RequestParam("skuId")Long skuId,@RequestParam("number")Integer number){Stock stock = stockService.getById(skuId);if(stock.getStock() < number){throw new RuntimeException("库存不⾜,SkuId:" + skuId);}stock.setStock(stock.getStock() - number);stockService.updateById(stock);return ResponseEntity.ok(stock);}}订单服务在插⼊订单后,使⽤Feign调⽤了减库存的服务@Servicepublic class OrderDetailServiceImpl extends ServiceImpl<OrderDetailMapper, OrderDetail> implements IOrderDetailService {//库存服务Feign@Autowiredprivate StockFeignClient stockFeignClient;// @Transactional@GlobalTransactional(rollbackFor = {Exception.class})@Overridepublic void makeOrder(OrderDetail orderDetail) {this.save(orderDetail); //保存订单int x = 11 / 0; //抛出异常//减库存stockFeignClient.reduceSkuStock(orderDetail.getSkuId(),orderDetail.getNum());}}插订单和减库存属于两个服务,传统的@Transactional已经不能保证它们的原⼦性了这⾥使⽤了Seata提供的@GlobalTransactional全局事务注解,出现任何异常后都能实现业务回滚。
在SQL SERVER中使用分布式事务全攻略(图解)[原创文章] 作者:cyw操作系统:Win2003 Enterprise Edition。
版本:5.2.3790 Service Pack 2 内部版本号 3790。
数据库:SQL Server 2000 企业版 + SP4 + SP4后的补丁。
版本:8.00.2187 (Intel X86) Mar 9 2006。
网络环境:两台服务器仅安装TCP/IP协议,处于相同网段,工作组可以不同,相互间Ping主机名成功,Ping IP地址也能成功。
如果不能Ping成功,请在两台服务器上安装NETBIOS协议后再重试。
如果还不行,请在“C:\WINDOWS\system32\drivers\etc\hosts”文件中增加一条记录:xxx.xxx.xxx.xxx 服务器主机名作用同样是把服务器名对应到链接服务器的IP地址。
一、建立链接服务器假设服务器A的IP是172.16.10.6,SQLServer登录用户sa,密码8888;服务器B的IP是172.16.10.16,SQLServer登录用户sa,密码9999。
现在先在服务器A上建立与B通信的远程链接服务器,假设链接的别名是BServer,如图:点击“确定”,完成。
同理,在B服务器上也建立对A服务器的远程链接,链接别名为AServer,数据源地址改为172.16.10.6,密码输入8888,其他相同。
当然,也可以使用SQL语句完成以上操作,如下:-- 建立远程链接服务器BServerEXEC sp_addlinkedserve r @server = 'BServer', @srvproduct = '', @provider = 'SQLOLEDB',@datasrc = '172.16.10.16', @catalog = 'HYCommon'-- 建立远程登录到BServerEXEC sp_addlinkedsrvlogin@rmtsrvname = 'BServer', @useself = 'false', @rmtuser = 'sa',@rmtpassword = '9999'-- 设置远程服务器选项:允许RPC和RPC输出(该步可选)Exec sp_serveroption'BServer', 'RPC', 'true'Exec sp_serveroption'BServer', 'RPC Out', 'true'现在测试一下链接是否成功,打开查询分析器,登录到A服务器,输入以下SQL运行:Select * From BServer.pubs.dbo.titles正常的话就可以看到B服务器上pubs数据库的titles表数据,如果不行,请检查网络连接是否满足文章开头所述的网络环境。

TCC分布式事务解决⽅案⼀、什么是 TCC事务TCC 是Try、Confirm、Cancel三个词语的缩写,TCC要求每个分⽀事务实现三个操作:预处理Try、确认Confirm、撤销Cancel。
Try操作做业务检查及资源预留,Confirm做业务确认操作,Cancel实现⼀个与 Try或者 Commit相反的操作即回滚操作。
TM⾸先发起所有的分⽀事务的 try操作,任何⼀个分⽀事务的 try操作执⾏失败,TM将会发起所有分⽀事务的 Cancel操作,若 Try操作全部成功,TM将会发起所有分⽀事务的 Confirm操作,其中 Confirm/Cancel 操作若执⾏失败,TM会进⾏重试。
⼆、TCC 解决⽅案⽬前市⾯上的 TCC框架众多⽐如下⾯这⼏种:框架名称Gitbub地址star数量tcc-transaction4351Hmily2788ByteTCC2156EasyTransaction1907Seata也⽀持TCC,但 Seata的 TCC模式对 Spring Cloud并没有提供⽀持。
因此更请倾向于轻量级易于理解的框架Hmily,来理解 TCC的原理以及事务协调运作的过程。
Hmily是⼀个⾼性能分布式事务 TCC开源框架。
基于Java语⾔来开发,⽀持Dubbo,Spring Cloud等。
RPC框架进⾏分布式事务。
它⽬前⽀持以下特性:■⽀持嵌套事务(Nested transaction support);■采⽤ disruptor框架进⾏事务⽇志的异步读写,与 RPC框架的性能毫⽆差别;■⽀持 SpringBoot-starter 项⽬启动,使⽤简单;■ RPC框架⽀持 : dubbo,motan,springcloud;■本地事务存储⽀持 : redis,mongodb,zookeeper,fifile,mysql;■事务⽇志序列化⽀持:java,hessian,kryo,protostuff;■采⽤ Aspect AOP 切⾯思想与 Spring⽆缝集成,天然⽀持集群;■ RPC事务恢复,超时异常恢复等;Hmily利⽤ AOP对参与分布式事务的本地⽅法与远程⽅法进⾏拦截处理,通过多⽅拦截,事务参与者能透明的调⽤到另⼀⽅的Try、Confirm、Cancel⽅法;传递事务上下⽂;并记录事务⽇志,酌情进⾏补偿,重试等。

解析分布式事务的四种解决方案分布式事务指事务的操作位于不同的节点上,需要保证事务的 AICD 特性。
例如在下单场景下,库存和订单如果不在同一个节点上,就涉及分布式事务。
在分布式系统中,要实现分布式事务,无外乎那几种解决方案。
一、两阶段提交(2PC)两阶段提交(Two-phase Commit,2PC),通过引入协调者(Coordinator)来协调参与者的行为,最终决定这些参与者是否要真正执行事务。
1、运行过程①准备阶段:协调者询问参与者事务是否执行成功,参与者发回事务执行结果。
②提交阶段:如果事务在每个参与者上都执行成功,事务协调者发送通知让参与者提交事务;否则,协调者发送通知让参与者回滚事务。
需要注意的是,在准备阶段,参与者执行了事务,但是还未提交。
只有在提交阶段接收到协调者发来的通知后,才进行提交或者回滚。
2、存在的问题①同步阻塞:所有事务参与者在等待其它参与者响应的时候都处于同步阻塞状态,无法进行其它操作。
②单点问题:协调者在 2PC 中起到非常大的作用,发生故障将会造成很大影响。
特别是在阶段二发生故障,所有参与者会一直等待状态,无法完成其它操作。
③数据不一致:在阶段二,如果协调者只发送了部分 Commit 消息,此时网络发生异常,那么只有部分参与者接收到 Commit 消息,也就是说只有部分参与者提交了事务,使得系统数据不一致。
④太过保守:任意一个节点失败就会导致整个事务失败,没有完善的容错机制。
二、补偿事务(TCC)TCC 其实就是采用的补偿机制,其核心思想是:针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。
它分为三个阶段:①Try 阶段主要是对业务系统做检测及资源预留。
②Confirm 阶段主要是对业务系统做确认提交,Try阶段执行成功并开始执行Confirm阶段时,默认 Confirm阶段是不会出错的。
即:只要Try成功,Confirm一定成功。
③Cancel 阶段主要是在业务执行错误,需要回滚的状态下执行的业务取消,预留资源释放。

C#分布式事务解决⽅案-TransactionScope引⽤⼀下别⼈的导读:在实际开发⼯作中,执⾏⼀个事件,然后调⽤另⼀接⼝插⼊数据,如果处理逻辑出现异常,那么之前插⼊的数据将成为垃圾数据,我们所希望的是能够在整个这个⽅法定义为⼀个事务,TransactionScope 类提供⼀个简单⽅法,通过这⼀⽅法,您不必与事务本⾝交互,即可将代码块标记为参与某个事务。
TransactionScope对象创建了⼀个事务,同时将该事务设置给Transaction类的Current属性。
⼀、TransactionScope的优点1、使⽤起来⽐较⽅便.TransactionScope可以实现隐式的事务,使你可以在写数据访问层代码的时候不⽤考虑到事务,⽽在业务层的控制事务.2、可以实现分布式事务,⽐如跨库或MSMQ.⼆、TransactionScope缺点1、性价⽐不⾼.⽐如,你只是在"Scope"⾥控制⼀个库的事务.⽤"TransactionScope"就有点浪费了.2、⼀般情况下只要你使⽤"TransactionScope",都要配置MSDTC,要配防⽕墙,要开139端⼝.这个端⼝不可以更改三、如果你不得不⽤分布式事务,那也得琢磨琢磨1.这步操作⼀定得在事务当中吗?这步操作如果没完成或者失败了,值得回滚整个事务吗?难道没有优雅的补偿措施或者容错措施?2.分布式事务涉及到的点,必须的这么多?必须得实时的操作这⼀⼤串?不能通过通知类操作去精简掉某些点?3.在发起分布式事务之后,你是不是做了事务⽆关的操作,尽管这些操作跟事务⽆关?(如,读取数据、计算、等⽤户返回消息、等其他模块的调⽤返回等等)要知道事务应该尽快结束。
4.你没有把⼀些读操作也算在事务⾥⾯了吧?这是很容易犯的错误,你在事务中Enlist了⼀个select 操作。
5.你的操作,某些步骤可以等全部操作完成之后再执⾏.这类操作具有明显的通知类特点。

详解Java分布式事务的6种解决⽅案介绍在分布式系统、微服务架构⼤⾏其道的今天,服务间互相调⽤出现失败已经成为常态。
如何处理异常,如何保证数据⼀致性,成为微服务设计过程中,绕不开的⼀个难题。
在不同的业务场景下,解决⽅案会有所差异,常见的⽅式有:1. 阻塞式重试;2. 2PC、3PC 传统事务;3. 使⽤队列,后台异步处理;4. TCC 补偿事务;5. 本地消息表(异步确保);6. MQ 事务。
本⽂侧重于其他⼏项,关于 2PC、3PC 传统事务,⽹上资料已经⾮常多了,这⾥不多做重复。
阻塞式重试在微服务架构中,阻塞式重试是⽐较常见的⼀种⽅式。
伪代码⽰例:m := db.Insert(sql)err := request(B-Service,m)func request(url string,body interface{}){for i:=0; i<3; i ++ {result, err = request.POST(url,body)if err == nil {break}else {log.Print()}}}如上,当请求 B 服务的 API 失败后,发起最多三次重试。
如果三次还是失败,就打印⽇志,继续执⾏下或向上层抛出错误。
这种⽅式会带来以下问题1. 调⽤ B 服务成功,但由于⽹络超时原因,当前服务认为其失败了,继续重试,这样 B 服务会产⽣ 2 条⼀样的数据。
2. 调⽤ B 服务失败,由于 B 服务不可⽤,重试 3 次依然失败,当前服务在前⾯代码中插⼊到 DB 的⼀条记录,就变成了脏数据。
3. 重试会增加上游对本次调⽤的延迟,如果下游负载较⼤,重试会放⼤下游服务的压⼒。
第⼀个问题:通过让 B 服务的 API ⽀持幂等性来解决。
第⼆个问题:可以通过后台定时脚步去修正数据,但这并不是⼀个很好的办法。
第三个问题:这是通过阻塞式重试提⾼⼀致性、可⽤性,必不可少的牺牲。
阻塞式重试适⽤于业务对⼀致性要求不敏感的场景下。

多数据源事务控制解决方案(分布式事务控制)在分布式系统中,多数据源事务控制是一个常见的挑战。
分布式系统中的数据通常存储在不同的数据库中,每个数据库都有自己的事务管理机制。
在跨多个数据源执行事务时,确保数据的一致性和正确性变得非常重要。
为了解决这个问题,可以采用以下几种多数据源事务控制解决方案。
两阶段提交是一种经典的分布式事务控制协议。
它通过协调者(coordinator)和参与者(participant)之间的通信来实现多数据源事务的一致性。
协议的执行过程分为两个阶段:准备阶段和提交阶段。
在准备阶段,协调者向所有参与者发送准备请求,询问它们是否可以执行事务。
如果所有参与者都同意,则进入提交阶段,并向所有参与者发送提交请求。
否则,协调者会向所有参与者发送回滚请求,取消事务的执行。
尽管两阶段提交能够确保事务的一致性,但它的缺点是协调者的单点故障和阻塞问题。
三阶段提交是对两阶段提交的改进。
它引入了超时机制来应对协调者的单点故障和阻塞问题。
三阶段提交的执行过程分为准备阶段、提交前准备阶段和提交阶段。
在准备阶段,协调者向所有参与者发送准备请求,询问它们是否可以执行事务。
如果所有参与者都同意,则进入提交前准备阶段,并向所有参与者发送预提交请求。
在预提交阶段,参与者将事务写入日志,并等待协调者的最终决策。
如果参与者在预提交阶段发生故障,则会进入回滚状态。
最后,在提交阶段,协调者向所有参与者发送提交请求,参与者根据日志的状态来确定是否提交或回滚事务。
三阶段提交相对于两阶段提交,能够减少长时间的阻塞情况,但仍然存在协调者故障时的一致性问题。
3. 可靠消息服务(Reliable message service)可靠消息服务是一种解耦发送方和接收方的通信机制。
在多数据源事务控制中,可靠消息服务可以用来确保不同数据源之间的事务操作的一致性。
发送方将事务消息发送到消息队列中,并等待确认。
接收方从消息队列中接收消息进行处理,并给发送方发送一个确认消息。

分布式事务解决⽅案3--本地消息表(事务最终⼀致⽅案)⼀、本地消息表原理1、本地消息表⽅案介绍本地消息表的最终⼀致⽅案采⽤BASE原理,保证事务最终⼀致在⼀致性⽅⾯,允许⼀段时间内的不⼀致,但最终会⼀致。
在实际系统中,要根据具体情况,判断是否采⽤。
(有些场景对⼀致性要求较⾼,谨慎使⽤)2、本地消息表的使⽤场景基于本地消息表的⽅案中,将本事务外操作,记录在消息表中其他事务,提供操作接⼝定时任务轮询本地消息表,将未执⾏的消息发送给操作接⼝。
操作接⼝处理成功,返回成功标识,处理失败,返回失败标识。
定时任务接到标识,更新消息的状态定时任务按照⼀定的周期反复执⾏对于屡次失败的消息,可以设置最⼤失败次数超过最⼤失败次数的消息,不进⾏接⼝调⽤等待⼈⼯处理例如使⽤⽀付宝的⽀付场景,系统⽣成订单,⽀付宝系统⽀付成功后,调⽤我们系统提供的回调接⼝,回调接⼝更新订单状态为已⽀付。
回调通知执⾏失败,⽀付宝会过⼀段时间再次调⽤。
3、本地消息表架构图4、优缺点优点:避免了分布式事务,实现了最终⼀致性缺点:注意重试时的幂等性操作⼆、本地消息表数据库设计整体⼯程复⽤前⾯的my-tcc-demo1、两台数据库 134和129。
user_134 创建⽀付消息表payment_msg, user_129数据库创建订单表t_order2、使⽤MyBatis-generator ⽣成数据库映射⽂件,⽣成后的结构如下图所⽰三、⽀付接⼝1、创建⽀付服务PaymentService@Servicepublic class PaymentService {@Resourceprivate AccountAMapper accountAMapper;@Resourceprivate PaymentMsgMapper paymentMsgMapper;/*** ⽀付接⼝* @param userId ⽤户Id* @param orderId 订单Id* @param amount ⽀付⾦额* @return 0: 成功; 1:⽤户不存在 2:余额不⾜*/public int payment(int userId, int orderId, BigDecimal amount){//⽀付操作AccountA accountA = accountAMapper.selectByPrimaryKey(userId);if(accountA == null){return 1;}if(accountA.getBalance().compareTo(amount) < 0){return 2;}accountA.setBalance(accountA.getBalance().subtract(amount));accountAMapper.updateByPrimaryKey(accountA);PaymentMsg paymentMsg = new PaymentMsg();paymentMsg.setOrderId(orderId);paymentMsg.setStatus(0); //未发送paymentMsg.setFailCnt(0); //失败次数paymentMsg.setCreateTime(new Date());paymentMsg.setCreateUser(userId);paymentMsg.setUpdateTime(new Date());paymentMsg.setUpdateUser(userId);paymentMsgMapper.insertSelective(paymentMsg);return 0;}}2、创建Controller层@RestControllerpublic class PaymentController {@Autowiredprivate PaymentService paymentService;//localhost:8080/payment?userId=1&orderId=10010&amount=200@RequestMapping("payment")public String payment(int userId, int orderId, BigDecimal amount){int result = paymentService.payment(userId, orderId,amount);return "⽀付结果:" + result;}}3、调⽤接⼝localhost:8080/payment?userId=1&orderId=10010&amount=200查看表。

分布式事务是指会涉及到操作多个数据库(服务)的事务其实就是将对同一数据库(服务)事务的概念扩大到了对多个数据库(服务)的事务目的:是为了保证分布式系统中的数据一致性分布式事务处理的关键是必须有一种方法可以知道事务在任何地方所做的所有动作,提交或回滚事务的决定必须产生统一的结果(全部提交或全部回滚)XA规范:AP:应用程序,AP通过TM界定事务,AP通过RM操作资源TM:事务管理器(协调者),TM和RM交互事务信息RM:资源管理器(DB),TM和RM交互事务信息总之一句话:就是定义的事务协调者与数据库之间的接口规范,事务协调者用它来通知数据库事务的开始、结束以及提交、回滚等。
XA接口由数据库厂商提供XA规范的实现:内部XA:单机的情况下,binlog充当TM(事务协调者)的角色。
一个事务过来,写入redo log日志和undo log日志。
事务提交时,同时写入redo log 和binlog,保证redo log 和binlog一致。
如果事务撤销,则根据undo log进行撤销。
外部XA:分布式集群的情况下,一般加代理层(第三方)来充当TM的角色,实现对事务的支持。
两阶段提交协议(2PC)和三阶段提交协议(3PC)就是根据这一思想衍生出来的。
两阶段提交主要保证了分布式事务的原子性,即所有结点要么全做要么全不做CAP理论Consistency:一致性,分布式环境下多个节点的数据是否强一致,即客户端每次读操作,要么读到的是最新的数据,要么读取失败。
Availability: 可用性, 任何客户端的请求都能得到响应数据,不会出现响应错误。
即我一定会给你返回数据,不会给你返回错误,但不保证数据最新,强调不会出错。
Partition Tolerance:分区容忍性,由于分布式系统通过网络进行通信,而网络是不可靠的。
当任意数量的消息丢失或延迟产生,系统仍会继续提供服务,不会挂掉。
即承诺系统会一直运行,不管系统刚问出现何种数据同步问题,强调的是系统不挂掉。
分布式事务的处理方法嘿,朋友!今天咱来唠唠分布式事务的处理方法,这可是个相当重要的玩意儿哦!咱先来说说第一步哈,你得把各个系统之间的关系整明白咯,就像你得知道家里的各种电器咋连接的一样。
别到时候这个系统和那个系统闹矛盾了,你还在那儿懵圈呢!想象一下,这系统就好比一群小伙伴,你得让他们和谐相处,别打架呀!接下来第二步呢,就像是给这些小伙伴们定规矩。
咱得设计好事务的流程,让它们知道啥时候该干啥,不能瞎整。
比如说,一个系统先干啥,另一个系统再干啥,可不能乱了套。
就好比你和朋友约好一起出去玩,谁先出门,谁在哪个地方等,都得说好,不然那不就抓瞎啦!第三步呀,要做好事务的协调。
这就好像是个裁判一样,看着各个系统有没有按照规矩来。
要是有哪个系统调皮捣蛋不听话,咱这裁判就得出来管管啦!有一次我就遇到个系统,就跟个调皮孩子似的,不好好干活,可把我给气坏了!然后呢,第四步,要处理好可能出现的异常情况。
这世界上啥事都有可能发生,就像出门突然下大雨一样。
咱得提前想好各种可能出问题的情况,然后想好应对办法。
别到时候出了问题,你在那儿傻眼,不知道咋办。
再来说说这第五步哈,监控和优化可不能少。
你得时刻盯着这些系统,看看它们干得咋样。
就跟你看着自己种的花一样,得看看有没有长歪啦,需不需要浇水施肥啦。
要是发现有啥问题,赶紧调整优化,让它们干得更棒!咱再举个例子哈,比如说有个电商系统,买东西的时候涉及到好多系统呢。
订单系统、库存系统、支付系统等等。
这就像是一个团队在合作,要是哪个环节出了问题,那这交易可就搞不定啦!所以咱得把这分布式事务处理好,让大家都能愉快地合作。
哎呀,说了这么多,你可别嫌我啰嗦呀!这分布式事务的处理方法可重要啦,你可得好好记住。
就跟学骑自行车一样,一开始可能会摔倒,但是多练几次就会啦!咱这处理方法也是,多实践几次,你就会发现越来越得心应手啦!好啦,朋友,今天就先唠到这儿,你赶紧去试试这超级厉害的分布式事务处理方法吧!加油哦!。
分布式事务详解1. 什么是分布式事务1.1 事务严格意义上的事务实现应该是具备原⼦性、⼀致性、隔离性和持久性,简称 ACID。
通俗意义上来说,事务就是为了使得⼀些更新等操作要么都成功,要么都失败。
原⼦性(Atomicity):可以理解为⼀个事务内的所有操作要么都执⾏,要么都不执⾏。
⼀致性(Consistency):可以理解为数据是满⾜完整性约束的,也就是不会存在中间状态的数据,⽐如你账上有400,我账上有100,你给我打200块,此时你账上的钱应该是200,我账上的钱应该是300,不会存在我账上钱加了,你账上钱没扣的中间状态。
隔离性(Isolation):指的是多个事务并发执⾏的时候不会互相⼲扰,即⼀个事务内部的数据对于其他事务来说是隔离的。
持久性(Durability):指的是⼀个事务完成了之后数据就被永远保存下来,之后的其他操作或故障都不会对事务的结果产⽣影响。
其中,原⼦性和持久性就是靠undo和redo⽇志来实现的。
在Mysql中,有许多⽇志⽂件,这2个⽂件就是与事务有关的。
1.2 undo⽇志undo⽇志:⽤于保证事务的原⼦性。
原理:1. 在操作任何数据之前,先将数据备份到Undo Log。
2. 然后进⾏数据的修改。
3. 若出现了错误或⽤户执⾏了ROLLBACK语句,系统就可以利⽤Undo Log中的备份数据恢复到事务开始之前的状态。
流程举例:1. 事务开始2. 记录A=1到undo log3. 修改A=34. 记录B=2到undo log5. 修改B=46. 将undo log写到磁盘7. 将数据写到磁盘8. 事务提交1.3 redo⽇志redo⽇志:⽤于保证事务的持久性原理:1. redo log与undo log 相反,redo log记录的是新数据的备份,undo log记录的是旧数据的备份2. 在事务提交前只需要将redo log持久化即可。
流程举例:1. 事务开始2. 记录A=1到undo log3. 修改A=34. 记录A=3到redo log5. 记录B=2到undo log6. 修改B=47. 记录B=4到redo log8. 将undo log写到磁盘9. 将redo log写⼊磁盘10. 事务提交1.4 分布式事务分布式事务:顾名思义就是要在分布式系统中实现事务,它其实是由多个本地事务组合⽽成。
分布式事务seata的使用方法小伙伴!今天咱们来唠唠分布式事务里的Seata怎么用哈。
Seata是个超酷的分布式事务解决方案呢。
那第一步呀,咱得把Seata的服务端给搭建起来。
这就像是盖房子打地基一样重要哦。
你要去Seata的官方仓库下载对应的版本,然后按照文档里的说明去配置它的一些基本参数,像存储模式啦,要是用数据库存储事务信息,就得把数据库相关的连接信息啥的配置得妥妥当当。
接着就是在咱们的项目里引入Seata的客户端啦。
这时候就看你用啥开发语言啦,如果是Java项目,就把Seata的Java客户端依赖加到你的项目里。
这个过程就像是给你的项目注入一股神奇的力量,让它能处理分布式事务啦。
在代码里呢,你得对那些需要参与分布式事务的方法做一些特殊的标记。
比如说在Spring Boot项目里,你可以用注解的方式。
像@GlobalTransactional这个注解,就像是给方法穿上了一件特殊的“分布式事务外套”,告诉Seata这个方法是要在分布式事务的管控之下的。
还有哦,不同的数据库操作在Seata里也有一些小讲究。
比如说,你要是对数据库做更新操作,Seata会帮你记录操作前后的状态,就像一个贴心的小管家。
如果在分布式事务执行过程中出了岔子,它就能根据这些记录把数据恢复到正确的状态。
在配置Seata客户端的时候呀,要记得把服务端的地址告诉它,这样客户端才能找到服务端这个“大管家”来协调分布式事务呢。
这就好比你要去朋友家玩,得知道朋友家的地址一样。
而且呀,Seata在处理分布式事务的时候,会涉及到很多的角色,像事务协调器、事务参与者之类的。
每个角色都有自己的任务,它们就像一个团队一样默契配合。
咱们在使用的时候不用太担心这些角色内部复杂的交互,只要按照规则配置好,Seata就会自动让它们好好工作啦。
总之呢,使用Seata虽然一开始可能觉得有点小复杂,但是只要你按照步骤一步一步来,就像搭积木一样,慢慢就能把分布式事务管理得井井有条啦。
分布式事务常见面试题分布式事务是现代分布式系统中一个重要的话题,也是面试中较为常见的考点之一。
下面给出一些常见的关于分布式事务的面试题,以帮助你进一步了解和准备相关内容。
一、基础概念1. 什么是分布式系统?2. 什么是分布式事务?3. 传统关系型数据库中的事务是如何保证一致性的?4. 分布式事务与单机事务有何区别?二、分布式事务的实现方式1. 分布式事务的实现方式有哪些?2. 请分别介绍两阶段提交和三阶段提交协议。
3. 什么是本地消息表?4. 什么是可靠消息中间件?三、分布式事务的常见问题1. 分布式事务有哪些典型的问题?2. 分布式事务的最终一致性如何保证?3. 分布式事务的性能问题如何解决?4. 分布式事务的可扩展性如何提高?四、分布式事务的应用场景1. 什么样的应用场景适合使用分布式事务?2. 分布式事务在电子商务、支付系统等领域中的应用举例。
3. 分布式事务在微服务架构中的应用如何实现?五、分布式事务的发展趋势1. 目前主流的分布式事务解决方案有哪些?2. 基于容器化技术的分布式事务方案有哪些?3. 分布式事务的未来发展方向有哪些?六、你对分布式事务的理解和实践经验1. 你是如何理解分布式事务的一致性和可用性的?2. 请举一个你曾经遇到的涉及分布式事务的问题,并分享你是如何解决的。
3. 分布式事务中的数据一致性如何保证?4. 你在实际项目中如何选择和应用不同的分布式事务方案?以上面试题,涵盖了分布式事务的基础概念、实现方式、常见问题、应用场景、发展趋势等方面的内容。
在准备面试时,可以结合相关知识点进行复习和思考,以便能够给出清晰、全面的回答。
同时,也可根据具体面试岗位的要求,针对性地准备和深入研究相关内容,以展示自己的专业能力和实践经验。
祝你面试顺利!。
MySQL的分布式事务处理和跨库事务的解决方案随着互联网的快速发展和大数据的兴起,对于数据库系统的性能和可扩展性提出了更高的要求。
在很多应用场景中,单一的数据库已经无法满足需求,需要将数据分布在多个数据库上进行处理和存储。
而在这种分布式环境下,如何保证事务的一致性和数据的可靠性成为了一个重要的挑战。
本文将介绍MySQL的分布式事务处理和跨库事务的解决方案。
一、MySQL的事务机制MySQL是一个开源的关系型数据库管理系统,它的事务机制是基于ACID原则的。
ACID是指原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。
MySQL通过实现多版本并发控制(MVCC)和锁机制来实现事务的隔离性,对于单个数据库的事务处理是非常可靠的。
然而,在分布式环境下,由于存在多个数据库节点,每个节点之间可能存在网络延迟和故障等问题,导致事务的一致性无法得到保证。
二、分布式事务处理的问题在分布式架构中,事务跨越多个数据库节点是很常见的需求。
然而,由于每个节点拥有自己的独立事务,没有统一的事务控制机制,导致跨库事务会面临以下问题:1. 事务的一致性:由于网络延迟和节点故障等原因,导致事务在某个节点上失败,可能会引起数据不一致的问题。
例如,一个转账操作同时操作了两个数据库节点,如果其中一个节点操作成功,而另一个节点操作失败,那么账户的余额就会不一致。
2. 事务的隔离性:在分布式环境下,每个节点都有自己的事务隔离级别,可能导致事务的隔离性无法保证。
例如,一个事务读取了一个节点的数据后,如果读取到了另一个节点正在修改的数据,就可能导致读取到脏数据。
3. 事务的并发性:在分布式环境下,并发访问多个数据库节点的事务会导致性能问题。
由于每个节点都有自己的事务处理机制,无法有效地并发执行事务。
三、跨库事务的解决方案为了解决分布式事务的问题,MySQL提供了多种跨库事务的解决方案。