基于STM32单片机的嵌入式语音识别系统设计
- 格式:pdf
- 大小:2.53 MB
- 文档页数:3

基于STM32的声音定位系统引言声音定位技术是近年来备受关注的一项技术,它可以通过声音信号的接收和处理,确定声源的位置。
这项技术在军事、安防、医疗等领域均有着广泛的应用,而随着技术的发展,声音定位系统也逐渐向普通民用领域渗透。
为了满足市场对于声音定位系统的需求,一些厂家推出了基于STM32的声音定位系统。
本文将介绍基于STM32的声音定位系统的设计及实现方法。
一、声音定位系统的工作原理声音定位系统是通过多个麦克风阵列收集声音信号,并利用算法处理声音信号,从而确定声源的位置。
通常,声音定位系统包括声音采集模块、数字信号处理模块和控制模块。
声音采集模块:声音采集模块采用多个麦克风构成的麦克风阵列,用于接收来自不同方向的声音信号。
多个麦克风可以接收到同一声源的声音信号,并通过麦克风之间的时间差或声音强度差来确定声源的位置。
数字信号处理模块:声音信号采集后,需要进行数字信号处理,一般包括信号滤波、时域分析、频域分析、噪声抑制等处理步骤。
处理后的声音信号可以更准确地确定声源的位置。
控制模块:控制模块通常采用微处理器或嵌入式系统,用于控制声音采集模块和数字信号处理模块的工作,并根据处理结果确定声源的位置。
二、基于STM32的声音定位系统的设计与实现基于STM32的声音定位系统通常包括硬件设计和软件设计两部分。
硬件设计:声音定位系统的硬件设计主要包括声音采集模块、数字信号处理模块和控制模块。
声音采集模块一般采用麦克风阵列,通过多个麦克风接收声音信号。
数字信号处理模块一般采用DSP或FPGA芯片,用于对采集到的声音信号进行处理。
控制模块一般采用STM32系列的单片机,用于控制声音采集模块和数字信号处理模块的工作,并进行数据处理和结果输出。
软件设计:声音定位系统的软件设计主要包括嵌入式软件和PC端软件。
嵌入式软件主要运行在STM32单片机上,用于控制硬件模块的工作,并进行声音信号的处理。
PC端软件一般用于与声音定位系统进行通信,接收处理结果并进行显示、记录等操作。

嵌入式设计论文…基于PWM的语音0~9数字播报班级: 1221201专业:测控技术与仪器姓名:朱宇杰学号: 201220120118指导老师:钟老师东华理工大学利用PWM进行数字语音的播报设计摘要随着嵌入式领域的拓展,目前许多微控制器芯片一般都不具备数据一模拟的双向通道,但几乎都集成有PWM产生模块。
本文利用stm32单片机的PWM模块,还原存储在存储器中的声音采样数据,在几乎不增加成本的情况下,实现嵌入式应用中的扩展语音功能。
关键词stm32 PWM 语音低通滤波STM32的PWM精讲通过对TIM1定时器进行控制,使之各通道输出插入死区的互补PWM输出,各通道输出频率均为17.57KHz。
其中,通道1输出的占空比为50%,通道2输出的占空比为25%,通道3输出的占空比为12.5%。
各通道互补输出为反相输出。
TIM1定时器的通道1到4的输出分别对应PA.08、PA.09、PA.10和PA.11引脚,而通道1到3的互补输出分别对应PB.13、PB.14和PB.15引脚,中止输入引脚为PB.12。
将这些引脚分别接入示波器,在示波器上观查相应通道占空比的方波配置好各通道后, 编译运行工程;点击MDK 的Debug菜单,点击Start/Stop Debug Session;通过示波器察看PA.08、PA.09、PA.10、PB.13、PB.14、PB.15的输出波形,其中PA.08和PB.13为第一通道和互补通道,PB.09和PB.14为第二通道和其互补通道,PB.10和PB.15为第三通道和其互补通道;第一通道显示占空比为50%,第二通道占空比为25%,第三通道占空比为12.5%。
STM32处理器概述STM32F103xx增强型系列产品中内置了多达3个同步的标准定时器。
每个定时器都有一个16位的自动加载递加/递减计数器、一个16位的预分频器和4个独立的通道,每个通道都可用于输入捕获、输出比较、PWM和单脉冲模式输出,在最大的封装配置中可提供最多12个输入捕获、输出比较或PWM通道。

基于单片机的智能语音识别系统设计(硬件部分)系别:专业班:姓名:学号:指导教师:基于单片机的智能语音识别系统设计(硬件部分)The Design of Intelligent SpeechRecognition System Based onSingle-chip Computer(HardWare)摘要本文设计一个让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高技术的语音识别系统。
本语音识别系统以LD3320语音识别芯片为核心部件,主控MCU选用STC10L08XE。
主控MCU通过控制LD3320内部寄存器以及SPI flash实现语音识别和对话。
通过麦克风将声音信息输入LD3320进行频谱分析,分析后将提取到的语音特征和关键词语列表中的关键词语进行对比匹配,找出得分最高的关键词语作为识别结果输出给MCU,MCU针对不同的语音输入情况通过继电器对语音命令所对应的电器实现控制。
同时也可以通过对寄存器中语音片段的调用,实现人机对话。
设计中,电源模块采用3.3V供电,主要控制及识别部分采用LM1117-3.3稳压芯片,语音播放及继电器部分采用7812为其提供稳定的电流电压。
寄存器采用一片华邦SPI flash芯片W25Q40AVSNIG,大小为512Kbyte。
系统声音接收模块采用的传感器为一小型麦克风——驻极体话筒,在它接收到声音信号后会产生微弱的电压信号并送给MCU。
另外系统还采用单片机产生不同的频率信号驱动蜂鸣器来完成声音提示,此方案能完成声音提示功能,给人以提示的可懂性不高,但在一定程度上能满足要求,而且易于实现,成本也不高。
关键词:语音识别 LD3320 STC10L08XE单片机频谱分析AbstractThis paper designs a hi-tech speech recognition system which enables machines to transfer speech signals into corresponding texts or orders by recognizing and comprehending. The centerpiece of the speech recognition system is LD3320 voice recognition chip,its master MCU is STC10L08XE. Master MCU achieve voice conversation by controlling the internal registers and SPI flash LD3320.The sound information is inputted into LD3320 by microphone to do spectrum analysis. After analyzing the voice characteristics extracted are compared and matched with the key words in the list of key words.Then the highest scores of key words found would be output to MCU as recognition results. MCU can control the corresponding electrical real of speech recognition for different voice input through the relays and can also achieve voice conversation through a call to voice clips in register.In the design,power module uses 3.3V.The main control and identification part adopt LM1117-3.3 voltage regulator chip,and 7812 is used to provide stable current and voltage for the part of voice broadcast and relay.Register uses chip SPI flash W25Q40A VSNIG which is 512Kbyte. The sensor used in the speech reception module of the design is microphone,namely electrit microphone.After receiveing the sound signal,it can produce a weak voltage signal which will be sent to MCU. In addition,the system also adopts a different frequency signals generated by microcontroller to drive the buzzer to complete the voice prompt, and this program can complete the voice prompt.The program gives a relatively poor intelligibility Tips.However, to some extent,it can meet the requirements and is easy to implement and the cost is not high.Key words:Speech Recognition LD3320 STC10L08XE Single-chip computer Spectrum Analysis目录摘要 (I)Abstract (II)绪论 (1)1设计方案 (5)1.1 系统设计要求 (5)1.2总体方案设计 (5)2 系统硬件电路设计 (6)2.1电源模块 (6)2.2 寄存器模块 (6)2.3 控制单元模块 (7)2.3.1 STC10L08XE单片机简介 (8)2.3.2 STC11/10xx系列单片机的内部结构 (10)2.4 声音接收器模块 (10)2.5 声光指示模块 (11)2.6 语音识别模块 (11)2.6.1 LD3320芯片简介 (11)2.6.2 功能介绍 (12)2.6.3 应用场景 (13)2.6.4 芯片模式选择 (15)2.6.5 吸收错误识别 (16)2.6.6 口令触发模式 (17)2.6.7 关键词的ID及其设置 (18)2.6.8 反应时间 (18)3 系统软件设计 (20)3.1 系统程序流程图 (20)3.2 系统各模块程序设计 (20)3.2.1 主程序 (20)3.2.2 芯片复位程序 (27)3.2.3 语音识别程序 (28)3.2.4 声音播放程序 (37)4 系统调试 (44)4.1 软件调试 (44)4.1.1 上电调试 (44)4.1.2 读写寄存器调试 (44)4.1.3 检查寄存器初始值 (44)4.2 硬件电路调试 (45)4.2.1 硬件检查 (45)4.2.2 硬件功能检查 (45)4.3 综合调试 (46)结论 (47)致谢 (48)参考文献 (49)附录1实物图片 (50)附录2系统电路图 (51)绪论课题背景及意义让机器听懂人类的语音,这是人们长期以来梦寐以求的事情。

基于STM32的智能语音提醒器设计摘要:随着生活节奏的加快,人们迫切需要合理的时间安排。
电子备忘录便携易用但缺少即时提醒功能,而常见的具有备忘录功能的语音提醒器功能单一、随意性差。
因此,本文基于STM32设计了一款智能语音提醒器,该提醒器具有功能多、随意性好、即时提醒等特点。
关键词:提醒器; STM32 ; 即时提醒1.引言随着生活节奏的加快,人们经常会遇到必须在短时间内完成很多事情的情况。
如果没有合理的时间安排,将会导致生活的一片混乱。
而合理的时间安排需要强大的记忆,这对于许多平常人而言是难以达到的,因此备忘录便占有了重要的地位。
目前,文本备忘录因其携带困难且记录复杂而基本消失;常见便携式电子备忘录作为附件需在手机、平板电脑等电子产品上使用或需与网络实时连接使用[1-2],能以文字或语音记录,但操作较为复杂,对于反应滞后的老人或不适宜使用电子产品的少儿是不方便的。
而市面上常见的独立语音提醒器种类繁多,但具有功能单一、随意性差等缺点[3-5]。
因此,本文基于STM32设计了一款智能语音提醒器,该提醒器具有功能多、随意性好、操作简洁、可以即时提醒等特点。
2.提醒器设计方案由于智能提醒器具有功能多样、随意性好且即时提醒等特点,因此其所需具备的功能有以下几点:(1)可以显示时间和日期;(2)可以按照时间顺序播放语音提醒;(3)可以随时录音,并设定播放时间,同时可以根据事情的重要性设定播放次数;(4)可以随时进入或退出语音;(5)可以删除语音;(6)具有50-100条的语音存储空间。
3.提醒器的硬件设计根据智能提醒器的功能要求,选择了意法半导体的STM32F103ZET6作为核心芯片,加上语音模块VS1053B、SD存储模块以及LCD显示模块,构成了提醒器的硬件系统。
如图1所示。
STM32F103ZET6芯片是基于ARM Cortex-M3内核的32位微控制器,拥有着512K的片内FLASH和64K片内RAM,能多线程操作。

基于STM32的智能语音控制系统设计
刘迷
【期刊名称】《工业仪表与自动化装置》
【年(卷),期】2022()4
【摘要】依托于云端的智能语音设备,虽然在运算速度、数据量、智能化程度等方面有很大的优势,但也极大地增加了被黑客攻击的风险。
基于听觉的嵌入式人机交互便是该领域的一个热门研究课题。
本设计采用STM32F103C8T6的32位微控制器、LD3320的语音识别芯片、MR628-TTS语音合成模块和OLED液晶显示屏对整体结构以及软硬件设计,最终实现由一级指令触发,二级指令持续控制的非接触式语音控制系统,通过语音关键词来达到对外部电器的非接触式语音控制。
【总页数】5页(P14-18)
【作者】刘迷
【作者单位】郑州商学院信工学院
【正文语种】中文
【中图分类】TP274
【相关文献】
1.基于STM32系统的智能语音控制的垃圾桶设计
2.基于STM32的智能语音沙盘控制系统设计与实现
3.基于STM32的智能语音沐浴控制系统
4.基于STM32的智能语音药箱控制系统的设计
5.基于STM32的智能语音控制药箱
因版权原因,仅展示原文概要,查看原文内容请购买。

智能应用0 前言权威统计数据显示,截止到2019年末,中国60岁以上的老年人口数已经超过2.5亿,人口老龄化衍生出的问题逐渐加重。
在这一群体中,超七成的老年人正在被至少一种慢性病所困扰,需要依靠长期服药来维持正常生活,然而有相当一部分老年人记忆力减退,甚至患有健忘症,时常忘记服药,给身体健康造成很大隐患。
另一方面,大型医疗机构每天都要接诊很多患者,开出大量药方,传统的配药方式对配药护士的劳动强度要求较大,且容易出现失误。
针对这两种现象,设计出了一款可以识别用户语音信息的智能语音药箱控制系统,该系统既可以提醒老年人按时服药,方便药物的存取,又可以应用于医疗机构的配药工作中,减轻医务工作者的劳动强度,提高配药的速度和准确性。
1 系统方案■1.1 功能分析该系统使用基于ARM Crotex-M3内核的32位单片机STM32F103C8T6作为控制芯片,该芯片功能强大,功耗较低,引脚数量适中,便于进行功能扩展,完全能够应对智能语音药箱产品的开发。
系统主要实现语音识别、键盘输入检测、定时报警提醒以及电机驱动等四大功能。
语音识别功能主要是对用户的语音信号进行识别,当用户说出的药品名称与系统预设值匹配成功时,电机驱动功能即发挥作用,自动打开存放相应药品的药箱;此外,用户也可通过键盘手动打以提醒用户按时服药。
■1.2 系统框图根据功能分析,确定了系统总体框图。
系统主要由单片机最小系统控制电路、电源电路、语音识别电路、电机驱动控制电路和键盘检测电路等几部分组成,各部分之间的联系如图1所示。
2 硬件电路设计硬件电路的设计充分考虑了产品的实际生产需求,在保证系统能够安全稳定工作的前提下,对主要元器件的价格、体积、主要性能指标等因素做了充分考虑。
系统硬件主要由电源电路、单片机最小系统电路、语音信号输入与识别电路、键盘输入电路和电机驱动电路等几部分组成,各部分具体介绍如下。
■2.1 电源电路用户可以使用5mm DC插座或micro_USB接口为系统提供5V直流电源,该电源一部分直接供给继电器用以驱动开关药箱抽屉的直流减速电机,另一部分经过芯片AMS1117-3.3的稳压降压以及外围滤波电路的处理后产生3.3V 电压供给STM32单片机和语音信号处理模块等器件使用。

基于STM32的智能音箱系统设计智能音箱在近年来越来越受到消费者的欢迎,而其中的一大因素就是音箱的功能性越来越强大。
目前的智能音箱不仅仅可以进行音乐播放,还可以进行语音识别、智能家居控制以及智能助理操作等。
本篇文章将介绍一种基于STM32的智能音箱系统设计方案。
1. 智能音箱系统设计思路智能音箱系统的设计主要包括音频采集、语音识别、智能家居操控和音频播放四个模块。
其中,智能家居操控包括对开关、空调、电视等家电设备的控制,这个模块需要添加Wifi模块来实现。
音频采集模块使用麦克风将用户语音录入,并传输到主控芯片——STM32上。
语音识别模块使用现有的语音识别SDK或自行编写,用于将用户的语音转化为文字,并向智能助理发送用户的语音指令。
智能家居操控模块使用Wifi模块连接智能家居设备,并通过命令向设备发送指令以实现操控。
音频播放模块使用扬声器进行声音输出。
2. STM32 MCU选型STM32是意法半导体(ST)公司推出的基于ARM Cortex-M3内核的32位微控制器,集成了模拟与数字、通信接口等多个模块,适用于嵌入式系统中。
在智能音箱系统中,STM32可作为主控芯片,负责控制系统中的多个硬件模块的工作,而工作稳定性和运行速度方面,STM32具有较高的性能价格比。
3. 音频采集模块设计音频采集部分采用全向电容麦克风作为音频采集模块,STM32通过ADC模块将收集到的信号转换为数字信号,并通过DMA方式存储到片内存中,以供语音识别模块使用。
由于语音信号的频率为0.3Hz到4kHz之间,且在过程中伴随许多噪声干扰,需要进行滤波处理。
可以使用一个低通滤波器滤除高频噪声,一个高通滤波器滤除低频噪声,保留中频信号,使语音输入麦克风后能够更加清晰准确地传递到下一模块。
4. 语音识别模块设计在语音识别模块上,可以采用现有的语音识别SDK,如百度、阿里等,实现将用户的语音指令转化为文字指令。
本文以百度语音识别为例,可使用其提供的API接口,将传入的语音数据上传到服务器中,获得语音转文字的结果。
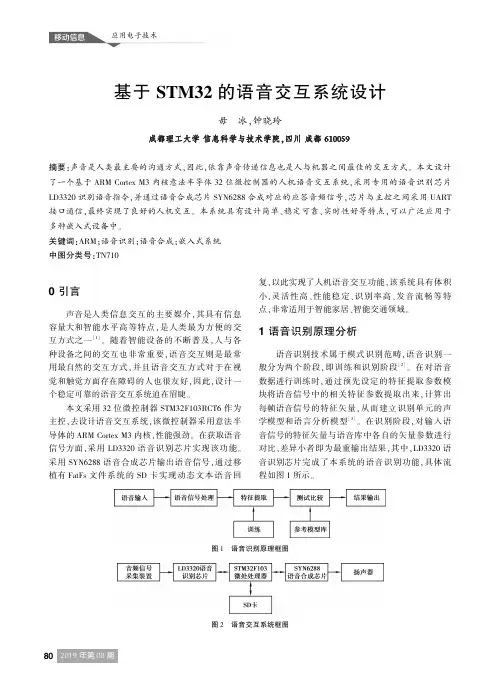
基于STM32的语音交互系统设计毋㊀冰ꎬ钟晓玲成都理工大学信息科学与技术学院ꎬ四川成都610059摘要:声音是人类最主要的沟通方式ꎬ因此ꎬ依靠声音传递信息也是人与机器之间最佳的交互方式ꎮ本文设计了一个基于ARMCortexM3内核意法半导体32位微控制器的人机语音交互系统ꎬ采用专用的语音识别芯片LD3320识别语音指令ꎬ并通过语音合成芯片SYN6288合成对应的应答音频信号ꎬ芯片与主控之间采用UART接口通信ꎬ最终实现了良好的人机交互ꎮ本系统具有设计简单㊁稳定可靠㊁实时性好等特点ꎬ可以广泛应用于多种嵌入式设备中ꎮ关键词:ARMꎻ语音识别ꎻ语音合成ꎻ嵌入式系统中图分类号:TN7100引言声音是人类信息交互的主要媒介ꎬ其具有信息容量大和智能水平高等特点ꎬ是人类最为方便的交互方式之一[1]ꎮ随着智能设备的不断普及ꎬ人与各种设备之间的交互也非常重要ꎬ语音交互则是最常用最自然的交互方式ꎬ并且语音交互方式对于在视觉和触觉方面存在障碍的人也很友好ꎬ因此ꎬ设计一个稳定可靠的语音交互系统迫在眉睫ꎮ本文采用32位微控制器STM32F103RCT6作为主控ꎬ去设计语音交互系统ꎬ该微控制器采用意法半导体的ARMCortexM3内核ꎬ性能强劲ꎮ在获取语音信号方面ꎬ采用LD3320语音识别芯片实现该功能ꎮ采用SYN6288语音合成芯片输出语音信号ꎬ通过移植有FatFs文件系统的SD卡实现动态文本语音回复ꎬ以此实现了人机语音交互功能ꎬ该系统具有体积小ꎬ灵活性高㊁性能稳定㊁识别率高㊁发音流畅等特点ꎬ非常适用于智能家居㊁智能交通领域ꎮ1语音识别原理分析语音识别技术属于模式识别范畴ꎬ语音识别一般分为两个阶段ꎬ即训练和识别阶段[2]ꎮ在对语音数据进行训练时ꎬ通过预先设定的特征提取参数模块将语音信号中的相关特征参数提取出来ꎬ计算出每帧语音信号的特征矢量ꎬ从而建立识别单元的声学模型和语言分析模型[3]ꎮ在识别阶段ꎬ对输入语音信号的特征矢量与语音库中各自的矢量参数进行对比ꎬ差异小者即为最重输出结果ꎬ其中ꎬLD3320语音识别芯片完成了本系统的语音识别功能ꎬ具体流程如图1所示ꎮ图1㊀语音识别原理框图图2㊀语音交互系统框图2系统总体方案设计如图2所示ꎬ为语音交互系统的组成图ꎮ主要包括嵌入式控制器㊁语音识别模块SD卡及FatFs文件系统㊁语音合成模块四部分构成[4]ꎮ其中ꎬ嵌入式控制器以STM32F103RCT6作为主控核心ꎬ语音识别模块核心为LD3320非特定人识别芯片ꎬ语音合成模块则由宇音天下科技有限公司的SYN6288中文语音合成芯片及相关外围电路构成ꎬ同时扬声器将电信号转换为声音信号ꎮ当使用人向系统发出命令时ꎬ语音识别模块中的MIC将采集到的声音信号转化为电信号ꎬ将其送入LD3320芯片ꎬLD3320芯片接收到该信号后ꎬ与内置语音库中的数据进行对比ꎬ识别完成后ꎬ通过UART将输出结果发送至主控芯片ꎬ主控芯片根据识别结果从SD卡中选择对应的音频数据ꎬ将数据通过UART送入SYN6288语音合成模块ꎬ由SYN6288解码后输出对应的模拟音频数据ꎮ3硬件电路设计3.1主控器电路设计本文采用32位Arm微控制器STM32F103RCT6作为主控核心ꎬ该MCU最高频率可达72MHzꎬ在存储器的0等待周期访问时可达1.25Mips/MHzꎮ拥有多达13个通信接口ꎬ例如IIC㊁SPI㊁USART㊁CAN㊁SDIO等外设接口[5]ꎬ该控制器带512K字节高速闪存ꎬ并且配备64K字节的SRAMꎬ同时具备多达11个定时器㊁稳定可靠的电源管理系统ꎬ具有快速㊁低功耗等优点ꎬ所以该芯片非常适合作为语音人机交互系统的主控ꎮ如图3所示ꎬ为本文所设计的STM32最小系统原理图ꎬ图4是PCB版图ꎮ图3㊀STM32最小系统原理图图4㊀STM32最小系统PCB版图3.2语音识别电路设计如图5所示ꎬ为语音识别电路原理图ꎮ本系统采用ICRoute公司的非特定人声语音识别芯片LD3320ꎬ该芯片是基于频域特征提取的方式提取语音特征ꎬ不需要用户提前训练数据集ꎬ即可实现非特定人声语音识别ꎬ准确率可达95%ꎮ在本设计中ꎬ采用了速度更快的并行通信方式与STM32F103RCT6进行通信ꎬ并行端口均采用1K欧姆电阻上拉ꎬ其中A0为地址/数据选择端ꎬRDB㊁WRB㊁CSB为芯片的控制信号ꎬ复位信号为RSTBꎬ中断信号INTB直连到主控的外部中断引脚ꎮ为了保证能输出浮动电压给MICꎬ芯片的第12引脚作为MIC偏置ꎬ由RC振荡电路组成ꎮ3.3语音合成电路设计如图6所示的语音合成电路是基于SYN6288语音芯片所设计的ꎬSYN6288芯片支持GB2312㊁GBK㊁BIG5和UNICODE等多种内码格式字符ꎬ通过异步串口接收待合成的文本ꎬ实现文本到声音的解析转换ꎮ在本设计中波特率设为9600bpsꎬ使用BUSY引脚作为查询芯片状态引脚ꎬ当BUSY引脚为低电平时ꎬ表示SYN6288芯片处于空闲状态ꎬ高电平则处于工作状态ꎬ主控可根据该引脚的状态决定是否发送待合成的文本ꎮ该芯片支持休眠模式ꎬ在休眠状态下可以降低功耗ꎮ图5㊀语音识别电路原理图图6㊀语音合成电路原理图4系统软件设计系统软件使用C语言编写ꎬ并采用KeiluVision5环境设计ꎬ通过裸机编程方式模块化编程ꎬ这样会使程序架构清晰完整ꎮ4.1软件总体流程主控芯片上电后ꎬ先进行一系列硬件初始化ꎬ配置外设的工作条件等ꎬ具体包括:STM32内部时钟配置㊁中断系统配置㊁GPIO端口配置等㊁USART寄存器配置等ꎮ初始化完成后ꎬ系统进入等待阶段ꎬ直到LD3320语音模块识别到声音信号产生中断信号ꎬ且将结果通过串口发送至单片机ꎬ单片机进入中断进行匹配识别ꎬ选择出需要播放的音频信息ꎬ送入到SYN6288语音合成模块ꎬ播放语音ꎬ完成了一次语音识别ꎬ系统再次进入等待阶段[6]ꎮ程序流程图如图7所示ꎮ初始化代码如下:GPIO_Init()ꎻ//GPIO初始化USART_Init()ꎻ//串口初始化EXTI_Config()ꎻ//外部中断配置LD3320_Reset()ꎻ//复位语音识别芯片Syn6288_Init()ꎻ//初始化语音合成芯片Syn6288_SoftReset()ꎻ//语音合成芯片软复位Syn6288_SetVol()ꎻ//设置输出音频音量4.2非特定人语音识别流程本系统为及时响应LD3320语音识别模块ꎬ采用图7㊀软件整体流程图了外部中断方式ꎮ首先进行初始化ꎬ包括软复位和FIFO设定等ꎬ将识别条目内容和命令字按固定格式封装为数据包ꎬ然后将封装好的数据包和对应返回值组成的二维数组表ꎬ通过串口写入到模块中ꎬ出于测设目的ꎬ向芯片写入了50个测试条目ꎬ返回值设定区间为00H ̄FFHꎬ编号可以相同ꎬ也可以不连续ꎮ写入内置数据后ꎬ即可进行识别ꎮ当MIC采集到声音信号ꎬ片内数模转换器将模拟信号转换为数字信号ꎬ与内置数据库进行特征对比ꎬ比对成功后ꎬ模块产生下降沿ꎬ使单片机进入中断处理ꎬ中断函数中判断返回的对应识别结果ꎬ即可进入语音应答流程[7]ꎬ至此ꎬ非特定人语音识别完成ꎮ4.3语音文件播报流程语音信号识别完成后ꎬ单片机中断函数根据不同语音指令返回的识别结果编号ꎬ向SYN6288语音合成芯片发送对应的任务帧ꎬ每一个完整的数据流都应包括帧头㊁帧长度㊁命令字㊁待合成的文本㊁编码格式㊁校验字等[8]ꎮ在SYN6288语音合成芯片BUSY引脚为低电平时ꎬ通过UART将数据帧送入芯片ꎬ进行语音合成ꎬ当收到新的数据帧时ꎬ芯片会立即停止当前的合成任务ꎬ转而合成最新的文本内容ꎮ文本数据经过预处理后通过芯片内部AD转换为模拟音频信号ꎬ通过扬声器放大ꎬ完成语音信号的输出回应ꎮ至此ꎬ一次完整的人机语音交互流程完成ꎬ系统进入等待阶段ꎬ等待下一次语音指令ꎮ5性能测试及应用为了验证本系统识别的稳定性㊁准确率和响应速度ꎬ本文对所设计的系统进行了测试ꎮ分别对随机抽取的8条语音指令在安静和嘈杂的两种环境下进行10次的测试ꎬ并对3名实验对象(非特定人1㊁2为男性ꎬ3为女性)进行了单独的测试ꎬ记录成功识别语音信号且判断正确回应的次数ꎬ统计结果如下表所示ꎮ表1㊀语音交互系统实际测试结果统计环境语句安静嘈杂非特定人1非特定人2非特定人3非特定人1非特定人2非特定人3你好1091010910请关门9109998打开窗户9109888开灯91010999前进1099999后退101010898左转999889右转10109887识别率/(%)9596.2593.7586.2586.2585㊀㊀通过分析以上测试结果ꎬ可以清晰地看出ꎬ在安静的环境下ꎬ对非特定人的语音识别率可达95%ꎬ而对于一般的嘈杂的环境ꎬ也可以达到85%以上识别准确率ꎬ在安静环境下的识别的成功率明显要高于嘈杂环境下ꎬ稳定性方面同样安静环境下要更为出色ꎮ安静的情况下ꎬ非特定人只需要发出一次指令即可识别成功ꎬ而嘈杂的情况下ꎬ个别命令需要两次甚至三次才会被成功识别ꎮ实时性方面ꎬ安静的环境下能保证系统的实时响应ꎬ嘈杂的环境下会有不到1s的延迟ꎮ6结语本文设计了一套基于STM32F103RCT6微控制器的语音交互系统ꎬ并对整个系统的各个软硬件模块进行了详述ꎮ在本设计采用LD3320语音芯片识别非特定人声信号ꎬ采用SYN6288中文语音合成芯片合成需要播放的语音信号ꎬ并采用模块化编程ꎬ最终实现了人机语音交互ꎮ本系统结构简单㊁运行稳定㊁成本低廉ꎬ可广泛应用于智能音响㊁智能家居㊁服务机器人等多个领域ꎮ参考文献[1]HansenJHLꎬNajafianMꎬLileikyteRꎬetal.Speechandlanguageprocessingforassessingchild ̄adultinteractionbasedondiarizationandlocation[J].InternationalJournalofSpeechTechnologyꎬ2019(3):697 ̄709.[2]郭永刚.基于STM32的智能语音交互式沙盘控制系统设计与实现[D].兰州:兰州大学ꎬ2017.[3]王智国.嵌入式人机语音交互系统关键技术研究[D].合肥:中国科学技术大学ꎬ2014.[4]顾亚平.基于智能语音交互技术的智慧语音助理系统实现[D].南京:南京邮电大学ꎬ2015.[5]周根ꎬ杨操ꎬ张琴ꎬ等.基于STM32单片机语音远程控制系统设计[J].电子世界ꎬ2016(12):80.[6]杨振江.基于STM32ARM处理器的编程技术[M].西安:西安电子科技大学出版社ꎬ2016.[7]张鹏远ꎬ计哲ꎬ侯炜ꎬ等.小资源下语音识别算法设计与优化[J].清华大学学报:自然科学版ꎬ2017(2):38 ̄43. [8]范会敏ꎬ何鑫ꎬFANHui ̄Minꎬ等.中文语音合成系统的设计与实现[J].计算机系统应用ꎬ2017(2):73 ̄77.。


基于STM32的声音定位系统【摘要】基于STM32的声音定位系统是一种新兴的技术,具有广泛的应用前景。
本文首先介绍了声音定位系统的背景和研究意义,明确了研究目的。
接着,详细探讨了STM32在声音定位系统中的应用以及声音定位算法原理。
然后,介绍了系统的硬件设计与实现,并进行了系统性能测试。
对系统进行了优化,并总结出了创新点。
未来,我们可以进一步探讨声音定位系统在各个领域的应用,并完善系统的功能和效率。
通过本文的研究,为声音定位技术的发展提供了重要的参考和指导。
【关键词】STM32、声音定位系统、声音定位算法、硬件设计、系统性能测试、系统优化、创新点、研究展望、结论1. 引言1.1 背景介绍声音定位是一种在智能技术领域中十分重要的技术,它可以通过对声音信号的分析和处理,确定声源的位置信息。
随着科技的发展和人工智能的应用越来越普及,声音定位系统在安防监控、智能家居、无人驾驶等领域都有着广泛的应用前景。
研究基于STM32的声音定位系统具有重要的理论意义和实际价值。
随着STM32单片机在嵌入式系统中的广泛应用,它在声音定位系统中也被广泛采用。
STM32具有低功耗、高性能、丰富的外设接口等优势,能够满足声音定位系统对实时性、稳定性和精度的要求。
基于STM32开发声音定位系统成为了当前研究的热点之一。
本文旨在探讨基于STM32的声音定位系统的设计与实现,通过对声音定位算法原理的介绍和硬件设计的讨论,结合系统性能测试和优化,使得声音定位系统能够更好地适应不同场景的需求,提高系统的性能和稳定性。
希望通过本文的研究能够为声音定位系统的发展提供一些有益的参考和借鉴。
1.2 研究意义声音定位系统是一种能够准确识别声音来源方向的智能系统,具有广泛的应用前景和重要的研究意义。
在智能家居领域,声音定位系统可以帮助用户实现声控操作,提高生活的便利性和舒适性。
在安防监控领域,声音定位系统可以帮助监控人员快速定位异常声音来源,提升安防监控的效率和准确性。

基于STM32单片机的智能家居语音控制系统的设计摘要:智能家居是一个当今热门的领域,本文设计了一个基于STM32单片机的智能家居语音控制系统。
该系统主要包括语音识别模块、控制单元以及家居设备。
该系统通过语音识别模块实现用户的语音指令识别,并通过控制单元进行相应的输出控制。
实验结果表明,该系统能够准确地识别用户的语音指令,并可有效地控制家居设备的输出。
关键词:智能家居;语音控制;单片机1. 引言智能家居是一种通过智能技术的互联网络实现的家居设备智能化的系统,其主要功能是通过传感器信息、智能控制等技术获取相关家居信息,从而实现自动化、远程监控和智能化控制。
在智能家居的系统中,智能语音控制技术的应用日益广泛。
本文基于STM32单片机设计了一种智能家居语音控制系统,旨在实现家庭设备的智能化控制及智能化辅助功能。
2. 系统设计2.1 系统框架本系统主要由以下三部分构成:语音识别模块、控制单元以及家居设备。
其中,语音识别模块通过声音传感器将用户的指令转化为数字信号,控制单元接收并解析数字信号以实现相应的指令控制,相应地从家居设备中实现输出控制。
2.2 硬件设计本系统采用了STM32单片机作为控制器,通过声音传感器将语音指令转化为数字信号并进行处理。
由于家庭设备具有不同的输入信号,因此在本系统中,我们采用了多路输出控制的方式,以满足不同的家庭设备控制需求。
2.3 软件设计软件设计主要包括两部分:语音识别模块和控制单元。
语音识别模块主要通过语音识别算法将输入的语音指令转换为数字信号,并通过控制单元进行解析,以实现相应的输出控制。
3. 实验结果为验证本系统的有效性和可行性,我们将其应用于家庭环境中。
实验结果表明,本系统可以准确地识别用户的语音指令,并实现相应的家庭设备控制。
此外,本系统还支持远程控制和智能化辅助功能,可实现更智能化的家居设备控制。
4. 结论本文设计了一种基于STM32单片机的智能家居语音控制系统,该系统可以实现家居设备的智能化控制以及智能化辅助功能。
语音识别智能家居控制系统设计摘要:本系统主要介绍语音识别智能家居控制系统,系统以实现通过语音智能控制家用电器的开关为目的,采用非特定人SNR8016芯片,通过ZigBee无线通信技术进行数据采集传输,实现对室内LED灯、窗帘、空调、除湿器等电器进行控制。
本系统在实现基本语音控制的同时,系统还具有成本低、功耗小、易操作、安全可靠等优点,能够给用户带来更好的体验感和舒适感。
关键词:智能家居;语音识别;STM32;ZigBee1 引言在传统的家电控制中,通常采用的是手动控制和遥控控制,这两种控制方法都是由人来操作,既有一定的危险性,又不能通过墙壁进行远程操作。
而随着技术水平的不断提高,使用者对使用体验的需求也越来越高,因此在两种传统控制中延伸出一种新兴控制方法—语音控制,语音控制最大的特点是简单、直接。
语音识别智能家居控制系统具有更好的可控性和便捷性,它突破了传统的控制方式对距离的限制,同时也满足了用户对智能家居的需求。
而语言控制所必须的语音识别技术成为了家庭智能系统中的一个关键技术。
近年来,随着语音识别、人工智能等高新技术的不断涌现,在智能家居领域得到了巨大的发展,并已经被广泛应用于智能家居领域。
2 系统总体设计在本系统中,主机模块是控制板主要实现语音控制家电的功能,人们通过唤醒指令唤醒语音识别模块,然后发出相应的命令指令,SNR8016语音识别模块识别后,通过串口将识别结果传送给STM32主控芯片,由STM32主控芯片对识别结果进行解析,将解析之后的结果命令发送给终端设备从而控制各电器的开关状态。
而从机模块是监测板主要利用温湿度传感器采集室内环境温湿度值,并将采集的数据通过ZigBee发送到主机的ZigBee,主机的ZigBee将信息发送给主控在OLED显示屏幕上进行实时显示,并将当前温湿度值和设定值进行对比,当温湿度的值达到设定值后系统会自动启动空调和除湿器。
系统功能框图如图1所示。
图1 系统功能框图3 系统硬件设计3.1 STM32主控芯片STM32芯片是意法半导体开发的一系列的微控制器,STM32处理器目前有3个系列多种型号,开发者可以根据设计需求自行选择合适型号。
基于stm32的嵌入式课程设计一、教学目标本课程的教学目标是使学生掌握基于STM32的嵌入式系统的基本原理和开发技能,培养学生进行嵌入式系统设计和开发的能力。
知识目标:使学生了解STM32的基本结构、工作原理和编程方法,掌握嵌入式系统的基本概念和关键技术。
技能目标:培养学生使用STM32开发板进行嵌入式系统设计和开发的能力,包括硬件连接、程序编写、系统调试等。
情感态度价值观目标:培养学生对嵌入式系统的兴趣和热情,提高学生解决实际问题的能力,培养学生的创新精神和团队合作意识。
二、教学内容本课程的教学内容主要包括STM32的基本结构和工作原理、嵌入式编程方法、嵌入式系统设计和开发流程等。
1.STM32的基本结构和工作原理:介绍STM32的CPU、内存、外设等基本组成部分,理解其工作原理和性能特点。
2.嵌入式编程方法:学习STM32的编程语言,掌握基本的编程技巧和编程规范,学会使用开发工具进行程序编写和调试。
3.嵌入式系统设计和开发流程:学习嵌入式系统的设计方法和开发流程,包括需求分析、系统设计、硬件选型、软件开发、系统测试等环节。
三、教学方法本课程采用讲授法、实验法、案例分析法等多种教学方法,以激发学生的学习兴趣和主动性。
1.讲授法:通过讲解STM32的基本原理、编程方法和系统设计流程,使学生掌握相关知识。
2.实验法:安排实验课程,使学生在实际操作中掌握STM32的开发技能,提高实际动手能力。
3.案例分析法:通过分析具体的嵌入式系统案例,使学生了解嵌入式系统在实际应用中的工作原理和开发方法。
四、教学资源本课程的教学资源包括教材、实验设备、多媒体资料等。
1.教材:选用合适的教材,为学生提供系统的学习资料。
2.实验设备:提供STM32开发板和相关实验设备,为学生提供实际操作的机会。
3.多媒体资料:制作课件、视频等多媒体资料,丰富教学手段,提高学生的学习兴趣。
五、教学评估本课程的教学评估包括平时表现、作业、实验和期末考试等几个方面,以全面、客观、公正地评估学生的学习成果。
基于STM32的智能家居语音控制系统设计作者:彭森盛安妮来源:《环球市场》2019年第26期摘要:STM32语音识别控制系统运用的是ASR语音识别软件,对家居照明进行控制,甚至亮度也能够调节。
此外,系统在运行中还可以控制音响。
使用智能手机就可以远程控制各种家具设备,实现无感化设计。
本论文着重研究基于STM32的智能家居语音控制系统设计方面的问题。
关键词:STM32;智能家居;语音控制系统;设计从当前的智能家居系统设计情况来看,其中所包括的内容为智能家电控制、智能照明控制、智能安全防护控制等等,各种家用电器都可以采用智能控制的方式,这是当前的社会发展趋势,人们生活的舒适度也有所提高。
人们使用智能手机就可以体验智能化的家居生活,机器对自己的意图做出判断,对环境产生感应性,通过智能技术的控制,联动解决。
一、智能家居语音控制系统的设计基于STM32的智能家居语音控制系统在设计的过程中,所构建的模块为Zigbee模块,结合使用TM32语音芯片和STC15F2K60S2芯片。
整个的系统控制都是采用无线组网技术来完成的[1]。
STC单片机集成,数据信息传输的过程中所发挥的是Zigbee组网技术的作用,在主要的控制平台上嵌入语音芯片,就可以应用语音控制的方式对各种家用电器进行调控。
二、智能家居语音控制系统的硬件设计(一)MCU的选择智能家居语音控制系统设计中选择MCU的时候,以STC15F2K60S2单片机作为主要控制单元。
这个单片机的优点在于不仅控制的速度快,而且具有较高的安全可靠性,资源丰富、功耗低,而且还具有温度范围宽的特点。
STC15F2K60S2具有大容量片内RAM数据存储器,可以达到2048个字节,还有通用I/O引脚26个,ADC是10位高速的,共8通道。
这些都可以满足语音控制智能家居系统的设计要求,另外其不仅操作简单,而且成本也非常低。
(二)智能語音控制系统的设计方案本设计是运用STM32语音识别模块处理语音信号,并对信号进行识别,数据信息的传输采用Zigbee模块数据,还要结合使用单片机主控芯片,这样就可以控制智能开关系统,同时还可以控制智能功率放大器系统,智能家居照明系统得到远程控制。
基于语音识别的空调控制系统的硬件设计摘要如今的时代处于科技飞速发展的时期,我们的生活以及进入到了自动化,智能化的时代。
在第四次科技革命即将到来或者说已经到来的现在,人工智能技术的发展不断地改变着我们的生活方式以及工作方式。
其中语音识别技术的快速发展也在不断地改变着我们的生活,最常见的变化就是越来越多的手机自带语音识别功能来快速的启动程序以及搜索想要的资料。
因此研究嵌入式语音识别系统,具有重要的研究意义以及广泛的市场应用。
本文根据嵌入式平台的语音识别系统的相关模块,设计一款基于STM32控制LD3320语音模块进行识别的空调控制系统。
可以通过串口通信,使改系统可以与PC端自由连接,不仅可以通过串口直接修改识别指令,还可以直接将其之后的结果进行修改,使得整个交互过程更加灵活而便捷。
本文的主要研究工作包括:1.选取一块作为控制模块的单片机STM32F103C8T6,将其为核心构建一个语音识别系统。
该单片机主要是将识别成功后的信号进行处理,发送指令给空调设备。
2.选取一块语言识别芯片LD3320作为识别模块,采集收集语音信号并加以识别。
3.测试语音识别系统的识别性能。
实验表明,用户通过语音发送指令,系统达到了预期的设计目标。
关键词:语音识别;语音识别模块;控制模块AbstractToday's era is a period of rapid development of science and technology, our life and into the era of automation, intelligent. In the fourth technological revolution is coming or has come now,the development of artificial intelligence technology is constantly changing our way of life and work.Among them, the rapid development of voice recognition technology is also constantly changing our lives.The most common change is that more and more mobile phones come with voice recognition function to quickly launch programs and search for the desired information.Therefore,the research on embedded speech recognition system has important research significance and extensive market application.The article, an air conditioning control system based on STM32 control LD3320 voice module is designed according to the related modules of embedded platform voice recognition system.It can communicate through parallel port,so that the system can be freely connected with PC terminal. It can not only modify the recognition instructions directly through parallel port,but also modify the results after the separation,making the whole interactive process more flexible and convenient.The main research work of this paper includes:1. Select a single chip microcomputer STM32F103C8T6 as the control module and build a speech recognition system with it as the core.The single-chip microcomputer is mainly used to process the identified signal successfully and send instructions to the air conditioning equipment.2. A language recognition chip LD3320 is selected as the recognition module to collect and recognize speech signals.3. Test the recognition performance of the speech recognition system. The experiment shows that the system achieves the expected design goal by the user sending voice commands.Keywords: speech recognition;speech recognition module;control module目录第1章绪论 (1)1.1 研究的背景以及意义 (1)1.2 语音识别的发展历史以及趋势 (2)1.2.1 发展历史 (2)1.2.2 发展趋势 (2)1.3 本次研究的主要内容 (3)1.4 论文的结构安排 (4)第2章语音识别的简单介绍 (5)2.1 语音识别的原理 (5)2.2 语音识别的工作流程 (5)2.3 语音识别的分类 (6)2.3.1.孤立词、连续词、连续语音识别系统 (6)2.3.2.大词汇、中词汇和小词汇量语音识别系统 (6)2.3.3.特定人和非特定人语音识别系统 (6)2.3.4.实时语音识别和非实时语音识别 (6)2.4 语音识别的算法 (7)2.4.1特征参数匹配法 (7)2.4.2隐马尔柯夫法 (7)2.4.3神经网络法 (7)2.5 嵌入式系统的介绍 (8)2.6 本章小结 (8)第3章语音识别系统的硬件设计 (9)3.1 控制模块硬件的选择 (9)3.2 主流语音识别芯片的选择 (10)3.3 语音识别的设计系统 (10)3.3.1 电源模块 (11)3.3.2 主控模块 (11)3.3.2.1 时钟电路 (12)3.3.2.2 复位电路 (12)3.3.3语音识别模块 (13)3.3.4 外部温度传感模块 (13)3.3.5 外部设备模块 (14)3.4 整体设计 (15)3.5 本章小结 (16)第4章语音识别系统的软件设计 (17)4.1 开发环境 (17)4.2 程序流程图 (18)4.3 子程序流程图 (19)4.3.1 执行语音识别程序 (19)4.3.2 OLED显示程序 (20)4.4 程序烧录 (21)4.5 本章小结 (22)第5章语音识别系统的测试分析 (23)5.1 关键词测试分析 (23)5.2 应用测试 (23)5.3 测试结果分析 (24)5.4 本章小结 (24)结语 (25)附录 (27)参考文献 (29)致谢......................................................第1章绪论1.1 研究的背景以及意义近年来,随着社会现代化进程的飞速加快和新科学科技的蓬勃发展,人们对生活品质的追求也日益渐深。
基于STM32的嵌入式语音识别模块设计和实现苏鹏 2011/03/24摘要:介绍了一种以ARM为核心的嵌入式语音识别模块的设计与实现。
模块的核心处理单元选用ST公司的基于ARM Cortex-M3内核的32位处理器STM32F103C8T6。
本模块以对话管理单元为中心,通过以LD3320芯片为核心的硬件单元实现语音识别功能,采用嵌入式操作系统μC/OS-II来实现统一的任务调度和外围设备管理。
经过大量的实验数据验证,本文设计的语音识别模块具有高实时性、高识别率、高稳定性的优点。
关键词:ARM;语音识别;对话管理;LD3320;μC/OS-II引言服务机器人以服务为目的,因此人们需要一种更方便、更自然、更加人性化的方式与机器人交互,而不再满足于复杂的键盘和按钮操作。
基于听觉的人机交互是该领域的一个重要发展方向。
目前主流的语音识别技术是基于统计模式。
然而,由于统计模型训练算法复杂,运算量大,一般由工控机、PC机或笔记本来完成,这无疑限制了它的运用。
嵌入式语音交互已成为目前研究的热门课题。
嵌入式语音识别系统和PC机的语音识别系统相比,虽然其运算速度和内存容量有一定限制,但它具有体积小、功耗低、可靠性高、投入小、安装灵活等优点,特别适用于智能家居、机器人及消费电子等领域。
1 模块整体方案及架构语音识别的基本原理如图1所示。
语音识别包括两个阶段:训练和识别。
不管是训练还是识别,都必须对输入语音预处理和特征提取。
训练阶段所做的具体工作是通过用户输入若干次训练语音,经过预处理和特征提取后得到特征矢量参数,最后通过特征建模达到建立训练语音的参考模型库的目的。
而识别阶段所做的主要工作是将输入语音的特征矢量参数和参考模型库中的参考模型进行相似性度量比较,然后把相似性最高的输入特征矢量作为识别结果输出。
这样,最终就达到了语音识别的目的。
现有的语音识别技术按照识别对象可以分为特定人识别和非特定人识别。
特定人识别是指识别对象为专门的人,非特定人识别是指识别对象是针对大多数用户,一般需要采集多个人的语音进行录音和训练,经过学习,达到较高的识别率。
基于STM32单片机的嵌入式语音识别系统设计陈心灵1,钱宁博2,胡佳辉1,王战中1(1.石家庄铁道大学机械工程学院,河北石家庄050043;2.石家庄铁道大学电气与电子工程学院,河北石家庄050043)摘要:设计了一款以STM32F103为核心的自然语言识别系统,为满足实时语音识别系统对内存资源和运算速度的要求,基于硬件资源合理设计语音处理算法,在嵌入式平台上实现了对孤立词语的语音识别。
首先根据背景噪声和语音信号的时域特征差异设定相应门限值,从而实现了对语音信号的端点检测。
然后针对语音识别中传统梅尔倒谱系数对语音的高频信息敏感度较低,对语音信号分别提取梅尔倒谱系数(MFCC)与翻转梅尔倒谱系数(IMFCC),结合Fisher 准则构造混合特征参数。
最后采用动态时间规整算法实现语音识别。
因系统体积小、便携性好等特点,易于实现对不同设备的语音控制,有一定的市场前景。
关键词:语音识别;梅尔倒谱系数;翻转梅尔倒谱系数;Fisher 准则;动态时间规整算法;STM32F103中图分类号:TP391.4文献标识码:A文章编号:1009-9492(2019)06-0135-03Embedded Speech Recognition System Design Based on STM32F103CHEN Xin-ling 1,QIAN Ning-bo 2,HU Jia-hui 1,WANG Zhan-zhong 1(1.College of Mechanical Engineering ,Shijiazhuang Tiedao University ,Shijiazhuang 050043,China ;2.College of Electrical and Electronic Engineering ,Shijiazhuang Tiedao University ,Shijiazhuang 050043,China )Abstract:A natural language recognition system is designed based on STM32F103.To meet the requirements of real-time speech recognition systemfor memory resources and computing speed ,the speech processing algorithm is designed based on hardware resources and speech recognition ofisolated words is implemented on the embedded platform.Firstly ,the corresponding threshold is set according to the time domain characteristic difference of the speech signal and the background noise and thereby realizing the endpoint detection of the speech signal.Concerning the traditional Mel Frequency Cepstral Coefficient (MFCC)in speech recognition is less sensitive to high frequency signals of speech ,MFCC and IMFCC (InvertedMFCC)are extracted respectively for the speech signal and the Fisher criterion is used to construct the mixed feature parameters.Dynamic time warping algorithm is used in speech recognition process.Due to the small size of the system and good portability ,it is easy to implement voice control for different devices and has much marker potential.Key words:speech recognition ;MFCC ;IMFCC ;Fisher criterion ;DTW ;STM32F103收稿日期:2018-12-22DOI:10.3969/j.issn.1009-9492.2019.06.0450引言语音识别是人机交互很重要的模块,应用领域相当广阔。
集成电路的快速发展使得将具有先进功能的语音识别系统固化到更加微小的芯片或模块上成为可能[1],更便于语音识别系统的推广与使用,嵌入式语音识别技术开发变得更加有价值。
本文设计一个基于STM32F103单片机的嵌入式语音识别系统,包括硬件设计和软件设计[2-3]。
语音特征提取在传统梅尔倒谱系数基础上,运用Fisher 比结合梅尔倒谱系数与翻转梅尔倒谱系数,构建了混合特征参数[4],识别算法采用动态时间规整算法。
硬件设计上实现了语音信号采集、语音信号处理、语音信息存储、语音识别结果的显示等功能。
1系统硬件设计本系统主要由电源部分(LDO )、主控(STM32F103)、语音采样电路、LCD 显示模块等组成,如图1所示。
1.1MCU 选择STM32F103开发板基于Cortex-M3处理器,内置2个12位模数转换器,2个DMA 控制器,共12个DMA 通道,其可以满足本系统中的语音处理需求。
1.2采样电路采样电路选用差分放大电路,抑制共模干扰,放大有用信号,有效地解决采样噪声硬件预处理的问题。
其原理图如图2。
在设计过程中,其输出端(即Q1\Q2的C 极)静态工作点为1/2Vcc 最为适宜,能保障其最大动态输出范围。
电路设计尽可能使Q1、Q2的静态工作参数一致,构成对称电路。
图1系统硬件框图Fig.1The system hardware blockdiagram··1351.3硬件存储语音的模拟信号通过模数转换器转换为数字信号,MCU 读取语音数据缓冲区的信息并处理,将模板训练过程得到的特征模板存储于指定的Flash 地址,系统再次上电时不丢失模板信息。
2系统软件设计2.1语音识别软件设计整体思路本系统主要由语音信号的预处理、端点检测、特征提取、模板匹配等部分组成,如图3所示。
预处理过程包括分帧、数据加窗、预加重等;特征提取旨在去除语音信号中的冗余信息提取特征参数;模板匹配基于提取的特征参数,按一定的方法表征测试语音模板与参考模板的相似度,从而判断出测试语音的信息。
2.2语音识别算法2.2.1端点检测原理提取识别前200ms 作为背景噪声,依据噪声信息和语音信息的短时平均幅度值的差异,设置相应门限T 1。
因为噪声信息的能量主要集中在较高频段,而语音信息的能量主要集中在较低频段,设定正负阈值,根据单位时间跨过正负阈值的次数设置相应门限T 2。
设定当语音信号至少超过T 1、T 2中的一个门限值且持续时间超过一定时间,则将此作为语音的起始点;设定语音信号同时低于T 1、T 2门限且持续时间超过一定时间,则将此作为语音的结束点。
2.2.2特征提取参考模板训练和待测语音识别基于语音的特征参数进行,特征参数的提取尤为关键,本系统改进了传统梅尔倒谱系数。
梅尔频率[5]与实际频率的变换关系如式(1):f Mel =2595×lg(1+f /700)(1)梅尔倒谱系数(MFCC )基于滤波器组得到,构造Mel 频域下等间距的12个梅尔滤波器,转换到实际频域,滤波器在低频段分布密集,在高频段分布相对稀疏。
每一帧语音信号的MFCC 参数提取过程如图4。
语音信号的能量谱经MFCC 滤波器滤波,再将每个滤波器频带内的能量进行积分,得到功率谱;将每个滤波器对应的功率值取对数,再进行反离散余弦变换,最终得到12个MFCC 系数。
梅尔倒谱系数对低频语音信息更加敏感,针对高频信息,提出结合翻转梅尔倒谱系数,翻转梅尔频率与实际频率的变换关系[6]如式(2):f Mel =2195.268-2595lg(1+(4031.25-f )/700)(2)翻转梅尔倒谱系数(IMFCC )同样是基于滤波器组得到的,转换到实际频域,滤波器在高频段分布密集,在低频段分布相对稀疏。
IMFCC 参数的提取流程与MFCC 参数的提取流程一致。
以上得到的MFCC 参数与IMFCC 参数分别主要表征了低频段和高频段的语音特点,提出一种评价特征参数的方案,使用Fisher 线性判别准则[6]:r Fi sh er =σbetweenσwi th in式3中:r Fi sh er 是特征分量的Fisher 比;σbetween 表示特征分量的类间方差,可以反映不同语音的差异程度;σwi th in 表示特征分量的类内方差,可以反映同一语音中分量的密集程度。
σbetween =∑i =1c (m i k -m k )2σwi th in =∑i =1c[1n i ∑c ∈ωi(c i k -m i k )2]式中:k 等于特征参数的维数,k =1,2,⋯,12;m k 表示语音所有类别上第k 个特征分量的均值;m ik 表示语音的第i 类中第k 个特征分量的均值;ωi 表示第i 类的语音特征序列;c 、n i 分别表示语音的类别数及各类的样本数;c ik 表示第i 类语音特征中的第k 个分量。
Fisher 比从类内方差与类间方差表征了语音的可分离程度。
Fisher 比越大,该特征参数更适合描述此人的语音特征信息。
从上文得到的MFCC 与IMFCC 参数中各选择Fisher 比最大的6个分量组合成12维的混合特征参数。
识别匹配动态时间规整算法[7](DTW )的实质是运用了动态规划的思想,求解最优化问题。
经过上文的语音处理过程,得到参考模板与测试模板。
参考模板表示为R ={R (1),R (2),⋯R (m ),⋯}R (M)图2采样电路Fig.2Samplingcircuit图3语音识别系统原理图Fig.3Schematic diagram of speech recognition system图4MFCC 提取流程图Fig.4Extraction flow chart ofMFCC··136测试模板表示为T ={T (1),T (2),⋯T (n ),⋯}T (N ),M ,N 表示帧数,M ≠N 。