最新3.2两因素方差分析汇总
- 格式:ppt
- 大小:1.83 MB
- 文档页数:92

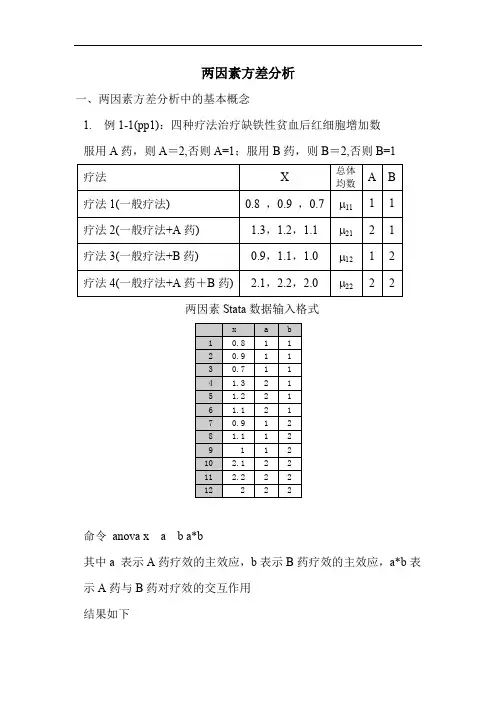
两因素方差分析一、两因素方差分析中的基本概念1. 例1-1(pp1):四种疗法治疗缺铁性贫血后红细胞增加数服用A药,则A=2,否则A=1;服用B药,则B=2,否则B=1两因素Stata数据输入格式命令anova x a b a*b其中a 表示A药疗效的主效应,b表示B药疗效的主效应,a*b表示A药与B药对疗效的交互作用结果如下结果表明:对于 =0.05而言H10:没有交互作用并且A药和B药疗效的主效应都没有差异H11:有交互作用或A药主效应有差异或B药主效应有差异F Model=98.75,P值<0.05,因此认为模型是有效的(或有交互作用或有主效应)。
H20:没有交互作用H21:有交互作用F A×B=36.75,P值=0.0003<0.05,因此A药与B药的疗效有交互作用,并且有统计意义。
H30:A药没有差异H31:A药主效应有差异F A=168.75,P值<0.05,A药的主效应有统计意义H40:B药没有差异H41:B药主效应有差异F B =90.75,P 值<0.05,B 药的主效应也有统计意义。
问题:模型是什么? 模型:..()ab a b ab μμαβαβ=+++其中μab 是x 的总体均数,αa 称为A 因素的主效应,βb 称为B 因素的主效应,(αβ)ab 称为A 因素和B 因素对因变量x(观察指标变量)的交互作用。
2. 主效应的意义A 药B 药平均A 主效应表示未服用服用 未服用 μ11μ1211121.2μμμ+=1...1μμα=+服用 μ21 μ22 21222.2μμμ+= 2...2μμα=+ 平均1121.12μμμ+= 1222.22μμμ+= 11122122..4μμμμμ+++= B 主效应 .1..1μμβ=+ .2..2μμβ=+称α1和α2为A 因素的主效应,β1和β2为B 因素的主效应。
并且可以验证:α1+α2=0(即:α1=-α2)以及β1+β2=0(β1=-β2) 若α1=α2(即α1=α2=0),则对应A 因素的主效应没有作用。

⽅差分析2(双因素⽅差分析、多元⽅差分析、可视化)1 双因素⽅差分析1.1 双因素⽅差分析的实战dat<-ToothGrowthdatattach(dat)table(dat$supp,dat$dose)aggregate(len,by=list(dat$supp,dat$dose),FUN=mean)解释:根据投⽅式(橙汁OJ,维C素VC)supp和剂量dose来对⽛齿的长度len进⾏求均值dose<-factor(dose)解释:为了避免把dose变量认为是数值变量,⽽是把dose认为成分组变量,所以设置成因⼦类型factorfit<-aov(dat$len~dat$supp*dat$dose)解释:aov()做⽅差分析,把 + 换成了 * ,这两项dat$supp和dat$dosee就变成了交互项summary(fit)结果分析:可以看出P值很⼩,三个P值都⼩于0.05,说明不同的投喂⽅式supp对⽛齿的⽣长长度len是有显著影响的;说明不同的剂量dose对⽛齿的⽣长长度len是有显著影响的;说明在两种投喂⽅式下,不同的投喂⽅式supp和剂量dose的交互效应对⽛齿的⽣长长度len是有显著影响的1.2 可视化⽅法1interaction.plot(dat$dose,dat$supp,dat$len,type = "b",col=c("red","blue"),pch=c(16,18),main="XX")1.3 可视化⽅法2library(gplots)plotmeans(dat$len~interaction(dat$supp,dat$dose,sep=" "),connect=list(c(1,3,5),c(2,4,6)),col=c("red","blue"),main="XX",xlab="xlab")1.4 可视化⽅法3library(HH)interaction2wt(dat$len~dat$supp*dat$dose)2 重复测量⽅差分析dat<-CO2CO2$conc<-factor(CO2$conc)w1b1<-subset(CO2,Treatment=="chilled")uptake是植物光合作⽤对⼆氧化碳的吸收量,是因变量y,type是组间因⼦,是互斥的,表⽰的是两个不同地区的植物类型,要么是加拿⼤的植物,要么是美国的植物,不可能两个地⽅都是,conc是不同的⼆氧化碳的浓度,每⼀种植物都在所有的⼆氧化碳浓度下,所以conc是组内因⼦研究不同地区的植物作⽤,在某种⼆氧化碳的浓度作⽤下,对植物的光合作⽤效果有没有影响2.1 含有单个组内因⼦w和单个组间因⼦B的重复测量ANOVAfit<-aov(uptake~conc*Type+Error(Plant/(conc)),w1b1)summary(fit)结果分析:⼆氧化碳浓度和类型对植物光合作⽤都有显著影响2.2 可视化图形呈现(1)⽅式⼀par(las=2)par(mar=c(10,4,4,2))with(w1b1,interaction.plot(conc,Type,uptake,type = "b",col=c("red","blue"),pch=c(16,18)))(2)⽅式⼆boxplot(uptake~Type*conc,data=w1b1,col=c("red","blue"))3 多元⽅差分析library(MASS)attach(UScereal)dat<-UScerealshelf<-factor(shelf)y<-cbind(calories,fat,sugars)fit<-manova(y~shelf)summary(fit)结果分析:不同的货架shelf上,⾷物的热量calories,脂肪含量fat和含糖量sugars是⾮常显著不同的3.1 多元正态性center<-colMeans(y)n<-nrow(y) #⾏数p<-ncol(y) #列数cov<-cov(y) #计算⽅差d<-mahalanobis(y,center,cov)coord<-qqplot(qchisq(ppoints(n),df=p),d) #画图abline(a=0,b=1) #画参考线identify(coord$x,coord$y,labels = s(UScereal)) #给出交互式标出离群点3.2 稳健多元⽅差分析install.packages("rrcov")library(rrcov)wilks.test(y,shelf,method="mcd")结果分析:P值⼩于0.05,说明结果是显著性的,即不同货架上⾷物的热量calories,脂肪含量fat和含糖量sugars是⾮常显著不同的4 ⽤回归来做ANOVAlibrary(multcomp)dat<-cholesterollevels(dat$trt)fit.aov<-aov(response~trt,data=dat)summary(fit.aov)结果分析:aov⽅差分析,trt对response的影响⾮常显著fit.lm<-lm(response~trt,data=dat)summary(fit.lm)结果分析:lm回归分析,trt对response的影响⾮常显著,并且trt的每⼀项都显⽰出来了。

例题:笔画数和字频是影响汉字识别时间的重要变量,一项研究综合考察了这两个变量对汉字识别的影响。
研究者设计了3*2两因素设计的实验。
第一个因素笔画数有三个水平,分别为多笔画字(12画以上)、中等笔画数(6画-13画)和少笔画字(1到6画);第二个因素字频有两个水平,分别为高频字和低频字。
两因素各个实验水平交叉后形成6个条件单元。
研究者使用的实验材料是60个汉字,每个条件单元中有10个汉字。
参加实验的被试来自某高校随机抽取的60名本科生,他们被随机分为6组,每组10人,每一组被试仅对一组实验材料进行命名。
问:笔画数和字频对汉字命名有什么影响?。



多因素方差分析公式了解多因素方差分析的计算公式多因素方差分析公式——了解多因素方差分析的计算公式多因素方差分析是一种统计方法,用于分析多个因素对观察结果的影响。
它通过比较不同因素水平下的观察值差异来判断这些因素对实验结果的影响程度。
在多因素方差分析中,我们需要了解与计算一些重要的公式。
1. 多因素方差分析的总平方和(SS_total)公式:SS_total = SS_between + SS_within其中,SS_total是总平方和,表示所有观测值与总均值之间的偏离程度;SS_between是组间平方和,表示不同因素水平下的观测值与总均值之间的偏离程度;SS_within是组内平方和,表示同一因素水平下的观测值与该水平下的均值之间的偏离程度。
2. 多因素方差分析的组间平方和(SS_between)公式:SS_between = ∑(ni * (μi - μ)²)其中,ni是第i组的观测值个数,μi是第i组观测值的均值,μ为所有观测值的总均值。
3. 多因素方差分析的组内平方和(SS_within)公式:SS_within = ∑∑((Xij - μi)²)其中,Xij表示第i组的第j个观测值,μi为第i组观测值的均值。
4. 多因素方差分析的组间平均平方(MS_between)公式:MS_between = SS_between / (k - 1)其中,k为不同因素水平的个数。
5. 多因素方差分析的组内平均平方(MS_within)公式:MS_within = SS_within / (N - k)其中,N为总观测值的个数。
6. 多因素方差分析的F统计量公式:F = MS_between / MS_withinF统计量用于判断不同因素水平的均值之间的差异是否显著。
若F 值大于某个临界值,则认为不同因素水平的均值存在显著差异。
通过以上公式,我们可以计算出组间平方和、组内平方和、组间平均平方、组内平均平方和F统计量,从而进行多因素方差分析。

双因素方差分析一、双因素方差分析的含义和类型(一)双因素方差分析的含义和内容在实际问题的研究中,有时需要考虑两个因素对实验结果的影响。
例如上一节中饮料销售量的例子,除了关心饮料颜色之外,我们还想了解销售地区是否影响销售量,如果在不同的地区,销售量存在显著的差异,就需要分析原因,采用不同的推销策略,使该饮料品牌在市场占有率高的地区继续深入人心,保持领先地位,在市场占有率低的地区,进一步扩大宣传,让更多的消费者了解,接受该产品。
在方差分析中,若把饮料的颜色看作影响销售量的因素A,饮料的销售地区看作影响因素B。
同时对因素A和因素B进行分析,就称为双因素方差分析。
双因素方差分析的内容包括:对影响因素进行检验,究竟一个因素在起作用,还是两个因素都起作用,或是两个因素的影响都不显著。
双因素方差分析的前提假定:采样地随机性,样本的独立性,分布的正态性,残差方差的一致性。
(二)双因素方差分析的类型双因素方差分析有两种类型:一个是无交互作用的双因素方差分析,它假定因素A 和因素B的效应之间是相互独立的,不存在相互关系;另一个是有交互作用的双因素方差分析,它假定因素A和因素B的结合会产生出一种新的效应。
例如,若假定不同地区的消费者对某种品牌有与其他地区消费者不同的特殊偏爱,这就是两个因素结合后产生的新效应,属于有交互作用的背景;否则,就是无交互作用的背景。
有交互作用的双因素方差分析已超出本书的范围,这里介绍无交互作用的双因素方差分析。
1.无交互作用的双因素方差分析。
无交互作用的双因素方差分析是假定因素A和因素B的效应之间是相互独立的,不存在相互关系;2.有交互作用的双因素方差分析。
有交互作用的双因素方差分析是假定因素A和因素B的结合会产生出一种新的效应。
例如,若假定不同地区的消费者对某种颜色有与其他地区消费者不同的特殊偏爱,这就是两个因素结合后产生的新效应,属于有交互作用的背景,否则,就是无交互作用的背景。
二、数据结构方差分析的基本思想:通过分析研究中不同来源的变异对总变异的贡献大小,从而确定可控因素对研究结果影响力的大小。



三、方差分析1、单因素方差分析例1这是某些汽车品牌的耗油量相关数据。
检验汽车品牌是否对耗油量有影响。
从表3.1可以看出,计算出的levene统计量为0.157,显著性值为0.856,远大于0.05表3.2为方差分析表,从左到右分别为平方和、自由度、均方和、F值和显著性指标。
从表3.2中的数据可以看出,组间的显著性指标值为0.008,小于0.05,即认为各组之间是有差异的。
也就是说至少有一种品牌的车耗油量与其他品牌的车的耗油量有显著差异。
表3.3所示是各类汽车品牌之间的显著性差异两两比较的结果。
从表中的数据可以看出,由于品牌B与其他两个品牌A、B比较的显著性结果都是小于0.05的,所以认为其同其他品牌在耗油量上有显著差异。
而另外两个品牌的车可认为其品牌的不同对耗油量的影响不显著。
图3.1 各组均值比较图从图3.1上可以印证标表3.3的结论。
通过观察图发现,品牌B车的平均耗油量远高于其他品牌的车。
2、多因素方差分析例2 关于不同专业不同大学的学生的收入情况。
试分析专业、大学及交互作用对收入是否有显著影响。
表3.4 主体间因子表值标签N专业 1 A1 152 A2 153 A3 154 A4 15大学 1 B1 122 B2 123 B3 124 B4 125 B5 12表3.4给出了因素在各个水平下的样本个数。
从表中的数据可以得出,专业有4个水平,每个水平下有15个样本,大学有5个水平,每个水平下有12个样本。
表3.5是两因素方差分析表。
表格左上方给出了指标变量是“收入”。
表中各列依次代表了方差的来源、III 型平方和、自由度、均方和、F值和显著性指标。
表中第一行代表对方差分析模型的检验。
其显著性指标值取为0.331,大于0.05,说明该模型是不适用的。
第二行代表的是截距,可以忽略。
第三四行代表的是专业、大学对收入的影响。
其中专业的显著性指标为0.456,大于0.05,则说明其对指标收入的影响不显著,大学的显著性指标值为0.048,小于0.05,则说明大学对指标收入有影响。
双因素重复测量方差应用条件1.引言1.1 概述双因素重复测量方差是一种统计分析方法,常用于研究实验中的重复测量数据。
在某些情况下,我们需要考察两个或两个以上因素对实验结果的影响,并希望了解这些因素之间是否存在相互作用。
双因素重复测量方差方法的应用条件是实验数据需要满足一定的前提条件,才能准确地使用该方法进行数据分析。
在具体的应用中,我们需要关注以下几个方面。
首先,实验数据需要满足正态性的要求。
正态性是指数据呈现出类似于正态分布的特征,即数据点在均值附近分布,并且两侧分布的形状对称。
如果数据违背了正态性的假设,那么双因素重复测量方差的应用结果可能会失真。
其次,实验数据需要满足独立性的要求。
独立性是指实验数据的观测值之间相互独立,彼此之间的测量结果不会互相影响。
如果实验数据存在相关性或序列效应,那么我们需要采取相应的方法来处理这种相关性,以确保研究结果的准确性。
此外,实验数据还需要满足方差齐性的要求。
方差齐性是指在不同水平或条件下,方差具有相同的性质,即方差的大小不会因为因素或条件的变化而改变。
如果实验数据的方差缺乏齐性,那么我们需要进行方差分析的修正,以确保分析结果的可靠性。
综上所述,双因素重复测量方差的应用条件包括正态性、独立性和方差齐性。
只有在满足这些条件的情况下,我们才能准确地使用双因素重复测量方差方法进行数据分析,并得出相关的结论。
这种方法的应用对于揭示实验因素对结果的影响以及因素之间的相互作用具有重要意义,可以帮助研究人员更加准确地理解实验结果的含义。
1.2文章结构1.2 文章结构本文将分为三个部分来探讨双因素重复测量方差的应用条件。
首先,我们将在引言中概述本文的背景和目的,为读者提供一个整体的了解。
接下来,将详细介绍双因素重复测量方差的定义和计算方法,以便读者能够理解其数学原理和计算过程。
最后,在结论部分将阐述双因素重复测量方差的应用条件和其对实际问题的实际意义。
在每个部分中,我们将提供清晰的解释和示例,以帮助读者更好地理解和应用所述概念。
双因素方差分析一、无交互作用下的方差分析设A 与B 是可能对试验结果有影响的两个因素,相互独立,无交互作用。
设在双因素各种水平的组合下进行试验或抽样,得数据结构如下表:表中每行的均值.i X (i=1,2,…r )是在因素A 的各个水平上试验结果的平均数;每列的均值jX .(j=1,2,…,n)是在因素B 的各种水平上试验的平均数。
以上数据的离差平方和分解形式为:SST=SSA+SSB+SSE (6.13) 上式中:∑∑-=2)(X X SST ij(6.14)∑-=∑∑-=2.2.)()(X X n X XSSA i i (6.15)∑-=∑∑-=2.2)()(X Xr X XSSB j j(6.16)∑+-∑-=2..)(X X X X SSE ji ij(6.17)SSA 表示的是因素A 的组间方差总和,SSB 是因素B 的组间方差总和,都是各因素在不同水平下各自均值差异引起的;SSE 仍是组内方差部分,由随机误差产生。
各个方差的自由度是:SST 的自由度为nr-1,SSA 的自由度为r-1,SSB 的自由度为n-1,SSE 的自由度为nr-r-n-1=(r-1)(n-1)。
各个方差对应的均方差是:对因素A 而言: 1-=r SSA MSA (6.18) 对因素B 而言: 1-=n SSB MSB (6.19)对随机误差项而言:1---=n r nr SSEMSE (6.20)我们得到检验因素A 与B 影响是否显著的统计量分别是:)]1)(1(,1[~---=n r r F MSE MSA F A (6.21))]1)(1(,1[~---=n r n F MSE MSBF B (6.22)【例6-2】某企业有三台不同型号的设备,生产同一产品,现有五名工人轮流在此三台设备上操作,记录下他们的日产量如下表。
试根据方差分析说明这三台设备之间和五名工人之间对日产量的影响是否显著?(α=0.05)。